
2014年9月25日
摘要: 需求描述:公司通过APP产品分享出去的需求和简历是做了一个H5页面作为分享的链接,通过APP分享出去自然是没问题,也是第一次分享,之后通过微信打开H5页面后想再次分享出去时候就变成了一个链接了,而不是自己定制的卡片模式,初次分享后如下:但是打开以后的H5页面再分享出去就变成这个样子了:也就是说需要在H5页面做微信分享的相关工作,JS-SDK上场了,首先看看JS-SDK的官方说明文档:https:/...
阅读全文
posted @
2016-12-16 17:05 小人物_Amor 阅读(3612) |
评论 (0) |
编辑 收藏Apache Zeppelin启动默认是匿名(anonymous)模式登录的,也就是任何人都可以访问,这个可以在/zeppelin/conf下的zeppelin-site.xml中看到:
<property>
<name>zeppelin.anonymous.allowed</name>
<value>true</value>
<description>Anonymous user allowed by default</description>
</property>
description中写道Anonymous user allowed by default(匿名用户默认被允许),这样我们访问我们安装的zepplin界面里是这样的:

右上角显示anonymous表示匿名模式。
接下来我们要做的就是如何通过修改配置来让我们的zeppelin拥有验证登录的功能:
- 修改/zeppelin/conf/zeppelin-site.xml文件选项zeppelin.anonymous.allowed的value为false,表示不允许匿名访问:
- <property>
<name>zeppelin.anonymous.allowed</name>
<value>false</value>
<description>Anonymous user allowed by default</description>
</property>
- 修改/zeppelin/conf/shiro.ini文件,显然zeppelin采用了shiro作为他的验证登录权限控制框架,那么我们需要对shiro有一些了解,我们去看该文件的最后几行:
[urls]
# anon means the access is anonymous.
# authcBasic means Basic Auth Security
# authc means Form based Auth Security
# To enfore security, comment the line below and uncomment the next one
/api/version = anon
/** = anon
#/** = authc
显然是对localhost:7878/#/**的进行验证,对/**的不验证,那我们就修改为对任何url访问都需要验证:把/**=anon修改为/**=authc,这样重启zeppelin后访问我们的zeppelin主页就变成这个样子了:

看见右上角的Login按钮了吧?对的,你现在zeppelin已经需要登录才能继续访问了,可是满屏幕的去找也没找到注册的地方,那么我们通过什么账号来进行登录呢?继续修改zeppelin/conf/shiro.ini文件:
[users]
# List of users with their password allowed to access Zeppelin.
# To use a different strategy (LDAP / Database / ...) check the shiro doc at http://shiro.apache.org/configuration.html#Configuration-INISections
admin = admin
user1 = password2, role1, role2
user2 = password3, role3
user3 = password4, role2
已经给我们加了这些账号了,看第一条注释提供了用户以及对应的密码用来允许访问zeppelin,然后你自己可以在下面加一些用户xxx = yyy,其中的角色也可以自行选择,需要详细了解的可以熟悉熟悉shiro的角色权限控制。重启zeppelin用你知道的账号去登录吧~!
输入对应账号进入主页后选择一个你已经添加过的notebook进去然后去右上角看见有一把小锁:

会显示Note Permissions点击后出现上图所示可以填写该notebook的Owners(所有者)、Readers(只读用户)、Writers(读写用户),这样每一个notebook就可以归属于某一个具体的用户了,避免了多用户同时使用zeppelin可能造成的冲突。
还有很多其他功能值得你去发现、研究!
posted @
2016-11-09 15:32 小人物_Amor 阅读(3212) |
评论 (0) |
编辑 收藏
Apache Zeppelin介绍:A web-based notebook that enables interactive data analytics. You can make beautiful data-driven, interactive and collaborative documents with SQL, Scala and more.
安装说明:
点击下载后解压到指定文件夹,你的zeppelin就安装完成了,很简单。但是zeppelin依赖于jdk,所以使用zeppelin前还需要机器拥有jdk环境。
解压完毕后需要配置几个地方:
- 将conf中的zeppelin-env.sh.template与zeppelin-site.xml.template 重命名,去掉template
-
修改conf/zepplin-env.sh 新增
export SPARK_MASTER_IP=127.0.0.1
export SPARK_LOCAL_IP=127.0.0.1
修改 export ZEPPELIN_MEM="-Xmx2048m -XX:PermSize=256M"
需要注意的是lib下的jar包,默认带的jackson-databind-2.5.3.jar包是无法使用的,这点不知道为什么zeppelin怎么处理的,需要将jackson-databind/jackson-annonations/jackson-core三个jar包全部替换成2.6.5版本的就可以了。
启动zeppelin:进入bin目录下执行 ./zeppelin-daemon.sh start
然后浏览器访问127.0.0.1:8080就进入如下页面:

ok,你的zeppelin安装成功了!
其实zeppelin就是一个java web项目,这样理解起来似乎就容易点了,接下来为了可以使用sql统计数据,我们来操作一下如何添加interpreter:
- 首先修改conf/zeppelin-site.xml,添加org.apache.zeppelin.jdbc.JdbcInterpreter
- 进入lib目录下上传 JdbcInterpreter.jar、mysql-connection-.....jar两个jar包
- 然后重启zeppelin,进入web页面的interpreter下,点击create:添加完成之后是这个样子:

- 然后进入notebook页面:
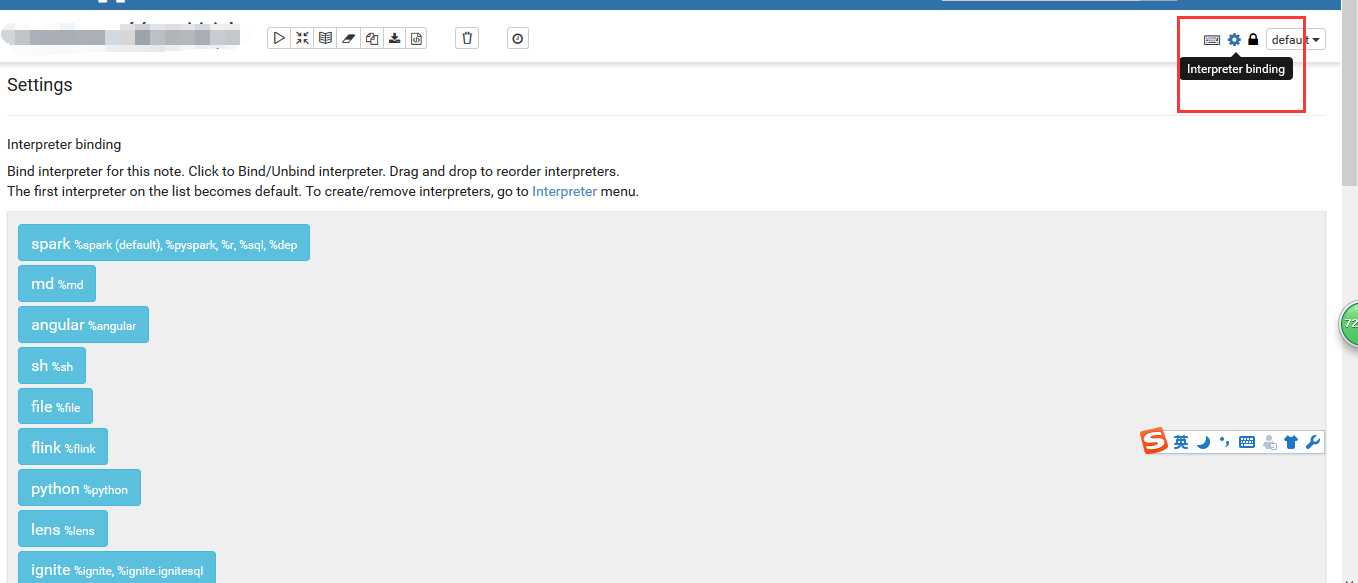 绑定刚刚添加的interpreter就可以使用了:
绑定刚刚添加的interpreter就可以使用了:
这样一个JdbcInterpreter就添加完毕了。
至于以后再想和redis、solr一起使用也是相应的加入jar包就可以了~
就我个人来说zeppelin可以满足企业运营这块的需求,包括日活、百度引流统计、ngnix日志分析、用户行为分析、热门词汇、整体数据统计、多维度数据统计等等。
posted @
2016-11-09 15:16 小人物_Amor 阅读(2105) |
评论 (0) |
编辑 收藏1.JDK和JRE的区别:
JDK是Java Development Kit。是面向开发人员使用的SDK,提供了java的开发环境以及运行环境。
JRE是Java Runtime Enviroment。是指java的运行环境,是面向java程序得使用者,而不是开发者。
2.序列化的目的:
Java中,一切都是对象,在分布式环境中经常需要将Object从这一端网络或设备传递到另一端。这就需要有一种可以在两端传输数据的协议。Java序列化机制就是为了解决这个问题而产生。
以某种存储形式使自定义对象持久化。
将对象从一个地方传到另一个地方。
3.equals和==的区别:
基本数据类型应该用“==”来比较他们的值。
当比较对象时候,如果对象里重写了equals方法,比如String,Integer,Date这些类,比较对象的内存地址应该用“==”,比较对象的值用“equals”,如果没有重写equals方法,两者本质上是相同的,都是比较值。
4.什么时候使用Comparator and Comparable 接口
当需要排序的集合或数组不是单纯的数字类型的时候,通常可以使用Comparator或Comparable,以简单的方式实现对象排序和自定义排序。
Comparable用在对象本身,说明这个对象是可以被比较的,也就是说可以被排序的。(String和Integer之所以可以比较大小,是因为它们都实现了Comparable接口,并实现了compareTo()方法)。
Compator用在对象外,相当于定义了一个排序算法。
5.转发和重定向的区别:
转发时URL不会改变,request请求内的对象将可以继续使用,重定向时浏览器URL会改变,之前的request会丢失,因此request里的数据也不会得到。
通常情况下转发速度更快,而且能保持request内的对象,但是转发之后,浏览器的连接还在先前页面所以可以重载先前页面。
转发:request.getRequestDispatcher("apage.jsp").forward(request, response);
重定向:response.sendRedirect("apage.jsp");
6.编译期异常和运行时异常
编译时异常可以捕捉,比如我们读写文件时候会抛出IOException,操作数据库时会有SQLException,运行时异常不可以捕捉,比如数组下标溢出,空指针异常等
7.Struts1原理和Struts2原理以及区别和联系,在什么项目中用过,有什么体会?
struts1原理:客户端发送HttpServletRequest请求给ActionServlet,ActionServlet会检索和用户请求匹配的ActionMapping实例,如果不存在就返回请求路径无效的信息,如果存在就会把请求的表单数据保存到ActionForm中去,如果ActionForm不存在就会创建一个ActionForm对象,然后再根据配置信息决定是否需要表单验证,如果需要验证就调用ActionForm的validate()方法,验证通过后ActionServlet根据ActionMapping实例包含的映射信息决定将请求转发给哪个Action,如果相应的Action实例不存在就先创建这个Action然后调用Action的execute()方法。Action的execute()方法返回一个ActionForward对象,ActionServlet再把客户请求转发给ActionForward对象指向的jsp组件。
struts2原理:客户端发送HttpServletRequest请求,请求被提交到一系列的Filter,首先是ActionContextCleanUp,然后是其他Filter,最后是FilterDispatcher。FilterDispatcher是Struts2的核心,就是MVC的Struts2实现中控制层的核心。FilterDispatcher询问ActionMapper决定需要调用哪个Action,FilterDispatcher会把请求交给ActionProxy,ActionProxy会根据Struts.xml配置文件找到需要调用的Action类。ActionProxy创建一个ActionInvocation实例,同时ActionInvocation通过代理模式调用Action类,调用之前会加载Action相关的所有拦截器,一旦Action执行完毕,ActionInvocation根据Struts.xml配置文件返回对应的result。
区别:1.Struts1是通过Servlet启动的,struts1要求Action继承一个抽象类,而不是接口,Struts2的Action类可以实现一个Action接口也可以实现其他接口。
2.struts1的Action是单例模式线程是不安全的,struts2是线程安全的,Action为每一个请求都生成了一个实例。
3.struts1是以ActionServlet为核心控制器,struts2是以FilterDispatcher为核心控制器。
执行流程:
a)struts1
jsp发起httprequest请求->servlet捕获->struts.xml->namespace+ActionName-> Action->填充表单setXxx()->action.execute()->”success”->Result->设置request属性->跳转目标页
b) Action(jsp发起httprequest请求,被过滤器捕获)->FilterDispatcher->struts.xml->namespace+ActionName->new Action->填充表单setXxx()->action.execute()->”success”->Result->设置request属性->跳转目标页
8.spring原理
spring的最大作用ioc/di,将类与类的依赖关系写在配置文件中,程序在运行时根据配置文件动态加载依赖的类,降低的类与类之间的藕合度。它的原理是在applicationContext.xml加入bean标记,在bean标记中通过class属性说明具体类名、通过property标签说明该类的属性名、通过constructor-args说明构造子的参数。其一切都是反射,当通过applicationContext.getBean(“id名称”)得到一个类实例时,就是以bean标签的类名、属性名、构造子的参数为准,通过反射实例对象,唤起对象的set方法设置属性值、通过构造子的newInstance实例化得到对象。正因为spring一切都是反射,反射比直接调用的处理速度慢,所以这也是spring的一个问题。
spring第二大作用就是aop,其机理来自于代理模式,代理模式有三个角色分别是通用接口、代理、真实对象。代理、真实对象实现的是同一接口,将真实对象作为代理的一个属性,向客户端公开的是代理,当客户端调用代理的方法时,代理找到真实对象,调用真实对象方法,在调用之前之后提供相关的服务,如事务、安全、日志。其名词分别是代理、真实对象、装备、关切点、连接点。
9.简要概述一下SpringMVC和StrutsMVC
Spring的MVC框架主要由DispatcherServlet、处理器映射、处理器、视图解析器、视图组成。
1)DispatcherServlet接收到请求后,根据对应配置文件中配置的处理器映射,找到对应的处理器映射项(HandlerMapping),根据配置的映射规则,找到对应的处理器(Handler)。
2)调用相应处理器中的处理方法,处理该请求,处理器处理结束后会将一个ModelAndView类型的数据传给DispatcherServlet,这其中包含了处理结果的视图和视图中要使用的数据。
3)DispatcherServlet 根据得到的ModelAndView中的视图对象,找到一个合适的ViewResolver(视图解析器),根据视图解析器的配 置,DispatcherServlet将视图要显示的数据传给对应的视图,最后给浏览器构造一个HTTP响应。
DispatcherServlet是整个Spring MVC的核心。它负责接收HTTP请求组织协调Spring MVC的各个组成部分。其主要工作有以下三项:
1)截获符合特定格式的URL请求。
2)初始化DispatcherServlet上下文对应的WebApplicationContext,并将其与业务层、持久化层的WebApplicationContext建立关联。
3)初始化Spring MVC的各个组成组件,并装配到DispatcherServlet中。
StrutsMVC
1.当启动容器时,容器(tomcat、weblogic)实例化ActionServlet,初始化ActionServlet,在初始化
ActionServlet时加载struts-config.xml文件。
2.当客户通过url.do将请求发给ActionServlet,ActionServlet将处理转发给助手RequestProcessor,RequestProcess通过struts-config.xml找到对应的actionForm及 action,如果有ActionForm用已有的,没有通过类的反射实例化一个新的ActionForm,放置到作用域对象,通过反射
- 将表单域的值填充到actionForm中。如果有Action用已有的,没有产生一个新的,通过反射调用action实例的execute方法,在执行前将actionForm通过参数注入到execute方法中。
- 3.execute方法执行结束前通过actionMapping找到actionForward转发到另一个页面。
10.Servlet的工作原理、生命周期
Servlet的工作原理:
Servlet 生命周期:Servlet 加载--->实例化--->服务--->销毁。 init():在Servlet的生命周期中,仅执行一次init()方法。它是在服务器装入Servlet时执行的,负责初始化Servlet 对象。可以配置服务器,以在启动服务器或客户机首次访问Servlet时装入Servlet。无论有多少客户机访问Servlet,都不会重复执行 init()。 service():它是Servlet的核心,负责响应客户的请求。每当一个客户请求一个HttpServlet对象,该对象的 Service()方法就要调用,而且传递给这个方法一个“请求”(ServletRequest)对象和一个“响应” (ServletResponse)对象作为参数。在HttpServlet中已存在Service()方法。默认的服务功能是调用与HTTP请求的方法 相应的do功能。 destroy(): 仅执行一次,在服务器端停止且卸载Servlet时执行该方法。当Servlet对象退出生命周期时,负责释放占用的资 源。一个Servlet在运行service()方法时可能会产生其他的线程,因此需要确认在调用destroy()方法时,这些线程已经终止或完成。
Servlet工作原理:
1、首先简单解释一下Servlet接收和响应客户请求的过程,首先客户发送一个请求,Servlet是调用service()方法对请求进行响应 的,通过源代码可见,service()方法中对请求的方式进行了匹配,选择调用doGet,doPost等这些方法,然后再进入对应的方法中调用逻辑层 的方法,实现对客户的响应。在Servlet接口和GenericServlet中是没有doGet()、doPost()等等这些方法 的,HttpServlet中定义了这些方法,但是都是返回error信息,所以,我们每次定义一个Servlet的时候,都必须实现doGet或 doPost等这些方法。
2、每一个自定义的Servlet都必须实现Servlet的接口,Servlet接口中定义了五个方法,其中比较重要的三个方法涉及到 Servlet的生命周期,分别是上文提到的init(),service(),destroy()方法。GenericServlet是一个通用的,不 特定于任何协议的Servlet,它实现了Servlet接口。而HttpServlet继承于GenericServlet,因此 HttpServlet也实现了Servlet接口。所以我们定义Servlet的时候只需要继承HttpServlet即可。
3、Servlet接口和GenericServlet是不特定于任何协议的,而HttpServlet是特定于HTTP协议的类,所以 HttpServlet中实现了service()方法,并将请求ServletRequest、ServletResponse 强转为HttpRequest 和 HttpResponse。
11.OOA、OOD、OOP含义
Object-Oriented Analysis:面向对象分析方法
Object-Oriented Design:面向对象设计
Object Oriented Programming:面向对象编程
OOA是对系统业务调查了解之后根据面向对象的思想进行系统分析,在OOA分析的基础上对系统根据面向对象的思想进行系统设计,从而能够直接进行OOP面向对象编程。
12.mysql分页查询
对于有大数据量的mysql表来说,使用LIMIT分页存在很严重的性能问题。
查询从第1000000之后的30条记录:
SQL代码1:平均用时6.6秒 SELECT * FROM `cdb_posts` ORDER BY pid LIMIT 1000000 , 30
SQL代码2:平均用时0.6秒 SELECT * FROM `cdb_posts` WHERE pid >= (SELECT pid FROM `cdb_posts` ORDER BY pid LIMIT 1000000 , 1) LIMIT 30
因为要取出所有字段内容,第一种需要跨越大量数据块并取出,而第二种基本通过直接根据索引字段定位后,才取出相应内容,效率自然大大提升。
可以看出,越往后分页,LIMIT语句的偏移量就会越大,两者速度差距也会越明显。
实际应用中,可以利用类似策略模式的方式去处理分页,比如判断如果是一百页以内,就使用最基本的分页方式,大于一百页,则使用子查询的分页方式。
Oracle查询:SELECT * FROM (SELECT A.*, ROWNUM RN FROM (SELECT * FROM TABLE_NAME) A WHERE ROWNUM <= 40) WHERE RN >= 21
13.单例模式、工厂模式、代理模式
枚举实现单例模式:
public enum Singleton {
/**
* 定义一个枚举的元素,它就代表了Singleton的一个实例。
*/
uniqueInstance;
/**
* 单例可以有自己的操作
*/
public void singletonOperation(){
//功能处理
}
}
懒汉同步单例模式:
public class LazySingleton { private static LazySingleton instance = null;
/**
* 私有默认构造子
*/
private LazySingleton(){} /**
* 静态工厂方法
*/
public static synchronized LazySingleton getInstance(){ if(instance == null){ instance = new LazySingleton();
}
return instance;
}
}
工厂模式:http://www.cnblogs.com/java-my-life/archive/2012/03/28/2418836.html
代理模式:http://yangguangfu.iteye.com/blog/815787
未完待续...
posted @
2014-10-08 16:50 小人物_Amor 阅读(395) |
评论 (0) |
编辑 收藏- Servlet 生命周期:Servlet 加载--->实例化--->服务--->销毁。
- init():在Servlet的生命周期中,仅执行一次init()方法。它是在服务器装入Servlet时执行的,负责初始化Servlet 对象。可以配置服务器,以在启动服务器或客户机首次访问Servlet时装入Servlet。无论有多少客户机访问Servlet,都不会重复执行 init()。
- service():它是Servlet的核心,负责响应客户的请求。每当一个客户请求一个HttpServlet对象,该对象的 Service()方法就要调用,而且传递给这个方法一个“请求”(ServletRequest)对象和一个“响应” (ServletResponse)对象作为参数。在HttpServlet中已存在Service()方法。默认的服务功能是调用与HTTP请求的方法 相应的do功能。
- destroy(): 仅执行一次,在服务器端停止且卸载Servlet时执行该方法。当Servlet对象退出生命周期时,负责释放占用的资 源。一个Servlet在运行service()方法时可能会产生其他的线程,因此需要确认在调用destroy()方法时,这些线程已经终止或完成。
Tomcat 与 Servlet 是如何工作的:

步骤:
- Web Client 向Servlet容器(Tomcat)发出Http请求
- Servlet容器接收Web Client的请求
- Servlet容器创建一个HttpRequest对象,将Web Client请求的信息封装到这个对象中。
- Servlet容器创建一个HttpResponse对象
- Servlet容器调用HttpServlet对象的service方法,把HttpRequest对象与HttpResponse对象作为参数传给 HttpServlet 对象。
- HttpServlet调用HttpRequest对象的有关方法,获取Http请求信息。
- HttpServlet调用HttpResponse对象的有关方法,生成响应数据。
- Servlet容器把HttpServlet的响应结果传给Web Client。
Servlet工作原理:
1、首先简单解释一下Servlet接收和响应客户请求的过程,首先客户发送一个请求,Servlet是调用service()方法对请求进行响应 的,通过源代码可见,service()方法中对请求的方式进行了匹配,选择调用doGet,doPost等这些方法,然后再进入对应的方法中调用逻辑层 的方法,实现对客户的响应。在Servlet接口和GenericServlet中是没有doGet()、doPost()等等这些方法 的,HttpServlet中定义了这些方法,但是都是返回error信息,所以,我们每次定义一个Servlet的时候,都必须实现doGet或 doPost等这些方法。
2、每一个自定义的Servlet都必须实现Servlet的接口,Servlet接口中定义了五个方法,其中比较重要的三个方法涉及到 Servlet的生命周期,分别是上文提到的init(),service(),destroy()方法。GenericServlet是一个通用的,不 特定于任何协议的Servlet,它实现了Servlet接口。而HttpServlet继承于GenericServlet,因此 HttpServlet也实现了Servlet接口。所以我们定义Servlet的时候只需要继承HttpServlet即可。
3、Servlet接口和GenericServlet是不特定于任何协议的,而HttpServlet是特定于HTTP协议的类,所以 HttpServlet中实现了service()方法,并将请求ServletRequest、ServletResponse 强转为HttpRequest 和 HttpResponse。
创建Servlet对象的时机:
- Servlet容器启动时:读取web.xml配置文件中的信息,构造指定的Servlet对象,创建ServletConfig对象,同时将ServletConfig对象作为参数来调用Servlet对象的init方法。
- 在Servlet容器启动后:客户首次向Servlet发出请求,Servlet容器会判断内存中是否存在指定的Servlet对象,如果没有则 创建它,然后根据客户的请求创建HttpRequest、HttpResponse对象,从而调用Servlet 对象的service方法。
- Servlet Servlet容器在启动时自动创建Servlet,这是由在web.xml文件中为Servlet设置的<load- on-startup>属性决定的。从中我们也能看到同一个类型的Servlet对象在Servlet容器中以单例的形式存在。
<servlet>
<servlet-name>Init</servlet-name>
<servlet-class>org.xl.servlet.InitServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
posted @
2014-10-08 15:16 小人物_Amor 阅读(333) |
评论 (0) |
编辑 收藏Arrays.sort(T[], Comparator < ? super T > c) 方法用于对象数组按用户自定义规则排序。
Collections.sort(List<T>, Comparator < ? super T > c)方法用于对象集合按用户自定义规则排序。
Comparable用在对象本身,说明这个对象是可以被比较的,也就是说可以被排序的。(String和Integer之所以可以比较大小,是因为它们都实现了Comparable接口,并实现了compareTo()方法)。
Compator用在对象外,相当于定义了一个排序算法。
还是代码来的直接:
package com.zx.ww.comparable;
import java.util.Arrays;
import java.util.Comparator;
public class ComparatorTest {
public static void main(String[] args) {
Dog d1 = new Dog(2);
Dog d2 = new Dog(1);
Dog d3 = new Dog(3);
Dog[] dogArray = {d1, d2, d3};
printDogs(dogArray);
Arrays.sort(dogArray, new DogSizeComparator());
printDogs(dogArray);
}
public static void printDogs(Dog[] dogArray) {
for (Dog dog : dogArray) {
System.out.print(dog.size+" ");
}
System.out.println();
}
}
class Dog{
int size;
public Dog(int size) {
this.size = size;
}
}
class DogSizeComparator implements Comparator<Dog> {
@Override
public int compare(Dog dog1, Dog dog2) {
// TODO Auto-generated method stub
return dog1.size - dog2.size;
}
}
输出结果:
2 1 3
1 2 3
这是对象数组用了Comparator的结果。
下面看对象自身实现了Comparable接口的方式:
/**
*
*/
package com.zx.ww.comparable;
import java.util.Arrays;
/**
* @author wuwei
* 2014年9月29日
*/
public class User implements Comparable<Object>{
private int id;
private String name;
private int age;
public User(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Object o) {
// TODO Auto-generated method stub
return this.age - ((User)o).getAge();
}
public static void main(String[] args) {
User[] users = new User[] {new User(1,"zhangsan",28), new User(2,"lisi",25)};
Arrays.sort(users);
for (int i = 0; i < users.length; i++) {
User user = users[i];
System.out.println(user.getId()+" "+user.getAge());
}
}
}
输出结果:
2 25
1 28
上述都是Arrays.sort()的应用方式,同理Collections.sort()一样的实现,代码如下,比较简单:
package com.zx.ww.comparable;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class CollectionSortTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("ac");
list.add("ab");
list.add("aa");
list.add("db");
list.add("ca");
for (String string : list) {
System.out.print(string + " ");
}
System.out.println();
Collections.sort(list);
for (String string : list) {
System.out.print(string + " ");
}
System.out.println();
//对象A自身实现Comparable接口
List<A> aList = new ArrayList<A>();
aList.add(new A("wuwei", 1));
aList.add(new A("zhangsan", 3));
aList.add(new A("lisi", 2));
for (A a : aList) {
System.out.print(a+" ");
}
System.out.println();
Collections.sort(aList);
for (A a : aList) {
System.out.print(a+" ");
}
System.out.println();
//重写Conparator接口方法
List<B> bList = new ArrayList<B>();
bList.add(new B("wuwei", 1));
bList.add(new B("zhangsan", 3));
bList.add(new B("lisi", 2));
for (B b : bList) {
System.out.print(b+" ");
}
System.out.println();
Collections.sort(bList, new Comparator<B>() {
@Override
public int compare(B b1, B b2) {
// TODO Auto-generated method stub
return b1.getCount().compareTo(b2.getCount());
}
});
for (B b : bList) {
System.out.print(b+" ");
}
System.out.println();
}
}
//对象A自身实现Comparable接口
class A implements Comparable<A>{
private String name;
private Integer order;
public A(String name, Integer order) {
this.name = name;
this.order = order;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getOrder() {
return order;
}
public void setOrder(Integer order) {
this.order = order;
}
public String toString() {
return "name is " +name+" order is "+order;
}
@Override
public int compareTo(A o) {
// TODO Auto-generated method stub
return this.order.compareTo(o.getOrder());
}
}
class B{
private String name;
private Integer count;
public B(String name, Integer count) {
this.name = name;
this.count = count;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getCount() {
return count;
}
public void setCount(Integer count) {
this.count = count;
}
public String toString() {
return "name is "+name+" count is "+count;
}
}
输出结果:
ac ab aa db ca
aa ab ac ca db
name is wuwei order is 1 name is zhangsan order is 3 name is lisi order is 2
name is wuwei order is 1 name is lisi order is 2 name is zhangsan order is 3
name is wuwei count is 1 name is zhangsan count is 3 name is lisi count is 2
name is wuwei count is 1 name is lisi count is 2 name is zhangsan count is 3
posted @
2014-09-29 16:08 小人物_Amor 阅读(1182) |
评论 (0) |
编辑 收藏/**
*
*/
package com.zx.ww.arraysort;
import java.text.Collator;
import java.util.Arrays;
import java.util.Calendar;
import java.util.Comparator;
import java.util.Locale;
/**
* @author xue
* 2014年9月24日
*/
public class QuickSort {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
test();
}
}
public static void test() {
int len = 8000000;
int[] array = new int[len];
for (int i = 0; i < len; i++) {
array[i] = (int)(Math.random()*10000);
}
Calendar cal_before = Calendar.getInstance();
double before = cal_before.getTimeInMillis();
System.out.println(cal_before.getTime());
quickSort(array, 0, array.length-1);
Calendar cal_after = Calendar.getInstance();
double after = cal_after.getTimeInMillis();
System.out.println(cal_after.getTime());
double time = after-before;
System.out.println("用时:" + time + "ms");
System.out.println("==================================");
}
public static void quickSort(int[] array, int left, int right) {
if(left < right) {
int privot = getPrivot(array, left, right);
quickSort(array, left, privot-1);
quickSort(array, privot+1, right);
}
}
//将数组划分为两个数组,左边的数组都比中轴privot小,右边的都比中轴privot大
public static int getPrivot(int[] array, int left, int right) {
int tmp = array[left];
while(left < right) {
while(left < right && array[right] >= tmp) {
right--;
}
array[left] = array[right];
while(left < right && array[left] <= tmp) {
left++;
}
array[right] = array[left];
}
array[left] = tmp;
return left;
}
}
运行十次输出的结果:
Thu Sep 25 13:09:40 CST 2014
Thu Sep 25 13:09:41 CST 2014
用时:1613.0ms
==================================
Thu Sep 25 13:09:41 CST 2014
Thu Sep 25 13:09:43 CST 2014
用时:1614.0ms
==================================
Thu Sep 25 13:09:43 CST 2014
Thu Sep 25 13:09:45 CST 2014
用时:1691.0ms
==================================
Thu Sep 25 13:09:45 CST 2014
Thu Sep 25 13:09:47 CST 2014
用时:1622.0ms
==================================
Thu Sep 25 13:09:47 CST 2014
Thu Sep 25 13:09:48 CST 2014
用时:1621.0ms
==================================
Thu Sep 25 13:09:49 CST 2014
Thu Sep 25 13:09:50 CST 2014
用时:1615.0ms
==================================
Thu Sep 25 13:09:50 CST 2014
Thu Sep 25 13:09:52 CST 2014
用时:1614.0ms
==================================
Thu Sep 25 13:09:52 CST 2014
Thu Sep 25 13:09:54 CST 2014
用时:1632.0ms
==================================
Thu Sep 25 13:09:54 CST 2014
Thu Sep 25 13:09:55 CST 2014
用时:1614.0ms
==================================
Thu Sep 25 13:09:56 CST 2014
Thu Sep 25 13:09:57 CST 2014
用时:1614.0ms
==================================
上述是快速排序八百万条数据用时基本在1.6s左右。
接下来看冒泡排序:
/**
*
*/
package com.zx.ww.arraysort;
import java.text.Collator;
import java.util.Arrays;
import java.util.Calendar;
import java.util.Comparator;
import java.util.Locale;
/**
* @author wuwei
* 2014年9月24日
*/
public class BubbleSort {
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
test();
}
}
public static void test() {
int len = 80000;
int[] array = new int[len];
for (int i = 0; i < array.length; i++) {
array[i] = (int)(Math.random()*10000);
}
Calendar calBefore = Calendar.getInstance();
System.out.println(calBefore.getTime());
bubbleSort(array);
Calendar calAfter = Calendar.getInstance();
System.out.println(calAfter.getTime());
System.out.println("总共用时" + (calAfter.getTimeInMillis()-calBefore.getTimeInMillis()) + "ms");
System.out.println("==========================");
}
public static void bubbleSort(int[] array) {
int tmp;
for (int i = 0; i < array.length; i++) {
for (int j = 0; j < array.length-i-1; j++) {
if(array[j] > array[j+1]) {
tmp = array[j+1];
array[j+1] = array[j];
array[j] = tmp;
}
}
}
}
}
运行五次输出如下结果:
Thu Sep 25 14:44:14 CST 2014
Thu Sep 25 14:44:23 CST 2014
总共用时8822ms
==========================
Thu Sep 25 14:44:23 CST 2014
Thu Sep 25 14:44:32 CST 2014
总共用时8829ms
==========================
Thu Sep 25 14:44:32 CST 2014
Thu Sep 25 14:44:41 CST 2014
总共用时8915ms
==========================
Thu Sep 25 14:44:41 CST 2014
Thu Sep 25 14:44:50 CST 2014
总共用时8748ms
==========================
Thu Sep 25 14:44:50 CST 2014
Thu Sep 25 14:44:58 CST 2014
总共用时8529ms
==========================
冒泡排序八万条数据用时接近9s。
需要注意的是快速排序是八百万条数据只用了1.6s左右。
posted @
2014-09-25 13:09 小人物_Amor 阅读(337) |
评论 (0) |
编辑 收藏