工作忙,有些许时间没有更新Blog了,这次在开发监控模块的时候遇到了这个问题,整个问题定位过程真是走了不少路,所以觉得有必要记录下来分享一下。在我看来很多时候结果也许就很简单一个原因,但是开发人员却要探究很久,也许在找到了其他可实现业务逻辑方法的情况下,就会放弃寻找原因,这期间我也是一样。
问题初现:
在服务集成平台中需要新增一块写入数据库的逻辑,因此考虑最简便就是弄个Spring的BeanFactory来搞定这一切,谁知道,问题就这么出现了。很简单,通过Spring的ClassPathXmlApplicationContext来构建BeanFactory,下面的语句大家应该很熟悉:
ctx = new ClassPathXmlApplicationContext("/spring/sip-*.xml");
通过通配符来载入ClassPath下的所有的符合规则的spring配置文件。然后在Eclipse中作完单元测试和集成测试,一切正常。然后用我们内部的打包部署,而这些配置文件都被打在Jar中作为lib库依赖。结果启动以后,在分析完日志需要写入到数据库的时候出现异常:
Could not resolve bean definition resource pattern [/spring/sip-*.xml]; nested exception is java.io.FileNotFoundException: class path resource [spring/] cannot be resolved to URL because it does not exist
就提示来说,就是没有找到spring这个目录,也就是在ClassPath下面就没有找到资源。
第一次试图解决问题:
以前调整过Jboss关于ClassLoader的配置,即自上而下搜索还是自下而上搜索,以及是否采用Web容器的ClassLoader,开始怀疑是否是这种修改造成的问题。修改了没有问题,然后就设置断点跟踪Spring的ClassPathXmlApplicationContext的构造过程,发现Spring在分析此类通配类型的过程中,首先将前面的文件目录和后面的具体通配文件分开,先定位文件目录资源,也就是在定位文件目录资源的过程中,找不到spring目录,而出现了那个异常。看了代码中也有对Jar的处理,但是在处理之前就出现了问题。
自己做了尝试,将spring目录和其内容解压到Web的Classes目录下运行正常,或者解压到war下面也是正常的,这些地方其实都是ClassPath可以找到的,但是lib目录下的jar也应该是可以找到的。在仔细跟踪了代码中最后载入这些资源的ClassLoader内的数据,所有的Jar都是包含在内的。
由于工作太多,因此将原有的打包模式作了修改,每次打包将这部分配置解压到war下面,这样就找到了可解决方案了,因此细致的缘由也就没有再去追究。(如果不是后面再次遇到,这个问题就会在此了结)
问题再现:
监控模块中需要新增一块写入数据库的逻辑,在单元测试和集成测试通过的情况下出现了问题,由于此次是普通的J2SE的应用,所有的配置和依赖都打入在了Jar中,所以问题和前次一样。
这次决定花一些时间好好找到问题所在,首先觉的Spring的资源载入应该不会不支持从Jar中载入,这是最基本的功能,因此再次打开了Spring的源码。
问题二次定位:
先看看ClassPathXmlApplicationContext的类图结构:
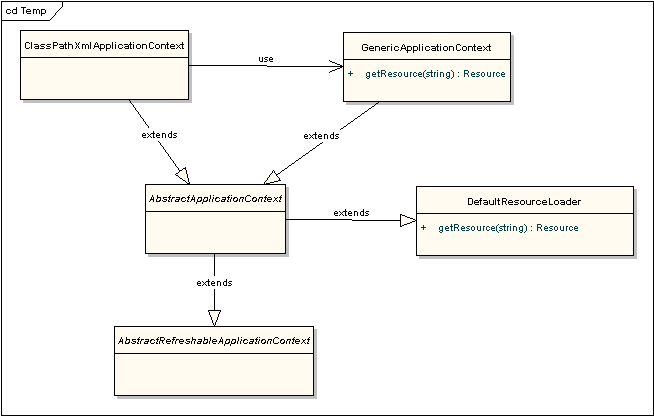
关键方法就是
getResource
方法,ClassPathXmlApplicationContext
的资源定位就是采用了DefaultResourceLoader
的getResource
方法。内部也没有做太多的工作,其实就是如下的代码:
try
{
// Try to parse the location as a URL...
URL url = new URL(location);
returnnew UrlResource(url);
}
catch (MalformedURLException ex)
{
// No URL -> resolve as resource path.
return getResourceByPath(location);
}
上面的代码都是标准的j2se的代码.作为URL通过字符串来构造,通常需要能够首先获得URL的资源全路径,而在当前情况下发现到获取资源的时候location还是保持了spring/的状态,而没有被替换成为所在jar的资源全路径,那么就先作以下测试:
新建简单的项目,然后在项目中加入包含spring配置的jar,然后作单元测试,测试代码如下:
URL url = Thread.currentThread().getClass().getResource("/spring/");
未获取到URL,出现异常。
URL url = Thread.currentThread().getClass().getResource("/spring/sip-analyzer-dataSource.xml");
正常获取到了URL。
由此看来应该是在获取Jar中的目录资源路径的时候出现问题导致后续载入出现问题,尝试直接传入具体的文件名:
ctx = new ClassPathXmlApplicationContext("/spring/sip-analyzer-dataSource.xml");
发现还是出现问题,在new URL的时候传入的是没有翻译过的文件名,考虑在传入的过程中就直接替换成为资源路径,因此写了一个简单的方法:
publicstatic String[] getRealClassPath(String[] locationfile)
{
String[] result = locationfile;
for(int i = 0 ; i < locationfile.length; i++)
{
try
{
URL url = Thread.currentThread().getClass().getResource(locationfile[i]);
String file = url.getFile();
if (file.indexOf(".jar!") > 0)
result[i] = new StringBuffer("jar:").append(file.substring(0,file.indexOf(".jar!")+".jar!".length()))
.append(locationfile[i]).toString();
}
catch(Exception ex)
{}
}
returnresult;
}
在将构造工厂类修改为:
ctx = new ClassPathXmlApplicationContext(BaseUtil.getRealClassPath(new String[]{"/spring/sip-analyzer-dataSource.xml"}));
运行测试,正常启动,这也就是又变成最原始的文件罗列的模式。问题虽然找到了解决方案,但是始终觉得很别扭,同时对于无法在Jar中载入配置资源的情况我一直都还是觉得应该不是Spring的问题。
峰回路转:
晚上到家还是有点不死心,就直接建了个项目作单元测试,然后将一个自己建立的Jar加入到Classpath下面,作单元测试,结果大吃一惊。
URL url = Thread.currentThread().getClass().getResource("/test/");
URL url = Thread.currentThread().getClass().getResource("/test/test.txt");
都正常获取到了资源,这完全推翻了我早先认为在Jar中无法获得目录作为资源的问题。然后把公司里面的项目重新打包然后加入到ClassPath下,验证spring的目录,出错,目录无法获取,此时我确定看来应该不是应用的问题,而是环境问题。检查了两个Jar,看似没有什么区别,将公司项目的Jar中的spring目录拷贝到测试的jar中,然后作测试,可以找到目录。那么问题完全定位到了Jar本身。通过RAR的压缩工具看了一下两个Jar的信息,除了显示所谓的压缩平台不同(一个是DOS,一个是Unix)其他没有任何区别。然后自己用RAR打了一个Jar以及在linux下打了一个Jar做了测试,两个Jar内的目录都是正常可以被获取。
无意中我换了一下需要获取的目录名称,也就是说在公司项目中有多个目录在jar中,这次换成为ibatis目录,正常获取,看来不是Jar的格式。回想了一下,公司的打包工具是自己人写的,其中提供了一个特性,如果一个项目内部的一些配置信息是需要让调用它的第三方在编译期配置,那么可以通过在第三方项目构建的过程中,动态的生成配置文件然后植入到被依赖的jar中。而spring这个目录中由于那些数据库的配置都是需要动态配置的,因此spring的那个目录是后期被写入的,而ibatis是早先就固化在项目中的。
由于我们的Jar在META-INF中都有INDEX.LIST文件,过去遇到过在JAR中自己手工放入一些文件由于没有修改INDEX.LIST而导致虽然文件已经存在但是不会被发现,于是打开公司项目中的Jar,果然INDEX.LIST中只有ibatis,而没有spring,看来是我的同事在写入的时候没有将INDEX.LIST更新。立刻将INDEX.LIST作了更新,测试spring目录,结果依然出错。看来这还不是问题的根本。
立刻问了我们开发打包工具的同事,向他们要写入Jar的代码,对方的回答是就是采用简单的JarOutputStream来写入,没有什么特殊的。那我就开始怀疑是否是因为采用这种方式写入到Jar中的目录在被资源定位的时候会出现问题。于是写了下面的代码:
JarOutputStream jos;
try
{
jos = new JarOutputStream(new BufferedOutputStream(new FileOutputStream(file)));
String f = "spring/sip-analyzer-dataSource.xml";
File source = new File(f);
JarEntry je = new JarEntry(f);
jos.putNextEntry(je);
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("D:/work/sip3/analyzer/src/conf.test/spring/sip-analyzer-dataSource.xml"));
int i = 0;
while ((i=bis.read())!=-1)
{
jos.write(i);
}
bis.close();
jos.closeEntry();
jos.close();
} catch ...
结果创建出来的Jar中的spring目录无法被资源定位,同样在这个Jar中直接拖入一个目录test,然后刷新测试,test目录可以被定位。
后续
就到了这个阶段来看如果以上面这种方式写入,对于目录资源定位的却存在问题。这个问题还没有最终的肯定的结论,在我现在所有的试验来看,不论是否有INDEX.LIST,或者INDEX.LIST,如果用程序写入到Jar中,目录作为资源定位都会出现问题(起码是上面那种普通写入方式)。
这种情况可能是由于这种写法还有一些其他需要配置的,例如写入到META-INF/INDEX.LIST中,或者就是J2SE现在API存在的一个问题。不过不管是什么问题,起码值得引起重视,特别是现在类似于Spring框架载入Jar目录下的配置。