velocity开发eclipse插件
http://code.google.com/p/veloeclipse/
目录结构
点我下载工程代码
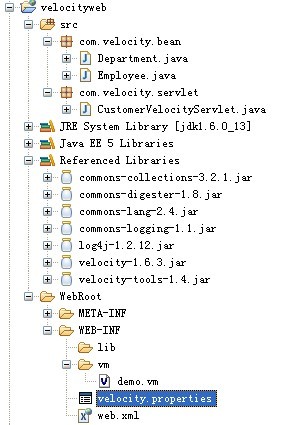
俩实体类不用说了
看CustomerVelocityServlet类
package com.velocity.servlet;
import java.util.ArrayList;
import java.util.List;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.velocity.Template;
import org.apache.velocity.context.Context;
import org.apache.velocity.tools.view.servlet.VelocityViewServlet;
import com.velocity.bean.Department;
import com.velocity.bean.Employee;
@SuppressWarnings("serial")
public class CustomerVelocityServlet extends VelocityViewServlet{
//设置返回视图为text/html编码为gbk
@Override
protected void setContentType(HttpServletRequest request,
HttpServletResponse response) {
response.setContentType("text/html;charset=gbk");
}
//处理请求
@Override
protected Template handleRequest(HttpServletRequest request,
HttpServletResponse response, Context ctx) throws Exception {
ctx.put("username", "张三");
ctx.put("password", "123456789");
ctx.put("age", "20");
ctx.put("address", "陕西西安");
ctx.put("blog", "http://blogjava.net/sxyx2008");
List<Employee> list=new ArrayList<Employee>();
list.add(new Employee(1,"张三","陕西西安",18,new Department(1,"软件研发部1")));
list.add(new Employee(2,"张三","陕西西安",19,new Department(2,"软件研发部2")));
list.add(new Employee(3,"张三","陕西西安",20,new Department(3,"软件研发部3")));
list.add(new Employee(4,"张三","陕西西安",21,new Department(4,"软件研发部4")));
list.add(new Employee(5,"张三","陕西西安",22,new Department(5,"软件研发部5")));
list.add(new Employee(6,"张三","陕西西安",23,new Department(6,"软件研发部6")));
list.add(new Employee(7,"张三","陕西西安",24,new Department(7,"软件研发部7")));
list.add(new Employee(8,"张三","陕西西安",25,new Department(8,"软件研发部8")));
list.add(new Employee(9,"张三","陕西西安",26,new Department(9,"软件研发部9")));
list.add(new Employee(10,"张三","陕西西安",27,new Department(10,"软件研发部10")));
ctx.put("list", list);
//调用父类的方法getTemplate()
return getTemplate("demo.vm", "gbk");
}
}
继承org.apache.velocity.tools.view.servlet.VelocityViewServlet,覆写setContentType和handleRequest方法,其中setContentType用于设置浏览器的响应,handleRequest处理用户的请求,返回Template,我们调用父类中的getTemplate()方法返回
在WEB-INF目录下创建一vm目录,用于存放模板文件
在WEB-INF目录下创建velocity.properties(名字可以任意取)
内容为
resource.loader = webapp
webapp.resource.loader.class = org.apache.velocity.tools.view.servlet.WebappLoader
webapp.resource.loader.path=/WEB-INF/vm/
input.encoding="gbk"
output.encoding="gbk"
resource.loader = webapp 加载方式为webapp
webapp.resource.loader.class = org.apache.velocity.tools.view.servlet.WebappLoader webapp方式加载处理类
webapp.resource.loader.path=/WEB-INF/vm/ 模板文件目录
input.encoding="gbk" 输入字符编码
output.encoding="gbk" 输出字符编码
配置web.xml
<servlet>
<servlet-name>customerVelocityServlet</servlet-name>
<servlet-class>com.velocity.servlet.CustomerVelocityServlet</servlet-class>
<init-param>
<param-name>org.apache.velocity.properties</param-name>
<param-value>/WEB-INF/velocity.properties</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>customerVelocityServlet</servlet-name>
<url-pattern>/customerVelocityServlet</url-pattern>
</servlet-mapping>
<init-param>
<param-name>org.apache.velocity.properties</param-name>
<param-value>/WEB-INF/velocity.properties</param-value>
</init-param>
加载自定义的velocity.properties
demo.vm
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE> velocity </TITLE>
</HEAD>
##嘿嘿,我是velocity中的注释噢
#*
嘿嘿,我也是velocity中的注释噢
*#
<BODY>
<h1>hehe,这是经过由servlet返回的velocity视图</h1>
hello ${username},这是你的信息
<ul>
<li>用户密码为:${password}</li>
<li>年龄为:${age}</li>
<li>出生地址为:${address}</li>
<li>个人主页为:<a href='${blog}'>${blog}</a></li>
</ul>
<br/>
#foreach($emp in $!{list})
$!{velocityCount}
$!{emp.id}
$!{emp.ename}
$!{emp.eaddress}
$!{emp.age}
$!{emp.department.id}
$!{emp.department.deptname} <hr/>
#end
</BODY>
</HTML>
http://localhost:8080/velocityweb/customerVelocityServlet
效果图
 点我下载工程代码
点我下载工程代码