在JDBC应用中,如果你已经是稍有水平开发者,你就应该始终以PreparedStatement代替Statement.也就是说,在任何时候都不要使用Statement.
基于以下的原因:
一.代码的可读性和可维护性.
虽然用PreparedStatement来代替Statement会使代码多出几行,但这样的代码无论从可读性还是可维护性上来说.都比直接用Statement的代码高很多档次:
stmt.executeUpdate("insert into tb_name (col1,col2,col2,col4) values ('"+var1+"','"+var2+"',"+var3+",'"+var4+"')");
perstmt = con.prepareStatement("insert into tb_name (col1,col2,col2,col4) values (?,?,?,?)");
perstmt.setString(1,var1);
perstmt.setString(2,var2);
perstmt.setString(3,var3);
perstmt.setString(4,var4);
perstmt.executeUpdate();
不用我多说,对于第一种方法.别说其他人去读你的代码,就是你自己过一段时间再去读,都会觉得伤心.
二.PreparedStatement尽最大可能提高性能.
每一种数据库都会尽最大努力对预编译语句提供最大的性能优化.因为预编译语句有可能被重复调用.所以语句在被DB的编译器编译后的执行代码被缓存下来,那么下次调用时只要是相同的预编译语句就不需要编译,只要将参数直接传入编译过的语句执行代码中(相当于一个涵数)就会得到执行.这并不是说只有一个 Connection中多次执行的预编译语句被缓存,而是对于整个DB中,只要预编译的语句语法和缓存中匹配.那么在任何时候就可以不需要再次编译而可以直接执行.而statement的语句中,即使是相同一操作,而由于每次操作的数据不同所以使整个语句相匹配的机会极小,几乎不太可能匹配.比如:
insert into tb_name (col1,col2) values ('11','22');
insert into tb_name (col1,col2) values ('11','23');
即使是相同操作但因为数据内容不一样,所以整个个语句本身不能匹配,没有缓存语句的意义.事实是没有数据库会对普通语句编译后的执行代码缓存.这样每执行一次都要对传入的语句编译一次.
当然并不是所以预编译语句都一定会被缓存,数据库本身会用一种策略,比如使用频度等因素来决定什么时候不再缓存已有的预编译结果.以保存有更多的空间存储新的预编译语句.
三.最重要的一点是极大地提高了安全性.
即使到目前为止,仍有一些人连基本的恶义SQL语法都不知道.
String sql = "select * from tb_name where name= '"+varname+"' and passwd='"+varpasswd+"'";
如果我们把[' or '1' = '1]作为varpasswd传入进来.用户名随意,看看会成为什么?
select * from tb_name = '随意' and passwd = '' or '1' = '1';
因为'1'='1'肯定成立,所以可以任何通过验证.更有甚者:
把[';drop table tb_name;]作为varpasswd传入进来,则:
select * from tb_name = '随意' and passwd = '';drop table tb_name;有些数据库是不会让你成功的,但也有很多数据库就可以使这些语句得到执行.
而如果你使用预编译语句.你传入的任何内容就不会和原来的语句发生任何匹配的关系.(前提是数据库本身支持预编译,但上前可能没有什么服务端数据库不支持编译了,只有少数的桌面数据库,就是直接文件访问的那些)只要全使用预编译语句,你就用不着对传入的数据做任何过虑.而如果使用普通的statement, 有可能要对drop,;等做费尽心机的判断和过虑.
上面的几个原因,还不足让你在任何时候都使用PreparedStatement吗?
有的新人可能此时对于用法还不太理解下面给个小例子
Code Fragment 1:
String updateString = "UPDATE COFFEES SET SALES = 75 " + "WHERE COF_NAME LIKE ′Colombian′";
stmt.executeUpdate(updateString);
Code Fragment 2:
PreparedStatement updateSales = con.prepareStatement("UPDATE COFFEES SET SALES = ? WHERE COF_NAME LIKE ? ");
updateSales.setInt(1, 75);
updateSales.setString(2, "Colombian");
updateSales.executeUpdate();
set中的1对应第一个? 2对应第二个? 同时注意你set 的类型 是int还是string 哈哈很简单吧
原文出处:http://blog.csdn.net/spcusa/archive/2009/05/09/4164076.aspx
//ValueObject类
public class AdEntity {
private String id;
private String name;
private String broker;
private String date;
private String body;
//get/set
public String toString(){
return "【编号为:"+id+",广告名称为:"+name+",代理商为:"+broker+",发布日期为:"+date+",内容为:"+body+"】";
}
}
//调用任务类
public class AdTask implements Callable<AdEntity> {
@Override
public AdEntity call() throws Exception {
// 模拟远程调用花费的一些时间
Thread.sleep(5*1000);
AdEntity vo=new AdEntity();
vo.setId(String.valueOf(new Random().nextInt(1000)));
vo.setName("Ad@内衣广告");
vo.setBroker("CHANNEL");
Date date=new Date();
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd");
String dateStr=sdf.format(date);
vo.setDate(dateStr);
vo.setBody("远端内容");
return vo;
}
}
//主函数
public class TestQueryMemg {
/**
* @param args
* @throws ExecutionException
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService exec=Executors.newCachedThreadPool();
//创建Future来完成网络调用任务
Callable<AdEntity> returnAd=new AdTask();
Future<AdEntity> future=exec.submit(returnAd);
//开始执行本地化查询信息
AdEntity localAd=new AdEntity();
localAd.setId(String.valueOf(new Random().nextInt(1000)));
localAd.setName("Ad@食品广告");
localAd.setBroker("蒙牛");
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd");
String dateStr=sdf.format(new Date());
localAd.setDate(dateStr);
localAd.setBody("内容本地");
System.out.println("当前本地化查询内容为:"+localAd.toString());
System.out.println("稍等片刻以获取远端信息");
while(!future.isDone()){
try {
Thread.sleep(1*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
AdEntity entityRemote=(AdEntity)future.get();
System.out.println("合并查询内容为:\n"+localAd.toString()+"\n"+entityRemote.toString());
}
}
个人账户类:
public class PrivateAccount implements Callable {
Integer total;
public Object call() throws Exception {
Thread.sleep(5*1000);
total=new Integer(new Random().nextInt(10000));
System.out.println("您个人账户上还有"+total+" 存款可以支配");
return total;
}
}
主函数测试:
public class SumTest {
/**
* @param args
* @throws ExecutionException
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException, ExecutionException {
Callable privateAccount=new PrivateAccount();
FutureTask task=new FutureTask(privateAccount);
//创建新线程获取个人账户信息
Thread thread=new Thread(task);
thread.start();
int total=new Random().nextInt(1000);
System.out.println("主线程在这工作");
System.out.println("您目前操作金额为: "+total+" .");
System.out.println("请等待计算个人账户的金额");
while(!task.isDone()){//判断是否已经获取返回值
try {
Thread.sleep(3*1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Integer privateSingle=(Integer)task.get();
int post=privateSingle.intValue();
System.out.println("您当前账户共有金额为:"+(total+post)+" ¥");
}
}
Memcached,人所皆知的remote distribute cache(不知道的可以javaeye一下下,或者google一下下,或者baidu一下下,但是鉴于baidu的排名商业味道太浓(从最近得某某事件可以看出),所以还是建议javaeye一下下),使用起来也非常的简单,它被用在了很多网站上面,几乎很少有大型的网站不会使用memcached。
曾经我也看过很多剖析memcached内部机制的文章,有一点收获,但是看过之后又忘记了,而且没有什么深刻的概念,但是最近我遇到一个问题,这个问题迫使我重新来认识memcache,下面我阐述一下我遇到的问题
问题:我有几千万的数据,这些数据会经常被用到,目前来看,它必须要放到memcached中,以保证访问速度,但是我的memcached中数据经常会有丢失,而业务需求是memcached中的数据是不能丢失的。我的数据丢失的时候,memcached server的内存才使用到60%,也就是还有40%内存被严重的浪费掉了。但不是所有的应用都是这样,其他应用内存浪费的就比较少。为什么内存才使用到60%的时候LRU就执行了呢(之所以确定是LRU执行是因为我发现我的数据丢失的总是前面放进去的,而且这个过程中,这些数据都没有被访问,比如第一次访问的时候,只能访问第1000w条,而第300w条或者之前的数据都已经丢失了,从日志里看,第300w条肯定是放进去了)。
带着这些疑问,我开始重新审视memcached这个产品,首先从它的内存模型开始:我们知道c++里分配内存有两种方式,预先分配和动态分配,显然,预先分配内存会使程序比较快,但是它的缺点是不能有效利用内存,而动态分配可以有效利用内存,但是会使程序运行效率下降,memcached的内存分配就是基于以上原理,显然为了获得更快的速度,有时候我们不得不以空间换时间。
也就是说memcached会预先分配内存,对了,memcached分配内存方式称之为allocator,首先,这里有3个概念:
1 slab
2 page
3 chunk
解释一下,一般来说一个memcahced进程会预先将自己划分为若干个slab,每个slab下又有若干个page,每个page下又有多个chunk,如果我们把这3个咚咚看作是object得话,这是两个一对多得关系。再一般来说,slab得数量是有限得,几个,十几个,或者几十个,这个跟进程配置得内存有关。而每个slab下得page默认情况是1m,也就是说如果一个slab占用100m得内存得话,那么默认情况下这个slab所拥有得page得个数就是100,而chunk就是我们得数据存放得最终地方。
举一个例子,我启动一个memcached进程,占用内存100m,再打开telnet,telnet localhost 11211,连接上memcache之后,输入stats slabs,回车,出现如下数据:
- STAT 1:chunk_size 80
- STAT 1:chunks_per_page 13107
- STAT 1:total_pages 1
- STAT 1:total_chunks 13107
- STAT 1:used_chunks 13107
- STAT 1:free_chunks 0
- STAT 1:free_chunks_end 13107
- STAT 2:chunk_size 100
- STAT 2:chunks_per_page 10485
- STAT 2:total_pages 1
- STAT 2:total_chunks 10485
- STAT 2:used_chunks 10485
- STAT 2:free_chunks 0
- STAT 2:free_chunks_end 10485
- STAT 3:chunk_size 128
- STAT 3:chunks_per_page 8192
- STAT 3:total_pages 1
- STAT 3:total_chunks 8192
- STAT 3:used_chunks 8192
- STAT 3:free_chunks 0
- STAT 3:free_chunks_end 8192
STAT 1:chunk_size 80
STAT 1:chunks_per_page 13107
STAT 1:total_pages 1
STAT 1:total_chunks 13107
STAT 1:used_chunks 13107
STAT 1:free_chunks 0
STAT 1:free_chunks_end 13107
STAT 2:chunk_size 100
STAT 2:chunks_per_page 10485
STAT 2:total_pages 1
STAT 2:total_chunks 10485
STAT 2:used_chunks 10485
STAT 2:free_chunks 0
STAT 2:free_chunks_end 10485
STAT 3:chunk_size 128
STAT 3:chunks_per_page 8192
STAT 3:total_pages 1
STAT 3:total_chunks 8192
STAT 3:used_chunks 8192
STAT 3:free_chunks 0
STAT 3:free_chunks_end 8192
以上就是前3个slab得详细信息
chunk_size表示数据存放块得大小,chunks_per_page表示一个内存页page中拥有得chunk得数量,total_pages表示每个slab下page得个数。total_chunks表示这个slab下chunk得总数(=total_pages * chunks_per_page),used_chunks表示该slab下已经使用得chunk得数量,free_chunks表示该slab下还可以使用得chunks数量。
从上面得示例slab 1一共有1m得内存空间,而且现在已经被用完了,slab2也有1m得内存空间,也被用完了,slab3得情况依然如此。 而且从这3个slab中chunk得size可以看出来,第一个chunk为80b,第二个是100b,第3个是128b,基本上后一个是前一个得1.25倍,但是这个增长情况我们是可以控制得,我们可以通过在启动时得进程参数 –f来修改这个值,比如说 –f 1.1表示这个增长因子为1.1,那么第一个slab中得chunk为80b得话,第二个slab中得chunk应该是80*1.1左右。
解释了这么多也该可以看出来我遇到得问题得原因了,如果还看不出来,那我再补充关键的一句:memcached中新的value过来存放的地址是该value的大小决定的,value总是会被选择存放到chunk与其最接近的一个slab中,比如上面的例子,如果我的value是80b,那么我这所有的value总是会被存放到1号slab中,而1号slab中的free_chunks已经是0了,怎么办呢,如果你在启动memcached的时候没有追加-M(禁止LRU,这种情况下内存不够时会out of memory),那么memcached会把这个slab中最近最少被使用的chunk中的数据清掉,然后放上最新的数据。这就解释了为什么我的内存还有40%的时候LRU就执行了,因为我的其他slab中的chunk_size都远大于我的value,所以我的value根本不会放到那几个slab中,而只会放到和我的value最接近的chunk所在的slab中(而这些slab早就满了,郁闷了)。这就导致了我的数据被不停的覆盖,后者覆盖前者。
问题找到了,解决方案还是没有找到,因为我的数据必须要求命中率时100%,我只能通过调整slab的增长因子和page的大小来尽量来使命中率接近100%,但是并不能100%保证命中率是100%(这话怎么读起来这么别扭呢,自我检讨一下自己的语文水平),如果您说,这种方案不行啊,因为我的memcached server不能停啊,不要紧还有另外一个方法,就是memcached-tool,执行move命令,如:move 3 1,代表把3号slab中的一个内存页移动到1号slab中,有人问了,这有什么用呢,比如说我的20号slab的利用率非常低,但是page却又很多,比如200,那么就是200m,而2好slab经常发生LRU,明显page不够,我就可以move 20 2,把20号slab的一个内存页移动到2号slab上,这样就能更加有效的利用内存了(有人说了,一次只移动一个page,多麻烦啊?ahuaxuan说,还是写个脚本,循环一下吧)。
有人说不行啊,我的memcache中的数据不能丢失啊,ok,试试新浪的memcachedb吧,虽然我没有用过,但是建议大家可以试试,它也使利用memcache协议和berkeleyDB做的(写到这里,我不得不佩服danga了,我觉得它最大的贡献不是memcache server本身,而是memcache协议),据说它被用在新浪的不少应用上,包括新浪的博客。
补充,stats slab命令可以查看memcached中slab的情况,而stats命令可以查看你的memcached的一些健康情况,比如说命中率之类的,示例如下:
- STAT pid 2232
- STAT uptime 1348
- STAT time 1218120955
- STAT version 1.2.1
- STAT pointer_size 32
- STAT curr_items 0
- STAT total_items 0
- STAT bytes 0
- STAT curr_connections 1
- STAT total_connections 3
- STAT connection_structures 2
- STAT cmd_get 0
- STAT cmd_set 0
- STAT get_hits 0
- STAT get_misses 0
- STAT bytes_read 26
- STAT bytes_written 16655
- STAT limit_maxbytes 104857600
STAT pid 2232
STAT uptime 1348
STAT time 1218120955
STAT version 1.2.1
STAT pointer_size 32
STAT curr_items 0
STAT total_items 0
STAT bytes 0
STAT curr_connections 1
STAT total_connections 3
STAT connection_structures 2
STAT cmd_get 0
STAT cmd_set 0
STAT get_hits 0
STAT get_misses 0
STAT bytes_read 26
STAT bytes_written 16655
STAT limit_maxbytes 104857600
从上面的数据可以看到这个memcached进程的命中率很好,get_misses低达0个,怎么回事啊,因为这个进程使我刚启动的,我只用telnet连了一下,所以curr_connections为1,而total_items为0,因为我没有放数据进去,get_hits为0,因为我没有调用get方法,最后的结果就是misses当然为0,哇哦,换句话说命中率就是100%,又yy了。
该到总结的时候了,从这篇文章里我们可以得到以下几个结论:
结论一,memcached得LRU不是全局的,而是针对slab的,可以说是区域性的。
结论二,要提高memcached的命中率,预估我们的value大小并且适当的调整内存页大小和增长因子是必须的。
结论三,带着问题找答案理解的要比随便看看的效果好得多。
- 关闭所有oracle的服务和程序
- 选择开始| 程序|oracle Installation Products命令,运行Universal Installer,弹出欢迎对话框
- 单机 卸载产品 按钮,弹出Inventory对话框
- 选中Inventroy对话框中的所有节点,点击删除,确认即可
- 选 择 开始|运行 输入regedit并按ENTER键,选择HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE,删除此象,然后选择 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services,滚动此列表,删除与oracle有关的所 有选项。
- 从桌面上、STARTUP和程序菜单中删除所有ORACLE的组和图标。
- 重启系统。
- 删除包括文件在内的安装目录。至此ORACLE的全部卸载完成。
位运算应用口诀
清零取位要用与,某位置一可用或
若要取反和交换,轻轻松松用异或
移位运算
要点 1 它们都是双目运算符,两个运算分量都是整形,结果也是整形。
2 "<<" 左移:右边空出的位上补0,左边的位将从字头挤掉,其值相当于乘2。
3 ">>"右移:右边的位被挤掉。对于左边移出的空位,如果是正数则空位补0,若为负数,可能补0或补1,这取决于所用的计算机系统。
4 ">>>"运算符,右边的位被挤掉,对于左边移出的空位一概补上0。
位运算符的应用 (源操作数s 掩码mask)
(1) 按位与-- &
1 清零特定位 (mask中特定位置0,其它位为1,s=s&mask)
2 取某数中指定位 (mask中特定位置1,其它位为0,s=s&mask)
(2) 按位或-- |
常用来将源操作数某些位置1,其它位不变。 (mask中特定位置1,其它位为0 s=s|mask)
(3) 位异或-- ^
1 使特定位的值取反 (mask中特定位置1,其它位为0 s=s^mask)
2 不引入第三变量,交换两个变量的值 (设 a=a1,b=b1)
目 标 操 作 操作后状态
a=a1^b1 a=a^b a=a1^b1,b=b1
b=a1^b1^b1 b=a^b a=a1^b1,b=a1
a=b1^a1^a1 a=a^b a=b1,b=a1
二进制补码运算公式:
-x = ~x + 1 = ~(x-1)
~x = -x-1
-(~x) = x+1
~(-x) = x-1
x+y = x - ~y - 1 = (x|y)+(x&y)
x-y = x + ~y + 1 = (x|~y)-(~x&y)
x^y = (x|y)-(x&y)
x|y = (x&~y)+y
x&y = (~x|y)-~x
x==y: ~(x-y|y-x)
x!=y: x-y|y-x
x< y: (x-y)^((x^y)&((x-y)^x))
x<=y: (x|~y)&((x^y)|~(y-x))
x< y: (~x&y)|((~x|y)&(x-y))//无符号x,y比较
x<=y: (~x|y)&((x^y)|~(y-x))//无符号x,y比较
应用举例
(1) 判断int型变量a是奇数还是偶数
a&1 = 0 偶数
a&1 = 1 奇数
(2) 取int型变量a的第k位 (k=0,1,2……sizeof(int)),即a>>k&1
(3) 将int型变量a的第k位清0,即a=a&~(1<<k)
(4) 将int型变量a的第k位置1, 即a=a|(1<<k)
(5) int型变量循环左移k次,即a=a<<k|a>>16-k (设sizeof(int)=16)
(6) int型变量a循环右移k次,即a=a>>k|a<<16-k (设sizeof(int)=16)
(7)整数的平均值
对于两个整数x,y,如果用 (x+y)/2 求平均值,会产生溢出,因为 x+y 可能会大于INT_MAX,但是我们知道它们的平均值是肯定不会溢出的,我们用如下算法:
int average(int x, int y) //返回X,Y 的平均值
{
return (x&y)+((x^y)>>1);
}
(8)判断一个整数是不是2的幂,对于一个数 x >= 0,判断他是不是2的幂
boolean power2(int x)
{
return ((x&(x-1))==0)&&(x!=0);
}
(9)不用temp交换两个整数
void swap(int x , int y)
{
x ^= y;
y ^= x;
x ^= y;
}
(10)计算绝对值
int abs( int x )
{
int y ;
y = x >> 31 ;
return (x^y)-y ; //or: (x+y)^y
}
(11)取模运算转化成位运算 (在不产生溢出的情况下)
a % (2^n) 等价于 a & (2^n - 1)
(12)乘法运算转化成位运算 (在不产生溢出的情况下)
a * (2^n) 等价于 a<< n
(13)除法运算转化成位运算 (在不产生溢出的情况下)
a / (2^n) 等价于 a>> n
例: 12/8 == 12>>3
(14) a % 2 等价于 a & 1
(15) if (x == a) x= b;
else x= a;
等价于 x= a ^ b ^ x;
(16) x 的 相反数 表示为 (~x+1)
posted @
2010-03-30 13:59 叶澍成 阅读(445) |
评论 (0) |
编辑 收藏线程,是指正在执行的一个指点令序列。在java平台上是指从一个线程对象的start()开始。运行run方法体中的那一段相对独立的过程。
线程的并发与并行
在过去的电脑都已单CPU作为主要的处理方式,无论是PC或者是服务器都是如此。系统调用某一个时刻只能有一个线程运行。当然这当中采用了比较多的策略来做时间片轮询。通过不断的调度切换来运行线程运行,而这种方式就叫做并发(concurrent)。
随着工艺水平的逐渐提升,CPU的技术也在不断增进。因此在如今多个CPU已经不是什么特别的,而大家常常以SMP的方式来形容多个CPU来处理两个或者两个以上的线程运行方式就称为并行(parallel)。
JAVA线程对象
继承Thread,实现start()方法
要实现线程运行,JAVA中有两种方式:
实现Runnable,然后再传递给Thread实例
注意:线程对象和线程是两个截然不同的概念。
线程对象是JVM产生的一个普通的Object子类
线程是CPU分配给这个对象的一个运行过程
public class Test {
public static void main(String[] args) throws Exception{
MyThread mt = new MyThread();
mt.start();
mt.join();
Thread.sleep(3000);
mt.start();
}
}
当线程对象mt运行完成后,我们让主线程休息一下,然后我们再次在这个线程对象上启动线程.结果我们看到:
Exception in thread "main" java.lang.IllegalThreadStateException
根本原因是在以下源代码中找出:
public synchronized void start() {
if (started)
throw new IllegalThreadStateException();
started = true;
group.add(this);
start0();
}
一个Thread的实例一旦调用start()方法,这个实例的started标记就标记为true,事实中不管这个线程后来有没有执行到底,只要调用了一次start()就再也没有机会运行了,这意味着:
【通过Thread实例的start(),一个Thread的实例只能产生一个线程】
interrupt()方法
当一个线程对象调用interrupt()方法,它对应的线程并没有被中断,只是改变了它的中断状态。使当前线程的状态变以中断状态,如果没有其它影响,线程还会自己继续执行。只有当线程执行到sleep,wait,join等方法时,或者自己检查中断状态而抛出异常的情况下,线程才会抛出异常。
join()方法
join()方法,正如第一节所言,在一个线程对象上调用join方法,是当前线程等待这个线程对象对应的线程结束
例如:有两个工作,工作A要耗时10秒钟,工作B要耗时10秒或更多。我们在程序中先生成一个线程去做工作B,然后做工作A。
new B().start();//做工作B
A();//做工作A
工作A完成后,下面要等待工作B的结果来进行处理。如果工作B还没有完成我就不能进行下面的工作C,所以:
B b = new B();
b.start();//做工作B
A();//做工作A
b.join();//等工作B完成.
C();//继续工作C
原则:【join是测试其它工作状态的唯一正确方法】
yield()方法
yield()方法也是类方法,只在当前线程上调用,理由同上,它主是让当前线程放弃本次分配到的时间片,调用这个方法不会提高任何效率,只是降低了CPU的总周期上面介绍的线程一些方法,基于(基础篇)而言只能简单提及。以后具体应用中我会结合实例详细论述。
原则:【不是非常必要的情况下,没有理由调用它】
wait()、notify()/notityAll()方法
首先明确一点他们的属于普通对象方法,并非是线程对象方法;其次它们只能在同步方法中调用。线程要想调用一个对象的wait()方法就要先获得该对象的监视锁,而一旦调用wait()后又立即释放该锁。
线程的互斥控制
多个线程同时操作某一对象时,一个线程对该对象的操作可能会改变其状态,而该状态会影响另一线程对该对象的真正结果。
synchornized关键字
把一个单元声明为synchornized,就可以让在同一时间只有一个线程操作该方法。作为记忆可以把synchronized看作是一个锁。但是我们要理解锁是被动的,还是主动的呢?换而言之它到底锁什么了?锁谁了?
例如:
synchronized(obj){
//todo…
}
如果代码运行到此处,synchronized首先获取obj参数对象的锁,若没有获取线程只能等待,如果多个线程运行到这只能有一个线程获取obj的锁,然后再执行{}中的代码。因此obj作用范围不同,控制程序也不同。
如果一个方法声明为synchornized的,则等同于把在为个方法上调用synchornized(this)。
如果一个静态方法被声明为synchornized,则等同于把在为个方法上调用synchornized(类.class)
真正的停止线程
要让一个线程得到真正意义的停止,需要了解当前的线程在干什么,如果线程当前没有做什么,那立刻让对方退出,当然是没有任何问题,但是如果对方正在手头赶工,那就必须让他停止,然后收拾残局。因此,首先需要了解步骤:
1. 正常运行;
2. 处理结束前的工作,也就是准备结束;
3. 结束退出。
注:以上部分概括出自某位牛人大哥的笔记,经常拜读他的博客
posted @
2009-07-20 10:00 叶澍成 阅读(435) |
评论 (0) |
编辑 收藏对于这本书的阅读,说来也很惭愧。过去黎敏基本对于他翻译过的书,都有邮寄送给我,书拿到手后,都是内心的高兴——哇,不用花钱的书,爽!(自己YY下)唯一要求就是能够读后能写个读后感,但是很多次都抱歉的忽悠了他。尽管如此他这次翻译的书还是一如既往的邮寄给我(当然也是在我厚脸皮的去索要的前提下,哈哈),同样答应写一篇读后感,可是迟到的读后感一直到现在才肯出炉,确实有点对不住他。这本书是在我每天早早挤车一个星期多读出来的,那个汽车真叫热啊,嘿嘿。切入正题,谈谈对于本书的一个看法和意见。
这本书整体风格基本还是沿袭了第一版本的套路,把每个重点都写成一个条目来针对性的阐述,本书总共条目为七十八条(第一版书共有五十七条)。当中很多是在JDK5基础上作为第一版的更新(与第一版比较明显特征是把原有第一版的第五章,第六章的结构化特征和方法换成JDK5的新特性:泛型,枚举,方法)。
这本书我到现在都怀疑出版社没有花很多时间在排版上,为什么这么说?在黎敏在翻译阶段也就有拿书的样稿给我看过,我第一看到就是封面问题——居然是黄色的,当时就跟他提出来,这个需要他和出版社去很好的斟酌一番。当时黎敏也说已经跟出版社商量过,哪知道最后拿到手上的居然还是“黄色”。可见出版社不知道是出于什么来考虑,让我来猜想下:难道是怕大伙都是色盲非要用黄色来提醒大家吗?更为失望的居然标题使用红色,晕啊!其次就要说书纸张也未免太扯淡了吧?我第一感觉纸张就是草稿纸一般,实在无语。在代码处理方面,显得不如第一版的那种爽朗,是不是出版社考虑节省纸张啊?非要把很多代码的间隔弄的特小,这样对于可读性来说确实很有疲劳感。所以这里向提醒以后的出版社——你忽悠是可以,但是别把读者当傻瓜。
上面是谈到在书的编排和效果的问题。现在谈谈书中内容的一些感受。整体上说书翻译还是可以,不过当中也不乏一些乏味用词过当的问题,这里要说到最明显的就是书中出现很多在每一个条目后的总结词汇都或多或少带有“本条目”一词,个人觉得偶尔写写是没很大问题,但是过多重复显得机械化的审美疲劳,甚至有时候过多这样的词汇对于阅读流畅性稍微欠佳。像这样类似的词汇还有——“不严格地讲”,“简而言之”,这些词汇确实稍微影响阅读感。这里小纠下不爽或者错误的位置:P240处第二段第三行和第四行中出现两个“现在”,这个可能在校正时没有很好去润色。P216倒数第二段第三行有一个估计是印刷错误:【原】仅仅一个异常就会导致该方法不得不外于… 如果没有错的话,这个字应该是:处。
还有类似第二章谈到的:静态工厂方法与构造器不同的第三的优势在于,它们可以返回原返回类型的任何子类型的对象。就这句话,老实讲我真看了很久才明白啥意思。
以上是谈到一些不足的细微之处,不过阅读此书后,确实对于以前一些不起眼的所谓了解语法也很好的得到一次重新的认识。比如以前在使用非检测警告上,以前很习惯的直接在整个类上直接使用标记表示;对于了解for-each的循环上得到进一步的认识;对于枚举类型的使用上更加灵活。这些都是个人对于此书泛读之后的一些浅薄的看法。如果对于译者有不敬之处还望原谅!
posted @
2009-07-17 18:09 叶澍成 阅读(358) |
评论 (0) |
编辑 收藏
摘要: Xml Schema的用途
1. 定义一个Xml文档中都有什么元素
2. 定义一个Xml文档中都会有什么属性
3. 定义某个节点的都有什么样的子节点,可以有多少个子节点,子节点出现的顺序
4. 定义元素或者属性的数据类型
5. 定义元素或者属性的默认值或者固定值
Xml Schema的根元素:
<?xml version="1....
阅读全文
引言
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的
使用与发展,得到不断地完善和扩展。目前在WWW中使用的是HTTP/1.0的第六版,HTTP/1.1的规范化工作正在进行之中,而且HTTP-
NG(Next Generation of HTTP)的建议已经提出。
HTTP协议的主要特点可概括如下:
1.支持客户/服务器模式。
2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服
务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3.灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方
式可以节省传输时间。
5.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则
它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
一、HTTP协议详解之URL篇
http(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,常基于TCP的连接方
式,HTTP1.1版本中给出一种持续连接的机制,绝大多数的Web开发,都是构建在HTTP协议之上的Web应用。
HTTP URL (URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息)的格式如下:
http://host[":"port][abs_path]
http表示要通过HTTP协议来定位网络资源;host表示合法的Internet主机域名或者IP地址;port指定一个端口号,
为空则使用缺省端口80;abs_path指定请求资源的URI;如果URL中没有给出abs_path,那么当它作为请求URI
时,必须以“/”的形式给出,通常这个工作浏览器自动帮我们完成。
eg:
1、输入:www.guet.edu.cn
浏览器自动转换成:http://www.guet.edu.cn/
2、http:192.168.0.116:8080/index.jsp
二、HTTP协议详解之请求篇
http请求由三部分组成,分别是:请求行、消息报头、请求正文
1、请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本,格式如下:Method Request-
URI HTTP-Version CRLF
其中 Method表示请求方法;Request-URI是一个统一资源标识符;HTTP-Version表示请求的HTTP协议版本;
CRLF表示回车和换行(除了作为结尾的CRLF外,不允许出现单独的CR或LF字符)。
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源
POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识
DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
应用举例:
GET方法:在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源,
eg:GET /form.html HTTP/1.1 (CRLF)
POST方法要求被请求服务器接受附在请求后面的数据,常用于提交表单。
eg:POST /reg.jsp HTTP/ (CRLF)
Accept:image/gif,image/x-xbit,... (CRLF)
...
HOST:www.guet.edu.cn (CRLF)
Content-Length:22 (CRLF)
Connection:Keep-Alive (CRLF)
Cache-Control:no-cache (CRLF)
(CRLF) //该CRLF表示消息报头已经结束,在此之前为消息报头
user=jeffrey&pwd=1234 //此行以下为提交的数据
HEAD方法与GET方法几乎是一样的,对于HEAD请求的回应部分来说,它的HTTP头部中包含的信息与通过
GET请求所得到的信息是相同的。利用这个方法,不必传输整个资源内容,就可以得到Request-URI所标识的资
源的信息。该方法常用于测试超链接的有效性,是否可以访问,以及最近是否更新。
2、请求报头后述
3、请求正文(略)
三、HTTP协议详解之响应篇
在接收和解释请求消息后,服务器返回一个HTTP响应消息。
HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文
1、状态行格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
其中,HTTP-Version表示服务器HTTP协议的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase
表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报 //头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后, //可能恢复正常
eg:HTTP/1.1 200 OK (CRLF)
2、响应报头后述
3、响应正文就是服务器返回的资源的内容
四、HTTP协议详解之消息报头篇
HTTP消息由客户端到服务器的请求和服务器到客户端的响应组成。请求消息和响应消息都是由开始行(对
于请求消息,开始行就是请求行,对于响应消息,开始行就是状态行),消息报头(可选),空行(只有
CRLF的行),消息正文(可选)组成。
HTTP消息报头包括普通报头、请求报头、响应报头、实体报头。
每一个报头域都是由名字+“:”+空格+值 组成,消息报头域的名字是大小写无关的。
1、普通报头
在普通报头中,有少数报头域用于所有的请求和响应消息,但并不用于被传输的实体,只用于传输的消息。
eg:
Cache-Control 用于指定缓存指令,缓存指令是单向的(响应中出现的缓存指令在请求中未必会出现),且是
独立的(一个消息的缓存指令不会影响另一个消息处理的缓存机制),HTTP1.0使用的类似的报头域为Pragma。
请求时的缓存指令包括:no-cache(用于指示请求或响应消息不能缓存)、no-store、max-age、max-stale、min-
fresh、only-if-cached;
响应时的缓存指令包括:public、private、no-cache、no-store、no-transform、must-revalidate、proxy-revalidate、
max-age、s-maxage.
eg:为了指示IE浏览器(客户端)不要缓存页面,服务器端的JSP程序可以编写如下:response.sehHeader
("Cache-Control","no-cache");
//response.setHeader("Pragma","no-cache");作用相当于上述代码,通常两者//合用
这句代码将在发送的响应消息中设置普通报头域:Cache-Control:no-cache
Date普通报头域表示消息产生的日期和时间
Connection普通报头域允许发送指定连接的选项。例如指定连接是连续,或者指定“close”选项,通知服务
器,在响应完成后,关闭连接
2、请求报头
请求报头允许客户端向服务器端传递请求的附加信息以及客户端自身的信息。
常用的请求报头
Accept
Accept请求报头域用于指定客户端接受哪些类型的信息。eg:Accept:image/gif,表明客户端希望接受GIF图象
格式的资源;Accept:text/html,表明客户端希望接受html文本。
Accept-Charset
Accept-Charset请求报头域用于指定客户端接受的字符集。eg:Accept-Charset:iso-8859-1,gb2312.如果在请求消
息中没有设置这个域,缺省是任何字符集都可以接受。
Accept-Encoding
Accept-Encoding请求报头域类似于Accept,但是它是用于指定可接受的内容编码。eg:Accept-Encoding:gzip.deflate.如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
Accept-Language
Accept-Language请求报头域类似于Accept,但是它是用于指定一种自然语言。eg:Accept-Language:zh-cn.如果请
求消息中没有设置这个报头域,服务器假定客户端对各种语言都可以接受。
Authorization
Authorization请求报头域主要用于证明客户端有权查看某个资源。当浏览器访问一个页面时,如果收到服务器
的响应代码为401(未授权),可以发送一个包含Authorization请求报头域的请求,要求服务器对其进行验证。
Host(发送请求时,该报头域是必需的)
Host请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的,eg:
我们在浏览器中输入:http://www.guet.edu.cn/index.html
浏览器发送的请求消息中,就会包含Host请求报头域,如下:
Host:www.guet.edu.cn
此处使用缺省端口号80,若指定了端口号,则变成:Host:www.guet.edu.cn:指定端口号
User-Agent
我们上网登陆论坛的时候,往往会看到一些欢迎信息,其中列出了你的操作系统的名称和版本,你所使用的
浏览器的名称和版本,这往往让很多人感到很神奇,实际上,服务器应用程序就是从User-Agent这个请求报头
域中获取到这些信息。User-Agent请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。不
过,这个报头域不是必需的,如果我们自己编写一个浏览器,不使用User-Agent请求报头域,那么服务器端就
无法得知我们的信息了。
请求报头举例:
GET /form.html HTTP/1.1 (CRLF)
Accept:image/gif,image/x-xbitmap,image/jpeg,application/x-shockwave-flash,application/vnd.ms-excel,application/vnd.ms-
powerpoint,application/msword,*/* (CRLF)
Accept-Language:zh-cn (CRLF)
Accept-Encoding:gzip,deflate (CRLF)
If-Modified-Since:Wed,05 Jan 2007 11:21:25 GMT (CRLF)
If-None-Match:W/"80b1a4c018f3c41:8317" (CRLF)
User-Agent:Mozilla/4.0(compatible;MSIE6.0;Windows NT 5.0) (CRLF)
Host:www.guet.edu.cn (CRLF)
Connection:Keep-Alive (CRLF)
(CRLF)
3、响应报头
响应报头允许服务器传递不能放在状态行中的附加响应信息,以及关于服务器的信息和对Request-URI所标识
的资源进行下一步访问的信息。
常用的响应报头
Location
Location响应报头域用于重定向接受者到一个新的位置。Location响应报头域常用在更换域名的时候。
Server
Server响应报头域包含了服务器用来处理请求的软件信息。与User-Agent请求报头域是相对应的。下面是
Server响应报头域的一个例子:
Server:Apache-Coyote/1.1
WWW-Authenticate
WWW-Authenticate响应报头域必须被包含在401(未授权的)响应消息中,客户端收到401响应消息时候,并发
送Authorization报头域请求服务器对其进行验证时,服务端响应报头就包含该报头域。
eg:WWW-Authenticate:Basic realm="Basic Auth Test!" //可以看出服务器对请求资源采用的是基本验证机制。
4、实体报头
请求和响应消息都可以传送一个实体。一个实体由实体报头域和实体正文组成,但并不是说实体报头域和实体正文要在一起发送,可以只发送实体报头域。实体报头定义了关于实体正文(eg:有无实体正文)和请求所标识的资源的元信息。
常用的实体报头
Content-Encoding
Content-Encoding实体报头域被用作媒体类型的修饰符,它的值指示了已经被应用到实体正文的附加内容的编
码,因而要获得Content-Type报头域中所引用的媒体类型,必须采用相应的解码机制。Content-Encoding这样用
于记录文档的压缩方法,eg:Content-Encoding:gzip
Content-Language
Content-Language实体报头域描述了资源所用的自然语言。没有设置该域则认为实体内容将提供给所有的语言
阅读
者。eg:Content-Language:da
Content-Length
Content-Length实体报头域用于指明实体正文的长度,以字节方式存储的十进制数字来表示。
Content-Type
Content-Type实体报头域用语指明发送给接收者的实体正文的媒体类型。eg:
Content-Type:text/html;charset=ISO-8859-1
Content-Type:text/html;charset=GB2312
Last-Modified
Last-Modified实体报头域用于指示资源的最后修改日期和时间。
Expires
Expires实体报头域给出响应过期的日期和时间。为了让代理服务器或浏览器在一段时间以后更新缓存中(再次
访问曾访问过的页面时,直接从缓存中加载,缩短响应时间和降低服务器负载)的页面,我们可以使用Expires
实体报头域指定页面过期的时间。eg:Expires:Thu,15 Sep 2006 16:23:12 GMT
HTTP1.1的客户端和缓存必须将其他非法的日期格式(包括0)看作已经过期。eg:为了让浏览器不要缓存页
面,我们也可以利用Expires实体报头域,设置为0,jsp中程序如下:response.setDateHeader("Expires","0");
五、利用telnet观察http协议的通讯过程
实验目的及原理:
利用MS的telnet工具,通过手动输入http请求信息的方式,向服务器发出请求,服务器接收、解释和接受请求
后,会返回一个响应,该响应会在telnet窗口上显示出来,从而从感性上加深对http协议的通讯过程的认识。
实验步骤:
1、打开telnet
1.1 打开telnet
运行-->cmd-->telnet
1.2 打开telnet回显功能
set localecho
2、连接服务器并发送请求
2.1 open www.guet.edu.cn 80 //注意端口号不能省略
HEAD /index.asp HTTP/1.0
Host:www.guet.edu.cn
/*我们可以变换请求方法,请求桂林电子主页内容,输入消息如下*/
open www.guet.edu.cn 80
GET /index.asp HTTP/1.0 //请求资源的内容
Host:www.guet.edu.cn
2.2 open www.sina.com.cn 80 //在命令提示符号下直接输入telnet www.sina.com.cn 80
HEAD /index.asp HTTP/1.0
Host:www.sina.com.cn
3 实验结果:
3.1 请求信息2.1得到的响应是:
HTTP/1.1 200 OK //请求成功
Server: Microsoft-IIS/5.0 //web服务器
Date: Thu,08 Mar 200707:17:51 GMT
Connection: Keep-Alive
Content-Length: 23330
Content-Type: text/html
Expries: Thu,08 Mar 2007 07:16:51 GMT
Set-Cookie: ASPSESSIONIDQAQBQQQB=BEJCDGKADEDJKLKKAJEOIMMH; path=/
Cache-control: private
//资源内容省略
3.2 请求信息2.2得到的响应是:
HTTP/1.0 404 Not Found //请求失败
Date: Thu, 08 Mar 2007 07:50:50 GMT
Server: Apache/2.0.54 <Unix>
Last-Modified: Thu, 30 Nov 2006 11:35:41 GMT
ETag: "6277a-415-e7c76980"
Accept-Ranges: bytes
X-Powered-By: mod_xlayout_jh/0.0.1vhs.markII.remix
Vary: Accept-Encoding
Content-Type: text/html
X-Cache: MISS from zjm152-78.sina.com.cn
Via: 1.0 zjm152-78.sina.com.cn:80<squid/2.6.STABLES-20061207>
X-Cache: MISS from th-143.sina.com.cn
Connection: close
失去了跟主机的连接
按任意键继续...
4 .注意事项:1、出现输入错误,则请求不会成功。
2、报头域不分大小写。
3、更深一步了解HTTP协议,可以查看RFC2616,在http://www.letf.org/rfc上找到该文件。
4、开发后台程序必须掌握http协议
六、HTTP协议相关技术补充
1、基础:
高层协议有:文件传输协议FTP、电子邮件传输协议SMTP、域名系统服务DNS、网络新闻传输协议NNTP和
HTTP协议等
中介由三种:代理(Proxy)、网关(Gateway)和通道(Tunnel),一个代理根据URI的绝对格式来接受请求,重写全部
或部分消息,通过 URI的标识把已格式化过的请求发送到服务器。网关是一个接收代理,作为一些其它服务
器的上层,并且如果必须的话,可以把请求翻译给下层的服务器协议。一 个通道作为不改变消息的两个连接
之间的中继点。当通讯需要通过一个中介(例如:防火墙等)或者是中介不能识别消息的内容时,通道经常被使
用。
代理(Proxy):一个中间程序,它可以充当一个服务器,也可以充当一个客户机,为其它客户机建立请求。
请求是通过可能的翻译在内部或经过传递到其它的 服务器中。一个代理在发送请求信息之前,必须解释并且
如果可能重写它。代理经常作为通过防火墙的客户机端的门户,代理还可以作为一个帮助应用来通过协议处
理没有被用户代理完成的请求。
网关(Gateway):一个作为其它服务器中间媒介的服务器。与代理不同的是,网关接受请求就好象对被请求的
资源来说它就是源服务器;发出请求的客户机并没有意识到它在同网关打交道。
网关经常作为通过防火墙的服务器端的门户,网关还可以作为一个协议翻译器以便存取那些存储在非
HTTP系统中的资源。
通道(Tunnel):是作为两个连接中继的中介程序。一旦激活,通道便被认为不属于HTTP通讯,尽管通道可能
是被一个HTTP请求初始化的。当被中继 的连接两端关闭时,通道便消失。当一个门户(Portal)必须存在或中介
(Intermediary)不能解释中继的通讯时通道被经常使用。
2、协议分析的优势—HTTP分析器检测网络攻击
以模块化的方式对高层协议进行分析处理,将是未来入侵检测的方向。
HTTP及其代理的常用端口80、3128和8080在network部分用port标签进行了规定
3、HTTP协议Content Lenth限制漏洞导致拒绝服务攻击
使用POST方法时,可以设置ContentLenth来定义需要传送的数据长度,例如ContentLenth:999999999,在传送完
成前,内 存不会释放,攻击者可以利用这个缺陷,连续向WEB服务器发送垃圾数据直至WEB服务器内存耗
尽。这种攻击方法基本不会留下痕迹。
http://www.cnpaf.net/Class/HTTP/0532918532667330.html
4、利用HTTP协议的特性进行拒绝服务攻击的一些构思
服务器端忙于处理攻击者伪造的TCP连接请求而无暇理睬客户的正常请求(毕竟客户端的正常请求比率非常之
小),此时从正常客户的角度看来,服务器失去响应,这种情况我们称作:服务器端受到了SYNFlood攻击(SYN洪水攻击)。
而Smurf、TearDrop等是利用ICMP报文来Flood和IP碎片攻击的。本文用“正常连接”的方法来产生拒绝服务攻击。
19端口在早期已经有人用来做Chargen攻击了,即Chargen_Denial_of_Service,但是!他们用的方法是在两台
Chargen 服务器之间产生UDP连接,让服务器处理过多信息而DOWN掉,那么,干掉一台WEB服务器的条件就
必须有2个:1.有Chargen服务2.有HTTP 服务
方法:攻击者伪造源IP给N台Chargen发送连接请求(Connect),Chargen接收到连接后就会返回每秒72字节的
字符流(实际上根据网络实际情况,这个速度更快)给服务器。
5、Http指纹识别技术
Http指纹识别的原理大致上也是相同的:记录不同服务器对Http协议执行中的微小差别进行识别.Http指纹识
别比TCP/IP堆栈指纹识别复杂许 多,理由是定制Http服务器的配置文件、增加插件或组件使得更改Http的响应
信息变的很容易,这样使得识别变的困难;然而定制TCP/IP堆栈的行为 需要对核心层进行修改,所以就容易识
别.
要让服务器返回不同的Banner信息的设置是很简单的,象Apache这样的开放源代码的Http服务器,用户可以在
源代码里修改Banner信息,然 后重起Http服务就生效了;对于没有公开源代码的Http服务器比如微软的IIS或者
是Netscape,可以在存放Banner信息的Dll文件中修 改,相关的文章有讨论的,这里不再赘述,当然这样的修改的效果
还是不错的.另外一种模糊Banner信息的方法是使用插件。
常用测试请求:
1:HEAD/Http/1.0发送基本的Http请求
2:DELETE/Http/1.0发送那些不被允许的请求,比如Delete请求
3:GET/Http/3.0发送一个非法版本的Http协议请求
4:GET/JUNK/1.0发送一个不正确规格的Http协议请求
Http指纹识别工具Httprint,它通过运用统计学原理,组合模糊的逻辑学技术,能很有效的确定Http服务器的类型.它
可以被用来收集和分析不同Http服务器产生的签名。
6、其他:为了提高用户使用浏览器时的性能,现代浏览器还支持并发的访问方式,浏览一个网页时同时建立
多个连接,以迅速获得一个网页上的多个图标,这样能更快速完成整个网页的传输。
HTTP1.1中提供了这种持续连接的方式,而下一代HTTP协议:HTTP-NG更增加了有关会话控制、丰富的内容
协商等方式的支持,来提供
更高效率的连接。
posted @
2009-02-17 17:26 叶澍成 阅读(288) |
评论 (0) |
编辑 收藏数据对于输入和输出的操作耗时是非常严重的问题,如果把这个问题放入到网络上去看待更甚是值得注意的一个问题了。假如结合基础的OS知识我们也知道如果要减少这种I/O操作的耗时或者也可以说提升这种效率的话,最大的可能就是减少物理读写的次数,而且尽可能做到主存数据的重读性(操作系统也在加强说明更多减少抖动现象的产生)。
在java.nio包中我们可以直接来操作相对应的API了。可以让java更加方便的直接控制和运用缓冲区。缓冲区有几个需要了解的特定概念需要详尽来解释,才能更好的知道我们下面一些列需要针对的问题实质。
属性
容量(capacity):顾名思义就是表示缓冲区中可以保存多少数据;
极限(limit):缓冲区中的当前数据终结点。不过它是可以动态改变的,这样做的好处也是充分利用重用性;
位置(position):这个也好理解,其实就是指明下一个需要读写数据的位置。
上面上个关系还可以具体用图示的方式来表达整体概念,如下图所示:
在极限的时候就说到可以修改它,所以对于它的操作由以下方法:
l clear():首先把极限设置为容量,再者就是需要把位置设置为0;
l flip():把极限设置为位置区,再者就是需要把位置设置为0;
l rewind():不改变极限,不过还是需要把位置设置为0。
最为最基础的缓冲区ByteBuffer,它存放的数据单元是字节。首先要强调的是ByteBuffer没有提供公开的构造方法,只是提供了两个静态的工厂方法。
l allocate(int capacity):返回一个ByteBuffer对象,参数表示缓冲区容量大小。
l allocateDirect (int capacity):返回一个ByteBuffer对象,参数也是一样表示缓冲区容量大小。
在这里需要注意的是在使用两者的时候需要特别小心,allocateDirect和当前操作系统联系的非常紧密,它牵涉到使用native method的方法,大家知道一旦本地方法就是需要考虑调用dll(动态链接库)这个时候基本也就失去了JAVA语言的特性,言外之意对于耗资源非常大。所以如果考虑到当前使用的缓存区比较庞大而且是一个长期驻留使用的,这个时候可以考虑使用它。
posted @
2009-02-13 20:56 叶澍成 阅读(291) |
评论 (0) |
编辑 收藏
摘要:
在上篇blog中谈到RMI的问世由来只是大致的把一些概念结构说明了下,自己静静想想要有好的说明干脆用代码说明比较妥当也最为有说明性。事后自己倒腾了一个简单的代码DEMO。代码中有个简单的场景,比如你是属于某地区医保范围内的成员,到医院看病,这个候医院为了审核你的相关个人资料需要到医保管理部门调阅信息,你只需要给出用户名称或者其他一个有...
阅读全文
posted @
2009-02-03 21:56 叶澍成 阅读(1859) |
评论 (3) |
编辑 收藏
综述
Rmi自从JDK1.1就已经出现了。而对于为什么在JAVA的世界里需要一个这样 思想理念就需要看下:RMI问世由来。其实真正在国内使用到它的比较少,不过在前些年比较火的EJB就是在它的基础上进一步深化的。从本质上来讲RMI的兴起正是为了设计分布式的客户、服务器结构需求而应运而生的,而它的这种B/S结构思想能否和我们通常的JAVA编程更加贴切呢?言外之意就是能否让这种分布式的状态做到更加透明,作为开发人员只需要按照往常一样开发JAVA应用程序一样来开发分布式的结构。那现在的问题是如何来划平这个鸿沟呢?首先我们来分析下在JAVA世界里它的一些特点因素:
l JAVA使用垃圾收集确定对象的生命周期。
l JAVA使用异常处理来报告运行期间的错误。这里就要和我们网络通讯中的异常相联系起来了。在B/S结构的网络体系中我们的这种错误性是非常常见的。
l JAVA编写的对象通过调用方法来调用。由于网络通讯把我们的客户与服务器之间阻隔开了。但是代理的一种方式可以很好的提供一种这样的假象,让开发人员或者使用者都感觉是在本地调用。
l JAVA允许一种高级的使用类加载器(CLassLoader)机制提供系统类路径中没有的类。这话什么意思?
主要特点
上面说到了分布式的方式和我们的JAVA中如何更好的划平这个鸿沟,需要具备的特质。
那这里我们来看看我们所谓的RMI到底跟我们普通的JAVA(或者说JavaBean)存在一些什么样的差异:
l RMI远程异常(Remote Exception):在上面我们也提到了一个网络通讯难免有一些无论是软件级别的还是硬件级别的异常现象,有时候这些异常或许是一种无法预知的结果。让我们开发人缘如何来回溯这种异常信息,这个是我们开发人员要关心的。因此在调用远程对象的方法中我们必须在远程接口中(接口是一种规范的标准行为)所以在调用的这个方法体上需要签名注明:java.rmi,RemoteException.。这也就注明了此方法是需要调用远程对象的。
l 值传递 :当把对象作为参数传递给一个普通的JAVA对象方法调用时,只是传递该对象的引用。请注意这里谈到的是对象的“引用”一词,如果在修改该参数的时候,是直接修改原始对象。它并不是所谓的一个对象的备份或者说拷贝(说白了就是在本JVM内存中的对象)。但是如果说使用的是RMI对象,则完全是拷贝的。这与普通对象有着鲜明的对比。也正是由于这种拷贝的资源消耗造就了下面要说到的性能缺失了。
l 调用开销:凡是经过网络通讯理论上来说都是一种资源的消耗。它需要通过编组与反编组方式不断解析类对象。而且RMI本身也是一种需要返回值的一个过程定义。
l 安全性:一谈到网络通讯势必会说到如何保证安全的进行。
概念定义
在开始进行原理梳理之前我们需要定义清楚几个名词。对于这些名词的理解影响到后的深入进行。
1. Stub(存根,有些书上也翻译成:桩基在EJB的相关书籍中尤为体现这个意思):
这里举例说明这个概念起(或许不够恰当)。例如大家因公出差后,都有存在一些报销的发票或者说小票。对于你当前手头所拿到的发票并不是一个唯一的,它同时还在你发生消费的地点有一个复印件,而这个复印件就是所谓的存根。但是这个存根上并没有很多明细的描述,只是有一个大概的金额定义。它把很多的细节费用都忽略了。所以这个也是我们说的存根定义。而在我们RMI的存根定义就是使用了这样一个理解:在与远程发生通讯调用时,把通讯调用的所有细节都通过对象的封装形式给隐藏在后端。这本身就符合OOAD的意思理念。而暴露出来的就是我们的接口方式,而这种接口方式又和服务器的对象具有相同的接口(这里就和我们前面举例说的报销单据联系上了,报销单据的存根不知道会有一个什么形式发生具体问题,而你手执的发票具体就需要到贵公司去报销费用,而这里的公司财务处就是所谓的服务器端,它才是真正干实质性问题的。)因此作为开发人员只需要把精力集中在业务问题的解决上,而不需要考虑复杂的分布式计算。所有这些问题都交给RMI去一一处理。
2. Skeleton(一些书翻译叫骨架,也叫结构体):它的内部就是真正封装了一个类的形成调用体现机制。包括我们熟知的ServerSocket创建、接受、监听、处理等。
3. Mashalling(编组):在内存中的对象转换成字节流,以便能够通过网络连接传输。
4. Unmashalling(反编组):在内存中把字节流转换成对象,以便本地化调用。
5. Serialization(序列化):编组中使用到的技术叫序列化。
6. Deserializationg(反序列化):反编组中使用到的技术叫反序列化。
客户端
既然我们知道stub主要是以接口的方式来暴露体现,而stub主要 也是以代理的方式来具体实施。那在RMI中的这种接口有哪些特性呢?(Remote Interface)
1) 必须扩展(extends)java.rmi.Remote接口,因为远程接口并不包含任何一个方法,而是作为一个标记出现,它就是需要告诉JVM在RunTime的时候哪些是常规对象,哪些属于远程对象。通过这种标识的定义能让JVM了解类中哪些方法需要编组,通过了编组的方式才能通过网络序列化的调用;
2) 接口必须为public(公共),它的好处不言而喻的——能够方便的让所有人员来调用。
3) 接口方法还需要以异常抛出(例如:RemoteException),至于它的用处我们在前面也提到这里就不再复述;
4) 在调用一个远程对象期间(运行期间),方法的参数和返回值都要必须是可序列化的。至于为什么需要这么做?这里的缘由不用多说大家也应该清楚了解。
服务端
既然我们知道stub所做的事情是一个简单的代理转发动作,那我们真正要做的对象就在服务端来做了。对于使用简单的RMI我们直接去指定,但是往往一旦使用了RMI对象就存在非常多的远程方法调用,这个时候服务器端对于这么多的调用如何来判别或者说识别呢?这里就要说到的是对于RMI实现它会创建一个标识符,以便以后的stub可以调用转发给服务器对象使用了,而这种方式我们通常叫服务器RMI的注册机制。言外之意就是让服务器端的对象注册在RMI机制中,然后可以导出让今后的stub按需来调用。那它又是如何做到这种方式的呢?对于RMI来说有两种方式可以达到这种效果:
a) 直接使用UnicastRemoteObject的静态方法:exportObject;
b) 继承UnicastRemoteObject类则缺省的构造函数exportObject。
现在大家又会问他们之间又有什么区别呢?我该使用哪种方式来做呢,这不是很难做抉择吗?从一般应用场景来说区别并不是很大,但是,这里说了“但是”哦,呵呵。大家知道继承的方式是把父类所具备的所有特质都可以完好无损的继承到子类中而对于类的总老大:Object来说里面有:equals()、hashCode()、toString()等方法。这是个什么概念呢?意思就是说如果对于本地化的调用,他们两个的方法(a,b)基本区别不是很大。但是我们这里强调的RMI如果是一种分布式的特定场景,具备使用哈希表这种特性就显得尤为重要了。
刚才说了服务端采用什么方法行为导出对象的。那现在导出后的对象又对应会发生什么情况呢?
首先被导出的对象被分配一个标识符,这个标识符被保存为:java.rmi.server.ObjID对象中并被放到一个对象列表中或者一个映射中。而这里的ID是一个关键字,而远程对象则是它的一个值(说到这大家有没有觉得它原理非常像HashMap的特质呢?没错,其实就是使用了它的特性),这样它就可以很好的和前面创建的stub沟通。如果调用了静态方法UnicastRemoteObject.export(Remote …),RMI就会选择任意一个端口号,但这只是第一调用发生在随后的exportObject每次调用都把远程对象导出到该远程对象第一被导出时使用的端口号。这样就不会产生混乱,会把先前一一导出的对象全部放入到列表中。当然如果采用的是指定端口的,则按照对应显示的调用方式使用。这里稍作强调的是一个端口可以导出任意数目的对象。
(待续……)
posted @
2009-02-02 12:04 叶澍成 阅读(3476) |
评论 (3) |
编辑 收藏/
服务器结构特点,使用的一个核心技术就是网络通讯层。在最早的OSI
的概念基础上,建立了完善具体协议层。而客户想要能够与位于其他物理层主机上的服务器通讯,需要能够想服务器发送数据,然后以某种方式获得响应。这当中就牵涉到我们熟悉的协议层面了,在这里就不再复述这些协议概念了。对于网络通讯来说我们所要了解的是最为常用的就是两种连接方式:无连接协议(UDP
)、面向连接协议(TCP/IP
)。
多数网络编程库中(以JAVA为主来说明),在JAVA平台中一样的提供了这些元素。而作为面向连接协议来说使用的是套接字(Socket)进行了更进一步的抽象描述。一般我们在JAVA的网络编程中都觉得在使用套接字这块相对方便,它不需要你去更多的了解操作系统的细节以及硬件的传递处理方式。TCP/IP的所有细节之处都得到了套接字的封装使用,让程序员关注到业务层面的处理。
对象是一种抽象思维物质,对于计算机来说它只对数字电路的存储方式能够加以识别而且在网络传输当中也是一种信号量,而这一切只有使用字节流方式传输才是真正需要做到的。所以在本地主机与远程服务器的通讯传输就在对象与字节流之间不断相互转化才是我们真正需要的人性物质与机器所需要的。(有点墨迹了,切入整体)总体来说就是需要两种方式来认定这种传输行为:编组(Marshalling)与反编组(Unmarshalling)。而这一切的手段方式才是通过:序列化(Serialiazable)与反序列化的方式不断完成。如下图所示:
图:对象到字节再到对象的转换
对于数据的传输本质就是上图说明的。那我们一般是如何使用套接字来构造我们这一行为呢?对于这里强调的主要是一种大致方法说明,所以只能以部分代码来说明客户端怎么来发送这个请求。
Socket socket=new Socket("http://www.wgh.com.cn",8888);
OutputStream out=socket.getOutputStream();
ObjectOutputStream obj=new ObjectOutputStream(out);
obj.writeObject(object);
InputStream in=socket.getInputStream();
ObjectInputStream objIn=new ObjectInputStream(in);
Object objFoo=(Object)objIn.readObject();
//todo 这里就是具体进行操作的相关传值参数处理了…
obj.close();
objIn.close();
socket.close();
而作为服务器的接收方则把以上数据做一个逆转相反处理就可以。即服务器需要读取发送过来的对象数据,最终得到结果。现在假设还是一个甚至更多这样的对象处理,我们又要处理和以上代码差不多的过程。好,到这里我们可曾想到难道没有一种办法把这些过多的重复过程做一个通用的方式来提供吗?我如果不想去做这些繁杂的对象处理可以吗?比如,我想直接得到:
//其中clientObjectji就是从客户端传输过来的副本;
MyObject myObject=server.getFoo(clientObject);
这样就能让我们把底层的那些庞杂数据转换能够透明封装起来呢?既然这个问题一经提出,那就意味着肯定有很多类似的需求。技术永远都是在需求的提出应运而生的。上面提出的需求就是我们要讨论的,既然我们想把一些套接字的重复处理过程来个封装清理,那需要面对的问题是什么呢?
1. 能够把所有的相同处理过程全部都移入到服务端呢?
2. 对于客户端来说能否只预留接口行为呢?
3. 把过多的复杂处理过程完善的做个封装?
4. 如果以上过程能够形成,那客户端又是如何办到可以连接到服务器端的组件行为呢?
既然能够把遇到的问题提出然后总结出来也就意味着我们需要去解决它。不知道是否还
记得设计模式中有一个叫:代理模式?没错,就是这个代理模式开始我们的描述。代理是一个实现给定接口的对象,但是不直接去执行代码结果,而是代表其他一些对象执行实际计算的对象。怎么理解这个话呢?举例说,如今很多城市都有火车票或者飞机票的代售点,这里的代售点其实就是采用了一种代理机制。我们想买某天的火车或者飞机票有时候并不需要到火车站或者飞机票的总点去购买票,而是找一个你最近的代售点去购买。代售点就是起到一个中间桥梁的作用,至于买票人员无需关心他们如何去订购,这些具体的动作都由他们内部去处理,你只关心最终是否有你需要的票就行。知道这个原理接下来就好理解很多了,我们最好以类图的方式来说明这个代理的机制,如图所示:
到这里如果还觉得抽象,没关系接下来我以更加贴切的实例来结合类图的方式给出对应的参照说明。假如我们把上面的proxy模式再做个深入的探讨剖析(结合上面说的客户端发送参数作为请求和提出的问题综述)。大家都知道一个接口是能够在安全甚至在扩展上能够帮助我们非常大的功能。作为客户端最为希望的就是只关心我们需要的参数(或者变量)、返回值,而它如何而来,做了哪些具体工作这些都不是客户端关心的。Ok,现在结合我们说的接口方式,确实可以解决这个问题(接口的简单化,没有具体实现),但是你可能会问:
1. 既然接口如此简单,那参数又是如何传递过去的呢?
2. 服务端又如何知道我要的是什么呢?
带着问题我们来解决这个问题,当然也是大家所关心的问题了。现在开始要对于上面的proxy模式做个深入剖析了。我们先来看一个proxy模式演变的过程的图示:
图:RMI核心结构
我们可以从图示看出从传统的proxy模式变化到一个变化的结构有什么不同呢?对于先前我们提出的两个问题就可以很好的做出解释了:
n 既然接口如此简单,那参数又是如何传递过去的呢?
A:既然是对客户端只开接口暴露,那么我们是就需要一个后台的socket来传输接口中已经定义好的参数,通过参数的编组(序列化)方式请求到远程服务上去响应处理。这当中要求定义到对方服务的服务名称和端口号。(这里也就是我们最先提到的那段代码了)
n 服务端又如何知道我要的是什么呢?
A:ok,既然客户端是通过socket来发送数据,那势必一定需要ServerSocket来做这个响应的接收处理了。问题是传过来的参数如何与我们的业务实现类关联上呢?所以这个也就是skeleton的职责所在了,在skeleton的封装处理中(启动中就把响应实现类给嵌入,聚合实现类),然后通过类转换处理和匹配处理来得到需要响应的结果了。
本来说到这想大概有个收尾,但是总觉得还没有把一些问题说透彻。索性想再深入写写。
从套接字衍生到RMI代码思路
posted @
2009-02-02 11:57 叶澍成 阅读(3668) |
评论 (1) |
编辑 收藏
进程的创建
进程本身是一个动态的实体,所以它本身在运行期间也通过创建进程系统调用,并且可以创建多个新进程,对于这句话我同样使用图解的方式来做个简单说明:
当一个进程创建一个新进程时,会存在两种可能的方式执行:
1. 父进程(继续执行)和子进程并行的执行;
2. 父进程等待部分或者全部子进程终止执行;
而新进程的地址空间也存在两种可能:
1. 子进程是父进程的一个COPY了;
2. 载入一个程序来运行;
到这里就有点感觉Erlang的进程思想端倪了(开始我咋看感觉有点象,但是越深入后就觉得确实就是到这个思想才形成了Erlang程序语言的意义本质,个人揣度啊,哈哈)既然有那么点思想的感觉,那我们就开始进入探讨阶段了。也正是下面即将要讲到的问题才印证一句话:技术的本质还存留在简单事物之上(个人总结,哈哈)。
进程间通信
进程间通信有两种本质的方式:
1. 共享缓冲区提供通信;
2. 消息传递;
大家有没有认真看到上面的四个字“消息传递”,对没错就是消息传递!那这里我就感觉是否就是这里和Erlang的语言所谈到的消息传递呢?尽管一个处于操作系统级别,而另一处于语言级别,但是初看给我的感觉是原理是否一致呢?呵呵,那就让我们来看看OS级别的进程间通信本质起了。
消息传递系统
消息系统的功能是允许进程与其他进程之间通讯不必借助共享数据,他们各自独立。而这里要说到一个概念,什么是IPC?
如果我们先不看它定义,而了解具体做法,看是一个什么效果。
到这里为止是不是感觉又和我们说的Erlang非常类似呢?真的没错。。。那就继续往下看看它到底如何而做了。有以下几种方法实现和Send/Receive操作的方法:
u 直接或者间接通信
u 对称或不对称通信
u 自动或手动缓冲
u 发送copy或者引用
u 定长消息或者变长消息
为了更好的说明上面各自的特征是如何引入和体现的,使用两个典型的进程p,q作为两个进程之间的通讯来加以演示。
直接通信:
这里就是两个非常赤裸的而且是非常利索的通信了:
u send(P,message) P发送一个消息给进程Q;
u receive(Q,message) 从进程Q中接收一个消息
特点:
1. 每对需要通信的进程之间自动建立一条链路,进程只需要知道彼此的进程标识符(Pid);
2. 一个连接就只连接到这两个进程;
因此这种机制在寻址上是对称的;发送者与接收者进程都必须要指明通信一方。不过这里要谈到它的一种特例:发送者需要知道接收者,但是接收者不需要知道发送者,其原语定义为:
Send(P,Message) 发送一个消息给P;
Receive(id,Message)从任意进程中接受一个消息;
由于通信是一种交互行为,所以一般情况来说我们有发送自然希望存在一个回复的交互动作,而像这种特例就无法知道它的这种情形,因此这种情况也是我们不希望所见的。
间接通信
间接通信中消息发送和接收则是通过邮箱(实际中更多的是端口方式,这里为了更好理解我们比作邮箱方式)进行的。若把邮箱看成一个对象,进程就可以把消息邮寄(放置)在其中,显而易见既然能够放入自然也就可以从邮箱中取出了。而每一个邮箱都有一个唯一的地址(标识符),进程可以通过不同的邮箱和其它进程通信了。两个进程只有共享一个邮箱才可以进程通信。因此基本构建和原语定义图示如下:
Send(A,M):发送消息(Message)给邮箱A;
Receive(A,M):从邮箱A接收到消息(M);
特点:
1. 只有在两个进程间有一个共享邮件箱下才能两者建立一个连接;
2. 一条链路可以连接两个或者更多的进程;
3. 每对通信进程之间可以同时存在多个不同的链路,而且每条链路对应一个邮箱;
那我们来看看直接通信和间接通信最大的区别是什么?没错,其实间接通信存在中间一个共享的邮箱,而正是这种方式才在以后的应用中得到广泛利用。这里就联想到Erlang语法的:Pid!M是否感觉很相似(注:M消息通知标示符为Pid的进程操作事件,而且具体在接受中也存在得到一个receive来获取消化了),在我看来它就是典型使用到了这个原理机制。这里来看一道例题:假如有两个进程P1,P2和P3都存在共享邮箱A,而且P2与P3正是从A中接收。那么谁 接收到P1发送来的消息呢?图示:
这里我们就需要具体讨论问题的实质了:
对照上面说讲到的间接通信特点,我们知道一条链路最多连接两个进程,同时最多允许任意选择进程来接收消息(现在这个例子中只存在P2,P3),所以他们两者只允许单独接收消息而不是同时接收消息。至于消息会发送给谁,这就需要系统本身来确定接收者了。因此,一个邮箱可能为一个进程或者操作系统所有,不难看出这个例子存在以下情况:
一旦拥有邮箱
A的
进程终止时,邮箱也就同时要消失,随后向该邮箱发送消息的进程就会被告知邮箱不存在。这里需要强调的是作为操作系统本身来说拥有一个邮箱是独立的不依赖于任何进程。所以操作系统有必要提供一种机制允许一个进程来专门做这个工作了,那是什么工作呢?具体有以下特征:
u 创建一个新邮箱;
u 通过这个邮箱发送和接收信息;
u 删除一个邮箱;
接下来就开始单独讨论所谓的这个“邮箱”的单独机制能够引发的一些线索了。
进程同步
通过消息传送来进程通信,这个是它本质所在。但是消息传送可能有阻塞或者无阻塞——同步和异步。所以这里就存在对于发送者和接收者的阻塞或无阻塞现象的讨论了,对于他们有一下特点:
1. 发送进程阻塞:发送进程被阻塞,直到接收进程接收消息;
2. 发送进程无阻塞:发送进程发送消息并且立刻恢复执行;
3. 接收进程阻塞:接收进程被阻塞,知道一个消息为有效;
4. 接收进程无阻塞:接收进程获取一个有效或空消息;
以上的方式还可以组合形成。
既然有阻塞和无阻塞现象,那立刻可以联想到我们的邮箱扩展成一种管道方式呢?没错这里就需要讲解下面的定义形成。
缓冲
这里只想对于三个定义了解:
u 零长度:无缓冲消息系统;
u 限定长度:
自动缓冲
u 无限长度:
这里单独把限定长度和无限长度提取出来定义:
限定长度:消息队列中存在N个消息,发送者在发送未满的队列中无阻塞。一旦队列满则阻塞直到出现空闲空间。
无线长度:消息队列有无限个消息,也不会阻塞发送者。
下面我们就要通过这些概念扩展到程序开发中经常会遇到的实例。
(待续。。。。。。)
posted @
2008-12-14 12:42 叶澍成 阅读(1256) |
评论 (0) |
编辑 收藏在学习Erlang程序过程中,总觉得对于进程还是没有很好的把握。所以自己对于进程的再次提及让我不得不重温操作系统这门看似抽象的课程了。但是总觉得如果单一讲解进程或许略显抽象不够理解,自己就想把某些经验和知识片段有个很好的系统联系起来,我想这样可以让自己更好加强记忆理解。长话短说,我们进入主题,既然在Erlang的学习中始终围绕着进程一词来深入研究,我们就从进程这个话题谈起。
进程概念
1. 进程是运行中的程序。这里我们就可以稍微延伸下以便帮助我们记忆理解了:
在这里我们只要抓住“运动”词汇,就不然发现进程是个动态的实体,与之对应的是我们常说的程序,程序而是一个静态实体了。(bw:这里突然想到以前对于认识EJB2中也有一个对应的概念就是EntityBean与SessionBean,它们与之对应的就是一个典型的名词和动词概念了,哈哈啰嗦了,转回正题)。那我们会想是什么来体现我们说的进程为一个动态实体呢?立刻会联系产生接下来的一个特点了。
2. 进程不仅仅是程序代码,它包含了当前状态。而这种状态由两个方面来表示:
u 程序计数器(program counter)
u cpu中的寄存器(registers)
就是由于进程中有程序计数器—指明下一条要执行的指令而且拥有一组相关的资源。这里又要继续反问:到底是一个什么资源呢?那就要看下面会讲到的PCB的概念了。
3. 进程还包含进程栈(process stack)。
例如:方法参数(method parameters);返回地址与本地变量等
4. 两个进程可能会关联到同样的程序,刚才我们说到了所谓程序是一个静态实体。顾名思义就是两个进程允许使用同样的代码段,只是在参数不同而已。但是仍然认为这两个进程是独立执行的序列。例如:几个用户可能会同事运行主程序的不同拷贝一样。
进程状态
注:上面就是一个完整的进程状态图了。这里没有必要多说什么了,图表给了我们一个轮廓。
进程控制块(PCB)
这里就是我们要讲到的进程控制块了,对于操作系统都是需要通过PCB来表示进程的。有些资料上也称作为:任务控制块。对于PCB的整体描述我们还是以图表的方式来说明(这也是本人最喜欢也觉得最直观的一种理解方式了):
|
Pointer(指针)
|
Process state(进程状态)
|
|
Process number(进程序列号)
|
|
Program counter(程序计数器)
|
|
Register(寄存器)
|
|
Memory limits(主存中受限说明)
|
|
List of open files
|
|
。。。(这里其实还有很多,就不再一一列举了)
|
PCB描述图
既然是操作系统都需要通过进程控制块来调用进程过程,那我们在这里举例说明下如果有两个进程结合PCB是如何在CPU之中切换使用进程的。为了更加清晰了解它们的过程,还是老规矩使用一个图表来展示两个进程分别为P1,P2怎么运行的。
(这个图在自己的笔记本上已经用笔画出来了,可就是找不到一个好的工具,暂时放置在这,待续画图了)
进程调度
由于我们目前接触的其实多半都是以分时系统为主的,其目标也是为了在进程之间频繁转换cpu以便由于用户与运行的程序来交互。
1. 进程进入系统后,都被放在队列中了,我们称这个队列为:作业队列(也有些书上不是这么称呼的),所有的进程都在这个其中。
2. 处于就绪进程都被保留在一个列表中——就绪列表
3. 一旦进程获得了CPU并且执行,就可能发生一下某个事件存在:
u 进程可能发出一个I/O请求,然后被放置在I/O队列中;
u 进程也可能创建一个新的子进程并且等待它终止;
u 有时候发生一个中断,导致进程强行从CPU里移除并返回就绪队列;
调度程序
这里需要了解两个主要的概念:
1. 长程调度(操作系统调度程序):从一个池中选择进程并其载入内存中。
注:咋看不是很了解,可能这里需要了解虚拟存储过程对于这个概念就比较好理解。这里大致说明下。由于过去我们所使用的内存(主存储器)空间非常有限,在抢占的进程志愿中如果都想放入内存中显然是不够科学,而对于我们的后备动力辅助存储器——磁盘(这里我们说是硬盘,当然也有3.5英寸的小磁盘了,呵呵)来说,就可以充分考虑到使用它来做个过度动态的存储器。所以这样一来我们就不需要把一个进程中所有的信息都装载到内存中,而是在需要是再来考虑换入;而与之相反的就是不需要时就换出了(bw:这里的换入/换出如果比较频繁也就证明我们的内耗比较严重,一般称作这个叫:抖动现象。大家有时候感兴趣的可以观察我们主机的硬盘灯如果在频繁的闪动就表示资源在不断换入换出了,呵呵)。而这也就是虚拟存储的一个本质过程,当然中间需要通过逻辑转换表来过度,在这里我们就不再具体复述了。有兴趣的可以去看看相关OS方面的书籍。
2. 近程调度(CPU调度程序):从这些进程中选择就绪进程并为其某个分配CPU
注:说白了这里就是我们的cpu直接通过缓冲通道来调用就绪的程序进入运行。
上下文转换
前面我们也谈到了进程是在CPU中来回切换运行的,既然是一种来回切换运行那势必需要让CPU知道我们切换到下一个状态执行的地址或者说切入点在哪了。这个就是为什么需要一个程序计数器的功效了。那我们把这种来回切换状态,同时需要保存当前运行进程状态信息给记录下来以便下一次能够定位到的方式称作是——上下文转换。
就上面的这样一次转换表述在一定程度上需要耗的硬件资源非常大(这里又要我强调下,更多的信息需要你还了解一些计算机组成体系结构了。希望有时间自己也总结一篇关于一个简单程序在体系中运行过程)。因此上下文转换在很大程度上就取决于硬件的支持了。
接下来要讲到的应该是最核心的也是对以后我们无论是写程序好还是学习一门新语言好,都需要很好理解的部分了。在这里也尽可能表述清楚。
(待续......)
posted @
2008-12-14 00:25 叶澍成 阅读(1463) |
评论 (0) |
编辑 收藏云计算应该所具备的特质如下:
1. 高负载
2. 正常运转
3. 容错性
4. 分布式
5. 容易伸缩
Erlang(读音:['ə:læŋ]厄兰,中文意思为:占线小时(话务负载单位))正是由于它属于开放的电信业务平台,也就不难理解它的意义了。几乎完全具备以上特质,而且它也是典型的函数式语言。和我们OOP的思想有着截然不同的概念。在以下的学习过程中主要还是以《Erlang程序设计》这本书作为一个学习的依据。
原子
定义:在Erlang中原子用来表示不同的非数字常量值。这里说白了其实就是一种常量的定义。Erlang中原子是全局有效的,不需要像以前c/c++那样通过宏来定义或者包含文件。在定义原子的时候只需要注意以下一些特点就可以:
1. 一般情况原子是以一串以小写字母开头,后面有数字、字母、下划线、邮件符号(@);
2. 使用单引号引用起来的字符也属于原子,例如’Monday’;
3. 一个原子的值就是原子本身;
元组(tuple)
定义:首先它是Erlang中具有特质的一个定义,如果说把它和我们java中的一个JavaBean来类比可能稍显类似,书上引用的是c语言数据结构来解说元组的结构,尽管非强浅显能看懂。但是作为一个java程序员我觉得采用自己熟悉的语言结构来对比,学习效果更佳吧(对于记忆有很大帮助)。
比如我们一般对于JavaBean的定义是如下结构:
public class Person {
private String name;
private int height;
private int footSize;
private String eyeColor;
// get/set...
}
那在我们引用定义的时候就可以直接:
Person person1=new Person();
person1.setName("yeshucheng");
person1.setHeight(111);
person1.setFootSize(40);
person1.setEyeColor("black");
......
与之相对应的是我们使用Erlang来定义了,对于Erlang的定义就截然和c/c++或者java有着明显不同,相对于更加精炼明了:(这里我直接使用书上说的所谓二元组)
Person={person,{name,yeshucheng},{height,111},{footsize,40},{eyecolor,black}}.
没错,就是这么直截了当的来定义,甚至赋值(严格说Erlang不能这么说,但是为了好记忆可以这么理解)
对于以上的定义这里要说明注意的地方:
1. 定义元组,元组中字段没有名字,通常可以使用一个原子作为元组的第一元素来标明(请注意这里花括号内第一原子都是解释逗号后面一个说明),这个元组所能代表的含义就是上面列出的程序定义了。
2. 创建元组,在声明元组的同时其实已经创建了元组,这个也是Erlang的一大特点之一了。如果不再使用,也随之销毁。Erlang使用的垃圾搜集器去收回没有使用的内存。
如:F={firstName,wan}
L={lastName,andy}
P={person,F,L}//这里就应对我们第一条说明的一样第一个名称表示就是后面所有逗号的整体列举,如果在Erlang环境中对于上面写完后,直接敲回车(语句结束后存在”.”这里稍微注意下)就会得到以下结果,正好印证我们所说明这这个问题了
==》{persong,{firstName,wan},{lastName,andy}}.
如果在创建过程中存在一个未定义的变量,则程序编译就会产生错误。
3. 提取元组的字段值,刚才我们在程序中有定义一个Person的元组而且也设置值了,现在如果我们想得到或者说提取我们的值,那需要如何而做呢?首先我们采用基本的元组方式来试着看看如下:
1> Point={point,10,45}.
2> {point,X,Y}=Point.
3> X.
10
4> Y.
45
注明:这里又再次强调下point逗号后面的都是为他而说明的。
1>Person={person,{name,yeshucheng},{height,111},{footsize,40},{eyecolor,black}}.
2>{_,{_,Who},{_,_},{_,_},{_,_}}=Person.
3>Who.
yeshucheng
说明下,如果上面想得到的是值,那么位置响应对号入座然后Who换成What就成(我开始也犯错误,编译立马出错,后来想想用过一个What试试,果然正确,呵呵)。
列表
定义:列表第一个元素称为列表的头(head),后部分称为列表尾(tail),一般[H|T]来标示列表了。
注:列表的头可以是任何东西,但是列表的尾通常还是一个列表。
至于具体的细节问题还是需要找找相关文档看下为好,它的概念牵涉到后面的非常多的定义了。
posted @
2008-12-09 10:20 叶澍成 阅读(1046) |
评论 (0) |
编辑 收藏边缘技术人员,这里是个人的一个定义阐述而已,所有的售前售后咨询师、维护人员、培训讲师等都包含在这个头衔中。咋看感觉自己对这个头衔有失偏颇的定论,其实不然我对这个行业的人员还是挺敬佩的。为什么这么说呢?因为他们当中多数是在和我们的客户一线打交道,客户的喜怒哀乐,喜形于色都能第一时间映入他们的脑海,他们需要学会最大的程度“承受”,即使受到某种轻视或者诋毁的状态都需要忍受,同时还要很快的去更好处理当时的尴尬场景。某种程度来说他们类似一些公司业务跑单人员,但是他们有更多的技术背景同时这里面也有很多的牛人。这类人员所具备的素养更加强调人性的一面,也正是由于接触不同社会个阶层人员的广泛,相对于那些整天坐在办公室电脑前敲代码的程序员来说是截然不同的天地。程序员的思维缜密这个都是毋庸置疑的,但是也正是这种思维方式让他们容易陷入规则死板的世界,甚至有些人员会钻牛角尖(你可别不承认哦?或许就是你自己了,哈哈)而对于这里的边缘技术人员来说如果遇到同样的一件事情很有可能他处理的方式会有很大不同,他的某种圆滑处理问题的方式或许就是你需要学习的。而作为公司的老板们也是最多和这类人员交涉的,因为他们了解公司的整体的宗旨方案,也了解客户的需求,他们的老练思维往往会让老板更加乐于倾听。这也不难想象为什么这类人员有时候拿钱或许比你做孺子牛的自己来说更多的缘故了,更加受到器重让你有嫉妒之嫌。你可曾想过如果老板让你去做,自己又能否胜任呢?呵呵。
说到这里可能大家会觉得我讲的似乎在说一名老练的销售业务人员吗?没错,如果你想做一个高端的边缘技术人员(说到这自己都感觉有点不大确切了,呵呵)上面谈到的那种圆滑是你必修课程,但是有这些个人认为还远远不够!为什么这么说呢?在我看来,过去一些年确实很多做销售的人员比做纯技术的人员赚钱多这个也是不争的事实。在未来如果你想在这个职位闯荡,需要的素养再也不是靠过去的“牛皮嘴”了更多的是需要一个务实的干练大气者。你需要知道在什么场合说话到位的分寸;你需要知道如何行云流水般的写一份好材料;你需要有细心的观察和不失吝啬的豪迈口才;更甚你还不能缺少酒桌文化。。。。。。所有的这些或许你不具备,每个人都不是天生赋予有这些能力,但是你只要还年轻懂得如何去“学”就是你最大的资本。当然这些前提都是需要你性格已经具备它的潜质所在,不然劝你另择道路或许也是你的一片天地呢?
写到这回过头看看,仿佛这个并不是自己的所谓“总结”了,连我自己都觉得自己都在天马行空,哈哈。因为我们听过太多的领导的年终评述,八股文的段落着实让自己不想再陈词滥调一番“在这辞旧迎新的新春,借着党的春风我们回顾过去,展望未来在接下来的09年。。。”
既然09年马上要到来,我也简述下吧,俗是俗了点但是形式上还是要走一下的,呵呵。对于个人发展来说,09年自己还是想有个新的环境。人老在一个地方呆容易把自己给“停滞”成为惯性的“懒惰”。尽管自己有很多想法,但是有想法确实是不够的,需要着实的执行一番。在09年开始有空就写blog了,做看官N年之久。把自己的一些心得体会写出来。若干年之后自己回头看看或许是一种美妙的回忆呢?呵呵。在09年继续巩固自己的技术基石,同时也开始学习一门新语言:Erlang。在它的迈进同时还是不忘JAVA给我带来无穷乐资。最后就是希望上天多给我一些机会,我时刻准备着,哈哈。相信自己一定行!
(唧唧歪歪这么多写到这算都结束了!不知所云,哈哈)
PS:“有想法是不够的,执行力度还很差”---崔,我非常谢谢有你这个朋友,你的直率和指点让我知道太多的无知,也让我知道人的奋斗目标是什么;尽管有时候你喜欢给我吃“棒棒糖”,内心甜滋滋的,但正是你的这些语言从某些侧面刺激了我的思维,很是感谢你!真的。我希望我们09年我们都共勉。
08年总结评述(一)
08年总结评述(二)
08年总结评述(三)
posted @
2008-12-08 01:48 叶澍成 阅读(1631) |
评论 (1) |
编辑 收藏而至于架构师这里只是作为个人对这个头衔认定,或许以下对此评述有点片面或者主观看法。首先我承认我更多的是倾向于它,同时也是我努力的目标(呵呵,或许自己离这个还有很大一段差距),当然我也相信很多朋友都有这个向往,但正是它的淡定、从容务实让我内心的佩服。很多朋友都认为国内没有真正的所谓架构师一说,相对于国外的那些牛牛们简直就是小儿科。这点我首先承认确实目前中国整体大环境不是很好,所以在某些层面上社会的浮躁气息都会把很多有才华的程序员特别是那些有架构师的气质的朋友毫无顾忌的抹杀掉。但是如果你静心坐下来想想,如果你无法改变这个环境何不更加务实的换位思考从自身做起呢?多问问自己:我是否已经具备架构师的特质呢?如果能这么想,那很好说明自己在某些问题首先能够有淡定的决策感。
首先架构师在我看来需要有“存储”非常庞大的知识面能力,他可以涉猎非常多技术层次;视野也需要够广阔;对于新生技术敏锐的感知度;甚至在技术的角度来说他还是一个狂热者;在某个特定领域是一个行家(这里我并没有说是专家,因为在我看来专家是一个非常有压力的词汇。呵呵)。所以这个也就印证一些朋友说的:首先你要有知识的广博,一旦水到渠成后自然能够从纷乱繁杂的技术中脱颖而出,认知到自己更加对什么感兴趣,什么领域才是自己未来的方向。也就不存在很多朋友经常会问一些老鸟一样的疑问:我该学习什么呢?我该如何学?我适合什么呢?。。。所有的这些看似初哥的问题在架构师的他根本就不存在疑问,因为他自己非常清晰自己下面的路是如何而走。而更多的是务实贴近他去更快更准确的把握问题的所在。计算机的语言对他来说已经是一种超脱思维,他更注重事物的本质所在。语言对架构师来说就是一种工具,而他要选择的如何更加高效利用好工具。当然架构师也不是神,他也会有很多缺陷。例如在某些基础知识的欠缺,但是他知道如何回头去补充他的弱点,而且他也知道自己的欠缺是什么,他也需要别人去揭示他的不足。没有关系,只要他还是个普通人不是神,他也就有不断的长足进步可能。这些看上去觉得都挺虚幻,而且感觉自己比较难靠近甚至是觉得难以触及。但是我觉得如果你连试的勇气都没有,何来谈及这个词汇价值呢?呵呵,上面说的这些可能对于我们来说非常浅显的道理,但是都觉得这样的人离我们比较遥远(或许你也可能否认这个问题)。在这里我也就个人的角度来看到这个对于我来说都是“神”一样的职位。这里没有多谈该如何的步骤成为一个理想的架构师,因为每个人的情况境遇不尽相同。但是对于你自己心中的他,我觉得还是需要有定位的。其实对于要想达到这样一种也不是太远及,只要你从现在做起,相信我们都能。
(待续……)
08年总结评述(一)
08年总结评述(二)
08年总结评述(四)
posted @
2008-12-06 11:29 叶澍成 阅读(1915) |
评论 (1) |
编辑 收藏 对于这一年中自己更加清晰自己想要的是什么,也对技术的定位有着稍许自己的见解。特别是对于我们这些程序员来说,大家谈到最多的还是自己未来的归宿问题。每个人的性格不同对于事情的看法也就自然不一样,但是个人认为无论你如何去寻求别人帮助来看清自己属于哪种性格,更适合什么方向,这个还是有难度的。他人的意见更多的是参考,最后决定还是你自己。更多的认知度决定了一种水到渠成的站点。
程序员最终的归宿在我看来无非就是三大类:项目经理,架构师,边缘技术人员(这当中包括了:售前售后咨询师、维护人员、培训讲师)。当然这个概括或许是不准确的,这里只是谈到我自己一种认定方式而已。
先来谈谈项目经理,尽管在我接触的这些年同行中挂在嘴边最多的还是这个头衔,但是大家对于这个职业的定位还是不够清晰或许每个人心中的项目经理的层次不同。也印证了一句:一百个人看哈姆雷特就有一百个不一样的哈姆雷特,呵呵。但是在这个行业中大家不得不承认,每个人的水平和对于知识层次的不一样也造就了这种现象,而且这种现象也是正常的。这里列举几个典型对于项目经理描述的观点:
u 项目经理的职责就是需要把现实中的事件通过你的沟通传输与技术人员来沟通翻译,最终利用有效的资源来高效组合达到客户预期的目标。
u 项目经理的职责就是需要对行业定位够劲道,非常熟悉行业的业务流程。技术已经不在是你的讲究的资本,如何高效协调组员来完成任务才是本职工作,和客户沟通好也是最大的责任。
u 项目经理的职责就是需要对业务数据结构够清晰,业务流程够明白。
上面只是列举比较常见的观点(期间做了些修饰,但是大体意思基本是一样的)其实它们的观点理论上来说本质是一样的,但是在个人看来扣住几个关键词:沟通、协调、行业业务、组织能力。能够把它们更加“和谐”的共处发挥到权衡的量度上还是需要一定功力和技巧的。这个职业是需要经验的累计,他的每次决策行径都是要靠前一次或者说以前的经验体会来推进的。在这之前强调更多的还是人性世界的主题,但是这里我发觉很多的程序员在这个职业的论道上缺少或者说尽可能的避免谈论:技术知识面的掌控。很多人会说:你一旦做技术到了4,5年再不在项目经理上,那你就废了。这种说法咋看都诧异,但是现实截然不同在我接触的人当中有太多人是这种意识。开始我也觉得他们这种认知度是对的,但是随着时间上的推移我慢慢发觉有这种思路的人多少带点惰性思维。为什么这么说?很多人都认为程序员在第三年,第五年都是一个坎或者说遇到所谓的瓶颈。而这些人把这些话一推出后,更多的是喜欢和有类似的人员通过近似的思维碰撞找到一个内心的平衡点,继而思维的“散发”也就慢慢蔓延开。他们就感觉:哦,原来我的想法还是对的原来不止我一个人有这样的观点。。。我不在这说有这种想法的人观点是否正确,但是接下来我要谈到的架构师多数的思维还是有不一样的境界。可以肯定的是如果人云亦云,那只能说明你的惰性在潜意识一直在做块遮羞布,“瓶颈”的效应能否让你可曾联想想到我们的CPU为什么要找突破口,如果你确实能够坦白这个现实。那说明真正的项目经理才是一种质的升华。(待续……)
08年总结评述(一)
08年总结评述(三)
08年总结评述(四)
posted @
2008-12-05 09:43 叶澍成 阅读(1846) |
评论 (6) |
编辑 收藏
昨天无意间被朋友问道:你今年的收获是什么?自己才意识到原来不平凡的08年就要过去了,大到国家小到周围朋友在这一年都有不同的变迁。这一年国家经历了前所未有的艰难之路,大雪灾、地震、北京奥运、金融海啸这些都让每个中国人或多或少的经历着不同的感受,最起码你是这当中的一个看似微小的组成原子也感同身受。看着朋友、同学个个都相继组建家庭,步入幸福的婚姻殿堂。每每参加一次为他们祝福的同时也是怜惜自己的尴尬处境,呵呵。这或许就是一个人随年龄的变化而不同的思维情绪了。这里就是一种我自认的缘分未到吧。
而这一年对于自己的表象变化不大,工作依然,情绪依旧。但是内心对于事物的认知度觉得有明显的不一样。对事情的看法更加的务实也更加的切合实际。人一生中可能会让自己永远无法忘记几个时间点,以前我真的不相信。但是自己着实的经历过才真切的能够感受到,08年3月4日,这天让我对事物的看法层面有着截然扭转。也是这天对我对今后的技术认知度有着全然不同看法。尽管当天我没有步入自己梦寐以求的技术殿堂,但是我确实很感谢当时的几位同仁(PS:这里让我记忆犹新的就是那位当时给我当头一棒的女同胞,经历过这么多交谈应该说什么样的对手都碰到过,但是能让我真正“汗”颜的就只有她了)给了我一种视野的开阔,也让我知道浮躁的背面就是坚实的基底,所以非常庆幸这天能给我一个来的稍显晚点的忠告。也正是这天让我真正梳理清晰我需要的是什么;我的方向是什么;我的不足是什么;我的目标是什么。这些所有的roadmap非常清晰在脑海里展现。那一刻让我更加鄙视自己的无知,也让自己知道:机会一定是留给一个时刻有准备的人。
至此那天之后我清楚的认识到我的不足也让我有向往的一种超越精神。自己的清晰定位让我阅读大量的技术书籍。一旦没有特别的应酬都只会闷在家中读书,把以前大学“存储”高阁的书本全部捡拾温习(PS:记得在一个QQ群中聊天时候当时有位朋友说,你这么做成本代价会很高,当时说实在的真没有悟到这个话的内涵,或许自己愚钝的缘故。但是我相信晚意识比没有意识要强)。在这种阅读的过程中,真正让我了解了互联网的水有多“深”,需要了解它需要非常夯实的基底。当然在阅读书籍时,我更多的是带着问题去寻找答案,所以也就自然感觉越到后面越觉得自己的认知度很渺小。因为一个知识点会牵动到其它问题的入口,自己便马上停下来找寻涉及到这个问题的入口寻找答案。。。。。。慢慢就知道自己了解的还是在一个圆内,自己不知道的圆都在这之外,自己也在不断的把所知道的这个圆慢慢的画大。
(待续……)
08年总结评述(二)
08年总结评述(三)
08年总结评述(四)
posted @
2008-12-03 10:02 叶澍成 阅读(1040) |
评论 (2) |
编辑 收藏了解HashMap原理对于日后的缓存机制多少有些认识。在网络中也有很多方面的帖子,但是很多都是轻描淡写,很少有把握的比较准确的信息,在这里试着不妨说解一二。
对于HashMap主要以键值(key-value)的方式来体现,笼统的说就是采用key值的哈希算法来,外加取余最终获取索引,而这个索引可以认定是一种地址,既而把相应的value存储在地址指向内容中。这样说或许比较概念化,也可能复述不够清楚,来看列式更加清晰:
int hash=key.hashCode();//------------------------1
int index=hash%table.lenth;//table表示当前对象的长度-----------------------2
其实最终就是这两个式子决定了值得存储位置。但是以上两个表达式还有欠缺。为什么这么说?例如在key.hashCode()后可能存在是一个负整数,你会问:是啊,那这个时候怎么办呢?所以在这里就需要进一步加强改造式子2了,修改后的:
int index=(hash&Ox7FFFFFFF)%table.lenth;
到这里又迷惑了,为什么上面是这样的呢?对于先前我们谈到在hash有可能产生负数的情况,这里我们使用当前的hash做一个“与”操作,在这里需要和int最大的值相“与”。这样的话就可以保证数据的统一性,把有符号的数值给“与”掉。而一般这里我们把二进制的数值转换成16进制的就变成了:Ox7FFFFFFF。(注:与操作的方式为,不同为0,相同为1)。而对于hashCode()的方法一般有:
public int hashCode(){
int hash=0,offset,len=count;
char[] var=value;
for(int i=0;i<len;i++){
h=31*hash+var[offset++];
}
return hash;
}
说道这里大家可能会说,到这里算完事了吧。但是你可曾想到如果数据都采用上面的方式,最终得到的可能index会相同怎么办呢?如果你想到的话,那恭喜你!又增进一步了,这里就是要说到一个名词:冲突率。是的就是前面说道的一旦index有相同怎么办?数据又该如何存放呢,而且这个在数据量非常庞大的时候这个基率更大。这里按照算法需要明确的一点:每个键(key)被散列分布到任何一个数组索引的可能性相同,而且不取决于其它键分布的位置。这句话怎么理解呢?从概率论的角度,也就是说如果key的个数达到一个极限,每个key分布的机率都是均等的。更进一步就是:即便key1不等于key2也还是可能key1.hashCode()=key2.hashCode()。
对于早期的解决冲突的方法有折叠法(folding),例如我们在做系统的时候有时候会采用部门编号附加到某个单据标号后,这里比如产生一个9~11位的编码。通过对半折叠做。
现在的策略有:
1. 键式散列
2. 开放地址法
在了解这两个策略前,我们先定义清楚几个名词解释:
threshold[阀值],对象大小的边界值;
loadFactor[加载因子]=n/m ;其中n代表对象元素个数,m表示当前表的容积最大值
threshold=(int)table.length*loadFactor
清晰了这几个定义,我们再来看具体的解决方式
键式散列:
我们直接看一个实例,这样就更加清晰它的工作方式,从而避免文字定义。我们这里还是来举一个图书编号的例子,下面比如有这样一些编号:
78938-0000
45678-0001
72678-0002
24678-0001
16678-0001
98678-0003
85678-0002
45232-0004
步骤:
1. 把编号作为key,即:int hash=key.hashCode();
2. int index=hash%表大小;
3. 逐步按顺序插入对象中
现在问题出现了:对于编号通过散列算法后很可能产生相同的索引值,意味着存在冲突。

解释上面的操作:如果对于key.hashCode()产生了冲突(比如途中对于插入24678-0001对于通过哈希算法后可能产生的index或许也是501),既而把相应的前驱有相同的index的对象指向当前引用。这也就是大家认定的单链表方式。以此类推…
而这里存在冲突对象的元素放在Entry对象中,Entry具有以下一些属性:
int hash;
Object key;
Entry next;
对于Entry对象就可以直接追溯到链表数据结构体中查阅。
开放地址法:
1. 线性地址探测法:
如何理解这个概念呢,一句话:就是通过算法规则在对象地址N+1中查阅找到为NULL的索引内容。
处理方式:如果index索引与当前的index有冲突,即把当前的索引index+1。如果在index+1已经存在占位现象(index+1的内容不为NULL)试图接着index+2执行。。。直到找到索引为内容为NULL的为止。这种处理方式也叫:线性地址探测法(offset-of-1)
如果采用线性地址探测法会带来一个效率的不良影响。现在我们来分析这种方式会带来哪些不良因素。大家试想下如果一个非常庞大的数据存储在Map中,假如在某些记录集中有一些数据非常相似(他们产生的索引在内存的某个块中非常的密集),也就是说他们产生的索引地址是一个连续数值,而造成数据成块现象。另一个致命的问题就是在数据删除后,如果再次查询可能无法定到下一个连续数字,这个又是一个什么概念呢?例如以下图片就很好的说明开发地址散列如何把数据按照算法插入到对象中:
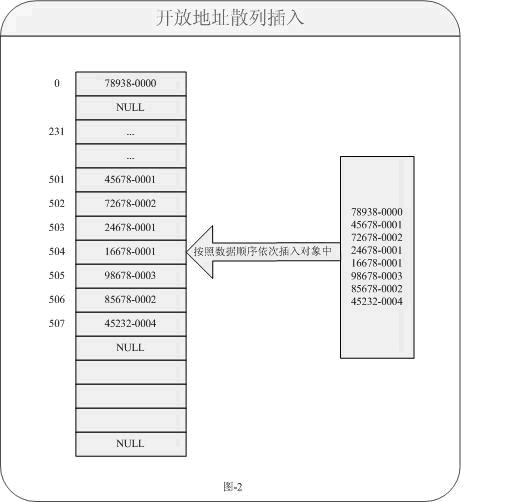
对于上图的注释步骤说明:
从数据“78938-0000”开始通过哈希算法按顺序依次插入到对象中,例如78938-0000通过换
算得到索引为0,当前所指内容为NULL所以直接插入;45678-0001同样通过换算得到索引为地址501所指内容,当前内容为NULL所以也可以插入;72678-0002得到索引502所指内容,当前内容为NULL也可以插入;请注意当24678-0001得到索引也为501,当前地址所指内容为45678-0001。即表示当前数据存在冲突,则直接对地址501+1=502所指向内容为72678-0002不为NULL也不允许插入,再次对索引502+1=503所指内容为NULL允许插入。。。依次类推只要对于索引存在冲突现象,则逐次下移位知道索引地址所指为NULL;如果索引不冲突则还是按照算法放入内容。对于这样的对象是一种插入方式,接下来就是我们的删除(remove)方法了。按照常理对于删除,方式基本区别不大。但是现在问题又出现了,如果删除的某个数据是一个存在冲突索引的内容,带来后续的问题又会接踵而来。那是什么问题呢?我们还是同样来看看图示的描述,对于图-2中如果删除(remove)数据24678-0001的方法如下图所示:
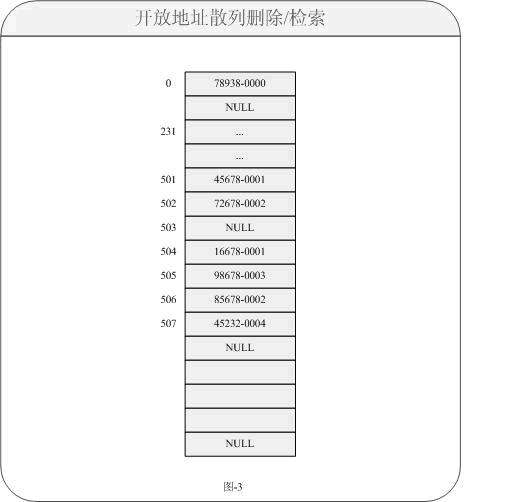
对于我们会想当然的觉得只要把指向数据置为NULL就可以,这样的做法对于删除来说当然是没有问题的。如果再次定位检索数据16678-0001不会成功,因为这个时候以前的链路已经堵上了,但是需要检索的数据事实上又存在。那我们如何来解决这个问题呢?对于JDK中的Entry类中的方法存在一个:boolean markedForRemoval;它就是一个典型的删除标志位,对于对象中如果需要删除时,我们只是对于它做一个“软删除”即置一个标志位为true就可以。而插入时,默认状态为false就可以。这样的话就变成以下图所示:
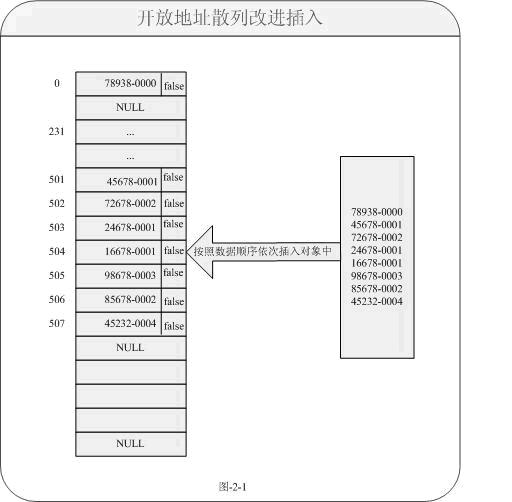
通过以上方式更好的解决冲突地址删除数据无法检索其他链路数据问题了。
2. 双散列(余商法)
在了解开放地址散列的时候我们一直在说解决方法,但是大家都知道一个数据结构的完善更多的是需要高效的算法。这当中我们却没有涉及到。接下来我们就来看看在开放地址散列中它存在的一些不足以及如何改善这样的方法,既而达到无论是在方法的解决上还是在算法的复杂度上更加达到高效的方案。
在图2-1中类似这样一些数据插入进对象,存在冲突采用不断移位加一的方式,直到找到不为NULL内容的索引地址。也正是由于这样一种可能加大了时间上的变慢。大家是否注意到像图这样一些数据目前呈现出一种连续索引的插入,而且是一种成块是的数据。如果数据量非常的庞大,或许这种可能性更大。尽管它解决了冲突,但是对于数据检索的时间度来说,我们是不敢想象的。所有分布到同一个索引index上的key保持相同的路径:index,index+1,index+2…依此类推。更加糟糕的是索引键值的检索需要从索引开始查找。正是这样的原因,对于线性探索法我们需要更进一步的改进。而刚才所描述这种成块出现的数据也就定义成:簇。而这样一种现象称之为:主簇现象。
(主簇:就是冲突处理允许簇加速增长时出现的现象)而开放式地址冲突也是允许主簇现象产生的。那我们如何来避免这种主簇现象呢?这个方式就是我们要来说明的:双散列解决冲突法了。主要的方式为:
u int hash=key.hasCode();
u int index=(hash&Ox7FFFFFFF)%table.length;
u 按照以上方式得到索引存在冲突,则开始对当前索引移位,而移位方式为:
offset=(hash&Ox7FFFFFFF)/table.length;
u 如果第一次移位还存在同样的冲突,则继续:当前冲突索引位置(索引号+余数)%表.length
u 如果存在的余数恰好是表的倍数,则作偏移位置为一下移,依此类推
这样双散列冲突处理就避免了主簇现象。至于HashSet的原理基本和它是一致的,这里不再复述。在这里其实还是主要说了一些简单的解决方式,而且都是在一些具体参数满足条件下的说明,像一旦数据超过初始值该需要rehash,加载因子一旦大于1.0是何种情况等等。还有很多问题都可以值得我们更加进一步讨论的,比如:在java.util.HashMap中的加载因子为什么会是0.75,而它默认的初始大小为什么又是16等等这些问题都还值得说明。要说明这些问题可能又需要更加详尽的说明清楚。
posted @
2008-09-15 21:53 叶澍成 阅读(3816) |
评论 (6) |
编辑 收藏