Perf4j使用一主要演示了性能监控的日志直接打印在标准输出流。那么使用二呢则主要来演示怎么来分析打印出来的日志文件。
由于我们还没有跟log4j集成,日志文件打印在标准输出流,我们需要把标准输出流重定向到times.log文件中。重定向有两种方式:直接copy到文件中,或者在eclipse里指定下输出文件。我主要是用eclipse指定输出文件。

然后运行代码(Perf4j使用一的Example.java),控制台会在第一句话中打出[Console output redirected to file:E:\yangpingyu\work\times.log],这样运行的结果会同时打印在文件中和标准输出中。
有了times.log,我们就可以对日志文件进行分析,以找出有问题的代码。
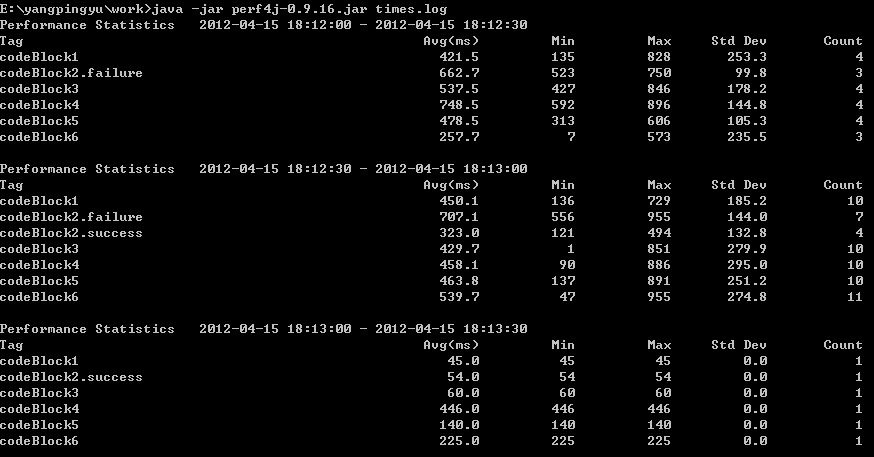
分析日志命令:
E:\yangpingyu\work>java -jar perf4j-0.9.16.jar times.log
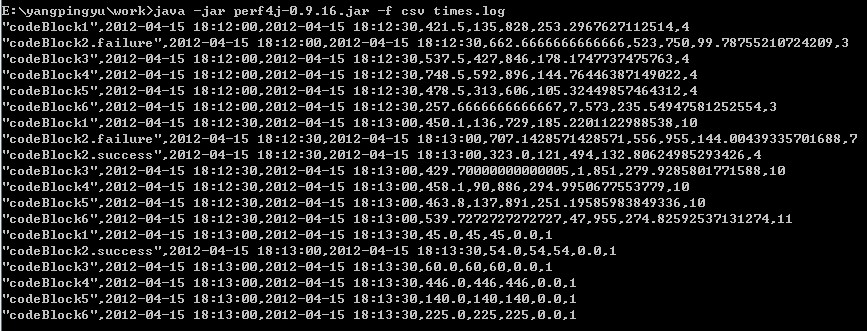
以csv的格式来查看结果,命令如下:
java -jar perf4j-0.9.16.jar -f csv times.log
以上都是以文本的格式进行输出,但文本没有图表更具有表达力。所以把结果以图表形式输出是必不可少,幸好perf4j也支持,命令如下:
java -jar perf4j-0.9.16.jar --graph perfGraphs.html times.log
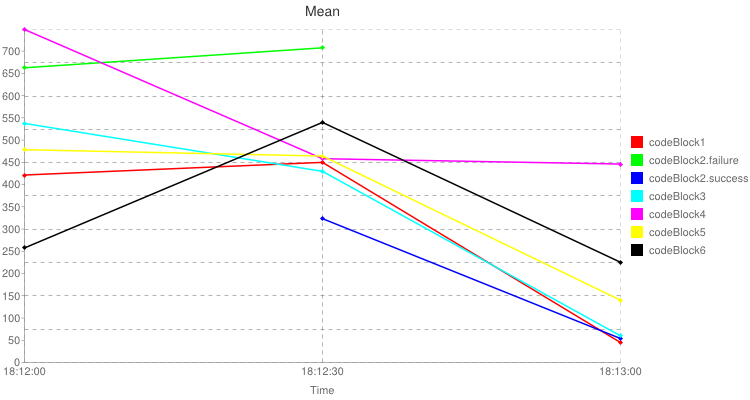
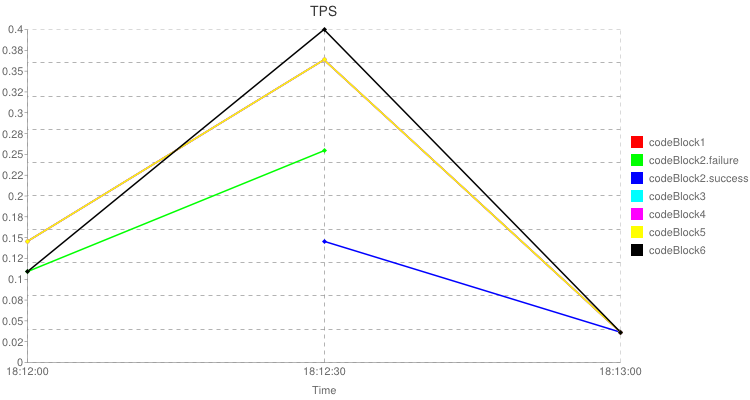
执行命令后,在控制台输出相应的统计信息,相应的在磁盘上也生成了一个html,html里包含平均值图表和tps图表。
<html>
<head><title>Perf4J Performance Graphs</title></head>
<body>
<br/><br/><img src="http://chart.apis.google.com/chart?cht=lxy&chtt=Mean&chs=750x400&chxt=x,x,y&chd=t:0.0,50.0,100.0|56.3,60.1,6.0|0.0,50.0|88.5,94.5|50.0,100.0|43.2,7.2|0.0,50.0,100.0|71.8,57.4,8.0|0.0,50.0,100.0|100.0,61.2,59.6|0.0,50.0,100.0|63.9,62.0,18.7|0.0,50.0,100.0|34.4,72.1,30.1&chco=ff0000,00ff00,0000ff,00ffff,ff00ff,ffff00,000000&chm=d,ff0000,0,-1,5.0|d,00ff00,1,-1,5.0|d,0000ff,2,-1,5.0|d,00ffff,3,-1,5.0|d,ff00ff,4,-1,5.0|d,ffff00,5,-1,5.0|d,000000,6,-1,5.0&chdl=codeBlock1|codeBlock2.failure|codeBlock2.success|codeBlock3|codeBlock4|codeBlock5|codeBlock6&chxr=2,0,748.5&chxl=0:|18:12:00|18:12:30|18:13:00|1:|Time&chxp=0,0.0,50.0,100.0|1,50&chg=50.0,10"/>
<br/><br/><img src="http://chart.apis.google.com/chart?cht=lxy&chtt=TPS&chs=750x400&chxt=x,x,y&chd=t:0.0,50.0,100.0|36.4,90.9,9.1|0.0,50.0|27.3,63.6|50.0,100.0|36.4,9.1|0.0,50.0,100.0|36.4,90.9,9.1|0.0,50.0,100.0|36.4,90.9,9.1|0.0,50.0,100.0|36.4,90.9,9.1|0.0,50.0,100.0|27.3,100.0,9.1&chco=ff0000,00ff00,0000ff,00ffff,ff00ff,ffff00,000000&chm=d,ff0000,0,-1,5.0|d,00ff00,1,-1,5.0|d,0000ff,2,-1,5.0|d,00ffff,3,-1,5.0|d,ff00ff,4,-1,5.0|d,ffff00,5,-1,5.0|d,000000,6,-1,5.0&chdl=codeBlock1|codeBlock2.failure|codeBlock2.success|codeBlock3|codeBlock4|codeBlock5|codeBlock6&chxr=2,0,0.4&chxl=0:|18:12:00|18:12:30|18:13:00|1:|Time&chxp=0,0.0,50.0,100.0|1,50&chg=50.0,10"/>
</body></html>
以上是html的内容,里面最重要的信息就是两个img标签,里面具体的图片是google chart api生成。可以打开html直接查看图表。
如果想要看更详细的参数,可以使用—help来查看。java -jar perf4j-0.9.16.jar –help。