SeleniumRC支持多种编程语言驱动客户端浏览器,这里主要介绍使用
Python在
Windows下驱动SeleniumRC。Python是一种面向对象的解释性的计算机程序设计语言。
1、准备工作:
下载Java:目前是1.6update7,下载地址:http://www.java.com/zh_CN/
下载Python:目前稳定版本为2.5.2,下载地址:http://www.python.org/download/,Python的相关信息参见:http://www.python.org/
下载SeleniumRC:目前是1.0Beta1版本,下载地址:http://selenium-rc.openqa.org/download.html,SeleniumRC相关信息参见:http://selenium-rc.openqa.org/
2、开始运行
“首先启动SeleniumServer,把下载的SeleniumRC解压后,会有一个selenium-server-1.0-beta-1的文件 夹,就是SeleniumServer的存放目录,通过命令行Java-jarselenium-server.jar来启动 SeleniumServer端的服务,

“以在Google上搜索HelloWorld为例,Python的脚本如下:
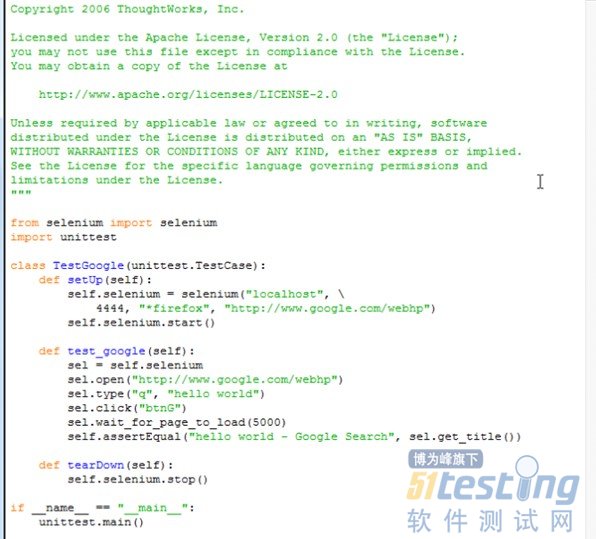
“*firefox”是指支持的浏览器或是通过SeleniumRC调用的浏览器,Selenium支持以下的浏览器类型,
Supportedbrowsersinclude:
*iexplore
*konqueror
*firefox
*mock
*pifirefox
*piiexplore
*chrome
*safari
*opera
*iehta
*custom
在这里,仅使用*iexplore或*firefox则表示浏览器安装在默认的路径,即IE安装在“C:\ProgramFiles \InternetExplorer\iexplore.exe”,Firefox安装在“C:\ProgramFiles \MozillaFirefox\firefox.exe”。如果不是安装在默认的路径,需要指明浏览器安装的地址,如:“*firefoxD: \ProgramFiles\MozillaFirefox\\firefox.exe”。
“deftearDown(self):
self.selenium.stop()”
这段表示浏览器运行结束后直接关闭浏览器,这里可以注释掉。
“首先,使用IE为浏览器运行一次,代码如下:
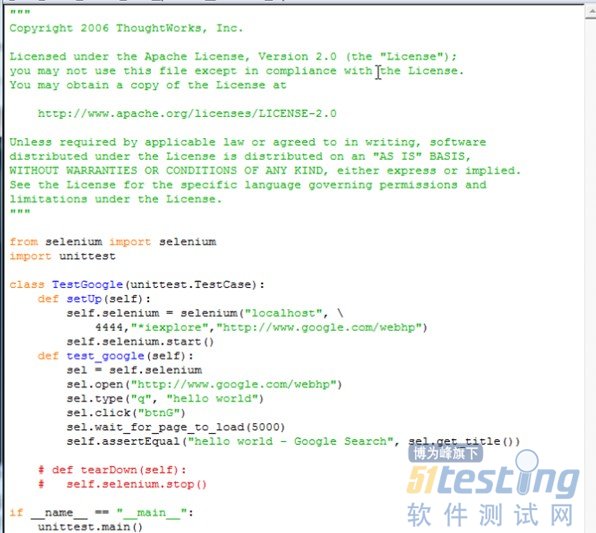
点击PythonIDE上的Run菜单下拉中的RunModule或是快捷键F5,开始运行Python代码。通过Selenium直接调用IE浏览器进行客户端运行。
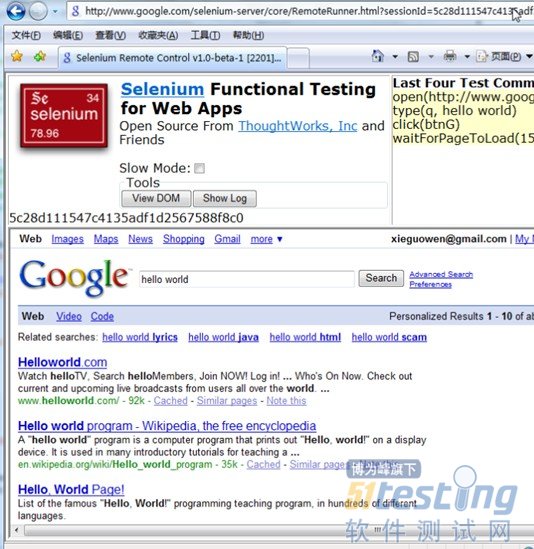
同时命令行窗口显示SeleniumServer进行的每个步骤操作
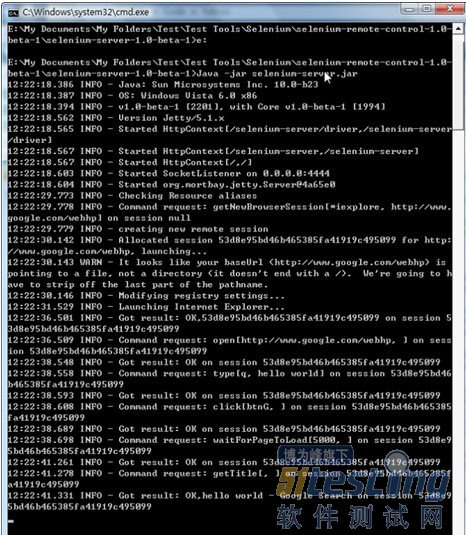
“接下来使用Firefox作为浏览器进行访问
修改代码,*iexplore”修改为“*customD:\ProgramFiles \MozillaFirefox\\firefox.exe”,因为我电脑上的Firefox为3.0版本,目前SeleniumRC不支持此版本,不管 是使用“*chrome”还是“*firefox”,都无法把Firefox调出;但是如果你机器上使用的Firefox是低于3.0版本,那么可以直接 使用“*chrome”这个参数。
在运行之前,需要将Firefox中的代理设置成和SeleniumServer一致,Localhost,端口为4444。
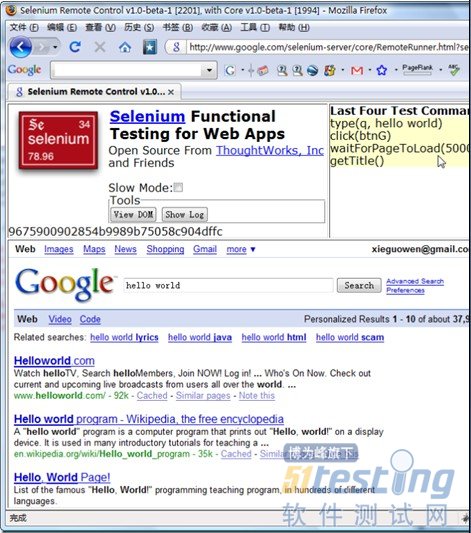

对于其他的浏览器只需要相应的修改参数为如*safari或*opera等,就能调用访问,实现一个多浏览器的兼容性测试。
本文思考
自动化测试工具开发设计时需要考虑的一个方面:自动化
测试工具生态系统的建设。
百度百科上查到,软件生态系统指的是:能够创造战略优势、迅速适应不断变化的业务需求并具备高度可靠性与伸缩性的应用程序。自动化测试工具软件作为一种特殊的软件分类,也应该有自己的生态系统。在这方面的思考和探索,会给我们带来更大的收益。
先回顾一下,咱们工具组对外提供的主要的工具。
软件开发出 来是要卖的,自动化测试工具开发出来也是需要推广的。自助式是我很推崇的一种方式,什么都展示出来,供有需要的人自行挑选。如果我们的业务测试团队清楚地 知道我们能提供什么样的工具,他们就会去主动选择工具组提供的工具!如其等着别人来索取,绝对不如主动对外发布。一个人向你索取,你需要花费一番精力提供 信息,第二个向你索取,你还是需要花费同样的一番精力提供信息,第三个、第四个,你都需要重复花费等量的精力。但是你主动推广、主动发布信息,其他同事知 道去哪里获取信息,就不会打扰你,你的思路不会中断,你才会更有效率。对于需要获取信息的人,也很快捷!
作为工具开发部门,主动发布、推广现有的工具是工作内容的一部分,也是测试工具生态系统建设的一部分。对于工具的介绍,我们有专门的站点来维护一个工具展示列表;对于工具的培训、使用手册,我们维护在内部分享平台上;对于工具的获取我们提供了SVN来发布对外提供的工具。
我个人来讲,主要负责Web应用、开放平台开放接口的自动化测试,对外提供的分别是SmartAutomation For Web、SmartAutomation For Open API。SmartAutomation For Web为基于Selenium Server开发的针对Web应用的自动化测试工具,测试用例脚 本文件基于XML格式。测试脚本开发人员不需要熟悉Java或其他编程语言,即可用编写满足各种业务需求的自动化测试用例脚本。 SmartAutomation For Open API适用于测试开放接口OpenAPI的自动化测试,即用于处理、解析访问URL返回的普通分割文本、XML格式的文本、JSON文本,并支持对返回的 文本进行验证等。该工具支持HTTP GET、HTTP POST请求方式,支持HTTPS。支持正则表达式验证、支持自定义属性$PROPERTY、支持对URL的参数化等。同样不需要编程即可完成自动化测 试。使用、曾经使用或参加过这些工具相关培训的同事主要有o**y、**y、**钦、**斐、**裕、**鹏、**波、**佳、**ie、**旭、** 伟、**ex、**超、**磊、**盟、**勇、**芳、**伟、**春、**花等,来自技**持、**测试部、**测试部、实**务部、**中心等部 门。
上面说的是两个工具,其实是基于同样底层架构设计的一套工具。拿到SmartAutomation的发布版本之后,可以用来测试 Web应用,你也可以用它自动化测试开发接口。都是基于XML,语法规则都相似,学会一个之后,另外一个几乎无师自通,就像MS Word和MS Excel的关系一样!还有一个SmartAutomation For Android,我的同事们在负责。虽然系出同门,都是基于XML设计的同样的code base,但遗憾的是,为适应android,语法规则上渐行渐远。
上面提到若干部门、若干同事、若干工具,当工具增多,使用工具的人增多时,才开始逐渐的形成一个生态圈。工具增多,但不各自独立,拥有共同的语法规则,降低学习成本,共同形成一个大的测试工具平台。使用者增多,对工具的使用经验可以移植,相互之间可以交流使用经验,相互推广等。
一些粗浅想法,欢迎交流!
本文转载自:http://loggingselenium.com/?p=355
测试需求的意义 无论对于开发还是测试,一个全面精准有预见性的设计是保证项目顺利进行的前提。实际项目操作中,常常感受到测试过程有着各种问题:
1、产品质量维度关注的不全面,测试类型不完整;
2、测试规格设计较为随意,测试分解分配比较随意;
导致测试过程中,经常会出现需求遗漏、测试设计遗漏的问题;
因此一份详细精准的测试需求分析有利于这些问题的解决。
测试需求的定义
软件需求定义的是要产品要实现的功能是什么,而测试需求这个名词业界并没有权威的定义,多数的意见认为测试需求定义测试的范围(即主要解决测什么、及测 到什么程度的问题),这样说还是太过泛泛,换个说法,测试人员依据初期功能需求,评估需要测试的功能点都有什么,每个功能点需要什么类型的测试,每个功能 点测试到什么程度算是通过,这样初步评估出了测试的规模、复杂程度和风险,同时可以初步预估出哪个环节需要研发同事提供测试接口。
测试需求设计的愈加详细精准,代表对待测试的软件了解的愈深,对各种测试手段了解的愈深,但是这往往要求测试需求的设计者拥有一定的测试经验。
测试需求的流程
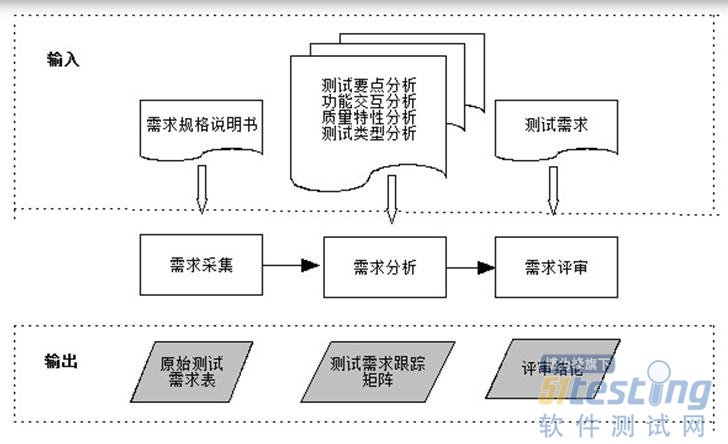
测试需求的采集
测试需求最直接的来源是:
1、软件需求规格;
2、业界协议规范;
3、测试经验库;
4、对于已有旧版本的软件测试,还需要考虑继承性的测试需求。
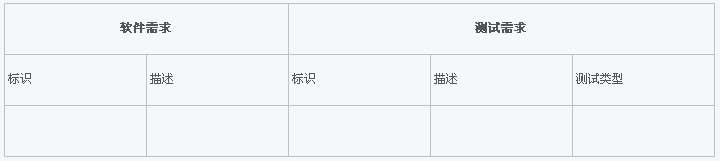
对以上内容进行梳理,形成原始测试需求表,列表的内容包括需求标识、原始测试需求描述、信息来源,如下:
来源编号 | 测试原始需求编号 | 测试原始需求描述 | 开发特性 | 需求标识 | 需求描述 | 需求优先级 | 测试规格分析的工程方法 |
DR001 | EMAIL-001 | 能够支持电子邮件的收发 | Email | OR_MKT.00010 | 能够支持电子邮件的收发 | | |
测试人员需要对开发需求进行整理,首先需要确认软件需求的正确性、其次保证软件需求的可测试性。所谓的可测试指的是“存在一个可明确预知的结果,可用某 种方法对这个明确的结果进行判断、验证。”原则上,所有的软件需求都应该是可测试的,因为如果作为测试人员对需求无法产生准确的理解(即无法得出明确的结 果),那么开发人员也同样无法对同一条需求产生准确的理解。每一个测试需求需要保证一条需求只包含一项测试内容,因此一条软件需求通常可能对应多条测试需 求。
这个阶段的测试需求整理,最重要的一点就是要注意广泛性和全面性,要尽可能的收集更多的原始需求,不存在遗漏,并且可以对需求进行适当的扩充,这些需求应该不仅仅局限于上述的五种来源类型,也不仅仅局限于各种文档、资料。
1 引言 1.1 编写目的
本软件需求规格说明的目的在于为《软件测试工程师管理系统》项目的开发提供:
a. 提出软件总体要求,作为软件开发人员和最终使用者之间相互了解的基础;
b. 提出软件功能要求、性能要求、接口要求、数据结构等要求,作为软件设计和程序编制的基础;
c. 为软件测试提供依据。
本软件需求规格说明的读者对象主要是项目主管、软件设计人员和最终用户。
1.2 项目背景
该项目的实施主要是为提高北京梅梅公司的人事管理效率而编制的。
1.3 定义
1.4 参考资料
a. 《软件测试工程师管理项目条款》-北京梅梅公司。
2 项目概述
2.1 软件总体说明
本项目的目标是完成一个计算机人事管理系统,实现人事管理的自动化。系统的主要功能包括:人事信息的录入、管理、查询、删除、生成报表等。
进入本系统提供用户选择菜单,要求人机界面友好,具有错误处理和故障恢复能力。
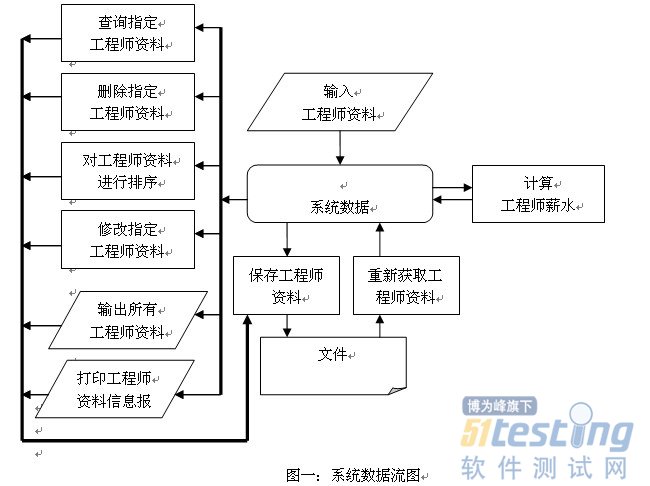
2.2 总体数据流图
按照功能设计,系统数据流图如下:
图一:系统数据流图
2.3 使用者的特点
本软件的最终用户是北京梅梅公司的人事专员和财务专员。具有计算机操作和使用技能。且熟悉业务。
2.4 条件和限制
为了使本系统尽快投入使用,要求本系统的开发周期较短,要求在年内两个月内完成。因此要求系统设计一人,程序员一人,测试工程师一人。
3 运行环境
本软件的最终运行环境是操作系统DOS5.0以上,或Windows95/98/2000/me/NT/XP等DOS环境上,要求有中文平台或操作系统为中文的计算机上,配有一台打印机。
3.1 运行软件系统所需的设备能力
一台微机:主频>=100,硬盘>=1M,内存>=1M;
一台打印机;
3.2 支持软件环境
操作系统:DOS5.0以上,或Windows95/98/2000/me/NT/XP。
开发环境:Microsoft Visual C++6.0;
3.3 接口
该系统硬件和软件与外界软件没有接口,也不需要网络环境;
在界面上,要求使用DOS菜单选择,用户可以随时选择菜单进行;
在操作上,要求操作简单,通过少数的选择菜单或单击按钮即可完成操作;
在系统运行任何阶段,提示给用户当前系统的状态。
3.4 故障处理
当系统缺少参数等情况时,给出提示,并返回安全状态;
当系统出现故障无法返回时,用户的数据不能丢失,重新其它系统,可实现数据恢复。
4 软件详细要求
4.1 性能需求
要求本系统在完成各项功能的同时,要求系统处理迅速,处理事务需要长时间时,提示用户等待且等待时间在用户可接收的范围之内。
4.2功能需求
根据系统功能的需要,对系统的功能进行划分,表示如下图:

图二:软件测试工程师管理系统功能
下面详述每一项功能的要求:
4.2.1输入工程师资料 工程师的资料主要包括:编号、姓名、性别、生日、籍贯、学历、地址、电话、工龄、基本薪水。
要求:编号为数字,编号使用4为位数字,格式为0001、0002….,不能重复。
姓名:为字符,最长不超过20个字符。不能为空。
性别:用数字表示0表示女,1表示男。不能为其它数值。
生日:用数字分别表示年、月、日。格式例如:年使用四位数字表示,月使用1-12表示,日使用1-31表示。范围是(1900,2004)
籍贯:使用字符表示,最长不超过10个字符。不能为空。
学历:使用数字表示高中0、学士1、硕士2、博士3、其它为4。不能为其它数字。
地址:使用字符表示,最长不超过30个字符。不能为空。
电话:使用字符表示,最长不超过15个字符。不能为空。
工龄:使用数字表示,工龄范围是(0,50]。
基本薪水:为实型,不能为0。
对这些输入的信息进行合法性检查。保证系统接收合法的输入。用户输入错误时具有提示功能和重新输入功能。
4.2.2删除指定工程师资料
可根据两种方式删除指定工程师资料,一是工程师的编号,二是工程师的姓名。删除资料后,该工程师的信息则完全在系统中删除了。其它工程师编号不变。
4.2.3查询指定工程师资料
可根据两种方式查询指定工程师资料,一是工程师的编号,二是工程师的姓名。查询后打印该工程师的信息,如果没有该工程师资料则给用户提示。
4.2.4修改指定工程师资料
可根据两种方式找到要修改的工程师,一是工程师的编号,二是工程师的姓名。打印原来该工程师的信息,同时提示用户进行修改。
4.2.5计算工程师月薪水
根据当月的月效益,计算工程师的当月工资。在计算机工资时要扣除当月的保险金。计算薪水的算法如下:
程师的月应发的薪水如下计算方法:
薪水=(基本工资+10╳月有效工作日天数+月效益╳工作年限÷100)╳0.9-月保险金
4.2.6保存工程师资料
当用户输入工程师资料、修改、排序后需要用户决定是否保存工程师资料。如果用户不保存,则默认输入和修改等不做保存。
4.2.7输入工程师资料
对工程师资料进行排序,排序使用三种方式:编号排序(升序)、姓名排序(升序)和工龄排序(降序)。采用哪种排序方式,由用户选择。
4.2.8输出工程师资料
打印所有的工程师资料(不包括当月薪水)。
4.2.9清空所有工程师资料
把所有的工程师资料删除,可以重新输入工程师资料。
4.2.10打印工程师资料信息报表
这时输出工程师的所有资料和当月薪水,以表格的形式输出。格式如下:
****************************************************
*编号:0001*
****************************************************
*姓名:张大同*
****************************************************
*性别:男*
****************************************************
…….
4.2.11从文件重新得到工程师资料
这项功能主要是为了用户进行某些操作后,没有保存到文件前,可以从文件重新得到这些数据信息,使用户的操作不起作用。
4.2.12退出系统
当用户不再使用该系统后,可退出该系统。如果用户进行了影响工程师资料信息的操作,提示用户是否进行保存。
5数据需求
软件测试工程师资料数据类型和说明。
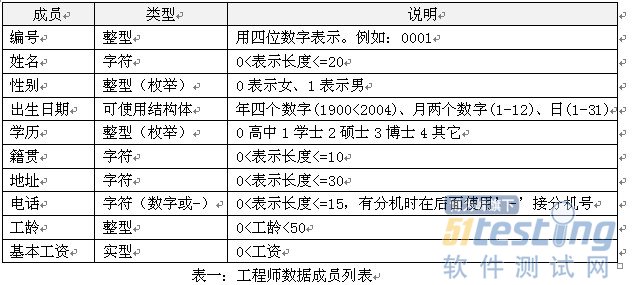
其它数据需要:
月效益:实型
月保险金:实型
月工资:实型
保存工程师资料文件:在当前目录下,名称为engineer.txt,为文本格式。
输出报表:在当前目录下,名称为report.txt,为文本格式。
测试需求的意义 无论对于开发还是测试,一个全面精准有预见性的设计是保证项目顺利进行的前提。实际项目操作中,常常感受到测试过程有着各种问题:
1、产品质量维度关注的不全面,测试类型不完整;
2、测试规格设计较为随意,测试分解分配比较随意;
导致测试过程中,经常会出现需求遗漏、测试设计遗漏的问题;
因此一份详细精准的测试需求分析有利于这些问题的解决。
测试需求的定义
软件需求定义的是要产品要实现的功能是什么,而测试需求这个名词业界并没有权威的定义,多数的意见认为测试需求定义测试的范围(即主要解决测什么、及测 到什么程度的问题),这样说还是太过泛泛,换个说法,测试人员依据初期功能需求,评估需要测试的功能点都有什么,每个功能点需要什么类型的测试,每个功能 点测试到什么程度算是通过,这样初步评估出了测试的规模、复杂程度和风险,同时可以初步预估出哪个环节需要研发同事提供测试接口。
测试需求设计的愈加详细精准,代表对待测试的软件了解的愈深,对各种测试手段了解的愈深,但是这往往要求测试需求的设计者拥有一定的测试经验。
测试需求的流程
测试需求的采集
测试需求最直接的来源是:
1、软件需求规格;
2、业界协议规范;
3、测试经验库;
4、对于已有旧版本的软件测试,还需要考虑继承性的测试需求。
对以上内容进行梳理,形成原始测试需求表,列表的内容包括需求标识、原始测试需求描述、信息来源,如下:
来源编号 | 测试原始需求编号 | 测试原始需求描述 | 开发特性 | 需求标识 | 需求描述 | 需求优先级 | 测试规格分析的工程方法 |
DR001 | EMAIL-001 | 能够支持电子邮件的收发 | Email | OR_MKT.00010 | 能够支持电子邮件的收发 | | |
测试人员需要对开发需求进行整理,首先需要确认软件需求的正确性、其次保证软件需求的可测试性。所谓的可测试指的是“存在一个可明确预知的结果,可用某 种方法对这个明确的结果进行判断、验证。”原则上,所有的软件需求都应该是可测试的,因为如果作为测试人员对需求无法产生准确的理解(即无法得出明确的结 果),那么开发人员也同样无法对同一条需求产生准确的理解。每一个测试需求需要保证一条需求只包含一项测试内容,因此一条软件需求通常可能对应多条测试需 求。
这个阶段的测试需求整理,最重要的一点就是要注意广泛性和全面性,要尽可能的收集更多的原始需求,不存在遗漏,并且可以对需求进行适当的扩充,这些需求应该不仅仅局限于上述的五种来源类型,也不仅仅局限于各种文档、资料。
测试需求的分析 测试需求采集之后得到的是一张没有优化的需求表,需要对这份原始需求表进行初步的规划:
1、删除冗余重复的需求,各个需求间没有过多的交集;
2、需求需覆盖业务流程、功能、非功能方面的需求;
业务流程:任何一套软件都会有一定的业务流,也就是用户用该软件来实现自己实际业务的一个流程。简单的来说,在做测试需求分析时需要列出以下类别:
1)常用的或规定的业务流程
2)各业务流程分支的遍历
3)明确规定不可使用的业务流程
4)没有明确规定但是应该不可以执行的业务流程
5)其他异常或不符合规定的操作
1、需求需考虑了各功能模块之间交互关系分析;
2、确定测试特性(即测试功能点);
3、确定需求的测试类型;

1、确定需求的质量属性;

2、确定本版本测试所属的阶段;
测试阶段:产品的不同阶段,对于测试阶段的要求也不一样。对于初期版本的产品,更侧重于关注:功能是否实现(这个功 能正常场景下是否顺利)、较为成熟阶段之后,会关注:功能是否实现的够完善(异常场景下,是否正常处理),更加成熟之后会关注,是否通得过各种压力测试场 景。
测试需求跟踪矩阵
建立测试需求跟踪矩阵,对测试需求进行管理。将上述步骤分析、确定的开发需求、测试需求、测试类型填入测试跟踪需求矩阵。
建立测试需求跟踪矩阵,对测试需求进行管理。将上述步骤分析、确定的开发需求、测试需求、测试类型填入测试跟踪需求矩阵。
通过测试需求跟踪矩阵的方式对需求变更实施管理。软件需求一旦发生变化,就要对需求跟踪表进行维护,启动配置管理过程,将与软件需求变更相关的内容进行同步变更。
测试需求评审
评审的内容:
完整性审查:应保证测试需求能充分覆盖软件需求的各种特征,重点关注功能要求、数据定义、接口定义、性能要求、安全性要求、可靠性要求、系统约束等方面,同时还应关注是否覆盖开发人员遗漏的、系统隐含的需求;
准确性审查:应保证所描述的内容能够得到相关各方的一致理解,各项测试需求之间没有矛盾和冲突,各项测试需求在详尽程度上保持一致,每一项测试需求都可以作为测试用例设计的依据。
现在在网上看
文章,貌似不
敏捷就 落伍了。公司内部各team在show off的时候也是大谈如何从瀑布走向敏捷,貌似一敏捷就药到病除。最近在coolshell的blog上看到一篇老文“再谈敏捷和 ThoughtWorks中国咨询师”,顿感心有戚戚焉。现在就结合我这里的具体项目谈谈什么样的项目适合做敏捷以及如何做好敏捷开发。
PS:哥虽然有Scrum Master的证书但还是反对什么都往敏捷头上套。
公司之所以选择这个项目进行Scrum试点有如下几个原因:
1、上一个版本原计划半年结果做了1年,公司近三分之一的开发和测试资源砸了上去。
2、需求频繁变化,产品经理和开发测试人员相互扯皮。
3、产品仓促上线,大量功能未经充分测试。
4、新上任的工程总监是敏捷开发爱好者,正好拿此项目开刀。
现在Scrum正式开始了,但是我在这里要问一句我们开发软件的目的是什么?这个还要问吗?不就是为了发行后赚钱吗!带着这个问题,我们美国的项目经理 我们准备什么时候发行?哥承认被shock了,那位大哥的回答是:我们现在开始敏捷了,一个sprint接一个sprint做,啥时干完啥时发行。好吧, 幸亏这个项目的测试不是哥直接负责,你爱咋地咋地。(其实哥是对自己手下的兄弟有信心,真要做砸了我们估计还能成为仅有的亮点。)
带着 同志们的祝福,项目开始了。每个sprint不管3721只要产品经理脑袋一拍,一堆需求就塞进来了。开发看着只有一句话描述的需求面对的回复是:现在是 敏捷开发了,要多沟通少文档。沟你妹啊!一个在中国,一个在美国,邮件沟通一来一去一天就没有了。电话?是你熬夜呢还是我黎明即起?3周一个 sprint,光把需求搞明白就一周去掉了,然后做啊做啊,还有2天sprint就要结束了,可是突然一看任务列表,50个只完成了30个,怎么办?根据 Scrum的教条,sprint是不能延期的,那么做不完的就踢到下一个sprint去好了,反正没有发行日期,慢慢做好了。嗯,很好,这个sprint 我们顺利完成了35个任务!做啊做啊,3个月过去了,产品经理看看几个大功能也有模有样了,很好,我们宣布某某新版本顺利发行!!!(先开枪再画圈,很好 很强大!)
显然这样的敏捷开发是不能让高层满意的,大家坐下来总结经验教训,推出了2.0版,更新如下:
1、大老板希望更快的看到成果汇报,sprint周期由三周缩短为两周。
2、中美各成立一个Scrum小组,本地测试支持本地开发,每个sprint的任务按比例分配。
3、产品经理必须提供更完善的设计文档。
4、加强沟通,每周双方召开例会。
5、除去在美国的主产品负责人和Scrum master,在上海增设本地的产品负责人和Scrum master,部分决策可以就地做出,不必请示美国。
6、开发必须写单元测试。
这些改动,3456点都是对项目整体有利的。第1点带来的问题是如果开发工作稍 有延误,留给测试的空间就十分有限了。第2点则喜忧参半,好处是上海团队有了更大的自主权,坏处是测试开发比严重不足。因为上海的测试leader要兼任 Scrum master,所以测试和开发是2.5比7,而美国的测试和开发则是4比6。不过考虑到本地测试生产率高于美国,而且开发也愿意挤出时间来帮助测试执行测试用例,在2个sprint之后,上海团队表现良好,而美国团队依然落后于进度。
虽然2.0版的Scrum比起1.0版大有进步,但是依然存在以下几个问题:
1、周期太短,开发完成工作后留给测试的时间太少。
2、上海的测试长期超负荷工作。
3、因为周期太短,所以没有时间做测试自动化,这样导致在无法做自动化的回归测试,只能依赖手工测试选取几个关键测试用例保证之前的功能正常工作。
虽然还是有种种问题,但好歹是稳步前进了。周期恢复到三个星期,人手不够开始招实习生,自动化测试没时间做那么就上线后集中拉一段时间补课。
通过近半年的Scrum实践,我总结了一些经验和大家分享一下:
1、一定要有一个release目标,要根据这个目标倒过来排计划。
2、PO和Scrum master必须有丰富的传统开发模式经验,不然项目很容易失控。
3、每天的例会后Scrum master要迅速跟进,重大问题要立刻解决,什么工作生活平衡全是扯淡,执行力必须是第一位。
4、虽说搞Scrum要求每个员工都积极主动,但是开发和测试leader还是要花很多时间分配任务,调整优先级。开发必须为测试和修复bug留出足够时间。
5、自动化测试非常重要,早做晚做一定要做。
6、员工之间的知识共享非常重要,谁都有个头疼脑热,不能因为一个人暂时离开就影响项目进度。
7、单元测试帮助很大,一是避免了很多基础的业务逻辑错误,二是可以让开发更清楚业务逻辑。
好的技术选型,能最大程度地提高企业和团队的效率,从而开发出满足用户需求的产品。作为一线的技术管理者,他们都是怎样做的呢?
大公司或者大一点的团队的技术选型几乎不需要太多讨论,因为最后会不可避免地绕到技术官僚的话题上去。这里我简单说说技术型创业团队的技术选型问题。
拥抱开源技术
如果只能选择微软的 技术路线,比如团队只会用微软技术,也不想学别的,那么似乎没有别的办法,将就一下吧。如果还有的选择,尽量使用开源技术。这样不但可以有效降低软硬件成 本,还有更多的部署方案可供选择,服务器上线甚至还能避免病毒的侵袭。开源技术的好处是出了问题,你总有办法可以找到答案。而用微软的产品,可能平时不出 问题,但一出问题,你根本没什么办法。微软的产品使用门槛倒是低,但复杂度可一点都不小,而且随着发展,成本越来越高。国内有几个大中型网站,比如天涯、 5173、大众点评、京东等,怕是深有感触吧,有的因为成本太高而继续被捆绑,有的则破釜沉舟要摆脱这种束缚,但不管怎样,总要付出一定的开销。
开源技术路线有数种分支,该怎样选择呢?选择大路货,选择可以掌控的开源技术产品、语言、程序、框架,乃至解决方案。比如PHP,比不上Ruby阳春白雪,但用户基数大,总能找到不错的工程师。PHP虽然粗糙,但是管用。以PHP作为开发语言的成功产品不计其数,很多东西根本不需要你再开发,稍加定制即可。技术本身没有高下之分,差别在于使用技术的人。
避免过度炫技
技术人员创业最容易犯的一个错误就是“炫技”,即热衷于使用最新、最时髦的技术。新东西的确可以给技术人员以满足感,但也很快会将你的时间资源消耗进去,除非你准备做的是一款基础产品,否则你要花时间去学新规范、熟悉新功能、对付新出现的软件Bug……但这时你最需要做的是开发产品,而不是捣鼓其他东西。一些新技术或者方案,可以花些时间分析一下但没必要立刻就用,只需确保将来有一天能真的用上时,对一些重大的陷阱或是缺陷能够了然即可。
很多人神往37Signals的成功,但你一定要知道类似37Signals的团队,默默无闻地夭折掉的不知道有多少。每当看到创业团队就那么1~2个 人还整天捣鼓Go、Erlang这些东西,并想硬生生地用到产品中去,我就知道,这样的团队要悬了。有这些精力和能力,应该想办法尽快让技术变现,研究一 下怎样改进产品、怎样给用户带来更大的价值,而这些不一定用最好的技术才能做好。想办法尽快让产品发布,尽快接受更多人给你第一轮反馈,只凭创业团队几个 人闭门冥想是很难出来好产品的,有时产品推出的时机比完备的功能更重要:GroupOn最早不过是搭建在WordPress上的几个页面,而阿里巴巴网站最初也不过是一个论坛,你又何必等到所有细节都打磨好呢?
拥抱开源技术,避免过度炫技,如果技术型团队创业(做互联网),这两条都能坚持的话,我想你已经抓住了问题的80%的部分,基本上你不会做太多的无用功。
另外,刚启动时不要直接招技术总监、技术经理、架构师这些看起来级别很高的人,因为他们未必认同你的想法和你现在的团队。建议找能实现你产品想法的人。最后有一点必须要说一下:不要因为一个人的技术喜好而舍弃整个技术团队,在任何时候这都是很愚蠢的事情。
作者冯大辉,丁香园网站CTO
在重大产品决策或者大规模应用开发前一般需要进行技术选型,其目的是为了降低产品研发的技术风险。所以首先需要明确为什么需要技术选型、需要达到什么目的,整个过程需要有一套的组织流程来保证。
一般可以将整个过程分为调研、候选对比、关键技术验证、原型验证几个阶段。在调研阶段主要调研对象是目前该范围业内主要产品以及开源产品,需要了解其主 要技术特点和各自的优势和劣势;在候选对比阶段,是在前一阶段基础上选出两种倾向用于最终路线的技术进行进一步的研究和对比。在关键技术验证阶段,需要列 出所有的技术验证点,对验证点描述、验证方法、验证步骤、验证前提、验证环境以及最后的交付物和评估方法指标在验证方案中体现;在原型验证阶段,主要是针 对重点关注的场景,通过一个原型来整体验证比较。在这个阶段一般需要进行概念模型、编程模型以及结构设计例如设计时视图、系统结构图等,定义需要的 API,必要时还需要划分子场景,在场景中包括场景描述、Feature、预研点以及相关设计。
当然也需要对人员角色进行分工,一般划分程序经理、开发人员、测试人 员几种角色。程序经理需要确定原型目标范围,编写原型目标文档并组织评审;制订和跟踪原型开发计划,对原型进行验证,确保原型符合原型目标要求。开发人员 需要从开发角度提出原型需求,评审原型目标文档,按照原型目标文档和原型开发计划完成原型相关设计和开发。测试人员需要Review原型目标文档,根据原 型目标文档采用一定的测试手段验证原型是否符合原型目标要求。
在最近我们进行的ESB新产品中,就采用了类似上述的流程。我们确信技术 选型的最主要目标是要自主掌控,所以从非常底层的技术开始,重点关注并发、资源隔离这样的目标,解决在不确定环境中实现交易控制和可扩展的目标。所以我们 设计了一个三段式的SEDA架构,基本原则是要实现架构的资源可分配性,提升吞吐率,当然最初实现的功能可以比较简单。通过上述流程,有效保证了我们在新 产品研发过程中的效率和产品架构质量。
最后,在技术选型产出物上,一般的结果可以有三类,有马上转化应用的新产品,也可以是结合现有产品的一个解决方案,或者是某个方面的一个提升点(如一个新的组件)。
作者冯兴智,普元信息资深架构师
关于公司/团队技术选型的话题涉及到很多非技术层面的问题,特别是大公司在技术选型方面,不可避免要受到企业官僚的影响。
下面我结合自己公司的实际情况,谈谈初创企业或小型开发团队的技术选型。技术选型涉及产品/项目开发流程中各个环节所用到的工具和技术。例如项目开发前期的需求收集、整理分析工具、开发阶段的IDE和版本控制系统、测试阶段的测试工具等。
我们作为初创企业在进行技术选型时会根据产品的需求、技术的复杂性、可扩展性、跨平台可移植性以及成本来做出最终的决策。
成本因素
初创企业的资源特别是资金往往不是很充裕,如果采用商业化的技术解决方案,往往价格不菲,像Visual Studio专业版、Windows Server、SQL Server的价格动辄上万,这种情况下不妨考虑一些免费开源的技术框架。比如使用SharpDevelop代替Visual Studio,MySQL代替SQL Server。此外,也可关注并加入一些针对初创企业的扶植计划。例如我们创业前所工作的公司采用的都是微软技术,大家对微软技术掌握得很熟练,这样自己 成立公司开发自己的产品时同样优先考虑微软技术。我们通过加入微软的BizSpark计划,有效降低了成本。
复杂性,成熟度
我们在做技术选型时最忌讳的就是盲目追崇新技术和框架。有些技术刚刚面世不久,还没有成熟的社区支持和成功案例。如果这时为了赶时髦或者在产品 的推广宣传上加点花头而采用新技术的话,往往会导致项目陷入泥潭。采用不成熟技术而导致失败的案例比比皆是,如网景在Java刚面世不久就使用Java重 写Netscape Navigator浏览器,导致用户体验大幅下降及用户群的流失。还有当时被称为下一代Windows客户端技术的WPF,到现在发展得仍然不瘟不火,如 果仅仅是为了更炫的展现效果而使用WPF,结果肯定会得不偿失。
产品自身因素
技术选型不可避免地要以产品为中心。如果产品是Windows智能客户端软件,那么微软的技术框架必然成为优先考虑。如果开发Android软件,Eclipse和Android SDK同样必不可少。
作者石钰,奈特软件联合创始人、首席架构师
我在微软和腾讯从事了三年的软件测试和团队管理工作,期间涉及两大类的研发工作:第一,用于质量控制的各种平台系统,例如缺陷管理系统、用例管 理系统、产品健康指数可视化系统、自动测试管理系统等;第二,用于具体的产品测试工具,例如桌面软件的UI自动化测试工具、JavaScript自动化测 试工具、Web服务压力/性能测试工具等。
在团队的建设和技术选型上,遇到过一些困惑也走过一些弯路,总结出来有两点经验。
阅读公司文化,借鉴成功团队经验
测试团队一定要深刻阅读和理解公司文化,作为其技术选型的首要考虑因素。比如,在微软,无论是构建质量控制系统,还是开发各种产品测试工具,都以Windows+IIS+.NET作为技术框架;在腾讯,就会选择LAMP这样的开源技术框架。
在选定了技术框架的基础上,还面临一个问题,就是应该如何去设计和实现出具体的系统或者工具。一个非常重要的经验就是一定要借鉴成功团队的经 验,站在巨人的肩上。例如,当初在腾讯,我们需要评测QQ地图的POI检索功能的质量和用户满意度。于是,我们花两周时间设计了一个自以为完美的盲测系 统,结果在评审时才发现该盲测系统功能过于简单而且性能达不到指标。后来,我们在与腾讯SOSO团队讨论时,才发现他们经过多年的研发,已经有一款非常完 善的搜索盲测系统,直接借鉴过来,就能很好地解决项目测试的问题。这点特别是对很多新任命的团队负责人,是很重要的经验。
敏捷务实,持续集成,切勿过设计
工程的基本要素是实用和强调执行力。对于一个软件/互联网企业或者团队而言,最重要的是先解决眼前遇到的具体问题,而不是盲目追求系统的扩展性 和性能。例如,我们在测评QQ地图后台服务的性能状况时,首先想到的是选用的测试方案要具备良好的功能特性,可扩展性要强、足够开放,能够与已有的一个研 发管理系统做集成。按照这个标准,我们选择了LoadRunner,这是一个比较复杂的工具,光配置就花掉了大量的时间。结果,导致实际测试的时间太靠 后,发现的性能问题都无法在即将发布的版本中得到修正。这就是一个非常典型的因为过设计而引发的技术选型耽误工程进度的例子。后来,我们选用 http_load这个开源、简单、实用的工具对后台服务做快速的压力测试,从而在第一时间得到测试报告。然后在没有测试任务的时候,花时间将该工具集成 至研发管理系统中,做到了持续集成。
其实总结起来,测试团队的技术选型首先要顺应公司的框架性要求,然后在具体实施过程中,要以解决问题作为决策目标,多向成功团队取经,敏捷务实,切勿过设计。
作者刘舒,阿里巴巴高级产品经理,曾任微软测试开发工程师、腾讯测试经理
转载自:http://www.programmer.com.cn/8514/
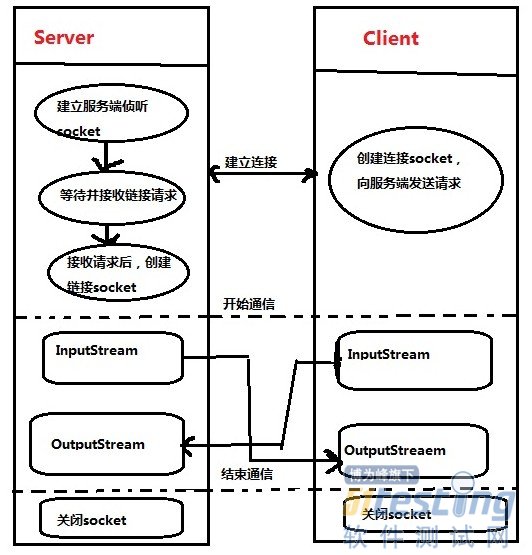
Socket是指在一个特定编程模型下,进程间通信链路的端点。因为这个特定编程模型的流行,Socket这个名字在其他领域得到了复用,包括
Java叫技术。
如果要建立连接,一台机器必须运行一个进程来等待连接,而另一台机器必须试图到达第一台机器。这个电话系统类似:一方必须发起呼叫,而另一方在此时必须等待电话呼叫。
java网络模型图
下面通过一个有“回显”功能的服务器和客户端来介绍应用java.net包编写网络应用程序。
这个例子主要功能是服务器端的程序等待客户的输入,然后将读取到的信息回显给客户端,同时在服务器端的控制台输出。而客户端从控制台接收信息后,向客户端发送输入,并接收服务器的回显数据,然后显示在控制台。
客户端程序代码如下:
package com.javapp.ch11;
import java.io.*;
import java.net.*;
/**
* Description: 具有“回显”功能的服务器端和客户端程序
*/
public class EchoClientDemo {
// 服务器端的服务端口。
public static final int SERVERPORT = 990;
public static void main(String[] args) {
try {
// 建立连接套接字。
Socket s = new Socket("localhost",SERVERPORT);
System.out.println("socket = " + s);
// 新建网络连接的输入流。
BufferedReader in = new BufferedReader(new InputStreamReader(s
.getInputStream()));
// 新建网络连接的自动刷新的输出流。
PrintWriter out = new PrintWriter(new BufferedWriter(
new OutputStreamWriter(s.getOutputStream())),true);
// 先使用System.in构造InputStreamReader,再构造BufferedReader。
BufferedReader stdin = new BufferedReader(
new InputStreamReader(System.in));
System.out.println("Enter a string, Enter BYE to exit! ");
while (true) {
// 读取从控制台输入的字符串,并向网络连接输出,即向服务器端发送数据。
out.println(stdin.readLine());
// 从网络连接读取一行,即接收服务器端的数据。
String str = in.readLine();
// 如果接收到的数据为空(如果直接按Enter,不是空数据),则退出循环,关闭连接。
if (str == null) {
break;
}
System.out.println(str);
}
s.close();
} catch (IOException e) {
System.err.println("IOException" + e.getMessage());
}
}
} |
上面客户端程序中。首先用java.net包中的Socket类建立一个连接套接字,其后应用的Socket对象的getInputStream 方法从服务器接收数据,并且应用Socket对象的getOuputStream方法发送数据到服务器。创建完输入输出流,就可以像读写文件的方式来读写 数据。
支持多客户端的“回显”服务器端程序代码如下:
package com.javapp.ch11;
import java.io.*;
import java.net.*;
/**
* Description:支持多客户端的“回显”服务器端程序
*/
public class EchoServerThreadDemo {
// 服务器端的服务端口。
public static final int SERVERPORT = 990;
public static void main(String[] args) {
try {
// 已经连接上的客户端的序号。
int number = 1;
// 建立服务器端倾听套接字。
ServerSocket s = new ServerSocket(SERVERPORT);
System.out.println("Started: " + s);
while (true) {
// 等待并接收请求,建立连接套接字。
Socket incoming = s.accept();
System.out.println("Connection " + number + " accepted: ");
System.out.println(incoming);
// 启动一个线程来进行服务器端和客户端的数据传输。
// 主程序继续监听是否有请求到来。
Thread t = new EchoThread(incoming,number);
t.start();
number++;
}
} catch (IOException e) {
System.err.println("IOException");
}
}
}
class EchoThread extends Thread {
private Socket s;
int n;
public EchoThread(Socket incoming,int number) {
s = incoming;
n = number;
}
public void run() {
try {
// 新建网络连接的输入流。
BufferedReader in = new BufferedReader(new InputStreamReader(s
.getInputStream()));
// 新建网络连接的自动刷新的输出流。
PrintWriter out = new PrintWriter(new BufferedWriter(
new OutputStreamWriter(s.getOutputStream())),true);
System.out.println("Hello! Enter BYE to exit.");
// 回显客户端的输入。
while (true) {
// 从网络连接读取一行,即接收客户端的数据。
String line = in.readLine();
// 如果接收到的数据为空(如果直接按Enter,不是空数据),则退出循环,关闭连接。
if (line == null) {
break;
} else {
if (line.trim().equals("BYE")) {
System.out.println("The client " + n + " entered BYE!");
System.out.println("Connection " + n + " will be closed!");
break;
}
System.out.println("Echo " + n + ": " + line);
// 向网络连接输出一行,即向客户端发送数据。
out.println("Echo " + n + ": " + line);
}
}
// 关闭套接字。
s.close();
} catch (IOException e) {
System.err.println("IOException");
}
}
} |
在服务器端程序中,首先用java.net包中的ServerSocket类创建一个服务器端侦听套接字。其后应用ServerSocket类 的accept方法等待并接收用户请求。当服务器每接收到一个连接请求后,就启动一个线程来单独处理服务器和客户端的数据传输。服务器端数据的接收和发送 与上面介绍的客户端数据的发送和介绍相同。
Java省略了许多很少用到,缺乏了解,混淆功能的C + +,在我们的经验中带来更多的悲伤大于收益 。
-----James Gosling
James Gosling 这个人大家应该很熟悉,就是最初设计Java 语言的的程序员,被称为“Java之父”,现在也有50多岁了,前几天还看过他的视频,很平易近人的一个白头老人,可能和在中国小镇随处可见的老人是一样 的,完全看不出是那 SUN 的副总裁,也没有中国商人特有的做秀和狡黠。
上面那段话是别人问到他关于 Java 为什么不能运算符重载(虽然它确实有方法重载),多重继承,以及广泛的自动强制转换时回答的一段话。他老人家说多继承会带来更多的悲伤,这悲伤到底在什么地方纳?以下是我自己的一点分析(如有不正,希望大神你出手):
多继承的优点是显而易见的,一个子类能有多个父类的属性和方法,比如上面的那个希腊神话当中的半人马先生,继承了人和马,上半身是人的躯干,包括手和头,下半身则是马身,也包括躯干和腿,既有速度又有思维和抓取东西的能力。
但是多继承的缺点也是一点就破:
(1)如果一个子类继承的多个父类中拥有相同名字的实例变量,子类在引用该变量时将产生歧义,无法判断应该使用哪个父类的变量;
贴段代码给看看:
| public class ClassA {
protected String a = "same" ;
}
public class ClassB {
protected String a = "Unsame" ;
} public class ClassC extends ClassA, ClassB {
public void printOut() {
System.out.println( super .a); //-----关键的一行-------
}
public static void main(String[] args) {
ClassC classC = new ClassC();
classC.printOut();
}
} |
(PS:上面这段代码是不能编译的,我是举个例子而已)classC到底会打印same还是Unsame纳?
(2)如果一个子类继承的多个父类中拥有相同方法,子类中有没有覆盖该方法,那么调用该方法时将产生歧义,无法判断应该调用哪个父类的方法;
贴段代码看看:
| class ClassA {
public void printOut() {
System.out.println( "same" );
}
} class ClassB {
public void printOut() {
System.out.println( "Unsame" );
}
} public class ClassC extends ClassA, ClassB {
public static void main(String[] args) {
ClassC classC = new ClassC();
classC.printOut(); //-----关键的一行-----
}
} |
(PS:上面这段代码是不能编译的,我是举个例子而已)classC到底会调用上面哪个父类的printOur()方法
上面的这些都是致命的歧义,所以java中禁止一个类继承多个父类;
但是那个白头发的老人在很多年前就给 java提供了接口,并能通过接口的功能获得多继承的许多优点而又摒弃了类与类多继承的缺点。
这到底是怎们做到的纳?嗯,好了,我们也来详细的分析一下:
java允许一个接口继承多个父接口,也允许一个类实现多个接口,而这样的多继承有上面提到的缺点吗?
因为有接口的抽象性,所以答案肯定是没有;
1)在接口中不能有实例变量,只能有静态的常量,每个静态的常量在程序开始运行前都已经初始化成功,如果有重命名的出现,编译器先生会及时的告诉你的;
2)接口中不能有具体的方法(包含方法体),只能有抽象方法,具体的方法只能由实现接口的类实现,在调用的时候也只会调用实现类的方法,这样是不会存在歧义的;
那门开篇的那半人马就可以这样来写了:
| interface Humain {
String arm = "2只能抓东西的胳膊"; void output();
} interface Horse {
String leg = "4只能跑的腿"; void output();
} interface Half extends Humain, Horse {
} public class HalfHorse implements Half {
// 实现上面俩个接口里面的同名方法
// 这个类拥有两个接口的静态变量
public void output() {
System.out.println("我是个有" + arm + "和" + leg + "的半人马");
} public static void main(String[] args) {
HalfHorse halfhorse = new HalfHorse();
halfhorse.output(); }
} |
(PS:上面这段代码是可以编译通过的)
因为引入了接口,所以程序员有很大空间的想象力,这可能就是Java吸引许多人的魅力之一了。
网上里有很不错的介绍SQL Server事务隔离的文章,感觉很多都从概念入手介绍的,对那些初学者来说,看得见摸得着的理解才深刻,故不再重复,重点在于实例演示上面。
首先解释下事务隔离是干什么的,一个事务的隔离级别控制了它怎么样影响其它事务和被其它事务所影响。
1、READ UNCOMMITTED,会导致脏读(能读取其它事务没有提交的更改)和不可重复读(事务读取的数据被其它事务所修改,再次读取时不一致)
初始化:
CREATE TABLE TranLevel (k int IDENTITY(1,1), val int) INSERT INTO TranLevel(val) values(1) INSERT INTO TranLevel(val) values(2) INSERT INTO TranLevel(val) values(3) |
首先执行Query1,再新建查询立即执行Query2
Query1:
BEGIN TRAN Query1 -- 在事务中修改 UPDATE TranLevel SET val = 9 -- '等待10秒,期间事务2运行' WAITFOR DELAY '00:00:10' -- 不提交修改,回滚事务 ROLLBACK TRAN Query1 |
Query2:
-- 设置当前会话事务隔离级别为未提交读 SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED BEGIN TRAN Query2 SELECT '事务2开始并发执行,读取到了事务1修改了但没有提交的数据,是脏读' SELECT * FROM Tranlevel SELECT '事务2等待10秒,让事务1执行完' WAITFOR DELAY '00:00:10' SELECT '两次读取的结果不一致,是不可重复读' SELECT * FROM TranLevel COMMIT TRAN Query2 |
下面就看看Query2执行的结果是怎样的:
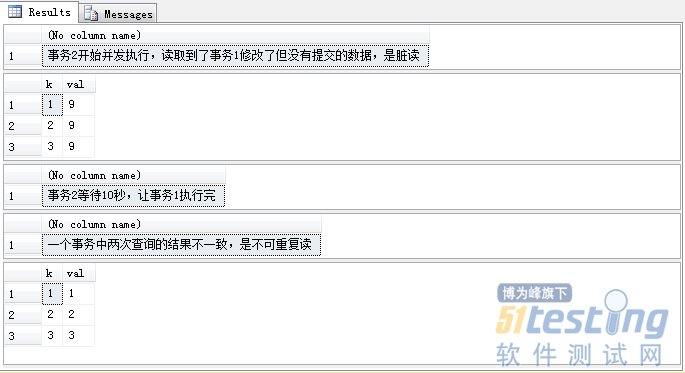
结果显而易见,如果将事务隔离级别设置为未提交读,则会造成脏读和不可重复读的问题,在这几个事务隔离级别中是限制最小的一个,SQL Server分配的资源也最小。
2、READ COMMITTED,提交读,默认的事务隔离级别,会造成不可重复读。
初始化:
| drop Table tranlevel CREATE TABLE TranLevel (k int IDENTITY(1,1), val int) INSERT INTO TranLevel(val) values(1) INSERT INTO TranLevel(val) values(2) INSERT INTO TranLevel(val) values(3) |
Query3:
| SET TRANSACTION ISOLATION LEVEL READ COMMITTED BEGIN TRAN Query3 -- 等待10秒,再修改数据 WAITFOR DELAY '00:00:10' UPDATE TranLevel SET val = 10 COMMIT TRAN Query3 |
Query 4:
| SET TRANSACTION ISOLATION LEVEL READ COMMITTED BEGIN TRAN Query4 SELECT '查到的是Query3没有提交前的数据' SELECT * FROM TranLevel SELECT '让Query3执行完' WAITFOR DELAY '00:00:10' SELECT '再次查询,数据就变成Query3执行完后的数据了' SELECT * FROM TranLevel COMMIT TRAN Query4 |
执行Query3后,新建查询执行Query4。下面看看Querry4查询得到的数据。
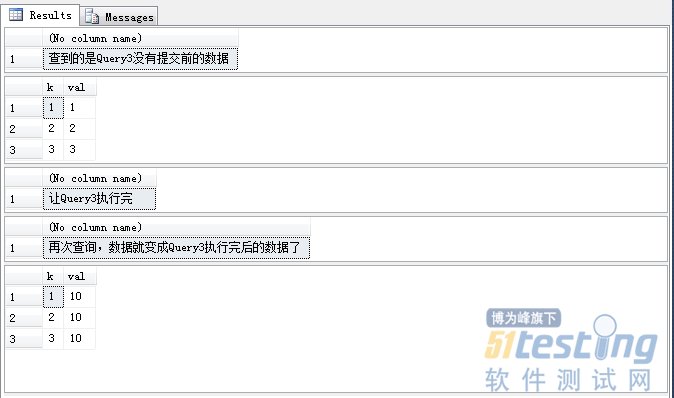
结果就是Query4中的事务查询获得了在Query3提交后的数据,在同一事务中读取的数据不一致,造成了不可重复读。