在上一节中我们分析了WTP TLD Content Model的关键特性,并简要介绍了WTP Content Model的整体结构。在本节中,我们将开发一个WTP TLD Content Model分析视图,帮助我们更直观的了解所谓的WTP TLD内容模型。本视图的开发和前面开发过的WTP StructuredDocument分析视图和WTP Structured Model分析视图非常类似,有些技术实现细节的分析可以参见前面相应的章节。
【需求】
1、提供一个TLD Content Model分析视图,以树状方式将当前编辑器中JSP文档对应的TLD内容模型显示出来,每个TLDDocument为一个独立节点,TLDDocument下面持有TLD Element和TLD Attribute两级子节点
2、交互(编辑器 ---> TLD Content Model分析视图):
激活 JSP编辑器,即时更新TLD Content Model分析视图
当编辑器中的内容改变时,即时更新TLD Content Model分析视图
当前激活编辑器关闭时,清空TLD Content Model分析视图内容
3、交互(TLD Content Model分析视图 ---> 编辑器)
双击视图中TLD Document节点时,打开对应的TLD定义文件
4、进一步需求,当编辑器中的光标位置变化时,即时更新TLD Content Model分析视图。(说明:在上一节中我们分析过,一个TLD Document有位置相关的特性,获取光标位置相关的TLD Document列表,也就是光标位置之前可以被识别的TLD导入^_^)
【效果预览】
1、位置无关的TLD Content Model分析效果预览 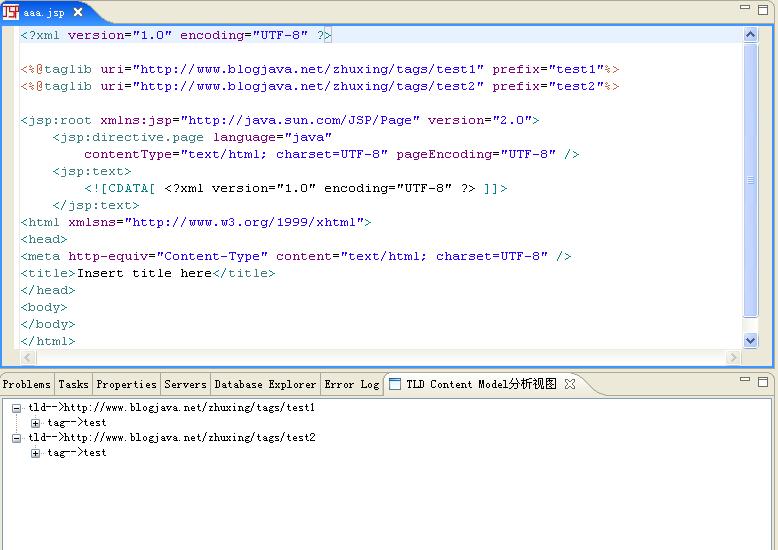
如图所示,不管光标位于编辑器中的任何位置,都会列举出所有的TLD Content Document。
2、位置相关的TLD Content Model分析效果预览
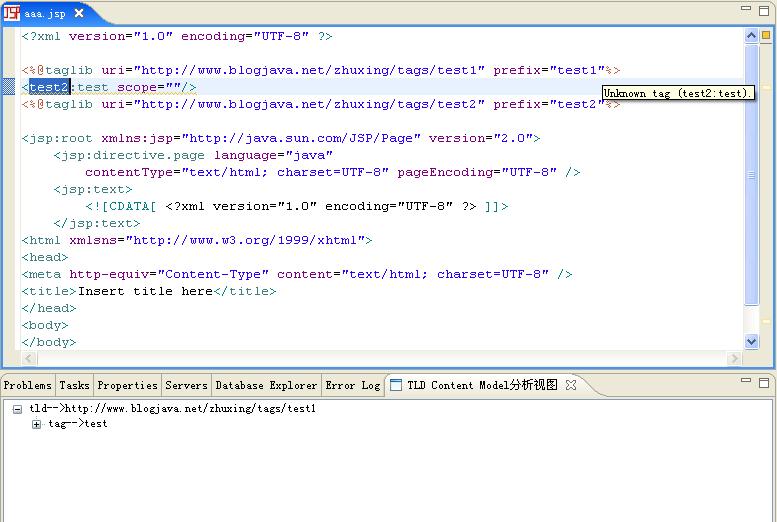
如图所示,光标位于test1 tld和test2 tld之间,这时候分析视图中只列举除了当前位置可以识别的TLD信息。在此位置,test2 tld还不能够获取到,所以使用test2中的标签会得到WTP的一个错误提示:不能识别的标签。(我想,理解了TLD Content Document位置相关的特性,也就理解了WTP中对特定标签在特定位置是否可以被识别是怎么实现的了^_^)
【实现摘要(文章后门会附上对应的源码)】
说明:有关视图实现类创建、如何利用Eclipse工作台的selection service和part service等代码实现,请参照前面章节中的两个分析视图的实现:
基于WTP开发自定义的JSP编辑器(四):Strucutured Document分析视图
基于WTP开发自定义的JSP编辑器(六):IStructuredModel(DOM Document)分析视图
1、
位置无关场景下TLD Content Document列表的获取代码:
/**
* 获取指定文档对应的TLD Content Document列表
*
* @param structuredDocument jsp structured document
* @return
*/
private TLDDocument[] getTLDDocuments(IStructuredDocument structuredDocument) {
TLDCMDocumentManager tldDocumentManager = TaglibController.getTLDCMDocumentManager(structuredDocument);
List taglibTrackers = tldDocumentManager.getTaglibTrackers();
TLDDocument[] tldDocuments = new TLDDocument[taglibTrackers.size()];
for (int i = 0; i < tldDocuments.length; i++) {
TaglibTracker taglibTracker = (TaglibTracker)taglibTrackers.get(i);
tldDocuments[i] = (TLDDocument)taglibTracker.getDocument();
}
return tldDocuments;
}
上一节中,我们阐述过taglib tracker的获取方式,TLDCMDocumentManager.getTaglibTrackers()就是位置无关的获取方式,具体细节请参见上一节中的内容。
2、
位置相关场景下TLD Content Document列表的获取代码:
/**
* 获取指定文档中特定位置对应的TLD Content Document列表
*
* @param structuredDocument jsp structured document
* @param offset 文档中的位置
* @return
*/
private TLDDocument[] getTLDDocuments(IStructuredDocument structuredDocument, int offset) {
TLDCMDocumentManager tldDocumentManager = TaglibController.getTLDCMDocumentManager(structuredDocument);
List taglibTrackers = tldDocumentManager.getCMDocumentTrackers(offset);
TLDDocument[] tldDocuments = new TLDDocument[taglibTrackers.size()];
for (int i = 0; i < tldDocuments.length; i++) {
TaglibTracker taglibTracker = (TaglibTracker)taglibTrackers.get(i);
tldDocuments[i] = (TLDDocument)taglibTracker.getDocument();
}
return tldDocuments;
}
taglib tracker列表的获取方式:TLDCMDocumentManager.getCMDocumentTrackers(int offset),位置相关。
3、
对用户选择事件的处理:
/* (non-Javadoc)
* @see org.eclipse.ui.ISelectionListener#selectionChanged(org.eclipse.ui.IWorkbenchPart, org.eclipse.jface.viewers.ISelection)
*/
public void selectionChanged(IWorkbenchPart part, ISelection selection) {
if (!(part instanceof TextEditor))
return ;
IEditorInput editorInput = ((TextEditor)part).getEditorInput();
IDocument document = ((TextEditor)part).getDocumentProvider().getDocument(editorInput);
if (!(document instanceof IStructuredDocument)) {
this.viewer.setInput(null);
return ;
}
//记录source part和source document
this.sourcePart = part;
this.sourceDocument = document;
//注册对应的document change listener
document.addDocumentListener(this.documentListener);
// //获取TLD Content Document列表(位置无关方式),并更新tree viewer输入
// TLDDocument[] tldDocuments = this.getTLDDocuments((IStructuredDocument)document);
// this.viewer.setInput(tldDocuments);
// this.viewer.expandToLevel(2);
//获取TLD Content Document列表(位置相关方式),并更新tree viewer输入
int offset = ((ITextSelection)selection).getOffset();
TLDDocument[] tldDocuments = this.getTLDDocuments((IStructuredDocument)document, offset);
this.viewer.setInput(tldDocuments);
this.viewer.expandToLevel(2);
}
在处理用户选择事件时候,根据只需要调用不同的TLD Content Document获取方式(1、2点中阐述的)就可以了^_^。
4、
视图中TLD Document节点的双击事件的处理:
//添加双击支持
this.viewer.addDoubleClickListener(new IDoubleClickListener() {
public void doubleClick(DoubleClickEvent event) {
ITreeSelection treeSelection = (ITreeSelection)event.getSelection();
Object selectedElement = treeSelection.getFirstElement();
if (!(selectedElement instanceof TLDDocument))
return ;
//获取TLD Document对应的TLD文件
String baseLocation = ((TLDDocument)selectedElement).getBaseLocation();
IFile file = ResourcesPlugin.getWorkspace().getRoot().getFileForLocation(new Path(baseLocation));
if (!file.exists())
return ;
//打开TLD定义文件
try {
IWorkbenchPage page = PlatformUI.getWorkbench().getActiveWorkbenchWindow().getActivePage();
IDE.openEditor(page, file);
} catch (PartInitException e) {
IStatus status = new Status(IStatus.ERROR, "wtp.tldcontentdocument", 1111, "打开TLD定义文件失败", e);
Activator.getDefault().getLog().log(status);
}
}
});
主要步骤如下:
1、利用TLDDocument接口中的getBaseLocation获取该TLDDocument对应的页面资源的绝对路径信息
2、定位工作区中对应的TLD资源文件,打开
5、
视图tree viewer对应的content provider:
/* (non-Javadoc)
* @see org.eclipse.jface.viewers.ITreeContentProvider#getChildren(java.lang.Object)
*/
public Object[] getChildren(Object parentElement) {
if (parentElement == null)
return new Object[0];
if (parentElement instanceof TLDDocument[])
return (TLDDocument[])parentElement;
//如果是tld content document, 则获取对应的tld element列表
if (parentElement instanceof TLDDocument) {
CMNamedNodeMap tagMap = ((TLDDocument)parentElement).getElements();
Object[] children = new Object[tagMap.getLength()];
for (int i = 0; i < children.length; i++) {
children[i] = tagMap.item(i);
}
return children;
}
//如果是tld element(tag),则获取对应的attrbute列表
if (parentElement instanceof TLDElementDeclaration) {
CMNamedNodeMap attributeMap = ((TLDElementDeclaration)parentElement).getAttributes();
Object[] children = new Object[attributeMap.getLength()];
for (int i = 0; i < children.length; i++) {
children[i] = attributeMap.item(i);
}
return children;
}
return new Object[0];
}
如果输入是tld content document(TLDDocument),则获取对应的tld element列表,也就是tld中定义的tag列表;如果输入是tld element(TLDElementDeclaration),则获取对应的tld attribute列表,也就是特定tag下面定义的标签属性列表。
其他具体代码实现细节,参见附件中的源码。^_^
【后记】
本插件工程需要依赖的插件列表为:
org.eclipse.ui,
org.eclipse.core.runtime,
org.eclipse.jface.text,
org.eclipse.ui.editors,
org.eclipse.ui.workbench.texteditor,
org.eclipse.wst.sse.core,
org.eclipse.jst.jsp.core,
org.eclipse.wst.xml.core,
org.eclipse.core.resources,
org.eclipse.ui.ide
源码为实际工程以Export ---> Archive File方式导出的,
下载链接:
TLD Content Model分析视图源码
本博客中的所有文章、随笔除了标题中含有引用或者转载字样的,其他均为原创。转载请注明出处,谢谢!