服务集成平台5.6的性能测试进入尾声,这期的优化也算告一段落。这次主要的优化工作还是在三个方面:应用服务器(Apache,JBoss)配置,业务流程,Cache Client包(http://code.google.com/p/memcache-client-forjava/ )。这里把过去和这次优化对于Cache的使用作一个经验分享,希望大家能够用好Cache,提速你的应用。
这里还是通过一些点滴的启示来介绍优化的一些心得,很多时候还是要根据具体情况来判断如何去具体实施,因此这里所说的仅仅是在一些场景下适用,并非放之四海皆准的教条。同时也希望看此文的各位同学,如果有更好的思路可以给我反馈,技术在交流中才会有发展。
积少成多,集腋成裘
性能提不上去,多半是在一些容易成为瓶颈的“暗点”(IO,带宽,连接数,资源竞争等等)。Memcached Cache现在已经被大家广泛使用,但是千万不要认为对Cache的操作是低损耗的,要知道这类集中式Cache对Socket连接数(会牵涉到linux操作系统文件句柄可用数),带宽,网络IO都是有要求的,有要求就意味着会有损失,因此积少成多,集腋成裘。服务集成平台是一个高速的服务路由器,其大部分的业务数据,访问控制策略,安全策略以及对应的一些控制阀值被缓存在Cache服务端,因此对于Cache的依赖性很强。每一次对于客户端的性能提升,总会给服务集成平台性能带来不小的影响,但是每一次优化速度后,客户端可以优化的空间越来越小,这时候需要一些策略来配合,提升应用整体性能。当前主要采用了以下几点策略:
1. 从数据获取角度来做优化,采用本地数据缓存。(因为大家的应用需要能够线形扩展,支持集群,所以才不使用应用服务器本地缓存,但是在某些缓存数据时间性不敏感或者修改几率较小的情况下,可以采用本地缓存结合集中式缓存,减少对远端服务器访问次数,提升应用性能)。
Cache Client的IMemcachedCache 接口中的public Object get(String key,int localTTL)方法就是本地数据缓存结合远程Cache获取数据的接口。具体流程参看下图:
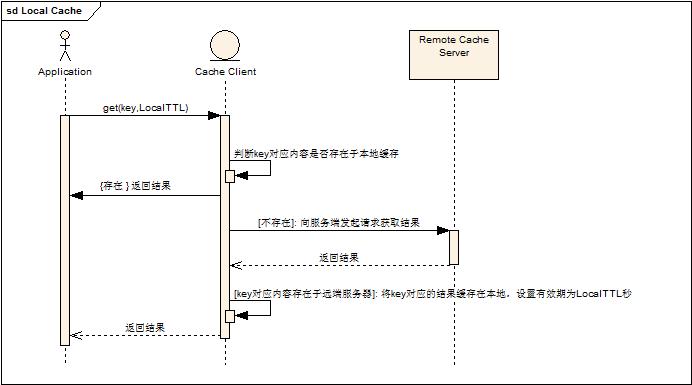
2. 从数据更新角度,采用异步数据更新。(即不等待数据更新结果,直接进行其他业务流程)。这类操作使用场景比较局限,首先数据不会用作判断(特别是高并发系统中的阀值),其次不需要返回结果作为后续流程处理输入(例如计数器),时时性要求比较低。(这类操作其实是采用了集群数据传播的一种策略,原先对于集群中所有节点都想即时传播到,但是这样对于性能损失很大,因此采用key对应的主Node采用即时设置数据,其他的通过后台任务数据传播来实现,由于key对应的主Node是数据第一操作和读取节点,因此这类数据传播操作时时性要求较低,适合这样处理)。具体接口参见Cache Client 使用文档。
3. 一次获取,多次使用。这点和系统设计有关,当前服务集成平台的安全流程是链状的,一次请求会经历很多安全拦截器,而在每一个安全拦截器中会根据情况获取具体的业务数据或者流程控制策略等缓存数据,每一个安全拦截器都是彼此独立的,在很早以前是每一个安全拦截器各自在需要数据的时候去远程获取,但是压力测试下来发现请求次数相当多,而且好些重复获取,因此将这些业务数据作为上下文在链式检查中传递,按需获取和设置,最大程度上复用了数据。(其实也是一种减少数据获取的方式)。
4. 规划好你的Cache区。有些同学在使用Cache的时候问我是否有什么需要注意的,我觉得在使用Cache之前,针对需要缓存的数据需要做好规划。那些数据需要放在一个Cache虚拟节点上,那些数据必须分开放。一方面是根据自己业务系统的数据耦合程度(未来系统是否需要合并或者拆分),另一方面根据数据量及读写频繁度来合理分配(毕竟网络IO还是稀缺资源)。当然有时候业务系统设计者自己也不知道未来的发展,那么最简单的方式给Key加上前缀,当前可以合并,未来也可以拆分。同时数据粒度也需要考虑,粒度设计太小,那么交互频繁度就会很高,如果粒度太大,那么网络流量就会很大,同时将来业务模块拆分就会有问题。
巧用Memcached Cache特有接口
Memcached Cache提供了计数器一整套接口和add,replace两个接口。这些特有接口可以很好的满足一些应用的高并发性处理需求。例如对于资源访问次数控制,采用Cache的计数器接口就可以实现在集群中的数量控制,原本通过Cache的get和put是无法解决并发问题的(就算是本地缓存一样),这就是一组原子操作的接口。而Add和Replace可以满足无需通过get方法获取内容,就可以对于key是否存在的不同情况作出相应处理,也是一种原子性操作。这些原子操作接口对于高并发系统在集群中的设计会很有帮助。
Cache Client Cluster
Memcached Cache是集中式Cache,它仅仅是支持将数据能够分片分区的存储到一台或者多台的Cache Server实例中,但是这些数据并没有作冗余,因此任何一个服务实例不可用,都会导致部分缓存数据丢失。当然很多人采取持久化等方式来保证数据的完整性,但是这种方式对于效率以及恢复的复杂性都会有影响。
简单的来想,为什么不把数据在多保存一份或者多份呢,当其中一份不可用的情况下,就用另外一份补上。这就是最原始的Cache Client Cluster的构想。在这里具体的设计细节就不多说了,主要说一下几个要点,也让使用Cache Client Cluster的同学有大致的一个了解。
先来看看Cache Cluster的结构图:
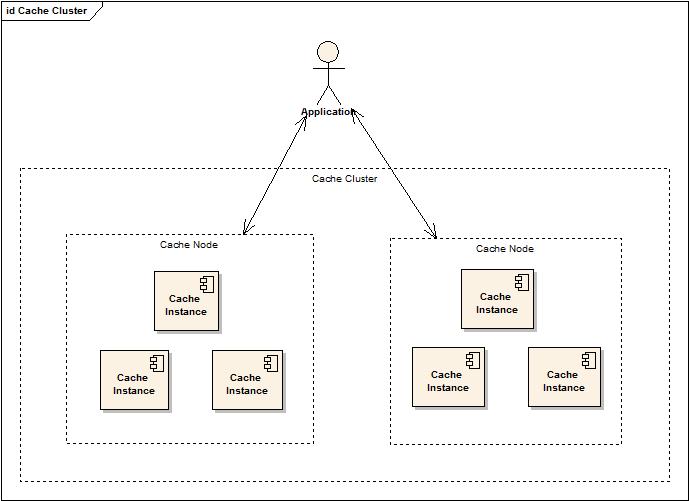
这张图上需要注意四个角色:Application(使用Cache的应用),Cache Cluster(Cache配置的虚拟集群),Cache Node(Cache的虚拟节点,在同一个Cluster中的Cache Node数据保持完全一致),Cache Instance(Cache虚拟节点中实际包含的Memcached Cache服务端实例)。
应用仅仅操作Cache Node,不了解具体数据存储或数据获取是操作哪一个Cache 服务端实例。(这点也就是Memcached Cache可扩展性的基础设计)。Cache Cluster又将多个Cache Node组成了虚拟的集群,通过数据冗余,保证了服务可用性和数据完整性。
当前 Cache Client Cluster主要有两种配置模式:active 和 standby。(这里是借鉴了硬件的名词,其实并不完全一样,因为还是考虑到了效率问题)
Cache Client Cluster主要的功能点:
1. 容错。当被分配到读取或者操作数据的Cache虚拟节点不可用的情况下,集群其他节点支持代替错误节点服务于客户端应用。
2. 数据冗余。当操作集群中某一个Cache虚拟节点时,数据会异步传播到其他集群节点。
3. 软负载。客户端通过对操作的key作算法(当前采用简单的key hash再取余的方式)选择集群中的节点,达到集群中节点简单的负载分担。同时也由于这种模式,可以使得key都有默认的第一操作节点,此节点的操作保持时时更新,而其他节点可以通过客户端异步更新来实现效率提升。
4. 数据恢复。当集群中某一节点失效后恢复时,其数据可能已经完全丢失,此时通过配置成为Active模式可以将其他节点上冗余的数据Lazy复制到该节点(获取一个复制一个,同时只支持一个冗余节点的数据获取(不采取遍历,防止低效))。
Active模式拥有1,2,3,4的特性。Standby模式拥用1,2,3特性。(其实本来只考虑让Standby拥有1特性)。未来不排除还会有更多需要的特性加入。Active在key不存在的情况下会有些低效,因为会判断一个冗余节点是否存在内容,然后决定是否修复当前节点。(考虑采用短期失败标示之类的,不过效率不一定高,同时增加了复杂度)
运行期动态扩容部署
Memcached cache客户端算法中比较出名的是Consistent Hashing算法,其目的也就是为了在节点增加或者减少以后,通过算法尽量减小数据重新分布的代价。采用虚拟节点,环状和二叉树等方式可以部分降低节点增加和减少对于数据分布的影响,但是始终还是有部分数据会失效,这点还是由于Memcached Cache是集中式Cache所决定的。
但如果有了Cache Cluster的话,数据有了冗余,就可以通过逐步修改集群中虚拟节点配置,达到对于单个虚拟节点的配置动态扩容。
支持动态部署前提:
配置文件动态加载。(配置文件可以在Classpath中,也可以是Http资源的方式)通过Cache Client 中Cache Manager可以停止Cache 服务,重新加载配置文件,即时生效。
当前动态部署的两种方式:
1. 修改集群配置中某一套虚拟节点的服务实例配置(socketPool配置),增加或者减少后端数据存储实例。然后动态加载新的配置文件(可以通过指定远端的http配置作为新的配置文件),通过集群的lazy的修复方式,逐渐的将数据从冗余节点复制到新的节点上来,最终实现数据迁移。
2. 修改集群配置中某一套虚拟节点的服务实例配置(socketPool配置),增加或者减少后端数据存储实例。然后动态加载新的配置文件(可以通过指定远端的http配置作为新的配置文件),在调用Cache Manager主动将数据由某一虚拟节点复制到指定的集群中,实现数据批量迁移,然后根据需要看是否需要修改其他几套虚拟节点配置。
存在的问题:
1. 当前没有做到不停止服务来动态部署。(后续考虑实现,当前将编译配置和重新启动服务器的工作节省了)
2. 不论是lazy复制还是批量数据迁移,都是会将原本有失效时间的数据变成了无失效时间的数据。(这个问题暂时还没有一种可行的高效的方式解决)
后话
性能优化这点事还是那句老话,需要了再去做也不迟。同时如果你开发的是一个每天服务访问量都是上亿,甚至更高的系统,那么有时候斤斤计较会收获不少。(当然是不影响系统本身业务流程的基础)。
Cache客户端自从作为开源放在Google上也收到了不少朋友的支持和反馈,同时自己业务系统以及其他部门同学的使用促使我不断的去优化和满足必要的一些功能扩展(但是对于Cache来说,还是那句话,简单就是美,高效是使用Cache的最原始的需求)。
当前Cache Client版本已经到了2.5版本,在Google上有详细的Demo(单元测试,压力测试,集群测试)和说明使用文档。是否速度会慢于其他Memcached客户端,这不好说的很绝对,反正大家自己拉下去比较一下看看就知道了,当然为了集群和其他的一些必要的附加功能还是做了一些性能牺牲。
项目地址在:http://code.google.com/p/memcache-client-forjava/
在首页的右侧有demo,doc,binary,src的链接,直接可以下载使用和察看。希望对需要的同学有帮助。