
2014年10月8日
1.JDK和JRE的区别:
JDK是Java Development Kit。是面向开发人员使用的SDK,提供了java的开发环境以及运行环境。
JRE是Java Runtime Enviroment。是指java的运行环境,是面向java程序得使用者,而不是开发者。
2.序列化的目的:
Java中,一切都是对象,在分布式环境中经常需要将Object从这一端网络或设备传递到另一端。这就需要有一种可以在两端传输数据的协议。Java序列化机制就是为了解决这个问题而产生。
以某种存储形式使自定义对象持久化。
将对象从一个地方传到另一个地方。
3.equals和==的区别:
基本数据类型应该用“==”来比较他们的值。
当比较对象时候,如果对象里重写了equals方法,比如String,Integer,Date这些类,比较对象的内存地址应该用“==”,比较对象的值用“equals”,如果没有重写equals方法,两者本质上是相同的,都是比较值。
4.什么时候使用Comparator and Comparable 接口
当需要排序的集合或数组不是单纯的数字类型的时候,通常可以使用Comparator或Comparable,以简单的方式实现对象排序和自定义排序。
Comparable用在对象本身,说明这个对象是可以被比较的,也就是说可以被排序的。(String和Integer之所以可以比较大小,是因为它们都实现了Comparable接口,并实现了compareTo()方法)。
Compator用在对象外,相当于定义了一个排序算法。
5.转发和重定向的区别:
转发时URL不会改变,request请求内的对象将可以继续使用,重定向时浏览器URL会改变,之前的request会丢失,因此request里的数据也不会得到。
通常情况下转发速度更快,而且能保持request内的对象,但是转发之后,浏览器的连接还在先前页面所以可以重载先前页面。
转发:request.getRequestDispatcher("apage.jsp").forward(request, response);
重定向:response.sendRedirect("apage.jsp");
6.编译期异常和运行时异常
编译时异常可以捕捉,比如我们读写文件时候会抛出IOException,操作数据库时会有SQLException,运行时异常不可以捕捉,比如数组下标溢出,空指针异常等
7.Struts1原理和Struts2原理以及区别和联系,在什么项目中用过,有什么体会?
struts1原理:客户端发送HttpServletRequest请求给ActionServlet,ActionServlet会检索和用户请求匹配的ActionMapping实例,如果不存在就返回请求路径无效的信息,如果存在就会把请求的表单数据保存到ActionForm中去,如果ActionForm不存在就会创建一个ActionForm对象,然后再根据配置信息决定是否需要表单验证,如果需要验证就调用ActionForm的validate()方法,验证通过后ActionServlet根据ActionMapping实例包含的映射信息决定将请求转发给哪个Action,如果相应的Action实例不存在就先创建这个Action然后调用Action的execute()方法。Action的execute()方法返回一个ActionForward对象,ActionServlet再把客户请求转发给ActionForward对象指向的jsp组件。
struts2原理:客户端发送HttpServletRequest请求,请求被提交到一系列的Filter,首先是ActionContextCleanUp,然后是其他Filter,最后是FilterDispatcher。FilterDispatcher是Struts2的核心,就是MVC的Struts2实现中控制层的核心。FilterDispatcher询问ActionMapper决定需要调用哪个Action,FilterDispatcher会把请求交给ActionProxy,ActionProxy会根据Struts.xml配置文件找到需要调用的Action类。ActionProxy创建一个ActionInvocation实例,同时ActionInvocation通过代理模式调用Action类,调用之前会加载Action相关的所有拦截器,一旦Action执行完毕,ActionInvocation根据Struts.xml配置文件返回对应的result。
区别:1.Struts1是通过Servlet启动的,struts1要求Action继承一个抽象类,而不是接口,Struts2的Action类可以实现一个Action接口也可以实现其他接口。
2.struts1的Action是单例模式线程是不安全的,struts2是线程安全的,Action为每一个请求都生成了一个实例。
3.struts1是以ActionServlet为核心控制器,struts2是以FilterDispatcher为核心控制器。
执行流程:
a)struts1
jsp发起httprequest请求->servlet捕获->struts.xml->namespace+ActionName-> Action->填充表单setXxx()->action.execute()->”success”->Result->设置request属性->跳转目标页
b) Action(jsp发起httprequest请求,被过滤器捕获)->FilterDispatcher->struts.xml->namespace+ActionName->new Action->填充表单setXxx()->action.execute()->”success”->Result->设置request属性->跳转目标页
8.spring原理
spring的最大作用ioc/di,将类与类的依赖关系写在配置文件中,程序在运行时根据配置文件动态加载依赖的类,降低的类与类之间的藕合度。它的原理是在applicationContext.xml加入bean标记,在bean标记中通过class属性说明具体类名、通过property标签说明该类的属性名、通过constructor-args说明构造子的参数。其一切都是反射,当通过applicationContext.getBean(“id名称”)得到一个类实例时,就是以bean标签的类名、属性名、构造子的参数为准,通过反射实例对象,唤起对象的set方法设置属性值、通过构造子的newInstance实例化得到对象。正因为spring一切都是反射,反射比直接调用的处理速度慢,所以这也是spring的一个问题。
spring第二大作用就是aop,其机理来自于代理模式,代理模式有三个角色分别是通用接口、代理、真实对象。代理、真实对象实现的是同一接口,将真实对象作为代理的一个属性,向客户端公开的是代理,当客户端调用代理的方法时,代理找到真实对象,调用真实对象方法,在调用之前之后提供相关的服务,如事务、安全、日志。其名词分别是代理、真实对象、装备、关切点、连接点。
9.简要概述一下SpringMVC和StrutsMVC
Spring的MVC框架主要由DispatcherServlet、处理器映射、处理器、视图解析器、视图组成。
1)DispatcherServlet接收到请求后,根据对应配置文件中配置的处理器映射,找到对应的处理器映射项(HandlerMapping),根据配置的映射规则,找到对应的处理器(Handler)。
2)调用相应处理器中的处理方法,处理该请求,处理器处理结束后会将一个ModelAndView类型的数据传给DispatcherServlet,这其中包含了处理结果的视图和视图中要使用的数据。
3)DispatcherServlet 根据得到的ModelAndView中的视图对象,找到一个合适的ViewResolver(视图解析器),根据视图解析器的配 置,DispatcherServlet将视图要显示的数据传给对应的视图,最后给浏览器构造一个HTTP响应。
DispatcherServlet是整个Spring MVC的核心。它负责接收HTTP请求组织协调Spring MVC的各个组成部分。其主要工作有以下三项:
1)截获符合特定格式的URL请求。
2)初始化DispatcherServlet上下文对应的WebApplicationContext,并将其与业务层、持久化层的WebApplicationContext建立关联。
3)初始化Spring MVC的各个组成组件,并装配到DispatcherServlet中。
StrutsMVC
1.当启动容器时,容器(tomcat、weblogic)实例化ActionServlet,初始化ActionServlet,在初始化
ActionServlet时加载struts-config.xml文件。
2.当客户通过url.do将请求发给ActionServlet,ActionServlet将处理转发给助手RequestProcessor,RequestProcess通过struts-config.xml找到对应的actionForm及 action,如果有ActionForm用已有的,没有通过类的反射实例化一个新的ActionForm,放置到作用域对象,通过反射
- 将表单域的值填充到actionForm中。如果有Action用已有的,没有产生一个新的,通过反射调用action实例的execute方法,在执行前将actionForm通过参数注入到execute方法中。
- 3.execute方法执行结束前通过actionMapping找到actionForward转发到另一个页面。
10.Servlet的工作原理、生命周期
Servlet的工作原理:
Servlet 生命周期:Servlet 加载--->实例化--->服务--->销毁。 init():在Servlet的生命周期中,仅执行一次init()方法。它是在服务器装入Servlet时执行的,负责初始化Servlet 对象。可以配置服务器,以在启动服务器或客户机首次访问Servlet时装入Servlet。无论有多少客户机访问Servlet,都不会重复执行 init()。 service():它是Servlet的核心,负责响应客户的请求。每当一个客户请求一个HttpServlet对象,该对象的 Service()方法就要调用,而且传递给这个方法一个“请求”(ServletRequest)对象和一个“响应” (ServletResponse)对象作为参数。在HttpServlet中已存在Service()方法。默认的服务功能是调用与HTTP请求的方法 相应的do功能。 destroy(): 仅执行一次,在服务器端停止且卸载Servlet时执行该方法。当Servlet对象退出生命周期时,负责释放占用的资 源。一个Servlet在运行service()方法时可能会产生其他的线程,因此需要确认在调用destroy()方法时,这些线程已经终止或完成。
Servlet工作原理:
1、首先简单解释一下Servlet接收和响应客户请求的过程,首先客户发送一个请求,Servlet是调用service()方法对请求进行响应 的,通过源代码可见,service()方法中对请求的方式进行了匹配,选择调用doGet,doPost等这些方法,然后再进入对应的方法中调用逻辑层 的方法,实现对客户的响应。在Servlet接口和GenericServlet中是没有doGet()、doPost()等等这些方法 的,HttpServlet中定义了这些方法,但是都是返回error信息,所以,我们每次定义一个Servlet的时候,都必须实现doGet或 doPost等这些方法。
2、每一个自定义的Servlet都必须实现Servlet的接口,Servlet接口中定义了五个方法,其中比较重要的三个方法涉及到 Servlet的生命周期,分别是上文提到的init(),service(),destroy()方法。GenericServlet是一个通用的,不 特定于任何协议的Servlet,它实现了Servlet接口。而HttpServlet继承于GenericServlet,因此 HttpServlet也实现了Servlet接口。所以我们定义Servlet的时候只需要继承HttpServlet即可。
3、Servlet接口和GenericServlet是不特定于任何协议的,而HttpServlet是特定于HTTP协议的类,所以 HttpServlet中实现了service()方法,并将请求ServletRequest、ServletResponse 强转为HttpRequest 和 HttpResponse。
11.OOA、OOD、OOP含义
Object-Oriented Analysis:面向对象分析方法
Object-Oriented Design:面向对象设计
Object Oriented Programming:面向对象编程
OOA是对系统业务调查了解之后根据面向对象的思想进行系统分析,在OOA分析的基础上对系统根据面向对象的思想进行系统设计,从而能够直接进行OOP面向对象编程。
12.mysql分页查询
对于有大数据量的mysql表来说,使用LIMIT分页存在很严重的性能问题。
查询从第1000000之后的30条记录:
SQL代码1:平均用时6.6秒 SELECT * FROM `cdb_posts` ORDER BY pid LIMIT 1000000 , 30
SQL代码2:平均用时0.6秒 SELECT * FROM `cdb_posts` WHERE pid >= (SELECT pid FROM `cdb_posts` ORDER BY pid LIMIT 1000000 , 1) LIMIT 30
因为要取出所有字段内容,第一种需要跨越大量数据块并取出,而第二种基本通过直接根据索引字段定位后,才取出相应内容,效率自然大大提升。
可以看出,越往后分页,LIMIT语句的偏移量就会越大,两者速度差距也会越明显。
实际应用中,可以利用类似策略模式的方式去处理分页,比如判断如果是一百页以内,就使用最基本的分页方式,大于一百页,则使用子查询的分页方式。
Oracle查询:SELECT * FROM (SELECT A.*, ROWNUM RN FROM (SELECT * FROM TABLE_NAME) A WHERE ROWNUM <= 40) WHERE RN >= 21
13.单例模式、工厂模式、代理模式
枚举实现单例模式:
public enum Singleton {
/**
* 定义一个枚举的元素,它就代表了Singleton的一个实例。
*/
uniqueInstance;
/**
* 单例可以有自己的操作
*/
public void singletonOperation(){
//功能处理
}
}
懒汉同步单例模式:
public class LazySingleton { private static LazySingleton instance = null;
/**
* 私有默认构造子
*/
private LazySingleton(){} /**
* 静态工厂方法
*/
public static synchronized LazySingleton getInstance(){ if(instance == null){ instance = new LazySingleton();
}
return instance;
}
}
工厂模式:http://www.cnblogs.com/java-my-life/archive/2012/03/28/2418836.html
代理模式:http://yangguangfu.iteye.com/blog/815787
未完待续...
posted @
2014-10-08 16:50 小人物_Amor 阅读(388) |
评论 (0) |
编辑 收藏- Servlet 生命周期:Servlet 加载--->实例化--->服务--->销毁。
- init():在Servlet的生命周期中,仅执行一次init()方法。它是在服务器装入Servlet时执行的,负责初始化Servlet 对象。可以配置服务器,以在启动服务器或客户机首次访问Servlet时装入Servlet。无论有多少客户机访问Servlet,都不会重复执行 init()。
- service():它是Servlet的核心,负责响应客户的请求。每当一个客户请求一个HttpServlet对象,该对象的 Service()方法就要调用,而且传递给这个方法一个“请求”(ServletRequest)对象和一个“响应” (ServletResponse)对象作为参数。在HttpServlet中已存在Service()方法。默认的服务功能是调用与HTTP请求的方法 相应的do功能。
- destroy(): 仅执行一次,在服务器端停止且卸载Servlet时执行该方法。当Servlet对象退出生命周期时,负责释放占用的资 源。一个Servlet在运行service()方法时可能会产生其他的线程,因此需要确认在调用destroy()方法时,这些线程已经终止或完成。
Tomcat 与 Servlet 是如何工作的:

步骤:
- Web Client 向Servlet容器(Tomcat)发出Http请求
- Servlet容器接收Web Client的请求
- Servlet容器创建一个HttpRequest对象,将Web Client请求的信息封装到这个对象中。
- Servlet容器创建一个HttpResponse对象
- Servlet容器调用HttpServlet对象的service方法,把HttpRequest对象与HttpResponse对象作为参数传给 HttpServlet 对象。
- HttpServlet调用HttpRequest对象的有关方法,获取Http请求信息。
- HttpServlet调用HttpResponse对象的有关方法,生成响应数据。
- Servlet容器把HttpServlet的响应结果传给Web Client。
Servlet工作原理:
1、首先简单解释一下Servlet接收和响应客户请求的过程,首先客户发送一个请求,Servlet是调用service()方法对请求进行响应 的,通过源代码可见,service()方法中对请求的方式进行了匹配,选择调用doGet,doPost等这些方法,然后再进入对应的方法中调用逻辑层 的方法,实现对客户的响应。在Servlet接口和GenericServlet中是没有doGet()、doPost()等等这些方法 的,HttpServlet中定义了这些方法,但是都是返回error信息,所以,我们每次定义一个Servlet的时候,都必须实现doGet或 doPost等这些方法。
2、每一个自定义的Servlet都必须实现Servlet的接口,Servlet接口中定义了五个方法,其中比较重要的三个方法涉及到 Servlet的生命周期,分别是上文提到的init(),service(),destroy()方法。GenericServlet是一个通用的,不 特定于任何协议的Servlet,它实现了Servlet接口。而HttpServlet继承于GenericServlet,因此 HttpServlet也实现了Servlet接口。所以我们定义Servlet的时候只需要继承HttpServlet即可。
3、Servlet接口和GenericServlet是不特定于任何协议的,而HttpServlet是特定于HTTP协议的类,所以 HttpServlet中实现了service()方法,并将请求ServletRequest、ServletResponse 强转为HttpRequest 和 HttpResponse。
创建Servlet对象的时机:
- Servlet容器启动时:读取web.xml配置文件中的信息,构造指定的Servlet对象,创建ServletConfig对象,同时将ServletConfig对象作为参数来调用Servlet对象的init方法。
- 在Servlet容器启动后:客户首次向Servlet发出请求,Servlet容器会判断内存中是否存在指定的Servlet对象,如果没有则 创建它,然后根据客户的请求创建HttpRequest、HttpResponse对象,从而调用Servlet 对象的service方法。
- Servlet Servlet容器在启动时自动创建Servlet,这是由在web.xml文件中为Servlet设置的<load- on-startup>属性决定的。从中我们也能看到同一个类型的Servlet对象在Servlet容器中以单例的形式存在。
<servlet>
<servlet-name>Init</servlet-name>
<servlet-class>org.xl.servlet.InitServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
posted @
2014-10-08 15:16 小人物_Amor 阅读(325) |
评论 (0) |
编辑 收藏
2014年9月25日
/**
*
*/
package com.zx.ww.arraysort;
import java.text.Collator;
import java.util.Arrays;
import java.util.Calendar;
import java.util.Comparator;
import java.util.Locale;
/**
* @author xue
* 2014年9月24日
*/
public class QuickSort {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
test();
}
}
public static void test() {
int len = 8000000;
int[] array = new int[len];
for (int i = 0; i < len; i++) {
array[i] = (int)(Math.random()*10000);
}
Calendar cal_before = Calendar.getInstance();
double before = cal_before.getTimeInMillis();
System.out.println(cal_before.getTime());
quickSort(array, 0, array.length-1);
Calendar cal_after = Calendar.getInstance();
double after = cal_after.getTimeInMillis();
System.out.println(cal_after.getTime());
double time = after-before;
System.out.println("用时:" + time + "ms");
System.out.println("==================================");
}
public static void quickSort(int[] array, int left, int right) {
if(left < right) {
int privot = getPrivot(array, left, right);
quickSort(array, left, privot-1);
quickSort(array, privot+1, right);
}
}
//将数组划分为两个数组,左边的数组都比中轴privot小,右边的都比中轴privot大
public static int getPrivot(int[] array, int left, int right) {
int tmp = array[left];
while(left < right) {
while(left < right && array[right] >= tmp) {
right--;
}
array[left] = array[right];
while(left < right && array[left] <= tmp) {
left++;
}
array[right] = array[left];
}
array[left] = tmp;
return left;
}
}
运行十次输出的结果:
Thu Sep 25 13:09:40 CST 2014
Thu Sep 25 13:09:41 CST 2014
用时:1613.0ms
==================================
Thu Sep 25 13:09:41 CST 2014
Thu Sep 25 13:09:43 CST 2014
用时:1614.0ms
==================================
Thu Sep 25 13:09:43 CST 2014
Thu Sep 25 13:09:45 CST 2014
用时:1691.0ms
==================================
Thu Sep 25 13:09:45 CST 2014
Thu Sep 25 13:09:47 CST 2014
用时:1622.0ms
==================================
Thu Sep 25 13:09:47 CST 2014
Thu Sep 25 13:09:48 CST 2014
用时:1621.0ms
==================================
Thu Sep 25 13:09:49 CST 2014
Thu Sep 25 13:09:50 CST 2014
用时:1615.0ms
==================================
Thu Sep 25 13:09:50 CST 2014
Thu Sep 25 13:09:52 CST 2014
用时:1614.0ms
==================================
Thu Sep 25 13:09:52 CST 2014
Thu Sep 25 13:09:54 CST 2014
用时:1632.0ms
==================================
Thu Sep 25 13:09:54 CST 2014
Thu Sep 25 13:09:55 CST 2014
用时:1614.0ms
==================================
Thu Sep 25 13:09:56 CST 2014
Thu Sep 25 13:09:57 CST 2014
用时:1614.0ms
==================================
上述是快速排序八百万条数据用时基本在1.6s左右。
接下来看冒泡排序:
/**
*
*/
package com.zx.ww.arraysort;
import java.text.Collator;
import java.util.Arrays;
import java.util.Calendar;
import java.util.Comparator;
import java.util.Locale;
/**
* @author wuwei
* 2014年9月24日
*/
public class BubbleSort {
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
test();
}
}
public static void test() {
int len = 80000;
int[] array = new int[len];
for (int i = 0; i < array.length; i++) {
array[i] = (int)(Math.random()*10000);
}
Calendar calBefore = Calendar.getInstance();
System.out.println(calBefore.getTime());
bubbleSort(array);
Calendar calAfter = Calendar.getInstance();
System.out.println(calAfter.getTime());
System.out.println("总共用时" + (calAfter.getTimeInMillis()-calBefore.getTimeInMillis()) + "ms");
System.out.println("==========================");
}
public static void bubbleSort(int[] array) {
int tmp;
for (int i = 0; i < array.length; i++) {
for (int j = 0; j < array.length-i-1; j++) {
if(array[j] > array[j+1]) {
tmp = array[j+1];
array[j+1] = array[j];
array[j] = tmp;
}
}
}
}
}
运行五次输出如下结果:
Thu Sep 25 14:44:14 CST 2014
Thu Sep 25 14:44:23 CST 2014
总共用时8822ms
==========================
Thu Sep 25 14:44:23 CST 2014
Thu Sep 25 14:44:32 CST 2014
总共用时8829ms
==========================
Thu Sep 25 14:44:32 CST 2014
Thu Sep 25 14:44:41 CST 2014
总共用时8915ms
==========================
Thu Sep 25 14:44:41 CST 2014
Thu Sep 25 14:44:50 CST 2014
总共用时8748ms
==========================
Thu Sep 25 14:44:50 CST 2014
Thu Sep 25 14:44:58 CST 2014
总共用时8529ms
==========================
冒泡排序八万条数据用时接近9s。
需要注意的是快速排序是八百万条数据只用了1.6s左右。
posted @
2014-09-25 13:09 小人物_Amor 阅读(323) |
评论 (0) |
编辑 收藏
2014年7月29日
因为项目框架hibernate里的hibernate.hbm2ddl.auto属性设置为create(为了使得开发人员只关注于实体类而不必去关心数据库设计。。。),所以我们每次部署项目的时候都会把数据库生成的表全删除了然后根据实体类生成数据表,这样就需要在maven项目写一个测试类来初始化项目需要的一些基础数据,如用户、权限、资源、字典等。因为maven在构建到特定的生命周期阶段的时候会通过插件来执行JUnit或者TestNG的测试用例,这个插件就是maven-surefire-plugin(这是需要配置的,当然也可以禁止去执行测试类,甚至禁止编译测试类),需要了解的请学习相关maven文档,或者参考http://blog.csdn.net/sin90lzc/article/details/7543262。
考虑到上述因素,那么我就在src/test/java文件夹下新建一个测试类,那么这个测试类就会在clean install时候会执行,那么在这个时候执行数据初始化是合适的。因为初始化数据来自于sql脚本,所以我得读取sql脚本的内容并解析成相关的sql语句通过java的jdbc执行sql语句。那就开始做吧。不多说,上代码:
1 package com.infopatent.juangetljc.core;
2
3 import java.io.BufferedReader;
4 import java.io.FileInputStream;
5 import java.io.InputStream;
6 import java.sql.Connection;
7 import java.sql.DriverManager;
8 import java.sql.SQLException;
9 import java.sql.Statement;
10 import java.util.ArrayList;
11 import java.util.Arrays;
12 import java.util.List;
13
14 import org.junit.Test;
15
16 import junit.framework.TestCase;
17
18 public class InitDataTest extends TestCase {
19
20 private String url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8";
21 private String driver = "com.mysql.jdbc.Driver";
22 private String userName = "root";
23 private String password = "";
24 String filePathIn = "F://workspace/juange-tljc/juange-tljc-core/src/test/java/basedata.sql";
25
26 @Test
27 public void test() {
28
29 try {
30 execute(filePathIn);
31 } catch (Exception e) {
32 // TODO Auto-generated catch block
33 e.printStackTrace();
34 }
35 }
36
37 /*
38 * 读取sql文件,获取sql语句
39 * 返回所有sql语句的list集合
40 * */
41 private List<String> loadSql(String sqlFile) throws Exception {
42 List<String> sqlList = new ArrayList<String>();
43 /*
44 * 读取文件的内容并写道StringBuffer中去
45 * */
46 InputStream sqlFileIn = new FileInputStream(sqlFile);
47 StringBuffer sqlSb = new StringBuffer();
48 byte[] buff = new byte[sqlFileIn.available()];
49 int byteRead = 0;
50 while((byteRead = sqlFileIn.read(buff)) != -1) {
51 sqlSb.append(new String(buff, 0, byteRead));
52 }
53 /*
54 * windows下换行是/r/n,Linux下是/n,
55 * 此处需要根据导出的sql文件进行具体的处理,我在处理的时候
56 * 也遇到了很多的问题,如果我这个不行可以在网上找找别的解析方法
57 * */
58 String sqlArr[] = sqlSb.toString().split("(;\\s*\\rr\\n)|(;\\s*\\n)");
59 for(int i = 0; i<sqlArr.length; i++) {
60 String sql = sqlArr[i].replaceAll("--.*", "").trim();
61 if(!"".equals(sql)) {
62 sqlList.add(sql);
63 }
64 }
65 return sqlList;
66
67 }
68
69 /*
70 * 传入文件执行sql语句
71 *
72 * */
73 private void execute(String sqlFile) throws SQLException {
74 Statement stmt = null;
75 List<String> sqlList = new ArrayList<String>();
76 Connection conn = getConnection();
77 try {
78 sqlList = loadSql(sqlFile);
79 conn.setAutoCommit(false);
80 stmt = conn.createStatement();
81 for (String sql : sqlList) {
82 System.out.println(sql);
83 stmt.addBatch(sql);
84 }
85 int[] rows = stmt.executeBatch();
86 System.out.println("Row count:" + Arrays.toString(rows));
87 conn.commit();
88 System.out.println("数据更新成功");
89 } catch (Exception e) {
90 e.printStackTrace();
91 conn.rollback();
92 }finally{
93 stmt.close();
94 conn.close();
95 }
96
97 }
98
99 /*
100 * 获取sql连接
101 * */
102 private Connection getConnection(){
103 Connection conn = null;
104 try {
105 Class.forName(driver);
106 conn = DriverManager.getConnection(url, userName, password);
107 if(!conn.isClosed()) {
108 System.out.println("数据库连接成功!");
109 }
110 } catch (Exception e) {
111 e.printStackTrace();
112 }
113 return conn;
114 }
115 }
116
在这个过程中遇到了很多的问题,曾经一度使我陷入迷糊状态中,后来好好梳理了一下思路,一个一个的去排查问题终于成功了~
首先在读取文件的时候,发现读取的文件内容显示是正常的不是乱码,但是插入到数据库中就是乱码,好吧,我又遇到了这种问题,我依次检查了我java文件的编码,数据库的编码,都设置为utf-8,url也加上编码
"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8"。结果还是乱码,那就再看看mysql下的my.ini文件中的编码设置在[mysqld]节点下加上default-character-set=utf8(如果没有就改为utf8),这下终于不是乱码了。然后我开始maven clean install,去查看数据库发现又出现了乱码的问题,真是折磨人啊,我发现唯一不同的就是之前正常的插入数据是我在测试类下run as junit,而现在用的是maven clean install,刚接触maven完全不知道症结所在啊,百度一下,发现maven构建到特定的生命周期时候运行测试用例是依靠maven-surefire-plugin这个插件的,而这个插件也需要指定字符集编码的,于是我在项目的pom.xml中加入了如下代码(本来竟然没有!):
1 <build>
2 <plugins>
3 <plugin>
4 <groupId>org.apache.maven.plugins</groupId>
5 <artifactId>maven-surefire-plugin</artifactId>
6 <version>2.7.2</version>
7 <configuration>
8 <forkMode>once</forkMode>
9 <argLine>-Dfile.encoding=UTF-8</argLine>
10 <systemProperties>
11 <property>
12 <name>net.sourceforge.cobertura.datafile</name>
13 <value>target/cobertura/cobertura.ser</value>
14 </property>
15 </systemProperties>
16 </configuration>
17 </plugin>
18 </plugins>
19 </build>
这个时候再去maven clean install,终于不乱码了,终于不乱码了!花了我四个小时,长见识了!此处记录自己遇到的问题以及如何解决,希望对各位有帮助!
posted @
2014-07-29 15:07 小人物_Amor 阅读(3373) |
评论 (0) |
编辑 收藏
2014年5月30日
各位如果想找合适的树形菜单,不放试试dtree,去官网看看www.destroydrop.com/javascript/tree/,下载dtree.zip下来解压之后有dtree.js,dtree.css,img文件夹,api.html,example01.html这几个文件,可以看看api.html,里面有参数和方法说明,实际上在项目应用时,我们是需要从数据库里的菜单表里读取数据进行树形菜单构建的,根据api.html里面的参数说明可建立一张s_menu的数据表:
CREATE TABLE `s_menu` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`pid` int(11) DEFAULT NULL COMMENT '父级id',
`name` varchar(45) DEFAULT NULL COMMENT '菜单名称',
`url` varchar(255) DEFAULT NULL COMMENT '菜单url',
`title` varchar(45) DEFAULT NULL COMMENT '鼠标放上去显示的title',
`target` varchar(45) DEFAULT NULL COMMENT '目标iframe',
`icon` varchar(255) DEFAULT NULL COMMENT '菜单折叠时候显示的图片',
`iconOpen` varchar(255) DEFAULT NULL COMMENT '菜单打开时候显示的图片',
`open` int(1) DEFAULT '0' COMMENT '是否打开',
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=12 DEFAULT CHARSET=utf8;
并且插入一些测试数据来使用:
INSERT INTO `s_menu` VALUES ('1', '-1', '浏览器', '#', '浏览器', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('2', '1', 'IE', '#', 'IE浏览器', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('3', '2', 'IE6', '#', 'IE6', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('4', '2', 'IE7', '#', 'IE7', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('5', '2', 'IE8', '#', 'IE8', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('6', '2', 'IE10', '#', 'IE10', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('7', '1', 'Firefox', '#', 'Firefox', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('8', '7', 'Firefox15.0', '#', 'Firefox15.0', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('9', '7', 'Firefox15.1', '#', 'Firefox15.1', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('10', '1', '360浏览器', '#', '360浏览器', null, null, null, '0');
INSERT INTO `s_menu` VALUES ('11', '1', '搜狗浏览器', '#', '搜狗浏览器', null, null, null, '0');
接下来把解压好的dtree.js以及dtree.css放到项目的对应目录下,并在页面引入,后台执行方法我就不说了,就是查询出s_menu里所有的数据就可以了,在jsp里面实现:
<%@ page contentType="text/html;charset=UTF-8" %>
<%@ include file="/common/taglibs.jsp" %>
<%@ page import="org.springframework.context.ApplicationContext,org.springframework.context.support.ClassPathXmlApplicationContext,com.zx.ww.entity.base.Menu,com.zx.ww.service.base.MenuManager,java.util.List" %>
<%
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
MenuManager menuManager = (MenuManager)context.getBean("menuManager");
List<Menu> menus = menuManager.findAllMenu();
request.setAttribute("menus", menus);
%>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>SSH2</title>
</head>
<body>
<table width="100%" height="100%" border="0" cellspacing="0" cellpadding="0">
<tr>
<td valign="top">
<div id="treearea" style="overflow: scroll;height:100%;width:100%"></div>
</td>
</tr>
</table>
</body>
</html>
<script type="text/javascript">
var dtree = new dTree('dtree', '${ctx}/images/dtree/');
dtree.config.folderLinks = true;
dtree.config.useCookies = true;
<c:forEach items="${menus}" var="menu">
dtree.add(${menu.id},${menu.pid},"${menu.name}","${menu.url}","${menu.title}");
</c:forEach>
document.getElementById('treearea').innerHTML = dtree;
</script>
看效果:
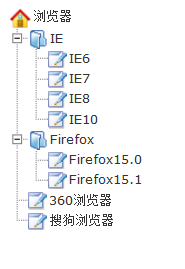
这是从数据库里读出数据的方式,本地的话构建这样的数据就行了:
<script type="text/javascript">
<!--
d = new dTree('d');
d.add(0,-1,'My example tree');
d.add(1,0,'Node 1','example01.html');
d.add(2,0,'Node 2','example01.html');
d.add(3,1,'Node 1.1','example01.html');
d.add(4,0,'Node 3','example01.html');
d.add(5,3,'Node 1.1.1','example01.html');
d.add(6,5,'Node 1.1.1.1','example01.html');
d.add(7,0,'Node 4','example01.html');
d.add(8,1,'Node 1.2','example01.html');
d.add(9,0,'My Pictures','example01.html','Pictures I\'ve taken over the years','','','img/imgfolder.gif');
d.add(10,9,'The trip to Iceland','example01.html','Pictures of Gullfoss and Geysir');
d.add(11,9,'Mom\'s birthday','example01.html');
d.add(12,0,'Recycle Bin','example01.html','','','img/trash.gif');
document.write(d);
//-->
</script>
网上有很多关于dtree的说明,在此看不明白的再去网上找找别的,有说的比较详细的PPT,关于各个参数以及方法说明都有~
ok,留着以后会有用的!
posted @
2014-05-30 17:46 小人物_Amor 阅读(1332) |
评论 (0) |
编辑 收藏