三句话背景 科技子公司或者IT部门在一个大金融团体里面只能算是个成本中心,对IT团队来说,核心使命就是稳定运营、降低成本。这对于自动化测试来 说,意味着非常有限的资源预算、不稳定的测试环境、复杂的系统耦合关系、严苛的测试数据要求,还有那近乎无理的信息安全规范。如此种种,让我们并不能按照 自己想象的那样去实施自己的规划,以致会走很多弯路;而再回首你会觉得,有时候只是方法欠妥而不是资源不够,有时候只是导向错误而非技术不够高。
关键字:金融系统;自动化测试;单元测试;环境监控;测试数据;持续集成;
传统金融系统
以往,很多传统金融企业所使用的系统依赖采购和外包开发、维护的占比较大,这可能会让他们自己的IT队伍的经验少一些,而对商业工具、产品和解决方案的依赖性较强。而现在,这些IT队伍要么在新技术和互联网的压力下做艰难的转型,要么还在坚持着古老的体制文化,要么非常年轻,经验不足。他们的开发流程也有可能会臃肿僵化,也可能会做敏捷做得些敏而不捷,也可能测试自动化水平低下,也可能太过冒进——在我看来,这个行业里优秀的IT队伍远少于外面精彩的大世界,但是,无论是主动地还是被动地,他们都在随着时代在慢慢改变。
对于金融核心业务系统来说,大部分都是将前端按照业务属主的部门划分而做模块化设计。例如我们的保险系统,被拆分为网销、新契约、保全、理赔、渠道人 管、财务、电销与客服、查询与报表等等很多子系统;银行则可能会有客户管理、存贷款、外汇、国际结算、渠道、报表等等,有更多的模块。而无论前端如何拆 分,一个子公司的业务数据和大部分核心业务逻辑在后端都是共享的,所以整个系统群的基础业务数据和业务逻辑都是紧密耦合的。
在这个行业 里,我体会到,为了领先同业,仓促启动和上线的产品项目不胜枚举。因为这些项目的经营策略相关性或者政治敏感性较高,所以无论在DeadLine之前实现 了多少,只要没有致命问题,总要如期上线,而把遗留的问题通过后续排期解决。这种快餐式的设计和实现让很多项目和产品看似风光的按期上线,都附带了相当多 的系统债务的产生:紧耦合、难重构、难以自动化测试、运维成本高。而且这种债务是增量累积的,没有额外的人力很难清理掉。要么在日常工作之外付出额外的努力,要么任其自生自灭,造就“前人宿醉、后人埋单”的奇观。
在当今综合金融的大潮中,这些子系统必须满足的条件不仅是数据在系统群内共享,还要与集团其他子公司共享、与监管部门共享,以后也许会和医院与医疗机 构、社保机构甚至其他政府部门共享。看起来在我们现有的架构下,综合金融就意味着更多、更复杂的耦合,对测试来说就意味着测试数据使用难度的提升,从而对 测试的要求更高。同互联网一样,如今的金融产品也需要抢占市场先机,也需要快速的发布,但是快速发布不等于快餐式开发,否则久而久之系统维护债务的累积迟 早将达到无法负担的地步。而谢绝快餐式的发布,就需要新的开发模式,作为开发流程中的一个重要环节,软件测试也在被逼无奈地随着改变、转型,来面临新的要求。
时之沙聚金字塔
我们反复被教导,测试要越早越好:越早发现,修复成本就越低,所以就有了个分层测试的金字塔概念,而这个理论也经过很多优秀的公司的成功实践和论证,我 们不怀疑其正确性。但如果要做更多的单元测试,就需要代码有足够好的可测性,而现有的系统动辄就有着几十万、几百万行的陈旧代码,跨系统的逻辑调用比比皆 是,离传说中的高内聚、低耦合相去甚远。所以,在我们的实际操作中看起来,要做多少单元测试就要做多少代码重构,而做多少代码重构就需要多少能够守护代码 重构行为的测试。在这种情况下,只做代码重构或者只做单元测试的编写都是不靠谱的,这看起来是个死循环。
但是,不仅通过单元测试自动化 能够达成质量守护,通过GUI去做的自动化测试和手动测试也能够做到。虽然长期使用通过业务展示层去做测试自动化的成本很高,但是它的建设可以快速完成。 同时须知,同步做代码重构和单元测试编写的风险很大,如果在做的时候没有稳定的质量守护,作为涉费的金融核心业务系统,这种发布风险是不能被接受的。所以 比较现实的路看起来只有一条路:快速建设好GUI层驱动的自动化测试,用它来守护代码重构和单元测试。
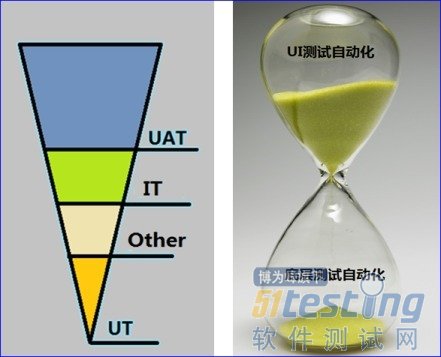
我想借用这个沙漏图来说明我的观点:推动这种系统测试的 转型,不能幻想一蹴而就的单元测试的建设,可以考虑通过GUI来做测试自动化,将其做扎实,以其为基础来推动这些陈旧的系统群的自动化测试转型。而接下 来,要慢慢地用单元测试自动化来逐步替换这个基于用户展示层的测试自动化,直到它们之间形成一个合理的比例。在测试水平提高和转型的过程中,每个类型的测 试都有可能成为瓶颈;尤其是通过业务展示层来做的自动化测试,没有它,代码重构和单元测试自动化也无法稳步地推动。在现实中的人力配比下,聚沙成塔对我们 来说是一个神话,信念支持我们朝着目标持续迈进,但是在短时间内却不易企及。
单元测试纵与横 对绝大多数人来说,谈到单元测试,第一个冲入脑海的是“覆盖”这两个字,而其中部分人对覆盖率这三个字的关注度要远远高于四种覆盖设计方法。假 设我们的目标测试范围内有N个功能,平均每个功能有9个逻辑分支(含Exception分支)。如果要考量单元测试的覆盖方法,我想绝大多数人会选择每个 功能点选择少于4个的主要分支去覆盖。我的确也在公司的持续集成邮件组里看到这种争论,参与讨论的开发同事无一例外地赞同这种做法,他们主要考虑的因素是 ROI,他们认为在非常有限的时间里,将单个功能点的分支覆盖太多并没有太多意义,因为用户经常使用的是主要的那两三个分支。这种看法似乎符合常理,但实 际上并没有他们想象的那么经济,我实际上并不指望他们现在这个阶段做多么好的单元测试,但是却不愿意看到他们按照这种想法做下去。
我们不妨把每个功能覆盖主要分支,覆盖尽可能多的功能点的覆盖取向称做横向覆盖;对于每个功能点,争取覆盖尽可能多分支,而不计较有限的时间内 覆盖了多少功能点的覆盖取向叫做纵向覆盖。我个人的观点是:尽量采取纵向覆盖,自动化测试这同军事机械化作战一样,大纵深要比长战线好。我之所以在这种系 统群的测试转型过程中,对单元测试建设推崇纵向覆盖策略,理由如下:
1)时间短、人力少,短时间无法覆盖全面,无论纵横,双方在这一点上的论据一致。
2)一个功能的N个分支,如果在设计单元测试的时候只覆盖其中少数分支,在后续进行更深入覆盖的时候可能需要重构所有的测试以保证测试代码的逻 辑一致性和可维护性,这是一种重复工作的浪费。换言之,与被测代码一样,测试用例不能习惯于采取快餐式设计,而应该在一开始就针对该功能全面设计好。
3)对于这些待重构代码来说,全面考量一个功能点尽可能多的分支的覆盖,能够驱动更加完美的重构,反之,测试的设计与开发一旦分批进行,必然招致额外的重构工作。
4)至于有些开发认为在短时间内覆盖主要分支主要是因为用户平常只用那么几个主要的分支功能,我觉得恰恰相反。我们可以挑选用户使用最多的功能 而不是所有功能的主要分支,因为主要功能里面的“非主要分支”甚至是Exception分支同样有发生致命故障的可能。例如,对个退费转账,如果在某个异 常中没有处理好,可能会出转账数据反复生成的情况,这样的资金流入个人账户之后是基本再也无法追回的。这种故障即便快速恢复,也远比那些次要的功能不可用 招致的损失大。
5)有些人认为,那些不重要的分支,在UI回归测试的时候着重测试一下就好了,这更是违背金字塔模型核心的经济原则。要知道UI回归测试的强项 在于对主流程的覆盖,而分支和异常通过它去覆盖本身就是非常难的事情;既然认同单元测试的经济性,还要依赖GUI测试去做那些非常难以实现的分支的测试, 这岂不是自相矛盾么?
6)此外,这种纵深覆盖更能锻炼测试代码编写者的测试思维,完整的经验比被阻断的实践更具参考价值。后续编写新的功能模块的代码时,会因为做测 试设计时近乎完整的分支考量而更加能够兼顾所有的分支和异常。单元测试是一种高效的编码能力提升的手段,而在做单元测试的时候将分支的全面覆盖,则是高效 的设计技能的提升手段。
单元测试覆盖的纵与横的概念只是一家之言,无需纠结概念。我其实只是希望大家在考虑“覆盖率”这三个字之前都去考虑一下覆盖的策略,而不要吧眼 光只放在那些乏味的覆盖率统计数字上。做测试规划,好的方略比优秀的代码更加能解决实际问题;宁可让沙子漏得慢一点,也不要为了暂时看起来流得快而对沙子 中混入的石子视而不见,否则迟早会因为石子堵住瓶口而无法继续聚沙成塔的梦想。
耦合关系的处理
对于我们讨论的这种系统,有人说mock对单元测试来说不是银弹,滥用mock会影响交互点的验证,降低测试的有效性。对这种看法,我深以为然,而且单元测试且如此,通过GUI做的测试就更不用说了,盲目的解耦会大大提高为测试有效性所付出的代价。
拿我们一个较为单纯的系统为例,中间价是weblogic,数据库是oracle,部署逻辑关系如下:
1)Browser通过HTTP访问单点认证系统、用户管理系统、影像系统、打印平台与印章系统等;
2)Web服务通过TCP访问单点认证系统,通过LDAP访问OID,通过NFS访问NAS,通过T3访问App服务;
3)App服务通过JDBC访问数据库,通过T3访问用户管理系统、工作流、单证系统、后援集中录入系统和集团公网前置系统,通过LDAP访问OID,通过NFS访问NAS……
4)核心DB通过TJS/ETL/GoldenGate与集团其他应用数据库相连。
连同上文所述的系统群内部的业务逻辑和数据的共用,我们可以把我们的系统耦合分为两级:系统群内的耦合与平台级耦合。这两层耦合稍有区别,很多人 在通过GUI做自动化测试的时候,要么懒得去做mock工作,全部依赖所有的测试环境的稳定性;要么就花功夫把所有的关联系统全部mock掉。这两种做法 都是不妥当的,因为要指望所有环境都稳定无异于买彩票。另一方面,这些平台级的耦合关系,如果想通过mock的手法来解耦,将付出很大的代价,而程序的正 常功能也无法测试完整。例如,如果要绕过SSO和UM的认证,可能就要分析和运行时修改cookie,而这本身就是不安全的,也不是一定能够实现的。而 且,如果中间件的一个provider配置错误,绕过去的测试也不能发现这个问题,尤其是全部依赖自动化测试的情况下。
那么是否要在通过GUI去测试的时候始终保持所有这种平台级耦合的测试环境稳定呢?根据我们的经验,答案是肯定的,因为如果通过GUI去做测 试,这种耦合关系是保证被测功能完整性的基本条件。无论这些平台或系统有着多么频繁的构建与发布,在我们通过GUI去做测试的时候都要保持一个稳定可用的 版本,对于我们的系统的持续集成,这种需求更甚。我曾经说过:在通过GUI快速构建的时候要彻底mock掉对关联系统的依赖,这彻底二字其实并不贴切,我 本意所指只是系统群内的关联关系而已。而理论终归是理论,根据我们公司的实际流程,我又把这种系统群内耦合关系的mock分为两种:
自动化BVT/冒烟:在持续集成频繁的构建中,由于系统群内业务逻辑和数据的共用,关联系统的版本移交时间和频率不定,无法要求其保持稳定不变的版本以供关联测试,需要将这部分关联mock掉。
自动化回归测试:在同一个系统群内,所有版本发布的最终日期是一致的,故尔最终的回归测试都将在一个集中的时段内完成,而这段时间内基本所有的版本都已经趋于稳定。在这种状态下,出于测试全面和有效性的考量,自动化回归测试将不mock任何关联。
那么同一套测试脚本能否支持这种测试执行需求呢?我们借鉴了功能开关的特性,通过采集版本计划信息进行推算,做出一个判断是否回归测试的公共接 口。在测试脚本中调用共用接口,得到测试运行信息,决定如何处理对关联系统的依赖。持续集成对于很多公司或产品来说都不是件很难做的事情,而对于本文所述 的陈旧的紧耦合金融系统群来说却有一定的难度。我观察了我们公司一些持续集成做得比较成功的案例,大都是业务源头系统,如网销,基本不存在业务数据依赖 性,或是系统群内部关系简单或者索性就是独立不成群的系统。除了实施手段较为高明和付出的努力较多之外,最重要的是他们成功地规避了这里提到的紧耦合的问 题,或者根本就没有遇到这种问题。所以我个人的见解是:在通过GUI去做自动化测试的过程中,要确保平台级耦合系统环境的稳定性,分场景地mock系统群 内部的耦合关系,而不能一概而论。
监控辅助的测试
有人纠结测试自动化和自动化测试之间的差别,简单举个例子说明一下个人的理解:在测试环境搭建监控系统,用其辅助自动化测试运行,这个行为总的 来说可以称作测试自动化。而自动化测试主要的内容则是自动化(主要指脚本化)的测试执行动作,这二者之间还是有点差别的。如果非要咬文嚼字,我觉得其差异 在于自动化测试行为必定包含verifying,而测试自动化行为则可以只有甚至没有checking。如果将测试自动化的行为或体系在运用的时候加上 verifying,就可能变成自动化测试。
提到测试环境监控,我觉得它的价值绝不亚于生产环境的监控,它能够帮助测试节省很多问题定位的成本,帮助发现一些在页面上无法发现的异常。根据 个人理解,除去基础架构统一管理的相关内容,我将其划分为5个部分(目前并未完成建设):测试环境应用服务器监控、测试环境数据库状态监控、其他测试服务 的状态监控、自动化测试运行相关监控、业务系统逻辑健康度检查。用环境监控与自动化测试相互辅佐,可以发现更多的潜在问题,下面讲两个简单的例子来说一下 自动化测试和测试环境监控的关系。
例1、数据传输自动测试(未亲自实施)
很多时候,我们会使用几种商业工具和一些其他的企业级应用。在日常的测试工作中,针对这些工具或它们的特性也需要做大量的测试。例如,在平安科 技,单就数据传输管理而言,会用到:ESB/EAI/TJS、ETL(DataStage)、GoldenGate(Oracle)等。因为这些工具使用 的频率非常大,所以有想法的人就想着把这部分工作内容也做成自动化或者半自动化。
大家知道,这些数据传输的service或者job本身可能存在一定的加工和转换的逻辑(GoldenGate可能会较为单纯),自动化测试可能 需要对其内部逻辑做细致的测试。而对数据加工转换的逻辑做自动化测试,无异于换个人重写一套逻辑去验证原先开发的逻辑,十分复杂,ROI并不高。
这样一来,可能有人就把这个自动化变成了对这些service和job工作状态的checking,同时仍然简称这是在做自动化测试,并且试图 说明这样的测试通过就能够保证不出Level-1级别的故障事件。不过我认为,如果只是对这些service和job的基本可用性做checking,而 不是verifying,那么这部分自动化工作做成测试环境的一个监控即可,而不是自动化测试,而且这种checking是无法保证不出Level-1级 别事件的。
例2、报表生成自动测试(指导同事实施中)
我们的查询系统分三类:实时查询系统、综合报表系统和MIS系统,时效从高到低。实时查询系统自动化测试较为简单;而MIS系统由于维度和指标 非常复杂,暂时采用手动测试的方法。而这个综合报表系统有数百长单一维度的报表,每张报表使用一个独立的存储过程来生成,生成的结果文件含xls、 csv、zip、html等各多文件类型。报表之间的关联影响几乎可以忽略,而报表的正确性则会受其他公用逻辑改动的影响。此外,这种报表介于oltp和 olap之间,生成的效率从几秒到几小时不等,提交之后由quartz控制生成异步任务,是测试自动化的难题之一。
因为测试执行的机器资源有限,所以一般来说自动化测试的运行都是实时的,但是报表生成的时长却长短不一。理论上,如果不想占用太多资源,只能依 赖有轮询机制的工具或者系统来检查它运行的结果。恰好,我们的监控系统就有这种机制,而且既然监控系统能够检查报表是否已经生成完毕并触发邮件发送,它就 一定可以触发对其结果正确性校验的自动化测试程序的运行。我们可以考虑在监控平台配置一个新的监控和一组规则,随后实现这种报表系统的测试:
1)建立被测报表生成的存储过程代码的基线版本,存放于自动化测试的基线版本库中。
2)将自动化测试代码分为自动化报表生成和自动化报表结果校验两部分。
3)在任何变更引发的综合报表系统测试中,使用基线版本代码运行报表,取得报表结果文件;在最新的被测报表代码版本上,用自动化GUI测试再度生成这些报表,并取得结果文件。
4)使用监控系统轮询报表生成情况,已经完成的报表则调用其自动化结果校验的代码再度运行,解析并比对两次获得的结果文件,进行报告反馈。
5)被测报表逻辑发生变更,则更新被测报表基线代码。
很显然,这种系统的自动化测试,决不是单靠一段单纯的自动化测试代码的运行就能解决的,辅助的方法或许有很多,但是善用已有的资源,无疑是一个很好的办法。如上文所述,监控系统的checking行为由于它联动了自动化的verifying动作,就变成了自动化测试。
(未完待续)