
2006年6月2日
Question:
The restore command works fine, but while attempting the rolforward of the sql logs, it complains about database falling short on bufferpool,and then terminates the rollforward process. One close look at the db2diag.log file, I noticed that db2 tried to start the database with the hidden bufferpool. But, apparently, that hidden bufferpool was pretty small to rollforward the logs and bring it online.
I cannot reduce the bufferpool size as the database cannot be connected to.I cannot connect to the database as it is in rollforward pending state. I cannot rollforward the database, as it's not happy with the size of the *hidden* bufferpool and terminates.
Answer:
db2set DB2_OVERRIDE_BPF=50000
This will bring up all configured bufferpools using 50000 pages each. You
can choose a smaller/larger value that is suitable for your number of
bufferpools and available system memory. You can also configure each
bufferpool individually if you want
値: 正数のページ数
OR
<entry>[;<entry>...] (<entry>=<バッファー・プール ID>,<ページ数> )
There is sitiuation that above solution does not work.
When you try to create a bufferpool or alter a bufferpool to a
very large size and there is not enough memory in the system
, DB2 may occupies all pagespace and overrall performance of
the system become slow and may get hang at last because no
pagespace is available. Then after you connect the database
next time, DB2 will do crash recovery and still try to
allocate memory for this big bufferpool and occupy all
pagespace again. when you specify DB2_OVERRIDE_BPF parameter
to override bufferpool size, it doesn't take effect in this
situation. This is becasue DB2_OVERRIDE_BPF only applies for
bufferpools that already exist at startup, and not to
bufferpools that are created during crash recovery or roll
forward. We will fix this problem and check DB2_OVERRIDE_BPF
registry when creating bufferpools during crash recovery or
roll forward. This problem only occurs in a 64 bit instance.
Local fix
You can use db2iupdt -w 32 <INSTNAME> to update the instance to
a 32 bit instance, then you can connect to the database
succefully. After that, use db2iupdt -w 64 <INSTNAME> to update
the instance to 64 bit again. Please take a backup at this
point, so we don't have to roll forward through bufferpool
creation that fails if we need restore and roll forward
database.
Problem summary
Users Affected:
All users using 64 bit instance
Problem Description:
When you try to create a bufferpool or alter a bufferpool to a
very large size and there is not enough memory in the system
, DB2 may occupies all pagespace and overrall performance
of the system become slow and may get hang at last
because no pagespace is available. Then after you connect the
database at next time, DB2 will do crash recovery and still try
to allocate
memory for this big bufferpool and occupy all pagespace again.
In this situation, when you specify DB2_OVERRIDE_BPF parameter
to override bufferpool size, it doesn't take effect in this
situation. This
is becasue DB2_OVERRIDE_BPF only applies for bufferpools that
already exist at startup, and not to bufferpools that are
created during crash recovery or roll forward. We will fix
this problem and check
DB2_OVERRIDE_BPF registry when creating bufferpools during crash
recovery or roll forward. This problem only occurs in 64 bit
instance.
Problem Summary:
This problem is caused by a misoperation, when you create or alt
er a bufferpool, the size is too large to allocated from OS and
cause overrall performance of the system is very slow and seems
hang. Another problem is that DB2_OVERRIDE_BPF registry only app
lies to bufferpools that already exists, and not bufferpools wil
l be created in crash recovery or roll forward. So DB2 will try
to create this big bufferpool again when doing crash recovery or
roll forward. We will fix this problem and check DB2_OVERRIDE_B
PF registry in our crash recovery and roll forward code.
Problem conclusion
Temporary fix
You can use db2iupdt -w 32 <INSTNAME> to update the instance to
a 32 bit instance, then you can connect to the database
succefully. After that, use db2iupdt -w 64 <INSTNAME> to update
the instance to 64 bit again. Please take a backup at this
point, so we don't have to roll forward through bufferpool
creation that fails if we need restore and roll
forward database.Please also notice that be careful when creati
ng bufferpool, don't specify a too large value.
posted @
2007-03-15 15:21 MyJavaWorld 阅读(774) |
评论 (0) |
编辑 收藏DB2 depends on operation system level authorization to control DB2 system access.In some case, our db2...
DB2 depends on operation system level authorization to control DB2 system access.
In some case, our db2 account only allows to connect to instance or database, but not log on the system. In other words, we are not able to use the account to get a shell on unix or logon locally on windows.
As usual, when we need to change db2 password, we take action on the system level because it's more frank. But in the case above that we can't get logon, we have to do it on db2 level. There are 2 ways.
- Use the GUI tool DB2 Configuration Assistance
- Use the command line tools DB2 CLP or CE
Using DB2 Configuration Assistance
Right click on a database name, then choose "Change password".

Note: When more than one databases live in same system, we might share the same account in multi-database. Changing password for one of them will affect all databases in this system. In other words, we don't need to do the change on each database, we could choose any we have privileges on the system.
Limitation: We are not able to change our password in the case of that we are only allowed to attach to the node but not connect to any database, or we don't get the catalog information for any database in the node.
For this limitation, it works out with the 2nd way.
Using DB2 CLP and CE
We could use CLP and CE to change password for databases and nodes that we connected or attached to.
- Change by connecting to database
C:\> db2 connect to SAMPLE user TEST using OLDPWD new NEWPWD confirm NEWPWD
C:\> db2 connect to SAMPLE user TEST using OLDPWD change password
- Change by attaching to node, this way works out for the limitation in Configuration Assistance
C:\> db2 attach to NODE user TEST using OLDPWD new NEWPWD confirm NEWPWD
C:\> db2 attach to NODE user TEST using OLDPWD change password
There's an object called index view since MS SQL Server 2000, it's an index which is...
There's an object called index view since MS SQL Server 2000, it's an index which is created on an view which is based on a local table. it is attent to imporve the select performence on the view when this view is based on multi-table and has complex logic.
I try to find a simular thing in DB2, but there's no the simular solution in DB2 v8.2 for now. Instead, I found another thing instested.
DB2 allows creating index on the tables or views in remote data source, such as a database on another host or an XML data source. To be exactly, that's Not true Index, it's Index Specification. It requests that the tables in remote data source have created index in its own system. And it only repeat the index description in local system.
Local DB2 Env Remote DB2 Env
Index Specification -> Nickname - - -> True Index -> Table
See following example in DB2 info center.
-
CREATE INDEX statement
http://publib.boulder.ibm.com/infocenter/db2luw/v8//topic/com.ibm.db2.udb.doc/admin/r0000919.htm?resultof=%22%63%72%65%61%74%65%22%20%22%63%72%65%61%74%22%20%22%69%6e%64%65%78%22%20%22%73%74%61%74%65%6d%65%6e%74%22%20
Example 3: The nickname EMPLOYEE references a data source table called CURRENT_EMP. After this nickname was created, an index was defined on CURRENT_EMP. The columns chosen for the index key were WORKDEBT and JOB. Create an index specificationindex. Through this specification, the optimizer will know that the index exists and what its key is. With this information, the optimizer can improve its strategy to access the table. that describes this
CREATE UNIQUE INDEX JOB_BY_DEPT
ON EMPLOYEE (WORKDEPT, JOB)
SPECIFICATION ONLY
Note: the Nickname is only allowed to be created on tables in local database and on much kind of objects at remote data source. It's not allowed to be created on views in local database.
posted @
2007-03-15 15:00 MyJavaWorld 阅读(567) |
评论 (0) |
编辑 收藏
三个UNIX文件时间ctime、mtime、atime
我曾经根据文件的状态在指定时间内是否改变写过一个WatchDog来对服务进行监控,其间曾被这三个时间搞混淆,所以觉得很有必要和大家分享我对这三个术语的理解。
ctime(change time)改变时间:是指文件状态最后一次被改变的时间;
mtime(modification time)修改时间:是指文件内容最后一次被改变的时间;
atime(access time)访问时间:是指文件最后一次被读取的时间。
前两者的区别就在于文件状态的改变既包括文件索引节点的改变,也包括文件内容的改变。也就是说如果你改变了文件内容,则同时更新了ctime和mtime,但是如果你只改变了文件索引节点则只是改变了ctime。atime只有在文件被读取的时侯才会改变。它的改变与文件状态以及文件内容的改变没有直接的联系。
例如:echo “Hello World” >> myfile 则同时改变了ctime和mtime,atime不变;
chmod u+x myfile 则只改变了ctime,mtime和atime不变。
cat myfile,则只改变了atime,ctime和mtime不变
ps:以上操作均在redhat linux下验证通过
posted @
2007-03-13 17:51 MyJavaWorld 阅读(1207) |
评论 (0) |
编辑 收藏
DB2/SQL命令大全
2006-12-25 13:21
连接数据库:
connect to [数据库名] user [操作用户名] using [密码]
创建缓冲池(8K):
create bufferpool ibmdefault8k IMMEDIATE SIZE 5000 PAGESIZE 8 K ;
创建缓冲池(16K)(OA_DIVERTASKRECORD):
create bufferpool ibmdefault16k IMMEDIATE SIZE 5000 PAGESIZE 16 K ;
创建缓冲池(32K)(OA_TASK):
create bufferpool ibmdefault32k IMMEDIATE SIZE 5000 PAGESIZE 32 K ;
创建表空间:
CREATE TABLESPACE exoatbs IN DATABASE PARTITION GROUP IBMDEFAULTGROUP PAGESIZE 8K MANAGED BY SYSTEM USING ('/home/exoa2/exoacontainer') EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT8K OVERHEAD 24.10 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
CREATE TABLESPACE exoatbs16k IN DATABASE PARTITION GROUP IBMDEFAULTGROUP PAGESIZE 16K MANAGED BY SYSTEM USING ('/home/exoa2/exoacontainer16k' ) EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT16K OVERHEAD 24.1 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
CREATE TABLESPACE exoatbs32k IN DATABASE PARTITION GROUP IBMDEFAULTGROUP PAGESIZE 32K MANAGED BY SYSTEM USING ('/home/exoa2/exoacontainer32k' ) EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT32K OVERHEAD 24.1 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
GRANT USE OF TABLESPACE exoatbs TO PUBLIC;
GRANT USE OF TABLESPACE exoatbs16k TO PUBLIC;
GRANT USE OF TABLESPACE exoatbs32k TO PUBLIC;
创建系统表空间:
CREATE TEMPORARY TABLESPACE exoasystmp IN DATABASE PARTITION GROUP IBMTEMPGROUP PAGESIZE 8K MANAGED BY SYSTEM USING ('/home/exoa2/exoasystmp' ) EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT8K OVERHEAD 24.10 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
CREATE TEMPORARY TABLESPACE exoasystmp16k IN DATABASE PARTITION GROUP IBMTEMPGROUP PAGESIZE 16K MANAGED BY SYSTEM USING ('/home/exoa2/exoasystmp16k' ) EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT16K OVERHEAD 24.10 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
CREATE TEMPORARY TABLESPACE exoasystmp32k IN DATABASE PARTITION GROUP IBMTEMPGROUP PAGESIZE 32K MANAGED BY SYSTEM USING ('/home/exoa2/exoasystmp32k') EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT32K OVERHEAD 24.10 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
1. 启动实例(db2inst1):
db2start
2. 停止实例(db2inst1):
db2stop
3. 列出所有实例(db2inst1)
db2ilist
5.列出当前实例:
db2 get instance
4. 察看示例配置文件:
db2 get dbm cfg|more
5. 更新数据库管理器参数信息:
db2 update dbm cfg using para_name para_value
6. 创建数据库:
db2 create db test
7. 察看数据库配置参数信息
db2 get db cfg for test|more
8. 更新数据库参数配置信息
db2 update db cfg for test using para_name para_value
10.删除数据库:
db2 drop db test
11.连接数据库
db2 connect to test
12.列出所有表空间的详细信息。
db2 list tablespaces show detail
13.查询数据:
db2 select * from tb1
14.删除数据:
db2 delete from tb1 where id=1
15.创建索引:
db2 create index idx1 on tb1(id);
16.创建视图:
db2 create view view1 as select id from tb1
17.查询视图:
db2 select * from view1
18.节点编目
db2 catalog tcp node node_name remote server_ip server server_port
19.察看端口号
db2 get dbm cfg|grep SVCENAME
20.测试节点的附接
db2 attach to node_name
21.察看本地节点
db2 list node direcotry
22.节点反编目
db2 uncatalog node node_name
23.数据库编目
db2 catalog db db_name as db_alias at node node_name
24.察看数据库的编目
db2 list db directory
25.连接数据库
db2 connect to db_alias user user_name using user_password
26.数据库反编目
db2 uncatalog db db_alias
27.导出数据
db2 export to myfile of ixf messages msg select * from tb1
28.导入数据
db2 import from myfile of ixf messages msg replace into tb1
29.导出数据库的所有表数据
db2move test export
30.生成数据库的定义
db2look -d db_alias -a -e -m -l -x -f -o db2look.sql
31.创建数据库
db2 create db test1
32.生成定义
db2 -tvf db2look.sql
33.导入数据库所有的数据
db2move db_alias import
34.重组检查
db2 reorgchk
35.重组表tb1
db2 reorg table tb1
36.更新统计信息
db2 runstats on table tb1
37.备份数据库test
db2 backup db test
38.恢复数据库test
db2 restore db test
399\.列出容器的信息
db2 list tablespace containers for tbs_id show detail
40.创建表:
db2 ceate table tb1(id integer not null,name char(10))
41.列出所有表
db2 list tables
42.插入数据:
db2 insert into tb1 values(1,’sam’);
db2 insert into tb2 values(2,’smitty’);
. 建立数据库DB2_GCB
CREATE DATABASE DB2_GCB ON G: ALIAS DB2_GCB
USING CODESET GBK TERRITORY CN COLLATE USING SYSTEM DFT_EXTENT_SZ 32
2. 连接数据库
connect to sample1 user db2admin using 8301206
3. 建立别名
create alias db2admin.tables for sysstat.tables;
CREATE ALIAS DB2ADMIN.VIEWS FOR SYSCAT.VIEWS
create alias db2admin.columns for syscat.columns;
create alias guest.columns for syscat.columns;
4. 建立表
create table zjt_tables as
(select * from tables) definition only;
create table zjt_views as
(select * from views) definition only;
5. 插入记录
insert into zjt_tables select * from tables;
insert into zjt_views select * from views;
6. 建立视图
create view V_zjt_tables as select tabschema,tabname from zjt_tables;
7. 建立触发器
CREATE TRIGGER zjt_tables_del
AFTER DELETE ON zjt_tables
REFERENCING OLD AS O
FOR EACH ROW MODE DB2SQL
Insert into zjt_tables1 values(substr(o.tabschema,1,8),substr(o.tabname,1,10))
8. 建立唯一性索引
CREATE UNIQUE INDEX I_ztables_tabname
[size=3]ON zjt_tables(tabname);
9. 查看表
select tabname from tables
where tabname='ZJT_TABLES';
10. 查看列
select SUBSTR(COLNAME,1,20) as 列名,TYPENAME as 类型,LENGTH as 长度
from columns
where tabname='ZJT_TABLES';
11. 查看表结构
db2 describe table user1.department
db2 describe select * from user.tables
12. 查看表的索引
db2 describe indexes for table user1.department
13. 查看视图
select viewname from views
where viewname='V_ZJT_TABLES';
14. 查看索引
select indname from indexes
where indname='I_ZTABLES_TABNAME';
15. 查看存贮过程
SELECT SUBSTR(PROCSCHEMA,1,15),SUBSTR(PROCNAME,1,15)
FROM SYSCAT.PROCEDURES;
16. 类型转换(cast)
ip datatype:varchar
select cast(ip as integer)+50 from log_comm_failed
17. 重新连接
connect reset
18. 中断数据库连接
disconnect db2_gcb
19. view application
LIST APPLICATION;
20. kill application
FORCE APPLICATION(0);
db2 force applications all (强迫所有应用程序从数据库断开)
21. lock table
lock table test in exclusive mode
22. 共享
lock table test in share mode
23. 显示当前用户所有表
list tables
24. 列出所有的系统表
list tables for system
25. 显示当前活动数据库
list active databases
26. 查看命令选项
list command options
27. 系统数据库目录
LIST DATABASE DIRECTORY
28. 表空间
list tablespaces
29. 表空间容器
LIST TABLESPACE CONTAINERS FOR
Example: LIST TABLESPACE CONTAINERS FOR 1
30. 显示用户数据库的存取权限
GET AUTHORIZATIONS
31. 启动实例
DB2START
32. 停止实例
db2stop
33. 表或视图特权
grant select,delete,insert,update on tables to user
grant all on tables to user WITH GRANT OPTION
34. 程序包特权
GRANT EXECUTE
ON PACKAGE PACKAGE-name
TO PUBLIC
35. 模式特权
GRANT CREATEIN ON SCHEMA SCHEMA-name TO USER
36. 数据库特权
grant connect,createtab,dbadm on database to user
37. 索引特权
grant control on index index-name to user
38. 信息帮助 (? XXXnnnnn )
例:? SQL30081
39. SQL 帮助(说明 SQL 语句的语法)
help statement
例如,help SELECT
40. SQLSTATE 帮助(说明 SQL 的状态和类别代码)
? sqlstate 或 ? class-code
41. 更改与"管理服务器"相关的口令
db2admin setid username password
42. 创建 SAMPLE 数据库
db2sampl
db2sampl F:(指定安装盘)
43. 使用操作系统命令
! dir
44. 转换数据类型 (cast)
SELECT EMPNO, CAST(RESUME AS VARCHAR(370))
FROM EMP_RESUME
WHERE RESUME_FORMAT = 'ascii'
45. UDF
要运行 DB2 Java 存储过程或 UDF,还需要更新服务器上的 DB2 数据库管理程序配置,以包括在该机器上安装 JDK 的路径
db2 update dbm cfg using JDK11_PATH d:sqllibjavajdk
TERMINATE
update dbm cfg using SPM_NAME sample
46. 检查 DB2 数据库管理程序配置
db2 get dbm cfg
47. 检索具有特权的所有授权名
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'DATABASE' FROM SYSCAT.DBAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'TABLE ' FROM SYSCAT.TABAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'PACKAGE ' FROM SYSCAT.PACKAGEAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'INDEX ' FROM SYSCAT.INDEXAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'COLUMN ' FROM SYSCAT.COLAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'SCHEMA ' FROM SYSCAT.SCHEMAAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'SERVER ' FROM SYSCAT.PASSTHRUAUTH
ORDER BY GRANTEE, GRANTEETYPE, 3
create table yhdab
(id varchar(10),
password varchar(10),
ywlx varchar(10),
kh varchar(10));
create table ywlbb
(ywlbbh varchar(8),
ywmc varchar(60))
48. 修改表结构
alter table yhdab ALTER kh SET DATA TYPE varchar(13);
alter table yhdab ALTER ID SET DATA TYPE varchar(13);
alter table lst_bsi alter bsi_money set data type int;
insert into yhdab values
('20000300001','123456','user01','20000300001'),
('20000300002','123456','user02','20000300002');
49. 业务类型说明
insert into ywlbb values
('user01','业务申请'),
('user02','业务撤消'),
('user03','费用查询'),
('user04','费用自缴'),
('user05','费用预存'),
('user06','密码修改'),
('user07','发票打印'),
('gl01','改用户基本信息'),
('gl02','更改支付信息'),
('gl03','日统计功能'),
('gl04','冲帐功能'),
('gl05','对帐功能'),
('gl06','计费功能'),
('gl07','综合统计')
备份数据库:
CONNECT TO EXOA;
QUIESCE DATABASE IMMEDIATE FORCE CONNECTIONS;
CONNECT RESET;
BACKUP DATABASE EXOA TO "/home/exoa2/db2bak/" WITH 2 BUFFERS BUFFER 1024 PARALLELISM 1 WITHOUT PROMPTING;
CONNECT TO EXOA;
UNQUIESCE DATABASE;
CONNECT RESET;
以下是小弟在使用db2move中的一些经验,希望对大家有所帮助。
db2 connect to YOURDB
连接数据库
db2look -d YOURDB -a -e -x -o creatab.sql
导出建库表的SQL
db2move YOURDB export
用db2move将数据备份出来
vi creatab.sql
如要导入的数据库名与原数据库不同,要修改creatab.sql中CONNECT 项
如相同则不用更改
db2move NEWDB load
将数据导入新库中
在导入中可能因为种种原因发生中断,会使数据库暂挂
db2 list tablespaces show detail
如:
详细说明:
装入暂挂
总页数 = 1652
可用页数 = 1652
已用页数 = 1652
空闲页数 = 不适用
高水位标记(页) = 不适用
页大小(字节) = 4096
盘区大小(页) = 32
预读取大小(页) = 32
容器数 = 1
状态更改表空间标识 = 2
状态更改对象标识 = 59
db2 select tabname,tableid from syscat.tables where tableid=59
查看是哪张表挂起
表名知道后到db2move.lst(在db2move YOURDB export的目录中)中找到相应的.ixf文件
db2 load from tab11.ixf of ixf terminate into db2admin.xxxxxxxxx
tab11.ixf对应的是xxxxxxxxx表
数据库会恢复正常,可再用db2 list tablespaces show detail查看
30.不能通过GRANT授权的权限有哪种?
SYSAM
SYSCTRL
SYSMAINT
要更该述权限必须修改数据库管理器配置参数
31.表的类型有哪些?
永久表(基表)
临时表(说明表)
临时表(派生表)
32.如何知道一个用户有多少表?
SELECT*FROMSYSIBM.SYSTABLESWHERECREATOR='USER'
33.如何知道用户下的函数?
select*fromIWH.USERFUNCTION
select*fromsysibm.SYSFUNCTIONS
34.如何知道用户下的VIEW数?
select*fromsysibm.sysviewsWHERECREATOR='USER'
35.如何知道当前DB2的版本?
select*fromsysibm.sysvERSIONS
36.如何知道用户下的TRIGGER数?
select*fromsysibm.SYSTRIGGERSWHERESCHEMA='USER'
37.如何知道TABLESPACE的状况?
select*fromsysibm.SYSTABLESPACES
38.如何知道SEQUENCE的状况?
select*fromsysibm.SYSSEQUENCES
39.如何知道SCHEMA的状况?
select*fromsysibm.SYSSCHEMATA
40.如何知道INDEX的状况?
select*fromsysibm.SYSINDEXES
41.如何知道表的字段的状况?
select*fromsysibm.SYSCOLUMNSWHERETBNAME='AAAA'
42.如何知道DB2的数据类型?
select*fromsysibm.SYSDATATYPES
43.如何知道BUFFERPOOLS状况?
select*fromsysibm.SYSBUFFERPOOLS
44.DB2表的字段的修改限制?
只能修改VARCHAR2类型的并且只能增加不能减少.
45.如何查看表的结构?
DESCRIBLETABLETABLE_NAME
OR
DESCRIBLESELECT*FROMSCHEMA.TABLE_NAME
|
posted @
2006-12-28 16:57 MyJavaWorld 阅读(2812) |
评论 (0) |
编辑 收藏
DB2 UDB中用户出口程序是如何工作的?
采用用户出口程序与DB2 UDB共同工作背后的基本思想是提供一种归档和检索数据库日志文件的方法以实现日志冗余处理并从易失性介质上转储出来。重要的,值得注意的是,根据你的特殊需求,在用户出口程序当中,除了能实现归档和检索日志之外,你还可以实现其他的操作。
如果一个数据库需要采用归档日志文件来进行恢复,在DB2 UDB中实行用户出口程序策略将不能恢复100%的事务。用户出口程序只是一种通过拷贝已经存在的日志文件到一个安全的地方来为其提供更多保护的方法。它是数据完整性策略中的一部分,而且是重要的一部分。
编译了用户出口程序之后,可执行程序db2uext2被放置在数据库管理器可以找到的目录当中。在UNIX©中,这个目录是/sqllib/adm;在Windows©中,是Program FilesIBMSQLLIBBIN。
除非数据库管理器知道用户出口程序是可用的,不然它不会调用db2uext2。让数据库管理器知道db2uext2可以被调用的唯一方法是将数据库配置参数userexit设置为on。一旦这个参数被设定好而且DB2实例被重复利用了,数据库管理器将每五分钟调用一次用户出口程序来检查那些可以被归档到程序相关的归档目录的日志文件。
如果数据库的恢复是必要的,在前滚操作期间,数据库管理器将调用db2uext2把归档日志文件拷贝回活动的日志目录当中。然后,日志文件被再次运用到重建的数据库中。
让我们看看被数据库管理器生成的到用户出口程序的调用的格式。注意,这一信息也可以在用户出口示例程序的注释部分找到。
db2uext2 -OS -RL
-RQ -DB -NN
-LP -LN [-AP]
其中:
os=操作系统
release=DB2发行版本
request= 'ARCHIVE' 或 'RETRIEVE'
dbname=数据库名
nodenumber=节点号
logpath=日志文件目录
logname=日志文件名
logsize=日志文件大小(可选)
startingpage=以4k页为单位的起始偏移量(可选)
adsmpasswd=ADSM密码(可选)
注意:只有当logpath为裸设备时才使用logsize和startingpage。
归档或者从磁盘检索日志文件遵从以下命名规则:
归档:归档路径+数据库名+节点号+日志文件名
检索:检索路径+数据库名+节点号+日志文件名
比如:如果归档的路径为”c:mylogs”,
检索路径是“c:mylogs”,
数据库名是“SAMPLE”,
节点号是 NODE0000,
文件名是 S0000001.LOG,
日志文件将是:
归档到 - c:mylogsSAMPLENODE0000S0000001.LOG
检索自 - c:mylogsSAMPLENODE0000S0000001.LOG
以下描述了用户出口程序中的逻辑是如何运转的:
1) 安装信号处理程序。
2) 验证传递的参数个数。
3) 验证操作请求。
4) 开始审计跟踪(如果有此请求)。
5) 根据操作需求的不同获取以下路径中的一个:
a) 如果操作需求为归档一个文件,将日志文件从日志路径拷贝到归档路径中。
i) 如果没有找到日志文件,执行第6点。
b) 如果操作需求是检索一个文件,将日志文件从检索路径拷贝到日志路径中。
i) 如果没有找到日志文件,执行第6点。
6) 将错误记入日志(如果要求或者有需要的话)。
7) 结束审计跟踪(如果有请求)。
8) 以适当的返回码退出。
手工调用用户出口程序来归档日志文件是可以的,但最好还是使用ARCHIVE LOG命令以便在定义以上参数时不会因为你的原因导致错误。在这篇文章的末尾,可以找到关于ARCHIVE LOG命令的链接。
日志文件术语
DB2 中用户出口程序的基本功能是将日志文件拷贝到活动日志目录或反之。这里,值得指出一些术语来阐明活动的日志目录被置于何处以及数据库日志文件的状态如何。
活动日志目录:
该目录被置于你的数据库目录中。在Windows中,如果在C:中创建了一个叫做SAMPLE的单一数据库且实例名为db2inst1,则将会出现以下的目录结构:
C:DB2INST1NODE0000SQL000001SQLOGDIR
SQL00001是SAMPLE数据库的数据库目录,SQLOGDIR 是活动日志目录。
以下的图1显示了Windows操作系统上的活动日志目录:
PATH o:extrusionok="f" gradientshapeok="t" o:connecttype="rect" />SHAPE id=_x0000_i1025 style="WIDTH: 299.25pt; HEIGHT: 180.75pt" type="#_x0000_t75" />/P>
图 1活动日志目录
日志文件状态
在活动日志目录中,日志文件可以是活动日志,也可以是联机归档日志。活动日志是那些被 DB2 用于当前事务处理和崩溃恢复的日志。联机归档日志是那些 DB2 UDB 进行常规处理时不再需要,而进行数据库恢复时可能还会需要的日志。当实现用户出口程序时,这些联机归档日志将最终以归档日志目录中的副本形式出现。
既然 DB2 UDB 中用户出口程序的目的是将数据库日志拷贝到归档目录中,你将最终在活动日志目录(缺省为 SQLOGDIR)中得到重复的日志文件。你可能考虑删除这些重复的联机归档日志以释放文件系统空间。在从数据库目录中除去这些日志之前,要十分小心地确认它们是否已经将成功地被复制到归档目录中。还必须确保数据库管理器进行崩溃恢复时不再需要它们。要确定你的活动日志目录中哪些日志文件不为正常处理所需要,可用通过以下命令检查数据库配置:
db2 "get db cfg for sample"
这条命令的数据库配置输出结果将包含第一个活动日志文件,如:
First active log file = S000009.LOG
在如上所示的输出当中,日志文件S000009.LOG是数据库当前的活动日志。任何编号比该日志文件小的日志文件都被看作联机归档日志。
这里有一个例子:
在这个场景中,活动日志目录中有日志文件 S000000.LOG - S000009.LOG,归档日志目录中有 S000000.LOG - S000008.LOG。因为 S000009.LOG 是第一个活动日志文件,所以,可以从活动日志目录中移走 S000001.LOG - S000008.LOG 以释放磁盘空间。S000009.LOG 文件必须保留在活动日志目录中,因为它仍然被当前事务使用。
同样可以通过检查数据库历史文件来查看活动日志目录中哪些日志文件不再有用。以下命令将列出数据库备份信息:
db2 "list history backup all for database sample"
以下是该命令的输出结果的一个例子:
List History File for sample
Number of matching file entries = 4
Op Obj Timestamp+Sequence Type Dev Earliest Log Current Log
-- --- ------------------ ---- --- ------------------------
B D 20030416162026001 F D S0000010.LOGS0000014.LOG
------------------------------------------------------------
Contains 2 tablespace(s):
00001 SYSCATSPACE
00002 USERSPACE1
------------------------------------------------------------
在上面的输出中,最早的日志将表示,需要 S0000010.LOG 及其之后的任何日志。 S00000010.LOG 之前的任何日志可以被安全的删除。再次提醒,在从活动日志目录中删除日志文件之前,验证在活动日志目录中存在这些日志文件的拷贝是十分重要的。
虽然可以手动的从活动日志目录中删除日志文件,删除联机归档日志文件的安全方法是通过prune logfile命令。该命令可以用来删除活动归档目录中的日志文件。在下面的示例中,以下命令将删除日志文件 S000000.LOG - S000008.LOG:
db2 "prune logfile prior to S000009.LOG"
注意:根据您的恢复策略,可能会出现之前的前滚操作在数据库上执行的场景。归档目录中的老日志文件可能被同名的新日志文件所覆盖,从而阻止你使用旧日志文件对数据库进行时间点恢复。对用户出口程序的设计程序员来说,考虑类似这样的情况是很重要的。
设置用户出口
在本文中,我们将采用DB2提供的db2uext2.cdisk样例c程序,它位于你的c目录当中。在UNIX中,c目录位于/sqllib/samples。Windows中,这目录位于Program Files/IBM//samples。
在Windows中设置用户出口
修改和编译用户出口程序
1. 创建名为C:mylogs的目录
2. 将C:Program filesIBMSQLLIBsamplescdb2uext2.cdisk拷贝到一个工作目录当中
3. 对于本示例,用户出口程序的以下部分应该得以验证以反映路径 c:\mylogs\
#define ARCHIVE_PATH "c:\mylogs\"
#define RETRIEVE_PATH "c:\mylogs\"
#define AUDIT_ACTIVE 1 /* enable audit trail logging */
#define ERROR_ACTIVE 1 /* enable error trail logging */
#define AUDIT_ERROR_PATH "c:\mylogs\"
/* path must end with a slash */
#define AUDIT_ERROR_ATTR "a" /* append to text file */
#define BUFFER_SIZE 32
/* # of 4K pages for output buffer */
4. 确定在你的系统中安装了被支持的C编译器(比如,Microsoft Visual Studio)而且环境中有该编译器的路径。
5. 通过命令行,将db2uext2.cdisk更名为db2uext2.c并构建:
cl db2uext2.c
一旦程序被编译,将创建db2uext2.exe和db2uext2.obj文件。
6. 将可执行文件db2uext2.exe放到/SQLLIB/BIN目录当中从而使数据库管理器能够定位并执行它用以归档和检索日志。
为用户出口创建并准备数据库
7. 在 DB2 命令窗口中用 db2sampl 命令创建 SAMPLE 数据库。这将使你对下面的示例使用样本表。
db2sampl
8. 更新数据库配置文件以便为数据库打开用户出口。请注意:只能为一个数据库分配用户出口程序,因为 bin 目录被所有 DB2 实例共享。
db2 "update db cfg for sample using userexit on"
db2stop force
<span lang="EN-US" style="FONT-SIZE: 10pt; COLOR: black; FONT-FAMILY: 宋体; mso-hansi-font-family: 'Times New Roman'; mso-bidi-font-family: 宋体; mso-
/P>
posted @
2006-12-08 18:12 MyJavaWorld 阅读(458) |
评论 (0) |
编辑 收藏
其实主要的就是要创建一个密钥仓库以管理您的公钥
/
私钥对来自您所信任实体的证书。
第一步:生成密钥对
您首先要做的是创建一个密钥仓库和生成密钥对。您可以使用以下命令:
keytool -genkey -keyalg RSA -keysize 512 -dname "cn=hyq,o=eagle,c=cn" -alias weblogic -keypass 123456 -keystore C:/mykeystore/weblogic.jks -storepass 123456 -validity 365
(请注意:键入该命令时必须使其成为一行。此处用多行来显示,主要是为了可读性。)如下图:
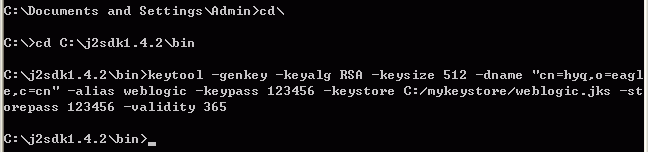

该命令将在
C
盘的
“mykeystore”
目录中创建名为
“weblogic.jks”
的密钥仓库,并赋予它口令
“
123456
”
。它将为实体生成公钥
/
私钥对,该实体的
“
特征名
”
为:常用名
“hyq”
、组织
“eagle”
和两个字母的国家代码
“cn”
。“
-keyalg
”指定它使用的是那种密钥生成算法来创建密钥,缺省的是
“DSA”
密钥生成算法(会使用缺省的
“
带
DSA
的
SHA1”
签名算法),两个密钥(公钥与私钥)的长度是
512
位,由
-keysize
来指定,默认的是
1024
位。
该证书包括公钥和特征名信息。该证书的有效期为
365
天,由
-validity
来指定,且与别名
“business”
所代表的密钥仓库项关联。私钥被赋予口令
“
123456
”
。
命令行里
DName
信息注解
|
DN
信息域
|
含义
|
|
CN
|
域名或
IP
|
|
OU
|
部门,没有部门的可不要此项
|
|
O
|
单位名称
|
|
L
|
单位地址
|
|
S
|
省份的拼音(第一个字母大写)
|
|
C
|
国家的简写 (
CN
代表中国)
|
如果采用选项的缺省值,可以大大缩短该命令。实际上,这些选项并不是必需的;对于有缺省值的选项,未指定时将使用缺省值,对于任何被要求的值,您将会得到要求输入它的提示。例如:输入命令
keytool -genkey -keystore "C:/tone.jks" -storepass 123456 -keyalg RSA
,就会有如下提示:
注意:这里的
密钥仓库路径一定要存在,如果不存在的话,它就会抛如下的异常

第二步
:
产生证书请求certreq.pem 文件
使用如下命令:
keytool -certreq -alias weblogic -sigalg "MD5withRSA" -file C:/mykeystore/certreq.pem -keypass 123456 -keystore C:/mykeystore/weblogic.jks -storepass 123456

这样在
C:/mykeystore/
目录下
就会产生一个
certreq.pem
文件,内容如下:
-----BEGIN NEW CERTIFICATE REQUEST-----
MIHlMIGQAgEAMCsxCzAJBgNVBAYTAmNuMQ4wDAYDVQQKEwVlYWdsZTEMMAoGA1UEAxMDaHlxMFww
DQYJKoZIhvcNAQEBBQADSwAwSAJBAMhaIG2Ki7+RwZUP4gPBdTbnY38bisW16u1XUyysPxdNwSie
aSd6E3Hm277E7NjHoz56ZoaYdPPDmdiTkMrS9rcCAwEAAaAAMA0GCSqGSIb3DQEBBAUAA0EAYRNl
l5dyGgV9hhu++ypcJNQTrDIwjx1QT4fgVubrtIaHU0fzHamD5QG6PYddw9TL51XQHvu6tOS0NUc/
ItNKJw==
-----END NEW CERTIFICATE REQUEST-----
第三步:这就相对来说简单多了,就是向CA提交证书请求。
你可以随便从网上找一家免费的CA认证适用机构(很多的),然后按照上面的提示进行操作就可以了,这一步就要用到前面生成的certreq.pem 文件了。(注意:一定要下载根证书)
将生成的证书和下载的根证书放至你比较容易找到的位置,我一般将它们和生成的jks文件放到一起。
第四步:导入证书
通过命令:keytool -import -alias RootCA -trustcacerts -file C:/mykeystore/RootCADemo.cer -keystore C:/mykeystore/weblogic.jks -storepass 123456将根证书导入第一步生成的weblogic.jks中,接着将所有其它的证书按照此命令全部导入。(注意证书的别名不能重复,同时一定注意要用上 -trustcacerts,否则,你在以后使用时,它将会认为你导入的这些证书是不可信任的 ,就会导致你在配置SSL时不能正常的工作。)
这就全部完成了密钥仓库的创建。然后就可以在支持这些证书格式的服务器上使用了。下一篇将会写一下在weblogic上如何配置双向SSL
|
|
|
posted @
2006-10-31 17:18 MyJavaWorld 阅读(476) |
评论 (0) |
编辑 收藏
现在的DB2 UDB系统中, 主要通过锁和隔离级别这两个主要的工具来控制并发连接,维护数据库中的数据在高并发的环境下的安全。
我们在这里将简要的阐述一下锁和隔离级别。
锁:
DB2 UDB中, 锁的主要作用对象是表和行, 其他如表空间和索引也是锁的对象, 但是因为其多为系统控制, 管理员和用户使用较少,在这里就不涉及了。
对于行级锁和表级锁, 它们的区别不言而喻, 主要是锁的对象不同。 当然锁对象的不同连带也会影响DB2的并发能力。
DB2中的表级锁主要有以下几种:
1. IS锁: 此锁作用于整个表,表示拥有此锁的应用连接要读取表中的某些数据, 但是在此应用连接读取具体的数据时, 还必须获得该行的行级锁;
2. IX锁: 此锁作用于整个表,表示拥有此锁的应用连接需要独占使用表中的某些数据, 但是在此应用连接独占使用具体的数据时, 还必须获得该行上相应的行级锁;
3. SIX锁: 此锁是锁转换的产物,表示应用连接拥有S和IX锁的特性;
4. S锁: 此锁作用于整个表, 拥有此锁的应用连接可以读取表中的任何纪录;
5. U锁: 此锁作用于整个表, 拥有此锁的应用连接可以读取表中的任何纪录,也可以更新表中的纪录, 但是更新时需要再获得X锁; 此锁主要在“select … with update”语句建立的可更新游标中起作用, 其他的应用可以读取表中的纪录, 但是不能更新它;
6. X锁: 此锁作用于整个表, 拥有此锁的应用连接独占的使用表中的任何纪录;可以进行更新或其他操作;
7. Z锁: 此锁作用于整个表, 也称超级独占锁,主要是在象修改表的定义、 删除表这一类的语句中会使用。 拥有此锁的应用连接对该表有完全的控制权。 其他的任何应用不能读取或更新表中的任何纪录。
在这里我们主要要看一下 IS/IX/SIX这三个锁。 在这三个锁中IS/IX本身并不具备使得应用连接可以读取或更新纪录的能力,应用连接要读取和更新纪录时, 需要再得到相应的行级锁; 反之亦然, 任何应用要获得行级锁操作数据记录之前, 也必须获得某个相应的表级锁。 SIX锁也是类似的情况。这就是为什麽在很多情况下我们使用的是行级锁, 但是用快照(SNAPSHOT)等工具却能够看到有表级锁存在的原因。
那麽DB2中又有哪些行级锁呢? 让我们来看下面的这张图:

此图中列出了DB2中包含的行级锁。 表中的第三列指出, 要获得此行级锁之前, 需要预先获得的表级锁, 这里列出的是最低要求。
这六个行级锁的主要功能如下:
1. S锁:此行级锁的拥有者可以读取该行的信息;
2. U锁:此行级锁的拥有者可以读取该行的信息,如果要更新该行,则仍然需要一个行级的X锁;其他的应用只能读取该行的信息;此锁主要是用于FOR UPDATE的游标。
3. X锁:此行级锁的拥有者可以更新该行的纪录,其他的应用不能连接此行的信息;
4. W锁:此锁和X锁类似,不同之处是此锁和NW锁兼容;
5. NS锁:类似于S锁,用于Next Key;
6. NW锁:类似于W锁,用于Next Key;
在DB2数据库中, 是通过行级锁和表级锁协调作用来提供较好的并发性, 同时保证数据库中数据的安全。 在DB2中缺省情况下使用行级锁(当然需要IS/IX锁配合),只有当出现锁资源不足, 或者是用命令指定使用表级锁的情况下, 才会在应用连接中使用表级锁。 对锁资源分配有兴趣的读者可以参考DB2的管理手册, 查找其中关于locklist和maxlocks参数的论述。对于用命令指定表级锁的情况, 可以参考DB2的命令手册中的lock table命令, 此命令用于直接锁表。
隔离级别:
下面让我们来看一下隔离级别。 隔离级别主要用于控制在DB2根据应用提交的SQL语句向DB2数据库中的相应对象加锁时, 会锁住哪些纪录, 也就是锁定的范围。 隔离级别的不同, 锁定的纪录的范围可能会有很大的差别。
隔离级别分为RR/RS/CS/UR这四个级别。 下面让我们来逐一论述:
1. RR隔离级别: 在此隔离级别下, DB2会锁住所有相关的纪录。 在一个SQL语句执行期间, 所有执行此语句扫描过的纪录都会被加上相应的锁。 具体的锁的类型还是由操作的类型来决定, 如果是读取,则加共享锁; 如果是更新, 则加独占锁。 由于会锁定所有为获得SQL语句的结果而扫描的纪录, 所以锁的数量可能会很庞大, 这个时候, 索引的增加可能会对SQL语句的执行有很大的影响,因为索引会影响SQL语句扫描的纪录数量。
2. RS隔离级别: 此隔离级别的要求比RR隔离级别稍弱,此隔离级别下会锁定所有符合条件的纪录。 不论是读取, 还是更新, 如果SQL语句中包含查询条件, 则会对所有符合条件的纪录加相应的锁。 如果没有条件语句, 也就是对表中的所有记录进行处理,则会对所有的纪录加锁。
3. CS隔离级别: 此隔离级别仅锁住当前处理的纪录。
4. UR隔离级别:此隔离级别下,如果是读取操作,不会出现任何的行级锁。对于非只读的操作,它的锁处理和CS相同。
在这四种隔离级别中, CS是缺省值。 这四种隔离级别均可以保证DB2数据库在并发的环境下不会有数据丢失的情况发生。 要注意的是如果对纪录进行了修改,需要在相应的纪录上加独占类型的锁, 这些独占类型的锁直到交易结束时才会被释放, 这一点在四种隔离级别下都是相同的。
posted @
2006-08-22 12:07 MyJavaWorld 阅读(909) |
评论 (0) |
编辑 收藏REORG TABLE 语句压缩与指定的表相关联的数据。
调用
此语句可以在使用 DB2 CLI 函数的应用程序中使用,也可以通过 CLP 发出。
语法
>>-REORG TABLE--table-name--+------------+---------------------><
'-int1--int2-'
描述
-
REORG TABLE table-name
- 标识重组操作的表。名称必须标识现有的表。
-
int1
- 需要恢复的字节的可选最小百分比。
-
int2
- 需要为将要执行的表压缩恢复的最小字节数。
规则
- 可选的值 int1 和 int2 必须一起使用,或全都不用。
- 可选的值 int1 必须是非负数。
- 可选的值 int1 必须介于 0 与 100 之间。
注意事项
- DB2 Everyplace 可以以内部方式调用表重组。
- 第一个可选参数是表必须包含的不可用的字节的百分比(即百分之十(10)意味“至少百分之十的空间不可用”。)第二个可选参数是表必须包含的不可用的字节数(即 1000 将意味“至少 1000 个字节必须是不可用的空间”。)必须符合两个条件,才可以进行表的实际重组。
- 如果没有指定参数,DB2 Everyplace 对这此选项使用缺省值。缺省百分比是 30 且缺省字节是 6144。因此,“reorg table t1”与“reorg table t1 30 6144”相同。
- 如果重组方式设置为已启用,则 DB2 Everyplace 将自动重组表。如果在 DELETE 或 UPDATE 上启用了重组,则在执行语句之后,会对目标表执行“reorg table table_name 50 30270”。如果在 DROP TABLE 上启用了重组,则在删除表处理结束时执行“reorg table DB2eSYSTABLES 30 10240”(对于 DB2eSYSCOLUMNS 和 DB2eSYSRELS 也是如此)。
- 在 C/C++ 程序中,通过使用具有属性 SQL_ATTR_REORG_MODE 的 CLI/ODBC 函数 SQLSetStmtAttr 设置重组方式。在 JAVA 程序中,通过 DB2eStatement 接口 enableReorg 方法设置重组方式。缺省值是启用重组。
- 重组表时,通过物理上回收删除和更新创建的不可用空间来压缩包含表的数据文件。然后将表的索引更新为指向行的新物理位置。
- 可以重组“DB2 Everyplace 系统目录”基本表。
- 在执行 REORG TABLE 语句时,数据库中不应发生任何其它活动。
示例
使用缺省值压缩 VNNURSE 表。
REORG TABLE VNNURSE
posted @
2006-07-26 22:10 MyJavaWorld 阅读(955) |
评论 (0) |
编辑 收藏
摘要: 在数据库应用程序中使用存储过程有许多好处,包括减少对网络的使用、提高性能以及降低开发成本。Java 存储过程是 DB2 支持的最流行的例程之一。原因之一是,由于 Java 编程语言非常流行,所以 Java 开发人员非常多。因此,在有多种语言可供选择时,Java 例程往往是首选的。
DB2 存储过程不一定非用 Java 来编写。如果业务逻辑只需要简单的存储过程,那么可以考虑用 ...
阅读全文
posted @
2006-07-21 10:03 MyJavaWorld 阅读(5739) |
评论 (0) |
编辑 收藏
J***A正则表达式
关键词: 正则表达式
。正则表达式(regular expression)是JDK 1.4的新功能,但是对sed和awk这样的Unix的标准实用工具,以及Python,Perl之类的语言来讲,它早就已经成为其不可或缺的组成部分了(有人甚至认为,它还是Perl能大获成功的最主要的原因)。单从技术角度来讲,正则表达式只是一种处理字符串的工具(过去Java这个任务是交由String,StringBuffer以及StringTokenizer处理的),但是它常常和I/O一起使用,所以放到这里来讲也不算太离题吧。 正则表达式是一种功能强大但又非常灵活的文本处理工具。它能让你用编程的方式来描述复杂的文本模式,然后在字符串里把它找出来。一旦你找到了这种模式,你就能随心所欲地处理这些文本了。虽然初看起来正则表达式的语法有点让人望而生畏,但它提供了一种精练的动态语言,使我们能用一种通用的方式来解决各种字符串的问题,包括匹配,选择,编辑以及校验。 你可以从比较简单的东西入手学习正则表达式。要想全面地掌握怎样构建正则表达式,可以去看JDK文档的java.util.regex的Pattern类的文档。 | 字符 |
|---|
| B | 字符B | | \xhh | 16进制值0xhh所表示的字符 | | \uhhhh | 16进制值0xhhhh所表示的Unicode字符 | | \t | Tab | | \n | 换行符 | | \r | 回车符 | | \f | 换页符 | | \e | Escape |
正则表达式的强大体现在它能定义字符集(character class)。下面是一些最常见的字符集及其定义的方式,此外还有一些预定义的字符集: | 字符集 |
|---|
| . | 表示任意一个字符 | | [abc] | 表示字符a,b,c中的任意一个(与a|b|c相同) | | [^abc] | 除a,b,c之外的任意一个字符(否定) | | [a-zA-Z] | 从a到z或A到Z当中的任意一个字符(范围) | | [abc[hij]] | a,b,c,h,i,j中的任意一个字符(与a|b|c|h|i|j相同)(并集) | | [a-z&&[hij]] | h,i,j中的一个(交集) | | \s | 空格字符(空格键, tab, 换行, 换页, 回车) | | \S | 非空格字符([^\s]) | | \d | 一个数字,也就是[0-9] | | \D | 一个非数字的字符,也就是[^0-9] | | \w | 一个单词字符(word character),即[a-zA-Z_0-9] | | \W | 一个非单词的字符,[^\w] |
如果你用过其它语言的正则表达式,那么你一眼就能看出反斜杠的与众不同。在其它语言里,"\\"的意思是"我只是要在正则表达式里插入一个反斜杠。没什么特别的意思。"但是在Java里,"\\"的意思是"我要插入一个正则表达式的反斜杠,所以跟在它后面的那个字符的意思就变了。"举例来说,如果你想表示一个或更多的"单词字符",那么这个正则表达式就应该是"\\w+"。如果你要插入一个反斜杠,那就得用"\\\\"。不过像换行,跳格之类的还是只用一根反斜杠:"\n\t"。 这里只给你讲一个例子;你应该JDK文档的java.util.regex.Pattern加到收藏夹里,这样就能很容易地找到各种正则表达式的模式了。 | 逻辑运算符 |
|---|
| XY | X 后面跟着 Y | | X|Y | X或Y | | (X) | 一个"要匹配的组(capturing group)". 以后可以用\i来表示第i个被匹配的组。 |
| 边界匹配符 |
|---|
| ^ | 一行的开始 | | $ | 一行的结尾 | | \b | 一个单词的边界 | | \B | 一个非单词的边界 | | \G | 前一个匹配的结束 |
举一个具体一些的例子。下面这些正则表达式都是合法的,而且都能匹配"Rudolph": Rudolph
[rR]udolph
[rR][aeiou][a-z]ol.*
R.*
"数量表示符(quantifier)"的作用是定义模式应该匹配多少个字符。 - Greedy(贪婪的): 除非另有表示,否则数量表示符都是greedy的。Greedy的表达式会一直匹配下去,直到匹配不下去为止。(如果你发现表达式匹配的结果与预期的不符),很有可能是因为,你以为表达式会只匹配前面几个字符,而实际上它是greedy的,因此会一直匹配下去。
- Reluctant(勉强的): 用问号表示,它会匹配最少的字符。也称为lazy, minimal matching, non-greedy, 或ungreedy。
- Possessive(占有的): 目前只有Java支持(其它语言都不支持)。它更加先进,所以你可能还不太会用。用正则表达式匹配字符串的时候会产生很多中间状态,(一般的匹配引擎会保存这种中间状态,)这样匹配失败的时候就能原路返回了。占有型的表达式不保存这种中间状态,因此也就不会回头重来了。它能防止正则表达式的失控,同时也能提高运行的效率。
| Greedy | Reluctant | Possessive | 匹配 |
|---|
| X? | X?? | X?+ | 匹配一个或零个X | | X* | X*? | X*+ | 匹配零或多个X | | X+ | X+? | X++ | 匹配一个或多个X | | X{n} | X{n}? | X{n}+ | 匹配正好n个X | | X{n,} | X{n,}? | X{n,}+ | 匹配至少n个X | | X{n,m} | X{n,m}? | X{n,m}+ | 匹配至少n个,至多m个X |
再提醒一下,要想让表达式照你的意思去运行,你应该用括号把'X'括起来。比方说: abc+
似乎这个表达式能匹配一个或若干个'abc',但是如果你真的用它去匹配'abcabcabc'的话,实际上只会找到三个字符。因为这个表达式的意思是'ab'后边跟着一个或多个'c'。要想匹配一个或多个完整的'abc',你应该这样: (abc)+
正则表达式能轻而易举地把你给耍了;这是一种建立在Java之上的新语言。 JDK 1.4定义了一个新的接口,叫CharSequence。它提供了String和StringBuffer这两个类的字符序列的抽象: interface CharSequence {
charAt(int i);
length();
subSequence(int start, int end);
toString();
}
为了实现这个新的CharSequence接口,String,StringBuffer以及CharBuffer都作了修改。很多正则表达式的操作都要拿CharSequence作参数。 先给一个例子。下面这段程序可以测试正则表达式是否匹配字符串。第一个参数是要匹配的字符串,后面是正则表达式。正则表达式可以有多个。在Unix/Linux环境下,命令行下的正则表达式还必须用引号。 当你创建正则表达式时,可以用这个程序来判断它是不是会按照你的要求工作。 //: c12:TestRegularExpression.java// Allows you to easly try out regular expressions.// {Args: abcabcabcdefabc "abc+" "(abc)+" "(abc){2,}" }import java.util.regex.*;
publicclass TestRegularExpression {
publicstaticvoid main(String[] args) {
if(args.length < 2) {
System.out.println("Usage:\n" +
"java TestRegularExpression " +
"characterSequence regularExpression+");
System.exit(0);
}
System.out.println("Input: \"" + args[0] + "\"");
for(int i = 1; i < args.length; i++) {
System.out.println(
"Regular expression: \"" + args[i] + "\"");
Pattern p = Pattern.compile(args[i]);
Matcher m = p.matcher(args[0]);
while(m.find()) {
System.out.println("Match \"" + m.group() +
"\" at positions " +
m.start() + "-" + (m.end() - 1));
}
}
}
} ///:~ |
Java的正则表达式是由java.util.regex的Pattern和Matcher类实现的。Pattern对象表示经编译的正则表达式。静态的compile( )方法负责将表示正则表达式的字符串编译成Pattern对象。正如上述例程所示的,只要给Pattern的matcher( )方法送一个字符串就能获取一个Matcher对象。此外,Pattern还有一个能快速判断能否在input里面找到regex的(注意,原文有误,漏了方法名) staticboolean matches( regex, input)
以及能返回String数组的split( )方法,它能用regex把字符串分割开来。 只要给Pattern.matcher( )方法传一个字符串就能获得Matcher对象了。接下来就能用Matcher的方法来查询匹配的结果了。 boolean matches()
boolean lookingAt()
boolean find()
boolean find(int start)
matches( )的前提是Pattern匹配整个字符串,而lookingAt( )的意思是Pattern匹配字符串的开头。 Matcher.find( )的功能是发现CharSequence里的,与pattern相匹配的多个字符序列。例如: //: c12:FindDemo.javaimport java.util.regex.*;
import com.bruceeckel.simpletest.*;
import java.util.*;
publicclass FindDemo {
privatestatic Test monitor = new Test();
publicstaticvoid main(String[] args) {
Matcher m = Pattern.compile("\\w+")
.matcher("Evening is full of the linnet's wings");
while(m.find())
System.out.println(m.group());
int i = 0;
while(m.find(i)) {
System.out.print(m.group() + " ");
i++;
}
monitor.expect(new String[] {
"Evening",
"is",
"full",
"of",
"the",
"linnet",
"s",
"wings",
"Evening vening ening ning ing ng g is is s full " +
"full ull ll l of of f the the he e linnet linnet " +
"innet nnet net et t s s wings wings ings ngs gs s "
});
}
} ///:~ |
"\\w+"的意思是"一个或多个单词字符",因此它会将字符串直接分解成单词。find( )像一个迭代器,从头到尾扫描一遍字符串。第二个find( )是带int参数的,正如你所看到的,它会告诉方法从哪里开始找——即从参数位置开始查找。 Group是指里用括号括起来的,能被后面的表达式调用的正则表达式。Group 0 表示整个表达式,group 1表示第一个被括起来的group,以此类推。所以; A(B(C))D
里面有三个group:group 0是ABCD, group 1是BC,group 2是C。 你可以用下述Matcher方法来使用group: public int groupCount( )返回matcher对象中的group的数目。不包括group0。 public String group( ) 返回上次匹配操作(比方说find( ))的group 0(整个匹配) public String group(int i)返回上次匹配操作的某个group。如果匹配成功,但是没能找到group,则返回null。 public int start(int group)返回上次匹配所找到的,group的开始位置。 public int end(int group)返回上次匹配所找到的,group的结束位置,最后一个字符的下标加一。 下面我们举一些group的例子: //: c12:Groups.javaimport java.util.regex.*;
import com.bruceeckel.simpletest.*;
publicclass Groups {
privatestatic Test monitor = new Test();
staticpublicfinal String poem =
"Twas brillig, and the slithy toves\n" +
"Did gyre and gimble in the wabe.\n" +
"All mimsy were the borogoves,\n" +
"And the mome raths outgrabe.\n\n" +
"Beware the Jabberwock, my son,\n" +
"The jaws that bite, the claws that catch.\n" +
"Beware the Jubjub bird, and shun\n" +
"The frumious Bandersnatch.";
publicstaticvoid main(String[] args) {
Matcher m =
Pattern.compile("(?m)(\\S+)\\s+((\\S+)\\s+(\\S+))$")
.matcher(poem);
while(m.find()) {
for(int j = 0; j <= m.groupCount(); j++)
System.out.print("[" + m.group(j) + "]");
System.out.println();
}
monitor.expect(new String[]{
"[the slithy toves]" +
"[the][slithy toves][slithy][toves]",
"[in the wabe.][in][the wabe.][the][wabe.]",
"[were the borogoves,]" +
"[were][the borogoves,][the][borogoves,]",
"[mome raths outgrabe.]" +
"[mome][raths outgrabe.][raths][outgrabe.]",
"[Jabberwock, my son,]" +
"[Jabberwock,][my son,][my][son,]",
"[claws that catch.]" +
"[claws][that catch.][that][catch.]",
"[bird, and shun][bird,][and shun][and][shun]",
"[The frumious Bandersnatch.][The]" +
"[frumious Bandersnatch.][frumious][Bandersnatch.]"
});
}
} ///:~ |
这首诗是Through the Looking Glass的,Lewis Carroll的"Jabberwocky"的第一部分。可以看到这个正则表达式里有很多用括号括起来的group,它是由任意多个连续的非空字符('\S+')和任意多个连续的空格字符('\s+')所组成的,其最终目的是要捕获每行的最后三个单词;'$'表示一行的结尾。但是'$'通常表示整个字符串的结尾,所以这里要明确地告诉正则表达式注意换行符。这一点是由'(?m)'标志完成的(模式标志会过一会讲解)。 如果匹配成功,start( )会返回此次匹配的开始位置,end( )会返回此次匹配的结束位置,即最后一个字符的下标加一。如果之前的匹配不成功(或者没匹配),那么无论是调用start( )还是end( ),都会引发一个IllegalStateException。下面这段程序还演示了matches( )和lookingAt( ): //: c12:StartEnd.javaimport java.util.regex.*;
import com.bruceeckel.simpletest.*;
publicclass StartEnd {
privatestatic Test monitor = new Test();
publicstaticvoid main(String[] args) {
String[] input = new String[] {
"Java has regular expressions in 1.4",
"regular expressions now expressing in Java",
"Java represses oracular expressions"
};
Pattern
p1 = Pattern.compile("re\\w*"),
p2 = Pattern.compile("Java.*");
for(int i = 0; i < input.length; i++) {
System.out.println("input " + i + ": " + input[i]);
Matcher
m1 = p1.matcher(input[i]),
m2 = p2.matcher(input[i]);
while(m1.find())
System.out.println("m1.find() '" + m1.group() +
"' start = "+ m1.start() + " end = " + m1.end());
while(m2.find())
System.out.println("m2.find() '" + m2.group() +
"' start = "+ m2.start() + " end = " + m2.end());
if(m1.lookingAt()) // No reset() necessary
System.out.println("m1.lookingAt() start = "
+ m1.start() + " end = " + m1.end());
if(m2.lookingAt())
System.out.println("m2.lookingAt() start = "
+ m2.start() + " end = " + m2.end());
if(m1.matches()) // No reset() necessary
System.out.println("m1.matches() start = "
+ m1.start() + " end = " + m1.end());
if(m2.matches())
System.out.println("m2.matches() start = "
+ m2.start() + " end = " + m2.end());
}
monitor.expect(new String[] {
"input 0: Java has regular expressions in 1.4",
"m1.find() 'regular' start = 9 end = 16",
"m1.find() 'ressions' start = 20 end = 28",
"m2.find() 'Java has regular expressions in 1.4'" +
" start = 0 end = 35",
"m2.lookingAt() start = 0 end = 35",
"m2.matches() start = 0 end = 35",
"input 1: regular expressions now " +
"expressing in Java",
"m1.find() 'regular' start = 0 end = 7",
"m1.find() 'ressions' start = 11 end = 19",
"m1.find() 'ressing' start = 27 end = 34",
"m2.find() 'Java' start = 38 end = 42",
"m1.lookingAt() start = 0 end = 7",
"input 2: Java represses oracular expressions",
"m1.find() 'represses' start = 5 end = 14",
"m1.find() 'ressions' start = 27 end = 35",
"m2.find() 'Java represses oracular expressions' " +
"start = 0 end = 35",
"m2.lookingAt() start = 0 end = 35",
"m2.matches() start = 0 end = 35"
});
}
} ///:~ |
注意,只要字符串里有这个模式,find( )就能把它给找出来,但是lookingAt( )和matches( ),只有在字符串与正则表达式一开始就相匹配的情况下才能返回true。matches( )成功的前提是正则表达式与字符串完全匹配,而lookingAt( )[67]成功的前提是,字符串的开始部分与正则表达式相匹配。 compile( )方法还有一个版本,它需要一个控制正则表达式的匹配行为的参数: Pattern Pattern.compile(String regex, int flag)
flag的取值范围如下:
| 编译标志 | 效果 |
|---|
| Pattern.CANON_EQ | 当且仅当两个字符的"正规分解(canonical decomposition)"都完全相同的情况下,才认定匹配。比如用了这个标志之后,表达式"a\u030A"会匹配"?"。默认情况下,不考虑"规范相等性(canonical equivalence)"。 | Pattern.CASE_INSENSITIVE
(?i) | 默认情况下,大小写不明感的匹配只适用于US-ASCII字符集。这个标志能让表达式忽略大小写进行匹配。要想对Unicode字符进行大小不明感的匹配,只要将UNICODE_CASE与这个标志合起来就行了。 | Pattern.COMMENTS
(?x) | 在这种模式下,匹配时会忽略(正则表达式里的)空格字符(译者注:不是指表达式里的"\\s",而是指表达式里的空格,tab,回车之类)。注释从#开始,一直到这行结束。可以通过嵌入式的标志来启用Unix行模式。 | Pattern.DOTALL
(?s) | 在这种模式下,表达式'.'可以匹配任意字符,包括表示一行的结束符。默认情况下,表达式'.'不匹配行的结束符。 | Pattern.MULTILINE
(?m) | 在这种模式下,'^'和'$'分别匹配一行的开始和结束。此外,'^'仍然匹配字符串的开始,'$'也匹配字符串的结束。默认情况下,这两个表达式仅仅匹配字符串的开始和结束。 | Pattern.UNICODE_CASE
(?u) | 在这个模式下,如果你还启用了CASE_INSENSITIVE标志,那么它会对Unicode字符进行大小写不明感的匹配。默认情况下,大小写不明感的匹配只适用于US-ASCII字符集。 | Pattern.UNIX_LINES
(?d) | 在这个模式下,只有'\n'才被认作一行的中止,并且与'.','^',以及'$'进行匹配。 |
在这些标志里面,Pattern.CASE_INSENSITIVE,Pattern.MULTILINE,以及Pattern.COMMENTS是最有用的(其中Pattern.COMMENTS还能帮我们把思路理清楚,并且/或者做文档)。注意,你可以用在表达式里插记号的方式来启用绝大多数的模式。这些记号就在上面那张表的各个标志的下面。你希望模式从哪里开始启动,就在哪里插记号。 可以用"OR" ('|')运算符把这些标志合使用: //: c12:ReFlags.javaimport java.util.regex.*;
import com.bruceeckel.simpletest.*;
publicclass ReFlags {
privatestatic Test monitor = new Test();
publicstaticvoid main(String[] args) {
Pattern p = Pattern.compile("^java",
Pattern.CASE_INSENSITIVE | Pattern.MULTILINE);
Matcher m = p.matcher(
"java has regex\nJava has regex\n" +
"J***A has pretty good regular expressions\n" +
"Regular expressions are in Java");
while(m.find())
System.out.println(m.group());
monitor.expect(new String[] {
"java",
"Java",
"J***A"
});
}
} ///:~ |
这样创建出来的正则表达式就能匹配以"java","Java","J***A"...开头的字符串了。此外,如果字符串分好几行,那它还会对每一行做匹配(匹配始于字符序列的开始,终于字符序列当中的行结束符)。注意,group( )方法仅返回匹配的部分。 所谓分割是指将以正则表达式为界,将字符串分割成String数组。 String[] split(CharSequence charseq)
String[] split(CharSequence charseq, int limit)
这是一种既快又方便地将文本根据一些常见的边界标志分割开来的方法。 //: c12:SplitDemo.javaimport java.util.regex.*;
import com.bruceeckel.simpletest.*;
import java.util.*;
publicclass SplitDemo {
privatestatic Test monitor = new Test();
publicstaticvoid main(String[] args) {
String input =
"This!!unusual use!!of exclamation!!points";
System.out.println(Arrays.asList(
Pattern.compile("!!").split(input)));
// Only do the first three:
System.out.println(Arrays.asList(
Pattern.compile("!!").split(input, 3)));
System.out.println(Arrays.asList(
"Aha! String has a split() built in!".split(" ")));
monitor.expect(new String[] {
"[This, unusual use, of exclamation, points]",
"[This, unusual use, of exclamation!!points]",
"[Aha!, String, has, a, split(), built, in!]"
});
}
} ///:~ |
第二个split( )会限定分割的次数。 正则表达式是如此重要,以至于有些功能被加进了String类,其中包括split( )(已经看到了),matches( ),replaceFirst( )以及replaceAll( )。这些方法的功能同Pattern和Matcher的相同。 正则表达式在替换文本方面特别在行。下面就是一些方法: replaceFirst(String replacement)将字符串里,第一个与模式相匹配的子串替换成replacement。 replaceAll(String replacement),将输入字符串里所有与模式相匹配的子串全部替换成replacement。 appendReplacement(StringBuffer sbuf, String replacement)对sbuf进行逐次替换,而不是像replaceFirst( )或replaceAll( )那样,只替换第一个或全部子串。这是个非常重要的方法,因为它可以调用方法来生成replacement(replaceFirst( )和replaceAll( )只允许用固定的字符串来充当replacement)。有了这个方法,你就可以编程区分group,从而实现更强大的替换功能。 调用完appendReplacement( )之后,为了把剩余的字符串拷贝回去,必须调用appendTail(StringBuffer sbuf, String replacement)。 下面我们来演示一下怎样使用这些替换方法。说明一下,这段程序所处理的字符串是它自己开头部分的注释,是用正则表达式提取出来并加以处理之后再传给替换方法的。 //: c12:TheReplacements.javaimport java.util.regex.*;
import java.io.*;
import com.bruceeckel.util.*;
import com.bruceeckel.simpletest.*;
/*! Here's a block of text to use as input to
the regular expression matcher. Note that we'll
first extract the block of text by looking for
the special delimiters, then process the
extracted block. !*/publicclass TheReplacements {
privatestatic Test monitor = new Test();
publicstaticvoid main(String[] args) throws Exception {
String s = TextFile.read("TheReplacements.java");
// Match the specially-commented block of text above:
Matcher mInput =
Pattern.compile("/\\*!(.*)!\\*/", Pattern.DOTALL)
.matcher(s);
if(mInput.find())
s = mInput.group(1); // Captured by parentheses// Replace two or more spaces with a single space:
s = s.replaceAll(" {2,}", " ");
// Replace one or more spaces at the beginning of each// line with no spaces. Must enable MULTILINE mode:
s = s.replaceAll("(?m)^ +", "");
System.out.println(s);
s = s.replaceFirst("[aeiou]", "(VOWEL1)");
StringBuffer sbuf = new StringBuffer();
Pattern p = Pattern.compile("[aeiou]");
Matcher m = p.matcher(s);
// Process the find information as you// perform the replacements:while(m.find())
m.appendReplacement(sbuf, m.group().toUpperCase());
// Put in the remainder of the text:
m.appendTail(sbuf);
System.out.println(sbuf);
monitor.expect(new String[]{
"Here's a block of text to use as input to",
"the regular expression matcher. Note that we'll",
"first extract the block of text by looking for",
"the special delimiters, then process the",
"extracted block. ",
"H(VOWEL1)rE's A blOck Of tExt tO UsE As InpUt tO",
"thE rEgUlAr ExprEssIOn mAtchEr. NOtE thAt wE'll",
"fIrst ExtrAct thE blOck Of tExt by lOOkIng fOr",
"thE spEcIAl dElImItErs, thEn prOcEss thE",
"ExtrActEd blOck. "
});
}
} ///:~ |
我们用前面介绍的TextFile.read( )方法来打开和读取文件。mInput的功能是匹配'/*!' 和 '!*/' 之间的文本(注意一下分组用的括号)。接下来,我们将所有两个以上的连续空格全都替换成一个,并且将各行开头的空格全都去掉(为了让这个正则表达式能对所有的行,而不仅仅是第一行起作用,必须启用多行模式)。这两个操作都用了String的replaceAll( )(这里用它更方便)。注意,由于每个替换只做一次,因此除了预编译Pattern之外,程序没有额外的开销。 replaceFirst( )只替换第一个子串。此外,replaceFirst( )和replaceAll( )只能用常量(literal)来替换,所以如果你每次替换的时候还要进行一些操作的话,它们是无能为力的。碰到这种情况,你得用appendReplacement( ),它能让你在进行替换的时候想写多少代码就写多少。在上面那段程序里,创建sbuf的过程就是选group做处理,也就是用正则表达式把元音字母找出来,然后换成大写的过程。通常你得在完成全部的替换之后才调用appendTail( ),但是如果要模仿replaceFirst( )(或"replace n")的效果,你也可以只替换一次就调用appendTail( )。它会把剩下的东西全都放进sbuf。 你还可以在appendReplacement( )的replacement参数里用"$g"引用已捕获的group,其中'g' 表示group的号码。不过这是为一些比较简单的操作准备的,因而其效果无法与上述程序相比。 此外,还可以用reset( )方法给现有的Matcher对象配上个新的CharSequence。 //: c12:Resetting.javaimport java.util.regex.*;
import java.io.*;
import com.bruceeckel.simpletest.*;
publicclass Resetting {
privatestatic Test monitor = new Test();
publicstaticvoid main(String[] args) throws Exception {
Matcher m = Pattern.compile("[frb][aiu][gx]")
.matcher("fix the rug with bags");
while(m.find())
System.out.println(m.group());
m.reset("fix the rig with rags");
while(m.find())
System.out.println(m.group());
monitor.expect(new String[]{
"fix",
"rug",
"bag",
"fix",
"rig",
"rag"
});
}
} ///:~ |
如果不给参数,reset( )会把Matcher设到当前字符串的开始处。 到目前为止,你看到的都是用正则表达式处理静态字符串的例子。下面我们来演示一下怎样用正则表达式扫描文件并且找出匹配的字符串。受Unix的grep启发,我写了个JGrep.java,它需要两个参数:文件名,以及匹配字符串用的正则表达式。它会把匹配这个正则表达式那部分内容及其所属行的行号打印出来。 //: c12:JGrep.java// A very simple version of the "grep" program.// {Args: JGrep.java "\\b[Ssct]\\w+"}import java.io.*;
import java.util.regex.*;
import java.util.*;
import com.bruceeckel.util.*;
publicclass JGrep {
publicstaticvoid main(String[] args) throws Exception {
if(args.length < 2) {
System.out.println("Usage: java JGrep file regex");
System.exit(0);
}
Pattern p = Pattern.compile(args[1]);
// Iterate through the lines of the input file:
ListIterator it = new TextFile(args[0]).listIterator();
while(it.hasNext()) {
Matcher m = p.matcher((String)it.next());
while(m.find())
System.out.println(it.nextIndex() + ": " +
m.group() + ": " + m.start());
}
}
} ///:~ |
文件是用TextFile打开的(本章的前半部分讲的)。由于TextFile会把文件的各行放在ArrayList里面,而我们又提取了一个ListIterator,因此我们可以在文件的各行当中自由移动(既能向前也可以向后)。 每行都会有一个Matcher,然后用find( )扫描。注意,我们用ListIterator.nextIndex( )跟踪行号。 测试参数是JGrep.java和以[Ssct]开头的单词。 看到正则表达式能提供这么强大的功能,你可能会怀疑,是不是还需要原先的StringTokenizer。JDK 1.4以前,要想分割字符串,只有用StringTokenizer。但现在,有了正则表达式之后,它就能做得更干净利索了。 //: c12:ReplacingStringTokenizer.javaimport java.util.regex.*;
import com.bruceeckel.simpletest.*;
import java.util.*;
publicclass ReplacingStringTokenizer {
privatestatic Test monitor = new Test();
publicstaticvoid main(String[] args) {
String input = "But I'm not dead yet! I feel happy!";
StringTokenizer stoke = new StringTokenizer(input);
while(stoke.hasMoreElements())
System.out.println(stoke.nextToken());
System.out.println(Arrays.asList(input.split(" ")));
monitor.expect(new String[] {
"But",
"I'm",
"not",
"dead",
"yet!",
"I",
"feel",
"happy!",
"[But, I'm, not, dead, yet!, I, feel, happy!]"
});
}
} ///:~ |
有了正则表达式,你就能用更复杂的模式将字符串分割开来——要是交给StringTokenizer的话,事情会麻烦得多。我可以很有把握地说,正则表达式可以取代StringTokenizer。 要想进一步学习正则表达式,建议你看Mastering Regular Expression, 2nd Edition,作者Jeffrey E. F. Friedl (O’Reilly, 2002)。 Java的I/O流类库应该能满足你的基本需求:你可以用它来读写控制台,文件,内存,甚至是Internet。你还可以利用继承来创建新的输入和输出类型。你甚至可以利用Java会自动调用对象的toString( )方法的特点(Java仅有的"自动类型转换"),通过重新定义这个方法,来对要传给流的对象做一个简单的扩展。 但是Java的I/O流类库及其文档还是留下了一些缺憾。比方说你打开一个文件往里面写东西,但是这个文件已经有了,这么做会把原先的内容给覆盖了 。这时要是能有一个异常就好了——有些编程语言能让你规定只能往新建的文件里输出。看来Java是要你用File对象来判断文件是否存在,因为如果你用FileOutputStream或FileWriter的话,文件就会被覆盖了。 我对I/O流类库的评价是比较矛盾的;它确实能干很多事情,而且做到了跨平台。但是如果你不懂decorator模式,就会觉得这种设计太难理解了,所以无论是对老师还是学生,都得多花精力。此外这个类库也不完整,否则我也用不着去写TextFile了。此外它没有提供格式化输出的功能,而其他语言都已经提供了这种功能。
|
|
|
posted @
2006-07-20 15:48 MyJavaWorld 阅读(356) |
评论 (0) |
编辑 收藏
摘要: Why is RUNSTATS important?
Almost every major database today uses some method of updating catalog statistics to provide the best information possi...
阅读全文
posted @
2006-06-23 15:40 MyJavaWorld 阅读(484) |
评论 (0) |
编辑 收藏

|
| When you update table statistics using the RUNSTATS command, it requires that you run the command against each table, one by one. REORGCHK gives you the capability to update the statistics of a group of tables or all the tables in the database, with only one command. |
|
.
|
|
_
|
DB2 UDB uses the statistics information in the catalog table to derive the best access plan. The DBA should regularly run the RUNSTATS command to keep the database statistics updated. This procedure will ensure the best performance on queries.
If you want to update statistics on all the tables or a group of tables in the database, you can use the REORGCHK command with the UPDATE STATISTICS option. This would be run instead of running the RUNSTATS command against each table. The UPDATE STATISTICS option will first call the RUNSTATS routine to update the table statistic. You can then use these new statistics to determine if a reorg is needed.
The REORGCHK command allows you to update statistics on a group of tables with one command.
To update all the user and system tables use:
REORGCHK UPDATE STATISTICS ON TABLE ALL
To update all the tables of a particular schema use:
REORGCHK UPDATE STATISTICS on SCHEMA schema_name
To update all the tables of a particular table system use:
REORGCHK UPDATE STATISTICS on TABLE SYSTEM
|
|
|
|
|
posted @
2006-06-23 15:19 MyJavaWorld 阅读(496) |
评论 (0) |
编辑 收藏
<html:radio idName=" idName " value="value" name=" name" property=" property " />
表示在输出时,html:radio输出为input type="radio";name输出为name="name";对
于value的输出,当不指定idName时,value="value",当指定idName时,输出是由bean
名为" idName ",属性名为"value"的属性值;当bean名为" name ",属性名为" property "的属性值等于上述value的输出值时,输出checked="checked"。
我的例子:
<logic:iterate id = "answer" name = "answerList" scope = "page">
<html:radio idName = "answer" value = "answerItem" name = "question" property = "rightAnswer" ></html:radio>
</logic:iterate>
如果从bean answer的answerItem属性中取出的值等于从bean question的rightAnswer
属性中取出的值相等,那么该radio将被选中
|
|
|
posted @
2006-06-21 16:54 MyJavaWorld 阅读(1440) |
评论 (0) |
编辑 收藏
|
1. 一个表如果建有大量索引会影响 INSERT、UPDATE 和 DELETE 语句的性能,因为在表中的数据更改时,所有索引都须进行适当的调整。另一方面,对于不需要修改数据的查询(SELECT 语句),大量索引有助于提高性能,因为数据库有更多的索引可供选择,以便确定以最快速度访问数据的最佳方法。
2. 组合索引:组合索引即多列索引,指一个索引含有多个列。一个组合索引相当于多个单列索引,如索引(ColA, ColB, ColC)至少相当于(ColA)、(ColA, ColB)、(ColA, ColB, ColC)三个索引。
2. 覆盖的查询可以提高性能。覆盖的查询是指查询中所有指定的列都包含在同一个索引(组合索引)中。例如,如果在一个表的 a、b 和 c 列上创建了组合索引,则从该表中检索 a 和 b 列的查询被视为覆盖的查询。创建覆盖一个查询的索引可以提高性能,因为该查询的所有数据都包含在索引自身当中;检索数据时只需引用表的索引页,不必引用数据页,因而减少了 I/O 总量。尽管给索引添加列以覆盖查询可以提高性能,但在索引中额外维护更多的列会产生更新和存储成本。
3. 对小型表进行索引可能不会产生优化效果,因为数据库在遍历索引以搜索数据时,花费的时间可能会比简单的表扫描还长。
4. 应使用 SQL 事件探查器和索引优化向导帮助分析查询,确定要创建的索引。为数据库及其工作负荷选择正确的索引是非常复杂的,需要在查询速度和更新成本之间取得平衡。窄索引(搜索关键字中只有很少的列的索引)需要的磁盘空间和维护开销都更少。而另一方面,宽索引可以覆盖更多的查询。确定正确的索引集没有简便的规则。经验丰富的数据库管理员常常能够设计出很好的索引集,但是,即使对于不特别复杂的数据库和工作负荷来说,这项任务也十分复杂、费时和易于出错。可以使用索引优化向导使这项任务自动化。有关更多信息,请参见索引优化向导。
5. 可以在视图上指定索引。
6. 可以在计算列上指定索引。
7. 避免在索引列上使用IS NULL和IS NOT NULL。避免在索引中使用任何可以为空的列,数据库将无法使用该索引。对于单列索引,如果列包含空值,索引中将不存在此记录;对于复合索引,如果每个列都为空,索引中同样不存在此记录. 如果至少有一个列不为空,则记录存在于索引中。
8. 如果经常检索包含大量数据的表中的少于15%的行则需要创建索引。
9. 衡量索引效率的 95/5 规则:如果查询的结果返回的行数少于表中所有行的5%,则索引是检索数据的最快方法,如果查询的结果超过5%,那么通常使用索引就不是最快的方式。
10.主关键字和唯一关键字所在的列自动具有索引,但外部关键字没有自动索引。
二、索引的特征
在确定某一索引适合某一查询之后,可以自定义最适合具体情况的索引类型。索引特征包括:
●聚集还是非聚集
●唯一还是不唯一
●单列还是多列
●索引中的列顺序为升序还是降序(索引缺省为升序,但目前多数大型数据库已经能够支持反向索引)
●覆盖还是非覆盖
●还可以自定义索引的初始存储特征,通过设置填充因子优化其维护,并使用文件和文件组自定义其位置以优化性能。
●位映射索引(bitmap)
|
|
|
posted @
2006-06-21 16:50 MyJavaWorld 阅读(2335) |
评论 (0) |
编辑 收藏
|
基础
要使用 sql 获得当前的日期、时间及时间戳记,请参考适当的 db2 寄存器:
select current date from sysibm.sysdummy1
select current time from sysibm.sysdummy1
select current timestamp from sysibm.sysdummy1
|
sysibm.sysdummy1表是一个特殊的内存中的表,用它可以发现如上面演示的 db2 寄存器的值。您也可以使用关键字 values 来对寄存器或表达式求值。例如,在 db2 命令行处理器(command line processor,clp)上,以下 sql 语句揭示了类似信息:
values current date
values current time
values current timestamp
|
在余下的示例中,我将只提供函数或表达式,而不再重复 select ... from sysibm.sysdummy1 或使用 values 子句。
要使当前时间或当前时间戳记调整到 gmt/cut,则把当前的时间或时间戳记减去当前时区寄存器:
current time - current timezone
current timestamp - current timezone
|
给定了日期、时间或时间戳记,则使用适当的函数可以单独抽取出(如果适用的话)年、月、日、时、分、秒及微秒各部分:
year (current timestamp)
month (current timestamp)
day (current timestamp)
hour (current timestamp)
minute (current timestamp)
second (current timestamp)
microsecond (current timestamp)
|
从时间戳记单独抽取出日期和时间也非常简单:
date (current timestamp)
time (current timestamp)
|
因为没有更好的术语,所以您还可以使用英语来执行日期和时间计算:
current date + 1 year
current date + 3 years + 2 months + 15 days
current time + 5 hours - 3 minutes + 10 seconds
|
要计算两个日期之间的天数,您可以对日期作减法,如下所示:
days (current date) - days (date(''1999-10-22''))
|
而以下示例描述了如何获得微秒部分归零的当前时间戳记:
current timestamp - microsecond (current timestamp) microseconds
|
如果想将日期或时间值与其它文本相衔接,那么需要先将该值转换成字符串。为此,只要使用 char() 函数:
char(current date)
char(current time)
char(current date + 12 hours)
|
要将字符串转换成日期或时间值,可以使用:
timestamp (''2002-10-20-12.00.00.000000'')
timestamp (''2002-10-20 12:00:00'')
date (''2002-10-20'')
date (''10/20/2002'')
time (''12:00:00'')
time (''12.00.00'')
|
timestamp()、date() 和 time() 函数接受更多种格式。上面几种格式只是示例,我将把它作为一个练习,让读者自己去发现其它格式。
|
警告:
摘自 db2 udb v8.1 sql cookbook,作者 graeme birchall(see http://ourworld.compuserve.com/homepages/graeme_birchall).
如果你在日期函数中偶然地遗漏了引号,那将如何呢?结论是函数会工作,但结果会出错:
select date(2001-09-22) from sysibm.sysdummy1;
|
结果:
为什么会产生将近 2000 年的差距呢?当 date 函数得到了一个字符串作为输入参数的时候,它会假定这是一个有效的 db2 日期的表示,并对其进行适当地转换。相反,当输入参数是数字类型时,函数会假定该参数值减 1 等于距离公元第一天(0001-01-01)的天数。在上面的例子中,我们的输入是 2001-09-22,被理解为 (2001-9)-22, 等于 1970 天,于是该函数被理解为 date(1970)。
|
日期函数
有时,您需要知道两个时间戳记之间的时差。为此,db2 提供了一个名为 timestampdiff() 的内置函数。但该函数返回的是近似值,因为它不考虑闰年,而且假设每个月只有 30 天。以下示例描述了如何得到两个日期的近似时差:
timestampdiff (<n>, char(
timestamp(''2002-11-30-00.00.00'')-
timestamp(''2002-11-08-00.00.00'')))
|
对于 <n>,可以使用以下各值来替代,以指出结果的时间单位:
- 1 = 秒的小数部分
- 2 = 秒
- 4 = 分
- 8 = 时
- 16 = 天
- 32 = 周
- 64 = 月
- 128 = 季度
- 256 = 年
当日期很接近时使用 timestampdiff() 比日期相差很大时精确。如果需要进行更精确的计算,可以使用以下方法来确定时差(按秒计):
(days(t1) - days(t2)) * 86400 +
(midnight_seconds(t1) - midnight_seconds(t2))
|
为方便起见,还可以对上面的方法创建 sql 用户定义的函数:
create function secondsdiff(t1 timestamp, t2 timestamp)
returns int
return (
(days(t1) - days(t2)) * 86400 +
(midnight_seconds(t1) - midnight_seconds(t2))
)
@
|
如果需要确定给定年份是否是闰年,以下是一个很有用的 sql 函数,您可以创建它来确定给定年份的天数:
create function daysinyear(yr int)
returns int
return (case (mod(yr, 400)) when 0 then 366 else
case (mod(yr, 4)) when 0 then
case (mod(yr, 100)) when 0 then 365 else 366 end
else 365 end
end)@
|
最后,以下是一张用于日期操作的内置函数表。它旨在帮助您快速确定可能满足您要求的函数,但未提供完整的参考。有关这些函数的更多信息,请参考 sql 参考大全。
| sql 日期和时间函数 |
| dayname |
返回一个大小写混合的字符串,对于参数的日部分,用星期表示这一天的名称(例如,friday)。 |
| dayofweek |
返回参数中的星期几,用范围在 1-7 的整数值表示,其中 1 代表星期日。 |
| dayofweek_iso |
返回参数中的星期几,用范围在 1-7 的整数值表示,其中 1 代表星期一。 |
| dayofyear |
返回参数中一年中的第几天,用范围在 1-366 的整数值表示。 |
| days |
返回日期的整数表示。 |
| julian_day |
返回从公元前 4712 年 1 月 1 日(儒略日历的开始日期)到参数中指定日期值之间的天数,用整数值表示。 |
| midnight_seconds |
返回午夜和参数中指定的时间值之间的秒数,用范围在 0 到 86400 之间的整数值表示。 |
| monthname |
对于参数的月部分的月份,返回一个大小写混合的字符串(例如,january)。 |
| timestamp_iso |
根据日期、时间或时间戳记参数而返回一个时间戳记值。 |
| timestamp_format |
从已使用字符模板解释的字符串返回时间戳记。 |
| timestampdiff |
根据两个时间戳记之间的时差,返回由第一个参数定义的类型表示的估计时差。 |
| to_char |
返回已用字符模板进行格式化的时间戳记的字符表示。to_char 是 varchar_format 的同义词。 |
| to_date |
从已使用字符模板解释过的字符串返回时间戳记。to_date 是 timestamp_format 的同义词。 |
| week |
返回参数中一年的第几周,用范围在 1-54 的整数值表示。以星期日作为一周的开始。 |
| week_iso |
返回参数中一年的第几周,用范围在 1-53 的整数值表示。 |
改变日期格式
在日期的表示方面,这也是我经常碰到的一个问题。用于日期的缺省格式由数据库的地区代码决定,该代码在数据库创建的时候被指定。例如,我在创建数据库时使用 territory=us 来定义地区代码,则日期的格式就会像下面的样子:
values current date
1
----------
05/30/2003
1 record(s) selected.
|
也就是说,日期的格式是 mm/dd/yyyy. 如果想要改变这种格式,你可以通过绑定特定的 db2 工具包来实现. 其他被支持的日期格式包括:
| def |
使用与地区代码相匹配的日期和时间格式。 |
| eur |
使用欧洲日期和时间的 ibm 标准格式。 |
| iso |
使用国际标准组织(iso)制订的日期和时间格式。 |
| jis |
使用日本工业标准的日期和时间格式。 |
| loc |
使用与数据库地区代码相匹配的本地日期和时间格式。 |
| usa |
使用美国日期和时间的 ibm 标准格式。 |
在 windows 环境下,要将缺省的日期和时间格式转化成 iso 格式(yyyy-mm-dd),执行下列操作:
- 在命令行中,改变当前目录为
sqllib\bnd 。
例如:
在 windows 环境:c:\program files\ibm\sqllib\bnd
在 unix 环境:/home/db2inst1/sqllib/bnd
- 从操作系统的命令行界面中用具有 sysadm 权限的用户连接到数据库:
db2 connect to dbname
db2 bind @db2ubind.lst datetime iso blocking all grant public
|
(在你的实际环境中, 用你的数据库名称和想使用的日期格式分别来替换 dbname and iso。)
现在,你可以看到你的数据库已经使用 iso 作为日期格式了:
values current date
1
----------
2003-05-30
1 record(s) selected.
|
定制日期/时间格式
在上面的例子中,我们展示了如何将 db2 当前的日期格式转化成系统支持的特定格式。但是,如果你想将当前日期格式转化成定制的格式(比如‘yyyymmdd’),那又该如何去做呢?按照我的经验,最好的办法就是编写一个自己定制的格式化函数。
下面是这个 udf 的代码:
create function ts_fmt(ts timestamp, fmt varchar(20))
returns varchar(50)
return
with tmp (dd,mm,yyyy,hh,mi,ss,nnnnnn) as
(
select
substr( digits (day(ts)),9),
substr( digits (month(ts)),9) ,
rtrim(char(year(ts))) ,
substr( digits (hour(ts)),9),
substr( digits (minute(ts)),9),
substr( digits (second(ts)),9),
rtrim(char(microsecond(ts)))
from sysibm.sysdummy1
)
select
case fmt
when ''yyyymmdd''
then yyyy || mm || dd
when ''mm/dd/yyyy''
then mm || ''/'' || dd || ''/'' || yyyy
when ''yyyy/dd/mm hh:mi:ss''
then yyyy || ''/'' || mm || ''/'' || dd || '' '' ||
hh || '':'' || mi || '':'' || ss
when ''nnnnnn''
then nnnnnn
else
''date format '' || coalesce(fmt,'' <null> '') ||
'' not recognized.''
end
from tmp
|
乍一看,函数的代码可能显得很复杂,但是在仔细研究之后,你会发现这段代码其实非常简单而且很优雅。最开始,我们使用了一个公共表表达式(cte)来将一个时间戳记(第一个输入参数)分别剥离为单独的时间元素。然后,我们检查提供的定制格式(第二个输入参数)并将前面剥离出的元素按照该定制格式的要求加以组合。
这个函数还非常灵活。如果要增加另外一种模式,可以很容易地再添加一个 when 子句来处理。在使用过程中,如果用户提供的格式不符合任何在 when 子句中定义的任何一种模式时,函数会返回一个错误信息。
使用方法示例:
values ts_fmt(current timestamp,''yyyymmdd'')
''20030818''
values ts_fmt(current timestamp,''asa'')
''date format asa not recognized.''
|
|
|
|
posted @
2006-06-13 11:29 MyJavaWorld 阅读(393) |
评论 (0) |
编辑 收藏
tomcat5.5的管理功能非常强,只要你配置好了tomcat-user.xml.
主要是增加一个具有系统管理权限的用户,比如增加一个用户名和密码都是suxiaoyong的用户,只需要在在最后一行增加
| 代码 | | <user username="suxiaoyong" password="suxiaoyong" roles="admin,manager"/> |
其他的用户都可以删掉了
然后,我们可以进入http://localhost:8080/manager/status 来查看服务器的各种状态.
也可以通过url来直接对应用进行监控
命令格式
| 代码 | | http://{ host }:{ port }/manager/{ command }?{ parameters } |
部署一个应用
列出已经部署的应用
| 代码 | | http://localhost:8080/manager/list |
重新加载一个应用
比如你更新了class或者lib的话,需要重新加载系统
| 代码 | | http://localhost:8080/manager/reload?path=/examples |
查看jvm和系统信息
| 代码 | | http://localhost:8080/manager/serverinfo |
查看可用的安全角色
| 代码 | | http://localhost:8080/manager/roles |
查看某个应用默认的session超时时间和当前活跃的session数
| 代码 | | http://localhost:8080/manager/sessions?path=/examples |
启动一个应用
比如有时候重新启动数据库后可能需要重新启动应用
| 代码 | | http://localhost:8080/manager/start?path=/examples |
关闭一个应用
关闭后,任何发往该应用的请求都将转向404错误的页面
| 代码 | | http://localhost:8080/manager/stop?path=/examples |
undeploy
慎用,将删除应用的目录及其war文件
ant脚本,更多的详见tomcat5.5的文档
| 代码 | <project name="My Application" default="compile" basedir=".">
<!-- Configure the directory into which the web application is built -->
<property name="build" value="${ basedir }/build"/>
<!-- Configure the context path for this application -->
<property name="path" value="/myapp"/>
<!-- Configure properties to access the Manager application -->
<property name="url" value="http://localhost:8080/manager"/>
<property name="username" value="myusername"/>
<property name="password" value="mypassword"/>
<!-- Configure the custom Ant tasks for the Manager application -->
<taskdef name="deploy" classname="org.apache.catalina.ant.DeployTask"/>
<taskdef name="list" classname="org.apache.catalina.ant.ListTask"/>
<taskdef name="reload" classname="org.apache.catalina.ant.ReloadTask"/>
<taskdef name="resources" classname="org.apache.catalina.ant.ResourcesTask"/>
<taskdef name="roles" classname="org.apache.catalina.ant.RolesTask"/>
<taskdef name="start" classname="org.apache.catalina.ant.StartTask"/>
<taskdef name="stop" classname="org.apache.catalina.ant.StopTask"/>
<taskdef name="undeploy" classname="org.apache.catalina.ant.UndeployTask"/>
<!-- Executable Targets -->
<target name="compile" description="Compile web application">
<!-- ... construct web application in ${ build } subdirectory, and
generated a ${ path }.war ... -->
</target>
<target name="deploy" description="Install web application"
depends="compile">
<deploy url="${ url }" username="${ username }" password="${ password }"
path="${ path }" war="${ build }${ path }.war"/>
</target>
<target name="reload" description="Reload web application"
depends="compile">
<reload url="${ url }" username="${ username }" password="${ password }"
path="${ path }"/>
</target>
<target name="undeploy" description="Remove web application">
<undeploy url="${ url }" username="${ username }" password="${ password }"
path="${ path }"/>
</target>
</project> |
|
|
|
|
posted @
2006-06-12 10:28 MyJavaWorld 阅读(481) |
评论 (0) |
编辑 收藏
1. 配置系统管理(Admin Web Application)
大多数商业化的J2EE服务器都提供一个功能强大的管理界面,且大都采用易于理解的Web应用界面。Tomcat按照自己的方式,同样提供一个成熟的管理工具,并且丝毫不逊于那些商业化的竞争对手。Tomcat的Admin Web Application最初在4.1版本时出现,当时的功能包括管理context、data source、user和group等。当然也可以管理像初始化参数,user、group、role的多种数据库管理等。在后续的版本中,这些功能将得到很大的扩展,但现有的功能已经非常实用了。
Admin Web Application被定义在自动部署文件:CATALINA_BASE/webapps/admin.xml 。
(译者注:CATALINA_BASE即tomcat安装目录下的server目录)
你必须编辑这个文件,以确定Context中的docBase参数是绝对路径。也就是说,CATALINA_BASE/webapps/admin.xml 的路径是绝对路径。作为另外一种选择,你也可以删除这个自动部署文件,而在server.xml文件中建立一个Admin Web Application的context,效果是一样的。你不能管理Admin Web Application这个应用,换而言之,除了删除CATALINA_BASE/webapps/admin.xml ,你可能什么都做不了。
如果你使用UserDatabaseRealm(默认),你将需要添加一个user以及一个role到CATALINA_BASE/conf/tomcat-users.xml 文件中。你编辑这个文件,添加一个名叫“admin”的role 到该文件中,如下:
<role name="admin"/>
你同样需要有一个用户,并且这个用户的角色是“admin”。象存在的用户那样,添加一个用户(改变密码使其更加安全):
<user name="admin" password="deep_dark_secret" roles="admin"/>
当你完成这些步骤后,请重新启动Tomcat,访问http://localhost:8080/admin,你将看到一个登录界面。Admin Web Application采用基于容器管理的安全机制,并采用了Jakarta Struts框架。一旦你作为“admin”角色的用户登录管理界面,你将能够使用这个管理界面配置Tomcat。
2.配置应用管理(Manager Web Application)
Manager Web Application让你通过一个比Admin Web Application更为简单的用户界面,执行一些简单的Web应用任务。
Manager Web Application被被定义在一个自动部署文件中:
CATALINA_BASE/webapps/manager.xml 。
你必须编辑这个文件,以确保context的docBase参数是绝对路径,也就是说CATALINA_HOME/server/webapps/manager的绝对路径。
(译者注:CATALINA_HOME即tomcat安装目录)
如果你使用的是UserDatabaseRealm,那么你需要添加一个角色和一个用户到CATALINA_BASE/conf/tomcat-users.xml文件中。接下来,编辑这个文件,添加一个名为“manager”的角色到该文件中:
<role name=”manager”>
你同样需要有一个角色为“manager”的用户。像已经存在的用户那样,添加一个新用户(改变密码使其更加安全):
<user name="manager" password="deep_dark_secret" roles="manager"/>
然后重新启动Tomcat,访问http://localhost/manager/list,将看到一个很朴素的文本型管理界面,或者访问http://localhost/manager/html/list,将看到一个HMTL的管理界面。不管是哪种方式都说明你的Manager Web Application现在已经启动了。
Manager application让你可以在没有系统管理特权的基础上,安装新的Web应用,以用于测试。如果我们有一个新的web应用位于/home/user/hello下在,并且想把它安装到 /hello下,为了测试这个应用,我们可以这么做,在第一个文件框中输入“/hello”(作为访问时的path),在第二个文本框中输入“file:/home/user/hello”(作为Config URL)。
Manager application还允许你停止、重新启动、移除以及重新部署一个web应用。停止一个应用使其无法被访问,当有用户尝试访问这个被停止的应用时,将看到一个503的错误——“503 - This application is not currently available”。
移除一个web应用,只是指从Tomcat的运行拷贝中删除了该应用,如果你重新启动Tomcat,被删除的应用将再次出现(也就是说,移除并不是指从硬盘上删除)。
3.部署一个web应用
有两个办法可以在系统中部署web服务。
1> 拷贝你的WAR文件或者你的web应用文件夹(包括该web的所有内容)到$CATALINA_BASE/webapps目录下。
2> 为你的web服务建立一个只包括context内容的XML片断文件,并把该文件放到$CATALINA_BASE/webapps目录下。这个web应用本身可以存储在硬盘上的任何地方。
如果你有一个WAR文件,你若想部署它,则只需要把该文件简单的拷贝到CATALINA_BASE/webapps目录下即可,文件必须以“.war”作为扩展名。一旦Tomcat监听到这个文件,它将(缺省的)解开该文件包作为一个子目录,并以WAR文件的文件名作为子目录的名字。接下来,Tomcat将在内存中建立一个context,就好象你在server.xml文件里建立一样。当然,其他必需的内容,将从server.xml中的DefaultContext获得。
部署web应用的另一种方式是写一个Context XML片断文件,然后把该文件拷贝到CATALINA_BASE/webapps目录下。一个Context片断并非一个完整的XML文件,而只是一个context元素,以及对该应用的相应描述。这种片断文件就像是从server.xml中切取出来的context元素一样,所以这种片断被命名为“context片断”。
举个例子,如果我们想部署一个名叫MyWebApp.war的应用,该应用使用realm作为访问控制方式,我们可以使用下面这个片断:
<!--
Context fragment for deploying MyWebApp.war
-->
<Context path="/demo" docBase="webapps/MyWebApp.war"
debug="0" privileged="true">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
</Context>
把该片断命名为“MyWebApp.xml”,然后拷贝到CATALINA_BASE/webapps目录下。
这种context片断提供了一种便利的方法来部署web应用,你不需要编辑server.xml,除非你想改变缺省的部署特性,安装一个新的web应用时不需要重启动Tomcat。
4.配置虚拟主机(Virtual Hosts)
关于server.xml中“Host”这个元素,只有在你设置虚拟主机的才需要修改。虚拟主机是一种在一个web服务器上服务多个域名的机制,对每个域名而言,都好象独享了整个主机。实际上,大多数的小型商务网站都是采用虚拟主机实现的,这主要是因为虚拟主机能直接连接到Internet并提供相应的带宽,以保障合理的访问响应速度,另外虚拟主机还能提供一个稳定的固定IP。
基于名字的虚拟主机可以被建立在任何web服务器上,建立的方法就是通过在域名服务器(DNS)上建立IP地址的别名,并且告诉web服务器把去往不同域名的请求分发到相应的网页目录。因为这篇文章主要是讲Tomcat,我们不准备介绍在各种操作系统上设置DNS的方法,如果你在这方面需要帮助,请参考《DNS and Bind》一书,作者是Paul Albitz and Cricket Liu (O'Reilly)。为了示范方便,我将使用一个静态的主机文件,因为这是测试别名最简单的方法。
在Tomcat中使用虚拟主机,你需要设置DNS或主机数据。为了测试,为本地IP设置一个IP别名就足够了,接下来,你需要在server.xml中添加几行内容,如下:
<Server port="8005" shutdown="SHUTDOWN" debug="0">
<Service name="Tomcat-Standalone">
<Connector className="org.apache.coyote.tomcat4.CoyoteConnector"
port="8080" minProcessors="5" maxProcessors="75"
enableLookups="true" redirectPort="8443"/>
<Connector className="org.apache.coyote.tomcat4.CoyoteConnector"
port="8443" minProcessors="5" maxProcessors="75"
acceptCount="10" debug="0" scheme="https" secure="true"/>
<Factory className="org.apache.coyote.tomcat4.CoyoteServerSocketFactory"
clientAuth="false" protocol="TLS" />
</Connector>
<Engine name="Standalone" defaultHost="localhost" debug="0">
<!-- This Host is the default Host -->
<Host name="localhost" debug="0" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Context path="" docBase="ROOT" debug="0"/>
<Context path="/orders" docBase="/home/ian/orders" debug="0"
reloadable="true" crossContext="true">
</Context>
</Host>
<!-- This Host is the first "Virtual Host": www.example.com -->
<Host name="www.example.com" appBase="/home/example/webapp">
<Context path="" docBase="."/>
</Host>
</Engine>
</Service>
</Server>
Tomcat的server.xml文件,在初始状态下,只包括一个虚拟主机,但是它容易被扩充到支持多个虚拟主机。在前面的例子中展示的是一个简单的server.xml版本,其中粗体部分就是用于添加一个虚拟主机。每一个Host元素必须包括一个或多个context元素,所包含的context元素中必须有一个是默认的context,这个默认的context的显示路径应该为空(例如,path=””)。
5.配置基础验证(Basic Authentication)
容器管理验证方法控制着当用户访问受保护的web应用资源时,如何进行用户的身份鉴别。当一个web应用使用了Basic Authentication(BASIC参数在web.xml文件中auto-method元素中设置),而有用户访问受保护的web应用时,Tomcat将通过HTTP Basic Authentication方式,弹出一个对话框,要求用户输入用户名和密码。在这种验证方法中,所有密码将被以64位的编码方式在网络上传输。
注意:使用Basic Authentication通过被认为是不安全的,因为它没有强健的加密方法,除非在客户端和服务器端都使用HTTPS或者其他密码加密码方式(比如,在一个虚拟私人网络中)。若没有额外的加密方法,网络管理员将能够截获(或滥用)用户的密码。但是,如果你是刚开始使用Tomcat,或者你想在你的web应用中测试一下基于容器的安全管理,Basic Authentication还是非常易于设置和使用的。只需要添加<security-constraint>和<login-config>两个元素到你的web应用的web.xml文件中,并且在CATALINA_BASE/conf/tomcat-users.xml 文件中添加适当的<role>和<user>即可,然后重新启动Tomcat。
下面例子中的web.xml摘自一个俱乐部会员网站系统,该系统中只有member目录被保护起来,并使用Basic Authentication进行身份验证。请注意,这种方式将有效的代替Apache web服务器中的.htaccess文件。
<!--
Define the Members-only area, by defining
a "Security Constraint" on this Application, and
mapping it to the subdirectory (URL) that we want
to restrict.
-->
<security-constraint>
<web-resource-collection>
<web-resource-name>
Entire Application
</web-resource-name>
<url-pattern>/members/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>member</role-name>
</auth-constraint>
</security-constraint>
<!-- Define the Login Configuration for this Application -->
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>My Club Members-only Area</realm-name>
</login-config>
6.配置单点登录(Single Sign-On)
一旦你设置了realm和验证的方法,你就需要进行实际的用户登录处理。一般说来,对用户而言登录系统是一件很麻烦的事情,你必须尽量减少用户登录验证的次数。作为缺省的情况,当用户第一次请求受保护的资源时,每一个web应用都会要求用户登录。如果你运行了多个web应用,并且每个应用都需要进行单独的用户验证,那这看起来就有点像你在与你的用户搏斗。用户们不知道怎样才能把多个分离的应用整合成一个单独的系统,所有他们也就不知道他们需要访问多少个不同的应用,只是很迷惑,为什么总要不停的登录。
Tomcat 4的“single sign-on”特性允许用户在访问同一虚拟主机下所有web应用时,只需登录一次。为了使用这个功能,你只需要在Host上添加一个SingleSignOn Valve元素即可,如下所示:
<Valve className="org.apache.catalina.authenticator.SingleSignOn"
debug="0"/>
在Tomcat初始安装后,server.xml的注释里面包括SingleSignOn Valve配置的例子,你只需要去掉注释,即可使用。那么,任何用户只要登录过一个应用,则对于同一虚拟主机下的所有应用同样有效。
使用single sign-on valve有一些重要的限制:
1> value必须被配置和嵌套在相同的Host元素里,并且所有需要进行单点验证的web应用(必须通过context元素定义)都位于该Host下。
2> 包括共享用户信息的realm必须被设置在同一级Host中或者嵌套之外。
3> 不能被context中的realm覆盖。
4> 使用单点登录的web应用最好使用一个Tomcat的内置的验证方式(被定义在web.xml中的<auth-method>中),这比自定义的验证方式强,Tomcat内置的的验证方式包括basic、digest、form和client-cert。
5> 如果你使用单点登录,还希望集成一个第三方的web应用到你的网站中来,并且这个新的web应用使用它自己的验证方式,而不使用容器管理安全,那你基本上就没招了。你的用户每次登录原来所有应用时需要登录一次,并且在请求新的第三方应用时还得再登录一次。当然,如果你拥有这个第三方web应用的源码,而你又是一个程序员,你可以修改它,但那恐怕也不容易做。
6> 单点登录需要使用cookies。
7.配置用户定制目录(Customized User Directores)
一些站点允许个别用户在服务器上发布网页。例如,一所大学的学院可能想给每一位学生一个公共区域,或者是一个ISP希望给一些web空间给他的客户,但这又不是虚拟主机。在这种情况下,一个典型的方法就是在用户名前面加一个特殊字符(~),作为每位用户的网站,比如:
http://www.cs.myuniversity.edu/~username
http://members.mybigisp.com/~username
Tomcat提供两种方法在主机上映射这些个人网站,主要使用一对特殊的Listener元素。Listener的className属性应该是org.apache.catalina.startup.UserConfig,userClass属性应该是几个映射类之一。如果你的系统是Unix,它将有一个标准的/etc/passwd文件,该文件中的帐号能够被运行中的Tomcat很容易的读取,该文件指定了用户的主目录,使用PasswdUserDatabase 映射类。
<Listener className="org.apache.catalina.startup.UserConfig"
directoryName="public_html"
userClass="org.apache.catalina.startup.PasswdUserDatabase"/>
web文件需要放置在像/home/users/ian/public_html 或者 /users/jbrittain/public_html一样的目录下面。当然你也可以改变public_html 到其他任何子目录下。
实际上,这个用户目录根本不一定需要位于用户主目录下里面。如果你没有一个密码文件,但你又想把一个用户名映射到公共的像/home一样目录的子目录里面,则可以使用HomesUserDatabase类。
<Listener className="org.apache.catalina.startup.UserConfig"
directoryName="public_html" homeBase="/home"
userClass="org.apache.catalina.startup.HomesUserDatabase"/>
这样一来,web文件就可以位于像/home/ian/public_html 或者 /home/jasonb/public_html一样的目录下。这种形式对Windows而言更加有利,你可以使用一个像c:\home这样的目录。
这些Listener元素,如果出现,则必须在Host元素里面,而不能在context元素里面,因为它们都用应用于Host本身。
8.在Tomcat中使用CGI脚本
Tomcat主要是作为Servlet/JSP容器,但它也有许多传统web服务器的性能。支持通用网关接口(Common Gateway Interface,即CGI)就是其中之一,CGI提供一组方法在响应浏览器请求时运行一些扩展程序。CGI之所以被称为通用,是因为它能在大多数程序或脚本中被调用,包括:Perl,Python,awk,Unix shell scripting等,甚至包括Java。当然,你大概不会把一个Java应用程序当作CGI来运行,毕竟这样太过原始。一般而言,开发Servlet总要比CGI具有更好的效率,因为当用户点击一个链接或一个按钮时,你不需要从操作系统层开始进行处理。
Tomcat包括一个可选的CGI Servlet,允许你运行遗留下来的CGI脚本。
为了使Tomcat能够运行CGI,你必须做如下几件事:
1. 把servlets-cgi.renametojar (在CATALINA_HOME/server/lib/目录下)改名为servlets-cgi.jar。处理CGI的servlet应该位于Tomcat的CLASSPATH下。
2. 在Tomcat的CATALINA_BASE/conf/web.xml 文件中,把关于<servlet-name> CGI的那段的注释去掉(默认情况下,该段位于第241行)。
3. 同样,在Tomcat的CATALINA_BASE/conf/web.xml文件中,把关于对CGI进行映射的那段的注释去掉(默认情况下,该段位于第299行)。注意,这段内容指定了HTML链接到CGI脚本的访问方式。
4. 你可以把CGI脚本放置在WEB-INF/cgi 目录下(注意,WEB-INF是一个安全的地方,你可以把一些不想被用户看见或基于安全考虑不想暴露的文件放在此处),或者你也可以把CGI脚本放置在context下的其他目录下,并为CGI Servlet调整cgiPathPrefix初始化参数。这就指定的CGI Servlet的实际位置,且不能与上一步指定的URL重名。
5. 重新启动Tomcat,你的CGI就可以运行了。
在Tomcat中,CGI程序缺省放置在WEB-INF/cgi目录下,正如前面所提示的那样,WEB-INF目录受保护的,通过客户端的浏览器无法窥探到其中内容,所以对于放置含有密码或其他敏感信息的CGI脚本而言,这是一个非常好的地方。为了兼容其他服务器,尽管你也可以把CGI脚本保存在传统的/cgi-bin目录,但要知道,在这些目录中的文件有可能被网上好奇的冲浪者看到。另外,在Unix中,请确定运行Tomcat的用户有执行CGI脚本的权限。
9.改变Tomcat中的JSP编译器(JSP Compiler)
在Tomcat 4.1(或更高版本,大概),JSP的编译由包含在Tomcat里面的Ant程序控制器直接执行。这听起来有一点点奇怪,但这正是Ant有意为之的一部分,有一个API文档指导开发者在没有启动一个新的JVM的情况下,使用Ant。这是使用Ant进行Java开发的一大优势。另外,这也意味着你现在能够在Ant中使用任何javac支持的编译方式,这里有一个关于Apache Ant使用手册的javac page列表。使用起来是容易的,因为你只需要在<init-param> 元素中定义一个名字叫“compiler”,并且在value中有一个支持编译的编译器名字,示例如下:
<servlet>
<servlet-name>jsp</servlet-name>
<servlet-class>
org.apache.jasper.servlet.JspServlet
</servlet-class>
<init-param>
<param-name>logVerbosityLevel</param-name>
<param-value>WARNING</param-value>
</init-param>
<init-param>
<param-name>compiler</param-name>
<param-value>jikes</param-value>
</init-param>
<load-on-startup>3</load-on-startup>
</servlet>
当然,给出的编译器必须已经安装在你的系统中,并且CLASSPATH可能需要设置,那处决于你选择的是何种编译器。
10.限制特定主机访问(Restricting Access to Specific Hosts)
有时,你可能想限制对Tomcat web应用的访问,比如,你希望只有你指定的主机或IP地址可以访问你的应用。这样一来,就只有那些指定的的客户端可以访问服务的内容了。为了实现这种效果,Tomcat提供了两个参数供你配置:RemoteHostValve 和RemoteAddrValve。
通过配置这两个参数,可以让你过滤来自请求的主机或IP地址,并允许或拒绝哪些主机/IP。与之类似的,在Apache的httpd文件里有对每个目录的允许/拒绝指定。
例如你可以把Admin Web application设置成只允许本地访问,设置如下:
<Context path="/path/to/secret_files" ...>
<Valve className="org.apache.catalina.valves.RemoteAddrValve"
allow="127.0.0.1" deny=""/>
</Context>
如果没有给出允许主机的指定,那么与拒绝主机匹配的主机就会被拒绝,除此之外的都是允许的。与之类似,如果没有给出拒绝主机的指定,那么与允许主机匹配的主机就会被允许,除此之外的都是拒绝的。
--------------------------------------
posted @
2006-06-09 17:32 MyJavaWorld 阅读(225) |
评论 (0) |
编辑 收藏
JSP视窗组件所使用的struts标记库由四类标记组成:
2. Bean标记:用来在JSP页中管理bean
3. 逻辑标记:用来在JSP页中控制流程
4. HTML标记:用来生成HTML标记,在表单中显示数据,使用会话ID对URL进行编程
5. 模板标记:使用动态模板构造普通格式的页
2.1 Bean标记
这个标记库中包含用于定义新bean、访问bean及其属性的标记。Struts框架提供了多种自定义标记用来在JSP页中处理JavaBean。这些标记被封装在一个普通的标记库中,在文件struts-bean.tld中定义了它的标记库描述器。Bean标记库将标记定义在四个子类别中:
创建和复制bean的标记
脚本变量定义标记
bean翻译标记
消息国际化标记
2.1.1 Bean复制标记
可定义新bean,可复制现有bean,还可从现有bean复制属性。
<bean:define>标记用来:
定义新字符串常数
将现有的bean复制到新定义的bean对象
复制现有bean的属性来创建新的bean
<bean:define>标记属性:
属性描述Id 新定义的bean脚本变量名称,必须设置Type 定义引入脚本变量的类Value 为id属性定义的脚本变量分配一个新的对象Name 目标bean的名称。若value属性没有设置,这个属性就必须设置property Name属性定义的bean的属性名称,用来定义新的bean
13
Scope 源bean的作用域。若没有设置,搜索范围是从页作用域到应用程序作用域toScope 目标bean的作用域。若没有设置,默认值是页作用域
例如:定义一个bean:
<bean:define id=”test” value=”this is a test”/>
源bean在页作用域中被拷贝大哦请求作用域中的另一个bean:
<bean:define id=”targetBean” name=”sourceBean”
scope=”page” toScope=”request”/>
2.1.2 定义脚本变量的标记
从多种资源中定义和生成脚本变量,这些资源包括cookie,请求参数,HTTP标头等等。属性如下:
属性描述Id 脚本变量和要定义的页作用域属性的名称Name cookie/标头/参数的名称multiple 如果这个属性设置了任意一个数值,所有匹配的cookie都会被积累并存储到一个Cookie[](一个数组)类型的bean里。若无设置,指定cookie的第一个值将作为Cookie类型的值Value 如果没有匹配的cookie或数值,就返回这个属性指定的默认值
例如:
<bean:cookie id=”myCookie” name=”userName”/>
脚本变量名称是myCookie,用来创建这个属性的cookie的名称是userName。
<bean:header id=”myHeader” name=”Accept-Language”/>
脚本变量名称是myHeader,请求标头的名称是Accept-Language.
<bean:parameter id=”myParameter” name=”myParameter”>
脚本变量名称是myPatameter,它保存的请求参数的名称也是myParameter.
<bean:include>标记将对一个资源的响应进行检索,并引入一个脚本变量和字符串类型的页作用域属性。这个资源可以是一个页,一个ActionForward或一个外部URL。与<jsp:include>的不同是资源的响应被存储到一个页作用域的bean中,而不是写入到输出流。属性如下:
属性描述Id 脚本变量和要定义的页作用域属性的名称Page 一个内部资源forward 一个ActionForward Href 要包含的资源的完整URL
例如:
<bean:include id=”myInclude” page=”MyJsp?x=1”/>
脚本变量的名称是myInclude,要检索的响应来自资源MyJsp?x=1。
<bean:resource>标记将检索web应用中的资源,并引入一个脚本变量和InputStream或字符串类型的页作用域属性。如果在检索资源时发生问题,就会产生一个请求时间异常。属性如下:
属性描述
14
Id 脚本变量和要定义的页作用域属性的名称Name 资源的相对路径Input 如果这个属性不存在,资源的类型就是字符串
例如:
<bean:resource id=”myResource” name=”/WEB-INF/images/myResource.xml”/>
脚本变量的名称是myResource,要检索的资源的名称是myResource.xml。
2.1.3 显示Bean属性
标记库中定义了<bean:write>标记,用来将bean的属性输送到封装的JSP页写入器。这个标记与<jsp:getProperty>类似,属性如下:
属性描述Name 要进行属性显示的bean的名称property 要显示的属性的名称。如果这个属性类有java.beans.PropertyEditor,getAsText()或toString 方法会被调用Scope Bean的作用域,若没有设置,搜索范围是从页到应用程序作用域Filter 如果设置true,属性中的所有特殊HTML字符都将被转化为相应的实体引用Ignore 如果设置false,当发现属性时会产生一个请求时间异常,否则返回null
例如:
<bean:write name=”myBean” property=”myProperty” scope=”request”
filter=”true”/>
myBean的属性myProperty将会被显示,作用域为请求,如果发现任何HTML特殊字符都将被转化为相应的实体引用。
2.1.4 消息标记和国际化
strtus框架支持国际化和本地化。用户在他们的计算机中定义自己所在的区域,当web应用程序需要输出一条消息时,它将引用一个资源文件,在这个文件中所有的消息都使用了适当的语言。一个应用程序可能提供了很多资源文件,每个文件提供了用不同语言编写的消息。如果没有找到所选语言的资源文件,就将使用默认的资源文件。
struts框架对国际化的支持是使用<bean:message>标记,以及使用java.util数据包中定义的Locale和ResourceBundle类来实现Java2平台对这些任务的支持。Java.text.MessageFormat类定义的技术可以支持消息的格式。利用此功能,开发人员不需了解这些类的细节就可进行国际化和设置消息的格式。
用strtus实现国际化和本地化:
第一步要定义资源文件的名称,这个文件会包含用默认语言编写的在程序中会出现的所有消息。这些消息以“关键字-值”的形式存储,如下:
error.validation.location = The entered location is invalid
这个文件需要存储在类的路径下,而且它的路径要作为初始化参数传送给ActionServlet作为参数进行传递时,路径的格式要符合完整Java类的标准命名规范。比如,如果资源文件存储在WEB-INFclasses目录中,文件名是
15
ApplicationResources.properties,那么需要传递的参数值是ApplicationResources。如果文件在WEB-INFclassescomtest中,那么参数值就应该是com.test. ApplicationResources.
为了实现国际化,所有的资源文件必须都存储在基本资源文件所在的目录中。基本资源文件包含的是用默认地区语言-本地语言编写的消息。如果基本资源文件的名称是ApplicationResources.properties,那么用其他特定语言编写的资源文件的名称就应该是ApplicationResources_xx.properties(xx为ISO编码,如英语是en)。因此这些文件应包含相同的关键字,但关键字的值是用特定语言编写的。
ActionServlet的区域初始化参数必须与一个true值一起传送,这样ActionServlet就会在用户会话中的Action.LOCALE_KEY关键字下存储一个特定用户计算机的区域对象。现在可以运行一个国际化的web站点,它可以根据用户计算机上的设置的区域自动以相应的语言显示。
我们还可以使用特定的字符串来替换部分消息,就象用java.text.MessageFormat的方法一样:
error.invalid.number = The number {0} is valid
我们可以把字符串{0}替换成任何我们需要的数字。<bean:message>标签属性如下:
属性描述Key 资源文件中定义消息关键字Locale 用户会话中存储的区域对象的属性名称。若没有设置,默认值是Action.LOCALE_KEY Bundle 在应用程序上下文中,存储资源对象的属性的名称。如果没有设置这个属性,默认值是Action.MESSAGE_KEY arg0 第一个替换参数值arg1 第二个替换参数值arg2 第三个替换参数值arg3 第四个替换参数值
例如:资源文件中定义了一个消息:
info.myKey = The numbers entered are {0},{1},{2},{3}
我们可使用下面的消息标记:
<bean:message key=”info.myKey” arg0=”5” arg1=”6” arg2=”7” arg3=”8”/>
这个信息标记输出到JSP页会显示为:The numbers entered are 5,6,7,8
2.2 逻辑标记
逻辑库的标记能够用来处理外观逻辑而不需要使用scriptlet。Struts逻辑标签库包含的标记能够有条件地产生输出文本,在对象集合中循环从而重复地产生输出文本,以及应用程序流程控制。它也提供了一组在JSP页中处理流程控制的标记。这些标记封装在文件名为struts-logic.tld的标记包中。逻辑标记库定义的标记能够执行下列三个功能:
条件逻辑
重复
转发/重定向响应
16
2.2.1 条件逻辑
struts有三类条件逻辑。第一类可以比较下列实体与一个常数的大小:
cookie
请求参数
bean或bean的参数
请求标头
以下列出了这一类标记:
标记功能<equal> 如果常数与被定义的实体相等,返回true <notEqual> 如果常数与被定义的实体不相等,返回true <greaterEqual> 如果常数大于等于被定义的实体,返回true <lessEqual> 如果常数小于等于被定义的实体,返回true <lessThan> 如果常数小于被定义的实体,返回true <greaterThan> 如果常数大于被定义的实体,返回true
这一类的所有标记有相同的属性
属性描述Value 要进行比较的常数值Cookie 要进行比较的HTTP cookie的名称Header 要进行比较的HTTP请求标头的名称parameter 要进行比较的HTTP请求参数的名称Name 如果要进行比较的是bean或bean的属性,则这个属性代表bean的名称property 要进行比较的bean属性的名称Scope Bean的作用域,如果没有指定作用域,则它的搜索范围是从页到应用程序
例如:
<logic:equal parameter=”name” value=”SomeName”>
The entered name is SomeName
</logic:equal>
判断名为”name”的请求参数的值是否是”SomeName”。
<logic:greaterThan name=”bean” property=”prop” scope=”page” value=”7”>
The value of bean.Prop is greater than 7
</logic:greaterThan>
判断在页的作用域中是否有一个名为”bean”的bean,它有一个prop属性,这个属性的值是否大于7。如果这个属性能够转化为数值,就进行数值比较,否则就进行字符串比较。
第二类条件标记定义了两个标记:
<logic:present>
<logic:notPresent>
它们的功能是在计算标记体之前判断特定的项目是否存在。标记的属性和属性值决定了要进行检查的项目。
属性描述
17
Cookie 由这个属性指定的cookie将被检查是否存在Header 由这个属性指定的请求标头将被检查是否存在parameter 由这个属性指定的请求参数将被检查是否存在Name 如果没有设置property属性,那么有这个属性指定的bean将被检查是否存在。如果设置了,那么bean和bean属性都将被检查是否存在。property 检查有name属性指定的bean中是否存在指定的属性Scope 如果指定了bean的名称,这就是bean的作用域。如果没有指定作用域,搜索的范围从页到应用程序作用域。Role 检查当前已经确认的用户是否属于特殊的角色User 检查当前已经确认的用户是否有特定的名称
例如:
<logic:notPresent name=”bean” property=”prop” scope=”page”>
The bean property bean.prop is present
</logic:notPresent>
标记判断在页作用域中是否存在一个名为”bean”的bean,这个bean有一个prop属性。
第三类条件标记比较复杂,这些标记根据模板匹配的结果检查标记体的内容。换句话说,这些标记判断一个指定项目的值是否是一个特定常数的子字符串:
<logic:match>
<logic:notMatch>
这些标记允许JSP引擎在发现了匹配或是没有发现时计算标记主体。属性如下:
属性描述Cookie 要进行比较的HTTP cookie的名称Header 要进行比较的的HTTP标头的名称parameter 要进行比较的的HTTP请求参数的名称Name 若要对bean或bean的属性进行比较,这个属性是用户指定bean的名称location 如果设置了这个属性的值,将会在这个指定的位置(索引值)进行匹配scope 如果对bean进行比较,这个属性指定了bean的作用域。如果没有设置这个参数,搜索范围是从页到应用程序作用域property 要进行比较的bean的属性名称value 要进行比较的常数值
例如:
<logic:match parameter=”name” value=”xyz” location=”1”>
The parameter name is a sub-string of the string xyz from index 1
</logic:match>
标记检查名为”name”的请求参数是否是”xyz”的子字符串,但是子字符串必须从”xyz”的索引位置1开始(也就是说子字符串必须是”y”或”yz”)。
2.2.2 重复标记
在逻辑标记库中定义了<logic:iterate>标记,它能够根据特定集合中元素的数目对标记体的内容进行重复的检查。集合的类型可以是java.util.Iterator,java.util.Collection
18
,java.util.Map或是一个数组。有三种方法可以定义这个集合:
使用运行时间表达式来返回一个属性集合的集合
将集合定义为bean,并且使用name属性指定存储属性的名称。
使用name属性定义一个bean,并且使用property属性定义一个返回集合的bean属性。
当前元素的集合会被定义为一个页作用域的bean。属性如下,所有这些属性都能使用运行时表达式。
属性描述collection 如果没有设置name属性,它就指定了要进行重复的集合Id 页作用域bean和脚本变量的名称,它保存着集合中当前元素的句柄indexed 页作用域JSP bean的名称,它包含着每次重复完成后集合的当前索引Length 重复的最大次数Name 作为集合的bean的名称,或是一个bean名称,它由property属性定义的属性,是个集合Offset 重复开始位置的索引property 作为集合的Bean属性的名称Scope 如果指定了bean名称,这个属性设置bean的作用域。若没有设置,搜索范围从页到应用程序作用域Type 为当前定义的页作用域bean的类型
例如:
<logic:iterate id=”currentInt”
collection=”<% =myList %>”
type=”java.lang.Integer”
offset=”1”
length=”2”>
<% =currentint %>
</logic:iterate>
代码将从列表中的第一个元素开始重复两个元素并且能够让当前元素作为页作用域和java.lang.Integer类型的脚本变量来使用。也就是说,如果myList包含元素1,2,3,4等,代码将会打印1和2。
2.2.3 转发和重定向标记
转发标记
<logic:forward>标记能够将响应转发给重定向到特定的全局ActionForward上。ActionForward的类型决定了是使用PageContext转发响应,还是使用sendRedirect将响应进行重定向。此标记只有一个”name”属性,用来指定全局ActionForward的名称,例如:
<logic:forward name=”myGlobalForward”/>
重定向标记
<logic:redirect>标记是一个能够执行HTTP重定向的强大工具。根据指定的不同属性,它能够通过不同的方式实现重定向。它还允许开发人员指定重定向URL的查询参数。属性如下:
19
属性描述Forward 映射了资源相对路径的ActionForward Href 资源的完整URL Page 资源的相对路径Name Map类型的页名称,请求,会话或程序属性的名称,其中包含要附加大哦重定向URL(如果没有设置property属性)上的“名称-值”参数。或是具有Map类型属性的bean名称,其中包含相同的信息(没有设置property属性) Property Map类型的bean属性的名称。Bean的名称由name属性指定。Scope 如果指定了bean的名称,这个属性指定搜索bean的范围。如果没有设置,搜索范围从页到应用程序作用域ParamID 定义特定查询参数的名称ParamName 字符串类型的bean的名称,其中包含查询参数的值(如果没有设置paramProperty属性);或是一个bean的名称,它的属性(在paramProperty属性中指定)包含了查询参数值paramProperty 字符串bean属性的名称,其中包含着查询参数的值ParamScope ParamName定义的bean的搜索范围
使用这个标记时至少要指定forward,href或page中的一个属性,以便标明将响应重定向到哪个资源。
2.3 HTML标记
Struts HTML标记可以大致地分为以下几个功能:
显示表单元素和输入控件
显示错误信息
显示其他HTML元素
2.3.1 显示表单元素和输入控件
struts将HTML表单与为表单操作而定义的ActionForm bean紧密联系在一起。表单输入字段的名称与ActionForm bean里定义的属性名称是对应的。当第一次显示表单时,表单的输入字段是从ActionForm bean中移植过来的,当表单被提交时,请求参数将移植到ActionForm bean实例。
所有可以在<form>标记中使用的用来显示HTML输入控件的内嵌标记都使用下列属性来定义JavaScript事件处理器。
属性描述Onblur 字段失去了焦点Onchange 字段失去了焦点并且数值被更改了Onclick 字段被鼠标点击Ondblclick 字段被鼠标双击Onfocus 字段接收到输入焦点Onkeydown 字段拥有焦点并且有键按下
20
onkeypress 字段拥有焦点并且有键按下并释放Onkeyup 字段拥有焦点并且有键被释放onmousedown 鼠标指针指向字段并且点击onmousemove 鼠标指针指向字段并且在字段内移动onmouseout 鼠标指针指向控件,但是指针在元素外围移动onmouseover 鼠标指针没有指向字段,但是指针在元素内部移动Onmouseup 鼠标指针指向字段,并且释放了鼠标按键
<form>元素中能够被定义的其他一般属性有:
属性描述Accesskey 定义访问输入字段的快捷键Style 定义输入字段的样式styleClass 定义输入字段的样式表类Tabindex 输入字段的tab顺序
a) 表单标记
<html:form>标记用来显示HTML标记,可以指定AcitonForm bean的名称和它的类名。如果没有设置这些属性,就需要有配置文件来指定ActionMapping以表明当前输入的是哪个JSP页,以及从映射中检索的bean名和类。如果在ActionMapping指定的作用域中没有找到指定的名称,就会创建并存储一个新的bean,否则将使用找到的bean。
<form>标记能够包含与各种HTML输入字段相对应的子标记。
<html:form>标记属性如下:
属性描述Action 与表单相关的操作。在配置中,这个操作也用来标识与表单相关的ActionForm bean Enctype 表单HTTP方法的编码类型Focus 表单中需要初始化焦点的字段Method 表单使用的HTTP方法Name 与表单相关的ActionForm bean的名称。如果没有设置这个属性,bean的名称将会从配置信息中获得Onreset 表单复位时的JavaScript事件句柄Onsubmit 表单提交时的JavaScript事件句柄Scope 搜索ActionForm bean的范围。如果没有设置,将从配置文件中获取Style 使用的格式styleClass 这个元素的格式表类Type ActionForm bean的完整名称。如果没有设置,将从配置文件获得
例如:
<html:form action=”validateEmploee.do” method=”post”>
</html:form>
与表单相关的操作路径是validateEmployee,而表单数据是通过POST传递的。对于这个表单来说,ActionForm bean的其他信息,如bean名称类型,作用域,都是从表单指定操作的ActionMapping中检索得到的:
21
<form-beans>
<form-bean name=”empForm” type=”com.example.EmployeeForm”/>
</form-beans>
<action-mappings>
<action path=”/validateEmployee”
type=”com.example.ValidateExampleAction”
name=”empForm”
scope=”request”
input=”/employeeInput.jsp”>
<forward name=”success” path=”/employeeOutput.jsp”>
</action>
</action-mapping>
如果配置文件中包含上述信息,并且请求URI的*.do被映射到ActionServlet,与表单相关的ActionForm bean的名称,类型和作用域分别是empForm,com.example.EmployeeForm和request.这些属性也可以使用<html:form>标记属性进行显示的定义。
以下标记必须嵌套在<html:form>标记里
b) 按钮和取消标记
<html:button>标记显示一个按钮控件;<html:cancel>标记显示一个取消按钮。属性如下:
属性描述Property 定义在表单被提交时返回到服务器的请求参数的名称Value 按钮上的标记
c) 复位和提交标记
<html:reset>和<html:submit>标记分别能够显示HTML复位按钮和提交按钮。
d) 文本和文本区标记
<html:text>和<html:textarea>标记分别HTML文本框和文本区,属性如下:
属性描述Property 定义当表单被提交时送回到服务器的请求参数的名称,或用来确定文本元素当前值的bean的属性名称Name 属性被查询的bean的名称,它决定了文本框和文本区的值。如果没有设置,将使用与这个内嵌表单相关的ActionForm的名称
<html:text>标记还有以下属性:
属性描述Maxlength 能够输入的最大字符数
22
Size 文本框的大小(字符数)
<html:textarea>标记特有的属性如下:
属性描述Rows 文本区的行数Cols 文本区的列数
e) 检查框和复选框标记
<html:checkbox>标记能够显示检查框控件。<html:multibox>标记能够显示HTML复选框控件,请求对象在传递检查框名称时使用的getParameterValues()调用将返回一个字符串数组。属性如下:
属性描述Name Bean的名称,其属性会被用来确定检查是否以选中的状态显示。如果没有设置,将使用与这个内嵌表单相关的ActionFrom bean的名称。Property 检查框的名称,也是决定检查框是否以选中的状态显示的bean属性名称。在复选框的情况下,这个属性必须是一个数组。Value 当检查框被选中时返回到服务器的请求参数的值
例如:
<html:checkbox property=”married” value=”Y”/>
一个名为married的检查框,在表单提交时会返回一个”Y”.
f) 文件标记
<html:file>标记可以显示HTML文件控件。属性如下:
属性描述Name Bean的名称,它的属性将确定文件控件中显示的内容。如果没设置,将使用与内嵌表单相关的ActionForm bean的名称property 这个属性定义了当表单被提交时送回到服务器的请求参数的名称,以及用来确定文件控件中显示内容的bean属性名称Accept 服务器能够处理的内容类型集。它也将对客户浏览器对话框中的可选文件类型进行过滤Value 按钮上的标记,这个按钮能够在本地文件系统中浏览文件
g) 单选钮标记
<html:radio>标记用来显示HTML单选钮控件,属性如下:
属性描述Name Bean的名称,其属性会被用来确定单选钮是否以选中的状态显示。如果没有设置,将使用与这个内嵌表单相关的ActionFrom bean的名称。property 当表单被提交时送回到服务器的请求参数的名称,以及用来确定单选钮是否以被选中状态进行显示的bean属性的名称
23
Value 当单选钮被选中时返回到服务器的值
h) 隐藏标记
<html:hidden>标记能够显示HTML隐藏输入元素,属性如下:
属性描述Name Bean的名称,其属性会被用来确定隐藏元素的当前值。如果没有设置,将使用与这个内嵌表单相关的ActionFrom bean的名称。property 定义了当表单被提交时送回到服务器的请求参数的名称,以及用来确定隐藏元素当前值的bean属性的名称Value 用来初始化隐藏输入元素的值
i) 密码标记
<html:password>标记能够显示HTML密码控件,属性如下:
属性描述maxlength 能够输入的最大字符数Name Bean的名称,它的属性将用来确定密码元素的当前值。如果没有设置,将使用与这个内嵌表单相关的ActionFrom bean的名称。property 定义了当表单被提交时送回到服务器的请求参数的名称,以及用来确定密码元素当前值的bean属性的名称redisplay 在显示这个字段时,如果相应的bean属性已经被设置了数据,这个属性决定了是否显示密码的内容Size 字段的大小
j) 选择标记
<html:select>标记能够显示HTML选择控件,属性如下:
属性描述multiple 表明这个选择控件是否允许进行多选Name Bean的名称,它的属性确定了哪个。如果没有设置,将使用与这个内嵌表单相关的ActionFrom bean的名称。property 定义了当表单被提交时送回到服务器的请求参数的名称,以及用来确定哪个选项需要被选中的bean属性的名称Size 能够同时显示的选项数目Value 用来表明需要被选中的选项
k) 选项标记(这个元素需要嵌套在<html:select>标记里)
<html:option>标记用来显示HTML选项元素集合,属性如下:
24
属性描述collection Bean集合的名称,这个集合存储在某个作用域的属性中。选项的数目与集合中元素的数目相同。Property属性能够定义选项值所使用的bean属性,而labelProperty属性定义选项标记所使用的bean的属性labelName 用来指定存储于某个作用域的bean,这个bean是一个字符串的集合,能够定义<html:option>元素的标记(如果标志与值不相同) labelProperty 与collection属性共同使用时,用来定义了存储于某个作用域的bean,这个bean将返回一个字符串集合,能够用来写入<html:option>元素的value属性Name 如果这是唯一被指定的属性,它就定义了存储于某个作用域的bean,这个bean将返回一个字符串集合,能够用来写入<html:option>元素的value属性property 这个属性在与collection属性共同使用时,定义了每个要显示选项值的独立bean的name属性。如果不是与collection属性共同使用,这个属性定义了由name属性指定的bean的属性名称(如果有name属性),或是定义了一个ActionForm bean,这个bean将返回一个集合来写入选项的值
我们看一下这个标记的一些例子:
<html:option collection=”optionCollection” property=”optionValue”
labelProperty=”optionLabel”/>
标记假设在某个作用域中有一个名为optionCollection的集合,它包含了一些具有optionValue属性的独立的bean,每个属性将作为一个选项的值。每个选项的标志由bean的optionLabel属性属性进行定义。
<html:option name=”optionValues” labelName=”optionLabels”/>
标记中optionValues代表一个存储在某个作用域中的bean,它是一个字符串集合,能够用来写入选项的值,而optionLabels代表一个存储在某个作用域中的bean,它也是一个字符串集合,能够用来写入选项的标志。
2.3.2.显示错误信息的标记
<html:errors>标记能够与ActionErrors结合在一起来显示错误信息。这个标记首先要从当前区域的资源文件中读取消息关键字errors.header,然后显示消息的文本。接下去它会在ActionErrors对象(通常作为请求参数而存储在Action.ERROR_KEY关键字下)中循环,读取单个ActionError对象的消息关键字,从当前区域的资源文件中读取并格式化相应的消息,并且显示它们。然后它读取与errors.footer关键字相对应的消息并且显示出来。
通过定义property属性能够过滤要显示的消息,这个属性的值应该与ActionErrors对象中存储ActionError对象的关键字对应。属性如下:
属性描述Bundle 表示应用程序作用域属性的名称,它包含着消息资源,其默认值Acion.MESSAGE_KEY Locale 表示会话作用域属性的名称,它存储着用户当前登录的区域信息。其默认值是Action.ERROR_KEY
25
Name 表示请求属性的名称,它存储着ActionErrors对象。其默认值是Action.ERROR_KEY property 这个属性指定了ActionErrors对象中存储每个独立ActionError对象的关键字,它可以过滤消息
例子:
<html:errors/>
显示集合中所有的错误。
<html:errors property=”missing.name”/>
显示存储在missing.name关键字的错误。
2.3.3.其他HTML标记
struts HTML标记还定义了下列标记来显示其他HTML元素:
<html:html> : 显示HTML元素
<html:img> : 显示图象标记
<html:link> : 显示HTML链接或锚点
<html:rewrite> : 创建没有锚点标记的URI
这些标记的详细内容请参照struts文档。
2.4. 模板标记
动态模板是模块化WEB页布局设计的强大手段。Struts模板标记库定义了自定义标记来实现动态模板。
2.4.1.插入标记
<template:insert>标记能够在应用程序的JSP页中插入动态模板。这个标记只有一个template属性,用来定义模板JSP页。要插入到模板的页是有多个<template:put>标记来指定的,而这些标记被定义为<template:insert>标记的主体内容。
2.4.2.放置标记
<template:put>标记是<template:insert>标记内部使用的,用来指定插入到模板的资源。属性如下:
属性描述content 定义要插入的内容,比如一个JSP文件或一个HTML文件direct 如果这个设置为true,由content属性指定的内容将直接显示在JSP上而不是作为包含文件Name 要插入的内容的名称Role 如果设置了这个属性,只有在当前合法用户具有特定角色时才能进行内容的插入。
26
2.4.3.获得标记
在模板JSP页中使用<template:get>标记能够检索由<template:put>标记插入到JSP页的资源。属性如下:
属性描述Name 由<template:put>标记插入的内容的名称Role 如果设置了这个属性,只有在当前合法用户具有特定角色时才能进行内容的检索
2.4.4.使用模板标记
首先编写一个模板JSP页,它将被所有的web页使用:
<html>
<%@ taglib uri=”/template” prefix=”template” %>
<head>
<title></title>
</head>
<body>
<table width=”100%” height=”100%” >
<tr height=”10%”>
<td>
<template:get name=”header”/>
</td>
</tr>
<tr height=”80%”>
<td>
<template:get name=”content”/>
</td>
</tr>
<tr height=”10%”>
<td>
<template:get name=”footer”/>
</td>
</tr>
</table>
</body>
</html>
我们将这个文件命名为template.jsp。这个文件使用<template:get>标记来获得由JSP页使用<template:put>标记提供的内容,并且将内容在一个HTML表格中显示出来。这三个内容是标题,内容和页脚。典型的内容JSP会是这样:
<%@ taglib uri=”/template” prefix=”/template” %>
<template:insert template=”template.jsp”>
<template:put name=”header” content=”header.html”/>
27
<template:put name=”content” content=”employeeList.jsp”/>
<template:put name=”footer” content=”footer.html”/>
</template:insert>
这个应用程序JSP页使用<template:insert标记来定义模板,然后使用<template:put>标记将特定内容名称指定的资源放到模板JSP页中。如果我们有上百个布局相同的页,但突然想改变这个模板,我们只需要改变template.jsp文件。 |
|
|
posted @
2006-06-08 13:00 MyJavaWorld 阅读(296) |
评论 (0) |
编辑 收藏
|
指令名称:sudo
使用权限:在 /etc/sudoers 中有出现的使用者
使用方式:sudo -V
sudo -h
sudo -l
sudo -v
sudo -k
sudo -s
sudo -H
sudo [ -b ] [ -p prompt ] [ -u username/#uid] -s
sudo command
说明:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行
参数:
-V 显示版本编号
-h 会显示版本编号及指令的使用方式说明
-l 显示出自己(执行 sudo 的使用者)的权限
-v 因为 sudo 在第一次执行时或是在 N 分钟内没有执行(N 预设为五)会问密码,这个参数是重新做一次确认,如果超过 N 分钟,也会问密码
-k 将会强迫使用者在下一次执行 sudo 时问密码(不论有没有超过 N 分钟)
-b 将要执行的指令放在背景执行
-p prompt 可以更改问密码的提示语,其中 %u 会代换为使用者的帐号名称, %h 会显示主机名称
-u username/#uid 不加此参数,代表要以 root 的身份执行指令,而加了此参数,可以以 username 的身份执行指令(#uid 为该 username 的使用者号码)
-s 执行环境变数中的 SHELL 所指定的 shell ,或是 /etc/passwd 里所指定的 shell
-H 将环境变数中的 HOME (家目录)指定为要变更身份的使用者家目录(如不加 -u 参数就是系统管理者 root )
command 要以系统管理者身份(或以 -u 更改为其他人)执行的指令
范例:
sudo -l 列出目前的权限
sudo -V 列出 sudo 的版本资讯
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
以root身份执行指令 名称
sudo - 以超级使用者 (superuser; root) 的身分执行指令
visudo - 编辑 sudoers 档案
语法
sudo command
描述
Sudo 允许经过同意的使用者以超级使用者的身分执行指令。 Sudo 参考/etc/sudoers 这个档案来判定谁是被授权的使用者。Sudo 将会提示使用者输入密码来启始一段 N 分钟的允许时间(其中 N 是在安装的时候定义的且预设值为 5 分钟)。
Sudoers 这个档案是由一个选择性的主机别名 (host alias) 节区,一个选择性的指令别名 (command alias) 节区以及使用者说明 (user specification)节区所组成的。所有的指令别名或主机别名必须需以他们自己的关键字作为开始 (Host_Alias/Cmnd_Alias)。注意,只有第一次使用者(在使用者说明节区里有记录的使用者)使用时会有说明。
使用者说明节区格式:
使用者 接取群组 [: 接取群组 ] ...
接取群组 ::= 主机象徵 = [op]指令象徵 [,[op]指令象徵] ...
主机象徵 ::= 一个小写的主机名称或主机别名。
指令象徵 ::= 一个指令或指令别名。
op ::= 逻辑的 ! 否定运算元。
主机别名节区格式:
Host_Alias 主机别名 = 主机列表
Host_Alias ::= 这是一个关键字。
主机别名 ::= 一个大写的别名。
主机列表 ::= 以逗号间隔的一些主机名称。
指令别名节区格式:
Cmnd_Alias 指令别名 = 指令列表
Cmnd_Alias ::= 这是一个关键字。
指令别名 ::= 一个大写的别名。
指令列表 ::= 以逗号间隔的一些指令。
所有在 # 符号後面的文字都会被当作是注解。
太长的行可以使用倒斜线 字元来分成新的行。
保留的别名 ALL 在 {Host,Cmnd}_Alias 里都可以使用。
不要用 ALL 来定义一个别名,这个别名无效。
注意到 ALL 暗示全部的主机跟指令。
你可以使用这个语法从整个范围中减掉一些项目:
user host=ALL,!ALIAS1,!/etc/halt...
范例
# Host alias specification
Host_Alias HUB=houdini.rootgroup.com:
REMOTE=merlin,kodiakthorn,spirit
Host_Alias MACHINES=kalkan,alpo,milkbones
Host_Alias SERVERS=houdini,merlin,kodiakthorn,spirit
# Command alias specification
Cmnd_Alias LPCS=/usr/etc/lpc,/usr/ucb/lprm
Cmnd_Alias SHELLS=/bin/sh,/bin/csh,/bin/tcsh
Cmnd_Alias MISC=/bin/rm,/bin/cat:
SHUTDOWN=/etc/halt,/etc/shutdown
# User specification
britt REMOTE=SHUTDOWN:ALL=LPCS
robh ALL=ALL,!SHELLS
nieusma SERVERS=SHUTDOWN,/etc/reboot:
HUB=ALL,!SHELLS
jill houdini.rootgroup.com=/etc/shutdown,MISC
markm HUB=ALL,!MISC,!/etc/shutdown,!/etc/halt
billp ALL=/usr/local/bin/top:MACHINES=SHELLS
davehieb merlin=ALL:SERVERS=/etc/halt:
kodiakthorn=ALL
上面的 sudoers 说明档案是由 4 个主机别名说明,4 个指令别名说明以及 7 个使用者说明所组成的。Britt 被允许在远端机器 (merlin, kodiakthorn, 还有 spirit) 上执行 /etc/halt, /etc/shutdown, /usr/etc/lpc 以及/usr/ucb/lprm 。Rohn 被允许在任何机器上执行除了 SHELL 指令群以外的任何指令。Jill 被允许在 houdini 上执行 /etc/shotdown, /bin/rm, 以及/bin/cat 。Davehieb 可以在 merlin 以及 kodiakthorn 上执行任何指令并且可以 halt SERVERS 。
Sudoers 档案应该用 visudo 指令编辑,它会锁住该档并且做文法检查。这提供了一个可以避免愚蠢文法错误的机制。
Sudo 被设计成经由 4.3 BSD syslogging 来记录,但是如果真的想要的话还是可以记录到一个档案来取代。
如果一个没有被授权的使用者执行了 sudo 的话,将会有一封 mail 从该使用者寄送到当地的授权者处(在安装的时候定义的)。
所有的设定都是在安装的时后定义的,从 sudo.h 含入档及 Makefile 取得。
未来加强
允许巢状的主机以及指令别名。
允许在 sudoers 档案中使用 host specifier
以便使用全区符号 (user ALL,!SERVERS, ... = commands) 。
允许在 sudores 档案里的使用者别名(就如同主机/指令别名一样)。
使 visudo 对 sudoers 档案做更广泛的检查。
档案
/etc/sudoers 经授权的使用者档案。
/etc/stmp visudo 的 lock file 。
/usr/local/bin/sudo sudo 的执行档。
/usr/local/etc/visudo 修改 sudoers 档案的工具。
|
|
|
posted @
2006-06-08 12:57 MyJavaWorld 阅读(350) |
评论 (0) |
编辑 收藏Struts的Token(令牌)机制能够很好的解决表单重复提交的问题,基本原理是:服务器端在处理到达的请求之前,会将请求中包含的令牌值与保存在当前用户会话中的令牌值进行比较,看是否匹配。在处理完该请求后,且在答复发送给客户端之前,将会产生一个新的令牌,该令牌除传给客户端以外,也会将用户会话中保存的旧的令牌进行替换。这样如果用户回退到刚才的提交页面并再次提交的话,客户端传过来的令牌就和服务器端的令牌不一致,从而有效地防止了重复提交的发生。
这时其实也就是两点,第一:你需要在请求中有这个令牌值,请求中的令牌值如何保存,其实就和我们平时在页面中保存一些信息是一样的,通过隐藏字段来保存,保存的形式如: 〈input type="hidden" name="org.apache.struts.taglib.html.TOKEN" value="6aa35341f25184fd996c4c918255c3ae"〉,这个value是TokenProcessor类中的generateToken()获得的,是根据当前用户的session id和当前时间的long值来计算的。第二:在客户端提交后,我们要根据判断在请求中包含的值是否和服务器的令牌一致,因为服务器每次提交都会生成新的Token,所以,如果是重复提交,客户端的Token值和服务器端的Token值就会不一致。下面就以在数据库中插入一条数据来说明如何防止重复提交。
在Action中的add方法中,我们需要将Token值明确的要求保存在页面中,只需增加一条语句:saveToken(request);,如下所示:
public ActionForward add(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
//前面的处理省略
saveToken(request);
return mapping.findForward("add");
}在Action的insert方法中,我们根据表单中的Token值与服务器端的Token值比较,如下所示:
public ActionForward insert(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
if (isTokenValid(request, true)) {
// 表单不是重复提交
//这里是保存数据的代码
} else {
//表单重复提交
saveToken(request);
//其它的处理代码
}
}
222222222222222222222222222222222222222222222222222222222222222222222
1。重复提交、重复刷新的场景
重复提交、重复刷新都是来解决系统重复记录的问题。也就是说某个人在多次的提交某条记录(为什么?也许是闲了没有事情干的;最有可能是用户根本就不知道自己的提交结果是否已经执行了?!)。
但出现了这样的问题并不见得就必须处理,要看你所开发的系统的类别而定。比如你接手的是某个资源管理系统,系统本身从需求的角度根本就不允许出现"重复"的记录,在这样需求的约束条件下,去执行重复的提交动作只会引发“业务级异常”的产生,根本就不可能执行成功也就无所谓避免不避免的问题了。
2。防止后退的场景
了解了重复刷新、重复提交的场景,我们来了解一下"防止后退"操作的原因是什么?比如你在开发某个投票系统,它有很多的步骤,并且这些步骤之间是有联系的,比如第一步会将某些信息发送给第二步,第二步缓存了这些信息,同时将自身的信息发送给了第三步。。。。。等等,如果此时用户处在第三步骤下,我们想象一下某个淘气用户的用户点击了后退按钮,此时屏幕出现了第二步骤的页面,他再次的修改或者再次的提交,进入到下一个步骤(也就是第三步骤),错误就会在此产生?!什么错误呢?最为典型的就是这样的操作直接导致了对于第一个步骤信息的丢失!(如果这样的信息是依靠Request存放的话,当然你可以存放在Session或者更大的上下文环境中,但这不是个好主意!关于信息存放的问题,下次在就这个问题详细的讨论)
三。如何处理的问题
当然很多的系统(比如订票系统从需求上本身是允许个人重复订票的)是必须要避免重复刷新、重复提交、以及防止后退的问题的,但即使是这样的问题,也要区分如何处理以及在哪里处理的(网上只是告诉你如何处理,但很少去区分在哪里处理的),显然处理的方式无非是客户端或者服务器端两种,而面对不同的位置处理的方式也是不同的,但有一点要事先声明:任何客户端(尤其是B/S端)的处理都是不可信任的,最好的也是最应该的是服务器端的处理方法。
客户端处理:
面对客户端我们可以使用Javascript脚本来解决,如下
1。重复刷新、重复提交
Ways One:设置一个变量,只允许提交一次。
<script language="javascript">
var checkSubmit*** = false;
function checkSubmit() {
if (checkSubmit*** == true) {
return false;
}
checkSubmit*** = true;
return true;
}
document.ondblclick = function docondblclick() {
window.event.returnValue = false;
}
document.onclick = function doconclick() {
if (checkSubmit***) {
window.event.returnValue = false;
}
}
</script>
<html:form action="myAction.do" method="post" onsubmit="return checkSubmit();">
Way Two : 将提交按钮或者image置为disable
<html:form action="myAction.do" method="post"
onsubmit="getElById('submitInput').disabled = true; return true;">
<html:image styleId="submitInput" src="images/ok_b.gif" border="0" />
</html:form>
2。防止用户后退
这里的方法是千姿百态,有的是更改浏览器的历史纪录的,比如使用window.history.forward()方法;有的是“用新页面的URL替换当前的历史纪录,这样浏览历史记录中就只有一个页面,后退按钮永远不会变为可用。”比如使用javascript:location.replace(this.href); event.returnValue=false;
2.服务器端的处理(这里只说Struts框架的处理)
利用同步令牌(Token)机制来解决Web应用中重复提交的问题,Struts也给出了一个参考实现。
基本原理:
服务器端在处理到达的请求之前,会将请求中包含的令牌值与保存在当前用户会话中的令牌值进行比较,
看是否匹配。在处理完该请求后,且在答复发送给客户端之前,将会产生一个新的令牌,该令牌除传给
客户端以外,也会将用户会话中保存的旧的令牌进行替换。这样如果用户回退到刚才的提交页面并再次
提交的话,客户端传过来的令牌就和服务器端的令牌不一致,从而有效地防止了重复提交的发生。
if (isTokenValid(request, true)) {
// your code here
return mapping.findForward("success");
} else {
saveToken(request);
return mapping.findForward("submitagain");
}
Struts根据用户会话ID和当前系统时间来生成一个唯一(对于每个会话)令牌的,具体实现可以参考
TokenProcessor类中的generateToken()方法。
1. //验证事务控制令牌,<html:form >会自动根据session中标识生成一个隐含input代表令牌,防止两次提交
2. 在action中:
//<input type="hidden" name="org.apache.struts.taglib.html.TOKEN"
// value="6aa35341f25184fd996c4c918255c3ae">
if (!isTokenValid(request))
errors.add(ActionErrors.GLOBAL_ERROR,
new ActionError("error.transaction.token"));
resetToken(request); //删除session中的令牌
3. action有这样的一个方法生成令牌
protected String generateToken(HttpServletRequest request) {
HttpSession session = request.getSession();
try {
byte id[] = session.getId().getBytes();
byte now[] =
new Long(System.currentTimeMillis()).toString().getBytes();
MessageDigest md = MessageDigest.getInstance("MD5");
md.update(id);
md.update(now);
return (toHex(md.digest()));
} catch (IllegalStateException e) {
return (null);
} catch (NoSuchAlgorithmException e) {
return (null);
}
}
总结
对于重复提交、重复刷新、防止后退等等都是属于系统为避免重复记录而需要解决的问题,在客户端去处理需要针对每一种的可能提出相应的解决方案,然而在服务器端看来只不过是对于数据真实性的检验问题,基于令牌的处理就是一劳永逸的方法。
同时我们也看到,从不同的角度去看待问题,其解决的方法也是不同的。客户端更追求的是用户的操作,而服务端则将注意力放在了数据的处理上,所以在某个对于服务器端看似容易的问题上,用客户端来解决却麻烦了很多!反之依然。所以在某些问题的处理上我们需要综合考虑和平衡,是用客户端来解决?还是用服务器端来处理
posted @
2006-06-02 18:15 MyJavaWorld 阅读(3321) |
评论 (4) |
编辑 收藏
将特定请求映射到特定Action的相关信息存储在ActionMapping中,ActionServelt将ActionMapping传送到Action类的execute()方法,Action将使用ActionMapping的findForward()方法,此方法返回一个指定名称的ActionForward,这样Action就完成了本地转发。若没有找到具体的ActionForward,就返回一个null.
ActionMapping的方法:
public ExceptionConfig findException(Class type) ,查找异常对象
public ActionForward findForward(String name) 可在映射中动态添加ActionForward:
public String[] findForwards()找到一个Action可以使用的actionForward列表
public ActionForward getInputForward() 得到本action的输入ActionForard.
ActionMapping继承于org.apache.struts.config.ActionConfig
Action类
Action类真正实现应用程序的事务逻辑,它们负责处理请求。在收到请求后,ActionServlet会:
1.为这个请求选择适当的Action
2.如果需要,创建Action的一个实例
3.调用Action的execute()方法
如果ActionServlet不能找到有效的映射,它会调用默认的Action类(在配置文件中定义)。如果找到了ActionServlet将适当的ActionMapping类转发给Action,这个Action使用ActionMapping找到本地转发,然后获得并设置ActionMapping属性。根据servlet的环境和被覆盖的execute ()方法的签名,ActionServlet也会传送ServletRequest对象或HttpServletRequest对象。
所有Action类都扩展org.apache.struts.action.Action类,并且覆盖类中定义的某一个execute ()方法。有两个execute ()方法:
处理非HTTP(一般的)请求:
public ActionForward execute (ActionMapping action,
Acionform form,
ServletRequest request,
ServletResponse response)
throws java.lang.Exception
处理HTTP请求:
public ActionForward execute (ActionMapping action,
Acionform form,
HttpServletRequest request,
HttpServletResponse response)
throws java.lang.Exception
Action类必须以”线程安全”的方式进行编程,因为控制器会令多个同时发生的请求共享同一个实例,相应的,在设计Action类时就需要注意以下几点:
不能使用实例或静态变量存储特定请求的状态信息,它们会在同一个操作中共享跨越请求的全局资源
如果要访问的资源(如JavaBeans和会话变量)在并行访问时需要进行保护,那么访问就要进行同步
Action类的方法
除了execute ()方法外,还有以下方法:
可以获得或设置与请求相关联的区域:
public Locale getLocale(HttpServletRequest request)
public void setLocale(HttpServletRequest request,Locale locale)
为应用程序获得消息资源:
protected MessageResources getResources(HttpServletRequest request)
protected MessageResources getResources(HttpServletRequest request,String key)
检查用户是否点击表单上的”取消”键,如果是,将返回true:
public Boolean isCancelled(HttpServletRequest request)
当应用程序发生错误时,Action类能够使用下面方法存储错误信息:
public void saveErrors(HttpServletRequest request,ActionErrors errors)
public void saveMessages(HttpServletRequest request,ActionMessages messages)
ActionError实例被用来存储错误信息,这个方法在错误关键字下的请求属性列表中存储ActionError对象。通过使用在struts标记库中定义的自定义标记,JSP页能够显示这些错误信息。ActionMessages 用来存储一些提示信息,不是错误,在jsp页面可以使用标记现实这些提示信息。
请求有效性处理,使用令牌可以有效的防止重复提交。
protected String generateToken(HttpServletRequest request) 创建一个令牌.
protected boolean isTokenValid(HttpServletRequest request) 检查令牌是否有效
protected boolean isTokenValid(HttpServletRequest request,Boolean reset) 检查令牌是否有效,并且重置令牌(如果reset 是true)
protected void resetToken(HttpServletRequest request) 重置令牌
protected void saveToken(HttpServletRequest request) 添加令牌
获取数据库连接
protected DataSource getDataSource(HttpServletRequest request)
protected DataSource getDataSource(HttpServletRequest request, String key)
其他的
ActionServlet getServlet() 可以获得本action的配置信息.
DispatchAction类
DispatchAction是Action的子类,主要功能可以实现,动态的方法调用。例如action中有一个方法update(ActionMapping mapping, Actionform form, HttpServletRequest request, HttpServletResponse response), 可以通过 saveSubscription.do?method=update来调用update方法。这个类不需要我们实现其他方法,我们只要实现 XXX(ActionMapping mapping, Actionform form, HttpServletRequest request, HttpServletResponse response)就可以了。
在http://www.chinajavaworld.net/forum/topic.cgi?forum=48&topic=1166&show=150和
http://www.chinajavaworld.net/forum/topic.cgi?forum=48&topic=1129有对DispatchAction和LookupDispatchAction的详细介绍
SwitchAction类
SwitchAction是Action的子类,主要功能是将请求在不同的模块之间转发。对于大的项目很有用。具体看http://www.chinajavaworld.net/forum/topic.cgi?forum=48&topic=1029&show=0
Actionform类
假设用户在应用程序中为每个表单都创建了一个Actionform bean,对于每个在struts-config.xml文件中定义的bean,框架在调用Action类的execute()方法之前会进行以下操作:
在相关联的关键字下,它检查用于适当类的bean实例的用户会话(或请求),如果在会话(或请求)中没有可用的bean,它就会自动创建一个新的bean并添加到用户的会话(或请求)中。至于是在会话还是请求取决于struts-config.xml 中Action 的scope属性。在创建Actionform的时候,系统会将请求中的值,进行相应的类型转换以后对Actionform进行初始化。
对于请求中每个与bean属性名称对应的参数,Action调用相应的设置方法。
当Action execute()被调用时,最新的Actionform bean传送给它,参数值就可以立即使用了。
Actionform类扩展org.apache.struts.action.Actionform类,程序开发人员创建的bean能够包含额外的属性,而且ActionServlet可能使用反射(允许从已加载的对象中回收信息)访问它。
Actionform类提供了另一种处理错误的手段,提供两个方法:
Public ActionErrors validate(ActionMappin mapping, ServletRequest request)
Public ActionErrors validate(ActionMappin mapping, HttpServletRequest request)
你应该在自己的bean里覆盖validate()方法,并在配置文件里设置<action>元素的validate为true。在ActionServlet调用Action类前,它会调用validate(),如果返回的ActionErrors不是null,则Actinform会根据错误关键字将ActionErrors存储在请求属性列表中。
如果返回的不是null,而且长度大于0,则根据错误关键字将实例存储在请求的属性列表中,然后ActionServlet将响应转发到配置文件<action>元素的input属性所指向的目标。
如果需要执行特定的数据有效性检查,最好在Action类中进行这个操作,而不是在Actionform类中进行。
方法reset()可将bean的属性恢复到默认值:
public void reset(ActionMapping mapping,HttpServletRequest request)
public void reset(ActionMapping mapping,ServletRequest request)
典型的ActionFrom bean只有属性的设置与读取方法(getXXX),而没有实现事务逻辑的方法。只有简单的输入检查逻辑,使用的目的是为了存储用户在相关表单中输入的最新数据,以便可以将同一网页进行再生,同时提供一组错误信息,这样就可以让用户修改不正确的输入数据。而真正对数据有效性进行检查的是Action类或适当的事务逻辑bean。
Actionform中属性允许的类型boolean,byte,short,char,int,long,float,double,Boolean,Btye,Short, Character,Integer,Long,Float,Double,String,Date,Time,Timestamp,Object,以及以上类型的数组。
如果Actionform bean 的属性是一个数组则相应的设置和读取方法要做部分修改。对于数组setXXX(…),和getXXX()在jsp页面中意义不大。应该将添加setXXX( int index , …. ) 方法和getXXX ( int index )方法。这两个方法对于jsp页面来说更有意义。jsp中的property应该是XXX[0]。
如果Actionform bean的属性是一个 Map则应该提供方法setXXX( String key , … )和getXXX(String key),使得jsp页面可以访问Map属性。jsp中的properry应该是XXX(keyname)。
通过getXXX(int index),setXXX (int index,…),getXXX(String key),setXXX(String key,…)可以方便的实现重复html输入框。
例如:
public class Fooform extends Actionform {
private String yourName;
public String getYourName() {
return yourName;
}
public void setYourName(String yourName) {
this.yourName = yourName;
}
private final Map values = new HashMap();
public void setvalue(String key, Object value) {
values.put(key, value);
}
public Object getvalue(String key) {
if ( values.containsKey(key)){
return values.get(key);
}else{
return "";
}
}
…
}
Validatorform类
org.apache.struts.validator.Validatorform类继承了Actionform类。使用本类可以方便的实现表单参数的校验。在校验的时候,使用在struts-config.xml中action元素中的name属性,确定要在validation.xml中取得校验规则的依据。
使用本类可以方便的解决同一个form在不同的Action中使用不同的校验规则的问题。在继承了Validatorform的类中不再需要我们去写validate方法。而是由Validatorform中的validate方法通过读取validation.xml中的描述信息来进行数据的校验。使用Validatorform也可以方便的实现在浏览器端实现利用脚本的校验。
Validatorform中的新增加的方法:
int getPage()
java.util.Map getResultvalueMap()
ValidatorResults getValidatorResults()
void setPage(int page)
void setValidatorResults()
使用本类可以大大提高我们的编程效率。
ValidatorActionform类
org.apache.struts.validator.ValidatorActionform类继承了Validatorform类。使用本类可以方便的实现表单参数的校验。在校验的时候,使用在struts-config.xml中action元素中的path属性,确定要在validation.xml中取得校验规则的依据。
DynaActionform类
org.apache.struts.action.DynaActionform类继承了Actionform类。使用本类可以方便的实现动态表单。创建不确定的表单,如果jsp发生了变化只需要修改jsp页面和struts-config.xml文件中的form-bean元素就可以了。我们的程序中完全可以不用手工书写actionform的类了。
DynaActionform中的方法:
boolean contains(String name, String key) 检测name(key)在actionform中是否存在。
Object get(String name) 从actionform中取得name的值。
Object get(String name,int index) 从actionform中取得 name对象的index个值。
Object get(String name,String key)从actionform中取得name对象的key对应的值。
Map getMap() 返回对象中包含的对象属性名列表。
void remove(String name, String key) 删除一个元素。
void set(String name, int index,Object value) 对actionform中的属性进行赋值。
void set(String name,Object value)
void set(String name, Strign key ,Object value)
DynaValidatorform类
org.apache.struts.validator.DynaValidatorform类继承了DynaActionform类。使用本类可以方便的实现表单参数的校验。在校验的时候,使用在struts-config.xml中action元素中的name属性,确定要在validation.xml中取得校验规则的依据。
至于校验,同Validatorform。
DynaValidatorform中的新增加的方法:
int getPage()
java.util.Map getResultvalueMap()
ValidatorResults getValidatorResults()
void setPage(int page)
void setValidatorResults()
DynaValidatorActionform类
org.apache.struts.validator.DynaValidatorActionform类继承了DynaValidatorform类。使用本类可以方便的实现表单参数的校验。在校验的时候,使用在struts-config.xml中action元素中的path属性,确定要在validation.xml中取得校验规则的依据。
至于校验,同Validatorform。
ActionForward类
ActionForward类继承了org.apache.struts.config.ForwardConfig。
ForwardConfig的方法:
String getName() 虚名字
String getPath() 实际路径
boolean getRedirect() 是否重定向
void setName(String name)
void setPath(String path)
void setRedirect(boolean redirect)
ActionForward目的是控制器将Action类的处理结果转发至目的地。
Action类获得ActionForward实例的句柄,然后可用两种方法返回到ActionServlet,
ActionMapping实例被传送到execute()方法,使用actionMapping的findForward(String name)根据名称获取一个全局转发或本地转发。
另一种是调用下面的一个构造器来创建它们自己的一个实例:
public ActionForward()
public ActionForward(String path)
public ActionForward(String path,Boolean redirect)
public ActionForward(String name,String path,Boolean redirect)
public ActionForward(String name,String path,Boolean redirect, boolean contextRelative)
或下面的构造方法(下面是ActionForward的子类)
ForwardingActionForward()
ForwardingActionForward(String path)
RedirectingActionForward()
RedirectingActionForward(String path
posted @
2006-06-02 18:14 MyJavaWorld 阅读(929) |
评论 (2) |
编辑 收藏
1 定义头和根元素
部署描述符文件就像所有XML文件一样,必须以一个XML头开始。这个头声明可以使用的XML版本并给出文件的字符编码。
DOCYTPE声明必须立即出现在此头之后。这个声明告诉服务器适用的servlet规范的版本(如2.2或2.3)并指定管理此文件其余部分内容的语法的DTD(Document Type Definition,文档类型定义)。
所有部署描述符文件的顶层(根)元素为web-app。请注意,XML元素不像HTML,他们是大小写敏感的。因此,web-App和WEB-APP都是不合法的,web-app必须用小写。
2 部署描述符文件内的元素次序
XML 元素不仅是大小写敏感的,而且它们还对出现在其他元素中的次序敏感。例如,XML头必须是文件中的第一项,DOCTYPE声明必须是第二项,而web- app元素必须是第三项。在web-app元素内,元素的次序也很重要。服务器不一定强制要求这种次序,但它们允许(实际上有些服务器就是这样做的)完全拒绝执行含有次序不正确的元素的Web应用。这表示使用非标准元素次序的web.xml文件是不可移植的。
下面的列表给出了所有可直接出现在web-app元素内的合法元素所必需的次序。例如,此列表说明servlet元素必须出现在所有servlet-mapping元素之前。请注意,所有这些元素都是可选的。因此,可以省略掉某一元素,但不能把它放于不正确的位置。
l icon icon元素指出IDE和GUI工具用来表示Web应用的一个和两个图像文件的位置。
l display-name display-name元素提供GUI工具可能会用来标记这个特定的Web应用的一个名称。
l description description元素给出与此有关的说明性文本。
l context-param context-param元素声明应用范围内的初始化参数。
l filter 过滤器元素将一个名字与一个实现javax.servlet.Filter接口的类相关联。
l filter-mapping 一旦命名了一个过滤器,就要利用filter-mapping元素把它与一个或多个servlet或JSP页面相关联。
l listener servlet API的版本2.3增加了对事件监听程序的支持,事件监听程序在建立、修改和删除会话或servlet环境时得到通知。Listener元素指出事件监听程序类。
l servlet 在向servlet或JSP页面制定初始化参数或定制URL时,必须首先命名servlet或JSP页面。Servlet元素就是用来完成此项任务的。
l servlet-mapping 服务器一般为servlet提供一个缺省的URL:http://host/webAppPrefix/servlet/ServletName。但是,常常会更改这个URL,以便servlet可以访问初始化参数或更容易地处理相对URL。在更改缺省URL时,使用servlet-mapping元素。
l session-config 如果某个会话在一定时间内未被访问,服务器可以抛弃它以节省内存。可通过使用HttpSession的setMaxInactiveInterval方法明确设置单个会话对象的超时值,或者可利用session-config元素制定缺省超时值。
l mime-mapping 如果Web应用具有想到特殊的文件,希望能保证给他们分配特定的MIME类型,则mime-mapping元素提供这种保证。
l welcom-file-list welcome-file-list元素指示服务器在收到引用一个目录名而不是文件名的URL时,使用哪个文件。
l error-page error-page元素使得在返回特定HTTP状态代码时,或者特定类型的异常被抛出时,能够制定将要显示的页面。
l taglib taglib元素对标记库描述符文件(Tag Libraryu Descriptor file)指定别名。此功能使你能够更改TLD文件的位置,而不用编辑使用这些文件的JSP页面。
l resource-env-ref resource-env-ref元素声明与资源相关的一个管理对象。
l resource-ref resource-ref元素声明一个资源工厂使用的外部资源。
l security-constraint security-constraint元素制定应该保护的URL。它与login-config元素联合使用
l login-config 用login-config元素来指定服务器应该怎样给试图访问受保护页面的用户授权。它与sercurity-constraint元素联合使用。
l security-role security-role元素给出安全角色的一个列表,这些角色将出现在servlet元素内的security-role-ref元素的role-name子元素中。分别地声明角色可使高级IDE处理安全信息更为容易。
l env-entry env-entry元素声明Web应用的环境项。
l ejb-ref ejb-ref元素声明一个EJB的主目录的引用。
l ejb-local-ref ejb-local-ref元素声明一个EJB的本地主目录的应用。
3 分配名称和定制的UL
在web.xml中完成的一个最常见的任务是对servlet或JSP页面给出名称和定制的URL。用servlet元素分配名称,使用servlet-mapping元素将定制的URL与刚分配的名称相关联。
3.1 分配名称
为了提供初始化参数,对servlet或JSP页面定义一个定制URL或分配一个安全角色,必须首先给servlet或JSP页面一个名称。可通过 servlet元素分配一个名称。最常见的格式包括servlet-name和servlet-class子元素(在web-app元素内),如下所示:
<servlet>
<servlet-name>Test</servlet-name>
<servlet-class>moreservlets.TestServlet</servlet-class>
</servlet>
这表示位于WEB-INF/classes/moreservlets/TestServlet的servlet已经得到了注册名Test。给 servlet一个名称具有两个主要的含义。首先,初始化参数、定制的URL模式以及其他定制通过此注册名而不是类名引用此servlet。其次,可在 URL而不是类名中使用此名称。因此,利用刚才给出的定义,URL http://host/webAppPrefix/servlet/Test 可用于 http://host/webAppPrefix/servlet/moreservlets.TestServlet 的场所。
请记住:XML元素不仅是大小写敏感的,而且定义它们的次序也很重要。例如,web-app元素内所有servlet元素必须位于所有servlet- mapping元素(下一小节介绍)之前,而且还要位于5.6节和5.11节讨论的与过滤器或文档相关的元素(如果有的话)之前。类似地,servlet 的servlet-name子元素也必须出现在servlet-class之前。5.2节”部署描述符文件内的元素次序”将详细介绍这种必需的次序。
例如,程序清单5-1给出了一个名为TestServlet的简单servlet,它驻留在moreservlets程序包中。因为此servlet是扎根在一个名为deployDemo的目录中的Web应用的组成部分,所以TestServlet.class放在deployDemo/WEB- INF/classes/moreservlets中。程序清单5-2给出将放置在deployDemo/WEB-INF/内的web.xml文件的一部分。此web.xml文件使用servlet-name和servlet-class元素将名称Test与TestServlet.class相关联。图 5-1和图5-2分别显示利用缺省URL和注册名调用TestServlet时的结果。
程序清单5-1 TestServlet.java
package moreservlets;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** Simple servlet used to illustrate servlet naming
* and custom URLs.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
* http://www.moreservlets.com/.
* ? 2002 Marty Hall; may be freely used or adapted.
*/
public class TestServlet extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
String uri = request.getRequestURI();
out.println(ServletUtilities.headWithTitle("Test Servlet") +
"<BODY BGCOLOR=\"#FDF5E6\">\n" +
"<H2>URI: " + uri + "</H2>\n" +
"</BODY></HTML>");
}
}
程序清单5-2 web.xml(说明servlet名称的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<!-- … -->
<servlet>
<servlet-name>Test</servlet-name>
<servlet-class>moreservlets.TestServlet</servlet-class>
</servlet>
<!-- … -->
</web-app>
3.2 定义定制的URL
大多数服务器具有一个缺省的serlvet URL:
http://host/webAppPrefix/servlet/packageName.ServletName。虽然在开发中使用这个URL很方便,但是我们常常会希望另一个URL用于部署。例如,可能会需要一个出现在Web应用顶层的URL(如,http: //host/webAppPrefix/Anyname),并且在此URL中没有servlet项。位于顶层的URL简化了相对URL的使用。此外,对许多开发人员来说,顶层URL看上去比更长更麻烦的缺省URL更简短。
事实上,有时需要使用定制的URL。比如,你可能想关闭缺省URL映射,以便更好地强制实施安全限制或防止用户意外地访问无初始化参数的servlet。如果你禁止了缺省的URL,那么你怎样访问servlet呢?这时只有使用定制的URL了。
为了分配一个定制的URL,可使用servlet-mapping元素及其servlet-name和url-pattern子元素。Servlet- name元素提供了一个任意名称,可利用此名称引用相应的servlet;url-pattern描述了相对于Web应用的根目录的URL。url- pattern元素的值必须以斜杠(/)起始。
下面给出一个简单的web.xml摘录,它允许使用URL http://host/webAppPrefix/UrlTest而不是http://host/webAppPrefix/servlet/Test或
http: //host/webAppPrefix/servlet/moreservlets.TestServlet。请注意,仍然需要XML头、 DOCTYPE声明以及web-app封闭元素。此外,可回忆一下,XML元素出现地次序不是随意的。特别是,需要把所有servlet元素放在所有 servlet-mapping元素之前。
<servlet>
<servlet-name>Test</servlet-name>
<servlet-class>moreservlets.TestServlet</servlet-class>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name>Test</servlet-name>
<url-pattern>/UrlTest</url-pattern>
</servlet-mapping>
URL模式还可以包含通配符。例如,下面的小程序指示服务器发送所有以Web应用的URL前缀开始,以..asp结束的请求到名为BashMS的servlet。
<servlet>
<servlet-name>BashMS</servlet-name>
<servlet-class>msUtils.ASPTranslator</servlet-class>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name>BashMS</servlet-name>
<url-pattern>/*.asp</url-pattern>
</servlet-mapping>
3.3 命名JSP页面
因为JSP页面要转换成sevlet,自然希望就像命名servlet一样命名JSP页面。毕竟,JSP页面可能会从初始化参数、安全设置或定制的URL中受益,正如普通的serlvet那样。虽然JSP页面的后台实际上是servlet这句话是正确的,但存在一个关键的猜疑:即,你不知道JSP页面的实际类名(因为系统自己挑选这个名字)。因此,为了命名JSP页面,可将jsp-file元素替换为servlet-calss元素,如下所示:
<servlet>
<servlet-name>Test</servlet-name>
<jsp-file>/TestPage.jsp</jsp-file>
</servlet>
命名JSP页面的原因与命名servlet的原因完全相同:即为了提供一个与定制设置(如,初始化参数和安全设置)一起使用的名称,并且,以便能更改激活 JSP页面的URL(比方说,以便多个URL通过相同页面得以处理,或者从URL中去掉.jsp扩展名)。但是,在设置初始化参数时,应该注意,JSP页面是利用jspInit方法,而不是init方法读取初始化参数的。
例如,程序清单5-3给出一个名为TestPage.jsp的简单JSP页面,它的工作只是打印出用来激活它的URL的本地部分。TestPage.jsp放置在deployDemo应用的顶层。程序清单5-4给出了用来分配一个注册名PageName,然后将此注册名与http://host/webAppPrefix/UrlTest2/anything 形式的URL相关联的web.xml文件(即,deployDemo/WEB-INF/web.xml)的一部分。
程序清单5-3 TestPage.jsp
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE>
JSP Test Page
</TITLE>
</HEAD>
<BODY BGCOLOR="#FDF5E6">
<H2>URI: <%= request.getRequestURI() %></H2>
</BODY>
</HTML>
程序清单5-4 web.xml(说明JSP页命名的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<!-- ... -->
<servlet>
<servlet-name>PageName</servlet-name>
<jsp-file>/TestPage.jsp</jsp-file>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name> PageName </servlet-name>
<url-pattern>/UrlTest2/*</url-pattern>
</servlet-mapping>
<!-- ... -->
</web-app>
4 禁止激活器servlet
对servlet 或JSP页面建立定制URL的一个原因是,这样做可以注册从 init(servlet)或jspInit(JSP页面)方法中读取得初始化参数。但是,初始化参数只在是利用定制URL模式或注册名访问 servlet或JSP页面时可以使用,用缺省URL http://host/webAppPrefix/servlet/ServletName 访问时不能使用。因此,你可能会希望关闭缺省URL,这样就不会有人意外地调用初始化servlet了。这个过程有时称为禁止激活器servlet,因为多数服务器具有一个用缺省的servlet URL注册的标准servlet,并激活缺省的URL应用的实际servlet。
有两种禁止此缺省URL的主要方法:
l 在每个Web应用中重新映射/servlet/模式。
l 全局关闭激活器servlet。
重要的是应该注意到,虽然重新映射每个Web应用中的/servlet/模式比彻底禁止激活servlet所做的工作更多,但重新映射可以用一种完全可移植的方式来完成。相反,全局禁止激活器servlet完全是针对具体机器的,事实上有的服务器(如ServletExec)没有这样的选择。下面的讨论对每个Web应用重新映射/servlet/ URL模式的策略。后面提供在Tomcat中全局禁止激活器servlet的详细内容。
4.1 重新映射/servlet/URL模式
在一个特定的Web应用中禁止以http://host/webAppPrefix/servlet/ 开始的URL的处理非常简单。所需做的事情就是建立一个错误消息servlet,并使用前一节讨论的url-pattern元素将所有匹配请求转向该 servlet。只要简单地使用:
<url-pattern>/servlet/*</url-pattern>
作为servlet-mapping元素中的模式即可。
例如,程序清单5-5给出了将SorryServlet servlet(程序清单5-6)与所有以http://host/webAppPrefix/servlet/ 开头的URL相关联的部署描述符文件的一部分。
程序清单5-5 web.xml(说明JSP页命名的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<!-- ... -->
<servlet>
<servlet-name>Sorry</servlet-name>
<servlet-class>moreservlets.SorryServlet</servlet-class>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name> Sorry </servlet-name>
<url-pattern>/servlet/*</url-pattern>
</servlet-mapping>
<!-- ... -->
</web-app>
程序清单5-6 SorryServlet.java
package moreservlets;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** Simple servlet used to give error messages to
* users who try to access default servlet URLs
* (i.e., http://host/webAppPrefix/servlet/ServletName)
* in Web applications that have disabled this
* behavior.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
* http://www.moreservlets.com/.
* ? 2002 Marty Hall; may be freely used or adapted.
*/
public class SorryServlet extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
String title = "Invoker Servlet Disabled.";
out.println(ServletUtilities.headWithTitle(title) +
"<BODY BGCOLOR=\"#FDF5E6\">\n" +
"<H2>" + title + "</H2>\n" +
"Sorry, access to servlets by means of\n" +
"URLs that begin with\n" +
"http://host/webAppPrefix/servlet/\n" +
"has been disabled.\n" +
"</BODY></HTML>");
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
4.2 全局禁止激活器:Tomcat
Tomcat 4中用来关闭缺省URL的方法与Tomcat 3中所用的很不相同。下面介绍这两种方法:
1.禁止激活器: Tomcat 4
Tomcat 4用与前面相同的方法关闭激活器servlet,即利用web.xml中的url-mapping元素进行关闭。不同之处在于Tomcat使用了放在 install_dir/conf中的一个服务器专用的全局web.xml文件,而前面使用的是存放在每个Web应用的WEB-INF目录中的标准 web.xml文件。
因此,为了在Tomcat 4中关闭激活器servlet,只需在install_dir/conf/web.xml中简单地注释出/servlet/* URL映射项即可,如下所示:
<!--
<servlet-mapping>
<servlet-name>invoker</servlet-name>
<url-pattern>/servlet/*</url-pattern>
</servlet-mapping>
-->
再次提醒,应该注意这个项是位于存放在install_dir/conf的Tomcat专用的web.xml文件中的,此文件不是存放在每个Web应用的WEB-INF目录中的标准web.xml。
2.禁止激活器:Tomcat3
在Apache Tomcat的版本3中,通过在install_dir/conf/server.xml中注释出InvokerInterceptor项全局禁止缺省 servlet URL。例如,下面是禁止使用缺省servlet URL的server.xml文件的一部分。
<!--
<RequsetInterceptor
className="org.apache.tomcat.request.InvokerInterceptor"
debug="0" prefix="/servlet/" />
-->
5 初始化和预装载servlet与JSP页面
这里讨论控制servlet和JSP页面的启动行为的方法。特别是,说明了怎样分配初始化参数以及怎样更改服务器生存期中装载servlet和JSP页面的时刻。
5.1 分配servlet初始化参数
利用init-param元素向servlet提供初始化参数,init-param元素具有param-name和param-value子元素。例如,在下面的例子中,如果initServlet servlet是利用它的注册名(InitTest)访问的,它将能够从其方法中调用getServletConfig(). getInitParameter(”param1″)获得”Value 1″,调用getServletConfig().getInitParameter(”param2″)获得”2″。
<servlet>
<servlet-name>InitTest</servlet-name>
<servlet-class>moreservlets.InitServlet</servlet-class>
<init-param>
<param-name>param1</param-name>
<param-value>value1</param-value>
</init-param>
<init-param>
<param-name>param2</param-name>
<param-value>2</param-value>
</init-param>
</servlet>
在涉及初始化参数时,有几点需要注意:
l 返回值。GetInitParameter的返回值总是一个String。因此,在前一个例子中,可对param2使用Integer.parseInt获得一个int。
l JSP中的初始化。JSP页面使用jspInit而不是init。JSP页面还需要使用jsp-file元素代替servlet-class。
l 缺省URL。初始化参数只在通过它们的注册名或与它们注册名相关的定制URL模式访问Servlet时可以使用。因此,在这个例子中,param1和 param2初始化参数将能够在使用URL http://host/webAppPrefix/servlet/InitTest 时可用,但在使用URL http://host/webAppPrefix/servlet/myPackage.InitServlet 时不能使用。
例如,程序清单5-7给出一个名为InitServlet的简单servlet,它使用init方法设置firstName和emailAddress字段。程序清单5-8给出分配名称InitTest给servlet的web.xml文件。
程序清单5-7 InitServlet.java
package moreservlets;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** Simple servlet used to illustrate servlet
* initialization parameters.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
* http://www.moreservlets.com/.
* ? 2002 Marty Hall; may be freely used or adapted.
*/
public class InitServlet extends HttpServlet {
private String firstName, emailAddress;
public void init() {
ServletConfig config = getServletConfig();
firstName = config.getInitParameter("firstName");
emailAddress = config.getInitParameter("emailAddress");
}
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
String uri = request.getRequestURI();
out.println(ServletUtilities.headWithTitle("Init Servlet") +
"<BODY BGCOLOR=\"#FDF5E6\">\n" +
"<H2>Init Parameters:</H2>\n" +
"<UL>\n" +
"<LI>First name: " + firstName + "\n" +
"<LI>Email address: " + emailAddress + "\n" +
"</UL>\n" +
"</BODY></HTML>");
}
}
程序清单5-8 web.xml(说明初始化参数的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<!-- ... -->
<servlet>
<servlet-name>InitTest</servlet-name>
<servlet-class>moreservlets.InitServlet</servlet-class>
<init-param>
<param-name>firstName</param-name>
<param-value>Larry</param-value>
</init-param>
<init-param>
<param-name>emailAddress</param-name>
<param-value>Ellison@Microsoft.com</param-value>
</init-param>
</servlet>
<!-- ... -->
</web-app>
5.2 分配JSP初始化参数
给JSP页面提供初始化参数在三个方面不同于给servlet提供初始化参数。
1)使用jsp-file而不是servlet-class。因此,WEB-INF/web.xml文件的servlet元素如下所示:
<servlet>
<servlet-name>PageName</servlet-name>
<jsp-file>/RealPage.jsp</jsp-file>
<init-param>
<param-name>...</param-name>
<param-value>...</param-value>
</init-param>
...
</servlet>
2) 几乎总是分配一个明确的URL模式。对servlet,一般相应地使用以http://host/webAppPrefix/servlet/ 开始的缺省URL。只需记住,使用注册名而不是原名称即可。这对于JSP页面在技术上也是合法的。例如,在上面给出的例子中,可用URL http://host/webAppPrefix/servlet/PageName 访问RealPage.jsp的对初始化参数具有访问权的版本。但在用于JSP页面时,许多用户似乎不喜欢应用常规的servlet的URL。此外,如果 JSP页面位于服务器为其提供了目录清单的目录中(如,一个既没有index.html也没有index.jsp文件的目录),则用户可能会连接到此 JSP页面,单击它,从而意外地激活未初始化的页面。因此,好的办法是使用url-pattern(5.3节)将JSP页面的原URL与注册的 servlet名相关联。这样,客户机可使用JSP页面的普通名称,但仍然激活定制的版本。例如,给定来自项目1的servlet定义,可使用下面的 servlet-mapping定义:
<servlet-mapping>
<servlet-name>PageName</servlet-name>
<url-pattern>/RealPage.jsp</url-pattern>
</servlet-mapping>
3)JSP页使用jspInit而不是init。自动从JSP页面建立的servlet或许已经使用了inti方法。因此,使用JSP声明提供一个init方法是不合法的,必须制定jspInit方法。
为了说明初始化JSP页面的过程,程序清单5-9给出了一个名为InitPage.jsp的JSP页面,它包含一个jspInit方法且放置于 deployDemo Web应用层次结构的顶层。一般,http://host/deployDemo/InitPage.jsp 形式的URL将激活此页面的不具有初始化参数访问权的版本,从而将对firstName和emailAddress变量显示null。但是, web.xml文件(程序清单5-10)分配了一个注册名,然后将该注册名与URL模式/InitPage.jsp相关联。
程序清单5-9 InitPage.jsp
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD><TITLE>JSP Init Test</TITLE></HEAD>
<BODY BGCOLOR="#FDF5E6">
<H2>Init Parameters:</H2>
<UL>
<LI>First name: <%= firstName %>
<LI>Email address: <%= emailAddress %>
</UL>
</BODY></HTML>
<%!
private String firstName, emailAddress;
public void jspInit() {
ServletConfig config = getServletConfig();
firstName = config.getInitParameter("firstName");
emailAddress = config.getInitParameter("emailAddress");
}
%>
程序清单5-10 web.xml(说明JSP页面的init参数的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<!-- ... -->
<servlet>
<servlet-name>InitPage</servlet-name>
<jsp-file>/InitPage.jsp</jsp-file>
<init-param>
<param-name>firstName</param-name>
<param-value>Bill</param-value>
</init-param>
<init-param>
<param-name>emailAddress</param-name>
<param-value>gates@oracle.com</param-value>
</init-param>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name> InitPage</servlet-name>
<url-pattern>/InitPage.jsp</url-pattern>
</servlet-mapping>
<!-- ... -->
</web-app>
5.3 提供应用范围内的初始化参数
一般,对单个地servlet或JSP页面分配初始化参数。指定的servlet或JSP页面利用ServletConfig的 getInitParameter方法读取这些参数。但是,在某些情形下,希望提供可由任意servlet或JSP页面借助ServletContext 的getInitParameter方法读取的系统范围内的初始化参数。
可利用context-param元素声明这些系统范围内的初始化值。context-param元素应该包含param-name、param-value以及可选的description子元素,如下所示:
<context-param>
<param-name>support-email</param-name>
<param-value>blackhole@mycompany.com</param-value>
</context-param>
可回忆一下,为了保证可移植性,web.xml内的元素必须以正确的次序声明。但这里应该注意,context-param元素必须出现任意与文档有关的元素(icon、display-name或description)之后及filter、filter-mapping、listener或 servlet元素之前。
5.4 在服务器启动时装载servlet
假如servlet或JSP页面有一个要花很长时间执行的init (servlet)或jspInit(JSP)方法。例如,假如init或jspInit方法从某个数据库或ResourceBundle查找产量。这种情况下,在第一个客户机请求时装载servlet的缺省行为将对第一个客户机产生较长时间的延迟。因此,可利用servlet的load-on- startup元素规定服务器在第一次启动时装载servlet。下面是一个例子。
<servlet>
<servlet-name> … </servlet-name>
<servlet-class> … </servlet-class> <!-- Or jsp-file -->
<load-on-startup/>
</servlet>
可以为此元素体提供一个整数而不是使用一个空的load-on-startup。想法是服务器应该在装载较大数目的servlet或JSP页面之前装载较少数目的servlet或JSP页面。例如,下面的servlet项(放置在Web应用的WEB-INF目录下的web.xml文件中的web-app元素内)将指示服务器首先装载和初始化SearchServlet,然后装载和初始化由位于Web应用的result目录中的index.jsp文件产生的 servlet。
<servlet>
<servlet-name>Search</servlet-name>
<servlet-class>myPackage.SearchServlet</servlet-class> <!-- Or jsp-file -->
<load-on-startup>1</load-on-startup>
</servlet>
<servlet>
<servlet-name>Results</servlet-name>
<servlet-class>/results/index.jsp</servlet-class> <!-- Or jsp-file -->
<load-on-startup>2</load-on-startup>
</servlet>
6 声明过滤器
servlet版本2.3引入了过滤器的概念。虽然所有支持servlet API版本2.3的服务器都支持过滤器,但为了使用与过滤器有关的元素,必须在web.xml中使用版本2.3的DTD。
过滤器可截取和修改进入一个servlet或JSP页面的请求或从一个servlet或JSP页面发出的相应。在执行一个servlet或JSP页面之前,必须执行第一个相关的过滤器的doFilter方法。在该过滤器对其FilterChain对象调用doFilter时,执行链中的下一个过滤器。如果没有其他过滤器,servlet或JSP页面被执行。过滤器具有对到来的ServletRequest对象的全部访问权,因此,它们可以查看客户机名、查找到来的cookie等。为了访问servlet或JSP页面的输出,过滤器可将响应对象包裹在一个替身对象(stand-in object)中,比方说把输出累加到一个缓冲区。在调用FilterChain对象的doFilter方法之后,过滤器可检查缓冲区,如有必要,就对它进行修改,然后传送到客户机。
例如,程序清单5-11帝国难以了一个简单的过滤器,只要访问相关的servlet或JSP页面,它就截取请求并在标准输出上打印一个报告(开发过程中在桌面系统上运行时,大多数服务器都可以使用这个过滤器)。
程序清单5-11 ReportFilter.java
package moreservlets;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import java.util.*;
/** Simple filter that prints a report on the standard output
* whenever the associated servlet or JSP page is accessed.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
* http://www.moreservlets.com/.
* ? 2002 Marty Hall; may be freely used or adapted.
*/
public class ReportFilter implements Filter {
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws ServletException, IOException {
HttpServletRequest req = (HttpServletRequest)request;
System.out.println(req.getRemoteHost() +
" tried to access " +
req.getRequestURL() +
" on " + new Date() + ".");
chain.doFilter(request,response);
}
public void init(FilterConfig config)
throws ServletException {
}
public void destroy() {}
}
一旦建立了一个过滤器,可以在web.xml中利用filter元素以及filter-name(任意名称)、file-class(完全限定的类名)和(可选的)init-params子元素声明它。请注意,元素在web.xml的web-app元素中出现的次序不是任意的;允许服务器(但不是必需的)强制所需的次序,并且实际中有些服务器也是这样做的。但这里要注意,所有filter元素必须出现在任意filter-mapping元素之前, filter-mapping元素又必须出现在所有servlet或servlet-mapping元素之前。
例如,给定上述的ReportFilter类,可在web.xml中作出下面的filter声明。它把名称Reporter与实际的类ReportFilter(位于moreservlets程序包中)相关联。
<filter>
<filter-name>Reporter</filter-name>
<filter-class>moresevlets.ReportFilter</filter-class>
</filter>
一旦命名了一个过滤器,可利用filter-mapping元素把它与一个或多个servlet或JSP页面相关联。关于此项工作有两种选择。
首先,可使用filter-name和servlet-name子元素把此过滤器与一个特定的servlet名(此servlet名必须稍后在相同的 web.xml文件中使用servlet元素声明)关联。例如,下面的程序片断指示系统只要利用一个定制的URL访问名为SomeServletName 的servlet或JSP页面,就运行名为Reporter的过滤器。
<filter-mapping>
<filter-name>Reporter</filter-name>
<servlet-name>SomeServletName</servlet-name>
</filter-mapping>
其次,可利用filter-name和url-pattern子元素将过滤器与一组servlet、JSP页面或静态内容相关联。例如,相面的程序片段指示系统只要访问Web应用中的任意URL,就运行名为Reporter的过滤器。
<filter-mapping>
<filter-name>Reporter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
例如,程序清单5-12给出了将ReportFilter过滤器与名为PageName的servlet相关联的web.xml文件的一部分。名字 PageName依次又与一个名为TestPage.jsp的JSP页面以及以模式http: //host/webAppPrefix/UrlTest2/ 开头的URL相关联。TestPage.jsp的源代码已经JSP页面命名的谈论在前面的3节”分配名称和定制的URL”中给出。事实上,程序清单5- 12中的servlet和servlet-name项从该节原封不动地拿过来的。给定这些web.xml项,可看到下面的标准输出形式的调试报告(换行是为了容易阅读)。
audit.irs.gov tried to access
mycompany.com/deployDemo/UrlTest2/business/tax-plan.html
on Tue Dec 25 13:12:29 EDT 2001.
程序清单5-12 Web.xml(说明filter用法的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<filter>
<filter-name>Reporter</filter-name>
<filter-class>moresevlets.ReportFilter</filter-class>
</filter>
<!-- ... -->
<filter-mapping>
<filter-name>Reporter</filter-name>
<servlet-name>PageName</servlet-name>
</filter-mapping>
<!-- ... -->
<servlet>
<servlet-name>PageName</servlet-name>
<jsp-file>/RealPage.jsp</jsp-file>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name> PageName </servlet-name>
<url-pattern>/UrlTest2/*</url-pattern>
</servlet-mapping>
<!-- ... -->
</web-app>
7 指定欢迎页
假如用户提供了一个像http: //host/webAppPrefix/directoryName/ 这样的包含一个目录名但没有包含文件名的URL,会发生什么事情呢?用户能得到一个目录表?一个错误?还是标准文件的内容?如果得到标准文件内容,是 index.html、index.jsp、default.html、default.htm或别的什么东西呢?
Welcome-file-list 元素及其辅助的welcome-file元素解决了这个模糊的问题。例如,下面的web.xml项指出,如果一个URL给出一个目录名但未给出文件名,服务器应该首先试用index.jsp,然后再试用index.html。如果两者都没有找到,则结果有赖于所用的服务器(如一个目录列表)。
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
<welcome-file>index.html</welcome-file>
</welcome-file-list>
虽然许多服务器缺省遵循这种行为,但不一定必须这样。因此,明确地使用welcom-file-list保证可移植性是一种良好的习惯。
8 指定处理错误的页面
现在我了解到,你在开发servlet和JSP页面时从不会犯错误,而且你的所有页面是那样的清晰,一般的程序员都不会被它们的搞糊涂。但是,是人总会犯错误的,用户可能会提供不合规定的参数,使用不正确的URL或者不能提供必需的表单字段值。除此之外,其它开发人员可能不那么细心,他们应该有些工具来克服自己的不足。
error-page元素就是用来克服这些问题的。它有两个可能的子元素,分别是:error-code和exception- type。第一个子元素error-code指出在给定的HTTP错误代码出现时使用的URL。第二个子元素excpetion-type指出在出现某个给定的Java异常但未捕捉到时使用的URL。error-code和exception-type都利用location元素指出相应的URL。此 URL必须以/开始。location所指出的位置处的页面可通过查找HttpServletRequest对象的两个专门的属性来访问关于错误的信息,这两个属性分别是:javax.servlet.error.status_code和javax.servlet.error.message。
可回忆一下,在web.xml内以正确的次序声明web-app的子元素很重要。这里只要记住,error-page出现在web.xml文件的末尾附近,servlet、servlet-name和welcome-file-list之后即可。
8.1 error-code元素
为了更好地了解error-code元素的值,可考虑一下如果不正确地输入文件名,大多数站点会作出什么反映。这样做一般会出现一个404错误信息,它表示不能找到该文件,但几乎没提供更多有用的信息。另一方面,可以试一下在www.microsoft.com、www.ibm.com 处或者特别是在www.bea.com 处输出未知的文件名。这是会得出有用的消息,这些消息提供可选择的位置,以便查找感兴趣的页面。提供这样有用的错误页面对于Web应用来说是很有价值得。事实上rm-error-page子元素)。由form-login-page给出的HTML表单必须具有一个j_security_check的 ACTION属性、一个名为j_username的用户名文本字段以及一个名为j_password的口令字段。
例如,程序清单5-19指示服务器使用基于表单的验证。Web应用的顶层目录中的一个名为login.jsp的页面将收集用户名和口令,并且失败的登陆将由相同目录中名为login-error.jsp的页面报告。
程序清单5-19 web.xml(说明login-config的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<!-- ... -->
<security-constraint> ... </security-constraint>
<login-config>
<auth-method> FORM </auth-method>
<form-login-config>
<form-login-page>/login.jsp</form-login-page>
<form-error-page>/login-error.jsp</form-error-page>
</form-login-config>
</login-config>
<!-- ... -->
</web-app>
9.2 限制对Web资源的访问
现在,可以指示服务器使用何种验证方法了。”了不起,”你说道,”除非我能指定一个来收到保护的 URL,否则没有多大用处。”没错。指出这些URL并说明他们应该得到何种保护正是security-constriaint元素的用途。此元素在 web.xml中应该出现在login-config的紧前面。它包含是个可能的子元素,分别是:web-resource-collection、 auth-constraint、user-data-constraint和display-name。下面各小节对它们进行介绍。
l web-resource-collection
此元素确定应该保护的资源。所有security-constraint元素都必须包含至少一个web-resource-collection项。此元素由一个给出任意标识名称的web-resource-name元素、一个确定应该保护的URL的url-pattern元素、一个指出此保护所适用的 HTTP命令(GET、POST等,缺省为所有方法)的http-method元素和一个提供资料的可选description元素组成。例如,下面的 Web-resource-collection项(在security-constratint元素内)指出Web应用的proprietary目录中所有文档应该受到保护。
<security-constraint>
<web-resource-coolection>
<web-resource-name>Proprietary</web-resource-name>
<url-pattern>/propritary/*</url-pattern>
</web-resource-coolection>
<!-- ... -->
</security-constraint>
重要的是应该注意到,url-pattern仅适用于直接访问这些资源的客户机。特别是,它不适合于通过MVC体系结构利用 RequestDispatcher来访问的页面,或者不适合于利用类似jsp:forward的手段来访问的页面。这种不匀称如果利用得当的话很有好处。例如,servlet可利用MVC体系结构查找数据,把它放到bean中,发送请求到从bean中提取数据的JSP页面并显示它。我们希望保证决不直接访问受保护的JSP页面,而只是通过建立该页面将使用的bean的servlet来访问它。url-pattern和auth-contraint元素可通过声明不允许任何用户直接访问JSP页面来提供这种保证。但是,这种不匀称的行为可能让开发人员放松警惕,使他们偶然对应受保护的资源提供不受限制的访问。
l auth-constraint
尽管web-resource-collention元素质出了哪些URL应该受到保护,但是auth-constraint元素却指出哪些用户应该具有受保护资源的访问权。此元素应该包含一个或多个标识具有访问权限的用户类别role- name元素,以及包含(可选)一个描述角色的description元素。例如,下面web.xml中的security-constraint元素部门规定只有指定为Administrator或Big Kahuna(或两者)的用户具有指定资源的访问权。
<security-constraint>
<web-resource-coolection> ... </web-resource-coolection>
<auth-constraint>
<role-name>administrator</role-name>
<role-name>kahuna</role-name>
</auth-constraint>
</security-constraint>
重要的是认识到,到此为止,这个过程的可移植部分结束了。服务器怎样确定哪些用户处于任何角色以及它怎样存放用户的口令,完全有赖于具体的系统。
例如,Tomcat使用install_dir/conf/tomcat-users.xml将用户名与角色名和口令相关联,正如下面例子中所示,它指出用户joe(口令bigshot)和jane(口令enaj)属于administrator和kahuna角色。
<tomcat-users>
<user name="joe" password="bigshot" roles="administrator,kahuna" />
<user name="jane" password="enaj" roles="kahuna" />
</tomcat-users>
l user-data-constraint
这个可选的元素指出在访问相关资源时使用任何传输层保护。它必须包含一个transport-guarantee子元素(合法值为NONE、 INTEGRAL或CONFIDENTIAL),并且可选地包含一个description元素。transport-guarantee为NONE值将对所用的通讯协议不加限制。INTEGRAL值表示数据必须以一种防止截取它的人阅读它的方式传送。虽然原理上(并且在未来的HTTP版本中),在 INTEGRAL和CONFIDENTIAL之间可能会有差别,但在当前实践中,他们都只是简单地要求用SSL。例如,下面指示服务器只允许对相关资源做 HTTPS连接:
<security-constraint>
<!-- ... -->
<user-data-constraint>
<transport-guarantee>CONFIDENTIAL</transport-guarantee>
</user-data-constraint>
</security-constraint>
l display-name
security-constraint的这个很少使用的子元素给予可能由GUI工具使用的安全约束项一个名称。
9.3 分配角色名
迄今为止,讨论已经集中到完全由容器(服务器)处理的安全问题之上了。但servlet以及JSP页面也能够处理它们自己的安全问题。
例如,容器可能允许用户从bigwig或bigcheese角色访问一个显示主管人员额外紧贴的页面,但只允许bigwig用户修改此页面的参数。完成这种更细致的控制的一种常见方法是调用HttpServletRequset的isUserInRole方法,并据此修改访问。
Servlet的 security-role-ref子元素提供出现在服务器专用口令文件中的安全角色名的一个别名。例如,假如编写了一个调用 request.isUserInRole(”boss”)的servlet,但后来该servlet被用在了一个其口令文件调用角色manager而不是boss的服务器中。下面的程序段使该servlet能够使用这两个名称中的任何一个。
<servlet>
<!-- ... -->
<security-role-ref>
<role-name>boss</role-name> <!-- New alias -->
<role-link>manager</role-link> <!-- Real name -->
</security-role-ref>
</servlet>
也可以在web-app内利用security-role元素提供将出现在role-name元素中的所有安全角色的一个全局列表。分别地生命角色使高级IDE容易处理安全信息。
10 控制会话超时
如果某个会话在一定的时间内未被访问,服务器可把它扔掉以节约内存。可利用HttpSession的setMaxInactiveInterval方法直接设置个别会话对象的超时值。如果不采用这种方法,则缺省的超时值由具体的服务器决定。但可利用session-config和session- timeout元素来给出一个适用于所有服务器的明确的超时值。超时值的单位为分钟,因此,下面的例子设置缺省会话超时值为三个小时(180分钟)。
<session-config>
<session-timeout>180</session-timeout>
</session-config>
11 Web应用的文档化
越来越多的开发环境开始提供servlet和JSP的直接支持。例子有Borland Jbuilder Enterprise Edition、Macromedia UltraDev、Allaire JRun Studio(写此文时,已被Macromedia收购)以及IBM VisuaAge for Java等。
大量的web.xml元素不仅是为服务器设计的,而且还是为可视开发环境设计的。它们包括icon、display-name和discription等。
可回忆一下,在web.xml内以适当地次序声明web-app子元素很重要。不过,这里只要记住icon、display-name和description是web.xml的web-app元素内的前三个合法元素即可。
l icon
icon元素指出GUI工具可用来代表Web应用的一个和两个图像文件。可利用small-icon元素指定一幅16 x 16的GIF或JPEG图像,用large-icon元素指定一幅32 x 32的图像。下面举一个例子:
<icon>
<small-icon>/images/small-book.gif</small-icon>
<large-icon>/images/tome.jpg</large-icon>
</icon>
l display-name
display-name元素提供GUI工具可能会用来标记此Web应用的一个名称。下面是个例子。
<display-name>Rare Books</display-name>
l description
description元素提供解释性文本,如下所示:
<description>
This Web application represents the store developed for
rare-books.com, an online bookstore specializing in rare
and limited-edition books.
</description>
12 关联文件与MIME类型
服务器一般都具有一种让Web站点管理员将文件扩展名与媒体相关联的方法。例如,将会自动给予名为mom.jpg的文件一个image/jpeg的MIME 类型。但是,假如你的Web应用具有几个不寻常的文件,你希望保证它们在发送到客户机时分配为某种MIME类型。mime-mapping元素(具有 extension和mime-type子元素)可提供这种保证。例如,下面的代码指示服务器将application/x-fubar的MIME类型分配给所有以.foo结尾的文件。
<mime-mapping>
<extension>foo</extension>
<mime-type>application/x-fubar</mime-type>
</mime-mapping>
或许,你的Web应用希望重载(override)标准的映射。例如,下面的代码将告诉服务器在发送到客户机时指定.ps文件作为纯文本(text/plain)而不是作为PostScript(application/postscript)。
<mime-mapping>
<extension>ps</extension>
<mime-type>application/postscript</mime-type>
</mime-mapping>
13 定位TLD
JSP taglib元素具有一个必要的uri属性,它给出一个TLD(Tag Library Descriptor)文件相对于Web应用的根的位置。TLD文件的实际名称在发布新的标签库版本时可能会改变,但我们希望避免更改所有现有JSP页面。此外,可能还希望使用保持taglib元素的简练性的一个简短的uri。这就是部署描述符文件的taglib元素派用场的所在了。Taglib包含两个子元素:taglib-uri和taglib-location。taglib-uri元素应该与用于JSP taglib元素的uri属性的东西相匹配。Taglib-location元素给出TLD文件的实际位置。例如,假如你将文件chart-tags- 1.3beta.tld放在WebApp/WEB-INF/tlds中。现在,假如web.xml在web-app元素内包含下列内容。
<taglib>
<taglib-uri>/charts.tld</taglib-uri>
<taglib-location>
/WEB-INF/tlds/chart-tags-1.3beta.tld
</taglib-location>
</taglib>
给出这个说明后,JSP页面可通过下面的简化形式使用标签库。
<%@ taglib uri="/charts.tld" prefix="somePrefix" %>
14 指定应用事件监听程序
应用事件监听器程序是建立或修改servlet环境或会话对象时通知的类。它们是servlet规范的版本2.3中的新内容。这里只简单地说明用来向Web应用注册一个监听程序的web.xml的用法。
注册一个监听程序涉及在web.xml的web-app元素内放置一个listener元素。在listener元素内,listener-class元素列出监听程序的完整的限定类名,如下所示:
<listener>
<listener-class>package.ListenerClass</listener-class>
</listener>
虽然listener元素的结构很简单,但请不要忘记,必须正确地给出web-app元素内的子元素的次序。listener元素位于所有的servlet 元素之前以及所有filter-mapping元素之后。此外,因为应用生存期监听程序是serlvet规范的2.3版本中的新内容,所以必须使用 web.xml DTD的2.3版本,而不是2.2版本。
例如,程序清单5-20给出一个名为ContextReporter的简单的监听程序,只要Web应用的Servlet-Context建立(如装载Web应用)或消除(如服务器关闭)时,它就在标准输出上显示一条消息。程序清单5-21给出此监听程序注册所需要的web.xml文件的一部分。
程序清单5-20 ContextReporterjava
package moreservlets;
import javax.servlet.*;
import java.util.*;
/** Simple listener that prints a report on the standard output
* when the ServletContext is created or destroyed.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
* http://www.moreservlets.com/.
* ? 2002 Marty Hall; may be freely used or adapted.
*/
public class ContextReporter implements ServletContextListener {
public void contextInitialized(ServletContextEvent event) {
System.out.println("Context created on " +
new Date() + ".");
}
public void contextDestroyed(ServletContextEvent event) {
System.out.println("Context destroyed on " +
new Date() + ".");
}
}
程序清单5-21 web.xml(声明一个监听程序的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<!-- ... -->
<filter-mapping> … </filter-mapping>
<listener>
<listener-class>package.ListenerClass</listener-class>
</listener>
<servlet> ... </servlet>
<!-- ... -->
</web-app>
15 J2EE元素
本节描述用作J2EE环境组成部分的Web应用的web.xml元素。这里将提供一个简明的介绍,详细内容可以参阅http://java.sun.com/j2ee/j2ee-1_3-fr-spec.pdf的Java 2 Plantform Enterprise Edition版本1.3规范的第5章。
l distributable
distributable 元素指出,Web应用是以这样的方式编程的:即,支持集群的服务器可安全地在多个服务器上分布Web应用。例如,一个可分布的应用必须只使用 Serializable对象作为其HttpSession对象的属性,而且必须避免用实例变量(字段)来实现持续性。distributable元素直接出现在discription元素之后,并且不包含子元素或数据,它只是一个如下的标志。
l resource-env-ref
resource -env-ref元素声明一个与某个资源有关的管理对象。此元素由一个可选的description元素、一个resource-env-ref- name元素(一个相对于java:comp/env环境的JNDI名)以及一个resource-env-type元素(指定资源类型的完全限定的类),如下所示:
<resource-env-ref>
<resource-env-ref-name>
jms/StockQueue
</resource-env-ref-name>
<resource-env-ref-type>
javax.jms.Queue
</resource-env-ref-type>
</resource-env-ref>
l env-entry
env -entry元素声明Web应用的环境项。它由一个可选的description元素、一个env-entry-name元素(一个相对于java: comp/env环境JNDI名)、一个env-entry-value元素(项值)以及一个env-entry-type元素(java.lang程序包中一个类型的完全限定类名,java.lang.Boolean、java.lang.String等)组成。下面是一个例子:
<env-entry>
<env-entry-name>minAmout</env-entry-name>
<env-entry-value>100.00</env-entry-value>
<env-entry-type>minAmout</env-entry-type>
</env-entry>
l ejb-ref
ejb -ref元素声明对一个EJB的主目录的应用。它由一个可选的description元素、一个ejb-ref-name元素(相对于java: comp/env的EJB应用)、一个ejb-ref-type元素(bean的类型,Entity或Session)、一个home元素(bean的主目录接口的完全限定名)、一个remote元素(bean的远程接口的完全限定名)以及一个可选的ejb-link元素(当前bean链接的另一个 bean的名称)组成。
l ejb-local-ref
ejb-local-ref元素声明一个EJB的本地主目录的引用。除了用local-home代替home外,此元素具有与ejb-ref元素相同的属性并以相同的方式使用
|
|
|
posted @
2006-06-02 12:48 MyJavaWorld 阅读(256) |
评论 (0) |
编辑 收藏