正则表达式经典 (转)
"^\d+$" //非负整数(正整数 + 0)
"^[0-9]*[1-9][0-9]*$" //正整数
"^((-\d+)|(0+))$" //非正整数(负整数 + 0)
"^-[0-9]*[1-9][0-9]*$" //负整数
"^-?\d+$" //整数
"^\d+(\.\d+)?$" //非负浮点数(正浮点数 + 0)
"^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数
"^((-\d+(\.\d+)?)|(0+(\.0+)?))$" //非正浮点数(负浮点数 + 0)
"^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数
"^(-?\d+)(\.\d+)?$" //浮点数
"^[A-Za-z]+$" //由26个英文字母组成的字符串
"^[A-Z]+$" //由26个英文字母的大写组成的字符串
"^[a-z]+$" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串
"^\w+$" //由数字、26个英文字母或者下划线组成的字符串
"^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$" //email地址
"^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$"
----------------------------------------------------------------------------------------------------------------------
字符描述: \:将下一个字符标记为特殊字符或字面值。例如"n"与字符"n"匹配。"\n"与换行符匹配。序列"\\"与"\"匹配,"\("与"("匹配。
^ :匹配输入的开始位置。
$ :匹配输入的结尾。
* :匹配前一个字符零次或几次。例如,"zo*"可以匹配"z"、"zoo"。
+ :匹配前一个字符一次或多次。例如,"zo+"可以匹配"zoo",但不匹配"z"。
? :匹配前一个字符零次或一次。例如,"a?ve?"可以匹配"never"中的"ve"。
.:匹配换行符以外的任何字符。
(pattern) 与模式匹配并记住匹配。匹配的子字符串可以从作为结果的 Matches 集合中使用 Item [0]...[n]取得。如果要匹配括号字符(和 ),可使用"\(" 或 "\)"。
x|y:匹配 x 或 y。例如 "z|food" 可匹配 "z" 或 "food"。"(z|f)ood" 匹配 "zoo" 或 "food"。
{n}:n 为非负的整数。匹配恰好n次。例如,"o{2}" 不能与 "Bob 中的 "o" 匹配,但是可以与"foooood"中的前两个o匹配。
{n,} :n 为非负的整数。匹配至少n次。例如,"o{2,}"不匹配"Bob"中的"o",但是匹配"foooood"中所有的o。"o{1,}"等价于"o+"。"o{0,}"等价于"o*"。
{n,m} :m 和 n 为非负的整数。匹配至少 n 次,至多 m 次。例如,"o{1,3}" 匹配 "fooooood"中前三个o。"o{0,1}"等价于"o?"。
[xyz] :一个字符集。与括号中字符的其中之一匹配。例如,"[abc]" 匹配"plain"中的"a"。
[^xyz] :一个否定的字符集。匹配不在此括号中的任何字符。例如,"[^abc]" 可以匹配"plain"中的"p".
[a-z] :表示某个范围内的字符。与指定区间内的任何字符匹配。例如,"[a-z]"匹配"a"与"z"之间的任何一个小写字母字符。
[^m-z] :否定的字符区间。与不在指定区间内的字符匹配。例如,"[m-z]"与不在"m"到"z"之间的任何字符匹配。
\b :与单词的边界匹配,即单词与空格之间的位置。例如,"er\b" 与"never"中的"er"匹配,但是不匹配"verb"中的"er"。
\B :与非单词边界匹配。"ea*r\B"与"never early"中的"ear"匹配。
\d :与一个数字字符匹配。等价于[0-9]。
\D :与非数字的字符匹配。等价于[^0-9]。
\f :与分页符匹配。
\n :与换行符字符匹配。
\r :与回车字符匹配。
\s :与任何白字符匹配,包括空格、制表符、分页符等。等价于"[ \f\n\r\t\v]"。
\S :与任何非空白的字符匹配。等价于"[^ \f\n\r\t\v]"。
\t :与制表符匹配。
\v :与垂直制表符匹配。
\w :与任何单词字符匹配,包括下划线。等价于"[A-Za-z0-9_]"。
\W :与任何非单词字符匹配。等价于"[^A-Za-z0-9_]"。
\num :匹配 num个,其中 num 为一个正整数。引用回到记住的匹配。例如,"(.)\1"匹配两个连续的相同的字符。
\n:匹配 n,其中n 是一个八进制换码值。八进制换码值必须是 1, 2 或 3 个数字长。
例如,"\11" 和 "\011" 都与一个制表符匹配。"\0011"等价于"\001" 与 "1"。八进制换码值不得超过 256。否则,只有前两个字符被视为表达式的一部分。允许在正则表达式中使用ASCII码。
\xn:匹配n,其中n是一个十六进制的换码值。十六进制换码值必须恰好为两个数字长。例如,"\x41"匹配"A"。"\x041"等价于"\x04" 和 "1"。允许在正则表达式中使用 ASCII 码。
好了,常用的方法和属性就是这些了,上面的语法介绍的已经很详细了,我们就没有必要在罗嗦了,接下来我们来看看在具体的例子里面如何使用这些方法和属性来校验数据的合法性,我们还是举个例子吧,比如,我们想要对用户输入的电子邮件进行校验,那么,什么样的数据才算是一个合法的电子邮件呢?我可以这样输入:uestc95@263.net,当然我也会这样输入:xxx@yyy.com.cn,但是这样的输入就是非法的:xxx@@com.cn或者@xxx.com.cn,等等,所以我们得出一个合法的电子邮件地址至少应当满足以下几个条件:
1. 必须包含一个并且只有一个符号“@”
2. 必须包含至少一个至多三个符号“.”
3. 第一个字符不得是“@”或者“.”
4. 不允许出现“@.”或者.@
5. 结尾不得是字符“@”或者“.”
所以根据以上的原则和上面表中的语法,我们很容易的就可以得到需要的模板如下:"(\w)+[@]{1}(\w)+[.]{1,3}(\w)+"
接下来我们仔细分析一下这个模板,首先“\w”表示邮件的开始字符只能是包含下划线的单词字符,这样,满足了第三个条件;“[@]{1}”表示在电子邮件中应当匹配并且只能匹配一次字符“@”,满足了条件一;同样的“[.]{1,3}”表示在电子邮件中至少匹配1个至多匹配3个字符“.” ,满足了第二个条件;模板最后的“(\w)+”表示结尾的字符只能是包含下划线在内的单词字符,满足了条件五;模板中间的“(\w)+”满足了条件四。
然后,我们就直接调用刚才的那个函数CheckExp("(\w)+[@]{1}(\w)+[.]{1}(\w)+",待校验的字符串)就好了,如果返回True就表示数据是合法的,否则就是不正确的,怎么样,简单吧。我们还可以写出来校验身份证号码的模板:"([0-9]){15}";校验URL的模板:"^http://{1}((\w)+[.]){1,3}"等等;我们可以看到,这些模板为我们提供了很好的可重利用的模块,利用自己或者别人提供的各种模板,我们就可以方便快捷的进行数据的合法性校验了,相信你一定会写出非常通用的模板的。
这样,我们只要定制不同的模板,就可以实现对不同数据的合法性校验了。所以,正则表达式对象中最重要的属性就是:“Pattern”属性,只要真正掌握了这个属性,才可以自由的运用正则表达式对象来为我们的数据校验进行服务。
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=560411
posted @
2006-12-04 09:36 一缕青烟 阅读(278) |
评论 (0) |
编辑 收藏TCP协议
==> TCP首部
源端口号、目的端口号、位序号、位确认序号、首部长度、标志位、窗口大小、检验和、紧急指针和其它选项。
一个IP地址和一个端口号也成为一个插口(socket)。插口对可唯一确定互联网中每个TCP连接的双方。
==> TCP连接的建立与终止
TCP是一个面向连接的协议,无论哪方向另一方发送数据之前,都必须先在双方之间建立一条连接。
TCP连接的建立——三次握手。
TCP连接的终止——四次握手。这是由TCP的半关闭造成的。因为TCP是全双工的,因此每个方向必须单独的进行关闭。
==> 最大报文段长度MSS
MSS越大,允许每个报文段传递的数据越多,相对TCP和IP的首部有更高的利用率。
有些情况下,MSS是可以在建立TCP连接时进行协商的选项,但是有些情况下不行 。
* 如果是本地网络,TCP可以根据网络外出接口处的MTU值减去固定的IP首部(20)和TCP长度(20),对于以太网,可以达到1460。
* 如果IP地址为非本地的,则MSS通常定为默认值536字节(允许20字节的IP首部和20字节的TCP首部以适合576字节的IP数据报)。
MSS让主机限制另一端发送数据的长度,同时也能控制它自己发送数据报的长度,避免较小MTU发生分片。
==> TCP的半关闭
TCP连接的一端在结束它的发送后还能接收来自另一端数据(直到它也发送FIN)的能力,这就是所谓的半关闭。应用程序很少用到。
==> 复位报文段
* 不存在的端口(目的端口没有进程监听)。目的主机将对SYN请求返回一个RST报文段。(UDP则将产生一个端口不可达的信息)
* 异常终止。
* 检测半打开的连接。
==> TCP服务器的设计
* 大多数TCP服务器的进程是并发的.
* 只有处于监听的进程才能处理客户端的连接请求.
* TCP服务器可以对本地IP地址进行限制,但是一般不能对远程IP地址进行限制.
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=561075
posted @
2006-12-04 09:35 一缕青烟 阅读(378) |
评论 (0) |
编辑 收藏关于Java栈与堆的思考
1. 栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
2. 栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享,详见第3点。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
3. Java中的数据类型有两种。
一种是基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
另外,栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义
int a = 3;
int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与 b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
另一种是包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java用new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。
4. String是一个特殊的包装类数据。即可以用String str = new String("abc");的形式来创建,也可以用String str = "abc";的形式来创建(作为对比,在JDK 5.0之前,你从未见过Integer i = 3;的表达式,因为类与字面值是不能通用的,除了String。而在JDK 5.0中,这种表达式是可以的!因为编译器在后台进行Integer i = new Integer(3)的转换)。前者是规范的类的创建过程,即在Java中,一切都是对象,而对象是类的实例,全部通过new()的形式来创建。Java 中的有些类,如DateFormat类,可以通过该类的getInstance()方法来返回一个新创建的类,似乎违反了此原则。其实不然。该类运用了单例模式来返回类的实例,只不过这个实例是在该类内部通过new()来创建的,而getInstance()向外部隐藏了此细节。那为什么在String str = "abc";中,并没有通过new()来创建实例,是不是违反了上述原则?其实没有。
5. 关于String str = "abc"的内部工作。Java内部将此语句转化为以下几个步骤:
(1)先定义一个名为str的对String类的对象引用变量:String str;
(2)在栈中查找有没有存放值为"abc"的地址,如果没有,则开辟一个存放字面值为"abc"的地址,接着创建一个新的String类的对象o,并将o 的字符串值指向这个地址,而且在栈中这个地址旁边记下这个引用的对象o。如果已经有了值为"abc"的地址,则查找对象o,并返回o的地址。
(3)将str指向对象o的地址。
值得注意的是,一般String类中字符串值都是直接存值的。但像String str = "abc";这种场合下,其字符串值却是保存了一个指向存在栈中数据的引用!
为了更好地说明这个问题,我们可以通过以下的几个代码进行验证。
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2); //true
注意,我们这里并不用str1.equals(str2);的方式,因为这将比较两个字符串的值是否相等。==号,根据JDK的说明,只有在两个引用都指向了同一个对象时才返回真值。而我们在这里要看的是,str1与str2是否都指向了同一个对象。
结果说明,JVM创建了两个引用str1和str2,但只创建了一个对象,而且两个引用都指向了这个对象。
我们再来更进一步,将以上代码改成:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
System.out.println(str1 + "," + str2); //bcd, abc
System.out.println(str1==str2); //false
这就是说,赋值的变化导致了类对象引用的变化,str1指向了另外一个新对象!而str2仍旧指向原来的对象。上例中,当我们将str1的值改为"bcd"时,JVM发现在栈中没有存放该值的地址,便开辟了这个地址,并创建了一个新的对象,其字符串的值指向这个地址。
事实上,String类被设计成为不可改变(immutable)的类。如果你要改变其值,可以,但JVM在运行时根据新值悄悄创建了一个新对象,然后将这个对象的地址返回给原来类的引用。这个创建过程虽说是完全自动进行的,但它毕竟占用了更多的时间。在对时间要求比较敏感的环境中,会带有一定的不良影响。
再修改原来代码:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
String str3 = str1;
System.out.println(str3); //bcd
String str4 = "bcd";
System.out.println(str1 == str4); //true
str3 这个对象的引用直接指向str1所指向的对象(注意,str3并没有创建新对象)。当str1改完其值后,再创建一个String的引用str4,并指向因str1修改值而创建的新的对象。可以发现,这回str4也没有创建新的对象,从而再次实现栈中数据的共享。
我们再接着看以下的代码。
String str1 = new String("abc");
String str2 = "abc";
System.out.println(str1==str2); //false
创建了两个引用。创建了两个对象。两个引用分别指向不同的两个对象。
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1==str2); //false
创建了两个引用。创建了两个对象。两个引用分别指向不同的两个对象。
以上两段代码说明,只要是用new()来新建对象的,都会在堆中创建,而且其字符串是单独存值的,即使与栈中的数据相同,也不会与栈中的数据共享。
6. 数据类型包装类的值不可修改。不仅仅是String类的值不可修改,所有的数据类型包装类都不能更改其内部的值。
7. 结论与建议:
(1)我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,我们创建了String类的对象str。担心陷阱!对象可能并没有被创建!唯一可以肯定的是,指向 String类的引用被创建了。至于这个引用到底是否指向了一个新的对象,必须根据上下文来考虑,除非你通过new()方法来显要地创建一个新的对象。因此,更为准确的说法是,我们创建了一个指向String类的对象的引用变量str,这个对象引用变量指向了某个值为"abc"的String类。清醒地认识到这一点对排除程序中难以发现的bug是很有帮助的。
(2)使用String str = "abc";的方式,可以在一定程度上提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。而对于String str = new String("abc");的代码,则一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象,从而加重了程序的负担。这个思想应该是享元模式的思想,但JDK的内部在这里实现是否应用了这个模式,不得而知。
(3)当比较包装类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用==。
(4)由于String类的immutable性质,当String变量需要经常变换其值时,应该考虑使用StringBuffer类,以提高程序效率。
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=561129
posted @
2006-12-04 09:31 一缕青烟 阅读(486) |
评论 (0) |
编辑 收藏
提高JSP应用程序的七大秘籍绝招
你时常被客户抱怨JSP页面响应速度很慢吗?你想过当客户访问次数剧增时,你的WEB应用能承受日益增加的访问量吗?本文讲述了调整JSP和servlet的一些非常实用的方法,它可使你的servlet和JSP页面响应更快,扩展性更强。而且在用户数增加的情况下,系统负载会呈现出平滑上长的趋势。在本文中,我将通过一些实际例子和配置方法使得你的应用程序的性能有出人意料的提升。
其中,某些调优技术是在你的编程工作中实现的。而另一些技术是与应用服务器的配置相关的。在本文中,我们将详细地描述怎样通过调整servlet和JSP页面,来提高你的应用程序的总体性能。在阅读本文之前,假设你有基本的servlet和JSP的知识。
方法一:在servlet的init()方法中缓存数据
当应用服务器初始化servlet实例之后,为客户端请求提供服务之前,它会调用这个servlet的init()方法。在一个servlet的生命周期中,init()方法只会被调用一次。通过在init()方法中缓存一些静态的数据或完成一些只需要执行一次的、耗时的操作,就可大大地提高系统性能。
例如,通过在init()方法中建立一个JDBC连接池是一个最佳例子,假设我们是用jdbc2.0的DataSource接口来取得数据库连接,在通常的情况下,我们需要通过JNDI来取得具体的数据源。我们可以想象在一个具体的应用中,如果每次SQL请求都要执行一次JNDI查询的话,那系统性能将会急剧下降。解决方法是如下代码,它通过缓存DataSource,使得下一次SQL调用时仍然可以继续利用它:
public class ControllerServlet extends HttpServlet
{
private javax.sql.DataSource testDS = null;
public void init(ServletConfig config) throws ServletException
{
super.init(config);
Context ctx = null;
try
{
ctx = new InitialContext();
testDS = (javax.sql.DataSource)ctx.lookup("jdbc/testDS");
}
catch(NamingException ne)
{
ne.printStackTrace();
}
catch(Exception e)
{
e.printStackTrace();
}
}
public javax.sql.DataSource getTestDS()
{
return testDS;
}
...
...
} |
方法 2:禁止servlet和JSP 自动重载(auto-reloading)
Servlet/JSP提供了一个实用的技术,即自动重载技术,它为开发人员提供了一个好的开发环境,当你改变servlet和JSP页面后而不必重启应用服务器。然而,这种技术在产品运行阶段对系统的资源是一个极大的损耗,因为它会给JSP引擎的类装载器(classloader)带来极大的负担。因此关闭自动重载功能对系统性能的提升是一个极大的帮助。
方法 3: 不要滥用HttpSession
在很多应用中,我们的程序需要保持客户端的状态,以便页面之间可以相互联系。但不幸的是由于HTTP具有天生无状态性,从而无法保存客户端的状态。因此一般的应用服务器都提供了session来保存客户的状态。在JSP应用服务器中,是通过HttpSession对像来实现session的功能的,但在方便的同时,它也给系统带来了不小的负担。因为每当你获得或更新session时,系统者要对它进行费时的序列化操作。你可以通过对HttpSession的以下几种处理方式来提升系统的性能。
如果没有必要,就应该关闭JSP页面中对HttpSession的缺省设置。 如果你没有明确指定的话,每个JSP页面都会缺省地创建一个HttpSession。如果你的JSP中不需要使用session的话,那可以通过如下的JSP页面指示符来禁止它:
<%@ page session="false"%> |
不要在HttpSession中存放大的数据对像:如果你在HttpSession中存放大的数据对像的话,每当对它进行读写时,应用服务器都将对其进行序列化,从而增加了系统的额外负担。你在HttpSession中存放的数据对像越大,那系统的性能就下降得越快。
当你不需要HttpSession时,尽快地释放它:当你不再需要session时,你可以通过调用HttpSession.invalidate()方法来释放它。尽量将session的超时时间设得短一点:在JSP应用服务器中,有一个缺省的session的超时时间。当客户在这个时间之后没有进行任何操作的话,系统会将相关的session自动从内存中释放。超时时间设得越大,系统的性能就会越低,因此最好的方法就是尽量使得它的值保持在一个较低的水平。
方法 4: 将页面输出进行压缩
压缩是解决数据冗余的一个好的方法,特别是在网络带宽不够发达的今天。有的浏览器支持gzip(GNU zip)进行来对HTML文件进行压缩,这种方法可以戏剧性地减少HTML文件的下载时间。因此,如果你将servlet或JSP页面生成的HTML页面进行压缩的话,那用户就会觉得页面浏览速度会非常快。但不幸的是,不是所有的浏览器都支持gzip压缩,但你可以通过在你的程序中检查客户的浏览器是否支持它。下面就是关于这种方法实现的一个代码片段:
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws IOException, ServletException
{
OutputStream out = null
String encoding = request.getHeader("Accept-Encoding");
if (encoding != null && encoding.indexOf("gzip") != -1)
{
request.setHeader("Content-Encoding" , "gzip");
out = new GZIPOutputStream(request.getOutputStream());
}
else if (encoding != null && encoding.indexOf("compress") != -1)
{
request.setHeader("Content-Encoding" , "compress");
out = new ZIPOutputStream(request.getOutputStream());
}
else
{
out = request.getOutputStream();
}
...
...
} |
方法 5: 使用线程池
应用服务器缺省地为每个不同的客户端请求创建一个线程进行处理,并为它们分派service()方法,当service()方法调用完成后,与之相应的线程也随之撤消。由于创建和撤消线程会耗费一定的系统资源,这种缺省模式降低了系统的性能。但所幸的是我们可以通过创建一个线程池来改变这种状况。
另外,我们还要为这个线程池设置一个最小线程数和一个最大线程数。在应用服务器启动时,它会创建数量等于最小线程数的一个线程池,当客户有请求时,相应地从池从取出一个线程来进行处理,当处理完成后,再将线程重新放入到池中。如果池中的线程不够地话,系统会自动地增加池中线程的数量,但总量不能超过最大线程数。通过使用线程池,当客户端请求急剧增加时,系统的负载就会呈现的平滑的上升曲线,从而提高的系统的可伸缩性。
方法 6: 选择正确的页面包含机制
在JSP中有两种方法可以用来包含另一个页面:
1、使用include指示符
<%@ includee file=”test.jsp” %> |
2、使用jsp指示符
<jsp:includee page=”test.jsp” flush=”true”/> |
在实际中发现,如果使用第一种方法的话,可以使得系统性能更高。
方法 7:正确地确定javabean的生命周期
JSP的一个强大的地方就是对javabean的支持。通过在JSP页面中使用<jsp:useBean>标签,可以将javabean直接插入到一个JSP页面中。它的使用方法如下:
<jsp:useBean id="name" scope="page|request|session|application" class="package.className" type="typeName">
</jsp:useBean> |
其中scope属性指出了这个bean的生命周期。缺省的生命周期为page。如果你没有正确地选择bean的生命周期的话,它将影响系统的性能。
举例来说,如果你只想在一次请求中使用某个bean,但你却将这个bean的生命周期设置成了session,那当这次请求结束后,这个bean将仍然保留在内存中,除非session超时或用户关闭浏览器。这样会耗费一定的内存,并无谓的增加了JVM垃圾收集器的工作量。因此为bean设置正确的生命周期,并在bean的使命结束后尽快地清理它们,会使用系统性能有一个提高。
其它一些有用的方法
1、在字符串连接操作中尽量不使用“+”操作符:在java编程中,我们常常使用“+”操作符来将几个字符串连接起来,但你或许从来没有想到过它居然会对系统性能造成影响吧?由于字符串是常量,因此JVM会产生一些临时的对像。你使用的“+”越多,生成的临时对像就越多,这样也会给系统性能带来一些影响。解决的方法是用StringBuffer对像来代替“+”操作符。
2、避免使用System.out.println()方法:由于System.out.println()是一种同步调用,即在调用它时,磁盘I/O操作必须等待它的完成,因此我们要尽量避免对它的调用。但我们在调试程序时它又是一个必不可少的方便工具,为了解决这个矛盾,我建议你最好使用Log4j工具(http://Jakarta.apache.org ),它既可以方便调试,而不会产生System.out.println()这样的方法。
3、ServletOutputStream 与 PrintWriter的权衡:使用PrintWriter可能会带来一些小的开销,因为它将所有的原始输出都转换为字符流来输出,因此如果使用它来作为页面输出的话,系统要负担一个转换过程。而使用ServletOutputStream作为页面输出的话就不存在一个问题,但它是以二进制进行输出的。因此在实际应用中要权衡两者的利弊。
总结
本文的目的是通过对servlet和JSP的一些调优技术来极大地提高你的应用程序的性能,并因此提升整个J2EE应用的性能。通过这些调优技术,你可以发现其实并不是某种技术平台(比如J2EE和.NET之争)决定了你的应用程序的性能,重要是你要对这种平台有一个较为深入的了解,这样你才能从根本上对自己的应用程序做一个优化。
本文来自:http://www.blogjava.net/sgsoft/articles/2378.html
posted @
2006-11-08 20:42 一缕青烟 阅读(265) |
评论 (0) |
编辑 收藏
版权所有,转载请声明出处
zhyiwww@163.com
在读我自己的认识之前
,
我们先来看一下
servet
的结构图
:
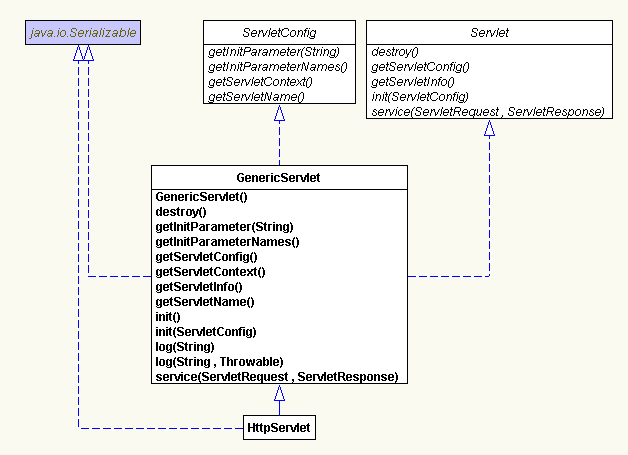
以下是我自己的一点浅见:
①
Servlet
在初始化的时候
,
是通过
init(ServletConfig config)
或
init()
来执行的。
ServletConfig
是一个接口,它怎样传递给他一格对象来进行初始化呢?其实,是这个对象是由
servlet
容器来实例化的,由容器产生一格
ServletConfig
的实现类的对象,然后传递给
Servlet
结论:
ServletConfig
由容器实例化
②
我们有些时候可能在
Servlet
初始化时给它一些固定的配置参数,那么这些参数是怎样传递到
Servlet
呢?
其实,我们在
web.xml
中给
servlet
配置启动参数,在容器对
servlet
进行初始化的时候,会收集你所配置的参数,记录在
ServletConfig
的实现类中,所以你才可以通过
ServletConfig
对象的
public String getInitParameter(String name);
或
public Enumeration getInitParameterNames();
方法来取得你已经配置好的参数,也就是说,你对
servlet
的配置都已经记录在
ServletConfig
对象中了。
结论:你对
Servlet
的配置,在
Servlet
的初始化时都由容器来收集并且记录到
ServletConfig
的实现类中。
③
我们来看一个
Servlet
的配置
<servlet>
<servlet-name>index</servlet-name>
<servlet-class>org.zy.pro.sw.servlet.IndexServlet</servlet-class>
<init-param>
<param-name>dbconfig</param-name>
<param-value>/WEB-INF/dbconfig.xml</param-value>
</init-param>
</servlet>
在此,我们实现对数据库的配置文件的加载。
当
Servlet
初始化完成后,我们可以通过
String dbconf=this.getServletConfig().getInitParameter("dbconfig")
来取得我们的配置的参数的值。
但是,我们仅能得到一个配置的字符串。之后我们可以通过配置文件取得我们的数据库的配置参数,然后对数据库进行初始化。
其实我们也可以通过传递一个类的名字串,然后再实例化。
<init-param>
<param-name>dbconfig</param-name>
<param-value>org.zy.util.db.DBUtil</param-value>
</init-param>
我们先取得配置参数:
String dbconf=this.getServletConfig().getInitParameter("dbconfig")
;
然后通过
Class.forName(dbconf).getInstance();
来实例化对象,就可以实现对数据库的调用了。
结论:在
web.xml
中对
Servlet
的初始化,只能传递字符串类型的数据
④
ServletContext
ServletContext
是负责和
Servlet
的上文和下文交互,上面和
Servlet
容器交互,下面和
Servlet
中的请求和相应进行交互。
在
ServletConfig
中,
public ServletContext getServletContext();
方法实现取得当前
ServletContext
的对象。
你可能要问,
ServletContext
是一个接口,那么你如何取得他的对象呢?
其实这个问题和
ServletConfig
相同,都是在
Servlet
进行初始化的时候产生的对象,是由容器来初始化的。
posted @
2006-10-30 19:54 一缕青烟 阅读(456) |
评论 (0) |
编辑 收藏