2017年4月6日
#
组织树报表中由id与父id来实现组织树报表,若层级数较多时,对每个单元格设置过滤条件和形态会比较繁琐,因此FineReport提供了一种特殊的数据集——树数据集,只需要简单的设置就能自动递归出层级,方便的实现如下图组织树报表:
图一

图二

构建树
新建工作薄,添加数据集ds1取出原始数据,SQL语句为SELECT * FROM 公司部门。
1)根据父字段构建树
使用情形:原始表结构中符合ID、parentID结构,我们可以通过父ID这个字段生成树,添加树数据集,如下图:


2)根据数据长度构建树
使用情形:原始表结构中所有ID都在一列中,且没有父ID字段,但是ID是有规律的,每组的长度相同,且子级的前N位就是父级编号,添加树数据集,如下图:


预览树数据集,可看到已自动生成递归树数据,FR_GEN_0为最高层,依次往下,如下:

纵向组织树编辑
按照下图所示将对应的数据列拖入到单元格中,并将A2单元格的左父格设置为A1,A3单元格的左父格设置为A2:

有上面预览数据可以看到从二层FR_GEN_1开始,就会有空白数据,这是因为数据库中存储的数据有上一级部门本身的部门名称和部门ID,其上一级部门的部门级数会低一级,比如说上述数据的第一行为总部,虽然总部下面有子部门,但是数据库中还是要存储总部这个部门的部门名称和部门ID的,总部对应的级数为一级,那么其对应的数据记录行里面就只有FR_GEN_0层,下面的FR_GEN_1和FR_GEN_2这两层就会没有数据,显示为空白。
在模板制作过程中,从第二层级开始就会有空白数据,需要将空白数据隐藏掉,选中A2和A3单元格,添加条件属性,当数据为空时隐藏该行,如下图: 
如果组织结构的层级结构不确定,即有的层级有子层,有的层级没有子层时,其组织树报表的实现方式请查看不规范组织树报表
由于自动生成的字段是编码,可以使用数据字典将其转为对应的部门名称,如下图:

保存模板,点击分页预览,效果如图一。
横向组织树编辑
按照下图所示将对应的数据列拖入到单元格中,在右侧单元格属性表-扩展属性中将B1、C1单元格的扩展方向设为横向,
并将B1单元格的左父格设置为A1,C1单元格的左父格设置为B1:

有上面预览数据可以看到从二层FR_GEN_1开始,就会有空白数据,这是因为数据库中存储的数据有上一级部门本身的部门名称和部门ID,其上一级部门的部门级数会低一级,比如说上述数据的第一列为总部,虽然总部下面有子部门,但是数据库中还是要存储总部这个部门的部门名称和部门ID的,总部对应的级数为一级,那么其对应的数据记录列里面就只有FR_GEN_0层,下面的FR_GEN_1和FR_GEN_2这两层就会没有数据,显示为空白。
在模板制作过程中,从第二层级开始就会有空白数据,需要将空白数据隐藏掉,选中B1和C1单元格,添加条件属性,当数据为空时隐藏该列,如下图:

如果组织结构的层级结构不确定,即有的层级有子层,有的层级没有子层时,其组织树报表的实现方式请查看不规则组织树报表
由于自动生成的字段是编码,可以使用数据字典将其转为对应的部门名称,如下图:

保存模板,点击分页预览,效果如图二。
2017年3月21日
#
2017年3月20日
#
在企业应用中,通常单个计算机的配置是有限的,而企业应用又是高并发的需求,这个时候会通过计算机集群的方式来提高并发数,从而提高整体应用服务的性能。集群是将多台计算机作为一个整体来提供相关应用的服务。FineBI支持多计算机服务的集群部署,通过集群部署利用有限的计算机资源来有效提高整体应用的并发性能。本文主要介绍整体FineBI集群的思路。
FineBI采用负载均衡集群的模式,将多台服务器创建为一个集群服务器。这里碰到这几个问题:1)web工程的存储问题:FineBI在集群中,由于自身的问题需要多台服务器读取同一个web工程。因此要实现web工程分享。2)系统数据一致性:在FineBI的运行过程中,存在读写的操作,同时有部分的数据的配置文件要写入数据库。需要保证集群的情况下,系统数据的一致性。3)负载均衡:一方面通过负载均衡来处理session的问题,另一方面达成负载均衡的集群环境,使用代理服务器可以将请求转发给集群内部的服务器,可以将负载均衡和代理服务器的高速缓存技术结合在一起,提供有益的性能。4)FS平台集群:如FineBI使用FS平台,则FS平台的各种配置也需要进行集群配置。
如下图是一个FineBI进去的架构的案例示意图,这种方式通过NFS文件共享来处理web工程。

Web工程存储问题
Web工程的存储,我们要解决的是多个服务器保证读取同一个web工程。我们可以通过ceph做到多块物理硬盘组件一块逻辑硬盘,从而实现所有节点都是在访问同一地址;也可以通过linux本身带有的nfs共享文件服务来达成访问同一web工程。无论使用哪一种方式,我们要保证:
<!--[if !supportLists]-->1)<!--[endif]-->访问同一web工程
<!--[if !supportLists]-->2)<!--[endif]-->Cube存储地址是一致的
因为同一个web工程下,要求cube的存储地址是一致的,因此要求cube存储地址一定要一样。
而真正使用的时候,ceph的实现需要至少三台计算机来实现,而实际企业应用中,比较少使用三台;而nfs均可以且是linux本身的,因此使用“nfs”方案。
系统数据配置
单节点的情况下,利用缓存和通过操作系统的文件系统来保存数据的方式,在集群模式下不再合适。主要原因在于数据的一致性问题,多个节点可能进行同时读写,更改系统数据,最终势必会造成整体数据不一致。最好的解决方案是系统配置数据全部交给MySQL等关系型数据库来管理。但由于这样工程量好大,更主要的原因为许多代码缺少维护,贸然更改可能带来意想不到的bug。于是我们采用一种折中的做法。在集群中选出一台几点作为主节点,简称M。其余节点担当子节点,简称S。当S上所有与更改系统配置相关的操作,全部发送到M上进行处理。M负责来更改系统状态,维护整个系统到底一致的状态。S节点放弃全部的缓存数据,读取状态的时候,不再通过读取自身数据,而是通过向M发送读取请求,获得M上的数据。M节点自身可以存在缓存数据。其他数据S节点与M节点时等同的,不存在从属关系。

因此按上述原由我们提供如下解决方案:
<!--[if !supportLists]-->1)<!--[endif]-->mysql数据库:原web工程中存在finedb的配置信息转存到mysql数据库中。因为finedb数据库只能有一个连接,无法多节点同时读取,而mysql数据库则不存在。Logdb也需迁移;
<!--[if !supportLists]-->2)<!--[endif]-->主子节点:我们使用主子节点的方式来配置集群,系统数据的更改均在主节点上进行,子节点只读取主节点上的数据;
<!--[if !supportLists]-->3)<!--[endif]-->Zookeeper:为了保证读写情况下,主子节点保证数据一致性,还需要zookeeper进行通信,充当文件锁的功能。
负载均衡
在FineBI的集群环境中,我们可以使用任何支持负载均衡的服务器来完成轮发的任务,并保证session粘滞。此处我们使用的是nginx反向代理,使用IP标识轮发,保证同一个用户在同一个session。(在一个服务器一个节点的情况下,同一个IP就保证session粘滞)。
FS平台集群
使用FS平台集群插件,将FS平台配置能够满足集群需求。在FS平台集群中,FS平台的所有操作都是发到主节点上来操作;子节点只是作计算服务器。
2017年3月14日
#
报表服务器
安装钉钉管理插件后,打开报表管理平台,管理系统下会增加钉钉管理节点,钉钉相关的配置管理都将会放在这个节点中去配置:
同时,设置定时任务的最后一步输出设置中,会增加推送钉钉消息:
钉钉企业应用
管理员登录钉钉企业号,进入微应用设置,需要关注的信息有:
CorpID:是企业在钉钉中的标识,每个企业拥有一个唯一的CorpID;
CorpSecret:是企业每个应用的凭证密钥
登录FineReport管理平台,点击管理系统>钉钉管理节点:将钉钉中的CorpID和CorpSecret分别填到钉钉企业号ID和管理组凭证密码中,设置Token获取路径,可以自定义获取的url,如果不写则采用内置的方式获取,保存,如下图:
钉钉提供的获取token接口本身有缺陷:
1)钉钉提供的接口,使用corpid和secret获取token,默认不会缓存,但是钉钉提倡做token缓存,2小时内可以重复使用,这样减少对钉钉服务器的访问,以免出现问题;
2)钉钉中集成多个应用的话,如果多个应用都会用到corpid和secret获取token,如果某个应用缓存了token,就会冲突
例如:应用a,做了缓存,第一次访问后获取到token1,应用b使用会重新取token2,此时应用a还是用的token就无法访问了。
针对这种情况,处理方式是所有应用统一到一个地方去取token,此时需要设置自定义token的获取地址
在钉钉插件中,钉钉管理>基本信息>设置Token获取路径,可以自定义获取的url,如果不写则采用内置的方式获取
Token获取接口规则:返回json类型的数据,{access_token:"xxxxx", jsapi_ticket:"xxxxx"}
钉钉管理后台创建FineReport报表微应用时,例如http://www.finereporthelp.com:8181/app2/ReportServer?op=fs&corpid=$CORPID$,后面要加上参数&corpid=$CORPID$,这样后台会获取到cropid,然后取到钉钉userid,做单点登录;
按照钉钉提供的方法,读取钉钉通讯录的成员,需要的字段有uesrid,name,department进入FineReport报表管理平台fs,点击钉钉管理节点,除了基本信息外,增加了钉钉成员管理,点击效果如下:
表格中会自动读取钉钉企业号通讯录中的所有成员,并且在每次打开该页面时刷新为最新的;默认钉钉成员与报表用户相同,因为大部分情况下,钉钉成员名和报表用户名是统一的;
如果您的钉钉成员名与报表用户名是不一样的,此时,可以取消勾选钉钉成员与报表用户相同设置,此时报表用户名,可以将钉钉成员与报表用户进行关联,如下图:
钉钉提供免登服务,与微信类似,通过code可以获取当前取号的userid,获取到userid后,通过关联关系自动登录报表后台
开发服务器可以主动的发送消息给企业成员,比如使用FineReport定时器生成报表后,发送消息给相应的人员进行查看。进入FineReport管理平台,添加定时任务:

到输出设置这步,比如我们将定时生成的结果挂在其他这个目录下面,并且命名为钉钉文档测试:
通知与存档选择推送钉钉消息,企业应用(AgentID)需要根据钉钉管理里的进行填写,例如下设置,这样定时任务结束后,这个钉钉成员可以收到消息
定时生成结果的文件名:对应发送消息的标题名
企业应用AgentID:发消息至哪个应用
钉钉用户:发消息给哪些成员,下拉框中会自动读取钉钉通讯录中的所有成员,多个成员之间用|分割,比如Jane|Saber
部门ID:发消息给某个部门的所有成员,该属性与钉钉用户是并的关系,不同部门之间也用|分割
消息内容:定义消息的正文内容
定时结果访问连接:勾选的话会在消息正文最后加上定时生成的结果连接,点击后就可以直接打开定时结果;不选的话则只发送纯文本消息。
定时任务设置好后,比如任务每天都会执行,每次执行后就会推送消息给对应的成员,效果如下:
点击连接,就可以看到定时生成的结果。
2017年3月8日
#
当报表中列出数据太多时,想通过显示按钮隐藏明细数据只显示统计数据。如下图示例,那么该如何实现呢?本文以FineReport为例,来讲述JS如何实现点击参数面板按钮显示或隐藏数据。

打开报表
在参数面板添加一个标签控件,控件名为lable,设置标签控件不可见,控件值为“显示”。

在参数面板添加一个按钮控件,控件名为button,控件值为“只显示合计数据”,并添加点击事件。

编辑点击事件,添加下面的JavaScript代码:

/*获取隐藏的标签控件的值*/
var label= this.options.form.getWidgetByName("label").getValue();
/*判断标签控件的值*/
if(label=='显示')
{
/*当标签控件的值为显示时,则改为隐藏,并修改按钮名称为显示所有数据*/
this.options.form.getWidgetByName("label").setValue("隐藏");
this.options.form.getWidgetByName("button").setValue("显示所有数据");
}
else
{
/*当标签控件的值不为显示时,则改为显示,并修改按钮名称为只显示合计数据*/
this.options.form.getWidgetByName("label").setValue("显示");
this.options.form.getWidgetByName("button").setValue("只显示合计数据");
}
/*执行查询*/
_g().parameterCommit();
点击参数面板空白处,将“点击查询前不显示报表内容”属性的勾去掉。

回到报表设计界面,右键B3单元格,添加条件属性,设置行高为0毫米,添加公式条件为$label = '隐藏'。

保存模板,点击分页预览即可看到上图的效果。
2017年3月1日
#
数据的重要性不言而喻,已经被越来越多的公司接受、熟知和应用。那么关乎数据,到底在哪些方面可以促进业务的腾飞?或者换种说法,业务对数据有哪些层次的需求?还有,数据对管理有哪些方面的贡献?
依据我多年在数据分析岗位上的工作经验和对业务的理解,业务对数据的需求可归纳为四个层次。
第一层:知其然
就是知道数据是多少,发生了什么情况。就如目前大多数企业都会有自己的数据库,严格一点会有对应的系统对应的业务数据库,数据收集的工作已经完备了,无论是通过报表还是数据分析的手段,都可以掌握发生了什么,程度如何,建立数据监控体系,做到“知其然”。也有一些企业,在管理内部数据的同时,也在考虑外部数据的引进,向第三方机构买数据,观察行业整体趋势、政策环境的影响,其次了解竞争对手的表现。这样的数据工作是长期的也可是周期性的管理。长期的可尽力数据展现模板,形成一定的管理规范,固化下来。短期性的比如监测某次营销活动的情况,可联合IT部门或者数据分析师自己动手,做到严格的“自省”。
1、数据是散的,看数据需要有框架。
数据展现很有讲究,把数据放到业务框架,能体现业务分析,才能发挥整体价值。所谓有效的框架至少包含两重作用:
(1)不同层级的人对数据的需求不同。比如市场销售数据,业务层需要指导自己每日指标的完成情况和等级排名,需要提交每日每周每月的数据。领导层需要知道固定周期的业绩完成率,各地区销售额,营销成本和组内业绩排名。管理层,CEO级别的可能需要知道每个业务部门的一些关键指标,比如总营收,市场增长率,重要的研发进度等等。有效的框架能够让不同的人各取所需。

(2)好的框架能定位问题,指导决策制定。例如电商销售额下降了30%,业务很可能出现了重大问题。我们需要分析问题原因,但如果只从客单价、交易单数、转化率难以说明问题,好的业务分析框架能够支持我们往下钻,从品类、流量渠道等找到问题所在,找到对应负责人。这也是我们通常所说的,看数据要落地。
2、数据,有对比才能考量。
日销售额100万,你说多还是少呢?一个孤零零的数据是很难说明问题的。数据判断要么有一个参考的指标,要么有能准确判断趋势的指标数据,如增长率上升率。这样一个基准可以是历史总结的同期数据,也可以是行业的平均水平,也可以是预先设定的而目标,一切脱离目标的数据分析都是“耍流氓”。

第二层:知其所以然
遇到问题寻找原因这是很顺当的衔接。但走到这一步还不够,解决问题才是真理。数据结合业务,找到数据表象背后的真正原因,解决之。解决问题的过程就会涉及数据整理、加工,还会涉及数据分析模型的建立和工具,这在以往的篇幅已经介绍的够多的了。
在第二层里也有两点分享:
1、数据是客观的,但对数据的解读则可能带有很强的主观意识。
数据本身是客观的,但解读数据的人都是有主观能动性的。这样的问题往往是因为多数人通多数据先对问题定性,而不是通过问题解决问题,这样的事儿总有发生。
2、懂业务才能真正懂数据。
笔者认为,数据分析业务占6分,方法占4分。不懂业务无法理解数据的真正含义也是有理可寻的,这里特地拿出来强调一下。
第三层:辅助业务,发现机会
利用数据可以帮助业务发现机会。举个电商的例子,通过用户搜索的关键词与实际成交的数据比较,发现有很多需求并没有被很好地满足,反映出需求旺盛,但供给不足。假如发现了这样的细分市场,公布出来给行业小二,公布出来给卖家,是不是可以帮助大家更好地去服务消费者呢?这个例子就是现在我们在做的“潜力细分市场发现”项目。
讲这个案例不是想吹牛数据有多厉害,而是想告诉大家:数据就在那里,有些人熟视无睹,但有些人却可以从中挖出“宝贝”来。差异就在于商业感觉,对数据的直觉。搜索数据和成交数据很多人都能够看到,但并没有人把这两份数据联系在一起,这背后体现出的就是商业的感觉。
第四层:建立数据化运营体系
我理解的数据化运营,包含了两重意思:数据作为直接生产力和间接生产力。
1、数据作为直接生产力。
数据作为直接生产力是指数据能将价值直接投入到前线,作用于消费者,时髦点讲就是“数据变现”,这也是大家最为关注的。以前有沃尔玛将啤酒和尿布两个产品关联摆放,引出了商品关联度的概念。如今,又有餐饮企业利用数据统计分析,选型餐厅面积,优化前后厅布置,使得单位面积营收最大。
2、数据作为间接生产力。
所谓间接生产力,是指数据价值不直接传递给消费者或企业,而是需要通过一系列的分析,制定策略传递给消费者,即通常所说的决策支持。数据工作者通常做的是产出报表、分析报告等供各级业务决策者参考。我们可以称之为决策支持1.0模式。然而随着业务开拓和业务人员对数据重要性理解的增强,对数据的需求会如雨后春笋般冒出来,显然单单依赖人数不多的分析师是满足不了的。授人以鱼不如授人以渔,让业务人员能够独立地进行数据分析,而不依赖于技术人员是我认为的决策支持2.0模式。
实现决策支持2.0模式有两个关键:工具和能力。
如果让他们和数据从业者一样,掌握SQL,学会SPSS,SAS甚至R和Python,大可不必要。现在自助型的BI工具等低门槛、用户体验良好的数据产品完全可以让用户快速上手,比如自助式BI工具FineBI,最佳的使用方式是让IT人员准备好数据,按照权限,业务人员可以自己决定分析维度,将分析字段拖入表中,类似excel的数据透视表。这是实现决策支持2.0模式的基础。

当然,这里讲的产品,不仅仅是操作功能集,还需要承载分析思路和实际案例。数据分析的门槛还是有的,深入的分析还是得往数据分析师方向走,这就会对大家提出一些其他的基本能力,比如统计学知识,数学能力等等。但是内心若有强大的意愿,有持之以恒的毅力,那都不叫事儿。
2017年1月24日
#
对于企业大多数员工来说,由于其工作位置是固定的,可以有多种方式进行上班打卡签到以保证该员工有按时正常来上班,但是对于经常需要出差,去客户现场的员工来说,就无法保证他们是否有去上班,所以希望能通过手机位置定位来保证员工有正常上班。
上述情况可以通过FineReport模板添加一个按钮控件,点击该按钮的时候,获取当前地理位置,并将该位置信息复制给某个单元格,最后员工填报当前模板即可。
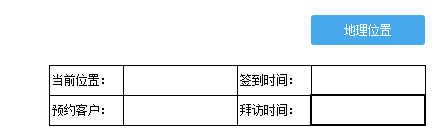
实现如下图所示效果,点击地理位置按钮获取当前位置与当前时间,并显示下下方对应的单元格中:

模板制作
打开设计器,新建一张模板,按照如下图所示样式设计模板,其中E2单元格为按钮控件,控件名称为地理位置,C5为下拉框控件,E5为时间控件:

获取当前地理位置
获取当前地理位置有两种方式,一个是点击按钮获取地理位置,一个是直接打开模板的时候就获取位置,示例中,想实现通过点击按钮获取地理位置。
1)通过点击按钮获取地理位置
打开按钮的控件位置,为该控件添加一个点击事件,如下图:

相应代码如下:
FR.location(function(status, message){ //获取地理位置
if(status=="success") {
//定位成功,message返回经纬度值
FR.Msg.alert("当前位置是" + message);
contentPane.setCellValue(2, 3, message);
} else {
//定位失败,message返回对应的错误信息
FR.Msg.alert(message); //定位失败
}
});
FineReport通过FR.location方法获取当前位置,如果status值为success,则表示获取地理位置成功,否则定位失败,如果定位成功,则将返回的地理位置信息赋值给C4单元格。
要注意的是该方法只在移动端有用,如果在web点击该按钮事件获取地理位置,则直接提示定位失败。
2)加载结束后获取当前位置
如果想在模板加载结束之后就获取到当前地理位置,那么只需要将上述代码添加到加载结束后事件中即可,打开模板,点击模板>模板web属性>填报页面设置,添加一个加载结束事件,如下图:

获取当前时间
在模板中还需要将当前签到时间也赋值过去,所以还需要在按钮的点击事件中获取到当前时间,即给E2单元格再添加一个点击事件,并赋值给E4单元格,代码如下:
var myDate = new Date();
var mytime=myDate.getFullYear()+"-"+myDate.getMonth()+1+"-"+myDate.getDate()+" "+myDate.getHours()+":"+myDate.getMinutes()+":"+myDate.getSeconds(); //获取当前时间
contentPane.setCellValue(4, 3, mytime);
按钮点击事件全部代码如下:
FR.location(function(status, message){ //获取地理位置
if(status=="success") {
//定位成功,message返回经纬度值
FR.Msg.alert("当前位置是" + message);
contentPane.setCellValue(2, 3, message);
var myDate = new Date();
var mytime=myDate.getFullYear()+"-"+myDate.getMonth()+1+"-"+myDate.getDate()+" "+myDate.getHours()+":"+myDate.getMinutes()+":"+myDate.getSeconds(); //获取当前时间
contentPane.setCellValue(4, 3, mytime);
} else {
//定位失败,message返回对应的错误信息
FR.Msg.alert(message); //定位失败
}
});
效果查看
将该模板添加到数据决策系统的节点树上,其中模板的预览方式为填报,如下图:

用移动端登录该系统,访问该张模板,点击地理位置按钮获取当前地理位置和当前时间,如下图:

FineReport中获取的地理位置是经纬度,如果需要确定其具体位置的话,还需要另外转换。
2017年1月19日
#
在报表填报成功后,发送消息至APP会提示数据已更新。再次期间用户需要有查看该模板的权限,如果没有的话,则无法接受到提示信息。那么在FineReport移动端中,如何手动推送APP消息呢?
具体用法
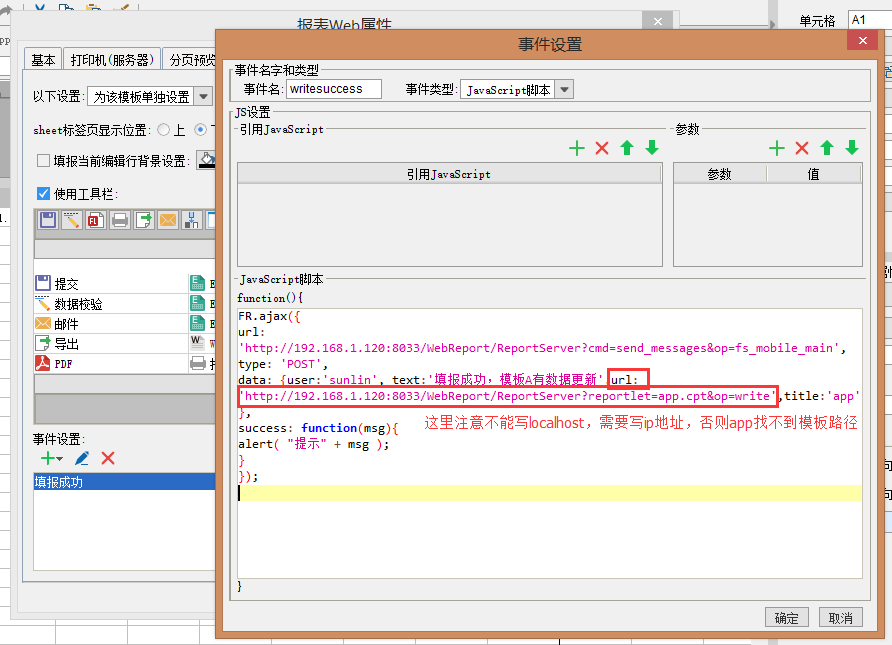
在报表填报成功后事件中添加js,使用ajac发送消息请求
FR.ajax({
url: 'http://192.168.1.120:8033/WebReport/ReportServer?cmd=send_messages&op=fs_mobile_main',
type: 'POST',
data: {user:'sunlin', text:'填报成功,模板A有数据更新',url:'http://192.168.1.120:8033/WebReport/ReportServer?reportlet=app.cpt&op=write',title:'app'},
success: function(msg){
alert( "提示" + msg );
}
});
User:接受消息的人,可以是多个,多个用户之间用逗号分割,如“A,B”(必填)
Text:消息内容(必填)
Url:打开地址(选填),在点击消息之后进入app打开的地址
Title:打开地址的页面标题(选填)
示例
效果一、推送纯文本消息
填报的模板,增加填报成功事件,示例代码如下:
FR.ajax({url: 'http://192.168.1.120:8033/WebReport/ReportServer?cmd=send_messages&op=fs_mobile_main',
type: 'POST', data: {user:'sunlin', text:'填报成功,模板A有数据更新'},success: function(msg){ alert( "提示" + msg ); } });
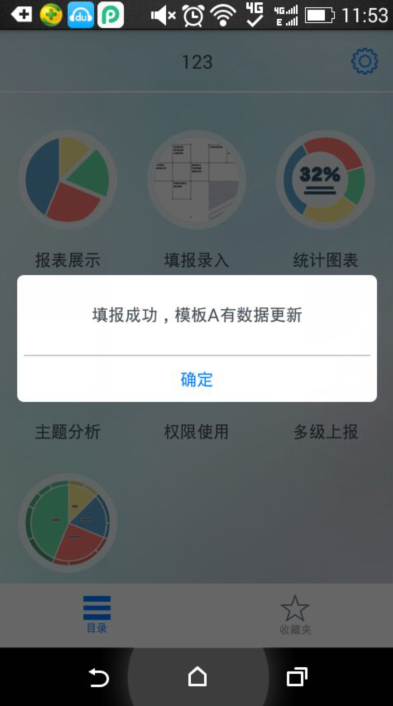
效果二、点击消息后,进入app,并且打开地址页面
填报的模板,增加填报成功事件,示例代码如下:
FR.ajax({
url: 'http://192.168.1.120:8033/WebReport/ReportServer?cmd=send_messages&op=fs_mobile_main',
type: 'POST',
data: {user:'sunlin', text:'填报成功,模板A有数据更新',url:'http://192.168.1.120:8033/WebReport/ReportServer?reportlet=app.cpt&op=write',title:'app'},
success: function(msg){
alert( "提示" + msg );
}
});

2017年1月6日
#
多台服务器集群后,配置权限、数据连接、模板、定时调度等,只能每台服务器一个个配置,不会自动同步到所有服务器。
针对上述情况,在FineReport中提供新集群部署插件,将xml配置文件、finedb/logdb数据(定时任务、报表目录管理、批量导入、统计信息)的修改都对主机生效。其他辅机的信息读取也都从主机读取,保证了数据同步。
实现了灾备,即主机当即后,次主机会上位接替主机的工作,保证系统正常运作。
同时还增加了集群灾备之文件同步,会将主机的finedb、xml、模板、jar包、插件等等备份到其他节点的应用上。支持可以手动同步和自动同步。
插件介绍
设计器插件、服务器插件安装好之后,新集群部署,有主机、次主机、辅机之分,配置文件都从主机读取,辅机只能用作计算引擎分担压力,有点事当改配置文件的时候,不需要每个节点都去修改,直接改主机即可。
分布式集群
分布式集群文件系统:每台计算机各自提供自己的存储空间,并各自协调管理所有计算机节点中的文件。
这里测试修改主机的报表管理目录树平台标题,然后可以看到辅机会同步修改的配置。其中报表管理目录树存在finedb中,平台样式的平台标题存在fsconfig.xml中。
设置tomcat1、tomcat2、tomcat3集群,tomcat1为主机,tomcat2为辅机,tomcat3为次主机,tomcat集群。
WebReport工程分别放在tomcat下的webapps文件夹里
集群配置完成之后,修改将配置包resource文件夹下的cluster.xml打开,如果没有这个文件的话,就新建一个,基本内容如下:

PublicURL是集群默认跳转地址,比如集群时对外地址是自定义端口的, ip:8888/WebReport/ReportServer?op=fs我们并不能获取到这个8888端口,因此这里需要填写实际的ip:端口号,如果这段省略不写,默认跳转80端口。
ServiceName是为tomcat的名字。
IP是该台服务器内网中的IP,就是其它服务器能与之通信的IP。
Port是报表应用的端口号,假如是部署在tomcat下,那么就是tomcat的端口号,默认是8080。例如我们的内置服务器是8079.
WebAppName是报表应用的名称,我们默认的是WebReport。
详细代码如下:
<?xml version="1.0" encoding="UTF-8" ?>
<ClusterConfig useCluster="true">
<PublicURL>
ip:端口
</PublicURL>
<ClusterService isMain="true">
<ServiceName>tomcat1</ServiceName>
<ip>192.168.101.82</ip>
<port>6080</port>
<WebAppName>WebReport</WebAppName>
</ClusterService>
<ClusterService>
<ServiceName>tomcat3</ServiceName>
<ip>192.168.101.82</ip>
<port>8080</port>
<WebAppName>WebReport</WebAppName>
</ClusterService>
<ClusterService isVice="true">
<ServiceName>tomcat2</ServiceName>
<ip>192.168.101.82</ip>
<port>7080</port>
<WebAppName>WebReport</WebAppName>
</ClusterService>
</ClusterConfig>
启动工程,等3分钟后,关闭主机,刷新fs和访问模板,此时是失败的,再等待3分钟,主次机上位,再次刷新fs和访问模板,此时是成功的。
集群同步设置
点击管理系统-集群同步,点击设置,选择需要同步的内容:配置文件(resources目录)、模板(reportlets目录)、插件和jar(plugins和lib文件夹),点击确定,然后可以选择手动同步,或者设置定时同步,点击保存即可,如下图:


共享式集群
共享式文件集群系统:多台计算机识别到同样的存储空间,并相互协调共同管理其上的文件,又被称为共享文件系统;
设置tomcat1和tomcat2集群,tomcat1为主机,tomcat2为辅机,tomcat集群。
Web项目部署在不同的服务器上,一般服务器都在同一局域网,那么共享式文件集群该如何访问呢?
这里通过共享局域网里某台电脑上的工程文件夹,多个tomcat都从这个共享的工程文件夹里读,如下图:

文件夹共享后,局域网内的服务器均可通过\\IP\文件夹访问共享的工程目录

tomcat1和tomcat2下,修改conf里server.xml文件,添加一个Context,指向项目的目录
集群配置完成之后,修改将配置包resource文件夹下的cluster.xml打开,如果没有cluster.xml,则新建一个,基本内容如下:

共享式的集群方式,因为本身就是指向同一个文件夹的,不需要我们来做文件的同步,这里插件的作用是负载均衡。如果需要用到决策平台,需要将finebd迁移到其他数据库,例如MySQL数据库中。
2016年12月28日
#
最简单的扩展列,扩展行的求“最大,最小,平均”值的例子
设计图

效果图

相关函数
=MAX(B2:E2)
=MIN(B2:E2)
=AVERAGE(B2:E2)
这个是(满足条件)的固定列,扩展行的求和例子
设计图

效果图

相关函数
=SUM(B2{B2 > 1} + C2{C2 > 1} + D2{D2 > 1} + E2{E2 > 1})
=SUM(B2{B2 < 1} + C2{C2 < 1} + D2{D2 < 1} + E2{E2 < 1})
=SUM(B2[!0]{B2 > 1})
=SUM(B2[!0]{B2 < 1})
固定列扩展行表求满足条件的(行/列)个数方法!
设计图

效果图

相关函数
=if(B2 > 1, 1, 0) + if(C2 > 1, 1, 0) + if(D2 > 1, 1, 0) + if(E2 > 1, 1, 0)
=count(greparray(B2:E2, item < 1))
=COUNT(B2{B2 > 1})
=COUNT(B2{B2 < 1})
扩展行扩展列求最大,最小,平均值!
设计图

效果图

相关函数
=MAX(B2)
=MIN(B2)
=AVERAGE(B2)