2008年3月2日
#

其实就是关键一句话:
window.opener.document.getElementById("XXX").value=“123456”;
例程如下:
http://www.blogjava.net/Files/junglesong/ParentChildWnd20080520140659.rar
类之间关联的Hibernate表现
在Java程序中,类之间存在多种包含关系,典型的三种关联关系有:一个类拥有另一个类的成员,一个类拥有另一个类的集合的成员;两个类相互拥有对象的集合的成员.在Hibernate中,我们可以使用映射文件中的many-to-one, one-to-many, many-to-many来实现它们.这样的关系在Hibernate中简称为多对一,一对多和多对多.
多对一的类代码
事件与地点是典型的多对一关系,多个事件可以在一个地点发生(时间不同),一个地点可发生多个事件.它们的对应关系是(多)事件对(一)地点.
两个类的代码如右:
public class Event{
private String id;
private String name;
private Location location;
}
public class Location{
private String id;
private String name;
}
多对一的映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Event"
table="Event_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<many-to-one name="location" column="locationId" class="com.sitinspring.domain.Location"/>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Location"
table="Location_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
</class>
</hibernate-mapping>
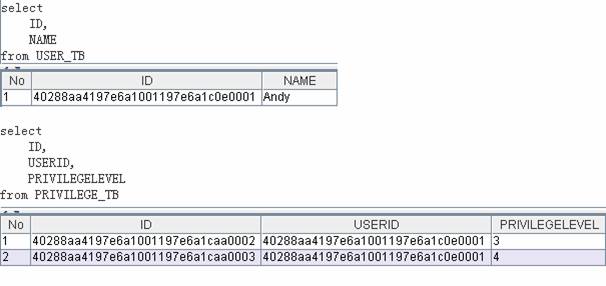
多对一的表数据

一对多的类代码
如果一个用户有多个权限,那么User类和Privilege类就构成了一对多的关系,User类将包含一个Privilege类的集合.
public class User{
private String id;
private String name;
private Set<Privilege> privileges=new LinkedHashSet<Privilege>();
}
public class Privilege{
private String id;
private String userId;
private int privilegeLevel;
}
一对多的映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="User_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<set name="privileges">
<key column="userId"/>
<one-to-many class="com.sitinspring.domain.Privilege"/>
</set>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Privilege"
table="Privilege_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="userId" column="userId" />
<property name="privilegeLevel" column="privilegeLevel" />
</class>
</hibernate-mapping>
一对多的表数据
多对多
多对多关系 是指两个类相互拥有对方的集合,如文章和标签两个类,一篇文章可能有多个标签,一个标签可能对应多篇文章.要实现这种关系需要一个中间表的辅助.
类代码如右:
public class Article{
private String id;
private String name;
private Set<Tag> tags = new HashSet<Tag>();
}
public class Tag{
private String id;
private String name;
private Set<Article> articles = new HashSet<Article>();
}
多对多的映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Article" table="ARTICLE_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="NAME" />
<set name="tags" table="ARTICLETAG_TB" cascade="all" lazy="false">
<key column="ARTICLEID" />
<many-to-many column="TAGID" class="com.sitinspring.domain.Tag" />
</set>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Tag" table="TAG_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="NAME" />
<set name="articles" table="ARTICLETAG_TB" cascade="all" lazy="false">
<key column="TAGID" />
<many-to-many column="ARTICLEID" class="com.sitinspring.domain.Article" />
</set>
</class>
</hibernate-mapping>
多对多的表数据

源码下载:
http://www.blogjava.net/Files/junglesong/HibernateMapping20080430203526.rar
Criteria查询
Hibernate中的Criteria API提供了另一种查询持久化的方法。它让你能够使用简单的API动态的构建查询,它灵活的特性通常用于搜索条件的数量可变的情况。
Criteria查询之所以灵活是因为它可以借助Java语言,在Java的帮助下它拥有超越HQL的功能。Criteria查询也是Hibernate竭力推荐的一种面向对象的查询方式。
Criteria查询的缺点在于只能检索完整的对象,不支持统计函数,它本身的API也抬高了一定的学习坡度。
Criteria查询示例代码
Session session=HibernateUtil.getSession();
Criteria criteria=session.createCriteria(User.class);
// 条件一:名称以关开头
criteria.add(Restrictions.like("name", "关%"));
// 条件二:email出现在数组中
String[] arr={"1@2.3","2@2.3","3@2.3"};
criteria.add(Restrictions.in("email", arr));
// 条件三:password等于一
criteria.add(Restrictions.eq("password", "1"));
// 排序条件:按登录时间升序
criteria.addOrder(Order.asc("lastLoginTime"));
List<User> users=(List<User>)criteria.list();
System.out.println("返回的User实例数为"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
Criteria查询实际产生的SQL语句
select
this_.ID as ID0_0_,
this_.name as name0_0_,
this_.pswd as pswd0_0_,
this_.email as email0_0_,
this_.lastLoginTime as lastLogi5_0_0_,
this_.lastLoginIp as lastLogi6_0_0_
from
USERTABLE_OKB this_
where
this_.name like '关%'
and this_.email in (
'1@2.3', '2@2.3', '3@2.3'
)
and this_.pswd='1'
order by
this_.lastLoginTime asc
注:参数是手工加上的。
HQL介绍
Hibernate中不使用SQL而是有自己的面向对象查询语言,该语言名为Hibernate查询语言(Hibernate Query Language).HQL被有意设计成类似SQL,这样开发人员可以利用已有的SQL知识,降低学习坡度.它支持常用的SQL特性,这些特性被封装成面向对象的查询语言,从某种意义上来说,由HQL是面向对象的,因此比SQL更容易编写.
本文将逐渐介绍HQL的特性.
查询数据库中所有实例
要得到数据库中所有实例,HQL写为”from 对象名”即可,不需要select子句,当然更不需要Where子句.代码如右.
Query query=session.createQuery("from User");
List<User> users=(List<User>)query.list();
for(User user:users){
System.out.println(user);
}
限制返回的实例数
设置查询的maxResults属性可限制返回的实例(记录)数,代码如右:
Query query=session.createQuery("from User order by name");
query.setMaxResults(5);
List<User> users=(List<User>)query.list();
System.out.println("返回的User实例数为"+users.size());
for(User user:users){
System.out.println(user);
}
分页查询
分页是Web开发的常见课题,每种数据库都有自己特定的分页方案,从简单到复杂都有.在Hibernate中分页问题可以通过设置firstResult和maxResult轻松的解决.
代码如右:
Query query=session.createQuery("from User order by name");
query.setFirstResult(3);
query.setMaxResults(5);
List<User> users=(List<User>)query.list();
System.out.println("返回的User实例数为"+users.size());
for(User user:users){
System.out.println(user);
}
条件查询
条件查询只要增加Where条件即可.
代码如右:
Hibernate中条件查询的实现方式有多种,这种方式的优点在于能显示完整的SQL语句(包括参数)如下.
select
user0_.ID as ID0_,
user0_.name as name0_,
user0_.pswd as pswd0_,
user0_.email as email0_,
user0_.lastLoginTime as lastLogi5_0_,
user0_.lastLoginIp as lastLogi6_0_
from
USERTABLE_OKB user0_
where
user0_.name like '何%'
public static void fetchByName(String prefix){
Session session=HibernateUtil.getSession();
Query query=session.createQuery("from User where name like'"+prefix+"%'");
List<User> users=(List<User>)query.list();
System.out.println("返回的User实例数为"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
}
位置参数条件查询
HQL中也可以象jdbc中PreparedStatement一样为SQL设定参数,但不同的是下标从0开始.
代码如右:
public static void fetchByPos(String prefix){
Session session=HibernateUtil.getSession();
Query query=session.createQuery("from User where name=?");
// 注意下标是从0开始,和jdbc中PreparedStatement从1开始不同
query.setParameter(0, prefix);
List<User> users=(List<User>)query.list();
System.out.println("返回的User实例数为"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
}
命名参数条件查询
使用位置参数条件查询最大的不便在于下标与?号位置的对应上,如果参数较多容易导致错误.这时采用命名参数条件查询更好.
使用命名参数时无需知道每个参数的索引位置,这样就可以节省填充查询参数的时间.
如果有一个命名参数出现多次,那在每个地方都会设置它.
public static void fetchByNamedParam(){
Session session=HibernateUtil.getSession();
Query query=session.createQuery("from User where name=:name");
query.setParameter("name", "李白");
List<User> users=(List<User>)query.list();
System.out.println("返回的User实例数为"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
}
命名查询
命名查询是嵌在XML映射文件中的查询。通常,将给定对象的所有查询都放在同一文件中,这种方式可使维护相对容易些。命名查询语句写在映射定义文件的最后面。
执行代码如下:
Session session=HibernateUtil.getSession();
Query query=session.getNamedQuery("user.sql");
List<User> users=(List<User>)query.list();
System.out.println("返回的User实例数为"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
映射文件节选:
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
</class>
<query name="user.sql">
<![CDATA[from User where email='2@2.3']]>
</query>
</hibernate-mapping>
主要的Hibernate组件
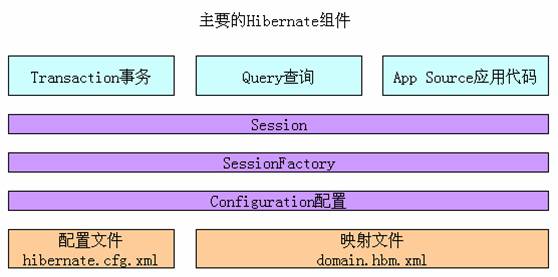
Configuration类
Configuration类启动Hibernate的运行环境部分,用于加载映射文件以及为它们创建一个SessionFacotry。完成这两项功能后,就可丢弃Configuration类。
// 从hibernate.cfg.xml创建SessionFactory 示例
sessionFactory = new Configuration().configure()
.buildSessionFactory();
SessionFactory类
Hibernate中Session表示到数据库的连接(不止于此),而SessionFactory接口提供Session类的实例。
SessionFactory实例是线程安全的,通常在整个应用程序中共享。
从Configuration创建SessionFacotry的代码如右。
// 从hibernate.cfg.xml创建SessionFactory 示例
SessionFactory sessionFactory = new Configuration().configure()
.buildSessionFactory();
Session类
Session表示到数据库的连接,session类的实例是到Hibernate框架的主要接口,使你能够持久化对象,查询持久化以及将持久化对象转换为临时对象。
Session实例不是线程安全的,只能将其用于应用中的事务和工作单元。
创建Session实例的代码如右:
SessionFactory sessionFactory = new Configuration().configure()
.buildSessionFactory();
Session session=sessionFactory.openSession();
保存一个对象
用Hibernate持久化一个临时对象也就是将它保存在Session实例中:
对user实例调用save时,将给该实例分配一个生成的ID值,并持久化该实例,在此之前实例的id是null,之后具体的id由生成器策略决定,如果生成器类型是assignd,Hibernate将不会给其设置ID值。
Flush()方法将内存中的持久化对象同步到数据库。存储对象时,Session不会立即将其写入数据库;相反,session将大量数据库写操作加入队列,以最大限度的提高性能。
User user=new User(“Andy”,22);
Session session=sessionFatory.openSession();
session.save(user);
session.flush();
session.close();
保存或更新一个对象
Hibernate提供了一种便利的方法用于在你不清楚实例对应的数据在数据库中的状态时保存或更新一个对象,也就是说,你不能确定具体是要保存save还是更新update,只能确定需要把对象同步到数据库中。这个方法就是saveOrUpdate。
Hibernate在持久化时会查看实例的id属性,如果其为null则判断此对象是临时的,在数据库中找不到对应的实例,其后选择保存这个对象;而不为空时则意味着对象已经持久化,应该在数据库中更新该对象,而不是将其插入。
User user=。。。;
Session session=sessionFatory.openSession();
session.saveOrUpdate(user);
Session.flush();
session.close();
删除一个对象
从数据库删除一个对象使用session的delete方法,执行删除操作后,对象实例依然存在,但数据库中对应的记录已经被删除。
User user=。。。;
Session session=sessionFatory.openSession();
session.delete(user);
session.flush();
session.close();
以ID从数据库中取得一个对象
如果已经知道一个对象的id,需要从数据库中取得它,可以使用Session的load方法来返回它。代码如右.
注意此放在id对应的记录不存在时会抛出一个HibernateException异常,它是一个非检查性异常。对此的正确处理是捕获这个异常并返回一个null。
使用此想法如果采用默认的懒惰加载会导致异常,对此最简单的解决方案是把默认的懒惰加载属性修改为false。如右:
User user=(User)session.load(User.class,"008");
session.close();
-----------------------------------------------
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
。。。。
</class>
</hibernate-mapping>
检索一批对象
检索一批对象需要使用HQL,session接口允许你创建Query对象以检索持久化对象,HQL是面向对象的,你需要针对类和属性来书写你的HQL而不是表和字段名。
从数据库中查询所有用户对象如下:
Query query=session.createQuery(“from User”);// 注意这里User是类名,from前没有select。
List<User> users=(List<User>)query.list();
从数据库中查询名为“Andy”的用户如下:
String name=“Andy”;
Query query=session.createQuery(“from User where name=‘”+name+”’”);
List<User> users=(List<User>)query.list();
以上方法类似于Statement的写法,你还可以如下书写:
Query query=session.createQuery("from User user where user.name = :name");
query.setString("name", “Andy");
List<User> users=(List<User>)query.list();
Hibernate的映射文件
映射文件也称映射文档,用于向Hibernate提供关于将对象持久化到关系数据库中的信息.
持久化对象的映射定义可全部存储在同一个映射文件中,也可将每个对象的映射定义存储在独立的文件中.后一种方法较好,因为将大量持久化类的映射定义存储在一个文件中比较麻烦,建议采用每个类一个文件的方法来组织映射文档.使用多个映射文件还有一个优点:如果将所有映射定义都存储到一个文件中,将难以调试和隔离特定类的映射定义错误.
映射文件的命名规则是,使用持久化类的类名,并使用扩展名hbm.xml.
映射文件需要在hibernate.cfg.xml中注册,最好与领域对象类放在同一目录中,这样修改起来很方便.
领域对象和类
public class User{
// ID
private String id;
// 名称
private String name;
// 密码
private String password;
// 邮件
private String email;
// 上次登录时间
private String lastLoginTime;
// 上次登录ip
private String lastLoginIp;
public User(String name,String password,String email){
this.name=name;
this.password=password;
this.email=email;
}
}
<?xml version="1.0"?><!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd"><hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
</class></hibernate-mapping>
hibernate.cfg.xml中的映射文件设置
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI数据源设置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect适合所有Oracle数据库 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
<!-- 显示SQL语句 -->
<property name="show_sql">true</property>
<!-- SQL语句整形 -->
<property name="format_sql">true</property>
<!-- 启动时创建表.这个选项在第一次启动程序时放开,以后切记关闭 -->
<!-- <property name="hbm2ddl.auto">create</property> -->
<!-- 持久化类的映射文件 -->
<mapping resource="com/sitinspring/domain/User.hbm.xml" />
<mapping resource="com/sitinspring/domain/Privilege.hbm.xml" />
<mapping resource="com/sitinspring/domain/Article.hbm.xml" />
<mapping resource="com/sitinspring/domain/Record.hbm.xml" />
</session-factory>
</hibernate-configuration>
映射文件物理位置示例
映射文件的基本结构
映射定义以hibernate-mapping元素开始, package属性设置映射中非限定类名的默认包.设置这个属性后,对于映射文件中列出的其它持久化类,只需给出类名即可.要引用指定包外的持久化类,必须在映射文件中提供全限定类名.
在hibernate-mapping标签之后是class标签.class标签开始指定持久化类的映射定义.table属性指定用于存储对象状态的关系表.class元素有很多属性,下面将逐个介绍.
ID
Id元素描述了持久化类的主码以及他们的值如何生成.每个持久化类必须有一个ID元素,它声明了关系表的主码.如右:
Name属性指定了持久化类中用于保存主码值的属性,该元素表明,User类中有一个名为id的属性.如果主码字段与对象属性不同,则可以使用column属性.
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
生成器
生成器创建持久化类的主码值.Hibernate提供了多个生成器实现,它们采用了不同的方法来创建主码值.有的是自增长式的,有点创建十六进制字符串, 还可以让外界生成并指定对象ID,另外还有一种Select生成器你那个从数据库触发器trigger检索值来获得主码值.
右边使用了用一个128-bit的UUID算法生成字符串类型的标识符, 这在一个网络中是唯一的(使用了IP地址)。UUID被编码为一个32位16进制数字的字符串 .这对字段类型是字符串的id字段特别有效.UUID作为ID字段主键是非常合适的,比自动生成的long类型id方式要好。
UUID示例
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
自动增长的id
<id name="id" column="ID" type="long">
<generator class="native"/>
</id>
属性
在映射定义中,property元素与持久化对象的一个属性对应,name表示对象的属性名,column表示对应表中的列(字段),type属性指定了属性的对象类型,如果type被忽略的话,Hibernate将使用运行阶段反射机制来判断类型.
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
获取Hibernate
在创建Hibernate项目之前,我们需要从网站获得最新的Hibernate版本。Hibernate主页是www.hibernate.org,找到其菜单中的download连接,选择最新的Hibernate版本即可。下载后将其解开到一个目录中。
右边是解开后的主要目录。其中最重要的是hibernate.jar,它包含全部框架代码;lib目录,包括Hibernate的所有依赖库;doc目录,包括JavDocs和参考文档。
Hibernate的配置文件
Hibernate能够与从应用服务器(受控环境,如Tomcat,Weblogic,JBoss)到独立的应用程序(非受控环境,如独立应用程序)的各种环境和谐工作,这在一定程度上要归功于其配置文件hibernate.cfg.xml,通过特定的设置Hibernate就能与各种环境配合。右边是hibernate.cfg.xml的一个示例。
配置Hibernate的所有属性是一项艰巨的任务,下面将依此介绍Hibernate部署将用到的基本配置。
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI数据源设置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect适合所有Oracle数据库 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
<!-- 显示SQL语句 -->
<property name="show_sql">true</property>
<!-- SQL语句整形 -->
<property name="format_sql">true</property>
<!-- 启动时创建表.这个选项在第一次启动程序时放开,以后切记关闭 -->
<!-- <property name="hbm2ddl.auto">create</property> -->
<!-- 持久化类的配置文件 -->
<mapping resource="com/sitinspring/domain/User.hbm.xml" />
<mapping resource="com/sitinspring/domain/Privilege.hbm.xml" />
<mapping resource="com/sitinspring/domain/Article.hbm.xml" />
<mapping resource="com/sitinspring/domain/Record.hbm.xml" />
</session-factory>
</hibernate-configuration>
使用Hibernate管理的JDBC连接
右边配置文件中的Database connection settings 部分制定了Hibernate管理的JDBC连接, 这在非受控环境如桌面应用程序中很常见。
其中各项属性为:
connection.driver_class:用于特定数据库的JDBC连接类
connection.url:数据库的完整JDBC URL
connection.username:用于连接到数据库的用户名
connection.password:用户密码
这种方案可用于非受控环境和基本测试,但不宜在生产环境中使用。
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- Database connection settings -->
<property name="connection.driver_class">org.hsqldb.jdbcDriver</property>
<property name="connection.url">jdbc:hsqldb:hsql://localhost</property>
<property name="connection.username">sa</property>
<property name="connection.password"></property>
<!-- JDBC connection pool (use the built-in) -->
<property name="connection.pool_size">1</property>
<!-- SQL dialect -->
<property name="dialect">org.hibernate.dialect.HSQLDialect</property>
<!-- Enable Hibernate's automatic session context management -->
<property name="current_session_context_class">thread</property>
。。。。。。。。
</session-factory>
</hibernate-configuration>
使用JNDI 数据源
在受控环境中,我们可以使用容器提供的数据源,这将使数据库访问更加快捷,右边就是使用Tomcat提供的数据源的配置部分。
附:Server.Xml中的数据源设置
<Context path="/MyTodoes" reloadable="true" docBase="E:\Program\Programs\MyTodoes" workDir="E:\Program\Programs\MyTodoes\work" >
<Resource name="jdbc/myoracle" auth="Container"
type="javax.sql.DataSource" driverClassName="oracle.jdbc.OracleDriver"
url="jdbc:oracle:thin:@192.168.104.173:1521:orcl"
username="hy" password="123456" maxActive="20" maxIdle="10"
maxWait="-1"/>
</Context>
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI数据源设置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect适合所有Oracle数据库 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
</hibernate-configuration>
数据库方言
Dialect属性能告知Hibernate执行特定的操作如分页时需要使用那种SQL方言,如MySql的分页方案和Oracle的大相径庭,如设置错误或没有设置一定会导致问题。
附录:常见的数据库方言
DB2 :org.hibernate.dialect.DB2Dialect
MySQL :org.hibernate.dialect.MySQLDialect
Oracle (any version) :org.hibernate.dialect.OracleDialect
Oracle 9i/10g :org.hibernate.dialect.Oracle9Dialect
Microsoft SQL Server :org.hibernate.dialect.SQLServerDialect
Sybase Anywhere :org.hibernate.dialect.SybaseAnywhereDialect
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI数据源设置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect适合所有Oracle数据库 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
<!-- 显示SQL语句 -->
<property name="show_sql">true</property>
<!-- SQL语句整形 -->
<property name="format_sql">true</property>
</hibernate-configuration>
其它属性
show_sql:它可以在程序运行过程中显示出真正执行的SQL语句来,建议将这个属性始终打开,它将有益于错误诊断。
format_sql:将这个属性设置为true能将输出的SQL语句整理成规范的形状,更方便用于查看SQL语句。
hbm2ddl.auto:将其设置为create能在程序启动是根据类映射文件的定义创建实体对象对应的表,而不需要手动去建表,这在程序初次安装时很方便。
如果表已经创建并有数据,切记关闭这个属性,否则在创建表时也会清除掉原有的数据,这也许会导致很严重的后果。
从后果可能带来的影响来考虑,在用户处安装完一次后就应该删除掉这个节点
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
。。。。。。
<!-- 显示SQL语句 -->
<property name="show_sql">true</property>
<!-- SQL语句整形 -->
<property name="format_sql">true</property>
<!-- 启动时创建表.这个选项在第一次启动程序时放开,以后切记关闭 -->
<!-- <property name="hbm2ddl.auto">create</property> -->
。。。。。。
</hibernate-configuration>
映射定义
在hibernate.cfg.xml中,还有一个重要部分就是映射定义,这些文件用于向Hibernate提供关于将对象持久化到关系数据库的信息。
一般来说,领域层有一个领域对象就有一个映射文件,建议将它们放在同一目录(domain)下以便查阅和修改,映射文件的命名规则是:持久化类的类名+.hbm.xml
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI数据源设置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
。。。。。。
<!-- 持久化类的配置文件 -->
<mapping resource="com/sitinspring/domain/User.hbm.xml" />
<mapping resource="com/sitinspring/domain/Privilege.hbm.xml" />
<mapping resource="com/sitinspring/domain/Article.hbm.xml" />
<mapping resource="com/sitinspring/domain/Record.hbm.xml" />
</session-factory>
</hibernate-configuration>
本文假定读者已经熟知以下知识
能够熟练使用JDBC创建Java应用程序;
创建过以数据库为中心的应用
理解基本的关系理论和结构化查询语言SQL (Strutured Query Language)
Hibernate
Hibernate是一个用于开发Java应用的对象/关系映射框架。它通过在数据库中为开发人员存储应用对象,在数据库和应用之间提供了一座桥梁,开发人员不必编写大量的代码来存储和检索对象,省下来的精力更多的放在问题本身上。
持久化与关系数据库
持久化的常见定义:使数据的存活时间超过创建该数据的进程的存活时间。数据持久化后可以重新获得它;如果外界进程没有修改它,它将与持久化之前相同。对于一般应用来说,持久化指的是将数据存储在关系数据库中。
关系数据库是为管理数据而设计的,它在存储数据方面很流行,这主要归功于易于使用SQL来创建和访问。
关系数据库使用的模型被称为关系模型,它使用二维表来表示数据。这种数据逻辑视图表示了用户如何看待包含的数据。表可以通过主码和外码相互关联。主码唯一的标识了表中的一行,而外码是另一个表中的主码。
对象/关系阻抗不匹配
关系数据库是为管理数据设计的,它适合于管理数据。然而,在面向对象的应用中,将对象持久化为关系模型可能会遇到问题。这个问题的根源是因为关系数据库管理数据,而面向对象的应用是为业务问题建模而设计的。由于这两种目的不同,要使这两个模型协同工作可能具有挑战性。这个问题被称为 对象/关系阻抗不匹配(Object/relational impedance mismatch)或简称为阻抗不匹配
阻抗不匹配的几个典型方面
在应用中轻易实现的对象相同或相等,这样的关系在关系数据库中不存在。
在面向对象语言的一项核心特性是继承,继承很重要,因为它允许创建问题的精确模型,同时可以在层次结构中自上而下的共享属性和行为。而关系数据库不支持继承的概念。
对象之间可以轻易的实现一对一,一对多和多对多的关联关系,而数据库并不理解这些,它只知道外码指向主码。
对象/关系映射
前页列举了一些阻抗不匹配的问题,当然开发人员是可以解决这些问题,但这一过程并不容易。对象/关系映射(Object/Relational Mapping)就是为解决这些问题而开发的。
ORM在对象模型和关系模型之间架起了一座桥梁,让应用能够直接持久化对象,而不要求在对象和关系之间进行转换。Hibernate就是ORM工具中最成功的一种。它的主要优点是简单,灵活,功能完备和高效。
Hibernate的优点之一:简单
Hibernate不像有些持久化方案那样需要很多的类和配置属性,它只需要一个运行阶段配置文件已经为每个要持久化的应用对象指定一个XML格式的映射文件。
映射文件可以很短,让框架决定映射的其它内容,也可以通过制定额外的属性,如属性的可选列名,向框架提供更多信息。如右就是一个映射文档的示例。
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
</class>
</hibernate-mapping>
Hibernate的优点之二:功能完备
Hibernate支持所有的面向对象特性,包括继承,自定义对象类型和集合。它可以让你创建模型时不必考虑持久层的局限性。
Hibernate提供了一个名为HQL的查询语言,它与SQL非常相似,只是用对象属性名代替了表的列。很多通过SQL实现的常用功能都能用HQL实现。
Hibernate的优点之三:高效
Hibernate使用懒惰加载提高了性能,在Hibernate并不在加载父对象时就加载对象集合,而只在应用需要访问时才生成。这就避免了检索不必要的对象而影响性能。
Hibernate允许检索主对象时选择性的禁止检索关联的对象,这也是一项改善性能的特性。
对象缓存在提高应用性能方面也发挥了很大的作用。Hibernate支持各种开源和缓存产品,可为持久化类或持久化对象集合启用缓存。
总结
在同一性,继承和关联三方面,对象模型和关系模型存在着阻抗不匹配,这是众多ORM框架致力解决的问题,hibernate是这些方案中最成功的一个,它的主要优点是简单,灵活,功能完备和高效。
使用Hibernate不要求领域对象实现特别的接口或使用应用服务器,它支持集合,继承,自定义数据类型,并携带一种强大的查询语言HQL,能减少很多持久化方面的工作量,使程序员能把更多精力转移到问题本身上来。
C/S 架构
C/S 架构是一种典型的两层架构,其全程是Client/Server,即客户端服务器端架构,其客户端包含一个或多个在用户的电脑上运行的程序,而服务器端有两种,一种是数据库服务器端,客户端通过数据库连接访问服务器端的数据;另一种是Socket服务器端,服务器端的程序通过Socket与客户端的程序通信。
C/S 架构也可以看做是胖客户端架构。因为客户端需要实现绝大多数的业务逻辑和界面展示。这种架构中,作为客户端的部分需要承受很大的压力,因为显示逻辑和事务处理都包含在其中,通过与数据库的交互(通常是SQL或存储过程的实现)来达到持久化数据,以此满足实际项目的需要。
C/S 架构的优缺点
优点:
1.C/S架构的界面和操作可以很丰富。
2.安全性能可以很容易保证,实现多层认证也不难。
3.由于只有一层交互,因此响应速度较快。
缺点:
1.适用面窄,通常用于局域网中。
2.用户群固定。由于程序需要安装才可使用,因此不适合面向一些不可知的用户。
3.维护成本高,发生一次升级,则所有客户端的程序都需要改变。
B/S架构
B/S架构的全称为Browser/Server,即浏览器/服务器结构。Browser指的是Web浏览器,极少数事务逻辑在前端实现,但主要事务逻辑在服务器端实现,Browser客户端,WebApp服务器端和DB端构成所谓的三层架构。B/S架构的系统无须特别安装,只有Web浏览器即可。
B/S架构中,显示逻辑交给了Web浏览器,事务处理逻辑在放在了WebApp上,这样就避免了庞大的胖客户端,减少了客户端的压力。因为客户端包含的逻辑很少,因此也被成为瘦客户端。
B/S架构的优缺点
优点:
1)客户端无需安装,有Web浏览器即可。
2)BS架构可以直接放在广域网上,通过一定的权限控制实现多客户访问的目的,交互性较强。
3)BS架构无需升级多个客户端,升级服务器即可。
缺点:
1)在跨浏览器上,BS架构不尽如人意。
2)表现要达到CS程序的程度需要花费不少精力。
3)在速度和安全性上需要花费巨大的设计成本,这是BS架构的最大问题。
4)客户端服务器端的交互是请求-响应模式,通常需要刷新页面,这并不是客户乐意看到的。(在Ajax风行后此问题得到了一定程度的缓解)
String的特殊之处
String是Java编程中很常见的一个类,这个类的实例是不可变的(immutable ).为了提高效率,JVM内部对其操作进行了一些特殊处理,本文就旨在于帮助大家辨析这些特殊的地方.
在进入正文之前,你需要澄清这些概念:
1) 堆与栈
2) 相同与相等,==与equals
3) =的真实意义.
栈与堆
1. 栈(stack)与堆(heap)都是Java用来在内存中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。每个函数都有自己的栈,而一个程序只有一个堆.
2. 栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享,详见第3点。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。 3. Java中的数据类型有两种。 一种是基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。 另外,栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义 int a = 3; int b = 3; 编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。 特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与 b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。 另一种是包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java用new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。
相同与相等,==与equals
在Java中,相同指的是两个变量指向的地址相同,地址相同的变量自然值相同;而相等是指两个变量值相等,地址可以不同.
相同的比较使用==,而相等的比较使用equals.
对于字符串变量的值比较来说,我们一定要使用equals而不是==.
=的真实意义
=即赋值操作,这里没有问题,关键是这个值有时是真正的值,有的是地址,具体来说会根据等号右边的部分而变化.
如果是基本类型(八种),则赋值传递的是确定的值,即把右边变量的值传递给左边的变量.
如果是类类型,则赋值传递的是变量的地址,即把等号左边的变量地址指向等号右边的变量地址.
指出下列代码的输出
String andy="andy";
String bill="andy";
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
String str=“andy”的机制分析
上页代码的输出是andy和bill地址相同.
当通过String str=“andy”;的方式定义一个字符串时,JVM先在栈中寻找是否有值为“andy”的字符串,如果有则将str指向栈中原有字符串的地址;如果没有则创建一个,再将str的地址指向它. String andy=“andy”这句代码走的是第二步,而String bill=“andy”走的是第一步,因此andy和bill指向了同一地址,故而andy==bill,andy和bill地址相等,所以输出是andy和bill地址相同.
这样做能节省空间—少创建一个字符串;也能节省时间—定向总比创建要省时.
指出下列代码的输出
String andy="andy";
String bill="andy";
bill="bill";
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
输出及解释
上页代码的输出是:andy和bill地址不同
当执行bill=“bill”一句时,外界看来好像是给bill变换了一个新值bill,但JVM的内部操作是把栈变量bill的地址重新指向了栈中一块值为bill的新地址,这是因为字符串的值是不可变的,要换值(赋值操作)只有将变量地址重新转向. 这样andy和bill的地址在执行bill=“bill”一句后就不一样了,因此输出是andy和bill地址不同.
指出下列代码的输出
String andy=new String("andy");
String bill=new String("andy");
// 地址比较
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比较
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
输出及机制分析
andy和bill地址不同
andy和bill值相等
我们知道new操作新建出来的变量一定处于堆中,字符串也是一样.
只要是用new()来新建对象的,都会在堆中创建,而且其字符串是单独存值的,即每个字符串都有自己的值,自然地址就不会相同.因此输出了andy和bill地址不同.
equals操作比较的是值而不是地址,地址不同的变量值可能相同,因此输出了andy和bill值相等.
指出下列代码的输出
String andy=new String("andy");
String bill=new String(andy);
// 地址比较
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比较
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
输出
andy和bill地址不同
andy和bill值相等
道理仍和第八页相同.只要是用new()来新建对象的,都会在堆中创建,而且其字符串是单独存值的,即每个字符串都有自己的值,自然地址就不会相同.
指出下列代码的输出
String andy="andy";
String bill=new String(“Bill");
bill=andy;
// 地址比较
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比较
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
输出及解析
andy和bill地址相同
andy和bill值相等
String bill=new String(“Bill”)一句在栈中创建变量bill,指向堆中创建的”Bill”,这时andy和bill地址和值都不相同;而执行bill=andy;一句后,栈中变量bill的地址就指向了andy,这时bill和andy的地址和值都相同了.而堆中的”Bill”则没有指向它的指针,此后这块内存将等待被垃圾收集.
指出下列代码的输出
String andy="andy";
String bill=new String("bill");
andy=bill;
// 地址比较
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比较
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
输出
andy和bill地址相同
andy和bill值相等
道理同第十二页
结论
使用诸如String str = “abc”;的语句在栈中创建字符串时时,str指向的字符串不一定会被创建!唯一可以肯定的是,引用str本身被创建了。至于这个引用到底是否指向了一个新的对象,必须根据上下文来考虑,如果栈中已有这个字符串则str指向它,否则创建一个再指向新创建出来的字符串. 清醒地认识到这一点对排除程序中难以发现的bug是很有帮助的。
使用String str = “abc”;的方式,可以在一定程度上提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。而对于String str = new String(“abc”);的代码,则一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象,从而加重了程序的负担。
如果使用new()来新建字符串的,都会在堆中创建字符串,而且其字符串是单独存值的,即每个字符串都有自己的值,且其地址绝不会相同
当比较包装类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用==。
由于String类的immutable性质,当String变量需要经常变换其值如SQL语句拼接,HTML文本输出时,应该考虑使用StringBuffer类,以提高程序效率。
摘要: 序言:本指南旨在帮助你建立全面的个人品牌战略。个人品牌的建立是你销售自己从而在商业上取得成功的重要一环。个人品牌的建立是一个持续的过程正如你不断认识自己的过程。你自己强大了,品牌也亦然。在全球化导致工作竞争加剧的今天,个人品牌的提升也显得尤为重要。正如像金子那样发光,你能在人群中崭露自己,就能步入精英的行列。如今这场角力将比你的预想更为激烈和艰难。
或许是David Samuel这个家伙把我带进个人品牌研究这一行的,几年前我看了他的报告。他在报告中说了我们为什么需要个人品牌。当时他的听众来自一个电信大公司:
“如果我们根据人的智力把他们划分三六九等,那么他们就是一群A,一群B,一群C和一群D。因为全球化趋势,C群和D群的工作已经被外包了。一切已经过去了。至于留下的你们,现在就要为跻身A群和B群而开始竞争。或许在这个人才济济的群体中,你会想用大声嚷嚷来取得关注了。如何才能让自己受到关注?你该如何让自己发光以证明自己可以获得额外的工作机会?你该如何从身边每个人都像你一样能干甚至更甚于你的环境中胜出?如果你身边的每个人都是很能干的A群B群,你又该如何与他
阅读全文
 package com.sitinspring;
package com.sitinspring;

 /** *//**
/** *//**
 * 全排列算法示例
* 全排列算法示例
如果用P表示n个元素的排列,而Pi表示不包含元素i的排列,(i)Pi表示在排列Pi前加上前缀i的排列,那么,n个元素的排列可递归定义为:
如果n=1,则排列P只有一个元素i
如果n>1,则排列P由排列(i)Pi构成(i=1、2、 .、n-1)。
.、n-1)。
根据定义,容易看出如果已经生成了k-1个元素的排列,那么,k个元素的排列可以在每个k-1个元素的排列Pi前添加元素i而生成。
例如2个元素的排列是1 2和2 1,对3个元素而言,p1是2 3和3 2,在每个排列前加上1即生成1 2 3和1 3 2两个新排列,
p2和p3则是1 3、3 1和1 2、2 1,
按同样方法可生成新排列2 1 3、2 3 1和3 1 2、3 2 1。
* @author: sitinspring(junglesong@gmail.com)
* @date: 2008-3-25
 */
*/
public class Permutation<T>{

 public static void main(String[] args){
public static void main(String[] args){
String[] arr={"1","2","3"};
Permutation<String> a=new Permutation<String>();
a.permutation(arr,0,arr.length);
 }
}
public void permutation(T[] arr,int start,int end){
if(start<end+1){
permutation(arr,start+1,end);
for(int i=start+1;i<end;i++){
T temp;
temp=arr[start];
arr[start]=arr[i];
arr[i]=temp;
permutation(arr,start+1,end);
temp=arr[i];
arr[i]=arr[start];
arr[start]=temp;
}
}
else{
for(int i=0;i<end;i++){
System.out.print(arr[i]);
}
System.out.print("\n");
}
}
}
JNDI(Java Naming and Directory Interface)的中文意思是Java命名和目录接口。
借助于JNDI ,开发者能够通过名字定位用户,机器,网络,对象,服务。 JNDI的常见功能有定位资源,如定位到内网中一台打印机,定位Java对象或RDBMS(关系型数据库管理系统)等
在EJB,RMI,JDBC等JavaEE(J2EE)API技术中JNDI得到了广泛应用。JNDI为J2EE平台提供了标准的机制,并借助于名字来查找网络中的一切对象。
理解“命名和目录服务”
在掌握JNDI之前,开发者必须理解命名和目录服务。
名字类似于引用,即能标识某实体如对象,人等。在企业应用中,经常需要借助于名字实现对各种对象的引用,如借助于名字引用电话号码,IP地址,远程对象等。
命名服务类似于话务员,如果需要打电话给某人,但又不知道他的电话号码,于是将电话打到查询台,以便能够询问到用户的电话号码,打电话者需要提供人名给他。随后,话务员就能查到那人的电话号码。
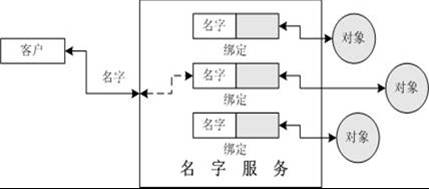
命名服务的功能
将名字与对象绑定在一起,这类似于电话公司提供的服务,比如将人名绑定到被叫端的电话。
提供根据名字查找对象的机制。这称为查找对象或者解析名字。这同电话公司提供的服务类似,比如根据人名查找到电话号码。
在现实的计算机环境中,命名服务很常见,如需要定位网络中的某台机器,则借助于域名系统(Domain Name System,DNS)能够将机器名转化成IP地址。
目录对象和目录服务
在命名服务中,借助名字能够找到任何对象,其中有一类对象比较特殊,它能在对象中存储属性,它们被称之为目录对象或称之为目录入口项(Directory Entry)。将目录对象连接在一起便构成了目录(Directory),它是一个树状结构的构成,用户可以通过节点和分支查找到每个目录对象。
目录服务是对命名服务的扩展,它能够依据目录对象的属性而提供目录对象操作。
JNDI的概念和主要用途
为实现命名和目录服务,基于java的客户端需要借助于JNDI系统,它为命名和目录服务架起了通信的桥梁。JNDI的主要用途有:
开发者使用JNDI,能够实现目录和Java对象之间的交互。
使用JNDI,开发者能获得对JAVA事务API中UserTransaction接口的引用。
借助于JNDI,开发者能连接到各种资源工厂,如JDBC数据源,Java消息服务等。
客户和EJB组件能够借助于JNDI查找到其他EJB组件。
名字,绑定和上下文的概念
JNDI中存在多种名字,一种是原子名,如src/com/sitinspring中的src,com和sitinspring;一种是复合名,它由0个或多个原子名构成,如src/com/sitinspring。
绑定就是将名字和对象关联起来的操作。如system.ini绑定到硬盘中的文件, src/com/sitinspring/.classpath分别绑定到三个目录和一个文件。
上下文(Context)由0个或多个绑定构成,每个绑定存在不同的原子名。如WEB-INF文件夹下分别含有.cvsignore和web.xml的文件名。在JNDI中, WEB-INF是上下文,它含有原子名.cvsignore和web.xml的绑定,它们分别绑定到硬盘中的文件。
上下文中也允许存在上下文,它们被成为子上下文(subcontext),子上下文和上下文类似,它也能含有多个名字到对象的绑定。这类似于文件夹下含有子文件夹。
命名系统和初始上下文
命名系统由一套连在一起的上下文构成,而且这些上下文使用了相同的命名语法。可以用目录树来类比这个概念。
浏览命名空间的起点称之为初始上下文(Initial Context),初始上下文类似于目录树中的根节点概念。
借助于初始上下文,能够开始命名和目录服务。
JNDI查找资源示例
try {
Context initCtx = new InitialContext();
// java:comp/env是命名空间,相当于是本机JNDI资源引用根目录
Context envCtx = (Context) initCtx.lookup("java:comp/env");
Member bean = (Member) envCtx.lookup("Member");
System.out.print("member name=" + bean.getMemberName() + " age="
+ bean.getAge());
} catch (NamingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
JNDI有关API
list():用于获得当前上下文的绑定列表
lookup():用于解析上下文中名字绑定,该操作将返回绑定到给定名字的对象。
rename():重新命名
createSubContext():从当前上下文创建子上下文。
destroySubContext():从当前上下文销毁子上下文。
bind()。从当前上下文中创建名字到对象的绑定。
rebind():再次绑定,如果已经存在同名绑定则覆盖之。
本文详细代码请见:
http://www.blogjava.net/sitinspring/archive/2008/03/14/186372.html
问题:将左边的SQL语句解析成右边的形式
Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2,g3 order by g2,g3
select
c1,
c2,
c3
from
t1,
t2,
t3
where
condi1=5 and
condi6=6 or
condi7=7
group by
g1,
g2,
g3
order by
g2,
g3
按关键字找出SQL语句中各部分
我们阅读SQL语句会把整句分来成列,表,条件,分组字段,排序字段来理解,解析SQL的目的也是这样.
分解SQL语句有规律可循,以列为例,它必定包含在select和from之间,我们只要能找到SQL语句中的关键字select和from,就能找到查询的列.
怎么找到select和from之间的文字呢?其实一个正则表达式就能解决:(select)(.+)(from),其中第二组(.+)代表的文字就是select和from之间的文字.
程序见右边.
/**
* 从文本text中找到regex首次匹配的字符串,不区分大小写
* @param regex: 正则表达式
* @param text:欲查找的字符串
* @return regex首次匹配的字符串,如未匹配返回空
*/
private static String getMatchedString(String regex,String text){
Pattern pattern=Pattern.compile(regex,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(text);
while(matcher.find()){
return matcher.group(2);
}
return null;
}
解析函数分析
private static String getMatchedString(String regex,String text){
Pattern pattern=Pattern.compile(regex,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(text);
while(matcher.find()){
return matcher.group(2);
}
return null;
}
左边的这个函数,第一个参数是拟定的正则表达式,第二个是整个SQL语句.
当正则表达式为(select)(.+)(from)时,程序将在SQL中查找第一次匹配的地方(有Pattern.CASE_INSENSITIVE的设置,查找不区分大小写),如果找到了则返回模式中的第二组代表的文字.
如果sql是select a,b from tc,则返回的文字是a,b.
选择的表对应的查找正则表达式
选择的表比较特殊,它不想选择的列一样固定处于select和from之间,当没有查找条件存在时,它处于from和结束之间;当有查找条件存在时,它处于from和where之间.
因此查询函数写为右边的形式:
/**
* 解析选择的表
*
*/
private void parseTables(){
String regex="";
if(isContains(sql,"\\s+where\\s+")){
regex="(from)(.+)(where)";
}
else{
regex="(from)(.+)($)";
}
tables=getMatchedString(regex,sql);
}
isContains函数
isContains函数用于在lineText中查找word,其中不区分大小些,只要找到了即返回真.
/**
* 看word是否在lineText中存在,支持正则表达式
* @param lineText
* @param word
* @return
*/
private static boolean isContains(String lineText,String word){
Pattern pattern=Pattern.compile(word,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(lineText);
return matcher.find();
}
解析查找条件的函数
private void parseConditions(){
String regex="";
if(isContains(sql,"\\s+where\\s+")){
// 包括Where,有条件
if(isContains(sql,"group\\s+by")){
// 条件在where和group by之间
regex="(where)(.+)(group\\s+by)";
}
else if(isContains(sql,"order\\s+by")){
// 条件在where和order by之间
regex="(where)(.+)(order\\s+by)";
}
else{
// 条件在where到字符串末尾
regex="(where)(.+)($)";
}
}
else{
// 不包括where则条件无从谈起,返回即可
return;
}
conditions=getMatchedString(regex,sql);
}
解析GroupBy的字段
private void parseGroupCols(){
String regex="";
if(isContains(sql,"group\\s+by")){
// 包括GroupBy,有分组字段
if(isContains(sql,"order\\s+by")){
// group by 后有order by
regex="(group\\s+by)(.+)(order\\s+by)";
}
else{
// group by 后无order by
regex="(group\\s+by)(.+)($)";
}
}
else{
// 不包括GroupBy则分组字段无从谈起,返回即可
return;
}
groupCols=getMatchedString(regex,sql);
}
解析OrderBy的字段
private void parseOrderCols(){
String regex="";
if(isContains(sql,"order\\s+by")){
// 包括order by,有分组字段
regex="(order\\s+by)(.+)($)";
}
else{
// 不包括GroupBy则分组字段无从谈起,返回即可
return;
}
orderCols=getMatchedString(regex,sql);
}
得到解析后的各部分
按以上解析方法获得了列,表,条件,分组条件,排序条件各部分之后,它们会存储到各个成员变量中.
注意这些成员变量的原值都是null,如果在SQL语句中能够找到对应的部分的话它们将借助getMatchedString获得值,否则还是null.我们通过判断这些成员变量是否为空就能知道它对应的部分是否被解析出来.
/**
* 待解析的SQL语句
*/
private String sql;
/**
* SQL中选择的列
*/
private String cols;
/**
* SQL中查找的表
*/
private String tables;
/**
* 查找条件
*/
private String conditions;
/**
* Group By的字段
*/
private String groupCols;
/**
* Order by的字段
*/
private String orderCols;
取得不需要单行显示时的SQL语句
进展到这一步,SQL语句中列,表,条件,分组条件,排序条件各部分都被获取了出来,这时把它们重新组合一下就能得到整理后的SQL语句.
如下面的SQL语句将变成右边的部分(先使静态成员isSingleLine=false):
Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2,g3 order by g2,g3
select
c1,c2,c3
from
t1,t2,t3
where
condi1=5 and condi6=6 or condi7=7
group by
g1,g2,g3
order by
g2,g3
进一步解析
有时我们需要把列,表,条件,分组条件,排序条件单行显示以方便查看或加上注释,这就要求我们对列,表,条件,分组条件,排序条件等进行进一步解析.
初看解析很方便,以固定的分隔符劈分即可,但需要注意的是查询条件中分隔符有and和or两种,如果贸然分隔会使重新组合时使SQL失真.
推荐一种做法,我们可以在分隔符后加上一个标志如空行,然后再以这个标志来劈分.这样就不会使SQL失真了.
请见下页的getSplitedParagraph函数.
getSplitedParagraph函数
private static List<String> getSplitedParagraph(String paragraph,String splitStr){
List<String> ls=new ArrayList<String>();
// 先在分隔符后加空格
Pattern p = Pattern.compile(splitStr,Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(paragraph);
StringBuffer sb = new StringBuffer();
boolean result = m.find();
while (result) {
m.appendReplacement(sb, m.group(0) + Crlf);
result = m.find();
}
m.appendTail(sb);
// 再按空格断行
String[] arr=sb.toString().split("[\n]+");
for(String temp:arr){
ls.add(FourSpace+temp+Crlf);
}
return ls;
}
处理结果
把静态成员变量isSingleLine=true后我们来看看执行结果:
select
c1,
c2,
c3
from
t1,
t2,
t3
where
condi1=5 and
condi6=6 or
condi7=7
group by
g1,
g2,
g3
order by
g2,
g3
小结
从这个例子中我们体会了分治的思想:分治是把一个大问题分解成小问题,然后分别解决小问题,再组合起来大问题的解决方法就差不多了.这种思想在工程领域解决问题时很普遍,我们要学会使用这种思想来看待,分析和解决问题,不要贪多求大,结果导致在大问题面前一筹莫展.
其次我们可以从这个例子中学习找规律,然后借助规律的过程,现实世界千变万化,但都有规律可循,只要我们找到了规律,就等于找到了事物之门的钥匙.
接下了我们复习了正则表达式用于查找的方法,以前的正则表达式学习多用于验证匹配,其实这只是正则表达式的一部分功能.
最后从解析条件成单行的过程中,我们可以学习到一种解决问题的技巧,即当现实中的规律存在变数时加入人为设置的规律,这有时能使我们更好更快的解决问题.
在XHTML中CSS的意义
传统的HTML能够并已经创建了大量优秀美观使用的网页,但随着时代的发展和客户要求的逐步提高,传统HTML网页将网页的数据,表现和行为混杂的方式妨碍了自身可维护性和精确性的提高。
在XHTML中,CSS能把网页的数据和表现(主要是格式和样式规则)分隔开来,使人对网页能有更精确细致的控制,同时可维护性也变得更好,更方便。
在本文中,我们将学习CSS的相关知识。
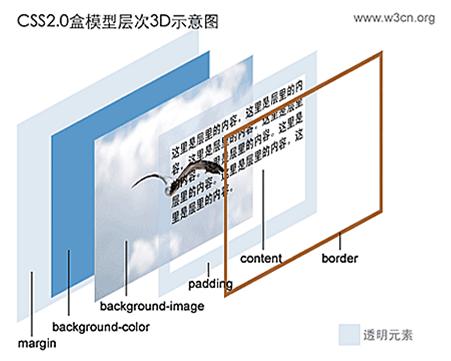
框模型
在CSS处理网页时,它认为网页包含的每一个元素都包含在一个不可见的框中,这个框由内容(Content),内容外的内边距(padding),内边距的外边框(border)和外边框的不可见空间-外边距(margin)组成。
块级元素和行内元素
在XHTML中,元素可能是块级(block)的,也可能是行级(inline)的。
块级元素会产生一个新行(段落),而行级元素是行内的,不会产生新行(段落)。
常见的块级元素有div,p等,常见的行级元素有a,span等。
在默认情况下,元素按照在XHTML中从上到下的次序显示,并且在每个块级元素的框的开头和结尾换行。
注意:块级元素和行级元素不是绝对的,我们可以通过样式设置来改变元素的这个属性。
元素的基本属性
内边距:padding
边框:border
外边距:margin
大小:width,height
对齐:text-align
颜色:color
背景:background
使元素浮动:float
下面将讲述如何对这些元素属性进行设置。
改变元素背景
Background有以下子属性:
background-color:背景颜色,默认值transparent,输入#rrggbb即可。
background-image:背景图像,默认值none
background-repeat:背景图像的重复显示,默认值repeat(纵横重复),repeat-x(水平重复),repeat-y(垂直重复),no-repeat(使图像不并排显示)
background-attachment:默认值scroll,表示随页面滚动,如果是fixed则不随页面滚动。
background-posistion:默认值top left。
这些属性也可以统一设置,如:background:#ccc url(theadbg.gif) repeat-x left center;
例:
TABLE.Listing TH {
FONT-WEIGHT: bold;
background:#ccc url(theadbg.gif) repeat-x left center;
BORDER-BOTTOM: #6b86b3 1px solid
}
设定元素的大小
设置width和height即可,如:
width:180px;
height:50%;
注意这里可以设置绝对大小如180px也可以设置相对大小50%,其中百分数是相对与父元素的比例,父元素即容纳本元素的元素。
此外设置元素大小还可以使用min-width,max-width,max-height,min-height等,但在部分浏览器中不支持这些属性。
例:
#content{
width:640px;
height:500px;
float:right;
background:#f8f8f8;
}
Px和em的区别
px像素(Pixel)。相对长度单位。像素px是相对于显示器屏幕分辨率而言的。(引自CSS2.0手册)
em是相对长度单位。相对于当前对象内文本的字体尺寸。如当前对行内文本的字体尺寸未被人为设置,则相对于浏览器的默认字体尺寸。(引自CSS2.0手册) 任意浏览器的默认字体高都是16px。所有未经调整的浏览器都符合: 1em=16px。那么12px=0.75em, 10px=0.625em。为了简化font-size的换算,需要在css中的body选择器中声明Font-size=62.5%,这就使em值变为 16px*62.5%=10px, 这样12px=1.2em, 10px=1em, 也就是说只需要将你的原来的px数值除以10,然后换上em作为单位就行了。
设置元素的外边距
外边距是一个元素与下一个元素之间的透明空间量,位于元素的边框外边。
设置外边距设置margin的值即可,如margin:1;它将应用与四个边。
如果要为元素的上右下左四个边设置不同的外边距,可以设置margin-top,margin-right,margin-bottom,margin-left四个属性。
例:
fieldset{
margin:1em 0;
padding:1em;
border:1px solid #ccc;
background:#f8f8f8;
}
添加元素的内边距
内边距是边框到内容的中间空间。使用它我们可以把内容和边界拉开一些距离。
设置内边距如右:padding:1px;
如果要为元素的上右下左四个边设置不同的内边距,可以设置padding-top,padding-right,padding-bottom,padding-left四个属性。
例:
li{
padding-left:10px;
}
控制元素浮动
float属性可以使元素浮动在文本或其它元素中,这种技术的最大用途是创建多栏布局(layout)
float可以取两个值:left,浮动到左边,right:浮动到右边
例:
#sidebar{
width:180px;
height:500px;
float:left;
background:#f8f8f8;
padding-top:20px;
padding-bottom:20px;
}
#content{
width:640px;
height:500px;
float:right;
background:#f8f8f8;
}
设置边框
边框位于外边距和内边距中间,在应用中常用来标示特定的区域。它的子属性有:
border-style:可以设定边框的样式,常见的有solid,dotted,dashed等。
border-width:边框的宽度。
border-color:边框颜色
border-top,border-right,border-bottom,border-left可以把边框限制在一条或几条边上。
例:
ul a{
display:block;
padding:2px;
text-align:center;
text-decoration:none;
width:130px;
margin:2px;
color:#8d4f10;
}
ul a:link{
background:#efb57c;
border:2px outset #efb57c;
}
控制元素内容的对齐
text-align属性可以让我们设置元素内容的对齐,它可以取的值有left,center,right等。
例:
body{
margin:0 auto;
text-align:center;
min-width:760px;
background:#e6e6e6;
}
#bodyDiv{
width:822px;
margin:0 auto;
text-align:left;
background:#f8f8f8;
border:1px solid #FFFFFf;
}
控制元素在父元素的垂直对齐
设置vertical-align可以控制元素在父元素的垂直对齐位置,它可以取的值有:
middle:垂直居中
text-top:在父元素中顶对齐
text-bottom:是元素的底线和父元素的底线对齐。
在网页中引入样式表
<title>"記賬系统"单项收支记录浏览页面</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script src="web/js/ajax.js" type="text/javascript"></script>
<link rel="stylesheet" rev="stylesheet" href="web/css/style.css"
type="text/css" />
</head>
样式表示例
body{
margin:0 auto;
text-align:center;
min-width:760px;
background:#e6e6e6;
}
#bodyDiv{
width:822px;
margin:0 auto;
text-align:left;
background:#f8f8f8;
border:1px solid #FFFFFf;
}
TABLE.Listing {
MARGIN: 0px 0px 8px;
WIDTH: 92%;
BORDER-BOTTOM: #6b86b3 3px solid
}
#content{
width:640px;
height:500px;
float:right;
background:#f8f8f8;
}
#content h1,#content h2,#content p{
padding-left:20px;
}
#footer{
clear:both;
}
fieldset{
margin:1em 0;
padding:1em;
border:1px solid #ccc;
background:#f8f8f8;
}
如何知道页面元素对应样式表的那部分?
如果页面元素设置了id,则它对应的样式表部分是#id,如#bodyDiv。
如果页面元素设定了class,则它在样式表中寻找”元素类型.class”对应的部分,如TABLE.Listing。
如果没有写明,则元素会找和自己类型对应的样式设置,如fieldset。
注意CSS中没有大小写的区别。
例:
<div id="content">
<table id="TbSort" class="Listing" width=100% align=center>
<fieldset><legend>添加账目</legend>
JavaScript的运行环境和代码位置
编写JavaScript脚本不需要任何特殊的软件,一个文本编辑器和一个Web浏览器就足够了,JavaScript代码就是运行在Web浏览器中。
用JavaScript编写的代码必须嵌在一份html文档才能得到执行,这可以通过两种方法得到,第一种是将JavaScript代码直接写在html文件中,这多用于仅适用于一个页面的JS程序;另一种是把JavaScript代码存入一个独立的文件中(.js作为扩展名),在利用<Script>标签的src属性指向该文件.
将JavaScript直接嵌入页面文件中
<%@ page contentType="text/html; charset=UTF-8" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>欢迎进入"我的事务备忘录"</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script src="web/js/strUtil.js" type="text/javascript"></script>
</head>
<body>
<div>这个页面应该很快消失,如果它停止说明Web容器已经停止运作了,或JavaScript功能未开启
<form method=post action="ShowPage?page=login">
</form>
<div>
</body>
</html>
<script LANGUAGE="JavaScript">
<!--
document.body.onload=function(){
document.forms[0].submit();
}
//-->
</script>
将JavaScript存入单独的文件中(页面文件)
<%@ page contentType="text/html; charset=UTF-8" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>"我的事务备忘录"用户登录页面</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script src="web/js/ajax.js" type="text/javascript"></script>
<link rel="stylesheet" rev="stylesheet" href="web/css/style.css"
type="text/css" />
</head>
<body>
<div id="branding">欢迎进入"个人事务备忘录",请输入您的用户名和密码,再按登录键登录
<form method=post action="ShowPage?page=loginCheck">
<table bgcolor="#ffffff" id="TbSort" class="Listing" width="200" align=center>
<tbody id="loginTable">
<tr><th align="center" colspan=3>用户登录.</th></tr>
<tr>
<td width=50>用户名:</td>
<td width=150><input type="text" name="userName" value=""
style="width: 300px; height: 20px" /></td>
</tr>
<tr>
<td width=50>密码:</td>
<td width=150><input type="text" name="userPswd" value=""
style="width: 300px; height: 20px" /></td>
</tr>
<tr>
<td width=50></td>
<td width=150><input type="submit" value="登录"
style="width: 100px; height: 20px" /></td>
</tr>
</tbody>
</table>
</form>
<div>
</body>
</html>
将JavaScript存入单独的文件中(ajax.js)
var prjName="/MyTodoes/";
var ajaxObj;
function createAjaxObject(){
try{return new ActiveXObject("Msxml2.XMLHTTP");}catch(e){};
try{return new ActiveXObject("Microsoft.XMLHTTP");}catch(e){};
try{return new XMLHttpRequest();}catch(e){};
alert("XmlHttpRequest not supported!");
return null;
}
function $(id){
return document.getElementById(id);
}
JavaScript中的语句和注释
JavaScript中的语句和Java中一样,也是一行书写一条语句,末尾加上分号’;’,虽然js中也可以把多条语句写在一行,但推荐不要这样做.
JavaScript中注释也和Java中一样,以// 来注释单行,/*….*/来注释多行,虽然HTML风格的注释<!-- ***** --> 在JS中也有效,但建议不要这样做.
JavaScript中的变量
在js中,变量允许字母,数字,美元符号和下划线字符.变量定义使用var关键字,如
var age;
age=23;
var name=“andy”;
虽然js允许程序员可以直接对变量进行赋值而无需提前对它们做出声明,但我们强烈建议不要这样做.
Js中变量和其它语法元素都是区分字母大小写的,如变量age,Age,AGE没有任何关系,它们都不是同一个变量.
JavaScript是一种弱类型语言
和强制要求程序员对数据类型做出声明的强类型(Strongly typed)程序设计语言如java,C#等不一样,js不要求程序员进行类型说明,这就是所谓的弱类型”weakly typed”语言.这意味着程序员可以随意改变某个变量的数据类型.
以下写法在Java中是绝对不允许的,但在js中完全没有问题:
var age=23;
age=“Twenty three”
Js并不关心age的值是字符串还是变量.
JavaScript中的数据类型-字符串
字符串必须放在单引号或双引号中.如
var name=“Andy”;
var name=‘Bill’;
一般情况下宜使用双引号,但如果字符串中有双引号则应该把字符串放在单引号中,反之则应该把字符串放在双引号中.
JavaScript中的数据类型-数值
Js中并没有int,float,double,long的区别,它允许程序员使用任意位数的小数和整数,实际上js中的数值应该被称为浮点数.
如:
var salary=10000;
var price=10.1;
var temperature=-6;
JavaScript中的数据类型-布尔值
Js中的布尔值和Java中的一致,true表示真,false表示假,如:
var isMale=true;
var isFemale=false;
注意布尔值true和false不要写成了字符串”true”和’false’.
JS中的函数
如果需要多次使用同一组语句,可以把这些语句打包成一个函数。所谓函数就是一组允许人们在代码中随时调用的语句。从效果上看,每个函数都相当于一个短小的脚本。
和Java中每个函数都在类中不一样,JS中函数不必属于一个类,在使用上它类似于Java中的静态公有函数,只要引入这个函数所在的文件就可以使用它。
JS中函数的语法
JS中,一个函数的大致语法如下:
function fname(args){
statements;
}
Function是函数的固定标志;fname是函数名;args是函数参数,它可以有很多个,只要你把它们用逗号分割开来即可;statements是其中的语句,每句结尾都和java中一样用“;”表示结束。
在定义了这个函数的脚本(页面)中,你可以从任意位置去调用这个函数;引入这个页面后,你还可以从其它页面访问它。
一般来说,对于共通性强,适用面广,会在多个页面中调用的函数,我们一般把它们放在一个JS页面中,然后由需要使用这些函数的页面引入它们;而对于只适用于一个页面的函数,还是把它放在单个页面中较好。
JS函数的返回值
在JS中,函数不仅能够以参数的形式接受数据,运行代码,它和其它编程语言中的函数一样,可以返回数据。
让JS函数返回数据,你不需要也不能在函数签名上动任何手脚,只需要用return语句返回你想返回的数字即可,举例如下:
function substract(op1,op2){
return op1-op2; }
}
JS中变量的作用域
在JS中,我们提倡用var来定义一个变量,凡是变量就会有作用域的问题,根据定义方式和位置的不同,它既可能是全局的,也有可能是局部的。
用var定义在脚本文件中,不属于任何一个函数的变量,它的作用域就是全局性的,它可以在脚本中的任何位置被引用,包括有关函数的内部。全局变量的作用域是整个脚本。
用var定义在函数中的变量,它的作用域就是局部性的,它的作用域仅限于这个函数,在函数的外部是无法使用它的。
不用var定义在函数中的变量,它的作用域是全局的,如果你的脚本里已经存在一个与之同名的变量,这个函数将覆盖那个现有变量的值。
定义函数时,我们必须明确的把它内部的变量都明确的声明为局部变量,如果从来没有忘记在函数中使用var关键字,就可以避免任何形式的二义性隐患。
JS中的数组
在JS中,我们使用Array关键字声明数组,在声明时对数组长度进行限定,如:
var arr=Array(3);
有时运行起来才知道数组长度,JS中我们也可以这样定义数组:
var arr=Array();
向数组中添加元素时你需要给出新元素的值,还需要在数组中为新元素制定存放位置,这个位置由下标给出,如arr[1]=4。
在JS中定义数组的例子
定义方式一:
var arr=Array(3);
arr[0]=“刘备”; arr[1]=“关于”; arr[2]=“张飞”;
定义方式二:
var arr=Array();
arr[0]=3; arr[1]=4;arr[2]=5;
定义方式三:
Var arr=Array(“1”,2,true);
定义方式四:
var arr=[“征东”,”平西”,”镇南”,”扫北”];
摘要: 考试分数排序是一种特殊的排序方式,从0分到最高分都可能有成绩存在,如果考生数量巨大如高考,大量考生都在同一分数上,如果需要从低到高排序的话,很多同样分数的成绩也被比较了,这对排序结果是没有意义的,因为同一分数不需要比较,对于这种情况如果使用传统排序就会有浪费,如果先按分数建立好档次,再把考生成绩按分数放入档次就可以了。下面分别列出了三种方案的代码和比较结果:
学生类:
package&nb...
阅读全文
摘要: 成员类:
package com.junglesong;
public class Member implements Comparable{
private String name;
private int&n...
阅读全文
package com.junglesong;
/** *//**
* 二分查找示例
* @author: sitinspring(junglesong@gmail.com)
* @date: 2008-3-8
*/
public class BinSearch{
public static void main(String[] args){
// 欲查找的数组
int[] arr={1,2,3,4,5,6,77,88,656,5000,40000};
// 测试数组
int[] temp={4,5,6,77,88,656,1,2,400};
for(int i:temp){
System.out.println("值"+i+"的下标为"+binSearch(arr,i));
}
}
/** *//**
* 二分查找
* @param sortedArray 已排序的欲查找的数组
* @param seachValue 查找的值
* @return 找到的元素下标,若找不到则返回-1
*/
public static int binSearch(int[] sortedArray,int seachValue){
// 左边界
int leftBound=0;
// 右边界
int rightBound=sortedArray.length-1;
// 当前下标位置
int curr;
while(true){
// 定位在左边界和右边界中间
curr=(leftBound+rightBound)/2;
if(sortedArray[curr]==seachValue){
// 找到值
return curr;
}
else if(leftBound>rightBound){
// 左边界大于右边界,已经找不到值
return -1;
}
else{
if(sortedArray[curr]<seachValue){
// 当当前下标对应的值小于查找的值时,缩短左边界
leftBound=curr+1;
}
else{
// 当当前下标对应的值大于查找的值时,缩短右边界
rightBound=curr-1;
}
}
}
}
}
代码下载:
http://www.blogjava.net/Files/junglesong/BinSearch20080308150836.rar
摘要: 原题(这里使用了数组代替集合)
有两个数组:
String[] arr01={"Andy","Bill","Cindy","Douglas","Felex","Green"};
String[] arr02={"Andy","Bill","Felex","Green","Gates"};
求存在于arr01而不存在于arr02的元素的集合?
最容易想到的解法-双重循环
packag...
阅读全文
适于表现表单的表单元素
Xhtml中提供了一些有用的元素用来在表单中增加结构和定义,它们是fieldset,legend和label。
Fieldset用来给相关的信息块进行分组,它在表现上类似于Swing中的border和VS中的frame。
Legend用来标识fieldset的用户,它相当于border的标题文字。
Label元素可以用来帮助添加结构和增加表单的可访问性,它用来在表单元素中添加有意义的描述性标签。
fieldset,legend和label的例图

页面代码
<form method=post action="#" onsubmit="return checkForm()">
<table width=200 bgcolor="#f8f8f8">
<tr><td>
<fieldset><legend>用户注册</legend>
<p><label for="name">用户名:</label><input type="text" name="name"
value="" /></p>
<p><label for="pswd">密码:</label><input type="text" name="pswd"
value="" /></p>
<p><label for="pswd">再次输入密码:</label><input type="text" name="pswd2"
value="" /></p>
<p><input type="button"
value="注册"/></p>
</fieldset>
</td></tr>
</table>
</form>
未加样式的效果

样式表中的设定
fieldset{
margin:1em 0;
padding:1em;
border:1px solid #ccc;
background:#f8f8f8;
}
legend{
font-weight:bold;
}
label{
display:block;
}
其中值得注意的是label的display属性设置为了block。Label默认是行内元素,但将display属性设置为了block后使其产生了自己的块框,是自己独占一行,因此输入表单就被挤到了下一行,形成了下图的效果。

加入上述样式的效果
More…
表单元素因为输入数据的限制经常宽度不一,当需要个别调整大小是可以这样设置:
<input type="text" name="negetiveinteger"
value="-1" style="width: 200px; height: 20px" />
加入必填字段的标识
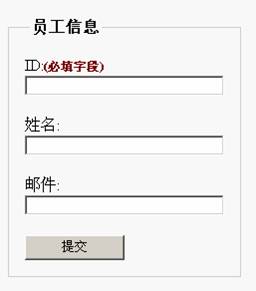
在许多表单中有必填字段,我们可以在label中使用Strong来表示出来。代码如下:
<label for="letterOrInteger">ID:<strong class="required">(必填字段)</strong></label>
样式设定如下:
.required{
font-size:12px;
color:#760000;
}
表单反馈效果
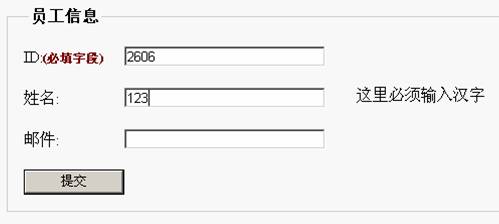
表单反馈样式及页面代码
fieldset{
margin:1em 0;
padding:1em;
border:1px solid #ccc;
background:#f8f8f8;
}
legend{
font-weight:bold;
}
label{
width:100px;
}
.feedbackShow{
position:absolute;
margin-left:11em;
left:200px;
right:0;
visibility: visible;
}
.feedbackHide{
position:absolute;
margin-left:11em;
left:200px;
right:0;
visibility: hidden;
}
.required{
font-size:12px;
color:#760000;
}
<table width=100% bgcolor="#f8f8f8">
<tr><td>
<fieldset><legend>员工信息</legend>
<p><label for="letterOrInteger">ID:<strong class="required">(必填字段)</strong></label><span id="idMsg" class="feedbackHide">这里必须输入英语或数字</span><input type="text" name="letterOrInteger"
value="" style="width: 200px; height: 20px" /></p>
<p><label for="character">姓名:</label><span id="nameMsg" class="feedbackHide">这里必须输入汉字</span><input type="text" name="character"
value="" style="width: 200px; height: 20px" /></p>
<p><label for="email">邮件:</label><span id="emailMsg" class="feedbackHide">这里必须输入符合邮件地址的格式</span><input type="text" name="email"
value="" style="width: 200px; height: 20px" /></p>
<p><input type="submit"
value="提交" style="width: 100px; height: 25px"/></p>
</fieldset>
</td></tr>
</table>
JavaScript验证代码
/**
* 检查验证
*/
function checkForm(){
// 英数字验证
var letterOrInteger=$("letterOrInteger").value;
if(isLetterOrInteger(letterOrInteger)==false){
$("letterOrInteger").focus();
$("idMsg").className="feedbackShow";
return false;
}
else{
$("idMsg").className="feedbackHide";
}
// 汉字验证
var character=$("character").value;
if(isCharacter(character)==false){
$("character").focus();
$("nameMsg").className="feedbackShow";
return false;
}
else{
$("nameMsg").className="feedbackHide";
}
// 邮件验证
var email=$("email").value;
if(isEmail(email)==false){
$("email").focus();
$("emailMsg").className="feedbackShow";
return false;
}
else{
$("emailMsg").className="feedbackHide";
}
return false;
}
Tomcat示例工程下载:
http://www.blogjava.net/Files/junglesong/CssTest20080305000633.rar
摘要: 分数排序的特殊问题
在java中实现排序远比C/C++简单,我们只要让集合中元素对应的类实现Comparable接口,然后调用Collections.sort();方法即可.
这种方法对于排序存在许多相同元素的情况有些浪费,明显即使值相等,两个元素之间也要比较一下,这在现实中是没有意义的.
典型例子就是学生成绩统计的问题,例如高考中,满分是150,成千上万的学生成绩都在0-150之间,平均一...
阅读全文
1.Collection接口
Java集合类中最基础的接口是Collection,它定义了两个基本方法:
Public interface Collection<E>{
boolean add(E element);
Iterator<E> iterator();
}
add是向Collection中添加一个元素,当添加的内容确实对Collection发生了有效变更的话add方法返回真,否则返回假,比如你向一个Set添加重复的元素时,Set内容不会变化,add方法会返回假。
iterator方法返回实现了Iterator接口的对象,你可以借此对Collection中的内容进行挨个遍历。
2.Iterator接口
Iterator有三个方法:
Public interface Iterator<E>{
E next();
boolean hasNext();
void remove();
}
通过重复调用next方法,你可以挨个遍历Collection中的元素。然而,当遍历到Collection末端时,此方法会抛出一个NoSuchElementException异常,因此在遍历时你就需要hasNext方法和next方法配合使用。 hasNext方法在当前遍历位置后仍有元素时会返回真。配合例子如下:
Collection<String> c=….;
Iterator<String> iterator=c.iterator();
While(iterator.hasNext()){
String str=iterator.next();
…….
}
remove方法能删除上一次调用next时指向的元素,注意不能连续两次调用remove方法,否则会抛出IllegalStateException.
3.Collection接口的其它方法
int size():返回当前存储的元素个数
boolean isEmpty():当集合中没有元素时返回真
boolean contains(Object obj):当集合中有元素和obj值相等时返回真.
boolean containsAll(Collection<?> other):当集合包含另一集合的全部元素时返回真.
bBoolean addAll (Collection<? extends E> other):把其它集合中的元素添加到集合中来,当此集合确实发生变化时返回真.
boolean remove(Object obj):删除一个和obj值相等的元素,当吻合的元素被删除时返回真.
boolean removeAll(Collection<?> other) :从本集合中删除和另一集合中相等的元素,当本集合确实发生变化时返回真.(差集)
void clear():清除集合中的所有元素
boolean retainAll(Collection<?> other) :从本集合中删除和另一集合中不相等的元素,当本集合确实发生变化时返回真.(交集)
Object[] toArray()
返回由集合中元素组成的数组
4.实现了Collection接口的具体类
ArrayList:带下标的队列,增加和收缩时都是动态的.
LinkedList:有序队列,在任意位置插入和删除都是高效的.
HashSet:不存在重复的非排序集合.
TreeSet:自动排序的不存在重复的集合.
LinkedHashSet:保持了插入时顺序的哈希表
PriorityQueue:优先级队列,能有效的删除最小元素.
5.没有重复元素存在的集合HashSet
HashSet通过哈希码来查找一个元素,这比链表的整体查找要迅速得多,但是由此带来的缺陷时它不能保持插入时的顺序.
由于HashSet靠hash码来识别元素,因此它不能包含重复元素,当集合中已经存在值相等的元素时,再次添加同样的元素HashSet不会发生变化.
Set<String> hashSet=new HashSet<String>();
hashSet.add("Andy");
hashSet.add("Andy");
hashSet.add("Bill");
hashSet.add("Cindy");
hashSet.add("Bill");
hashSet.add("Cindy");
Iterator<String> iter=hashSet.iterator();
while(iter.hasNext()){
System.out.println(iter.next());
}
输出:
Cindy
Andy
Bill
6.自动排序的集合 TreeSet
TreeSet和HashSet类似但它值得一提的一点是无论你以何顺序插入元素,元素都能保持正确的排序位置,这时因为TreeSet是以红黑树的形式存储数据,在插入时就能找到正确的位置.注意插入TreeSet的元素都要实现Comparable接口.
例:
SortedSet<String> treeSet=new TreeSet<String>();
treeSet.add("Andy");
treeSet.add("Andy");
treeSet.add("Bill");
treeSet.add("Cindy");
treeSet.add("Bill");
treeSet.add("Cindy");
Iterator<String> iter=treeSet.iterator();
while(iter.hasNext()){
System.out.println(iter.next());
}
输出:
Andy
Bill
Cindy
7.优先级队列PriorityQueue
PriorityQueue使用一种名为堆的二叉树高效的存储数据,它检索数据是按排序的顺序而插入则随意,当你调用remove方法时,你总能得到最小的元素.但PriorityQueue并不按序排列它的元素,当你遍历时它是不会排序的,这也没有必要. 在制作一个按优先级执行日程安排或事务安排时你应该首先想到PriorityQueue。
例:
PriorityQueue<String> pq=new PriorityQueue<String>();
pq.add("Cindy");
pq.add("Felix");
pq.add("Andy");
pq.add("Bill");
Iterator<String> iter=pq.iterator();
while(iter.hasNext()){
System.out.println(iter.next());
}
while(!pq.isEmpty()){
System.out.println(pq.remove());
}
8.保持插入顺序的哈希表LinkedHashMap
从1.4起Java集合类中多了一个LinkedHashMap,它在HashMap的基础上增加了一个双向链表,由此LinkedHashMap既能以哈希表的形式存储数据,又能保持查询时的顺序.
Map<String,String> members=new LinkedHashMap<String,String>();
members.put("001", "Andy");
members.put("002", "Bill");
members.put("003", "Cindy");
members.put("004", "Dell");
Iterator<String> iter=members.keySet().iterator();
while(iter.hasNext()){
System.out.println(iter.next());
}
Iterator<String> iter2=members.values().iterator();
while(iter2.hasNext()){
System.out.println(iter2.next());
}
9.自动按键进行排序的哈希表TreeMap
Map<String,String> members=new TreeMap<String,String>();
members.put("001", "Andy");
members.put("006", "Bill");
members.put("003", "Cindy");
members.put("002", "Dell");
members.put("004", "Felex");
for(Map.Entry<String,String> entry:members.entrySet()){
System.out.println("Key="+entry.getKey()+" Value="+entry.getValue());
}
10.1 集合工具类Collections的方法unmodifiable
此方法构建一个不可更改的集合视图,当使用其修改方法时会抛出一个UnsupportedOperationException
static Collection<E> unmodifiableCollection(Collection<E> c)
static List<E> unmodifiableList (List<E> c)
static Set<E> unmodifiableSet (Set<E> c)
static SortedSet<E> unmodifiableSortedSet (SortedSet<E> c)
static Map<K,V> unmodifiableMap (Map<K,V> c)
static SortedMap<K,V> unmodifiableSortedMap (SortedMap<K,V> c)
10.2 集合工具类Collections的方法synchronized
此方法会返回一个线程安全的集合视图
static Collection<E> synchronizedCollection(Collection<E> c)
static List<E> synchronizedList (List<E> c)
static Set<E> synchronizedSet (Set<E> c)
static SortedSet<E> synchronizedSortedSet (SortedSet<E> c)
static Map<K,V> synchronizedMap (Map<K,V> c)
static SortedMap<K,V> synchronizedSortedMap (SortedMap<K,V> c)
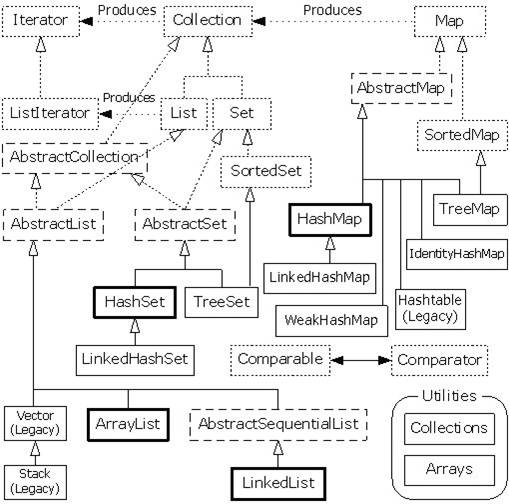
集合类静态类图
使用表格渲染器渲染表格
在使用JTable时,用户往往希望改变它缺省的渲染方式,比如使用间隔色的行,对特定的单元格进行特殊颜色显示等,这对一些可视化编程环境的表格并不是一件容易的事。
在Java Swing编程中我们可以使用DefaultTableCellRenderer的子类渲染表格来达到这个目的,实现和使用它都非常容易。
渲染效果一:

步骤一:实现一个javax.swing.table.DefaultTableCellRenderer的子类
/**
* 间隔色表格渲染类
*/
public class ColorTableCellRenderer extends DefaultTableCellRenderer {
private static final long serialVersionUID = -3378036327580475639L;
public Component getTableCellRendererComponent(
JTable table,
Object value,
boolean isSelected,
boolean hasFocus,
int row,
int column) {
// 得到单元格
Component cell =
super.getTableCellRendererComponent(
table,
value,
isSelected,
hasFocus,
row,
column);
// 进行渲染
if (hasFocus) {
// 如果获得焦点则设置背景色为红色
cell.setBackground(Color.red);
//cell.setForeground(Color.black);
} else {
if ((row % 2) == 0) {
// 偶数行设置为白色
cell.setBackground(Color.white);
} else {
// 奇数行设置为蓝色
cell.setBackground(Color.cyan);
}
}
return cell;
}
}
步骤二:将ColorTableCellRenderer设置为表格的渲染器
try {
ColorTableCellRenderer cellRender = new ColorTableCellRenderer();
table.setDefaultRenderer(Class.forName("java.lang.Object"),
cellRender);
} catch (Exception e) {
e.printStackTrace();
}
实现一个将特定单元格设置为红色的表格渲染器
如右,如果想将成员年龄大于37的单元格设置为红色。
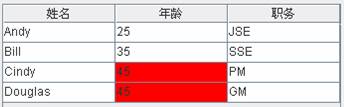
AgeTableCellRenderer的代码
public class AgeTableCellRenderer extends DefaultTableCellRenderer {
private static final long serialVersionUID = -334535475639L;
public Component getTableCellRendererComponent(
JTable table,
Object value,
boolean isSelected,
boolean hasFocus,
int row,
int column) {
// 得到单元格
Component cell =
super.getTableCellRendererComponent(
table,
value,
isSelected,
hasFocus,
row,
column);
// 先把所有单元格设置为白色
cell.setBackground(Color.white);
// 进行渲染
if (table.getColumnName(column).equals("年龄") ) { // 如果列名等于“年龄”
// 取得单元格的文字
String strValue=(String)value;
if(Pattern.matches("\\d+", strValue)){
if(Integer.parseInt(strValue)>37){
// 如果是数字且值大于37,将单元格背景设置为红色
cell.setBackground(Color.red);
}
}
}
return cell;
}
}
树和节点的基本概念
树可以用图形的方式显示众多的节点以及它们之间的关系,最常见的树的例子就是目录树。
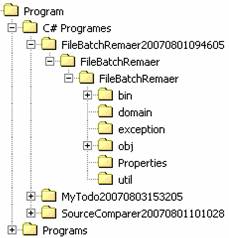
所有组成树的元素都成为节点(Node),一棵树的最顶层的节点称为根节点,如Program;而没有子节点的节点成为叶子节点,如domain。在层次结构中,上层的节点是下层节点的父节点,而下层节点是上层节点的子节点,如图:Program是C# Programs和Programs的父节点;FileBatchRemaer20070801094605是C# Programes的子节点。
有关树JTree的类和接口
JTree 显示树的核心基本类。
TreeModel 定义了树的数据模型接口
DefaultTreeModel 默认的树模型接口实现类
TreeModelListener 树模型的事件监听器
TreePath 树路径。一个路径就是一个对象数组,对应于树模型中从根节点到选定节点上的所有节点集合。数组的第一个元素是根节点,按树的层次关系依次在数组中给出中间节点,最后一个元素是选定的节点。
MutableTreeNode 树节点接口。对应树中的节点。树节点接口定义了与父子节点有关的方法。因此,利用树节点可以遍历整棵树。
DedaultMutableTreeNode 默认的树节点的实现类。
TreeSelectionModel 定义了在树上的选择节点的数据模型接口。树选择模型决定了选择节点的策略以及被选择节点的信息。
TreeSelectionModelListener 树选择模型事件的监听器。
代码实例:构建一棵树
DefaultMutableTreeNode root = new DefaultMutableTreeNode("Java");
DefaultMutableTreeNode j2seNode=new DefaultMutableTreeNode("J2SE(JavaSE)");
DefaultMutableTreeNode swingNode=new DefaultMutableTreeNode("Swing");
DefaultMutableTreeNode socketNode=new DefaultMutableTreeNode("Socket");
DefaultMutableTreeNode threadNode=new DefaultMutableTreeNode("Thread");
j2seNode.add(swingNode);
j2seNode.add(socketNode);
j2seNode.add(threadNode);
DefaultMutableTreeNode j2eeNode=new DefaultMutableTreeNode("J2EE(JavaEE)");
DefaultMutableTreeNode jspservletNode=new DefaultMutableTreeNode("Jsp/Servlet");
DefaultMutableTreeNode jdbcNode=new DefaultMutableTreeNode("JDBC");
DefaultMutableTreeNode javaMailNode=new DefaultMutableTreeNode("Java Mail");
j2eeNode.add(jspservletNode);
j2eeNode.add(jdbcNode);
j2eeNode.add(javaMailNode);
root.add(j2seNode);
root.add(j2eeNode);
tree = new JTree(root);

相关语句解释
// 创建一个树节点,文字为J2SE(JavaSE)
DefaultMutableTreeNode j2seNode=new DefaultMutableTreeNode("J2SE(JavaSE)");
// 创建一个文字为“Swing”的节点,添加在节点j2seNode下
DefaultMutableTreeNode swingNode=new DefaultMutableTreeNode("Swing");
j2seNode.add(swingNode);
// 创建一个文字为Java的节点作为根节点,然后以此根节点构建一棵树。j2seNode,j2eeNode挂在root 下
DefaultMutableTreeNode root = new DefaultMutableTreeNode("Java");
.......
root.add(j2seNode);
root.add(j2eeNode);
tree = new JTree(root);
注意: JTree和JTextArea,JTable一样,也需要放在一个JScrollPane中。
给树控件添加监听
tree.addTreeSelectionListener(new TreeSelectionListener() {
public void valueChanged(TreeSelectionEvent evt) {
// 取得选择状态变化的所有路径
TreePath[] paths = evt.getPaths();
for (int i=0; i<paths.length; i++) {
// 如果处于选择状态
if (evt.isAddedPath(i)) {
// 将路径转化为节点数组
Object[] nodes=paths[i].getPath();
// 得到最后一个节点,即选择的节点
DefaultMutableTreeNode node=(DefaultMutableTreeNode)nodes[nodes.length-1];
// 输出节点名
System.out.println(node.toString());
}
}
}
});
额外的一点美化工作:渲染节点
// 设定叶节点图标
Icon leafIcon = new ImageIcon(TreePanel.class.getResource("/leaf.gif"));
// 设定关闭状态节点图标
Icon closedIcon = new ImageIcon(TreePanel.class.getResource("/close.gif"));
// 设定打开状态节点图标
Icon openIcon = new ImageIcon(TreePanel.class.getResource("/open.gif"));
// 取得树的渲染器
DefaultTreeCellRenderer renderer = (DefaultTreeCellRenderer)tree.getCellRenderer();
renderer.setLeafIcon(leafIcon);// 设定叶节点图标
renderer.setClosedIcon(closedIcon);// 设定关闭状态节点图标
renderer.setOpenIcon(openIcon);// 设定打开状态节点图标
选项窗格JTabbedPane
JTabbedPane在Swing中实现选项窗格,它可以把多个组件放在多个选项卡中,从而使页面不致拥挤,其选项卡的形式也能为程序增色不少。
选项窗格和分隔窗格类似,创建出来需要添加到设置好布局的面板中,通常我们可以设置布局为1*1的网格布局或是边界布局。
选项窗格内部可以放置多个选项页,每个选项页都可以容纳一个JPanel作为子组件,我们只要设计好需要添加到选项页的面板即可。
JTabbedPane效果
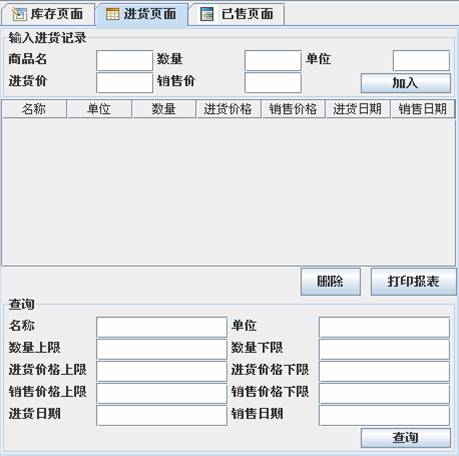
创建JTabbedPane
// 创建选项窗格
JTabbedPane tabPane = new JTabbedPane();
// 设置面板布局为网格布局
this.setLayout(new GridLayout(1,1));
tabPane.setTabPlacement(JTabbedPane.TOP);// 设定选项卡放在上部
this.add(tabPane);// 将选项窗格放置在面板中
// 创建一个StockPanel面板并添加到选项窗格,这是指定图标的方法
StockPanel stockPanel=new StockPanel();
tabPane.addTab("库存页面", new ImageIcon(TabbedPanel.class
.getResource("/stock.gif")), stockPanel);
ImportPanel importPanel=new ImportPanel();
tabPane.addTab("进货页面", new ImageIcon(TabbedPanel.class
.getResource("/import.gif")), importPanel);
// 创建一个SaledPanel面板并添加到选项窗格,这是不指定图标的方法
SaledPanel saledPanel=new SaledPanel();
tabPane.addTab("已售页面", saledPanel);
// 选择第一个选项页为当前选择的选项页
tabPane.setSelectedIndex(0);
C++模版(Template)类在Java中的体现-泛型类
泛型类是C++模版(Template)类思想在java新版本(1.5)中的应用体现.当对类型相同的对象操作时泛型是很有用的,但其中对象的具体类型直到对类实例化时才能知道.这种方式非常适合于包含关联项目的集合或设计查找的类.
泛型类的使用示例一
/**
* 泛型类示例一,成员变量为链表,T可以指代任意类类型.
* @author sitinspring
*
* @date 2007-12-28
*/
public class Service<T>{
// 元素为T的链表
private List<T> elements;
/**
* 构造函数,这里无须指定类型
*
*/
public Service(){
elements=new ArrayList<T>();
}
/**
* 向链表中添加类型为T的元素
* @param element
*/
public void add(T element){
elements.add(element);
}
/**
* 打印链表中元素
*
*/
public void printElements(){
for(T t:elements){
System.out.println(t);
}
}
/**
* 使用示例
* @param args
*/
public static void main(String[] args){
// 创建Service类的示例memberService
Service<Member> memberService=new Service<Member>();
// 向memberService中添加元素
memberService.add(new Member("Andy",25));
memberService.add(new Member("Bill",24));
memberService.add(new Member("Cindy",55));
memberService.add(new Member("Felex",35));
// 打印memberService中诸元素
memberService.printElements();
}
}
泛型类的使用示例二
/**
* 泛型类示例二,成员变量为哈希表,k,v可以指代任意类类型.
* @author sitinspring
*
* @date 2007-12-28
*/
public class ServiceHt<K,V>{
private Map<K,V> elements;
/**
* 向elements中添加元素
* @param k
* @param v
*/
public void add(K k,V v){
// 如果elements为空则创建元素
if(elements==null){
elements=new Hashtable<K,V>();
}
// 向elements中添加键值对
elements.put(k, v);
}
/**
* 打印哈希表中的元素
*
*/
public void printElements(){
Iterator it=elements.keySet().iterator();
while(it.hasNext()){
K k=(K)it.next();
V v=elements.get(k);
System.out.println("键="+k+" 值="+v);
}
}
/**
* 使用示例
* @param args
*/
public static void main(String[] args){
// 创建Service类的示例memberService
ServiceHt<String,Member> memberService=new ServiceHt<String,Member>();
// 向memberService中添加元素
memberService.add("Andy",new Member("Andy",25));
memberService.add("Bill",new Member("Bill",24));
memberService.add("Cindy",new Member("Cindy",55));
memberService.add("Felex",new Member("Felex",35));
// 打印memberService中诸元素
memberService.printElements();
}
}
JSplitPane可以显示两个组件,可以并排或上下显示,通过拖动出现在两个组件之间的分隔器,用户可以指定分隔窗格为每一个组件分配多少空间.通过在分隔窗格内设置分隔窗格,可以将屏幕空间分隔成三个或更多的组件.
除了直接将组件添加到分隔窗格外,通常会将每个组件放置在一个滚动窗格中,这使用户能拖动滚动条查看组件的任何部分.
创建分隔窗格示例
// 创建分隔窗口,第一个参数指定了分隔的方向,JSplitPane.HORIZONTAL_SPLIT表示水平分隔,另外一个选项是JSplitPane.VERTICAL_SPLIT,表示垂直分隔;另外两个参数是放置在该分隔窗格的组件.
JSplitPane splitPanel = new JSplitPane(JSplitPane.HORIZONTAL_SPLIT, tablePanel, textPanel);
// 设置分隔器的位置,可以用整数(像素)或百分比来指定.
splitPanel.setDividerLocation(200);
// 设置分隔器是否显示用来展开/折叠分隔器的控件
splitPanel.setOneTouchExpandable(true);
// 设置分隔器的大小,单位为像素
splitPanel.setDividerSize(5);
// 将分隔窗口添加到容器中
setLayout(new BorderLayout());
add(splitPanel, BorderLayout.CENTER);
举例说明事件响应
在Swing中,事件响应是通过监听器对象来处理事件的方式实行的,这种方式被称为事件委托模型.
以JButton举例,它内部有一个名为listenerList的链表,在点击按钮时,会产生一个ActionEvent事件,此后内部会依次调用位于listenerList中的每一个actionListener子类实例的actionPerformed方法,这就是事件响应的过程.
当调用JButton的addActionListener方法时, 外界actionListener子类实例的指针就被放入了listenerList中,当按钮点击事件产生时,这个实例的actionPerformed方法就会被调用,从而按钮的点击事件处理就被委托到了actionListener子类实例中进行处理.
实现ActionListener的三种方式
1.实现一个ActionListener子类,再把按钮的事件响应委托给这个子类的实例处理.这种方式并不常用,我在这里列出是为了教学.
2.让界面类实现ActionListener接口,再把事件响应委托给界面类.这种方式适合于处理一些短小简单或要求内聚的事件响应.
3.用匿名类实现ActionListener接口,再把事件委托给这个匿名类的实例.这种方式是Swing事件处理的主流.
方式一:实现一个ActionListener子类
// 实现了ActionListener接口的类
public class Button3ActionListener implements ActionListener{
public void actionPerformed(ActionEvent e) {
String buttonText=((JButton)e.getSource()).getText();
System.out.println("你按下了" + buttonText);
}
}
// 给按钮三添加事件处理
button3.addActionListener(new Button3ActionListener());
方式二:让界面类实现ActionListener接口
public class MyFrame extends JFrame implements ActionListener{
public MyFrame() {
....
button2.addActionListener(this);
}
/**
* 按钮二的事件响应在此
*/
public void actionPerformed(ActionEvent e) {
if(e.getSource()==button2){
showMsg("你按下了" + button2.getText());
}
}
}
方式三:用匿名类的方式添加事件响应
button1 = new JButton("按钮一");
button1.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) {
showMsg("你按下了" + button1.getText());
}
});
Java.swing包中的JFrame类对于创建窗口很有效,它继承Container类,能够包含其它的组件.
右边显示了创建窗口的代码和JFrame的几个常用函数.
public class MyFrame extends JFrame {
private static final long serialVersionUID = 1379963724699883220L;
/**
* 构造函数
*
*/
public MyFrame() {
// 设置窗口标题
this.setTitle("程序标题");
// 定位窗口
this.setLocation(20, 20);
// 设置窗口大小
this.setSize(480, 320);
// 显示窗口
setVisible(true);
}
public static void main(String[] args){
new MyFrame();
}
}
将窗口定位在屏幕正中
使用Toolkit.getDefaultToolkit().getScreenSize()方法可以取得屏幕的大小,再调用setLocation函数可以将程序定位在屏幕正中.
public class MyFrame extends JFrame {
private static final long serialVersionUID = 1379963724699883220L;
/**
* 构造函数
*
*/
public MyFrame() {
// 设置窗口标题
this.setTitle("程序标题");
// 设置程序大小并定位程序在屏幕正中
setSizeAndCentralizeMe(480, 320);
// 显示窗口
setVisible(true);
}
// 设置程序大小并定位程序在屏幕正中
private void setSizeAndCentralizeMe(int width, int height) {
Dimension screenSize = Toolkit.getDefaultToolkit().getScreenSize();
this.setSize(width, height);
this.setLocation(screenSize.width / 2 - width / 2, screenSize.height
/ 2 - height / 2);
}
public static void main(String[] args){
new MyFrame();
}
}
点击窗口右上角的关闭按钮关闭窗口,退出程序
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE)可以达到此功能,否则按关闭按钮窗口关闭但不退出程序.
public class MyFrame extends JFrame {
private static final long serialVersionUID = 1379963724699883220L;
/**
* 构造函数
*
*/
public MyFrame() {
// 设置窗口标题
this.setTitle("程序标题");
// 设置程序大小并定位程序在屏幕正中
setSizeAndCentralizeMe(480, 320);
// 显示窗口
setVisible(true);
// 点击窗口右上角的关闭按钮关闭窗口,退出程序
this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
}
// 设置程序大小并定位程序在屏幕正中
private void setSizeAndCentralizeMe(int width, int height) {
Dimension screenSize = Toolkit.getDefaultToolkit().getScreenSize();
this.setSize(width, height);
this.setLocation(screenSize.width / 2 - width / 2, screenSize.height
/ 2 - height / 2);
}
public static void main(String[] args){
new MyFrame();
}
}
添加窗口关闭事件处理
// 点击窗口右上角的关闭按钮关闭窗口,退出程序
this.addWindowListener(new WindowAdapter() {
public void windowClosing(WindowEvent e) {
System.out.println("程序退出.");
System.exit(0);
}
});
上面的代码实现了一个WindowAdapter的匿名类,并将它注册为窗口事件的监听器.
public class MyFrame extends JFrame {
private static final long serialVersionUID = 1379963724699883220L;
/**
* 构造函数
*
*/
public MyFrame() {
// 设置窗口标题
this.setTitle("程序标题");
// 设置程序大小并定位程序在屏幕正中
setSizeAndCentralizeMe(480, 320);
// 显示窗口
setVisible(true);
// 点击窗口右上角的关闭按钮关闭窗口,退出程序
this.addWindowListener(new WindowAdapter() {
public void windowClosing(WindowEvent e) {
System.out.println("程序退出.");
System.exit(0);
}
});
}
// 设置程序大小并定位程序在屏幕正中
private void setSizeAndCentralizeMe(int width, int height) {
Dimension screenSize = Toolkit.getDefaultToolkit().getScreenSize();
this.setSize(width, height);
this.setLocation(screenSize.width / 2 - width / 2, screenSize.height
/ 2 - height / 2);
}
public static void main(String[] args) {
new MyFrame();
}
}
设置程序感观
UIManager.getInstalledLookAndFeels()可得到可用的感观数组,然后取数组中元素的getClassName()方法可得到感观类名,再调用
UIManager.setLookAndFeel(strLookFeel); SwingUtilities.updateComponentTreeUI(this);
方法可设置窗口感观.
public class MyFrame extends JFrame {
/**
* 构造函数
*
*/
public MyFrame() {
// 设置窗口标题
this.setTitle("程序标题");
// 设置程序大小并定位程序在屏幕正中
setSizeAndCentralizeMe(480, 320);
// 显示窗口
setVisible(true);
// 设置程序感观
setupLookAndFeel();
....;
}
...
// 设置程序感观
private void setupLookAndFeel() {
// 取得系统当前可用感观数组
UIManager.LookAndFeelInfo[] arr = UIManager.getInstalledLookAndFeels();
Random random = new Random();
String strLookFeel=arr[random.nextInt(arr.length)].getClassName();
try {
UIManager.setLookAndFeel(strLookFeel);
SwingUtilities.updateComponentTreeUI(this);
} catch (Exception e) {
System.out.println("Can't Set Lookandfeel Style to " + strLookFeel);
}
}
....
}
设置程序感观为跨平台的感观
UIManager.getCrossPlatformLookAndFeelClassName()可得到跨平台的感观.
public class MyFrame extends JFrame {
public MyFrame() {
// 设置窗口标题
this.setTitle("程序标题");
// 设置程序大小并定位程序在屏幕正中
setSizeAndCentralizeMe(480, 320);
// 显示窗口
setVisible(true);
// 设置程序感观
setupLookAndFeel();
}
// 设置程序感观
private void setupLookAndFeel() {
String strLookFeel = UIManager.getCrossPlatformLookAndFeelClassName();
try {
UIManager.setLookAndFeel(strLookFeel);
} catch (Exception e) {
System.out.println("Can't Set Lookandfeel Style to " + strLookFeel);
}
}
}
面板类JPanel
JPanel类常用来作为一批组件如JButton,JTextBox等的容器,一般来说对它的常见操作有设置其边框,设置其布局等.
设置边框代码:
setBorder(BorderFactory.createTitledBorder(title));
设置布局代码示例:
setLayout(new GridLayout(4, 1));
add(nameInputPanel);
add(ageInputPanel);
add(titleInputPanel);
add(ButtonsPanel);
按钮类JButton
当我们需要向界面添加按钮时需要用到JButton类.以下是它的一些常用方法
1.创建Button类实例
JButton csvButton=new JButton("csv下载");
2.设置按钮的最大尺寸,最小尺寸,首选尺寸.
Dimension dimension = new Dimension(80, 20);
csvButton.setMaximumSize(dimension);
csvButton.setMinimumSize(dimension);
csvButton.setPreferredSize(dimension);
单选框JRadioButton
我们需要单选按钮时需要用到JRadioButton,它的常用方法如下:
1.创建
JRadioButton xmlRadio=new JRadioButton("Xml",true);
JRadioButton db4oRadio=new JRadioButton("Db4o",false);
2.分组
ButtonGroup group = new ButtonGroup();
group.add(xmlRadio);
group.add(db4oRadio);
group.add(sqlRadio);
group.add(hibenateRadio);
3.取得单个JRadioButton是否被选择
boolean isSelected=db4oRadio.isSelected()
4.取得一组JRadioButton中被选择的单元的文字
for (Enumeration e=group.getElements(); e.hasMoreElements(); ) {
JRadioButton b = (JRadioButton)e.nextElement();
if (b.getModel() == group.getSelection()) {
return b.getText();
}
}
标签组件JLabel
JLabel是标签控件,也是Swing组件中最简单常用的一个.
创建JLabel:
JLabel label=new JLabel(“ABC");
修改标签文字
label.setText("DEF");
单行文本框JTextField
需要输入单行文字时我们可以用到JTextField,它的使用也很简单.
创建:
JTextField textBox=new JTextField();
设置文本框文字:
textBox.setText("ABC");
取得文本框文字:
String text=textBox.getText();
复合框JComboBox
JComboBox是既能提供输入又能提供选择一项的选择控件.
1) 创建JComboBox
String[] items = {"item1", "item2"};
JComboBox editableCB = new JComboBox(items); editableCB.setEditable(true);
表格控件JTable
表格控件是相对复杂的Swing控件之一,使用也相对复杂.
1) 创建表格控件
JTable table = new JTable();
2) 设置表格行高
table.setRowHeight(20);
3) 设置表格的行数和列数
DefaultTableModel tableModel = (DefaultTableModel) table
.getModel();
tableModel.setColumnCount(0);
tableModel.setRowCount(0);
4) 给表格添加表头
String[] headers = {"姓名","年龄", "职务"};
for (int i = 0; i < headers.length; i++) {
tableModel.addColumn(headers[i]);
}
5) 向表格添加内容
public void fillTable(List<Member> members){
DefaultTableModel tableModel = (DefaultTableModel) table
.getModel();
tableModel.setRowCount(0);
for(Member member:members){
String[] arr=new String[5];
arr[0]=member.getName();
arr[1]=member.getAge();
arr[2]=member.getTitle();
tableModel.addRow(arr);
}
table.invalidate();
}
6) 取得表格内的内容
public List<Member> getShowMembers(){
List<Member> members=new ArrayList<Member>();
DefaultTableModel tableModel = (DefaultTableModel) table
.getModel();
int rowCount=tableModel.getRowCount();
for(int i=0;i<rowCount;i++){
Member member=new Member();
member.setName((String)tableModel.getValueAt(i, 0));
member.setAge((String)tableModel.getValueAt(i, 1));
member.setTitle((String)tableModel.getValueAt(i, 2));
members.add(member);
}
return members;
}
字符串比较
字符串比较是java程序常遇到的问题,新手常用==进行两个字符串比较,实际上这时进行的地址比较,不一定会返回正确结果.在java中,正确的进行字符串比较的函数String类的equals()函数,这才是真正的值比较.
==的真正意义
Java中,==用来比较两个引用是否指向同一个内存对象.对于String的实例,运行时JVM会尽可能的确保任何两个具有相同字符串信息的String实例指向同一个内部对象,此过程称为”驻留”(interning),但它不助于每个String实例的比较.一个原因是垃圾收集器删除了驻留值,另一个原因是String所在的位置可能被别的String实例所取代.这样的话,==将不会返回预想的结果.
下页的示例说明了这个问题:
==和equals比较的示例
String str1,str2,str3;
str1="Andy";
str2=str1;
if(str1==str2){
System.out.println("str1,str2地址相等");
}
if(str1.equals(str2)){
System.out.println("str1,str2值相等");
}
str2=“Andy”;
if(str1==str2){
System.out.println("str1,str2通常地址相等");
}
if(str1.equals(str2)){
System.out.println("str1,str2值一定相等");
}
str3=new String("Andy");
if(str1==str3){
System.out.println("str1,str3地址相等");
}
else{
System.out.println("str1,str3地址不相等");
}
if(str1.equals(str3)){
System.out.println("str1,str3值一定相等");
}
结论
从上面的例子可以看出,==比较的是地址,在驻留机制的作用下,也许返回正确的结果,但并不可靠,这种不确定性会隐藏在阴暗的角落里,在你以为万事大吉时给你致命一击.
而equal始终进行值比较,它一定会返回正确的结果,无论在什么情况下.
我们应该记住:为了保证程序的正确,进行字符串比较时一定要使用equals,而一定不能使用==.
在运行过程中,应用程序可能遭遇各种严重程度不同的问题.异常提供了一种在不弄乱程序的情况下检查错误的巧妙方式.它也提供了一种直接报告错误的机制,而不必检查标志或者具有此作用的域.异常把方法能够报告的错误作为方法约定的一个显式部分.
异常能够被程序员看到,由编译器检查,并且由重载方法的子类保留.
如果遇到意外的错误将抛出异常,然后异常被方法调用栈上的子句捕获.如果异常未被捕获,将导致执行线程的终止.
异常的体系结构
毫无疑问,在java中异常是对象,它必定继承Throwable及其子类.Throwable中含有一个用于描述异常的字符串.Exception是Throwable的一个最常用子类,另一个子类是Error.而RuntimeException继承自Exception.

异常的种类
非检查型异常(Unchecked Exception):
非检查型异常反映了程序中的逻辑错误,不能从运行中合理恢复.
标准的运行时异常和错误构成非检查型异常,它们继承自RuntimeException和Error.
非检查型异常不用显示进行捕获.
检查型异常(Checked Exception):
这种异常描述了这种情况,虽然是异常的,但被认为是可以合理发生的,如果这种异常真的发生了,必须调用某种方法处理.
Java异常大多是检查型异常,继承自Exception类,你自己定义的异常必须是继承Exception的检查型异常.
检查型异常必须进行显示捕获.
自定义异常
继承Exception即可定义自己的异常,以下是一种常见写法
public class DBXmlFileReadException extends Exception{
public DBXmlFileReadException(String msg){
super(msg);
}
}
抛出异常
在Java语句中,可以用throw语句抛出异常,如throw new NoSuchElementException();
抛出的对象必须是Throwable类的子类型.
抛出异常的策略:
1) 如果抛出后不可能得到处理,可以抛出Error.
2) 如果你想让其它类自由选择是否处理这个异常,就可以抛出RuntimeException.
3) 如果你要求类的用户必须处理这个异常,则可以抛出Exception.
异常抛出后的控制权转移
一旦发生异常,异常发生点后的动作将不会发生.此后将要发生的操作不是在catch块和finally块.
当异常抛出时,导致异常发生的语句和表达式就被称为突然完成.语句的突然完成将导致调用链逐渐展开,直到该异常被捕获.
如果该异常没有捕获,执行线程将中止.
Try,catch和finally
异常由包含在try块中的语句捕获:
try{
正常执行语句
}
catch(XException e){
异常执行语句一
}
catch(XXException e){
异常执行语句二
}
catch(XXXException e){
异常执行语句三
}
finally{
中止语句
}
Try中的语句体要么顺利完成,要么执行到抛出异常.
如果抛出异常,就要找出对应于异常类或其父类的catch子句,如果未能找到合适的catch子句,异常就从try语句中扩散出来,进入到外层可能对它进行处理的try语句.
Catch子句可以有多个,只要这些子句捕获的异常类型不同.
如果在try中有finally子句,其代码在try把所有其它处理完成之后执行.
无论是正常完成或是出现异常,甚至是通过return或者break这样的控制语句结束,finally子句总是被执行.
Catch子句和finally子句在try语句之后至少有一个,不要求全部出现.
More…
在catch语句中捕获通用的异常Exception通常不是最佳策略,因为它会将所有异常进行等同处理.
不能把基类异常的catch语句放到子类异常的catch语句之前,编译器会在运行之前就检查出这样的错误.
Try…catch对每个catch语句都从头到尾检查,如果找到处理同类异常的catch子句,此catch块中的语句将得以执行,而不再处理同层次的其它catch块.
如果catch或finally抛出另一个异常,程序将不会再去检查try的catch子句.
Try...catch语句可以嵌套,内层抛出的异常可被外层处理.
Throws子句
函数能抛出的检查型异常用throws声明,它后面可以是带用逗号隔开的一系列异常类型.仅仅那些在方法中不被捕获的异常必须列出.
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in size
int size = s.readInt();
// Initialize header
header = new Entry<E>(null, null, null);
header.next = header.previous = header;
// Read in all elements in the proper order.
for (int i=0; i<size; i++)
addBefore((E)s.readObject(), header);
}
}
More…
Throws子句的约定是严格强制性的,只能抛出throws子句中声明的异常类型,抛出其它类型的异常是非法的,不管是直接利用throw,还是调用别的方法间接的抛出.
RuntimeException和Error是仅有的不必由throws子句列出的异常.
调用函数的函数要么处理对声明的异常进行处理,要么也声明同样的异常,将收到的异常抛向上层.
对检查型异常通常进行的几种处理
1) 用e.printStackTrace()输出异常信息.
2) 将异常记录到日志中以备查,如logger.error(e.getMessage()).
3) 试图进行异常恢复.
4) 告知维护者和用户发生的情况.
嵌套类和匿名类
内部类的出现
当进行Java开发时,有时需要实现一个仅包含1-2个方法的接口.在AWT和Swing开发中经常出现这种情况,例如当一个display组件需要一个事件回调方法如一个按钮的ActionListener时. 如果使用普通的类来实现此操作,最终会得到很多仅在单个位置上使用的小型类.
内部类用于处理这种情况,java允许定义内部类,而且可在Gui外使用内部类.
内部类的定义和实现
内部类是指在另一个类内部定义的一个类.可以将内部类定义为一个类的成员.
public class Linker{
public class LinkedNode{
private LinkedNode prev;
private LinkedNode next;
private String content;
public LinkedNode(String content){
this.content=content;
}
}
public Linker(){
LinkedNode first=new LinkedNode("First");
LinkedNode second=new LinkedNode("Second");
first.next=second;
second.prev=first;
}
}
定义在一个类方法中的内部类
public class Hapiness{
interface Smiler{
public void smile();
}
public static void main(String[] args){
class Happy implements Smiler{
public void smile(){
System.out.println(":-}");
}
}
Happy happy=new Happy();
happy.smile();
}
}
匿名类
对很多情况而言,定义在方法内部的类名意义不大,它可以保持为匿名的,程序员关心的只是它的实例名.
如:
Runnable runner=new Runnable(){
public void run(){
// Run statememnt
}
}
理解匿名类
匿名类并不难理解,它只是把类的定义过程和实例的创建过程混合而已,上页的语句实际上相当于如下语句:
// 定义类
Public class Runner implements Runnable{
public void run(){
// do sth
}
}
// 创建实例
Runner runner=new Runner();
使用匿名类的筛选解耦过程
需求:从公司的职员列表中,找出男性且年龄大于22的成员.
传统写法:
List allmembers=company.getMembers();// 取得所有成员
List results=new ArrayList();// 结果列表
for(Iterator it=allmembers.iterator();it.hasNext();){
Member member=(Member)it.next();
if(member.getAge()>22 && member.isMale()){ // 筛选,这里是把查询条件和遴选过程融合在一起,条件一变立即就得加个分支.
results.add(member);
}
}
传统方法的缺陷
这种写法没有错,但是不是面向对象的写法,它有以下缺陷:
1.查询条件和筛选过程没有分离.
2.这样写的后果使Company变成了一个失血模型而不是领域模型.
3.换查询条件的话,上面除了"筛选"一句有变化外其它都是模板代码,重复性很高.
使用匿名类实现的OO化查询
真正符合OO的查询应该是这样:
MemberFilter filter1=new MemberFilter(){
public boolean accept(Member member) {
return member.isMale() && member.getAge()>22;
}
};
List ls=company.listMembers(filter1);
这段代码成功的把查询条件作为一个接口分离了出去,接口代码如下:
public interface MemberFilter{
public boolean accept(Member member);
}
查询函数的变化
而类Company增加了这样一个函数:
public List searchMembers(MemberFilter memberFilter){
List retval=new ArrayList();
for(Iterator it=members.iterator();it.hasNext();){
Member member=(Member)it.next();
if(memberFilter.accept(member)){
retval.add(member);
}
}
return retval;
}
这就把模板代码归结到了类内部,外面不会重复书写了.Company也同时拥有了数据和行为,而不是原来的数据容器了.
匿名类的例子二
用匿名类处理分类汇总的方法 分类汇总是统计中常用,举例来说如统计学生成绩,及格不及格的归类,分优良中差等级归类等,每个单项代码很好写,但是如果分类汇总的项目多了,能一种汇总写一个函数吗? 比如说有些科目60分才算及格,有些科目50分就算;有些老师喜欢分优良中差四等,有些老师却喜欢分ABCD;不一而足,如果每个都写一个函数无疑是个编写和维护恶梦. 如果我们用匿名类把分类汇总的规则和分类汇总的过程分别抽象出来,代码就清晰灵活多了,以下代码讲述了这个过程.
基本类Student
public class Student{
private String name;
private int score;
public Student(String name,int score){
this.name=name;
this.score=score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
}
用于分类汇总的类
它强制子类实现getKey和getvalue两个方法:
public abstract class ClassifyRule {
public Student student;
public ClassifyRule(){
}
public void setStudent(Student student) {
this.student = student;
}
abstract public String getKey();
abstract public int getValue();
}
对Student进行统计处理的StudentService类
注意getSum方法,它保留了筛选过程,筛选规则则不在其中:
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.List;
public class StudentService {
private List<Student> students;
public StudentService() {
students = new ArrayList<Student>();
}
public void add(Student student) {
students.add(student);
}
public Hashtable<String, Integer> getSum(ClassifyRule rule) {
Hashtable<String, Integer> ht = new Hashtable<String, Integer>();
for (Student student : students) {
rule.setStudent(student);
String key = rule.getKey();
int value = rule.getValue();
if (ht.containsKey(key)) {
Integer oldValue = ht.remove(key);
oldValue += value;
ht.put(key, oldValue);
} else {
ht.put(key, value);
}
}
return ht;
}
}
测试代码,注意其中筛选规则的创建
public class Test {
public static void main(String[] args) {
// 初始化
StudentService service = new StudentService();
service.add(new Student("Andy", 90));
service.add(new Student("Bill", 95));
service.add(new Student("Cindy", 70));
service.add(new Student("Dural", 85));
service.add(new Student("Edin", 60));
service.add(new Student("Felix", 55));
service.add(new Student("Green", 15));
// 60分及格筛选
ClassifyRule rule60 = new ClassifyRule() {
public String getKey() {
return student.getScore() >= 60 ? "及格" : "不及格";
}
public int getValue() {
return 1;
}
};
System.out.println("60分及格筛选");
printHt(service.getSum(rule60));
// 50分及格筛选
ClassifyRule rule50 = new ClassifyRule() {
public String getKey() {
return student.getScore() >= 50 ? "及格" : "不及格";
}
public int getValue() {
return 1;
}
};
System.out.println("\n50分及格筛选");
printHt(service.getSum(rule50));
// 分"优良中差"等级
ClassifyRule ruleCn = new ClassifyRule() {
public String getKey() {
String retval = "";
int score = student.getScore();
if (score >= 90) {
retval = "优";
} else if (score >= 80) {
retval = "良";
} else if (score >= 60) {
retval = "中";
} else if (score > 0) {
retval = "差";
}
return retval;
}
public int getValue() {
return 1;
}
};
测试代码
System.out.println("\n分优良中差等级筛选");
printHt(service.getSum(ruleCn));
// 分"ABCD"等级
ClassifyRule ruleWest = new ClassifyRule() {
public String getKey() {
String retval = "";
int score = student.getScore();
if (score >= 90) {
retval = "A";
} else if (score >= 80) {
retval = "B";
} else if (score >= 60) {
retval = "C";
} else if (score > 0) {
retval = "D";
}
return retval;
}
public int getValue() {
return 1;
}
};
System.out.println("\n分ABCD等级筛选");
printHt(service.getSum(ruleWest));
}
private static void printHt(Hashtable ht) {
for (Iterator it = ht.keySet().iterator(); it.hasNext();) {
String key = (String) it.next();
Integer value = (Integer) ht.get(key);
System.out.println("Key=" + key + " Value=" + value);
}
}
}
测试结果如下:
60分及格筛选
Key=及格 Value=5
Key=不及格 Value=2
50分及格筛选
Key=及格 Value=6
Key=不及格 Value=1
分优良中差等级筛选
Key=优 Value=2
Key=良 Value=1
Key=中 Value=2
Key=差 Value=2
分ABCD等级筛选
Key=A Value=2
Key=D Value=2
Key=C Value=2
Key=B Value=1
后记
内部类也叫嵌套类,一般不提倡书写,但它在java核心类中都存在,如接口Map中的Entry,我们应该了解并能解读这种方法.
匿名类相对而言有用得多,在解耦合和事件回调注册中很常见,大家应该对它的运用融会贯通.
JavaScript中对正则表达式的支持
正则表达式在JS的最大用处就是验证表单字段,如验证数字,验证邮件和验证汉字等。
JavaScript中对正则表达式的支持是通过RegExp类实现的。你可以以如下方式建立一个正则表达式:
var regex=new RegExp("^[1-9]+\\d*$");
而验证的方法是regex.test(str),它返回str是否符合regex的结果。
JS中正则表达式和Java中的异同。
JavaScript
1.建立:
var regex=new RegExp("^[1-9]+\\d*$");
2.验证
return regex.test(str);
3.写法上,要验证字符串,JS中必须把起始符号^和结束符号$写全,否则就是包含验证而不是全匹配验证.除此外其它部分都是一致的.
Java
1.建立:
String regex="\\d*";
2.验证:
return Pattern.matches(regex,text);
3.写法上,JAVA中进行全匹配验证不需写全起始符号^和结束符号$.
一个完整的验证过程
表单元素:
<input type="text" name="positiveinteger"
value="1" />
表单提交之前的验证函数:
var positiveinteger=$("positiveinteger").value;
if(isPositiveInteger(positiveinteger)==false){
$("positiveinteger").focus();
$("checkMsg").innerHTML="正整数验证不通过";
return false;
}
else{
$("checkMsg").innerHTML="正整数验证通过";
}
验证函数:
function isPositiveInteger(str){
var regex=new RegExp("^[1-9]+\\d*$");
return regex.test(str);
}
常用验证函数
/**
* 正整数验证*/
function isPositiveInteger(str){
var regex=new RegExp("^[1-9]+\\d*$");
return regex.test(str);
}
/**
* 负整数验证
*/
function isNegativeInteger(str){
var regex=new RegExp("^-{1}\\d+$");
return regex.test(str);
}
/**
* 非负整数验证
*/
function isNonnegativeInteger(str){
var regex=new RegExp("^\\d+$");
return regex.test(str);
}
/**
* 整数验证
*/
function isInteger(str){
var regex=new RegExp("^-?\\d+$");
return regex.test(str);
}
/**
* 有理数验证
*/
function isRationalNumber(str){
var regex=new RegExp("^-?\\d+(\\.*)(\\d*)$");
return regex.test(str);
}
/**
* 英语字母验证
*/
function isLetter(str){
var regex=new RegExp("^[a-zA-Z]+$");
return regex.test(str);
}
/**
* 英数字验证
*/
function isLetterOrInteger(str){
var regex=new RegExp("^[a-zA-Z0-9]+$");
return regex.test(str);
}
/**
* 邮件验证
*/
function isEmail(str){
var regex=new RegExp("^\\w+([-+.]\\w+)*@\\w+([-.]\\w+)*\\.\\w+([-.]\\w+)*$");
return regex.test(str);
}
/**
* 汉字验证
*/
function isCharacter(str){
var regex=new RegExp("^[\u4E00-\u9FA5]+$");
return regex.test(str);
}
/**
* 货币验证
*/
function isCurrency(str){
return str.search("^\\d+(\\.\\d{0,2})*$")==0;
}
获取表单的引用
在开始对表单进行编程前,必须先获取表单<form>的引用.有以下方法可以来完成这一操作。
1)采用典型的DOM树中的定位元素的方法getElementById(),只要传入表单的id即可获得表单的引用:
var vform=document.getElementById(“form1”);
2)还可以用document的forms集合,并通过表单在form集合中的位置或者表单的name特性来进行引用:
var oform=document.forms[0];
var oform=document.forms[“formZ”];
访问表单字段
每个表单字段,不论它是按钮,文本框还是其它内容,均包含在表单的elements集合中.可以用它们的name特性或者它们在集合中的位置来访问不同的字段:
Var oFirstField=oForm.elements[0];
Var oTextBox1=oForm.elements[“textBox1”];
此外还可以通过名字来直接访问字段,如:
Var oTextBox1=oForm.textbox1;
如果名字中有标记,则可以使用方括号标记:
Var oTextBox1=oForm[“text box 1”];
最常见的访问表单字段的方法
最简单常用的访问表单元素的方法自然是document.getElementById(),举例如下:
<input type="text" name="count"
value="" />
在JS中取得此元素内容的代码为:
var name=document.getElementById("name").value
这种方法无论表单元素处于那个表单中甚至是不在表单中都能凑效,一般情况下是我们用JS访问表单元素的首选.
鉴于document.getElementById比较长,你可以用如下函数代替它:
function $(id){
return document.getElementById(id);
}
把这个函数放在共有JS库中,在jsp页面通过如下方法引用它:
<head>
<title>"記賬系统"添加资源页面</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script src="web/js/check.js" type="text/javascript"></script>
<link rel="stylesheet" rev="stylesheet" href="web/css/style.css"
type="text/css" />
</head>
此后你就可以直接使用$访问表单元素中的内容:
var name=$("name").value;
表单字段的共性
以下是所有表单字段(除了隐藏字段)
Disabled可以用来获取或设置表单控件是否被禁用.
Form特性用来指向字段所在的表单.
Blur()方法使表单字段失去焦点.
Focus()方法使表单字段获得焦点.
当字段失去焦点是,发生blur事件,执行onblur事件处理程序.
当字段获取焦点时,发生focus事件,执行onfocus事件处理函数.
当页面载入时将焦点放在第一个字段
在body代码中如此书写:
<body onload=“focusOnFirstElm()”>
JS函数如下书写:
Fucntion focusOnFirstElm(){
document.forms[0].elements[0].focus();
}
如果第一个字段不是隐藏字段此方法就是凑效的,如果是的话把elements的下标改成非隐藏字段的下标即可.
控制表单只被提交一次
由于Web的响应问题,用户有可能会点击多次提交按钮从而创建重复数据或是导致错误,我们可以使用JS对提交按钮进行设置以让表单只被提交一次。
<input type=“submit” value=“提交” onclick=“this.disabled=true;this.form.submit()”/>
这里在点击提交按钮时执行了两句JS代码,一次是this.disabled=true;这是让提交按钮被禁用;一次是this.form.submit()这是提交这个按钮所在的表单。
检查用户在表单元素中的按键
为控件添加 onkeydown事件处理,然后在函数查看keyCode,就能知道用户的按键,代码如下:
<input type="text" name="test"
value="" onkeydown="testkey(this,event)"/>
JS代码如下:
function testkey(obj,event){
alert(event.keyCode);
}
这种技巧在改善用户体验如按回车键提交表单时很常用。
Servlet与JSP综合讲述
Servlet和JSP的概念
Servlet是Sun推出的用于实现CGI(通用网关接口)的java语言版本,它不但具有跨平台的特性,而且还以多线程的方式为用户提供服务而不必为每个请求都启动一个线程,因此其效率要比传统的CGI程序要高很多.
JSP和MS的ASP类似,它把JSP标签嵌入到HTML格式的网页中,这样对程序员和网页编辑人员都很方便,JSP天生就是为表现层设计的.
实际上,Servlet只是继承了HttpRequest的Java类,而JSP最终也会被Servlet引擎翻译成Servlet并编译执行,JSP的存在主要是为了方便表现层.
Servlet与JSP之间的区别,决定了Servlet与JSP在MVC构架模式中的不同角色.Servlet一般作为MVC中的控制器,JSP一般作为MVC中的视图.
Servlet的生命周期
Servlet有三个生命周期:初始化,执行和结束,它们分别对应Servlet接口中的init,service和destroy三个函数.
初始化时期:当servlet被servlet容器(如tomcat)载入后,servlet的init函数就会被调用,在这个函数可以做一些初始化工作.init函数只会在servlet容器载入servlet执行一次,以后无论有多少客户端访问这个Servlet,init函数都不会被执行.
执行期:servlet采用多线程方式向客户提供服务,当有客户请求来到时, service会被用来处理它.每个客户都有自己的service方法,这些方法接受客户端请求,并且发挥相应的响应.程序员在实现具体的Servlet时,一般不重载service方法,服务器容器会调用service方法以决定doGet,doPost,doPut,doDelete中的一种或几种,因此应该重载这些方法来处理客户端请求.]
结束期:该时期服务器会卸载servlet,它将调用destroy函数释放占用的资源,注意Web服务器是有可能崩溃的,destroy方法不一定会被执行.
如何开发和部署一个Servlet
1)从java.servlet.http.HttpServlet继承自己的servlet类.
2)重载doGet或doPost方法来处理客户请求(一般是doPost,其安全性较好),如果要在加载Servlet时被加载时进行初始化操作,可以重载init方法.
3)在web.xml中配置这个servlet.其中servlet-class用来制定这个servlet的类全名,servlet-name用来标识这个servlet,它可以是任意的字符串,不一定要和类文件名一致.url-pattern用来表示servlet被映射到的url模式.
<!– Servlet在Web.xml中的配置示例 -->
<servlet>
<servlet-name>ShowPageServlet</servlet-name>
<servlet-class>
com.sitinspring.action.ShowPageServlet
</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>ShowPageServlet</servlet-name>
<url-pattern>/ShowPage</url-pattern>
</servlet-mapping>
开发一个启动时就被执行的Servlet
一般的Servlet都是在有来自客户端请求时才会执行,要让它在启动时就执行需要在配置中进行一些特殊设置,如右.
右边的代码中, load-on-startup说明了服务器一启动就加载并初始化它,0代表了加载它的优先级,注意它必须是一个正数,而且值小的要比值大的先加载.debug制定输出调试信息的级别,0为最低.
这样的servlet在用于读取WebApp的一些初始化参数很有用处,如取得配置文件的地址,设置log4j和得到WebApp的物理路径等.右边配置的servlet就是用来初始化log4j的.
<!-- InitServlet -->
<servlet>
<servlet-name>log4j-init</servlet-name>
<servlet-class>
com.sitinspring.action.Log4jInit
</servlet-class>
<init-param>
<param-name>log4j</param-name>
<param-value>WEB-INF/classes/log4j.properties</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
Serlet中出现的线程不安全的问题
Servlet是运行在多线程的服务器上的,它对每个用户的请求创建的是线程而不是进程,因此在高效的同时也带来了数据同步和一致性的问题.
服务器值实例化一个Servlet/JSP实例,然后在多个处理线程中调用该实例的相关方法来处理请求,因此servlet的成员变量可能会被多个线程调用该实例的相关方法改变,将有可能带来问题.这也是大家在众多的Servlet中很少看到成员变量的原因.

public class ThreadUnsafeServlet extends HttpServlet {
private String unsafeString="";
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, java.io.IOException {
request.setCharacterEncoding("UTF-8");
unsafeString=request.getParameter("str");
try{
Thread.sleep(5000);
}
catch(Exception ex){
ex.printStackTrace();
}
PrintWriter out=response.getWriter();
out.println(unsafeString);
}
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, java.io.IOException {
doPost(request, response);
}
}
关于重定向的两种方法
在servlet中,重定向一般是通过HttpResponse的sendRedirect()方法或RequestDispatcher的forward方法来实现的.
sendRedirect的参数可以是相对或绝对地址,如果以/开头容器将认为相对于当前Web引用的根.这种请求将导致客户端浏览器请求URL跳转,而且从Browser的地址栏中可以看到新的Url地址.另外使用这个方法时,前一个页面的状态不会被带到下一个页面,通过request.getAttribute(“XXXX”)方法将得到空值.
RequestDispatcher是一个Web资源的包装器,可以用来把当前请求传递到该资源,而且客户端浏览器的地址栏也不会显示为转向后的地址.另外此方法还可以将请求发送到任意一个服务器资源.
如果两种方法都能达到要求,最好使用forward方法,它比sendRedirect安全而高效.
获取当前绝对路径
Servlet/JSP有时需要对拥有的资源进行操作,这就要求得到它们所在的绝对路径.此时可以使用ServletContext接口提供的方法来得到当前应用所在的绝对路径,代码如下:
ServletContext sct = getServletContext();
String realPath=sct.getRealPath("/");
注: ServletContext 用于Servlet和Servlet容器交换信息.
XML的由来
XML是eXtensible Markup Language的缩写。扩展标记语言XML是一种简单的数据存储语言,使用一系列简单的标记描述数据,而这些标记可以用方便的方式建立,虽然XML占用的空间比二进制数据要占用更多的空间,但XML极其简单易于掌握和使用
XML是现代程序中一个必不可少的组成部分,也是世界上发展最快的技术之一。它的主要目的是以结构化的方式来表示数据,在某些方面,XML也类似于数据库,提供数据的结构化视图。
XML(可扩展标记语言)是从称为SGML(标准通用标记语言)发展而来的,SGML的主要目的是定义使用标签来表示数据的标记语言的语法。基于SGML的重要语言之一就是著名的HTML.
标签由包围在一个小于号<和一个大于号>之间的文本组成,起始标签(tag)表示一个特定区域的开始,例如<start>;结束标签定义了一个区域的结束,除了在小于号之后紧跟一个斜线外和起始标签一致,例如</end>.举例说明标签如下:
<member id=“007”>邦德</member>中,左边的<member id=“007”>是起始标签,邦德是标签中的文字,007是属性Attribute, </member >是结束标签.
XML的发展
由于SGML中存在特殊而随意的语法(如标签的非嵌套使用),使得建立一个SGML语言的解析器成了一项艰巨的任务,这些困难导致了SGML一直停步不前.
XML通过相对严格的语法规定使得建立一个XML解析器要容易得多,这些语法包括:
1)任何起始标签都必须有一个结束标签。
2)可以采用另一种简化语法,可以在一个标签中同时表示起始和结束标签。这种语法是在大于符号前紧跟一个斜线/.如<tag />等同于<tag></tag>.
3)标签必须按照合适的顺序进行嵌套,在没有关闭内部节点之前不能关闭外部节点。
4)所有的特性都必须有值,特性的值周围应该加上双引号。
XML文档示例
<?xml version="1.0" encoding="GBK"?>
<members>
<member name="Andy">
<age>25</age>
<title>JSE</title>
</member>
<member name="Bill">
<age>35</age>
<title>SSE</title>
</member>
<member name="Cindy">
<age>45</age>
<title>PM</title>
</member>
<member name="Douglas">
<age>45</age>
<title>GM</title>
</member>
</members>
<?xml version=“1.0” encoding=“GBK”?>是XML序言,这一行代码告诉解析器文件将按XML规则进行解析, GBK制定了此文件的编码方式。
<members>是文档的根节点,一个XML中有且只有一个根节点,否则会造成解析失败。
<member name=“Andy”>。。。</member>是根节点下面的子节点,name是其特性,特性的值为Andy。这个子节点下面有age和title两个子节点。
XML的用途
以文本的形式存储数据,这样的形式适于机器阅读,对于人阅读也相对方便.
作为程序的配置文件使用,如著名的web.xml,struts-config.xml
Ajax程序传递数据的载体.
WebService,SOAP的基础.
针对XML的API
将XML定义为一种语言之后,就出现了使用常见的编程语言(如Java)来同时表现和处理XML代码的需求。
首先出现的是Java上的SAX(Simple API for XML)项目。SAX提供了一个基于事件的XML解析的API。从其本质上来说,SAX解析器从文件的开头出发,从前向后解析,每当遇到起始标签或者结束标签、特性、文本或者其他的XML语法时,就会触发一个事件。然后,当事件发生时,具体要怎么做就由开发人员决定。
因为SAX解析器仅仅按照文本的方式来解析它们,所以SAX更轻量、更快速。而它们的主要缺点是在解析中无法停止、后退或者不从文件开始,直接访问XML结构中的指定部分。
DOM是针对XML的基于树的API。它关注的不仅仅是解析XML代码,而是使用一系列互相关联的对象来表示这些代码,而这些对象可以被修改且无需重新解析代码就能直接访问它们。
使用DOM,只需解析代码一次来创建一个树的模型;某些时候会使用SAX解析器来完成它。在这个初始解析过程之后,XML已经完全通过DOM模型来表现出来,同时也不再需要原始的代码。尽管DOM比SAX慢很多,而且,因为创建了相当多的对象而需要更多的开销,但由于它使用上的简便,因而成为Web浏览器和JavaScript最喜欢的方法。
最方便的XML解析利器-dom4j
Dom4j是一个易用的、开源的库,用于XML,XPath和XSLT。它应用于Java平台,采用了Java集合框架并完全支持DOM,SAX和JAXP.
sax和dom本身的api都比较复杂,不易使用,而开源包dom4j却综合了二者的优点,屏蔽了晦涩的细节,封装了一系列类和接口以方便用户使用它来读写XML.
Dom4j下载
要使用dom4j读写XML文档,需要先下载dom4j包,dom4j官方网站在 http://www.dom4j.org/ 目前最新dom4j包下载地址:http://nchc.dl.sourceforge.net/sourceforge/dom4j/dom4j-1.6.1.zip
解开后有两个包,仅操作XML文档的话把dom4j-1.6.1.jar加入工程就可以了,如果需要使用XPath的话还需要加入包jaxen-1.1-beta-7.jar.
使用dom4j读写xml的一些常用对象
1.Document:文档对象,它代表着整篇xml文档.
2.Element:节点元素,它代表着xml文档中的一个节点元素,如前面的<age>25</age>就是一个Element.其值(文本值)为25.
3.Attribute:节点属性,如前面的节点元素<member name=“Andy”>…< /member >中, name就是节点元素的一个属性,其值(文本值)为Andy.
与Document对象相关的API
1.读取XML文件,获得document对象.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
2.解析XML形式的文本,得到document对象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
3.主动创建document对象.
Document document = DocumentHelper.createDocument();
Element root = document.addElement("members");// 创建根节点
与Element有关的API
1.获取文档的根节点.
Element rootElm = document.getRootElement();
2.取得某节点的单个子节点.
Element memberElm=root.element(“member”);// “member”是节点名
3.取得节点的文字
String text=memberElm.getText();
也可以用:
String text=root.elementText("name");这个是取得根节点下的name字节点的文字.
4.取得某节点下名为"member"的所有字节点并进行遍历.
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
// do something
}
5.对某节点下的所有子节点进行遍历.
for(Iterator it=root.elementIterator();it.hasNext();){
Element element = (Element) it.next();
// do something
}
6.在某节点下添加子节点.
Element ageElm = newMemberElm.addElement("age");
7.设置节点文字.
ageElm.setText("29");
8.删除某节点.
parentElm.remove(childElm);// childElm是待删除的节点,parentElm是其父节点
与Attribute相关的API
1.取得某节点下的某属性
Element root=document.getRootElement();
Attribute attribute=root.attribute("size");// 属性名name
2.取得属性的文字
String text=attribute.getText();
也可以用:
String text2=root.element("name").attributeValue("firstname");这个是取得根节点下name字节点的属性firstname的值.
3.遍历某节点的所有属性
Element root=document.getRootElement();
for(Iterator it=root.attributeIterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text);
}
4.设置某节点的属性和文字.
newMemberElm.addAttribute("name", "sitinspring");
5.设置属性的文字
Attribute attribute=root.attribute("name");
attribute.setText("sitinspring");
6.删除某属性
Attribute attribute=root.attribute("size");// 属性名name
root.remove(attribute);
将document的内容写入XML文件
1.文档中全为英文,不设置编码,直接写入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(document);
writer.close();
2.文档中含有中文,设置编码格式写入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK"); // 指定XML编码
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"),format);
writer.write(document);
writer.close();
字符串与XML的转换
1.将字符串转化为XML
String text = "<members> <member>sitinspring</member> </members>";
Document document = DocumentHelper.parseText(text);
2.将文档或节点的XML转化为字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();
使用XPath快速找到节点.
读取的XML文档示例
<?xml version="1.0" encoding="UTF-8"?>
<projectDescription>
<name>MemberManagement</name>
<comment></comment>
<projects>
<project>PRJ1</project>
<project>PRJ2</project>
<project>PRJ3</project>
<project>PRJ4</project>
</projects>
<buildSpec>
<buildCommand>
<name>org.eclipse.jdt.core.javabuilder</name>
<arguments>
</arguments>
</buildCommand>
</buildSpec>
<natures>
<nature>org.eclipse.jdt.core.javanature</nature>
</natures>
</projectDescription>
使用XPath快速找到节点project.
public static void main(String[] args){
SAXReader reader = new SAXReader();
try{
Document doc = reader.read(new File("sample.xml"));
List projects=doc.selectNodes("/projectDescription/projects/project");
Iterator it=projects.iterator();
while(it.hasNext()){
Element elm=(Element)it.next();
System.out.println(elm.getText());
}
}
catch(Exception ex){
ex.printStackTrace();
}
}