数据驱动在大部分中小型系统,尤其是MIS系统中是最为适合的一种开发方式,在之后我也会写一篇基于数据驱动提升形成的对于业务系统的支持方式的文章,数据驱动也就是说基于持久层的设计来完成整个模块开发的过程。
MS对于数据驱动的支持无疑非常优秀,从以前的VB到现在的ASP.net 2.0都支持的非常好,而Java界在这方面也是引起了重视,比如由此推出的bstek,就是在java方面的数据驱动上做到了实现。
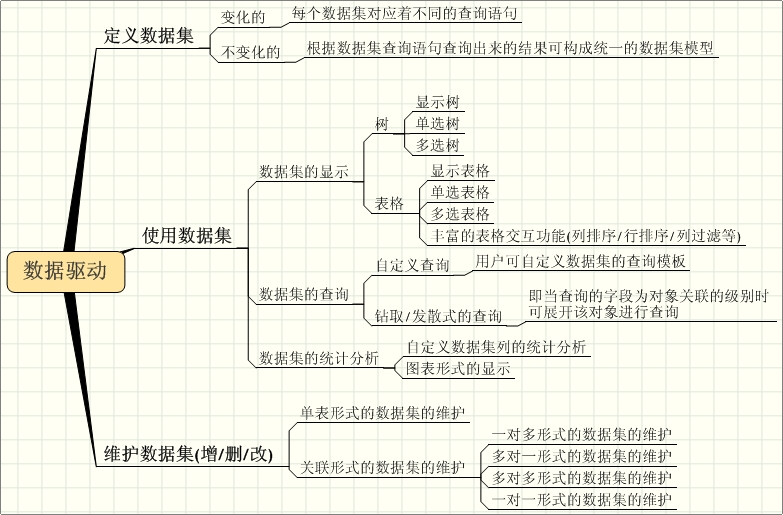
看看数据驱动的开发方式,通常来说,数据驱动的开发由定义持久层(数据表或持久层对象)、创建数据集(查询语句)以及绑定数据集至相应的表现层组件(树、表格)三个步骤来完成,此时基于此数据集的显示、维护、查询等均得到了实现,可见这样的一个开发过程对于数据型的应用来说确实是非常高效的。
根据开发步骤和实现的功能,怎么样才能满足数据驱动呢?将其归纳为三方面去看:
1、定义数据集
对于数据集而已,变化的为不同的查询语句,相同的为根据查询语句查询形成的统一的数据集模型。
2、使用数据集 主要又可分为数据集的显示、查询和统计分析三个方面。
数据集的显示 数据集的显示通常来说为两种:树和表格。其中树又有多种的显示形式,如单选树、多选树等;表格也有多种的显示形式,如单选表格(用于下拉选择)、多选表格等,同时还需要支持表格上的丰富的交互(如列排序、行排序等)。
数据集的查询 数据集的查询最需要的为自定义形式的查询,也就是说用户可自定义查询的条件构成一个查询模板,之后用户即可根据此模板对数据集进行查询。
数据集的统计分析 通常来说需要支持用户可自定义根据数据集的列来进行统计分析,图表化的显示形式也是必须的。
3、维护数据集(增/删/改)
对于数据集的维护,其实主要就两种形式:单表形式的数据集维护以及关联形式的数据集维护。
关联形式上主要有:一对多、多对一、多对多以及一对一。
附上一张图也许能表达的更清楚:
对于支持数据驱动的开发框架而已,最重要的无非就是将通用的部分进行实现,同时将变化或框架无法得知的部分交由开发人员自行实现,对之上的三方面进行分析,可以得知对于框架而言无法得知的为数据集所对应的查询语句,这就是要开发人员自行实现的,而其他的则均可做到通用,但通用也得考虑用户怎么样去控制,如采用表格显示数据集时,需要控制显示的列、显示的列的顺序等。
在实现了这些之后,基于数据驱动的开发就变得可行了。
通过这样的分析后,得到了设计需要解决的问题就是之上的三个方面,只要对之上的三个方面求解成功,就可实现数据驱动的开发框架。
对三个方面分别做分析:
1、定义数据集 不可知的数据集绑定的查询语句部分交由开发人员自行完成,此处的需要的为一个统一的数据集模型。
统一的数据集模型如何形成呢,这个和数据集的使用以及维护有直接的关系,数据集的使用以及维护的需要可产生出此数据集模型。
2、使用数据集
数据集的显示
根据开发步骤,开发人员将数据集绑定至相应的表现层组件即可完成数据集的显示,这个时候在开发框架中就要实现将数据集进行展示,对于表现层组件(树、表格等)而言需要的为将数据集查询出来的数据进行展示,这个时候每个组件的需求是不同的,如树组件就需要知道数据集中数据的父子关联关系,这样才能形成树,而表格组件则比较简单,只需要按照数据行进行展示即可;表现层组件的不同点交由各表现层组件自己完成,共性的部分进行抽象构成数据集模型,表现层组件就按照数据集模型以及结合自己的一些特性来完成数据集的显示。
数据集的查询 需要提供用户自定义的查询模板,这个时候在实现角度来说要做的就是根据用户自定义的查询模板同时结合数据集绑定的查询语句组装形成新的查询语句,由查询模板中的各查询字段自行形成查询语句的block,最后在提交时将各查询语句的block进行拼装即可完成查询语句的组装工作。
数据集的统计分析
和查询有些类似,需要根据用户的统计条件并结合现有的数据集绑定的查询语句组装形成新的查询语句,将查询的结果以图形化的方式进行显示即可。
3、维护数据集
对数据集的维护进行分析,可以知道在增/删/改的时候都是对应着一个持久层对象,只是可能同时会涉及该持久层对象的关联对象的维护,这个时候最重要的就是完全得到该持久层对象的元信息(每个持久属性的名称、类型、长度、是否主键、是否唯一、是否关联属性、关联对象的名称等),在拥有了这些元信息后数据集的维护就不难了,根据这些元信息即可组装出维护的数据集的对象,将对象进行相应的持久动作(保存、更新或删除)即可。
^_^,上面说的都比较简单,只是提了一个大概的实现思路,目前我的实现是基于DWR+Spring+Hibernate,在查询方面做到了可发散式的查询,也就是比如现在查询的是用户,由于用户和组织机构关联,则可根据关联的组织机构的信息来查找这个用户,同样的道理在统计分析上也是如此,可以一直发散下去(其实原理很简单,就是根据关联对象这点)。