
2008年8月11日
此问题是由于升级 macos sonoma 14.2.1 引起的
解决办法,重新安装xcode
rm -rf /Library/Developer/CommandLineTools
xcode-select --install
posted @
2024-02-04 13:57 一凡 阅读(90) |
评论 (0) |
编辑 收藏# Springboot
整合activiti
源代码:
https://gitee.com/yifan88899/acttest
## 版本说明
- springboot 2.4.2
- activiti 7.1.0.M6
- mysql 8.0.28
## 插件安装
- Activiti BPMN visualizer
## Bpmn
流程图位置
- 流程图xml
和png
需放在resources/processes
下
## Test
- Test Case
都可执行,包括:
- 流程查询
- 流程部署
- 流程启动
- 流程拾取、完成操作
## Mysql
- 需要启动Mysql8
- 数据库名Activiti7
- activiti
会版建表
posted @
2023-11-10 15:56 一凡 阅读(145) |
评论 (0) |
编辑 收藏1、打开my.cnf 加入 skip-grant-tables2、mysql.service stop && mysql.service start
3、清空root密码 并 退出
update mysql.user set authentication_string='' where user='root';
4、mysql.service stop && mysql.service start
5、mysql -root 免密登录并修改root密码
alter user 'root'@
'%' identified
by 'pass$123';
alter user 'root'@
'localhost' identified
by 'pass$123';
确定是否支持远程登录,host中有%的记录即支持
select host, user, authentication_string, plugin from user;
posted @
2021-08-05 18:06 一凡 阅读(242) |
评论 (0) |
编辑 收藏posted @
2021-06-22 17:46 一凡 阅读(114) |
评论 (0) |
编辑 收藏#!/usr/bin/expect
####################
set pass xxxx
set user yyyy
####################
spawn ssh -p 35000 -o StrictHostKeyChecking=no "${user}@xgrelay.xxxx.com"
expect {
-re ".*Dkey.*" { gets stdin dkey; send "$dkey\r"; exp_continue}
-re "Option>:" { send "1\r" ;}
-re "Password>:" { send "$pass\r" ; exp_continue }
-re "password:" { send "$pass\r" ; exp_continue }
}
posted @
2021-01-18 11:35 一凡 阅读(208) |
评论 (0) |
编辑 收藏-- data export csv 其中 $1=$1 如果不加指定分隔符不生效mysql -uadmin -ptest -h127.0.0.1 -P3306 -e "select * from test where create_time > unix_timestamp('2020-09-10 00:00:00') and status = 99" | awk '{OFS=","}{$1=$1;print $0}'#csv中文转码
tmpfn="exempt-update-3.30.csv";iconv -c -s -f UTF-8 -t GBK $tmpfn > /tmp/$tmpfn && mv /tmp/$tmpfn .
posted @
2020-09-10 22:08 一凡 阅读(227) |
评论 (0) |
编辑 收藏#!/bin/bash
for f in "$@"; do
if [ -f "$f" ]; then
iconv -s -c -f UTF8 -t GBK "$f" > /tmp/$f.tmp
mv /tmp/$f.tmp "$f"
fi
done
posted @
2020-04-20 10:03 一凡 阅读(215) |
评论 (0) |
编辑 收藏# -*- coding: utf-8 -*-
#!/usr/bin/python
import re
import io
import sys
# obj = re.compile(r'(?P<ip>.*?)- - \[(?P<time>.*?)\] "(?P<request>.*?)" (?P<status>.*?) (?P<bytes>.*?) "(?P<referer>.*?)" "(?P<ua>.*?)"')
# example:xxxx"id":2640914,"orderId":144115188137125591xxxx"state":10xxxxx"
# 日志整行都需要匹配,需要用的用具体正则匹配,如(\d{7}),不需要的用(.*)匹配,总之所有需要或不需要部分都用()括起来
obj = re.compile(r'(.*"id":)(\d{7})(.*"orderId":)(\d{18})(.*"state":)(\d{2})(.*)')
def load_log(path):
# 读取文件
with io.open(path, mode="r", encoding="utf-8") as f:
for line in f:
line = line.strip()
parse(line)
def stdin():
# 读取管道输入
for line in sys.stdin:
parse(line)
def parse(line):
# 解析单行nginx日志
try:
result = obj.match(line)
print(result.group(2,4,6))
except:
pass
if __name__ == '__main__':
# load_log("/tmp/227.log")
stdin()
posted @
2020-02-29 02:10 一凡 阅读(331) |
评论 (0) |
编辑 收藏- 新增中间件cors
func Cors() gin.HandlerFunc {
return func(c *gin.Context) {
method := c.Request.Method
c.Header("Access-Control-Allow-Origin", "*") //必选
c.Header("Access-Control-Allow-Headers", "*") //可选 �如果request有header, 必选
//c.Header("Access-Control-Allow-Credentials", "true") //可选
//c.Header("Access-Control-Allow-Methods", "*") //可选
//c.Header("Access-Control-Expose-Headers", "*") //可选
//放行所有OPTIONS方法
if method == "OPTIONS" {
c.AbortWithStatus(http.StatusOK)
}
// 处理请求
c.Next()
}
}
- 在router里增加cors,必须在group之前,全局设置
r.Use(gin.Logger(), gin.Recovery(), cors.Cors())
- 测试代码,header设置不能多于cors设置
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<link type="test/css" href="css/style.css" rel="stylesheet">
<script type="text/javascript" src="https://code.jquery.com/jquery-3.2.1.min.js"></script>
<script type="text/javascript">
$(function(){
$("#cors").click(
function(){
$.ajax({
headers:{
"Content-Type":"application/json;charset=UTF-8",
"Access":"adsad",
"Access-Token":"eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6InRlc3QiLCJwYXNzd29yZCI6InRlc3QxMjM0NTYiLCJleHAiOjE1NzczMzY3MTIsImlzcyI6Imdpbi1ibG9nIn0.wMlQXqZO2V0LR-FIgDh45LWI0OYMYi6an_NvRmF0Nug"
},
url:"http://127.0.0.1:8000/api/v1/articles",
success:function(data){
console.log("start");
console.log(data);
}
})
});
});
</script>
<body>
<input type="button" id="cors" value="core跨域测试">
</body>
</html>
- 请求的headers数量、名称与cors里的设置需要严格对应,不然报错如下
Access to XMLHttpRequest at 'http://127.0.0.1:8000/api/v1/articles' from origin 'http://localhost:9999' has been blocked by CORS policy: Request header field access is not allowed by Access-Control-Allow-Headers in preflight response.
posted @
2019-12-26 11:17 一凡 阅读(365) |
评论 (0) |
编辑 收藏
1、在main函数中增加全局配置,其中@name就是你确定的鉴权参数名,我的是token, @
in header 说明参数放在header,你的鉴权代码需要从header中获取
// @title gin-blog API
// @version 0.0.1
// @description This is a gin blog example
// @securityDefinitions.apikey ApiKeyAuth
// @in header
// @name token
// @BasePath /
2、在具体的handler里添加如下注释,此处的ApiKeyAuth和main中的apike对应,切记不要修改
// @Security ApiKeyAuth
3、swagger页面如下:
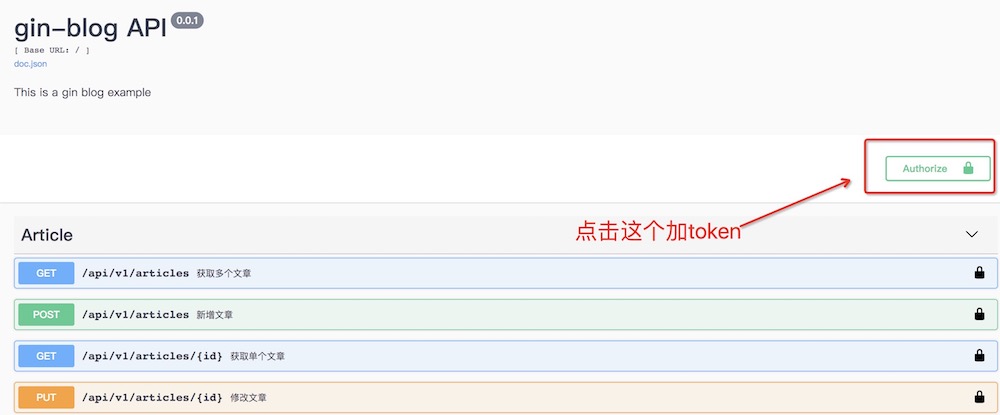
4、添加token后,后续所有有鉴权接口的header里自动携带token
posted @
2019-12-23 16:08 一凡 阅读(2075) |
评论 (0) |
编辑 收藏posted @
2019-11-19 16:41 一凡 阅读(178) |
评论 (0) |
编辑 收藏
- golang
./go_extract_json 0.95s user 0.12s system 99% cpu 1.081 total
- shell
bash segment.sh 0.64s user 0.07s system 101% cpu 0.695 total
- perl
perl extract.pl 39.57s user 0.54s system 98% cpu 40.579 total
posted @
2019-09-20 18:13 一凡 阅读(236) |
评论 (0) |
编辑 收藏- Invalid bound statement (not found)
在接口名称及方法名称对应OK的情况下,在application.properties中添加:
mybatis.mapperLocations=classpath:mapper/*Mapper.xml
mybatis.typeAliasesPackage=com.willpower.entity
posted @
2019-04-03 21:41 一凡 阅读(164) |
评论 (0) |
编辑 收藏推荐:
https://github.com/wming3/.vimToIDE
posted @
2017-05-08 16:33 一凡 阅读(257) |
评论 (0) |
编辑 收藏http://www.iteye.com/news/32170
Guice OKHttp Retrofit
posted @
2017-03-02 17:36 一凡 阅读(173) |
评论 (0) |
编辑 收藏http://www.iteye.com/news/32119
posted @
2017-02-10 18:57 一凡 阅读(212) |
评论 (0) |
编辑 收藏http://www.iteye.com/news/31877
posted @
2016-10-11 15:26 一凡 阅读(196) |
评论 (0) |
编辑 收藏 //mysql
mysql -uroot -proot -h127.0.0.1 testdb -e " select a, b, c, d from t_test where a='xxxx'" | sed 's/\t/","/g;s/^/"/;s/$/"/;s/\n//g' > /tmp/xxxxx.csv
posted @
2015-01-22 18:55 一凡 阅读(432) |
评论 (0) |
编辑 收藏 http://www.oracle.com/
wget下载方法:
1、在打开浏览器的开发者工具
2、在network里找到类似
http://download.oracle.com/otn/java/jdk/6u45-b06/jdk-6u45-linux-x64.bin?AuthParam=1416809306_8aff16bf46c832f44260abcc951c58eawget http://download.oracle.com/otn/java/jdk/6u45-b06/jdk-6u45-linux-x64.bin\?AuthParam=1416809306_8aff16bf46c832f44260abcc951c58ea
注意:红色,由于?是通配符,需要转义一下。
posted @
2014-11-24 14:09 一凡 阅读(246) |
评论 (0) |
编辑 收藏set hlsearch "高亮度反白
set backspace=2 "可随时用倒退键删除
set autoindent "自动缩排
set ruler "可显示最后一行的状态
set showmode "左下角那一行的状态
set nu "可以在每一行的最前面显示行号
set bg=dark "显示不同的底色色调
syntax on "进行语法检验,颜色显示
set wrap "自动折行
set shiftwidth=4
set tabstop=4
set softtabstop=4
set expandtab "将tab替换为相应数量空格
set smartindent
"phpcomplete
filetype plugin on
autocmd FileType php set omnifunc=phpcomplete#CompletePHP
"php-doc
source /home/qiaoy/sf/php-doc.vim
inoremap <C-P> <ESC>:call PhpDocSingle()<CR>i
nnoremap <C-P> :call PhpDocSingle()<CR>
vnoremap <C-P> :call PhpDocRange()<CR>
"neocomplcache
if &term=="xterm"
set t_Co=8
set t_Sb=^[[4%dm
set t_Sf=^[[3%dm
endif
let g:neocomplcache_enable_at_startup = 1
"autoload .vimrc
autocmd! bufwritepost .vimrc source %
posted @
2014-09-17 14:27 一凡 阅读(312) |
评论 (0) |
编辑 收藏#!/bin/bash
for((i=0; i<100; i++));do
curl -i -H "xxx -H "Accept:application/json" -H "Content-Type:application/json" -sd '{"xxx": 563,"xxx": 1,"xxx": 0,"xxx": "{\"xxx\":0,\"xxx\":\"xxx\"}"}' -H "Cookie: JSESSIONID=4F8F7834CEABB668BE84BD3B61AEBE9E" http://test.com;
done
posted @
2014-08-20 13:23 一凡 阅读(342) |
评论 (0) |
编辑 收藏pasting
log4j.properties 使用
一.参数意义说明
输出级别的种类
ERROR、WARN、INFO、DEBUG
ERROR 为严重错误 主要是程序的错误
WARN 为一般警告,比如session丢失
INFO 为一般要显示的信息,比如登录登出
DEBUG 为程序的调试信息
配置日志信息输出目的地
log4j.appender.appenderName = fully.qualified.name.of.appender.
class1.org.apache.log4j.ConsoleAppender(控制台)
2.org.apache.log4j.FileAppender(文件)
3.org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
4.org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
5.org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
配置日志信息的格式
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.
class1.org.apache.log4j.HTMLLayout(以HTML表格形式布局),
2.org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
3.org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
4.org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
控制台选项
Threshold=DEBUG:指定日志消息的输出最低层次。
ImmediateFlush=
true:默认值是true,意谓着所有的消息都会被立即输出。
Target=System.err:默认情况下是:System.out,指定输出控制台
FileAppender 选项
Threshold=DEBUF:指定日志消息的输出最低层次。
ImmediateFlush=
true:默认值是true,意谓着所有的消息都会被立即输出。
File=mylog.txt:指定消息输出到mylog.txt文件。
Append=
false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。
RollingFileAppender 选项
Threshold=DEBUG:指定日志消息的输出最低层次。
ImmediateFlush=
true:默认值是true,意谓着所有的消息都会被立即输出。
File=mylog.txt:指定消息输出到mylog.txt文件。
Append=
false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。
MaxFileSize=100KB: 后缀可以是KB, MB 或者是 GB. 在日志文件到达该大小时,将会自动滚动,即将原来的内容移到mylog.log.1文件。
MaxBackupIndex=2:指定可以产生的滚动文件的最大数。
log4j.appender.A1.layout.ConversionPattern=%-4r %-5p %d{yyyy-MM-dd HH:mm:ssS} %c %m%n
日志信息格式中几个符号所代表的含义:
-X号: X信息输出时左对齐;
%p: 输出日志信息优先级,即DEBUG,INFO,WARN,ERROR,FATAL,
%d: 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
%r: 输出自应用启动到输出该log信息耗费的毫秒数
%c: 输出日志信息所属的类目,通常就是所在类的全名
%t: 输出产生该日志事件的线程名
%l: 输出日志事件的发生位置,相当于%C.%M(%F:%L)的组合,包括类目名、发生的线程,以及在代码中的行数。举例:Testlog4.main (TestLog4.java:10)
%x: 输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像java servlets这样的多客户多线程的应用中。
%%: 输出一个"%"字符
%F: 输出日志消息产生时所在的文件名称
%L: 输出代码中的行号
%m: 输出代码中指定的消息,产生的日志具体信息
%n: 输出一个回车换行符,Windows平台为"/r/n",Unix平台为"/n"输出日志信息换行
可以在%与模式字符之间加上修饰符来控制其最小宽度、最大宽度、和文本的对齐方式。如:
1)%20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,默认的情况下右对齐。
2)%-20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,"-"号指定左对齐。
3)%.30c:指定输出category的名称,最大的宽度是30,如果category的名称大于30的话,就会将左边多出的字符截掉,但小于30的话也不会有空格。
4)%20.30c:如果category的名称小于20就补空格,并且右对齐,如果其名称长于30字符,就从左边较远输出的字符截掉。
二.文件配置Sample1
log4j.rootLogger=DEBUG,A1,R
#log4j.rootLogger=INFO,A1,R
# ConsoleAppender 输出
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%c]-[%p] %m%n
# File 输出 一天一个文件,输出路径可以定制,一般在根路径下
log4j.appender.R=org.apache.log4j.DailyRollingFileAppender
log4j.appender.R.File=blog_log.txt
log4j.appender.R.MaxFileSize=500KB
log4j.appender.R.MaxBackupIndex=10
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
文件配置Sample2
下面给出的Log4J配置文件实现了输出到控制台,文件,回滚文件,发送日志邮件,输出到数据库日志表,自定义标签等全套功能。
log4j.rootLogger=DEBUG,CONSOLE,A1,im
#DEBUG,CONSOLE,FILE,ROLLING_FILE,MAIL,DATABASE
log4j.addivity.org.apache=
true###################
# Console Appender
###################
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.Threshold=DEBUG
log4j.appender.CONSOLE.Target=System.out
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
#log4j.appender.CONSOLE.layout.ConversionPattern=[start]%d{DATE}[DATE]%n%p[PRIORITY]%n%x[NDC]%n%t[THREAD] n%c[CATEGORY]%n%m[MESSAGE]%n%n
#####################
# File Appender
#####################
log4j.appender.FILE=org.apache.log4j.FileAppender
log4j.appender.FILE.File=file.log
log4j.appender.FILE.Append=
false log4j.appender.FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
# Use
this layout
for LogFactor 5 analysis
########################
# Rolling File
########################
log4j.appender.ROLLING_FILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLING_FILE.Threshold=ERROR
log4j.appender.ROLLING_FILE.File=rolling.log
log4j.appender.ROLLING_FILE.Append=
true log4j.appender.ROLLING_FILE.MaxFileSize=10KB
log4j.appender.ROLLING_FILE.MaxBackupIndex=1
log4j.appender.ROLLING_FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLING_FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
####################
# Socket Appender
####################
log4j.appender.SOCKET=org.apache.log4j.RollingFileAppender
log4j.appender.SOCKET.RemoteHost=localhost
log4j.appender.SOCKET.Port=5001
log4j.appender.SOCKET.LocationInfo=
true # Set up
for Log Facter 5
log4j.appender.SOCKET.layout=org.apache.log4j.PatternLayout
log4j.appender.SOCET.layout.ConversionPattern=[start]%d{DATE}[DATE]%n%p[PRIORITY]%n%x[NDC]%n%t[THREAD]%n%c[CATEGORY]%n%m[MESSAGE]%n%n
########################
# Log Factor 5 Appender
########################
log4j.appender.LF5_APPENDER=org.apache.log4j.lf5.LF5Appender
log4j.appender.LF5_APPENDER.MaxNumberOfRecords=2000
########################
# SMTP Appender
#######################
log4j.appender.MAIL=org.apache.log4j.net.SMTPAppender
log4j.appender.MAIL.Threshold=FATAL
log4j.appender.MAIL.BufferSize=10
log4j.appender.MAIL.From=chenyl@yeqiangwei.com
log4j.appender.MAIL.SMTPHost=mail.hollycrm.com
log4j.appender.MAIL.Subject=Log4J Message
log4j.appender.MAIL.To=chenyl@yeqiangwei.com
log4j.appender.MAIL.layout=org.apache.log4j.PatternLayout
log4j.appender.MAIL.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
########################
# JDBC Appender
#######################
log4j.appender.DATABASE=org.apache.log4j.jdbc.JDBCAppender
log4j.appender.DATABASE.URL=jdbc:mysql:
//localhost:3306/test
log4j.appender.DATABASE.driver=com.mysql.jdbc.Driver
log4j.appender.DATABASE.user=root
log4j.appender.DATABASE.password=
log4j.appender.DATABASE.sql=INSERT INTO LOG4J (Message) VALUES ('[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n')
log4j.appender.DATABASE.layout=org.apache.log4j.PatternLayout
log4j.appender.DATABASE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
log4j.appender.A1=org.apache.log4j.DailyRollingFileAppender
log4j.appender.A1.File=SampleMessages.log4j
log4j.appender.A1.DatePattern=yyyyMMdd-HH'.log4j'
log4j.appender.A1.layout=org.apache.log4j.xml.XMLLayout
###################
#自定义Appender
###################
log4j.appender.im = net.cybercorlin.util.logger.appender.IMAppender
log4j.appender.im.host = mail.cybercorlin.net
log4j.appender.im.username = username
log4j.appender.im.password = password
log4j.appender.im.recipient = corlin@yeqiangwei.com
log4j.appender.im.layout=org.apache.log4j.PatternLayout
log4j.appender.im.layout.ConversionPattern =[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
三.高级使用
实验目的:
1.把FATAL级错误写入2000NT日志
2. WARN,ERROR,FATAL级错误发送email通知管理员
3.其他级别的错误直接在后台输出
实验步骤:
输出到2000NT日志
1.把Log4j压缩包里的NTEventLogAppender.dll拷到WINNT/SYSTEM32目录下
2.写配置文件log4j.properties
# 在2000系统日志输出
log4j.logger.NTlog=FATAL, A8
# APPENDER A8
log4j.appender.A8=org.apache.log4j.nt.NTEventLogAppender
log4j.appender.A8.Source=JavaTest
log4j.appender.A8.layout=org.apache.log4j.PatternLayout
log4j.appender.A8.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
3.调用代码:
Logger logger2 = Logger.getLogger("NTlog");
//要和配置文件中设置的名字相同
logger2.debug("debug!!!");
logger2.info("info!!!");
logger2.warn("warn!!!");
logger2.error("error!!!");
//只有这个错误才会写入2000日志
logger2.fatal("fatal!!!");
发送email通知管理员:
1. 首先下载JavaMail和JAF,
http:
//java.sun.com/j2ee/ja/javamail/index.html
http:
//java.sun.com/beans/glasgow/jaf.html
在项目中引用mail.jar和activation.jar。
2. 写配置文件
# 将日志发送到email
log4j.logger.MailLog=WARN,A5
# APPENDER A5
log4j.appender.A5=org.apache.log4j.net.SMTPAppender
log4j.appender.A5.BufferSize=5
log4j.appender.A5.To=chunjie@yeqiangwei.com
log4j.appender.A5.From=error@yeqiangwei.com
log4j.appender.A5.Subject=ErrorLog
log4j.appender.A5.SMTPHost=smtp.263.net
log4j.appender.A5.layout=org.apache.log4j.PatternLayout
log4j.appender.A5.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
3.调用代码:
//把日志发送到mail
Logger logger3 = Logger.getLogger("MailLog");
logger3.warn("warn!!!");
logger3.error("error!!!");
logger3.fatal("fatal!!!");
在后台输出所有类别的错误:
1. 写配置文件
# 在后台输出
log4j.logger.console=DEBUG, A1
# APPENDER A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
2.调用代码
Logger logger1 = Logger.getLogger("console");
logger1.debug("debug!!!");
logger1.info("info!!!");
logger1.warn("warn!!!");
logger1.error("error!!!");
logger1.fatal("fatal!!!");
--------------------------------------------------------------------
全部配置文件:log4j.properties
# 在后台输出
log4j.logger.console=DEBUG, A1
# APPENDER A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
# 在2000系统日志输出
log4j.logger.NTlog=FATAL, A8
# APPENDER A8
log4j.appender.A8=org.apache.log4j.nt.NTEventLogAppender
log4j.appender.A8.Source=JavaTest
log4j.appender.A8.layout=org.apache.log4j.PatternLayout
log4j.appender.A8.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
# 将日志发送到email
log4j.logger.MailLog=WARN,A5
# APPENDER A5
log4j.appender.A5=org.apache.log4j.net.SMTPAppender
log4j.appender.A5.BufferSize=5
log4j.appender.A5.To=chunjie@yeqiangwei.com
log4j.appender.A5.From=error@yeqiangwei.com
log4j.appender.A5.Subject=ErrorLog
log4j.appender.A5.SMTPHost=smtp.263.net
log4j.appender.A5.layout=org.apache.log4j.PatternLayout
log4j.appender.A5.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
全部代码:Log4jTest.java
/*
* 创建日期 2003-11-13
*/ package edu.bcu.Bean;
import org.apache.log4j.*;
//import org.apache.log4j.nt.*;
//import org.apache.log4j.net.*;
/**
* @author yanxu
*/ public class Log4jTest
{
public static void main(String args[])
{
PropertyConfigurator.configure("log4j.properties");
//在后台输出
Logger logger1 = Logger.getLogger("console");
logger1.debug("debug!!!");
logger1.info("info!!!");
logger1.warn("warn!!!");
logger1.error("error!!!");
logger1.fatal("fatal!!!");
//在NT系统日志输出
Logger logger2 = Logger.getLogger("NTlog");
//NTEventLogAppender nla = new NTEventLogAppender();
logger2.debug("debug!!!");
logger2.info("info!!!");
logger2.warn("warn!!!");
logger2.error("error!!!");
//只有这个错误才会写入2000日志
logger2.fatal("fatal!!!");
//把日志发送到mail
Logger logger3 = Logger.getLogger("MailLog");
//SMTPAppender sa = new SMTPAppender();
logger3.warn("warn!!!");
logger3.error("error!!!");
logger3.fatal("fatal!!!");
}
}
posted @
2014-07-17 11:10 一凡 阅读(236) |
评论 (0) |
编辑 收藏mac : lsof -i:8080
linux : netstat -anltp | grep 8080
posted @
2014-07-15 14:20 一凡 阅读(5502) |
评论 (1) |
编辑 收藏openssl rand 16 -base64
posted @
2014-06-16 16:48 一凡 阅读(288) |
评论 (0) |
编辑 收藏打开多个文件:
一、vim还没有启动的时候:
1.在终端里输入
vim file1 file2 ... filen便可以打开所有想要打开的文件
2.vim已经启动
输入
:e file
可以再打开一个文件,并且此时vim里会显示出file文件的内容。
3.同时显示多个文件:
:sp //水平切分窗口
:vsplit //垂直切分窗口
二、在文件之间切换:
1.文件间切换
Ctrl+6 //两文件间的切换
:bn //下一个文件
:bp //上一个文件
:ls //列出打开的文件,带编号
:b1~n //切换至第n个文件
对于用(v)split在多个窗格中打开的文件,这种方法只会在当前窗格中切换不同的文件。
2.在窗格间切换的方法
Ctrl+w+方向键——切换到前/下/上/后一个窗格
Ctrl+w+h/j/k/l ——同上
Ctrl+ww——依次向后切换到下一个窗格中
posted @
2014-02-19 18:34 一凡 阅读(33999) |
评论 (2) |
编辑 收藏find . ! -wholename '*.svn*' ! -wholename '*template_c*' -type f -exec grep -H test {} --color \;
posted @
2014-02-18 17:19 一凡 阅读(356) |
评论 (0) |
编辑 收藏curl -A "android;15;default" -d "detail=aaaaa" "http://test.com/"
posted @
2013-12-18 11:07 一凡 阅读(305) |
评论 (0) |
编辑 收藏update test set create_time=concat('2013-10-01 ', floor(10+rand()*10),':',floor(10+rand()*49),':',floor(10+rand()*49)) where create_time='0000-00-00 00:00:00'
posted @
2013-12-05 16:51 一凡 阅读(814) |
评论 (1) |
编辑 收藏load data infile
'/tmp/test.txt' into table test
character set utf8 (col1,col2,col3

);
绿色部分在mysql参考手册中都没有描述,坑爹啊!!!!!!!!posted @
2013-12-02 14:52 一凡 阅读(641) |
评论 (0) |
编辑 收藏#17点至23点
ls -l xxxx.log.20131117{1[7-8],2[0-3]}
posted @
2013-11-20 18:26 一凡 阅读(260) |
评论 (0) |
编辑 收藏ctrl键组合
ctrl+a:光标移到行首。
ctrl+b:光标左移一个字母
ctrl+c:杀死当前进程。
ctrl+d:退出当前 Shell。
ctrl+e:光标移到行尾。
ctrl+h:删除光标前一个字符,同 backspace 键相同。
ctrl+k:清除光标后至行尾的内容。
ctrl+l:清屏,相当于clear。
ctrl+r:搜索之前打过的命令。会有一个提示,根据你输入的关键字进行搜索bash的history
ctrl+u: 清除光标前至行首间的所有内容。
ctrl+w: 移除光标前的一个单词
ctrl+t: 交换光标位置前的两个字符
ctrl+y: 粘贴或者恢复上次的删除
ctrl+d: 删除光标所在字母;注意和backspace以及ctrl+h的区别,这2个是删除光标前的字符
ctrl+f: 光标右移
ctrl+z : 把当前进程转到后台运行,使用’ fg ‘命令恢复。比如top -d1 然后ctrl+z ,到后台,然后fg,重新恢复
esc组合
esc+d: 删除光标后的一个词
esc+f: 往右跳一个词
esc+b: 往左跳一个词
esc+t: 交换光标位置前的两个单词。
posted @
2013-11-07 14:04 一凡 阅读(299) |
评论 (0) |
编辑 收藏set nocompatible "关闭vi兼容
set enc=utf-8
"set number "显示行号
filetype plugin on "文件类型
set history=500 "历史命令
syntax on "语法高亮
"set autoindent "ai 自动缩进
"set smartindent "智能缩进
set showmatch "括号匹配
set ruler "右下角显示光标状态行
set nohls "关闭匹配的高亮显示
set incsearch "设置快速搜索
set foldenable "开启代码折叠
"set fdm=manual "手动折叠
set foldmethod=syntax "自动语法折叠
set modeline "自动载入模式行
"自动插入modeline
func! AppendModeline()
let l:modeline = printf(" vim: set ts=%d sw=%d tw=%d :",
\ &tabstop, &shiftwidth, &textwidth)
let l:modeline = substitute(&commentstring, "%s", l:modeline, "")
call append(line("$"), l:modeline)
endfunc
"按\ml,自动插入modeline
nnoremap <silent> <Leader>ml :call AppendModeline()<CR>
"空格展开折叠
nnoremap <space> @=((foldclosed(line('.')) < 0) ? 'zc' : 'zo')<CR>
"set tabstop=4
"set shiftwidth=4
set ts=4
set sw=4
set expandtab
"自动tab
if has("autocmd")
filetype plugin indent on
endif
autocmd filetype python setlocal et sta sw=4 sts=4
"根据文件类型自动插入文件头
autocmd BufNewFile *.py,*.sh exec ":call SetTitle()"
func SetTitle()
if &filetype == 'sh'
call setline(1, "\#!/bin/bash")
call append(line("."), "\# Author:itxx00@gmail.com")
call append(line(".")+1, "")
else
call setline(1, "\#!/bin/env python")
call append(line("."), "\#coding:utf-8")
call append(line(".")+1, "\#Author:itxx00@gmail.com")
call append(line(".")+2, "")
endif
endfunc
"新建文件后自动定位至文件末尾
autocmd BufNewFile * normal G
"F2去空行
nnoremap <F2> :g/^\s*$/d<CR>
posted @
2013-10-25 21:24 一凡 阅读(376) |
评论 (0) |
编辑 收藏
访问mysql出现如下error:
ERROR 1045 (28000): Access denied for user 'root'@'121.39.50.24' (using password: YES)
时,用root登录到数据库服务器,执行:
set password for 'root'@'%'=PASSWORD('abc123');
注:有时grant授权后也不行,必须再执行如上命令
posted @
2013-10-25 11:36 一凡 阅读(257) |
评论 (0) |
编辑 收藏
1、查看java证书的别名:
>keytool -list -keystore test.jks -v
执行命令后找到别名
2、下载jks2pfx:
http://www.willrey.com/support/jks2pfx.rar
3、解压jks2pfx后,进入此目录
D:\jks2pfx>JKS2PFX.bat ../tmp/test.jks pass mykey store C:\Program Files\Java\jdk1.7.0_05\bin
要转的jks 密码 别名 导出文件名 jdk路径
posted @
2013-06-19 19:05 一凡 阅读(1982) |
评论 (0) |
编辑 收藏
摘自:
http://www.oschina.net/code/snippet_1030827_21294 <?php
/*
新浪的IP查询接口:
新浪的:http://counter.sina.com.cn/ip?ip=IP地址
返回Js数据,感觉不是很精确,可以把问号后面的去掉,直接返回本机对应的IP所在地
有道的IP查询接口:
返回XML数据:http://www.yodao.com/smartresult-xml/search.s?type=ip&q=0.0.0.0
返回JSON数据:http://www.yodao.com/smartresult-xml/search.s?jsFlag=true&type=ip&q=0.0.0.0
把0.0.0.0换成需查询的IP地址即可,这个应该是用纯真的数据库
太平洋电脑网IP查询接口:
http://whois.pconline.com.cn/?ip=0.0.0.0
把0.0.0.0换成IP地址,页面上还有其他无关内容,这些内容是告诉我们哪些接口可以调用、接口调用参数和使用方法等
查询手机号码归属地接口:
返回XML数据:http://www.youdao.com/smartresult-xml/search.s?type=mobile&q=13888880000
返回JSON数据:http://www.youdao.com/smartresult-xml/search.s?jsFlag=true&type=mobile&q=13888880000
身份证查询接口:
返回XML数据:http://www.youdao.com/smartresult-xml/search.s?type=id&q=身份证号
返回JSON数据:http://www.youdao.com/smartresult-xml/search.s?jsFlag=true&type=id&q=身份证号
*/
echo file_get_contents("接口网址和参数");
?>
posted @
2013-05-14 12:10 一凡 阅读(906) |
评论 (1) |
编辑 收藏iconv -f from-encoding -t to-encoding inputfile
如:iconv -f GBK -t UTF8 test.txt
posted @
2013-05-08 18:53 一凡 阅读(241) |
评论 (0) |
编辑 收藏/usr/local/mysql55/bin/mysql --defaults-file=/usr/local/mysql55/var/my.cnf -uroot -pdev -e "select * from report.appcontent into outfile '/tmp/appcontent.csv' fields terminated by ',' optionally enclosed by '\"' escaped by '\"' lines terminated by '\r\n'"
posted @
2013-05-08 18:21 一凡 阅读(594) |
评论 (0) |
编辑 收藏cmake . -DCMAKE_INSTALL_PREFIX=/usr/local/mysql55 \
-DDEFAULT_CHARSET=gbk \
-DDEFAULT_COLLATION=gbk_chinese_ci \
-DWITH_EXTRA_CHARSETS:STRING=gbk,gb2312,utf8 \
-DWITH_MYISAM_STORAGE_ENGINE=1 \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DWITH_READLINE=1 \
-DENABLED_LOCAL_INFILE=1 \
-DWITH_PARTITION_STORAGE_ENGINE=1 \
-DWITH_ARCHIVE_STORAGE_ENGINE=1 \
-DMYSQL_UNIX_ADDR=/usr/local/mysql55/mysql.sock \
-DSYSCONFDIR=/usr/local/mysql55/conf \
-DMYSQL_DATADIR=/var/mysql/data
make
make install
posted @
2013-03-13 11:24 一凡 阅读(318) |
评论 (0) |
编辑 收藏>>>
>>> print urllib.quote("测试abc")
%E6%B5%8B%E8%AF%95abc
>>>
>>>
>>> print urllib.unquote("%E6%B5%8B%E8%AF%95abc")
测试abc
>>>
posted @
2013-03-05 09:57 一凡 阅读(960) |
评论 (0) |
编辑 收藏 find . -name *.php -exec grep 总记录数 {} -H \;
posted @
2013-02-22 11:36 一凡 阅读(346) |
评论 (0) |
编辑 收藏- 200 - 请求已成功,请求所希望的响应头或数据体将随此响应返回。
- 206 - 服务器已经成功处理了部分 GET 请求
- 301 - 被请求的资源已永久移动到新位置
- 302 - 请求的资源现在临时从不同的 URI 响应请求
- 400 - 错误的请求。当前请求无法被服务器理解
- 401 - 请求未授权,当前请求需要用户验证。
- 403 - 禁止访问。服务器已经理解请求,但是拒绝执行它。
- 404 - 文件不存在,资源在服务器上未被发现。
- 500 - 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。
- 503 - 由于临时的服务器维护或者过载,服务器当前无法处理请求。
HTTP 协议状态码定义可以参阅:Hypertext Transfer Protocol -- HTTP/1.1
posted @
2013-01-05 12:11 一凡 阅读(292) |
评论 (0) |
编辑 收藏posted @
2012-11-05 15:32 一凡 阅读(5035) |
评论 (0) |
编辑 收藏#/bin/bash
del_user() {
echo "请输入用户名:"
read user
echo "请确认是否删除(y/n)?"
read isDel
if [ $isDel = 'y' ]; then
userdel -r $user
echo -e "\t\t\t\t|------------------------------|"
echo -e "\t\t\t\t|------- 用户 '$user' 已删除 ------|"
echo -e "\t\t\t\t|------------------------------|"
fi
}
add_user() {
echo "请输入用户名:"
read user
useradd $user -d /work/$user
passwd $user
echo -e "\t\t\t\t|------------------------------|"
echo -e "\t\t\t\t|------- 用户 "$user" 已创建 ------|"
echo -e "\t\t\t\t|------------------------------|"
}
menu() {
while :
do
echo "1.添加用户"
echo "2.删除用户"
echo "0.退出"
echo -e "\n请选择:"
read choice
case $choice in
1) add_user;;
2) del_user;;
0) exit;;
*) menu;;
esac
done
}
menu
posted @
2012-10-17 11:25 一凡 阅读(306) |
评论 (0) |
编辑 收藏git clone http://github.com/gmarik/vundle.git ~/.vim/bundle/vundle
打开vim,执行如下命令:
:BundleInstall
:BundleSearch
:BundleClean
.vimrc
" For vundle
set nocompatible
filetype off
set rtp+=~/.vim/bundle/vundle/
call vundle#rc()
Bundle 'gmarik/vundle'
" vim-scripts repos
Bundle 'bash-support.vim'
Bundle 'perl-support.vim'
filetype plugin indent on
"let g:winManagerWindowLayout = "FileExplorer"
let g:winManagerWindowLayout = "FileExplorer|TagList"
map <c-w><c-f> :FirstExplorerWindow<cr>
map <c-w><c-b> :BottomExplorerWindow<cr>
map <c-w><c-t> : WMToggle<cr>
let g:persistentBehaviour=0
let g:winManagerWidth=30
nmap <silent><F8> :WMToggle<cr>
posted @
2012-08-24 18:23 一凡 阅读(1511) |
评论 (0) |
编辑 收藏sed -i "s/zhangsan/lisi/g" `grep -l zhangsan zzzzz_*`
posted @
2012-08-10 17:40 一凡 阅读(232) |
评论 (0) |
编辑 收藏
1、修改机器名
$sudo vi /etc/hostname
2、修改时区
$rm /etc/localetime
$ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localetime
posted @
2012-07-12 11:33 一凡 阅读(843) |
评论 (1) |
编辑 收藏引自:http://blog.csdn.net/lyuan13141234/article/details/5667570
在linux下,编译链接的时候,经常会遇到这样一个问题,undefined reference to.....,引起这个问题的原因在于在链接的时候缺少选项。下面举几个例子,并给出解决办法。
1、undefined reference to `dlerror'
undefined reference to `dlopen'
undefined reference to `dlerror'
解决办法:在makefile的LDFLAGS后面把选项 -ldl 添加上即可。
2、undefined reference to `main'
解决办法:在makefile的LDFLAGS后面添加 -nostartfiles 选项。
3、undefined reference to `pthread_setspecific'
undefined reference to `pthread_key_delete'
undefined reference to `pthread_key_create'
解决办法:在makefile的LDFLAGS后面添加 -lpthread 选项。
4、undefined reference to `clock_gettime'
解决办法:在makefile的LDFLAGS后面添加 -lrt 选项。
不过要注意的是,如果undefined reference to后面的内容是在自己的文件中声明或定义的东西,就不能用这种方法来解决了。这时就需要检查一下自己的makefile涉及到源文件、头文件的地方是否出错了,也有可能是其他的原因。
posted @
2012-07-04 17:29 一凡 阅读(5344) |
评论 (1) |
编辑 收藏
$ find . -name *.egg
./python/setuptools-0.6c11-py2.7.egg
./python/dist/protobuf-2.4.1-py2.7.egg
将这两个文件加用户环境
export PYTHONPATH=$SRC_DIR/protobuf-2.3.0-py2.5.egg:$SRC_DIR/setuptools-0.6c9-py2.5.egg
protocol buffer的安装
$ wget "http://protobuf.googlecode.com/files/protobuf-2.4.1.tar.bz2"
$ tar jxvf protobuf-2.4.1.tar.bz2
$ cd protobuf-2.4.1
$ ./configure
$ make
$ make check
$ make install
protocol buffer对python的支持
$ cd python/
$ python setup.py test
$ python setup.py install
1、下载最新版:http://www.python.org/download/
2、安装
$./configure
$make
$make install
与google Ad Exchange 代表处索取requester.tar.gz
$tar zxvf requester.tar.gz
$cd requester
$make
$python2.7 requester.py --url=http://127.0.0.1:8000 --max_qps=1 --requests=1
posted @
2012-07-03 15:27 一凡 阅读(1425) |
评论 (0) |
编辑 收藏
代码如下:(
说明:在车东代码的基础上加了ie和firefox兼容部分及html)测了几款手机:
小米:: 自带浏览器:
支持 iphone4s:: safari:
不支持 QQ浏览器:
不支持 UC8.3.1:
不支持NOKIA5238::自带浏览器:
支持 UC8.3:
不支持<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//WAPFORUM//DTD XHTML Mobile 1.0//EN" "http://www.wapforum.org/DTD/xhtml-mobile10.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<script defer language="javascript" type="text/javascript">
document.onclick = clickStat;
function clickStat() {
// 创建空html标签
e=arguments[0]||window.event;
var image=document.createElement("img");
//image.alt="abc";
image.height=0;
image.width=0;
x=e.clientX;
y=e.clientY;
//记录点击坐标
image.src="http://localhost:8080/r?width=" + screen.width + "&x=" + x + "&y=" + y;
//向服务器发送数据
document.body.insertBefore(image);
return true;
}
</script>
</head>
<body>
测试abc
</body>
</html>
posted @
2012-04-26 17:01 一凡 阅读(3867) |
评论 (1) |
编辑 收藏
本文实现二叉树的递归创建、遍历及深度计算。即输入:abd##e##cf###(按二叉树结构输入)
二叉树:

返回结果如下:

完整代码如下:
#include <stdio.h>
//树结构
typedef struct tree {
char data;
struct tree *lchild, *rchild;
} tree;
//创建树
struct tree* create_tree() {
char node_data;
scanf("%c", &node_data);
if(node_data == '#') {
return NULL;
} else {
struct tree *T = NULL;
T = (struct tree*)malloc(sizeof(struct tree));
T->data = node_data;
T->lchild = create_tree();
T->rchild = create_tree();
return T;
}
}
//先序遍历
void pre_traverse(struct tree *T) {
if(T == NULL) {
return;
} else {
printf("%c\t", T->data);
pre_traverse(T->lchild);
pre_traverse(T->rchild);
}
}
//中序遍历
void mid_traverse(struct tree *T) {
if(T == NULL) {
return;
} else {
mid_traverse(T->lchild);
printf("%c\t", T->data);
mid_traverse(T->rchild);
}
}
//后序遍历
void aft_traverse(struct tree *T) {
if(T == NULL) {
return;
} else {
aft_traverse(T->lchild);
aft_traverse(T->rchild);
printf("%c\t", T->data);
}
}
//深度
int tree_deepth(struct tree *T) {
int i,j;
if(!T) {
return 0;
} else {
if(T->lchild)
i = tree_deepth(T->lchild);
else
i = 0;
if(T->rchild)
j = tree_deepth(T->rchild);
else
j = 0;
return i > j ? (i + 1) : (j + 1);
}
}
int main(int argc, char **argv) {
struct tree *T = create_tree();
if(T) {
printf("%s\n", "先序:");
pre_traverse(T);
printf("\n%s\n", "中序:");
mid_traverse(T);
printf("\n%s\n", "后序:");
aft_traverse(T);
printf("\n%s\n", "深度:");
int deepth = tree_deepth(T);
printf("%d\n", deepth);
printf("\n");
}
return 0;
}
posted @
2012-04-09 17:19 一凡 阅读(347) |
评论 (0) |
编辑 收藏
最开心的事:我的宝贝女儿出生了(2011.2.15),给我带来了很多快乐,小家伙到今天已10个月零16天了,在学着走路,很可爱,希望她能快乐成长
最冲动的事:换了一辆车,科鲁兹1.8se --> 新迈腾2.0至尊型,有点冲动,不过家里添了一个小公主,大空间的车也是必要的啊,哈哈
最不解的事: 家庭生活中鸡毛事,家里人为这些生气,不开心值得吗?不解又躲不开,先从自己做起吧,改造自己
最大的感悟:自从为人父母后,深刻的体会到了做父母的不易,以后要更加孝敬老人、照顾老人
工作上的事,还是很平稳,工资比去年多了些,但在行业同水平里还是偏底的,毕业到现在换了不少公司了,不想再换了,如果不出什么意外,我想把现在公司做为我最后打工公司。今年负责的产品比较稳定,在技术上没有什么突破,感觉对什么都是三分钟热度,看不下去,钻不进去,明年计划在技术方面要加强学习,争取有所突破。
就写这么多了,这个叫流水体吧^_^比去年写的多了点.....
posted @
2011-12-31 16:16 一凡 阅读(360) |
评论 (0) |
编辑 收藏#encode
quote("客户")
#decode
print urllib.unquote('%CF%CA%BB%A8')
#utf8编码的解码方法,其中ignore参数可忽略不正确的数据
print de(str).decode("utf8","ignore")
#gbk编码的解码方法,其中ignore参数可忽略不正确的数据
print de(str).decode("utf8","ignore")
posted @
2011-12-29 16:53 一凡 阅读(239) |
评论 (0) |
编辑 收藏dir /tc /o-d /a-d *.* >d:\allfiles.txt
posted @
2011-10-21 17:17 一凡 阅读(1014) |
评论 (0) |
编辑 收藏
查看系统环境是否设置了“LD_LIBRARY_PATH”
办法一:
如没有设置,就将你的so路径设置为LD_LIBRARY_PATH:
export LD_LIBRARY_PATH="your so path"
或将上面命令添加到~/.bashrc里,执行:
source ~/.bashrc
办法二:
如没设置,将你的so拷至LD_LIBRARY_PATH路径下并执行:
/sbin/ldconfig -v
通过以上两种办法之一就能解决此问题,当然还可以修改/etc/ld.so.conf,但需要root权限,总之办法不止这两种,大家灵活应用吧。
posted @
2011-09-13 18:12 一凡 阅读(396) |
评论 (0) |
编辑 收藏在linux a上执行:
$ssh-keygen -t rsa #不需要任何输入,一路回车
$scp ~/.ssh/id_rsa.pub to linux B
在liunx b上执行:
$cat id_rsa.pub >>~/.ssh/authorized_keys
posted @
2011-09-07 12:18 一凡 阅读(356) |
评论 (0) |
编辑 收藏
如下代码:
private long testTime = 60 * 24 * 3600 * 1000;
testTime应该等于5184000000,但实际值为889032704,造成了int数据溢出。
开发中要牢记。
posted @
2011-08-31 11:30 一凡 阅读(222) |
评论 (0) |
编辑 收藏
可以通过加编译参数encoding gbk,执行时加-Dfile.encoding="GBK"的办法来解决,具体命令行:
javac -encoding gbk TTT.java
java -Dfile.encoding="GBK" TTT
posted @
2011-06-24 15:38 一凡 阅读(346) |
评论 (0) |
编辑 收藏
http://woodpecker.org.cn/diveintopython/toc/index.html
posted @
2011-03-16 16:39 一凡 阅读(285) |
评论 (0) |
编辑 收藏
春节过完了,也该总结一下我的2010了,这一年我过的很纠结,在辞职自己干和继续打工之间纠结,在年过30的恐慌中,对自己未来职业规划的迷茫中渡过,不管怎么说这一年算是过来了。这一年收获的不少,工作上很平稳,按部就班的,生活上我们也有了小宝宝(快要来到我们身边了),我很期待。
2011年我还得坚持,为了我们的小宝再打工一年......
不多写了,也不细写了,哈哈
posted @
2011-02-12 13:37 一凡 阅读(278) |
评论 (0) |
编辑 收藏
gcc test_get_ad.c -o test_get_ad -ldl
posted @
2010-11-03 13:06 一凡 阅读(332) |
评论 (0) |
编辑 收藏摘自:http://edu.codepub.com/2009/0929/15909.php
应用举例
(1) 判断int型变量a是奇数还是偶数
a&1 = 0 偶数
a&1 = 1 奇数
(2) 取int型变量a的第k位 (k=0,1,2……sizeof(int)),即a>>k&1
(3) 将int型变量a的第k位清0,即a=a&~(1 < <k)
(4) 将int型变量a的第k位置1, 即a=a ¦(1 < <k)
(5) int型变量循环左移k次,即a=a < <k ¦a>>16-k (设sizeof(int)=16)
(6) int型变量a循环右移k次,即a=a>>k ¦a < <16-k (设sizeof(int)=16)
(7)整数的平均值
对于两个整数x,y,如果用 (x+y)/2 求平均值,会产生溢出,因为 x+y 可能会大于INT_MAX,但是我们知道它们的平均值是肯定不会溢出的,我们用如下算法:
int average(int x, int y) //返回X,Y 的平均值
{
return (x&y)+((x^y)>>1);
}
(8)判断一个整数是不是2的幂,对于一个数 x >= 0,判断他是不是2的幂
boolean power2(int x)
{
return ((x&(x-1))==0)&&(x!=0);
}
(9)不用temp交换两个整数
void swap(int x , int y)
{
x ^= y;
y ^= x;
x ^= y;
}
(10)计算绝对值
int abs( int x )
{
int y ;
y = x >> 31 ;
return (x^y)-y ; //or: (x+y)^y
}
(11)取模运算转化成位运算 (在不产生溢出的情况下)
a % (2^n) 等价于 a & (2^n - 1)
(12)乘法运算转化成位运算 (在不产生溢出的情况下)
a * (2^n) 等价于 a < < n
(13)除法运算转化成位运算 (在不产生溢出的情况下)
a / (2^n) 等价于 a>> n
例: 12/8 == 12>>3
(14) a % 2 等价于 a & 1
(15) if (x == a) x= b;
else x= a;
等价于 x= a ^ b ^ x;
(16) x 的 相反数 表示为 (~x+1)
实例
功能 ¦ 示例 ¦ 位运算
----------------------+---------------------------+--------------------
去掉最后一位 ¦ (101101->10110) ¦ x >> 1
在最后加一个0 ¦ (101101->1011010) ¦ x < < 1
在最后加一个1 ¦ (101101->1011011) ¦ x < < 1+1
把最后一位变成1 ¦ (101100->101101) ¦ x ¦ 1
把最后一位变成0 ¦ (101101->101100) ¦ x ¦ 1-1
最后一位取反 ¦ (101101->101100) ¦ x ^ 1
把右数第k位变成1 ¦ (101001->101101,k=3) ¦ x ¦ (1 < < (k-1))
把右数第k位变成0 ¦ (101101->101001,k=3) ¦ x & ~ (1 < < (k-1))
右数第k位取反 ¦ (101001->101101,k=3) ¦ x ^ (1 < < (k-1))
取末三位 ¦ (1101101->101) ¦ x & 7
取末k位 ¦ (1101101->1101,k=5) ¦ x & ((1 < < k)-1)
取右数第k位 ¦ (1101101->1,k=4) ¦ x >> (k-1) & 1
把末k位变成1 ¦ (101001->101111,k=4) ¦ x ¦ (1 < < k-1)
末k位取反 ¦ (101001->100110,k=4) ¦ x ^ (1 < < k-1)
把右边连续的1变成0 ¦ (100101111->100100000) ¦ x & (x+1)
把右起第一个0变成1 ¦ (100101111->100111111) ¦ x ¦ (x+1)
把右边连续的0变成1 ¦ (11011000->11011111) ¦ x ¦ (x-1)
取右边连续的1 ¦ (100101111->1111) ¦ (x ^ (x+1)) >> 1
去掉右起第一个1的左边 ¦ (100101000->1000) ¦ x & (x ^ (x-1))
判断奇数 (x&1)==1
判断偶数 (x&1)==0
例如求从x位(高)到y位(低)间共有多少个1
public static int FindChessNum(int x, int y, ushort k)
{
int re = 0;
for (int i = y; i <= x; i++)
{
re += ((k >> (i - 1)) & 1);
}
return re;
}
posted @
2010-10-29 12:21 一凡 阅读(1498) |
评论 (0) |
编辑 收藏目录结构:com/test/JniTest.java
package : com.test
javac com/test/JniTest.java
javah -classpath ./ -jni com.test.JniTest
在当前目录下生成:
com_test_JniTest.h
posted @
2010-10-27 12:17 一凡 阅读(374) |
评论 (0) |
编辑 收藏方法一:
进入MySQL安装目录 打开MySQL配置文件 my.ini 或 my.cnf查找 max_connections=100 修改为 max_connections=1000 ,服务里重起MySQL即可
注意:如果新增max_connections,必须放在mysqld下,如:
 [mysqld]
[mysqld]
max_connections=300方法二:
登录至数据库,执行以下命令:
set GLOBAL max_connections=500;
show variables like 'max_con%';
posted @
2010-09-16 14:08 一凡 阅读(295) |
评论 (0) |
编辑 收藏
需求:广告按权重展现
基本算法描述如下:
1、每个广告增加权重
2、将所有匹配广告的权重相加sum,
3、以相加结果为随机数的种子,生成1~sum之间的随机数rd
4、.接着遍历所有广告,访问顺序可以随意.将当前节点的权重值加上前面访问的各节点权重值得curWt,判断curWt >= rd,如果条件成立则返回当前节点,如果不是则继续累加下一节点. 直到符合上面的条件,由于rd<=sum 因此一定存在curWt>=rd。
特别说明:
此算法和广告的顺序无关
测试代码如下:
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;

 public class Test {
public class Test {


 /** *//**
/** *//**
* @param args
 */
*/
@SuppressWarnings("unchecked")
public static void main(String[] args) {
List<Node> arrNodes = new ArrayList<Node>();
Node n = new Node(10, "测试1");
arrNodes.add(n);
n = new Node(20, "测试2");
arrNodes.add(n);
n = new Node(30, "测试3");
arrNodes.add(n);
n = new Node(40, "测试4");
arrNodes.add(n);
//Collections.sort(arrNodes, new Node());
Map<String, Integer> showMap = null;
int sum = getSum(arrNodes);
int random = 0;
Node kw = null;
for(int k = 0; k < 20; k++) {
showMap = new LinkedHashMap<String, Integer>();
for(int i = 0; i < 100; i++) {
random = getRandom(sum);
kw = getKW(arrNodes, random);
if(showMap.containsKey(kw.kw)) {
showMap.put(kw.kw, showMap.get(kw.kw) + 1);
} else {
showMap.put(kw.kw, 1);
}
//System.out.println(i + " " +random + " " + getKW(arrNodes, random));
}
System.out.print(k + " ");
System.out.println(showMap);
}
}
public static Node getKW(List<Node> nodes, int rd) {
Node ret = null;
int curWt = 0;
for(Node n : nodes){
curWt += n.weight;
if(curWt >= rd) {
ret = n;
break;
}
}
return ret;
}
public static int getSum(List<Node> nodes) {
int sum = 0;
for(Node n : nodes)
sum += n.weight;
return sum;
}
public static int getRandom(int seed) {
return (int)Math.round(Math.random() * seed);
}
 }
}
class Node implements Comparator{
int weight = 0;
String kw = "";
public Node() {}
public Node(int wt, String kw) {
this.weight = wt;
this.kw = kw;
}
public String toString(){
StringBuilder sbBuilder = new StringBuilder();
sbBuilder.append(" weight=").append(weight);
sbBuilder.append(" kw").append(kw);
return sbBuilder.toString();
}
public int compare(Object o1, Object o2) {
Node n1 = (Node)o1;
Node n2 = (Node)o2;
if(n1.weight > n2.weight)
return 1;
else
return 0;
}
}posted @
2010-08-31 17:08 一凡 阅读(3435) |
评论 (0) |
编辑 收藏#!/bin/bash
MYSQL_HOME="/home/work/local/mysql5"
MYSQL_SRC_HOME="mysql-5.1.38"
cd $MYSQL_SRC_HOME
make clean
./configure \
--prefix=$MYSQL_HOME \
--with-tcp-port=3308 \
--enable-thread-safe-client \
--enable-local-infile \
--with-unix-socket-path=$MYSQL_HOME/mysql.sock \
--with-charset=gbk \
--with-innodb \
--with-extra-charsets=gbk,utf8,ascii,big5,latin1 \
--enable-static \
--enable-assemble
make
make install
cd $MYSQL_HOME
cp ./share/mysql/my-huge.cnf ./my.cnf
./bin/mysql_install_db
./bin/mysqld_safe &
posted @
2010-08-30 16:43 一凡 阅读(273) |
评论 (0) |
编辑 收藏posted @
2010-08-30 14:41 一凡 阅读(227) |
评论 (0) |
编辑 收藏:
http://www.javaeye.com/topic/748178
posted @
2010-08-30 14:40 一凡 阅读(157) |
评论 (0) |
编辑 收藏posted @
2010-08-30 14:33 一凡 阅读(251) |
评论 (0) |
编辑 收藏摘自:http://hi.baidu.com/zhouqleilo/blog/item/f76297127ed0c9085aaf5330.html
经常使用的正则表达式
^
行首
$
行尾
. 任意一个字符
* 任意多个字符
\ 转义字符
^ [ t h e ]
以t h e开头行
[ S s ] i g
n a [ l L ] 匹配单词s i g n a l、s
i g n a L、S i g n a l、S i g n a L
[Ss]igna[lL]".
同上,但加一句点
[ m a y M A
Y ] 包含m a y大写或小写字母的行
^ U S E R $
只包含U S E R的行
[tty]$
以t t y结尾的行
\ .
带句点的行
^ d . . x .
. x . . x 对用户、用户组及其他用户组成员有可执行权限的目录
^ [ ^ l ] 排除关联目录的目录列表
^[^d] ls –l |
grep ^[^d] 只显示非文件夹的文件
[ . * 0 ]
0之前或之后加任意字符
[ 0 0 0 * ]
0 0 0或更多个
[ iI]
大写或小写I
[ i I ] [ n
N ] 大写或小写i或n
[ ^ $ ]
空行
[ ^ . * $ ]
匹配行中任意字符串
^ . . . . .
. $ 包括6个字符的行
[a- zA-Z]
任意单字符
[ a - z ] [ a - z ] * 至少一个小写字母
[ ^ 0 - 9 "
$ ] 非数字或美元标识
[ ^ 0 - 0 A
- Z a - z ] 非数字或字母
[ 1 2 3 ]
1到3中一个数字
[ D d ] e v
i c e 单词d e v i c e或D
e v i c e
D e . . c e
前两个字母为D e,后跟两个任意字符,
最后为c e
" ^ q
以^ q开始行
^ . $
仅有一个字符的行
^".[0-9][0-9]
以一个句点和两个数字开始的行
' " D e v i c e " ' 单词d e v i c e
D e [ V v ] i c e \ . 单词D e v i c e或d e v i c e
([0-9]{2}/[a-zA-Z]{3}/[0-9]{4}) 对
日期格式08/Jun/2010
([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) I P地址格式
[ ^ . * $ ]
匹配任意行
[A-Za-z]* 匹配所有单词
功能说明:查找文件里符合条件的字符串。
语 法:grep
[-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>]
[-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
补充说明:grep指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设
grep指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为“-”,则grep指令会从标准输入设备读取数据。
参 数:
-a或--text 不要忽略二进制的数据。
-A<显示列数>或--after-context=<显示列数>
除了显示符合范本样式的那一列之外,并显示该列之后的内容。
-b或--byte-offset 在显示符合范本样式的那一列之前,标示出该列第一个字符的位编号。
-B<显示列数>或--before-context=<显示列数>
除了显示符合范本样式的那一列之外,并显示该列之前的内容。
-c或--count 计算符合范本样式的列数。
-C<显示列数>或--context=<显示列数>或-<显示列数>
除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作>或--directories=<进行动作>
当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式>或--regexp=<范本样式> 指定字符串做为查找文件内容的范本样式。
-E或--extended-regexp 将范本样式为延伸的普通表示法来使用。
-f<范本文件>或--file=<范本文件>
指定范本文件,其内容含有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每列一个范本样式。
-F或--fixed-regexp 将范本样式视为固定字符串的列表。
-G或--basic-regexp 将范本样式视为普通的表示法来使用。
-h或--no-filename 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H或--with-filename 在显示符合范本样式的那一列之前,表示该列所属的文件名称。
-i或--ignore-case 忽略字符大小写的差别。
-l或--file-with-matches 列出文件内容符合指定的范本样式的文件名称。
-L或--files-without-match 列出文件内容不符合指定的范本样式的文件名称。
-n或--line-number 在显示符合范本样式的那一列之前,标示出该列的列数编号。
-q或--quiet或--silent 不显示任何信息。
-r或--recursive 此参数的效果和指定“-d recurse”参数相同。
-s或--no-messages 不显示错误信息。
-v或--revert-match 反转查找。
-V或--version 显示版本信息。
-w或--word-regexp 只显示全字符合的列。
-x或--line-regexp 只显示全列符合的列。
-y 此参数的效果和指定“-i”参数相同。
--help 在线帮助。
posted @
2010-07-15 19:40 一凡 阅读(777) |
评论 (0) |
编辑 收藏摘自:http://learn.akae.cn/media/ch03s03.html
Man Page
Man Page是Linux开发最常用的参考手册,由很多页面组成,每个页面描述一个主题,这些页面被组织成若干个Section。FHS(Filesystem Hierarchy Standard)标准规定了Man Page各Section的含义如下:
表 3.1. Man Page的Section
| Section |
描述 |
| 1 |
用户命令,例如ls(1) |
| 2 |
系统调用,例如_exit(2) |
| 3 |
库函数,例如printf(3) |
| 4 |
特殊文件,例如null(4)描述了设备文件/dev/null、/dev/zero的作用 |
| 5 |
系统配置文件的格式,例如passwd(5)描述了系统配置文件/etc/passwd的格式 |
| 6 |
游戏 |
| 7 |
其它杂项,例如bash-builtins(7)描述了bash的各种内建命令 |
| 8 |
系统管理命令,例如ifconfig(8) |
注意区分用户命令和系统管理命令,用户命令通常位于/bin和/usr/bin目录,系统管理命令通常位于/sbin和/usr/sbin目录,一般用户可以执行用户命令,而执行系统管理命令经常需要root权限。系统调用和库函数的区别将在第 2 节 “main函数和启动例程”说明。
Man Page中有些页面有重名,比如敲man printf命令看到的并不是C函数printf,而是位于第1个Section的系统命令printf,要查看位于第3个Section的printf函数应该敲man 3 printf,也可以敲man -k printf命令搜索哪些页面的主题包含printf关键字。本书会经常出现类似printf(3)这样的写法,括号中的3表示Man Page的第3个Section,或者表示“我这里想说的是printf库函数而不是printf命令”。
posted @
2010-06-21 15:20 一凡 阅读(480) |
评论 (0) |
编辑 收藏
执行到./configure --enable-shared一步时提示:
checking host system type... Invalid configuration `x86_64-unknown-linux-gnu ': machine `x86_64-unknown ' not recognized
解决办法:
cp /usr/share/libtool/config.guess . (覆盖到相关软件自带的config.guess,t1lib在解压包的ac-tools下)
cp /usr/share/libtool/config.sub . (覆盖到相关软件自带的config.sub)
./configure --enable-shared --enable-static
make libdir=/usr/lib64
make libdir=/usr/lib64 install
使用64位函数库编译.
posted @
2010-06-01 17:31 一凡 阅读(883) |
评论 (0) |
编辑 收藏
linux下用cp更新so后重启服务会出core原因:
用cp更新so会改变so的inode,服务找不到原来的inode,所以出core
解决办法:
1、先mv so,再cp so就不会出core了
2、先rm so,再cp so就不会出core了
posted @
2010-05-28 15:35 一凡 阅读(411) |
评论 (0) |
编辑 收藏
1、安装jprofiler6 google一下
2、修改~/.bashrc,根据你的安装路径配置:
export LD_LIBRARY_PATH='/home/work/jprofiler6/bin/linux-x64'
export JPROFILER_HOME='/home/work/jprofiler6/bin/linux-x64'
3、启动java应用程序
java -agentlib:jprofilerti=port=8849 -Xbootclasspath/a:/home/work/jprofiler6/bin/agent.jar JavaApp
posted @
2010-05-26 10:12 一凡 阅读(392) |
评论 (0) |
编辑 收藏
1、查看库函数原型:
在命令模式下,光标停在要看的函数上 ctrl+w i
2、查看库函数帮助:
在命令模式下,光标停在要看的函数上 shift+k(K)
posted @
2010-05-21 17:44 一凡 阅读(272) |
评论 (0) |
编辑 收藏
1、copy /etc/vimrc ~/.vimrc
2、vi ~/.vimrc
添加配置
export TERM=xterm-color
即可语法高亮
.vimrc
if v:lang =~ "utf8$" || v:lang =~ "UTF-8$"
set fileencodings=utf-8,latin1
endif
set nocompatible " Use Vim defaults (much better!)
set bs=2 " allow backspacing over everything in insert mode
"set ai " always set autoindenting on
"set backup " keep a backup file
set viminfo='20,\"50 " read/write a .viminfo file, don't store more
" than 50 lines of registers
set history=50 " keep 50 lines of command line history
set ruler " show the cursor position all the time
" Only do this part when compiled with support for autocommands
if has("autocmd")
" In text files, always limit the width of text to 78 characters
autocmd BufRead *.txt set tw=78
" When editing a file, always jump to the last cursor position
autocmd BufReadPost *
\ if line("'\"") > 0 && line ("'\"") <= line("$") |
\ exe "normal! g'\"" |
\ endif
endif
if has("cscope")
set csprg=/usr/bin/cscope
set csto=0
set cst
set nocsverb
" add any database in current directory
if filereadable("cscope.out")
cs add cscope.out
" else add database pointed to by environment
elseif $CSCOPE_DB != ""
cs add $CSCOPE_DB
endif
set csverb
endif
" Switch syntax highlighting on, when the terminal has colors
" Also switch on highlighting the last used search pattern.
if &t_Co > 2 || has("gui_running")
syntax on
set hlsearch
endif
if &term=="xterm"
set t_Co=8
set t_Sb=^[[4%dm
set t_Sf=^[[3%dm
endif
posted @
2010-05-11 11:32 一凡 阅读(1265) |
评论 (0) |
编辑 收藏
摘自:http://dikar.javaeye.com/blog/643436
如题,我这里简单说下我现在离线分析java内存的方式,所谓离线,就是需要dump出正在运行的java系统中的一些运行时堆栈数据,然后拿到线下来分析,分析可以包括内存,线程,GC等等,同时不会对正在运行的生产环境的机器造成很大的影响,对应着离线分析,当然是在线分析了,这个我在后面会尝试下,因为离线分析有些场景还是模拟不出来,需要借助LR来模拟压力,查看在线的java程序运行情况了。
首先一个简单的问题,如何dump出java运行时堆栈,这个SUN就提供了很好的工具,位于JAVA_HOME/bin目录下的jmap(java memory map之意),如果需要dump出当前运行的java进程的堆栈数据,则首先需要获得该java进程的进程ID,在linux下可以使用
- ps -aux
-
- ps -ef | grep java
ps -aux
ps -ef | grep java
或者使用jdk自带的一个工具jps,例如
/JAVA_HOME/bin/jps
找到了当前运行的java进程的id后,就可以对正在运行的java进程使用jmap工具进行dump了,例如使用以下命令:
- JAVA_HOME/bin/jmap -dump:format=b,file=heap.bin <pid>
JAVA_HOME/bin/jmap -dump:format=b,file=heap.bin <pid>
其中file = heap.bin的意思是dump出的文件名叫heap.bin, 当然你可以选择你喜欢的名字,我这里选择叫*.bin是为了后面使用方便,<pid>表示你需要dump的java进程的id。
这里需要注意的是,记住dump的进程是java进程,不会是jboss的进程,weblogic的进程等。dump过程中机器load可能会升高,但是在我这里测试发现load升的不是特别快,同时dump时需要的磁盘空间也比较大,例如我这里测试的几个系统,分别是500M 800M 1500M 3000M,所以确保你运行jmap命令时所在的目录中的磁盘空间足够,当然现在的系统磁盘空间都比较大。
以上是在java进程还存活的时候进行的dump,有的时候我们的java进程crash后,会生成一个core.pid文件,这个core.pid文件还不能直接被我们的java 内存分析工具使用,需要将其转换为java 内存分析工具可以读的文件(例如使用jmap工具dump出的heap.bin文件就是很多java 内存分析工具可以读的文件格式)。将core.pid文件转换为jmap工具dump出的文件格式还可以继续使用jmap工具,这个的说明可以见我前几篇中的一个转载(Create Java heapdumps with the help of core dumps ),这里我在补充点
- jmap -heap:format=b [java binary] [core dump file]
-
-
- jmap -dump:format=b,file=dump.hprof [java binary] [core dump file]
-
-
- 64位下可以指定使用64位模式
-
- jmap -d64 -dump:format=b,file=dump.hprof [java binary] [core dump file]
jmap -heap:format=b [java binary] [core dump file]
jmap -dump:format=b,file=dump.hprof [java binary] [core dump file]
64位下可以指定使用64位模式
jmap -d64 -dump:format=b,file=dump.hprof [java binary] [core dump file]
需要说明一下,使用jmap转换core.pid文件时,当文件格式比较大时,可能大于2G的时候就不能执行成功(我转换3G文件大小的时候没有成功)而报出
Error attaching to core file: Can't attach to the core file
查过sun的bug库中,这个bug还没有被修复,我想还是由于32位下用户进程寻址大小限制在2G的范围内引起的,在64位系统和64位jdk版本中,转换3G文件应该没有什么大的问题(有机会有环境得需要测试下)。如果有兴趣分析jmap转换不成功的同学,可以使用如下命令来分析跟踪命令的执行轨迹,例如使用
- strace jmap -heap:format=b [java binary] [core dum
strace jmap -heap:format=b [java binary] [core dum
对于strace的命令的说明,同样可以参考我前几篇文章中的一个 strace命令用法
同时对于core.pid文件的调试我也补充一下, 其中>>表示命令提示符
- >>gdb JAVA_HOME/bin/java core.pid
-
- >>bt
>>gdb JAVA_HOME/bin/java core.pid
>>bt
bt后就可以看到生成core.pid文件时,系统正在执行的一个操作,例如是哪个so文件正在执行等。
好了说了这么多,上面都是怎么生成java 运行期DUMP文件的,接下来我们就进入分析阶段,为了分析这个dump出的文件,需要将这个文件弄到你的分析程序所在的机器上,例如可以是windows上,linux上,这个和你使用的分析工具以及使用的操作系统有关。不管使用什么系统,总是需要把生产环境下打出的dump文件搞到你的分析机器上,由于dump出的文件经常会比较大,例如达到2G,这么大的文件不是很好的从生产环境拉下来,因此使用FTP的方式把文件拖到分析机器上,同时由于单个文件很大,因此为了快速的将文件下载到分析机器,我们可以使用分而治之的思想,先将文件切割为小文件下载,然后在合并为一个大文件即可,还好linux提供了很方便的工具,例如使用如下命令
- $ split -b 300m heap.bin
-
- $ cat x* > heap.bin
$ split -b 300m heap.bin
$ cat x* > heap.bin
在上面的 split 命令行中的 “300m” 表示分割后的每个文件为 300MB,“heap.bin” 为待分割的dump文件,分割后的文件自动命名为 xaa,xab,xac等
cat 命令可将这些分割后的文件合并为一个文件,例如将所有x开头的文件合并为heap.bin
如果我们是利用一个中间层的FTP服务器来保存数据的,那么我们还需要连接这个FTP服务器把合并后的文件拉下来,在windows下我推荐使用一个工具,速度很快而且简单,
winscp http://winscp.net/eng/docs/lang:chs
好了分析的文件终于经过一翻周折到了你的分析机器上,现在我们就可以使用分析工具来分析这个dump出的程序了,这里我主要是分析内存的问题,所以我说下我选择的内存分析工具,我这里使用的是开源的由SAP 和IBM 支持的一个内存分析工具
Memory Analyzer (MAT)
http://www.eclipse.org/mat/
我建议下载 Stand-alone Eclipse RCP 版本,不要装成eclipse的插件,因为这个分析起来还是很耗内存。
下载好了,解压开来就可以直接使用了(基于eclipse的),打开以后,在菜单栏中选择打开文件,选择你刚刚的dump文件,然后一路的next就可以了,最后你会看到一个报告,这个报告里会告诉你可能的内存泄露的点,以及内存中对象的一个分布,关于mat的使用请参考官方说明,当然你也可以自己徜徉在学习的海洋中 。
对于dump文件的分析还可以使用jdk中提供的一个jhat工具来查看,不过这个很耗内存,而且默认的内存大小不够,还需要增加参数设置内存大小才能分析出,不过我看了下分析出的结果不是很满意,而且这个用起来很慢。还是推荐使用mat 。
posted @
2010-05-07 10:31 一凡 阅读(2982) |
评论 (0) |
编辑 收藏参考手册里的9语言结构,9.3用户变量,9.4系统变量
设置用户变量的一个途径是执行SET语句:
SET @var_name = expr [, @var_name = expr] ...
也可以用语句代替SET来为用户变量分配一个值。在这种情况下,分配符必须为:=而不能用=,因为在非SET语句中=被视为一个比较 操作符,如下所示:
mysql> SET @t1=0, @t2=0, @t3=0;
mysql> SELECT @t1:=(@t2:=1)+@t3:=4,@t1,@t2,@t3;
对于使用select语句为变量赋值的情况,若返回多条记录,则变量的值为最后一条记录的值,不过不建议在这种情况下使用;若返回结果为空,即没有记录,此时变量的值为上一次变量赋值时的值,如果没有对变量赋过值,则为NULL。
一般我们可以这么使用:
set @tmp=0
select @tmp:=tmp from table_test;
set @tmp=@tmp+1
系统变量就直接拷贝吧:
MySQL可以访问许多系统和连接变量。当服务器运行时许多变量可以动态更改。这样通常允许你修改服务器操作而不需要停止并重启服务器。
mysqld服务器维护两种变量。全局变量影响服务器整体操作。会话变量影响具体客户端连接的操作。
当服务器启动时,它将所有全局变量初始化为默认值。这些默认值可以在选项文件中或在命令行中指定的选项进行更改。服务器启动后,通过连接服务器并执行SET GLOBAL var_name语句,可以动态更改这些全局变量。要想更改全局变量,必须具有SUPER权限。
服务器还为每个连接的客户端维护一系列会话变量。在连接时使用相应全局变量的当前值对客户端的会话变量进行初始化。对于动态会话变量,客户端可以通过SET SESSION var_name语句更改它们。设置会话变量不需要特殊权限,但客户端只能更改自己的会话变量,而不能更改其它客户端的会话变量。
对于全局变量的更改可以被访问该全局变量的任何客户端看见。然而,它只影响更改后连接的客户的从该全局变量初始化的相应会话变量。不影响目前已经连接的客户端的会话变量(即使客户端执行SET GLOBAL语句也不影响)。
可以使用几种语法形式来设置或检索全局或会话变量。下面的例子使用了sort_buffer_sizeas作为示例变量名。
要想设置一个GLOBAL变量的值,使用下面的语法:
mysql> SET GLOBAL sort_buffer_size=value;
mysql> SET @@global.sort_buffer_size=value;
要想设置一个SESSION变量的值,使用下面的语法:
mysql> SET SESSION sort_buffer_size=value;
mysql> SET @@session.sort_buffer_size=value;
mysql> SET sort_buffer_size=value;
LOCAL是SESSION的同义词。
如果设置变量时不指定GLOBAL、SESSION或者LOCAL,默认使用SESSION。参见13.5.3节,“SET语法”。
要想检索一个GLOBAL变量的值,使用下面的语法:
mysql> SELECT @@global.sort_buffer_size;
mysql> SHOW GLOBAL VARIABLES like 'sort_buffer_size';
要想检索一个SESSION变量的值,使用下面的语法:
mysql> SELECT @@sort_buffer_size;
mysql> SELECT @@session.sort_buffer_size;
mysql> SHOW SESSION VARIABLES like 'sort_buffer_size';
这里,LOCAL也是SESSION的同义词。
当你用SELECT @@var_name搜索一个变量时(也就是说,不指定global.、session.或者local.),MySQL返回SESSION值(如果存在),否则返回GLOBAL值。
对于SHOW VARIABLES,如果不指定GLOBAL、SESSION或者LOCAL,MySQL返回SESSION值。
当设置GLOBAL变量需要GLOBAL关键字但检索时不需要它们的原因是防止将来出现问题。如果我们移除一个与某个GLOBAL变量具有相同名字的SESSION变量,具有SUPER权限的客户可能会意外地更改GLOBAL变量而不是它自己的连接的SESSION变量。如果我们添加一个与某个GLOBAL变量具有相同名字的SESSION变量,想更改GLOBAL变量的客户可能会发现只有自己的SESSION变量被更改了。
关于系统启动选项和系统变量的详细信息参见5.3.1节,“mysqld命令行选项”和5.3.3节,“服务器系统变量”。在5.3.3.1节,“动态系统变量”中列出了可以在运行时设置的变量。
posted @
2010-05-05 13:43 一凡 阅读(3158) |
评论 (0) |
编辑 收藏JVM内存模型以及垃圾回收
摘自:http://hi.baidu.com/xuwanbest/blog/item/0587d82f2c44a73d1e30892e.html
JAVA堆的描述如下:
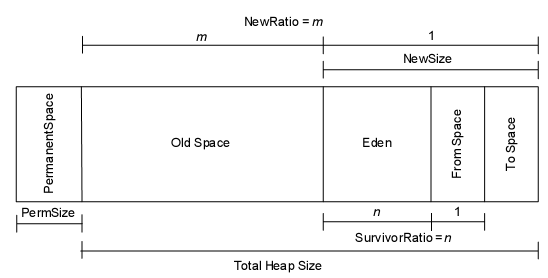
内存由 Perm 和 Heap 组成. 其中
Heap = {Old + NEW = { Eden , from, to } }
JVM内存模型中分两大块,一块是 NEW Generation, 另一块是Old Generation. 在New Generation中,有一个叫Eden的空间,主要是用来存放新生的对象,还有两个Survivor Spaces(from,to), 它们用来存放每次垃圾回收后存活下来的对象。在Old Generation中,主要存放应用程序中生命周期长的内存对象,还有个Permanent Generation,主要用来放JVM自己的反射对象,比如类对象和方法对象等。
垃圾回收描述:
在New Generation块中,垃圾回收一般用Copying的算法,速度快。每次GC的时候,存活下来的对象首先由Eden拷贝到某个Survivor Space, 当Survivor Space空间满了后, 剩下的live对象就被直接拷贝到Old Generation中去。因此,每次GC后,Eden内存块会被清空。在Old Generation块中,垃圾回收一般用mark-compact的算法,速度慢些,但减少内存要求.
垃圾回收分多级,0级为全部(Full)的垃圾回收,会回收OLD段中的垃圾;1级或以上为部分垃圾回收,只会回收NEW中的垃圾,内存溢出通常发生于OLD段或Perm段垃圾回收后,仍然无内存空间容纳新的Java对象的情况。
当一个URL被访问时,内存申请过程如下:
A. JVM会试图为相关Java对象在Eden中初始化一块内存区域
B. 当Eden空间足够时,内存申请结束。否则到下一步
C. JVM试图释放在Eden中所有不活跃的对象(这属于1或更高级的垃圾回收), 释放后若Eden空间仍然不足以放入新对象,则试图将部分Eden中活跃对象放入Survivor区
D. Survivor区被用来作为Eden及OLD的中间交换区域,当OLD区空间足够时,Survivor区的对象会被移到Old区,否则会被保留在Survivor区
E. 当OLD区空间不够时,JVM会在OLD区进行完全的垃圾收集(0级)
F. 完全垃圾收集后,若Survivor及OLD区仍然无法存放从Eden复制过来的部分对象,导致JVM无法在Eden区为新对象创建内存区域,则出现”out of memory错误”
JVM调优建议:
ms/mx:定义YOUNG+OLD段的总尺寸,ms为JVM启动时YOUNG+OLD的内存大小;mx为最大可占用的YOUNG+OLD内存大小。在用户生产环境上一般将这两个值设为相同,以减少运行期间系统在内存申请上所花的开销。
NewSize/MaxNewSize:定义YOUNG段的尺寸,NewSize为JVM启动时YOUNG的内存大小;MaxNewSize为最大可占用的YOUNG内存大小。在用户生产环境上一般将这两个值设为相同,以减少运行期间系统在内存申请上所花的开销。
PermSize/MaxPermSize:定义Perm段的尺寸,PermSize为JVM启动时Perm的内存大小;MaxPermSize为最大可占用的Perm内存大小。在用户生产环境上一般将这两个值设为相同,以减少运行期间系统在内存申请上所花的开销。
SurvivorRatio:设置Survivor空间和Eden空间的比例
内存溢出的可能性
1. OLD段溢出
这种内存溢出是最常见的情况之一,产生的原因可能是:
1) 设置的内存参数过小(ms/mx, NewSize/MaxNewSize)
2) 程序问题
单个程序持续进行消耗内存的处理,如循环几千次的字符串处理,对字符串处理应建议使用StringBuffer。此时不会报内存溢出错,却会使系统持续垃圾收集,无法处理其它请求,相关问题程序可通过Thread Dump获取(见系统问题诊断一章)单个程序所申请内存过大,有的程序会申请几十乃至几百兆内存,此时JVM也会因无法申请到资源而出现内存溢出,对此首先要找到相关功能,然后交予程序员修改,要找到相关程序,必须在Apache日志中寻找。
当Java对象使用完毕后,其所引用的对象却没有销毁,使得JVM认为他还是活跃的对象而不进行回收,这样累计占用了大量内存而无法释放。由于目前市面上还没有对系统影响小的内存分析工具,故此时只能和程序员一起定位。
2. Perm段溢出
通常由于Perm段装载了大量的Servlet类而导致溢出,目前的解决办法:
1) 将PermSize扩大,一般256M能够满足要求
2) 若别无选择,则只能将servlet的路径加到CLASSPATH中,但一般不建议这么处理
3. C Heap溢出
系统对C Heap没有限制,故C Heap发生问题时,Java进程所占内存会持续增长,直到占用所有可用系统内存
其他:
JVM有2个GC线程。第一个线程负责回收Heap的Young区。第二个线程在Heap不足时,遍历Heap,将Young 区升级为Older区。Older区的大小等于-Xmx减去-Xmn,不能将-Xms的值设的过大,因为第二个线程被迫运行会降低JVM的性能。
为什么一些程序频繁发生GC?有如下原因:l 程序内调用了System.gc()或Runtime.gc()。l 一些中间件软件调用自己的GC方法,此时需要设置参数禁止这些GC。l Java的Heap太小,一般默认的Heap值都很小。l 频繁实例化对象,Release对象。此时尽量保存并重用对象,例如使用StringBuffer()和String()。如果你发现每次GC后,Heap的剩余空间会是总空间的50%,这表示你的Heap处于健康状态。许多Server端的Java程序每次GC后最好能有65%的剩余空间。经验之谈:1.Server端JVM最好将-Xms和-Xmx设为相同值。为了优化GC,最好让-Xmn值约等于-Xmx的1/3[2]。2.一个GUI程序最好是每10到20秒间运行一次GC,每次在半秒之内完成[2]。注意:1.增加Heap的大小虽然会降低GC的频率,但也增加了每次GC的时间。并且GC运行时,所有的用户线程将暂停,也就是GC期间,Java应用程序不做任何工作。2.Heap大小并不决定进程的内存使用量。进程的内存使用量要大于-Xmx定义的值,因为Java为其他任务分配内存,例如每个线程的Stack等。2.Stack的设定每个线程都有他自己的Stack。
-Xss 每个线程的Stack大小
Stack的大小限制着线程的数量。如果Stack过大就好导致内存溢漏。-Xss参数决定Stack大小,例如-Xss1024K。如果Stack太小,也会导致Stack溢漏。3.硬件环境硬件环境也影响GC的效率,例如机器的种类,内存,swap空间,和CPU的数量。如果你的程序需要频繁创建很多transient对象,会导致JVM频繁GC。这种情况你可以增加机器的内存,来减少Swap空间的使用[2]。4.4种GC第一种为单线程GC,也是默认的GC。,该GC适用于单CPU机器。第二种为Throughput GC,是多线程的GC,适用于多CPU,使用大量线程的程序。第二种GC与第一种GC相似,不同在于GC在收集Young区是多线程的,但在Old区和第一种一样,仍然采用单线程。-XX:+UseParallelGC参数启动该GC。第三种为Concurrent Low Pause GC,类似于第一种,适用于多CPU,并要求缩短因GC造成程序停滞的时间。这种GC可以在Old区的回收同时,运行应用程序。-XX:+UseConcMarkSweepGC参数启动该GC。第四种为Incremental Low Pause GC,适用于要求缩短因GC造成程序停滞的时间。这种GC可以在Young区回收的同时,回收一部分Old区对象。-Xincgc参数启动该GC。
posted @
2010-05-04 09:29 一凡 阅读(340) |
评论 (0) |
编辑 收藏一款开源的压力测试工具,可以根据配置对一个WEB站点进行多用户的并发访问,记录每个用户所有请求过程的相应时间,并在一定数量的并发访问下重复进行。
获取:http://www.joedog.org/
官方提供ftp下载
解压:
# tar -zxf siege-latest.tar.gz
进入解压目录:
# cd siege-2.65/
安装:
#./configure ; make
#make install
使用
siege -c 200 -r 10 -f example.url
-c是并发量,-r是重复次数。 url文件就是一个文本,每行都是一个url,它会从里面随机访问的。
example.url内容:
http://www.taoav.com
http://www.tuhaoduo.com
http://www.tiaonv.com
结果说明
Lifting the server siege… done.
Transactions: 3419263 hits //完成419263次处理
Availability: 100.00 % //100.00 % 成功率
Elapsed time: 5999.69 secs //总共用时
Data transferred: 84273.91 MB //共数据传输84273.91 MB
Response time: 0.37 secs //相应用时1.65秒:显示网络连接的速度
Transaction rate: 569.91 trans/sec //均每秒完成 569.91 次处理:表示服务器后
Throughput: 14.05 MB/sec //平均每秒传送数据
Concurrency: 213.42 //实际最高并发数
Successful transactions: 2564081 //成功处理次数
Failed transactions: 11 //失败处理次数
Longest transaction: 29.04 //每次传输所花最长时间
Shortest transaction: 0.00 //每次传输所花最短时间
posted @
2010-04-09 23:03 一凡 阅读(563) |
评论 (0) |
编辑 收藏
mysql8.x:
alter mysql.user 'root'@'%' identified by '123456';
mysql 5.x:
GRANT ALL PRIVILEGES ON *.* TO 'monitor'@'%' IDENTIFIED BY 'monitor' WITH GRANT OPTION;
posted @
2010-03-16 15:38 一凡 阅读(431) |
评论 (0) |
编辑 收藏
又回到了工作状态,过去的一年收获很多,希望今年再接再励
posted @
2010-03-08 17:08 一凡 阅读(182) |
评论 (0) |
编辑 收藏
大致总结了一下linux下各种格式的压缩包的压缩、解压方法。但是部分方法我没有用到,也就不全,希望大家帮我补充,我将随时修改完善,谢谢!
整理:会游泳的鱼
来自:www.LinuxByte.net
最后更新时间:2005-2-20
.tar
解包:tar xvf FileName.tar
打包:tar cvf FileName.tar DirName
(注:tar是打包,不是压缩!)
———————————————
.gz
解压1:gunzip FileName.gz
解压2:gzip -d FileName.gz
压缩:gzip FileName
.tar.gz 和 .tgz
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
———————————————
.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
.tar.bz2
解压:tar jxvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
———————————————
.bz
解压1:bzip2 -d FileName.bz
解压2:bunzip2 FileName.bz
压缩:未知
.tar.bz
解压:tar jxvf FileName.tar.bz
压缩:未知
———————————————
.Z
解压:uncompress FileName.Z
压缩:compress FileName
.tar.Z
解压:tar Zxvf FileName.tar.Z
压缩:tar Zcvf FileName.tar.Z DirName
———————————————
.zip
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
———————————————
.rar
解压:rar x FileName.rar
压缩:rar a FileName.rar DirName
rar请到:http://www.rarsoft.com/download.htm 下载!
解压后请将rar_static拷贝到/usr/bin目录(其他由$PATH环境变量指定的目录也可以):
[root@www2 tmp]# cp rar_static /usr/bin/rar
———————————————
.lha
解压:lha -e FileName.lha
压缩:lha -a FileName.lha FileName
lha请到:http://www.infor.kanazawa-it.ac.jp/~ishii/lhaunix/下载!
>解压后请将lha拷贝到/usr/bin目录(其他由$PATH环境变量指定的目录也可以):
[root@www2 tmp]# cp lha /usr/bin/
———————————————
.rpm
解包:rpm2cpio FileName.rpm | cpio -div
———————————————
.deb
解包:ar p FileName.deb data.tar.gz | tar zxf -
———————————————
.tar .tgz .tar.gz .tar.Z .tar.bz .tar.bz2 .zip .cpio .rpm .deb .slp .arj .rar .ace .lha .lzh .lzx .lzs .arc .sda .sfx .lnx .zoo .cab .kar .cpt .pit .sit .sea
解压:sEx x FileName.*
压缩:sEx a FileName.* FileName
sEx只是调用相关程序,本身并无压缩、解压功能,请注意!
sEx请到: http://sourceforge.net/projects/sex下载!
解压后请将sEx拷贝到/usr/bin目录(其他由$PATH环境变量指定的目录也可以):
[root@www2 tmp]# cp sEx /usr/bin/
gzip 命令
减少文件大小有两个明显的好处,一是可以减少存储空间,二是通过网络传输文件时,可以减少传输的时间。gzip 是在 Linux 系统中经常使用的一个对文件进行压缩和解压缩的命令,既方便又好用。
语法:gzip [选项] 压缩(解压缩)的文件名
该命令的各选项含义如下:
-c 将输出写到标准输出上,并保留原有文件。
-d 将压缩文件解压。
-l 对每个压缩文件,显示下列字段:
压缩文件的大小;未压缩文件的大小;压缩比;未压缩文件的名字
-r 递归式地查找指定目录并压缩其中的所有文件或者是解压缩。
-t 测试,检查压缩文件是否完整。
-v 对每一个压缩和解压的文件,显示文件名和压缩比。
-num 用指定的数字 num 调整压缩的速度,-1 或 --fast 表示最快压缩方法(低压缩比),
-9 或--best表示最慢压缩方法(高压缩比)。系统缺省值为 6。
指令实例:
gzip *
% 把当前目录下的每个文件压缩成 .gz 文件。
gzip -dv *
% 把当前目录下每个压缩的文件解压,并列出详细的信息。
gzip -l *
% 详细显示例1中每个压缩的文件的信息,并不解压。
gzip usr.tar
% 压缩 tar 备份文件 usr.tar,此时压缩文件的扩展名为.tar.gz。
posted @
2010-01-14 11:03 一凡 阅读(281) |
评论 (0) |
编辑 收藏
# /etc/init.d/mysql stop
# mysqld_safe --user=mysql --skip-grant-tables --skip-networking &
# mysql -u root mysql
mysql> UPDATE user SET Password=PASSWORD(’newpassword’) where USER=’root’;
mysql> FLUSH PRIVILEGES;
mysql> quit
# /etc/init.d/mysql restart
# mysql -uroot -p
Enter password: <输入新设的密码newpassword>
mysql>
posted @
2010-01-08 11:12 一凡 阅读(2191) |
评论 (0) |
编辑 收藏
/meCall
发表于2007-09-26, 13:00
匹配中文字符的正则表达式: [u4e00-u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^x00-xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:ns*r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(S*?)[^>]*>.*?|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^s*|s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:d{3}-d{8}|d{4}-d{7}
评注:匹配形式如 


 0511-4405222
0511-4405222 或 021-87888822
或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]d{5}(?!d)
评注:中国邮政编码为6位数字
匹配身份证:d{15}|d{18}
评注:中国的身份证为15位或18位
匹配ip地址:d+.d+.d+.d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]d*$ //匹配正整数
^-[1-9]d*$ //匹配负整数
^-?[1-9]d*$ //匹配整数
^[1-9]d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]d*.d*|0.d*[1-9]d*$ //匹配正浮点数
^-([1-9]d*.d*|0.d*[1-9]d*)$ //匹配负浮点数
^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$ //匹配浮点数
^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
在使用RegularExpressionValidator验证控件时的验证功能及其验证表达式介绍如下:
只能输入数字:“^[0-9]*$”
只能输入n位的数字:“^d{n}$”
只能输入至少n位数字:“^d{n,}$”
只能输入m-n位的数字:“^d{m,n}$”
只能输入零和非零开头的数字:“^(0|[1-9][0-9]*)$”
只能输入有两位小数的正实数:“^[0-9]+(.[0-9]{2})?$”
只能输入有1-3位小数的正实数:“^[0-9]+(.[0-9]{1,3})?$”
只能输入非零的正整数:“^+?[1-9][0-9]*$”
只能输入非零的负整数:“^-[1-9][0-9]*$”
只能输入长度为3的字符:“^.{3}$”
只能输入由26个英文字母组成的字符串:“^[A-Za-z]+$”
只能输入由26个大写英文字母组成的字符串:“^[A-Z]+$”
只能输入由26个小写英文字母组成的字符串:“^[a-z]+$”
只能输入由数字和26个英文字母组成的字符串:“^[A-Za-z0-9]+$”
只能输入由数字、26个英文字母或者下划线组成的字符串:“^w+$”
验证用户密码:“^[a-zA-Z]w{5,17}$”正确格式为:以字母开头,长度在6-18之间,
只能包含字符、数字和下划线。
验证是否含有^%&’,;=?$”等字符:“[^%&’,;=?$x22]+”
只能输入汉字:“^[u4e00-u9fa5],{0,}$”
验证Email地址:“^w+[-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$”
验证InternetURL:“^http://([w-]+.)+[w-]+(/[w-./?%&=]*)?$”
验证电话号码:“^((d{3,4})|d{3,4}-)?d{7,8}$”
正确格式为:“XXXX-XXXXXXX”,“XXXX-XXXXXXXX”,“XXX-XXXXXXX”,
“XXX-XXXXXXXX”,“XXXXXXX”,“XXXXXXXX”。
验证身份证号(15位或18位数字):“^d{15}|d{}18$”
验证一年的12个月:“^(0?[1-9]|1[0-2])$”正确格式为:“01”-“09”和“1”“12”
验证一个月的31天:“^((0?[1-9])|((1|2)[0-9])|30|31)$”
正确格式为:“01”“09”和“1”“31”。
匹配中文字符的正则表达式: [u4e00-u9fa5]
匹配双字节字符(包括汉字在内):[^x00-xff]
匹配空行的正则表达式:n[s| ]*r
匹配HTML标记的正则表达式:/<(.*)>.*<!--1-->|<(.*) />/
匹配首尾空格的正则表达式:(^s*)|(s*$)
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配网址URL的正则表达式:http://([w-]+.)+[w-]+(/[w- ./?%&=]*)?
(1)应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
String.prototype.len=function(){return this.replace([^x00-xff]/g,”aa”).length;}
(2)应用:javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现
String.prototype.trim = function()
{
return this.replace(/(^s*)|(s*$)/g, “”);
}
(3)应用:利用正则表达式分解和转换IP地址
function IP2V(ip) //IP地址转换成对应数值
{
re=/(d+).(d+).(d+).(d+)/g //匹配IP地址的正则表达式
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1
}
else
{
throw new Error(”Not a valid IP address!”)
}
}
(4)应用:从URL地址中提取文件名的javascript程序
s=”http://www.9499.net/page1.htm”;
s=s.replace(/(.*/){0,}([^.]+).*/ig,”$2″) ; //Page1.htm
(5)应用:利用正则表达式限制网页表单里的文本框输入内容
用正则表达式限制只能输入中文:onkeyup=”value=”/blog/value.replace(/[”^u4E00-u9FA5]/g, '’) ” onbeforepaste=”clipboardData.setData(’text’,clipboardData.getData(’text’).replace(/[^u4E00-u9FA5]/g,'’))”
用正则表达式限制只能输入全角字符: onkeyup=”value=”/blog/value.replace(/[”^uFF00-uFFFF]/g,'’) ” onbeforepaste=”clipboardData.setData(’text’,clipboardData.getData(’text’).replace(/[^uFF00-uFFFF]/g,'’))”
用正则表达式限制只能输入数字:onkeyup=”value=”/blog/value.replace(/[”^d]/g,'’) “onbeforepaste= “clipboardData.setData(’text’,clipboardData.getData(’text’).replace(/[^d]/g,'’))”
用正则表达式限制只能输入数字和英文:onkeyup=”value=”/blog/value.replace(/[W]/g,”‘’) “onbeforepaste=”clipboardData.setData(’text’,clipboardData.getData(’text’).replace(/[^d]/
posted @
2009-10-14 09:59 一凡 阅读(338) |
评论 (0) |
编辑 收藏
在windows安装目录下找到dwmapi.api.dll改名就可解决此问题
posted @
2009-09-09 10:12 一凡 阅读(416) |
评论 (0) |
编辑 收藏
不平凡的一年,难忘的一年
posted @
2009-09-03 17:45 一凡 阅读(229) |
评论 (0) |
编辑 收藏 cd mysql_path
 find ./ -name mysql.server
find ./ -name mysql.server
cd mysql.server_path
mysql.server start
停止
mysql.server stop
posted @
2009-08-05 18:29 一凡 阅读(326) |
评论 (0) |
编辑 收藏以root连接到服务器上后,可以添加新账户。下面的语句使用GRANT来设置四个新账户:
mysql> GRANT ALL PRIVILEGES ON *.* TO 'monty'@'localhost'IDENTIFIED BY 'some_pass' WITH GRANT OPTION;
mysql> GRANT ALL PRIVILEGES ON *.* TO 'monty'@'%'IDENTIFIED BY 'some_pass' WITH GRANT OPTION;
mysql> GRANT RELOAD,PROCESS ON *.* TO 'admin'@'localhost';
mysql> GRANT USAGE ON *.* TO 'dummy'@'localhost';
用GRANT语句创建的账户有下面的属性:
·其中两个账户有相同的用户名monty和密码some_pass。两个账户均为超级用户账户,具有完全的权限可以做任何事情。一个账户 ('monty'@'localhost')只用于从本机连接时。另一个账户('monty'@'%')可用于从其它主机连接。请注意monty的两个账户必须能从任何主机以monty连接。没有localhost账户,当monty从本机连接时,mysql_install_db创建的localhost的匿名用户账户将占先。结果是,monty将被视为匿名用户。原因是匿名用户账户的Host列值比'monty'@'%'账户更具体,这样在user表排序顺序中排在前面。
·一个账户有用户名admin,没有密码。该账户只用于从本机连接。授予了RELOAD和PROCESS管理权限。这些权限允许admin用户执行mysqladmin reload、mysqladmin refresh和mysqladmin flush-xxx命令,以及mysqladmin processlist。未授予访问数据库的权限。你可以通过GRANT语句添加此类权限。
·一个账户有用户名dummy,没有密码。该账户只用于从本机连接。未授予权限。通过GRANT语句中的USAGE权限,你可以创建账户而不授予任何权限。它可以将所有全局权限设为'N'。假定你将在以后将具体权限授予该账户。
1. 从MySQL删除用户账户
要想移除账户,应使用DROP USER语句:
DROP USER user [, user] ...
2. 限制账户资源
要想用GRANT语句设置资源限制,使WITH子句来命名每个要限制的资源和根据每小时记数的限制值。例如,要想只以限制方式创建可以访问customer数据库的新账户,执行该语句:
mysql> GRANT ALL ON customer.* TO 'francis'@'localhost'
-> IDENTIFIED BY 'frank'
-> WITH MAX_QUERIES_PER_HOUR 20
-> MAX_UPDATES_PER_HOUR 10
-> MAX_CONNECTIONS_PER_HOUR 5
-> MAX_USER_CONNECTIONS 2;
要想设置或更改已有账户的限制,在全局级别使用GRANT USAGE语句(在*.*)。下面的语句可以将francis的查询限制更改为100:
mysql> GRANT USAGE ON *.* TO 'francis'@'localhost' WITH MAX_QUERIES_PER_HOUR 100;
该语句没有改变账户的已有权限,只修改了指定的限制值。
要想取消已有限制,将该值设置为零。例如,要想取消francis每小时可以连接的次数的限制,使用该语句:
mysql> GRANT USAGE ON *.* TO 'francis'@'localhost' WITH MAX_CONNECTIONS_PER_HOUR 0;
当账户使用资源时如果有非零限制,则对资源使用进行记数。
3. 设置账户密码
4. 可以用mysqladmin命令在命令行指定密码:
shell> mysqladmin -u user_name -h host_name password "newpwd"
该命令重设密码的账户为user表内匹配User列的user_name和Host列你发起连接的客户端的记录。
为账户赋予密码的另一种方法是执行SET PASSWORD语句:
mysql> SET PASSWORD FOR 'jeffrey'@'%' = PASSWORD('biscuit');
只有root等可以更新mysql数据库的用户可以更改其它用户的密码。如果你没有以匿名用户连接,省略FOR子句便可以更改自己的密码:
mysql> SET PASSWORD = PASSWORD('biscuit');
你还可以在全局级别使用GRANT USAGE语句(在*.*)来指定某个账户的密码而不影响账户当前的权限:
mysql> GRANT USAGE ON *.* TO 'jeffrey'@'%' IDENTIFIED BY 'biscuit';
一般情况下最好使用上述方法来指定密码,你还可以直接修改user表:
· 要想在创建新账户时建立密码,在Password列提供一个值:
· shell> mysql -u root mysql
· mysql> INSERT INTO user (Host,User,Password) VALUES('%','jeffrey',PASSWORD('biscuit'));
· mysql> FLUSH PRIVILEGES;
·
· 要想更改已有账户的密码,使用UPDATE来设置Password列值:
· shell> mysql -u root mysql
· mysql> UPDATE user SET Password = PASSWORD('bagel') WHERE Host = '%' AND User = 'francis';
· mysql> FLUSH PRIVILEGES;
当你使用SET PASSWORD、INSERT或UPDATE指定账户的密码时,必须用PASSWORD()函数对它进行加密。(唯一的特例是如果密码为空,你不需要使用PASSWORD())。需要使用PASSWORD()是因为user表以加密方式保存密码,而不是明文。如果你忘记了,你可能会象这样设置密码:
shell> mysql -u root mysql
mysql> INSERT INTO user (Host,User,Password) VALUES('%','jeffrey','biscuit');
mysql> FLUSH PRIVILEGES;
结果是密码'biscuit'保存到user表后没有加密。当jeffrey使用该密码连接服务器时,值被加密并同保存在user表中的进行比较。但是,保存的值为字符串'biscuit',因此比较将失败,服务器拒绝连接:
shell> mysql -u jeffrey -pbiscuit test
Access denied
如果你使用GRANT ... IDENTIFIED BY语句或mysqladmin password命令设置密码,它们均会加密密码。在这种情况下,不需要使用 PASSWORD()函数。
posted @
2009-08-05 18:21 一凡 阅读(3664) |
评论 (0) |
编辑 收藏
# /etc/init.d/mysql stop
# mysqld_safe --user=mysql --skip-grant-tables --skip-networking &
# mysql -u root mysql
mysql> UPDATE user SET Password=PASSWORD('newpassword') where USER='root';
mysql> FLUSH PRIVILEGES;
mysql> quit
# /etc/init.d/mysql restart
# mysql -uroot -p
Enter password: <输入新设的密码newpassword>
posted @
2009-08-05 18:01 一凡 阅读(307) |
评论 (0) |
编辑 收藏ZoneAlarm 进程关闭过慢可以采取以下办法解决:
1. 开始 > 运行 > 输入 "regedit" > 确认
2. 将 HKEY_CURRENT_USER\Control Panel\Desktop 下的HungAppTimeout 键值的数字改成 6000
3. 重新启动计算机
posted @
2009-07-17 10:53 一凡 阅读(291) |
评论 (0) |
编辑 收藏
1.下载jsch-0.1.24.jar及commons-net-ftp-2.0.jar
2.设置eclipse: window -- preferences -- ant -- Runtime -- Ant Home Entries (Default)下填加上面两个包即可在eclipse 的所有工程里使用这些功能,挺爽
3.ant task 网上很多,搜一下,推荐参考:http://www.blogjava.net/Good-Game/archive/2009/03/13/248113.html
4.ftp task:
<target name="ftp" depends="compile">
<ftp server="192.168.223" port="21" userid="work" password="abc123" remotedir="/home/work/coin/WEB-INF/lib/" depends="yes" verbose="yes">
<fileset dir="dist">
<include name="*.jar" />
</fileset>
</ftp>
</target>
posted @
2009-07-01 16:36 一凡 阅读(920) |
评论 (0) |
编辑 收藏import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import org.apache.commons.lang.StringUtils;
import com.sun.org.apache.commons.beanutils.PropertyUtils;
/** *//**
* create_date : 2009-6-16
*/
public class TestBean {
private String uid;
private String uname;
private String sex;
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getUname() {
return uname;
}
public void setUname(String uname) {
this.uname = uname;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String check() {
Method[] methods = this.getClass().getMethods();
for (int i = 0; i < methods.length; i++) {
Method method = methods[i];
if (method.getName().startsWith("get")) {
try {
if(StringUtils.isBlank((String)method.invoke(this))){
return method.getName().substring(3);
}
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
return null;
}
public static void main(String[] args) {
TestBean tBean = new TestBean();
tBean.setUid("1234");
System.out.println(tBean.check());
}
}
posted @
2009-06-16 15:35 一凡 阅读(554) |
评论 (0) |
编辑 收藏 在awk中使用shell变量的情况经常出现 , 使用 awk -v实现, 代码如下:
var="abc"
awk -v "fst=$var" '{print fst}'
posted @
2009-06-09 16:29 一凡 阅读(336) |
评论 (0) |
编辑 收藏
人生, 让房贷给废了
一手字,让键盘给废了
电视剧,让广告给废了
广告, 让脑白金给废了
猪肉, 让瘦肉精给废了
英雄, 让美人给废了
女孩, 让大款给废了
帅哥, 让富婆给废了
干部, 让人民币给废了
医德, 让医药代表给废了
书信, 让电话给废了
饭店, 让政府签单给废了
国足, 让足协给废了
运动员,让兴奋剂给废了
生命, 让医疗费给废了
胃, 让酒给废了
肺, 让香烟给废了
儿子, 让媳妇给废了
农民, 让欠薪给废了
法律, 让法院给废了
睡眠, 让夜总会给废了
景点, 让黄金周给废了
小孩, 让三鹿给废了
一个群,让不说话的给废了!
|
posted @
2009-04-29 13:56 一凡 阅读(462) |
评论 (0) |
编辑 收藏
在eclipse中,只有按下"."才会有代码提示功能,通过修改配置来实现多种条件触发代码提示:
1、进入window --> preferences --> java --> Editor --> Content Assist
改一下Auto activation triggers for java: 将"."改为".abc"
2、导出eclipse的Preferences:file->export->General->Preferences 保存为pre.epf
3、打开pre.epf文件,查找“content_assist_autoactivation”,将“.”改为“.abcdefghijklmnopqrstuvwxyz(,”保存
4、导入Preferences:file->import 选文件pre.epf
你会发现,在编辑器里输入刚才加入的任何一个字都会有代码提示,哈哈!
posted @
2009-03-24 14:45 一凡 阅读(470) |
评论 (2) |
编辑 收藏
问题:在firefox中相同URL不去访问,所以在刷新验证码时就出问题了,不去访问servlet。
解决办法如下:
function refresh(){
//重新获取验证码图片的src属性
document.getElementById("imageField").src='/servlet/MyGraphics'+'?r='+Math.random();
}
注意:"+'?r='+Math.random()"是必须的
posted @
2009-02-17 16:04 一凡 阅读(1079) |
评论 (4) |
编辑 收藏Ctrl+D 删除当前行
Ctrl+Alt+↓ 复制当前行到下一行(复制增加)
Ctrl+Alt+↑ 复制当前行到上一行(复制增加)
Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)
Alt+↑ 当前行和上面一行交互位置(同上)
Alt+← 前一个编辑的页面
Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)
Alt+Enter 显示当前选择资源(工程,or 文件 or文件)的属性
Shift+Enter 在当前行的下一行插入空行(这时鼠标可以在当前行的任一位置,不一定是最后)
Shift+Ctrl+Enter在当前行插入空行(原理同上条)
Ctrl+Q 定位到最后编辑的地方
Ctrl+L 定位在某行 (对于程序超过100的人就有福音了)
Ctrl+M 最大化当前的Edit或View (再按则反之)
Ctrl+/ 注释当前行,再按则取消注释
Ctrl+O 快速显示 OutLine
Ctrl+T 快速显示当前类的继承结构
Ctrl+W 关闭当前Editer
Ctrl+K 参照选中的Word快速定位到下一个
Ctrl+E 快速显示当前Editer的下拉列表(如果当前页面没有显示的用黑体表示)
Ctrl+/(小键盘) 折叠当前类中的所有代码
Ctrl+×(小键盘) 展开当前类中的所有代码
Ctrl+Space 代码助手完成一些代码的插入(但一般和输入法有冲突,可以修改输入法的热键,也可以暂用Alt+/来代替)
Ctrl+Shift+E 显示管理当前打开的所有的View的管理器(可以选择关闭,激活等操作)
Ctrl+J 正向增量查找(按下Ctrl+J后,你所输入的每个字母编辑器都提供快速匹配定位到某个单词,如果没有,
则在stutes line中显示没有找到了,查一个单词时,特别实用,这个功能Idea两年前就有了)
Ctrl+Shift+J 反向增量查找(和上条相同,只不过是从后往前查)
Ctrl+Shift+F4 关闭所有打开的Editer
Ctrl+Shift+X 把当前选中的文本全部变为小写
Ctrl+Shift+Y 把当前选中的文本全部变为小写
Ctrl+Shift+F 格式化当前代码
Ctrl+Shift+P 定位到对于的匹配符(譬如{}) (从前面定位后面时,光标要在匹配符里面,后面到前面,则反之)
posted @
2009-02-11 14:09 一凡 阅读(290) |
评论 (0) |
编辑 收藏
由于lucene2.0+heritrix一书示例用的网站(http://mobile.pconline.com.cn/,http:
//mobile.163.com/)改版了,书上实例不能运行,我又找了一个http://mobile.younet.com/进行开发并成功实现示
例,希望感兴趣的同学,近快实践,如果此网站也改了就又得改extractor了,哈哈!
search的Extractor代码如下,(别和书上实例相同)供大家参考:附件里有完整代码
package com.luceneheritrixbook.extractor.younet;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Date;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.AndFilter;
import org.htmlparser.filters.HasAttributeFilter;
import org.htmlparser.filters.HasChildFilter;
import org.htmlparser.filters.TagNameFilter;
import org.htmlparser.tags.ImageTag;
import org.htmlparser.util.NodeIterator;
import org.htmlparser.util.NodeList;
import com.luceneheritrixbook.extractor.Extractor;
import com.luceneheritrixbook.util.StringUtils;
/**
* <p></p>
* @author cnyqiao@hotmail.com
* @date Feb 6, 2009
*/
public class ExtractYounetMoblie extends Extractor {
@Override
public void extract() {
BufferedWriter bw = null;
NodeFilter title_filter = new AndFilter(new TagNameFilter("div"), new HasAttributeFilter("class", "mo_tit"));
NodeFilter attribute_filter = new AndFilter(new TagNameFilter("p"), new HasChildFilter(new AndFilter(new TagNameFilter("span"), new HasAttributeFilter("class", "gn_sp1 blue1"))));
NodeFilter img_filter = new AndFilter(new TagNameFilter("span"), new HasChildFilter(new TagNameFilter("img")));
//提取标题信息
try {
//Parser根据过滤器返回所有满足过滤条件的节点
// 迭代逐渐查找
NodeList nodeList=this.getParser().parse(title_filter);
NodeIterator it = nodeList.elements();
StringBuffer title = new StringBuffer();
while (it.hasMoreNodes()) {
Node node = (Node) it.nextNode();
String[] names = node.toPlainTextString().split(" ");
for(int i = 0; i < names.length; i++)
title.append(names[i]).append("-");
title.append(new Date().getTime());
//创建要生成的文件
bw = new BufferedWriter(new FileWriter(new File(this.getOutputPath() + title + ".txt")));
//获取当前提取页的完整URL地址
int startPos = this.getInuputFilePath().indexOf("mirror") + 6;
String url_seg = this.getInuputFilePath().substring(startPos);
url_seg = url_seg.replaceAll("\\\\", "/");
String url = "http:/" + url_seg;
//写入当前提取页的完整URL地址
bw.write(url + NEWLINE);
bw.write(names[0] + NEWLINE);
bw.write(names[1] + NEWLINE);
}
// 重置Parser
this.getParser().reset();
Parser attNameParser = null;
Parser attValueParser = null;
//Parser parser=new Parser("http://www.sina.com.cn");
NodeFilter attributeName_filter = new AndFilter(new TagNameFilter("span"), new HasAttributeFilter("class", "gn_sp1 blue1"));
NodeFilter attributeValue_filter = new AndFilter(new TagNameFilter("span"), new HasAttributeFilter("class", "gn_sp2"));
String attName = "";
String attValue = "";
// 迭代逐渐查找
nodeList=this.getParser().parse(attribute_filter);
it = nodeList.elements();
while (it.hasMoreNodes()) {
Node node = (Node) it.nextNode();
attNameParser = new Parser();
attNameParser.setEncoding("GB2312");
attNameParser.setInputHTML(node.toHtml());
NodeList attNameNodeList = attNameParser.parse(attributeName_filter);
attName = attNameNodeList.elements().nextNode().toPlainTextString();
attValueParser = new Parser();
attValueParser.setEncoding("GB2312");
attValueParser.setInputHTML(node.toHtml());
NodeList attValueNodeList = attValueParser.parse(attributeValue_filter);
attValue = attValueNodeList.elements().nextNode().toPlainTextString();
bw.write(attName.trim() + attValue.trim());
bw.newLine();
}
// 重置Parser
this.getParser().reset();
String imgUrl = "";
String fileType ="";
// 迭代逐渐查找
nodeList=this.getParser().parse(img_filter);
it = nodeList.elements();
while (it.hasMoreNodes()) {
Node node = (Node) it.nextNode();
ImageTag imgNode = (ImageTag)node.getChildren().elements().nextNode();
imgUrl = imgNode.getAttribute("src");
fileType = imgUrl.trim().substring(imgUrl
.lastIndexOf(".") + 1);
//生成新的图片的文件名
String new_iamge_file = StringUtils.encodePassword(imgUrl, HASH_ALGORITHM) + "." + fileType;
//imgUrl = new HtmlPaserFilterTest().replace(new_iamge_file, "+", " ");
//利用miorr目录下的图片生成的新的图片
this.copyImage(imgUrl, new_iamge_file);
bw.write(SEPARATOR + NEWLINE);
bw.write(new_iamge_file + NEWLINE);
}
} catch(Exception e) {
e.printStackTrace();
} finally {
try{
if (bw != null)
bw.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
}
运行书上的heritrix实例,并按书上的默认设置进行抓取如下URI:(请自己分析整理)
http://mobile.younet.com/files/list_1.html
http://mobile.younet.com/files/list_2.html
http://mobile.younet.com/files/list_3.html
posted @
2009-02-09 15:44 一凡 阅读(2407) |
评论 (5) |
编辑 收藏
转自:http://feirou520.javaeye.com/blog/290311
不同的Linux之间copy文件常用有3种方法 ,第一种就是ftp,也就是其中一台Linux安装ftp Server,这样可以另外一台使用ftp的client程序来进行文件的copy。第二种方法就是采用samba服务,类似Windows 文件copy的方式来操作,比较简洁方便,第三种就是利用scp命令来进行文件复制。
scp是有Security的文件copy,基于ssh登录。操作起来比较方便,比如要把当前一个文件copy到远程另外一台主机上,可以如下命令。
scp /home/daisy/full.tar.gz root@172.19.2.75:/home/root
然后会提示你输入另外那台172.19.2.75主机的root用户的登录密码,接着就开始cp和ungzip了
如果想反过来操作,把文件从远程主机copy到当前系统,也很简单。
scp root@172.19.2.75:/home/root /home/daisy/full.tar.gz
例如:
copy 本地的档案到远程的机器上
scp /etc/lilo.conf k@net67.ee.oit.edu.tw:/home/k
会将本地的 /etc/lilo.conf 这个档案 copy 到 net67.ee.oit.edu.tw,使用者 k 的家目录下。
copy远程机器上的档案到本地来
scp k@net67.ee.oit.edu.tw:/etc/lilo.conf /etc
会将 net67.ee.oitdu.tw 中 /etc/lilo.conf 档案 copy 到本地的 /etc 目录下。
保持从来源 host 档案的属性
scp –p k@net67.ee.tw:/etc/lilo.conf /etc
在此必须注意使用者的权限是否可读取远程上的档案,若想知道更多关于 scp 的使用方法,可去看看 scp 的使用手册。
ssh-keygen
产生公开钥 (pulib key) 和私人钥 (private key),以保障 ssh 联机的安性, 当 ssh 连 shd 服务器,会交换公开钥上,系统会检查 /etc/ssh_know_hosts 内储存的 key,如果找到客户端就用这个 key 产生一个随机产生的session key 传给服务器,两端都用这个 key 来继续完成 ssh 剩下来的阶段。
它会产生 identity.pub、identity 两个档案,私人钥存放于identity,公开钥 存放于 identity.pub 中,接下来使用 scp 将 identity.pub copy 到远程机器的家目录下.ssh下的authorized_keys。 .ssh/authorized_keys(这个 authorized_keys 档案相当于协议的 rhosts 档案),之后使用者能够不用密码去登入。RSA的认证绝对是比 rhosts 认证更来的安全可靠。
执行:
scp identity.pub k@linux1.ee.oit.edu.tw:.ssh/authorized_keys
若在使用 ssh-keygen 产生钥匙对时没有输入密码,则如上所示不需输入密码即可从 net67.ee.oit.edu.tw 去登入 linux1.ee.oit.edu.tw。在此,这里输入的密码可以跟帐号的密码不同,也可以不输入密码。
posted @
2008-12-30 18:44 一凡 阅读(450) |
评论 (0) |
编辑 收藏
1、查看CPU位数:getconf LONG_BIT或arch或
file /sbin/init或cat /proc/cpuinfo | grep "model name" | cut -d ':' -f 2
2、查看CPU信息:more /proc/cpuinfo
posted @
2008-12-11 12:01 一凡 阅读(244) |
评论 (0) |
编辑 收藏--查看数据库的字符集
show variables like 'character\_set\_%';
show variables like 'collation_%';
--设置数据库字符编码
set names GBK
alter database payment character set GBK;
create database mydb character set GBK;
set character_set_client=gbk;
set character_set_connection=gbk;
set character_set_database=gbk;
set character_set_results=gbk;
set character_set_server=gbk;
set character_set_system=gbk;
set collation_connection=gbk;
set collation_database=gbk;
set collation_server=gbk;
posted @
2008-11-25 13:26 一凡 阅读(714) |
评论 (0) |
编辑 收藏
mysql4.1.2的默认字符集是latin1,latin1属于ISO8859-1的子集(或者是一回事?毛深入研究),写入时需要为iso8859-1的编码,读出时要转换成gbk编码,就不会是乱码。
Class.forName("org.gjt.mm.mysql.Driver");
String url ="jdbc:mysql://localhost/mysql";
Connection conn=DriverManager.getConnection(url,"root","root");
Statement stmt=conn.createStatement();
String a="老哈斯蒂芬";
a=new String(a.getBytes("GBK"),"iso8859-1");
stmt.executeUpdate("insert into zquan (name) value ('"+a+"')");
ResultSet rs=stmt.executeQuery("select name from zquan");
while(rs.next()){
String aaa=rs.getString(1);
System.out.println(new String(aaa.getBytes("iso8859-1"),"GB2312"));
}
posted @
2008-11-25 11:12 一凡 阅读(907) |
评论 (0) |
编辑 收藏转自:http://mhbjava.javaeye.com/blog/26591
1.
<ec:table
items="presidents"
var="pres"
imagePath="${pageContext.request.contextPath}/images/*.gif"
action="${pageContext.request.contextPath}/presidents.run"
filterable="false"
sortable="false" >
...
</ec:table>
<ec:table>里的属性还有:
a. rowsDisplayed,rowsDisplayed也可以在extremecomponents.properties文件中设定
b. showPagination ,如果你想在一页中显示所有行,只需要设置showPagination为false。
c. TableTag关联了很多样式属性:
<ec:table cellspacing="0" cellpadding="0" border="0" width="80%" styleClass="" />
所有这些都是可选的。
2.
使用highlightRow属性可以设置行的高亮显示,它的值为true或false,默认值为false。
<ec:table items="presidents" var="pres" action="${pageContext.request.contextPath}/presidents.run" >
<ec:row highlightRow="true">
<ec:column property="name"/>
<ec:column property="term"/>
</ec:row>
</ec:table>
设置highlightRow属性后,它将插入设置行css类的javascript脚本,默认的css 类为highlight。你可以使用highlightClass来使用定制的css类。
3.
为了便于你对于行数据进行动态交互处理,提供了onclick、onmouseover和 onmouseout属性。
<ec:row onclick="" onmouseover="" onmouseout="" />
4.
RowTag关联了很多样式属性:
<ec:row styleClass="" highlightClass="" />
5.
提供可选取值方法的主要原因是使你能够对其他类型的html标签提供动作支持,例如显示 一幅图片或者通过定义href使该列成为到其它页的一个链接。
<ec:table items="presidents" var="pres" action="${pageContext.request.contextPath}/presidents.run" >
<ec:row>
<ec:column property="lastName">
<a href="http://goto.president.detail">${pageScope.pres.lastName}</a>
</ec:column>
</ec:row>
</ec:table>
6。
<ec:column property="time" title="时间" parse="yyyy-MM-dd" format="yyyy年MM月dd日" cell="date"/>
7。
TableTag
中有filterable和sortable属性,ColumnTag中也有相同的属性。
列的filterable和sortable属性将覆盖表的filterable和sortable属性设置。当你需要除了对表中的一、两列之外的
所有列进行过滤和排序时,十分便利。
<ec:table items="presidents" action="${pageContext.request.contextPath}/presidents.run" >
<ec:row>
<ec:column property="firstName" filterable="false"/>
<ec:column property="lastName" sortable="false"/>
</ec:row>
</ec:table>
8。视图问题:
viewsAllowed
属性制定类允许使用的视图。视图包括:html、pdf、xls、csv,以及任何定制的视图。
如果你指定一个或几个视图,那么列仅能使用这些指定的视图。例如:你指定viewsAllowed="pdf",这意味着
这列只允许PDF导出,而不能进行其他格式的导出或html视图。
<ec:table items="presidents" action="${pageContext.request.contextPath}/presidents.run" >
<ec:row>
<ec:column property="firstName"/>
<ec:column property="lastName" viewsAllowed="pdf"/>
</ec:row
</ec:table>
viewsDenied
属性制定类不允许使用的视图。视图包括:html、pdf、xls、csv,以及任何定制的视图。
如果你指定一个或几个视图,那么列仅这些指定的视图不能被使用。例如:你指定viewsDenied="html",这意味着
这列不允许使用html试图,但能进行任何形式的导出。
<ec:table items="presidents" action="${pageContext.request.contextPath}/presidents.run" >
<ec:row>
<ec:column property="firstName"/>
<ec:column property="lastName" viewsDenied="html"/>
</ec:row>
</ec:table>
9。ParameterTag
eXtremeTable
能够指定是否处理所有的参数。默认为处理所有的参数,这意味着当你进行
过滤、排序、分页时,所有的参数都被eXtremeTable保存并传到JSP中。通常这是你需要的功能,
然而,有时候你需要只允许一些特定的参数保存到eXtremeTable中。我喜欢把它看作锁定extremeTable,
可以通过设置表的autoIncludeParameters属性值为false来到达目的:
<ec:table
items="presidents"
action="${pageContext.request.contextPath}/presidents.run"
autoIncludeParameters=”false” >
...
</ec:table>
甚至当表被锁定时,你仍然可以通过简单地使用parameter标签来包含一些你想使用的参数。下例 包含了foo参数:
<ec:table
items="presidents"
action="${pageContext.request.contextPath}/presidents.run"
autoIncludeParameters=”false” >
<ec:parameter name=”foo” value=”${param.foo}”/>
...
</ec:table>
现在所有的eXtremeTable参数都被锁定。但过滤、排序和翻页时,foo参数仍将被传递。
10. .propeties取代
为了替代硬编码eXtremeTable使用的默认属性值,我在属性文件中配置所有用到的属性。 如果你需要覆盖任何默认的设置,你可以创建自己的extremecomponents.properties文件 并设置你想改变的值。
为了设置属性文件,你应该如下例所示在/WEB-INF/web.xml文件中声明一个context-param,并 指定你的属性文件的路径:
<context-param>
<param-name>extremecomponentsPreferencesLocation</param-name>
<param-value>/org/extremesite/resource/extremecomponents.properties</param-value></context-param>
你可以认为属性文件为你提供了一个对所有的eXtremeTables声明全局设置的一个方法。 创建属性文件的最大好处就是避免在标签中复制、粘贴相同的属性。典型的extremecomponents.properties文件如下所示:
table.imagePath=/extremesite/images/*.gif
table.rowsDisplayed=12
column.parse.date=yyyy-MM-dd
column.format.date=MM/dd/yyyy
column.format.currency=$###,###,##0.00
在属性文件定义的TableTag使用最多的两个属性是:imagePath和rowsDisplayed。如果你不在属性文件中声明 这些属性,你需要在每个eXtremeTable中添加他们。典型的表如下所示:
<ec:table
items="presidents"
action="${pageContext.request.contextPath}/presidents.run"
imagePath="${pageContext.request.contextPath}/images/*.gif"
rowsDisplayed="12" title="Presidents" > ...</ec:table>
如果在属性文件声明imagePath和rowsDisplayed,则表如下所示:
<ec:table
items="presidents"
action="${pageContext.request.contextPath}/presidents.run"
title="Presidents" > ...</ec:table>
正如你所见,属性文件避免了重复编码。
在属性文件定义的ColumnTag使用最多的两个属性是:parse和format。如果你不在属性文件中声明 这些属性,你需要在每个eXtremeTable中添加他们。典型的列使用日期cell如下所示:
<ec:column property="dateOfBirth" cell=”date” parse=”yyyy-MM-dd” format=”MM/dd/yyyy”/>
如果在属性文件声明parse和format,则列如下所示:
<ec:column property="dateOfBirth" cell=”date”/>
当然你仍然可以定义parse和format属性来覆盖全局设置,但是大多数工程对于日期使用一致的parse 和format。需要注意属性文件中parse.date和format.date的声明语法。
下例为使用货币cell的典型列:
<ec:column property="salary" cell=”currency” format=”$###,###,##0.00”/>
如果在属性文件声明format,则列如下所示:
<ec:column property="salary" cell=”currency”/>
另外,你可以声明一个定制的format并在列中通过使用列的basis来使用它,我把这想象为named属性。因此如果你的 extremecomponents.properties文件如下所示:
table.format.myCustomDate=yy-MM-dd
那么列可以如下使用定制的format:
<ec:column property="dateOfBirth" cell="date" format=”myCustomDate”>
11。ExportTag
eXtremeTable
具有导出不同格式文件的功能,导出的数据为过滤和排序后的所有结果集,
分页不会影响返回的结果集。换句话说,如果表数据分多页显示,那么所有页的数据都将被导出。 导出的格式为Microsoft Excel
(OpenOffice Calc)、PDF和CSV。
使用ExportXlsTag导出Microsoft Excel (OpenOffice Calc):
<ec:table items="presidents" action="${pageContext.request.contextPath}/presidents.run" />
<ec:exportXls fileName="presidents.xls" tooltip="Export Excel"/>
...
</ec:table>
使用ExportPdfTag导出PDF。所有要做的就是指定fileName属性和一些样式属性:
<ec:table items="presidents" action="${pageContext.request.contextPath}/presidents.run" />
<ec:exportPdf
fileName="presidents.pdf" tooltip="Export PDF"
headerColor="blue" headerBackgroundColor="red"
headerTitle="Presidents"/> ...
</ec:table>
使用ExportCsvTag导出CSV。当使用CSV导出是默认的分隔符为‘,’(comma)。你可以使用 delimiter属性来指定为其他的符号。下面为指定‘|’(pipe)为CSV分隔符的示例:
<ec:table items="presidents" action="${pageContext.request.contextPath}/presidents.run" />
<ec:exportCsv fileName="presidents.txt" tooltip="Export CSV" delimiter="|"/>
...
</ec:table>
posted @
2008-11-11 11:20 一凡 阅读(659) |
评论 (0) |
编辑 收藏
来源:
ChinaUnix博客 作者: 发布时间:2007-01-02 04:13:00
a w k是一种程式语言,对文件资料的处理具有非常强的功能。awk 名称是由他三个最初设计
者的姓氏的第一个字母而命名的: Alfred V. Aho、Peter J. We i n b e rg e r、Brian W. Kernighan。
a w k最初在1 9 7 7年完成。1 9 8 5年发表了一个新版本的a w k,他的功能比旧版本增强了不少。a w k 能够用非常短的程式对文件里的资料做修改、比较、提取、打印等处理。如果使用C 或P a s c a l
等语言编写程式完成上述的任务会十分不方便而且非常花费时间,所写的程式也会非常大。a w k不仅仅是个编程语言,他还是L i n u
x系统管理员和程式员的一个不可缺少的工具。a w k语言本身十分好学,易于掌控,并且特别的灵活。 gawk 是G N U计划下所做的a w
k,gawk 最初在1 9 8 6年完成,之后不断地被改进、更新。
gawk 包含awk 的所有功能。
6.1 gawk的主要功能
gawk 的主要功能是针对文件的每一行( l i n e ),也就是每一条记录,搜寻指定的格式。当某
一行符合指定的格式时,gawk 就会在此行执行被指定的动作。gawk 依此方式自动处理输入文
件的每一行直到输入文件档案结束。
g a w k经常用在如下的几个方面:
• 根据需求选择文件的某几行,几列或部分字段以供显示输出。
• 分析文件中的某一个字出现的频率、位置等。
• 根据某一个文件的信息准备格式化输出。
• 以一个功能十分强大的方式过滤输出文件。
• 根据文件中的数值进行计算。
6.2 怎么执行gawk程式
基本上有两种方法能执行g a w k程式。
如果gawk 程式非常短,则能将gawk 直接写在命令行,如下所示:
gawk ’program’ input-file1 input-file2 ...
其中program 包括一些pattern 和a c t i o n。
如果gawk 程式较长,较为方便的做法是将gawk 程式存在一个文件中,
gawk 的格式如下所示:
gawk -f program-file input-file1 input-file2 ...
gawk 程式的文件不止一个时,执行gawk 的格式如下所示:
gawk -f program-file1 -f program-file2 ... input-file1 input-file2 ...
6.3 文件、记录和字段
一般情况下,g a w k能处理文件中的数值数据,但也能处理字符串信息。如果数据没有
存储在文件中,能通过管道命令和其他的重定向方法给g a w k提供输入。当然, g a w k只能处
理文本文件(A S C I I码文件)。
电话号码本就是个g a w k能处理的文件的简单例子。电话号码本由非常多条目组成,每一
个条目都有同样的格式:姓、名、地址、电话号码。每一个条目都是按字母顺序排列。
在g a w k中,每一个这样的条目叫做一个记录。他是个完整的数据的集合。例如,电话号
码本中的Smith John这个条目,包括他的地址和电话号码,就是一条记录。
记录中的每一项叫做一个字段。在g a w k中,字段是最基本的单位。多个记录的集合组成了
一个文件。
大多数情况下,字段之间由一个特别的字符分开,像空格、TA B、分号等。这些字符叫做
字段分隔符。请看下面这个/ e t c / p a s s w d文件:
t p a r k e r ; t 3 6 s 6 2 h s h ; 5 0 1 ; 1 0 1 ; Tim Parker;/home/tparker;/bin/bash
etreijs;2ys639dj3h;502;101;Ed Tr e i j s ; / h o m e / e t r e i j s ; / b i n / t c s h
y c h o w ; 1 h 2 7 s j ; 5 0 3 ; 1 0 1 ; Yvonne Chow;/home/ychow;/bin/bash
你能看出/ e t c / p a s s w d文件使用分号作为字段分隔符。/ e t c / p a s s w d文件中的每一行都包括
七个字段:用户名;口令;用户I D;工作组I D;注释; h o m e目录;启始的外壳。如果你想要
查找第六个字段,只需数过五个分号即可。
但考虑到以下电话号码本的例子,你就会发现一些问题:
Smith John 13 Wilson St. 555-1283
Smith John 2736 Artside Dr Apt 123 555-2736
Smith John 125 Westmount Cr 555-1726
虽然我们能够分辨出每个记录包括四个字段,但g a w k却无能为力。电话号码本使用空格作
为分隔符,所以g a w k认为S m i t h是第一个字段, John 是第二个字段,1 3是第三个字段,依次类
推。就g a w k而言,如果用空格作为字段分隔符的话,则第一个记录有六个字段,而第二个记
录有八个字段。
所以,我们必须找出一个更好的字段分隔符。例如,像下面相同使用斜杠作为字段分隔
符:
Smith/John/13 Wilson St./555-1283
Smith/John/2736 Artside Dr/Apt/123/555-2736
Smith/John/125 Westmount Cr/555-1726
如果你没有指定其他的字符作为字段分隔符,那么g a w k将缺省地使用空格或TA B作为字段
分隔符。
6.4 模式和动作
在g a w k语言中每一个命令都由两部分组成:一个模式( p a t t e r n)和一个相应的动作
(a c t i o n)。只要模式符合,g a w k就会执行相应的动作。其中模式部分用两个斜杠括起来,而动
作部分用一对花括号括起来。例如:
/ p a t t e r n 1 / { a c t i o n 1 }
/ p a t t e r n 2 / { a c t i o n 2 }
/ p a t t e r n 3 / { a c t i o n 3 }
所有的g a w k程式都是由这样的一对对的模式和动作组成的。其中模式或动作都能够被省
略,不过两个不能同时被省略。如果模式被省略,则对于作为输入的文件里面的每一行,动作
都会被执行。如果动作被省略,则缺省的动作被执行,既显示出所有符合模式的输入行而不做
所有的改动。
下面是个简单的例子,因为gawk 程式非常短,所以将gawk 程式直接写在外壳命令行:
gawk ’/tparker/’ /etc/passwd
此程式在上面提到的/ e t c / p a s s w d文件中寻找符合t p a r k e r模式的记录并显示(此例中没有动
作,所以缺省的动作被执行)。
让我们再看一个例子:
gawk ’/UNIX/{print $2}’ file2.data
此命令将逐行查找f i l e 2 . d a t a文件中包含U N I X的记录,并打印这些记录的第二个字段。
你也能在一个命令中使用多个模式和动作对,例如:
gawk ’/scandal/{print $1} /rumor/{print $2}’ gossip_file
此命令搜索文件g o s s i p _ f i l e中包括s c a n d a l的记录,并打印第一个字段。然后再从头搜索
g o s s i p _ f i l e中包括r u m o r的记录,并打印第二个字段。
6.5 比较运算和数值运算
g a w k有非常多比较运算符,下面列出重要的几个:
= = 相等
! = 不相等
> 大于
= 大于等于
100’ testfile
将会显示文件testfile 中那些第四个字段大于1 0 0的记录。
下表列出了g a w k中基本的数值运算符。
运算符说明示例
+ 加法运算2+6
- 减法运算6-3
* 乘法运算2*5
/ 除法运算8/4
^ 乘方运算3^2 (=9)
% 求余数9%4 (=1)
例如:
{print $3/2}
显示第三个字段被2除的结果。
在g a w k中,运算符的优先权和一般的数学运算的优先权相同。例如:
{print $1+$2*$3}
显示第二个字段和第三个字段相乘,然后和第一个字段相加的结果。
你也能用括号改动优先次序。例如:
{print ($1+$2)*$3}
显示第一个字段和第二个字段相加,然后和第三个字段相乘的结果。
6.6 内部函数
g a w k中有各种的内部函数,目前介绍如下:
6.6.1 随机数和数学函数
sqrt(x) 求x 的平方根
sin(x) 求x 的正弦函数
cos(x) 求x 的余弦函数
a t a n 2 ( x,y) 求x / y的余切函数
log(x) 求x 的自然对数
exp(x) 求x 的e 次方
int(x) 求x 的整数部分
rand() 求0 和1之间的随机数
srand(x) 将x 设置为r a n d ( )的种子数
6.6.2 字符串的内部函数
• i n d e x ( i n,find) 在字符串in 中寻找字符串find 第一次出现的地方,返回值是字符串
find 出目前字符串in 里面的位置。如果在字符串in 里面未找到字符串f i n d,则返回值为
0。
例如:
print index("peanut"," a n " )
显示结果3。
• length(string) 求出string 有几个字符。
例如:
l e n g t h ( " a b c d e " )
显示结果5。
• m a t c h ( s t r i n g,r e g e x p ) 在字符串string 中寻找符合regexp 的最长、最靠左边的子字
符串。返回值是regexp 在string 的开始位置,即i n d e x值。match 函数将会设置系统变量
R S TA RT 等于i n d e x的值,系统变量RLENGTH 等于符合的字符个数。如果不符合,则会
设置R S TA RT 为0、RLENGTH 为- 1。
• s p r i n t f ( f o r m a t,e x p r e s s i o n 1,. . . ) 和printf 类似,不过sprintf 并不显示,而是返回字符
串。
例如:
sprintf("pi = %.2f (approx.)",2 2 / 7 )
返回的字符串为pi = 3.14 (approx.)
• s u b ( r e g e x p,r e p l a c e m e n t,t a rg e t ) 在字符串t a rget 中寻找符合regexp 的最长、最靠左的
地方,以字串replacement 代替最左边的r e g e x p。
例如:
str = "water,w a t e r,e v e r y w h e r e "
s u b ( / a t /, " i t h ",s t r )
结果字符串s t r会变成
w i t h e r,w a t e r,e v e r y w h e r e
• g s u b ( r e g e x p,r e p l a c e m e n t,t a rget) 和前面的s u b类似。在字符串t a rget 中寻找符合
r e g e x p的所有地方,以字符串replacement 代替所有的r e g e x p。
例如:
s t r = " w a t e r,w a t e r,e v e r y w h e r e "g s u b ( / a t /, " i t h ",s t r )
结果字符串s t r会变成
w i t h e r,w i t h e r,e v e r y w h e r e
• s u b s t r ( s t r i n g,s t a r t,length) 返回字符串string 的子字符串,这个子字符串的长度为
l e n g t h,从第start 个位置开始。
例如:
s u b s t r ( " w a s h i n g t o n ",5,3 )
返回值为i n g
如果没有length ,则返回的子字符串是从第start 个位置开始至结束。
例如:
s u b s t r ( " w a s h i n g t o n ",5 )
返回值为i n g t o n。
• tolower(string) 将字符串s t r i n g的大写字母改为小写字母。
例如:
tolower("MiXeD cAsE 123")
返回值为mixed case 123。
• toupper(string) 将字符串s t r i n g的小写字母改为大写字母。
例如:
toupper("MiXeD cAsE 123")
返回值为MIXED CASE 123。
6.6.3 输入输出的内部函数
• close(filename) 将输入或输出的文件filename 关闭。
• system(command) 此函数允许用户执行操作系统的指令,执行完毕后将回到g a w k程
序。
例如:
BEGIN {system("ls")}
6.7 字符串和数字
字符串就是一连串的字符,他能被g a w k逐字地翻译。字符串用双引号括起来。数字不能
用双引号括起来,并且g a w k将他当作一个数值。例如:
gawk ’$1 != "Tim" {print}’ testfile
此命令将显示第一个字段和Ti m不相同的所有记录。如果命令中Ti m两边不用双引号,
g a w k将不能正确执行。
再如:
gawk ’$1 == "50" {print}’ testfile
此命令将显示所有第一个字段和5 0这个字符串相同的记录。g a w k不管第一字段中的数值
的大小,而只是逐字地比较。这时,字符串5 0和数值5 0并不相等。
6.8 格式化输出
我们能让动作显示一些比较复杂的结果。例如:
gawk ’$1 != "Tim" {print $1,$ 5,$ 6,$2}’ testfile
将显示t e s t f i l e文件中所有第一个字段和Ti m不相同的记录的第一、第五、第六和第二个字
段。
进一步,你能在p r i n t动作中加入字符串,例如:
gawk ’$1 != "Tim" {print "The entry for ",$ 1,"is not Tim. ",$2}’ testfile
p r i n t动作的每一部分用逗号隔开。
借用C语言的格式化输出指令,能让g a w k的输出形式更为多样。这时,应该用p r i n t f而不
是p r i n t。例如:
{printf "%5s likes this language\n",$ 2 }
p r i n t f中的%5s 部分告诉gawk 怎么格式化输出字符串,也就是输出5个字符长。他的值由
printf 的最后部分指出,在此是第二个字段。\ n是回车换行符。如果第二个字段中存储的是人
名,则输出结果大致如下:
Tim likes this language
G e o ff likes this language
Mike likes this language
Joe likes this language
gawk 语言支持的其他格式控制符号如下:
• c 如果是字符串,则显示第一个字符;如果是整数,则将数字以ASCII 字符的形式显示。
例如:
printf “% c”,6 5
结果将显示字母A。
• d 显示十进制的整数。
• i 显示十进制的整数。
• e 将浮点数以科学记数法的形式显示。
例如:
print “$ 4 . 3 e”,1 9 5 0
结果将显示1 . 9 5 0 e + 0 3。
• f 将数字以浮点的形式显示。
• g 将数字以科学记数法的形式或浮点的形式显示。数字的绝对值如果大于等于0 . 0 0 0 1则
以浮点的形式显示,否则以科学记数法的形式显示。
• o 显示无符号的八进制整数。
• s 显示一个字符串。
• x 显示无符号的十六进制整数。1 0至1 5以a至f表示。
• X 显示无符号的十六进制整数。1 0至1 5以A至F表示。
• % 他并不是真正的格式控制字符,% %将显示%。
当你使用这些格式控制字符时,你能在控制字符前给出数字,以表示你将用的几位或几
个字符。例如,6 d表示一个整数有6位。再请看下面的例子:
{printf "%5s works for %5s and earns %2d an hour",$ 1,$ 2,$ 3 }
将会产生类似如下的输出:
Joe works for Mike and earns 12 an hour
当处理数据时,你能指定数据的精确位数
{printf "%5s earns $%.2f an hour",$ 3,$ 6 }
其输出将类似于:
Joe earns $12.17 an hour
你也能使用一些换码控制符格式化整行的输出。之所以叫做换码控制符,是因为g a w k对
这些符号有特别的解释。下面列出常用的换码控制符:
\a 警告或响铃字符。
\b 后退一格。
\f 换页。
\n 换行。
\r 回车。
\t Ta b。
\v 垂直的t a b。
6.9 改动字段分隔符
在g a w k中,缺省的字段分隔符一般是空格符或TA B。但你能在命令行使用- F选项改动字
符分隔符,只需在- F后面跟着你想用的分隔符即可。
gawk -F" ;"’/tparker/{print}’ /etc/passwd
在此例中,你将字符分隔符设置成分号。注意: - F必须是大写的,而且必须在第一个引号
之前。
6.10 元字符
g a w k语言在格式匹配时有其特别的规则。例如, c a t能够和记录中所有位置有这三个字符
的字段匹配。但有时你需要一些更为特别的匹配。如果你想让c a t只和c o n c a t e n a t e匹配,则需要
在格式两端加上空格:
/ cat / {print}
再例如,你希望既和c a t又和C AT匹配,则能使用或(|):
/ cat | CAT / {print}
在g a w k中,有几个字符有特别意义。下面列出能用在g a w k格式中的这些字符:
• ^ 表示字段的开始。
例如:
$3 ~ /^b/
如果第三个字段以字符b开始,则匹配。
• $ 表示字段的结束。
例如:
$3 ~ /b$/
如果第三个字段以字符b结束,则匹配。
• . 表示和所有单字符m匹配。
例如:
$3 ~ /i.m/
如果第三个字段有字符i,则匹配。
• | 表示“或”。
例如:
/ c a t | C AT/
和cat 或C AT字符匹配。
• * 表示字符的零到多次重复。
例如:
/UNI*X/
和U N X、U N I X、U N I I X、U N I I I X等匹配。
• + 表示字符的一次到多次重复。
例如:
/UNI+X/
和U N I X、U N I I X等匹配。
• \{a,b\} 表示字符a次到b次之间的重复。
例如:
/ U N I \ { 1,3 \ } X
和U N I X、U N I I X和U N I I I X匹配。
• ? 表示字符零次和一次的重复。
例如:
/UNI?X/
和UNX 和U N I X匹配。
• [] 表示字符的范围。
例如:
/I[BDG]M/
和I B M、I D M和I G M匹配
• [^] 表示不在[ ]中的字符。
例如:
/I[^DE]M/
和所有的以I开始、M结束的包括三个字符的字符串匹配,除了I D M和I E M之外。
6.11 调用gawk程式
当需要非常多对模式和动作时,你能编写一个g a w k程式(也叫做g a w k脚本)。在g a w k程式
中,你能省略模式和动作两边的引号,因为在g a w k程式中,模式和动作从哪开始和从哪结
束时是非常显然的。
你能使用如下命令调用g a w k程式:
gawk -f script filename
此命令使g a w k对文件f i l e n a m e执行名为s c r i p t的g a w k程式。
如果你不希望使用缺省的字段分隔符,你能在f选项后面跟着F选项指定新的字段分隔符
(当然你也能在g a w k程式中指定),例如,使用分号作为字段分隔符:
gawk -f script -F";" filename
如果希望gawk 程式处理多个文件,则把各个文件名罗列其后:
gawk -f script filename1 filename2 filename3 ...
缺省情况下, g a w k的输出将送往屏幕。但你能使用L i n u x的重定向命令使g a w k的输出送
往一个文件:
gawk -f script filename > save_file
6.12 BEGIN和END
有两个特别的模式在g a w k中非常有用。B E G I N模式用来指明g a w k开始处理一个文件之前执行一些动作。B E G I N经常用来初始化数值,设置参数等。E N D模式用来在文件处理完成后
执行一些指令,一般用作总结或注释。
BEGIN 和E N D中所有要执行的指令都应该用花括号括起来。BEGIN 和E N D必须使用大写。
请看下面的例子:
BEGIN { print "Starting the process the file" }
$1 == "UNIX" {print}
$2 > 10 {printf "This line has a value of %d",$ 2 }
END { print "Finished processing the file. Bye!"}
此程式中,先显示一条信息: Starting the process the file,然后将所有第一个字段等于
U N I X的整条记录显示出来,然后再显示第二个字段大于10 的记录,最后显示信息: F i n i s h e d
processing the file. Bye!。
6.13 变量
在g a w k中,能用等号( = )给一个变量赋值:
var1 = 10
在g a w k中,你不必事先声明变量类型。
请看下面的例子:
$1 == "Plastic" { count = count + 1 }
如果第一个字段是P l a s t i c,则c o u n t的值加1。在此之前,我们应当给c o u n t赋予过初值,一
般是在B E G I N部分。
下面是比较完整的例子:
BEGIN { count = 0 }
$5 == "UNIX" { count = count + 1 }
END { printf "%d occurrences of UNIX were found",count }
变量能和字段和数值一起使用,所以,下面的表达式均为合法:
count = count + $6
count = $5 - 8
count = $5 + var1
变量也能是格式的一部分,例如:
$2 > max_value {print "Max value exceeded by ",$2 - max_value}
$4 - var1 $2){
print "The first column is larger"
}
else {
print "The second column is larger"
} )
6.15.2 while 循环
while 循环的语法如下:
while (expression){
c o m m a n d s
}
例如:
# interest calculation computes compound interest
# inputs from a file are the amount,interest_rateand years
{var = 1
while (var 0){
print line[var]
v a r - -
}
}
此段程式读取一个文件的每一行,并用相反的顺序显示出来。我们使用N R作为数组的下
标来存储文件的每一条记录,然后在从最后一条记录开始,将文件逐条地显示出来。
6.17 用户自定义函数
复杂的gawk 程式常常能使用自己定义的函数来简化。调用用户自定义函数和调用内部
函数的方法相同。函数的定义能放在gawk 程式的所有地方。
用户自定义函数的格式如下:
function name (parameter-list) {
b o d y - o f - f u n c t i o n
}
name 是所定义的函数的名称。一个正确的函数名称可包括一序列的字母、数字、下标线
( u n d e r s c o r e s ),不过不可用数字做开头。p a r a m e t e r-list 是函数的全部参数的列表,各个参数之
间以逗点隔开。body-of-function 包含gawk 的表达式,他是函数定义里最重要的部分,他决定
函数实际要做的事情。
下面这个例子,会将每个记录的第一个字段的值的平方和第二个字段的值的平方加起来。
{print "sum =",S q u a r e S u m ( $ 1,$ 2 ) }
function SquareSum(x,y) {
s u m = x * x + y * y
return sum
}
到此,我们已知道了g a w k的基本用法。g a w k语言十分易学好用,例如,你能用g a w k
编写一段小程式来计算一个目录中所有文件的个数和容量。如果用其他的语言,如C语言,则
会十分的麻烦,相反,g a w k只需要几行就能完成此工作。
6.18 几个实例
最后,再举几个g a w k的例子:
gawk ’{if (NF > max) max = NF}
END {print max}’
此程式会显示所有输入行之中字段的最大个数。
gawk ’length($0) > 80’
此程式会显示出超过80 个字符的每一行。此处只有模式被列出,动作是采用缺省值显示
整个记录。
gawk ’NF > 0’
显示拥有至少一个字段的所有行。这是个简单的方法,将一个文件里的所有空白行删除。
gawk ’BEGIN {for (i = 1; i max) max = NF}
END {print max}’
此程式会显示所有输入行之中字段的最大个数。
gawk ’length($0) > 80’
此程式会显示出超过80 个字符的每一行。此处只有模式被列出,动作是采用缺省值显示
整个记录。
gawk ’NF > 0’
显示拥有至少一个字段的所有行。这是个简单的方法,将一个文件里的所有空白行删除。
gawk ’BEGIN {for (i = 1; i
posted @
2008-10-30 12:20 一凡 阅读(467) |
评论 (0) |
编辑 收藏
名称: crontab
使用权限: 所有使用者
使用方式:
crontab file [-u user] ——用指定的文件替代目前的crontab。
crontab -[-u user] ——用标准输入替代目前的crontab.
crontab -l[user] ——列出用户目前的crontab.
crontab -e[user] ——编辑用户目前的crontab.
crontab -d[user] ——删除用户目前的crontab.
crontab -c dir ——指定crontab的目录。
crontab文件的格式:M H D m d cmd.
M: 分钟(0-59)。
H:小时(0-23)。
D:天(1-31)。
m: 月(1-12)。
d: 一星期内的天(0~6,0为星期天)。
cmd要运行的程序,程序被送入sh执行,这个shell只有USER,HOME,SHELL这三个环境变量
说明 :
crontab
是用来让使用者在固定时间或固定间隔执行程序之用,换句话说,也就是类似使用者的时程表。-u user 是指设定指定 user
的时程表,这个前提是你必须要有其权限(比如说是 root)才能够指定他人的时程表。如果不使用 -u user 的话,就是表示设定自己的时程表。
参数 :
crontab -e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑器,则请先设定 VISUAL 环境变数来指定使用那个文字编辑器(比如说 setenv VISUAL joe)
crontab -r : 删除目前的时程表
crontab -l : 列出目前的时程表
crontab file [-u user] ——用指定的文件替代目前的crontab。
时程表的格式如下 :
f1 f2 f3 f4 f5 program
其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份中的第几日,f4 表示月份,f5 表示一个星期中的第几天。program 表示要执行的程序。
当 f1 为 * 时表示每分钟都要执行 program,f2 为 * 时表示每小时都要执行程序,其余类推。
当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其余类推。
当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为 */n 表示每 n 小时个时间间隔执行一次,其馀类推。
当 f1 为 a, b, c,... 时表示第 a, b, c,... 分钟要执行,f2 为 a, b, c,... 时表示第 a, b, c...个小时要执行,其馀类推。
使用者也可以将所有的设定先存放在档案 file 中,用 crontab file 的方式来设定时程表。
例子 :
#每天早上7点执行一次 /bin/ls :
0 7 * * * /bin/ls
在 12 月内, 每天的早上 6 点到 12 点中,每隔3个小时执行一次 /usr/bin/backup :
0/3 6-12 * 12 * /usr/bin/backup
#周一到周五每天下午 5:00 寄一封信给 alex@domain.name :
0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata
#每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha"
20 0-23/2 * * * echo "haha"
注意 :
当程序在你所指定的时间执行后,系统会寄一封信给你,显示该程序执行的内容,若是你不希望收到这样的信,请在每一行空一格之后加上 > /dev/null 2>&1 即可
例子2 :
#每天早上6点10分
10 6 * * * date
#每两个小时
0 */2 * * * date
#晚上11点到早上8点之间每两个小时,早上8点
0 23-7/2,8 * * * date
#每个月的4号和每个礼拜的礼拜一到礼拜三的早上11点
0 11 4 * mon-wed date
#1月份日早上4点
0 4 1 jan * date
原文地址:http://h1yn.itpub.net/post/2084/222108
posted @
2008-10-30 11:32 一凡 阅读(1532) |
评论 (0) |
编辑 收藏
举例:
oracle:
select decode(pay_name,'aaaa','bbb',pay_name),sum(comm_order),sum(suc_order),sum(suc_amount) From payment.order_tab group by decode(pay_name,'aaaaa','bbbb',pay_name)
转换成mysql:实现
select case when pay_name='aaa' then 'bbb' else pay_name end ,sum(comm_order),sum(suc_order),sum(suc_amount) From payment.order_tab group by case when pay_name='aaa' then 'bbb' else pay_name end
在mysql中有decode()是这样解释的:一种是加密,另外一种是比较
在Oracle中:
语法:DECODE(control_value,value1,result1[,value2,result2…] [,default_result]);control _value试图处理的数值。DECODE函数将该数值与后面的一系列的偶序相比较,以决定返回值。
value1是一组成序偶的数值。如果输入数值与之匹配成功,则相应的结果将被返回。对应一个空的返回值,可以使用关键字NULL于之对应
result1 是一组成序偶的结果值。
default_result 未能与任何一个值匹配时,函数返回的默认值。
例如:
selectdecode( x , 1 , ‘x is 1 ’, 2 , ‘x is 2 ’, ‘others’) from dual
当x等于1时,则返回‘x is 1’。
当x等于2时,则返回‘x is 2’。
否则,返回others’。
需要,比较2个值的时候,可以配合SIGN()函数一起使用。
SELECT DECODE( SIGN(5 -6), 1 'Is Positive', -1, 'Is Nagative', 'Is Zero')
同样,也可以用CASE实现:
SELECT CASE SIGN(5 - 6)
WHEN 1 THEN 'Is Positive'
WHEN -1 THEN 'Is Nagative'
ELSE 'Is Zero' END
FROM DUAL
|
此外,还可以在Order by中使用Decode。
例如:表table_subject,有subject_name列。要求按照:语、数、外的顺序进行排序。这时,就可以非常轻松的使用Decode完成要求了。
select * from table_subject order by decode(subject_name, '语文', 1, '数学', 2, , '外语',3)(责任编辑:卢兆林)
posted @
2008-10-28 18:26 一凡 阅读(10710) |
评论 (0) |
编辑 收藏
最近在项目里用到resin,以前也用过,但记不得是什么版本了,这次可把我给折腾的死了,TNND
我的项目架构是struts1.2+spring2+hibername3+eXtremeComponet,用这个eXtremeComponet的输出EXCEL或PDF时必需加filter,在resin-3.2.0、resin-3.1.6、resin-3.1.2下只要加上filter页面和action之间传递的中文就是乱码,去掉就OK,但又没了输出EXCEL或PDF,郁闷呀,后来又换成resin-3.0.26,一试一点问题也没有,没时间搞清是什么问题!只能先让这个项目上线再说了,有人知道怎么回,请回复一下,谢谢
posted @
2008-09-19 17:02 一凡 阅读(321) |
评论 (0) |
编辑 收藏
摘自http://www.blogjava.net/zilong/archive/2007/04/04/108415.html
很多网页都是框架结构的,在很多的情况下会通过按钮点击事件或链接,跳出框架转到其它界面。例如说点击“注销登录”返回到登录界面。
一、通过运行脚本跳出框架有以下几种写法:
1. <script language = javascript>window.open('Login.aspx','_top')</script>"
2. <script language = javascript>window.open('Login.aspx','_parent')</script>"
3. <script language = javascript>window.parent.location.href='login.aspx'</script>
4. Response.Write("<script>window.parent.opener=null;window.top.close();</script>")
Response.Write("<script>window.open('index.aspx','');</script>")
这种方法会先关闭原框架窗口,再重新打开一个新的窗口。这在很多功能界面对浏览器进行了改变设置,而回到登陆界面又用缺省设置的情况下适用。
二、链接跳出框架
这种情况就很简单了,加上 target="_top" 属性就可以了。
posted @
2008-08-20 11:03 一凡 阅读(377) |
评论 (0) |
编辑 收藏
有时mysql会占用过多cpu,解决办法之一是查看mysql线程的运行情况
mysqladmin proc stat
mysqladmin proc stat -i 1 (间隔1s)
mysqladmin kill pid (kill掉死锁的线程的pid)
posted @
2008-08-11 16:34 一凡 阅读(257) |
评论 (0) |
编辑 收藏