2007年10月2日
#
用java实现中国移动WLAN业务PORTAL协议规范
有需要代码的可联系本人。
QQ:316909543
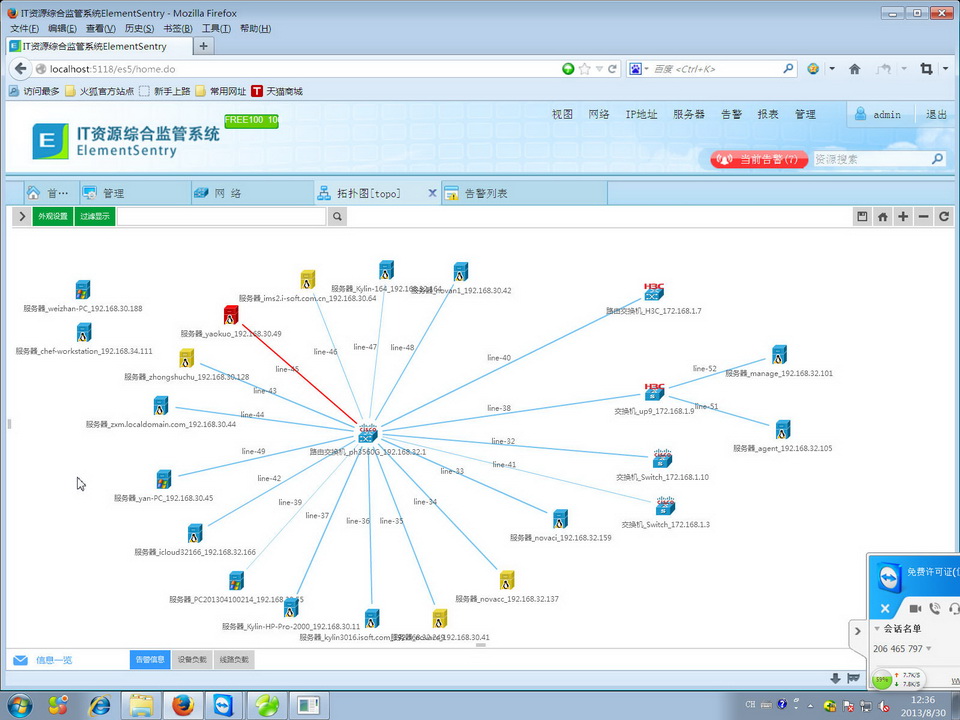
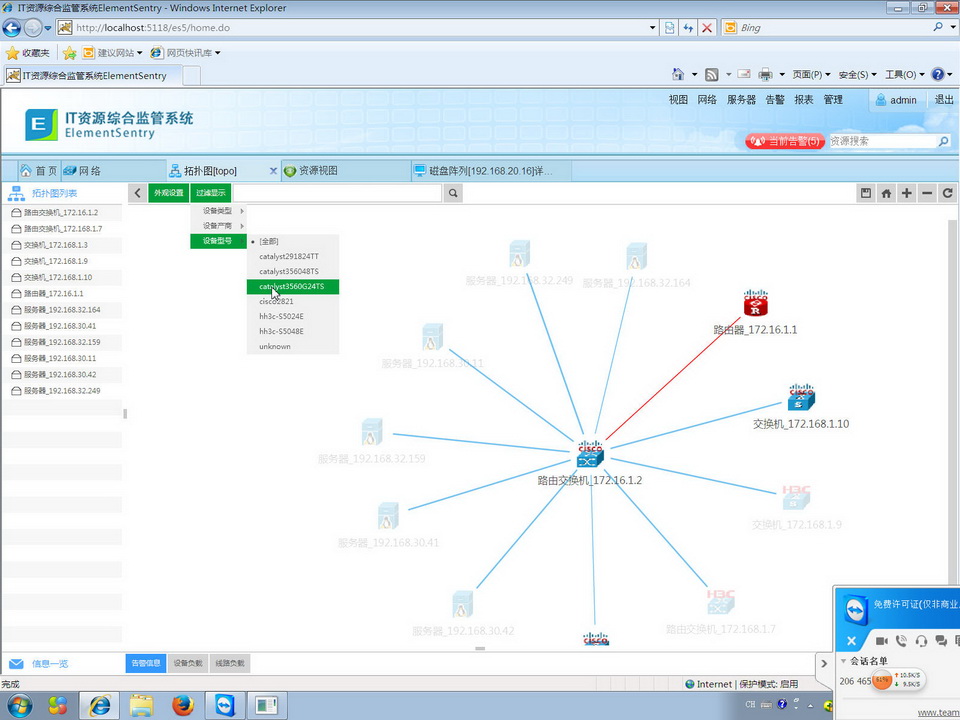
广州速方软件IT资源监管系统ElementSentry
V5.8,提供免费下载试用。http://www.soofound.com/biz/product/es/intro.htmQQ:316909543Email:afunms@soofound.com

通过SNMP实现对磁盘阵列的监控
Simple Network Management Protocol i.e. SNMP is a simple request/response protocol in which SNMP manager communicates with SNMP agents/managed devices using SNMP PDU’s (Packet Data Unit). These PDUs are encapsulated in SNMP Messages. An snmp message consists of a sequence that contains SNMP version, Community String, and SNMP PDU and an SNMP PDU forms the body of the message. Look here to read about seven types of SNMP PDUs.
We need to understand that SNMP Message is different from SNMP PDU and hence their formats. Let us now understand SNMP Message Format and SNMP PDUD Format for SNMPv1, SNMPv2 and SNMPv3.
SNMPv1 Message Format

- SNMP Version – It is an Integer that identifies the version of SNMP. For SNMPv1, it is 0.
- Community String – An Octet String that may contain a string used to add security to SNMP devices.
- SNMP PDU – The SNMP PDU (Protocol Data Unit) is used for communication between the SNMP entities.
SNMPv1 PDU Format
For SNMPv1, there are two pdu formats, one for Trap and other for rest of the pdu types.
Below PDU format is applicable for Get, GetNext, Set and Response PDUs:

- PDU Type – Specifies the type of PDU
- Request ID – Associates SNMP requests with responses.
- Error status – Indicates one of a number of errors and error types. It is set only in Response PDU, for rest it is set as 0.
- Error index – Associates an error with a particular object instance. It is set only in Response PDU, for rest it is set as 0.
- Variable bindings – Each variable binding associates a particular object instance with its current value. For Get and GetNext requests, the value is ignored.
Below PDU format is applicable for Trap PDU:

- PDU Type – Specifies the type of PDU as Trap
- Enterprise – Identifies the management enterprise under whose registration authority the trap was defined.
- Agent address – IP address of the agent
- Generic trap type – Used to identiy the generic trap. There are six types of generic traps.
- Specific trap type – Used to identify a specific trap.
- Time Stamp – Value of the sysUpTime mib object
SNMPv2 Message Format

- SNMP Version – It is an Integer that identifies the version of SNMP. For SNMPv2, it is 1.
- Community String – An Octet String that may contain a string used to add security to SNMP devices.
- SNMP PDU – The SNMP PDU (Protocol Data Unit) is used for communication between the SNMP entities.
SNMPv2 PDU Format
For SNMPv2, there are two pdu formats, one for GetBulk and other for rest of the pdu types.
Below PDU format is applicable for Get, GetNext, Set, Response, Trap and Inform PDUs:

- PDU Type- Specifies the type of PDU
- Request ID- Associates SNMP requests with responses.
- Error Status- Indicates one of a number of errors and error types. It is set only in Response PDU, for rest it is set as 0.
- Error Index- Associates an error with a particular object instance. It is set only in Response PDU, for rest it is set as 0.
- Variable Bindings- Each variable binding associates a particular object instance with its current value. For Get and GetNext requests, the value is ignored.
Below PDU format is applicable for GetBulk PDU:

- PDU Type – Specifies the type of PDU as GetBulk
- Request ID- Associates SNMP requests with responses.
- Non repeaters- Specifies the number of object instances in the variable bindings field that should be retrieved no more than once from the beginning of the request.
- Max repetitions- Defines the maximum number of times that other variables beyond those specified by the Non repeaters field should be retrieved.
- Variable Bindings- Each variable binding associates a particular object instance with its current value.
SNMPv3 Message Format
SNMPv3 message format is very different from the above two because of lot of security parameters introduced in this version. Below is how it looks like:

- Version – It is an Integer that identifies the version of SNMP. For SNMPv3, it is 3.
- ID – This field contains the SNMP message identifier which is a unique ID associated with the message. The msgID field is different from the reqID field available in the PDU.
- Max Size – This field represents the maximum size of message which the requesting SNMP entity can accept.
- Flags – This field contains the message security level. 0 – message is authenticated, 1 – message uses privacy, 2 – a report PDU is expected for the message
- Security Model – This field indicates the security model used to generate the message. When USM is used, it has a value of 3
- Engine ID – This field has the SNMPEngineID of the authoritative SNMP entity involved in the transaction. When a request PDU is generated from an SNMP engine, the remote peer (agent for Get request and manager for Trap request) is the authoritative SNMP entity.
- Engine Boots – This field has the snmpEngineBoots value of the authoritative SNMP entity involved in the transaction
- Engine Time – This field has the snmpEngineTime value of the authoritative SNMP entity involved in the transaction
- User Name – This field contains the principal who originated the request.
- Security Parameters – This field contains the security parameters that are security model dependent. It contains the authentication parameters and the privacy parameters for USM.
- Context Engine ID – Within an administrative domain, the contextEngineID uniquely identifies an SNMP entity that may realize an instance of a context with a particular contextName.
- Context Name – A contextName is used to name a context. Each contextName must be unique within an SNMP entity.
- PDU – The SNMP PDU (Protocol Data Unit) is used for communication between the SNMP entities.
SNMPv3 PDU Format
The PDU types for SNMPv3 are the same as the SNMPv2.
Thus, above are the message and pdu formats for SNMPv1, SNMPv2 and SNMPv3. Hope you find the information presented here useful. Feel free to leave your footprints for any queries, feedback or suggestions in the comments section below.
- Why is SNMP4J free?
Currently there is a lack of an affordable well object
oriented designed SNMP implementation for Java. SNMP4J tries to fill this gap.
It is free to get the best support and feedback from the Internet community. In
addition it is a small compensation for the help we got from other open source
projects.
Nevertheless you are welcome to support the development of SNMP4J
by purchasing commercial e-mail support.
- Where can I find examples for SNMP4J API usage?
Simple examples are provided by
the JavaDoc of the SNMP class which can be viewed here.
A (nearly) complete example for the SNMP4J API usage
is the console tool. It can be found in the org.snmp4j.tools.console.SnmpRequest
class.
- Is SNMP4J thread-safe?
Yes, SNMP4J is designed for multi-threaded
environments. Nevertheless, objects put into a PDU must not be modified while
the corresponding SNMP request is being processed.
- Why do I get sometimes a time-out (response == null) on a request although I see log
messages like “Received response that cannot be matched to any outstanding
request...”?
The response of the agent has been received after the
request had been timed out. To solve this, increase the time-out value for the
target.
- Why am I always getting a time-out (response == null) when sending a request?
Probably you have forgotten to call the listen() method of the
TransportMapping (once) or the Snmp class before sending the
request.
- Can I use a single Snmp instance to request data from multiple SNMP agents at the same time?
Yes, of course! You can either use asynchronous requests and
collect their responses in a one or more callback listeners or you can use
synchronous requests that are send from several threads concurrently.
- Can SNMP4J be used with Java EE?
Yes, the SNMP4JSettings class provides the
option to replace the default thread and timer factories by custom ones that use
Java EE resources instead of Java SE threads (timers).
Difference between SNMPv1 and SNMPv2
SNMP aka Simple
Network Management Protocol is a simple request/response protocol. Network
manager aka SNMP manager issues a request and managed device aka
SNMP agent returns
the response. This request/response behavior is implemented using protocol
operations and information between manager and agent is transferred using
SNMP PDUs (Packet Data Unit).
SNMPv1 is the
initial implementation of the protocol and SNMPv2 is an enhancement over
version 1. The significant differences between SNMPv1 and SNMPv2 are as below:
•Protocol operations used in SNMPv1 are Get,
GetNext, Set and Trap. SNMPv2 defines two more protocol options GetBulk and
Inform.
•Trap PDU format is different than other
PDU’s formats in SNMPv1. In version 2, trap pdu format is same as the format of
get and set pdu’s.
•In SNMPv1, if in a get request one of the
object instance in multiple-attribute request does not exist or is invalid, no
response would be given, only an error message would return. In SNMPv2, in such
a scenario, response would return for all other object instances or attributes except
the invalid value i.e. partial response would be there rather than error.
To know about the difference in implementation of security in SNMP version 1 & 2, please refer this link.
Difference Between SNMP Trap and SNMP Notification
We always try to clarify the differences between terminologies that otherwise seem to be similar. In our previous posts, we provided clarification on difference between trap and alarm & difference between trap and inform. As the title suggests, this post talks about difference between SNMP trap and SNMP notification.
If you refer to the SNMP PDU Formats for SNMPv1 and SNMPv2 here, you will realize that SNMPv1 has two different pdu formats, one for trap and another for all remaining snmp operations (get, set etc.). However, in SNMPv2 the pdu format for trap and all other snmp operations (except getbulk) is identical. To standardize the PDU Format of SNMPv1 traps, concept of Notification was introduced in SNMPv2 and same was carried forward to SNMPv3.
Thus, asynchronous event sent to manager by agent is known as Trap in SNMPv1 and Notification in SNMPv2 and SNMPv3.
With respect to the MIB definitions and PDU formats, below are the significant difference between Trap and Notification:
•The macro used for setting trap in SNMPv1 is TRAP-TYPE MACRO and the macro used for setting notifications in SNMPv2/v3 is NOTIFICATION-TYPE MACRO.
•Trap PDU contains agent address whereas Notification PDU contains error status and error index.
•TRAP PDU contains information about generic and specific traps whereas Notification PDU contains Trap OID.
•TRAP is asynchronous. Notification is asynchronous too but SNMV2/SNMPv3 supports confirmed notification known as Inform.
With reference to RFC2576, if a MIB module is changed to conform to the SMIv2, then each occurrence of the TRAP-TYPE macro MUST be changed to a corresponding invocation of the NOTIFICATION-TYPE macro. Have a look at RFC2576 here for translation rules and further clarification on traps and notifications.
Hope you find the information presented here useful. Feel free to leave your inputs in the comments section below.



先用ldapbrowser测试下AD服务器,保证AD是可用的。
以下是java代码:
 package com.coreware.ems;
package com.coreware.ems;
import java.util.Hashtable;
import javax.naming.Context;
import javax.naming.NamingEnumeration;
import javax.naming.NamingException;
import javax.naming.directory.*;

 public class SimpleLDAPClient
public class SimpleLDAPClient  {
{

 public static void main(String[] args) {
public static void main(String[] args) {
 Hashtable env = new Hashtable();
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,"com.sun.jndi.ldap.LdapCtxFactory");
env.put(Context.PROVIDER_URL, "ldap://192.168.80.130:389/dc=coreware,dc=com");
env.put(Context.SECURITY_AUTHENTICATION, "simple");
env.put(Context.SECURITY_PRINCIPAL, "cn=wangfm,cn=Users,dc=coreware,dc=com");
env.put(Context.SECURITY_CREDENTIALS, "abc123!@#");
DirContext ctx = null;
NamingEnumeration results = null;
try {
ctx = new InitialDirContext(env);
SearchControls controls = new SearchControls();
controls.setSearchScope(SearchControls.SUBTREE_SCOPE);
results = ctx.search("", "(objectclass=person)", controls);
while (results.hasMoreElements()) {
SearchResult searchResult = (SearchResult) results.next();
Attributes attributes = searchResult.getAttributes();
Attribute attr = attributes.get("cn");
String cn = (String) attr.get();
System.out.println(" Person Common Name = " + cn);
 }
}
} catch (NamingException e) {
e.printStackTrace();
} finally {
if (results != null) {
try {
results.close();
} catch (Exception e) {
}
}
if (ctx != null) {
try {
ctx.close();
} catch (Exception e) {
}
}
}
}
 }
}
运行结果:
Person Common Name = Administrator
Person Common Name = Guest
Person Common Name = afunms
Person Common Name = db2admin
Person Common Name = AFUNMS-WIN2008
Person Common Name = krbtgt
Person Common Name = wangfm
spring3---json
在applicationContext.xml中加入
<bean class="org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter">
<property name="messageConverters">
<util:list id="beanList">
<ref bean="mappingJacksonHttpMessageConverter" />
</util:list>
</property>
</bean>
<bean id="mappingJacksonHttpMessageConverter"
class="org.springframework.http.converter.json.MappingJacksonHttpMessageConverter" />
这样在action方法加返回bean或map,spring3会把它处理成json格式。如:
@Controller
public class JsonTestController {
@RequestMapping("/getJsonList")
@ResponseBody
public List<ItemTest> searchItemsList()
{
ItemTest item = new ItemTest();
item.setItemnum("123");
item.setItemDesc("123desc");
ItemTest item1 = new ItemTest();
item1.setItemnum("456");
item1.setItemDesc("456desc");
List<ItemTest> list = new ArrayList<ItemTest>();
list.add(item);
list.add(item1);
return list;
}
}
访问getJsonList.do返回的就是json形式的数据,注意要加上 @ResponseBody
================================================
spring3---ajax---json
网上搜索到一般都是这样:
$(function(){
$("#doImport").click(
function(){
var importInfo = $("#importInfo").serializeObject();
$.ajax({
url:"${base}cmb/doImport.do",
contentType :"application/json",
cache:false,
type:"POST",
data:JSON.stringify(importInfo),
dataType:"json",
success: function(data){
$('#result').val(data.message)
alert(data.message);
},
error:function(){
alert("失败");
}
});
});
});
我觉得这个方法写得太复杂了,于是改了它:
function doImport(){
$.ajaxSetup({ cache:false });
var data = {excelFileName:$("#excelFileName").val(),
sheetName:$("#sheetName").val(),
tableName:$("#tableName").val(),
startRow:$("#startRow").val(),
startCol:$("#startCol").val()};
$.getJSON("${base}cmb/doImport.do",data,function(form){
$("#result").val(form.message);
alert(form.message); });
}
action:
@RequestMapping("/cmb/doImport.do")
public @ResponseBody Map<String,String> doImport(HttpServletRequest request, ModelMap model){
System.out.println("===doImport===>>" + DateUtil.getCurrentDateTime());
String excelFileName = request.getParameter("excelFileName");
String sheetName = request.getParameter("sheetName");
String tableName = request.getParameter("tableName");
int startRow = Integer.parseInt(request.getParameter("startRow"));
int startCol = Integer.parseInt(request.getParameter("startCol"));
System.out.println("excelFileName=" + excelFileName);
System.out.println("sheetName=" + sheetName);
System.out.println("tableName="+tableName);
System.out.println("startRow="+startRow);
System.out.println("startCol="+startCol);
Map<String,String> result = new HashMap<String,String>();
result.put("message", "导入成功!");
return result;
}
注意以下几点:
1. ajax必须清缓存:$.ajaxSetup({ cache:false });
2. 将表单的数据组成json格式:
var data = {excelFileName:$("#excelFileName").val(),
sheetName:$("#sheetName").val(),
tableName:$("#tableName").val(),
startRow:$("#startRow").val(),
startCol:$("#startCol").val()};
# XX与表单组件中的ID对应,如
<input type="hidden" id="excelFileName" value="${excelFileName}" />
3.表单上必须有一个地方能存放返回值:
<input type="hidden" id="message" />
action中的返回值为json格式,
$("#result").val(form.message) 这句话将返回值中的result属性取出赋给表单中的message
public static void main(String[] args) throws Exception {
POIFSFileSystem pfs = new POIFSFileSystem(new FileInputStream("D:\\test_xls.xls"));
HSSFWorkbook hwk = new HSSFWorkbook(pfs);
HSSFSheet sheet = hwk.getSheet("Sheet1");
try{
int lrn = sheet.getLastRowNum();
for(int r = 0;r<lrn;r++){
Row row = sheet.getRow(r);
int lcn = row.getLastCellNum();
for(int c = 0;c<lcn;c++){
if(row.getCell(c)==null)
System.out.println("R=" + r + ",C=" + c + ":NULL");
else
System.out.println("R=" + r + ",C=" + c + ":" + row.getCell(c).toString());
}
}
}catch(Exception e){
e.printStackTrace();
}
}
从apache网上下载pluto-2.0.3-bundle.zip
解压后,修改bin\startup.bat,配置上jdk
set JAVA_HOME=../../jdk1.6.0_03
然后启动pluto,发现有错。查看日志
Caused by: java.lang.LinkageError: JAXB 2.0 API is being loaded from the bootstrap classloader, but this RI (from jar:file:/E:/nms4/pluto/webapps/pluto/WEB-INF/lib/jaxb-impl-2.1.9.jar!/com/sun/xml/bind/v2/model/impl/ModelBuilder.class) needs 2.1 API. Use the endorsed directory mechanism to place jaxb-api.jar in the bootstrap classloader. (See
http://java.sun.com/j2se/1.5.0/docs/guide/standards/)
at com.sun.xml.bind.v2.model.impl.ModelBuilder.<clinit>(ModelBuilder.java:173)
at com.sun.xml.bind.v2.runtime.JAXBContextImpl.getTypeInfoSet(JAXBContextImpl.java:432)
at com.sun.xml.bind.v2.runtime.JAXBContextImpl.<init>(JAXBContextImpl.java:297)
at com.sun.xml.bind.v2.ContextFactory.createContext(ContextFactory.java:139)
at com.sun.xml.bind.v2.ContextFactory.createContext(ContextFactory.java:117)
at com.sun.xml.bind.v2.ContextFactory.createContext(ContextFactory.java:188)
估计是jaxb造成的,于是将webapps\pluto\WEB-INF\lib下的jaxb-impl-2.1.9.jar删除。
再启动pluto,成功!
下载ipmiutil-2.7.8-win32,不用安装直接能用。
只可惜还没有开源或免费的java包来支持ipmi。
在dell服务器上测试
C:\ipmiutil>ipmiutil health
ipmiutil ver 2.78
ihealth ver 2.78
BMC version = 1.55, IPMI v2.0
BMC manufacturer = 0002a2 (Dell), product = 0100
BIOS Version = 1.2.2
IPMI driver type = 10 (ms)
Chassis Status = 21 00 00 (on, restore=last_state, last_pwr=)
Power State = 2a (unknown)
Selftest status = 0055 (OK)
Power On Hours = 0 hours (0 days)
get_chan_auth error: ret = c1
ipmiutil health, Invalid Command
C:\ipmiutil>ipmiutil sensor
ipmiutil ver 2.78
isensor: version 2.78
-- BMC version 1.55, IPMI version 2.0
supports device sdrs
_ID_ SDR_Type_xx ET Own Typ S_Num Sens_Description Hex & Interp Reading
0001 SDR Full 01 01 20 a 01 snum 01 CPU 1 Temp = 59 OK -39.00 degrees C
0002 SDR Full 01 01 20 a 01 snum 02 CPU 2 Temp = 56 OK -42.00 degrees C
0003 SDR Full 01 01 20 a 01 snum 03 CPU 3 Temp = 56 OK -42.00 degrees C
0004 SDR Full 01 01 20 a 01 snum 04 CPU 4 Temp = 56 OK -42.00 degrees C
0005 SDR Full 01 01 20 a 01 snum 05 PS 1 Temp = 00 Init 0.00 degrees C
0006 SDR Full 01 01 20 a 01 snum 06 PS 2 Temp = 00 Init 0.00 degrees C
0007 SDR Full 01 01 20 a 01 snum 07 PS 3 Temp = a6 OK 38.00 degrees C
0008 SDR Full 01 01 20 a 01 snum 08 PS 4 Temp = a3 OK 35.00 degrees C
0009 SDR Full 01 01 20 a 01 snum 09 IOR Temp = 9d OK 29.00 degrees C
000a SDR Full 01 01 20 a 01 snum 0c IOH 1 Temp = ab Warn-hi 43.00 degrees
C
000b SDR Full 01 01 20 a 01 snum 0d IOH 2 Temp = b0 Crit-hi 48.00 degrees
C
000c SDR Full 01 01 20 a 01 snum 0e Ambient Temp = 99 OK 25.00 degrees C
000d SDR Full 01 01 20 a 01 snum 0f Planar Temp = a1 OK 33.00 degrees C
000e SDR Full 01 01 20 a 01 snum b0 DIMM Bank A = 9d OK 29.00 degrees C
000f SDR Full 01 01 20 a 01 snum b1 DIMM Bank B = 00 Init 0.00 degrees C
0010 SDR Full 01 01 20 a 01 snum b2 DIMM Bank C = 9c OK 28.00 degrees C
0011 SDR Full 01 01 20 a 01 snum b3 DIMM Bank D = 00 Init 0.00 degrees C
0012 SDR Full 01 01 20 a 01 snum b4 DIMM Bank E = 9c OK 28.00 degrees C
0013 SDR Full 01 01 20 a 01 snum b5 DIMM Bank F = 00 Init 0.00 degrees C
0014 SDR Full 01 01 20 a 01 snum b6 DIMM Bank G = 9c OK 28.00 degrees C
0015 SDR Full 01 01 20 a 01 snum b7 DIMM Bank H = 00 Init 0.00 degrees C
0016 SDR Comp 02 6f 20 a 29 snum 10 CMOS Battery = 0000 OK
0017 SDR Comp 02 6f 20 a 29 snum 11 ROMB Battery = 0000 OK
0018 SDR Comp 02 03 20 a 02 snum 12 VCORE PG = 0001 Crit-hi
0019 SDR Comp 02 03 20 a 02 snum 13 VCORE PG = 0001 Crit-hi
001a SDR Comp 02 03 20 a 02 snum 14 VCORE = 0001 Crit-hi
001b SDR Comp 02 03 20 a 02 snum 15 VCORE = 0001 Crit-hi
001c SDR Comp 02 03 20 a 02 snum 16 VCACHE PG = 0001 Crit-hi
001d SDR Comp 02 03 20 a 02 snum 17 VCACHE PG = 0001 Crit-hi
001e SDR Comp 02 03 20 a 02 snum 18 VCACHE = 0001 Crit-hi
001f SDR Comp 02 03 20 a 02 snum 19 VCACHE = 0001 Crit-hi
0020 SDR Comp 02 03 20 a 02 snum 1a VIO PG = 0001 Crit-hi
0021 SDR Comp 02 03 20 a 02 snum 1b VIO PG = 0001 Crit-hi
0022 SDR Comp 02 03 20 a 02 snum 1c CPU 1.8 PLL PG = 0001 Crit-hi
0023 SDR Comp 02 03 20 a 02 snum 1d 8V Rear PG = 0001 Crit-hi
0024 SDR Comp 02 03 20 a 02 snum 1e 8V Front PG = 0001 Crit-hi
0025 SDR Comp 02 03 20 a 02 snum 1f 5V Rear PG = 0001 Crit-hi
0026 SDR Comp 02 03 20 a 02 snum 20 5V Front PG = 0001 Crit-hi
0027 SDR Comp 02 03 20 a 02 snum 21 3.3V PG = 0001 Crit-hi
0028 SDR Comp 02 03 20 a 02 snum 22 1.8V PG = 0001 Crit-hi
0029 SDR Comp 02 03 20 a 02 snum 23 1.5V PG = 0001 Crit-hi
002a SDR Comp 02 03 20 a 02 snum 24 1.1V PG = 0001 Crit-hi
002b SDR Comp 02 03 20 a 02 snum 25 0.9V PG = 0001 Crit-hi
002c SDR Comp 02 03 20 a 02 snum 26 Mem VR PG = 0001 Crit-hi
002d SDR Comp 02 03 20 a 02 snum 27 Mem VR PG = 0001 Crit-hi
002e SDR Comp 02 03 20 a 02 snum 28 Mem VR PG = 0001 Crit-hi
002f SDR Comp 02 03 20 a 02 snum 29 Mem VR PG = 0001 Crit-hi
0030 SDR Comp 02 03 20 a 02 snum 2a Mem VR PG = 0001 Crit-hi
0031 SDR Comp 02 03 20 a 02 snum 2b Mem VR PG = 0001 Crit-hi
0032 SDR Comp 02 03 20 a 02 snum 2c Mem VR PG = 0001 Crit-hi
0033 SDR Comp 02 03 20 a 02 snum 2d Mem VR PG = 0001 Crit-hi
0034 SDR Comp 02 03 20 a 02 snum 2f VR PG = 0001 Crit-hi
0035 SDR Comp 02 03 20 a 02 snum 2e VR1 PG = 0001 Crit-hi
0036 SDR Comp 02 03 20 a 02 snum a0 VR2 PG = 0001 Crit-hi
0037 SDR Comp 02 03 20 a 01 snum a1 IOH1 THERMTRIP = 0000 OK
0038 SDR Comp 02 03 20 a 01 snum a2 IOH2 THERMTRIP = 0000 OK
0039 SDR Comp 02 03 20 a 02 snum 5f PFault Fail Safe = 0000 Unknown
003a SDR Comp 02 6f 20 a 25 snum 5d Heatsink Pres = 0001 OK*
003b SDR Comp 02 6f 20 a 25 snum 70 iDRAC6 Ent Pres = 0001 OK*
003c SDR Comp 02 6f 20 a 25 snum 59 USB Cable Pres = 0001 OK*
003d SDR Comp 02 6f 20 a 25 snum 5a Stor Adapt Pres = 0001 OK*
003e SDR Comp 02 6f 20 a 25 snum 5b PCIe Riser Pres = 0002 Present
003f SDR Comp 02 6f 20 a 25 snum 5c IO Riser Pres = 0000 NotAvailable
0040 SDR Full 01 01 20 a 04 snum 30 FAN 1 RPM = 1b OK 3240.00 RPM
0041 SDR Full 01 01 20 a 04 snum 31 FAN 2 RPM = 1b OK 3240.00 RPM
0042 SDR Full 01 01 20 a 04 snum 32 FAN 3 RPM = 00 Crit-lo 0.00 RPM
0043 SDR Full 01 01 20 a 04 snum 33 FAN 4 RPM = 1d OK 3480.00 RPM
0044 SDR Full 01 01 20 a 04 snum 34 FAN 5 RPM = 1d OK 3480.00 RPM
0045 SDR Full 01 01 20 a 04 snum 35 FAN 6 RPM = 1d OK 3480.00 RPM
0046 SDR Full 01 01 20 a 04 snum 36 Fan RPM = 00 OK 0.00 RPM
0047 SDR Full 01 01 20 a 04 snum 37 Fan RPM = 00 OK 0.00 RPM
0048 SDR Full 01 01 20 a 04 snum 38 Fan RPM = 10 OK 1920.00 RPM
0049 SDR Full 01 01 20 a 04 snum 39 Fan RPM = 11 OK 2040.00 RPM
004a SDR Comp 02 6f 20 a 25 snum 50 Presence = 0001 OK*
004b SDR Comp 02 6f 20 a 25 snum 51 Presence = 0001 OK*
004c SDR Comp 02 6f 20 a 25 snum 52 Presence = 0001 OK*
004d SDR Comp 02 6f 20 a 25 snum 53 Presence = 0001 OK*
004e SDR Comp 02 6f 20 a 25 snum 54 Presence = 0001 OK*
004f SDR Comp 02 6f 20 a 25 snum 55 Presence = 0001 OK*
0050 SDR Comp 02 6f 20 a 25 snum 56 Presence = 0001 OK*
0051 SDR Comp 02 6f 20 a 25 snum 57 Presence = 0001 OK*
0052 SDR Comp 02 6f 20 a 25 snum 58 Presence = 0001 OK*
0053 SDR Comp 02 6f 20 a 07 snum 60 Status = 0080 ProcPresent
0054 SDR Comp 02 6f 20 a 07 snum 61 Status = 0080 ProcPresent
0055 SDR Comp 02 6f 20 a 07 snum 62 Status = 0080 ProcPresent
0056 SDR Comp 02 6f 20 a 07 snum 63 Status = 0080 ProcPresent
0057 SDR Comp 02 6f 20 a 08 snum 64 Status = 0009 AC_Lost
0058 SDR Comp 02 6f 20 a 08 snum 65 Status = 0009 AC_Lost
0059 SDR Comp 02 6f 20 a 08 snum 66 Status = 0001 Present
005a SDR Comp 02 6f 20 a 08 snum 67 Status = 0001 Present
005b SDR Full 01 01 20 a 03 snum 94 Current = 00 Unknown 0.00 Requested
sensor, data, or record not present
005c SDR Full 01 01 20 a 03 snum 95 Current = 00 Unknown 0.00 Requested
sensor, data, or record not present
005d SDR Full 01 01 20 a 03 snum 9a Current = 20 OK 1.28 Amps
005e SDR Full 01 01 20 a 03 snum 9b Current = 1e OK 1.20 Amps
005f SDR Full 01 01 20 a 02 snum 96 Voltage = 00 Unknown 0.00 Requested
sensor, data, or record not present
0060 SDR Full 01 01 20 a 02 snum 97 Voltage = 00 Unknown 0.00 Requested
sensor, data, or record not present
0061 SDR Full 01 01 20 a 02 snum 9c Voltage = 61 OK 194.00 Volts
0062 SDR Full 01 01 20 a 02 snum 9d Voltage = 61 OK 194.00 Volts
0063 SDR Comp 02 6f 20 a 1b snum 68 Riser Config = 0001 _
0064 SDR Comp 02 6f 20 a 23 snum 71 OS Watchdog = 0000 OK
0065 SDR Comp 02 6f 20 a 10 snum 72 SEL = 0000 Unknown
0066 SDR Comp 02 6f 20 a 05 snum 73 Intrusion = 0001 ChassisIntrus
0067 SDR Comp 02 0b 20 a 08 snum 74 PS Redundancy = 0040 NotAvailable
0068 SDR Comp 02 0b 20 a 04 snum 75 Fan Redundancy = 0002 RedunLost
0069 SDR Full 01 01 20 a 03 snum 98 System Level = 2e OK 460.00 Watts
006a SDR Comp 02 6f 20 a c0 snum 99 Power Optimized = 0001 Enabled
006b SDR Comp 02 6f 20 a 0d snum 80 Drive = 0001 Absent
006c SDR Comp 02 6f 20 a 0d snum 8f Drive 15 = 0000 Unused
006d SDR Comp 02 6f 20 a 1b snum 90 Cable SAS A = 0001 _
006e SDR Comp 02 6f 20 a 1b snum 91 Cable SAS B = 0001 _
006f SDR Comp 02 70 20 a 15 snum d0 SD1 Status = 0000 _
0070 SDR Comp 02 70 20 a 15 snum d1 SD2 Status = 0000 _
0071 SDR Comp 02 0b 20 a 15 snum d2 SD Redundancy = 0001 _
0072 SDR Comp 02 70 20 a 15 snum d3 VFlash Media = 0000 _
0073 SDR Full 01 01 20 a 01 snum b8 Mem Rsr A Temp = 9f OK 31.00 degrees C
0074 SDR Full 01 01 20 a 01 snum b9 Mem Rsr B Temp = 00 Init 0.00 degrees C
0075 SDR Full 01 01 20 a 01 snum ba Mem Rsr C Temp = 9f OK 31.00 degrees C
0076 SDR Full 01 01 20 a 01 snum bb Mem Rsr D Temp = 00 Init 0.00 degrees C
0077 SDR Full 01 01 20 a 01 snum bc Mem Rsr E Temp = 9e OK 30.00 degrees C
0078 SDR Full 01 01 20 a 01 snum bd Mem Rsr F Temp = 00 Init 0.00 degrees C
0079 SDR Full 01 01 20 a 01 snum be Mem Rsr G Temp = 9f OK 31.00 degrees C
007a SDR Full 01 01 20 a 01 snum bf Mem Rsr H Temp = 00 Init 0.00 degrees C
007b SDR Full 01 01 20 a 01 snum c0 MB A-A Temp = 98 OK 24.00 degrees C
007c SDR Full 01 01 20 a 01 snum c1 MB A-B Temp = 99 OK 25.00 degrees C
007d SDR Full 01 01 20 a 01 snum c2 MB B-A Temp = 00 Init 0.00 degrees C
007e SDR Full 01 01 20 a 01 snum c3 MB B-B Temp = 00 Init 0.00 degrees C
007f SDR Full 01 01 20 a 01 snum c4 MB C-A Temp = 96 OK 22.00 degrees C
0080 SDR Full 01 01 20 a 01 snum c5 MB C-B Temp = 98 OK 24.00 degrees C
0081 SDR Full 01 01 20 a 01 snum c6 MB D-A Temp = 00 Init 0.00 degrees C
0082 SDR Full 01 01 20 a 01 snum c7 MB D-B Temp = 00 Init 0.00 degrees C
0083 SDR Full 01 01 20 a 01 snum c8 MB E-A Temp = 93 OK 19.00 degrees C
0084 SDR Full 01 01 20 a 01 snum c9 MB E-B Temp = 98 OK 24.00 degrees C
0085 SDR Full 01 01 20 a 01 snum ca MB F-A Temp = 00 Init 0.00 degrees C
0086 SDR Full 01 01 20 a 01 snum cb MB F-B Temp = 00 Init 0.00 degrees C
0087 SDR Full 01 01 20 a 01 snum cc MB G-A Temp = 98 OK 24.00 degrees C
0088 SDR Full 01 01 20 a 01 snum cd MB G-B Temp = 98 OK 24.00 degrees C
0089 SDR Full 01 01 20 a 01 snum ce MB H-A Temp = 00 Init 0.00 degrees C
008a SDR Full 01 01 20 a 01 snum cf MB H-B Temp = 00 Init 0.00 degrees C
008b SDR Comp 02 03 20 a 02 snum a3 10G Power = 0001 Crit-hi
008c SDR Comp 02 01 20 a 01 snum ab VCORE Temp = 0000 Unknown
008d SDR Comp 02 01 20 a 01 snum ac VCACHE Temp = 0000 Unknown
008e SDR Comp 02 01 20 a 01 snum ad Mem VR Temp = 0000 Unknown
008f SDR Comp 02 03 20 a 01 snum ae Critical Cooling = 0000 Unknown
0090 SDR Comp 02 03 20 a 02 snum af Sys Pwr Draw = 0000 Unknown
0091 SDR IPMB 12 11 dev: 20 00 df 07 01 iDRAC6
0092 SDR FRU 11 17 dev: 20 00 80 00 07 01 System Board
0093 SDR FRU 11 0f dev: 20 b0 02 00 03 01 CPU1
0094 SDR FRU 11 0f dev: 20 b0 02 00 03 02 CPU2
0095 SDR FRU 11 0f dev: 20 b0 02 00 03 03 CPU3
0096 SDR FRU 11 0f dev: 20 b0 02 00 03 04 CPU4
0097 SDR FRU 11 0f dev: 20 02 80 00 0a 01 PS 1
0098 SDR FRU 11 0f dev: 20 03 80 00 0a 02 PS 2
0099 SDR FRU 11 0f dev: 20 04 80 00 0a 03 PS 3
009a SDR FRU 11 0f dev: 20 05 80 00 0a 04 PS 4
009b SDR FRU 11 12 dev: 20 06 80 00 1a 03 Storage
009c SDR FRU 11 12 dev: 20 07 80 00 1a 01 Storage
009d SDR FRU 11 13 dev: 20 08 02 00 10 01 IO Riser
009e SDR FRU 11 16 dev: 20 09 02 00 08 01 Mem Riser A
009f SDR FRU 11 16 dev: 20 0a 02 00 08 02 Mem Riser B
00a0 SDR FRU 11 16 dev: 20 0b 02 00 08 03 Mem Riser C
00a1 SDR FRU 11 16 dev: 20 0c 02 00 08 04 Mem Riser D
00a2 SDR FRU 11 16 dev: 20 0d 02 00 08 05 Mem Riser E
00a3 SDR FRU 11 16 dev: 20 0e 02 00 08 06 Mem Riser F
00a4 SDR FRU 11 16 dev: 20 0f 02 00 08 07 Mem Riser G
00a5 SDR FRU 11 16 dev: 20 10 02 00 08 08 Mem Riser H
00a6 SDR FRU 11 15 dev: 20 b0 02 00 10 02 PCIe Riser
00a7 SDR FRU 11 0b dev: 20 b0 02 00 0b 01
00a8 SDR FRU 11 0b dev: 20 b0 02 00 0b 02
00a9 SDR Comp 02 6f b1 a 0c snum 01 ECC Corr Err = 0000 Unknown
00aa SDR Comp 02 6f b1 a 0c snum 02 ECC Uncorr Err = 0000 Unknown
00ab SDR Comp 02 6f b1 a 13 snum 03 I/O Channel Chk = 0000 Unknown
00ac SDR Comp 02 6f b1 a 13 snum 04 PCI Parity Err = 0000 Unknown
00ad SDR Comp 02 6f b1 a 13 snum 05 PCI System Err = 0000 Unknown
00ae SDR Comp 02 6f b1 a 10 snum 06 SBE Log Disabled = 0000 Unknown
00af SDR Comp 02 6f b1 a 10 snum 07 Logging Disabled = 0000 Unknown
00b0 SDR Comp 02 6f b1 a 12 snum 08 Unknown = 0000 Unknown
00b1 SDR Comp 02 07 b1 a 07 snum 0a CPU Protocol Err = 0000 Unknown
00b2 SDR Comp 02 07 b1 a 07 snum 0b CPU Bus PERR = 0000 Unknown
00b3 SDR Comp 02 07 b1 a 07 snum 0c CPU Init Err = 0000 Unknown
00b4 SDR Comp 02 07 b1 a 07 snum 0d CPU Machine Chk = 0000 Unknown
00b5 SDR Comp 02 0b b1 a 0c snum 11 Memory Spared = 0000 Unknown
00b6 SDR Comp 02 0b b1 a 0c snum 12 Memory Mirrored = 0000 Unknown
00b7 SDR Comp 02 0b b1 a 0c snum 13 Memory RAID = 0000 Unknown
00b8 SDR Comp 02 6f b1 a 0c snum 14 Memory Added = 0000 Unknown
00b9 SDR Comp 02 6f b1 a 0c snum 15 Memory Removed = 0000 Unknown
00ba SDR Comp 02 6f b1 a 0c snum 16 Memory Cfg Err = 0000 Unknown
00bb SDR Comp 02 0b b1 a 0c snum 17 Mem Redun Gain = 0000 Unknown
00bc SDR Comp 02 6f b1 a 13 snum 18 PCIE Fatal Err = 0000 Unknown
00bd SDR Comp 02 6f b1 a 13 snum 19 Chipset Err = 0000 Unknown
00be SDR Comp 02 7e b1 a c1 snum 1a Err Reg Pointer = 0000 Unknown
00bf SDR Comp 02 07 b1 a 0c snum 1b Mem ECC Warning = 0000 Unknown
00c0 SDR Comp 02 07 b1 a 0c snum 1c Mem CRC Err = 0000 Unknown
00c1 SDR Comp 02 07 b1 a 0c snum 1d USB Over-current = 0000 Unknown
00c2 SDR Comp 02 6f b1 a 0f snum 1e POST Err = 0000 Unknown
00c3 SDR Comp 02 6f b1 a 2b snum 1f Hdwr version err = 0000 Unknown
00c4 SDR Comp 02 6f b1 a 0c snum 20 Mem Overtemp = 0000 Unknown
00c5 SDR Comp 02 6f b1 a 0c snum 21 Mem Fatal SB CRC = 0000 Unknown
00c6 SDR Comp 02 6f b1 a 0c snum 22 Mem Fatal NB CRC = 0000 Unknown
00c7 SDR Comp 02 6f b1 a 11 snum 23 OS Watchdog Time = 0000 Unknown
00c8 SDR Comp 02 6f b1 a c2 snum 26 Non Fatal PCI Er = 0000 Unknown
00c9 SDR Comp 02 6f b1 a c3 snum 27 Fatal IO Error = 0000 Unknown
00ca SDR Comp 02 6f b1 a c1 snum 28 MSR Info Log = 0000 Unknown
00cb SDR Comp 02 6f b1 a c2 snum 29 Non Fatal QPI Er = 0000 Unknown
00cc SDR Comp 02 6f b1 a c8 snum 30 QPIRC Warning = 0000 Unknown
00cd SDR Comp 02 6f b1 a c8 snum 31 MRC Non Fatal Er = 0000 Unknown
00ce SDR Comp 02 6f b1 a c8 snum 32 MRC SMI LFO = 0000 Unknown
00cf SDR Comp 02 6f b1 a c8 snum 33 MRC Warning = 0000 Unknown
00d0 SDR EntA 08 10 07 01 c0: 03 01 03 04 0a 01 0a 04
00d1 SDR EntA 08 10 07 01 c0: 10 01 10 02 08 01 08 08
00d2 SDR EntA 08 10 10 01 c0: 0b 01 0b 02 00 00 00 00
ipmiutil sensor, completed successfully
1.下载ow2-jotm-dist-2.2.1
2.把jotm所有的jar放到Tomcat/lib下
3.创建文件carol.properties
# # JNDI (Protocol Invocation)
carol.protocols=jrmp
# Local RMI Invocation
carol.jvm.rmi.local.call=true
# do not use CAROL JNDI wrapper
carol.start.jndi=false
# do not start a name server
carol.start.ns=false
# Naming Factory
carol.jndi.java.nameing.factory.url.pkgs=org.apache.nameing
4.修改数据源配置文件
<?xml version='1.0' encoding='utf-8'?>
<Context path="/xflow" debug="0" reloadable="false" docBase="D:\workspace\xflow\WebRoot\">
<Resource name="jdbc/afunms"
auth="Container"
type="javax.sql.DataSource"
factory="org.objectweb.jotm.datasource.DataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
username="root"
password="root"
url="jdbc:mysql://localhost:3306/netflow?useUnicode=true&characterEncoding=utf-8" />
<Resource name="UserTransaction"
auth="Container"
type="javax.transaction.UserTransaction" />
<Transaction factory="org.objectweb.jotm.UserTransactionFactory"
jotm.timeout="60" />
</Context>
5.java代码这样写:
Context ctx = new InitialContext();
DataSource ds = (DataSource)ctx.lookup("java:comp/env/jdbc/afunms");
UserTransaction ut = (UserTransaction)ctx.lookup("java:comp/UserTransaction");
研究Java来实现Portal。
1) Dynamic Include
首先,我们采用最简单的思路,我们用100个JSP文件(1.jsp, 2.jsp, 3.jsp, … 100.jsp等),代表100个Portlet。
用户页面MyPage.jsp包含用户选定的多个Portlet。
现在,假设用户选取的Portlet为1.jsp, 3.jsp, 7.jsp等3个Portlet,那么我们如何在MyPage.jsp中显示这些Portlet?最直观的做法是,用jsp:include。比如:
<table>
<tr><td>
<jsp:include page=”1.jsp” />
</td></tr>
<tr><td>
<jsp:include page=”3.jsp” />
</td></tr>
<tr><td>
<jsp:include page=”7.jsp” />
</td></tr>
</table>
由于<jsp:include>只能指定固定的jsp文件名,不能动态指定jsp文件名。我们需要把<jsp:include>翻译为Java code – RequestDispatcher.include();
下面我们换成这种写法。
Java代码
<table>
<tr><td>
<% request.getRequestDispatcher(”1.jsp”).include(request, response); />
</td></tr>
<tr><td>
<% request.getRequestDispatcher(”3.jsp”).include(request, response); />
</td></tr>
<tr><td>
<% request.getRequestDispatcher(”7.jsp”).include(request, response); />
</td></tr>
</table>
<table>
<tr><td>
<% request.getRequestDispatcher(”1.jsp”).include(request, response); />
</td></tr>
<tr><td>
<% request.getRequestDispatcher(”3.jsp”).include(request, response); />
</td></tr>
<tr><td>
<% request.getRequestDispatcher(”7.jsp”).include(request, response); />
</td></tr>
</table>
进一步改进MyPage.jsp。
Java代码
<% String[] fileNames = {“1.jsp”, “3.jsp”, “7.jsp”}; %>
<table>
<% for(int i = 0; i < fileNames.length; i++) {
String fileName = fileName s[i]; %>
<tr><td>
<% request.getRequestDispatcher(fileName).include(request, response); />
</td></tr>
<% } // end for %>
</table>
其中的fileNames的内容可以各种各样,只要RequestDispatcher能够处理。
比如Velocity,fileNames = {“1.vm”, “3.vm”, “7.vm”};
比如URL,fileNames = {“/portlet1.do”, “/portlet3.do”, “/portlet4.do”};
我们可以看到,如果我们从用户配置中读取fileNames的内容,这就是一个简单的Portal实现。
Java代码
<% String[] fileNames = (String[])session.getAttribute(“portlets.config”); %>
<table>
<% for(int i = 0; i < fileNames.length; i++) {
String fileName = fileNames[i]; %>
<tr><td>
<% request.getRequestDispatcher(fileName).include(request, response); />
</td></tr>
<% } // end for %>
</table>
2) Portlet Interface
下面我们来扩展这个例子。
假设每个Portlet都规定实现一个Portlet接口。
Java代码
interface Portlet {
void render(request, response);
};
MyPage.jsp如下:
<% String[] portletClassNames = (String[])session.getAttribute(“portlets.config”); %>
<table>
<% for(int i = 0; i < portletClassNames.length; i++) {
String className = portletClassNames[i];
Portlet portlet = (Portlet)Class.forName(className).newInstance(); %>
<tr><td>
<% portlet. render (request, response); />
</td></tr>
<% } // end for %>
</table>
Portlet类的示例代码如下:
public class Portlet7{
public void render(request, response){
request.getRequestDispatcher(“7.jsp”).include(request, response);
}
};
interface Portlet {
void render(request, response);
};
MyPage.jsp如下:
<% String[] portletClassNames = (String[])session.getAttribute(“portlets.config”); %>
<table>
<% for(int i = 0; i < portletClassNames.length; i++) {
String className = portletClassNames[i];
Portlet portlet = (Portlet)Class.forName(className).newInstance(); %>
<tr><td>
<% portlet. render (request, response); />
</td></tr>
<% } // end for %>
</table>
Portlet类的示例代码如下:
public class Portlet7{
public void render(request, response){
request.getRequestDispatcher(“7.jsp”).include(request, response);
}
};
上述代码是Portal显示Portlet的核心流程的一个简化版本。
JSR168 Portlet规范里面定义了真正的Portlet接口定义。
去年在揭阳痛苦了三天三夜也没把拓扑做出来,今天有机会再次在同一环境下测试程序。
与去年相比,产品的成熟度有较大提高。我也基本搞清楚H3C各型号FDB数据的获取方法。
拓扑发现结果
| |
开始时间 |
结束时间 |
耗时 |
| 1 |
2011-07-15 16:01:33 |
2011-07-15 16:08:03 |
6分钟30秒 |
|
发现设备
| |
IP地址 |
名称 |
型号 |
类型 |
| 1 |
10.46.129.100 |
jygaj7510E |
hh3c-s7510E |
路由交换机 |
| 2 |
10.46.129.111 |
jygaj4507 |
cat4507 |
路由交换机 |
| 3 |
10.46.131.146 |
JieXiDaDui |
hh3c-s5500-28C-EI |
路由交换机 |
| 4 |
10.46.159.51 |
JYSJ_5500 |
hh3c-s5500-28C-EI |
路由交换机 |
| 5 |
10.46.131.150 |
HuiLaiDaDui |
hh3c-s5500-28C-EI |
路由交换机 |
| 6 |
10.46.131.138 |
YuHuDaDui |
hh3c-s5500-28C-EI |
路由交换机 |
| 7 |
10.46.131.193 |
HuiLaiGaoSuDaDui |
hh3c-s5500-28C-EI |
路由交换机 |
| 8 |
10.46.131.169 |
RongChengDaDui |
hh3c-s5500-28C-EI |
路由交换机 |
| 9 |
10.46.131.190 |
JiaoJingZhiDui |
hh3c-S7503E-S |
路由交换机 |
| 10 |
10.46.131.158 |
JieDongGaoSuDaDui |
hh3c-s5500-28C-EI |
路由交换机 |
| 11 |
10.46.131.1 |
DongShanDaDui |
hh3c-s5500-28C-EI |
路由交换机 |
| 12 |
10.46.131.202 |
PuHuiGaoSuDaDui |
hh3c-s5500-28C-EI |
路由交换机 |
| 13 |
10.46.131.118 |
PuHuiGaoSu2Donggang |
hh3c-s5100-24P-SI |
路由交换机 |
| 14 |
10.46.131.166 |
GuiLingKaoChang |
hh3c-s5100-24P-SI |
路由交换机 |
| 15 |
10.46.130.128 |
jiedong |
hh3c-S7503E-S |
路由交换机 |
| 16 |
10.46.131.10 |
RongXinZhongDui |
hh3c-s5100-24P-SI |
路由交换机 |
| 17 |
10.46.131.170 |
JinXianZhongDui |
hh3c-s5100-24P-SI |
路由交换机 |
| 18 |
10.46.150.96 |
puning |
hh3c-S7503E-S |
路由交换机 |
| 19 |
10.46.155.160 |
huilai |
s3328 |
交换机 |
| 20 |
10.46.157.65 |
rongcheng |
hh3c-s5500-28C-EI |
路由交换机 |
| 21 |
10.46.155.130 |
AoJiang |
hh3c-S5120-28P-SI |
路由交换机 |
| 22 |
10.46.155.178 |
KuiFeng |
hh3c-S5120-28P-SI |
路由交换机 |
| 23 |
10.46.155.226 |
ZhouTian |
hh3c-S5120-28P-SI |
路由交换机 |
| 24 |
10.46.155.242 |
DongLong |
hh3c-S5120-28P-SI |
路由交换机 |
| 25 |
10.46.156.82 |
HeLin |
hh3c-S5120-28P-SI |
路由交换机 |
| 26 |
10.46.155.62 |
XianKanShouSuo |
hh3c-S5120-28P-SI |
路由交换机 |
| 27 |
10.46.131.6 |
YuQiaoZhongDui |
s2326TP |
路由交换机 |
| 28 |
10.46.136.18 |
jiexi |
hh3c-S7503E-S |
路由交换机 |
| 29 |
10.46.131.126 |
PuHuiGaosu_1_zd_xichang |
hh3c-s5100-24P-SI |
路由交换机 |
| 30 |
10.46.135.249 |
jygaj3560A |
catalyst3560G24TS |
交换机 |
| 31 |
10.46.129.226 |
jieyang_3640 |
cisco3640 |
路由交换机 |
| 32 |
10.46.159.100 |
puhua |
hh3c-s5100-24P-EI |
路由交换机 |
| 33 |
10.46.159.40 |
dananshan |
hh3c-s5100-24P-EI |
路由交换机 |
| 34 |
10.46.155.210 |
10.46.155.210 |
hh3c-S5120-28P-SI |
路由交换机 |
| 35 |
10.46.141.64 |
yuhu |
hh3c-s5500-28C-EI |
路由交换机 |
| 36 |
10.46.133.64 |
dongshan-master |
hh3c-s5500-28C-EI |
路由交换机 |
| 37 |
10.46.149.30 |
shuishangpaichusuo |
hh3c-s5100-24P-EI |
路由交换机 |
| 38 |
10.46.146.99 |
jingxiao |
hh3c-s5500-28C-EI |
路由交换机 |
| 39 |
10.46.135.44 |
kanshousuo |
hh3c-s5100-24P-EI |
路由交换机 |
| 40 |
10.46.135.8 |
tejing |
hh3c-s5100-24P-EI |
路由交换机 |
| 合计:40台 |
发现子网
| |
子网地址 |
子网掩码 |
| 1 |
10.46.128.0 |
255.255.224.0 |
| 2 |
10.46.128.112 |
255.255.255.248 |
| 3 |
10.46.128.120 |
255.255.255.248 |
| 4 |
10.46.128.128 |
255.255.255.248 |
| 5 |
10.46.128.136 |
255.255.255.248 |
| 6 |
10.46.128.16 |
255.255.255.248 |
| 7 |
10.46.128.160 |
255.255.255.248 |
| 8 |
10.46.128.176 |
255.255.255.248 |
| 9 |
10.46.128.184 |
255.255.255.248 |
| 10 |
10.46.128.192 |
255.255.255.248 |
| 11 |
10.46.128.200 |
255.255.255.248 |
| 12 |
10.46.128.208 |
255.255.255.240 |
| 13 |
10.46.128.224 |
255.255.255.248 |
| 14 |
10.46.128.232 |
255.255.255.248 |
| 15 |
10.46.128.248 |
255.255.255.248 |
| 16 |
10.46.128.8 |
255.255.255.248 |
| 17 |
10.46.129.0 |
255.255.255.0 |
| 18 |
10.46.130.0 |
255.255.255.0 |
| 19 |
10.46.131.0 |
255.255.255.252 |
| 20 |
10.46.131.100 |
255.255.255.252 |
| 21 |
10.46.131.116 |
255.255.255.252 |
| 22 |
10.46.131.12 |
255.255.255.252 |
| 23 |
10.46.131.124 |
255.255.255.252 |
| 24 |
10.46.131.128 |
255.255.255.252 |
| 25 |
10.46.131.136 |
255.255.255.252 |
| 26 |
10.46.131.140 |
255.255.255.252 |
| 27 |
10.46.131.144 |
255.255.255.252 |
| 28 |
10.46.131.148 |
255.255.255.252 |
| 29 |
10.46.131.156 |
255.255.255.252 |
| 30 |
10.46.131.164 |
255.255.255.252 |
| 31 |
10.46.131.168 |
255.255.255.252 |
| 32 |
10.46.131.172 |
255.255.255.252 |
| 33 |
10.46.131.176 |
255.255.255.252 |
| 34 |
10.46.131.180 |
255.255.255.252 |
| 35 |
10.46.131.188 |
255.255.255.252 |
| 36 |
10.46.131.192 |
255.255.255.252 |
| 37 |
10.46.131.196 |
255.255.255.252 |
| 38 |
10.46.131.200 |
255.255.255.252 |
| 39 |
10.46.131.240 |
255.255.255.252 |
| 40 |
10.46.131.244 |
255.255.255.252 |
| 41 |
10.46.131.248 |
255.255.255.248 |
| 42 |
10.46.131.4 |
255.255.255.252 |
| 43 |
10.46.131.8 |
255.255.255.252 |
| 44 |
10.46.131.80 |
255.255.255.252 |
| 45 |
10.46.131.88 |
255.255.255.252 |
| 46 |
10.46.131.92 |
255.255.255.252 |
| 47 |
10.46.131.96 |
255.255.255.252 |
| 48 |
10.46.132.0 |
255.255.255.0 |
| 49 |
10.46.133.0 |
255.255.255.0 |
| 50 |
10.46.134.0 |
255.255.255.0 |
| 51 |
10.46.135.0 |
255.255.255.0 |
| 52 |
10.46.135.128 |
255.255.255.128 |
| 53 |
10.46.135.32 |
255.255.255.224 |
| 54 |
10.46.135.64 |
255.255.255.192 |
| 55 |
10.46.136.0 |
255.255.255.252 |
| 56 |
10.46.136.100 |
255.255.255.252 |
| 57 |
10.46.136.108 |
255.255.255.252 |
| 58 |
10.46.136.136 |
255.255.255.252 |
| 59 |
10.46.136.16 |
255.255.255.252 |
| 60 |
10.46.136.20 |
255.255.255.252 |
| 61 |
10.46.136.200 |
255.255.255.252 |
| 62 |
10.46.136.32 |
255.255.255.252 |
| 63 |
10.46.137.0 |
255.255.255.0 |
| 64 |
10.46.138.0 |
255.255.255.0 |
| 65 |
10.46.139.0 |
255.255.255.224 |
| 66 |
10.46.139.128 |
255.255.255.224 |
| 67 |
10.46.139.192 |
255.255.255.240 |
| 68 |
10.46.139.232 |
255.255.255.248 |
| 69 |
10.46.139.240 |
255.255.255.240 |
| 70 |
10.46.139.32 |
255.255.255.224 |
| 71 |
10.46.139.64 |
255.255.255.192 |
| 72 |
10.46.140.0 |
255.255.255.0 |
| 73 |
10.46.141.0 |
255.255.255.128 |
| 74 |
10.46.141.128 |
255.255.255.128 |
| 75 |
10.46.142.0 |
255.255.255.240 |
| 76 |
10.46.142.128 |
255.255.255.224 |
| 77 |
10.46.142.16 |
255.255.255.240 |
| 78 |
10.46.142.160 |
255.255.255.224 |
| 79 |
10.46.142.192 |
255.255.255.224 |
| 80 |
10.46.142.224 |
255.255.255.224 |
| 81 |
10.46.142.32 |
255.255.255.240 |
| 82 |
10.46.142.64 |
255.255.255.192 |
| 83 |
10.46.143.0 |
255.255.255.192 |
| 84 |
10.46.143.128 |
255.255.255.224 |
| 85 |
10.46.143.160 |
255.255.255.224 |
| 86 |
10.46.143.192 |
255.255.255.192 |
| 87 |
10.46.143.64 |
255.255.255.224 |
| 88 |
10.46.143.96 |
255.255.255.224 |
| 89 |
10.46.144.0 |
255.255.255.224 |
| 90 |
10.46.144.112 |
255.255.255.240 |
| 91 |
10.46.144.128 |
255.255.255.240 |
| 92 |
10.46.144.144 |
255.255.255.240 |
| 93 |
10.46.144.160 |
255.255.255.240 |
| 94 |
10.46.144.176 |
255.255.255.240 |
| 95 |
10.46.144.224 |
255.255.255.240 |
| 96 |
10.46.144.240 |
255.255.255.240 |
| 97 |
10.46.144.64 |
255.255.255.224 |
| 98 |
10.46.144.96 |
255.255.255.240 |
| 99 |
10.46.145.0 |
255.255.255.240 |
| 100 |
10.46.145.128 |
255.255.255.240 |
| 101 |
10.46.145.144 |
255.255.255.240 |
| 102 |
10.46.145.16 |
255.255.255.240 |
| 103 |
10.46.145.160 |
255.255.255.240 |
| 104 |
10.46.145.176 |
255.255.255.240 |
| 105 |
10.46.145.192 |
255.255.255.240 |
| 106 |
10.46.145.208 |
255.255.255.240 |
| 107 |
10.46.145.224 |
255.255.255.240 |
| 108 |
10.46.145.32 |
255.255.255.240 |
| 109 |
10.46.145.48 |
255.255.255.240 |
| 110 |
10.46.145.64 |
255.255.255.240 |
| 111 |
10.46.145.80 |
255.255.255.240 |
| 112 |
10.46.145.96 |
255.255.255.240 |
| 113 |
10.46.146.0 |
255.255.255.0 |
| 114 |
10.46.147.0 |
255.255.255.0 |
| 合计:114个 |
发现链路
| |
名称 |
| 1 |
jygaj7510E[GigabitEthernet0/0/28]--JieXiDaDui[GigabitEthernet1/0/24] |
|
| 2 |
jygaj7510E[GigabitEthernet0/0/24]--JiaoJingZhiDui[GigabitEthernet1/0/39] |
|
| 3 |
JiaoJingZhiDui[GigabitEthernet1/0/6]--DongShanDaDui[GigabitEthernet1/0/21] |
|
| 4 |
jygaj7510E[GigabitEthernet0/0/26]--JieDongGaoSuDaDui[GigabitEthernet1/0/24] |
|
| 5 |
jygaj7510E[GigabitEthernet0/0/30]--RongChengDaDui[GigabitEthernet1/0/24] |
|
| 6 |
jygaj7510E[GigabitEthernet0/0/27]--HuiLaiDaDui[GigabitEthernet1/0/24] |
|
| 7 |
jygaj7510E[GigabitEthernet0/0/39]--JYSJ_5500[GigabitEthernet1/0/1] |
|
| 8 |
jygaj7510E[GigabitEthernet0/0/29]--YuHuDaDui[GigabitEthernet1/0/24] |
|
| 9 |
jygaj7510E[GigabitEthernet0/0/25]--HuiLaiGaoSuDaDui[GigabitEthernet1/0/24] |
|
| 10 |
jygaj7510E[GigabitEthernet0/0/40]--jygaj4507[GigabitEthernet3/32] |
|
| 11 |
jygaj4507[GigabitEthernet3/26]--jieyang_3640[FastEthernet2/0] |
|
| 12 |
jygaj7510E[GigabitEthernet0/0/6]--rongcheng[GigabitEthernet1/0/24] |
|
| 13 |
jygaj7510E[GigabitEthernet0/0/32]--PuHuiGaoSuDaDui[GigabitEthernet1/0/24] |
|
| 14 |
jygaj7510E[GigabitEthernet0/0/4]--jiexi[GigabitEthernet1/0/24] |
|
| 15 |
jygaj7510E[GigabitEthernet0/0/7]--yuhu[GigabitEthernet1/0/24] |
|
| 16 |
jygaj7510E[GigabitEthernet0/0/5]--dongshan-master[GigabitEthernet1/0/24] |
|
| 17 |
jygaj7510E[GigabitEthernet0/0/3]--puning[GigabitEthernet1/0/40] |
|
| 18 |
jygaj7510E[GigabitEthernet0/0/1]--jiedong[GigabitEthernet1/0/24] |
|
| 19 |
jygaj7510E[GigabitEthernet0/0/13]--jingxiao[GigabitEthernet1/0/24] |
|
| 20 |
DongShanDaDui[GigabitEthernet1/0/23]--YuQiaoZhongDui[Vlanif3] |
|
| 21 |
huilai[Ethernet0/0/8]--HeLin[GigabitEthernet1/0/24] |
|
| 22 |
JYSJ_5500[GigabitEthernet1/0/6]--shuishangpaichusuo[GigabitEthernet1/0/24] |
|
| 23 |
JYSJ_5500[GigabitEthernet1/0/3]--puhua[GigabitEthernet1/0/24] |
|
| 24 |
JYSJ_5500[GigabitEthernet1/0/5]--tejing[GigabitEthernet1/0/24] |
|
| 25 |
RongChengDaDui[GigabitEthernet1/0/22]--RongXinZhongDui[GigabitEthernet1/0/24] |
|
| 26 |
JYSJ_5500[GigabitEthernet1/0/2]--dananshan[GigabitEthernet1/0/24] |
|
| 27 |
JYSJ_5500[GigabitEthernet1/0/4]--kanshousuo[GigabitEthernet1/0/24] |
|
| 28 |
huilai[Ethernet0/0/7]--DongLong[GigabitEthernet1/0/24] |
|
| 29 |
huilai[Ethernet0/0/5]--KuiFeng[GigabitEthernet1/0/20] |
|
| 30 |
RongChengDaDui[GigabitEthernet1/0/21]--JinXianZhongDui[GigabitEthernet1/0/24] |
|
| 31 |
huilai[Ethernet0/0/2]--ZhouTian[GigabitEthernet1/0/24] |
|
| 32 |
huilai[Ethernet0/0/3]--10.46.155.210[GigabitEthernet1/0/24] |
|
| 33 |
huilai[Ethernet0/0/6]--AoJiang[GigabitEthernet1/0/24] |
|
| 34 |
huilai[Ethernet0/0/1]--XianKanShouSuo[GigabitEthernet1/0/24] |
|
| 35 |
JiaoJingZhiDui[GigabitEthernet1/0/40]--GuiLingKaoChang[GigabitEthernet1/0/24] |
|
| 36 |
jygaj7510E[GigabitEthernet0/0/48]--jygaj3560A[GigabitEthernet0/27] |
|
| 37 |
jygaj7510E[GigabitEthernet0/0/2]--huilai[Ethernet0/0/24] |
|
| 38 |
JiaoJingZhiDui[GigabitEthernet1/0/8]--PuHuiGaoSu2Donggang[GigabitEthernet1/0/2] |
|
| 39 |
JiaoJingZhiDui[GigabitEthernet1/0/7]--PuHuiGaosu_1_zd_xichang[GigabitEthernet1/0/24] |
|
| 40 |
jygaj4507[GigabitEthernet3/21]--jygaj3560A[GigabitEthernet0/22] |
|
| 合计:40条 |
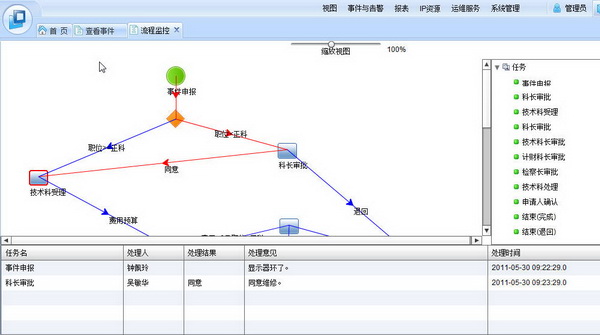
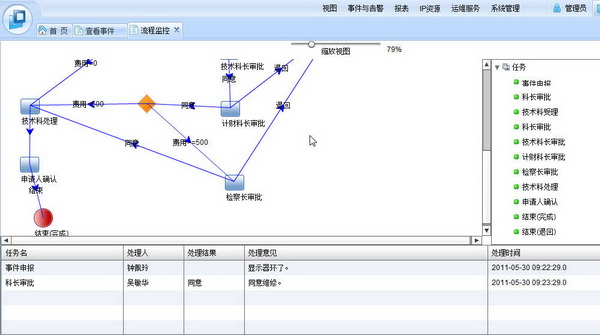
1.在连线加上文字
2.换了图标
摘要: Flex开发的JBPM流程展现器
---JBPM流程定义XML----
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--><?xml version="1.0" encoding="UTF-8"?><proces...
阅读全文
IT Service Management Objectives
ITIL is a Best Practice Framework used …..
1.To align IT services with the current and future needs
of the business and its Customers
2.To develop the quality of the IT services delivered
3.To reduce the long term cost of service provision
Why Service Management
1.Increasing IT visibility and Reliance
2.Increasing demand from Business to deliver effective
IT solutions/services (Cost Effective)
3.Increasing complexity of IT infrastructure and processes
4.Increasing competition
5.Increasing pressure to realise return on investment
Considerations
1.Do not be over ambitious
2.Consider what elements already exist, are in use and effective
3.Identify what can be re-used or needs to be developed
4.Adapt the guidelines to meet your requirements
Process Improvement Model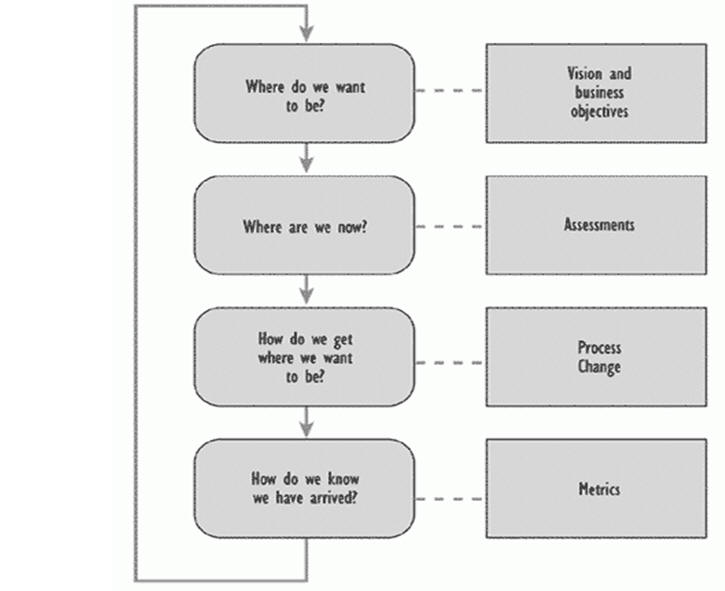
Process Improvement Stages
1.Process improvement definition
2.Communication
3.Planning
4.Implementation
5.Review and Audit
ITIL Service Management
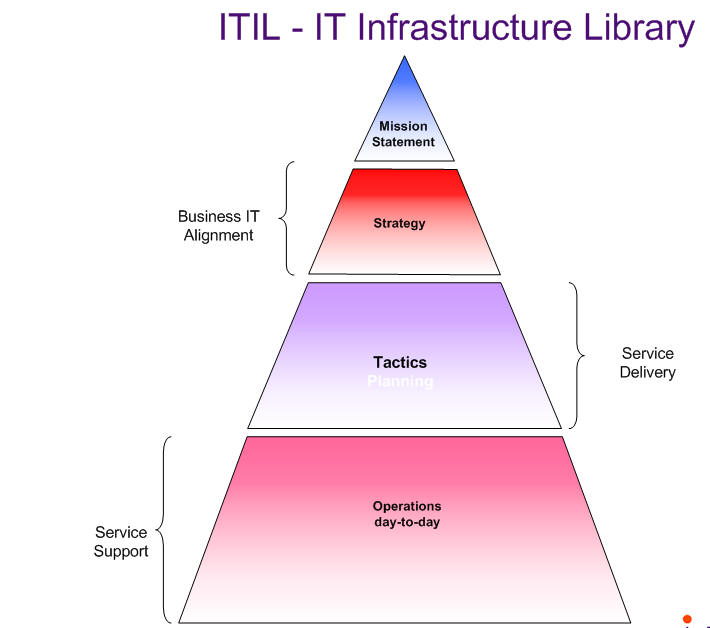
Service Support
Day to day operational support of IT services
Service Delivery
Long term planning and improvement of IT service provision
Key Definitions
Customer: recipient of a service: usually the Customer management
has responsibility for the funding of the service.
Provider: the unit responsible for the provision of IT service.
Supplier: a third party responsible for supplying or supporting
underpinning elements of the IT service.
User: the person using the service on a daily basis.
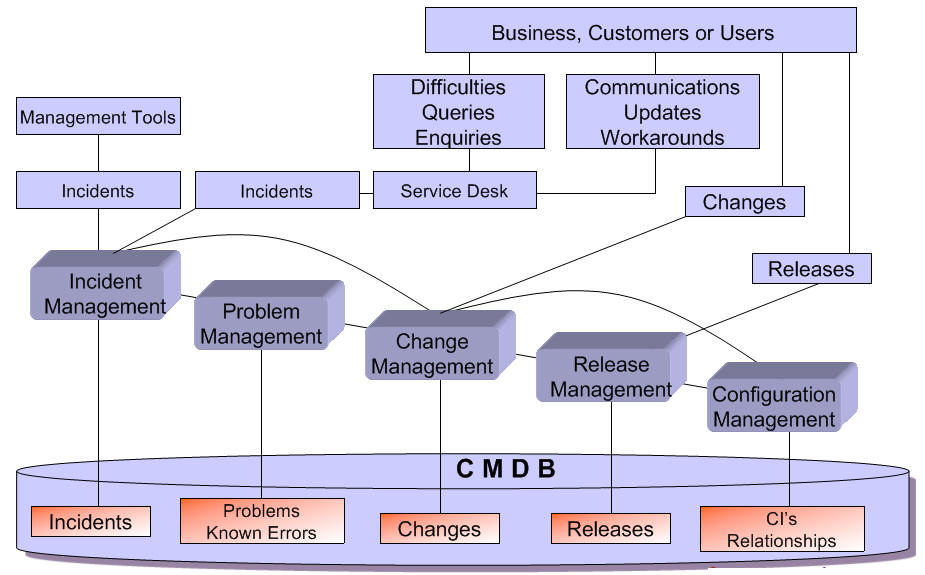
IT Service Management Overview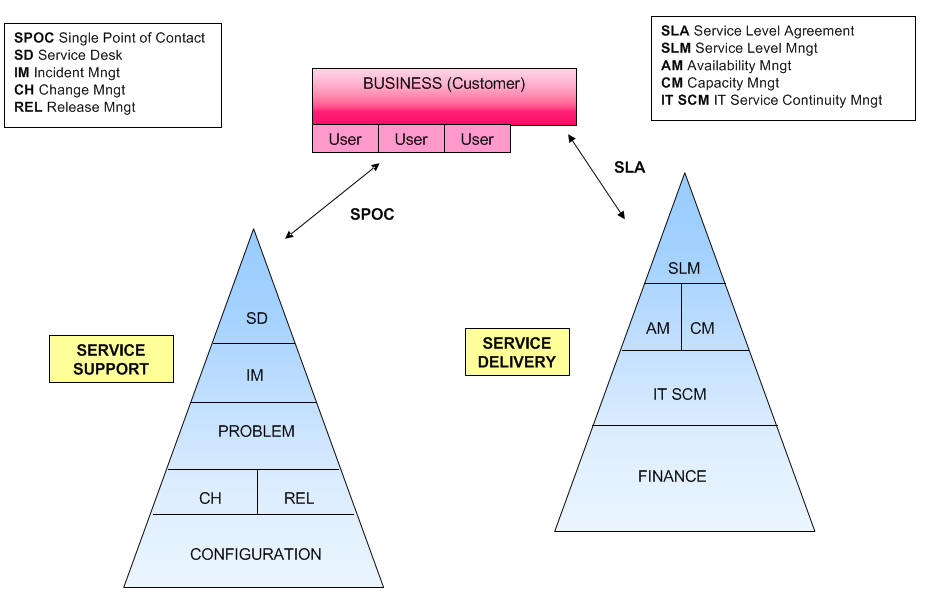

ITIL Service Management Foundation
Course Objectives
1.To introduce ITIL As Best Practice framework
Terms, Definitions, Phrases
2.Gain an understanding of the essential ITIL processes and how they relate
to each other,in order to support and deliver a quality IT service
Course Content – Day 1
1.Introduction
2.Introduction to IT Service Management
3.Service Desk
4.Configuration Management
5.Incident Management
6.Problem Management
7.Change Management
8.Release Management
Course Content – Day 2
1.Service Level Management
2.Financial Management for IT Services
3.Capacity Management
4.IT Service Continuity Management
5.Availability Management
ITIL Overview
1.ITIL is a Best Practice Framework
2.Integrated into OGC and BSI guidance
3.ITIL Philosophy – Scaleable Process driven approach
4.Key Objective 1
5.Align IT services with the Current and Future needs of the business and its Customers
6.Key Objective 2
7.To improve Quality of the services delivered
8.Key Objective 3
9.Reduce long term Cost of service provision
Introduction to Service Management
The Service Desk
Configuration Management
Incident Management
Problem Management
Change Management
Release Management
启动Tomcat后,服务器IP冲突或IP地址改变会导致以下错误:
I/O exception (java.net.ConnectException)
caught when processing request: Connection timed out: connect
Retrying request
除 .$ ^ { [ ( | ) * + ? \ 外,其他字符与自身匹配。
点的转义:. ==> \\u002E
美元符号的转义:$ ==> \\u0024
乘方符号的转义:^ ==> \\u005E
左大括号的转义:{ ==> \\u007B
左方括号的转义:[ ==> \\u005B
左圆括号的转义:( ==> \\u0028
竖线的转义:| ==> \\u007C
右圆括号的转义:) ==> \\u0029
星号的转义:* ==> \\u002A
加号的转义:+ ==> \\u002B
问号的转义:? ==> \\u003F
反斜杠的转义:\ ==> \\u005C
test:
public static void main(String[] args){
Pattern p = Pattern.compile("/\\u002A\\s{1,5}\\d{0,4}\\s{1,5}\\u002A/");
Matcher m = p.matcher("/* 1369 */");
System.out.println(m.find());
}
结果为true
转
http://dev.csdn.net/htmls/21/21291.html
log4j虽然用了很久,其实一直没搞清楚。今天认真学习了。
1.简介
程序开发环境中的日志记录是由嵌入在程序中以输出一些对开发人员有用信息的语句所组成。例如,跟踪语句(trace),结构转储和常见的System.out.println或printf调试语句。log4j提供分级方法在程序中嵌入日志记录语句。日志信息具有多种输出格式和多个输出级别。
使用一个专门的日志记录包,可以减轻对成千上万的System.out.println语句的维护成本,因为日志记录可以通过配置脚本在运行时得以控制。log4j维护嵌入在程序代码中的日志记录语句。通过规范日志记录的处理过程,一些人认为应该鼓励更多的使用日志记录并且获得更高程度的效率。
2.安装
为了使用我们即将要安装的日志记录工具,还必须要设置操作环境,只有这样,工具才能知道从哪里找到它所需要的信息,并且操作系统知道从哪里找到这个工具。那么,怎样做呢?实际上,它要求更改操作环境。我有一些这方面的资格文档。 Configuring A Windows Working Environment 和 Configuring A Unix Working Environment.
从 http://jakarta.apache.org/log4j/docs/download.html下载log4j发行版。
解压存档文件到合适的目录中。
添加文件 dist/lib/log4j-1.2.6.jar 到 CLASSPATH 环境变量中。
3.log4j的基本概念
使用log4j大概涉及3个主要概念:
公共类 Logger
Logger 负责处理日志记录的大部分操作。
公共接口 Appender
Appender 负责控制日志记录操作的输出。
公共抽象类Layout
Layout 负责格式化Appender的输出。
3.1.Logger
日志记录器(Logger)是日志处理的核心组件。log4j具有5种正常级别(Level)。 日志记录器(Logger)的可用级别Level (不包括自定义级别 Level), 以下内容就是摘自log4j API (http://jakarta.apache.org/log4j/docs/api/index.html):
static Level DEBUG
DEBUG Level指出细粒度信息事件对调试应用程序是非常有帮助的。
static Level INFO
INFO level表明 消息在粗粒度级别上突出强调应用程序的运行过程。
static Level WARN
WARN level表明会出现潜在错误的情形。
static Level ERROR
ERROR level指出虽然发生错误事件,但仍然不影响系统的继续运行。
static Level FATAL
FATAL level指出每个严重的错误事件将会导致应用程序的退出。
另外,还有两个可用的特别的日志记录级别: (以下描述来自log4j API http://jakarta.apache.org/log4j/docs/api/index.html):
static Level ALL
ALL Level是最低等级的,用于打开所有日志记录。
static Level OFF
OFF Level是最高等级的,用于关闭所有日志记录。
日志记录器(Logger)的行为是分等级的。如下表所示:
图.日志输出等级
日志记录器(Logger)将只输出那些级别高于或等于它的级别的信息。如果没有设置日志记录器(Logger)的级别,那么它将会继承最近的祖先的级别。因此,如果在包com.foo.bar中创建一个日志记录器(Logger)并且没有设置级别,那它将会继承在包com.foo中创建的日志记录器(Logger)的级别。如果在com.foo中没有创建日志记录器(Logger)的话,那么在com.foo.bar中创建的日志记录器(Logger)将继承root 日志记录器(Logger)的级别,root日志记录器(Logger)经常被实例化而可用,它的级别为DEBUG。
有很多方法可以创建一个日志记录器(Logger),下面方法可以取回root日志记录器:
Logger logger = Logger.getRootLogger();
还可以这样创建一个新的日志记录器:
Logger logger = Logger.getLogger("MyLogger");
比较常用的用法,就是根据类名实例化一个静态的全局日志记录器:
static Logger logger = Logger.getLogger(test.class);
所有这些创建的叫"logger"的日志记录器都可以用下面方法设置级别:
logger.setLevel((Level)Level.WARN);
可以使用7个级别中的任何一个; Level.DEBUG, Level.INFO, Level.WARN, Level.ERROR, Level.FATAL, Level.ALL and Level.OFF.
3.2.Appender
Appender 控制日志怎样输出。下面列出一些可用的Appender(log4j API中所描述的 http://jakarta.apache.org/log4j/docs/api/index.html):
ConsoleAppender:使用用户指定的布局(layout) 输出日志事件到System.out或者 System.err。默认的目标是System.out。
DailyRollingFileAppender 扩展FileAppender,因此多个日志文件可以以一个用户选定的频率进行循环日志记录。
FileAppender 把日志事件写入一个文件
RollingFileAppender 扩展FileAppender备份容量达到一定大小的日志文件。
WriterAppender根据用户的选择把日志事件写入到Writer或者OutputStream。
SMTPAppender 当特定的日志事件发生时,一般是指发生错误或者重大错误时,发送一封邮件。
SocketAppender 给远程日志服务器(通常是网络套接字节点)发送日志事件(LoggingEvent)对象。
SocketHubAppender 给远程日志服务器群组(通常是网络套接字节点)发送日志事件(LoggingEvent)对象。
SyslogAppender给远程异步日志记录的后台精灵程序(daemon)发送消息。
TelnetAppender 一个专用于向只读网络套接字发送消息的log4j appender。
还可以实现 Appender 接口,创建以自己的方式进行日志输出的Appender。
3.2.1.使用ConsoleAppender
ConsoleAppender可以用这种方式创建:
ConsoleAppender appender = new ConsoleAppender(new PatternLayout());
创建了一个控制台appender,具有一个默认的PatternLayout。它使用了默认的System.out 输出。
3.2.2.使用FileAppender
FileAppender可以用这种方式创建:
FileAppender appender = null;
try {
appender = new FileAppender(new PatternLayout(),"filename");
} catch(Exception e) {}
上面用到的构造函数:
FileAppender(Layout layout, String filename)
实例化一个FileAppender并且打开变量"filename"指定的文件。
另一个有用的构造函数是:
FileAppender(Layout layout, String filename, boolean append)
实例化一个FileAppender并且打开变量"filename"指定的文件。
这个构造函数还可以选择是否对指定的文件进行追加的方式输出。如果没有指定值,那么默认的方式就是追加。
3.2.3.使用WriterAppender
WriterAppender可以用这种方式创建:
WriterAppender appender = null;
try {
appender = new WriterAppender(new PatternLayout(),new FileOutputStream("filename"));
} catch(Exception e) {}
这个WriterAppender使用的构造函数带有PatternLayout和OutputStream参数,在这种情况下, FileOutputStream用于向一个文件输出。当然,它还具有其他可用的构造函数。
3.3.Layout
Appender必须使用一个与之相关联的 Layout,这样它才能知道怎样格式化它的输出。当前,log4j具有三种类型的Layout:
HTMLLayout 格式化日志输出为HTML表格。
PatternLayout 根据指定的 转换模式格式化日志输出,或者如果没有指定任何转换模式,就使用默认的转换模式。
SimpleLayout 以一种非常简单的方式格式化日志输出,它打印级别 Level,然后跟着一个破折号“-“ ,最后才是日志消息。
3.4.基本示例
3.4.1.SimpleLayout和 FileAppender
这里是一个非常简单的例子,程序实现了SimpleLayout和FileAppender:
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.log4j.SimpleLayout;
import org.apache.log4j.FileAppender;
public class simpandfile {
static Logger logger = Logger.getLogger(simpandfile.class);
public static void main(String args[]) {
SimpleLayout layout = new SimpleLayout();
FileAppender appender = null;
try {
appender = new FileAppender(layout,"output1.txt",false);
} catch(Exception e) {}
logger.addAppender(appender);
logger.setLevel((Level) Level.DEBUG);
logger.debug("Here is some DEBUG");
logger.info("Here is some INFO");
logger.warn("Here is some WARN");
logger.error("Here is some ERROR");
logger.fatal("Here is some FATAL");
}
}
你可以下载: simpandfile.java。 还可以查看它的输出: output1.txt.
3.4.2.HTMLLayout和 WriterAppender
这里是一个非常简单的例子,程序实现了 HTMLLayout和WriterAppender:
import java.io.*;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.log4j.HTMLLayout;
import org.apache.log4j.WriterAppender;
public class htmlandwrite {
static Logger logger = Logger.getLogger(htmlandwrite.class);
public static void main(String args[]) {
HTMLLayout layout = new HTMLLayout();
WriterAppender appender = null;
try {
FileOutputStream output = new FileOutputStream("output2.html");
appender = new WriterAppender(layout,output);
} catch(Exception e) {}
logger.addAppender(appender);
logger.setLevel((Level) Level.DEBUG);
logger.debug("Here is some DEBUG");
logger.info("Here is some INFO");
logger.warn("Here is some WARN");
logger.error("Here is some ERROR");
logger.fatal("Here is some FATAL");
}
}
你可以下载: simpandfile.java. 还可以查看它的输出:output1.txt.
3.4.3.PatternLayout和 ConsoleAppender
这里是一个非常简单的例子,程序实现了PatternLayout和ConsoleAppender:
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.log4j.PatternLayout;
import org.apache.log4j.ConsoleAppender;
public class consandpatt {
static Logger logger = Logger.getLogger(consandpatt.class);
public static void main(String args[]) {
// Note, %n is newline
String pattern = "Milliseconds since program start: %r %n";
pattern += "Classname of caller: %C %n";
pattern += "Date in ISO8601 format: %d{ISO8601} %n";
pattern += "Location of log event: %l %n";
pattern += "Message: %m %n %n";
PatternLayout layout = new PatternLayout(pattern);
ConsoleAppender appender = new ConsoleAppender(layout);
logger.addAppender(appender);
logger.setLevel((Level) Level.DEBUG);
logger.debug("Here is some DEBUG");
logger.info("Here is some INFO");
logger.warn("Here is some WARN");
logger.error("Here is some ERROR");
logger.fatal("Here is some FATAL");
}
}
你可以下载:simpandfile.java. 还可以查看它的输出: output2.txt.
4.使用外部配置文件
Log4j经常与外部日志文件联合使用,这样很多可选项不必硬编码在软件中。使用外部配置文件的优点就是修改可选项不需要重新编译程序。唯一的缺点就是,由于用到io 指令,速度稍微有些减慢。
有两个方法可以用来指定外部配置文件:文本文件或者XML文件。既然现在所有事情都写成XML文件,那么该教程就重点讲解XML文件方法,但是也包含相关文本文件的例子。首先,看看下面的XML配置文件示例:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="ConsoleAppender" class="org.apache.log4j.ConsoleAppender">
<layout class="org.apache.log4j.SimpleLayout"/>
</appender>
<root>
<priority value ="debug" />
<appender-ref ref="ConsoleAppender"/>
</root>
</log4j:configuration>
文件以标准的XML声明作为开始,后面跟着指出DTD(文档类型定义)的DOCTYPE声明,它定义了XML文件的结构,例如,什么元素可以嵌入在其他元素中等等。上面文件在log4j发行版的src/java/org/apache/log4j/xml目录中。 接着看看封装所有元素的 log4j:configuration 元素,它在DOCTYPE声明中被指定为根元素。嵌入在根元素中有两个结构:
<appender name="ConsoleAppender" class="org.apache.log4j.ConsoleAppender">
<layout class="org.apache.log4j.SimpleLayout"/>
</appender>
这里创建一个名叫"ConsoleAppender"的 Appender,注意,你可以选择任何名字,该示例之所以选择"ConsoleAppender",完全是为了示例的设计。接着这个appender类以全名形式给出,经常用规范(fully qualified)类名。 Appender必须具有一个指定的 name和class。嵌入在 Appender之内的是 layout元素,这里它被指定为SimpleLayout。 Layout 必须具有一个 class属性。
<root>
<priority value ="debug" />
<appender-ref ref="ConsoleAppender"/>
</root>
root元素必须存在且不能被子类化。示例中的优先级被设置为"debug",设置appender饱含一个appender-ref元素。还有更多的属性或元素可以指定。查看log4j发行版中的src/java/org/apache/log4j/xml/log4j.dtd以了解关于XML配置文件结构的更多信息。可以用下面这种方法把配置信息文件读入到Java程序中:
DOMConfigurator.configure("configurationfile.xml");
DOMConfigurator 用一棵DOM树来初始化log4j环境。这里是示例中的XML配置文件:plainlog4jconfig.xml。这里是执行该配置文件的程序: files/externalxmltest.java:
import org.apache.log4j.Logger;
import org.apache.log4j.xml.DOMConfigurator;
public class externalxmltest {
static Logger logger = Logger.getLogger(filetest.class);
public static void main(String args[]) {
DOMConfigurator.configure("xmllog4jconfig.xml");
logger.debug("Here is some DEBUG");
logger.info("Here is some INFO");
logger.warn("Here is some WARN");
logger.error("Here is some ERROR");
logger.fatal("Here is some FATAL");
}
}
这里是一个实现带有PatternLayout的FileAppender的日志记录器Logger的XML配置文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="appender" class="org.apache.log4j.FileAppender">
<param name="File" value="Indentify-Log.txt"/>
<param name="Append" value="false"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d [%t] %p - %m%n"/>
</layout>
</appender>
<root>
<priority value ="debug"/>
<appender-ref ref="appender"/>
</root>
</log4j:configuration>
你可以从这里下载示例: xmllog4jconfig2.xml。 想要得到更多的使用XML文件配置log4j环境的例子,请查看log4j发行版的目录src/java/org/apache/log4j/xml/examples/ 。
这就是上面讨论的文本文件形式的配置文件:
# initialise root logger with level DEBUG and call it BLAH
log4j.rootLogger=DEBUG, BLAH
# add a ConsoleAppender to the logger BLAH
log4j.appender.BLAH=org.apache.log4j.ConsoleAppender
# set set that layout to be SimpleLayout
log4j.appender.BLAH.layout=org.apache.log4j.SimpleLayout
从这里可以下载: plainlog4jconfig.txt。这就是执行该配置文件的程序:
import org.apache.log4j.Logger;
import org.apache.log4j.PropertyConfigurator;
public class externalplaintest {
static Logger logger = Logger.getLogger(externalplaintest.class);
public static void main(String args[]) {
PropertyConfigurator.configure("plainlog4jconfig.xml");
logger.debug("Here is some DEBUG");
logger.info("Here is some INFO");
logger.warn("Here is some WARN");
logger.error("Here is some ERROR");
logger.fatal("Here is some FATAL");
}
}
你可以下载使用该配置文件的示例: externalplaintest.java。想要获得更多的使用文本文件配置log4j环境的例子,请查看log4j发行版中的目录examples。
使用外部配置文件的例子就简单的讨论到这里,现在应该可以肯定你已经有能力独立学习更多的log4j发行版和测试版中提供的例子。
华为交换机FDB表四种取值方式:
1. bridge.mib
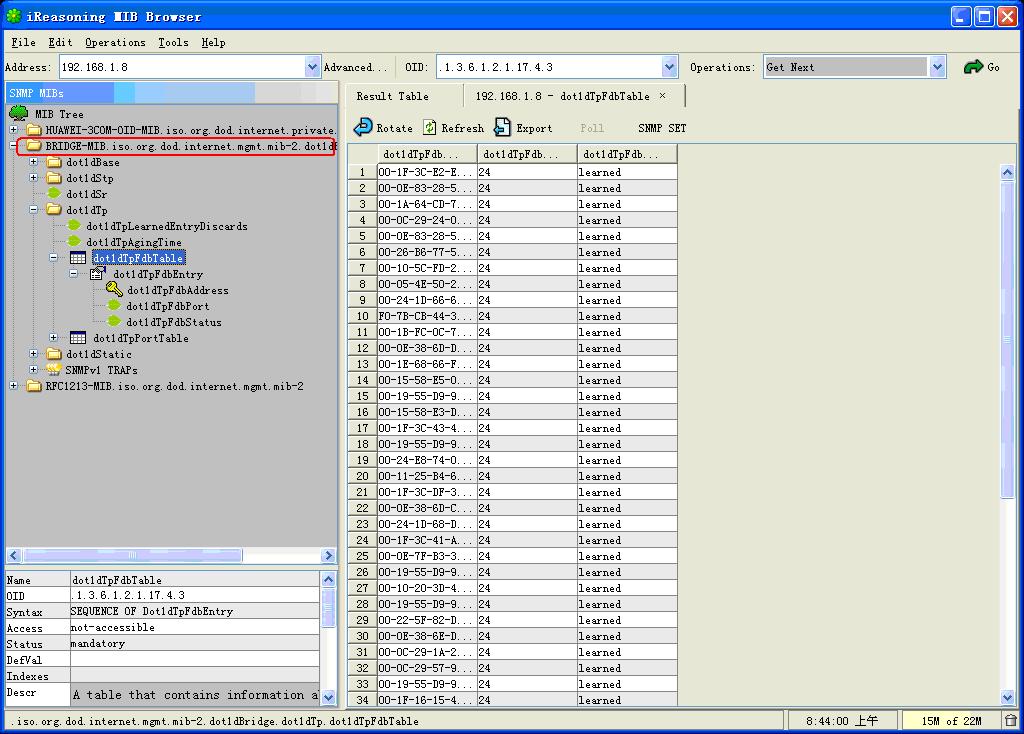
getTable(dot1dTpFdbAddress,dot1dTpFdbPort)
2.q-bridge.mib
 getTable(dot1dTpFdbAddress,dot1dTpFdbPort)
getTable(dot1dTpFdbAddress,dot1dTpFdbPort)
3. huawei-l2mam.mib

walk(hwDynFdbPort)
4. huawei-lswmam.mib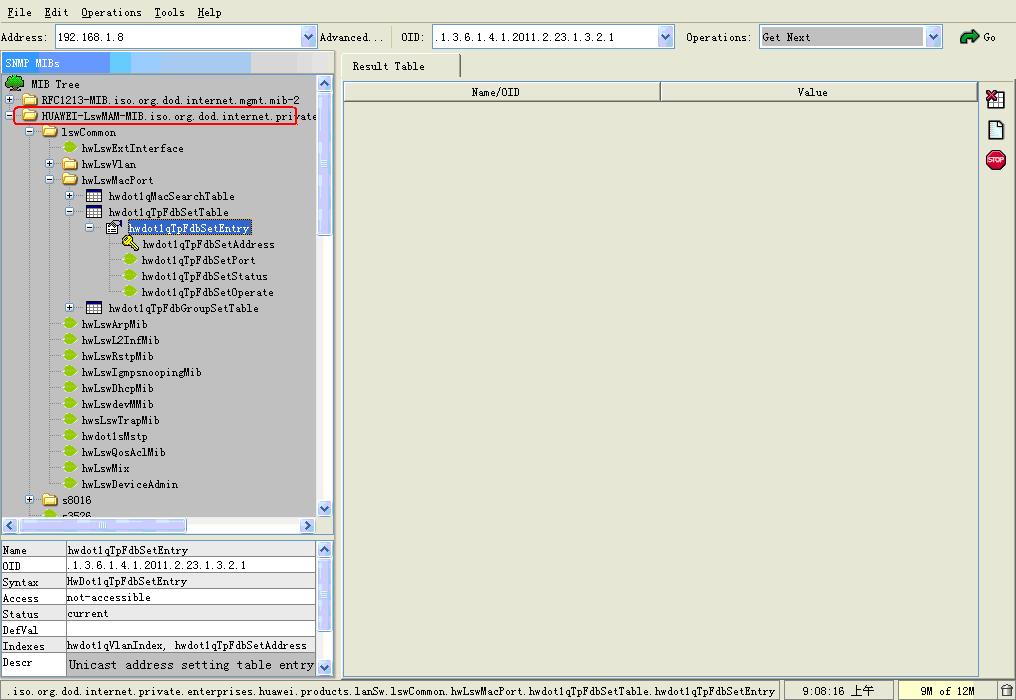
- 在Linux系统中,Tomcat 启动后默认将很多信息都写入到catalina.out 文件中,我们可以通过tail -f catalina.out 来跟踪Tomcat 和相关应用运行的情况。 在windows下,我们使用startup.bat启动Tomcat以后,会发现catalina日志与Linux记录的内容有很大区别,大多信息只输出到屏幕而没有记录到catalina.out里面。
- 本文的内容就是要实现在windows下,将相关的控制台输出记录到后台的catalina.out文件中以便将来查看。
- 关于在Windows2003下如何实现类似Linux下tail命令功能的方法,请见让windows也拥有tail功能一文
把控制台的信息输出到%CATALINA_BASE%\logs\catalina.out里:
一、修改startup.bat中
call "%EXECUTABLE%" start %CMD_LINE_ARGS%
为
call "%EXECUTABLE%" run %CMD_LINE_ARGS%
二、修改catalina.bat中
rem Execute Java with the applicable properties
if not "%JPDA%" == "" goto doJpda
if not "%SECURITY_POLICY_FILE%" == "" goto doSecurity
%_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION%
goto end
:doSecurity
%_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Djava.security.manager -Djava.security.policy=="%SECURITY_POLICY_FILE%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION%
goto end
:doJpda
if not "%SECURITY_POLICY_FILE%" == "" goto doSecurityJpda
%_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% -Xdebug -Xrunjdwp:transport=%JPDA_TRANSPORT%,address=%JPDA_ADDRESS%,server=y,suspend=n %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION%
goto end
:doSecurityJpda
%_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% -Xdebug -Xrunjdwp:transport=%JPDA_TRANSPORT%,address=%JPDA_ADDRESS%,server=y,suspend=n %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Djava.security.manager -Djava.security.policy=="%SECURITY_POLICY_FILE%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION%
goto end
为:
rem Execute Java with the applicable properties
if not "%JPDA%" == "" goto doJpda
if not "%SECURITY_POLICY_FILE%" == "" goto doSecurity
%_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION% >> %CATALINA_BASE%\logs\catalina.out
goto end
:doSecurity
%_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Djava.security.manager -Djava.security.policy=="%SECURITY_POLICY_FILE%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION% >> %CATALINA_BASE%\logs\catalina.out
goto end
:doJpda
if not "%SECURITY_POLICY_FILE%" == "" goto doSecurityJpda
%_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% -Xdebug -Xrunjdwp:transport=%JPDA_TRANSPORT%,address=%JPDA_ADDRESS%,server=y,suspend=n %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION% >> %CATALINA_BASE%\logs\catalina.out
goto end
:doSecurityJpda
%_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% -Xdebug -Xrunjdwp:transport=%JPDA_TRANSPORT%,address=%JPDA_ADDRESS%,server=y,suspend=n %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Djava.security.manager -Djava.security.policy=="%SECURITY_POLICY_FILE%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION% >> %CATALINA_BASE%\logs\catalina.out
goto end
NDP Neighbor Discovery Protocol 邻居发现协议
NTDP Network Topology Discovery Protocol 网络拓扑发现协议
NDP(Neighbor Discovery Protocol)是用来发现邻接点相关信息的协议。支持设备都维护NDP邻居信息表,表项是可以老化的。当老化时间到,自动删除相应的表项。同时,用户可以清除当前的NDP 信息以重新收集邻接信息。
NTDP(Neighbor Topology Discovery Protocol)是用来收集网络拓扑信息的协议。NTDP 为集群管理提供可加入集群的设备信息,收集指定跳数内的交换机的拓扑信息。NDP 为NTDP 提供邻接表信息,NTDP 根据邻接信息发送和转发NTDP 拓扑收集请求,收集一定网络范围内每个设备的NDP 信息和它与所有邻居的连接信息。收集完这些信息后,管理设备或者网管可以根据需要使用这些信息,完成所需的功能。当成员设备上的NDP 发现邻居有变化时,通过握手报文将邻居改变的消息通知管理设备,管理设备可以启动NTDP 进行指定拓扑收集,从而使NTDP 能够及时反映网络拓扑的变化。
生活如永定;价值如连城;
幸福如龙海;长寿比东山;
身体要永泰;事业定长泰;
生意拟建瓯;道路登上杭;
快乐永长乐;笑容如石狮;
人生愿福安;命运靠德化;
运气至将乐;财气冲云霄;
爱情似罗源;缘份聚浦城;
佳人倚屏南;秋眸透闽清;
生活悠宁德;稳定胜龙岩;
闲来学仙游;累了歇闽候;
悠然过连江;漫步武夷山;
春天踏漳浦;夏季潜安溪;
秋来往南靖;冬至望建阳;
客家祖长汀;土楼崇华安;
景美叹松溪;水幽赞尤溪;
世世祈诏安;代代久惠安;
居住乃福州;屋建依晋江;
家广置莆田;户望有霞浦;
雄伟大厦门;门奢赢金门;
饮水来泉州;想吃去沙县;
耕种有大田;丰收看古田;
心静能三明;神怡时南平;
大力举福鼎;脾性当平和;
人心慈平潭;量大自福清;
心静照明溪;为人切清流;
日子挺顺昌;滋润有光泽;
国盛须政和;民心盼永定;
乱世用武平;盛世民柘荣;
健康学邵武;产业富连城;
父母长寿宁;家人常泰宁;
交友圆周宁;诸事全宁化;
祈兄弟永安;祷爱人永春;
祝亲戚漳平;愿朋友南安;
风物满漳州;宝地属福建!
经过对揭阳数据的研究,我终于找到问题的根源。
1. 对路由的发现,以前的代码有点问题。又找出以前的论文,明确一下算法。
2. 揭阳设备路由表的nextHop全是VLAN。所以,这不是H3C或Cisco的问题。如果cisco这样设置,如果没有CDP,目前的程序一样得不出正确的结果。
3. 比较吃惊或者奇怪的是,H3C的设备有支持Bridge.mib,有的支持Q-brideg.mib,而有的二者都有。
4. 另一个,H3C的设备比较奇怪的是,它的bridge-mac不会出现在任何交换机的fdb表。因此,通用的二层链路发现算法无法运用。
5. 因为4,所以我只能从路由表进行发现,对于nextHop是VLAN,必须转成物理接口,然后用排除法(这个算法与通用二层链路算法有点类似,只是不用依赖bridge-mac)判断这条链路是否是真实的物理链路。
6. 根据5,修改了发现程序,对现在数据进行“发现”,得到了正确结果!
04-07
1. 测试了现有的代码,仅找到很少的几条链路,而且结果还不正确。
2. 最奇怪的是,bridge.mib里的fdb表都没有数据,我的发现算法是基于fdb来作的,
fdb表没数据,肯定找不到链路。
3. 突然想起北京同事说的NDP,于是想用华为的NDP试试,加载huawei-hgmp.mib,
结果发现H3C的设备里根本没有数据,太失望了。
04-08
1. 想起三年前在安徽恒源的痛苦经历,但最终是用STP得到正确的结果。于是,我又试了
基于STP的发现,还是没结果。为什么?因为STP里的数据不满足算法的要求。
2. 看来这次真的遇到挑战了。路由表里全是OSPF,我又想起曾经看过一篇文章,写的是基本
OSPF的拓扑发现。在网上搜索了半天,只有万方的论文里有相关文章,无奈之下,只好用
手机短信花了3块钱下了一篇论文。按论文里的算法,改了程序,经测试后,虽然有点进步,
但仍有多台设备处于孤立状态,找不到链路,太郁闷了。
3. 用SolarWinds下载了所有h3c上的mib,回宾馆研究。发现SolarWinds在win7下的一个bug,
导出功能完全不能用,我只好把结果存成txt。
04-09
1. 从下载的mib数据中惊奇地发现,h3c使用了Q-bridge而不是bridge,这就难怪bridge里的fdb
表没有数据。这又让我心中燃起了希望。但Q-bridge里的address这一字段没数据,所以要用
walk(而不是table)才能取到数据。
2. 专门写了一个取Q-bridge fdb表数据的类。核心交换h3c7510中的fdb表项巨大,大约有800条
之多,snmp4j没取完就超时了,用SolarWinds也会出现超时的现象。
3. 再次测试了发现程序,由于有了fdb表的数据,多找出好多链路,但仍不完整。
4. 收集了所有设备的mib数据,回广州慢慢研究。
在揭阳的三天三夜,紧张而痛苦。我真的遇到一个大难题......
stored procedure
创建
create procedure sp_name()
begin
………
end
调用
call sp_name()
注意:存储过程名称后面必须加括号,哪怕该存储过程没有参数传递
删除
drop procedure sp_name
其他
1.show procedure status
显示数据库中所有存储的存储过程基本信息,包括所属数据库,存储过程名称,创建时间等
2.show create procedure sp_name
显示某一个存储过程的详细信息
例子:
CREATE PROCEDURE `bag_app_flow`()
insert into bag_app_flow
select pid,avg(in_speed),avg(out_speed),max(log_time) log_time
from bag_app_flow_raw
where hour(now()) - hour(log_time) = 1
group by pid,date_format(log_time,'%Y-%m-%d %H');
--------------
event
使用下列的任意一句开启计划任务:
SET GLOBAL event_scheduler = ON;
SET @@global.event_scheduler = ON;
SET GLOBAL event_scheduler = 1;
SET @@global.event_scheduler = 1;
Event Scheduler创建的基本语法是:
CREATE EVENT
[IF NOT EXISTS]
event_name
ON SCHEDULE schedule
[ON COMPLETION [NOT] PRESERVE]
[ENABLE | DISABLE]
[COMMENT 'comment']
DO sql_statement
如果要调用procedure
call sp_name() ,如
create event flow_job
on schedule every 1 hour
starts '2009-12-26 18:06:00'
do
call bag_ip_flow();
如果有多个procedures,则要加begin...end,如
create event flow_job
on schedule every 1 hour
starts '2009-12-26 18:06:00'
do
begin
call bag_app_flow();
call bag_ip_flow();
call bag_ip_group_flow();
end
在研究了思科的Trap以及朗讯的Trap后,总结出处理trap的思路:
摘要: JPCAP——JAVA中的数据链路层控制
一.JPCAP简介
众所周知,JAVA语言虽然在TCP/UDP传输方面给予了良好的定义,但对于网络层以下的控制,却是无能为力的。JPCAP扩展包弥补了这一点。
JPCAP实际上并非一个真正去实现对数据链路层的控制,而是一个中间件,JPCAP调用wincap/libpcap,而给JAVA语言提供一个公共的接口,从而实现了平台无关性。...
阅读全文
码率就是数据传输时单位时间传送的数据位数,一般我们用的单位是kbps即千位每秒。
通俗一点的理解就是取样率,单位时间内取样率越大,精度就越高,处理出来的文件就越接近原始文件,但是文件体积与取样率是成正比的,所以几乎所有的编码格式重视的都是如何用最低的码率达到最少的失真,围绕这个核心衍生出来的cbr(固定码率)与vbr(可变码率),都是在这方面做的文章,不过事情总不是绝对的,从音频方面来说,码率越高,被压缩的比例越小,音质损失越小,与音源的音质越接近。
计算机中的信息都是二进制的0和1来表示,其中每一个0或1被称作一个位,用小写b表示,即bit(位);大写B表示byte,即字节,一个字节=八个位,即1B=8b;前面的大写K表示千的意思,即千个位(Kb)或千个字节(KB)。表示文件的大小单位,一般都使用字节(KB)来表示文件的大小。
Kbps:首先要了解的是,ps指的是/s,即每秒。Kbps又称比特率,指的是数字信号的传输速率,也就是每秒钟传送多少个千位的信息(K表示千位,Kb表示的是多少千个位);Kbps也可以表示网络的传输速度,为了在直观上显得网络的传输速度较快,一般公司都使用kb(千位)来表示,如果是KBps,则表示每秒传送多少千字节。1KByte/s=8Kbps(一般简写为1KBps=8Kbps)。ADSL上网时的网速是512Kbps,如果转换成字节,就是512/8=64KBps(即64千字节每秒)
在这里需要说明的问题是在单位换算上有一点是极其重要的即:1Mb=1024kb=1024000b 而1MB=1024KB=1024*1024B=1024*1024*8b=8388608b这在数量上差的很多
值得注意的是:
1KB=1024B=1024*8b 1kB=1000B=8000b
1Kb=1kb=1000b
在单位换算上一定要注意 正常是以KBps来表示带宽
KBps与kBps的区别
小k代表kilo,千的意思,也就是1000,而B就是字节的意思,ps就是每秒的意思,那么连起来Bps就是字节每秒的意思。
那么kBps就是1000Bps也就是一千字节每秒的意思。
而大家都知道在电脑里,KB和B是不同的单位,他们之间换算是1KB=1024B的。
而KBps(K为大写字母)就等于1024Bps。而kBps(k为小写字母)的意思是千字节每秒。
千字节每秒(KBps)与一千字节每秒(kBps)是不同的。
KBps=1024Bps,kBps=1000Bps
也就是说KBps>kBps [1]
人们常用Kbps形容音乐的听觉效果。
在WINDOWS 中它被称为“位速”,在一些播放器中被形容为“比特率”。
质量是指将数字声音由模拟格式转化成数字格式的采样率,采样率越高,还原后的音质就越好。
●Kbps值与现实音频对照:
16Kbps=电话音质
24Kbps=增加电话音质、短波广播、长波广播、欧洲制式中波广播
40Kbps=美国制式中波广播
56Kbps=话音
64Kbps=增加话音(手机铃声最佳比特率设定值、手机单声道MP3播放器最佳设定值)
112Kbps=FM调频立体声广播
128Kbps=磁带(手机立体声MP3播放器最佳设定值、低档MP3播放器最佳设定值)
160Kbps=HIFI高保真(中高档MP3播放器最佳设定值)
192Kbps=CD(高档MP3播放器最佳设定值)
256Kbps=Studio音乐工作室(音乐发烧友适用)
实际上随着技术的进步,音乐质量也越来越高,MP3的最高质量为320Kbps,但一些格式可以达到更高的质量和更高的音质。
比如正逐渐兴起的APE音频格式,能够提供真正发烧级的无损音质和相对于WAV格式更小的体积,其质量通常为550kbps-----950kbps。
其他: 常见编码模式:
VBR(Variable Bitrate)动态比特率 也就是没有固定的比特率,压缩软件在压缩时根据音频数据即时确定使用什么比特率,这是以质量为前提兼顾文件大小的方式,推荐编码模式;
ABR(Average Bitrate)平均比特率 是VBR的一种插值参数。LAME针对CBR不佳的文件体积比和VBR生成文件大小不定的特点独创了这种编码模式。ABR在指定的文件大小内,以每50帧(30帧约1秒)为一段,低频和不敏感频率使用相对低的流量,高频和大动态表现时使用高流量,可以做为VBR和CBR的一种折衷选择。
CBR(Constant Bitrate),常数比特率 指文件从头到尾都是一种位速率。相对于VBR和ABR来讲,它压缩出来的文件体积很大,而且音质相对于VBR和ABR不会有明显的提高。
产品功能介绍
一、 网络管理
1. 网络拓扑自动发现。输入核心设备的IP地址或核心子网的网络地址,系统自动发现设备以及链路,完成后画出全网物理拓扑图。
2. 拓扑图展现。
① 将网络自动发现结果的以拓扑图的形式进行展示,提供设备、链路的实时信息。用户也可对该图进行自定义的布局。
② 不同设备类型以不同的图标进行展示,而且随着设备运行状态(CPU使用率、内存使用率和链路连通状态等)变化其图标颜色(蓝>黄>红)亦相应变化。
③ 可按IP或机器名搜索,快速定位到设备。
④ 可将拓扑图另存为JPG图片。
⑤ 鹰眼视图为全网络的缩略图,点击其中任一个点可定位到视图上的设备。
3.设备基本性能数据。CPU、内存、接口表、路由表、ARP表等。同时,可下载设备配置文件,以作备份。
二、 服务器管理
1.基本性能信息:CPU、内存、硬盘/文件系统利用率。
2.端口使用情况、进程存活、安装软件、裸文件(Aix)。
3.可采集服务器日志作统计分析。
三、 数据库管理
1. Oracle
①基本信息:所处的服务器名、数据库版本、大小。
②响应时间、用户连接数、用户权限角色。
③数据库状态、表空间利用率、数据库锁。
④ SGA击中率、用户会话、SQL执行情况。
2. MS-SQL
①基本信息:数据库所在的主机名、数据库版本、数据库文件路径。
②响应时间、缓存击中率、内存使用信息、查询页信息。
③事务锁等待时间、数据文件大小、活动用户数。
3. My-SQL
①基本信息:数据库所在操作系统的类型、数据库版本、数据库安装路径、数据文件路径。
②响应时间、每分钟请求数、每秒发送/接收字节数、连接信息、线程信息。
③表详细信息、用户会话。
四、 中间件管理
1. Weblogic
①基本信息:操作系统类型、版本、使用JAVA版本、提供者。
②响应时间、JVM使用率、JDBC连接池。
③线程池、web应用会话。
2. Websphere
①响应时间、JVM使用率。
② JDBC连接池、线程池、servlet会话。
3. Tomcat
①基本信息:Tomcat版本、操作系统类型、版本、JAVA版本、提供者。
②响应时间、链接器线程、JVM堆栈使用情况、服务器请求。
③数据库连接池、web会话。
五、Web服务器
1. HTTP URL
①页面大小。
②响应时间。
2. IIS
①响应时间。
② IIS里各网站的性能参数。
六、IP地址管理
1. 基于子网的IP地址分布图。
2. 基于子网的IP地址使用情况统计。
3. IP-MAC地址绑定,或者IP-MAC-交换机端口绑定。
4. IP定位:确定IP地址上联交换机的端口。
七、事件及告警管理
1. 可接收设备Syslog数据,按关键字匹配把Syslog转成系统告警。
2. 可接收设备SNMP Trap数据,可处理通用Trap数据。同时,可按产商私有MIB来翻译产商特殊的Trap数据,并转换成系统告警(需定制开发)。
曾经成功完成对朗读ATM交换机Trap数据的完全解析。
3. 告警设置不仅限于阀值越界告警,还有属性匹配告警、属性变化告警以及实体增加或删除告警。
4. 告警分析实现告警压缩、告警合并(告警根源分析)、告警升级以及告警恢复通知。
5. 告警通知方式:Email、声音、弹出窗口和手机短信。
6. 控制告警通知方式:连续式(每产生一次告警都发通知)、跳跃式(每隔3次告警才发通知)和一次式(仅发一次通知)。
八、报表管理
1. 网络设备整体性能报表。
2. 服务器整体性能报表。
3.网络设备接口性能报表。
4.服务器接口性能报表。
九、流量管理
1. 支持Netflow V5和V9。
2. 对于较小的网络(设备数在100内),可以用交换机端口镜像(span)。系统用JPCAP采集原始数据。
十、可定制开发其它功能,比如实现对防火墙、防病毒系统和IDS的日志采集和分析。
系统截图
http://www.blogjava.net/afunms/gallery/43080.html
用jar打包classes,老是会忘记
C:\java\jdk1.6.0_03\bin>jar cvf c:/nms.jar classes/*.*
ATM
网的拓扑发现,在网上根本找不到相关资料,经过自己长时间的研究,终于有了结果。经过实际验证,证明是正确的。
其实它比IP网的拓扑发现要简单得多。
获取PVC:
PSAX ATM中有4种PVC:
ATM2ATM PVC
cirEm2ATM PVC
bridge2ATM PVC
gige2ATM PVC
由于在acmib中没有定义gige2ATM PVC,所以只能找到其他三种PVC。
三种PVC的获取方法:
|
PVC
|
Table
|
OID
|
|
ATM2ATM
|
atmPvcVccTable
|
1.3.6.1.4.1.1751.2.18.6.1.1
|
|
cirEm2ATM
|
cirEmAtmPvcVccTable
|
1.3.6.1.4.1.1751.2.18.6.6.1
|
|
bridge2ATM
|
bridgeAtmPvcVccTable
|
1.3.6.1.4.1.1751.2.18.6.13.1
|
算法:
(1) 找出所有active的pvc。
(2) pvc相同且pvc的服务类型(serviceType)相同的两个atm之间存在一条物理链路。这两表中sreviceType的代码所表示的serviceType不相同,比如在atmPvcVccTable中serviceType定义为
SYNTAX INTEGER {
ubr(1),
vbr-nrt2(2),
vbr-nrt1(3),
vbr-rt2(4),
vbr-rt1(5),
vbr-express(6),
cbr4(7),
cbr3(8),
cbr2(9),
cbr1(10),
gfr2(11)
}
而在cirEmAtmPvcVccTable中为
SYNTAX INTEGER {
cbr-1(1),
cbr-2(2),
cbr-3(3),
cbr-4(4)
}
所以不能比较数字,而应该比较字符串。
(3) 要得到pvc及其所在的接口,就必须得到三个表中的index,以bridgePvcVccTable为例:
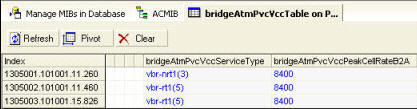
以第一行来说明 1305001.101001.11.260
1305001 interface sideA
101001 interface sideB
11.260 即PVC
所以在台ATM中11-260这条PVC就是接在sideB(为什么取sideB而不是sideA?我现在还不明白)101001这个接口上。Interface的格式为SSPPCCC,以此得到物理接口0101。
有些链路找不到,可以肯定地说,是因为找不到gige2ATM pvc。
有了以上三张表,很容易把PSAX Trap翻译过来:
/** *//**
* 翻译snmp trap
*/
private String translatePsaxTrap(Connection conn,SnmptrapDto dto) throws Exception{
StringBuffer trap = new StringBuffer(200);
Statement stat = conn.createStatement();
String oid = dto.getOid() + "." + dto.getSpecifics();
ResultSet rs = stat.executeQuery("select b.description from acmib_oid a,acmib_event b where a.oid='" + oid + "' and a.symbol=b.symbol");
if(rs.next())
trap.append(rs.getString(1));
String[] msgs = dto.getMessage().split(",");
/** *//**
* 过滤掉最后一行1.3.6.1.4.1.1751.2.18.1.146.
*/
for(int i=0;i < msgs.length - 1;i++){
String[] _msgs = msgs[i].split("=");
String _oid = _msgs[0].substring(0,_msgs[0].length() - 3); //去掉最后.0
String _value = _msgs[1].trim();
rs = stat.executeQuery("select * from acmib_oid where oid='" + _oid + "'");
if(rs.next()){
trap.append(rs.getString("symbol")).append("=").append(_msgs[1]);
if(rs.getString("symbol").endsWith("Code")){
ResultSet _rs = stat.executeQuery("select * from acmib_code where symbol='" + rs.getString("symbol") + "' and code=" + _value);
if(_rs.next())
trap.append("[").append(_rs.getString("description")).append("]");
}
trap.append(",");
}
}
return trap.toString();
}
(这里省略了接受SNMP Trap的代码)
举例1:
Trap原包内容:
oid=1.3.6.1.4.1.1751.2.18.8.4
specifics=67
message=
1.3.6.1.4.1.1751.2.18.6.31.1.1.0 = 1309001,
1.3.6.1.4.1.1751.2.18.6.33.1.1.0 = 14,
1.3.6.1.4.1.1751.2.18.6.33.1.2.0 = 153,
1.3.6.1.4.1.1751.2.18.6.33.1.3.0 = 45:86:20:02:00:88:01:00:0f:00:00:00:00:00:00:06:00:90:01:77,
1.3.6.1.4.1.1751.2.18.6.33.1.4.0 = 301001,
1.3.6.1.4.1.1751.2.18.6.33.1.5.0 = 0,
1.3.6.1.4.1.1751.2.18.6.33.1.6.0 = 669,
1.3.6.1.4.1.1751.2.18.1.146.1.1.0 = 100286
翻译后:
Notification that a SPVC connection between ATM and ATM endpoints has been deleted. spvcAddrIfA= 1309001,
atmAtmSpvcVccVpiA= 14,
atmAtmSpvcVccVciA= 153,
atmAtmSpvcVccRemoteAtmPortAddr= 45:86:20:02:00:88:01:00:0f:00:00:00:00:00:00:06:00:90:01:77,
atmAtmSpvcVccIfB= 301001,
atmAtmSpvcVccVpiB= 0,
atmAtmSpvcVccVciB= 669,
(这个atmAtmSpvcVccRemoteAtmPortAddr应该能转成一个IP或Interface,暂时没搞明白)
很明显,可以明白是一条ATM2ATM的SPVC被删除。
举例2:
Trap原包内容:
oid=1.3.6.1.4.1.1751.2.18.8.3
specifics=104
message=
1.3.6.1.4.1.1751.2.18.15.2.0 = 1309001,
1.3.6.1.4.1.1751.2.18.15.4.0 = 67,
1.3.6.1.4.1.1751.2.18.1.146.1.1.0 = 100374,
翻译后:
Notification that a interface has undergone reduction in bandwidth. Critical depending on Failure Reason Code.interfaceIndex= 1309001,interfaceFailureReasonCode= 67[newBWBelowCurrentAllocated]
可以看明白,是一个通道的带宽被改小了。
最后,用mibble把acmib所有代码和它相应的描述导入数据库。
/** *//**
* 导入acmib中所有类型代码与描述的对映
*/
public void importCode(){
MibBrowser mb = new MibBrowser();
Mib mib = mb.getMib("e:/ACMIB.mib");
List mvss = (List)mib.getAllSymbols();
Connection conn = ConnectionManager.getConnection();
int id = 1;
try{
Statement stat = conn.createStatement();
for(int i=0,n=mvss.size();i<n;i++){
if(mvss.get(i) instanceof MibValueSymbol
&& ((MibValueSymbol)mvss.get(i)).getType() instanceof SnmpObjectType) {
MibValueSymbol mvs = (MibValueSymbol)mvss.get(i);
SnmpObjectType soType = (SnmpObjectType)mvs.getType();
if(soType.getSyntax() instanceof IntegerType){
IntegerType intType = (IntegerType)soType.getSyntax();
MibValueSymbol[] itss = intType.getAllSymbols();
if(itss.length > 0)
for(int j=0;j < itss.length;j++){
stat.addBatch("insert into acmib_code(id,symbol,code,description)values("
+ id + ",'" + mvs.getName() + "'," + itss[j].getValue() + ",'" + itss[j].getName() + "')");
id++;
}
}
}
if( id % 100 == 0)
stat.executeBatch();
}
stat.executeBatch();
}catch(Exception e){
e.printStackTrace();
}
}
结果如下:
这样,为翻译psax trap的所有的基础数据都准备好了。
接着,用mibble把acmib中所有事件导入数据库:
/** *//**
* 导入事件
*/
public void importEvent(){
MibBrowser mb = new MibBrowser();
Mib mib = mb.getMib("e:/ACMIB.mib");
List mvss = (List)mib.getAllSymbols();
Connection conn = ConnectionManager.getConnection();
int id = 1;
try{
Statement stat = conn.createStatement();
for(int i=0,n=mvss.size();i<n;i++){
if(mvss.get(i) instanceof MibValueSymbol
&& ((MibValueSymbol)mvss.get(i)).getType() instanceof SnmpNotificationType) {
MibValueSymbol mvs = (MibValueSymbol)mvss.get(i);
SnmpNotificationType snt = (SnmpNotificationType)mvs.getType();
String descr = null;
String originDescr = null;
if(snt.getDescription().indexOf(":") > 0)
descr = snt.getDescription().substring(snt.getDescription().indexOf(":") + 2);
else
descr = snt.getDescription();
if(descr.indexOf("Return value") > 0)
descr = descr.substring(0,descr.indexOf("Return value"));
if(descr.indexOf("Data send with the trap") > 0)
descr = descr.substring(0,descr.indexOf("Data send with the trap"));
descr = descr.replaceAll("\n", " ");
descr = descr.replaceAll("'", "''");
originDescr = snt.getDescription().replaceAll("'", "''");
stat.addBatch("insert into acmib_event(id,symbol,description,origin_description)values(" + id + ",'" + mvs.getName() + "','" + descr + "','" + originDescr + "')");
id++;
if( id % 100 == 0)
stat.executeBatch();
}
}
stat.executeBatch();
}catch(Exception e){
e.printStackTrace();
}
}
结果如下:

今天终于实现把朗讯PSAX ATM交换机的SNMP Trap翻译成明文的功能。前后花了四天的时间。
开始,我想用mibble把acmib完全解析出来,但折腾了一整天,都没有结果,至少最重要的OID是终始出不来,可能是我不会用mibble吧。
接着换种思路,用SolarWinds(一个很好用的mib browser)把acmib copy成纯文本。
 文本如下:
文本如下:
acMIB 1.3.6.1.4.1.1751.2.18
connectionConfig 1.3.6.1.4.1.1751.2.18.6
atmAtmSpvcVccTable 1.3.6.1.4.1.1751.2.18.6.33
atmAtmSpvcVccEntry 1.3.6.1.4.1.1751.2.18.6.33.1
atmAtmSpvcVccStatsInOdometerCellCountHiB 1.3.6.1.4.1.1751.2.18.6.33.1.50
atmAtmSpvcVccStatsInOdometerCellCountLoA 1.3.6.1.4.1.1751.2.18.6.33.1.47
atmAtmSpvcVccStatsInOdometerCellCountLoB 1.3.6.1.4.1.1751.2.18.6.33.1.51
atmAtmSpvcVccStatsOdometerReset 1.3.6.1.4.1.1751.2.18.6.33.1.55
atmAtmSpvcVccStatsOdometerTimer 1.3.6.1.4.1.1751.2.18.6.33.1.54
atmAtmSpvcVccStatsOutCellCountHiA1.3.6.1.4.1.1751.2.18.6.33.1.37
atmAtmSpvcVccStatsOutCellCountHiB1.3.6.1.4.1.1751.2.18.6.33.1.41
atmAtmSpvcVccStatsOutCellCountLoA 1.3.6.1.4.1.1751.2.18.6.33.1.38
atmAtmSpvcVccStatsOutCellCountLoB 1.3.6.1.4.1.1751.2.18.6.33.1.42
atmAtmSpvcVccStatsOutOdometerCellCountHiA1.3.6.1.4.1.1751.2.18.6.33.1.48
atmAtmSpvcVccStatsOutOdometerCellCountHiB1.3.6.1.4.1.1751.2.18.6.33.1.52
atmAtmSpvcVccStatsOutOdometerCellCountLoA 1.3.6.1.4.1.1751.2.18.6.33.1.49
atmAtmSpvcVccStatsOutOdometerCellCountLoB 1.3.6.1.4.1.1751.2.18.6.33.1.53
atmAtmSpvcVccStatsTimer 1.3.6.1.4.1.1751.2.18.6.33.1.43
atmAtmSpvcVccSusCellRateA2B 1.3.6.1.4.1.1751.2.18.6.33.1.10
atmAtmSpvcVccSusCellRateB2A 1.3.6.1.4.1.1751.2.18.6.33.1.16
atmAtmSpvcVccTfcDescModify 1.3.6.1.4.1.1751.2.18.6.33.1.70
atmAtmSpvcVccTrafficShapingA2B 1.3.6.1.4.1.1751.2.18.6.33.1.64
atmAtmSpvcVccTrafficShapingB2A 1.3.6.1.4.1.1751.2.18.6.33.1.65
atmAtmSpvcVccType 1.3.6.1.4.1.1751.2.18.6.33.1.20
atmAtmSpvcVccVciA 1.3.6.1.4.1.1751.2.18.6.33.1.2
atmAtmSpvcVccVciB 1.3.6.1.4.1.1751.2.18.6.33.1.6
atmAtmSpvcVccViA 1.3.6.1.4.1.1751.2.18.6.33.1.56
……
把这个文本导入数据库:
/** *//**
* acmib.mib有两个版本,此方法把两个版本中数据都导入数据库.
* 但保证不会有重复的oid
*/
public void importOid(){
Connection conn = ConnectionManager.getConnection();
try{
Statement stat = conn.createStatement();
BufferedReader in1 = new BufferedReader(new FileReader("e:/acmib.txt"));
String row = null;
int id = 1;
while((row=in1.readLine())!=null){
int loc = row.indexOf("1.3.6.");
String symbol = row.substring(0, loc - 1).trim();
String oid = row.substring(loc).trim();
stat.addBatch("insert into acmib_oid(id,oid,symbol)values(" + id + ",'" + oid + "','" + symbol + "')");
id++;
if( id % 100 == 0)
stat.executeBatch();
}
stat.executeBatch();
ResultSet rs = stat.executeQuery("select oid from acmib_oid order by oid");
List<String> oids = new ArrayList<String>();
while(rs.next())
oids.add(rs.getString(1));
BufferedReader in2 = new BufferedReader(new FileReader("e:/acmib2.txt"));
while((row=in2.readLine())!=null){
String[] rowCols = row.split(" ");
if(oids.contains(rowCols[2])) continue;
stat.addBatch("insert into acmib_oid(id,oid,symbol)values(" + id + ",'" + rowCols[2] + "','" + rowCols[1] + "')");
id++;
if( id % 100 == 0)
stat.executeBatch();
}
stat.executeBatch();
}catch(Exception e){
e.printStackTrace();
}
}
结果如下:

2009年10月 江西之行:
庐山--九江--南昌
到目前为止,我走过的地方:
吉林:长春
辽宁:沈阳
河北:秦皇岛、衡水
北京
山东:济南、淄博、潍坊、泰安
安徽:淮北
江苏:徐州
重庆
陕西:安康
江西:南昌、九江
福建:福州、厦门、泉州、漳州、龙岩、南平、三明
广东:广州、佛山、中山、韶关、惠州、云浮、河源、阳江、潮州、茂名
在rfc1213.mib,接口组中:
if InOctets --接口发送的字节数
ifOutOctets --接口接收到的字节数
if InUcastPkts --输入的单播包数
ifOutUcastPkts --输出的单播包数
if InNUcastPkts --输入的非单播包数
ifOutNUcastPkts --输出的非单播包数
if InDiscards --接口丢弃的输入包数
ifOutDiscards --接口丢弃的输出包数
if InErrors --包含错误的输入包数
ifOutErrors --包含错误的输出包数
ifinUnkownProtos --由于定向到一个未知或
不支持的协议而被丢弃的包数
ifOutQlen --输出队列中的所有包数
portName --端口的名称
性能管理应用一般要观察接口的利用率、错误
率、丢包率等。这些性能参数都分为输入和输出两
种情况。下面给出计算公式:
输入利用率= (Δif InOctets * 8) / (ifSpeed * T) * 100 %
输出利用率= (ΔifOutOctets * 8) / (ifSpeed * T) * 100 %
输入差错率= Δif InErrors/ (Δif InUcastPks + Δif InNucastPks) * 100 %
输出差错率= ΔifOutErrors/ (ΔifOutUcastPks + ΔifOutNucastPks) * 100 %
输入丢包率=Δif InDiscards/ T
输出丢包率=ΔifOutDiscards/ T
与你同事一年多,你的敬业精神和技术水平都给大家留下很深的印象。
今天见你最后一眼,突然间,我哭了。
明天是父亲节,初为人父的你,还没来得及享受这个天伦之乐就匆匆离去.....
但愿你在另一个世界不再受病魔的折磨!
同时祝你的家人平安幸福。
7:30:起床。英国威斯敏斯特大学的研究人员发现,那些在早上5:22—7:21分起床的人,其血液中有一种能引起心 脏病的物质含量较高,因此,在7:21之后起床对身体健康更加有益。打开台灯。“一醒来,就将灯打开,这样将会重新调整体内的生物钟,调整睡眠和醒来模式。”拉夫堡大学睡眠研究中心教授吉姆·霍恩说。喝一杯水。水是身体内成千上万化学反应得以进行的必需物质。早上喝一杯清水,可以补充晚上的缺水状态。
7:30—8:00:在早饭之前刷牙。“在早饭之前刷牙可以防止牙齿的腐蚀,因为刷牙之后,可以在牙齿外面涂上一层含氟的保护层。要么,就等早饭之后半小时再刷牙。”英国牙齿协会健康和安全研究人员戈登·沃特金斯说。
8:00—8:30:吃早饭。“早饭必须吃,因为它可以帮助你维持血糖水平的稳定,”伦敦大学国王学院营养师凯文·威尔伦说。早饭可以吃燕麦粥等,这类食物具有较低的血糖指数。
8:30—9:00:避免运动。来自布鲁奈尔大学的研究人员发现,在早晨进行锻炼的运动员更容易感染疾病,因为免疫系统在这个时间的功能最弱。步行上班。马萨诸塞州大学医学院的研究人员发现,每天走路的人,比那些久坐不运动的人患感冒病的几率低25%。
9:30:开始一天中最困难的工作。纽约睡眠中心的研究人员发现,大部分人在每天醒来的一两个小时内头脑最清醒 。
10:30:让眼睛离开屏幕休息一下。如果你使用电脑工作,那么每工作一小时,就让眼睛休息3分钟。
11:00:吃点水果。这是一种解决身体血糖下降的好方法。吃一个橙子或一些红色水果,这样做能同时补充体内的铁含量和维生素C含量。
13:00:在面包上加一些豆类蔬菜。你需要一顿可口的午餐,并且能够缓慢地释放能量。“烘烤的豆类食品富含纤维素,番茄酱可以当作是蔬菜的一部分。”维伦博士说。
14:30—15:30:午休一小会儿。雅典的一所大学研究发现,那些每天中午午休30分钟或更长时间,每周至少午休3次的人,因心脏病死亡的几率会下降37%。
16:00:喝杯酸奶。这样做可以稳定血糖水平。在每天三餐之间喝些酸牛奶,有利于心脏健康。
17:00—19:00:锻炼身体。根据体内的生物钟,这个时间是运动的最佳时间,舍菲尔德大学运动学医生瑞沃·尼克说。
19:30:晚餐少吃点。晚饭吃太多,会引起血糖升高,并增加消化系统的负担,影响睡眠。晚饭应该多吃蔬菜,少吃富含卡路里和蛋白质的食物。吃饭时要细嚼慢咽。
21:45:看会电视。这个时间看会儿电视放松一下,有助于睡眠,但要注意,尽量不要躺在床上看电视,这会影响睡眠质量。
23:00:洗个热水澡。“体温的适当降低有助于放松和睡眠。”拉夫堡大学睡眠研究中心吉姆·霍恩教授说。
23:30:上床睡觉。如果你早上7点30起床,现在入睡可以保证你享受8小时充足的睡眠。
例:select * from tbl where uyear='''06'
请注意其中红色背景的单引号,它即表示转义字符,如果我们省略,则整个语句会出错,转义字符不会输出,上例中 uyear 的实际条件值为 '06,而不是 ''06
为什么不能省略呢,假如我们省略,上句变成:select * from tbl where uyear=''06'
由于在 SQL 中单引号表示字符串的开始和结束符号,于是 SQL 解释器会认为语句中灰色背景的为字符串,其后的语句显然是个错误的语句,当然会报错,为了解决字符串的单引号问题,就出现了转义字符单。
解决了我的一个大问题,不然程序就要大改了。
Source: CCTV.com
04-21-2009 13:29
Oracle Corporation has snapped up computer server and software maker Sun Microsystems for 7.4 billion US dollars. It trumped rival IBM's attempt to buy one of Silicon Valley's best known, and most troubled, companies.
Monday's deal comes after a month-long drama that entered its final chapter last week. IBM had retracted an earlier buyout offer after the two sides couldn't agree on key details.
Oracle has traditionally been a business software maker. It will now be able to use Sun's assets to build a more comprehensive one-stop technology shop. The deal gives Oracle ownership of the Java programming language, which runs on more than a billion devices around the world.
今天在电视上听到这消息,真是挺吃惊的。对于一个长期从事Java开发的程序员来说,对Sun有一种特殊的感情。现在Sun突然从地球上消失了。。。。,很难接受这样的事实。
http://en.wikipedia.org/wiki/Workflow
A workflow is a depiction of a sequence of operations, declared as work of a person, work of a simple or complex mechanism, work of a group of persons,work of an organization of staff, or machines. Workflow may be seen as any abstraction of real work, segregated in workshare, work split or whatever types of ordering. For control purposes, workflow may be a view on real work under a chosen aspect,thus serving as a virtual representation of actual work. The flow being described often refers to a document that is being transferred from one step to another.
A workflow is a model to represent real work for further assessment, e.g., for describing a reliably repeatable sequence of operations. More abstractly, a workflow is a pattern of activity enabled by a systematic organization of resources, defined roles and mass, energy and information flows, into a work process that can be documented and learned.Workflows are designed to achieve processing intents of some sort, such as physical transformation, service provision, or information processing.
Workflow concepts are closely related to other concepts used to describe organizational structure, such as silos, functions, teams, projects, policies and hierarchies. Workflows may be viewed as one primitive building block of organizations. The relationships among these concepts are described later in this entry.
The term workflow is used in computer programming to capture and develop human to machine interaction. Workflow software aims to provide end users with an easier way to orchestrate or describe complex processing of data in a visual form, much like flow charts but without the need to understand computers or programming.
(1) 创建MySQL数据库osworkflow
新建osworkflow数据库,然后导入osworkflow\src\etc\deployment\jdbc\mysql.sql
(2) 在Tomcat下创建配置文件
tomcat5.5.23\conf\Catalina\localhost\osworkflow.xml
<?xml version='1.0' encoding='utf-8'?>
<Context path="/osworkflow" debug="0" reloadable="true">
<Resource
name="jdbc/DefaultDS"
type="javax.sql.DataSource"
driverClassName="com.mysql.jdbc.Driver"
maxIdle="10"
maxWait="5000"
username="root"
password="root"
url="jdbc:mysql://localhost:3306/osworkflow?useUnicode=true&characterEncoding=utf-8"
maxActive="20"/>
</Context>
(3)修改WEB-INF\classes\osuser.xml
<opensymphony-user>
<provider class="com.opensymphony.user.provider.jdbc.JDBCAccessProvider">
<property name="user.table">os_user</property>
<property name="group.table">os_group</property>
<property name="membership.table">os_membership</property>
<property name="user.name">username</property>
<property name="user.password">passwordhash</property>
<property name="group.name">groupname</property>
<property name="membership.userName">username</property>
<property name="membership.groupName">groupname</property>
<property name="datasource">jdbc/DefaultDS</property>
</provider>
<provider class="com.opensymphony.user.provider.jdbc.JDBCCredentialsProvider">
<property name="user.table">os_user</property>
<property name="group.table">os_group</property>
<property name="membership.table">os_membership</property>
<property name="user.name">username</property>
<property name="user.password">passwordhash</property>
<property name="group.name">groupname</property>
<property name="membership.userName">username</property>
<property name="membership.groupName">groupname</property>
<property name="datasource">jdbc/DefaultDS</property>
</provider>
<provider class="com.opensymphony.user.provider.jdbc.JDBCProfileProvider">
<property name="user.table">os_user</property>
<property name="group.table">os_group</property>
<property name="membership.table">os_membership</property>
<property name="user.name">username</property>
<property name="user.password">passwordhash</property>
<property name="group.name">groupname</property>
<property name="membership.userName">username</property>
<property name="membership.groupName">groupname</property>
<property name="datasource">jdbc/DefaultDS</property>
</provider>
<authenticator class="com.opensymphony.user.authenticator.SmartAuthenticator" />
</opensymphony-user>
以前我对工作流根本没概念,但研究了OSWorkflow,特别是看了网上那个例子后,突然间豁然开朗。如果不是研究工作流,我从不认为系统中“组织架构”模块会如此复杂。公司的OA为什么不可扩展,就是因为“组织架构”设计得很不合理。
A test case in software engineering is a set of conditions or variables under which a tester will determine whether an application or software system meets specifications. The mechanism for determining whether a software program or system has passed or failed such a test is known as a test oracle. In some settings an oracle could be a requirement or use case. It may take many test cases to determine that a software program or system is functioning correctly. Test cases are often referred to as test scripts, particularly when written. Written test cases are usually collected into test suites.
Formal, requirement-based test cases
In order to fully test that all the requirements of an application are met, there must be at least one test case for each requirement unless a requirement has sub-requirements. In that situation, each sub-requirement must have at least one test case. This is frequently done using a traceability matrix. Some methodologies, like RUP, recommend creating at least two test cases for each requirement. One of them should perform positive testing of requirement and other should perform negative testing. Written test cases should include a description of the functionality to be tested, and the preparation required to ensure that the test can be conducted.
What characterizes a formal, written test case is that there is a known input and an expected output, which is worked out before the test is executed. The known input should test a precondition and the expected output should test a postcondition.
Tested configuration and discovery modules,this is the first time I test my program so carefully.Since SV2.0 has much bug,now I am aware of the importance of testing.
I tested the following cases:
Configuration
1. Add a network device to the network device list
2. Add a server to the server list
3. Remove a network device from the network device list
4. Remove a server from the server list
5. Add a network device to the server list(failure is correct)
6. Add a server to the network device list(failure is correct)
7. Add a link road
8. Remove a link road
9. Query a server/network device/link according to the given condition
Discovery
10. Totally new discover a network configuration
11. Re-discover a network configuration
12. Remove a network configuration
行程:
2月11日 下午 惠州ZFW 给客户培训SourceView基本操作
2月11日 下午 惠州GA 产品推广
2月12日 上午 惠州JCY 产品推广
bug:
1. IP资源没有数据;
2. 数据库某个表字段太短,字值插不进去;
3. 报表页面上有-1,没有处理;
4. 子网网关有NULL,干脆在页面上隐藏“网关”这列。
另,用户要求增加短信报警的功能。
总结:
1. 现在用户的技术水平也在提高,这对我们的专业水平、我们的产品质量都提出了更高的要求;
2. 市场潜力大,但不同的用户需求可能差别很大,这就要求我们的产品要有很强的扩展性。
摘要:
今天终于把NodeManager的接口确定下来了。代码不知改了多少次,才成为今天这个样子,
每个接口都有明确的定义和责任,真是不容易。2.0中这块写得极混乱,代码重用性不好,可扩
展性受到很大影响。3.0中能把NodeManager的接口设计好,算是整个架构的一个重大改进。
NodeManager完成以下功能:
1.加入网元前,检查用户输入的参数,以及这个网元是否已经存在...
阅读全文
1. 解决了有时发现程序结束不了的问题,根本原因在于有一个set没有同步,改为
hasDetected = Collections.synchronizedSet(new HashSet<String>())
后,问题解决。
2. 更改了路由发现中关于子网的一个bug:
原代码:
if(!pool.existSubnet(subnet)){
engine.addSubnet(subnet);
router.addSubnet(subnet);
}
改为:
Subnet subnet = pool.getSubnetByIP(item.getDest());
if(subnet==null){ //if subnet doesn't exist
subnet = new Subnet();
subnet.setNetAddress(item.getDest());
subnet.setNetMask(item.getNetMask());
engine.addSubnet(subnet);
}
router.addSubnet(subnet);
3. 2.0中只能对一个网络进行发现,3.0可以对多个网络进行发现,画出多个拓扑图。
4. 2.0中只能有一个发现范围,3.0可以增加多个发现范围。
5. 2.0中各表之间没有关联,初始化时要执行多条SQL代码,3.0中利用表外键,
只要删除一条记录,就可以删除所有相关数据。
6. 3.0在发现完之后,保存所有设备的SNMP表数据。
7. 3.0为再发现留有接口,使拓扑再发现成为可能,只是暂时没时间去实现。
8. 拓扑节点排序算法以及拓扑图的生成
排序算法 MapCompositor 给它节点以及连接,按一定算法计算出各节点的位置坐标。
DefaultCompositor实现接口computeCoordinate,把节点按排成若干个圆。
用DefaultMapBuilder dmb = new DefaultMapBuilder();
dmb.buildMap(config.getId());
来测试排序算法,因为它不要用到内存中的数据,直接取数据库的数据。
发现执行的是 NewDiscoveryVisitor.buildDefaultMap()
调用发现后内存中的数据。
9.增加网络设备的服务器时,可以重用发现模块中的代码。在2.0中是专门写了一长串代码,
与发现模块没关系。
对于在发现之后,再添加一个网络设备的处理有点麻烦。我认为除了增加设备本身还应该找出它与即有设备之间的链路,这必然要重用发现模块的代码,会造成代码的混乱,但这不是关键。关键如果在这个过程中“发现”出了异常,程序无法返回,会给用户奇怪的感觉。
目前的代码是按我的想法实现的,在公司的网络环境中测试中通过了。但不能保证在其他复杂的环境中得到一样的结果。
|
Modules of SourceView3.0:
1. Topology Discovery:System initializes,discovering all devices and the links among them.Devices includes routers,switches,route switches,ATM Switches and servers.
2. Configuration Management:Manages all of IT elements in NMS,including network devices,servers,DBs,midwares and web-servers.Add elements intoNMS,remove elements from it and so on.
3. Report Management:Defines some useful reports,users can review the performance data of any IT elements through these reports.
4. Business View:Users can define a view by themselves.The elements associate with the specified business system that they concern would be dragged into this view.
5. Topology View: Shows network topology and reflects real running status of the entire network.e.g.traffic of links.
6. Fault Management:Analyses the performance data collected by monitors,if it violates the rules defined by users,NMS would alarm immediately.
7. Performance Management:Collects performance data from IT elements by all Kinds of monitors.
|
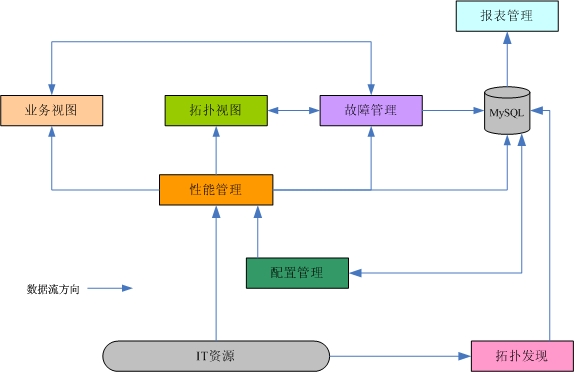
THE PRESIDENT: Fellow citizens: For eight years, it has been my honor to serve as your President. The first decade of this new century has been a period of consequence — a time set apart. Tonight, with a thankful heart, I have asked for a final opportunity to share some thoughts on the journey that we have traveled together, and the future of our nation.
Five days from now, the world will witness the vitality of American democracy. In a tradition dating back to our founding, the presidency will pass to a successor chosen by you, the American people. Standing on the steps of the Capitol will be a man whose history reflects the enduring promise of our land. This is a moment of hope and pride for our whole nation. And I join all Americans in offering best wishes to President-Elect Obama, his wife Michelle, and their two beautiful girls.
Tonight I am filled with gratitude — to Vice President Cheney and members of my administration; to Laura, who brought joy to this house and love to my life; to our wonderful daughters, Barbara and Jenna; to my parents, whose examples have provided strength for a lifetime. And above all, I thank the American people for the trust you have given me. I thank you for the prayers that have lifted my spirits. And I thank you for the countless acts of courage, generosity, and grace that I have witnessed these past eight years.
This evening, my thoughts return to the first night I addressed you from this house — September the 11th, 2001. That morning, terrorists took nearly 3,000 lives in the worst attack on America since Pearl Harbor. I remember standing in the rubble of the World Trade Center three days later, surrounded by rescuers who had been working around the clock. I remember talking to brave souls who charged through smoke-filled corridors at the Pentagon, and to husbands and wives whose loved ones became heroes aboard Flight 93. I remember Arlene Howard, who gave me her fallen son’s police shield as a reminder of all that was lost. And I still carry his badge.
As the years passed, most Americans were able to return to life much as it had been before 9/11. But I never did. Every morning, I received a briefing on the threats to our nation. I vowed to do everything in my power to keep us safe.
Over the past seven years, a new Department of Homeland Security has been created. The military, the intelligence community, and the FBI have been transformed. Our nation is equipped with new tools to monitor the terrorists’ movements, freeze their finances, and break up their plots. And with strong allies at our side, we have taken the fight to the terrorists and those who support them. Afghanistan has gone from a nation where the Taliban harbored al Qaeda and stoned women in the streets to a young democracy that is fighting terror and encouraging girls to go to school. Iraq has gone from a brutal dictatorship and a sworn enemy of America to an Arab democracy at the heart of the Middle East and a friend of the United States.
There is legitimate debate about many of these decisions. But there can be little debate about the results. America has gone more than seven years without another terrorist attack on our soil. This is a tribute to those who toil night and day to keep us safe — law enforcement officers, intelligence analysts, homeland security and diplomatic personnel, and the men and women of the United States Armed Forces.
Our nation is blessed to have citizens who volunteer to defend us in this time of danger. I have cherished meeting these selfless patriots and their families. And America owes you a debt of gratitude. And to all our men and women in uniform listening tonight: There has been no higher honor than serving as your Commander-in-Chief.
The battles waged by our troops are part of a broader struggle between two dramatically different systems. Under one, a small band of fanatics demands total obedience to an oppressive ideology, condemns women to subservience, and marks unbelievers for murder. The other system is based on the conviction that freedom is the universal gift of Almighty God, and that liberty and justice light the path to peace.
This is the belief that gave birth to our nation. And in the long run, advancing this belief is the only practical way to protect our citizens. When people live in freedom, they do not willingly choose leaders who pursue campaigns of terror. When people have hope in the future, they will not cede their lives to violence and extremism. So around the world, America is promoting human liberty, human rights, and human dignity. We’re standing with dissidents and young democracies, providing AIDS medicine to dying patients — to bring dying patients back to life, and sparing mothers and babies from malaria. And this great republic born alone in liberty is leading the world toward a new age when freedom belongs to all nations.
For eight years, we’ve also strived to expand opportunity and hope here at home. Across our country, students are rising to meet higher standards in public schools. A new Medicare prescription drug benefit is bringing peace of mind to seniors and the disabled. Every taxpayer pays lower income taxes. The addicted and suffering are finding new hope through faith-based programs. Vulnerable human life is better protected. Funding for our veterans has nearly doubled. America’s air and water and lands are measurably cleaner. And the federal bench includes wise new members like Justice Sam Alito and Chief Justice John Roberts.
When challenges to our prosperity emerged, we rose to meet them. Facing the prospect of a financial collapse, we took decisive measures to safeguard our economy. These are very tough times for hardworking families, but the toll would be far worse if we had not acted. All Americans are in this together. And together, with determination and hard work, we will restore our economy to the path of growth. We will show the world once again the resilience of America’s free enterprise system.
Like all who have held this office before me, I have experienced setbacks. There are things I would do differently if given the chance. Yet I’ve always acted with the best interests of our country in mind. I have followed my conscience and done what I thought was right. You may not agree with some of the tough decisions I have made. But I hope you can agree that I was willing to make the tough decisions.
The decades ahead will bring more hard choices for our country, and there are some guiding principles that should shape our course.
While our nation is safer than it was seven years ago, the gravest threat to our people remains another terrorist attack. Our enemies are patient, and determined to strike again. America did nothing to seek or deserve this conflict. But we have been given solemn responsibilities, and we must meet them. We must resist complacency. We must keep our resolve. And we must never let down our guard.
At the same time, we must continue to engage the world with confidence and clear purpose. In the face of threats from abroad, it can be tempting to seek comfort by turning inward. But we must reject isolationism and its companion, protectionism. Retreating behind our borders would only invite danger. In the 21st century, security and prosperity at home depend on the expansion of liberty abroad. If America does not lead the cause of freedom, that cause will not be led.
As we address these challenges — and others we cannot foresee tonight — America must maintain our moral clarity. I’ve often spoken to you about good and evil, and this has made some uncomfortable. But good and evil are present in this world, and between the two of them there can be no compromise. Murdering the innocent to advance an ideology is wrong every time, everywhere. Freeing people from oppression and despair is eternally right. This nation must continue to speak out for justice and truth. We must always be willing to act in their defense — and to advance the cause of peace.
President Thomas Jefferson once wrote, “I like the dreams of the future better than the history of the past.” As I leave the house he occupied two centuries ago, I share that optimism. America is a young country, full of vitality, constantly growing and renewing itself. And even in the toughest times, we lift our eyes to the broad horizon ahead.
I have confidence in the promise of America because I know the character of our people. This is a nation that inspires immigrants to risk everything for the dream of freedom. This is a nation where citizens show calm in times of danger, and compassion in the face of suffering. We see examples of America’s character all around us. And Laura and I have invited some of them to join us in the White House this evening.
We see America’s character in Dr. Tony Recasner, a principal who opened a new charter school from the ruins of Hurricane Katrina. We see it in Julio Medina, a former inmate who leads a faith-based program to help prisoners returning to society. We’ve seen it in Staff Sergeant Aubrey McDade, who charged into an ambush in Iraq and rescued three of his fellow Marines.
We see America’s character in Bill Krissoff — a surgeon from California. His son, Nathan — a Marine — gave his life in Iraq. When I met Dr. Krissoff and his family, he delivered some surprising news: He told me he wanted to join the Navy Medical Corps in honor of his son. This good man was 60 years old — 18 years above the age limit. But his petition for a waiver was granted, and for the past year he has trained in battlefield medicine. Lieutenant Commander Krissoff could not be here tonight, because he will soon deploy to Iraq, where he will help save America’s wounded warriors — and uphold the legacy of his fallen son.
In citizens like these, we see the best of our country - resilient and hopeful, caring and strong. These virtues give me an unshakable faith in America. We have faced danger and trial, and there’s more ahead. But with the courage of our people and confidence in our ideals, this great nation will never tire, never falter, and never fail.
It has been the privilege of a lifetime to serve as your President. There have been good days and tough days. But every day I have been inspired by the greatness of our country, and uplifted by the goodness of our people. I have been blessed to represent this nation we love. And I will always be honored to carry a title that means more to me than any other - citizen of the United States of America.
And so, my fellow Americans, for the final time: Good night. May God bless this house and our next President. And may God bless you and our wonderful country. Thank you. (Applause.)
2009.1.15 8:14 P.M. EST
今天在公司测试SourceView3.0发现程序,找出所有支持SNMP的设备以及它们的链路,
包括服务器到交换机的链路:
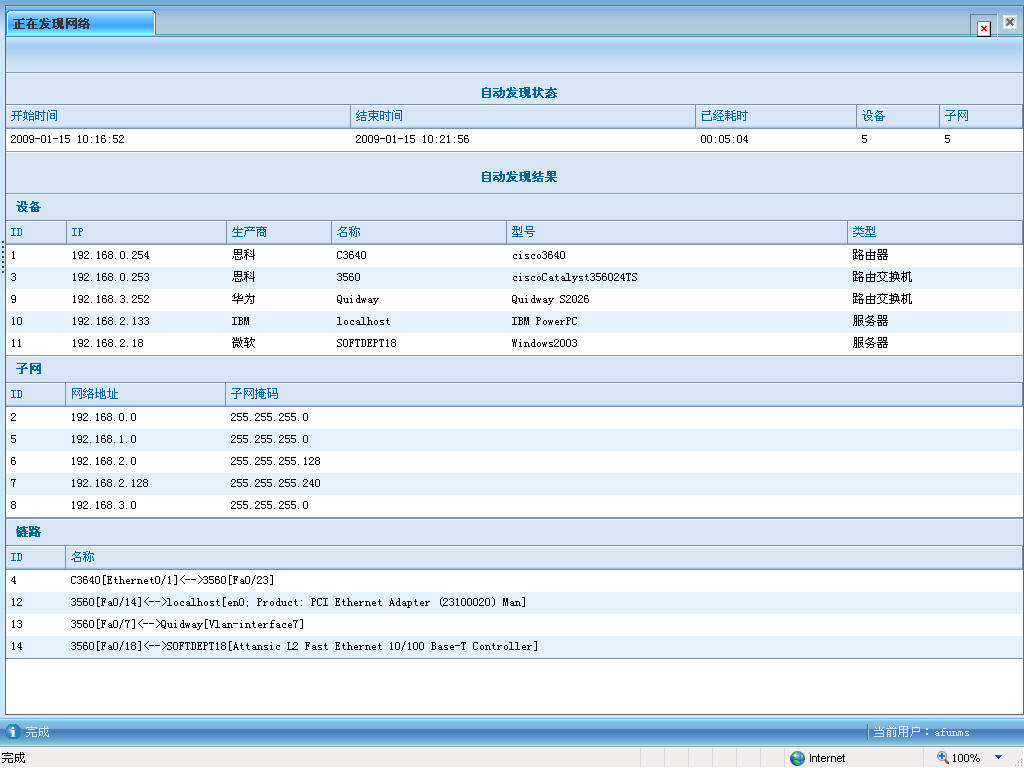 Discovery log:
Discovery log:
2009-01-15 14:09:44 - INFO - ----[SourceView3.0]Starting ----
2009-01-15 14:09:45 - INFO - Parsing configuration file [struts-default.xml]
2009-01-15 14:09:45 - INFO - Parsing configuration file [struts-plugin.xml]
2009-01-15 14:09:45 - INFO - Parsing configuration file [struts.xml]
2009-01-15 14:09:45 - INFO - Overriding property struts.i18n.reload - old value: false new value: true
2009-01-15 14:10:45 - INFO - 新主机加入:
1.路由器:ip=192.168.0.254,
sysOid=1.3.6.1.4.1.9.1.110,
sysName=C3640,
community=cisco,
symbol=cisco
---------------------
2009-01-15 14:10:46 - INFO - 新子网加入:
Subnet.2.addr[192.168.0.0],mask[255.255.255.0]
2009-01-15 14:10:56 - INFO - 新主机加入:
3.路由交换机:ip=192.168.0.253,
sysOid=1.3.6.1.4.1.9.1.633,
sysName=3560,
community=cisco,
mac=00:19:55:d9:9c:80,
symbol=cisco
---------------------
2009-01-15 14:10:57 - INFO - 新链路加入:
4.C3640[Ethernet0/1]<-->3560[Fa0/23],[route link](路由器到三层交换机)
2009-01-15 14:10:57 - INFO - 新子网加入:
Subnet.5.addr[192.168.1.0],mask[255.255.255.0]
2009-01-15 14:10:57 - INFO - 新子网加入:
Subnet.6.addr[192.168.2.0],mask[255.255.255.128]
2009-01-15 14:10:57 - INFO - 新子网加入:
Subnet.7.addr[192.168.2.128],mask[255.255.255.240]
2009-01-15 14:10:57 - INFO - 新子网加入:
Subnet.8.addr[192.168.3.0],mask[255.255.255.0]
2009-01-15 14:10:57 - INFO - 新子网加入:
Subnet.9.addr[192.168.4.0],mask[255.255.255.0]
2009-01-15 14:10:57 - INFO - 新子网加入:
Subnet.10.addr[192.168.5.0],mask[255.255.255.0]
2009-01-15 14:10:57 - INFO - 新子网加入:
Subnet.11.addr[192.168.6.0],mask[255.255.255.0]
2009-01-15 14:12:08 - INFO - 新主机加入:
12.路由交换机:ip=192.168.3.252,
sysOid=1.3.6.1.4.1.2011.2.23.22,
sysName=Quidway,
community=cisco,
mac=00:e0:fc:0c:9d:1b,
symbol=huawei
---------------------
2009-01-15 14:12:58 - INFO - 新主机加入:
13.服务器:ip=192.168.2.133,
sysOid=1.3.6.1.4.1.2.3.1.2.1.1.3,
sysName=localhost,
community=public,
symbol=aix
---------------------
2009-01-15 14:15:18 - INFO - 新主机加入:
14.服务器:ip=192.168.2.18,
sysOid=1.3.6.1.4.1.311.1.1.3.1.2,
sysName=SOFTDEPT18,
community=public,
symbol=windows
---------------------
2009-01-15 14:15:58 - INFO - ----discovering Layer 2 using the common method----
2009-01-15 14:15:58 - INFO - 新链路加入:
15.3560[Fa0/14]<-->localhost[en0; Product: PCI Ethernet Adapter (23100020) Man],[arp link](服务器到三层交换机)
2009-01-15 14:15:58 - INFO - find link from switch to the router or server:
0.null,[arp link]
2009-01-15 14:15:58 - INFO - find link from switch to the router or server:
0.null,[arp link]
2009-01-15 14:15:58 - INFO - find link from switch to the router or server:
0.null,[arp link]
2009-01-15 14:15:58 - INFO - find link from switch to the router or server:
0.null,[arp link]
2009-01-15 14:15:58 - INFO - find link from switch to the router or server:
15.3560[Fa0/14]<-->localhost[en0; Product: PCI Ethernet Adapter (23100020) Man],[arp link]
2009-01-15 14:15:58 - INFO - find link from switch to the router or server:
0.null,[arp link]
2009-01-15 14:15:58 - INFO - 新链路加入:
16.3560[Fa0/18]<-->SOFTDEPT18[Attansic L2 Fast Ethernet 10/100 Base-T Controller],[arp link] (服务器到三层交换机)
2009-01-15 14:15:58 - INFO - find link from switch to the router or server:
16.3560[Fa0/18]<-->SOFTDEPT18[Attansic L2 Fast Ethernet 10/100 Base-T Controller],[arp link]
2009-01-15 14:15:58 - INFO - 新链路加入:
17.3560[Fa0/7]<-->Quidway[Vlan-interface7],[arp link] (交换机到三层交换机)
2009-01-15 14:15:58 - INFO - find link from switch to the router or server:
0.null,[arp link]
2009-01-15 14:15:58 - INFO - find link from switch to the router or server:
0.null,[arp link]
2009-01-15 14:15:59 - INFO - ========全部发现完成了========
 完成用户手册,标志我们的软件向产品化、标准化又迈进了一步。
完成用户手册,标志我们的软件向产品化、标准化又迈进了一步。
希望2009年能把3.0做得更好。
背景:
用户环境比较简单,三台路由器和一台交换机。
问题总结:
1.长时间开着拓扑图,内存只增不减;
2.要一直开着IE才能及时看到报警,3.0准备开发一个windows客户端;
3.Tomcat使用了8080端口与Oracle使用的HTTP服务器端口冲突;
4.添加链路时,如果有一个接口是VLAN的,会有出错。

宝宝三个月,终于会爬了。

背景:
用户环境比较简单,一台路由器、3台windows2003服务器和一个Tomcat。
问题总结:
1.报表的数据存贮结构设计不好,导致程序复杂,容易出bug,而出了bug也不容易调试;
2.在这种相对简单的网络环境中,拓扑再发现还是很有用的,在3.0要实现这个功能;
3.应该支持在轮询时的发现,而不是要手动更改配置文件,这个在3.0中要改进;
4.报警配置经过上次的修改,现在已经比较好了,这是进步。

opennms的发现流程,基本看明白了:
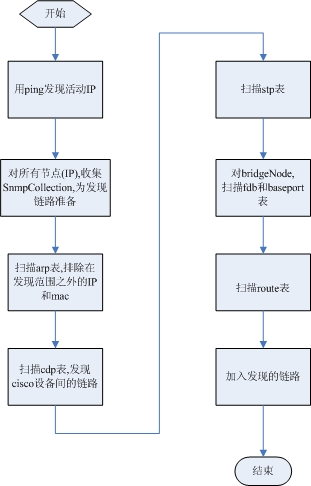
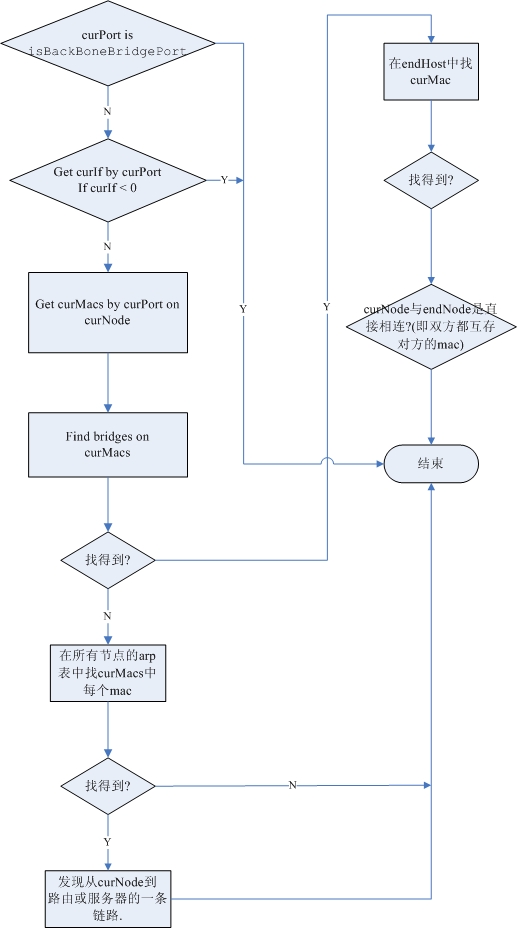
基于fdb表的发现,是二层发现最关键的部分。opennms这部分写得很好,给我很多启发。
另,1) 对backBoneBirdgePort的判定:对已经确定有链路的port为backBoneBirdgePort
2) 对bridgeIdentifier的判定:bridgeMac和fdb表中status=4的为bridgeIdentifier
很可惜,没看明白opennms关于stp发现这块。我觉得没这么复杂吧?
还好,我自己也能把基于STP的发现做出来。
opennms 对CDP表的探测流程:
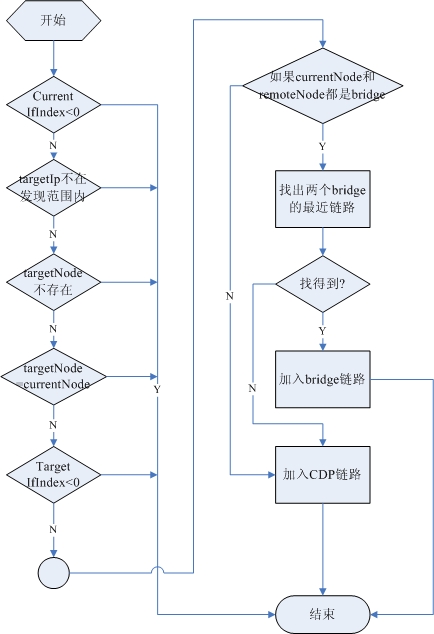
opennms对链路的发现全部在
DiscoveryLink这个类里。由于opennms对节点的发现没有确定节点
的设备类型,导致发现链路更加复杂。
opennms拓扑发现模块中,对路由表的探测流程如下:
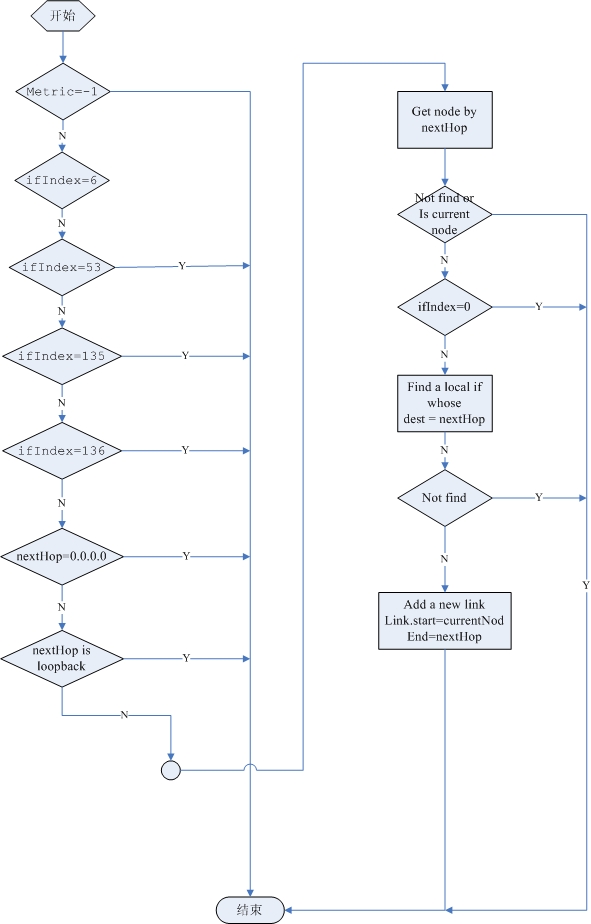
背景:
客户的WebSphere经常出问题,部署网管主要用于WebSphere的监控。
问题总结:
1. 对中间件的监控做得还不够细,可能我们以前的重点都放在对设备的监控。
2. 对中间件的监控可能对中间件性能造成影响,是否考虑改变监控方式?
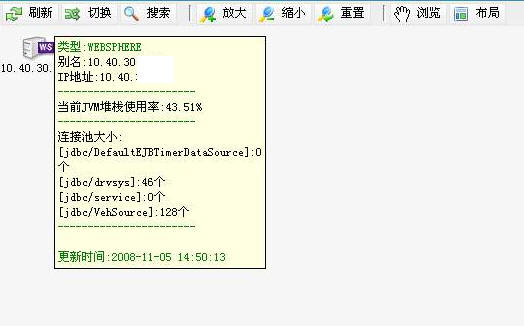
2008.10.30 女儿满月

http://www.oracle.com/technology/global/cn/pub/articles/hunter_meta.html
了解如何使用 J2SE 5.0 中提供的元数据批注
最新的 J2SE 5.0 版本(也以代号 "Tiger" 著称)为 Java 语言引进了许多变化,这些变化旨在使 Java 编程更有表现力、更加开发人员友好和更安全。我在 2003 年 9 月的一篇题目为“Java 即将发生巨大变化”的文章中介绍了许多 Java 新特性。我没有介绍的一个重大的变化 — 那时还没有完整概述它 — 是 Java 的元数据工具。从本文开始,在一个新的分为四个部分的文章系列中,我将从一年前离开的地方继续向您显示如何充分利用 Java 的元数据。
在第一篇文章中,我将说明元数据的用途并演示如何使用在核心的 J2SE 资料库中提供的元数据批注。
在第二篇文章中,我将显示如何编写您自己的批注(首先编写类似 @Copyright 的简单的批注,然后看看与核心语言中内置的那些批注类似的更高级的批注)。
在第三篇文章中,我将演示工具如何在构建时使用批注(创建新的源文件或支持文件)以及程序如何在运行时使用批注(以改变代码的行为)。
在最后的第四篇文章中,我将介绍如何利用在 JSR-181 下开发的标准元数据批注的帮助使编辑和部署 Web 服务在未来变得更容易(Oracle 是 JSR-181 的专家组的成员,并且是在开发工具中增加对设计时元数据的支持的一个积极的拥护者。)
元数据
我承认当我第一次看到 JSR-175 的提案“用于 Java 编程语言的元数据工具”(在 2004 年 9 月发布;Oracle 也是该专家组的成员)时,我预测它将创建必须放在 JAR 的 META-INF 目录下的另一个属性文件,或者必须与 JAR 捆绑的另一个 XML 部署描述符。幸运的是,这不是元数据要做的。事实上,它正好相反。Java 的新的元数据工具提供了从 Java 代码内部批注 Java 代码的一种标准方式。它使您能够在要说明的元素的旁边放置描述性的元数据。
当讨论元数据时,您将经常看到几个类似的术语,因此下面提供了一个小术语表来帮助您了解它们的差异:
| 术语 |
定义 |
| 元数据 |
关于数据的数据。JSR-175 的目标是在 Java 语言中提供元数据工具。 |
| 批注 |
一种特殊的 Java 结构,用来修饰类、方法、字段、参数、变量、构造器或包。它是 JSR-175 选择用来提供元数据的工具。 |
| 批注类型 |
具有特殊实施的各种命名批注 |
| 属性 |
由批注指定的一个特殊的元数据项目。有时可以和批注交替使用 |
例如:富士苹果有一个属性:它是红色的。假定有一个 FujiApple 类,您可以使用 @Color 批注类型的一个批注来指定它的颜色。通过这么做,您就提供了关于苹果的元数据。
自 1.0 版以来在 Java 中一直存在对元数据的需求。Java 从来没有提供记录元数据的标准机制,因而我们编程人员找到了各种技巧和窍门使用任意的工具来添加元数据。您看到在 J2SE 1.4 和更低版本中使用元数据的一些地方有:
- transient 关键字
- Serializable 标记接口
- SingleThreadModel servlet 接口
- web.xml 部署描述符内部的元素
- META-INF/MANIFEST.MF 文件
- BeanInfo 接口
- @deprecated Javadoc 注释
- 所有的 XDoclet Javadoc 标记。
当使用这些技巧时,您可能没有想到您正在添加元数据,但事实上您的确在添加元数据。上述方法存在的问题是它们都是解决同一问题的不同方法,但通用性不好。每一种方法都至少有一个缺点在新的元数据工具中得到了解决。
对于这个列表中的一些方法,局限很明显。使用关键字不能伸缩;您不能使用用户自己定义的关键字。标记接口没有提供除它们的存在性之外的任何信息(即,它们没有带参数),并且它们只能处理类,而不能处理字段或方法或包。
列表中的其他一些方法可能看起来合理。使用 XML 支持文件似乎是个好主意,而事实上在许多情况下仍是个好主意。但对于我们使用 XML 文件的许多用途,例如指示类的哪一个方法应当看作是 web 服务,在 Java 代码内部将规则直接放在方法的旁边将更加高效。利用元数据,您可以使 XML 描述符文件仅包含与部署相关的决策。
该列表中可能最高效的元数据的用法是 @deprecated Javadoc 注释和在其镜像中创建的 XDoclet 标记。这可能是 JSR-175 语法为什么看起来与 @deprecated 标记非常类似的原因(正如我们将在下一部分中看到的那样)。
批注
批注可以很容易地附加到代码结构上。您可以写一个 "at" 符号 (@),然后是批注类型名称,并将批注直接放在要批注的项目前面。下面是一个简单的例子:
import javax.jws.WebService;
import javax.jws.WebMethod;
@WebService
public class HelloWorldService {
@WebMethod
public String helloWorld() {
return "Hello World!";
}
}
当部署在正确的环境中时,增加 @WebService 和 @WebMethod 批注将指示 web 服务环境将该类变为 web 服务。
您可以批注方法、类、字段、参数、变量、构造器甚至整个包(利用一个特殊的外部 package-info.java 文件)。批注可以在括号内带任意数量的命名参数。下面是使用批注进行修饰以创建 web 服务的一个更高级的示例类。它包含了一个理论上的 JNDI 环境变量查找:
@WebService(
name = "PingService",
targetNamespace="http://acme.com/ping"
)
@SOAPBinding(
style=SOAPBinding.Style.RPC,
use=SOAPBinding.Use.LITERAL
)
public class Ping {
public @env double level = 500.0; // JNDI lookup
public @WebMethod(operationName = "Foo") {
void foo() { }
}
}
这个例子显示了附加到类、变量和方法(在类上实际上有两个方法)上的批注。@env 批注没有任何参数,因此它不需要括号。其他批注有一个或更多的命名参数。
当创建新的批注类型时,您将限定允许哪些参数名以及它们的类型。批注接受的类型是严格限定的;它们只可以是基本类型、String、Class、枚举类型、批注类型和前面这些类型的数组。传递的参数必须始终是非空的编译时常量。
要了解本示例中显示的批注有什么效果必须等到本系列的第四篇文章。让我们开始看看 J2SE 5.0 提供的简单的批注类型:@Override、@Deprecated 和 @SuppressWarnings。
内置的批注
当我们看这三种标准的用户级批注时,必须考虑:在可以提供的所有可能的批注类型中,为什么 Tiger 恰恰提供三种?原因是提供大量的标准批注并不是目标所在。
JSR-175 的宗旨严格规定了它是要定义一个元数据工具。编写自定义批注类型的任务留给了编程人员,而编写一组标准的批注类型的任务留给了其他 JSR。例如,有一个新的名称为“Java 平台的通用批注”的 JSR-250,其宗旨是“为 J2SE 和 J2EE 平台中的通用的语义概念开发适用于各种技术的批注”。JSR-250 计划在 2005 年春天的某个时候在 javax.annotations 程序包中提供它的标准的批注集。还有之前提到的 JSR-181,它将使得在 J2EE 容器中编写 Web 服务变得更容易(我们将在本系列中的第四篇文章中进行介绍)。事实上,大多数新的企业 JSR(从 Servlets 2.5 到 EJB 3.0 到 JDBC 4.0)都在考虑批注可以提供哪些优点。
@Override
第一个 J2SE 标准批注 @Override 使您能够在代码中增加新的可选的编译器检查。它在方法中存在表示该方法用于覆盖父类中的方法。如果编译器检测到该方法实际上没有覆盖任何东西,那么将出现编译错误。经常使用,@Override 可以帮助您避免当方法标记没有完全匹配时 — 当多态变为(您可以称之为)“单态” ("unimorphism") 时 — 将得到的细微的 bug。
例如,以下代码可能看起来很合理:
public class OverrideExample {
@Override
public boolean equals(OverrideExample obj) {
return false;
}
}
然而,当您编译 OverrideExample.java 时,您将得到一个错误,该错误指示一个细微的问题。
% javac OverrideExample.java
javac OverrideExample.java
OverrideExample.java:3: method does not override a method from its superclass
@Override
^
1 error
通过提示编译器您希望进行覆盖,使编译器能够捕获到 equals() 方法带 Object 类型参数的细微 bug。
@Override 批注在实际中有用吗?只有当您是一个愿意用 @Override 来标记每一个覆盖方法的非常严谨的编程人员时才有用。我们中有多少人能声称可以达到这种严谨程度?我认为我不能。可能 IDE 将找到一种方式来鼓励或强制使用 @Override。
@Deprecated
第二种标准批注是 @Deprecated,它与 @deprecated Javadoc 标记有几乎相同的行为。您可以用类似以下的方式来使用它:
public class DeprecatedExample {
@Deprecated
public static void badMethod() {
}
}
public class DeprecatedUser {
public static void main(String[] args) {
DeprecatedExample.badMethod();
}
}
The @Deprecated 批注看起来非常像 @deprecated 标记,除了它出现在注释外面的方法或类声明的前面,并且有一个大写字母 "D"。如果您试图编译上面的代码,javac 将产生警告:
% javac Deprecated*.java
Note:DeprecatedUser.java uses or overrides a deprecated API.
Note:Recompile with -Xlint:deprecation for details.
1 error
如果您遵循警告的建议并用 -Xlint:deprecation 进行编译,那么您将得到关于警告的详细信息:
% javac -Xlint:deprecation
DeprecatedUser.java:3: warning: [deprecation] badMethod() in DeprecatedExample
has been deprecated
DeprecatedExample.badMethod();
@Deprecated 批注比 @Override 更有用吗?我不这么认为。该批注不支持任何参数,因此与 Javadoc 标记不同,您不能提供一个字符串来说明不赞成使用该方法并推荐一个替代的方法进行使用。@Deprecated 批注提供的价值实际上比 @deprecated 标记少。该批注唯一的优势是您可以通过编程的方式在运行时检测不赞成使用的项目。因此,传统观点认为应当同时使用 @deprecated 标记和 @Deprecated 标记,一个用于文档,另一个用于运行时反射。
我觉得很不幸 JSR-175 没有选择对 @Deprecated 做更多的工作。至少该批注应当复制 @deprecated 标记的功能,包含一个字符串说明,从而编译器可以将其与“不赞成使用” (Deprecation) 警告一起输出。利用额外的参数,@Deprecated 还可以接收 "isError" 布尔类型参数,以指示是否完全不鼓励使用该方法或者使用它将被认为是编译错误(利用解释错误原因的清楚的自定义说明来进行完善)。查看 C# 的示例 1 找到属性 [Obsolete],该属性正好实现了这一点,它被证明非常有用。
@SuppressWarnings
J2SE 提供的最后一个批注是 @SuppressWarnings。该批注的作用是给编译器一条指令,告诉它对被批注的代码元素内部的某些警告保持静默。
一点背景:J2SE 5.0 为 Java 语言增加了几个新的特性,并且和它们一起增加了许多新的警告并承诺在将来增加更多的警告。您可以为 "javac" 增加 -Xlint 参数来控制是否报告这些警告(如上面的 @Deprecated 部分所示)。
默认情况下,Sun 编译器以简单的两行的形式输出警告。通过添加 -Xlint:keyword 标记(例如 -Xlint:finally),您可以获得关键字类型错误的完整说明。通过在关键字前面添加一个破折号,写为 -Xlint:-keyword,您可以取消警告。(-Xlint 支持的关键字的完整列表可以在 javac 文档页面上找到。)下面是一个清单:
| 关键字 |
用途 |
| deprecation |
使用了不赞成使用的类或方法时的警告 |
| unchecked |
执行了未检查的转换时的警告,例如当使用集合时没有用泛型 (Generics) 来指定集合保存的类型。 |
| fallthrough |
当 Switch 程序块直接通往下一种情况而没有 Break 时的警告。 |
| path |
在类路径、源文件路径等中有不存在的路径时的警告。 |
| serial |
当在可序列化的类上缺少 serialVersionUID 定义时的警告。 |
| finally |
任何 finally 子句不能正常完成时的警告。 |
| all |
关于以上所有情况的警告。 |
@SuppressWarnings 批注允许您选择性地取消特定代码段(即,类或方法)中的警告。其中的想法是当您看到警告时,您将调查它,如果您确定它不是问题,您就可以添加一个 @SuppressWarnings 批注,以使您不会再看到警告。虽然它听起来似乎会屏蔽潜在的错误,但实际上它将提高代码安全性,因为它将防止您对警告无动于衷 — 您看到的每一个警告都将值得注意。
下面是使用 @SuppressWarnings 来取消 deprecation 警告的一个例子:
public class DeprecatedExample2 {
@Deprecated
public static void foo() {
}
}
public class DeprecatedUser2 {
@SuppressWarnings(value={"deprecation"})
public static void main(String[] args) {
DeprecatedExample2.foo();
}
}
@SuppressWarnings 批注接收一个 "value" 变量,该变量是一个字符串数组,它指示将取消的警告。合法字符串的集合随编译器而变化,但在 JDK 上,可以传递给 -Xlint 的是相同的关键字集合(非常方便)。并且要求编译器忽略任何它们不能识别的关键字,这在您使用一些不同的编译器时非常方便。
因为 @SuppressWarnings 批注仅接收一个参数,并为该参数使用了特殊的名称 "value",所以您可以选择省略 value=,作为一种方便的缩写:
public class DeprecatedUser2 {
@SuppressWarnings({"deprecation"})
public static void main(String[] args) {
DeprecatedExample2.foo();
}
}
您可以将单个数组参数中的任意数量的字符串值传递给批注,并在任何级别上放置批注。例如,以下示例代码指示将取消整个类的 deprecation 警告,而仅在 main() 方法代码内取消 unchecked 和 fallthrough 警告:
import java.util.*;
@SuppressWarnings({"deprecation"})
public class NonGenerics {
@SuppressWarnings({"unchecked","fallthrough"})
public static void main(String[] args) {
Runtime.runFinalizersOnExit();
List list = new ArrayList();
list.add("foo");
}
public static void foo() {
List list = new ArrayList();
list.add("foo");
}
}
@SuppressWarnings 是否比前两个批注更有用?绝对是这样。不过,在 JDK 1.5.0 版本中还没有完全支持该批注,如果您用 1.5.0 来尝试它,那么它将类似无操作指令。调用 -Xlint:-deprecation 也没有任何效果。Sun 没有声明什么时候将增加支持,但它暗示这将在即将推出的一个 dot 版本中实现。
2008.09.30 凌晨1:30,可爱的女儿出生。
给她起名叫歆怿,即开开心心,高高兴兴的意思。
希望她一定过得比她爸爸好,活得比她爸爸精彩。

转:
http://news.csdn.net/n/20060801/93169.html
这篇文章中,我们选用MySQL 4.0.2-alpha与PostgreSQL 7.2进行比较,因为MySQL 4.0.2-alpha开始支持事务的概念,因此这样的比较对于MySQL应该较为有利。
我们这样的比较不想仅仅成为一份性能测试报告,因为至少从我个人来看,对于一个数据库,稳定性和速度并不能代表一切。对于一个成熟的数据库,稳定性肯定会日益提供。而随着硬件性能的飞速提高,速度也不再是什么太大的问题。
一、两者的共同优势
这两个产品都属于开放源码的一员,性能和功能都在高速地提高和增强。MySQL AB的人们和PostgreSQL的开发者们都在尽可能地把各自的数据库改得越来越好,所以对于任何商业数据库使用其中的任何一个都不能算是错误的选择。
二、两者不同的背景
MySQL的背后是一个成熟的商业公司,而PostgreSQL的背后是一个庞大的志愿开发组。这使得MySQL的开发过程更为慎重,而PostgreSQL的反应更为迅速。
这样的两种背景直接导致了各自固有的优点和缺点。
三、MySQL的主要优点
1、首先是速度,MySQL通常要比PostgreSQL快得多。MySQL自已也宣称速度是他们追求的主要目标之一,基于这个原因,MySQL在以前的文档中也曾经说过并不准备支持事务和触发器。但是在最新的文档中,我们看到MySQL 4.0.2-alpha已经开始支持事务,而且在MySQL的TODO中,对触发器、约束这样的注定会降低速度的功能也列入了日程。但是,我们仍然有理由相信,MySQL将有可能一直保持速度的优势。
2、MySQL比PostgreSQL更流行,流行对于一个商业软件来说,也是一个很重要的指标,流行意味着更多的用户,意味着经受了更多的考验,意味着更好的商业支持、意味着更多、更完善的文档资料。
3、与PostgreSQL相比,MySQL更适宜在Windows环境下运行。MySQL作为一个本地的Windows应用程序运行(在NT/Win2000/WinXP下,是一个服务),而PostgreSQL是运行在Cygwin模拟环境下。PostgreSQL在Windows下运行没有MySQL稳定,应该是可以想象的。
4、MySQL使用了线程,而PostgreSQL使用的是进程。在不同线程之间的环境转换和访问公用的存储区域显然要比在不同的进程之间要快得多。
5、MySQL可以适应24/7运行。在绝大多数情况下,你不需要为MySQL运行任何清除程序。PostgreSQL目前仍不完全适应24/7运行,这是因为你必须每隔一段时间运行一次VACUUM。
6、MySQL在权限系统上比PostgreSQL某些方面更为完善。PostgreSQL只支持对于每一个用户在一个数据库上或一个数据表上的INSERT、SELECT和UPDATE/DELETE的授权,而MySQL允许你定义一整套的不同的数据级、表级和列级的权限。对于列级的权限,PostgreSQL可以通过建立视图,并确定视图的权限来弥补。MySQL还允许你指定基于主机的权限,这对于目前的PostgreSQL是无法实现的,但是在很多时候,这是有用的。
7、由于MySQL 4.0.2-alpha开始支持事务的概念,因此事务对于MySQL不再仅仅成为劣势。相反,因为MySQL保留无事务的表类型。这就为用户提供了更多的选择。
8、MySQL的MERGE表提供了一个独特管理多个表的方法。
9、MySQL的myisampack可以对只读表进行压缩,此后仍然可以直接访问该表中的行。
四、PostgreSQL的主要优点:
1、对事务的支持与MySQL相比,经历了更为彻底的测试。对于一个严肃的商业应用来说,事务的支持是不可或缺的。
2、MySQL对于无事务的MyISAM表。采用表锁定,一个长时间运行的查询很可能会长时间地阻碍对表的更新。而PostgreSQL不存在这样的问题。
3、PostgreSQL支持存储过程,而目前MySQL不支持,对于一个严肃的商业应用来说,作为数据库本身,有众多的商业逻辑的存在,此时使用存储过程可以在较少地增加数据库服务器的负担的前提下,对这样的商业逻辑进行封装,并可以利用数据库服务器本身的内在机制对存储过程的执行进行优化。此外存储过程的存在也避免了在网络上大量的原始的SQL语句的传输,这样的优势是显而易见的。
4、对视图的支持,视图的存在同样可以最大限度地利用数据库服务器内在的优化机制。而且对于视图权限的合理使用,事实上可以提供行级别的权限,这是MySQL的权限系统所无法实现的。
5、对触发器的支持,触发器的存在不可避免的会影响数据库运行的效率,但是与此同时,触发器的存在也有利于对商业逻辑的封装,可以减少应用程序中对同一商业逻辑的重复控制。合理地使用触发器也有利于保证数据的完整性。
6、对约束的支持。约束的作用更多地表现在对数据完整性的保证上,合理地使用约束,也可以减少编程的工作量。
7、对子查询的支持。虽然在很多情况下在SQL语句中使用子查询效率低下,而且绝大多数情况下可以使用带条件的多表连接来替代子查询,但是子查询的存在在很多时候仍然不可避免。而且使用子查询的SQL语句与使用带条件的多表连接相比具有更高的程序可读性。
8、支持R-trees这样可扩展的索引类型,可以更方便地处理一些特殊数据。
9、PostgreSQL可以更方便地使用UDF(用户定义函数)进行扩展。
五、那么我究竟应该使用MySQL还是PostgreSQL
这个问题很难说得清,而且事实上除了MySQL和PostgreSQL外,使用Oracle、Sybase、Informix等也是明智的选择。如何你确定只在MySQL和PostgreSQL中进行选择,以下规则总是有效的。
1、如果你的操作系统是Windows,你应该使用MySQL。
2、如果你对数据库并不了十分了解,甚至不知道事务、存储过程等究竟是什么,你应该使用MySQL。
3、如果你的应用对数据的完整性和严肃性要求不高,但是追求处理的高速度。例如是一个论坛和社区,你应该使用MySQL。
4、你的应用是一个严肃的商业应用,对数据完整性要求很高。而且你希望对一些商业数据逻辑进行很好的封装,例如是一个网上银行,你应该使用PostgreSQL。
5、你的应用处理的是地理数据,由于R-TREES的存在,你应该使用PostgreSQL。
6、你是一个数据库内核的狂热爱好者,你甚至希望拥有你自己版本的数据库,毫无疑问,你必须使用PostgreSQL,没准下一个PostgreSQL版本中某一个模块的作者就是你。
六、后记
以上只是作者从自己的理解尽量客观公正地评价MySQL和PostgreSQL的优劣。其中的带有倾向性的意见只代表作者个人观点,有关这两个数据库,欢迎广大朋友提出自己的看法。
http://en.wikipedia.org/wiki/VTP
VLAN Trunking Protocol (VTP) is a Cisco proprietary Layer 2 messaging protocol that manages the addition, deletion, and renaming of VLANs on a network-wide basis. Virtual Local Area Network (VLAN) Trunk Protocol (VTP) reduces administration in a switched network. When you configure a new VLAN on one VTP server, the VLAN is distributed through all switches in the domain. This reduces the need to configure the same VLAN everywhere. To do this VTP carries VLAN information to all the switches in a VTP domain. VTP advertisements can be sent over ISL, 802.1q, IEEE 802.10 and LANE trunks. VTP traffic is sent over the management VLAN (VLAN1), so all VLAN trunks must be configured to pass VLAN1. VTP is available on most of the Cisco Catalyst Family products.
You can configure a switch to operate in any one of these VTP modes:
-
Server—In VTP server mode, you can create, modify, and delete VLANs and specify other configuration parameters, such as VTP version and VTP pruning, for the entire VTP domain. VTP servers advertise their VLAN configuration to other switches in the same VTP domain and synchronize their VLAN configuration with other switches based on advertisements received over trunk links. VTP server is the default mode.
-
Client—VTP clients behave the same way as VTP servers, but you cannot create, change, or delete VLANs on a VTP client.
-
Transparent—VTP transparent switches do not participate in VTP. A VTP transparent switch does not advertise its VLAN configuration and does not synchronize its VLAN configuration based on received advertisements, but transparent switches do forward VTP advertisements that they receive out their trunk ports in VTP Version 2.
-
Off (configurable only in CatOS switches)—In the three described modes, VTP advertisements are received and transmitted as soon as the switch enters the management domain state. In the VTP off mode, switches behave the same as in VTP transparent mode with the exception that VTP advertisements are not forwarded.
http://en.wikipedia.org/wiki/Spanning_tree_protocol
The Spanning Tree Protocol is an OSI layer-2 protocol that ensures a loop-free topology for any bridged LAN. It is based on an algorithm invented by Radia Perlman while working for Digital Equipment Corporation. Spanning tree allows a network design to include spare (redundant) links to provide automatic backup paths if an active link fails, without the danger of bridge loops, or the need for manual enabling/disabling of these backup links. Bridge loops must be avoided because they result in flooding the network.
The Spanning Tree Protocol (STP), is defined in the IEEE Standard 802.1D. As the name suggests, it creates a spanning tree within a mesh network of connected layer-2 bridges (typically Ethernet switches), and disables those links that are not part of the tree, leaving a single active path between any two network nodes.
http://en.wikipedia.org/wiki/VLAN
A virtual LAN, commonly known as a VLAN, is a group of hosts with a common set of requirements that communicate as if they were attached to the Broadcast domain, regardless of their physical location. A VLAN has the same attributes as a physical LAN, but it allows for end stations to be grouped together even if they are not located on the same network switch. Network reconfiguration can be done through software instead of physically relocating devices.
Uses
VLANs are created to provide the segmentation services traditionally provided by routers in LAN configurations. VLANs address issues such as scalability, security, and network management. Routers in VLAN topologies provide broadcast filtering, security, address summarization, and traffic flow management. By definition, switches may not bridge IP traffic between VLANs as it would violate the integrity of the VLAN broadcast domain.
This is also useful if one wants to create multiple Layer 3 networks on the same Layer 2 switch. For example if a DHCP server (which will broadcast its presence) were plugged into a switch it would serve anyone on that switch that was configured to do so. By using VLANs you easily split the network up so some hosts won't use that server and default to Link-local addresses.
Virtual LANs are essentially Layer 2 constructs, compared with IP subnets which are Layer 3 constructs. In a LAN employing VLANs, a one-to-one relationship often exists between VLANs and IP subnets, although it is possible to have multiple subnets on one VLAN or have one subnet spread across multiple VLANs. Virtual LANs and IP subnets provide independent Layer 2 and Layer 3 constructs that map to one another and this correspondence is useful during the network design process.
By using VLAN, one can control traffic patterns and react quickly to relocations. VLANs provide the flexibility to adapt to changes in network requirements and allow for simplified administration.
Motivation
In a legacy network, users were assigned to networks based on geography and were limited by physical topologies and distances. VLANs can logically group networks so that the network location of users is no longer so tightly coupled to their physical location. Technologies able to implement VLANs are:
Asynchronous Transfer Mode (ATM)
Fiber Distributed Data Interface (FDDI)
Fast Ethernet
Gigabit Ethernet
10 Gigabit Ethernet
HiperSockets
Protocols and design
The protocol most commonly used today in configuring virtual LANs is IEEE 802.1Q. The IEEE committee defined this method of multiplexing VLANs in an effort to provide multivendor VLAN support. Prior to the introduction of the 802.1Q standard, several proprietary protocols existed, such as Cisco's ISL (Inter-Switch Link, a variant of IEEE 802.10) and 3Com's VLT (Virtual LAN Trunk). ISL is no longer supported by Cisco.
Both ISL and IEEE 802.1Q tagging perform explicit tagging as the frame is tagged with VLAN information explicitly. ISL uses an external tagging process that does not modify the existing Ethernet frame whereas 802.1Q uses an internal tagging process that does modify the Ethernet frame. This internal tagging process is what allows IEEE 802.1Q tagging to work on both access and trunk links, because the frame appears to be a standard Ethernet frame.
The IEEE 802.1Q header contains a 4-byte tag header containing a 2-byte tag protocol identifier (TPID) and a 2-byte tag control information (TCI). The TPID has a fixed value of 0x8100 that indicates that the frame carries the 802.1Q/802.1p tag information. The TCI contains the following elements:
Three-bit user priority
One-bit canonical format indicator (CFI)
Twelve-bit VLAN identifier (VID)-Uniquely identifies the VLAN to which the frame belongs
The 802.1Q standard can create an interesting scenario on the network. Recalling that the maximum size for an Ethernet frame as specified by IEEE 802.3 is 1518 bytes, this means that if a maximum-sized Ethernet frame gets tagged, the frame size will be 1522 bytes, a number that violates the IEEE 802.3 standard. To resolve this issue, the 802.3 committee created a subgroup called 802.3ac to extend the maximum Ethernet size to 1522 bytes. Network devices that do not support a larger frame size will process the frame successfully but may report these anomalies as a "baby giant."
Inter-Switch Link (ISL) is a Cisco proprietary protocol used to interconnect multiple switches and maintain VLAN information as traffic travels between switches on trunk links. This technology provides one method for multiplexing bridge groups (VLANs) over a high-speed backbone. It is defined for Fast Ethernet and Gigabit Ethernet, as is IEEE 802.1Q. ISL has been available on Cisco routers since Cisco IOS Software Release 11.1.
With ISL, an Ethernet frame is encapsulated with a header that transports VLAN IDs between switches and routers. ISL does add overhead to the packet as a 26-byte header containing a 10-bit VLAN ID. In addition, a 4-byte CRC is appended to the end of each frame. This CRC is in addition to any frame checking that the Ethernet frame requires. The fields in an ISL header identify the frame as belonging to a particular VLAN.
A VLAN ID is added only if the frame is forwarded out a port configured as a trunk link. If the frame is to be forwarded out a port configured as an access link, the ISL encapsulation is removed.
Early network designers often configured VLANs with the aim of reducing the size of the collision domain in a large single Ethernet segment and thus improving performance. When Ethernet switches made this a non-issue (because each switch port is a collision domain), attention turned to reducing the size of the broadcast domain at the MAC layer. Virtual networks can also serve to restrict access to network resources without regard to physical topology of the network, although the strength of this method remains debatable as VLAN Hopping [1] is a common means of bypassing such security measures.
Virtual LANs operate at Layer 2 (the data link layer) of the OSI model. Administrators often configure a VLAN to map directly to an IP network, or subnet, which gives the appearance of involving Layer 3 (the network layer). In the context of VLANs, the term "trunk" denotes a network link carrying multiple VLANs, which are identified by labels (or "tags") inserted into their packets. Such trunks must run between "tagged ports" of VLAN-aware devices, so they are often switch-to-switch or switch-to-router links rather than links to hosts. (Note that the term 'trunk' is also used for what Cisco calls "channels" : Link Aggregation or Port Trunking). A router (Layer 3 device) serves as the backbone for network traffic going across different VLANs.
On Cisco devices, VTP (VLAN Trunking Protocol) maintains VLAN configuration consistency across the entire network. VTP uses Layer 2 trunk frames to manage the addition, deletion, and renaming of VLANs on a network-wide basis from a centralized switch in the VTP server mode. VTP is responsible for synchronizing VLAN information within a VTP domain and reduces the need to configure the same VLAN information on each switch.
VTP minimizes the possible configuration inconsistencies that arise when changes are made. These inconsistencies can result in security violations, because VLANs can crossconnect when duplicate names are used. They also could become internally disconnected when they are mapped from one LAN type to another, for example, Ethernet to ATM LANE ELANs or FDDI 802.10 VLANs. VTP provides a mapping scheme that enables seamless trunking within a network employing mixed-media technologies.
VTP provides the following benefits:
VLAN configuration consistency across the network
Mapping scheme that allows a VLAN to be trunked over mixed media
Accurate tracking and monitoring of VLANs
Dynamic reporting of added VLANs across the network
Plug-and-play configuration when adding new VLANs
As beneficial as VTP can be, it does have disadvantages that are normally related to the Spanning Tree Protocol (STP) as a bridging loop propagating throughout the network can occur. Cisco switches run an instance of STP for each VLAN, and since VTP propagates VLANs across the campus LAN, VTP effectively creates more opportunities for a bridging loop to occur.
Before creating VLANs on the switch that will be propagated via VTP, a VTP domain must first be set up. A VTP domain for a network is a set of all contiguously trunked switches with the same VTP domain name. All switches in the same management domain share their VLAN information with each other, and a switch can participate in only one VTP management domain. Switches in different domains do not share VTP information.
Using VTP, each Catalyst Family Switch advertises the following on its trunk ports:
Management domain
Configuration revision number
Known VLANs and their specific parameters
Establishing VLAN memberships
The two common approaches to assigning VLAN membership are as follows:
Static VLANs
Dynamic VLANs
Static VLANs are also referred to as port-based VLANs. Static VLAN assignments are created by assigning ports to a VLAN. As a device enters the network, the device automatically assumes the VLAN of the port. If the user changes ports and needs access to the same VLAN, the network administrator must manually make a port-to-VLAN assignment for the new connection.
Dynamic VLANs are created through the use of software packages such as CiscoWorks 2000. With a VLAN Management Policy Server VMPS, an administrator can assign switch ports to VLANs dynamically based on information such as the source MAC address of the device connected to the port or the username used to log onto that device. As a device enters the network, the device queries a database for VLAN membership. See also FreeNAC which implements a VMPS server.
Port-based VLANs
With port-based VLAN membership, the port is assigned to a specific VLAN independent of the user or system attached to the port. This means all users attached to the port should be members in the same VLAN. The network administrator typically performs the VLAN assignment. The port configuration is static and cannot be automatically changed to another VLAN without manual reconfiguration.
As with other VLAN approaches, the packets forwarded using this method do not leak into other VLAN domains on the network. After a port has been assigned to a VLAN, the port cannot send to or receive from devices in another VLAN without the intervention of a Layer 3 device.
The device that is attached to the port likely has no understanding that a VLAN exists. The device simply knows that it is a member of a subnet and that the device should be able to talk to all other members of the subnet by simply sending information to the cable segment. The switch is responsible for identifying that the information came from a specific VLAN and for ensuring that the information gets to all other members of the VLAN. The switch is further responsible for ensuring that ports in a different VLAN do not receive the information.
This approach is quite simple, fast, and easy to manage in that there are no complex lookup tables required for VLAN segmentation. If port-to-VLAN association is done with an application-specific integrated circuit (ASIC), the performance is very good. An ASIC allows the port-to-VLAN mapping to be done at the hardware level.
Protocol Based VLANs
This section needs additional citations for verification.
Please help improve this article by adding reliable references. Unsourced material may be challenged and removed. (February 2008)
In a protocol based VLAN enabled switch, traffic is forwarded through ports based on protocol. Essentially user tries to segregate or forward a particular protocol traffic from a port using the protocol based VLANs, traffic from any other protocol is not forwarded on the port. For example, if you have connected a host, pumping ARP traffic on the switch at port 10, connected a Lan pumping IPX traffic to the port 20 of the switch and connected a router pumping IP traffic on port 30. then if you define a protocol based VLAN supporting IP and including all the three ports 10, 20 and 30 then IP packets can be forwarded to the ports 10 and 20 also , but ARP traffic will not get forwarded to the ports 20 and 30, similarly IPX traffic will not get forwarded to ports 10 and 30.
http://en.wikipedia.org/wiki/Link_Layer_Discovery_Protocol
The Link Layer Discovery Protocol or LLDP is a vendor-neutral Layer 2 protocol that allows a network device to advertise its identity and capabilities on the local network. The protocol was formally ratified as IEEE standard 802.1AB-2005 in May 2005. It supersedes proprietary protocols like Cisco Discovery Protocol, Extreme Discovery Protocol and Nortel Discovery Protocol (also known as SONMP).
Information gathered with LLDP are stored in the device and can be queried using Simple Network Management Protocol. The topology of a LLDP-enabled network can be discovered by crawling the hosts and querying this database. Information that can be retrieved include:
system name and description
port name and description
VLAN name
IP management address
system capabilities (switching, routing, etc.)
MAC/PHY information
MDI power
link aggregation
Support
LLDP is still young but is supported on various types of equipment:
HP ProCurve switches and routers
Extreme switches and routers
Nortel 55x0 and 425 series
Allied Telesis switches and routers
Cisco switchs and routers with recent IOS
Alcatel-Lucent switches with AOS > 6.3.1
Juniper EX series switches
AASTRA 9480i (35i) and 675i series VoIP phones
Enterasys Secure Networks
如果所有设备都支持LLDP,那拓扑发现程序就很容易写了。
http://en.wikipedia.org/wiki/Cisco_Discovery_Protocol
The Cisco Discovery Protocol (CDP) is a proprietary layer 2 network protocol developed by Cisco Systems that runs on most Cisco equipment and is used to share information about other directly connected Cisco equipment such as the operating system version and IP address. CDP can also be used for On-Demand Routing (ODR), which is a method of including routing information in CDP announcements so that dynamic routing protocols do not need to be used in simple networks.
Cisco devices send CDP announcements to the multicast destination address 01-00-0c-cc-cc-cc (also used for other Cisco proprietary protocols such as VTP). CDP announcements (if supported and configured in IOS) are sent by default every 60 seconds on interfaces that support Subnetwork Access Protocol (SNAP) headers, including Ethernet, Frame Relay and ATM. Each Cisco device that supports CDP stores the information received from other devices in a table that can be viewed using the show cdp neighbors command. The CDP table's information is refreshed each time an announcement is received, and the holdtime for that entry is reset. The holdtime specifies how long an entry in the table will be kept - if no announcements are received from a device and the holdtime timer expires for that entry, the device's information is discarded (default 180 seconds).
The information contained in CDP announcements varies by the type of device and the version of the operating system running on it. Information contained includes the operating system version, hostname, every address for every protocol configured on the port where CDP frame is sent eg. IP address, the port identifier from which the announcement was sent, device type and model, duplex setting, VTP domain, native VLAN, power draw (for Power over Ethernet devices), and other device specific information. The details contained in these announcements is easily extended due to the use of the type-length-value (TLV) frame format. See external links for a technical definition.
HP removed support for sending CDP from HP Procurve products shipping after February 2006 and all future software upgrades. Receiving CDP and showing neighbor information is still supported. CDP support was replaced with LLDP.
Conclusions and Lessons Learned
What are the key lessons we have learned? In no particular order:
Address the provision of systems management in prioritized, manageable units of work. Don't try to do everything at once.
Manage the rollout of your systems management application just like any other implementation. After all, availability and integrity of your management application should ideally exceed that of the most critical component that it manages.
Get buy in from all the stakeholders in the process, from Management to Shift Operators.
Think about who will use the tool. You probably don't want to send alerts regarding printer failures to your DBA team. Similarly it's probably not a good idea to send arcane messages about network topology changes to application support teams. Prioritize system alerts and trim out noise.
Don't use it a stick to beat developers, network admin or systems admin staff. If your network management tool highlights a problem, use that information as a justification to provide the resources to fix it.
Do your research. Adopting an Open Source solution requires just as much rigor in the selection and evaluation process as a proprietary solution. By all means download your candidate solution and try it out, but don't allow a machine under a Systems Administrator's desk to become a mission critical component.
It's not been a totally smooth ride. We had repeated problems with memory leaks within the Java virtual machine (admittedly, not OpenNMS's fault). We also had a few nasty problems with corruption of OpenNMS's back-end database, which are now fixed. There were also a lot of "d'oh!" moments along the way, as we got up to speed with what is a pretty complex application. None of these problems ever seemed like show stoppers at the time. This had much to do with help extended by the development team and user community, to whom we extend our thanks.
Why OpenNMS?
OpenNMS checked a lot of these boxes. It was (mostly) java, so we could run it on our Sun hardware. OpenNMS was already running in environments an order of magnitude larger than ours. It had a lot of the enterprise level features absent from other Open Source products. There were documents available on the Internet [1],[2] that pointed to its extensibility. It was based on a lot of familiar components (tomcat, postgres, rrdtool). Finally, in Open Source terms, it was a relatively mature product.
We took a cautious approach deploying OpenNMS.
Simplest to replace, and therefore first to go were the existing network monitoring products. Only after a month of parallel running with OpenNMS did we decommission our existing solutions.
Second to go were the diverse collection of emails that were sent by applications or batch jobs. We replaced the destination email addresses with some mailboxes that delivered the notifications directly into OpenNMS. This turned out to be a bigger win than we'd expected. By having a central point where application alerts could be received and processed, we revealed hidden issues with applications that had existed for weeks or months.
This was painful at first. The respective teams were often uncomfortable in having their problems aired to the world. Once we started to address these problems, however, and the frequency of the alerts started to reduce, we started to see real benefits. The operations team had a single console to monitor applications, and we could reduce the number of application support staff on call.
The next target was system performance data collected by our existing tools. That which could be readily moved into OpenNMS went quickly. Platform specific data collectors (such as those which collected from Microsoft hosts using WMI) had any important alerts channeled in to OpenNMS.
Our current focus, now that we believe our OpenNMS installation is mature, is back in application space. We are extending the end-to-end monitoring capabilities of OpenNMS to our web services providers. We are also starting to use it to retrieve instrumentation data directly from applications themselves, as well as their hosts.
Did We Meet Our Requirements?
Here's how things shook out:
Platform independence: Yes. OpenNMS can run on spare hardware. But it's not a good idea. A year after our first rollout of OpenNMS, we moved from a shared SUN Ultrasparc 2 machine to a dedicated dual Xeon machine running RedHat Advanced Server.
Performance: Yes. We are comfortable in that there will always be users pushing the scalability of OpenNMS much harder than we are.
Enterprise Level Features: A cautious yes. OpenNMS met our initial requirements, but also quickly highlighted new ones. Some customers are never satisfied.
Rationalize Support Roles: Yes. OpenNMS is now the single point for the distribution of all actionable network, server and application events. This does need to be constantly policed, to ensure that non-standard notification paths do not creep in again.
Reduce Tasks: A cautious yes. In general, the operator's load has lessened, if only because it has reduced the numbers of open windows on their desktops.
Extensibility: Yes. OpenNMS has proved to be highly extensible.
Low cost of entry: We deployed OpenNMS with minimal capital outlay. We believe that the subsequent people based operational costs have been roughly equivalent to those of a commercial solution.
Longevity: We seem to have backed a product with "legs." The mailing lists [3] are as busy as ever and new features are being added to OpenNMS faster than we can make use of them.
The "sweet spot" for OpenNMS seems to be about as wide as any Open Source solution and getting bigger by the month. We look forward to enhancements in the web user interface, a new JMX based data collector and support for event correlation in the near future.
Why Do We Need a Systems Management Tool?
Current trends in the IT world continue to accelerate the rate of change in every area. Applications, server platforms and networks are no longer the slow moving entities they once were. They are subject to change on an almost daily basis. In this environment, it becomes more and more important for the IT Operations team to quickly detect, and respond to changes, or anomalous events.
My employer is a relatively new business. Applications would be customized packages, and a large section of its core IT systems would be outsourced. Slowly, those package based solutions morphed into custom applications and, for a variety of reasons, these outsourced systems were brought back in-house a couple of years ago. This presented those of us in the IT department with some interesting challenges. One of those challenges was how to go about managing our newly re-acquired IT infrastructure and applications.
When we first decided to move our core systems from an outsourced to an in-house IT Operations Department, our requirements were limited. Checking the availability of some services and the load on the network and key servers was about as much as we thought we needed.
It became obvious over time that this was rather optimistic. Each new service added seemed to result in a new management tool being installed on a System Administrator's workstation. At one point we had three separate network monitoring systems, three separate performance management tools and a plethora different scripts, web pages and command line tools. The DBA team had one tool, the Network Admins another, the Unix and Windows teams yet another. We sent out critical alerts by email, pager, and SMS, often to completely inappropriate people.
The company was growing, and it looked like it was beginning to need a grown-up systems management tool, but which one?
What Do We Expect from a Systems Management Application?
There is definitely a "sweet spot" for systems management applications. Some are suited to smaller environments, others are most definitely suited to enterprise scale environments with more demanding requirements. Unsurprisingly the enterprise scale products often come with enterprise scale price tags and learning curves.
We had a few key requirements:
Platform independence: Our network management system would have to run on available hardware (at the time, SPARC/Solaris).
Performance: Any solution would need to scale from a few hundred nodes to a few thousand nodes.
Enterprise level features: We required at least SNMP trap management, configurable alert escalation and availability and performance reports for the management team.
Rationalize support roles: We needed to be able to take individuals out of the process. That meant an end to emails sent by systems to developers in the middle of the night. Our operations team needed to be the first contact for every event.
Reduce tasks: It would need to lighten the burden on the Operations Team, not increase it.
Extensibility: Previous experience indicated that there was no such thing as a complete solution.
Low cost of entry: It needed to replace a portfolio of Open Source products.
Longevity: Some Open Source products seem to wither on the vine with no apparent cause, or fragment through disagreements between developers. Commercial products too are subject to the vagaries of the market.
摘要: package afu.mymail;
import java.io.*;
import javax.mail.internet.*;
import javax.mail.*;
import java.util.*;
public class RecieveMail
{
...
阅读全文
摘要: package afu.proxy;
import java.net.*;
import java.io.*;
import org.apache.commons.httpclient.*;
import org.apache.commons.httpclient.methods.*;
public class&nb...
阅读全文
N/A是指:Not Applicable。不是Not Available 的缩写。
是指表格中空出的地方要填的一栏,与你的情况不合。N/A是你填进去的字,不是原有印在上面的。比如表格要你填state或prorinve,但你的国家或你住的地方,没有“省”这个概念,如有的国家,国家下面就是“区”了。还有,有的表格问你有几个孩子,你连结婚都没有结,自然填N/A。
见下面N/A即Not Applicable的释意:
A commonly used abbreviation in the English language for the lack of data in a form or table field, because it does not apply to the situation.
Ethernet Frame Formats:
Ethernet (a.k.a. Ethernet II)
+---------+---------+---------+----------
| Dst | Src | Type | Data...
+---------+---------+---------+----------
<-- 6 --> <-- 6 --> <-- 2 --> <-46-1500->
Type 0x80 0x00 = TCP/IP
Type 0x06 0x00 = XNS
Type 0x81 0x37 = Novell NetWare
802.3
+---------+---------+---------+----------
| Dst | Src | Length | Data...
+---------+---------+---------+----------
<-- 6 --> <-- 6 --> <-- 2 --> <-46-1500->
802.2 (802.3 with 802.2 header)
+---------+---------+---------+-------+-------+-------+----------
| Dst | Src | Length | DSAP | SSAP |Control| Data...
+---------+---------+---------+-------+-------+-------+----------
<- 1 -> <- 1 -> <- 1 -> <-43-1497->
SNAP (802.3 with 802.2 and SNAP headers)
+---------+---------+---------+-------+-------+-------+-----------+---------+-----------
| Dst | Src | Length | 0xAA | 0xAA | 0x03 | Org Code | Type | Data...
+---------+---------+---------+-------+-------+-------+-----------+---------+-----------
<-- 3 --> <-- 2 --> <-38-1492->
Ethernet中存在这四种Frame的格式,如果不能很好的区分他们,那么肯定会造成网络的混乱,
现实中网络设备可以很好的识别它们,那么网络设备又是如何识别的呢?
(1) 如何区分EthernetII与其他格式的帧
如果帧头跟随source mac地址的2 bytes的值大于1500则此Frame为EthernetII格式的。否则就是其他格式的帧。
(2)其他帧格式的区别
接着比较紧接着的两bytes如果为0xFFFF则为Novell Ethernet 类型的Frame
如果为0xAAAA则为Ethernet SNAP格式的Frame ,如果都不是则为Ethernet
802.3/802.2格式的帧
在/etc/profile加入
export JAVA_HOME=/usr/java/jdk1.6.0_06
export PATH=$JAVA_HOME/bin:$CATALINA_HOME/bin:$PATH
export TOMCAT_HOME=/software/apache-tomcat-6.0.16
export BASEDIR=/software/apache-tomcat-6.0.16
export CATALINA_BASE=/software/apache-tomcat-6.0.16
export CATALINA_HOME=/software/apache-tomcat-6.0.16
export CATALINA_TMPDIR=/software/apache-tomcat-6.0.16/temp
重启后,用java -version查看
[root@afunms bin]# java -version
java version "1.6.0_06"
Java(TM) SE Runtime Environment (build 1.6.0_06-b02)
Java HotSpot(TM) Client VM (build 10.0-b22, mixed mode, sharing)
Oracle SQL Developer is a new, free graphical tool that enhances productivity and simplifies database development tasks.
With SQL Developer, you can browse database objects, run SQL statements and SQL scripts, and edit and debug PL/SQL statements. You can also run any number of provided reports, as well as create and save your own.
1. 安装JDK
rpm -Uhv jdk-6u6-linux-i586.rpm
安装在/usr/java/jdk1.6.0_06
2. 安装sql-developer
rpm -Uhv sqldeveloper-1.5.54.40-1.noarch.rpm
安装在/opt/sqldeveloper
3. 启动sql-developer
虽然在程序菜单中有sql-developer的图标,但单击并不能启动,估计是
没有配置jdk的路径。所以,只能用命令行启动。
./sqldeveloper.sh 出现
Oracle SQL Developer
Copyright (c) 2008, Oracle. All rights reserved.
Type the full pathname of a J2SE installation (or Ctrl-C to quit), the path will be stored in ~/.sqldeveloper/jdk
要求输入jdk路径
/usr/java/jdk1.6.0_06
之后,终于看到sqldeveloper的启动图面 
安装Oracle10g会遇到的问题及解决方法:
1. 缺少libXp.so.6
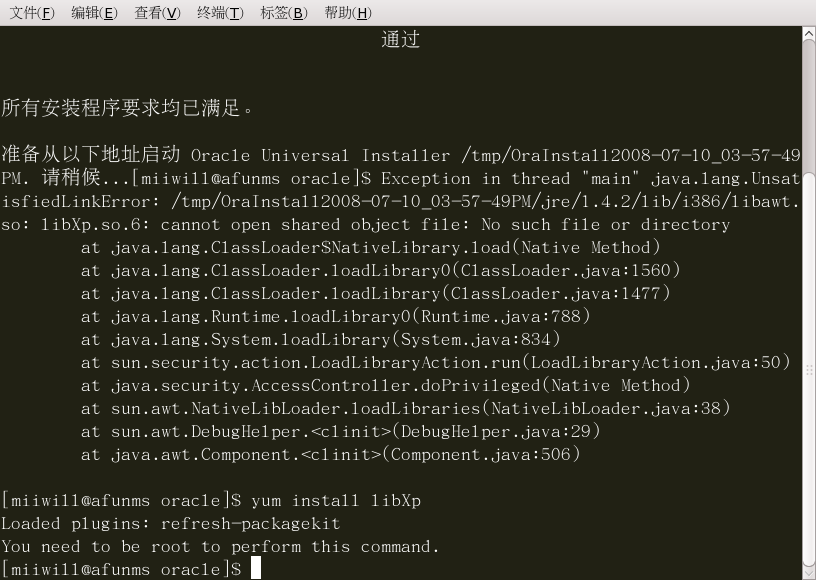
执行命令:yum install libXp.so.6
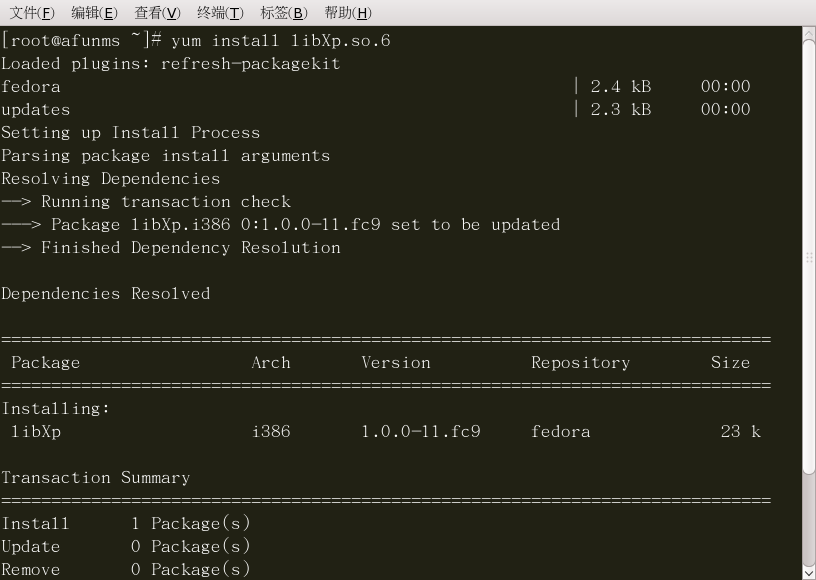
2. 操作系统限制

修改/etc/redhat-release 把Fedora release 9改成redhat-3
3. Can't connect to X11 window server using....
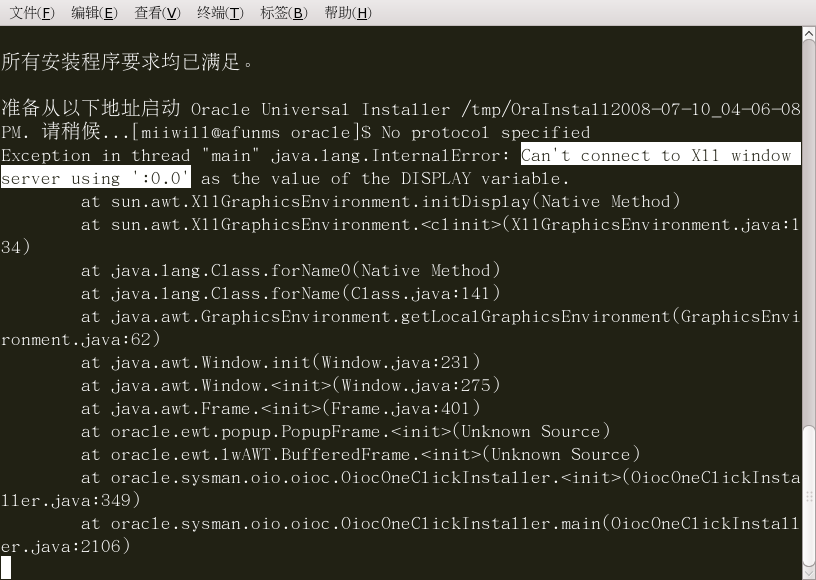
以root的用户执行 xhost +
然后 su - oracle(用户)
export DISPLAY=:0
再运行runInstaller安装oracle
4. 安装界面乱码
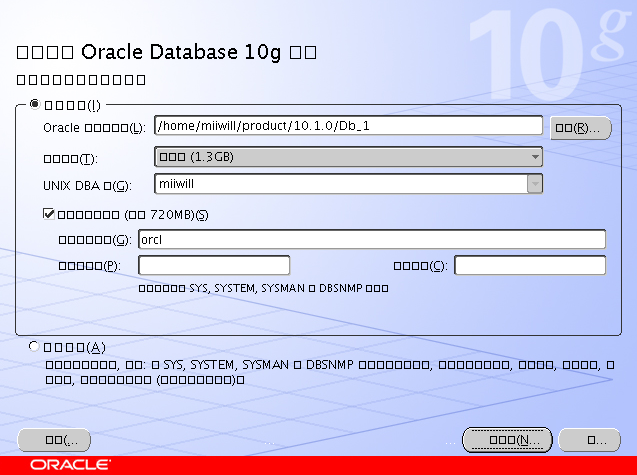
export LANG=en
(改成export LANG=zh_CN.GB18030不管用)
界面变成英文。
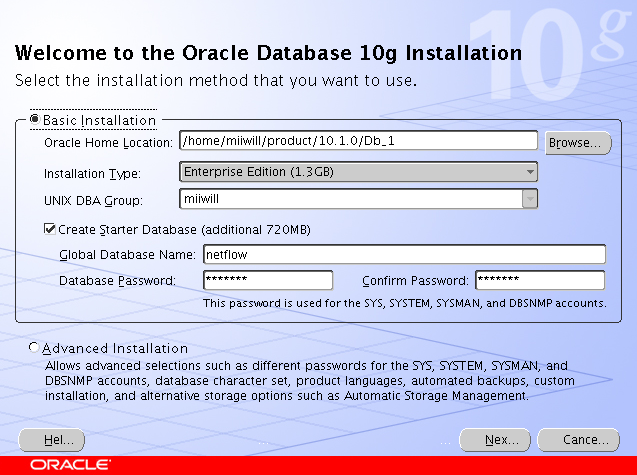
Linux下安装软件,不像Windows那么简单,所以每安装成功一个软件都让我兴奋。
注意飞鸽的版本是:g2ipmsg-0.9.5
1. 安装XML-Parser
perl Makefile.PL
make
make install
2. 修改src/codeset.c
/* #define IPMSG_PROTO_CODE IPMSG_EXTERNAL_CHARCODE */
#define IPMSG_PROTO_CODE "GB2312"
3. 安装飞鸽g2ipmsg-0.9.5
configure
make
make install
4. 开启防火墙端口tcp/udp:2425
这步很重要,不然飞鸽上一个人也没有。
今天安装了Fedora9,装完之后发现竟然没有输入法!太奇怪了,Fedora8可没这现象。
Google之后,得知
yum install scim-lang-chinese,之后重启即出现输入法。
cd /u01/app/oracle/bin
export ORACLE_BASE=/u01/app/oracle
export ORACLE_SID=ORCL
export ORACLE_HOME=$ORACLE_BASE
export PATH=$PATH:$ORACLE_HOME/bin
#启动监听
lsnrctl start
#关闭监听
lsnrctl stop
#启动数据库
sqlplus "/as sysdba"
sql>startup
#停止数据库
sql>shutdown immediate
#启动dbconsole服务
emctl start dbconsole
#停止dbconsole服务
emctl stop dbconsole
#启动或停止 iSQL*Plus:
isqlplusctl start | stop
摘要:
专辑名
01.新年快乐
发行时间
...
阅读全文
安装MyEclipse时遇到
java: xcb_xlib.c:50: xcb_xlib_unlock: Assertion `c->xlib.lock' failed.错误
解决办法:
[root@localhost software]# export LIBXCB_ALLOW_SLOPPY_LOCK=1
[root@localhost software]# yum --enablerepo=development update libxcb
执行以上两条命令,之后出现:
[root@localhost software]# export LIBXCB_ALLOW_SLOPPY_LOCK=1
[root@localhost software]# yum --enablerepo=development update libxcb
development 100% |=========================| 2.4 kB 00:00
primary.sqlite.bz2 100% |=========================| 6.5 MB 06:44
fedora 100% |=========================| 2.1 kB 00:00
updates 100% |=========================| 2.3 kB 00:00
Setting up Update Process
Resolving Dependencies
--> Running transaction check
---> Package libxcb.i386 0:1.1-4.fc9 set to be updated
--> Finished Dependency Resolution
Dependencies Resolved
=============================================================================
Package Arch Version Repository Size
=============================================================================
Updating:
libxcb i386 1.1-4.fc9 development 124 k
Transaction Summary
=============================================================================
Install 0 Package(s)
Update 1 Package(s)
Remove 0 Package(s)
Total download size: 124 k
Is this ok [y/N]: y
Downloading Packages:
(1/1): libxcb-1.1-4.fc9.i 100% |=========================| 124 kB 00:03
Running rpm_check_debug
Running Transaction Test
Finished Transaction Test
Transaction Test Succeeded
Running Transaction
Updating : libxcb ######################### [1/2]
Cleanup : libxcb ######################### [2/2]
Updated: libxcb.i386 0:1.1-4.fc9
Complete!
Installed NetBeans6.0,which is a java development IDE.
This is my first time to install a software under Fedora.
However,I was disappointed in NetBeans for two reason.
The first,tomcat6 who bind with NetBeans can not be shut down.
The second,java file can not be build at once after it was saved.
Installed libpcap successfully.We can not use libpcap before installation.
Study the first program of grabing packet using libpcap.
I was exciting today since I learned more.
在Fedora8下安装netbeans
命令:
# chmod +x
netbeans-6.1-ml-javaee-linux.sh (更改权限)
# ./
netbeans-6.1-ml-javaee-linux.sh (安装netbeans)

集成了Tomcat6.0.16,不过感觉还是没MyEclipse好用,两点原因:
1. Tomcat关闭不了,好奇怪。
2. 保存java文件后不马上编译class,而是到启动Tomcat时才编译所有更新过的java.
编译带有libpcap的程序一直没成功,后来才知道libpcap还需要安装!!
1. 解压libpcap(双击即可)
2. 进入刚才解开的libpcap目录,执行
#./configure
命令,生成Makefile文件
3. 输入
#make install
将生成的库安装到系统默认目录中,/usr/local/lib。
琢磨好几天,不知道详细设计文档要写些什么,参考了很多资料,
确定写以下一些内容。
详细设计文档
1.模块设计
包括输入、输出项
对于逻辑比较复杂的画出数据流图和文件结构(对每个类的说明)
2.界面设计
3.数据库设计
ER图和表结构说明
4.UML
类图、时序图等

我的目标是在三到五年的时间内,做一个类似netscout的软件。
所以又重新学习C语言。
What is NetFlow?
NetFlow is a technology developed by Cisco Systems that is also supported by many other hardware vendors. NetFlow is far easier to setup and use than other network traffic monitoring technologies that require the deployment of distributed hardware probes. Basically, the router or switch is setup to summarize every conversation incoming on each network interface and forwards it on to a collector, like Scrutinizer, where the details are compiled and displayed in an easy to understand format that allows IT professionals to analyze the behavior of their network.
ATM Layer Link
A section of an ATM Layer connection between two adjacent active ATM Layer entities (ATM-entities).
ATM链路层
ATM层的一部分,位于两个邻近的ATM层活动实体(ATM-entities)之间。
ATM Link
A virtual path link (VPL) or a virtual channel link (VCL).
ATM链路
虚通道链路(VPL)或虚路径链路(VCL)。
ATM Machine
See ATM.
ATM设备
参见ATM。
ATM Peer-to-Peer Connection
A virtual channel connection (VCC) or a virtual path connection (VPC).
ATM对等连接
虚路径连接(VCC)或虚通道连接(VPC)。
ATM Protocol Reference Model
A multidimensional protocol model consisting of 4 layers and 3 planes and serving as a point of reference for understanding, developing and implementing ATM technology. Each layer addresses a discrete set of related functions, with all layers closely interrelated. The layers include the Physical Layer, ATM Layer, ATM Adaptation Layer, and Higher Layers related to the specifics of the native user data protocol. The planes include the Control Plane, User Plane and Management Plane.
ATM 协议参考模型
一种多维协议模型,包括4个分层和3个平面,用作理解、开发和实现ATM技术的参考点。每一个分层执行一组离散的相关功能,所有分层都紧密的相互关联。这些分层包括物理层、ATM层、ATM适配层以及与原来的用户数据协议细节相关的高层。3个平面有控制平面、用户平面以及管理平面。
ATM Switch
A networking device that forwards 53-byte ATM-standard cells between different devices. These switches can be designed for both LAN and WAN environments. An ATM switch acts as both a traffic aggregator, such as when terminating unchannelized DS-3 trunks from DSLAMs, and as a multiservice switch that is capable of forwarding traffic in different ways, depending on what has to be done with it. For example, an ATM switch forwards customer IP traffic directly to an IP network by shunting it to a router or subscriber management system, frame-relay traffic to a frame switch, voice-over-ATM traffic to a voice/data gateway, or long-distance traffic to other central offices via a SONET inter-office ring.
ATM交换机
一种网络设备,在两个不同设备之间传输53字节ATM标准信元。这些交换机可以设计用于LAN(局域网)和WAN(广域网)。 ATM交换机可以用作信息传输集合器,例如可以终止来自DSLAM的未作信道使用的DS-3中继线;也可以用作多业务交换机,能够根据预先设置以不同方式传输信息。例如,ATM交换机通过将信息分流到路由器或用户管理系统、将帧中继信息分流到帧交换机、将ATM话音信息分流到话音/数据网关或者将长途信息通过SONET局间环路分流到其他市话局来将客户IP信息流直接传输到IP网络。
ATM Token Ring LAN Service Unit
The ATM TLSU provides a powerful tool for offering internetworking services over ATM networks. Emulated token rings consist of up to 64 TLSU token ring ports located anywhere in the ATM network, interconnected with PVCs. These emulated token ring networks can be completely isolated from one another to ensure security and fairness among the attached LANs. The TLSUs are designed for flexible deployment, either local to an ATM switch or at a remote site. See ATM Ethernet LAN Service Unit.
ATM令牌环服务单元
ATM TLSU提供了功能强大的工具,在ATM网络中提供网间服务。仿真令牌环最多可以由多达64个TLSU令牌环端口组成,放置在ATM网络任意位置,提供PVC间的互连。这些仿真令牌环网络可以完全独立于其他仿真令牌环,以确保连接到局域网的各仿真令牌环的安全和公平。TLSU的设计使其能够灵活应用,无论是本地环路连接ATM交换机还是远端站连接ATM交换机。参见ATM Ethernet LAN Service Unit。
ATM Traffic Descriptor
A generic list of traffic parameters that can be used to capture the intrinsic traffic characteristics of a requested ATM connection.
ATM流量描述符
一种普通的流量参数列表,可以用于获取所需的ATM连接内在流量特性。
ATM User-User Connection
An association established by the ATM Layer to support communication between two or more ATM service users (i.e., between two or more next higher entities or between two or more ATM-entities). The communications over an ATM Layer connection may be either bidirectional or unidirectional. The same Virtual Channel Identifier (VCI) is issued for both directions of a connection at an interface.
ATM用户和用户连接
ATM层建立的一种联系,支持两个或两个以上ATM服务用户(即两个或两个以上高级实体之间或两个或两个以上ATM实体之间)之间的通信。ATM层连接上的通信可以是双向的或者的单向的。在一个接口中,相同的虚路径标识符(VCI)可以沿链路双向传输。
ATMARP
ATM Address Resolution Protocol. The means of mapping IETF classical IP addresses to ATM hardware addresses. The process works in much the same way as conventional ARP, which maps network-layer addresses to the MAC (Media Access Control) layer in a LAN.
摘要:
专辑名
01.追风少年
发行时间
...
阅读全文
第5名前几天生病了,并且由于某些事情,心情非常的不好,中午没有胃口去吃饭,一直到下午才突然觉得肚子有点饿了,于是便打算下楼去找点东西吃。在电梯口等的时候,来了个漂亮的MM,很娇小可爱的样子,穿着和她年龄并不相称的职业装,里面米黄色的内衣,连乳沟都露出来,看了就让人垂涎欲滴啊。她看起来很小的,好象学生一样,估计是刚毕业的吧。这时候电梯到了,我们一大群人挤了进去,我刚好就在她的旁边,被其他人一挤,就和她靠的更近了,胳膊压在了她的胸脯上,很舒服的感觉。当然我觉得这样可能会让她觉得不舒服,于是就准备挪下身体,可里面的人实在很多,等我调整好位置的时候,发现她的整个人都被我的身体给包围了,而且我的眼睛下面就是她的乳房,几乎是一览无余了,白色的蕾丝BRA衬着挺拔可爱的MIMI,看得我心神荡漾,我整个人都快飘了起来,正偷偷的瞄着她的乳房,并窃喜陶醉的时候,发生了一件意外的情况,正如前面所说,由于饿了一个下午的缘故,不知为什么看了她的乳房,使人口中生津,我还没意识到的时候,口水不知怎么就流了下来(我想强调下,我流口水肯定是因为饿的缘故,而并不是我的RPWT),然而令人尴尬的是,我的口水竟然就流到了她的乳房上,顺着乳沟流了下来,我的脸刷的就红了,那个MM也不知如何是好,差点都哭了起来,还好电梯里其他人都没能看出来,我当时恨不得能钻到地底下,或者一头碰死了,等到了一楼,我们都出了电梯,MM跑到一旁拿纸巾擦了起来,我也跟了过去,红着脸说对不起,MM瞪了我一眼说大色狼,然后继续擦,我正不知如何是好的时候,MM忽然就真的红着眼睛哭了起来,我当时那叫一个紧张啊,旁边好多人在看了,还好她们以为我和那个MM是男女朋友关系。然后我就一直陪在那个MM的身边,直到她把我流在她身上的口水擦干净……唉
第4名 有一天下午,我困在银行排队的行列中,我刚学会走路的女儿决定要发泄一下她被压抑过久的精力,开始胡闹起来,在接收到其他顾客嫌恶和不耐烦的眼光後,好不容易我终於抓住她,我告诉她,如果不立刻乖乖听话 就要处罚她。没想到她看著我,用威胁的口气说:「如果你不放开我,我就要告诉奶奶我昨天 晚上看见你在亲爸爸的小鸡鸡!」 当场整个银行里一片安静,行员们全都停下手边的事,想看看究竟是怎麽回事,我死撑著最後的一点尊严,拖著女儿走出银行,当门关上的那一刹那,我听到一阵狂笑从我背後传来。
第3名 那是我18岁生日那天,我当时住在家里,但我父母晚上不在,所以我把女朋友找来,想过个浪漫独处的夜晚。办完事後,我们躺在床上,听到有电话声从楼下传来,我提议我们玩骑马游戏下楼去接电话。既然我们不想漏接这通电话,当然没时间穿衣服了。当我们走完楼梯,灯忽然亮了!一大群人喊 「Surprise!」 我一大家子的亲戚,我的姑姑阿姨、叔叔舅舅、祖父母、表弟妹、还有我的朋友…都站在那儿!我跟我女友被这震惊、难堪又漫长的一刻吓呆了。从此以後,我的家人再也没人为我办这种surprise party。
第2名 一位小姐在折扣商店挑了一些东西,终於轮到她结帐时,才发现有一个商品上没有标价,柜台用广播向在货架附近的店员查询价格,整间店的人都听得到,接下来想像一下这情况有多尴尬「第13排的,查一下,特大号的TAMPAX(卫生棉条)多少钱?」更糟的是,在後面的某人,很显然是误解了,把『TAMPAX』听成『Thumbtack』 (图钉),广播传来他非常"专业"的语气问:「你要那种可以用手指推进去的?还是要用榔头钉进去的?」
第1名 这个故事发生在去年10月一所美国一流大学中。生物学的课堂中,教正在讲解精液里含有很高比例的葡萄糖。一个女生新鲜人举手发问:「如果我理解得没错,你的意思是说男人精液里的葡萄糖和砂糖里的一样多?」「对!」教授回答,并准备要补充一些数据。那个女生又举手问:「那为什麽它吃起来不是甜的?」一阵死寂之後,全班爆笑,而那个可怜的女生终於理解到自己无意间说了(或暗示了) 什麽,胀红了脸,拿起课本,一句话也没说,走出了教室。不过当她正走出门时,教授的回应才真是经典!他回答了那个问题:「它吃起来不是甜的,那是因为感觉甜味的味蕾是在舌尖,不是在後面的喉咙。
DoS(Denial of Service拒绝服务)和DDoS(Distributed Denial of Service分布式拒绝服务)攻击是大型网站和网络服务器的安全威胁之一。
SYN Flood由于其攻击效果好,已经成为目前最流行的DoS和DDoS攻击手段。
SYN Flood利用TCP协议缺陷,发送了大量伪造的TCP连接请求,使得被攻击方资源耗尽,无法及时回应或处理正常的服务请求。一个正常的TCP连接需要三次握手,首先客户端发送一个包含SYN标志的数据包,其后服务器返回一个SYN/ACK的应答包,表示客户端的请求被接受,最后客户端再返回一个确认包ACK,这样才完成TCP连接。在服务器端发送应答包后,如果客户端不发出确认,服务器会等待到超时,期间这些半连接状态都保存在一个空间有限的缓存队列中;如果大量的SYN包发到服务器端后没有应答,就会使服务器端的TCP资源迅速耗尽,导致正常的连接不能进入,甚至会导致服务器的系统崩溃。
报表模块已不知改进了多少次。在SourceFlow2.0,报表模块的设计有了质的飞跃,
用到了两种设计模式,Builder Pattern和Decorator Pattern,具有很好的可扩展性。
<?xml version="1.0" encoding="gb2312" ?>
- <reports-config>
- <report id="ifTraffic">
<dao-class>com.shine.sourceflow.mvc.show.dao.IfTrafficDao</dao-class>
<report-class>com.shine.sourceflow.mvc.show.report.IfTrafficReport</report-class>
<title>设备接口流量统计</title>
<target>/show/ifTraffic.jsp</target>
- <parameters>
<parameter name="timeType" type="int" default_value="4" />
<parameter name="day" default_value="today" />
</parameters>
</report>
- <report id="ipTraffic">
<dao-class>com.shine.sourceflow.mvc.show.dao.IPTrafficDao</dao-class>
<report-class>com.shine.sourceflow.mvc.show.report.IPTrafficReport</report-class>
<title>IP地址流量统计</title>
<target>/show/ipTraffic.jsp</target>
- <parameters>
<parameter name="timeType" type="int" default_value="1" />
<parameter name="ipType" type="int" default_value="1" />
<parameter name="topN" type="int" default_value="10" />
<parameter name="day" default_value="today" />
</parameters>
</report>
- <report id="ipGroupTraffic">
<dao-class>com.shine.sourceflow.mvc.show.dao.IPGroupTrafficDao</dao-class>
<report-class>com.shine.sourceflow.mvc.show.report.IPGroupTrafficReport</report-class>
<title>IP分组流量统计</title>
<target>/show/ipGroupTraffic.jsp</target>
- <parameters>
<parameter name="timeType" type="int" default_value="1" />
<parameter name="topN" type="int" default_value="10" />
<parameter name="day" default_value="today" />
</parameters>
</report>
- <report id="appTraffic">
<dao-class>com.shine.sourceflow.mvc.show.dao.AppTrafficDao</dao-class>
<report-class>com.shine.sourceflow.mvc.show.report.AppTrafficReport</report-class>
<title>应用流量统计</title>
<target>/show/appTraffic.jsp</target>
- <parameters>
<parameter name="timeType" type="int" default_value="1" />
<parameter name="topN" type="int" default_value="10" />
<parameter name="day" default_value="today" />
</parameters>
</report>
- <report id="sessionTraffic">
<dao-class>com.shine.sourceflow.mvc.show.dao.SessionTrafficDao</dao-class>
<report-class>com.shine.sourceflow.mvc.show.report.SessionTrafficReport</report-class>
<title>会话流量统计</title>
<target>/show/sessionTraffic.jsp</target>
- <parameters>
<parameter name="timeType" type="int" default_value="1" />
<parameter name="topN" type="int" default_value="10" />
<parameter name="day" default_value="today" />
</parameters>
</report>
</reports-config>
今天完成设备接口流量统计。

会话流量报表

我有一个强大祖国
5月14日作于成都市抗震救灾指挥部
成都市林业和园林管理局副局长 叶浪
那是一张熟悉的脸
是我痛失亲人后看到的最真切的笑脸
眼里闪着泪花
话里充满着力量
那一刻
我感到自己有一个强大的祖国
那是一张陌生的脸
是我埋在瓦砾下看见的最勇敢的脸
撬开了残垣
搬走了巨石
那一刻
我感到自己有一个强大的祖国
那是一张美丽的脸
是我躺在病床上看见的天使的脸
包扎我的创伤
驱走我的恐惧
那一刻,
我感到自己有一个强大的祖国
那是一张慈祥的脸
是我奔离教室前看过的最镇静的脸
为了自己的学生
成就了自己的永恒
那一刻
我感到自己有一个强大的祖国
那是一张年轻的脸
是我在排队长列里看到的最急切的脸
为了灾区的伤员
献出了自己的殷殷鲜血
那一刻
我感到自己有一个强大的祖国
那是一张忙碌的脸
是我在救灾一线上看到的最疲惫的脸
眼里布满血丝
来不及顾及自己的家人
那一刻
我感到有一个强大的祖国
那是世上最可爱的脸
是家乡地震后不曾面见过的男男女女的脸
虽远在他乡海外
温暖的目光却紧紧地落在了我的身上
那一刻
我感到自己有一个强大的祖国
地动天不塌
大灾有大爱
我感到自己有一个强大的祖国
吸取了上个版本的经验和教训,把SourceFlow2.0设计成这样:
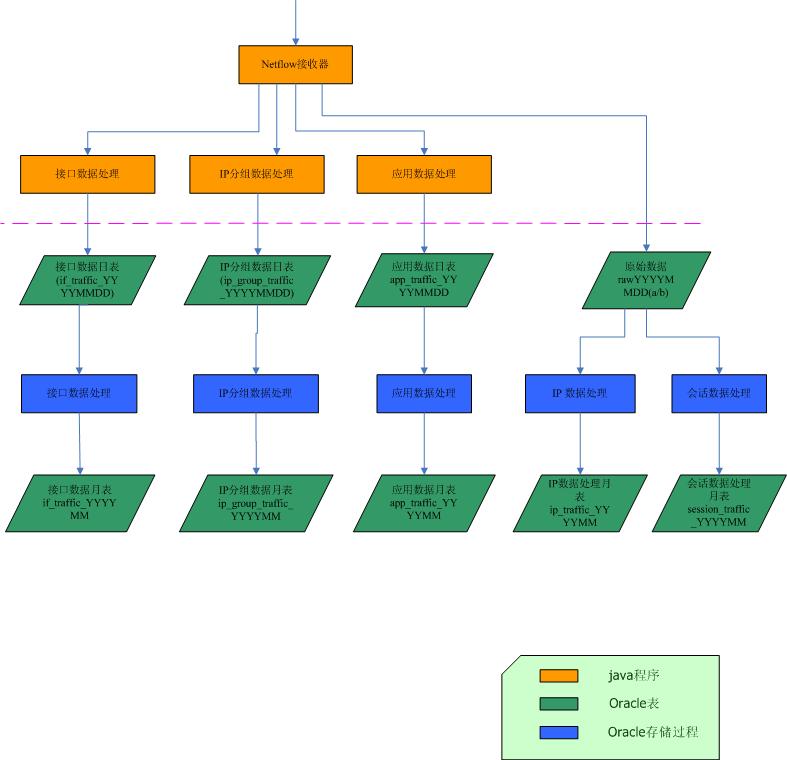

为了写好软件构架文档而专门买了这本书,结果发现它太深奥,
不适合我。
以前真不知道ARP攻击会导致IP冲突,今天下午遇到怪事了,不论
怎么改IP,系统总是报“系统警告-IP冲突”。我断定一定是病毒
的原因。果断,在网上找到了答案,“ARP攻击导致IP冲突”。
下载安装“ARP防火墙单机版”,问题解决。
在工作中遇到一些概念模糊的地方, 需要记住:
bit 为“位”或“比特”,是计算机运算的基础;
byte 为“字节”,是计算机文件大小的基本计算单位;
octet 为八位组,八比特组。
因此:
1 byte = 8 bits
octet = byte
-------------
I did not receive much feedback on this issue, and what I did receive
went both ways.
I've given it a lot of thought and have decided to stick to *-byte in
the names as there is simply no advantage in changing to octet. In
this day and age "byte" is universally accepted as being 8 bits and
any argument that it could be misinterpreted is simply not realistic.
"octet" on the other hand is a less well known term used primarily by
network engineers and in RFCs, and could be confusing to those not
familiar with it who may wonder how you intend to pull eight musicians
out of a port. Programming libraries and APIs almost universally use
"byte" and so newcomers are likely to be more comfortable with this.
In a nutshell, you could argue forever either way, but as this is a
library for programmers and the most well known programming term is
"byte," including specific precedence in Lisp and Scheme functions of
the same name, I'm going to stick with "byte."
一件想了很久的事,今天实现了。终于有了自己的本本,小黑Thinkpad T61 AT9。

We held a meeting to discuss ZSP project.
Kingdee Middleware Co.,Ltd introduced their middle ware (apusic) and j2ee framework (aom) for us.
I respect this great company despite that their software held no interest for me.
chenhao,我知道你是谁了,呵呵。还在北京吧?
tomcat监视确实是两年就做出来了,不过在SourceView2.0中才把它以图形方式展现出来。
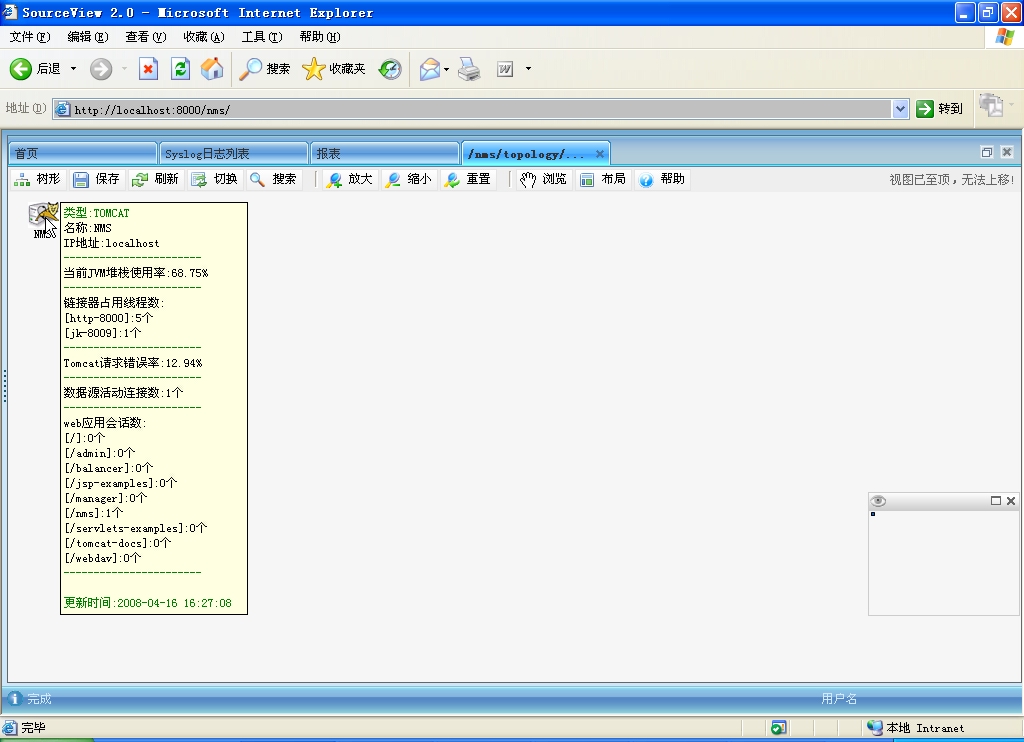
结论1:交换机非叶端口与交换机直接相连判定:交换机Si其下行非叶端口Sij的MAC表的集合Aij等于其最大子树的根节点Sk的所有下行端口的MAC表的和再加上Sk的MAC地址即Aij=Ak + Sk_MAC,则Si通过下行端口Sij与Sk的上行端口直接连接。
------------------
Aij=Ak 或
Aij=Ak + if_mac (if为Si的下行端口的mac)
在ZSP证明了以上这两种情况都可以判定两交换机是直连的。
而在公司的网络中Aij=Ak + Sk_MAC,所以,综上
这三种情况都有可能。
1.网管系统:
网络部分给用户简单演示了一下。由于把子网的别名都改为各分局的实际中文名,在拓扑图上很直观,所以他暂时还比较满意。据他说,领导的意思是将来会把拓扑图放在大屏幕上,这样网络有什么问题,管理人员可以及时发现。
应用部分增加了对IIS web服务器,以及对URL网页的监控。
就像当年在安徽恒源证明了STP的正确性,今天在中山证明了CDP的正确性。
二层拓扑发现通用算法,也得到验证。现在只有以下两个问题成为难点:存在HUB的情况;接口的FDB表空的情况。
2.流量系统:
上周的问题已经解决,系统在接收数据方面已没有问题。
但在数据存贮方面遇到挑战。目前oracle和tomcat装同一台PC上,在大数据面前(平均一秒钟有2000条记录),系统运行缓慢。解决方法就是需要一台高性能的服务器(最好有4个CPU,200G的硬盘)。当时,在下一版本的设计中,会接受这次项目的经验。相信我们会越做越好。

这本书里面的一些句子还是挺经典的。
We came to ZS again.After making unremitting efforts,SourceFlow succeeded in receiving netflow
data steadily.
I was busy with research work for layer-2 discovery.Further study shows not only Aij=Ak + Sk_MAC
is right,there are conditions under which Aij=Ak or Aij=Ak + if_mac can deduce two switches are
directly connected.
This is a very important conclusion.
** Version 2.2.1.Alpha, Release Date 2008.04.13
* Attached chinese alias to subnets and devices,so the topological map became more direct.
* Fixed a bug in the report module.
** Version 2.3.0.Alpha, Release Date 2008.04.14
* Added a monitor for http url.
* Added a monitor for IIS.
Building a layer-3 topology is relatively easy because routers must be
explicitly aware of their neighbors in order to perform their basic function.
Therefore, standard routing information is adequate to capture
and represent layer-3 connectivity. Unfortunately, layer-3 topology
covers only a small fraction of the interrelationships in an IP
network, since it fails to capture the complex interconnections of
layer-2 network elements (e.g., switches and bridges) that comprise
each subnet. As more switches are deployed to provide
more bandwidth through subnet microsegmentation, the portions
of the network infrastructure that are invisible to a layer-3
mapping will continue to grow. Under such conditions, it is obvious
that the network manager’s ability to troubleshoot end-toend
connectivity or assess the potential impact of link or device
failures in switched networks will be severely impaired.
The lack of automated solutions for capturing physical (i.e.,
layer-2) topology information means that network managers are
routinely forced to manually input such information for each
management tool that they use. Given the dynamic nature and
the ever-increasing complexity of today’s IP networks, keeping
track of topology information manually is a daunting (if not impossible)
task. This situation clearly mandates the development
of effective, general-purpose algorithmic solutions for automatically
discovering the up-to-date physical topology of an IP network.
An additional challenge in the design of such algorithms
is dealing with the lack of established, industry-wide standards
on the topology information maintained locally at each element
and the diversity of elements and protocols present in today’s
multi-vendor IP networks. The combination of these factors implies
that any practical solution to the problem of discovering
physical IP topology needs to deal with three fundamental difficulties.
1. Limited local information.
2. Transparency of elements across protocol layers.
3. Heterogeneity of network elements.
1. 对于网管系统,主要调试网络管理部分,包括拓扑发现和事件告警等。
修改了一些bug,这周基本完成预期计划。
对二层发现问题,有更加清晰地认识。如果不存在Hub,我的程序可以准确地运行,
但对于存在hub的情况,算法太复杂,我还没认真去研究。
下周去,首先把网络部分演示给管网络的用户看一下,看是否还有需要改进的。
其次,对小型机的监视,与用户作进一步沟通。
从目前情况看,系统稳定。但因为现在没有固定的服务器,暂时无法测试系统长
时间(至少是10天)连续运行情况。
2. 对于流量系统,在公司测试时没问题,但在ZSP,数据比我们估计大得多,
我们的程序撑不住。
这几天改进程序,待下周再去测试。
我觉得我们的系统如果能在ZSP正常运行,就基本能适合一般的企业应用。
所以现在遇到些问题并不是件坏事。
待这个项目之后,netflow会重新设计,升级到2.0。
昨天发现很sysoid为1.3.6.1.4.1.6889.1.69.1.6的设备,程序判断为路由器,
因为路由表有好多项,但我相信它肯定不是路由器。
1.3.6.1.4.1.6889.为Avaya的企业oid,那wind river systems与avaya公司又
是什么关系呢?
但我最想知道的是这种设备有是干什么用的。
但了wind river和cisco的网站
http://www.windriver.com/products/vxworks/
http://www.cisco.com/en/US/docs/net_mgmt/cisco_network_connectivity_monitor/
1.1_IDU_2/device_support/table/ncm_idu2_dev.html
猜想这设备应该能内嵌入cisco的交换机,具体做什么就不清楚了。
Improved topological map showing program,reduced code duplication.
The result was my expectation,but was not the best.It's necessary to
develop a new algorithm.
Expanded the discovery scope,form 128.1 to 191.255,instead of from
182.1 to 191.255.Lots more devices were discovered,including some of
windows and aix servers.
Moreover,some of strange devices were discovered too,whose SYSOID is
1.3.6.1.4.1.6889.1.69.1.6,SYSDESCR is VxWorks SNMPv1/v2c Agent by
Wind River Systems.
Layer-2 discovery is very difficult in a environment without CDP or STP.
My final goal is my program can get a accurate result in any network.
ZSP is a good place to test my discovery program of the general algorithm
instead of CDP.
The program of the general algorithm was wrote according to a paper,
that was proved to be correct in our company lan.However,it didn't work
at all in ZSP environment.The radical reason is the switch mac(bridge mac)
does not exist in fdb table of the other switch which is dircet connected
with it,so the algorithm lose its effectiveness.
I modified the program,set the mac address of some designated interfaces to be
the symbol mac intead of the bridge mac.This time,program run a satisfactory
conclusion excluding those switches who were connected with hubs.
As for the environment with hubs,I should study more.
Discovered ZSP network, using CDP protocol for all devices
here were cisco.The scope was from 182.1 to 191.255.
SourceView2.0 spent 4 minutes on topological discovery,then
drawing a distinct map.The amount of devices is 165.
I renamed those subnets to their relevant chinese alias.
This is the first step for ZSP project,it is a crucial step too,
I completed it sucessfully.So I set my heart at rest.
Release Notes - SourceView2.0
** Version 2.0.0.Alpha, Release Date 2008.04.01
* Completed almost all features according to the requestment document.
** Version 2.1.0.Alpha, Release Date 2008.04.03
* Completed the program related to discovery,including general and CDP algorithm.
* Completed modification of topological map showing,add two classes,using strategy
pattern.
** Version 2.1.1.Alpha, Release Date 2008.04.05
* Add a field to TOPO_SUBNET table,alias,which stores chinese name for the subnet.
* Add a table,HOST_SUBNET_MAPPING,which stores the relationship between hosts and subnets.
* Add a table,FDB_TABLE,to store fdb data from switches.
** Version 2.2.0.Alpha, Release Date 2008.04.07
* Add a monitor for monitoring oracle users.
* Improve operability of topological map,user can search device interfaces' ip directly
on topological map.
* Attach subnets' information to topological map.
1.Completed modification of topological discovery.
2.Tested the program based on the LAN of our company successfully.
3.The relationship between hosts and subnets is very important for
network discovery,so I wrote program to save the data related to that into DB.
4.Wrote a new class,FdbCollector,to extract fdb data from devices.
结论1:交换机非叶端口与交换机直接相连判定:交换机Si其下行非叶端口Sij的MAC表的集合Aij等于其最大子树的根节点Sk的所有下行端口的MAC表的和再加上Sk的MAC地址即Aij=Ak + Sk_MAC,则Si通过下行端口Sij与Sk的上行端口直接连接。
------------------
只有这个算法最适用,今天我把这个算法写出来了,并在公司的网络中测试通过。
引理1:如果Lij∪Lkl=u(u指子网内所有交换机的合集)且Lij∩Lkl=∮(∮空集)则端口Sij与端口Skl直接连接[1]。
-------------------------------
这个算法也不适合,因为Lij∪Lkl=u是很难实现的。
间接连接定理:
只要满足以下3个条件之一,就可以确定交换机A和B通过x和y端口间接相连。设交换机A在x端口上学习到的MAC地址的集合为FxA。
1.FxA和FyB中同时存在着对方的MAC地址;
2.FxA中存在B的MAC地址,并且A上存在一个端口k(k≠x),使得FyB∩FkA≠ф;
3.在B上存在两个端口i,j,使得FxA∩FiB≠ф且FxA∩FjB≠ф,并且A上存在端口k(k≠x),使得FkA∩FyB≠ф。
由于交换机之间很少通信,所以条件1和2中要求的交换机A的FxA中存在B的MAC地址很难满足,可以利用IP欺骗的方法尽量地使条件满足。具体做法是:对于子网中的每个交换机Si,利用IP欺骗方法,以Si的IP地址为源地址,向子网中的其他交换机发送ICMP ECHO消息。在Si收到回应后,将导致Si的FDB中保存有其他交换机的MAC地址。
基于间接连接确定直接连接
根据子网内交换机之间的间接连接关系,就可以确定交换机之间的直接连接关系。设子网内的所有交换机构成的集合为G。根据STP协议,交换机之间将构成一棵树。任选其中一个交换机Si为根,假设Si通过n个端口与其他交换机构成间接连接,则可以将G-{Si}构成一个划分Πi,划分中包含n个元素,每个元素是与Si的某个端口p相间接连接的交换机的集合,设为Gp。在Gp中任选一个交换机Sj,则Sj必然通过某个端口q与Si的端口p间接连接,如果Sj不通过端口q与Gp中的其他交换机间接连接,则可以判定Sj通过端口q与Si的端口p直接连接。
------------------------------
这是很久以前看过一篇论文里的一部分。
从间接连接中推出直接连接,这个不难。但要找出间接连接是困难的,为什么?因为要实现那三个条件判断,代码量和运算量都极大,所以我没有选择这个算法。
不过其中提到IP欺骗的方法倒是很实用,因为如果两交换机不通信,那么其中各接口的FDB表就不完整,甚至FDB表完全没有数据。
Program related to map showing wrote by Zhanghf could not go well now.I must write the
program again by myself.
Netflow,which ftped by Yang occured an error.
Today is not my day.
Wrote two classes to realize topological map showing,using strategy pattern,each class run
the different algorithm.However,I could not develop a program who adapts any network
enviroment.
ZSP project started.SourceView2.0 and SourceFlow1.0 will be
deployed there.
This project is my first project since I came to GZ,wishing it
success.
Fedora为什么不用mp3,而选择ogg?
Freedom: Make ogg, not mp3
Why is mp3 popular? Because it's better than everything else out there?
No. mp3 is popular because its creators licensed it broadly to spur its adoption. Then, once it was the de facto format, they started to enforce their patents aggressively and restrictively.
The free and open multimedia codecs such as the Ogg family of codecs are superior, and they are not patent-encumbered. Never have been, never will be. That's why we support free and open formats like Ogg Vorbis (lossy) and FLAC (lossless) for general audio and Ogg Theora for video.
For those people who insist upon using mp3, it's not difficult to figure out how to get these players. Still, we'd much rather change the world instead of going along with it.
http://fedoraproject.org/wiki/Overview
An operating system, a set of projects, and a mindset.
What is Fedora? Fedora is a Linux-based operating system that showcases the latest in free and open source software. Fedora is always free for anyone to use, modify, and distribute. It is built by people across the globe who work together as a community: the Fedora Project. The Fedora Project is open and anyone is welcome to join. The Fedora Project is out front for you, leading the advancement of free, open software and content.
The operating system is Fedora. It comes out twice a year. It's completely free, and we're committed to keeping it that way. It's the best combination of robust and latest software that exists in the free software world.
The mindset is doing the right thing. To us, that means providing free and open software and content, at no cost, freely usable, modifiable, redistributable, and unencumbered by software patents.
觉得Fedora做得挺好,特别是对我们这样的程序员。
集成了MySQL,Tomcat,JDK,Eclipse,C的编译器以及C的库文件,简直是天然的开发环境。
今天用c连接mysql,调试成功。
编译包含mysql的c程序的命令如下:
[root@localhost ~]# gcc -o /forc/testmy /forc/testmy.c -lz /usr/lib/mysql/libmysqlclient.so.15.0.0
同时,也试了一下Tomcat。
启动tomcat使用如下命令:
cd /usr/share/tomcat5/bin
java -jar bootstrap.jar
停止tomcat:
java -jar bootstrap.jar stop
今天真正理解什么是“
Free software”
What is Free Software?
“Free software” is a matter of liberty, not price. To understand the concept, you should think of “free” as in “free speech”, not as in “free beer”.
Free software is a matter of the users' freedom to run, copy, distribute, study, change and improve the software. More precisely, it refers to four kinds of freedom, for the users of the software:
The freedom to run the program, for any purpose (freedom 0).
The freedom to study how the program works, and adapt it to your needs (freedom 1). Access to the source code is a precondition for this.
The freedom to redistribute copies so you can help your neighbor (freedom 2).
The freedom to improve the program, and release your improvements to the public, so that the whole community benefits (freedom 3). Access to the source code is a precondition for this.
大约有10年没写过c程序了。由于工作需要,我又重新开始学习c。
今天解决两个问题:
1.段错误
原来字符串数组在使用前必须为它分配内存,这跟java可不一样。用calloc就可以。
2.警告:隐式声明与内建函数 ‘calloc’ 不兼容
加入#include "stdlib.h" 就可以了。
struct sockaddr {
unsigned short sa_family; /* address family, AF_xxx */
char sa_data[14]; /* 14 bytes of protocol address */
};
sa_family是地址家族,一般都是“AF_xxx”的形式。好像通常大多用的是都是AF_INET。
sa_data是14字节协议地址。
此数据结构用做bind、connect、recvfrom、sendto等函数的参数,指明地址信息。
但一般编程中并不直接针对此数据结构操作,而是使用另一个与sockaddr等价的数据结构
sockaddr_in(在netinet/in.h中定义):
struct sockaddr_in {
short int sin_family; /* Address family */
unsigned short int sin_port; /* Port number */
struct in_addr sin_addr; /* Internet address */
unsigned char sin_zero[8]; /* Same size as struct sockaddr */
};
struct in_addr {
unsigned long s_addr;
};
sin_family指代协议族,在socket编程中只能是AF_INET
sin_port存储端口号(使用网络字节顺序)
sin_addr存储IP地址,使用in_addr这个数据结构
sin_zero是为了让sockaddr与sockaddr_in两个数据结构保持大小相同而保留的空字节。
s_addr按照网络字节顺序存储IP地址
sockaddr_in和sockaddr是并列的结构,指向sockaddr_in的结构体的指针也可以指向
sockadd的结构体,并代替它。也就是说,你可以使用sockaddr_in建立你所需要的信息,
在最后用进行类型转换就可以了bzero((char*)&mysock,sizeof(mysock));//初始化
mysock结构体名
mysock.sa_family=AF_INET;
mysock.sin_addr.s_addr=inet_addr("192.168.0.1");
……
等到要做转换的时候用:
(struct sockaddr*)mysock
---------send to--------
#include "stdio.h"
#include "sys/socket.h"
#include "netinet/in.h"
int main(void)
{
struct sockaddr_in sockin;
int sockId = 0,ret = 0;
char* buf;
sockId = socket(AF_INET,SOCK_DGRAM,0);
if(sockId < 0)
{
printf("Socket Failed!\n");
return 1;
}
memset(&sockin,0x0,sizeof(sockin));
sockin.sin_family = AF_INET;
sockin.sin_port = htons(1234);
sockin.sin_addr.s_addr = inet_addr("192.168.2.4");
//memset(&buf,'A',100);
buf = "This is message from server";
ret = sendto(sockId,buf,100,0,(struct sockaddr *)&sockin,sizeof(sockin));
if(ret != 100)
{
printf("Sendto failed!\n");
return 1;
}
close(sockId);
printf("Sendto succeed!\n");
return 0;
}
-----------receive----------
#include "stdio.h"
#include "sys/socket.h"
#include "netinet/in.h"
int main(void)
{
struct sockaddr_in sockin;
int sockId = 0,ret = 0;
char buf[100];
sockId = socket(AF_INET,SOCK_DGRAM,0);
if(sockId < 0)
{
printf("Socket Failed!\n");
return 1;
}
memset(&sockin,0x0,sizeof(sockin));
sockin.sin_family = AF_INET;
sockin.sin_port = htons(1234);
sockin.sin_addr.s_addr = INADDR_ANY;
ret = bind(sockId,(struct sockaddr *)&sockin,sizeof(sockin));
if(ret < 0)
{
printf("bind failed!\n");
return 1;
}
ret = recvfrom(sockId,buf,100,0,NULL,NULL);
if(ret < 0)
{
printf("Recvfrom failed!\n");
return 1;
}
printf("Recvfrom result=%d\n",ret);
close(sockId);
printf("%s\n",buf);
return 0;
}
http://www.knowsky.com/366521.html
在实际的任何一个系统中,查询都是必不可少的一个功能,而查询设计的好坏又影响到系统的响应时间和性能这两个要害指标,尤其是当数据量变得越来越大时,于是如何处理大数据量的查询成了每个系统架构设计时都必须面对的问题。本文将从数据及数据查询的特点分析出发,结合讨论现有各种解决方案的优缺点及其适用范围,来阐述J2EE平台下如何进行查询框架的设计。
Value List Handler模式及其局限性
在J2EE应用中,对于大数据量查询的处理有许多好的成功经验,比如Value List Handler设计模式就是其中非常经典的一个,见图1。该模式创建一个ValueListHandler对象来控制查询的执行以及结果集的缓存,它通过DAO(Data Access Object)来执行查询,并将数据库返回的结果集(传输对象Transfer Object的集合)缓存起来,接下来的客户端查询请求将直接从缓存中获得。它的特点主要体现在两点:服务器端缓存数据,每次只返回客户端本次操作所需的数据,通过这两个措施来减少数据库的访问次数以及增加客户端的响应速度,达到最优的查询效果。当然,这里面隐含一个前提就是客户端采用分页的方式来浏览数据。关于该模式的具体介绍,请参考[Core J2EE Patterns]一书。
但是在实际的应用过程中,会发现该模式存在一定的局限性,其实可以说是该模式应用具有一些前提条件:
1、由于缓存是以内存来换性能,这对于小数据量会工作得很好,但是假如结果集很大,内存消耗将会非常严重。同时,消耗在处理结果集上的时间也会越来越长,比如要循环读取记录集中的数据,然后依次填充每个传输对象,想想看几百万条数据这样处理起来肯定让人不能忍受。过长的处理时间不仅降低反应速度,同时还会占用宝贵的数据库连接资源,造成其它地方无连接可用。虽然,在DAO模式中利用CachedRowSet,Read Only RowSet ,RowSet Wrapper List等策略(详见参考资料)来代替Transfer Object Collection策略,有效地提高了处理速度,但是仍然存在着在大集合数据中进行定位、遍历等问题。试想一想,即使在CachedRowSet中的absolute(2000000)也是非常费时的操作。所有这一切的根源就在于缓存是一次性读取所有的数据,虽然有时你可以利用业务逻辑来强制性增加一些限制条件(比如产品查询必须选择大类和次类),但这种限制往往是不牢靠的或者说只是一时的权宜之计。也有人提出,可以不必缓存所有的查询结果,而采取只缓存部分结果集,比如500,1000条,但这样一来,就涉及到复杂的查询数据是否越界的控制,增加了复杂度,同时也不易实现。
2、既然使用缓存,那就不得不面对一个数据更新的问题,使用缓存,实际上就假定了在数据缓存期间,数据库中的数据不会改变,或者这些改变可以不被反映出来。但是,在很多场合下(比如常见的业务系统中)这些数据库中的数据经常会发生变化,而且这些改变需要及时反映给客户端。
3、缓存其实存在一个基本前提,就是缓存的数据会被客户端反复查询使用,具体到分页查询就是客户会选择不同的页数来查看数据。假如客户端的查询条件始终变化,或者用户基本上只关心第一页的数据(仔细琢磨一下用户的习惯,这在很多中应用场合都很常见),那缓存就失去了应有的意义,变得多此一举了。
数据分析
所以说,在决定是否应用某种设计模式前,我们需要对被查询数据的特点以及这些数据以何种方式被使用(查询的特点)进行一个分析,根据不同的结论来决定采用何种处理策略。而且,数据本身的特点和被使用的方式往往交织在一起,需要综合起来考虑,但这其中主要的考量点还是数据查询的特点。
一般来说,可以从以下几个方面来分析数据:
1、 数据量大。
这是我们今天讨论的数据的一个最基本特点,这个特点在查询框架设计时要引起足够的重视。
注重:大数据量的查询是指查询时匹配条件的数据量大,而不是指表中的数据量大,虽然大部分时候这两者都是一致的。因为在某些情况下,业务逻辑可以限制或者只需要一次获取很少量的数据,而查询的表中的数据量却可能很大,那这种情况就不属于本文的讨论范围。
2、 关联复杂,多表关联。
越是简单的数据可能关联越少,而越是复杂的数据往往都是多表关联,这样很多时候你需要将这几张表作为一个整体来考虑。
3、 变化频率。
从这个角度出发,可以大致将数据分为以下几类:几乎不变化的睡眠数据;有规律定时更新的数据,比如招聘网站的职位信息;经常性无规律更新的数据。
4、 成长性。
数据是否具有成长性,要预见数据的成长性,并在现有方案中考虑这种成长性,避免到时候查询框架的重新设计,象大部分的业务数据都具有这种成长性。
注重:这里也要非凡注重区分数据本身的成长性和数据查询的成长性,这看似等同的两者其实还是存在很大的区别。就拿招聘网站来说,有效职位的数据肯定是一天天在增加,具有高成长性,但是在某个区间(比如一个月,一个星期)内的有效职位查询则变化不会太大,不具有成长性。而后者却往往是实际系统中最常碰到的查询情况。
5、 数据查询的频率和方式。
所有的数据查询不可能被等同地使用,你要分清楚系统中的几个要害查询,这些查询使用频率高,响应要快。试想一想,假如一个电子商务系统的产品查询每次都要让顾客等上十秒钟,结果就可想而知。
用户的使用习惯分析
除了对数据查询本身需要进行分析之外,我们还需要去分析一下用户如何来使用或者看待这些数据,用户的使用习惯如何。有人可能觉得这作用不大,或者很难去分析,其实查询的最终使用者是用户,他们的一些习惯会很大程度上左右你的设计。
1、 用户关心数据哪些方面的特性,不关心哪些方面的特性。
上面我们分析了数据本身的许多特性,那用户对其中哪些特性最敏感呢?比如说对脏数据非凡不能接受,那我们就必须在查询框架设计时非凡照顾到这一点。因为再好的框架设计都不可能在每个方面都能达到最优的效果,当必须有所取舍的时候,我们就要明白哪些特性是客户最关心的。
2、 用户如何来使用数据。
现在一般查询的客户端都采用分页的方式,一个查询可能会存在十几页甚至几十页结果。对于某些查询,用户可能往往只关心第一页或者前几页的结果,比如用户需要查询出最近完成的工单,而对于另外一些查询,用户可能对所有页结果都很关注,比如用户查询出最近三天新增的招聘职位。这不同类型的查询在查询框架设计的时候都需要有所考虑并给予不同的处理策略。
查询框架的设计
对数据及用户使用习惯进行了仔细的分析,接下来就可以根据这些分析来设计你的查询框架了。在J2EE架构下,对于大数据量的查询主要采取以下两种方法:
基于缓存的方式:
从数据库得到全部(部分)数据,并将其在服务器端进行缓存,接下来的客户端请求,将直接从缓存中取得需要的数据。这其实就是Value List Handler模式的原理,它主要适用于数据量不是非常大,变化不是很频繁(或者变化频繁但是有规律)且不具有成长性的情况,比如招聘网站或者电子商务网站的大部分查询就非常适合采取这种方式。
采用这种方式,要非凡注重第一次查询问题,避免响应性能达不到要求,因为每个查询第一次都需要连接数据库,从中获取数据并缓存起来,所以第一次查询会比接下来的查询都显得更慢一些。
对于数据的缓存,有以下几种实现方式:
? 直接缓存在服务器端
Value List Handler模式就采取这种方式,并且可以根据不同的情况采取不同的缓存策略,比如Transfer Object集合,CachedRowSet等,这取决于你的DAO实现策略。
? 用临时表来保存查询结果
WLDJ(www.sys-con.com/weblogic/)杂志2004年第7期上有一篇名为“Handling Large Database Result Sets”的文章,它具体介绍了如何利用临时表来改良Value List Handler模式以支持大型的J2EE应用。
当然除了以上这些方法以外,实现缓存也可以求助于操作系统的特定实现,以前我在IBM DW发表过一篇探讨MMF在Java中应用的文章(见参考资料),可惜未有深入,有爱好的朋友可以参考一下。
在使用Value List Handler模式时,要非凡注重以下几点:
1、 该模式一般和DAO模式搭配使用。
2、 该模式有POJO,stateful session bean两种实现策略。
3、 假如采取stateful session bean实现策略,则默认该缓存的时间长度为整个用户会话。
前面我们也提到过,假如数据不是绝对不变的,那缓存就面临更新的问题,一旦更新就可能存在着数据不一致,假如恰巧客户也希望能够看到变化的效果,这个时候就需要采取某种措施来保证这种一致性。常见的措施可以是设置一个标志位,每次发生数据更新后都将其对应的标志位更新,查询时假如发现标志位更新了,就直接从数据库获取数据,而不是从缓存中获取数据。另外一种方式就是数据更新的同时主动去清空session中的缓存,假如采用stateful session bean实现策略的话。
当然,采取缓存方式的大数据量查询一般来说都不大可能碰到设置更新标志位的问题,因为这种应用方式决定了数据不大可能变化,或者数据变化不要求马上反应给用户。比如招聘网站新增加了一些职位信息,假如这些更新恰巧发生在某些用户的会话期间,且没有设置更新标志位,那这些新增信息就不会反应到用户的查询结果中,这种处理方式也是可以接受的。
经过UI工程师的努力,我们的软件变得更加美观。
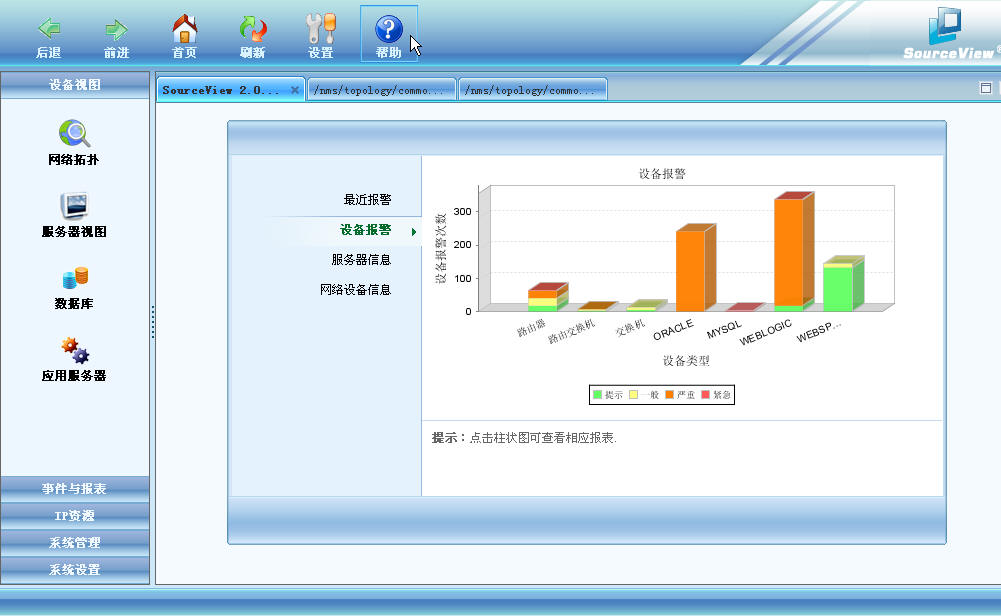
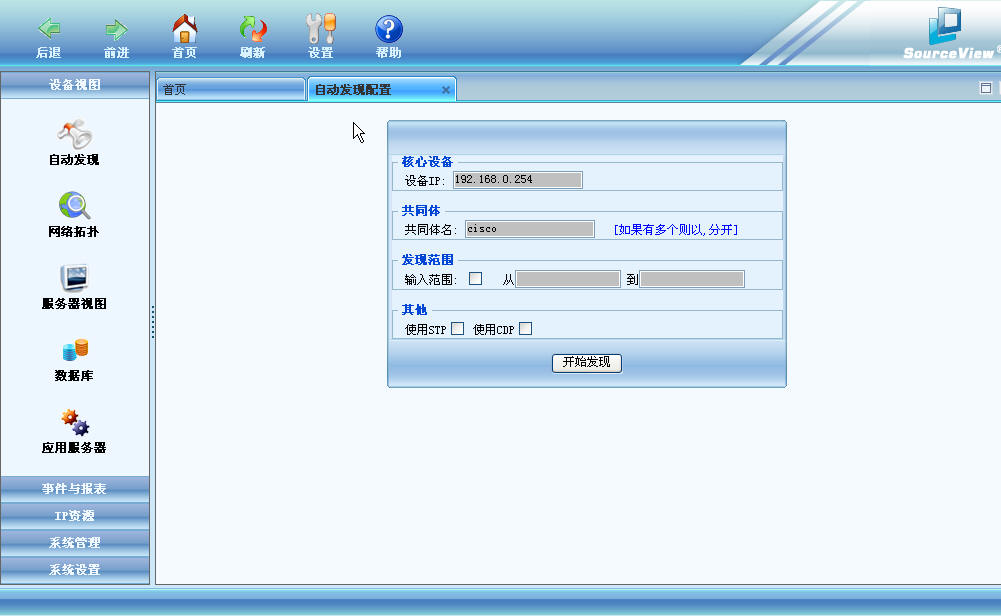
http://bbs.8s8s.com/linux/linux7571.htm
高速路由器的系统交换能力与处理能力是其有别于一般路由器能力的重要体现。目前,高速路由器的背板交换能力应达到40Gbps以上,同时系统即使暂时不提供OC-192/STM-64接口,也必须在将来无须对现有接口卡和通用部件升级的情况下支持该接口。在设备处理能力方面,当系统满负荷运行时,所有接口应该能够以线速处理短包,如40字节、64字节,同时,高速路由器的交换矩阵应该能够无阻塞地以线速处理所有接口的交换,且与流量的类型无关。
指标之一: 吞吐量
吞吐量是路由器的包转发能力。吞吐量与路由器端口数量、端口速率、数据包长度、数据包类型、路由计算模式(分布或集中)以及测试方法有关,一般泛指处理器处理数据包的能力。高速路由器的包转发能力至少达到20Mpps以上。吞吐量主要包括两个方面:
1. 整机吞吐量
整机指设备整机的包转发能力,是设备性能的重要指标。路由器的工作在于根据IP包头或者MPLS 标记选路,因此性能指标是指每秒转发包的数量。整机吞吐量通常小于路由器所有端口吞吐量之和。
2. 端口吞吐量
端口吞吐量是指端口包转发能力,它是路由器在某端口上的包转发能力。通常采用两个相同速率测试接口。一般测试接口可能与接口位置及关系相关,例如同一插卡上端口间测试的吞吐量可能与不同插卡上端口间吞吐量值不同。
指标之二:路由表能力
路由器通常依靠所建立及维护的路由表来决定包的转发。路由表能力是指路由表内所容纳路由表项数量的极限。由于在Internet上执行BGP协议的路由器通常拥有数十万条路由表项,所以该项目也是路由器能力的重要体现。一般而言,高速路由器应该能够支持至少25万条路由,平均每个目的地址至少提供2条路径,系统必须支持至少25个BGP对等以及至少50个IGP邻居。
指标之三:背板能力
背板指输入与输出端口间的物理通路。背板能力是路由器的内部实现,传统路由器采用共享背板,但是作为高性能路由器不可避免会遇到拥塞问题,其次也很难设计出高速的共享总线,所以现有高速路由器一般采用可交换式背板的设计。背板能力能够体现在路由器吞吐量上,背板能力通常大于依据吞吐量和测试包长所计算的值。但是背板能力只能在设计中体现,一般无法测试。
指标之四:丢包率
丢包率是指路由器在稳定的持续负荷下,由于资源缺少而不能转发的数据包在应该转发的数据包中所占的比例。丢包率通常用作衡量路由器在超负荷工作时路由器的性能。丢包率与数据包长度以及包发送频率相关,在一些环境下,可以加上路由抖动或大量路由后进行测试模拟。
指标之五:时延
时延是指数据包第一个比特进入路由器到最后一个比特从路由器输出的时间间隔。该时间间隔是存储转发方式工作的路由器的处理时间。时延与数据包长度和链路速率都有关,通常在路由器端口吞吐量范围内测试。时延对网络性能影响较大, 作为高速路由器,在最差情况下, 要求对1518字节及以下的IP包时延均都小于1ms。
指标之六:背靠背帧数
背靠背帧数是指以最小帧间隔发送最多数据包不引起丢包时的数据包数量。该指标用于测试路由器缓存能力。具有线速全双工转发能力的路由器,该指标值无限大。
指标之七:时延抖动
时延抖动是指时延变化。数据业务对时延抖动不敏感,所以该指标通常不作为衡量高速路由器的重要指标。对IP上除数据外的其他业务,如语音、视频业务,该指标才有测试的必要性。
指标之八:服务质量能力
1.队列管理机制
队列管理控制机制通常指路由器拥塞管理机制及其队列调度算法。常见的方法有RED、WRED、 WRR、DRR、WFQ、WF2Q等。
排队策略:
● 支持公平排队算法。
● 支持加权公平排队算法。该算法给每个队列一个权(weight),由它决定该队列可享用的链路带宽。这样,实时业务可以确实得到所要求的性能,非弹性业务流可以与普通(Best-effort)业务流相互隔离。
● 在输入/输出队列的管理上,应采用虚拟输出队列的方法。
拥塞控制:
● 必须支持WFQ、RED等拥塞控制机制。
● 必须支持一种机制,由该机制可以为不符合其业务级别CIR/Burst合同的流量标记一个较高的丢弃优先级,该优先级应比满足合同的流量和尽力而为的流量的丢弃优先级高。
● 在有可能存在输出队列争抢的交换环境中,必须提供有效的方法消除头部拥塞。
2.端口硬件队列数
通常路由器所支持的优先级由端口硬件队列来保证。每个队列中的优先级由队列调度算法控制。
指标之九:网络管理
网管是指网络管理员通过网络管理程序对网络上资源进行集中化管理的操作,包括配置管理、计账管理、性能管理、差错管理和安全管理。设备所支持的网管程度体现设备的可管理性与可维护性,通常使用SNMPv2协议进行管理。网管粒度指示路由器管理的精细程度,如管理到端口、到网段、到IP地址、到MAC地址等粒度。管理粒度可能会影响路由器转发能力。
指标之十:可靠性和可用性
1.设备的冗余
冗余可以包括接口冗余、插卡冗余、电源冗余、系统板冗余、时钟板冗余、设备冗余等。冗余用于保证设备的可靠性与可用性,冗余量的设计应当在设备可靠性要求与投资间折衷。 路由器可以通过VRRP等协议来保证路由器的冗余。
2.热插拔组件
由于路由器通常要求24小时工作,所以更换部件不应影响路由器工作。部件热插拔是路由器24小时工作的保障。
3.无故障工作时间
该指标按照统计方式指出设备无故障工作的时间。一般无法测试,可以通过主要器件的无故障工作时间计算或者大量相同设备的工作情况计算。
4.内部时钟精度
拥有ATM端口做电路仿真或者POS口的路由器互连通常需要同步。在使用内部时钟时,其精度会影响误码率。
在高速路由器技术规范中,高速路由器的可靠性与可靠性规定应达到以下要求:
① 系统应达到或超过99.999%的可用性。
② 无故障连续工作时间:MTBF>10万小时。
③ 故障恢复时间:系统故障恢复时间 < 30 mins。
④ 系统应具有自动保护切换功能。主备用切换时间应小于50ms。
⑤ SDH和ATM接口应具有自动保护切换功能,切换时间应小于50ms。
⑥ 要求设备具有高可靠性和高稳定性。主处理器、主存储器、交换矩阵、电源、总线仲裁器和管理接口等系统主要部件应具有热备份冗余。线卡要求m+n备份并提供远端测试诊断功能。电源故障能保持连接的有效性。
⑦ 系统必须不存在单故障点。
好几年没写过存诸过程了,都忘光了。今天由于需求,又写了一个。
create or replace procedure stat_app_traffic
as
queryhour varchar2(15);
lasthour number;
begin
lasthour:= to_number(to_char(sysdate,'HH24')) - 1;
if(lasthour=-1) then
queryhour:= to_char(sysdate-1,'YYYY-MM-DD ') || '23';
else
queryhour:= to_char(sysdate,'YYYY-MM-DD ') || lasthour;
end if;
insert into app_traffic(app,bytes,log_time)
select app,round(sum(bytes)/1024/1024,2),max(log_time) from
((select b.app,a.src_port port,a.out_bytes bytes,a.log_time
from raw_netflow a,app_config b
where a.src_port=b.port and a.protocol=b.protocol_id
and to_char(log_time,'YYYY-MM-DD HH24')=queryhour)
union
(select b.app,a.dst_port port,a.in_bytes bytes,a.log_time
from raw_netflow a,app_config b
where a.dst_port=b.port and a.protocol=b.protocol_id
and to_char(log_time,'YYYY-MM-DD HH24')=queryhour)) group by app;
commit;
end stat_app_traffic;
完成首页,实现了JFreeChart柱状图可钻取的功能。
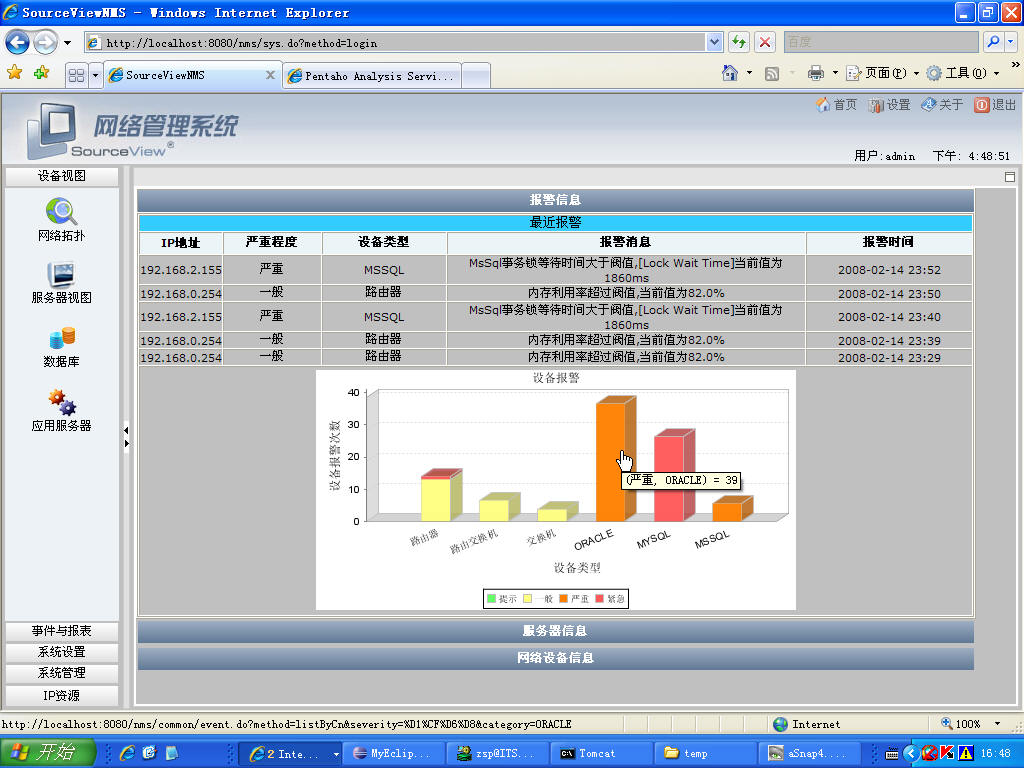

读后,终于对BI的一些基本概念有比较清楚地认识。
Started to write relative desigen document for my NMS system.First of all,
I should make a summary of topological discovery.
Network management has already become the key of network system. The automatic
topological discovery of network is the precondition of network management, analysis of
performance and localization of fault. With the enlargement of the network size, the
topological structure Of the network layer can't reflect the connecting relation between the
network devices accurately. So, according to the protocol SNMP, ICMP and relevant MIB
information, this text proposes a new and effective automatic topology discovery algorithm
for Ethernet. The algorithm is based on theorem for determining the connection between two
Ethernet devices. Compared with other approaches to Ethernet topology discovery, this
algorithm doesn't require all network devices to support SNMP and it is more efficient and
practical. The experimental result demonstrates that the algorithm can construct the
physical topology of IP network fast and exactly.
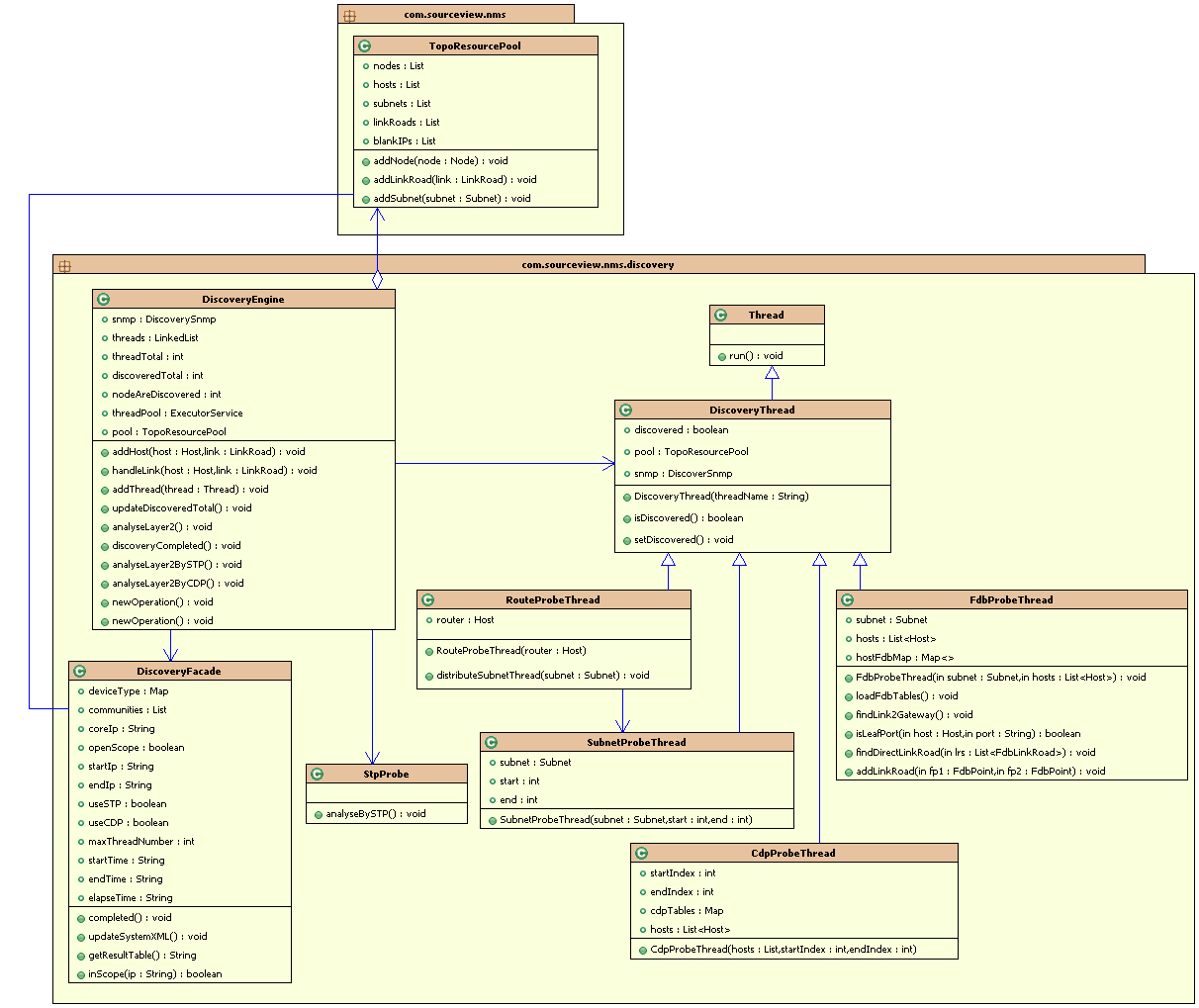
在过去两年里,曾经花了很多时间来研究拓扑发现这个难题,但以后不打算再继续
深入了,准备把它交给新人,趁这几天有空,把拓扑发现的思路整理一下。
---------activity diagram for network auto-discovery---------
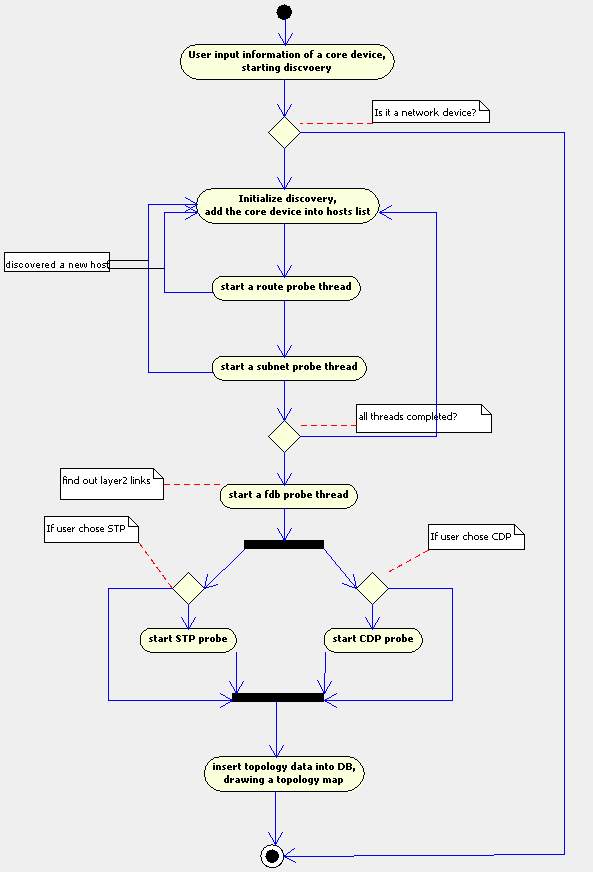
---------sequence diagram for network auto-discovery---------

先把文档的纲要写下来,然后按这个思路写。
没有文档等于没有积累,所以我们必须重视文档。
纲要
一、 引言
1. 目的;
2. 缩略词及术语。
二、 总体设计
1. 思路以及发现方式说明;
2. 算法说明,附流程图和时序图。
三、 设备和链路的发现方法
1. 一个IP的判别流程
2. 基于路由的发现;
3. 基于子网的发现;
4. 基于通用算法的链路发现,即由间接连接推导出直接连接;
5. 基于STP的链路发现;
6. 基于CDP的链路发现。
7. 关于IP定位问题
四、 总结(后续工作)
待深入研究的问题。
通过学习,对什么是BI以及OLAP,在概念上有了明确的认识。
商业智能(BI)是通常被理解为将企业中现有的数据转化为知识,帮助企业做出明智决策的软件解决方案。它包含以下技术:
数据集市(Data Mart)和数据仓库(Data Warehouse, DW);
用户查询和报表(Query & Reports);
联机分析处理(On-Line Analytical Processing, OLAP),也称为多维分析;
数据挖掘(Data Mining);
关键绩效指标(KPI);
分析型应用(Analytic Application)。
前段时间下载了openi,部署安装后跑不起来,今天有空专门下载了
mondrian。
本来想用mysql作为数据源,可FoodMartCreateData.sql导入mysql会出错,不知这个
SQL适合哪种数据库。只好用odbc连接那个access文件,总算安装成功了,呵呵。
不知为何用mondrian这个名字,也许跟tomcat和catalina一样吧。
Mondrian, 蒙得里安·皮特1872-1944荷兰画家,作品以交错的三原色为基色的垂直
线条和平面为特点,他的著作包括 新造型主义(1920年),对抽象艺术的发展曾经产
生很深影响。(金山词霸)
Mondrian是一个用Java写成的OLAP(在线分析性处理)引擎。它用MDX语言实现查询
,从关系数据库(RDBMS)中读取数据。然后经过Java API用多维的方式对结果进行展示。
Mondrian面向ROLAP包含4层:表示层、计算层、聚集层、存储层。
● 表示层:指最终呈现在用户显示器上的以及与用户之间的交互,有许多方法来展现多维数据,
包括数据透视表、饼、柱、线状图。
● 计算层:分析、验证、执行MDX查询。
● 聚集层:一个聚集指内存中一组计算值(cell),这些值通过维列来限制。计算层发送单元请求,
如果请求不在缓存中,或者不能通过旋转聚集导出的话,那么聚集层向存储层发送请求。聚合层
是一个数据缓冲层,从数据库来的单元数据,聚合后提供给计算层。聚合层的主要作用是提高系
统的性能。
● 存储层:提供聚集单元数据和维表的成员。包括三种需要存储的数据,分别是事实数据、聚集和维。
OLAP客户端
JPivot是JSP风格的标签库,用来支持OLAP表,使用户可以执行典型的OLAP操作,如切片、切块、
上钻、下钻等。JPivot使用Mondrian服务器,分析结果可以导出为Excel或PDF文件格式。

完整开源BI解决方案
1.Pentaho
它是一个以流程为中心的、面向解决方案的框架,具有商务智能组件。BI 平台是以流程为中心的,其中枢控制器是一个工作流引擎。工作流引擎使用流程定义来定义在 BI 平台上执行的商务智能流程。流程可以很容易被定制,也可以添加新的流程。BI 平台包含组件和报表,用以分析这些流程的性能。BI 平台是面向解决方案的,平台的操作是定义在流程定义和指定每个活动的 action 文档里。这些流程和操作共同定义了一个商务智能问题的解决方案。这个 BI 解决方案可以很容易地集成到平台外部的商业流程。一个解决方案的定义可以包含任意数量的流程和操作。
BI平台包括一个 BI 框架、BI 组件、一个 BI 工作台和桌面收件箱。BI 工作台是一套设计和管理工具,集成到Eclipse环境。这些工具允许商业分析人员或开发人员创建报表、仪表盘、分析模型、商业规则和 BI 流程。Pentaho BI 平台构建于服务器、引擎和组件的基础之上,包括J2EE 服务器、安全与权限控制、portal、工作流、规则引擎、图表、协作、内容管理、数据集成、多维分析和系统建模等功能。这些组件的大部分是基于标准的,可使用其他产品替换之。
2.ObjectWeb
该项目近日发布了SpagoBi 1.8版本。SpagoBi 是一款基于Mondrain+JProvit的BI方案,能够通过OpenLaszlo产生实时报表,为商务智能项目提供了一个完整开源的解决方案,它涵盖了一个BI系统所有方面的功能,包括:数据挖掘、查询、分析、报告、Dashboard仪表板等等。SpagoBI使用核心系统与功能模块集成的架构,这样在确保平台稳定性与协调性的基础上又保证了系统具有很强的扩展能力。用户无需使用SpagoBI的所有模块,而是可以只利用其中的一些模块。
SpagoBI使用了许多已有的开源软件,如Spago和Spagosi等。因此,SpagoBI集成了 Spago的特征和技术特点,使用它们管理商务智能对象,如报表、OLAP分析、仪表盘、记分卡以及数据挖掘模型等。SpagoBI支持BI系统的监控管理,包括商务智能对象的控制、校验、认证和分配流程。SpagoBI采用Portalet技术将所有的BI对象发布到终端用户,因此BI对象就可以集成到为特定的企业需求而已经选择好的Portal系统中去。
3.Bee
该项目是一套支持商务智能项目实施的工具套件,包括ETL工具和OLAP 服务器。Bee的ETL工具使用基于Perl的BEI,通过界面描述流程,以XML形式进行存储。用户必须对转换过程进行编码。Bee的ROLAP 服务器保证多通SQL 生成和强有力的高速缓存管理(使用MySQL数据库管理系统)。ROLAP服务器通过SOAP应用接口提供丰富的客户应用。Web Portal作为主要的用户接口,通过Web浏览器进行报表设计、展示和管理控制,分析结果可以以Excel、PDF、PNG、PowerPoint、 text和XML等多种形式导出。
Bee项目的特点在于:
● 简单快捷的数据访问;
● 支持预先定义报表和实时查询;
● 通过拖拽方式轻松实现报表定制;
● 完整报表的轻松控制;
● 以表和图进行高质量的数据展示。
开源ETL工具
1.CloverETL是一个Java的ETL框架,用来转换结构化的数据,支持多种字符集之间的转换(如ASCII、UTF-8和ISO-8859-1等);支持JDBC,同时支持dBase和FoxPro数据文件;支持基于XML的转换描述。
2.Octupus是一个基于Java的ETL工具,它也支持JDBC数据源和基于XML的转换定义。Octupus提供通用的方法进行数据转换,用户可以通过实现转换接口或者使用Jscript代码来定义转换流程。
开源OLAP客户端
JPivot是JSP风格的标签库,用来支持OLAP表,使用户可以执行典型的OLAP操作,如切片、切块、上钻、下钻等。JPivot使用Mondrian服务器,分析结果可以导出为Excel或PDF文件格式。
开源OLAP服务器
1.Lemur主要面向HOLAP,虽然采用C++编写,但是可以被其他语言的程序所调用。Lemur支持基本的操作,如切片、切块和旋转等基本操作。
2.Mondrian面向ROLAP包含4层:表示层、计算层、聚集层、存储层。
● 表示层:指最终呈现在用户显示器上的以及与用户之间的交互,有许多方法来展现多维数据,包括数据透视表、饼、柱、线状图。
● 计算层:分析、验证、执行MDX查询。
● 聚集层:一个聚集指内存中一组计算值(cell),这些值通过维列来限制。计算层发送单元请求,如果请求不在缓存中,或者不能通过旋转聚集导出的话,那么聚集层向存储层发送请求。聚合层是一个数据缓冲层,从数据库来的单元数据,聚合后提供给计算层。聚合层的主要作用是提高系统的性能。
● 存储层:提供聚集单元数据和维表的成员。包括三种需要存储的数据,分别是事实数据、聚集和维。
The report module is becoming more and more mature.I am satisfied to this version.
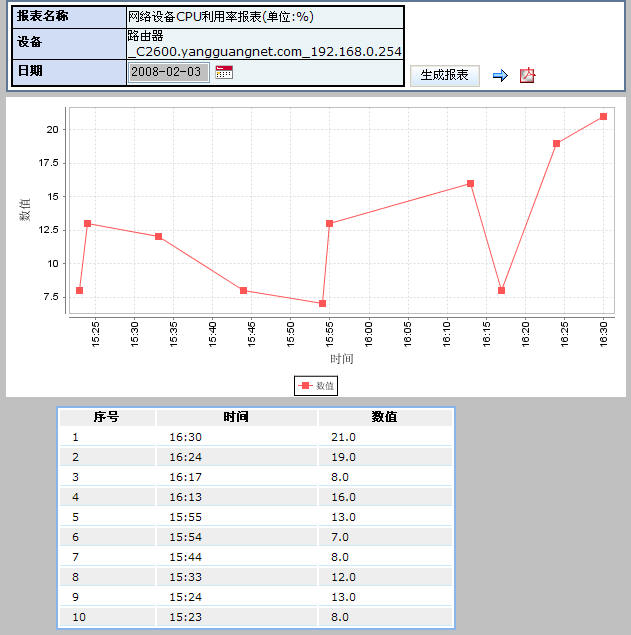

(经网上资料整理后)
OLAP(在线分析处理)这个名词是在1993年由E.F.Codd提出来的。OLAP专门用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以应分析人员要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观易懂的形式将查询结果提供决策人员。
1993年,E.F.Codd 将这类技术定义为OLAP。鉴于Codd 关系数据库之父的影响。OLAP 的提出引起了很大反响,OLAP作为一类产品同OLTP明显区别开来。
Codd提出OLAP的12条准则来描述OLAP系统:
* 准则1 OLAP模型必须提供多维概念视图
* 准则2 透明性准则
* 准则3 存取能力推测
* 准则4 稳定的报表能力
* 准则5 客户/服务器体系结构
* 准则6 维的等同性准则
* 准则7 动态的稀疏矩阵处理准则
* 准则8 多用户支持能力准则
* 准则9 非受限的跨维操作
* 准则10 直观的数据操纵
* 准则11 灵活的报表生成
* 准则12 不受限的维与聚集层次
OLAP产品不少,本文将主要涉及Cognos(Powerplay)、Hyperion (Essbase)、微软(Analysis Service)以及MicroStrategy几大厂商的产品。
单纯从成本角度考虑,微软的产品算是最能节省成本的,Cognos和MicroStrategy则在同一水平线,都比微软贵一些。而Hyperion (Essbase)产品比较独立,也曾占有美国OLAP市场最大的份额,其产品价格又要更高一些。
从市场份额来看,就国外的市场报告分析,微软、Cognos、Hyerion三家占据主流。在国内,目前还没有权威的市场报告,如果仅从所接触到的项目来看的话,用Cognos的很多,买Essbase的也不少。这些年都是一些大企业建设BI项目,有足够的预算,多选用Cognos、Essbase;而Microstrategy,进入中国不算早,这几年在政府、金融行业也颇有建树。
若论开发应用,微软的产品向来以友好的用户界面著称,上手迅速。在OLAP产品上,微软依然发扬了这一优良传统,并有进一步标准化的趋势,开发了OLE DB for OLAP以及MDX(Multi-Dimensional Express多维表达式);参与XMLA(XML for Analysis)规范制定,也是想作为OLAP服务器和前端分析应用的数据传输标准。
而Cognos以桌面OLAP开始,一直以轻便、快捷的操作闻名。所谓桌面OLAP,是可以用客户端将cube下载到本地进行访问。虽然Poweplay早已演变成C/S结构的OLAP服务器,但其轻便的特点还是延续下来,而且提供可以简洁部署且具有交互性的PowerPlay Web Explorer界面。从互联网上,我们可以很快搜索出许多基于PowerPlay Web的分析应用。
Essbase作为老牌的OLAP服务器,是一个比较复杂的产品。所谓复杂,有两层意思,一是提供了丰富的API,让你可以充分定制开发;二是开发的难度较大,部署起来不容易。这也是国内很多用户难以将这个产品用好的一大原因。
比较Essbase和Powerplay,会发现截然相反的两个特点:Essbase的复杂和Powerplay的简洁。对于这两者,单独说哪一种更好都不够客观,因为当你抱怨Essbase繁杂的接口时,也有人在抱怨Powerplay的定制功能怎么如此之少。这种情形其实跟这两种产品的定位有关,Essbase比较专注于高性能的多维存储服务,而Powerplay则更专注于快捷的多维访问。换句话讲,Essbase之于Powerplay正像专业相机之于傻瓜相机,在选哪一个更好的问题上,不同的人肯定有不一样的答案。
当然,如果你想在找复杂和简洁之间找一个中间者,我想微软的 Analysis Service就是这样的产品。不过要注意的是,这个产品和SQL Server绑定得比较紧,这是微软的一贯策略。
根据多维数据存储的位置,OLAP一般分为MOLAP(Multi-Dimensional OLAP)和ROLAP(Relational OLAP)两种,此外,还有混合的HOLAP(Hybrid OLAP)。rolap 中的r是relational的意思,使用关系数据库RDBMS,所以性能的更多是靠RDBMS的性能和技巧,ROLAP支持更多的用户和数据量,ROLAP将多维数据库的多维结构划分为两类表:一类是事实表,用来存储数据和维关键字(外键);另一类是维表,每个维至少使用一个表来存放维的层次,所谓的'"星型模式"就是指维表和事实表通过主关键字和外关键字联系在一起。对于层次复杂的维,为避免冗余数据占用过大的存储空间,可以使用多个表来描述, 这种星型模式的扩展称为“雪花模式”。
rolap和molap的比较:
rolap使用现有的RDBMS,相对容易建模和控制。相应速度比MOLAP慢,数据装载的速度快,储存空间小,没有文件大小的限制,数据库可以做很多优化.
molap性能好,反映速度快,但是建模的难度很大,而且无法支持维度的动态变化,文件大小有限制,没有象关系型数据库那样有标准的访问接口比如JDBC,ODBC之类的。
HOLAP 是混合OLAP。
DOLAP 是 Desktop的OLAP , 应用不是很广,了解一下就够了。
其中, Cognos的Powerplay、Hyperion 的Essbase和微软的Analysis Service这些产品都是MOLAP产品。这类产品将数据从关系数据库(甚至是文本文件、Excel文件)中抽取出来,存储在自己的数据库中。这种数据库跟平常我们所见的Oracle、DB2这类关系数据库不同之处在于,它是专有格式的,且没有标准的访问接口。因此,这些产品如何实现多维存储也都不尽相同,大致的原理是以编程语言中多维数组的方式存放数据。度量值存放在数组的单元格中,而数组每个维就对应一个维度,其中,维元素就维的坐标。
可以想象,多维数据库的单元格跟维度、维元素的多少有莫大关系,而随着维度增加,数据库也迅速膨胀。因此,对于MLOAP产品,多维存储的存储空间、性能自然是比较关键的。Essbase在这方面提供很多优化工作,但有时候也会显得过于复杂。Powerplay也提供某些选项,诸如cube分区等,这是比较简单的优化方法。
OLAP产品的核心功能是提供多维存储,另外就是能够将OLAP访问操作转换为对数据的请求并返回,这些OLAP访问操作大多是用户通过前端发出的,因此要考虑OLAP产品能够和哪些前端工具对接。
Cognos Powerplay是个相对封闭的产品,它有自己的客户端和Web Explorer,你也甭想着用其他前端来访问它。Hyperion和微软都采用开放式接口,提供丰富的访问API,第三方可以用这些API访问其数据库。上文曾提到微软开发的MDX和参与的XMLA(XML for Analysis)规范,事实上,一些第三方的前端工具正是基于这样的标准和OLAP产品对接,比如可以用BO WebI连接Essbase。更有甚者,微软的服务器还提供用MDX来查询多维数据,就像用SQL来访问关系数据库一样。
诚然,这看起来的确比较酷,但有一点也要明确:目前虽然有XMLA、MDX这样的标准,但还不是非常成熟,且并非唯一标准。所以即使有第三方前端工具访问这些OLAP服务器,但只能说是多了一些选择,真正在前端功能上,并不能保证比封闭结构更丰富。
如果说OLAP产品市场几乎都被MOLAP占领,那么,有一家公司肯定不同意,那就是MicroStrategy,它几乎是目前唯一一家还占据一定市场份额的ROLAP产品。这是一件非常奇怪的事情,从第一个ROLAP产品Metaphor到Metacube、WhiteLight、MicroStrategy,这些独立的ROLAP厂商似乎都是难以生存下去,只有MicroStrategy坚挺到现在。究竟是它的产品厉害,还是市场做得到位?目前还不得而知。
从原理上讲,ROLAP将数据存放在关系数据库中,当然要求关系模型要非常严格,比如要遵循星型模式或雪花模式,才能定义出维度、度量、事实表、聚集表等元数据。但这样就增加了部署的难度,并且如果聚集表构建得不好,最后的访问性能就难以保证。恐怕这也是ROLAP难以生存下去的原因吧。
目前,很多OLAP产品都会混合MOLAP和ROLAP,特别是那些本身就做关系数据库的厂商,在现有数据库上面增加一些ROLAP的特性并不困难。IBM在与Essbase终止OEM合同之后,推出一个名为CubeViews的产品,就可以说是一个ROLAP产品。
虽然国内市场上已经涌现出这么多产品,但实际上,OLAP并没有被广泛接受,即使在已经建设BI系统好几年的电信行业也是如此。
ZSP用户特殊需求
|
需求
|
完成时间/未完成原因
|
|
1
|
监视BEA Weblogic 8.0
|
2008-01-20
|
|
2
|
监视IBM Websphere 6.0
|
2008-01-25
|
|
3
|
监视路由器的路由表
|
2008-01-27
|
|
4
|
监视 红旗Linux 4.0
|
没有机器,待进入用户现场后开发。
|
|
5
|
监视 HP-UX 11.0
|
同上
|
|
6
|
监视 Unix 的I/O状态
|
同上
|
|
7
|
Unix日志
|
同上
|
|
8
|
Unix Syslog
|
2008-01-29
|
|
9
|
telnet SSH加密
|
2008-01-30
|
|
10
|
监视服务器进程
|
暂时不做。
|
|
11
|
Oracle日志
|
除非用户同意ftp,不然无法取到服务器上的日志文件。
|
|
12
|
Oracle用户权限变化
|
可以实现,但还没做。
|
 Why nodes' status is confused? I always have no answer.
Why nodes' status is confused? I always have no answer.
I obtained the reason finally .We must calculate the node's status
after it is polled every time,then we can get a accurate value.
I fixed this fatal bug today.
package com.test;
import de.mud.ssh.*;
/** *//**
* This is an example for using the SshWrapper class. Note that the
* password here is in plaintext, so do not make this .class file
* available with your password inside it.
*/
public class SshWrapperExample
{
public static void main(String args[])
{
SshWrapper ssh = new SshWrapper();
try
{
byte[] buffer = new byte[256];
ssh.connect("192.168.2.155", 23);
ssh.login("root", "root");
ssh.setPrompt("#");
ssh.send("sar 1 3");
ssh.read(buffer);
System.out.println(new String(buffer));
}
catch (java.io.IOException e)
{
e.printStackTrace();
}
}
}
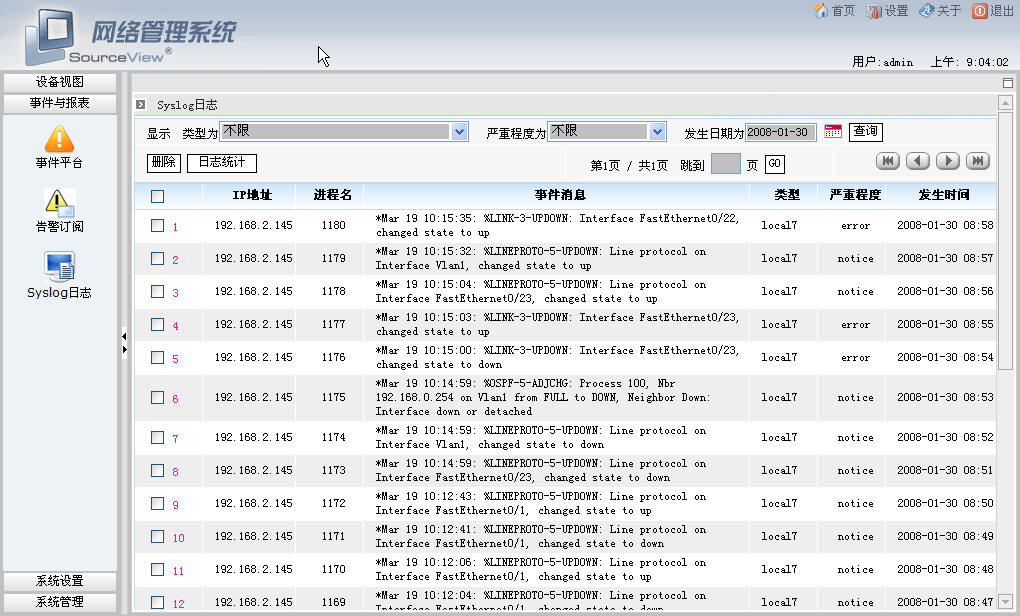

User from GDPLN asked me to add a feature of receiving syslog.SourceView1.0 possesses of that,
but it is just very simple. I improved syslog module those days by imitating EventLogAnalyzer.
In order to satisfy the new requestment,I addressed myself to the new feature,
monitoring route table of routers.If the content is modified accidently,
SourceView would give an alarm.

Compare with two tables:
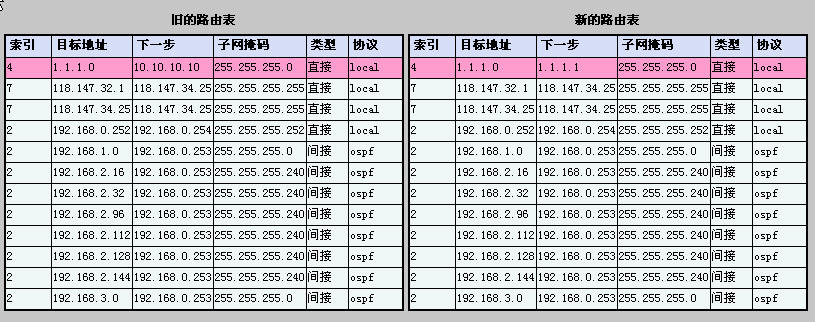
Completed a new feature:add or delete a monitor.
It seems very easy,however it could not be implemented without a good system architecture.
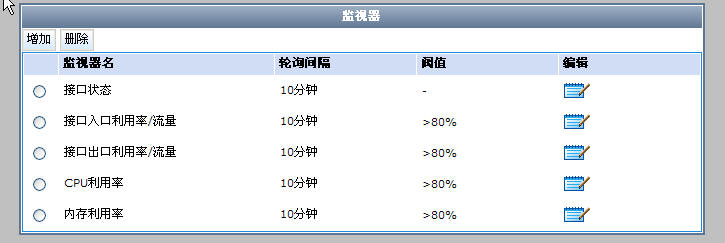
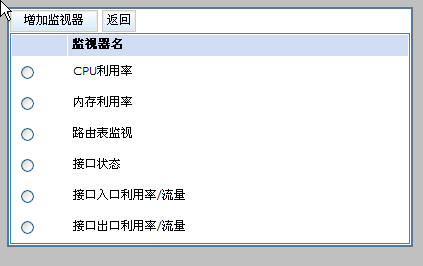
Enlighten by EventLogAnalyzer, I acquired a perfect solution for alarm subscrible.
Users can subscrible alarm from devices which belong to many categories,
or even a single device.
Completed four messagers,which are used to send alarm message.
POPMessager,popping a window in the right bottom.
SMSMessager,sending alarm message with sms.
EmailMessager,sending alarm message with email.
ItsmMessager,sending alarm message to ITSM service.
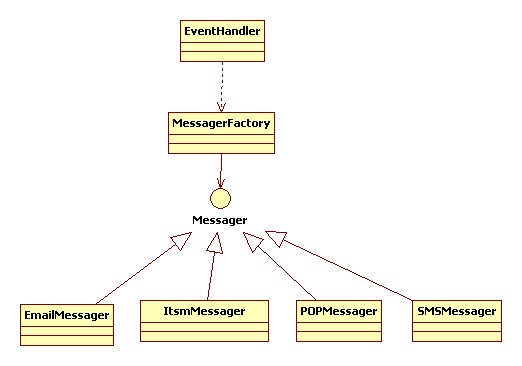
 Today is my birthday.
Today is my birthday.
In the aspects of Syslog and SNMP Trap,SourceView1.0 is immature.
I improved the two parts in SourceView2.0.
For Syslog,Priority is got first,then we compute Facility and
Severity according to Priority,rather than on the contrary.
Priority = Facility * 8 + Severity
As for SNMPTrap,I have new cognition too.The default trap processors
such as cold start,warm start,link down and link up etc,would give
their corresponding trap message when they receive SNMP trap.
Whenas,if the trap's generic is 6 (EnterpriseSpecific),we should develop
a new processor to translate its trap message.
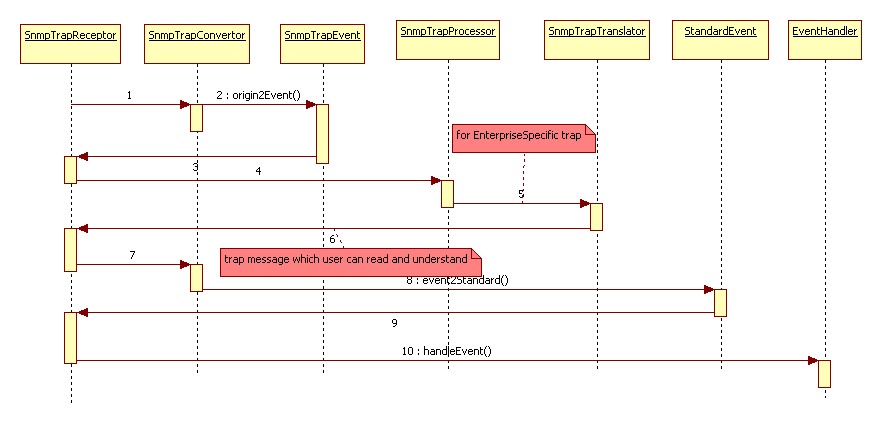
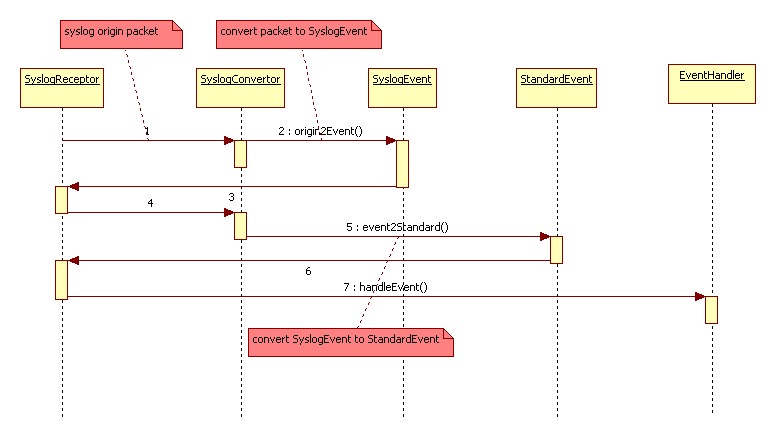
Modified HtmlUtil to adapt the new scenario,the source data from Iterator.
Reconstructed event module,I considered it as the most important in 2.0.
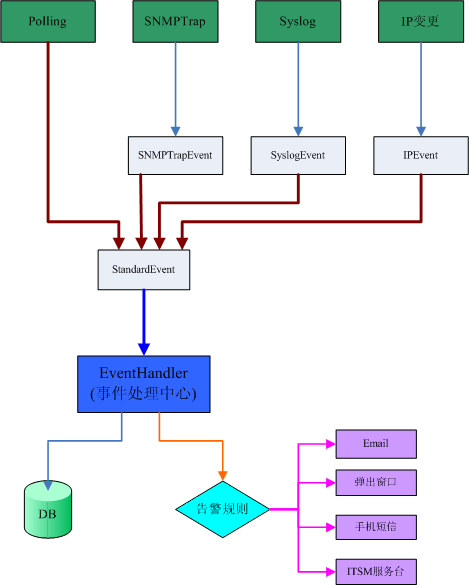
Completed LinkReport.There are two questions should be improved in the
next version.
The first,the relevant DAO classes filled with repetitious code.I consider to
reconstruct these DAOs.
The second,suddenly I am aware that Builder Pattern is the best way to
solve the complex problem of creating a report.
The code likely be following:
ReportBuilder builder = new ReportBuilder();
Director director = new Director( builder );
director.construct();
Report report = builder.createReport();
-----------------Builder Pattern------------
The Builder pattern allows a client object to construct a complex object by specifying only its
type and content.The client is shielded from the details of the object's construction.
It is a pattern for step-by-step creation of a complex object so that the same construction process
can create different representations is the routine in the builder pattern that also makes for finer
control over the construction process. All the different builders generally inherit from an abstract
builder class that declares the general functions to be used by the director to let the builder create
the product in parts.
Builder has a similar motivation to the abstract factory but, whereas in that pattern, the client uses
the abstract factory class methods to create its own object, in Builder the client instructs the builder
class on how to create the object and then asks it for the result. How the class is put together is up
to the Builder class. It's a subtle difference.
The Builder pattern is applicable when the algorithm for creating a complex object should be
independent of the parts that make up the object and how they are assembled and the construction
process must allow different representations for the object that is constructed.
I revised my afu-framework,giving it to a colleague,then he can develop
SourceFlow based my framework.
Hopefully,the two sections including JDBC and Report could be used
in SourceFlow.
In addition,I wrote code about drawing a horizontal bar chart through
JFreeChart.
DAO design was revised repeatedly recent days,I am glad of getting a perfect DAO solution
finally.
The sticking point in DAO design is where a DB connection is opened and when
to close it. Sometimes,one action executes only one DAO method,the connection
should be closed immediately follow the method. Sometimes, However, one action
may contain many DAOs or a series of methods in a DAO, (in other words, called transaction).
A same connection is used in DAOs,so closing connection after method execution is incorrect.
Therefore,I wrote two DAO's constructors for above two scenarios.For the first scenario,
opening a connection inside DAO,and close it at once after a method is invoked.For the second
scenario,a connection is created outside DAO, when instantiating a new DAO class,the connection
is passed from outside.We cope with this case (a transaction) in a service,the service invokes more
than one DAOs.DB connection is opened when service starting,and closed at the end of service.
A reflection on my SourceView’s architecture from Li showing it is awkward to add a
new node in TopoResource.I accepted it with an open mind(modestly).
I modified the base class NodeLoader.class,defines three abstract methods:
addNode(DtoInterface dto):adds the node’s information into DB table,at the same time,
add this node into topo map(a xml file).This method is used during polling period.
loadAll():loads all table records onto memory,in other words,transforms persistence
data to memory objectsThis methods is invoked while starting Tomcat.
loadOne(DtoInterface dto): transforms a table record to a memory object. This method
is used during polling period too.
今天到南方电视介绍我们的产品,跟中山电台类似,我们又碰壁了。
人家要的是供电系统的监控软件,而不是网络监控软件。对网络的监控,
他们早有相应的软件了。
搞得我们扫兴而归。
前段时间,用snmp4j取cdpCacheAddress时,发现snmp4j有问题,取出的值是乱码。
所以下载的最新的版本,问题解决。
可今天发现新的snmp4j也有问题,就是取windows interface时,ifDescr是乱码,
把旧的snmp4j替换新的,问题解决,晕倒。
因为cdpCacheAddress用得少,所以还是用旧版的snmp4j吧。
Li到政法网办最后一次更新程序。
解决atm snmp trap接收和翻译的问题。
因为用户没有了提什么要求,所以我们没有再去政法网。
这个项目做得不算好,因为对于ATM,我们能取到的数据实在有限。
今天到中山电视台,但根本没与用户深入交流的机会。
如果真是做HFC网络的监测,那我们肯定不行,只能放弃。
不过听他的意思,又好像是要做一般IP网络监测,那我们还有机会。
用TreeMap装载snmp的ifTable,真是个不错的选择
优点:能排序,又有hashMap的功能。
唯一的不好就是只能按主键排序
public class IfEntityTable extends TreeMap<String,IfEntity>
{
private static final long serialVersionUID = 25611283245733824L;
public void add(IfEntity ifObj)
{
put(ifObj.getIndex(),ifObj);
}
}
public class IfEntity implements TableItem
{
//------------property----------
private String index;
private String descr;
}
SourceView综合监控管理系统总体设计如下:
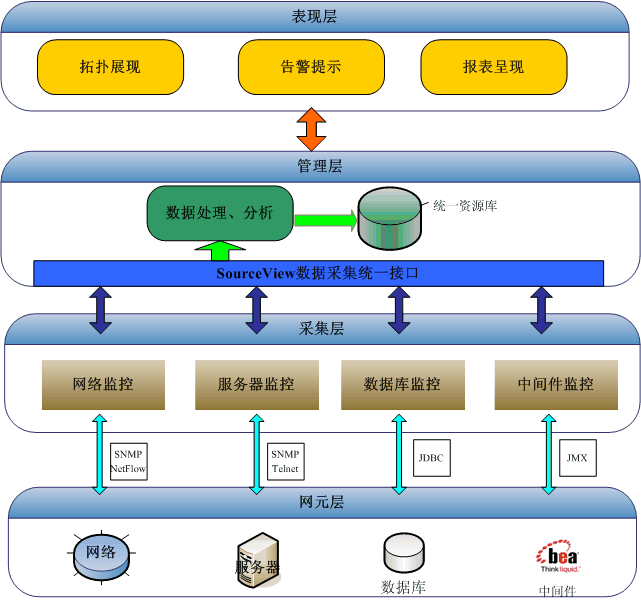
底层实现数据采集,系统通过多种方式对网络设备、服务器、数据库系统以及中间件进行数据采集。采集方式主要有SNMP、NetFlow、SysLog、SNMPTrap、Telnet、JDBC和JMX。
中间层负责数据处理和分析,包括系统的主要功能,实现了IT系统静态数据和动态数据的整合;并实现配置管理、事件管理、故障管理、性能管理等。这一层次中主要实现数据的集中分析和关联分析,将各个监控对象的故障数据和性能数据进行集中整合。
上层是综合监控管理系统的表现层,这一层主要包含拓扑视图、性能报表和故障提示等。用户可以通过web的方式,以图形的方式查询设备的运行情况,可以分为实时和历史两种模式;对于设备运行过程中出现的故障能够在图形上展现出来,并且按照用户设定的方式进行告警。
以前画这个总体结构图都是copy别人的,但其实没有一个能真正反映我的设计思想,
所以今天专门花了好长时间用visio画了个自己的结构图。
根据用户需求,XX公安综合监控管理系统项目的建设目标如下:
1.建立面向运维业务需要的自动化监控管理体系,提高管理质量。
2.保证系统可靠性和可用性,为用户提供7×24小时不间断的可靠服务。
3.在复杂的异构环境中实现集中统一管理,轻松维护复杂的异构环境并使之有效运行。
4.把运维人员从管理产品的复杂负担中解放出来,系统能实现自动的检测和告警。
5.将错综复杂的系统信息,各类系统事件按照运行管理的需求进行过滤整理,帮助系统维护人员专注于重要事件的管理和响应。
6.总结出对系统管理、业务管理、服务管理有用的信息,为管理者提供更全面,更直接的管理信息,为制订相关决策提供依据。
系统设计原则:
1.标准化原则:遵循TCP/IP、SNMP和NetFlow等相关的国际标准或工业标准,支持对设备厂商通用MIB的管理;
2.开放性原则:支持对各种网络设备厂商管理工具的集成,具有开放的API接口,支持对网管系统的二次开发;
3.易用性原则:要求管理功能以良好直观的界面和图形方式实现,能通过浏览器方式进入系统;
4.健壮性原则:系统监控的设备多,数据量巨大,系统本身应健壮、易于维护;
5.节省资源原则:系统设计在满足用户需求的基础上,应尽量减少对网络带宽及系统资源的占用。
今天对XX公安进行需求调研。根据调研,XX公安主要有以下四个方面需求:
1. 网络
(1)XX公安的网络拓扑为星加环结构,其中星形结构作备份用。如果网络拓扑从环形变为星形,系统必须给出告警。
(2)对于汇接层的路由设备,如果其路由表发生变化,系统应给出告警。
(3)对于汇接层的路由设备,可以开启netflow协议,网管系统捕获netflow数据包,以分析网络流量以及带宽利用率,对于异常流量,系统应给出告警。
2. 服务器
XX公安服务器安装有多种操作系统,其中包括Windows2003、AIX、Hp-Ux和Fedora Linux。
对于这些服务器,主要监控:
服务器基本性能指标;
服务器进程;
服务器的错误日志;
3. 数据库
XX公安现有的数据库系统包括Oracle8i、Oracle9i、Oracle10g和MS SQL-Server2000。
对于这些数据库系统,主要监控:
数据库基本性能指标;
数据库错误日志。
4. 中间件
XX公安现有的中间件系统包括WebLogic8.0和WebSphere5.0,主要监控中
间件中数据库连接池当前工作状况。
Architecture Reconstruction
Intended vs. realized architecture. Evaluation of an architecture's properties is critical to successful system development. However, reasoning about a system's intended architecture must be recognized as distinct from reasoning about its realized architecture. As design and eventually implementation of an architecture proceed, faithfulness to the assumptions of the intended architecture is not always achieved. This is particularly true in cases where the intended architecture is not completely specified, documented or disseminated to all of the project members. This problem is exacerbated during maintenance and evolutionary development, as architectural drift and erosion occur.
Why architecture reconstruction important. To apply reasoning about the properties of a system's intended architecture to the properties of the implemented system, we must either ensure that the realized architecture conforms to the intended architecture or change the intended architecture to match reality. Both cases may require reconstructing the architecture of the realized system.
Phases of reconstruction. Architecture reconstruction is an iterative and interactive process, comprising four phases.
- The first phase is the extraction, from implementation artifacts (including source code and dynamic information such as event traces), of a set of extracted views that represent the system's fundamental structural and behavioral elements.
- The second phase is fusion of the extracted views to create fused views that augment or improve the extracted views.
- During the third phase, the analyst iteratively and interactively develops and applies patterns to the fused views to reconstruct architecture-level derived views. Patterns provide the medium for an analyst to express their understanding of a system's architecture as structural and attribute-based relationships among its components.
- Finally, the derived views may be explored for the purposes of evaluating architectural conformance, identifying targets for reengineering or reuse and analyzing the architecture's qualities.
The reconstruction process can be most effectively supported by the integration of existing tools and techniques. There currently exist a large number of commercial and research tools that provide the basic mechanisms for view extraction. Similarly, there are several tools and techniques available for performing view fusion and reconstruction. The synthesis of these tools and techniques provides a support environment for software architects and analysts reconstructing architectures.
To compliment our previous work in reconstruction we are currently surveying tools that are available for reconstruction to determine the current state of the practice for reconstructing architectural representations. We will study the information that these tools extract with emphasis on how they present the extracted views and how they aid in analysis of legacy systems.
The SEI will assist organizations with architecture reconstruction exercises.
Methods for Software Architecture Design
Software architecture forms the backbone for any successful software-intensive system. An architecture is the primary carrier of a software system's quality attributes such as performance or reliability. Designing the right architecture is the linchpin for software project success. Designing the wrong one is a recipe for guaranteed disaster.
Methods for Software Architecture Evaluation
How do you know if a software architecture for a system is suitable without having to build the system first?
The answer is to conduct an evaluation of it. A formal software architecture evaluation should be a standard part of the architecture-based software development life cycle. Architecture evaluation is a cost-effective way of mitigating the substantial risks associated with this highly important artifact.
The achievement of a software system's qualities attributes depends much more on the software architecture than on code-related issues such as language choice, fine-grained design, algorithms, data structures, testing, and so forth. Most complex software systems are required to be modifiable and have good performance. They may also need to be secure, interoperable, portable, and reliable. But for any particular system, what precisely do these quality attributes - modifiability, security, performance, reliability - mean? Can a system be analyzed to determine these desired qualities? How soon can such an analysis occur? What happens these quality attributes are in conflict with each other? How can the tradeoffs be examined, analyzed, and captured?
Methods for Software Architecture Documentation
Because architectures are intellectual constructs of enduring and long-lived importance, communicating an architecture to its stakeholders becomes as important a job as creating it in the first place. If the architecture cannot be understood so that others can build systems from it, analyze it, maintain it, and learn from it, then the effort put into crafting it will by and large have been wasted.
Documenting a software architecture is a matter of choosing a set of relevant views of the architecture, documenting each of those views, and then documenting information that applies to more than one view or to the set of views as a whole.
琢磨了一个多星期,终于把netflow做出来了。
关键在于理解Cisco netflow v9白皮书《Cisco IOS NetFlow Version 9 Flow-Record Format》。
我想要的就是得到源IP、目标IP、源端口、目标端口以及使用的协议,
这是程序运行的结果:
Router IP=192.168.0.254
收到netflow包,包长=1420
version=9
count=29
unixSecs=2007-11-23 03:15:19
packageSequence=9329
源IP=59.41.62.50
目标IP=192.168.3.90
协议=6
源Port=7709
目标Port=2620
源IP=58.251.60.66
目标IP=58.253.18.208
协议=6
源Port=12000
目标Port=1469
源IP=192.168.2.20
目标IP=58.61.32.11
协议=17
源Port=4000
目标Port=8000
源IP=202.106.46.151
目标IP=58.253.18.208
协议=17
源Port=53
目标Port=1034
源IP=192.168.2.20
目标IP=219.133.60.243
协议=17
源Port=4000
目标Port=8000
源IP=219.133.60.153
目标IP=58.253.18.208
协议=17
源Port=8000
目标Port=1035
源IP=192.168.3.90
目标IP=61.152.112.125
协议=6
源Port=2633
目标Port=80
-------------------------/192.168.0.254
收到netflow包,包长=1424
version=9
count=29
unixSecs=2007-11-23 03:16:12
packageSequence=9354
源IP=58.251.60.182
目标IP=192.168.2.154
协议=6
源Port=80
目标Port=2244
源IP=219.133.49.75
目标IP=58.253.18.208
协议=17
源Port=8000
目标Port=2851
源IP=192.168.2.156
目标IP=219.133.49.75
协议=6
源Port=2851
目标Port=80
源IP=4.2.2.4
目标IP=58.253.18.208
协议=17
源Port=53
目标Port=2166
源IP=192.168.2.156
目标IP=222.141.220.165
协议=6
源Port=2981
目标Port=80
下一步就是把结果入库,然后分析,得出用户想要的东西。
1. 设备管理中->查寻,要支持模糊查寻。
2. 拓扑图中可以无限滚动,不好。
3. 报警数据应该立即插入数据库,才能在告警平台上显示。
4. 报表上设备太多,没有查找功能。
5. 生成的excel报表中,没有设备名称以及查询时间
6. 修改了告警平台,压缩告警,以及删除告警(同时删除多条相同的记录)
7. 去掉Cisco的电源和风扇监视器(因为没什么用,而且耗资源)。
8. 要动态更新接口数据。
9. 如果ping不通,其它监视器则不运行。
10. 网络拓扑太大,应该按子网来分。
这些意见对我们系统改进很有帮助,将在2.0中一一改进。
In order to make a analysis of business applications,we decide to
add netflow feature into SourceView2.0.
NetFlow, much like RMON-based probes, can give you information on where,
why, how and by whom specific applications are being used and how the usage
might affect the network. NetFlow is a part of Cisco’s IOS software, and the current
version, 9, is currently moving toward standardization in the IETF as IPFIX.
Networking vendors other than Cisco, such as Enterasys and Juniper, are taking a
role in shaping the standard, and are already showing interest in adopting IPFIX.
This, of course, makes NetFlow/IPFIX far more attractive as a consistent source
for information about application flows over a network in heterogeneous environments.
NetFlow provides the following information:
* IP address source (who is sending an application service?)
* IP address destination (who is receiving service?)
* Source port (what application is it?)
* Destination port (what application is it?)
* Layer 3 protocol type
* Class of service
以前对SNMP Trap没有真正理解,今天收集到了Lucent ATM trap信息,
突然间有了收获,明白了两点:
1. 以前看过的Trap都是公用的。而设备产商可自定义Trap,比如Lucent
ATM发出来的Trap就全是自定义的。generic=6(enterpriseSpecific)表示这
个Trap是自定义的。
2. 这些Trap中的oid其实在acmib.mib中都有定义,查acmib就可以知道这
个trap是什么意思。所以,只要能把解析acmib,把acmib中symbol和oid都导
入数据库中,便可根据oid来查询symbol,从而知道这个trap的意思。
snmp trap from=172.16.1.36
generic=6
specific=5
oid=1.3.6.1.4.1.1751.2.18.8.3
version=V1TRAP
1.3.6.1.4.1.1751.2.18.15.2.0 = 905004
1.3.6.1.4.1.1751.2.18.15.3.0 = 12
1.3.6.1.4.1.1751.2.18.2.23.1.2.0 = 2
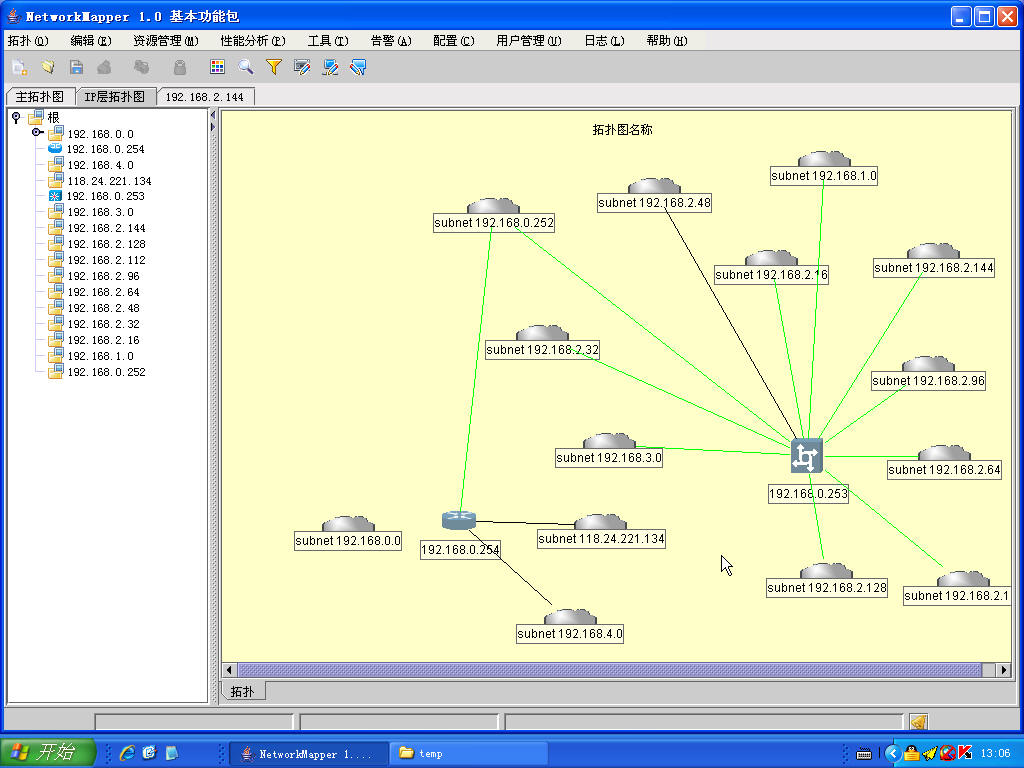
“NetworkMapper 是由本公司和清华大学联合研制的以太网络管理产品。系统采用具有自主知识产权的在国际上处于领先位置的核心技术”,不知有啥核心技术?
拓扑发现还可以,但其他基本没什么亮点,而且这个界面很久以前肯定看过,只是记不得是哪个产品了,呵呵。
很久以前一个网管给我的一个软件,系统为c/s程序。它的技术支持http://www.alliedtelesis.com.cn/support.htm已经不能访问了,呵呵。
最大的优点就是发现得比较全面,而且操作比较方便,在拓扑图上基本可以找到你想要的所有操作。
还有,可查看的内容也很丰富。
Gdplno系统修改记录
|
修改ID
|
日期
|
文件
|
原因
|
操作
|
修改人
|
|
war2007112101
|
2007-11-21
|
com.sunshine.sourceview.event.SyslogReceptor
|
取消Rule过滤,目前的需求不需要Rule过滤
|
把30行代码注释掉,把63,64行的代码从判断中提出来,把判断注释掉
|
Warcrafthero
|
|
war2007112102
|
2007-11-21
|
com.sunshine.sourceview.event.SnmpTrapReceptor
|
取消Rule过滤,目前的需求不需要Rule过滤
|
把42、62行代码注释掉
|
warcrafthero
|
|
war2007112103
|
2007-11-21
|
com.sunshine.sourceview.event.Filter
|
doFilter方法没有对参数rules进行为空判断
|
增加判断
|
warcrafthero
|
|
war2007112104
|
2007-11-21
|
com.sunshine.sourceview.event.SnmpTrapConvertor
|
Event2Standar方法中没有对str进行为空判断
|
增加判断
|
warcrafthero
|
|
War2007112105
|
2007-11-21
|
com.sunshine.sourceview.core.polling.PollingDao
|
对SNMP TRAP记录进行批量插入,要等到缓存池满了,才把记录插入到数据库,在客户端不能实时查看到。
|
改为单处理
|
warcrafthero
|
|
War2007112201
|
2007-11-22
|
/atm/atm/find.jsp
|
只有对ATM名称的查询
|
增加几个字段的查询
|
Warcrafthero
|
|
com.sunshine.sourceview.atm.dao.PLATMDao
|
|
com.sunshine.sourceview.atm.PLATMManager
|
|
War2007112202
|
2007-11-22
|
com.sunshine.sourceview.sysset.util.AreaHelper
|
转换编码时00依然保存在转换成的编码当中
|
把areaID=”00”和unitID=”00”改为areaID=”%”和unitID=”%”
|
warcrafthero
|
|
War2007112203
|
2007-11-22
|
/atm/atm/find.jsp
|
不能在页面点击表格标题使表格按照点击的标题排列
|
增加了一个javascript方法orderBy
在页面的后面给表单进行赋值
|
warcrafthero
|
|
com.sunshine.sourceview.atm.PLATMManager
|
在find方法中让request对象添加两个属性,是表单的下拉列表的选项的值和查询关键字
|
|
com.sunshine.sourceview.atm.dao.PLATMDao
|
在find方法增加了一个order参数
|
|
War2007112301
|
2007-11-23
|
/atm/atm/list.jsp
|
不能在页面点击表格标题使表格按照点击的标题排列
|
增加了一个javascript方法orderBy
|
Warcrafthero
|
|
com.sunshine.sourceview.atm.PLATMManager
|
改动list方法,在PLATMDao对象调用listByPage方法时从session读取排列字段属性
|
同事用dephi写了一个ocx控件,在html直接调用即可生成报表,功能强大的报表
就这样生成了,打印预览也变得如何简单,真是太酷了。
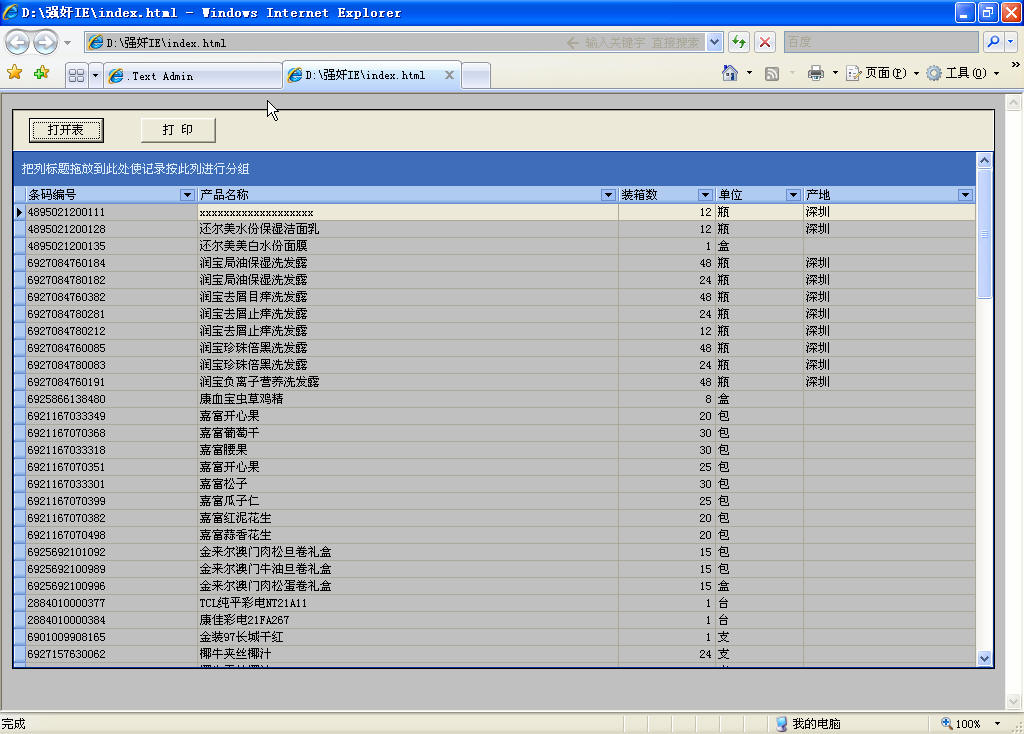
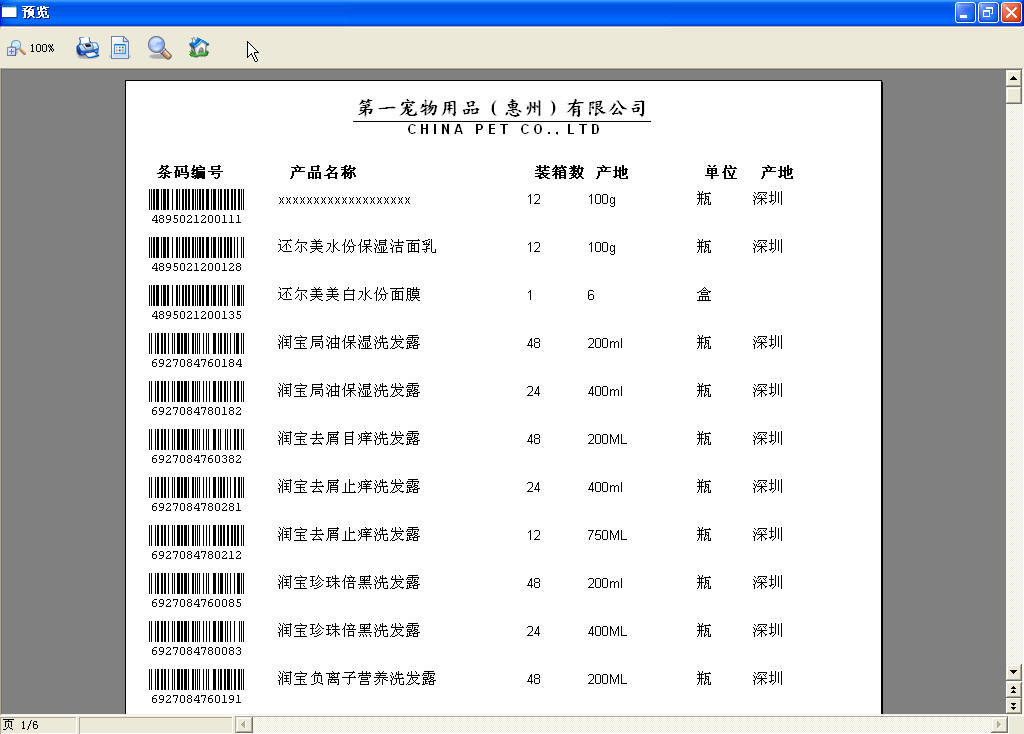
看了AdventNet eventlog analyzer,原来简单的日志也有这么多文章也做,不服不行。
---complete----
1. fixed bug in the report module.
2. fixed bug in the topology module.
3. modified accurate query to blur query.
---remain-----
1. Test program about device backboard.
2. Receive SNMP Trap from Lucent ATM,and interpreting integer varbinds in
SNMP trap events to message that user can understand.
3. Find out those physical ports who have links.
opManager应该算是网管软件中比较老的一个,三年前刚接触网管软件的时候就知道op。
op最大的优点就是界面设计极美观,而且功能安排得比较合理,操作也方便。市场上有些
网管产品还是模仿op做的。
我比较喜欢op,唯一的不足就是没有自动发现功能。
现在功能应该比当初强多了吧,呵呵。下面是op6.0的首页。

http://demo.opmanager.com/overview.do?selectedTab=Home
今天原来北京的同事来广州,谈到DHC开发一年半的ens2.0,
他说:“上次演示都走不下去了,大家都气死了,老刘看了后,
刚看了个开头就走不下去了,然后他说了两点意见,就走了,
很失望哦。”
我早说ens2.0的设计有很大问题,现在的现实再次证明我当初
的想法。
1.0是一批人做,2.0是另一批人做,1.0中存在的问题在2.0没有
针对性的解决。2.0不是1.0的升级版,而完全是另一个版本。
最关键的是,2.0比1.0更失败。
SourceView1.0的需要改进的几点意见:
1. 对于节点状态,当节点fail时,不准确.而且,detail页不应该是只有出错信息,
应该把能显示的信息都显示出来
2. 设备背板图,光口与一般的接口要有区别
3. 在关键监视器不能用的时候,其他监视器不应该再继续执行
4. 处理接口增加多的情况
5. 报表只生成pdf,而且要做得更丰富,参考op
6. 拓扑图按子网划分
7. 拓扑发现,增加cdp发现,补充发现。
8. 考虑基于基线的报警
9. 基于vlan的流量
两个亮点:
1. 连续扫描侵入检测系统
可用来识别整个网络中的有害节点,并能禁止那些不可靠节点对网络的访问。
2. 管理集线器(Hub)端口
网络资源管理系统的网络设备连接图显示了所有与你所管理
的交换机或集线器直接相连的节点,以及与其相邻的端口信息。另外,网络资源管理系统的特色是,
它能够提供标准的交换机/集线器端口报告,提供为该报告而选定的设备所连接的,所有节点的信息表。
http://www.javvin.net/LANsurveyor/index.php#5
今天听了美国netscout公司介绍他们的产品,给我颇多启发。尤其是那个“基准分析”。
一般的做法都是给某个指标设置一个阀值,如果超过则报警。可是一天中每个时段的情
况都不一样,所以单一的阀值对有些时段是有意义,对另一些时段则没意义,这时“基
准(baseline)分析”就显出它的优越性。

软件部部门经理职责
一、 日常职责
1. 负责本部门员工的日常考勤和劳动纪律管理工作。
2. 负责本部门员工的绩效考评工作。
3. 负责拟定部门月度工作计划、目标及总结。
4. 负责本部门员工的招聘工作。
5. 抓好本部门项目组总结分析报告工作,定期进行项目分析、总结经验、找出存在
的问题,提出改进工作的意见和建议,并组织本部门员工学习。
6. 规范部门内部管理,编制、完善软件开发流程,提高员工整体技术水平,把握技
术发展方向。
二、 项目管理
1. 在需求调研中,配合项目经理进行需求调研工作,并对生成的需求调研报告进行审 核评定。
2. 会同项目经理组织设计和开发工作,控制开发进度。
3. 明确文档编写的种类及格式,对项目组需要生成的文档进行质量、数量和时间控制,并组织召开评审会。
4. 制定适合于公司及项目实际情况的软件工程方法,并指导开发组予以实现。
5. 组织软件项目的集成测试工作,对软件产品的质量负责。
6. 管理好所有已验收项目的源代码以及文档,会同售后服务部提供售后服务(软件维护)。
三、 销售支持
1. 配合市场部门开展工作,向市场部门提供必要的技术支持。
2. 参与软件合同的洽谈、制定和审核工作,对公司所签合同有关软件技术合同部分中工期、
技术方案、软件合同额等方面提供技术支持。
3. 配合项目开发组以及市场部门在软件项目的实施及项目验收过程中协调开发人员与用户之间的沟通
工作。
去年有机会看到networkstar部署在tomcat下的程序,程序结构极其混乱,
JSP中存在着大量业务逻辑的java代码。这样的系统,我不敢用。
访问了networkstar的主网,对每个产品的介绍缺少实际截图,只有一堆无力的文字,
不知是真是假。
BroadviewBCC业务监控平台--对数据库和中间件的监视。
BroadviewNCC网络管理平台--通用网管,没什么特别的。
BroadviewSCC安全监控平台--按我理解,应该是用了netflow来分析业务。
BroadviewCOSS集中运行管理平台--ITSM服务台。
BroadviewDCC桌面管理平台。
1. 界面做得不错。
2. 各方面的产品都有,能形成一个完整的解决方案。
3. 在同类产品中算是比较好的。
http://www.broada.com/
IronView(美国网捷)
1. 业务管理:加入netflow的功能,对业务进行分析,这也是我想做的。
2. Vlan和ACL管理,统计vlan的流量。不知ACL管理它是怎么实现的。
宏视
多阈值报警及动态统计阈值报警使警报处理更加精确、灵活,并且减少了误报的可能性。
这有点像netscout的基于基线的报警,比较灵活。
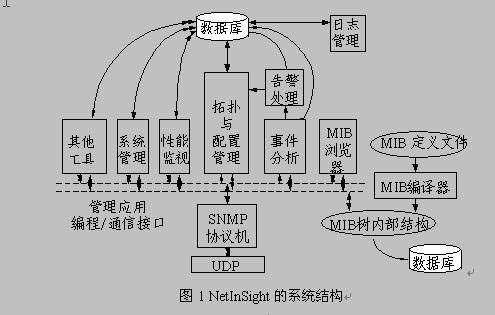
系统结构图是画得很合理,但整个系统基本没什么亮点,通用网管的功能大家都能做出来。
可取之处:
非法主机入侵预警功能的实现,如果真像它说的那样,那还不错:)
-----GDPLN-----
1. PvcPollinger.java:Keep polling pvc and collecting pvc data,including pvc
status(active or inactive),pvc traffic and pvc bandwitdh utilization.
On the other hand,insert these data into db.
2. TotalPvcReport.java:List all pvc traffic data.
3. SinglePvcReport.java:Build the report for a single PVC, user can query by date.
前几天完成了新了mvc架构,今天用这个new framework完成了“系统管理”部分,
等于是测试这个framework。感觉还不错,至少代码可以少写很多,而且层次结构更
加清晰。
之前我对新产品(SourceView2.0)的设计是有三个部分:mvc、nms和distributed,
今天算是完成了mvc这部分。对于另外两部分,想法还不成熟,还有很多需要考虑的。
如果来得及的话,我希望把新的产品用在新的项目中。
但目前最要赶的事还是把PLN这个项目先搞定。
http://www.infoq.com
http://www.theserverside.com
http://www.javablogs.com
http://www.java.net
http://www.javasoft.com
http://blogs.sun.com
http://blogs.sun.com/roumen/
http://blogs.sun.com/geertjan/
http://blogs.sun.com/theaquarium/
http://www.ibm.com/developerworks
http://www.onjava.com/
http://www.developer.com/java/
http://www.javaworld.com/
http://www.java.com/
http://www.netbeans.org/kb/index.html
http://www.eclipse.org
http://www.oracle.com/technology/tech/java/index.html
http://www.javaranch.com
http://www.javablackbelt.com
http://www.jugcologne.org
http://www.dzone.com
Interesting Resources For Java SE/EE Developers
Some interesting links for (motivated) Java developers, programmers, architects and leaders:
http://www.infoq.com
http://www.theserverside.com
http://www.javablogs.com
http://www.java.net
http://www.javasoft.com
http://blogs.sun.com especially http://blogs.sun.com/roumen/, http://blogs.sun.com/geertjan/, http://blogs.sun.com/theaquarium/
http://www.ibm.com/developerworks
http://www.onjava.com/
http://www.developer.com/java/
http://www.javaworld.com/
http://www.java.com/
http://www.netbeans.org/kb/index.html
http://www.eclipse.org
http://www.oracle.com/technology/tech/java/index.html
http://www.javaranch.com
http://www.javablackbelt.com
http://www.jugcologne.org
http://www.dzone.com
Enjoy! ...but don't forget programming :-)
EasyTouch
不足之处:
1. 用java做的c/s系统,界面肯定很难看。
2. 做了好些没意义的,或者用户基本不会去关心的东西,比如
“接收/发送SNMP包流量统计”。
可取之处:
1. 监视网络事件,比较人性化。
2. 后台任务轮询控制,有点像“再发现”的功能,如果真能实现,
就算是一个亮点了。
1. 重新整理了PVC相关程序,分页列出PVC信息,包括两端的单位名(IP地址),
流量、利用率、类型和状态。
2. 列出PVC时,按VPI和VCI排序,原来数据全在内存中,排序有困难,所以今天
把VPI-VCI存入数据库,这样方便排序和查找。
3. 把与PVC有关事件加入“告警平台”,比如PVC宽带变化、PVC利用率过高和PVC
状态改变(从active变成inactive)。
4. 每15分钟扫描一次所有PVC,然后把流量和带宽利用率存入数据库,以便形成报表。
1. Discovered the routers in PL network.The following map is the result:
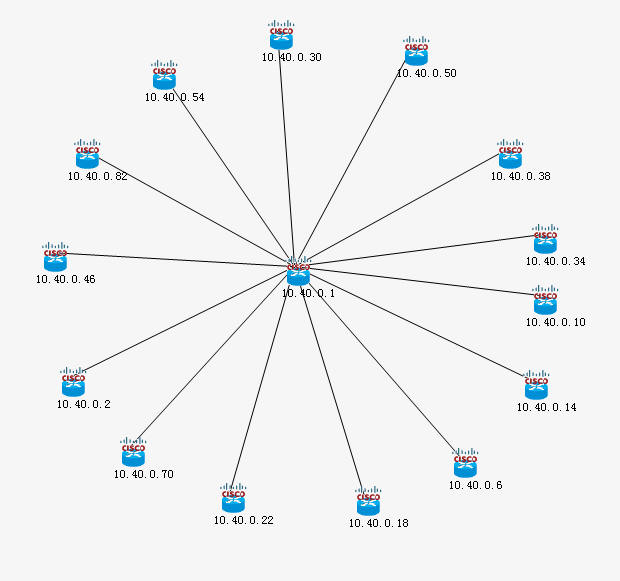
2. Completed the program about PVC traffic and bandwidth utilization.
However,"Bandwidth for UBR conns will not be accounted for"(acmib.mib)
So,bandwidth utilization for ubr PVC is unavailable.
虽然SpringJdbc中很多东西我看不太明白,但学习Spring源码仍然给我很大收获,
让我思考很多问题并努力去寻找答案。
为什么需要JTA?Jdbc不就能处理事务了吗?
JDBC事务的一个缺点是事务的范围局限于一个数据库连接。一个JDBC事务不
能跨越多个数据库。
而JTA(Java Transaction API) 事务为J2EE平台提供了分布式事务服务,即可实现
多个数据库的事务处理。
因为目前的项目不会遇到跨越多个数据库的操作,所以在以后设计中,我暂时
不会考虑用JTA。
对于UNIX类主机之间记录日志,由于协议、软件和日志信息格式等都大同小异,
因此实现起来比较简单,但是windows的系统日志格式不同,日志记录软件,方式等都
不同。因此,我们需要第三方的软件来将windows的日志转换成syslog类型的日志后,
转发给syslog服务器。
这里我们用第三方软件evtsys (全称是evntlog to syslog),这是一个非常小巧而且免费
的第三方日志记录软件,文件才几十K大小,非常小巧,解压后是两个文件evtsys.dll和
evtsys.exe。
把这两个文件拷贝到 c:\windows\system32目录下。
C:\>evtsys –i –h 192.168.2.155
-i 表示安装成系统服务
-h 指定log服务器的IP地址
如果要卸载evtsys,则:
net stop evtsys
evtsys -u

关于PVC的一些常用信息都记录在atmPvcVccTable中
(1)
pvc类型:atmPvcVccServiceTypeA2B
atmPvcVccServiceTypeA2B OBJECT-TYPE
SYNTAX INTEGER {
ubr(1),
vbr-nrt2(2),
vbr-nrt1(3),
vbr-rt2(4),
vbr-rt1(5),
vbr-express(6),
cbr4(7),
cbr3(8),
cbr2(9),
cbr1(10),
gfr2(11)
}
通过对比前后两次扫描结果,如果atmPvcVccServiceTypeA2B有变化,
则应该给出报警,告知用户PVC类型有变化。
(2)
pvc当前状态(active/inactive):atmPvcVccConnectionStatus
atmPvcVccConnectionStatus OBJECT-TYPE
SYNTAX INTEGER {
active(1),
inactive(2),
inactiveA2B-B2A(3),
inactiveA2B(4),
inactiveB2A(5)
}
如果atmPvcVccConnectionStatus != 1,
应该给出报警,告知用户PVC状态为inactive。
(3) PVC带宽 (单位:cell/s)
atmPvcVccPeakCellRateA2B(也可能是atmPvcVccSusCellRateA2B,目前来看两者的值一样)
通过对比前后两次扫描结果,如果atmPvcVccPeakCellRateA2B有变化,
则应该给出报警,告知用户PVC带宽有变化。
关于atm pvc带宽利用率如何计算,网上找不到任何资料,这也是我研究了好久才搞出来的,
至于是否正确,还得看程序的运行结果。
AtmPvcVccStatsTable中有PVC两端的数据。以前计算IP网链路流量时只计算链路一端端口的
流量即可,据此,我也只计算PVC一端的数据,即A端。
atmPvcVccStatsInCellCountHiA
atmPvcVccStatsInCellCountLoA
A端“进”的数据。经观察发现HiA不会变化,所以我选择LoA
atmPvcVccStatsOutCellCountHiA
atmPvcVccStatsOutCellCountLoA
同时,A端“出”的数据。经观察发现HiA不会变化,所以我选择LoA
atmPvcVccPeakCellRateA2B
A端最大流量,我想就是带宽了。
atmPvcVccSusCellRateA2B
A端持续流量,如果atmPvcVccPeakCellRateA2B不是带宽,那就是这个了。
反正这两个总有一个是,我暂时选atmPvcVccPeakCellRateA2B。
而且我看到的是两者的值都是一样。
atmPvcVccStatsTimer
秒数
另:一个pvc cell(信元)是53个字节。
根据以上分析,得到计算PVC流量的公式:(单位:kpbs)
pvcInTraffic = (△atmPvcVccStatsInCellCountLoA * 53) / △atmPvcVccStatsTimer / 1024
pvcOutTraffic = (△atmPvcVccStatsOutCellCountLoA * 53) / △atmPvcVccStatsTimer / 1024
PVC利用率的公式:(单位:%)
pvcInUtilization = (△atmPvcVccStatsInCellCountLoA / △atmPvcVccStatsTimer / atmPvcVccPeakCellRateA2B ) * 100
pvcOutUtilization = (△atmPvcVccStatsOutCellCountLoA / △atmPvcVccStatsTimer / atmPvcVccPeakCellRateA2B ) * 100
与PVC关系最大的两张表
T1:我称它为PVC基本信息表。
AtmPvcVccEntry ::= SEQUENCE {
atmPvcVccIfA IntfIndex,
atmPvcVccVpiA INTEGER,
atmPvcVccVciA INTEGER,
atmPvcVccIfB IntfIndex,
atmPvcVccVpiB INTEGER,
atmPvcVccVciB INTEGER,
atmPvcVccServiceTypeA2B INTEGER,
atmPvcVccSarTypeA2B INTEGER,
atmPvcVccPeakCellRateA2B Integer32,
atmPvcVccSusCellRateA2B Integer32,
atmPvcVccMaxBurstSizeA2B Integer32,
atmPvcVccServiceTypeB2A INTEGER,
atmPvcVccSarTypeB2A INTEGER,
atmPvcVccPeakCellRateB2A Integer32,
atmPvcVccSusCellRateB2A Integer32,
atmPvcVccMaxBurstSizeB2A Integer32,
atmPvcVccType INTEGER,
atmPvcVccFlow INTEGER,
atmPvcVccRowStatus RowStatus,
atmPvcVccFrwdErrCorrectionA2B INTEGER,
atmPvcVccFrwdErrCorrectionB2A INTEGER,
atmPvcVccConnectionStatus INTEGER,
atmPvcVccOamStatus INTEGER,
atmPvcVccDualHomed INTEGER,
atmPvcVccViA INTEGER,
atmPvcVccViB INTEGER,
atmPvcVccCnfrmTypeA2B INTEGER,
atmPvcVccCnfrmTypeB2A INTEGER,
atmPvcVccVUNIA INTEGER,
atmPvcVccVUNIB INTEGER,
atmPvcVccOamStatusB INTEGER,
atmPvcVccOAMConnEndPtStatusA INTEGER,
atmPvcVccOAMConnEndPtStatusB INTEGER,
atmPvcVccOAMConnSegEndPtStatusA INTEGER,
atmPvcVccOAMConnSegEndPtStatusB INTEGER,
atmPvcVccMfsA2B INTEGER,
atmPvcVccMfsB2A INTEGER,
atmPvcVccConnFailureCauseA AtmConnFailureCause,
atmPvcVccConnFailureCauseB AtmConnFailureCause,
atmPvcVccTrafficShapingA2B INTEGER,
atmPvcVccTrafficShapingB2A INTEGER
}
T2:PVC状态表。
AtmPvcVccStatsEntry ::= SEQUENCE {
atmPvcVccStatsIfA IntfIndex,
atmPvcVccStatsVpiA INTEGER,
atmPvcVccStatsVciA INTEGER,
atmPvcVccStatsIfB IntfIndex,
atmPvcVccStatsVpiB INTEGER,
atmPvcVccStatsVciB INTEGER,
atmPvcVccStatsInCellCountHiA Integer32,
atmPvcVccStatsInCellCountLoA Integer32,
atmPvcVccStatsOutCellCountHiA Integer32,
atmPvcVccStatsOutCellCountLoA Integer32,
atmPvcVccStatsInCellCountHiB Integer32,
atmPvcVccStatsInCellCountLoB Integer32,
atmPvcVccStatsOutCellCountHiB Integer32,
atmPvcVccStatsOutCellCountLoB Integer32,
atmPvcVccStatsTimer Integer32,
atmPvcVccStatsFrwdErrCrrctnRateA2B INTEGER,
atmPvcVccStatsFrwdErrCrrctnRateB2A INTEGER,
atmPvcVccStatsInOdometerCellCountHiA Integer32,
atmPvcVccStatsInOdometerCellCountLoA Integer32,
atmPvcVccStatsOutOdometerCellCountHiA Integer32,
atmPvcVccStatsOutOdometerCellCountLoA Integer32,
atmPvcVccStatsInOdometerCellCountHiB Integer32,
atmPvcVccStatsInOdometerCellCountLoB Integer32,
atmPvcVccStatsOutOdometerCellCountHiB Integer32,
atmPvcVccStatsOutOdometerCellCountLoB Integer32,
atmPvcVccStatsOdometerTimer Integer32,
atmPvcVccStatsOdometerReset INTEGER,
atmPvcVccStatsOamAisTxA Integer32,
atmPvcVccStatsOamAisRxA Integer32,
atmPvcVccStatsOamRdiTxA Integer32,
atmPvcVccStatsOamRdiRxA Integer32,
atmPvcVccStatsOamAisTxB Integer32,
atmPvcVccStatsOamAisRxB Integer32,
atmPvcVccStatsOamRdiTxB Integer32,
atmPvcVccStatsOamRdiRxB Integer32,
atmPvcVccStatsCellsDroppedA Integer32,
atmPvcVccStatsCellsTaggedA Integer32,
atmPvcVccStatsCellsDroppedB Integer32,
atmPvcVccStatsCellsTaggedB Integer32
}
今天签了购房合同,终于把房子买下了,算是完成人生一大事。
明年7月就能入住新房,真的很高兴。
与ATM PVC有关的就三个表:
atmPvcVccTable,atmPvcVccStatsTable(T1)
cirEmPvcVccTable,cirEmPvcVccStatsTable(T2)
ipAtmAppPvcVccTable,ipAtmAppPvcVccStatsTable(T3)
对于Lucent4500有T1,对于Lucent1000有T2。
对于Lucent1250有T1也有T2(整个网络只有一台1250,即172.16.1.82)。
对于有些Lucent2300,有T1。
以前想用T1和T2结合的方法找出所有PVC,然后根据PVC再找出物理链路,
后来发现好些2300既没有T1也没有T2,这意味着这些设备是孤立点,没有物理连线。
如果是一两台设备这样,还有可能,可是至少有15台设备是这样,我认为就有问题。
所以后来选择T3来找出物理链路,根据结果(画出的拓扑图)来看,这些物理是正
确的。
但T3中所带的PVC信息与T1或T2都不同,以用户提供的excel文件为依据,判断
T3中所带的PVC信息是不正确的(至于为什么,我也不知道),而T1或T2中所带PVC
信息与excel文件比较接近。
结论:要找物理链路用T3;要找PVC用T1或T2。
另外,PVC active/inactive这个重要参数,在表cirEmPvcVccTable中。
cirEmAtmPvcVccConnectionStatus OBJECT-TYPE
SYNTAX INTEGER {
active(1),
inactive(2),
inactiveA2B-B2A(3),
inactiveA2B(4),
inactiveB2A(5)
}
以及表atmPvcVccTable中。
atmPvcVccConnectionStatus OBJECT-TYPE
SYNTAX INTEGER {
active(1),
inactive(2),
inactiveA2B-B2A(3),
inactiveA2B(4),
inactiveB2A(5)
}
东京
在人流不息的银座广场,一男子不小心刮开了一单身女人的超短裙。
男人还没有开口,那单身女人一个90度的大鞠躬:不好意思,给您添麻烦了!都怪裙子的质量不好......说完,取出一个别针别好,又匆匆走掉。
美国纽约
在人来人往的时代广场,一美国男子不小心刮开了一美国单身女人的超短裙。
美国男人还没开口,那美国单身女人立刻从身上摸出一张名片来:这是我律师的电话,
他会找你详细谈关于你性骚扰我的事情,你可以做好准备,我们法庭上见.....
说完记下美国男子的姓名电话,扬头走掉。
法国巴黎
在闻名于世的凯旋门广场上,一法国男子不小心刮开了一法国单身女人的超短裙。
法国男人还没开口,那法国单身女人咯咯一笑,然後细手搭肩的说道:如果你不介意的话,送我一枝玫瑰来向我道歉......说完。法国男人从花店买了一枝玫瑰,还请她去酒吧喝上一杯,然後两人一起去一家小旅馆再研究一下超短裙以内的事情了......
英国伦敦
b泰晤士河边的教堂广场上,一英国男子不小心刮开了一英国单身女人的超短裙。
英国男人还没开口,那英国单身女人忙用手里的报纸遮住裙子开了的部分,
红著脸说:先生,可以先送我回家吗?我家就在前面不远......说完。
英国男人把自己的上衣脱下来,披在她上。
叫了一辆Taix,安全的把她送到家,又换了一件裙子。
中国重庆
在人头簇动的解放碑前,一重庆男子不小心刮开了一重庆单身女人的超短裙。
重庆男人还没开口,那重庆单身女人扬手一记响亮的耳光,还抓住重庆男人的脖领子不放:你这个宝器!敢吃老**豆腐,跟我去见110去......
台湾西门町
在台湾的西门町里,一台客不小心刮开了一女学生的超短学生裙。
台客还没开口,那个女学生咯咯一笑,对著你说:价钱还没谈隆就要先看货了啊!
香港铜锣湾
在人山人海的时代广场,一中年男子不小心刮开了一年约18女生的超短裙。
中年男人还没有开口,那女生就开口 : 我x你**呀!你当我流架?你咪x走呀!
我依家拖马来收你皮
韩国斧山
在斧山的街上,一中年男子不小心刮开了一年约18女生的超短裙。中年男人还没有开口,那女生二话不说便踢出一个turning kick,然後冷冷地说: 你不知道我可是跆拳道黑带2段的吗?
泰国曼谷
在曼谷的街上,一中年男子不小心刮开了一年约18女生的超短裙。中年男人忙乱地道歉,那女生优雅地双手合十於面前,缓慢地作一姿势优美的敬礼,以娇人欲滴的声音说:先生…唔紧要,其实我系男人
看贴不回的你就是那泰国人...
http://network.ccidnet.com/art/3723/20071114/1275025_1.html
1.1 共享技术
所谓共享技术即在一个逻辑网络上的每一个工作站都处于一个相同的网段上。
以太网采用CSMA/CD 机制,这种冲突检测方法保证了只能有一个站点在总线上传输。如果有两个站点试图同时访问总线并传输数据,这就意味着“冲突”发生了,两站点都将被告知出错。然后它们都被拒发,并等待一段时间以备重发。
这种机制就如同许多汽车抢过一座窄桥,当两辆车同时试图上桥时,就发生了“冲突”,两辆车都必须退出,然后再重新开始抢行。当汽车较多时,这种无序的争抢会极大地降低效率,造成交通拥堵。
网络也是一样,当网络上的用户量较少时,网络上的交通流量较轻,冲突也就较少发生,在这种情况下冲突检测法效果较好。当网络上的交通流量增大时,冲突也增多,同进网络的吞吐量也将显著下降。在交通流量很大时,工作站可能会被一而再再而三地拒发。
1.2 交换技术
局域网交换技术是作为对共享式局域网提供有效的网段划分的解决方案而出现的,它可以使每个用户尽可能地分享到最大带宽。交换技术是在OSI 七层网络模型中的第二层,即数据链路层进行操作的,因此交换机对数据包的转发是建立在MAC(Media Access Control )地址--物理地址基础之上的,对于IP 网络协议来说,它是透明的,即交换机在转发数据包时,不知道也无须知道信源机和信宿机的IP 地址,只需知其物理地址即MAC 地址。交换机在操作过程当中会不断的收集资料去建立它本身的一个地址表,这个表相当简单,它说明了某个MAC 地址是在哪个端口上被发现的,所以当交换机收到一个TCP /IP 封包时,它便会看一下该数据包的目的MAC 地址,核对一下自己的地址表以确认应该从哪个端口把数据包发出去。由于这个过程比较简单,加上这功能由一崭新硬件进行--ASIC(Application Specific Integrated Circuit),因此速度相当快,一般只需几十微秒,交换机便可决定一个IP 封包该往那里送。值得一提的是:万一交换机收到一个不认识的封包,就是说如果目的地MAC 地址不能在地址表中找到时,交换机会把IP 封包"扩散"出去,即把它从每一个端口中送出去,就如交换机在处理一个收到的广播封包时一样。二层交换机的弱点正是它处理广播封包的手法不太有效,比方说,当一个交换机收到一个从TCP/IP 工作站上发出来的广播封包时,他便会把该封包传到所有其他端口去,哪怕有些端口上连的是IPX 或DECnet 工作站。这样一来,非TCP/IP 节点的带宽便会受到负面的影响,就算同样的TCP/IP 节点,如果他们的子网跟发送那个广播封包的工作站的子网相同,那么他们也会无原无故地收到一些与他们毫不相干的网络广播,整个网络的效率因此会大打折扣。从90 年代开始,出现了局域网交换设备。从网络交换产品的形态来看,交换产品大致有三种:端口交换、帧交换和信元交换。
(1)端口交换
端口交换技术最早出现于插槽式集线器中。这类集线器的背板通常划分有多个以太网段(每个网段为一个广播域)、各网段通过网桥或路由器相连。以太网模块插入后通常被分配到某个背板网段上,端口交换适用于将以太模块的端口在背板的多个网段之间进行分配。这样网管人员可根据网络的负载情况,将用户在不同网段之间进行分配。这种交换技术是基于OSI第一层(物理层)上完成的,它并没有改变共享传输介质的特点,因此并不是真正意义上的交换。
(2)帧交换
帧交换是目前应用的最广的局域网交换技术,它通过对传统传输媒介进行分段,提供并行传送的机制,减少了网络的碰撞冲突域,从而获得较高的带宽。不同厂商产品实现帧交换的技术均有差异,但对网络帧的处理方式一般有:存储转发式和直通式两种。存储转发式(Store-and-Forward :当一个数据包以这种技术进入一个交换机时,交换机将读取足够的信息,以便不仅能决定哪个端口将被用来发送该数据包,而且还能决定是否发送该数据包。这样就能有效地排除了那些有缺陷的网络段。虽然这种方式不及使用直通式产品的交换速度,但是它们却能排除由破坏的数据包所引起的经常性的有害后果。直通式Cut-Through :当一个数据包使用这种技术进入一个交换机时,它的地址将被读取。然后不管该数据包是否为错误的格式,它都将被发送。由于数据包只有开头几个字节被读取,所以这种方法提供了较多的交换次数。然而所有的数据包即使是那些可能已被破坏的都将被发送。直到接收站才能测出这些被破坏的包,并要求发送方重发。但是如果网络接口卡失效,或电缆存在缺陷;或有一个能引起数据包遭破坏的外部信号源,则出错将十分频繁。随着技术的发展,直通式交换将逐步被淘汰。在“直通式”交换方式中,交换机只读出网络帧的前几个字节,便将网络帧传到相应的端口上,虽然交换速度很快,但缺乏对网络帧的高级控制,无智能性和安全性可言,同时也无法支持具有不同速率端口的交换;而“存储转发”交换方式则通过对网络帧的读取进行验错和控制。联想网络的产品都采用“存储转发”交换方式。
(3)信元交换
信元交换的基本思想是采用固定长度的信元进行交换,这样就可以用硬件实现交换,从而大大提高交换速度,尤其适合语音、视频等多媒体信号的有效传输。目前,信元交换的实际应用标准是ATM (异步传输模式),但是ATM 设备的造价较为昂贵,在局域网中的应用已经逐步被以太网的帧交换技术所取代。
1.2.1 第二层交换技术
第二层的网络交换机依据第二层的地址传送网络帧。第二层的地址又称硬件地址(MAC 地址),第二层交换机通常提供很高的吞吐量(线速)、低延时(10 微秒左右),每端口的价格比较经济。第二层的交换机对于路由器和主机是“透明的”,主要遵从802.1d 标准。该标准规定交换机通过观察每个端口的数据帧获得源MAC 地址,交换机在内部的高速缓存中建立MAC 地址与端口的映射表。当交换机接受的数据帧的目的地址在该映射表中被查到,交换机便将该数据帧送往对应的端口。如果它查不到,便将该数据帧广播到该端口所属虚拟局域网(VLAN )的所有端口,如果有回应数据包,交换机便将在映射表中增加新的对应关系。当交换机初次加入网络中时,由于映射表是空的,所以,所有的数据帧将发往虚拟局域网内的全部端口直到交换机“学习”到各个MAC 地址为止。这样看来,交换机刚刚启动时与传统的共享式集线器作用相似的,直到映射表建立起来后,才能真正发挥它的性能。这种方式改变了共享式以太网抢行的方式,如同在不同的行驶方向上铺架了立交桥,去往不同方向的车可以同时通行,因此大大提高了流量。从虚拟局域网(VLAN )角度来看,由于只有子网内部的节点竞争带宽,所以性能得到提高。主机1 访问主机2 同时,主机3 可以访问主机4 。当各个部门具有自己独立的服务器时,这一优势更加明显。但是这种环境正发生巨大的变化,因为服务器趋向于集中管理,另外,这一模式也不适合Internet 的应用。不同虚拟局域网(VLAN )之间的通讯需要通过路由器来完成,另外为了实现不同的网段之间通讯也需要路由器进行互连。
路由器处理能力是有限的,相对于局域网的交换速度来说路由器的数据路由速度也是较缓慢的。路由器的低效率和长时延使之成为整个网络的瓶颈。虚拟局域网(VLAN )之间的访问速度是加快整个网络速度的关键,某些情况下(特别是Intranet ),划定虚拟局域网本身是一件困难的事情。第三层交换机的目的正在于此,它可以完成Intranet 中虚拟局域网(VLAN )之间的数据包以高速率进行转发。
1.2.2 VLAN 技术
在传统的局域网中,各站点共享传输信道所造成的信道冲突和广播风暴是影响网络性能的重要因素。通常一个IP 子网或者IPX 子网属于一个广播域,因此网络中的广播域是根据物理网络来划分的。这样的网络结构无论从效率和安全性角度来考虑都有所欠缺。同时,由于网络中的站点被束缚在所处的物理网络中,而不能够根据需要将其划分至相应的逻辑子网,因此网络的结构缺乏灵活性。为解决这一问题,从而引发了虚拟局域网(VLAN )的概念,所谓VLAN 是指网络中的站点不拘泥于所处的物理位置,而可以根据需要灵活地加入不同的逻辑子网中的一种网络技术。
VLAN 技术的基础
基于交换式以太网的VLAN
在交换式以太网中,利用VLAN 技术,可以将由交换机连接成的物理网络划分成多个逻辑子网。也就是说,一个VLAN中的站点所发送的广播数据包将仅转发至属于同一VLAN 的站点。而在传统局域网中,由于物理网络和逻辑子网的对应关系,因此任何一个站点所发送的广播数据包都将被转发至网络中的所有站点。在交换式以太网中,各站点可以分别属于不同的VLAN 。构成VLAN 的站点不拘泥于所处的物理位置,它们既可以挂接在同一个交换机中,也可以挂接在不同的交换机中。VLAN 技术使得网络的拓扑结构变得非常灵活,例如位于不同楼层的用户或者不同部门的用户可以根据需要加入不同的VLAN 。到目前为止,基于交换式以太网实现VLAN 主要有三种途径:基于端口的VLAN 、基于MAC 地址的VLAN 和基于IP 地址的VLAN 。
1、基于端口的VLAN
基于端口的VLAN 就是将交换机中的若干个端口定义为一个VLAN ,同一个VLAN 中的站点具有相同的网络地址,不同的VLAN 之间进行通信需要通过路由器。采用这种方式的VLAN 其不足之处是灵活性不好,例如当一个网络站点从一个端口移动到另外一个新的端口时,如果新端口与旧端口不属于同一个VLAN ,则用户必须对该站点重新进行网络地址配置,否则,该站点将无法进行网络通信。
2、基于MAC 地址的VLAN
在基于MAC 地址的VLAN 中,交换机对站点的MAC 地址和交换机端口进行跟踪,在新站点入网时根据需要将其划归至某一个VLAN ,而无论该站点在网络中怎样移动,由于其MAC 地址保持不变,因此用户不需要进行网络地址的重新配置。这种VLAN 技术的不足之处是在站点入网时,需要对交换机进行比较复杂的手工配置,以确定该站点属于哪一个VLAN 。
3、基于IP 地址的VLAN
在基于IP 地址的VLAN 中,新站点在入网时无需进行太多配置,交换机则根据各站点网络地址自动将其划分成不同的VLAN 。在三种VLAN 的实现技术中,基于IP 地址的VLAN 智能化程度最高,实现起来也最复杂。VLAN 作为一种新一代的网络技术,它的出现为解决网络站点的灵活配置和网络安全性等问题提供了良好的手段。虽然VLAN 技术目前还有许多问题有待解决,例如技术标准的统一问题、VLAN 管理的开销问题和VALN 配置的自动化问题等等。然而,随着技术的不断进步,上述问题将逐步加以解决,VLAN 技术也将在网络建设中得到更加广泛的应用,从而为提高网络的工作效率发挥更大的作用。事实上一个VLAN(虚拟局域网)就是一个广播域。为了避免在大型交换机上进行的广播所引起的广播风暴,可将连接到大型交换机上的网络划分为多个VLAN(虚拟局域网)。在一个VLAN(虚拟局域网)内,由一个工作站发出的信息只能发送到具有相同VLAN(虚拟局域网)号的其他站点。其它VLAN(虚拟局域网)的成员收不到这些信息或广播帧。
采用VLAN 有如下优势:
1. 抑制网络上的广播风暴;
2. 增加网络的安全性;
3. 集中化的管理控制。
这就是在局域网交换机上采用VLAN(虚拟局域网)技术的初衷,也确实解决了一些问题。但这种技术也引发出一些新的问题:随着应用的升级,网络规划/实施者可根据情况在交换式局域网环境下将用户划分在不同VLAN(虚拟局域网)上。但是VLAN(虚拟局域网)之间通信是不允许的,这也包括地址解析(ARP)封包。要想通信就需要用路由器桥接这些VLAN(虚拟局域网)。这就是VLAN(虚拟局域网)的问题:不用路由器是嫌它慢,用交换机速度快但不能解决广播风暴问题,在交换机中采用VLAN(虚拟局域网)技术可以解决广播风暴问题,但又必须放置路由器来实现VLAN(虚拟局域网)之间的互通。形成了一个不可逾越的怪圈。这就是网络的核心和枢纽路由器的问题。在这种网络系统集成模式中,路由器是核心。
路由器所起的作用是:
1.网段微化(网段之间通过路由器进行连接):
2. 网络的安全控制;
3. VLAN(虚拟局域网)间互连;
4. 异构网间的互连。
1.2.3 局域网瓶颈
1、 采用路由器作为网络的核心将产生的问题:
● 路由器增加了3 层路由选择的时间,数据的传输效率低;
● 增加、移动和改变节点的复杂性有增无减;
● 路由器价格昂贵、结构复杂;
● 增加子网/ VLAN(虚拟局域网)的互连意味着要增加路由器端口,投资也增大。
相比之下,路由器是在OSI 七层网络模型中的第三层--网络层操作的,它在网络中,收到任何一个数据包(包括广播包在内),都要将该数据包第二层(数据链路层)的信息去掉(称为"拆包"),查看第三层信息(IP 地址)。然后,根据路由表确定数据包的路由,再检查安全访问表;若被通过,则再进行第二层信息的封装(称为"打包"),最后将该数据包转发。如果在路由表中查不到对应MAC 地址的网络地址,则路由器将向源地址的站点返回一个信息,并把这个数据包丢掉。与交换机相比,路由器显然能够提供构成企业网安全控制策略的一系列存取控制机制。由于路由器对任何数据包都要有一个"拆打"过程,即使是同一源地址向同一目的地址发出的所有数据包,也要重复相同的过程。这导致路由器不可能具有很高的吞吐量,也是路由器成为网络瓶颈的原因之一。如果路由器的工作仅仅是在子网与子网间、网络与网络间交换数据包的话,我们可能会买到比今天便宜得多的路由器。实际上路由器的工作远不止这些,它还要完成数据包过滤、数据包压缩、协议转换、维护路由表、计算路由、甚至防火墙等许多工作。而所有这些都需要大量CPU 资源,因此使得路由器一方面价格昂贵,另一方面越来越成为网络瓶颈。
昨天还在考虑怎么能把Class限制在某个类型上,而且一直以来都不理解 Class<? extends XXX>是什么意思。
今天终于理解了Class<? extends XXX>的用法,并把昨天那个问题解决了。
所以,有些东西就是只有当真正需要时才会去认真考虑它,呵。
看了一天ext,头都晕了。感觉学习新的东西成本真是太大了。对js不熟悉,
学起ajax和ext来真是费劲。呵呵,还是算了吧,就算以后项目中真的要用到这
些东西,那就专门招这方面的人来做,我自己就不用再学这些新东西了。
另外,无间中发现FineReport,这个报表制作工具,试了一下,还真好用,
至少比iReport容易上手。如果以后要用到报表,可以考虑FineReport。
安装Oracle后MyEclipse不能启动,经常遇到这个问题。解决方法:
更改环境变量path
去掉C:\Program Files\Oracle\jre\1.3.1\bin;C:\Program Files\Oracle\jre\1.1.8\bin;
加上C:\Program Files\Java\jdk1.5.0_05\bin
今天学习了Spring中jdbc framework,感觉spring jdbc framework真的搞得太复杂了。
平时我们根本用不到那么多东西。但我还是得把所有的源码都看一遍,因为这是我
的学习内容。
同时,还了解了一下ajax dwr和ext ,下一个版本可以考虑要用ajax,ext做出来的
界面真的太漂亮了,将来,软件界面将成为软件的一个卖点。
http://network.ccidnet.com/art/3723/20071114/1274987_1.html
为了适应网络应用深化带来的挑战,网络在规模和速度方向都在急剧发展,局域网的速度已从最初的10Mbit/s 提高到100Mbit/s,目前千兆以太网技术已得到普遍应用。在网络结构方面也从早期的共享介质的局域网发展到目前的交换式局域网。交换式局域网技术使专用的带宽为用户所独享,极大的提高了局域网传输的效率。可以说,在网络系统集成的技术中,直接面向用户的第一层接口和第二层交换技术方面已得到令人满意的答案。但是,作为网络核心、起到网间互连作用的路由器技术却没有质的突破。在这种情况下,一各新的路由技术应运而生,这就是第三层交换技术:说它是路由器,因为它可操作在网络协议的第三层,是一种路由理解设备并可起到路由决定的作用;说它是交换器,是因为它的速度极快,几乎达到第二层交换的速度。二层交换机、三层交换机和路由器这三种技术究竟谁优谁劣,它们各自适用在什么环境?为了解答这问题,我们先从这三种技术的工作原理入手
1.二层交换技术
二层交换机是数据链路层的设备,它能够读取数据包中的MAC地址信息并根据MAC地址来进行交换。交换机内部有一个地址表,这个地址表标明了MAC地址和交换机端口的对应关系。当交换机从某个端口收到一个数据包,它首先读取包头中的源MAC地址,这样它就知道源MAC地址的机器是连在哪个端口上的,它再去读取包头中的目的MAC地址,并在地址表中查找相应的端口,如果表中有与这目的MAC地址对应的端口,则把数据包直接复制到这端口上,如果在表中找不到相应的端口则把数据包广播到所有端口上,当目的机器对源机器回应时,交换机又可以学习一目的MAC地址与哪个端口对应,在下次传送数据时就不再需要对所有端口进行广播了。二层交换机就是这样建立和维护它自己的地址表。由于二层交换机一般具有很宽的交换总线带宽,所以可以同时为很多端口进行数据交换。如果二层交换机有N个端口,每个端口的带宽是M,而它的交换机总线带宽超过N×M,那么这交换机就可以实现线速交换。二层交换机对广播包是不做限制的,把广播包复制到所有端口上。
二层交换机一般都含有专门用于处理数据包转发的ASIC (Application specific Integrated Circuit)芯片,因此转发速度可以做到非常快。
2.路由技术
路由器是在OSI七层网络模型中的第三层——网络层操作的。路由器内部有一个路由表,这表标明了如果要去某个地方,下一步应该往哪走。路由器从某个端口收到一个数据包,它首先把链路层的包头去掉(拆包),读取目的IP地址,然后查找路由表,若能确定下一步往哪送,则再加上链路层的包头(打包),把该数据包转发出去;如果不能确定下一步的地址,则向源地址返回一个信息,并把这个数据包丢掉。
路由技术和二层交换看起来有点相似,其实路由和交换之间的主要区别就是交换发生在OSI参考模型的第二层(数据链路层),而路由发生在第三层。这一区别决定了路由和交换在传送数据的过程中需要使用不同的控制信息,所以两者实现各自功能的方式是不同的。
路由技术其实是由两项最基本的活动组成,即决定最优路径和传输数据包。其中,数据包的传输相对较为简单和直接,而路由的确定则更加复杂一些。路由算法在路由表中写入各种不同的信息,路由器会根据数据包所要到达的目的地选择最佳路径把数据包发送到可以到达该目的地的下一台路由器处。当下一台路由器接收到该数据包时,也会查看其目标地址,并使用合适的路径继续传送给后面的路由器。依次类推,直到数据包到达最终目的地。
路由器之间可以进行相互通讯,而且可以通过传送不同类型的信息维护各自的路由表。路由更新信息主是这样一种信息,一般是由部分或全部路由表组成。通过分析其它路由器发出的路由更新信息,路由器可以掌握整个网络的拓扑结构。链路状态广播是另外一种在路由器之间传递的信息,它可以把信息发送方的链路状态及进的通知给其它路由器。
3.三层交换技术
一个具有第三层交换功能的设备是一个带有第三层路由功能的第二层交换机,但它是二者的有机结合,并不是简单的把路由器设备的硬件及软件简单地叠加在局域网交换机上。
从硬件上看,第二层交换机的接口模块都是通过高速背板/总线(速率可高达几十Gbit/s)交换数据的,在第三层交换机中,与路由器有关的第三层路由硬件模块也插接在高速背板/总线上,这种方式使得路由模块可以与需要路由的其他模块间高速的交换数据,从而突破了传统的外接路由器接口速率的限制。在软件方面,第三层交换机也有重大的举措,它将传统的基于软件的路由器软件进行了界定,其做法是: 对于数据包的转发:如IP/IPX包的转发,这些规律的过程通过硬件得以高速实现。
对于第三层路由软件:如路由信息的更新、路由表维护、路由计算、路由的确定等功能,用优化、高效的软件实现。
假设两个使用IP协议的机器通过第三层交换机进行通信的过程,机器A在开始发送时,已知目的IP地址,但尚不知道在局域网上发送所需要的MAC地址。要采用地址解析(ARP)来确定目的MAC地址。机器A把自己的IP地址与目的IP地址比较,从其软件中配置的子网掩码提取出网络地址来确定目的机器是否与自己在同一子网内。若目的机器B与机器A在同一子网内,A广播一个ARP请求,B返回其MAC地址,A得到目的机器B的MAC地址后将这一地址缓存起来,并用此MAC地址封包转发数据,第二层交换模块查找MAC地址表确定将数据包发向目的端口。若两个机器不在同一子网内,如发送机器A要与目的机器C通信,发送机器A要向“缺省网关”发出ARP包,而“缺省网关”的IP地址已经在系统软件中设置。这个IP地址实际上对应第三层交换机的第三层交换模块。所以当发送机器A对“缺省网关”的IP地址广播出一个ARP请求时,若第三层交换模块在以往的通信过程中已得到目的机器C的MAC地址,则向发送机器A回复C的MAC地址;否则第三层交换模块根据路由信息向目的机器广播一个ARP请求,目的机器C得到此ARP请示后向第三层交换模块回复其MAC地址,第三层交换模块保存此地址并回复给发送机器A。以后,当再进行A与C之间数据包转发进,将用最终的目的机器的MAC地址封装,数据转发过程全部交给第二层交换处理,信息得以高速交换。既所谓的一次选路,多次交换。
第三层交换具有以下突出特点:
有机的硬件结合使得数据交换加速;
优化的路由软件使 得路由过程效率提高;
除了必要的路由决定过程外,大部分数据转发过程由第二层交换处理;
多个子网互连时只是与第三层交换模块的逻辑连接,不象传统的外接路由器那样需增加端口,保护了用户的投资。
4.三种技术的对比
可以看出,二层交换机主要用在小型局域网中,机器数量在二、三十台以下,这样的网络环境下,广播包影响不大,二层交换机的快速交换功能、多个接入端口和低谦价格为小型网络用户提供了很完善的解决方案。在这种小型网络中根本没必要引入路由功能从而增加管理的难度和费用,所以没有必要使用路由器,当然也没有必要使用三层交换机。
三层交换机是为IP设计的,接口类型简单,拥有很强二层包处理能力,所以适用于大型局域网,为了减小广播风暴的危害,必须把大型局域网按功能或地域等因素划他成一个一个的小局域网,也就是一个一个的小网段,这样必然导致不同网段这间存在大量的互访,单纯使用二层交换机没办法实现网间的互访而单纯使用路由器,则由于端口数量有限,路由速度较慢,而限制了网络的规模和访问速度,所以这种环境下,由二层交换技术和路由技术有机结合而成的三层交换机就最为适合。
路由器端口类型多,支持的三层协议多,路由能力强,所以适合于在大型网络之间的互连,虽然不少三层交换机甚至二层交换机都有异质网络的互连端口,但一般大型网络的互连端口不多,互连设备的主要功能不在于在端口之间进行快速交换,而是要选择最佳路径,进行负载分担,链路备份和最重要的与其它网络进行路由信息交换,所有这些都是路由完成的功能。在这种情况下,自然不可能使用二层交换机,但是否使用三层交换机,则视具体情况而下。影响的因素主要有网络流量、响应速度要求和投资预算等。三层交换机的最重要目的是加快大型局域网内部的数据交换,揉合进去的路由功能也是为这目的服务的,所以它的路由功能没有同一档次的专业路由器强。在网络流量很大的情况下,如果三层交换机既做网内的交换,又做网间的路由,必然会大大加重了它的负担,影响响应速度。在网络流量很大,但又要求响应速度很高的情况下由三层交换机做网内的交换,由路由器专门负责网间的路由工作,这样可以充分发挥不同设备的优势,是一个很好的配合。当然,如果受到投资预算的限制,由三层交换机兼做网间互连,也是个不错的选择。
annotation 不能对private的属性进行注解,真让人郁闷。
其实对private属性注解,不会出错,只Class.getFields()只能得到那些public属性,
取不private属性,当然就不可能取到它的注解了,这个问题不知怎么解决。
struts里总用到Thread.currentThread().getContextClassLoader()
而我们一般只用到Class.forName()或Class.getClassLoader()
所以想知道二者有什么区别,以下是从网上找到的:
Classloader存在下面问题:
在一个JVM中可能存在多个ClassLoader,每个ClassLoader拥有自己的NameSpace。
一个ClassLoader只能拥有一个class对象类型的实例,但是不同的ClassLoader可能
拥有相同的class对象实例,这时可能产生致命的问题。如ClassLoaderA,装载了
类A的类型实例A1,而ClassLoaderB,也装载了类A的对象实例A2。逻辑上讲A1=
A2,但是由于A1和A2来自于不同的ClassLoader,它们实际上是完全不同的,
如果A中定义了一个静态变量c,则c在不同的ClassLoader中的值是不同的。
Class.getClassLoader() returns the ClassLoader that loaded the class it
is invoked on.
Thread.getContextClassLoader() returns the ClassLoader set as the
context ClassLoader for the Thread it is invoked on, which can be
different from the ClassLoader that loaded the Thread class itself if
the Thread's setContextClassLoader(ClassLoader) method has been invoked.
This can be used to allow the object starting a thread to specify a
ClassLoader that objects running in the thread should use, but the
cooperation of some of those objects is required for that to work.
PVC数据有从Excel中导入的,也有程序自动扫描的结果,真是挺乱的。
但用户最关心这个PVC数据,所以我必须把两部分数据整合到一起。
1. 程序扫描整个网络,得到所有PVC数据,把数据存入nms_atm_pvc
2. 把nms_atm_pvc数据整合到pl_pvc_info中去,对于pl_pvc_info中没有数据,则加入。
3. 以后每隔两小时扫描全网PVC,与pl_pvc_info对比,如果有增加则报警。
4. 对于从ITSM来的PVC数据,是用户手工加入的合法数据,加入pl_pvc_info。
|
1
|
在ITSM新增一条PVC后,自动把PVC信息插入NMS。
|
|
2
|
PVC报警:
a.如果PVC带宽变大,要报警;
b.如果有增加PVC,而且又不是从ITSM那边过来的,也要报警;
c.如果PVC状态从active变为inactive也要报警;
报警考虑以声音报警。
|
|
3
|
对于PVC数据,以程序自动扫描结果为主,以Excel文件为参考。
|
|
4
|
对于路由器,8个部门应该有8张图。
|
|
5
|
把“纵向专网带宽分配”PPT加入NMS系统,以便给领导演示。
|
水长从福州到东莞,拐道过来广州看我。呵呵,三年没见过了。见了老同学特别高兴。
晚上也给在厦门的多位同学打了电话,确实很久没与他们联系了。
这个周末很愉快。
JDK、Tomcat和MySQL的绿色安装方法。
要制作web系统setup一键安装程序,必须先解决JDK、Tomcat和MySQL三者的绿色
安装问题。今天研究了半天,终于有了结果。
现在假设我们要把这三者安装到C:\SourceView目录下。
1. JDK。Copy安装好的JDK,C:\Program Files\Java\jdk1.5.0_11到
C:\SourceView下就可以了。
2. Tomcat。Copy安装好的Tomcat到C:\Sourceview下。然后修改bin下的startup.bat
在文件顶部加上
set CATALINA_HOME=C:\SourceView\tomcat
set JAVA_HOME=C:\SourceView\jdk1.5.0_11
3. MySQL。最麻烦的就是MySQL了。Copy安装好的MySQL到C:\SourceView下。
首先修改my.ini.
basedir=C:/sourceview/MySQL/
datadir=C:/sourceview/MySQL/data/
然后,执行
C:\sourceview\MySQL\bin>mysqld-nt --install MySQL5.0
--defaults-file="C:\sourceview\MySQL\my.ini"
安装MySQL服务,服务名MySQL5.0。
C:\windows\system32\net start MySQL5.0
启动MySQL服务。
这样,以后只要copy SourceView到需要安装的地方,然后修改一下几点文件,
这三者就能用了。
把ATM Discovery独立出来,而且去掉了一个bug,多发现了四台设备,
下图是今天发现的结果。估计这是我能做出最好的结果了,呵呵

1. createConnection,close,rollback这些操作都应该在dao之外的service来做。
2. 默认connection的autoCommit为true。当要执行事务时,应该置为false,
因为autoCommit=true时,rollback不能用。
3. 当conn.getAutoCommit()=false时,说明要去进行事务操作,这时commit
应该由调用dao的service来执行。
4. 涉及到update的dao方法都应该throw exception,以便在service中catch。
5. dao的设计遵循原子操作的原则,不在这些接口中实现复杂的业务逻辑。
学习Struts的过程中认识了DynaBean,一时不理解何为动态Bean。看了以下的例子,
就很容易明白了。
import java.util.Date;
import org.apache.commons.beanutils.BasicDynaClass;
import org.apache.commons.beanutils.DynaBean;
import org.apache.commons.beanutils.DynaClass;
import org.apache.commons.beanutils.DynaProperty;
public class TestService {
public static void main(String[] hey) throws Exception{
DynaProperty[] pro = new DynaProperty[]{//准备一个属性,动态定义类依靠这些属性来决定类的构成。
new DynaProperty("title", String.class),
new DynaProperty("content", String.class),
new DynaProperty("createdTime", Date.class),
new DynaProperty("id", Integer.class),
};
DynaClass articleClass = new BasicDynaClass("Article",null,pro);//定义了一个类
DynaBean article = articleClass.newInstance();//声明了一个ArticleClass的对象
article.set("title","this is a test");//对该对象进行操作
article.set("content","oh my god");
article.set("createdTime",new Date());
article.set("id",new Integer(1));
System.out.println(article.get("title"));
System.out.println(article.get("content"));
System.out.println(article.get("createdTime"));
System.out.println(article.get("id"));
}
}
1.Java Annotations.A new feature of Java Tiger.I realized this functionality
would be helpful to our next architecture design(next version of our NMS
product).
2.Java Concurrency Programming.The section is particularly useful to us as
polling thread is an important element in NMS product,so I should learn
more about concurrency programming.
3.JMX.It provides a simple,scalable management solution to a distributed
system,I think it is the best instrument for me.With Java Management
Extensions (JMX), you can configure, manage and monitor your Java
applications at run-time, as well as break your applications into components
that can be swapped out. JMX provides a window into an application's state
and its behavior, and a protocol-independent way of altering both state and
behavior. It lets you expose portions of your application in just a few lines of
code.
JMX in action is a good book,The examples were easy to follow and thorough
though sometimes trivial.
4.Spring.A powerful framework,I don't use it at all, but I want to study its
thinking.My goal is to build a simple,scalable MVC framework,must be better
than our present.
原来不理解Spring jdbc中的核心类JdbcTemplate的DataSource为什么都是当参数从外面传入,
今天看了一篇“DAO的困惑-事务处理”,其中提到“Dao只能使用资源,而不应该管理资源,
也就是说,Dao可以使用Connection,但不能维护它--生成和关闭”。
在简单的应用系统中,也许根本不会遇到事务,但在一个比较复杂的系统中,经常要处理
事务,这时JdbcTemplate的这种设计就显示出它的合理和完美。 在SourceView的一个版本中,
我一定会重新考虑Dao的设计。
老爸要我翻译下面这句话:
福建省三明市总商会 广东会员联络处
The Chamber of Commerce of Sanming City Fujian Province
Liaison Office for GuangDong Member
呵呵,不知对不对。坚持学习英语,这是我必须做的。
我认为至少满足以下三个条件,才能算是一个好的DAO设计:
1. 多个数据源的问题;
2. new 一个Dao后,可以连续两个(或以上)方法,而且最后connection是关闭,
但不显示调用dao.close()。
3. 对事务的支持,就是对两个(或以上)dao的不同方法(对两张以上表进行操作),
必须同时成功或不成功。
这是长期困扰我的问题,所以,我觉得如果能解决好这些问题,
就是一个好的dao设计。
10月4日下午,韶关市区,风采楼。仅一楼而已,看一眼就罢。
10月4日晚,回广州。
----------------风采楼简介--------------
风采楼座落在韶关市区风采路与上后街(旧名学宫街)之交叉口,建筑雄伟独特,
气势轩昂,被誉为韶关的标记。
风采楼是明代弘治十年(公元1497年)韶州知府钱镛为纪念韶关藉北宋名臣余靖
而建的,屡经重修。风采楼在中“风采楼”三个大字,写得柔韧而苍劲,笔力神韵活
跃于字中,是明代书法家陈白沙(献章)茅笔字的存世珍品。
风采楼与北京天安门、故宫为同时代同风格的建筑物,楼高22米,正方形,顶为
三重飞檐翘角,正中有华饰小圆顶。占地100多平方米,原是砖林结构,于1932年以水
泥钢筋结构重建,保持原有建筑的一些特色,楼底可通行各种车辆,北门建有铁栅小
门,循回环形楼梯而上便是一层主楼,东西巩园上有“风采楼”三个大字,风采楼内
有一块玉石碑,署有《风采楼前后记》。“风采”两字取自当时的刑部尚书蔡君谟的
诗:“必有谋猷禅帝石,更加风采动朝端“之名。风采楼西望武水,东临浈江,气势
轩昂,建筑精巧、古色古香、气势轩昂。这座建筑物现为韶关市博物馆馆址,楼上有
余靖的生平介绍展,晚上在彩灯的装饰下更显其“风彩”。
余靖,公元1000年生于韶州府城,二十四岁一举高中进士,初授官为赣县尉,很
快又升为新建(江西南昌县)知县。三十四岁入朝延做官任秘书丞。四十三岁升为右
正言(谏官),后又出使辽国,使当时宋、辽西夏三足鼎立的局面得以和解,为巩固
宋代天下立下了不可磨灭的丰功伟绩。余靖是岭南继张九龄后又一显赫的朝延重官,
他与张九龄一样刚正不阿,廉洁自重。与范仲淹、欧阳修、尹沂被尊为宋朝“四贤”,
与欧阳修、王素、蔡襄被称为“四谏”,后来官于工部尚书。公元1065年病逝于江宁
(今南京)。广东省广州曾有“八贤堂”,余靖就是八贤之一。
10月2日下午游完了阳元山,原打算去爬长老峰,第二天可以看日出,无奈老天不长眼,下起了雨。
我们只好找个宾馆暂时住下。 10月3日,早上6点出发,10点登上了长老峰。
10月3日晚回到韶关市区。南华寺原本不在计划之内,但游之后感觉:不来就太可惜,因为这的风
景实在太美了。
10月4日早,南华寺。
-------------南华寺简介--------------------
南华寺是广东六大寺庙之一,是全国重点开放寺庙及国家级重点保护文物单位,同时也是闻名中外
的禅宗祖庭、佛教圣地。它座落在曲江县马坝东南效曹溪之畔,距韶关市22公里。南华寺是禅宗六祖惠
能和尚栖身说法的地方,后因其弟子又创立了沩仰(湖南)、临济(河北)、曹洞(江西)、云门(广
东)、法眼(南京)等五宗,即所谓一花五叶,法眼宗远传于泰国、朝鲜;曹洞、临济盛行于日本;云
门及临济更远播于欧美。因此南华寺又有“祖庭”之称。
南华寺始建于南北朝时的梁武帝天鉴元年(公元502)年,至今已有1489年的历史。据有关史料记载,
梁武帝天鉴元年印度高僧智药三藏来中国传播佛教,从广州北上途经曹溪,掬水而饮,溪水甘美异常,
他便溯源而上,只见这一带峦紫翠,便建议在此建寺。那时韶州牧侯敬中将议表奏梁武帝,天鉴三年建成,
梁武帝赐额为“宝林寺”。隋末,寺院一度荒败。唐高宗龙朔元年(公元661年)重修。中国佛教第六祖、
南宗禅法的创始人惠能大师从湖北黄梅东山寺得法南归,在宝寺说法三十六载,弟子遍布天下,改称“曹
溪宗”。惠能大师死后,寺院曾几度兴衰,唐中宗神龙元年(公元705年),改为“中兴寺”;神龙三年,
又改为“法泉寺”;宋初寺院半毁于火,开宝元年(公元968年)复修,赐名“南华禅寺”,自此,南华
寺的名字沿用至今。元朝末期,寺宇三遭兵灾,寺僧颓败,庙庭衰落。明朝万历二十八年(公元1600年),
德清和尚大力中兴,修建庙宇。清康熙七年(公元1688年),平南王尚可喜重修全寺。民国二十二年(19
33年)春,原广东省政府主席李汉魂发起重修。翌年,虚云和尚来寺募化重修,调整布局,改为阶梯式
中轴线布局,建筑面积约为1.2万多平方米。解放后,人民政府对这座古寺和历史文物非常重视,多次拨款
修缮。
南华寺原有的建筑面积为12000多平方米,整体上为中轴线阶梯式的平面布局。分前、中、后三个部
分。前部有曹溪门、放生池、五香亭、宝林门;中部以大雄宝殿为中心,殿前有天王宝殿,两侧为钟楼、
鼓楼,殿后藏经阁;后部为灵照塔、陈亚仙祖墓、六祖殿、方丈室、苏程庵及卓锡泉等。结构上主次分明,
安排合理。
10月2日早10点从广州坐火车,下午2点到韶关丹霞山。
----丹霞山简介----
世界地质公园——丹霞山,位于韶关市境内,面积290平方千米,是广东省面积最大、
景色最美的风景区。1988年以来,丹霞山分别被评为国家风景名胜区、国家级地质地貌自
然保护区、国家AAAA级旅游区、国家地质公园和世界地质公园。
丹霞山是世界“丹霞地貌”命名地。丹霞山由680多座顶平、身陡、麓缓的红色砂砾
岩石构成,“色如渥丹,灿若明霞”,以赤壁丹崖为特色。据地质学家研究表明:在世界
已发现1200多处丹霞地貌中,丹霞山是发育最典型、类型最齐全、造型最丰富、景色最优
美的丹霞地貌集中分布区。
在距今1.4亿年至7000万年间,丹霞山区是一个大型内陆盆地,受喜马拉雅造山运动影
响,四周山地强烈隆起,盆地内接受大量碎屑沉积,形成了巨厚的红色地层;在距今7000
年前后,地壳上升而逐渐受侵蚀。距今600万年以来,盆地又发生多次间歇上升,平均大约
每万年上升1米,同时流水下切侵蚀,丹霞红层被切割成一片红色山群,也就是现在的丹霞
山区。
丹霞山在地层、构造、地貌表现、发育过程、营力作用以及自然环境、生态演化等方
面的研究在全国丹霞地貌区最为详细和深入,已经成为全国乃至世界丹霞地貌的研究基地
以及科普教育和教学实习基地。丹霞山风景区内有大小石峰、石墙、石柱、天生桥680多座,
群峰如林,疏密相生,高下参差,错落有序;山间高峡幽谷,古木葱郁,淡雅清静,风尘不
染。锦江秀水纵贯南北,沿途丹山碧水,竹树婆娑,满江风物,一脉柔情。
丹霞山现有佛教别传禅寺以及80多处石窟寺遗址,历代文人墨客在这里留下了许多传
奇故事、诗词和摩崖石刻,具有极大的历史文化价值。
目前,丹霞山已开发长老峰、翔龙湖、锦江长廊、阳元山、韶石山等景区。