
【软件缺陷的定义】
首先是Bug的定义:在软件程序中存在的任何一种破坏正常运行能力的问题或缺陷,都可以叫做“Bug”。
(1)软件未达到软件产品需求说明书中的要求
(2)软件出现了软件产品需求说明书中指明不会出现的错误
(3)软件功能超出了软件产品需求说明书中指明的范围
(4)软件未达到软件产品说明书中未指明但应达到的要求
(5)测试人员认为难以理解、不易使用、运行缓慢或最终用户认为不好的问题
【软件缺陷的级别】
建议:可用性方面的一些建议,如字体颜色等一些不影响使用的问题。
提示:一些小问题,如有个别错别字、文字排版不整齐等,对功能几乎没有影响,软件产品仍可使用。
一般:不太严重的错误,如次要功能模块丧失、提示信息不够准确、用户界面差和操作时间长等。
严重:严重错误,指功能模块或特性没有实现,主要功能部分丧失,次要功能全部丧失或致命的错误声明。
致命:致命的错误,造成系统崩溃、死机或造成数据丢失、主要功能完全丧失等。
【软件缺陷的状态】
凡是使用过缺陷管理工具,如BugFree、JIRA等都会知道Bug无非是这几种状态:新建、接受/处理、拒绝、已修复、关闭、重新打开、挂起。状态之间的跳转图如下:
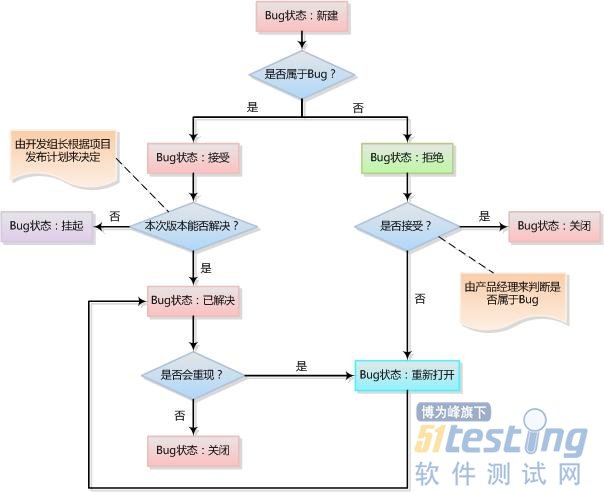
【软件缺陷的处理】
上面的知识点在各种网站和书籍上都可以查找到,但实际测试当中,测试人员需要严格的按照测试流程执行,时时检查开发人员是否在未沟通的情况下挂起或挂起BUG,另外软件发布时,基本上很少能达到100%的Bug修复后上线,那么如何在还有Bug遗留的情况下,评估是否可以发布呢?
1、缺陷的挂起率
首先项目发布时,缺陷的挂起率不能超过15%,并且被挂起的Bug也需要对影响面进行评估,对用户影响大的,比如有延迟问题,延迟时间超过15s,这类bug都原则上不允许挂起,需要优化解决,另外在测试报告中的测试建议中可以说明:
● 可以全量发布:适用于没有挂起bug或没有重现率高的严重致命的挂起bug。
● 建议灰度发布:适用于挂起的严重致命bug重现率低(低于50%),或用户不容易感知。
● 不建议发布:适用于挂起的严重致命bug必现,或很干扰用户体验。
2、遗留Bug的影响
测试人员在报告中要对遗留Bug的影响度进行大致评估,关注的地方有Bug的重现概率、Bug对用户造成的影响、Bug是否会引发其他功能模块的使用来进行判断。
注:先明确一下这里所说的产品设计师的职责:需求收集、信息架构、交互设计、产品设计文档撰写。
“我们的设计很好,可开发的产品很差!”,这个问题想必困扰着不少公司或团队,在近期的工作中,逐渐体会到一套行之有效的方法–让产品设计师跟踪测试自己设计的产品。设计师不要小看这测试的工作,跟踪测试起来颇有成就,你可以知道你的设计被实施了多少,看着实施符合设计,设计师会很有成就感。我也是被CTO逼着走过了这个过程才逐渐体会到它的好处。
产品设计师不大可能与程序员一起写程序,但可以跟踪测试开发的产品,并把测试结果直接反馈给大家(程序员、项目经理、产品经理、测试人员)。这应该算是一个管理问题,确切的说是协作流程问题。所以这种做法,必须得到cto等高层管理者的大力推行,否则编程者是不买帐的,毕竟谁都不愿意让人跟在屁股后面指责哪里做错了,高管把产品设计师的测试工作纳入流程,大家照章办事,工作起来会更顺利一些。
测试的时机:
产品开发基本成型,功能基本完备,研发者能提供可测试版本。
测试的相关协作:
发送测试文档给开发者,同时抄送给项目经理、产品经理、测试等等相关人员;遇到争议主动找项目经理、产品经理等相关领导协商。
测试依据的文档:
做过测试工程师的应该都知道,测试工程师是根据自己编写的测试用例(精简测试用例、详细测试用例)来测试,一般情况下,设计师根据精简测试用例文档来测试就好了,设计师只是要依据某个使用过程来试用并发现问题。当然如果设计师愿意写几个主要使用场景,然后根据自己的使用场景来测试更好,不过要注意自己的使用场景和设计文档保持一致。
让产品设计师跟踪测试的好处:
1、设计师比测试工程师更多关注可用性,可以保证产品的高质量。毕竟设计师对评判产品好坏较强的审美能力。
2、遇到问题可以直接给出解决方案,效率高。
3、可以看到更多的设计问题,便于及时补充和修正设计文档。设计师可以锻炼细节关注能力,积累更多经验。(本条的收获很大呀!)
4、设计师可以很好的参与到开发中去。
分享一下自己做跟踪测试的经验和教训
1、设计师在跟踪测试之前应做足的工作:确保设计文档写的更详细和易读,确保无主要逻辑缺失。最好做出原型并依据原型多体验几遍,或者邀请其他设计师一起来体验,争取在开发前发现更多的问题,确保文档质量。否则,一旦开发出现问题或者开发进度延迟,会把全部责任推到产品设计师身上。开发者会说:“文档没写”或“文档没写明白,看不懂。”遇到这样的情况,设计师百口难辨,设计师的确是有责任的(虽然不是全部)。
2、搞好关系,不要直接指责开发人员或开发中的问题。理智的做法应该是:”客观的表述操作,客观的提出正确的方案。”描述问题时不要有任何情绪,或者可能让合作者产生“逆反心理”的语气。比如:“竟然”“居然”“错误”等,当然适当的夸奖一下也是可以的。
3、在遇到争议时,通过正确的渠道解决问题,主动通过双方主管协商解决,开发人员不会听你的,不要试图说服他们,和他们争论的结果只会让他们记恨你,还有肯能找机会给你穿小鞋,设计师争取避免这个问题。遇到问题要先学会倾听,然后才有可能正确处理问题。否则容易产生误解,让别人误以为你不好合作或不好沟通(但实际上你是为产品质量而挣)。
4、和开发人员、测试人员保持紧密的沟通,提高解决问题的速度;有需求变动或文档改动要迅速反应,并及时通知大家。否则,如果研发没有按照变动来修改,会怪罪你没有及时通知。
……,更多感受还需到工作中去体会。
小结:说了那么多,这样做还得公司高层大力支持并推行为前提;设计师要真正处理好各种关系还得自己实际去体会,毕竟每个公司的情况都不尽相同;设计师可以获得很多,更清楚要向开发者“表达什么?如果表达?”。
性能测试新手误区(一):找不到测试点,不知为何而测
性能测试新手误区(二):为什么我模拟的百万测试数据是无效的?
同样的项目、同样的性能需求,让不同的测试人员来测,会是相同的结果么?
假设有这样一个小论坛,性能测试人员得到的需求是“支持并发50人,响应时间要在3秒以内”,性能测试人员A和B同时开始进行性能测试(各做各的)。
只考虑发帖这个操作,A设计的测试场景是50人并发发帖,得到的测试结果是平均完成时间是5秒。于是他提出了这个问题,认为系统没有达到性能期望,需要开发人员进行优化。
B设计的测试场景是,50个人在线,并且在5分钟内每人发一个帖子,也就是1分钟内有10个人发帖子,最后得到的测试结果是平均完成时间2秒。于是他的结论是系统通过性能测试,可以满足上线的压力。
两个人得到了不同的测试结果,完全相反的测试结论,谁做错了?
或许这个例子太极端,绝对并发和平均分布的访问压力当然是截然不同的,那我们再来看个更真实的例子。
还是一个小论坛,需求是“100人在线时,页面响应时间要小于3秒”。A和B又同时开工了,这时他们都成长了,经验更加丰富了,也知道了要设计出更符合实际的测试场景。假设他们都确认了用户的操作流程为“登录-进入子论坛-(浏览列表-浏览帖子)×10-发帖”,即每个用户看10个帖子、发一个帖子。于是他们都录制出了同样的测试脚本。
A认为,每个用户的操作,一般间隔30s比较合适,于是他在脚本中的每两个事务之间加上了30秒的等待(思考时间)。
B想了想自己看论坛时的情景,好像平均每次鼠标点击要间隔1分钟,于是他在脚本中的每两个事务之间加上了1分钟的等待。
他们都认为自己的测试场景比较接近实际情况,可惜测试结果又是不同的,很显然A场景的压力是B的两倍。那谁错了呢?或者有人说是需求不明确导致的,那么你需要什么样的需求呢?
看看我随手在网上(51testing)找的提问吧,和上面的内容如出一辙。一定有很多的性能测试人员每天接到的就是这种需求,又这样就开展了测试,结果可想而知。
这里我想问几个问题,希望各位看完了上面的小例子后想一想:
如果有另一个人和你测同样的系统,你们的测试结果会一致么?
如果不一致,那么谁是正确的?
如何证明测试结果是有效的?
如果你有了一些疑惑,对之前的测试结果少了一些自信,那么请继续。
服务器视角 vs. 用户视角
性能测试中非常重要的一块内容就是模拟预期的压力,测试系统运行在此压力下,用户的体验是什么样的。
那么压力是什么?压力是服务器在不断的处理事情、甚至是同时处理很多事情。压力是服务器直接处理的“事情”,而不是远在网络另一端的用户。
下图中,每一个颜色的线段代表一种操作。在任意一个时刻,服务器都知道它有10个事务需要处理,这10个事务也是有10个用户产生的。但它不知道的是,整个时间段内的所有事务,是由多少个用户与系统交互而产生的。
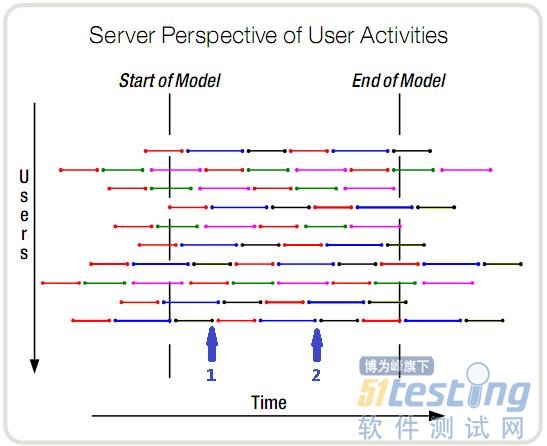
这句话好像有点绕,我再试着更形象的解释一下。时刻1,10个当前事务是由10个用户发起的。时刻2,依然是10个正在进行的事务,但可能是完全不同的10个人发起的。在这段时间内,服务器每一个时刻都在处理10个事务,但是参与了这个交互过程(对服务器产生压力)的人可能会达到上百个,也可能只有最开始的10个。
那么,对于服务器来说,压力是什么呢?显然只是每时刻这10个同时处理的事务,而到底是有10个人还是1000个人,区别不大(暂不考虑session等问题)。
下面再从用户的视角来看看。实际的情况中,不可能出现很多用户同一时刻开始进行操作的场景,而是有一定的时间顺序的。正如下图所示,在这个时间段内,一共有23个用户进行了操作。
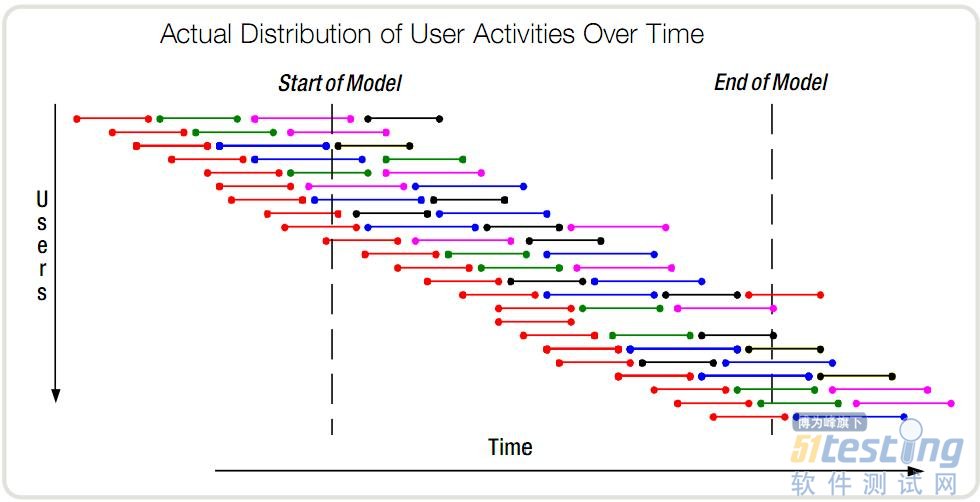
但是服务器能看到这些用户么?它知道的只是某一个时间点上,有多少个正在执行的事务。大家可以数一下,此图中任意时刻的并发事务依然是10个。
其实这两个图描述的本来就是同一个场景,只不过观察者的视角不同罢了。
那么大家想想,在性能需求中最常见到的“并发用户”到底是指的什么呢? 并发用户
很多使用“并发用户”这个词的人,并没有从服务器视角进行考虑。他们想的是坐在电脑前使用这个系统、对系统产生压力的人的个数。基于这个原因,我很少使用这个容易让人误解的词汇,而是进行了更细的划分。主要有这么几个:系统用户数(注册用户数)、在线用户数(相对并发用户数)、绝对并发用户数。
上面几个例子中所说的“并发用户”,实际就是在线用户数。其实我更喜欢叫做相对并发用户数,因为这个词更容易让人感受到“压力”。相对并发用户数指的是,在一个时间段内,与服务器进行了交互、对服务器产生了压力的用户的数量。这个时间段,可以是一天,也可以是一个小时。而需求人员必须要描述的,也正是这个内容。
而绝对并发用户,主要是针对某一个操作进行测试,即多个用户同一时刻发起相同请求。可以用来验证是否存在并发逻辑上的处理问题,如线程不安全、死锁等问题;也可提供一些性能上的参考信息,比如1个用户需要1秒,而10个用户并发却需要30秒,那很可能就会有问题,需要进行关注,因为10个用户请求排队处理也应该只需要10秒啊。但这种绝对并发的测试,同实际压力下的用户体验关系不大。
再回到相对并发这个概念上来,它与服务器的压力到底是什么关系呢?如果你理解了前面的所有内容,那么就会知道这两者其实没有直接联系(当然了,同一个测试用例中,肯定是用户数越多压力越大)。也就是说,你得到的这种性能需求,是无法知道服务器到底要承受多大压力的。
那么如何开展性能测试?
如何模拟压力
既然我们知道了所谓的压力其实是从服务器视角来讲的,服务器要处理的事务才是压力,那么我们就从这出发,来探寻一下性能测试需要的信息。依然用之前的小论坛为例,我们需要测试活跃用户为500人时,系统的性能是否能还能提供良好的用户感受。
假设现在的活跃用户有50个人(或者通过另一个类似的系统来推算也行),平均每天总的发帖量是50条、浏览帖子500次,也就是每人每天发一个帖子、浏览十个帖子(为了方便讲解,假设论坛只有这两个基本功能)。那么我们就可以推算,活跃用户达到500时,每天的业务量也会成比例的增长,也就是平均每天会产生500个新帖子、浏览帖子5000次。
进一步分析数据,又发现。用户使用论坛的时间段非常集中,基本集中在中午11点到1点和晚上18点到20点。也就是说每天的这些业务,实际是分布在4个小时中完成的。
那我们的测试场景,就是要用500个用户在4小时内完成“每人发一个帖子、浏览十个帖子”的工作量。
注意上面的两处,“平均每天……”、“分布在4个小时……”。敏感的测试人员应该能发现,这个场景测的是平均压力,也就是一个系统最平常一天的使用压力,我喜欢称之为日常压力。
显然,除了日常压力,系统还会有压力更大的使用场景,比如某天发生了一件重要的事情,那么用户就会更加热烈的进行讨论。这个压力,我习惯叫做高峰期压力,需要专门设计一个测试场景。
这个场景,需要哪些数据呢,我们依然可以从现有的数据进行分析。比如上面提到的是“平均每天总的发帖量……”,那么这次我们就要查到过去最高一日的业务量。“分布在4个小时”也需要进行相应的修改,比如查查历史分布图是否有更为集中的分布,或者用更简单通用的80-20原则,80%的工作在20%的时间内完成。根据这些数据可以再做适当的调整,设计出高峰期的测试场景。
实际工作中可能还需要更多的测试场景,比如峰值压力场景。什么是峰值压力呢,比如一个银行网站,可能会由于发布一条重磅消息使访问量骤增,这个突发的压力也是性能测试人员需要考虑的。
需要注意高峰期压力和峰值压力的区别,高峰期压力是指系统正常的、预期内压力的一个高峰。而峰值压力是指那些不在正常预期内的压力,可能几年才出现一次。
这里只是举了个最简单的例子,实际工作远比这复杂的多。需要哪些数据、如何获取,很可能要取得这些数据就要花费很大的功夫。这其实就涉及到了一个很重要的内容,用户模型和压力模型的建立,以后会有专门的文章进行讲述。
为什么要花这么大的精力来收集这些信息呢?是因为只有通过这些有效的数据,才能准确的去模拟用户场景,准确的模拟压力,获取到更加真实的用户体验。只有这样,“不同的测试人员,测出相同的结果”才会有可能实现,而且结果都是准确有效的。
要点回顾
● 最后通过几个小问题来总结回顾一下:
● 你真的理解“并发用户”的意义么?
● 什么是用户视角和服务器视角?
● 什么是压力?
● 如何模拟预期压力?
相关链接:
性能测试新手误区(一):找不到测试点,不知为何而测
性能测试新手误区(二):为什么我模拟的百万测试数据是无效的?
摘要: 本篇来聊聊如何书写漂亮、整洁、优雅的SQL脚本,下面这些是我个人总结、整理出来的。姑且做个抛砖引玉吧,呵呵,欢迎大家一起来讨论。 我们首先来看看一段创建数据表的脚本(如下所示),你是否觉得有什么不妥或是不足呢?如果是你,你怎样书写呢?Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHig...
阅读全文
Java集合框架是最常被问到的Java面试问题,要理解Java技术强大特性就有必要掌握集合框架。这里有一些实用问题,常在核心Java面试中问到。
1、什么是Java集合API
Java集合框架API是用来表示和操作集合的统一框架,它包含接口、实现类、以及帮助程序员完成一些编程的算法。简言之,API在上层完成以下几件事:
● 编程更加省力,提高城程序速度和代码质量
● 非关联的API提高互操作性
● 节省学习使用新API成本
● 节省设计新API的时间
● 鼓励、促进软件重用
具体来说,有6个集合接口,最基本的是Collection接口,由三个接口Set、List、SortedSet继承,另外两个接口是Map、SortedMap,这两个接口不继承Collection,表示映射而不是真正的集合。

2、什么是Iterator
一些集合类提供了内容遍历的功能,通过java.util.Iterator接口。这些接口允许遍历对象的集合。依次操作每个元素对象。当使用 Iterators时,在获得Iterator的时候包含一个集合快照。通常在遍历一个Iterator的时候不建议修改集合本省。
3、Iterator与ListIterator有什么区别?
Iterator:只能正向遍历集合,适用于获取移除元素。ListIerator:继承Iterator,可以双向列表的遍历,同样支持元素的修改。
4、什么是HaspMap和Map?
Map是接口,Java 集合框架中一部分,用于存储键值对,HashMap是用哈希算法实现Map的类。
5、HashMap与HashTable有什么区别?对比Hashtable VS HashMap
两者都是用key-value方式获取数据。Hashtable是原始集合类之一(也称作遗留类)。HashMap作为新集合框架的一部分在Java2的1.2版本中加入。它们之间有一下区别:
● HashMap和Hashtable大致是等同的,除了非同步和空值(HashMap允许null值作为key和value,而Hashtable不可以)。
● HashMap没法保证映射的顺序一直不变,但是作为HashMap的子类LinkedHashMap,如果想要预知的顺序迭代(默认按照插入顺序),你可以很轻易的置换为HashMap,如果使用Hashtable就没那么容易了。
● HashMap不是同步的,而Hashtable是同步的。
● 迭代HashMap采用快速失败机制,而Hashtable不是,所以这是设计的考虑点。
6、在Hashtable上下文中同步是什么意思?
同步意味着在一个时间点只能有一个线程可以修改哈希表,任何线程在执行hashtable的更新操作前需要获取对象锁,其他线程等待锁的释放。
7、什么叫做快速失败特性
从高级别层次来说快速失败是一个系统或软件对于其故障做出的响应。一个快速失败系统设计用来即时报告可能会导致失败的任何故障情况,它通常用来停止正常的操作而不是尝试继续做可能有缺陷的工作。当有问题发生时,快速失败系统即时可见地发错错误告警。在Java中,快速失败与iterators有关。如果一个iterator在集合对象上创建了,其它线程欲“结构化”的修改该集合对象,并发修改异常 (ConcurrentModificationException) 抛出。
8、怎样使Hashmap同步?
HashMap可以通过Map m = Collections.synchronizedMap(hashMap)来达到同步的效果。
9、什么时候使用Hashtable,什么时候使用HashMap
基本的不同点是Hashtable同步HashMap不是的,所以无论什么时候有多个线程访问相同实例的可能时,就应该使用Hashtable,反之使用HashMap。非线程安全的数据结构能带来更好的性能。
如果在将来有一种可能—你需要按顺序获得键值对的方案时,HashMap是一个很好的选择,因为有HashMap的一个子类 LinkedHashMap。所以如果你想可预测的按顺序迭代(默认按插入的顺序),你可以很方便用LinkedHashMap替换HashMap。反观要是使用的Hashtable就没那么简单了。同时如果有多个线程访问HashMap,Collections.synchronizedMap()可以代替,总的来说HashMap更灵活。
10、为什么Vector类认为是废弃的或者是非官方地不推荐使用?或者说为什么我们应该一直使用ArrayList而不是Vector
你应该使用ArrayList而不是Vector是因为默认情况下你是非同步访问的,Vector同步了每个方法,你几乎从不要那样做,通常有想要同步的是整个操作序列。同步单个的操作也不安全(如果你迭代一个Vector,你还是要加锁,以避免其它线程在同一时刻改变集合).而且效率更慢。当然同样有锁的开销即使你不需要,这是个很糟糕的方法在默认情况下同步访问。你可以一直使用Collections.sychronizedList来装饰一个集合。
事实上Vector结合了“可变数组”的集合和同步每个操作的实现。这是另外一个设计上的缺陷。Vector还有些遗留的方法在枚举和元素获取的方法,这些方法不同于List接口,如果这些方法在代码中程序员更趋向于想用它。尽管枚举速度更快,但是他们不能检查如果集合在迭代的时候修改了,这样将导致问题。尽管以上诸多原因,oracle也从没宣称过要废弃Vector。
在网络上流畅很广的一篇旧文,暂时没找到原作者,作者用轻松的语言,形象解释了 23 种模式,有很好的启发作用。
创建型模式
1、FACTORY—追MM少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是MM爱吃的东西,虽然口味有所不同,但不管你带MM去麦当劳或肯德基,只管向服务员说“来四个鸡翅”就行了。麦当劳和肯德基就是生产鸡翅的Factory
工厂模式:客户类和工厂类分开。消费者任何时候需要某种产品,只需向工厂请求即可。消费者无须修改就可以接纳新产品。缺点是当产品修改时,工厂类也要做相应的修改。如:如何创建及如何向客户端提供。
2、BUILDER—MM最爱听的就是“我爱你”这句话了,见到不同地方的MM,要能够用她们的方言跟她说这句话哦,我有一个多种语言翻译机,上面每种语言都有一个按键,见到MM我只要按对应的键,它就能够用相应的语言说出“我爱你”这句话了,国外的MM也可以轻松搞掂,这就是我的“我爱你”builder。(这一定比美军在伊拉克用的翻译机好卖)
建造模式:将产品的内部表象和产品的生成过程分割开来,从而使一个建造过程生成具有不同的内部表象的产品对象。建造模式使得产品内部表象可以独立的变化,客户不必知道产品内部组成的细节。建造模式可以强制实行一种分步骤进行的建造过程。
3、FACTORY METHOD—请MM去麦当劳吃汉堡,不同的MM有不同的口味,要每个都记住是一件烦人的事情,我一般采用Factory Method模式,带着MM到服务员那儿,说“要一个汉堡”,具体要什么样的汉堡呢,让MM直接跟服务员说就行了。
工厂方法模式:核心工厂类不再负责所有产品的创建,而是将具体创建的工作交给子类去做,成为一个抽象工厂角色,仅负责给出具体工厂类必须实现的接口,而不接触哪一个产品类应当被实例化这种细节。
4、PROTOTYPE—跟MM用QQ聊天,一定要说些深情的话语了,我搜集了好多肉麻的情话,需要时只要copy出来放到QQ里面就行了,这就是我的情话prototype了。(100块钱一份,你要不要)
原始模型模式:通过给出一个原型对象来指明所要创建的对象的类型,然后用复制这个原型对象的方法创建出更多同类型的对象。原始模型模式允许动态的增加或减少产品类,产品类不需要非得有任何事先确定的等级结构,原始模型模式适用于任何的等级结构。缺点是每一个类都必须配备一个克隆方法。
5、SINGLETON—俺有6个漂亮的老婆,她们的老公都是我,我就是我们家里的老公Sigleton,她们只要说道“老公”,都是指的同一个人,那就是我(刚才做了个梦啦,哪有这么好的事)
单例模式:单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例单例模式。单例模式只应在有真正的“单一实例”的需求时才可使用。
结构型模式
6、ADAPTER—在朋友聚会上碰到了一个美女Sarah,从香港来的,可我不会说粤语,她不会说普通话,只好求助于我的朋友kent了,他作为我和Sarah之间的Adapter,让我和Sarah可以相互交谈了(也不知道他会不会耍我)
适配器(变压器)模式:把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口原因不匹配而无法一起工作的两个类能够一起工作。适配类可以根据参数返还一个合适的实例给客户端。
7、BRIDGE—早上碰到MM,要说早上好,晚上碰到MM,要说晚上好;碰到MM穿了件新衣服,要说你的衣服好漂亮哦,碰到MM新做的发型,要说你的头发好漂亮哦。不要问我“早上碰到MM新做了个发型怎么说”这种问题,自己用BRIDGE组合一下不就行了
桥梁模式:将抽象化与实现化脱耦,使得二者可以独立的变化,也就是说将他们之间的强关联变成弱关联,也就是指在一个软件系统的抽象化和实现化之间使用组合/聚合关系而不是继承关系,从而使两者可以独立的变化。
8、COMPOSITE—Mary今天过生日。“我过生日,你要送我一件礼物。”“嗯,好吧,去商店,你自己挑。”“这件T恤挺漂亮,买,这条裙子好看,买,这个包也不错,买。”“喂,买了三件了呀,我只答应送一件礼物的哦。”“什么呀,T恤加裙子加包包,正好配成一套呀,小姐,麻烦你包起来。”“……”,MM都会用Composite模式了,你会了没有?
合成模式:合成模式将对象组织到树结构中,可以用来描述整体与部分的关系。合成模式就是一个处理对象的树结构的模式。合成模式把部分与整体的关系用树结构表示出来。合成模式使得客户端把一个个单独的成分对象和由他们复合而成的合成对象同等看待。
9、DECORATOR—Mary过完轮到Sarly过生日,还是不要叫她自己挑了,不然这个月伙食费肯定玩完,拿出我去年在华山顶上照的照片,在背面写上“最好的的礼物,就是爱你的Fita”,再到街上礼品店买了个像框(卖礼品的MM也很漂亮哦),再找隔壁搞美术设计的Mike设计了一个漂亮的盒子装起来……,我们都是Decorator,最终都在修饰我这个人呀,怎么样,看懂了吗?
装饰模式:装饰模式以对客户端透明的方式扩展对象的功能,是继承关系的一个替代方案,提供比继承更多的灵活性。动态给一个对象增加功能,这些功能可以再动态的撤消。增加由一些基本功能的排列组合而产生的非常大量的功能。
10、FACADE—我有一个专业的Nikon相机,我就喜欢自己手动调光圈、快门,这样照出来的照片才专业,但MM可不懂这些,教了半天也不会。幸好相机有Facade设计模式,把相机调整到自动档,只要对准目标按快门就行了,一切由相机自动调整,这样MM也可以用这个相机给我拍张照片了。
门面模式:外部与一个子系统的通信必须通过一个统一的门面对象进行。门面模式提供一个高层次的接口,使得子系统更易于使用。每一个子系统只有一个门面类,而且此门面类只有一个实例,也就是说它是一个单例模式。但整个系统可以有多个门面类。
11、FLYWEIGHT—每天跟MM发短信,手指都累死了,最近买了个新手机,可以把一些常用的句子存在手机里,要用的时候,直接拿出来,在前面加上MM的名字就可以发送了,再不用一个字一个字敲了。共享的句子就是Flyweight,MM的名字就是提取出来的外部特征,根据上下文情况使用。
享元模式:FLYWEIGHT在拳击比赛中指最轻量级。享元模式以共享的方式高效的支持大量的细粒度对象。享元模式能做到共享的关键是区分内蕴状态和外蕴状态。内蕴状态存储在享元内部,不会随环境的改变而有所不同。外蕴状态是随环境的改变而改变的。外蕴状态不能影响内蕴状态,它们是相互独立的。将可以共享的状态和不可以共享的状态从常规类中区分开来,将不可以共享的状态从类里剔除出去。客户端不可以直接创建被共享的对象,而应当使用一个工厂对象负责创建被共享的对象。享元模式大幅度的降低内存中对象的数量。
12、PROXY—跟MM在网上聊天,一开头总是“hi,你好”,“你从哪儿来呀?”“你多大了?”“身高多少呀?”这些话,真烦人,写个程序做为我的Proxy吧,凡是接收到这些话都设置好了自动的回答,接收到其他的话时再通知我回答,怎么样,酷吧。
代理模式:代理模式给某一个对象提供一个代理对象,并由代理对象控制对源对象的引用。代理就是一个人或一个机构代表另一个人或者一个机构采取行动。某些情况下,客户不想或者不能够直接引用一个对象,代理对象可以在客户和目标对象直接起到中介的作用。客户端分辨不出代理主题对象与真实主题对象。代理模式可以并不知道真正的被代理对象,而仅仅持有一个被代理对象的接口,这时候代理对象不能够创建被代理对象,被代理对象必须有系统的其他角色代为创建并传入。
行为模式
13、CHAIN OF RESPONSIBLEITY—晚上去上英语课,为了好开溜坐到了最后一排,哇,前面坐了好几个漂亮的MM哎,找张纸条,写上“Hi,可以做我的女朋友吗?如果不愿意请向前传”,纸条就一个接一个的传上去了,糟糕,传到第一排的MM把纸条传给老师了,听说是个老处女呀,快跑!
责任链模式:在责任链模式中,很多对象由每一个对象对其下家的引用而接
起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。客户并不知道链上的哪一个对象最终处理这个请求,系统可以在不影响客户端的情况下动态的重新组织链和分配责任。处理者有两个选择:承担责任或者把责任推给下家。一个请求可以最终不被任何接收端对象所接受。
14、COMMAND—俺有一个MM家里管得特别严,没法见面,只好借助于她弟弟在我们俩之间传送信息,她对我有什么指示,就写一张纸条让她弟弟带给我。这不,她弟弟又传送过来一个COMMAND,为了感谢他,我请他吃了碗杂酱面,哪知道他说:“我同时给我姐姐三个男朋友送COMMAND,就数你最小气,才请我吃面。”,:-(
命令模式:命令模式把一个请求或者操作封装到一个对象中。命令模式把发出命令的责任和执行命令的责任分割开,委派给不同的对象。命令模式允许请求的一方和发送的一方独立开来,使得请求的一方不必知道接收请求的一方的接口,更不必知道请求是怎么被接收,以及操作是否执行,何时被执行以及是怎么被执行的。系统支持命令的撤消。
15、INTERPRETER—俺有一个《泡MM真经》,上面有各种泡MM的攻略,比如说去吃西餐的步骤、去看电影的方法等等,跟MM约会时,只要做一个Interpreter,照着上面的脚本执行就可以了。
解释器模式:给定一个语言后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器。客户端可以使用这个解释器来解释这个语言中的句子。解释器模式将描述怎样在有了一个简单的文法后,使用模式设计解释这些语句。在解释器模式里面提到的语言是指任何解释器对象能够解释的任何组合。在解释器模式中需要定义一个代表文法的命令类的等级结构,也就是一系列的组合规则。每一个命令对象都有一个解释方法,代表对命令对象的解释。命令对象的等级结构中的对象的任何排列组合都是一个语言。
16、ITERATOR—我爱上了Mary,不顾一切的向她求婚。
Mary:“想要我跟你结婚,得答应我的条件”
我:“什么条件我都答应,你说吧”
Mary:“我看上了那个一克拉的钻石”
我:“我买,我买,还有吗?”
Mary:“我看上了湖边的那栋别墅”
我:“我买,我买,还有吗?”
Mary:“你的小弟弟必须要有50cm长”
我脑袋嗡的一声,坐在椅子上,一咬牙:“我剪,我剪,还有吗?”
迭代子模式:迭代子模式可以顺序访问一个聚集中的元素而不必暴露聚集的内部表象。多个对象聚在一起形成的总体称之为聚集,聚集对象是能够包容一组对象的容器对象。迭代子模式将迭代逻辑封装到一个独立的子对象中,从而与聚集本身隔开。迭代子模式简化了聚集的界面。每一个聚集对象都可以有一个或一个以上的迭代子对象,每一个迭代子的迭代状态可以是彼此独立的。迭代算法可以独立于聚集角色变化。
17、MEDIATOR—四个MM打麻将,相互之间谁应该给谁多少钱算不清楚了,幸亏当时我在旁边,按照各自的筹码数算钱,赚了钱的从我这里拿,赔了钱的也付给我,一切就OK啦,俺得到了四个MM的电话。
调停者模式:调停者模式包装了一系列对象相互作用的方式,使得这些对象不必相互明显作用。从而使他们可以松散偶合。当某些对象之间的作用发生改变时,不会立即影响其他的一些对象之间的作用。保证这些作用可以彼此独立的变化。调停者模式将多对多的相互作用转化为一对多的相互作用。调停者模式将对象的行为和协作抽象化,把对象在小尺度的行为上与其他对象的相互作用分开处理。
18、MEMENTO—同时跟几个MM聊天时,一定要记清楚刚才跟MM说了些什么话,不然MM发现了会不高兴的哦,幸亏我有个备忘录,刚才与哪个MM说了什么话我都拷贝一份放到备忘录里面保存,这样可以随时察看以前的记录啦。
备忘录模式:备忘录对象是一个用来存储另外一个对象内部状态的快照的对象。备忘录模式的用意是在不破坏封装的条件下,将一个对象的状态捉住,并外部化,存储起来,从而可以在将来合适的时候把这个对象还原到存储起来的状态。
19、OBSERVER—想知道咱们公司最新MM情报吗?加入公司的MM情报邮件组就行了,tom负责搜集情报,他发现的新情报不用一个一个通知我们,直接发布给邮件组,我们作为订阅者(观察者)就可以及时收到情报啦
观察者模式:观察者模式定义了一种一队多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态上发生变化时,会通知所有观察者对象,使他们能够自动更新自己。
20、STATE—跟MM交往时,一定要注意她的状态哦,在不同的状态时她的行为会有不同,比如你约她今天晚上去看电影,对你没兴趣的MM就会说“有事情啦”,对你不讨厌但还没喜欢上的MM就会说“好啊,不过可以带上我同事么?”,已经喜欢上你的MM就会说“几点钟?看完电影再去泡吧怎么样?”,当然你看电影过程中表现良好的话,也可以把MM的状态从不讨厌不喜欢变成喜欢哦。
状态模式:状态模式允许一个对象在其内部状态改变的时候改变行为。这个对象看上去象是改变了它的类一样。状态模式把所研究的对象的行为包装在不同的状态对象里,每一个状态对象都属于一个抽象状态类的一个子类。状态模式的意图是让一个对象在其内部状态改变的时候,其行为也随之改变。状态模式需要对每一个系统可能取得的状态创立一个状态类的子类。当系统的状态变化时,系统便改变所选的子类。
21、STRATEGY—跟不同类型的MM约会,要用不同的策略,有的请电影比较好,有的则去吃小吃效果不错,有的去海边浪漫最合适,单目的都是为了得到MM的芳心,我的追MM锦囊中有好多Strategy哦。
策略模式:策略模式针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下发生变化。策略模式把行为和环境分开。环境类负责维持和查询行为类,各种算法在具体的策略类中提供。由于算法和环境独立开来,算法的增减,修改都不会影响到环境和客户端。
22、TEMPLATE METHOD——看过《如何说服女生上床》这部经典文章吗?女生从认识到上床的不变的步骤分为巧遇、打破僵局、展开追求、接吻、前戏、动手、爱抚、进去八大步骤(Template method),但每个步骤针对不同的情况,都有不一样的做法,这就要看你随机应变啦(具体实现);
模板方法模式:模板方法模式准备一个抽象类,将部分逻辑以具体方法以及具体构造子的形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑。不同的子类可以以不同的方式实现这些抽象方法,从而对剩余的逻辑有不同的实现。先制定一个顶级逻辑框架,而将逻辑的细节留给具体的子类去实现。
23、VISITOR—情人节到了,要给每个MM送一束鲜花和一张卡片,可是每个MM送的花都要针对她个人的特点,每张卡片也要根据个人的特点来挑,我一个人哪搞得清楚,还是找花店老板和礼品店老板做一下Visitor,让花店老板根据MM的特点选一束花,让礼品店老板也根据每个人特点选一张卡,这样就轻松多了;
访问者模式:访问者模式的目的是封装一些施加于某种数据结构元素之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构可以保持不变。访问者模式适用于数据结构相对未定的系统,它把数据结构和作用于结构上的操作之间的耦合解脱开,使得操作集合可以相对自由的演化。访问者模式使得增加新的操作变的很容易,就是增加一个新的访问者类。访问者模式将有关的行为集中到一个访问者对象中,而不是分散到一个个的节点类中。当使用访问者模式时,要将尽可能多的对象浏览逻辑放在访问者类中,而不是放到它的子类中。访问者模式可以跨过几个类的等级结构访问属于不同的等级结构的成员类。
数据库最 重要是的为前台应用服务。 在众多决定应用性能的因素中, 如何快速有效从后台读取数据很大程度上地影响到最终效果。本文将对不同的数据往返(round-trip)读取进行比较和归纳总结。最后的结果非常出人意 料。往往在时间紧迫的情况下,我们会本能地使用最简单的方法来完成任务,但是这种编译习惯会让我们的前台应用的性能大打折扣。
返回 15,000 条数据:这个测试会从一个表格里面读取15000条数据。我们通过用三种不同的编译方式来看如何提高数据库提取的效率。
以下这个脚本用来创建表格然后放入一百万条数据。因为我们需要足够多的数据来完成3个测试,每个测试读取新鲜的数据,所以创建了一百万条。我创建的这个 列表每15000条数据一小组,这样确保了测试读取15000条数据的准确性。不会因为数据的不同,而影响测试的结果。
这个脚本稍作修改就可以放在MS SQL服务器上跑:
createtabletest000 (
intpkintprimarykey
,fillerchar(40)
)
-- BLOCK 1, first 5000 rows
-- pgAdmin3: run as pgScript
-- All others: modify as required
--
declare@x,@y;
set@x = 1;
set@y = string(40,40,1);
while @x <= 5000begin
insertintotest000 (intpk,filler)
values((@x-1)*200 +1,'@y');
set@x = @x + 1;
end
-- BLOCK 2, put 5000 rows aside
--
select *intotest000_tempfromtest000
-- BLOCK 3, Insert the 5000 rows 199 more
-- times to get 1million altogether
-- pgAdmin3: run as pgScript
-- All others: modify as required
--
declare@x;
set@x = 1;
while @x <= 199begin
insertintotest000 (intpk,filler)
selectintpk+@x,fillerfromtest000_temp;
set@x = @x + 1;
end
|
|
测试-:基本代码
最简单的代码就是通过一个直白的查询语句跑15000次往返。
# Make adatabaseconnection
$dbConn = pg_connect("dbname=roundTrips user=postgres");
# Program 1, Individual explicit fetches
$x1 = rand(0,199)*5000 + 1;
$x2 = $x1 + 14999;
echo"\nTest 1, using $x1 to $x2";
$timeBegin = microtime(true);
while ($x1++ <= $x2) {
$dbResult = pg_exec("select * from test000 where intpk=$x1");
$row = pg_fetch_array($dbResult);
}
$elapsed = microtime(true)-$timeBegin;
echo"\nTest 1, elapsed time: ".$elapsed;
echo"\n";
测试二:准备语句(Prepared Statement) 这个代码通过在循环前做一个准备语句,虽然还是跑15000个往返,但是每次只是变化准备语句的参数。
# Make a database connection
$dbConn = pg_connect("dbname=roundTrips user=postgres");
# Program 2, Individual fetches with prepared statements
$x1 = rand(0,199)*5000 + 1;
$x2 = $x1 + 14999;
echo "\nTest 2, using $x1 to $x2";
$timeBegin = microtime(true);
$dbResult = pg_prepare("test000","select * from test000 where intpk=$1");
while ($x1++ <= $x2) {
$pqResult = pg_execute("test000",array($x1));
$row = pg_fetch_all($pqResult);
}
$elapsed = microtime(true)-$timeBegin;
echo "\nTest 2, elapsed time: ".$elapsed;
echo "\n";
|
测试三:一个往返
我们准备一个语句命令去拿到所有15000条数据,然后把他们一次返回过来。
# Make a database connection
$dbConn = pg_connect("dbname=roundTrips user=postgres");
# Program 3, One fetch, pull all rows
$timeBegin = microtime(true);
$x1 = rand(0,199)*5000 + 1;
$x2 = $x1 + 14999;
echo "\nTest 3, using $x1 to $x2";
$dbResult = pg_exec(
"select * from test000 where intpk between $x1 and $x2"
);
$allRows = pg_fetch_all($dbResult);
$elapsed = microtime(true)-$timeBegin;
echo "\nTest 3, elapsed time: ".$elapsed;
echo "\n";
|
结果

一共跑了5次,平均结果如下
基本 准备 一次往返
~1.800 秒 ~1.150 秒 ~0.045 秒
相比基本代码,最后一个一次往返的逻辑快了大概40倍,比用准备语句快了25倍左右。
服务器和语言是否会影响性能呢?
这个测试是在PHP/PostgresSQL上做的。其他语言和服务器上会不会得到不同的结果呢?如果是同样的硬件,有可能这个数据绝对值会有所差异,但是相对的差距应该是差不多。从一个往返里面读取所有要索引的数据条比人和多次往返的语句都要快。
活用活学
这次测试最显而易见的结论就是任何多于一条数据的索引都应该使用这个方法。实际上,我们应该把这个设置为默认语法,除非有绝好的理由。那么有哪些好理由呢?
我跟我们的程序员聊过,有一位同学说:“你看,我们的应用每次都是只要20-100个数据。绝对不会多了。我实在想 象不出20-100个数据的读取值得翻新所有代码。”所以我听了以后,又去试了一下,实际上是这个方法确实只有100以上的才能看见显著区别。在20的时 候,几乎没有区别。到了100, 一次往返的比基本的快6倍,比第二种方法快4倍。所以,使用与否的判断在于个人。
但是这里还有一个要考虑的因素是有多少同时进行的读取在进行。如果你的系统是基于实时的设计,那么就有可能是不同的情况。我们这个测试是基于一个用户,如果是多个用户同时读取,这种用户行为会带给数据库一些额外的负担,我们需要一个更加宏观的环境来比较。
还有一个反对的声音有可能是“我们是从不同的表格里面读取数据。我们在某些线程上我们走一条条的,需要从不同的表格里面一条条读取。”如果是这样的话,你绝对需要使用一次往返,用几个JOIN一次拿到。如果一个表格,都是慢10倍,几个就慢好几十倍了。
面试的时候,经常会遇到这样的笔试题:给你两个类的代码,它们之间是继承的关系,每个类里只有构造器方法和静态块,它们只包含一些简单的输出字符串到控制台的代码,然后让我们写出正确的输出结果。这实际上是在考察我们对于类的初始化知识的了解。
首先,我们先看看下面的代码,这就是很经典的考察方式。
- public class InitField {
- public static void main(String[] args) {
- SuperInitField p = new SuperInitField();
- SuperInitField c = new SubInitField();
- }
- }
- class SuperInitField {
- public SuperInitField() {
- System.out.println("parent");
- }
- static {
- System.out.println("static parent");
- }
- }
- class SubInitField extends SuperInitField {
- public SubInitField() {
- System.out.println("child");
- }
- static {
- System.out.println("static child");
- }
- }
|
不管你是否能很快速的写出正确的答案,我们先把这个程序放一边,了解一下Java虚拟机初始化的原理。
JVM通过加装、连接和初始化一个Java类型,使该类型可以被正在运行的Java程序所使用。类型的生命周期如下图所示:
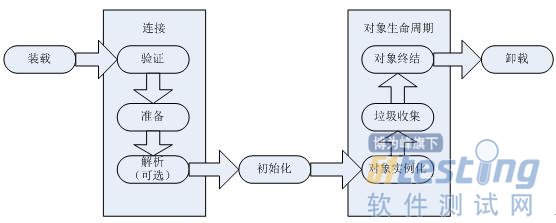
装载和连接必须在初始化之前就要完成。
类初始化阶段,主要是为类变量赋予正确的初始值。这里的“正确”初始值指的是程序员希望这个类变量所具备的起始值。一个正确的初始值是通过类变量初始化语句或者静态初始化语句给出的。初始化一个类包含两个步骤:
1)如果类存在直接超类的话,且直接超类还没有被初始化,就先初始化直接超类。
2)如果类存在一个类初始化方法,就执行此方法。
那什么时候类会进行初始化呢?Java 虚拟机规范为类的初始化时机做了严格定义:在首次主动使用时初始化。
那哪些情形才符合首次主动使用的标准呢?Java虚拟机规范对此作出了说明,他们分别是:
1)创建类的新实例;
2)调用类的静态方法;
3)操作类或接口的静态字段(final字段除外);
4)调用Java的特定的反射方法;
5)初始化一个类的子类;
6)指定一个类作为Java虚拟机启动时的初始化类。
除了以上六种情形以外,所有其它的方式都是被动使用的,不会导致类的初始化。
一旦一个类被装载、连接和初始化,它就随时可以使用了。现在我们来关注对象的实例化,对象实例化和初始化是就是对象生命的起始阶段的活动。
Java编译器为它编译的每个类都至少生成一个实例初始化方法,即<init>()方法。源代码中的每一个类的构造方法都有一个相 对应的<init>()方法。如果类没有明确地声明任何构造方法,编译器则为该类生成一个默认的无参构造方法,这个默认的构造器仅仅调用父类 的无参构造器。
一个<init>()方法内包括的代码内容可能有三种:调用另一个<init>() 方法;对实例变量初始化;构造方法体的代码。
如果构造方法是明确地从调用同一个类中的另一个构造方法开始,那它对应的 <init>() 方法体内包括的内容为:
1、一个对本类的<init>()方法的调用;
2、实现了对应构造方法的方法体的字节码。
如果构造方法不是通过调用自身类的其它构造方法开始,并且该对象不是 Object 对象,那 <init>() 法内则包括的内容为:
1、一个父类的<init>()方法的调用;
2、任意实例变量初始化方法的字节码;
3、实现了对应构造方法的方法体的字节码。
通过上面的讲解是不是对你理解Java类型的初始化有一定的帮助呢?
好,那我们再来分析一下开始的那段代码:
- SuperInitField p = new SuperInitField();
- //SuperInitField的超类是Object
- //创建SuperInitField对象,属于首次主动使用,因此要先初始化Object类,然后再调用SuperInitField类变量初始化语句或者静态初始化语句,所以要输出static parent
- //类被装载、连接和初始化之后,创建一个对象,因此需要首先调用了Object的默认构造方法,然后再调用自己的构造方法,所以要输出parent
-
- SuperInitField c = new SubInitField();
- //SubInitField继承自SuperInitField
- //创建SubInitField对象,属于首次主动使用,父类SuperInitField已被初始化,因此只要调用SubInitField类变量初始化语句或者静态初始化语句,所以要输出static child
- //类被装载、连接和初始化之后,创建一个对象,因此需要首先调用了SuperInitField的构造方法,然后再调用自己的构造方法,所以要输出parent,然后再输出child
|
到现在你应该大体了解了Java类初始化的原理了吧,那我就留一到练习题吧,写出下列代码的运行结果。
- public class Test {
- public Test(){
- System.out.println("parent");
- }
- static{
- System.out.println("static parent");
- }
- public static void main(String[] args) {
- System.out.println("main");
- }
- }
|
这道题是关于初始化顺序的,已经有人写过这方面的文章了,我就不多说了。
Java中,类的实例化方法有四种途径:
1)使用new操作符
2)调用Class对象的newInstance()方法
3)调用clone()方法,对现有实例的拷贝
4)通过ObjectInputStream的readObject()方法反序列化类
1、ClassInstance.java
- import java.io.*;
-
- class ClassInstance implements Cloneable, Serializable {
- private String str = "测试...";
- public void fun(){
- System.out.println(str);
- }
- public ClassInstance(String str){
- System.out.println("有参类的实例化");
- this.str += str;
- }
- public ClassInstance(){
- System.out.println("无参类的实例化");
- }
- public Object clone(){
- return this;
- }
- }
|
2、ClassInstanceTest.java
- import java.io.*;
- import java.lang.reflect.*;
-
- public class ClassInstanceTest{
- public static void main(String[] args) throws ClassNotFoundException, InstantiationException,
- IllegalAccessException, IOException,InvocationTargetException, NoSuchMethodException{
- //第一种类的实例化方式
- ClassInstance ci01 = new ClassInstance("01");
- ci01.fun();
-
- //第二种类的实例化方式
- ClassInstance ci02 = (ClassInstance) Class.forName("ClassInstance").newInstance();
- ci02.fun();
-
- //第三种类的实例化方式
- ClassInstance ci03 = (ClassInstance) ci01.clone();
- ci03.fun();
-
- //第四种类的实例化方式
- FileOutputStream fos = new FileOutputStream("ci.tmp");
- ObjectOutputStream oos = new ObjectOutputStream(fos);
- oos.writeObject(ci01);
- oos.close();
- fos.close();
-
- FileInputStream fis = new FileInputStream("ci.tmp");
- ObjectInputStream ois = new ObjectInputStream(fis);
-
- ClassInstance ci04 = (ClassInstance) ois.readObject();
- ois.close();
- fis.close();
-
- ci04.fun();
- System.out.println("--------------------额外测试--------------------");
- ClassInstance ci05 = null;
- //额外的思考 在第二种类实例化的方式中有没有一种方法实现有参数的构造方式
- //获得类的构造信息
- Constructor[] ctor = Class.forName("ClassInstance").getDeclaredConstructors();
- //找到我们需要的构造方法
- for(int i=0;i<ctor.length;i++ ){
- Class[] cl = ctor[i].getParameterTypes();
- if(cl.length == 1){
- //实例化对象
- ci05 = (ClassInstance) Class.forName("ClassInstance").getConstructor(cl).newInstance(new Object[]{"05"});
- }
- }
- ci05.fun();
- }
- }
|
3、输出结果
- 有参类的实例化
- 测试...01
- 无参类的实例化
- 测试...
- 测试...01
- 测试...01
- -------------------额外测试--------------------
- 有参类的实例化
- 测试...05
|
除了这几种情况可以实例化一个Java类对象外,隐式调用实例化也是利用了已上集中情况。例如常见的方法:
- public class ClassInstance{
- public ClassInstance(){
- }
- public ClassInstance getInstance(){
- return new ClassInstance();
- }
- }
|
通过观察结果,我们发现无论哪一种方式必须经过的一步---调用构造方法。无论怎样构造函数作为初始化类的意义怎样都不会改变。
最近在工作中和一个同事因为自增是不是原子性操作争论的面红耳赤,那Java的自增操作到底是不是原子性操作呢,答案是否的,即Java的自增操作不是原子性操作。
1、首先我们先看看Bruce Eckel是怎么说的:
In the JVM an increment is not atomic and involves both a read and a write. (via the latest Java Performance Tuning Newsletter)
意思很简单,就是说在jvm中自增不是原子性操作,它包含一个读操作和一个写操作。
2、以上可能还不能让你信服,要想让人心服口服,就必须用代码说话。正如FaceBook的文化一样:代码赢得争论。那我们就看一段代码:
以下的代码是用100个线程同时执行自增操作,每个线程自增100次,如果自增操作是原子性操作的话,那么执行完amount的值为10,000。运行代码之后,你会发现amount的值小于10,000,这就说明自增操作不是原子性的
- /**
- *
- * @author renrun.wu
- */
- public class MultiThread implements Runnable {
- private int count;
- private int amount = 1;
-
- public MultiThread() {
- count = 100;
- }
-
- public MultiThread(int count) {
- this.count = count;
- }
-
- @Override
- public void run() {
- for (int i = 0; i < count; i++) {
- amount++;
- }
- }
-
- public static void main(String[] args) {
- ExecutorService executorService = Executors.newCachedThreadPool();
- MultiThread multiThread =new MultiThread();
- for (int i = 0; i < 100; i++) {
- executorService.execute(multiThread);
- }
- executorService.shutdown();
-
- try {
- Thread.sleep(60000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println(multiThread.amount);
- }
- }
|
3、如果以上还不能让你信服的话,也没关系。我们就把自增操作反编译出来,看看java字节码是怎么操作的
以下是一个简单的自增操作代码
- public class Increment {
- private int id = 0;
- public void getNext(){
- id++;
- }
- }
|
我们看看反编译之后的Java字节码,主要关注getNext()方法内部的Java字节码。
- public class Increment extends java.lang.Object{
- public Increment();
- Code:
- : aload_0
- : invokespecial #1; //Method java/lang/Object."<init>":()V
- : aload_0
- : iconst_0
- : putfield #2; //Field id:I
- : return
-
- public void getNext();
- Code:
- : aload_0 //加载局部变量表index为0的变量,在这里是this
- : dup //将当前栈顶的对象引用复制一份
- : getfield #2; //Field id:I,获取id的值,并将其值压入栈顶
- : iconst_1 //将int型的值1压入栈顶
- : iadd //将栈顶两个int类型的元素相加,并将其值压入栈顶
- : putfield #2; //Field id:I,将栈顶的值赋值给id
- : return
-
- }
|
很明显,我们能够看到在getNext()方法内部,对于类变量id有一个先取值后加一再赋值的过程。因此,我们可以很肯定的说Java中的自增操作不是原子性的。
4、也许你会问,那局部变量的自增操作是否是原子性的。好,我们在看看一下代码:
- public class Increment {
- public void getNext(){
- int id = 0;
- id++;
- }
- }
|
我们再看看反编译之后的Java字节码,主要还是关注getNext()方法内部的Java字节码。
- public class Increment extends java.lang.Object{
- public Increment();
- Code:
- : aload_0
- : invokespecial #1; //Method java/lang/Object."<init>":()V
- : return
-
- public void getNext();
- Code:
- : iconst_0
- : istore_1
- : iinc 1, 1
- : return
-
- }
|
与全局变量的自增操作相比,很明显局部变量的自增操作少了getfield与putfield操作。而且对于局部变量来说,它无论如何都不会涉及到多线程的操作,因此局部变量的自增操作是否是原子操作也就显得不那么重要了。