|
一.引言
ORACLE数据库字符集,即Oracle全球化支持(Globalization Support),或即国家语言支持(NLS)其作用是用本国语言和格式来存储、处理和检索数据。利用全球化支持,ORACLE为用户提供自己熟悉的数据库母语环境,诸如日期格式、数字格式和存储序列等。Oracle可以支持多种语言及字符集,其中oracle8i支持48种语言、76个国家地域、229种字符集,而oracle9i则支持57种语言、88个国家地域、235种字符集。由于oracle字符集种类多,且在存储、检索、迁移oracle数据时多个环节与字符集的设置密切相关,因此在实际的应用中,数据库开发和管理人员经常会遇到有关oracle字符集方面的问题。本文通过以下几个方面阐述,对oracle字符集做简要分析
二.字符集基本知识
2.1字符集
实质就是按照一定的字符编码方案,对一组特定的符号,分别赋予不同数值编码的集合。Oracle数据库最早支持的编码方案是US7ASCII。
Oracle
的字符集命名遵循以下命名规则
:
即: <语言><比特位数><编码
>
比如: ZHS16GBK表示采用GBK编码格式、16位(两个字节)简体中文字符集
2.2字符编码方案
2.2.1
单字节编码
(1)单字节7位字符集,可以定义128个字符,最常用的字符集为
US7ASCII
(2)单字节8位字符集,可以定义256个字符,适合于欧洲大部分国家
例如:WE8ISO8859P1(西欧、8位、ISO标准8859P1编码
)
2.2.2 多字节编码
(1)变长多字节编码
某些字符用一个字节表示,其它字符用两个或多个字符表示,变长多字节编码常用于对亚洲语言的支持, 例如日语、汉语、印地语等
例如:AL32UTF8(其中AL代表ALL,指适用于所有语言)、
zhs16cgb231280
(2)定长多字节编码
每一个字符都使用固定长度字节的编码方案,目前oracle唯一支持的定长多字节编码是AF16UTF16,也是仅用于国家字符集
2.2.3 unicode
编码
Unicode
是一个涵盖了目前全世界使用的所有已知字符的单一编码方案,也就是说Unicode为每一个字符提供唯一的编码。UTF-16是unicode的16位编码方式,是一种定长多字节编码,用2个字节表示一个unicode字符,AF16UTF16是UTF-16编码字符集。
UTF-8
是unicode的8位编码方式,是一种变长多字节编码,这种编码可以用1、2、3个字节表示一个unicode字符,AL32UTF8,UTF8、UTFE是UTF-8编码字符集
2.3 字符集超级
当一种字符集(字符集A)的编码数值包含所有另一种字符集(字符集B)的编码数值,并且两种字符集相同编码数值代表相同的字符时,则字符集A是字符集B的超级,或称字符集B是字符集A的子集。
Oracle8i
和oracle9i官方文档资料中备有子集-超级对照表(subset-superset pairs),例如:WE8ISO8859P1是WE8MSWIN1252的子集。由于US7ASCII是最早的Oracle数据库编码格式,因此有许多字符集是US7ASCII的超集,例如WE8ISO8859P1、ZHS16CGB231280、ZHS16GBK都是US7ASCII的超集。
2.4 数据库字符集(oracle服务器端字符集)
数据库字符集在创建数据库时指定,在创建后通常不能更改。在创建数据库时,可以指定字符集(CHARACTER SET)和国家字符集(NATIONAL CHARACTER SET)。
2.4.1
字符集
(1)
用来存储CHAR, VARCHAR2, CLOB, LONG等类型数据
(2)
用来标示诸如表名、列名以及PL/SQL变量等
(3)
用来存储SQL和PL/SQL程序单元等
2.4.2
国家字符集:
(1)
用以存储NCHAR, NVARCHAR2, NCLOB等类型数据
(2)
国家字符集实质上是为oracle选择的附加字符集,主要作用是为了增强oracle的字符处理能力,因为NCHAR数据类型可以提供对亚洲使用定长多字节编码的支持,而数据库字符集则不能。国家字符集在oracle9i中进行了重新定义,只能在unicode编码中的AF16UTF16和UTF8中选择,默认值是
AF16UTF16
2.4.3查询字符集参数
可以查询以下数据字典或视图查看字符集设置情况
nls_database_parameters
、props$、
v$nls_parameters
查询结果中NLS_CHARACTERSET表示字符集,NLS_NCHAR_CHARACTERSET表示国家字符集
2.4.4
修改数据库字符集
按照上文所说,数据库字符集在创建后原则上不能更改。如果需要修改字符集,通常需要导出数据库数据,重建数据库,再导入数据库数据的方式来转换,或通过ALTER DATABASE CHARACTER SET语句修改字符集,但创建数据库后修改字符集是有限制的,只有新的字符集是当前字符集的超集时才能修改数据库字符集,例如UTF8是US7ASCII的超集,修改数据库字符集可使用ALTER DATABASE CHARACTER SET UTF8。
2.5 客户端字符集(NLS_LANG参数)
2.5.1
客户端字符集含义
客户端字符集定义了客户端字符数据的编码方式,任何发自或发往客户端的字符数据均使用客户端定义的字符集编码,客户端可以看作是能与数据库直接连接的各种应用,例如sqlplus,exp/imp等。客户端字符集是通过设置NLS_LANG参数来设定的。
2.5.2 NLS_LANG
参数格式
NLS_LANG=_.
Language:
显示oracle消息,校验,日期命名
Territory
:指定默认日期、数字、货币等格式
Client character set
:指定客户端将使用的字符集
例如:
NLS_LANG=AMERICAN_AMERICA.US7ASCII
AMERICAN是语言,AMERICA是地区,US7ASCII是客户端字符集
2.5.3
客户端字符集设置方法
1)UNIX
环境
$NLS_LANG=“simplified chinese”_china.zhs16gbk
$export NLS_LANG
编辑oracle用户的profile文件
2)Windows
环境
编辑注册表
Regedit.exe---HKEY_LOCAL_MACHINE---SOFTWARE---ORACLE—HOME0
2.5.4 NLS
参数查询
Oracle
提供若干NLS参数定制数据库和用户机以适应本地格式,例如有NLS_LANGUAGE,NLS_DATE_FORMAT,NLS_CALENDER等,可以通过查询以下数据字典或v$视图查看。
NLS_DATABASE_PARAMETERS--
显示数据库当前NLS参数取值,包括数据库字符集取值
NLS_SESSION_PARAMETERS--
显示由NLS_LANG 设置的参数,或经过alter session 改变后的参数值(不包括由NLS_LANG 设置的客户端字符集)
NLS_INSTANCE_PARAMETE--
显示由参数文件init.ora 定义的参数V$NLS_PARAMETERS--显示数据库当前NLS参数取值
2.5.5
修改NLS参数
使用下列方法可以修改NLS参数
(1)修改实例启动时使用的初始化参数文件
(2)修改环境变量
NLS_LANG
(3)使用ALTER SESSION语句,在oracle会话中修改
(4)使用某些SQL函数
NLS
作用优先级别:Sql function>alter session>环境变量或注册表>参数文件>数据库默认参数
三.导入/导出与字符集转换
3.1 EXP/IMP
Export 和 Import 是一对读写Oracle数据的工具。Export 将 Oracle 数据库中的数据输出到操作系统文件中, Import 把这些文件中的数据读到Oracle 数据库中,由于使用exp/imp进行数据迁移时,数据从源数据库到目标数据库的过程中有四个环节涉及到字符集,如果这四个环节的字符集不一致,将会发生字符集转换。
EXP
____________ _________________ _____________
|imp导入文件|<-><->
------------ ----------------- -------------
IMP
____________ _________________ _____________
|imp导入文件|->|环境变量NLS_LANG|->|数据库字符集|
------------ ----------------- -------------
四个字符集是
(1)源数据库字符集
(2)Export过程中用户会话字符集(通过NLS_LANG设定)
(3)Import过程中用户会话字符集(通过NLS_LANG设定)
(4)目标数据库字符集
3.2导出的转换过程
在Export过程中,如果源数据库字符集与Export用户会话字符集不一致,会发生字符集转换,并在导出文件的头部几个字节中存储Export用户会话字符集的ID号。在这个转换过程中可能发生数据的丢失。
例:如果源数据库使用ZHS16GBK,而Export用户会话字符集使用US7ASCII,由于ZHS16GBK是16位字符集,而US7ASCII是7位字符集,这个转换过程中,中文字符在US7ASCII中不能够找到对等的字符,所以所有中文字符都会丢失而变成“?? ”形式,这样转换后生成的Dmp文件已经发生了数据丢失。
因此如果想正确导出源数据库数据,则Export过程中用户会话字符集应等于源数据库字符集或是源数据库字符集的超集
3.3导入的转换过程
(1)确定导出数据库字符集环境
通过读取导出文件头,可以获得导出文件的字符集设置
(2)确定导入session的字符集,即导入Session使用的NLS_LANG环境变量
(3)IMP读取导出文件
读取导出文件字符集ID,和导入进程的NLS_LANG进行比较
(4)如果导出文件字符集和导入Session字符集相同,那么在这一步骤内就不需要转换,如果不同,就需要把数据转换为导入Session使用的字符集。可以看出,导入数据到数据库过程中发生两次字符集转换
第一次:导入文件字符集与导入Session使用的字符集之间的转换,如果这个转换过程不能正确完成,Import向目标数据库的导入过程也就不能完成。
第二次:导入Session字符集与数据库字符集之间的转换。
然而,oracle8i的这种转换只能在单字节字符集之间进行,oracle8i导入Session不支持多字节字符集之间的转换,因此为了避免第一次转换,导入Session使用的NLS_LANG与导出文件字符集相同,第二次转换(通过SQL*Net)支持任何两种字符集。以上情况在Oracle9i中略有不同
四.乱码问题
oracle在数据存储、迁移过程中经常发生字符乱码问题,归根到底是由于字符集使用不当引起。下面以使用客户端sqlplus向数据库插入数据和导入/导出(EXP/IMP)过程为例,说明乱码产生的原因。
4.1使用客户端sqlplus向数据库存储数据
这个过程存在3个字符集设置
(1)客户端应用字符集
(2)客户端NLS_LANG参数设置
(3)服务器端数据库字符集(Character Set)设置
客户端应用sqlplus中能够显示什么样的字符取决于客户端操作系统语言环境(客户端应用字符集),但在应用中录入这些字符后,这些字符能否在数据库中正常存储,还与另外两个字符集设置紧密相关,其中客户端NLS_LANG参数主要用于字符数据传输过程中的转换判断。常见的乱码大致有两种情形:
(1)汉字变成问号“?”;
当从字符集A 转换成字符集B时,如果转换字符之间不存在对应关系,NLS_LANG使用替代字符“?”替代无法映射的字符
(2)汉字变成未知字符(虽然有些是汉字,但与原字符含义不同)
转换存在对应关系,但字符集A 中的字符编码与字符集B 中的字符编码代表不同含义
4.2发生乱码原因
乱码产生是由于几个字符集之间转换不匹配造成,分以下几种情况:
(注:字符集之间如果不存在子集、超集对应关系时的情况不予考虑,因为这种情况下字符集之间转换必产生乱码)
1)服务器端数据库字符集与客户端应用字符集相同,与客户端NLS_LANG参数设置不同
如果客户端NLS_LANG字符集是其它两种字符集的子集,转换过程将出现乱码。
解决方法:将三种字符集设置成同一字符集,或NLS_LANG字符集是其它两种字符集的超集
2
)服务器端数据库字符集与客户端NLS_LANG参数设置相同,与客户端应用字符集不同
如果客户端应用字符集是其它两种字符集的超集时,转换过程将出现乱码,但对于单字节编码存储中文问题,可参看本文第5章节的分析
3
)客户端应用字符集、客户端NLS_LANG参数设置、服务器端数据库字符集互不相同
此种情况较为复杂,但三种字符集之间只要有不能转换的字符,则必产生乱码
4.3导入/导出过程出现乱码原因
这个过程存在4个字符集设置,在3.1章节中已分析
(1)源数据库字符集
(2)EXP过程中NLS_LANG参数
(3)IMP过程中NLS_LANG参数
(4)目标数据库字符集
出现乱码原因
1
)当源数据库字符集不等于EXP过程中NLS_LANG参数,且源数据库字符集是EXP过程中NLS_LANG的子集,才能保证导出文件正确,其他情况则导出文件字符乱码
2
)EXP过程中NLS_LANG字符集不等于IMP过程中NLS_LANG字符集,且EXP过程中NLS_LANG字符集是IMP过程中NLS_LANG字符集的子级, 才能保证第一次转换正常,否则第一次转换中出现乱码。
3
)如果第一次转换正常,IMP过程中NLS_LANG字符集是目标数据库字符集的子集或相同,才能保证第二次转换正常,否则则第二次转换中出现乱码
五.单字节编码存储中文问题
由于历史的原因,早期的oracle没有中文字符集(如oracle6、oracle7、oracle7.1),但有的用户从那时起就使用数据库了,并用US7ASCII字符集存储了中文,或是有的用户在创建数据库时,不考虑清楚,随意选择一个默认的字符集,如WE8ISO8859P1或US7ASCII,而这两个字符集都没有汉字编码,虽然有些时候选用这种字符集好象也能正常使用,但用这种字符集存储汉字信息从原则上说就是错误的,它会给数据库的使用与维护带来一系列的麻烦。
正常情况下,要将汉字存入数据库,数据库字符集必须支持中文,而将数据库字符集设置为US7ASCII等单字节字符集是不合适的。US7ASCII字符集只定义了128个符号,并不支持汉字。另外,如果在SQL*PLUS中能够输入中文,操作系统缺省应该是支持中文的,但如果在NLS_LANG中的字符集设置为US7ASCII,显然也是不正确的,它没有反映客户端的实际情况。但在实际应用中汉字显示却是正确的,这主要是因为Oracle检查数据库与客户端的字符集设置是同样的,那么数据在客户与数据库之间的存取过程中将不发生任何转换,但是这实际上导致了数据库标识的字符集与实际存入的内容是不相符的。而在SELECT的过程中,Oracle同样检查发现数据库与客户端的字符集设置是相同的,所以它也将存入的内容原封不动地传送到客户端,而客户端操作系统识别出这是汉字编码所以能够正确显示。
在这个例子中,数据库与客户端都没有设置成中文字符集,但却能正常显示中文,从应用的角度看好象没问题。然而这里面却存在着极大的隐患,比如在应用length或substr等字符串函数时,就可能得到意外的结果。
对于早期使用US7ASCII字符集数据库的数据迁移到oracle8i/9i中(使用zhs16gbk),由于原始数据已经按照US7ASCII格式存储,对于这种情况,可以通过使用Oracle8i的导出工具,设置导出字符集为US7ASCII,导出后使用UltraEdit等工具打开dmp文件,修改第二、三字符,修改 0001 为0354,这样就可以将US7ASCII字符集的数据正确导入到ZHS16GBK的数据库中。
六.结束语
为了避免在数据库迁移过程中由于字符集不同导致的数据损失,oracle提供了字符集扫描工具(character set scanner),通过这个工具我们可以测试在数据迁移过程中由于字符集转换可能带来的问题,然后根据测试结果,确定数据迁移过程中最佳字符集解决方案。
参考文献
[1]Biju Thomas , Bob Bryla
《oracle9i DBA基础I 学习指南》电子工业出版社
2002
|
posted @
2007-02-13 13:12 一缕青烟 阅读(231) |
评论 (0) |
编辑 收藏
表格部分代码如下:
<table id="testTbl" border=1>
<tr id="tr1">
<td width=6%><input type=checkbox id="box1"></td>
<td id="b">第一行</td>
</tr>
<tr id="tr2">
<td width=6%><input type=checkbox id="box2"></td>
<td id="b">第二行</td>
</tr>
<tr>
<td width=6%><input type=checkbox id="box3"></td>
<td>第三行</td>
</tr>
</table>
动态添加表行的javascript函数如下:
<script language="javascript">
function addRow(){
//添加一行
var newTr = testTbl.insertRow();
//设置行背景
newTr.bgColor = '#008040';
//添加两列
var newTd0 = newTr.insertCell();
var newTd1 = newTr.insertCell();
//设置列内容和属性
newTd0.innerHTML = '<input type=checkbox id="box4">';
newTd1.innerText= '新增加的行';
}
</script>
<BR>
<a href="#" onclick="addRow();">增加一行</a>
就这么简单,做点详细的说明:
1、inserRow()和insertCell()函数
insertRow()函数可以带参数,形式如下:
insertRow(index)
这个函数将新行添加到index的那一行前,比如insertRow(0),是将新行添加到第一行之前。默认的insertRow()函数相当于insertRow(-1),将新行添加到表的最后。
insertCell()和insertRow的用法相同。
2、动态设置属性和事件
上面行数中的innerHTML和innerText都是列的属性。
这个inner,就是“inner”到<tb></tb>之间,innerText是添加到<tb></tb>之间的文本,innerHTML是添加到<tb></tb>之间的HTML代码(这个so简单,这个解释挺多余的)
设置其他属性也是用同样的方式,比如,设置行背景色
newTr.bgColor = 'red';
设置事件也一样,需要简单说明一点。
比如,我要让点击新加行的时候执行一个自己定义的函数 newClick,newClick行数如下:
function newClick(){
alert("这是新添加的行");
}
对onclick事件设置这个函数的代码如下:
newTr.onclick = newClick;
这里需要主义的是,=后面的部分必须是函数名,而且不能带引号,
newTr.onclick = newClick();
newTr.onclick = 'newClick';
newTr.onclick = "newClick";
上面的写法都是错误的。
为什么,其实知道为什么没有什么意思,知道怎么用就OK了,如果不想知道,可以跳过下面这一段。
实际上这个=后面的newClick是指向自己定义的newClick函数的指针,javascript里面函数名就是指向函数的指针,加了引号括号什么的浏览器就找不到那个函数了。
下面的写法,也是正确的
newTr.onclick = function newClick(){
alert("这是新添加的行");
}
这个使用函数名实际上是一样的
设置其他的事件用法相同。
posted @
2007-01-18 14:39 一缕青烟 阅读(1861) |
评论 (0) |
编辑 收藏
|
J2EE程序中使用oracle数据库LOB字段的总结(elathen)
|
| http://www.souzz.net 2005-10-23 文章出处:博客园 |
| |
|
posted on 2005-05-27 09:36 轻松逍遥子 最近在J2EE的项目中需要使用LOB字段保存文本信息以及图片和文件,到网上搜拉一下,还不少,仔细看拉一下,但都不是很全有的还有错误,经过几天的实践,把问题都解决拉,顺便总结一下,希望对需要的朋友有点参考
LOB中我们用的比较多的主要有两种CLOB和BLOB,我们对两种类型分别讨论
1.CLOB是字符型LOB,主要存储文本信息,,最长为4G.,在J2EE程序中,比如网页的textarea中的字符信息比较长,Varchar2字段类型不能满足时,我们就得用CLOB数据类型,我们这次项目中就碰到这种情况.现在我们先说说如何存取CLOB字段
现在我要把网页中的textarea元素的信息保存到数据库的CLOB字段中, 我们都知道textarea中的信息当然不能直接保存成CLOB,我们在后台得到的是String类型的,不多说拉,我们还是以一个实例讲吧!
先建一个test表,表有2个字段:ID,CONTENTS,其中CONTENTS保存CLOB类型的文本数据
create table TEST
(
ID VARCHAR2(18) not null,
CONTENTS CLOB,
)
接着我们编写一个测试用的jsp文件ClobTest.jsp,代码如下
<%@ page language="java" contentType="text/html; charset=gb2312" %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>Clob对象的存取测试</title>
</head>
<body>
<form name="test" method="post" action="clobTest.action">
<table width="80%" height="88" border="0" align="center" cellpadding="0" cellspacing="0">
<tr>
<td height="30" align="center">输入ID号<input type="text" name="ID">
</tr>
<tr>
<td align="center">
<textarea rows="28" cols="68" name="CONTENTS">
注册用户需遵守:
尊重会员个人隐私、保障会员隐私安全是CSDN的一项基本政策,CSDN不会公开、编辑或透露会员的注册资料,除非符合以下情况:
(1) 根据中华人民共和国国家安全机构、公安部门的要求及根据相应的法律程序要求。
(2) 维护CSDN的商标所有权及其它权益。
(3) 在紧急情况下竭力维护会员个人、其它社会个体和社会大众的安全。
(4) 严重违反CSDN有关规定。
CSDN保留结束会员使用网络服务资格的权利,并保证结束会员资格后仍为会员保密所有个人隐私。
</textarea>
</td>
</tr>
<tr>
<td align="center">
<input type="submit" name="Submit" value="提交">
</td>
</tr>
</table>
</form>
</body>
</html>
点击”提交”按钮,我们在后台的到的是2个String类型的对象
String strID = request.getParameter(“ID”);
String strCONTENTS = request.getParameter(“CONTENTS”);
接着我们要做的任务就是如何把String类型CONTENTS存到数据库中的CLOB类型字段中!
注意:LOB数据不能象其它类型数据一样直接插入(INSERT)。插入前必须先插入一个空的LOB对象,CLOB类型的空对象为EMPTY_CLOB(),BLOB类型的空对象为EMPTY_BLOB()。之后通过SELECT命令查询得到先前插入的记录并锁定,继而将空对象修改为所要插入的LOB对象。
//我们先插入一个空的CLOB对象
public int insertEmptyClob() throws Exception {
Statement statement = null;
int intResult = -1;
try {
//创建数据库操作语句
statement = connection.createStatement();
//定义SQL语句
String strSQL = “INSET INTO TEST (ID,CONTENTS) VALUES(strID, EMPTY_CLOB())”;
//执行SQL语句
intResult = statement.executeUpdate(strSQL);
System.out.println(" intResult valus is"+intResult);
return intResult;
} catch(Exception e) {
e.printStackTrace();
return -1;
} finally {
if (statement != null) {
statement.close();
}
}
}
//把strCONTENT插入CLOB字段
public void insertClob() throws Exception {
Statement statement = null;
ResultSet resultset = null;
try {
//设置不自动提交
connection.setAutoCommit(false);
//创建数据库操作语句
statement = connection.createStatement();
//定义SQL语句
String strSQL = “SELECT CONTENTS FROM TEST WHERE ID=strID"”
resultset = statement.executeQuery(strSQL);
oracle.sql.CLOB contents = null;
while(resultset.next()) {
//取出CLOB对象
contents = (oracle.sql.CLOB)resultset.getClob("CONTENTS");
}
Writer out = contents.getCharacterOutputStream();
out.write(strContents);
out.flush();
out.close();
//数据库提交
connection.commit();
} catch(Exception e) {
e.printStackTrace();
}finally{
if(resultset != null) {
resultset.close();
}
if(statement != null) {
statement.close();
}
}
}
OK,我们已经把这段文本以CLOB字段的形式保存到数据库中了,在实际应用中,如果要保存或修改一条记录,我们要分2步做,先保存或修改非LOB字段类型的字段,再保存或修改LOB字段!接下来我们来把刚才保存到数据库中的CLOB字段读到jsp页面中去。
我们在保存的时候,CLOB字段会把上面textarea中的文本按原来的格式一行一行(包括空格)都保存到CLOB字段中,读取的时候我们只要按照原来格式读起出来就行了(我这里自己用了一个小处理方法,但如果你有更好的方法请告诉我)。在这里我们把CLOB读到StringBuffer中,为了保存不同行我在行之间加了个“&”字符来区分。最后转化成String
放到VO中,这样就保证从前台到后台,从后台到前台的数据传递的一致性!代码如下:
/**
* 获取CLOB文本对象
* @param sbSQL
* @return
* @throws java.lang.Exception
*/
public String selectIncludeClob(StringBuffer sbSQL) throws Exception {
Statement stmt = null;
ResultSet rs = null;
StringBuffer sbResult = new StringBuffer();
try {
//设定数据库不自动提交
//connection.setAutoCommit(false);
//创建数据库操作语句
stmt = connection.createStatement();
//获取结果集
rs = stmt.executeQuery(sbSQL.toString());
while(rs.next()) {
CLOB clob = (CLOB)rs.getClob("CONTENTS");
Reader isClob = clob.getCharacterStream();
BufferedReader bfClob = new BufferedReader(isClob);
String strClob = bfClob.readLine();
while(strClob != null) {
sbResult.append(strClob);
sbResult.append("&");
strClob = bfClob.readLine();
}
}
//提交事务
// connection.commit();
} catch(Exception e) {
e.printStackTrace();
throw e;
} finally {
if(rs != null) {
rs.close();
}
if(stmt != null) {
stmt.close();
}
}
return sbResult.toString();
}
到jsp页面中,我们从VO中获取改文本信息。
<textarea rows="42" cols="68" name="CONTENTS" style="border-style: solid; border-color: #FFFFFF; font-family:仿宋_GB2312; font-size:14pt; line-height:200%; margin-top:8; margin-bottom:6" >
<%
String content = vo.getContent();
String[] contentArray = content.split("&");
for(int i=0;i<contentArray.length;i++) {
String s= contentArray[i];
out.println(s);
}
%>
</textarea>
这样我们就保证什么格式保存就以什么格式显示。
2.BLOB字段,二进制LOB,主要存储二进制数据,最长为4G,在J2EE程序中,一般类似于图片和文件的保存。当然也有另一种方法,就把图片和文件保存在硬盘上,数据库中只保存图片的链接地址和文件在服务器上的路径。如果遇到文件和图片比较重要的还是需要保存到数据库中(例如:我们做国土资源项目的时候,好多图片、文件就很重要,需要保存到数据库中),下面我写一个保存文件到数据库的Blob字段和从数据库的Blob字段中获取文件的方法(当然完全应用还要做其他工作,这里就不多说了,如果你不清楚的可以问我):
/**
* 把上传的文件保存到数据库的Blob字段中
* @param strTableName 对应的表名称
* @param strColumnName 表中保存文件的Blob字段名称
* @param inputStream 输入的文件流
* @param sbSQLWhere where条件
* @throws java.lang.Exception
*/
public static void fileUpload(String strTableName,
String strColumnName,
InputStream inputStream,
StringBuffer sbSQLWhere)
throws Exception {
Connection con = null;
ResultSet resultset = null;
Statement stmt = null;
try {
//得到数据库连接
con = DBConnector.getConnection();
//构建查询语句
StringBuffer sbSQL = new StringBuffer();
sbSQL.append(" UPDATE ");
sbSQL.append(strTableName);
sbSQL.append(" SET ");
sbSQL.append(strColumnName);
sbSQL.append("=EMPTY_BLOB() ");
sbSQL.append(sbSQLWhere);
System.out.println(" update sql value is*******"+sbSQL.toString());
//获取数据库操作语句
stmt=con.createStatement();
//插入空的blob对象
stmt.executeUpdate(sbSQL.toString());
con.setAutoCommit(false);
StringBuffer sbSQLBlob = new StringBuffer();
sbSQLBlob.append(" SELECT ");
sbSQLBlob.append(strColumnName);
sbSQLBlob.append(" FROM ");
sbSQLBlob.append(strTableName);
sbSQLBlob.append(sbSQLWhere);
sbSQLBlob.append(" FOR UPDATE");
System.out.println(" select sql value is*********"+sbSQL.toString());
resultset =stmt.executeQuery(sbSQLBlob.toString());
while (resultset.next()) {
/* 取出此BLOB对象 */
oracle.sql.BLOB blob = (oracle.sql.BLOB)resultset.getBlob("BODY");
/* 向BLOB对象中写入数据 */
BufferedOutputStream out = new BufferedOutputStream(blob.getBinaryOutputStream());
BufferedInputStream in = new BufferedInputStream(inputStream);
int c;
while ((c=in.read())!=-1) {
out.write(c);
}
in.close();
out.close();
}
con.setAutoCommit(false);
con.commit();
} catch (Exception ex) {
ex.printStackTrace();
throw ex;
} finally {
if (stmt != null) {
stmt.close();
}
if (resultset != null) {
resultset.close();
}
if (con!=null) {
con.close();
}
}
}
下面的方法是从数据库中得到上传的文件的输入流,把输入流写到servlet流中,再从页面中获取,servlet就不写了。
/**
* 方法描述:得到数据库上传的文件数据
*
* 输入参数: 1:表名(String)
* 2:字段名(String)
* 3: Where条件(StringBuffer)
* 5: 输出流(ServletOutputStream)
*
* 输出参数:void
* 编写人: */
public static void getdownFile(String strTableName,
String strColumnName,
StringBuffer sbSQLWhere,
ServletOutputStream sos) throws Exception {
Connection con = null;
PreparedStatement ps = null;
ResultSet resultset = null;
try {
//得到数据库连接
con = DBConnector.getConnection();
StringBuffer sbSQL = new StringBuffer();
//构建查询语句
sbSQL.append(" SELECT " + strColumnName + " FROM " + strTableName);
sbSQL.append(sbSQLWhere);
System.out.println(" sql value is:"+sbSQLWhere.toString());
ps = con.prepareStatement(sbSQL.toString());
//执行查询
resultset = ps.executeQuery();
while (resultset.next()) {
//读取数据流
InputStream is = resultset.getBinaryStream(strColumnName);
byte[] buf = new byte[2048];
while(is.read(buf)!=-1) {
//把数据流按块写到servlet的输出流中
sos.write(buf);
}
}
} catch (Exception ex) {
ex.printStackTrace();
throw ex;
} finally {
if (ps != null) {
ps.close();
}
if (resultset != null) {
resultset.close();
}
if (con!=null) {
con.close();
}
}
}
图片的保存和文件的保存一样,如果不清楚的可以和我联系
后记:
平时总忙着做项目,闲的时候也很懒,总想把自己实际中的一些问题和解决方法小结一下,但总没完成,这是第一次写,写的不好或不清楚的地方请包涵,下次改进,也希望大家多提意见,大家一起进步!!!!!!!!!!! |
|
posted @
2007-01-16 16:14 一缕青烟 阅读(218) |
评论 (0) |
编辑 收藏
|
J2EE程序中使用oracle数据库LOB字段的总结(elathen)
|
| http://www.souzz.net 2005-10-23 文章出处:博客园 |
| |
|
posted on 2005-05-27 09:36 轻松逍遥子 最近在J2EE的项目中需要使用LOB字段保存文本信息以及图片和文件,到网上搜拉一下,还不少,仔细看拉一下,但都不是很全有的还有错误,经过几天的实践,把问题都解决拉,顺便总结一下,希望对需要的朋友有点参考
LOB中我们用的比较多的主要有两种CLOB和BLOB,我们对两种类型分别讨论
1.CLOB是字符型LOB,主要存储文本信息,,最长为4G.,在J2EE程序中,比如网页的textarea中的字符信息比较长,Varchar2字段类型不能满足时,我们就得用CLOB数据类型,我们这次项目中就碰到这种情况.现在我们先说说如何存取CLOB字段
现在我要把网页中的textarea元素的信息保存到数据库的CLOB字段中, 我们都知道textarea中的信息当然不能直接保存成CLOB,我们在后台得到的是String类型的,不多说拉,我们还是以一个实例讲吧!
先建一个test表,表有2个字段:ID,CONTENTS,其中CONTENTS保存CLOB类型的文本数据
create table TEST
(
ID VARCHAR2(18) not null,
CONTENTS CLOB,
)
接着我们编写一个测试用的jsp文件ClobTest.jsp,代码如下
<%@ page language="java" contentType="text/html; charset=gb2312" %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>Clob对象的存取测试</title>
</head>
<body>
<form name="test" method="post" action="clobTest.action">
<table width="80%" height="88" border="0" align="center" cellpadding="0" cellspacing="0">
<tr>
<td height="30" align="center">输入ID号<input type="text" name="ID">
</tr>
<tr>
<td align="center">
<textarea rows="28" cols="68" name="CONTENTS">
注册用户需遵守:
尊重会员个人隐私、保障会员隐私安全是CSDN的一项基本政策,CSDN不会公开、编辑或透露会员的注册资料,除非符合以下情况:
(1) 根据中华人民共和国国家安全机构、公安部门的要求及根据相应的法律程序要求。
(2) 维护CSDN的商标所有权及其它权益。
(3) 在紧急情况下竭力维护会员个人、其它社会个体和社会大众的安全。
(4) 严重违反CSDN有关规定。
CSDN保留结束会员使用网络服务资格的权利,并保证结束会员资格后仍为会员保密所有个人隐私。
</textarea>
</td>
</tr>
<tr>
<td align="center">
<input type="submit" name="Submit" value="提交">
</td>
</tr>
</table>
</form>
</body>
</html>
点击”提交”按钮,我们在后台的到的是2个String类型的对象
String strID = request.getParameter(“ID”);
String strCONTENTS = request.getParameter(“CONTENTS”);
接着我们要做的任务就是如何把String类型CONTENTS存到数据库中的CLOB类型字段中!
注意:LOB数据不能象其它类型数据一样直接插入(INSERT)。插入前必须先插入一个空的LOB对象,CLOB类型的空对象为EMPTY_CLOB(),BLOB类型的空对象为EMPTY_BLOB()。之后通过SELECT命令查询得到先前插入的记录并锁定,继而将空对象修改为所要插入的LOB对象。
//我们先插入一个空的CLOB对象
public int insertEmptyClob() throws Exception {
Statement statement = null;
int intResult = -1;
try {
//创建数据库操作语句
statement = connection.createStatement();
//定义SQL语句
String strSQL = “INSET INTO TEST (ID,CONTENTS) VALUES(strID, EMPTY_CLOB())”;
//执行SQL语句
intResult = statement.executeUpdate(strSQL);
System.out.println(" intResult valus is"+intResult);
return intResult;
} catch(Exception e) {
e.printStackTrace();
return -1;
} finally {
if (statement != null) {
statement.close();
}
}
}
//把strCONTENT插入CLOB字段
public void insertClob() throws Exception {
Statement statement = null;
ResultSet resultset = null;
try {
//设置不自动提交
connection.setAutoCommit(false);
//创建数据库操作语句
statement = connection.createStatement();
//定义SQL语句
String strSQL = “SELECT CONTENTS FROM TEST WHERE ID=strID"”
resultset = statement.executeQuery(strSQL);
oracle.sql.CLOB contents = null;
while(resultset.next()) {
//取出CLOB对象
contents = (oracle.sql.CLOB)resultset.getClob("CONTENTS");
}
Writer out = contents.getCharacterOutputStream();
out.write(strContents);
out.flush();
out.close();
//数据库提交
connection.commit();
} catch(Exception e) {
e.printStackTrace();
}finally{
if(resultset != null) {
resultset.close();
}
if(statement != null) {
statement.close();
}
}
}
OK,我们已经把这段文本以CLOB字段的形式保存到数据库中了,在实际应用中,如果要保存或修改一条记录,我们要分2步做,先保存或修改非LOB字段类型的字段,再保存或修改LOB字段!接下来我们来把刚才保存到数据库中的CLOB字段读到jsp页面中去。
我们在保存的时候,CLOB字段会把上面textarea中的文本按原来的格式一行一行(包括空格)都保存到CLOB字段中,读取的时候我们只要按照原来格式读起出来就行了(我这里自己用了一个小处理方法,但如果你有更好的方法请告诉我)。在这里我们把CLOB读到StringBuffer中,为了保存不同行我在行之间加了个“&”字符来区分。最后转化成String
放到VO中,这样就保证从前台到后台,从后台到前台的数据传递的一致性!代码如下:
/**
* 获取CLOB文本对象
* @param sbSQL
* @return
* @throws java.lang.Exception
*/
public String selectIncludeClob(StringBuffer sbSQL) throws Exception {
Statement stmt = null;
ResultSet rs = null;
StringBuffer sbResult = new StringBuffer();
try {
//设定数据库不自动提交
//connection.setAutoCommit(false);
//创建数据库操作语句
stmt = connection.createStatement();
//获取结果集
rs = stmt.executeQuery(sbSQL.toString());
while(rs.next()) {
CLOB clob = (CLOB)rs.getClob("CONTENTS");
Reader isClob = clob.getCharacterStream();
BufferedReader bfClob = new BufferedReader(isClob);
String strClob = bfClob.readLine();
while(strClob != null) {
sbResult.append(strClob);
sbResult.append("&");
strClob = bfClob.readLine();
}
}
//提交事务
// connection.commit();
} catch(Exception e) {
e.printStackTrace();
throw e;
} finally {
if(rs != null) {
rs.close();
}
if(stmt != null) {
stmt.close();
}
}
return sbResult.toString();
}
到jsp页面中,我们从VO中获取改文本信息。
<textarea rows="42" cols="68" name="CONTENTS" style="border-style: solid; border-color: #FFFFFF; font-family:仿宋_GB2312; font-size:14pt; line-height:200%; margin-top:8; margin-bottom:6" >
<%
String content = vo.getContent();
String[] contentArray = content.split("&");
for(int i=0;i<contentArray.length;i++) {
String s= contentArray[i];
out.println(s);
}
%>
</textarea>
这样我们就保证什么格式保存就以什么格式显示。
2.BLOB字段,二进制LOB,主要存储二进制数据,最长为4G,在J2EE程序中,一般类似于图片和文件的保存。当然也有另一种方法,就把图片和文件保存在硬盘上,数据库中只保存图片的链接地址和文件在服务器上的路径。如果遇到文件和图片比较重要的还是需要保存到数据库中(例如:我们做国土资源项目的时候,好多图片、文件就很重要,需要保存到数据库中),下面我写一个保存文件到数据库的Blob字段和从数据库的Blob字段中获取文件的方法(当然完全应用还要做其他工作,这里就不多说了,如果你不清楚的可以问我):
/**
* 把上传的文件保存到数据库的Blob字段中
* @param strTableName 对应的表名称
* @param strColumnName 表中保存文件的Blob字段名称
* @param inputStream 输入的文件流
* @param sbSQLWhere where条件
* @throws java.lang.Exception
*/
public static void fileUpload(String strTableName,
String strColumnName,
InputStream inputStream,
StringBuffer sbSQLWhere)
throws Exception {
Connection con = null;
ResultSet resultset = null;
Statement stmt = null;
try {
//得到数据库连接
con = DBConnector.getConnection();
//构建查询语句
StringBuffer sbSQL = new StringBuffer();
sbSQL.append(" UPDATE ");
sbSQL.append(strTableName);
sbSQL.append(" SET ");
sbSQL.append(strColumnName);
sbSQL.append("=EMPTY_BLOB() ");
sbSQL.append(sbSQLWhere);
System.out.println(" update sql value is*******"+sbSQL.toString());
//获取数据库操作语句
stmt=con.createStatement();
//插入空的blob对象
stmt.executeUpdate(sbSQL.toString());
con.setAutoCommit(false);
StringBuffer sbSQLBlob = new StringBuffer();
sbSQLBlob.append(" SELECT ");
sbSQLBlob.append(strColumnName);
sbSQLBlob.append(" FROM ");
sbSQLBlob.append(strTableName);
sbSQLBlob.append(sbSQLWhere);
sbSQLBlob.append(" FOR UPDATE");
System.out.println(" select sql value is*********"+sbSQL.toString());
resultset =stmt.executeQuery(sbSQLBlob.toString());
while (resultset.next()) {
/* 取出此BLOB对象 */
oracle.sql.BLOB blob = (oracle.sql.BLOB)resultset.getBlob("BODY");
/* 向BLOB对象中写入数据 */
BufferedOutputStream out = new BufferedOutputStream(blob.getBinaryOutputStream());
BufferedInputStream in = new BufferedInputStream(inputStream);
int c;
while ((c=in.read())!=-1) {
out.write(c);
}
in.close();
out.close();
}
con.setAutoCommit(false);
con.commit();
} catch (Exception ex) {
ex.printStackTrace();
throw ex;
} finally {
if (stmt != null) {
stmt.close();
}
if (resultset != null) {
resultset.close();
}
if (con!=null) {
con.close();
}
}
}
下面的方法是从数据库中得到上传的文件的输入流,把输入流写到servlet流中,再从页面中获取,servlet就不写了。
/**
* 方法描述:得到数据库上传的文件数据
*
* 输入参数: 1:表名(String)
* 2:字段名(String)
* 3: Where条件(StringBuffer)
* 5: 输出流(ServletOutputStream)
*
* 输出参数:void
* 编写人: */
public static void getdownFile(String strTableName,
String strColumnName,
StringBuffer sbSQLWhere,
ServletOutputStream sos) throws Exception {
Connection con = null;
PreparedStatement ps = null;
ResultSet resultset = null;
try {
//得到数据库连接
con = DBConnector.getConnection();
StringBuffer sbSQL = new StringBuffer();
//构建查询语句
sbSQL.append(" SELECT " + strColumnName + " FROM " + strTableName);
sbSQL.append(sbSQLWhere);
System.out.println(" sql value is:"+sbSQLWhere.toString());
ps = con.prepareStatement(sbSQL.toString());
//执行查询
resultset = ps.executeQuery();
while (resultset.next()) {
//读取数据流
InputStream is = resultset.getBinaryStream(strColumnName);
byte[] buf = new byte[2048];
while(is.read(buf)!=-1) {
//把数据流按块写到servlet的输出流中
sos.write(buf);
}
}
} catch (Exception ex) {
ex.printStackTrace();
throw ex;
} finally {
if (ps != null) {
ps.close();
}
if (resultset != null) {
resultset.close();
}
if (con!=null) {
con.close();
}
}
}
图片的保存和文件的保存一样,如果不清楚的可以和我联系
后记:
平时总忙着做项目,闲的时候也很懒,总想把自己实际中的一些问题和解决方法小结一下,但总没完成,这是第一次写,写的不好或不清楚的地方请包涵,下次改进,也希望大家多提意见,大家一起进步!!!!!!!!!!! |
|
posted @
2007-01-16 16:14 一缕青烟 阅读(263) |
评论 (0) |
编辑 收藏方法1:
- xmlhttp.setRequestHeader("Cache-Control","no-cache");
- url += "&random="+Math.random();
- url += "×tamp="+new Date().getTime();
方法二:
//处理页面缓存
response.setHeader("Pragma","No-cache");
response.setHeader("Cache-Control","no-cache");
response.setDateHeader("Expires", 0);
posted @
2007-01-11 14:56 一缕青烟 阅读(600) |
评论 (0) |
编辑 收藏正则表达式经典 (转)
"^\d+$" //非负整数(正整数 + 0)
"^[0-9]*[1-9][0-9]*$" //正整数
"^((-\d+)|(0+))$" //非正整数(负整数 + 0)
"^-[0-9]*[1-9][0-9]*$" //负整数
"^-?\d+$" //整数
"^\d+(\.\d+)?$" //非负浮点数(正浮点数 + 0)
"^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数
"^((-\d+(\.\d+)?)|(0+(\.0+)?))$" //非正浮点数(负浮点数 + 0)
"^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数
"^(-?\d+)(\.\d+)?$" //浮点数
"^[A-Za-z]+$" //由26个英文字母组成的字符串
"^[A-Z]+$" //由26个英文字母的大写组成的字符串
"^[a-z]+$" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串
"^\w+$" //由数字、26个英文字母或者下划线组成的字符串
"^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$" //email地址
"^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$"
----------------------------------------------------------------------------------------------------------------------
字符描述: \:将下一个字符标记为特殊字符或字面值。例如"n"与字符"n"匹配。"\n"与换行符匹配。序列"\\"与"\"匹配,"\("与"("匹配。
^ :匹配输入的开始位置。
$ :匹配输入的结尾。
* :匹配前一个字符零次或几次。例如,"zo*"可以匹配"z"、"zoo"。
+ :匹配前一个字符一次或多次。例如,"zo+"可以匹配"zoo",但不匹配"z"。
? :匹配前一个字符零次或一次。例如,"a?ve?"可以匹配"never"中的"ve"。
.:匹配换行符以外的任何字符。
(pattern) 与模式匹配并记住匹配。匹配的子字符串可以从作为结果的 Matches 集合中使用 Item [0]...[n]取得。如果要匹配括号字符(和 ),可使用"\(" 或 "\)"。
x|y:匹配 x 或 y。例如 "z|food" 可匹配 "z" 或 "food"。"(z|f)ood" 匹配 "zoo" 或 "food"。
{n}:n 为非负的整数。匹配恰好n次。例如,"o{2}" 不能与 "Bob 中的 "o" 匹配,但是可以与"foooood"中的前两个o匹配。
{n,} :n 为非负的整数。匹配至少n次。例如,"o{2,}"不匹配"Bob"中的"o",但是匹配"foooood"中所有的o。"o{1,}"等价于"o+"。"o{0,}"等价于"o*"。
{n,m} :m 和 n 为非负的整数。匹配至少 n 次,至多 m 次。例如,"o{1,3}" 匹配 "fooooood"中前三个o。"o{0,1}"等价于"o?"。
[xyz] :一个字符集。与括号中字符的其中之一匹配。例如,"[abc]" 匹配"plain"中的"a"。
[^xyz] :一个否定的字符集。匹配不在此括号中的任何字符。例如,"[^abc]" 可以匹配"plain"中的"p".
[a-z] :表示某个范围内的字符。与指定区间内的任何字符匹配。例如,"[a-z]"匹配"a"与"z"之间的任何一个小写字母字符。
[^m-z] :否定的字符区间。与不在指定区间内的字符匹配。例如,"[m-z]"与不在"m"到"z"之间的任何字符匹配。
\b :与单词的边界匹配,即单词与空格之间的位置。例如,"er\b" 与"never"中的"er"匹配,但是不匹配"verb"中的"er"。
\B :与非单词边界匹配。"ea*r\B"与"never early"中的"ear"匹配。
\d :与一个数字字符匹配。等价于[0-9]。
\D :与非数字的字符匹配。等价于[^0-9]。
\f :与分页符匹配。
\n :与换行符字符匹配。
\r :与回车字符匹配。
\s :与任何白字符匹配,包括空格、制表符、分页符等。等价于"[ \f\n\r\t\v]"。
\S :与任何非空白的字符匹配。等价于"[^ \f\n\r\t\v]"。
\t :与制表符匹配。
\v :与垂直制表符匹配。
\w :与任何单词字符匹配,包括下划线。等价于"[A-Za-z0-9_]"。
\W :与任何非单词字符匹配。等价于"[^A-Za-z0-9_]"。
\num :匹配 num个,其中 num 为一个正整数。引用回到记住的匹配。例如,"(.)\1"匹配两个连续的相同的字符。
\n:匹配 n,其中n 是一个八进制换码值。八进制换码值必须是 1, 2 或 3 个数字长。
例如,"\11" 和 "\011" 都与一个制表符匹配。"\0011"等价于"\001" 与 "1"。八进制换码值不得超过 256。否则,只有前两个字符被视为表达式的一部分。允许在正则表达式中使用ASCII码。
\xn:匹配n,其中n是一个十六进制的换码值。十六进制换码值必须恰好为两个数字长。例如,"\x41"匹配"A"。"\x041"等价于"\x04" 和 "1"。允许在正则表达式中使用 ASCII 码。
好了,常用的方法和属性就是这些了,上面的语法介绍的已经很详细了,我们就没有必要在罗嗦了,接下来我们来看看在具体的例子里面如何使用这些方法和属性来校验数据的合法性,我们还是举个例子吧,比如,我们想要对用户输入的电子邮件进行校验,那么,什么样的数据才算是一个合法的电子邮件呢?我可以这样输入:uestc95@263.net,当然我也会这样输入:xxx@yyy.com.cn,但是这样的输入就是非法的:xxx@@com.cn或者@xxx.com.cn,等等,所以我们得出一个合法的电子邮件地址至少应当满足以下几个条件:
1. 必须包含一个并且只有一个符号“@”
2. 必须包含至少一个至多三个符号“.”
3. 第一个字符不得是“@”或者“.”
4. 不允许出现“@.”或者.@
5. 结尾不得是字符“@”或者“.”
所以根据以上的原则和上面表中的语法,我们很容易的就可以得到需要的模板如下:"(\w)+[@]{1}(\w)+[.]{1,3}(\w)+"
接下来我们仔细分析一下这个模板,首先“\w”表示邮件的开始字符只能是包含下划线的单词字符,这样,满足了第三个条件;“[@]{1}”表示在电子邮件中应当匹配并且只能匹配一次字符“@”,满足了条件一;同样的“[.]{1,3}”表示在电子邮件中至少匹配1个至多匹配3个字符“.” ,满足了第二个条件;模板最后的“(\w)+”表示结尾的字符只能是包含下划线在内的单词字符,满足了条件五;模板中间的“(\w)+”满足了条件四。
然后,我们就直接调用刚才的那个函数CheckExp("(\w)+[@]{1}(\w)+[.]{1}(\w)+",待校验的字符串)就好了,如果返回True就表示数据是合法的,否则就是不正确的,怎么样,简单吧。我们还可以写出来校验身份证号码的模板:"([0-9]){15}";校验URL的模板:"^http://{1}((\w)+[.]){1,3}"等等;我们可以看到,这些模板为我们提供了很好的可重利用的模块,利用自己或者别人提供的各种模板,我们就可以方便快捷的进行数据的合法性校验了,相信你一定会写出非常通用的模板的。
这样,我们只要定制不同的模板,就可以实现对不同数据的合法性校验了。所以,正则表达式对象中最重要的属性就是:“Pattern”属性,只要真正掌握了这个属性,才可以自由的运用正则表达式对象来为我们的数据校验进行服务。
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=560411
posted @
2006-12-04 09:36 一缕青烟 阅读(278) |
评论 (0) |
编辑 收藏TCP协议
==> TCP首部
源端口号、目的端口号、位序号、位确认序号、首部长度、标志位、窗口大小、检验和、紧急指针和其它选项。
一个IP地址和一个端口号也成为一个插口(socket)。插口对可唯一确定互联网中每个TCP连接的双方。
==> TCP连接的建立与终止
TCP是一个面向连接的协议,无论哪方向另一方发送数据之前,都必须先在双方之间建立一条连接。
TCP连接的建立——三次握手。
TCP连接的终止——四次握手。这是由TCP的半关闭造成的。因为TCP是全双工的,因此每个方向必须单独的进行关闭。
==> 最大报文段长度MSS
MSS越大,允许每个报文段传递的数据越多,相对TCP和IP的首部有更高的利用率。
有些情况下,MSS是可以在建立TCP连接时进行协商的选项,但是有些情况下不行 。
* 如果是本地网络,TCP可以根据网络外出接口处的MTU值减去固定的IP首部(20)和TCP长度(20),对于以太网,可以达到1460。
* 如果IP地址为非本地的,则MSS通常定为默认值536字节(允许20字节的IP首部和20字节的TCP首部以适合576字节的IP数据报)。
MSS让主机限制另一端发送数据的长度,同时也能控制它自己发送数据报的长度,避免较小MTU发生分片。
==> TCP的半关闭
TCP连接的一端在结束它的发送后还能接收来自另一端数据(直到它也发送FIN)的能力,这就是所谓的半关闭。应用程序很少用到。
==> 复位报文段
* 不存在的端口(目的端口没有进程监听)。目的主机将对SYN请求返回一个RST报文段。(UDP则将产生一个端口不可达的信息)
* 异常终止。
* 检测半打开的连接。
==> TCP服务器的设计
* 大多数TCP服务器的进程是并发的.
* 只有处于监听的进程才能处理客户端的连接请求.
* TCP服务器可以对本地IP地址进行限制,但是一般不能对远程IP地址进行限制.
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=561075
posted @
2006-12-04 09:35 一缕青烟 阅读(378) |
评论 (0) |
编辑 收藏关于Java栈与堆的思考
1. 栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
2. 栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享,详见第3点。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
3. Java中的数据类型有两种。
一种是基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
另外,栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义
int a = 3;
int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与 b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
另一种是包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java用new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。
4. String是一个特殊的包装类数据。即可以用String str = new String("abc");的形式来创建,也可以用String str = "abc";的形式来创建(作为对比,在JDK 5.0之前,你从未见过Integer i = 3;的表达式,因为类与字面值是不能通用的,除了String。而在JDK 5.0中,这种表达式是可以的!因为编译器在后台进行Integer i = new Integer(3)的转换)。前者是规范的类的创建过程,即在Java中,一切都是对象,而对象是类的实例,全部通过new()的形式来创建。Java 中的有些类,如DateFormat类,可以通过该类的getInstance()方法来返回一个新创建的类,似乎违反了此原则。其实不然。该类运用了单例模式来返回类的实例,只不过这个实例是在该类内部通过new()来创建的,而getInstance()向外部隐藏了此细节。那为什么在String str = "abc";中,并没有通过new()来创建实例,是不是违反了上述原则?其实没有。
5. 关于String str = "abc"的内部工作。Java内部将此语句转化为以下几个步骤:
(1)先定义一个名为str的对String类的对象引用变量:String str;
(2)在栈中查找有没有存放值为"abc"的地址,如果没有,则开辟一个存放字面值为"abc"的地址,接着创建一个新的String类的对象o,并将o 的字符串值指向这个地址,而且在栈中这个地址旁边记下这个引用的对象o。如果已经有了值为"abc"的地址,则查找对象o,并返回o的地址。
(3)将str指向对象o的地址。
值得注意的是,一般String类中字符串值都是直接存值的。但像String str = "abc";这种场合下,其字符串值却是保存了一个指向存在栈中数据的引用!
为了更好地说明这个问题,我们可以通过以下的几个代码进行验证。
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2); //true
注意,我们这里并不用str1.equals(str2);的方式,因为这将比较两个字符串的值是否相等。==号,根据JDK的说明,只有在两个引用都指向了同一个对象时才返回真值。而我们在这里要看的是,str1与str2是否都指向了同一个对象。
结果说明,JVM创建了两个引用str1和str2,但只创建了一个对象,而且两个引用都指向了这个对象。
我们再来更进一步,将以上代码改成:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
System.out.println(str1 + "," + str2); //bcd, abc
System.out.println(str1==str2); //false
这就是说,赋值的变化导致了类对象引用的变化,str1指向了另外一个新对象!而str2仍旧指向原来的对象。上例中,当我们将str1的值改为"bcd"时,JVM发现在栈中没有存放该值的地址,便开辟了这个地址,并创建了一个新的对象,其字符串的值指向这个地址。
事实上,String类被设计成为不可改变(immutable)的类。如果你要改变其值,可以,但JVM在运行时根据新值悄悄创建了一个新对象,然后将这个对象的地址返回给原来类的引用。这个创建过程虽说是完全自动进行的,但它毕竟占用了更多的时间。在对时间要求比较敏感的环境中,会带有一定的不良影响。
再修改原来代码:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
String str3 = str1;
System.out.println(str3); //bcd
String str4 = "bcd";
System.out.println(str1 == str4); //true
str3 这个对象的引用直接指向str1所指向的对象(注意,str3并没有创建新对象)。当str1改完其值后,再创建一个String的引用str4,并指向因str1修改值而创建的新的对象。可以发现,这回str4也没有创建新的对象,从而再次实现栈中数据的共享。
我们再接着看以下的代码。
String str1 = new String("abc");
String str2 = "abc";
System.out.println(str1==str2); //false
创建了两个引用。创建了两个对象。两个引用分别指向不同的两个对象。
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1==str2); //false
创建了两个引用。创建了两个对象。两个引用分别指向不同的两个对象。
以上两段代码说明,只要是用new()来新建对象的,都会在堆中创建,而且其字符串是单独存值的,即使与栈中的数据相同,也不会与栈中的数据共享。
6. 数据类型包装类的值不可修改。不仅仅是String类的值不可修改,所有的数据类型包装类都不能更改其内部的值。
7. 结论与建议:
(1)我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,我们创建了String类的对象str。担心陷阱!对象可能并没有被创建!唯一可以肯定的是,指向 String类的引用被创建了。至于这个引用到底是否指向了一个新的对象,必须根据上下文来考虑,除非你通过new()方法来显要地创建一个新的对象。因此,更为准确的说法是,我们创建了一个指向String类的对象的引用变量str,这个对象引用变量指向了某个值为"abc"的String类。清醒地认识到这一点对排除程序中难以发现的bug是很有帮助的。
(2)使用String str = "abc";的方式,可以在一定程度上提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。而对于String str = new String("abc");的代码,则一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象,从而加重了程序的负担。这个思想应该是享元模式的思想,但JDK的内部在这里实现是否应用了这个模式,不得而知。
(3)当比较包装类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用==。
(4)由于String类的immutable性质,当String变量需要经常变换其值时,应该考虑使用StringBuffer类,以提高程序效率。
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=561129
posted @
2006-12-04 09:31 一缕青烟 阅读(486) |
评论 (0) |
编辑 收藏
提高JSP应用程序的七大秘籍绝招
你时常被客户抱怨JSP页面响应速度很慢吗?你想过当客户访问次数剧增时,你的WEB应用能承受日益增加的访问量吗?本文讲述了调整JSP和servlet的一些非常实用的方法,它可使你的servlet和JSP页面响应更快,扩展性更强。而且在用户数增加的情况下,系统负载会呈现出平滑上长的趋势。在本文中,我将通过一些实际例子和配置方法使得你的应用程序的性能有出人意料的提升。
其中,某些调优技术是在你的编程工作中实现的。而另一些技术是与应用服务器的配置相关的。在本文中,我们将详细地描述怎样通过调整servlet和JSP页面,来提高你的应用程序的总体性能。在阅读本文之前,假设你有基本的servlet和JSP的知识。
方法一:在servlet的init()方法中缓存数据
当应用服务器初始化servlet实例之后,为客户端请求提供服务之前,它会调用这个servlet的init()方法。在一个servlet的生命周期中,init()方法只会被调用一次。通过在init()方法中缓存一些静态的数据或完成一些只需要执行一次的、耗时的操作,就可大大地提高系统性能。
例如,通过在init()方法中建立一个JDBC连接池是一个最佳例子,假设我们是用jdbc2.0的DataSource接口来取得数据库连接,在通常的情况下,我们需要通过JNDI来取得具体的数据源。我们可以想象在一个具体的应用中,如果每次SQL请求都要执行一次JNDI查询的话,那系统性能将会急剧下降。解决方法是如下代码,它通过缓存DataSource,使得下一次SQL调用时仍然可以继续利用它:
public class ControllerServlet extends HttpServlet
{
private javax.sql.DataSource testDS = null;
public void init(ServletConfig config) throws ServletException
{
super.init(config);
Context ctx = null;
try
{
ctx = new InitialContext();
testDS = (javax.sql.DataSource)ctx.lookup("jdbc/testDS");
}
catch(NamingException ne)
{
ne.printStackTrace();
}
catch(Exception e)
{
e.printStackTrace();
}
}
public javax.sql.DataSource getTestDS()
{
return testDS;
}
...
...
} |
方法 2:禁止servlet和JSP 自动重载(auto-reloading)
Servlet/JSP提供了一个实用的技术,即自动重载技术,它为开发人员提供了一个好的开发环境,当你改变servlet和JSP页面后而不必重启应用服务器。然而,这种技术在产品运行阶段对系统的资源是一个极大的损耗,因为它会给JSP引擎的类装载器(classloader)带来极大的负担。因此关闭自动重载功能对系统性能的提升是一个极大的帮助。
方法 3: 不要滥用HttpSession
在很多应用中,我们的程序需要保持客户端的状态,以便页面之间可以相互联系。但不幸的是由于HTTP具有天生无状态性,从而无法保存客户端的状态。因此一般的应用服务器都提供了session来保存客户的状态。在JSP应用服务器中,是通过HttpSession对像来实现session的功能的,但在方便的同时,它也给系统带来了不小的负担。因为每当你获得或更新session时,系统者要对它进行费时的序列化操作。你可以通过对HttpSession的以下几种处理方式来提升系统的性能。
如果没有必要,就应该关闭JSP页面中对HttpSession的缺省设置。 如果你没有明确指定的话,每个JSP页面都会缺省地创建一个HttpSession。如果你的JSP中不需要使用session的话,那可以通过如下的JSP页面指示符来禁止它:
<%@ page session="false"%> |
不要在HttpSession中存放大的数据对像:如果你在HttpSession中存放大的数据对像的话,每当对它进行读写时,应用服务器都将对其进行序列化,从而增加了系统的额外负担。你在HttpSession中存放的数据对像越大,那系统的性能就下降得越快。
当你不需要HttpSession时,尽快地释放它:当你不再需要session时,你可以通过调用HttpSession.invalidate()方法来释放它。尽量将session的超时时间设得短一点:在JSP应用服务器中,有一个缺省的session的超时时间。当客户在这个时间之后没有进行任何操作的话,系统会将相关的session自动从内存中释放。超时时间设得越大,系统的性能就会越低,因此最好的方法就是尽量使得它的值保持在一个较低的水平。
方法 4: 将页面输出进行压缩
压缩是解决数据冗余的一个好的方法,特别是在网络带宽不够发达的今天。有的浏览器支持gzip(GNU zip)进行来对HTML文件进行压缩,这种方法可以戏剧性地减少HTML文件的下载时间。因此,如果你将servlet或JSP页面生成的HTML页面进行压缩的话,那用户就会觉得页面浏览速度会非常快。但不幸的是,不是所有的浏览器都支持gzip压缩,但你可以通过在你的程序中检查客户的浏览器是否支持它。下面就是关于这种方法实现的一个代码片段:
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws IOException, ServletException
{
OutputStream out = null
String encoding = request.getHeader("Accept-Encoding");
if (encoding != null && encoding.indexOf("gzip") != -1)
{
request.setHeader("Content-Encoding" , "gzip");
out = new GZIPOutputStream(request.getOutputStream());
}
else if (encoding != null && encoding.indexOf("compress") != -1)
{
request.setHeader("Content-Encoding" , "compress");
out = new ZIPOutputStream(request.getOutputStream());
}
else
{
out = request.getOutputStream();
}
...
...
} |
方法 5: 使用线程池
应用服务器缺省地为每个不同的客户端请求创建一个线程进行处理,并为它们分派service()方法,当service()方法调用完成后,与之相应的线程也随之撤消。由于创建和撤消线程会耗费一定的系统资源,这种缺省模式降低了系统的性能。但所幸的是我们可以通过创建一个线程池来改变这种状况。
另外,我们还要为这个线程池设置一个最小线程数和一个最大线程数。在应用服务器启动时,它会创建数量等于最小线程数的一个线程池,当客户有请求时,相应地从池从取出一个线程来进行处理,当处理完成后,再将线程重新放入到池中。如果池中的线程不够地话,系统会自动地增加池中线程的数量,但总量不能超过最大线程数。通过使用线程池,当客户端请求急剧增加时,系统的负载就会呈现的平滑的上升曲线,从而提高的系统的可伸缩性。
方法 6: 选择正确的页面包含机制
在JSP中有两种方法可以用来包含另一个页面:
1、使用include指示符
<%@ includee file=”test.jsp” %> |
2、使用jsp指示符
<jsp:includee page=”test.jsp” flush=”true”/> |
在实际中发现,如果使用第一种方法的话,可以使得系统性能更高。
方法 7:正确地确定javabean的生命周期
JSP的一个强大的地方就是对javabean的支持。通过在JSP页面中使用<jsp:useBean>标签,可以将javabean直接插入到一个JSP页面中。它的使用方法如下:
<jsp:useBean id="name" scope="page|request|session|application" class="package.className" type="typeName">
</jsp:useBean> |
其中scope属性指出了这个bean的生命周期。缺省的生命周期为page。如果你没有正确地选择bean的生命周期的话,它将影响系统的性能。
举例来说,如果你只想在一次请求中使用某个bean,但你却将这个bean的生命周期设置成了session,那当这次请求结束后,这个bean将仍然保留在内存中,除非session超时或用户关闭浏览器。这样会耗费一定的内存,并无谓的增加了JVM垃圾收集器的工作量。因此为bean设置正确的生命周期,并在bean的使命结束后尽快地清理它们,会使用系统性能有一个提高。
其它一些有用的方法
1、在字符串连接操作中尽量不使用“+”操作符:在java编程中,我们常常使用“+”操作符来将几个字符串连接起来,但你或许从来没有想到过它居然会对系统性能造成影响吧?由于字符串是常量,因此JVM会产生一些临时的对像。你使用的“+”越多,生成的临时对像就越多,这样也会给系统性能带来一些影响。解决的方法是用StringBuffer对像来代替“+”操作符。
2、避免使用System.out.println()方法:由于System.out.println()是一种同步调用,即在调用它时,磁盘I/O操作必须等待它的完成,因此我们要尽量避免对它的调用。但我们在调试程序时它又是一个必不可少的方便工具,为了解决这个矛盾,我建议你最好使用Log4j工具(http://Jakarta.apache.org ),它既可以方便调试,而不会产生System.out.println()这样的方法。
3、ServletOutputStream 与 PrintWriter的权衡:使用PrintWriter可能会带来一些小的开销,因为它将所有的原始输出都转换为字符流来输出,因此如果使用它来作为页面输出的话,系统要负担一个转换过程。而使用ServletOutputStream作为页面输出的话就不存在一个问题,但它是以二进制进行输出的。因此在实际应用中要权衡两者的利弊。
总结
本文的目的是通过对servlet和JSP的一些调优技术来极大地提高你的应用程序的性能,并因此提升整个J2EE应用的性能。通过这些调优技术,你可以发现其实并不是某种技术平台(比如J2EE和.NET之争)决定了你的应用程序的性能,重要是你要对这种平台有一个较为深入的了解,这样你才能从根本上对自己的应用程序做一个优化。
本文来自:http://www.blogjava.net/sgsoft/articles/2378.html
posted @
2006-11-08 20:42 一缕青烟 阅读(265) |
评论 (0) |
编辑 收藏
版权所有,转载请声明出处
zhyiwww@163.com
在读我自己的认识之前
,
我们先来看一下
servet
的结构图
:
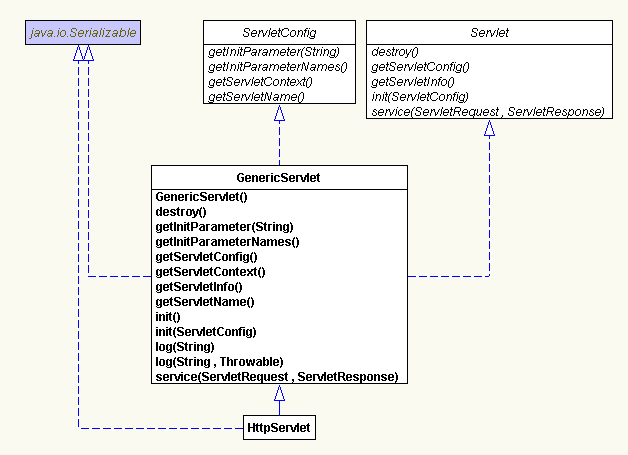
以下是我自己的一点浅见:
①
Servlet
在初始化的时候
,
是通过
init(ServletConfig config)
或
init()
来执行的。
ServletConfig
是一个接口,它怎样传递给他一格对象来进行初始化呢?其实,是这个对象是由
servlet
容器来实例化的,由容器产生一格
ServletConfig
的实现类的对象,然后传递给
Servlet
结论:
ServletConfig
由容器实例化
②
我们有些时候可能在
Servlet
初始化时给它一些固定的配置参数,那么这些参数是怎样传递到
Servlet
呢?
其实,我们在
web.xml
中给
servlet
配置启动参数,在容器对
servlet
进行初始化的时候,会收集你所配置的参数,记录在
ServletConfig
的实现类中,所以你才可以通过
ServletConfig
对象的
public String getInitParameter(String name);
或
public Enumeration getInitParameterNames();
方法来取得你已经配置好的参数,也就是说,你对
servlet
的配置都已经记录在
ServletConfig
对象中了。
结论:你对
Servlet
的配置,在
Servlet
的初始化时都由容器来收集并且记录到
ServletConfig
的实现类中。
③
我们来看一个
Servlet
的配置
<servlet>
<servlet-name>index</servlet-name>
<servlet-class>org.zy.pro.sw.servlet.IndexServlet</servlet-class>
<init-param>
<param-name>dbconfig</param-name>
<param-value>/WEB-INF/dbconfig.xml</param-value>
</init-param>
</servlet>
在此,我们实现对数据库的配置文件的加载。
当
Servlet
初始化完成后,我们可以通过
String dbconf=this.getServletConfig().getInitParameter("dbconfig")
来取得我们的配置的参数的值。
但是,我们仅能得到一个配置的字符串。之后我们可以通过配置文件取得我们的数据库的配置参数,然后对数据库进行初始化。
其实我们也可以通过传递一个类的名字串,然后再实例化。
<init-param>
<param-name>dbconfig</param-name>
<param-value>org.zy.util.db.DBUtil</param-value>
</init-param>
我们先取得配置参数:
String dbconf=this.getServletConfig().getInitParameter("dbconfig")
;
然后通过
Class.forName(dbconf).getInstance();
来实例化对象,就可以实现对数据库的调用了。
结论:在
web.xml
中对
Servlet
的初始化,只能传递字符串类型的数据
④
ServletContext
ServletContext
是负责和
Servlet
的上文和下文交互,上面和
Servlet
容器交互,下面和
Servlet
中的请求和相应进行交互。
在
ServletConfig
中,
public ServletContext getServletContext();
方法实现取得当前
ServletContext
的对象。
你可能要问,
ServletContext
是一个接口,那么你如何取得他的对象呢?
其实这个问题和
ServletConfig
相同,都是在
Servlet
进行初始化的时候产生的对象,是由容器来初始化的。
posted @
2006-10-30 19:54 一缕青烟 阅读(455) |
评论 (0) |
编辑 收藏
 关于web打印的总结
关于web打印的总结
方案一:
调用浏览器的打印函数利用浏览器的模版
源程序代码:
<
OBJECT id
=
"
WebBrowser
"
classid
=
"
CLSID:8856F961-340A-11D0-A96B-00C04FD705A2
"
height
=
"
0
"
width
=
"
0
"
VIEWASTEXT
>
</
OBJECT
>
说明:此代码放在html 中 打印模版的指定框架为此代码在的模块;
调用程序:
<
onclick
=
"
parent.main.focus();parent.main.WebBrowser.ExecWB(7,1);
"
调用浏览器的对象中的方法
<
2
>
调用直接打印
<
onclick
=
"
parent.main.focus();parent.main.WebBrowser..print (7,1);
"
<
3
>
当打印的时候不显示时的css样式
<
style media
=
"
print
"
>

 .Noprint
.Noprint
 {display:none;}
{display:none;}
.PageNext
{page
-
break
-
after: always;}
</
style
>
<
style
>
.TdCs1
{ border:solid windowtext
1
.0pt;}
.TdCs2
{ border:solid windowtext
1
.0pt; border
-
left:none;}
.TdCs3
{border
-
top:none;border
-
left:solid windowtext
1
.0pt; border
-
bottom:solid windowtext
1
.0pt; border
-
right:solid windowtext
1
.0pt;}
.TdCs4
{border
-
top:none; border
-
left:none;border
-
bottom:solid windowtext
1
.0pt;border
-
right:solid windowtext
1
.0pt;}
.underline
{border
-
top
-
style: none;border
-
right
-
style: none; border
-
bottom
-
style: solid; border
-
left
-
style: none;border
-
bottom
-
color: #
000000
;}
</
style
>
<
4
>
其余的设置
<
input type
=
"
button
"
value
=
"
打印
"
onclick
=
"
document.all.WebBrowser.ExecWB(6,1)
"
class
=
"
NOPRINT
"
>
<
input type
=
"
button
"
value
=
"
直接打onclick=
"
document.all.WebBrowser.ExecWB(
6
,
6
)
"
class=
"
NOPRINT
"
>
<
input type
=
"
button
"
value
=
"
页面设置
"
onclick
=
"
document.all.WebBrowser.ExecWB(8,1)
"
class
=
"
NOPRINT
"
>
<
input type
=
"
button
"
value
=
"
打印预览
"
onclick
=
"
document.all.WebBrowser.ExecWB(7,1)
"
class
=
"
NOPRINT
"
>
<html>
<head>
<title>看看</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<!--media=print 这个属性可以在打印时有效-->
<style media=print>
.Noprint{display:none;}
.PageNext{page-break-after: always;}
</style>
<style>
.tdp
{
border-bottom: 1 solid #000000;
border-left: 1 solid #000000;
border-right: 0 solid #ffffff;
border-top: 0 solid #ffffff;
}
.tabp
{
border-color: #000000 #000000 #000000 #000000;
border-style: solid;
border-top-width: 2px;
border-right-width: 2px;
border-bottom-width: 1px;
border-left-width: 1px;
}
.NOPRINT {
font-family: "宋体";
font-size: 9pt;
}
</style>
</head>
<body >
<center class="Noprint" >
<p>
<OBJECT id=WebBrowser classid=CLSID:8856F961-340A-11D0-A96B-00C04FD705A2 height=0 width=0>
</OBJECT>
<input type=button value=打印 onclick=document.all.WebBrowser.ExecWB(6,1)>
<input type=button value=直接打印 onclick=document.all.WebBrowser.ExecWB(6,6)>
<input type=button value=页面设置 onclick=document.all.WebBrowser.ExecWB(8,1)>
</p>
<p> <input type=button value=打印预览 onclick=document.all.WebBrowser.ExecWB(7,1)>
<br/>
</p>
<hr align="center" width="90%" size="1" noshade>
</center>
<table width="90%" border="0" align="center" cellpadding="2" cellspacing="0" class="tabp">
<tr>
<td colspan="3" class="tdp">第1页</td>
</tr>
<tr>
<td width="29%" class="tdp"> </td>
<td width="28%" class="tdp"> </td>
<td width="43%" class="tdp"> </td>
</tr>
<tr>
<td colspan="3" class="tdp"> </td>
</tr>
<tr>
<td colspan="3" class="tdp"><table width="100%" border="0" cellspacing="0" cellpadding="0">
<tr>
<td width="50%" class="tdp"><p>这样的报表</p>
<p>对一般的要求就够了。</p></td>
<td> </td>
</tr>
</table></td>
</tr>
</table>
<hr align="center" width="90%" size="1" noshade class="NOPRINT" >
<!--分页-->
<div class="PageNext"></div>
<table width="90%" border="0" align="center" cellpadding="2" cellspacing="0" class="tabp">
<tr>
<td class="tdp">第2页</td>
</tr>
<tr>
<td class="tdp">看到分页了吧</td>
</tr>
<tr>
<td class="tdp"> </td>
</tr>
<tr>
<td class="tdp"> </td>
</tr>
<tr>
<td class="tdp"><table width="100%" border="0" cellspacing="0" cellpadding="0">
<tr>
<td width="50%" class="tdp"><p>这样的报表</p>
<p>对一般的要求就够了。</p></td>
<td> </td>
</tr>
</table></td>
</tr>
</table>
</body>
</html>
posted @
2006-10-20 14:26 一缕青烟 阅读(921) |
评论 (1) |
编辑 收藏<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"><head>
<title>Pure CSS Scrollable Table with Fixed Header</title>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta http-equiv="language" content="en-us" />
<script type="text/javascript">
<!--
/* http://www.alistapart.com/articles/zebratables/ */
function removeClassName (elem, className) {
elem.className = elem.className.replace(className, "").trim();
}
function addCSSClass (elem, className) {
removeClassName (elem, className);
elem.className = (elem.className + " " + className).trim();
}
String.prototype.trim = function() {
return this.replace( /^\s+|\s+$/, "" );
}
function stripedTable() {
if (document.getElementById && document.getElementsByTagName) {
var allTables = document.getElementsByTagName('table');
if (!allTables) { return; }
for (var i = 0; i < allTables.length; i++) {
if (allTables[i].className.match(/[\w\s ]*scrollTable[\w\s ]*/)) {
var trs = allTables[i].getElementsByTagName("tr");
for (var j = 0; j < trs.length; j++) {
removeClassName(trs[j], 'alternateRow');
addCSSClass(trs[j], 'normalRow');
}
for (var k = 0; k < trs.length; k += 2) {
removeClassName(trs[k], 'normalRow');
addCSSClass(trs[k], 'alternateRow');
}
}
}
}
}
/* onload state is fired, append onclick action to the table's DIV */
/* container. This allows the HTML document to validate correctly. */
/* addIEonScroll added on 2005-01-28 */
/* Terence Ordona, portal[AT]imaputz[DOT]com */
function addIEonScroll() {
var thisContainer = document.getElementById('tableContainer');
if (!thisContainer) { return; }
var onClickAction = 'toggleSelectBoxes();';
thisContainer.onscroll = new Function(onClickAction);
}
/* Only WinIE will fire this function. All other browsers scroll the TBODY element and not the DIV */
/* This is to hide the SELECT elements from scrolling over the fixed Header. WinIE only. */
/* toggleSelectBoxes added on 2005-01-28 */
/* Terence Ordona, portal[AT]imaputz[DOT]com */
function toggleSelectBoxes() {
var thisContainer = document.getElementById('tableContainer');
var thisHeader = document.getElementById('fixedHeader');
if (!thisContainer || !thisHeader) { return; }
var selectBoxes = thisContainer.getElementsByTagName('select');
if (!selectBoxes) { return; }
for (var i = 0; i < selectBoxes.length; i++) {
if (thisContainer.scrollTop >= eval(selectBoxes[i].parentNode.offsetTop - thisHeader.offsetHeight)) {
selectBoxes[i].style.visibility = 'hidden';
} else {
selectBoxes[i].style.visibility = 'visible';
}
}
}
window.onload = function() { stripedTable(); addIEonScroll(); }
-->
</script>
<style type="text/css">
<!--
/* Terence Ordona, portal[AT]imaputz[DOT]com */
/* http://creativecommons.org/licenses/by-sa/2.0/ */
/* begin some basic styling here */
body {
background: #FFF;
color: #000;
font: normal normal 12px Verdana, Geneva, Arial, Helvetica, sans-serif;
margin: 10px;
padding: 0
}
table, td, a {
color: #000;
font: normal normal 12px Verdana, Geneva, Arial, Helvetica, sans-serif
}
h1 {
font: normal normal 18px Verdana, Geneva, Arial, Helvetica, sans-serif;
margin: 0 0 5px 0
}
h2 {
font: normal normal 16px Verdana, Geneva, Arial, Helvetica, sans-serif;
margin: 0 0 5px 0
}
h3 {
font: normal normal 13px Verdana, Geneva, Arial, Helvetica, sans-serif;
color: #008000;
margin: 0 0 15px 0
}
/* end basic styling */
/* define height and width of scrollable area. Add 16px to width for scrollbar */
/* allow WinIE to scale 100% width of browser by not defining a width */
/* WARNING: applying a background here may cause problems with scrolling in WinIE 5.x */
div.tableContainer {
clear: both;
border: 1px solid #963;
height: 285px;
overflow: auto;
width: 756px;
}
/* WinIE 6.x needs to re-account for it's scrollbar. Give it some padding */
\html div.tableContainer/* */ {
padding: 0 16px 0 0;
width: 740px;
}
/* clean up for allowing display Opera 5.x/6.x and MacIE 5.x */
html>body div.tableContainer {
height: auto;
padding: 0;
}
/* Reset overflow value to hidden for all non-IE browsers. */
/* Filter out Opera 5.x/6.x and MacIE 5.x */
head:first-child+body div[class].tableContainer {
height: 285px;
overflow: hidden;
width: 756px
}
/* define width of table. IE browsers only */
/* if width is set to 100%, you can remove the width */
/* property from div.tableContainer and have the div scale */
div.tableContainer table {
float: left;
width: 100%
}
/* WinIE 6.x needs to re-account for padding. Give it a negative margin */
\html div.tableContainer table/* */ {
margin: 0 -16px 0 0
}
/* define width of table. Opera 5.x/6.x and MacIE 5.x */
html>body div.tableContainer table {
float: none;
margin: 0;
width: 740px
}
/* define width of table. Add 16px to width for scrollbar. */
/* All other non-IE browsers. Filter out Opera 5.x/6.x and MacIE 5.x */
head:first-child+body div[class].tableContainer table {
width: 756px
}
/* set table header to a fixed position. WinIE 6.x only */
/* In WinIE 6.x, any element with a position property set to relative and is a child of */
/* an element that has an overflow property set, the relative value translates into fixed. */
/* Ex: parent element DIV with a class of tableContainer has an overflow property set to auto */
thead.fixedHeader tr {
position: relative;
/* expression is for WinIE 5.x only. Remove to validate and for pure CSS solution */
top: expression(document.getElementById("tableContainer").scrollTop);
}
/* set THEAD element to have block level attributes. All other non-IE browsers */
/* this enables overflow to work on TBODY element. All other non-IE, non-Mozilla browsers */
/* Filter out Opera 5.x/6.x and MacIE 5.x */
head:first-child+body thead[class].fixedHeader tr {
display: block;
}
/* make the TH elements pretty */
thead.fixedHeader th {
background: #C96;
border-left: 1px solid #EB8;
border-right: 1px solid #B74;
border-top: 1px solid #EB8;
font-weight: normal;
padding: 4px 3px;
text-align: left
}
/* make the A elements pretty. makes for nice clickable headers */
thead.fixedHeader a, thead.fixedHeader a:link, thead.fixedHeader a:visited {
color: #FFF;
display: block;
text-decoration: none;
width: 100%
}
/* make the A elements pretty. makes for nice clickable headers */
/* WARNING: swapping the background on hover may cause problems in WinIE 6.x */
thead.fixedHeader a:hover {
color: #FFF;
display: block;
text-decoration: underline;
width: 100%
}
/* define the table content to be scrollable */
/* set TBODY element to have block level attributes. All other non-IE browsers */
/* this enables overflow to work on TBODY element. All other non-IE, non-Mozilla browsers */
/* induced side effect is that child TDs no longer accept width: auto */
/* Filter out Opera 5.x/6.x and MacIE 5.x */
head:first-child+body tbody[class].scrollContent {
display: block;
height: 262px;
overflow: auto;
width: 100%
}
/* make TD elements pretty. Provide alternating classes for striping the table */
/* http://www.alistapart.com/articles/zebratables/ */
tbody.scrollContent td, tbody.scrollContent tr.normalRow td {
background: #FFF;
border-bottom: none;
border-left: none;
border-right: 1px solid #CCC;
border-top: 1px solid #DDD;
padding: 2px 3px 3px 4px
}
tbody.scrollContent tr.alternateRow td {
background: #EEE;
border-bottom: none;
border-left: none;
border-right: 1px solid #CCC;
border-top: 1px solid #DDD;
padding: 2px 3px 3px 4px
}
/* define width of TH elements: 1st, 2nd, and 3rd respectively. */
/* All other non-IE browsers. Filter out Opera 5.x/6.x and MacIE 5.x */
/* Add 16px to last TH for scrollbar padding */
/* http://www.w3.org/TR/REC-CSS2/selector.html#adjacent-selectors */
head:first-child+body thead[class].fixedHeader th {
width: 200px
}
head:first-child+body thead[class].fixedHeader th + th {
width: 240px
}
head:first-child+body thead[class].fixedHeader th + th + th {
border-right: none;
padding: 4px 4px 4px 3px;
width: 316px
}
/* define width of TH elements: 1st, 2nd, and 3rd respectively. */
/* All other non-IE browsers. Filter out Opera 5.x/6.x and MacIE 5.x */
/* Add 16px to last TH for scrollbar padding */
/* http://www.w3.org/TR/REC-CSS2/selector.html#adjacent-selectors */
head:first-child+body tbody[class].scrollContent td {
width: 200px
}
head:first-child+body tbody[class].scrollContent td + td {
width: 240px
}
head:first-child+body tbody[class].scrollContent td + td + td {
border-right: none;
padding: 2px 4px 2px 3px;
width: 300px
}
-->
</style>
</head><body>
<h1>(Almost) Pure CSS Scrollable Table with Fixed Header</h1>
<h2>Using CSS to allow scrolling within a single HTML table</h2>
<div><br/></div>
<h2>The Bullet Resistant Version</h2>
<h3>Lots of CSS Browser Filtering</h3>
<form id="sampleForm" action="bulletVersion.html" method="post">
<div id="tableContainer" class="tableContainer">
<table border="0" cellpadding="0" cellspacing="0" width="100%" class="scrollTable">
<thead class="fixedHeader" id="fixedHeader">
<tr>
<th><a href="#">Header 1</a></th>
<th><a href="#">Header 2</a></th>
<th><a href="#">Header 3</a></th>
</tr>
</thead>
<tbody class="scrollContent">
<tr>
<td>Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Nulla vitae wisi. Nulla euismod aliquet tellus.</td>
<td>In sit amet enim. Praesent vulputate tortor nec ante. Morbi sollicitudin est non neque.</td>
<td>Class aptent taciti sociosqu ad litora torquent per conubia nostra, per inceptos hymenaeos.</td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td><select name="sampleSelect1" id="sampleSelect1"><option>Option 1</option><option>Option 2</option><option>Option 3</option><option>Option 4</option><option>Option 5</option></select></td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td><select name="sampleSelect2" id="sampleSelect2" size="5" multiple="multiple"><option>Option 1</option><option>Option 2</option><option>Option 3</option><option>Option 4</option><option>Option 5</option></select></td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td><input type="text" name="sampleText" id="sampleText" value="This is a sample Text form element" /></td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td><input type="password" name="samplePassword" id="samplePassword" value="password" /></td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td><input type="submit" name="sampleSubmit" id="sampleSubmit" value="Sample Submit Button" /></td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td><input type="reset" name="sampleReset" id="sampleReset" value="Sample Reset Button" /></td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td><input type="button" name="sampleButton" id="sampleButton" value="Sample Button Element" /></td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td><input type="checkbox" name="sampleCheckbox" id="sampleCheckboxA" value="sampleCheckboxA" /> <label for="sampleCheckboxA">Sample Checkbox A</label></td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td><input type="checkbox" name="sampleCheckbox" id="sampleCheckboxB" value="sampleCheckboxB" /> <label for="sampleCheckboxB">Sample Checkbox B</label></td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td><input type="radio" name="sampleRadio" id="sampleRadioA" value="sampleRadioA" /> <label for="sampleRadioA">Sample Radio A</label></td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td><input type="radio" name="sampleRadio" id="sampleRadioB" value="sampleRadioB" /> <label for="sampleRadioB">Sample Radio B</label></td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td><select name="sampleSelect3" id="sampleSelect3"><option>Option 1</option><option>Option 2</option><option>Option 3</option><option>Option 4</option><option>Option 5</option></select></td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td><select name="sampleSelect4" id="sampleSelect4" size="5" multiple="multiple"><option>Option 1</option><option>Option 2</option><option>Option 3</option><option>Option 4</option><option>Option 5</option></select></td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td><textarea cols="20" rows="5" name="sampleTextarea" id="sampleTextarea">Cell Content 3</textarea></td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td>More Cell Content 3</td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td>Even More Cell Content 3</td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td>And Repeat 3</td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td><select name="sampleSelect5" id="sampleSelect5"><option>Option 1</option><option>Option 2</option><option>Option 3</option><option>Option 4</option><option>Option 5</option></select></td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td><select name="sampleSelect6" id="sampleSelect6"><option>Option 1</option><option>Option 2</option><option>Option 3</option><option>Option 4</option><option>Option 5</option></select></td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td>Even More Cell Content 3</td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td>And Repeat 3</td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td>Cell Content 3</td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td>More Cell Content 3</td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td>Even More Cell Content 3</td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td>And Repeat 3</td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td>Cell Content 3</td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td>More Cell Content 3</td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td>Even More Cell Content 3</td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td>And Repeat 3</td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td>Cell Content 3</td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td>More Cell Content 3</td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td>Even More Cell Content 3</td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td>And Repeat 3</td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td>Cell Content 3</td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td>More Cell Content 3</td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td>Even More Cell Content 3</td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td>And Repeat 3</td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td>Cell Content 3</td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td>More Cell Content 3</td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td>Even More Cell Content 3</td>
</tr>
<tr>
<td>And Repeat 1</td>
<td>And Repeat 2</td>
<td>And Repeat 3</td>
</tr>
<tr>
<td>Cell Content 1</td>
<td>Cell Content 2</td>
<td>Cell Content 3</td>
</tr>
<tr>
<td>More Cell Content 1</td>
<td>More Cell Content 2</td>
<td>More Cell Content 3</td>
</tr>
<tr>
<td>Even More Cell Content 1</td>
<td>Even More Cell Content 2</td>
<td>Even More Cell Content 3</td>
</tr>
<tr>
<td>End of Cell Content 1</td>
<td>End of Cell Content 2</td>
<td>End of Cell Content 3</td>
</tr>
</tbody>
</table>
</div>
</form>
<div>
<p>Also see the <a href="http://www.imaputz.com/cssStuff/bigFourVersion.html">The Big Four Version</a> :: Support for current generation of the four major Browsers</p>
<h3>Browser Support (table is scrollable with fixed headers)</h3>
<ul>
<li>Opera 7.x + (All Platforms) :: Tested with 7.2x and 7.5x</li>
<li>Mozilla 1.x + (All Platforms) :: Tested with 1.0x and 1.6x</li>
<li>IE 6.x + (Windows) :: Tested with 6.0x</li>
<li>IE 5.x + (Windows) :: Tested with 5.0x and 5.5x</li>
<li>Safari 1.x + (MacOS) :: Tested with 1.2x</li>
<li>Konqueror 3.x + (Linux / BSD) :: Tested with 3.2x</li>
</ul>
<h3>Almost works (table is viewable)</h3>
<ul>
<li>IE 5.x + (MacOS) :: Tested with 5.2x</li>
<li>Opera 5.x and 6.x :: Tested with 5.1x and 6.x</li>
</ul>
<h3>Degrades gracefully</h3>
<ul>
<li>All other non-supporting browsers</li>
</ul>
<h3>Notes:</h3>
<ul>
<li>Opera v5 to v7 adds margins to the THEAD and TBODY and their children</li>
<li>On Konqueror 3.x the scrollbar may be slightly off.</li>
<li>On Konqueror 3.x form elements may not hide correctly.</li>
<li>On MacIE 5.x the last table header cell may obscure the up arrow of the scrollbar.</li>
<li>Gecko/20041217 may have table cell alignment issues (bug?), Prior versions (eg: Gecko/20040113) do not have this</li>
</ul>
<h3>Updates:</h3>
<ul>
<li>2004.10.15 11am: Added link to Big Four Version</li>
<li>2004.11.02 01pm: Fixed incorrect width on 2nd Cell. Was 250px, should be 240px.</li>
<li>2005.01.28 07pm: Added form elements to aid in testing scrolling abilities</li>
<li>2005.01.28 08pm: Added JS IE Select element workaround.</li>
</ul>
</div>
<div>
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
put a bunch of breaks to test scrolling within the HTML document itself.
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
put a bunch of breaks to test scrolling within the HTML document itself.
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
put a bunch of breaks to test scrolling within the HTML document itself.
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
done.
</div>
</body></html>
posted @
2006-10-20 10:05 一缕青烟 阅读(307) |
评论 (0) |
编辑 收藏posted @
2006-10-20 09:47 一缕青烟 阅读(260) |
评论 (0) |
编辑 收藏方法一:
String.prototype.trim= function()
{
// 用正则表达式将前后空格
// 用空字符串替代。
return this.replace(/(^\s*)|(\s*$)/g, "");
}
方法二:
function trim(str)
{
for(var i = 0 ; i<str.length && str.charAt(i)==" " ; i++ ) ;
for(var j =str.length; j>0 && str.charAt(j-1)==" " ; j--) ;
if(i>j) return "";
return str.substring(i,j);
}
posted @
2006-10-19 09:12 一缕青烟 阅读(155) |
评论 (0) |
编辑 收藏
Oracle时间日期操作
sysdate+(5/24/60/60) 在系统时间基础上延迟5秒
sysdate+5/24/60 在系统时间基础上延迟5分钟
sysdate+5/24 在系统时间基础上延迟5小时
sysdate+5 在系统时间基础上延迟5天
add_months(sysdate,-5) 在系统时间基础上延迟5月
add_months(sysdate,-5*12) 在系统时间基础上延迟5年
上月末的日期:select last_day(add_months(sysdate, -1)) from dual;
本月的最后一秒:select trunc(add_months(sysdate,1),'MM') - 1/24/60/60 from dual
本周星期一的日期:select trunc(sysdate,'day')+1 from dual
年初至今的天数:select ceil(sysdate - trunc(sysdate, 'year')) from dual;
今天是今年的第几周 :select to_char(sysdate,'fmww') from dual
今天是本月的第几周:SELECT TO_CHAR(SYSDATE,'WW') - TO_CHAR(TRUNC(SYSDATE,'MM'),'WW') + 1 AS "weekOfMon" FROM dual
本月的天数
SELECT to_char(last_day(SYSDATE),'dd') days FROM dual
今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
下个星期一的日期
SELECT Next_day(SYSDATE,'monday') FROM dual
============================================
--计算工作日方法
create table t(s date,e date);
alter session set nls_date_format = 'yyyy-mm-dd';
insert into t values('2003-03-01','2003-03-03');
insert into t values('2003-03-02','2003-03-03');
insert into t values('2003-03-07','2003-03-08');
insert into t values('2003-03-07','2003-03-09');
insert into t values('2003-03-05','2003-03-07');
insert into t values('2003-02-01','2003-03-31');
-- 这里假定日期都是不带时间的,否则在所有日期前加trunc即可。
select s,e,e-s+1 total_days,
trunc((e-s+1)/7)*5 + length(replace(substr('01111100111110',to_char(s,'d'),mod(e-s+1,7)),'0','')) work_days
from t;
-- drop table t;
引此:http://www.itpub.net/showthread.php?s=1635506cd5f48b1bc3adbe4cde96f227&threadid=104060&perpage=15&pagenumber=1
================================================================================
判断当前时间是上午下午还是晚上
SELECT CASE
WHEN to_number(to_char(SYSDATE,'hh24')) BETWEEN 6 AND 11 THEN '上午'
WHEN to_number(to_char(SYSDATE,'hh24')) BETWEEN 11 AND 17 THEN '下午'
WHEN to_number(to_char(SYSDATE,'hh24')) BETWEEN 17 AND 21 THEN '晚上'
END
FROM dual;
================================================================================
Oracle 中的一些处理日期
将数字转换为任意时间格式.如秒:需要转换为天/小时
SELECT to_char(floor(TRUNC(936000/(60*60))/24))||'天'||to_char(mod(TRUNC(936000/(60*60)),24))||'小时' FROM DUAL
TO_DATE格式
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1.
日期和字符转换函数用法(to_date,to_char)
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.
求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4.
两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not
in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9.
select months_between(to_date('01-31-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.
获得小时数
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
获取年月日与此类似
13.
年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),
12 ) MONTHS,
newer_date,
older_date
from ( select hiredate older_date,
add_months(hiredate,rownum)+rownum newer_date
from emp )
)
14.
处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.
找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' ¦ ¦ :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.
yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.
5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.
一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
mod(mod(date2-date1, 365), 30)作为日.
23.next_day函数
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
1 2 3 4 5 6 7
日 一 二 三 四 五 六
---------------------------------------------------------------
select (sysdate-to_date('2003-12-03 12:55:45','yyyy-mm-dd hh24:mi:ss'))*24*60*60 from dual
日期 返回的是天 然后 转换为ss
转此:http://www.onlinedatabase.cn/leadbbs/Announce/Announce.asp?BoardID=42&ID=1769
将数字转换为任意时间格式.如秒:需要转换为天/小时
SELECT to_char(floor(TRUNC(936000/(60*60))/24))||'天'||to_char(mod(TRUNC(936000/(60*60)),24))||'小时' FROM DUAL
TO_DATE格式
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1.
日期和字符转换函数用法(to_date,to_char)
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.
求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4.
两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not
in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9.
select months_between(to_date('01-31-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.
获得小时数
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
获取年月日与此类似
13.
年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),
12 ) MONTHS,
newer_date,
older_date
from ( select hiredate older_date,
add_months(hiredate,rownum)+rownum newer_date
from emp )
)
14.
处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.
找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' ¦ ¦ :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.
yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.
5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.
一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
mod(mod(date2-date1, 365), 30)作为日.
23.next_day函数
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
1 2 3 4 5 6 7
日 一 二 三 四 五 六
---------------------------------------------------------------
select (sysdate-to_date('2003-12-03 12:55:45','yyyy-mm-dd hh24:mi:ss'))*24*60*60 from dual
日期 返回的是天 然后 转换为ss
转此:http://www.onlinedatabase.cn/leadbbs/Announce/Announce.asp?BoardID=42&ID=1769
将数字转换为任意时间格式.如秒:需要转换为天/小时
SELECT to_char(floor(TRUNC(936000/(60*60))/24))||'天'||to_char(mod(TRUNC(936000/(60*60)),24))||'小时' FROM DUAL
TO_DATE格式
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1.
日期和字符转换函数用法(to_date,to_char)
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.
求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4.
两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not
in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9.
select months_between(to_date('01-31-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.
获得小时数
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
获取年月日与此类似
13.
年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),
12 ) MONTHS,
newer_date,
older_date
from ( select hiredate older_date,
add_months(hiredate,rownum)+rownum newer_date
from emp )
)
14.
处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.
找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' ¦ ¦ :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.
yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.
5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.
一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
mod(mod(date2-date1, 365), 30)作为日.
23.next_day函数
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
1 2 3 4 5 6 7
日 一 二 三 四 五 六
---------------------------------------------------------------
select (sysdate-to_date('2003-12-03 12:55:45','yyyy-mm-dd hh24:mi:ss'))*24*60*60 from dual
日期 返回的是天 然后 转换为ss
转此:http://www.onlinedatabase.cn/leadbbs/Announce/Announce.asp?BoardID=42&ID=1769
将数字转换为任意时间格式.如秒:需要转换为天/小时
SELECT to_char(floor(TRUNC(936000/(60*60))/24))||'天'||to_char(mod(TRUNC(936000/(60*60)),24))||'小时' FROM DUAL
TO_DATE格式
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1.
日期和字符转换函数用法(to_date,to_char)
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.
求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4.
两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not
in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9.
select months_between(to_date('01-31-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.
获得小时数
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
获取年月日与此类似
13.
年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),
12 ) MONTHS,
newer_date,
older_date
from ( select hiredate older_date,
add_months(hiredate,rownum)+rownum newer_date
from emp )
)
14.
处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.
找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' ¦ ¦ :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.
yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.
5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.
一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
mod(mod(date2-date1, 365), 30)作为日.
23.next_day函数
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
1 2 3 4 5 6 7
日 一 二 三 四 五 六
---------------------------------------------------------------
select (sysdate-to_date('2003-12-03 12:55:45','yyyy-mm-dd hh24:mi:ss'))*24*60*60 from dual
日期 返回的是天 然后 转换为ss
转此:http://www.onlinedatabase.cn/leadbbs/Announce/Announce.asp?BoardID=42&ID=1769
|
posted @
2006-10-19 08:46 一缕青烟 阅读(236) |
评论 (0) |
编辑 收藏
JAVA程序员面试32问
第一,谈谈final, finally, finalize的区别。
第二,Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类,是否可以implements(实现)interface(接口)?
第三,Static Nested Class 和 Inner Class的不同,说得越多越好(面试题有的很笼统)。
第四,&和&&的区别。
第五,HashMap和Hashtable的区别。
第六,Collection 和 Collections的区别。
第七,什么时候用assert。
第八,GC是什么? 为什么要有GC?
第九,String s = new String("xyz");创建了几个String Object?
第十,Math.round(11.5)等於多少? Math.round(-11.5)等於多少?
第十一,short s1 = 1; s1 = s1 + 1;有什么错? short s1 = 1; s1 += 1;有什么错?
第十二,sleep() 和 wait() 有什么区别?
第十三,Java有没有goto?
第十四,数组有没有length()这个方法? String有没有length()这个方法?
第十五,Overload和Override的区别。Overloaded的方法是否可以改变返回值的类型?
第十六,Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
第十七,给我一个你最常见到的runtime exception。
第十八,error和exception有什么区别?
第十九,List, Set, Map是否继承自Collection接口?
第二十,abstract class和interface有什么区别?
第二十一,abstract的method是否可同时是static,是否可同时是native,是否可同时是synchronized?
第二十二,接口是否可继承接口? 抽象类是否可实现(implements)接口? 抽象类是否可继承实体类(concrete class)?
第二十三,启动一个线程是用run()还是start()?
第二十四,构造器Constructor是否可被override?
第二十五,是否可以继承String类?
第二十六,当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?
第二十七,try {}里有一个return语句,那么紧跟在这个try后的finally {}里的code会不会被执行,什么时候被执行,在return前还是后?
第二十八,编程题: 用最有效率的方法算出2乘以8等於几?
第二十九,两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?
第三十,当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
第三十一,swtich是否能作用在byte上,是否能作用在long上,是否能作用在String上?
第三十二,编程题: 写一个Singleton出来。
以下是答案
第一,谈谈final, finally, finalize的区别。
final—修饰符(关键字)如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承。因此一个类不能既被声明为 abstract的,又被声明为final的。将变量或方法声明为final,可以保证它们在使用中不被改变。被声明为final的变量必须在声明时给定初值,而在以后的引用中只能读取,不可修改。被声明为final的方法也同样只能使用,不能重载
finally—再异常处理时提供 finally 块来执行任何清除操作。如果抛出一个异常,那么相匹配的 catch 子句就会执行,然后控制就会进入 finally 块(如果有的话)。
finalize—方法名。Java 技术允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。它是在 Object 类中定义的,因此所有的类都继承了它。子类覆盖 finalize() 方法以整理系统资源或者执行其他清理工作。finalize() 方法是在垃圾收集器删除对象之前对这个对象调用的。
第二,Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类,是否可以implements(实现)interface(接口)?
匿名的内部类是没有名字的内部类。不能extends(继承) 其它类,但一个内部类可以作为一个接口,由另一个内部类实现。
第三,Static Nested Class 和 Inner Class的不同,说得越多越好(面试题有的很笼统)。
Nested Class (一般是C++的说法),Inner Class (一般是JAVA的说法)。Java内部类与C++嵌套类最大的不同就在于是否有指向外部的引用上。具体可见http: //
www.frontfree.net/articles/services/view.asp?id=704&page=1注: 静态内部类(Inner Class)意味着1创建一个static内部类的对象,不需要一个外部类对象,2不能从一个static内部类的一个对象访问一个外部类对象
第四,&和&&的区别。
&是位运算符。&&是布尔逻辑运算符。
第五,HashMap和Hashtable的区别。
都属于Map接口的类,实现了将惟一键映射到特定的值上。
HashMap 类没有分类或者排序。它允许一个 null 键和多个 null 值。
Hashtable 类似于 HashMap,但是不允许 null 键和 null 值。它也比 HashMap 慢,因为它是同步的。
第六,Collection 和 Collections的区别。
Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。
Collection是个java.util下的接口,它是各种集合结构的父接口。
第七,什么时候用assert。
断言是一个包含布尔表达式的语句,在执行这个语句时假定该表达式为 true。如果表达式计算为 false,那么系统会报告一个 AssertionError。它用于调试目的:
assert(a > 0); // throws an AssertionError if a <= 0
断言可以有两种形式:
assert Expression1 ;
assert Expression1 : Expression2 ;
Expression1 应该总是产生一个布尔值。
Expression2 可以是得出一个值的任意表达式。这个值用于生成显示更多调试信息的 String 消息。
断言在默认情况下是禁用的。要在编译时启用断言,需要使用 source 1.4 标记:
javac -source 1.4 Test.java
要在运行时启用断言,可使用 -enableassertions 或者 -ea 标记。
要在运行时选择禁用断言,可使用 -da 或者 -disableassertions 标记。
要系统类中启用断言,可使用 -esa 或者 -dsa 标记。还可以在包的基础上启用或者禁用断言。
可以在预计正常情况下不会到达的任何位置上放置断言。断言可以用于验证传递给私有方法的参数。不过,断言不应该用于验证传递给公有方法的参数,因为不管是否启用了断言,公有方法都必须检查其参数。不过,既可以在公有方法中,也可以在非公有方法中利用断言测试后置条件。另外,断言不应该以任何方式改变程序的状态。
第八,GC是什么? 为什么要有GC? (基础)。
GC是垃圾收集器。Java 程序员不用担心内存管理,因为垃圾收集器会自动进行管理。要请求垃圾收集,可以调用下面的方法之一:
System.gc()
Runtime.getRuntime().gc()
第九,String s = new String("xyz");创建了几个String Object?
两个对象,一个是“xyx”,一个是指向“xyx”的引用对象s。
第十,Math.round(11.5)等於多少? Math.round(-11.5)等於多少?
Math.round(11.5)返回(long)12,Math.round(-11.5)返回(long)-11;
第十一,short s1 = 1; s1 = s1 + 1;有什么错? short s1 = 1; s1 += 1;有什么错?
short s1 = 1; s1 = s1 + 1;有错,s1是short型,s1+1是int型,不能显式转化为short型。可修改为s1 =(short)(s1 + 1) 。short s1 = 1; s1 += 1正确。
第十二,sleep() 和 wait() 有什么区别? 搞线程的最爱
sleep()方法是使线程停止一段时间的方法。在sleep 时间间隔期满后,线程不一定立即恢复执行。这是因为在那个时刻,其它线程可能正在运行而且没有被调度为放弃执行,除非(a)“醒来”的线程具有更高的优先级
(b)正在运行的线程因为其它原因而阻塞。
wait()是线程交互时,如果线程对一个同步对象x 发出一个wait()调用,该线程会暂停执行,被调对象进入等待状态,直到被唤醒或等待时间到。
第十三,Java有没有goto?
Goto—java中的保留字,现在没有在java中使用。
第十四,数组有没有length()这个方法? String有没有length()这个方法?
数组没有length()这个方法,有length的属性。
String有有length()这个方法。
第十五,Overload和Override的区别。Overloaded的方法是否可以改变返回值的类型?
方法的重写Overriding和重载Overloading是Java多态性的不同表现。重写Overriding是父类与子类之间多态性的一种表现,重载Overloading是一个类中多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding)。子类的对象使用这个方法时,将调用子类中的定义,对它而言,父类中的定义如同被“屏蔽”了。如果在一个类中定义了多个同名的方法,它们或有不同的参数个数或有不同的参数类型,则称为方法的重载(Overloading)。Overloaded的方法是可以改变返回值的类型。
第十六,Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
Set里的元素是不能重复的,那么用iterator()方法来区分重复与否。equals()是判读两个Set是否相等。
equals()和==方法决定引用值是否指向同一对象equals()在类中被覆盖,为的是当两个分离的对象的内容和类型相配的话,返回真值。
第十七,给我一个你最常见到的runtime exception。
ArithmeticException, ArrayStoreException, BufferOverflowException, BufferUnderflowException, CannotRedoException, CannotUndoException, ClassCastException, CMMException, ConcurrentModificationException, DOMException, EmptyStackException, IllegalArgumentException, IllegalMonitorStateException, IllegalPathStateException, IllegalStateException,
ImagingOpException, IndexOutOfBoundsException, MissingResourceException, NegativeArraySizeException, NoSuchElementException, NullPointerException, ProfileDataException, ProviderException, RasterFormatException, SecurityException, SystemException, UndeclaredThrowableException, UnmodifiableSetException, UnsupportedOperationException
第十八,error和exception有什么区别?
error 表示恢复不是不可能但很困难的情况下的一种严重问题。比如说内存溢出。不可能指望程序能处理这样的情况。
exception 表示一种设计或实现问题。也就是说,它表示如果程序运行正常,从不会发生的情况。
第十九,List, Set, Map是否继承自Collection接口?
List,Set是
Map不是
第二十,abstract class和interface有什么区别?
声明方法的存在而不去实现它的类被叫做抽象类(abstract class),它用于要创建一个体现某些基本行为的类,并为该类声明方法,但不能在该类中实现该类的情况。不能创建abstract 类的实例。然而可以创建一个变量,其类型是一个抽象类,并让它指向具体子类的一个实例。不能有抽象构造函数或抽象静态方法。Abstract 类的子类为它们父类中的所有抽象方法提供实现,否则它们也是抽象类为。取而代之,在子类中实现该方法。知道其行为的其它类可以在类中实现这些方法。
接口(interface)是抽象类的变体。在接口中,所有方法都是抽象的。多继承性可通过实现这样的接口而获得。接口中的所有方法都是抽象的,没有一个有程序体。接口只可以定义static final成员变量。接口的实现与子类相似,除了该实现类不能从接口定义中继承行为。当类实现特殊接口时,它定义(即将程序体给予)所有这种接口的方法。然后,它可以在实现了该接口的类的任何对象上调用接口的方法。由于有抽象类,它允许使用接口名作为引用变量的类型。通常的动态联编将生效。引用可以转换到接口类型或从接口类型转换,instanceof 运算符可以用来决定某对象的类是否实现了接口。
第二十一,abstract的method是否可同时是static,是否可同时是native,是否可同时是synchronized?
都不能
第二十二,接口是否可继承接口? 抽象类是否可实现(implements)接口? 抽象类是否可继承实体类(concrete class)?
接口可以继承接口。抽象类可以实现(implements)接口,抽象类是否可继承实体类,但前提是实体类必须有明确的构造函数。
第二十三,启动一个线程是用run()还是start()?
启动一个线程是调用start()方法,使线程所代表的虚拟处理机处于可运行状态,这意味着它可以由JVM调度并执行。这并不意味着线程就会立即运行。run()方法可以产生必须退出的标志来停止一个线程。
第二十四,构造器Constructor是否可被override?
构造器Constructor不能被继承,因此不能重写Overriding,但可以被重载Overloading。
第二十五,是否可以继承String类?
String类是final类故不可以继承。
第二十六,当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?
不能,一个对象的一个synchronized方法只能由一个线程访问。
第二十七,try {}里有一个return语句,那么紧跟在这个try后的finally {}里的code会不会被执行,什么时候被执行,在return前还是后?
会执行,在return前执行。
第二十八,编程题: 用最有效率的方法算出2乘以8等於几?
有C背景的程序员特别喜欢问这种问题。
2 << 3
第二十九,两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?
不对,有相同的hash code。
第三十,当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
是值传递。Java 编程语言只由值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的内容可以在被调用的方法中改变,但对象的引用是永远不会改变的。
第三十一,swtich是否能作用在byte上,是否能作用在long上,是否能作用在String上?
switch(expr1)中,expr1是一个整数表达式。因此传递给 switch 和 case 语句的参数应该是 int、 short、 char 或者 byte。long,string 都不能作用于swtich。
第三十二,编程题: 写一个Singleton出来。
Singleton模式主要作用是保证在Java应用程序中,一个类Class只有一个实例存在。
一般Singleton模式通常有几种种形式:
第一种形式: 定义一个类,它的构造函数为private的,它有一个static的private的该类变量,在类初始化时实例话,通过一个public的getInstance方法获取对它的引用,继而调用其中的方法。
public class Singleton {
private Singleton(){}
//在自己内部定义自己一个实例,是不是很奇怪?
//注意这是private 只供内部调用
private static Singleton instance = new Singleton();
//这里提供了一个供外部访问本class的静态方法,可以直接访问
public static Singleton getInstance() {
return instance;
}
}
第二种形式:
public class Singleton {
private static Singleton instance = null;
public static synchronized Singleton getInstance() {
//这个方法比上面有所改进,不用每次都进行生成对象,只是第一次
//使用时生成实例,提高了效率!
if (instance==null)
instance=new Singleton();
return instance; }
}
其他形式:
定义一个类,它的构造函数为private的,所有方法为static的。
一般认为第一种形式要更加安全些
第三十三 Hashtable和HashMap
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许
还有就是,HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在
多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap
就必须为之提供外同步。
Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
posted @
2006-10-01 17:41 一缕青烟 阅读(176) |
评论 (0) |
编辑 收藏