我来解决手机电池问题 :
工具----设置------网络设置-------运营商选择------
手动
-------选择你使用的运营商------ok 。这样大概要待机多1/3时间
posted @
2007-01-10 11:06 rkind 阅读(275) |
评论 (0) |
编辑 收藏posted @
2006-12-08 16:19 rkind 阅读(282) |
评论 (0) |
编辑 收藏
今天在试验了一下在Struts-config中配置数据源,虽然说这种方法并不推荐,
操作步骤:
首先导入几个需要的包:首先自己连接数据库用的包,因为我用的是Mysql所以用的是“mm.mysql-2.0.4-bin.jar”,还有“commons-dbcp-1.2.1.jar”这个是数据源中要用到的包,还有“commons-pool-1.2.jar”这个不太清楚
其次在Struts-config.xml中加入如下代码
 <data-sources>
<data-sources>
<data-source key="rki" type="org.apache.commons.dbcp.BasicDataSource"> //type代表类,rki表示当有多个数据源时相
//当于一个索引,id值
<set-property property="driverClassName" value="org.gjt.mm.mysql.Driver" />//连接mysql所需的类库
<set-property property="url" value="jdbc:mysql://172.20.0.40:3306/test?useUnicode=true&characterEncoding=GBK" />
<set-property property="username" value="root" />
<set-property property="password" value="你的密码" />
<set-property property="maxActive" value="10" />
<set-property property="maxWait" value="500" />
<set-property property="defaultAutoCommit" value="false" />
<set-property property="defaultReadOnly" value="false" />
</data-source>
</data-sources>然后现在就可以在你的Action试验数据库的连接,简单引用的代码片断
datasource = getDataSource(request, "rki");
conn = datasource.getConnection();
Statement state = conn.createStatement();
System.out.println("hello");
String sql = "select * from notice where title='test'";
ResultSet rs = state.executeQuery(sql);

 while (rs.next())
while (rs.next())  {
{
 request.getSession().setAttribute("cont",
request.getSession().setAttribute("cont",
rs.getString("content"));
System.out.println("database connect true");
 }
}
rs.close(); 在试验的过程中,老是不能连接,出“Initializing application data source”我仔细检查过以上的配置并没有问题,重启了几次服务器也不行,查了N多资料,最后居然自己好了,郁闷的要死
一点总结,
可见在Struts中配置数据源要比别的连接方法要复杂,而且效率上来说也不一定要好,还不如自己通过自己编写简单的访问数据库的类,或者是直接采用Tomcat的数据源要方便 一些。
posted @
2006-10-31 15:49 rkind 阅读(408) |
评论 (0) |
编辑 收藏
在Struts中可以通过<html:errors/>来显示错误信息,今天简单看了一点,总结一下:
1)如果是采用了formbean的validate的话,首先,struts-config.xml中Action需要加入validate="true"
其实,在Actionform中的validate必须返回一个自己定义的Actionerrors,如例:
public ActionErrors validate(ActionMapping mapping,
HttpServletRequest request) {
ActionErrors errors = new ActionErrors();

 if (this.content.equals("")) {
if (this.content.equals("")) {
errors.add("content", new ActionError("error.user"));
 }
}
return errors;
} 2)如果没有采用,而是用Action验证的话,也需要先定义一个Actionerrors,然后再通过
saveErrors(request,errors);把Actionerrrors保存到request中
3)需要注意的
a,每个ActionErrors都有一个String,和一个ActionError构成,ActionError里面的String是和项目资源文件里的一一对应的,String是和html:errors中property相对应的。
posted @
2006-10-30 17:23 rkind 阅读(591) |
评论 (0) |
编辑 收藏这就是在前面的简单应用中,在view中,通过<bean:write name="myform" property="name">调用Actionform时出的问题,这个问题的直接原因很简单就是:找不到"myform"这个Bean,用网上的话说就是“在Action里一般会request.setAttribute()一些对象,然后在转向的jsp文件里(用tag或request.getAttribute()方法)得到这些对象并显示出来。这个异常是说jsp要得到一个对象,但前面的Action里并没有将对象设置到request(也可以是session、servletContext)里。可能是名字错了,请检查jsp里的tag的一般是name属性,或getAttribute()方法的参数值;或者是Action逻辑有问题没有执行setAttribute()方法就先转向了。
还有另外一个可能,纯粹是jsp文件的问题,例如<logic:iterate>会指定一个id值,然后在循环里<bean:write>使用这个值作为name的值,如果这两个值不同,也会出现此异常。(都是一个道理,request里没有对应的对象。)”。
我对Actionform的机制不理解,心中的疑问:
1)如果ActionForm是Struts自动封装到Request中,那么我可以直接在view.jsp中,能过<bean:write>调用这个ActionForm,如果假设这种情况成立时,那么Beanwrite中的bean名应该是ActionForm的类名,还是在Struts-config.xml里给ActionForm定义的类名?
2)如果没有封装的话,那么是不是需要在Action中把Actionform通过request.setAttribute("","")放到request中
还是要放到Session中,
我测试时候出的问题
有一次就是在1)的情况下测试成功的,但是以后再怎么试都不行,那次是引用的Struts-config.xml里给ActionForm定义的类名。非常奇怪,
还有就是2)的情况,测试中如果Action和Frombean在一个包下面,那么通过request.setAttribute("",""),就可以获取到Bean,如果不是的话,有时候行,有时候不行,
如果通过request.getSession.setAttribute()设置ActionForm的话,每次都可以,他们的Scope肯定在一个Request中,那么为什么Session就可以,而Request不行。(结论:因为是在Actionfoward中设置了“redirect='true',这样的话一跳转时,Request中的内容都会被重置,所以不行,把这一句去掉就可以了”)
posted @
2006-10-30 14:07 rkind 阅读(8570) |
评论 (1) |
编辑 收藏
1、简介
简单的页面输入并显示的功能,有两个页面,
upnews.jsp 提供输入内容的界面,show.jsp显示已经输入的内容
2、源码
struts-config,流程图
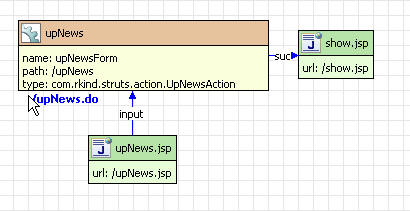
源代码
Strust-config.xml
<form-bean name="upNewsForm" type="com.rkind.struts.form.UpNewsForm" /> <action attribute="upNewsForm" input="/upNews.jsp" name="upNewsForm" path="/upNews" scope="request" type="com.rkind.struts.action.UpNewsAction">
<forward name="suc" path="/show.jsp" redirect="true" />
</action>
upnews.jsp
都是eclispe自动生成的
<html:form action="/upNews">
content : <html:text property="content"/><html:errors property="content"/><br/>
<html:submit/><html:cancel/>
</html:form>
show.jsp这个简单就一句话,
<bean:write name="upNewsForm" property="content"/>
模型的部分 formbean,自动生成,未做改动
Controller部分,核心啊
UpNewsForm upNewsForm = (UpNewsForm) form;
// TODO Auto-generated method stub
String te=upNewsForm.getContent();
try{
if(te.equals("")){
return new ActionForward(mapping.getInput());
}
return (mapping.findForward("suc"));
}catch(Exception e){
throw new RuntimeException(e.getMessage()); 好了,但是在测试的时候一直出问题,输入以后不能正常,原因有2
1、在链接时候,没有加“/”导致不能正常连接
2、
forward name="suc" path="/show.jsp" redirect="true" 起初没有加redirect,不能跳转。
posted @
2006-10-27 12:39 rkind 阅读(541) |
评论 (0) |
编辑 收藏
1、插入和包含
1) js,一般都放在head之间、注释的作用是当客户端浏览器版本过低时,不能识别而发生错误
<script language="JavaScript">
<!--
document.write( "Hello World!");
//-->
</script>
2)另外你也可以编辑.js文件,然后在页面里面直接引用就可以了
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>javascript</title><script language="javascript"src="Untitled-2.js"></script></head>
2、write
在js中要显示字符,需要用document.write()的形式,writeln区别就是再write的基础上加入了换行
3、如例
document.write("Hello World!");
document.write("test"+document.lastModified);
document.bgColor = " black "
其中,document是对象,write是method,输出字符可以用加的形式,,可以在js里面设定页面的背景
4、提示框
1)window.alert("testtesttest")
弹出窗口
2)window.confirm("test")
3)有输入框的提示框
window.prompt("test")
一不小心双击了标签了,写的全都没了!!!后面的不写了,写js时一定要注意“” ’号的运用!
js的功能是超级强大的,运用还是要靠脑筋的,
posted @
2006-10-26 12:09 rkind 阅读(505) |
评论 (0) |
编辑 收藏
一、术语session
在我的经验里,session这个词被滥用的程度大概仅次于transaction,更加有趣的是transaction与session在某些语境下的含义是相同的。
session,中文经常翻译为会话,其本来的含义是指有始有终的一系列动作/消息,比如打电话时从拿起电话拨号到挂断电话这中间的一系列过程可以称之为一个session。有时候我们可以看到这样的话“在一个浏览器会话期间,...”,这里的会话一词用的就是其本义,是指从一个浏览器窗口打开到关闭这个期间①。最混乱的是“用户(客户端)在一次会话期间”这样一句话,它可能指用户的一系列动作(一般情况下是同某个具体目的相关的一系列动作,比如从登录到选购商品到结账登出这样一个网上购物的过程,有时候也被称为一个transaction),然而有时候也可能仅仅是指一次连接,也有可能是指含义①,其中的差别只能靠上下文来推断②。
然而当session一词与网络协议相关联时,它又往往隐含了“面向连接”和/或“保持状态”这样两个含义,“面向连接”指的是在通信双方在通信之前要先建立一个通信的渠道,比如打电话,直到对方接了电话通信才能开始,与此相对的是写信,在你把信发出去的时候你并不能确认对方的地址是否正确,通信渠道不一定能建立,但对发信人来说,通信已经开始了。“保持状态”则是指通信的一方能够把一系列的消息关联起来,使得消息之间可以互相依赖,比如一个服务员能够认出再次光临的老顾客并且记得上次这个顾客还欠店里一块钱。这一类的例子有“一个TCP session”或者“一个POP3 session”③。
而到了web服务器蓬勃发展的时代,session在web开发语境下的语义又有了新的扩展,它的含义是指一类用来在客户端与服务器之间保持状态的解决方案④。有时候session也用来指这种解决方案的存储结构,如“把xxx保存在session里”⑤。由于各种用于web开发的语言在一定程度上都提供了对这种解决方案的支持,所以在某种特定语言的语境下,session也被用来指代该语言的解决方案,比如经常把Java里提供的javax.servlet.http.HttpSession简称为session⑥。
鉴于这种混乱已不可改变,本文中session一词的运用也会根据上下文有不同的含义,请大家注意分辨。
在本文中,使用中文“浏览器会话期间”来表达含义①,使用“session机制”来表达含义④,使用“session”表达含义⑤,使用具体的“HttpSession”来表达含义⑥
二、HTTP协议与状态保持
HTTP协议本身是无状态的,这与HTTP协议本来的目的是相符的,客户端只需要简单的向服务器请求下载某些文件,无论是客户端还是服务器都没有必要纪录彼此过去的行为,每一次请求之间都是独立的,好比一个顾客和一个自动售货机或者一个普通的(非会员制)大卖场之间的关系一样。
然而聪明(或者贪心?)的人们很快发现如果能够提供一些按需生成的动态信息会使web变得更加有用,就像给有线电视加上点播功能一样。这种需求一方面迫使HTML逐步添加了表单、脚本、DOM等客户端行为,另一方面在服务器端则出现了CGI规范以响应客户端的动态请求,作为传输载体的HTTP协议也添加了文件上载、cookie这些特性。其中cookie的作用就是为了解决HTTP协议无状态的缺陷所作出的努力。至于后来出现的session机制则是又一种在客户端与服务器之间保持状态的解决方案。
让我们用几个例子来描述一下cookie和session机制之间的区别与联系。笔者曾经常去的一家咖啡店有喝5杯咖啡免费赠一杯咖啡的优惠,然而一次性消费5杯咖啡的机会微乎其微,这时就需要某种方式来纪录某位顾客的消费数量。想象一下其实也无外乎下面的几种方案:
1、该店的店员很厉害,能记住每位顾客的消费数量,只要顾客一走进咖啡店,店员就知道该怎么对待了。这种做法就是协议本身支持状态。
2、发给顾客一张卡片,上面记录着消费的数量,一般还有个有效期限。每次消费时,如果顾客出示这张卡片,则此次消费就会与以前或以后的消费相联系起来。这种做法就是在客户端保持状态。
3、发给顾客一张会员卡,除了卡号之外什么信息也不纪录,每次消费时,如果顾客出示该卡片,则店员在店里的纪录本上找到这个卡号对应的纪录添加一些消费信息。这种做法就是在服务器端保持状态。
由于HTTP协议是无状态的,而出于种种考虑也不希望使之成为有状态的,因此,后面两种方案就成为现实的选择。具体来说cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案。同时我们也看到,由于采用服务器端保持状态的方案在客户端也需要保存一个标识,所以session机制可能需要借助于cookie机制来达到保存标识的目的,但实际上它还有其他选择。
三、理解cookie机制
cookie机制的基本原理就如上面的例子一样简单,但是还有几个问题需要解决:“会员卡”如何分发;“会员卡”的内容;以及客户如何使用“会员卡”。
正统的cookie分发是通过扩展HTTP协议来实现的,服务器通过在HTTP的响应头中加上一行特殊的指示以提示浏览器按照指示生成相应的cookie。然而纯粹的客户端脚本如JavaScript或者VBScript也可以生成cookie。
而cookie的使用是由浏览器按照一定的原则在后台自动发送给服务器的。浏览器检查所有存储的cookie,如果某个cookie所声明的作用范围大于等于将要请求的资源所在的位置,则把该cookie附在请求资源的HTTP请求头上发送给服务器。意思是麦当劳的会员卡只能在麦当劳的店里出示,如果某家分店还发行了自己的会员卡,那么进这家店的时候除了要出示麦当劳的会员卡,还要出示这家店的会员卡。
cookie的内容主要包括:名字,值,过期时间,路径和域。
其中域可以指定某一个域比如.google.com,相当于总店招牌,比如宝洁公司,也可以指定一个域下的具体某台机器比如www.google.com或者froogle.google.com,可以用飘柔来做比。
路径就是跟在域名后面的URL路径,比如/或者/foo等等,可以用某飘柔专柜做比。
路径与域合在一起就构成了cookie的作用范围。
如果不设置过期时间,则表示这个cookie的生命期为浏览器会话期间,只要关闭浏览器窗口,cookie就消失了。这种生命期为浏览器会话期的cookie被称为会话cookie。会话cookie一般不存储在硬盘上而是保存在内存里,当然这种行为并不是规范规定的。如果设置了过期时间,浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie仍然有效直到超过设定的过期时间。
存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存里的cookie,不同的浏览器有不同的处理方式。对于IE,在一个打开的窗口上按Ctrl-N(或者从文件菜单)打开的窗口可以与原窗口共享,而使用其他方式新开的IE进程则不能共享已经打开的窗口的内存cookie;对于Mozilla Firefox0.8,所有的进程和标签页都可以共享同样的cookie。一般来说是用javascript的window.open打开的窗口会与原窗口共享内存cookie。浏览器对于会话cookie的这种只认cookie不认人的处理方式经常给采用session机制的web应用程序开发者造成很大的困扰。
下面就是一个goolge设置cookie的响应头的例子
HTTP/1.1 302 Found
Location: http://www.google.com/intl/zh-CN/
Set-Cookie: PREF=ID=0565f77e132de138:NW=1:TM=1098082649:LM=1098082649:S=KaeaCFPo49RiA_d8; expires=Sun, 17-Jan-2038 19:14:07 GMT; path=/; domain=.google.com
Content-Type: text/html
这是使用HTTPLook这个HTTP Sniffer软件来俘获的HTTP通讯纪录的一部分
浏览器在再次访问goolge的资源时自动向外发送cookie
使用Firefox可以很容易的观察现有的cookie的值
使用HTTPLook配合Firefox可以很容易的理解cookie的工作原理。
IE也可以设置在接受cookie前询问
这是一个询问接受cookie的对话框。
四、理解session机制
session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。
当程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个客户端的请求里是否已包含了一个session标识 - 称为session id,如果已包含一个session id则说明以前已经为此客户端创建过session,服务器就按照session id把这个session检索出来使用(如果检索不到,可能会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个session id将被在本次响应中返回给客户端保存。
保存这个session id的方式可以采用cookie,这样在交互过程中浏览器可以自动的按照规则把这个标识发挥给服务器。一般这个cookie的名字都是类似于SEEESIONID,而。比如weblogic对于web应用程序生成的cookie,JSESSIONID=ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764,它的名字就是JSESSIONID。
由于cookie可以被人为的禁止,必须有其他机制以便在cookie被禁止时仍然能够把session id传递回服务器。经常被使用的一种技术叫做URL重写,就是把session id直接附加在URL路径的后面,附加方式也有两种,一种是作为URL路径的附加信息,表现形式为http://...../xxx;jsessionid=ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764另一种是作为查询字符串附加在URL后面,表现形式为http://...../xxx?jsessionid=ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764
这两种方式对于用户来说是没有区别的,只是服务器在解析的时候处理的方式不同,采用第一种方式也有利于把session id的信息和正常程序参数区分开来。
为了在整个交互过程中始终保持状态,就必须在每个客户端可能请求的路径后面都包含这个session id。
另一种技术叫做表单隐藏字段。就是服务器会自动修改表单,添加一个隐藏字段,以便在表单提交时能够把session id传递回服务器。比如下面的表单
在被传递给客户端之前将被改写成
这种技术现在已较少应用,笔者接触过的很古老的iPlanet6(SunONE应用服务器的前身)就使用了这种技术。实际上这种技术可以简单的用对action应用URL重写来代替。
在谈论session机制的时候,常常听到这样一种误解“只要关闭浏览器,session就消失了”。其实可以想象一下会员卡的例子,除非顾客主动对店家提出销卡,否则店家绝对不会轻易删除顾客的资料。对session来说也是一样的,除非程序通知服务器删除一个session,否则服务器会一直保留,程序一般都是在用户做log off的时候发个指令去删除session。然而浏览器从来不会主动在关闭之前通知服务器它将要关闭,因此服务器根本不会有机会知道浏览器已经关闭,之所以会有这种错觉,是大部分session机制都使用会话cookie来保存session id,而关闭浏览器后这个session id就消失了,再次连接服务器时也就无法找到原来的session。如果服务器设置的cookie被保存到硬盘上,或者使用某种手段改写浏览器发出的HTTP请求头,把原来的session id发送给服务器,则再次打开浏览器仍然能够找到原来的session。
恰恰是由于关闭浏览器不会导致session被删除,迫使服务器为seesion设置了一个失效时间,当距离客户端上一次使用session的时间超过这个失效时间时,服务器就可以认为客户端已经停止了活动,才会把session删除以节省存储空间。
五、理解javax.servlet.http.HttpSession
HttpSession是Java平台对session机制的实现规范,因为它仅仅是个接口,具体到每个web应用服务器的提供商,除了对规范支持之外,仍然会有一些规范里没有规定的细微差异。这里我们以BEA的Weblogic Server8.1作为例子来演示。
首先,Weblogic Server提供了一系列的参数来控制它的HttpSession的实现,包括使用cookie的开关选项,使用URL重写的开关选项,session持久化的设置,session失效时间的设置,以及针对cookie的各种设置,比如设置cookie的名字、路径、域,cookie的生存时间等。
一般情况下,session都是存储在内存里,当服务器进程被停止或者重启的时候,内存里的session也会被清空,如果设置了session的持久化特性,服务器就会把session保存到硬盘上,当服务器进程重新启动或这些信息将能够被再次使用,Weblogic Server支持的持久性方式包括文件、数据库、客户端cookie保存和复制。
复制严格说来不算持久化保存,因为session实际上还是保存在内存里,不过同样的信息被复制到各个cluster内的服务器进程中,这样即使某个服务器进程停止工作也仍然可以从其他进程中取得session。
cookie生存时间的设置则会影响浏览器生成的cookie是否是一个会话cookie。默认是使用会话cookie。有兴趣的可以用它来试验我们在第四节里提到的那个误解。
cookie的路径对于web应用程序来说是一个非常重要的选项,Weblogic Server对这个选项的默认处理方式使得它与其他服务器有明显的区别。后面我们会专题讨论。
关于session的设置参考[5] http://e-docs.bea.com/wls/docs70/webapp/weblogic_xml.html#1036869
六、HttpSession常见问题
(在本小节中session的含义为⑤和⑥的混合)
1、session在何时被创建
一个常见的误解是以为session在有客户端访问时就被创建,然而事实是直到某server端程序调用HttpServletRequest.getSession(true)这样的语句时才被创建,注意如果JSP没有显示的使用 <%@page session="false"%>关闭session,则JSP文件在编译成Servlet时将会自动加上这样一条语句HttpSession session = HttpServletRequest.getSession(true);这也是JSP中隐含的session对象的来历。
由于session会消耗内存资源,因此,如果不打算使用session,应该在所有的JSP中关闭它。
2、session何时被删除
综合前面的讨论,session在下列情况下被删除a.程序调用HttpSession.invalidate();或b.距离上一次收到客户端发送的session id时间间隔超过了session的超时设置;或c.服务器进程被停止(非持久session)
3、如何做到在浏览器关闭时删除session
严格的讲,做不到这一点。可以做一点努力的办法是在所有的客户端页面里使用javascript代码window.oncolose来监视浏览器的关闭动作,然后向服务器发送一个请求来删除session。但是对于浏览器崩溃或者强行杀死进程这些非常规手段仍然无能为力。
4、有个HttpSessionListener是怎么回事
你可以创建这样的listener去监控session的创建和销毁事件,使得在发生这样的事件时你可以做一些相应的工作。注意是session的创建和销毁动作触发listener,而不是相反。类似的与HttpSession有关的listener还有HttpSessionBindingListener,HttpSessionActivationListener和HttpSessionAttributeListener。
5、存放在session中的对象必须是可序列化的吗
不是必需的。要求对象可序列化只是为了session能够在集群中被复制或者能够持久保存或者在必要时server能够暂时把session交换出内存。在Weblogic Server的session中放置一个不可序列化的对象在控制台上会收到一个警告。我所用过的某个iPlanet版本如果session中有不可序列化的对象,在session销毁时会有一个Exception,很奇怪。
6、如何才能正确的应付客户端禁止cookie的可能性
对所有的URL使用URL重写,包括超链接,form的action,和重定向的URL,具体做法参见[6]
http://e-docs.bea.com/wls/docs70/webapp/sessions.html#100770
7、开两个浏览器窗口访问应用程序会使用同一个session还是不同的session
参见第三小节对cookie的讨论,对session来说是只认id不认人,因此不同的浏览器,不同的窗口打开方式以及不同的cookie存储方式都会对这个问题的答案有影响。
8、如何防止用户打开两个浏览器窗口操作导致的session混乱
这个问题与防止表单多次提交是类似的,可以通过设置客户端的令牌来解决。就是在服务器每次生成一个不同的id返回给客户端,同时保存在session里,客户端提交表单时必须把这个id也返回服务器,程序首先比较返回的id与保存在session里的值是否一致,如果不一致则说明本次操作已经被提交过了。可以参看《J2EE核心模式》关于表示层模式的部分。需要注意的是对于使用javascript window.open打开的窗口,一般不设置这个id,或者使用单独的id,以防主窗口无法操作,建议不要再window.open打开的窗口里做修改操作,这样就可以不用设置。
9、为什么在Weblogic Server中改变session的值后要重新调用一次session.setValue
做这个动作主要是为了在集群环境中提示Weblogic Server session中的值发生了改变,需要向其他服务器进程复制新的session值。
10、为什么session不见了
排除session正常失效的因素之外,服务器本身的可能性应该是微乎其微的,虽然笔者在iPlanet6SP1加若干补丁的Solaris版本上倒也遇到过;浏览器插件的可能性次之,笔者也遇到过3721插件造成的问题;理论上防火墙或者代理服务器在cookie处理上也有可能会出现问题。
出现这一问题的大部分原因都是程序的错误,最常见的就是在一个应用程序中去访问另外一个应用程序。我们在下一节讨论这个问题。
七、跨应用程序的session共享
常常有这样的情况,一个大项目被分割成若干小项目开发,为了能够互不干扰,要求每个小项目作为一个单独的web应用程序开发,可是到了最后突然发现某几个小项目之间需要共享一些信息,或者想使用session来实现SSO(single sign on),在session中保存login的用户信息,最自然的要求是应用程序间能够访问彼此的session。
然而按照Servlet规范,session的作用范围应该仅仅限于当前应用程序下,不同的应用程序之间是不能够互相访问对方的session的。各个应用服务器从实际效果上都遵守了这一规范,但是实现的细节却可能各有不同,因此解决跨应用程序session共享的方法也各不相同。
首先来看一下Tomcat是如何实现web应用程序之间session的隔离的,从Tomcat设置的cookie路径来看,它对不同的应用程序设置的cookie路径是不同的,这样不同的应用程序所用的session id是不同的,因此即使在同一个浏览器窗口里访问不同的应用程序,发送给服务器的session id也可以是不同的。
根据这个特性,我们可以推测Tomcat中session的内存结构大致如下。
笔者以前用过的iPlanet也采用的是同样的方式,估计SunONE与iPlanet之间不会有太大的差别。对于这种方式的服务器,解决的思路很简单,实际实行起来也不难。要么让所有的应用程序共享一个session id,要么让应用程序能够获得其他应用程序的session id。
iPlanet中有一种很简单的方法来实现共享一个session id,那就是把各个应用程序的cookie路径都设为/(实际上应该是/NASApp,对于应用程序来讲它的作用相当于根)。
/NASApp
需要注意的是,操作共享的session应该遵循一些编程约定,比如在session attribute名字的前面加上应用程序的前缀,使得setAttribute("name", "neo")变成setAttribute("app1.name", "neo"),以防止命名空间冲突,导致互相覆盖。
在Tomcat中则没有这么方便的选择。在Tomcat版本3上,我们还可以有一些手段来共享session。对于版本4以上的Tomcat,目前笔者尚未发现简单的办法。只能借助于第三方的力量,比如使用文件、数据库、JMS或者客户端cookie,URL参数或者隐藏字段等手段。
我们再看一下Weblogic Server是如何处理session的。
从截屏画面上可以看到Weblogic Server对所有的应用程序设置的cookie的路径都是/,这是不是意味着在Weblogic Server中默认的就可以共享session了呢?然而一个小实验即可证明即使不同的应用程序使用的是同一个session,各个应用程序仍然只能访问自己所设置的那些属性。这说明Weblogic Server中的session的内存结构可能如下
对于这样一种结构,在session机制本身上来解决session共享的问题应该是不可能的了。除了借助于第三方的力量,比如使用文件、数据库、JMS或者客户端cookie,URL参数或者隐藏字段等手段,还有一种较为方便的做法,就是把一个应用程序的session放到ServletContext中,这样另外一个应用程序就可以从ServletContext中取得前一个应用程序的引用。示例代码如下,
应用程序A
context.setAttribute("appA", session);
应用程序B
contextA = context.getContext("/appA");
HttpSession sessionA = (HttpSession)contextA.getAttribute("appA");
值得注意的是这种用法不可移植,因为根据ServletContext的JavaDoc,应用服务器可以处于安全的原因对于context.getContext("/appA");返回空值,以上做法在Weblogic Server 8.1中通过。
那么Weblogic Server为什么要把所有的应用程序的cookie路径都设为/呢?原来是为了SSO,凡是共享这个session的应用程序都可以共享认证的信息。一个简单的实验就可以证明这一点,修改首先登录的那个应用程序的描述符weblogic.xml,把cookie路径修改为/appA访问另外一个应用程序会重新要求登录,即使是反过来,先访问cookie路径为/的应用程序,再访问修改过路径的这个,虽然不再提示登录,但是登录的用户信息也会丢失。注意做这个实验时认证方式应该使用FORM,因为浏览器和web服务器对basic认证方式有其他的处理方式,第二次请求的认证不是通过session来实现的。具体请参看[7] secion 14.8 Authorization,你可以修改所附的示例程序来做这些试验。
八、总结
session机制本身并不复杂,然而其实现和配置上的灵活性却使得具体情况复杂多变。这也要求我们不能把仅仅某一次的经验或者某一个浏览器,服务器的经验当作普遍适用的经验,而是始终需要具体情况具体分析。
posted @
2006-04-27 14:38 rkind 阅读(313) |
评论 (0) |
编辑 收藏
输入 :*#92702689# 手机会出现
第一行, Serial no: 手机串号
手机串号是手机的身份证,此串号的第七第八位代码表示手机的产地,
nokia的代码如下:
10:芬兰;20:德国;30:韩国;40:北京;60:东莞
新的nokia手机已经不使用这个编号来区分产地了。
第二行, Made : 072003 生产日期
这个生产日期如果离当前日期太远,就有可能是翻新机
第三行, purchasing date : mmyyyy 购买日期
可以修改,修改以后没法更改了,即使你把手机软件刷新。
如果这里已有日期,肯定是翻新机或有毛病后人家退货的
提醒大家注意,赶快更改这里,不要给JS留下骗人的可乘之机。
第四行, Repaired : mmyyyy 上次维修日期
如果有说明此手机维修过(JS一般会注意这个冬冬,会把它刷掉的)
第五行, Life timer 00002:20
看看Life timer时间 通话时间 新的应该是没有通话时间的
**如果你忘了钱包的密码,输入*#7370925538#就可以还原。
第三行这里特别有用,
可以修改,修改以后没法更改了,即使你把手机软件刷新。
如果这里已有日期,肯定是翻新机或有毛病后人家退货的
提醒大家注意,赶快更改这里,不要给JS留下骗人的可乘之机。
posted @
2006-04-05 15:14 rkind 阅读(861) |
评论 (0) |
编辑 收藏
老久没有郁闷的心情,然而终于却是来了,
我总是想能想出很多东西来,然后反应却很慢,又做了一件很傻的事
这是一个教训!不管怎么样,现在都不可能补救了。
也许跟心情有关吧,以后好好努力吧
posted @
2006-03-09 16:49 rkind 阅读(297) |
评论 (0) |
编辑 收藏
可以自由的从MP3机上下载音乐文件,而且大大提升了传输的速度,
首先从:
http://bbs.imp3.net/attachment.php?aid=99466下载一个iriver的插件
运行TC--->菜单点配置--->插件---->文件系统插件点设置--->点添加新插件,这时候就添加下边附件中的插件就行了。
然后软件运行时的界面就和我们的IMM差不多,不过功能更强大,安装只占4.5MB。
不过要想访问MP3(有驱无驱都好使)请点主菜单栏下面的盘符栏的网上邻居
就会找到,然后一切OK
posted @
2006-02-24 17:52 rkind 阅读(560) |
评论 (0) |
编辑 收藏
一直以来,认为实现这种上传要比下载简单的多,可是等到真正去实现的时候,才发现原来挺麻烦的
遇到的问题有:
1中文文件名的问题。
2文件没有下载提示直接就打开,包括rar的。
就这么两个小问题却让我花了三天的时间,不得不汗一下我的效率。
首先来说中文链接的问题,tomcat默认是不支持中文URL的,但是可以在Sever.xml中把 Connector 的属性加上一条: URIEncoding="GBK";然后在传递之前,链接的中文还要先encode一下
例如:java.net.URLEncoder.encode(“测试.txt”); 这样中文就会变成%D%F之类的,总之就可以正常传递了。
而关于点击文件直接就打开了是比较郁闷,查找了些资料,也试了网上的一些方法,一直不行
,最后采用的文件流的方式,才顺利解决。代码大致如下:
while(rs.next()){
try{
OutputStream o=response.getOutputStream();
byte b[]=new byte[500];
filename=rs.getString("filename");//rs.为从数据库查找到的结果集
filename=java.net.URLEncoder.encode(filename).trim();
File file=new File("d:/upload/20060221/",rs.getString("filename"));
//
response.setHeader("Content-Disposition","attachment; filename="+filename);
response.setContentType("APPLICATION/OCTET-STREAM");
long fileLength=file.length();
String length=String.valueOf(fileLength);
response.setHeader("Content_Length",length);
java.io.FileInputStream in = new java.io.FileInputStream(file);
int n=0;
while ((n=in.read(b)) != -1) {
o.write(b,0,n);
}
in.close();
o.close();
}catch(Exception e){
System.out.print(e);
}
}
rs.close();
这样的话,中英文文件都能正常下载并使用,但是中文文件用Ie直接下载下来后文件名还是乱码,用下载工具则一切正常。
posted @
2006-02-21 15:58 rkind 阅读(294) |
评论 (0) |
编辑 收藏以前装过sql server,后来删掉。现在重装,却出现“以前的某个程序安装已在安装计算机上创建挂起的文件操作。运行安装程序之前必须重新启动计算机”错误。无法进行下去。
参考网上资料,总算搞定。步骤是:
1)添加/删除程序中彻底删除sql server。
2)将没有删除的sql server目录也删除掉。
3)打开注册表编辑器,在HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager中找到PendingFileRenameOperations项目,并删除它。这样就可以清除安装暂挂项目。
4)删除注册表中跟sql server相关的键。
其实估计只要做第3步就可以搞定,这样就可以清除安装暂挂项目。自己是先走了1,2,4,最后做了3才搞定。所以估计3才是最关键的。
ME too
posted @
2006-02-21 09:47 rkind 阅读(201) |
评论 (0) |
编辑 收藏前两天要把我们信息平台上的tomcat4加为服务,
刚一开始就想先迁移到tomcat5上可是迁移以后数据库总是联不上,郁闷了好久。
后来又从网上找直接把tomcat4加为服务的脚本,尝试了几次,总是找不到tomcat的目录,原来批处理文件里面不识别空格,把文件名改了下,服务算是加上了,可启动时却总是出错误,又重新装了一次tomcat4.1.3,发现装完以后在 /bin的文件夹里,根本就没有tomcat.exe,着实有些郁闷,看来原来那个tomcat.exe肯定是从tomcat5里面拷过来的。不经意间又装了一遍tomcat4.1.3,发现有一个选项(NT service xp/2000;only)郁闷啊,这不是直接就可以加为服务吗,晕死了过去。。。。
这说明我还是太粗心了,装过那么多回tomcat,也想过这个ntservice,怎么就记过这就是加成服务的呢
,我说网上相关的东西怎么这么少,原来是apahce已经带了这个功能。
posted @
2006-02-14 11:17 rkind 阅读(314) |
评论 (0) |
编辑 收藏把以下代码粘贴到首页中,就可以从counter.txt中读取访问量。
一定要注意路径的问题,刚开始直接用counter.txt,结果总是找不到文件,而且用绝对路径也不行,
但是用/counter.txt就没有问题
<%!
int number=0;
synchronized void countPeople(){
if(number==0){
try{
FileInputStream in=new FileInputStream("/counter.txt");
DataInputStream dataIn=new DataInputStream(in);
number=dataIn.readInt();
number++;
in.close();
dataIn.close();
}catch(FileNotFoundException e){
number++;
try{
FileOutputStream out=new FileOutputStream("/counter.txt");
DataOutputStream dataOut=new DataOutputStream(out);
dataOut.writeInt(number);
out.close();
dataOut.close();
}catch(IOException ffe){
System.out.print(ffe);
}
}catch(IOException ee){
System.out.println(ee);
}
}else{
number++;
try{
FileOutputStream out=new FileOutputStream("/counter.txt");
DataOutputStream dataOut=new DataOutputStream(out);
dataOut.writeInt(number);
out.close();
dataOut.close();
}catch(FileNotFoundException e){
System.out.println(e);
}
catch(IOException e){
System.out.println(e);
}
}
}
%>
<% countPeople();%>
posted @
2006-01-19 11:26 rkind 阅读(353) |
评论 (0) |
编辑 收藏
1、首先进入C:\WINDOWS\system32\drivers找到ETC这个文件夹
2、将ETC文件夹里面的hosts用记事本打开
3、在最后一栏上加上127.0.0.1 auto.search.msn.com
4、保存退出即可。
你试试,就清静多了
posted @
2006-01-18 15:37 rkind 阅读(562) |
评论 (0) |
编辑 收藏
|
您的人格类型是: ISFJ(内向,感觉,情感,判断) |
您的工作中的优势:
◆ 能够很好地集中精力,关注焦点
◆ 很强的工作伦理,工作努力而且很负责任
◆ 良好的协作技巧,能和别人建立和谐友好的关系
◆ 讲求实效的工作态度,办事方法切实可行
◆ 十分关注细节,能够准确把握事实
◆ 乐于助人,给同事和下属职员的工作提供支持和帮助
◆ 了解公司(或者组织)的经历,能够很好地维护公司的传统
◆ 杰出的组织才能
◆ 愿意在传统的机构中工作,而且兢兢业业,不遗余力
◆ 能够连续工作,对于相同的工作不会感到厌倦
◆ 非常强的责任意识,别人可以信赖
◆ 喜欢运用固定的办事程序,尊重别人的地位和能力
◆ 通情达理,视角现实
您工作中可能存在的不足:
◆ 可能会低估自己的能力,难于坚持维护自己的需要和利益
◆ 不愿意尝试新的和未经考验的观点和想法
◆ 对反对意见过于敏感,在紧张的环境中容易感到压抑
◆ 可能只关注眼前的细节,而对整体和未来不太重视
◆ 倾向于同时投入到过多的工作任务中去
◆ 难以适应新的情况,或者在不同工作任务中间来回切换时有困难
◆ 易于被需要同时解决太多的任务或者项目时会弄得无所适从
◆ 如果自己得不到充分的重视和赞赏,可能会感到灰心丧气
◆ 一旦做出决定,就不愿意从头考虑同一个问题
| |
posted @
2006-01-10 17:10 rkind 阅读(196) |
评论 (0) |
编辑 收藏<form action="submit_1.html" method=post>
<input type=image src="exa.gif" name="sub1">
</form>
就是这简单
posted @
2006-01-04 13:58 rkind 阅读(567) |
评论 (0) |
编辑 收藏
你可以通过下列途径学习spring:
(1) spring下载包中doc目录下的MVC-step-by-step和sample目录下的例子都是比较好的spring开发的例子。
(2) AppFuse集成了目前最流行的几个开源轻量级框架或者工具 Ant,XDoclet,Spring,Hibernate(iBATIS),JUnit,Cactus,StrutsTestCase,Canoo's WebTest,Struts Menu,Display Tag Library,OSCache,JSTL,Struts 。
你可以通过AppFuse源代码来学习spring。
AppFuse网站:http://raibledesigns.com/wiki/Wiki.jsp?page=AppFuse
(3)Spring 开发指南(夏昕)(http://www.xiaxin.net/Spring_Dev_Guide.rar)
一本spring的入门书籍,里面介绍了反转控制和依赖注射的概念,以及spring的bean管理,spring的MVC,spring和hibernte,iBatis的结合。
(4) spring学习的中文论坛
SpringFramework中文论坛(http://spring.jactiongroup.net)
Java视线论坛(http://forum.javaeye.com)的spring栏目
2、利用Spring框架编程,console打印出log4j:WARN Please initialize the log4j system properly?
说明你的log4j.properties没有配置。请把log4j.properties放到工程的classpath中,eclipse的classpath为bin目录,由于编译后src目录下的文件会拷贝到bin目录下,所以你可以把log4j.properties放到src目录下。
这里给出一个log4j.properties的例子:
log4j.rootLogger=DEBUG,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %5p (%F:%L) - %m%n |
3、出现 java.lang.NoClassDefFoundError?
一般情况下是由于你没有把必要的jar包放到lib中。
比如你要采用spring和hibernate(带事务支持的话),你除了spring.jar外还需要hibernat.jar、aopalliance.jar、cglig.jar、jakarta-commons下的几个jar包。
http://www.springframework.org/download.html下载spring开发包,提供两种zip包
spring-framework-1.1.3-with-dependencies.zip和spring-framework-1.1.3.zip,我建议你下载spring-framework-1.1.3-with-dependencies.zip。这个zip解压缩后比后者多一个lib目录,其中有hibernate、j2ee、dom4j、aopalliance、jakarta-commons等常用包。
4、java.io.FileNotFoundException: Could not open class path resource [....hbm.xml],提示找不到xml文件?
原因一般有两个:
(1)该xml文件没有在classpath中。
(2)applicationContext-hibernate.xml中的xml名字没有带包名。比如:
<bean id="sessionFactory" class="org.springframework.orm.hibernate.LocalSessionFactoryBean">
<property name="dataSource"><ref bean="dataSource"/></property>
<property name="mappingResources">
<list>
<value>User.hbm.xml</value>
错,改为:
<value>com/yz/spring/domain/User.hbm.xml</value>
</list>
</property>
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect"> net.sf.hibernate.dialect.MySQLDialect </prop>
<prop key="hibernate.show_sql">true</prop>
</props>
</property>
</bean> |
5、org.springframework.beans.NotWritablePropertyException: Invalid property 'postDao' of bean class?
出现异常的原因是在application-xxx.xml中property name的错误。
<property name="...."> 中name的名字是与bean的set方法相关的,而且要注意大小写。
比如
public class PostManageImpl extends BaseManage implements PostManage {
private PostDAO dao = null;
public void setPostDAO(PostDAO postDAO){
this.dao = postDAO;
}
} |
那么xml的定义应该是:
<bean id="postManage" parent="txProxyTemplate">
<property name="target">
<bean class="com.yz.spring.service.implement.PostManageImpl">
<property name="postDAO"><ref bean="postDAO"/></property> 对
<property name="dao"><ref bean="postDAO"/></property> 错
</bean>
</property>
</bean> |
6、Spring中如何实现事务管理?
首先,如果使用mysql,确定mysql为InnoDB类型。
事务管理的控制应该放到商业逻辑层。你可以写个处理商业逻辑的JavaBean,在该JavaBean中调用DAO,然后把该Bean的方法纳入spring的事务管理。
比如:xml文件定义如下:
<bean id="txProxyTemplate" abstract="true"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager"><ref bean="transactionManager"/></property>
<property name="transactionAttributes">
<props>
<prop key="save*">PROPAGATION_REQUIRED</prop>
<prop key="remove*">PROPAGATION_REQUIRED</prop>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
<bean id="userManage" parent="txProxyTemplate">
<property name="target">
<bean class="com.yz.spring.service.implement.UserManageImpl">
<property name="userDAO"><ref bean="userDAO"/></property>
</bean>
</property>
</bean> |
com.yz.spring.service.implement.UserManageImpl就是我们的实现商业逻辑的JavaBean。我们通过parent元素声明其事务支持。
7、如何管理Spring框架下更多的JavaBean?
JavaBean越多,spring配置文件就越大,这样不易维护。为了使配置清晰,我们可以将JavaBean分类管理,放在不同的配置文件中。 应用启动时将所有的xml同时加载。
比如:
DAO层的JavaBean放到applicationContext-hibernate.xml中,商业逻辑层的JavaBean放到applicationContext-service.xml中。然后启动类中调用以下代码载入所有的ApplicationContext。
String[] paths = {"com/yz/spring/dao/hibernate/applicationContext-hibernate.xml",
"com/yz/spring/service/applicationContext-service.xml"};
ctx = new ClassPathXmlApplicationContext(paths); |
8、web应用中如何加载ApplicationContext?
可以通过定义web.xml,由web容器自动加载。
<servlet>
<servlet-name>context</servlet-name>
<servlet-class>org.springframework.web.context.ContextLoaderServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/applicationContext-hibernate.xml</param-value>
<param-value>/WEB-INF/applicationContext-service.xml</param-value>
</context-param> |
9、在spring中如何配置的log4j?
在web.xml中加入以下代码即可。
<context-param>
<param-name>log4jConfigLocation</param-name>
<param-value>/WEB-INF/log4j.properties</param-value>
</context-param> |
10、Spring框架入门的编程问题解决了,我该如何更深地领会Spring框架呢?
这两本书你该去看看。这两本书是由Spring的作者Rod Johnson编写的。
Expert One on one J2EE Design and Development
Expert One on one J2EE Development Without EJB |
你也该看看martinfowler的Inversion of Control Containers and the Dependency Injection pattern。
| http://www.martinfowler.com/articles/injection.html |
再好好研读一下spring的文档。
| http://www.jactiongroup.net/reference/html/index.html(中文版,未全部翻译) |
还有就是多实践吧。
posted @
2005-12-06 17:54 rkind 阅读(237) |
评论 (0) |
编辑 收藏abstract class和interface是Java语言中对于抽象类定义进行支持的两种机制,正是由于这两种机制的存在,才赋予了Java强大的面向对象能力。abstract class和interface之间在对于抽象类定义的支持方面具有很大的相似性,甚至可以相互替换,因此很多开发者在进行抽象类定义时对于abstract class和interface的选择显得比较随意。
其实,两者之间还是有很大的区别的,对于它们的选择甚至反映出对于问题领域本质的理解、对于设计意图的理解是否正确、合理。本文将对它们之间的区别进行一番剖析,试图给开发者提供一个在二者之间进行选择的依据。
一、理解抽象类
abstract class和interface在Java语言中都是用来进行抽象类(本文中的抽象类并非从abstract class翻译而来,它表示的是一个抽象体,而abstract class为Java语言中用于定义抽象类的一种方法,请读者注意区分)定义的,那么什么是抽象类,使用抽象类能为我们带来什么好处呢?
在面向对象的概念中,我们知道所有的对象都是通过类来描绘的,但是反过来却不是这样。并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。抽象类往往用来表征我们在对问题领域进行分析、设计中得出的抽象概念,是对一系列看上去不同,但是本质上相同的具体概念的抽象。
比如:如果我们进行一个图形编辑软件的开发,就会发现问题领域存在着圆、三角形这样一些具体概念,它们是不同的,但是它们又都属于形状这样一个概念,形状这个概念在问题领域是不存在的,它就是一个抽象概念。正是因为抽象的概念在问题领域没有对应的具体概念,所以用以表征抽象概念的抽象类是不能够实例化的。
在面向对象领域,抽象类主要用来进行类型隐藏。我们可以构造出一个固定的一组行为的抽象描述,但是这组行为却能够有任意个可能的具体实现方式。这个抽象描述就是抽象类,而这一组任意个可能的具体实现则表现为所有可能的派生类。模块可以操作一个抽象体。由于模块依赖于一个固定的抽象体,因此它可以是不允许修改的;同时,通过从这个抽象体派生,也可扩展此模块的行为功能。熟悉OCP的读者一定知道,为了能够实现面向对象设计的一个最核心的原则OCP(Open-Closed Principle),抽象类是其中的关键所在。
二、从语法定义层面看abstract class和interface
在语法层面,Java语言对于abstract class和interface给出了不同的定义方式,下面以定义一个名为Demo的抽象类为例来说明这种不同。使用abstract class的方式定义Demo抽象类的方式如下:
abstract class Demo {
abstract void method1();
abstract void method2();
…
} |
使用interface的方式定义Demo抽象类的方式如下:
interface Demo {
void method1();
void method2();
…
} |
在abstract class方式中,Demo可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface方式的实现中,Demo只能够有静态的不能被修改的数据成员(也就是必须是static final的,不过在interface中一般不定义数据成员),所有的成员方法都是abstract的。从某种意义上说,interface是一种特殊形式的abstract class。
从编程的角度来看,abstract class和interface都可以用来实现"design by contract"的思想。但是在具体的使用上面还是有一些区别的。
首先,abstract class在Java语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface。也许,这是Java语言的设计者在考虑Java对于多重继承的支持方面的一种折中考虑吧。
其次,在abstract class的定义中,我们可以赋予方法的默认行为。但是在interface的定义中,方法却不能拥有默认行为,为了绕过这个限制,必须使用委托,但是这会 增加一些复杂性,有时会造成很大的麻烦。
在抽象类中不能定义默认行为还存在另一个比较严重的问题,那就是可能会造成维护上的麻烦。因为如果后来想修改类的界面(一般通过abstract class或者interface来表示)以适应新的情况(比如,添加新的方法或者给已用的方法中添加新的参数)时,就会非常的麻烦,可能要花费很多的时间(对于派生类很多的情况,尤为如此)。但是如果界面是通过abstract class来实现的,那么可能就只需要修改定义在abstract class中的默认行为就可以了。
同样,如果不能在抽象类中定义默认行为,就会导致同样的方法实现出现在该抽象类的每一个派生类中,违反了"one rule,one place"原则,造成代码重复,同样不利于以后的维护。因此,在abstract class和interface间进行选择时要非常的小心。
三、从设计理念层面看abstract class和interface
上面主要从语法定义和编程的角度论述了abstract class和interface的区别,这些层面的区别是比较低层次的、非本质的。本文将从另一个层面:abstract class和interface所反映出的设计理念,来分析一下二者的区别。作者认为,从这个层面进行分析才能理解二者概念的本质所在。
前面已经提到过,abstarct class在Java语言中体现了一种继承关系,要想使得继承关系合理,父类和派生类之间必须存在"is a"关系,即父类和派生类在概念本质上应该是相同的。对于interface 来说则不然,并不要求interface的实现者和interface定义在概念本质上是一致的,仅仅是实现了interface定义的契约而已。为了使论述便于理解,下面将通过一个简单的实例进行说明。
考虑这样一个例子,假设在我们的问题领域中有一个关于Door的抽象概念,该Door具有执行两个动作open和close,此时我们可以通过abstract class或者interface来定义一个表示该抽象概念的类型,定义方式分别如下所示:
使用abstract class方式定义Door:
abstract class Door {
abstract void open();
abstract void close();
}
使用interface方式定义Door:
interface Door {
void open();
void close();
} |
其他具体的Door类型可以extends使用abstract class方式定义的Door或者implements使用interface方式定义的Door。看起来好像使用abstract class和interface没有大的区别。
如果现在要求Door还要具有报警的功能。我们该如何设计针对该例子的类结构呢(在本例中,主要是为了展示abstract class和interface反映在设计理念上的区别,其他方面无关的问题都做了简化或者忽略)下面将罗列出可能的解决方案,并从设计理念层面对这些不同的方案进行分析。
解决方案一:
简单的在Door的定义中增加一个alarm方法,如下:
abstract class Door {
abstract void open();
abstract void close();
abstract void alarm();
}
或者
interface Door {
void open();
void close();
void alarm();
} |
那么具有报警功能的AlarmDoor的定义方式如下:
class AlarmDoor extends Door {
void open() { … }
void close() { … }
void alarm() { … }
}
或者
class AlarmDoor implements Door {
void open() { … }
void close() { … }
void alarm() { … }
} |
这种方法违反了面向对象设计中的一个核心原则ISP(Interface Segregation Priciple),在Door的定义中把Door概念本身固有的行为方法和另外一个概念"报警器"的行为方法混在了一起。这样引起的一个问题是那些仅仅依赖于Door这个概念的模块会因为"报警器"这个概念的改变(比如:修改alarm方法的参数)而改变,反之依然。
解决方案二:
既然open、close和alarm属于两个不同的概念,根据ISP原则应该把它们分别定义在代表这两个概念的抽象类中。定义方式有:这两个概念都使用abstract class方式定义;两个概念都使用interface方式定义;一个概念使用abstract class方式定义,另一个概念使用interface方式定义。
显然,由于Java语言不支持多重继承,所以两个概念都使用abstract class方式定义是不可行的。后面两种方式都是可行的,但是对于它们的选择却反映出对于问题领域中的概念本质的理解、对于设计意图的反映是否正确、合理。我们一一来分析、说明。
如果两个概念都使用interface方式来定义,那么就反映出两个问题:
1、我们可能没有理解清楚问题领域,AlarmDoor在概念本质上到底是Door还是报警器?
2、如果我们对于问题领域的理解没有问题,比如:我们通过对于问题领域的分析发现AlarmDoor在概念本质上和Door是一致的,那么我们在实现时就没有能够正确的揭示我们的设计意图,因为在这两个概念的定义上(均使用interface方式定义)反映不出上述含义。
如果我们对于问题领域的理解是:AlarmDoor在概念本质上是Door,同时它有具有报警的功能。我们该如何来设计、实现来明确的反映出我们的意思呢?前面已经说过,abstract class在Java语言中表示一种继承关系,而继承关系在本质上是"is a"关系。所以对于Door这个概念,我们应该使用abstarct class方式来定义。另外,AlarmDoor又具有报警功能,说明它又能够完成报警概念中定义的行为,所以报警概念可以通过interface方式定义。如下所示:
abstract class Door {
abstract void open();
abstract void close();
}
interface Alarm {
void alarm();
}
class AlarmDoor extends Door implements Alarm {
void open() { … }
void close() { … }
void alarm() { … }
} |
这种实现方式基本上能够明确的反映出我们对于问题领域的理解,正确的揭示我们的设计意图。其实abstract class表示的是"is a"关系,interface表示的是"like a"关系,大家在选择时可以作为一个依据,当然这是建立在对问题领域的理解上的,比如:如果我们认为AlarmDoor在概念本质上是报警器,同时又具有Door的功能,那么上述的定义方式就要反过来了。
abstract class和interface是Java语言中的两种定义抽象类的方式,它们之间有很大的相似性。但是对于它们的选择却又往往反映出对于问题领域中的概念本质的理解、对于设计意图的反映是否正确、合理,因为它们表现了概念间的不同的关系(虽然都能够实现需求的功能)。这其实也是语言的一种的惯用法,希望读者朋友能够细细体会
posted @
2005-12-06 11:03 rkind 阅读(288) |
评论 (0) |
编辑 收藏
|
JBUILDER的光标定位不准确的最佳解决方案是:进入%JBUILDER_HOME%/bin目录下,用写字板编辑jbuilder.config,把下面的配置加进去:
vmparam -Dprimetime.editor.useVariableWidthFont=true |
posted @
2005-12-06 11:02 rkind 阅读(253) |
评论 (0) |
编辑 收藏Ant的简介:类似make工具,但可以支持多平台
Ant的安装:配置ant的准备工作:ant_home 指Ant的安装目录,在path中加入%ant_home%/bin,用于命令行下
运 行ant
Ant的结构:主要是通过对build.xml的配置,
Ant内置任务: 描述
property 设置name/value的属性
mkdir 创建目录
copy 拷贝
delete 删除
javac 编绎
war 打包
下面是一个简单build.xml的示例:
<project name="bookstore" default="about" basedir=".">
<target name="init">
<tstamp/>
<property name="build" value="build" />
<property name="src" value="src" />
<property environment="myenv" />
<property name="servletpath" value="${myenv.CATALINA_HOME}/common/lib/servlet-api.jar" />
<property name="mysqlpath" value="WEB-INF/lib/mysqldriver.jar" />
<mkdir dir="${build}" />
<mkdir dir="${build}\WEB-INF" />
<mkdir dir="${build}\WEB-INF\classes" />
<copy todir="${build}" >
<fileset dir="${basedir}" >
<include name="*.jsp" />
<include name="*.bmp" />
<include name="WEB-INF/**" />
<exclude name="build.xml" />
</fileset>
</copy>
</target>
<target name="compile" depends="init">
<javac srcdir="${src}"
destdir="${build}/WEB-INF/classes"
classpath="${servletpath}:${mysqlpath}">
</javac>
</target>
<target name="bookstorewar" depends="compile">
<war warfile="${build}/bookstore.war" webxml="${build}/WEB-INF/web.xml">
<lib dir="${build}/WEB-INF/lib"/>
<classes dir="${build}/WEB-INF/classes"/>
<fileset dir="${build}"/>
</war>
</target>
<target name="about" >
<echo>
This build.xml file contains targets
for building bookstore web application
</echo>
</target>
</project>
从示例我们看出来,整个xml是一个project,project下有几个为init,compile,的target
运行时首先在这个目录下打开dos窗口,以这个xml为准,如果你只运行ant那么只会输出echo中的内容
因为project的default是about; 如果运行ant complie 它会执行两个target: init 和complie,因为complie是依靠init
的。
用了以后发现ant 原来很简单,当然现在只是学了个皮毛而已。
posted @
2005-11-25 14:53 rkind 阅读(281) |
评论 (0) |
编辑 收藏 RMI,远程方法调用(Remote Method Invocation)是Enterprise JavaBeans的支柱,是建立分布式Java应用程序的方便途径。RMI是非常容易使用的,但是它非常的强大。
RMI的基础是接口,RMI构架基于一个重要的原理:定义接口和定义接口的具体实现是分开的。下面我们通过具体的例子,建立一个简单的远程计算服务和使用它的客户程序
一个正常工作的RMI系统由下面几个部分组成:
● 远程服务的接口定义
● 远程服务接口的具体实现
● 桩(Stub)和框架(Skeleton)文件
● 一个运行远程服务的服务器
● 一个RMI命名服务,它允许客户端去发现这个远程服务
● 类文件的提供者(一个HTTP或者FTP服务器)
● 一个需要这个远程服务的客户端程序
下面我们一步一步建立一个简单的RMI系统。首先在你的机器里建立一个新的文件夹,以便放置我们创建的文件,为了简单起见,我们只使用一个文件夹存放客户端和服务端代码,并且在同一个目录下运行服务端和客户端。
如果所有的RMI文件都已经设计好了,那么你需要下面的几个步骤去生成你的系统:
1、 编写并且编译接口的Java代码
2、 编写并且编译接口实现的Java代码
3、 从接口实现类中生成桩(Stub)和框架(Skeleton)类文件
4、 编写远程服务的主运行程序
5、 编写RMI的客户端程序
6、 安装并且运行RMI系统
1、 接口
第一步就是建立和编译服务接口的Java代码。这个接口定义了所有的提供远程服务的功能,下面是源程序:
//Calculator.java
//define the interface
import java.rmi.Remote;
public interface Calculator extends Remote
{
public long add(long a, long b)
throws java.rmi.RemoteException;
public long sub(long a, long b)
throws java.rmi.RemoteException;
public long mul(long a, long b)
throws java.rmi.RemoteException;
public long div(long a, long b)
throws java.rmi.RemoteException;
}
注意,这个接口继承自Remote,每一个定义的方法都必须抛出一个RemoteException异常对象。
建立这个文件,把它存放在刚才的目录下,并且编译。
>javac Calculator.java
2、 接口的具体实现
下一步,我们就要写远程服务的具体实现,这是一个CalculatorImpl类文件:
//CalculatorImpl.java
//Implementation
import java.rmi.server.UnicastRemoteObject
public class CalculatorImpl extends UnicastRemoteObject implements Calculator
{
// 这个实现必须有一个显式的构造函数,并且要抛出一个RemoteException异常
public CalculatorImpl()
throws java.rmi.RemoteException {
super();
}
public long add(long a, long b)
throws java.rmi.RemoteException {
return a + b;
}
public long sub(long a, long b)
throws java.rmi.RemoteException {
return a - b;
}
public long mul(long a, long b)
throws java.rmi.RemoteException {
return a * b;
}
public long div(long a, long b)
throws java.rmi.RemoteException {
return a / b;
}
}
同样的,把这个文件保存在你的目录里然后编译他。
这个实现类使用了UnicastRemoteObject去联接RMI系统。在我们的例子中,我们是直接的从UnicastRemoteObject这个类上继承的,事实上并不一定要这样做,如果一个类不是从UnicastRmeoteObject上继承,那必须使用它的exportObject()方法去联接到RMI。
如果一个类继承自UnicastRemoteObject,那么它必须提供一个构造函数并且声明抛出一个RemoteException对象。当这个构造函数调用了super(),它久激活UnicastRemoteObject中的代码完成RMI的连接和远程对象的初始化。
3、 桩(Stubs)和框架(Skeletons)
下一步就是要使用RMI编译器rmic来生成桩和框架文件,这个编译运行在远程服务实现类文件上。
>rmic CalculatorImpl
在你的目录下运行上面的命令,成功执行完上面的命令你可以发现一个Calculator_stub.class文件,如果你是使用的Java2SDK,那么你还可以发现Calculator_Skel.class文件。
4、 主机服务器
远程RMI服务必须是在一个服务器中运行的。CalculatorServer类是一个非常简单的服务器。
//CalculatorServer.java
import java.rmi.Naming;
public class CalculatorServer {
public CalculatorServer() {
try {
Calculator c = new CalculatorImpl();
Naming.rebind("rmi://localhost:1099/CalculatorService", c);
} catch (Exception e) {
System.out.println("Trouble: " + e);
}
}
public static void main(String args[]) {
new CalculatorServer();
}
}
建立这个服务器程序,然后保存到你的目录下,并且编译它。
5、 客户端
客户端源代码如下:
//CalculatorClient.java
import java.rmi.Naming;
import java.rmi.RemoteException;
import java.net.MalformedURLException;
import java.rmi.NotBoundException;
public class CalculatorClient {
public static void main(String[] args) {
try {
Calculator c = (Calculator)
Naming.lookup(
"rmi://localhost
/CalculatorService");
System.out.println( c.sub(4, 3) );
System.out.println( c.add(4, 5) );
System.out.println( c.mul(3, 6) );
System.out.println( c.div(9, 3) );
}
catch (MalformedURLException murle) {
System.out.println();
System.out.println(
"MalformedURLException");
System.out.println(murle);
}
catch (RemoteException re) {
System.out.println();
System.out.println(
"RemoteException");
System.out.println(re);
}
catch (NotBoundException nbe) {
System.out.println();
System.out.println(
"NotBoundException");
System.out.println(nbe);
}
catch (
java.lang.ArithmeticException
ae) {
System.out.println();
System.out.println(
"java.lang.ArithmeticException");
System.out.println(ae);
}
}
}
保存这个客户端程序到你的目录下(注意这个目录是一开始建立那个,所有的我们的文件都在那个目录下),并且编译他。
6、 运行RMI系统
现在我们建立了所有运行这个简单RMI系统所需的文件,现在我们终于可以运行这个RMI系统啦!来享受吧。
我们是在命令控制台下运行这个系统的,你必须开启三个控制台窗口,一个运行服务器,一个运行客户端,还有一个运行RMIRegistry。
首先运行注册程序RMIRegistry,你必须在包含你刚写的类的那么目录下运行这个注册程序。
>rmiregistry
好,这个命令成功的话,注册程序已经开始运行了,不要管他,现在切换到另外一个控制台,在第二个控制台里,我们运行服务器CalculatorService,因为RMI的安全机制将在服务端发生作用,所以你必须增加一条安全策略。以下是对应安全策略的例子
grant {
permission java.security.AllPermission "", "";
};
注意:这是一条最简单的安全策略,它允许任何人做任何事,对于你的更加关键性的应用,你必须指定更加详细安全策略。
现在为了运行服务端,你需要除客户类(CalculatorClient.class)之外的所有的类文件。确认安全策略在policy.txt文件之后,使用如下命令来运行服务器。
> java -Djava.security.policy=policy.txt CalculatorServer
这个服务器就开始工作了,把接口的实现加载到内存等待客户端的联接。好现在切换到第三个控制台,启动我们的客户端。
为了在其他的机器运行客户端程序你需要一个远程接口(Calculator.class) 和一个stub(CalculatorImpl_Stub.class)。 使用如下命令运行客户端
prompt> java -Djava.security.policy=policy.txt CalculatorClient
如果所有的这些都成功运行,你应该看到下面的输出:
1
9
18
3
如果你看到了上面的输出,恭喜你,你成功了,你已经成功的创建了一个RMI系统,并且使他正确工作了。即使你运行在同一个计算机上,RMI还是使用了你的网络堆栈和TCP/IP去进行通讯,并且是运行在三个不同的Java虚拟机上。这已经是一个完整的RMI系统。
posted @
2005-11-15 18:46 rkind 阅读(288) |
评论 (0) |
编辑 收藏 在一个有密码保护的Web应用中,正确处理用户退出过程并不仅仅只需调用HttpSession的invalidate()方法。现在大部分浏览器上都有后退和前进按钮,允许用户后退或前进到一个页面。如果在用户在退出一个Web应用后按了后退按钮浏览器把缓存中的页面呈现给用户,这会使用户产生疑惑,他们会开始担心他们的个人数据是否安全。许多Web应用强迫用户退出时关闭整个浏览器,这样,用户就无法点击后退按钮了。还有一些使用javascript,但在某些客户端浏览器这却不一定起作用。这些解决方案都很笨拙且不能保证在任一情况下100%有效,同时,它也要求用户有一定的操作经验。
这篇文章以示例阐述了正确解决用户退出问题的方案。作者Kevin Le首先描述了一个密码保护Web应用,然后以示例程序解释问题如何产生并讨论解决问题的方案。文章虽然是针对JSP页面进行阐述,但作者所阐述的概念很容易理解切能够为其他Web技术所采用。最后作者展示了如何用Jakarta Struts优雅地解决这一问题。
大部分Web应用不会包含象银行账户或信用卡资料那样机密的信息,但一旦涉及到敏感数据,我们就需要提供一类密码保护机制。举例来说,一个工厂中工人通过Web访问他们的时间安排、进入他们的训练课程以及查看他们的薪金等等。此时应用SSL(Secure Socket Layer)有点杀鸡用牛刀的感觉,但不可否认,我们又必须为这些应用提供密码保护,否则,工人(也就是Web应用的使用者)可以窥探到工厂中其他雇员的私人机密信息。
与上述情形相似的还有位处图书馆、医院等公共场所的计算机。在这些地方,许多用户共同使用几台计算机,此时保护用户的个人数据就显得至关重要。设计良好编写优秀的应用对用户专业知识的要求少之又少。
我们来看一下现实世界中一个完美的Web应用是如何表现的:一个用户通过浏览器访问一个页面。Web应用展现一个登陆页面要求用户输入有效的验证信息。用户输入了用户名和密码。此时我们假设用户提供的身份验证信息是正确的,经过了验证过程,Web应用允许用户浏览他有权访问的区域。用户想退出时,点击退出按钮,Web应用要求用户确认他是否则真的需要退出,如果用户确定退出,Session结束,Web应用重新定位到登陆页面。用户可以放心的离开而不用担心他的信息会泄露。另一个用户坐到了同一台电脑前,他点击后退按钮,Web应用不应该出现上一个用户访问过的任何一个页面。事实上,Web应用在第二个用户提供正确的验证信息之前应当一直停留在登陆页面上。
通过示例程序,文章向您阐述了如何在一个Web应用中实现这一功能。
JSP示例
为了更为有效地阐述实现方案,本文将从展示一个示例应用logoutSampleJSP1中碰到的问题开始。这个示例代表了许多没有正确解决退出过程的Web应用。logoutSampleJSP1包含了下述jsp页面:login.jsp, home.jsp, secure1.jsp, secure2.jsp, logout.jsp, loginAction.jsp, and logoutAction.jsp。其中页面home.jsp, secure1.jsp, secure2.jsp, 和logout.jsp是不允许未经认证的用户访问的,也就是说,这些页面包含了重要信息,在用户登陆之前或者退出之后都不应该出现在浏览器中。login.jsp包含了用于用户输入用户名和密码的form。logout.jsp页包含了要求用户确认是否退出的form。loginAction.jsp和logoutAction.jsp作为控制器分别包含了登陆和退出代码。
第二个示例应用logoutSampleJSP2展示了如何解决示例logoutSampleJSP1中的问题。然而,第二个应用自身也是有疑问的。在特定的情况下,退出问题还是会出现。
第三个示例应用logoutSampleJSP3在第二个示例上进行了改进,比较完善地解决了退出问题。
最后一个示例logoutSampleStruts展示了Struts如何优美地解决登陆问题。
注意:本文所附示例在最新版本的Microsoft Internet Explorer (IE), Netscape Navigator, Mozilla, FireFox和Avant浏览器上测试通过。
Login action
Brian Pontarelli的经典文章《J2EE Security: Container Versus Custom》讨论了不同的J2EE认证途径。文章同时指出,HTTP协议和基于form的认证并未提供处理用户退出的机制。因此,解决途径便是引入自定义的安全实现机制。
自定义的安全认证机制普遍采用的方法是从form中获得用户输入的认证信息,然后到诸如LDAP (lightweight directory access protocol)或关系数据库的安全域中进行认证。如果用户提供的认证信息是有效的,登陆动作往HttpSession对象中注入某个对象。HttpSession存在着注入的对象则表示用户已经登陆。为了方便读者理解,本文所附的示例只往HttpSession中写入一个用户名以表明用户已经登陆。清单1是从loginAction.jsp页面中节选的一段代码以此阐述登陆动作:
Listing 1
//...
//initialize RequestDispatcher object; set forward to home page by default
RequestDispatcher rd = request.getRequestDispatcher("home.jsp");
//Prepare connection and statement
rs = stmt.executeQuery("select password from USER where userName = '" + userName + "'");
if (rs.next()) {
//Query only returns 1 record in the result set; only 1
password per userName which is also the primary key
if (rs.getString("password").equals(password)) { //If valid password
session.setAttribute("User", userName); //Saves username string in the session object
}
else { //Password does not match, i.e., invalid user password
request.setAttribute("Error", "Invalid password.");
rd = request.getRequestDispatcher("login.jsp");
}
} //No record in the result set, i.e., invalid username
else {
request.setAttribute("Error", "Invalid user name.");
rd = request.getRequestDispatcher("login.jsp");
}
}
//As a controller, loginAction.jsp finally either forwards to "login.jsp" or "home.jsp"
rd.forward(request, response);
//... |
本文所附示例均以关系型数据库作为安全域,但本文所阐述的观点对任何类型的安全域都是适用的。
Logout action
退出动作就包含了简单的删除用户名以及对用户的HttpSession对象调用invalidate()方法。清单2是从loginoutAction.jsp页面中节选的一段代码以此阐述退出动作:
Listing 2
//...
session.removeAttribute("User");
session.invalidate();
//... |
阻止未经认证访问受保护的JSP页面
从form中获取用户提交的认证信息并经过验证后,登陆动作简单地往 HttpSession对象中写入一个用户名,退出动作则做相反的工作,它从用户的HttpSession对象中删除用户名并调用invalidate()方法销毁HttpSession。为了使登陆和退出动作真正发挥作用,所有受保护的JSP页面都应该首先验证HttpSession中是否包含了用户名以确认当前用户是否已经登陆。如果HttpSession中包含了用户名,也就是说用户已经登陆,Web应用则将剩余的JSP页发送给浏览器,否则,JSP页将跳转到登陆页login.jsp。页面home.jsp, secure1.jsp, secure2.jsp和logout.jsp均包含清单3中的代码段:
Listing 3
//...
String userName = (String) session.getAttribute("User");
if (null == userName) {
request.setAttribute("Error", "Session has ended. Please login.");
RequestDispatcher rd = request.getRequestDispatcher("login.jsp");
rd.forward(request, response);
}
//...
//Allow the rest of the dynamic content in this JSP to be served to the browser
//... |
在这个代码段中,程序从HttpSession中减缩username字符串。如果字符串为空,Web应用则自动中止执行当前页面并跳转到登陆页,同时给出Session has ended. Please log in.的提示;如果不为空,Web应用则继续执行,也就是把剩余的页面提供给用户。
运行logoutSampleJSP1
运行logoutSampleJSP1将会出现如下几种情形:
1) 如果用户没有登陆,Web应用将会正确中止受保护页面home.jsp, secure1.jsp, secure2.jsp和logout.jsp的执行,也就是说,假如用户在浏览器地址栏中直接敲入受保护JSP页的地址试图访问,Web应用将自动跳转到登陆页并提示Session has ended.Please log in.
2) 同样的,当一个用户已经退出,Web应用也会正确中止受保护页面home.jsp, secure1.jsp, secure2.jsp和logout.jsp的执行
3) 用户退出后,如果点击浏览器上的后退按钮,Web应用将不能正确保护受保护的页面——在Session销毁后(用户退出)受保护的JSP页重新在浏览器中显示出来。然而,如果用户点击返回页面上的任何链接,Web应用将会跳转到登陆页面并提示Session has ended.Please log in.
阻止浏览器缓存 上述问题的根源在于大部分浏览器都有一个后退按钮。当点击后退按钮时,默认情况下浏览器不是从Web服务器上重新获取页面,而是从浏览器缓存中载入页面。基于Java的Web应用并未限制这一功能,在基于PHP、ASP和.NET的Web应用中也同样存在这一问题。
在用户点击后退按钮后,浏览器到服务器再从服务器到浏览器这样通常意思上的HTTP回路并没有建立,仅仅只是用户,浏览器和缓存进行了交互。所以,即使包含了清单3上的代码来保护JSP页面,当点击后退按钮时,这些代码是不会执行的。
缓存的好坏,真是仁者见仁智者见智。缓存的确提供了一些便利,但通常只在使用静态的HTML页面或基于图形或影响的页面你才能感受到。而另一方面,Web应用通常是基于数据的,数据通常是频繁更改的。与从缓存中读取并显示过期的数据相比,提供最新的数据才是更重要的!
幸运的是,HTTP头信息“Expires”和“Cache-Control”为应用程序服务器提供了一个控制浏览器和代理服务器上缓存的机制。HTTP头信息Expires告诉代理服务器它的缓存页面何时将过期。HTTP1.1规范中新定义的头信息Cache-Control可以通知浏览器不缓存任何页面。当点击后退按钮时,浏览器重新访问服务器已获取页面。如下是使用Cache-Control的基本方法:
1) no-cache:强制缓存从服务器上获取新的页面
2) no-store: 在任何环境下缓存不保存任何页面
HTTP1.0规范中的Pragma:no-cache等同于HTTP1.1规范中的Cache-Control:no-cache,同样可以包含在头信息中。
通过使用HTTP头信息的cache控制,第二个示例应用logoutSampleJSP2解决了logoutSampleJSP1的问题。logoutSampleJSP2与logoutSampleJSP1不同表现在如下代码段中,这一代码段加入进所有受保护的页面中:
//...
response.setHeader("Cache-Control","no-cache"); //Forces caches to obtain a new copy of the page from the origin server
response.setHeader("Cache-Control","no-store"); //Directs caches not to store the page under any circumstance
response.setDateHeader("Expires", 0); //Causes the proxy cache to see the page as "stale"
response.setHeader("Pragma","no-cache"); //HTTP 1.0 backward compatibility
String userName = (String) session.getAttribute("User");
if (null == userName) {
request.setAttribute("Error", "Session has ended. Please login.");
RequestDispatcher rd = request.getRequestDispatcher("login.jsp");
rd.forward(request, response);
}
//... |
通过设置头信息和检查HttpSession中的用户名确保了浏览器不缓存页面,同时,如果用户未登陆,受保护的JSP页面将不会发送到浏览器,取而代之的将是登陆页面login.jsp。
运行logoutSampleJSP2 运行logoutSampleJSP2后将回看到如下结果:
1) 当用户退出后试图点击后退按钮,浏览器并不会显示受保护的页面,它只会现实登陆页login.jsp同时给出提示信息Session has ended. Please log in.
2) 然而,当按了后退按钮返回的页是处理用户提交数据的页面时,IE和Avant浏览器将弹出如下信息提示:
警告:页面已过期……(你肯定见过)
选择刷新后前一个JSP页面将重新显示在浏览器中。很显然,这不是我们所想看到的因为它违背了logout动作的目的。发生这一现象时,很可能是一个恶意用户在尝试获取其他用户的数据。然而,这个问题仅仅出现在后退按钮对应的是一个处理POST请求的页面。
记录最后登陆时间 上述问题之所以出现是因为浏览器将其缓存中的数据重新提交了。这本文的例子中,数据包含了用户名和密码。无论是否给出安全警告信息,浏览器此时起到了负面作用。
为了解决logoutSampleJSP2中出现的问题,logoutSampleJSP3的login.jsp在包含username和password的基础上还包含了一个称作lastLogon的隐藏表单域,此表单域动态的用一个long型值初始化。这个long型值是调用System.currentTimeMillis()获取到的自1970年1月1日以来的毫秒数。当login.jsp中的form提交时,loginAction.jsp首先将隐藏域中的值与用户数据库中的值进行比较。只有当lastLogon表单域中的值大于数据库中的值时Web应用才认为这是个有效的登陆。
为了验证登陆,数据库中lastLogon字段必须以表单中的lastLogon值进行更新。上例中,当浏览器重复提交数据时,表单中的lastLogon值不比数据库中的lastLogon值大,因此,loginAction转到login.jsp页面,并提示Session has ended.Please log in.清单5是loginAction中节选的代码段:
清单5
//...
RequestDispatcher rd = request.getRequestDispatcher("home.jsp"); //Forward to homepage by default
//...
if (rs.getString("password").equals(password)) {
//If valid password
long lastLogonDB = rs.getLong("lastLogon");
if (lastLogonForm > lastLogonDB) {
session.setAttribute("User", userName); //Saves username string in the session object
stmt.executeUpdate("update USER set lastLogon= " + lastLogonForm + " where userName = '" + userName + "'");
}
else {
request.setAttribute("Error", "Session has ended. Please login.");
rd = request.getRequestDispatcher("login.jsp"); }
}
else { //Password does not match, i.e., invalid user password
request.setAttribute("Error", "Invalid password.");
rd = request.getRequestDispatcher("login.jsp");
}
//...
rd.forward(request, response);
//... |
为了实现上述方法,你必须记录每个用户的最后登陆时间。对于采用关系型数据库安全域来说,这点可以可以通过在某个表中加上lastLogin字段轻松实现。LDAP以及其他的安全域需要稍微动下脑筋,但很显然是可以实现的。
表示最后登陆时间的方法有很多。示例logoutSampleJSP3利用了自1970年1月1日以来的毫秒数。这个方法在许多人在不同浏览器中用一个用户账号登陆时也是可行的。
运行logoutSampleJSP3 运行示例logoutSampleJSP3将展示如何正确处理退出问题。一旦用户退出,点击浏览器上的后退按钮在任何情况下都不会是受保护的页面在浏览器上显示出来。这个示例展示了如何正确处理退出问题而不需要额外的培训。
为了使代码更简练有效,一些冗余的代码可以剔除掉。一种途径就是把清单4中的代码写到一个单独的JSP页中,通过标签<jsp:include>其他页面也可以引用。
Struts框架下的退出实现 与直接使用JSP或JSP/servlets相比,另一个可选的方案是使用Struts。为一个基于Struts的Web应用添加一个处理退出问题的框架可以优雅地不费气力的实现。这部分归功于Struts是采用MVC设计模式的因此将模型和视图清晰的分开。另外,Java是一个面向对象的语言,其支持继承,可以比JSP中的脚本更为容易地实现代码重用。在Struts中,清单4中的代码可以从JSP页面中移植到Action类的execute()方法中。
此外,我们还可以定义一个继承Struts Action类的基本类,其execute()方法中包含了清单4中的代码。通过使用类继承机制,其他类可以继承基本类中的通用逻辑来设置HTTP头信息以及检索HttpSession对象中的username字符串。这个基本类是一个抽象类并定义了一个抽象方法executeAction()。所有继承自基类的子类都应实现exectuteAction()方法而不是覆盖它。清单6是基类的部分代码:
清单6
public abstract class BaseAction extends Action {
public ActionForward execute(ActionMapping mapping, ActionForm form,HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
response.setHeader("Cache-Control","no-cache");
//Forces caches to obtain a new copy of the page from the origin server
response.setHeader("Cache-Control","no-store");
//Directs caches not to store the page under any circumstance
response.setDateHeader("Expires", 0); //Causes the proxy cache to see the page as "stale"
response.setHeader("Pragma","no-cache"); //HTTP 1.0 backward compatibility
if (!this.userIsLoggedIn(request)) {
ActionErrors errors = new ActionErrors();
errors.add("error", new ActionError("logon.sessionEnded"));
this.saveErrors(request, errors);
return mapping.findForward("sessionEnded");
}
return executeAction(mapping, form, request, response);
}
protected abstract ActionForward executeAction(ActionMapping mapping, ActionForm form, HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException;
private boolean userIsLoggedIn(HttpServletRequest request) {
if (request.getSession().getAttribute("User") == null) {
return false;
}
return true;
}
} |
清单6中的代码与清单4中的很相像,仅仅只是用ActionMapping findForward替代了RequestDispatcher forward。清单6中,如果在HttpSession中未找到username字符串,ActionMapping对象将找到名为sessionEnded的forward元素并跳转到对应的path。如果找到了,子类将执行其实现了executeAction()方法的业务逻辑。因此,在配置文件struts-web.xml中为所有子类声明个一名为sessionEnded的forward元素是必须的。清单7以secure1 action阐明了这样一个声明:
清单7
<action path="/secure1"
type="com.kevinhle.logoutSampleStruts.Secure1Action"
scope="request">
<forward name="success" path="/WEB-INF/jsps/secure1.jsp"/>
<forward name="sessionEnded" path="/login.jsp"/>
</action> |
继承自BaseAction类的子类Secure1Action实现了executeAction()方法而不是覆盖它。Secure1Action类不执行任何退出代码,如清单8:
public class Secure1Action extends BaseAction {
public ActionForward executeAction(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
HttpSession session = request.getSession();
return (mapping.findForward("success"));
}
} |
只需要定义一个基类而不需要额外的代码工作,上述解决方案是优雅而有效的。不管怎样,将通用的行为方法写成一个继承StrutsAction的基类是许多Struts项目的共同经验,值得推荐。
结论 本文阐述了解决退出问题的方案,尽管方案简单的令人惊讶,但却在所有情况下都能有效地工作。无论是对JSP还是Struts,所要做的不过是写一段不超过50行的代码以及一个记录用户最后登陆时间的方法。在Web应用中混合使用这些方案能够使拥护的私人数据不致泄露,同时,也能增加用户的经验。
posted @
2005-11-14 16:48 rkind 阅读(255) |
评论 (0) |
编辑 收藏Beanutils用了魔术般的反射技术,实现了很多夸张有用的功能,都是C/C++时代不敢想的。无论谁的项目,始终一天都会用得上它。我算是后知后觉了,第一回看到它的时候居然错过。
1.属性的动态getter,setter
在这框架满天飞的年代,不能事事都保证执行getter,setter函数了,有时候属性是要需要根据名字动态的取得的,就像这样:
BeanUtils.getProperty(myBean,"code");
而BeanUtils更强的功能是直接访问内嵌对象的属性,只要使用逗号分割。
BeanUtils.getProperty(orderBean, "address.city");
其他类库的BeanUtils通常都很简单,不能访问内嵌的对象,所以经常要用Jakata的BeanUtils替换它们。
BeanUtils还支持List和Map类型的属性。如下面的语法即可取得顾客列表中第一个顾客的名字
BeanUtils.getProperty(orderBean, "customers[1].name");
其中BeanUtils会使用ConvertUtils类把字符串转为Bean属性的真正类型,方便从HttpServletRequest等对象中提取bean,或者把bean输出到页面。
而PropertyUtils就会原色的保留Bean原来的类型。
2.beanCompartor 动态排序
还是通过反射,动态设定Bean按照哪个属性来排序,而不再需要在bean的Compare接口进行复杂的条件判断。 List peoples = ...; // Person对象的列表 Collections.sort(peoples, new BeanComparator("age")); }}} 如果要支持多个属性的复合排序,如"Order By lastName,firstName" ArrayList sortFields = new ArrayList();
sortFields.add(new BeanComparator("lastName"));
sortFields.add(new BeanComparator("firstName"));
ComparatorChain multiSort = new ComparatorChain(sortFields);
Collections.sort(rows,multiSort);
其中ComparatorChain属于jakata commons-collections包。
如果age属性不是普通类型,构造函数需要再传入一个comparator对象为age变量排序。
3.Converter 把Request中的字符串转为实际类型对象
经常要从request,resultSet等对象取出值来赋入bean中,下面的代码谁都写腻了,如果不用MVC框架的绑定功能的话。
String a = request.getParameter("a");
bean.setA(a);
String b = ....
不妨改为
MyBean bean = ...;
HashMap map = new HashMap();
Enumeration names = request.getParameterNames();
while (names.hasMoreElements())
{
String name = (String) names.nextElement();
map.put(name, request.getParameterValues(name));
}
BeanUtils.populate(bean, map);
其中BeanUtils的populate方法或者getProperty,setProperty方法其实都会调用convert进行转换。
但Converter只支持一些基本的类型,甚至连java.util.Date类型也不支持。而且它比较笨的一个地方是当遇到不认识的类型时,居然会抛出异常来。
对于Date类型,我参考它的sqldate类型实现了一个Converter,而且添加了一个设置日期格式的函数。要把这个Converter注册,需要如下语句:
ConvertUtilsBean convertUtils = new ConvertUtilsBean();
DateConverter dateConverter = new DateConverter();
convertUtils.register(dateConverter,Date.class);
//因为要注册converter,所以不能再使用BeanUtils的静态方法了,必须创建BeanUtilsBean实例
BeanUtilsBean beanUtils = new BeanUtilsBean(convertUtils,new PropertyUtilsBean());
beanUtils.setProperty(bean, name, value);
!4 其他功能
4.1 PropertyUtils,当属性为Collection,Map时的动态读取:
Collection: 提供index
{{{ BeanUtils.getIndexedProperty(orderBean,"items",1);或者
BeanUtils.getIndexedProperty(orderBean,"items[1]");
Map: 提供Key Value
BeanUtils.getMappedProperty(orderBean, "items","111");//key-value goods_no=111
或者
BeanUtils.getMappedProperty(orderBean, "items(111)");
4.2 PropertyUtils,获取属性的Class类型
public static Class getPropertyType(Object bean, String name)
4.3 ConstructorUtils,动态创建对象
public static Object invokeConstructor(Class klass, Object arg)
4.4 DynaClass动态类
其中ComparatorChain属于jakata commons-collections包。 经常要从request,resultSet等对象取出值来赋入bean中,下面的代码谁都写腻了,如果不用MVC框架的绑定功能的话。 不妨改为 其中BeanUtils的populate方法或者getProperty,setProperty方法其实都会调用convert进行转换。 或者 4.2 PropertyUtils,获取属性的Class类型
posted @
2005-11-14 15:12 rkind 阅读(172) |
评论 (0) |
编辑 收藏Struts的Token(令牌)机制能够很好的解决表单重复提交的问题,基本原理是:服务器端在处理到达的请求之前,会将请求中包含的令牌值与保存在当前用户会话中的令牌值进行比较,看是否匹配。在处理完该请求后,且在答复发送给客户端之前,将会产生一个新的令牌,该令牌除传给客户端以外,也会将用户会话中保存的旧的令牌进行替换。这样如果用户回退到刚才的提交页面并再次提交的话,客户端传过来的令牌就和服务器端的令牌不一致,从而有效地防止了重复提交的发生。
这时其实也就是两点,第一:你需要在请求中有这个令牌值,请求中的令牌值如何保存,其实就和我们平时在页面中保存一些信息是一样的,通过隐藏字段来保存,保存的形式如: 〈input type="hidden" name="org.apache.struts.taglib.html.TOKEN" value="6aa35341f25184fd996c4c918255c3ae"〉,这个value是TokenProcessor类中的generateToken()获得的,是根据当前用户的session id和当前时间的long值来计算的。第二:在客户端提交后,我们要根据判断在请求中包含的值是否和服务器的令牌一致,因为服务器每次提交都会生成新的Token,所以,如果是重复提交,客户端的Token值和服务器端的Token值就会不一致。下面就以在数据库中插入一条数据来说明如何防止重复提交。
在Action中的add方法中,我们需要将Token值明确的要求保存在页面中,只需增加一条语句:saveToken(request);,如下所示:
public ActionForward add(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
//前面的处理省略
saveToken(request);
return mapping.findForward("add");
}在Action的insert方法中,我们根据表单中的Token值与服务器端的Token值比较,如下所示:
public ActionForward insert(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
if (isTokenValid(request, true)) {
// 表单不是重复提交
//这里是保存数据的代码
} else {
//表单重复提交
saveToken(request);
//其它的处理代码
}
}
其实使用起来很简单,举个最简单、最需要使用这个的例子:
一般控制重复提交主要是用在对数据库操作的控制上,比如插入、更新、删除等,由于更新、删除一般都是通过id来操作(例如:updateXXXById, removeXXXById),所以这类操作控制的意义不是很大(不排除个别现象),重复提交的控制也就主要是在插入时的控制了。
先说一下,我们目前所做项目的情况:
目前的项目是用Struts+Spring+Ibatis,页面用jstl,Struts复杂View层,Spring在Service层提供事务控制,Ibatis是用来代替JDBC,所有页面的访问都不是直接访问jsp,而是访问Structs的Action,再由Action来Forward到一个Jsp,所有针对数据库的操作,比如取数据或修改数据,都是在Action里面完成,所有的Action一般都继承BaseDispatchAction,这个是自己建立的类,目的是为所有的Action做一些统一的控制,在Struts层,对于一个功能,我们一般分为两个Action,一个Action里的功能是不需要调用Struts的验证功能的(常见的方法名称有add,edit,remove,view,list),另一个是需要调用Struts的验证功能的(常见的方法名称有insert,update)。
就拿论坛发贴来说吧,论坛发贴首先需要跳转到一个页面,你可以填写帖子的主题和内容,填写完后,单击“提交”,贴子就发表了,所以这里经过两个步骤:
1、转到一个新增的页面,在Action里我们一般称为add,例如:
public ActionForward add(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
throws Exception {
//这一句是输出调试信息,表示代码执行到这一段了
log.debug(":: action - subject add");
//your code here
//这里保存Token值
saveToken(request);
//跳转到add页面,在Structs-config.xml里面定义,例如,跳转到subjectAdd.jsp
return mapping.findForward("add");
}
2、在填写标题和内容后,选择 提交 ,会提交到insert方法,在insert方法里判断,是否重复提交了。
public ActionForward insert(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response){
if (isTokenValid(request, true)) {
// 表单不是重复提交
//这里是保存数据的代码
} else {
//表单重复提交
saveToken(request);
//其它的处理代码
}
}
下面更详细一点(注意,下面所有的代码使用全角括号):
1、你想发贴时,点击“我要发贴”链接的代码可以里这样的:
〈html:link action="subject.do?method=add"〉我要发贴〈/html:link〉
subject.do 和 method 这些在struct-config.xml如何定义我就不说了,点击链接后,会执行subject.do的add方法,代码如上面说的,跳转到subjectAdd.jsp页面。页面的代码大概如下:
〈html:form action="subjectForm.do?method=insert"〉
〈html:text property="title" /〉
〈html:textarea property="content" /〉
〈html:submit property="发表" /〉
〈html:reset property="重填" /〉
〈html:form〉
如果你在add方法里加了“saveToken(request);”这一句,那在subjectAdd.jsp生成的页面上,会多一个隐藏字段,类似于这样〈input type="hidden" name="org.apache.struts.taglib.html.TOKEN" value="6aa35341f25184fd996c4c918255c3ae"〉,
2、点击发表后,表单提交到subjectForm.do里的insert方法后,你在insert方法里要将表单的数据插入到数据库中,如果没有进行重复提交的控制,那么每点击一次浏览器的刷新按钮,都会在数据库中插入一条相同的记录,增加下面的代码,你就可以控制用户的重复提交了。
if (isTokenValid(request, true)) {
// 表单不是重复提交
//这里是保存数据的代码
} else {
//表单重复提交
saveToken(request);
//其它的处理代码
}
注意,你必须在add方法里使用了saveToken(request),你才能在insert里判断,否则,你每次保存操作都是重复提交。
记住一点,Struts在你每次访问Action的时候,都会产生一个令牌,保存在你的Session里面,如果你在Action里的函数里面,使用了saveToken(request);,那么这个令牌也会保存在这个Action所Forward到的jsp所生成的静态页面里。
如果你在你Action的方法里使用了isTokenValid,那么Struts会将你从你的request里面去获取这个令牌值,然后和Session里的令牌值做比较,如果两者相等,就不是重复提交,如果不相等,就是重复提交了。
由于我们项目的所有Action都是继承自BaseDispatchAction这个类,所以我们基本上都是在这个类里面做了表单重复提交的控制,默认是控制add方法和insert方法,如果需要控制其它的方法,就自己手动写上面这些代码,否则是不需要手写的,控制的代码如下:
public abstract class BaseDispatchAction extends BaseAction {
protected ActionForward perform(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
throws Exception {
String parameter = mapping.getParameter();
String name = request.getParameter(parameter);
if (null == name) { //如果没有指定 method ,则默认为 list
name = "list";
}
if ("add".equals(name)) {
if ("add".equals(name)) {
saveToken(request);
}
} else if ("insert".equals(name)) {
if (!isTokenValid(request, true)) {
resetToken(request);
saveError(request, new ActionMessage("error.repeatSubmit"));
log.error("重复提交!");
return mapping.findForward("error");
}
}
return dispatchMethod2(mapping, form, request, response, name);
}
}
posted @
2005-11-14 14:32 rkind 阅读(345) |
评论 (0) |
编辑 收藏SELECT COUNT(*) AS Expr1 FROM History
DELETE FROM History WHERE (Id > 0)
truncate table youtable;
为什么要用TRUNCATE TABLE 语句代替DELETE语句?当你使用TRUNCATE TABLE语句时,记录的删除是不作记录的。也就是说,这意味着TRUNCATE TABLE 要比DELETE快得多。
posted @
2005-11-11 11:25 rkind 阅读(353) |
评论 (0) |
编辑 收藏
我今年39岁了,25岁研究生毕业,工作14年,回头看看,应该说走了不少的弯路,有一些经验和教训。现在开一个小公司,赚的钱刚够养家糊口的。看看这些刚毕业的学生,对前景也很迷茫,想抛砖引玉,谈谈自己的看法,局限于理工科的学生,我对文科的不懂,身边的朋友也没有这一类型的。
91年研究生毕业,那时出路就是1种:留在北京的国营单位,搞一个北京户口,这是最好的选择。到后来的2~3年内,户口落定了,又分成4条出路:
1、 上国内的大企业,如:华为
2、 自己做公司,做产品开发;
3、 上外企,比如:爱立信、诺基亚
4、 自己做公司,做买卖;
5、 移民加拿大
我想,首先要看自己适合做什么?做技术还是做买卖。
做技术,需要你对技术感兴趣。我掰着数了一遍,我们研究生班的30来号人,实际上,适合做技术的,大概只有3、4个人,这几个人,1个现在还在华为,3个移民加拿大了,现在这4个人混的还可以,在华为的同学也移民加拿大了,他在华为呆了6年,在华为奖金工资加起来大概30万吧,还有华为的股票,再过几年,华为的股票一上市,也能值个100~200万。要是一毕业就去华为,那现在就绝对不是这个数字了。
要是做技术,最好的就是上大公司,国内的大型企业,象华为中兴肯定是首选,能学到很多东西。华为虽然累,但是,年轻人不能怕累,要是到老了,还需要去打拼,那才是真的累啊。
在外企,我想他们主要就是技术支持和销售,但是技术是学不到的,当然不能一概而论,我指的是象爱立信和诺基亚,真正的研发不会在中国做的,学到的也不如在华为多,其它的中兴我不是很了解,我想应该也不错啊。
一个人都有一技之长,有傍身之技,那是最好的,走到哪里,都能有一口饭吃,还吃的不错,这是传统的观点。
任何技术都是要在某个行业去应用,这个行业市场越大当然越好;要在一个领域之内,做深做精,成为绝对的专家,这是走技术道路的人的选择。不要跳来跳去,在中国,再小的行业你要做精深了,都可以产生很大的利润。
研究生刚毕业的时候,做产品开发的有不少人,都是自己拍拍脑子,觉得这个产品有市场,就自己出来做。现在看来,我的这些同学,做产品开发的成功的没有一例,为什么?资源不足。
1. 资金,刚毕业的学生啊,就是没钱;没钱,也意味着你开发的东西都是小产品;而且只能哥几个自己上,研发、生产、销售都是一个人或者几个人自己来,没有积累,什么都是重新来过。
2. 人脉,任何一个行业,要想进去,需要有很深的人脉,否则,谁会用你的东西啊?谁敢用你的东西啊?
我看到的,我这个班上开发产品的,自己还在坚持的,只剩下一个人了,说实在的,到现在,没有自己的汽车,也没有自己的房子,混的挺惨的。现在出国的不说了,在外企、在华为,至少都是几十万的年薪了,还有各种福利,就是产品开发成功了,又能如何?也就是这样了,但是以前那些年,都没有金钱的积累,等于白干。
我身边的一个自动化系的研究生班的同学,能靠自己开发产品活得还可以的,也只有2个人。说明这条路不是那么好走的啊。
其次就是上外企。我的2个同学,一个上了爱立信,一个先到爱立信后到诺基亚,都混的不错。到诺基亚的后来利用在诺基亚结识的人脉(就是哪些电信的头头脑脑),自己开了公司,也赚了不少的钱。
外企最大的好处就是除了能学到比较规范的管理外,还能给你的职业生涯镀金。到了一个外企外,再到同行业的外企我想就很容易了。而且外企的收入高啊。
自己做公司,做买卖,一开始有3~4个人走这条路,但是真正发财的只有一个人,其他人后来上外企了。做买卖,还是要有一定的天赋,还有机遇。要有对金钱的赤裸裸的欲望,要有商业上的头脑。后来我们同学在一起谈,说,我们即使给自己这个机遇,也未必能做的好。何况当时那个同学看好的产品(做一个台湾产品的代理),我们大家都没有看好,说明,真理还是掌握在少数人手里。
到后来,同学们纷纷移民移民加拿大。
移民加拿大对搞技术的人来说,还是一个不错的选择,但是要尽早,练了几年的技术,就赶紧出去,大概是在1996年走了不到10个,现在都还可以,买了房子和车了。要是晚了,语言再学也难了,而且在国内都混的还可以了,也就没有必要出去了。
我自己呢,先是在国营的研究所混了4年,后来到一家公司干了6年,2002年出来自己做公司,现在也就是混了一个温饱吧,算是有房有车,有点积蓄,但是不多,还有一个可爱的女儿。回首这10来年,有一些经验和教训。
1. 要有一个职业生涯的规划。首先需要定位自己做什么合适,是做买卖还是做技术,一条路走到黑;当然,做了技术,后来改行也行;
2. 做技术,就是要做精做深,成为这个行业的这个技术的专家;最好就是去国内的大公司,才能全面学到东西,能够给你培训的机会;如果大公司进不去,先到小公司练技术,找机会再到大公司去镀金,学高深的技术。千万不要自己做产品,要做也是对这个行业熟悉了,再去做。
3. 积极争取机会。积极争取学习和进步的机会。比如,做技术,就需要多锻炼,多学习,来提高自己的水平。一门技术,只要有机会去学习,都能学的会;要是没有机会,天才也没有办法学到这个技术。柳传志就说,杨元庆就是“哭着喊着要进步”,实际上,就是争取自己的机会;当然,这种强烈的进步欲望,也是领导看重的地方。每一步都走在前面,积累10年,你就有了比其他人更多的机会了。
4. 积累个人的信誉。从你的职业生涯的第一天,就要按照诚信的原则办事。要做到,当人们提起你的名字的时候,说,这哥们还不错,做事还行。
5. 注意利用资源。如果你有有钱的亲戚、成功的长辈或者朋友,可以充分利用这些机会,得到更加顺利的发展前景。
6. 注意财富的不断积累。人生要想得到自由,财富是很关键的。否则,永远仰人鼻息,永远看人脸色。人都是势利眼。今后的家庭、职业生涯,金钱的积累很重要,没有钱,永远不能开张自己的事业,得到更多的机会;财富要做到逐年积累,你才能家庭生活幸福。没有钱是不可能有幸福的家庭的。
7. 注意人脉的积累。最终,事业要靠在社会上的人脉的资源。要注意认识在你这个行业的人,结交他们,最终他们会成为你事业上的助力。
8. 寻求贵人相助。要找大老板来帮助你,得到大老板的赏识。想想看,大蛋糕,切一点就够了,小蛋糕,都给你也吃不饱啊。
9. 多听听成功的前辈和成功的朋友的意见。注意少听家里长辈的意见,尤其是都已经退休的长辈,他们对社会的认识还停留在很久以前,而这个社会已经发生很大的变化呢。最重要的是,长辈有时候会强求你做一些事情,但是,最终的结果他们是不负责的。只有你才能对自己负责。
posted @
2005-11-10 15:02 rkind 阅读(272) |
评论 (0) |
编辑 收藏滚动公告栏的实现
用到如下html标签:
《MARQUEE id=mar onmouseout=this.start(); direction=up height=150 name="mar"
onmouseover="this.stop();" scrollAmount="1" scrollDelay="0"
style="LINE-HEIGHT: 100%; PADDING-LEFT: 0px; PADDING-RIGHT:0px"width="100%">
1净化社会环境
2也是净化社会平步青云
3净化社会环境
4也是净化社会平步青云
5净化社会环境
6也是净化社会平步青云
7净化社会环境
8也是净化社会平步青云
其中marquee中height中的属性可以更改每次显示的行数,……
posted @
2005-11-02 08:43 rkind 阅读(466) |
评论 (0) |
编辑 收藏
天凉好个秋
对我来说,如果只是降温的话,我未必会觉得秋来了,可是昨天早上走在路上,看到叶子在空中飞舞,地上布满了落叶,秋终于还是来了,这一年也快要过去了,我做了什么,我还能做什么。
昨天新装了个系统,换了个mac的主题,用着很舒服,不过装别的软件又浪费了半天的时候,终究还是忘了做个镜像了,

装好Sever-u后,测试什么问题都没有,后来从别的机子那里一访问,居然不行,怀疑卡巴的事,这个杀毒软件太BT,不怀疑不行啊,关了以后还是不行,难道是windows防火墙?禁掉果然OK
,那总不能禁掉它吧,暂且不说那个提示很烦,别外要装防火墙是让我很不爽的事,一共就这么点内存,哪够用啊

。看看防火墙里面有个例外选项,我把端口20,21,22,全都加上了,结果只能连上,但是不能建立socket,让人不爽的是,居然不能范围添加端口。
然后选例外程序,是在这里,server-u目录下有三个程序文件tray.exe有来系统托盘监控,dameon主程序后台运行,admini管理,这里我把dameon加上以后,一连接,果然ok,
起先加错了,加成tray.exe和admin,就没加dameon,结果怎么试都不行,还上网查了好长时间,真是……
看来我的英语,
posted @
2005-10-28 09:21 rkind 阅读(1528) |
评论 (2) |
编辑 收藏在jsp轻易实现下拉菜单,那么在struts中呢?
大概的步骤如下:
1首先定义一个bean,最少有两个属性,每个属性都有set和get的方法
2定义一个业务逻辑类,重复从数据库中读取纪录为Bean赋值,将这些bean添加入一个Collection
3将collection放入到Request中。
4在JSP中用的标签显示出来
实例:
要实现一个显示姓名返回Id值 的下拉菜单,
1首先实现一个user的bean,该bean有两个属性,name,id,每个属性都有对应set和get的方法
比如name就有,setname()和getname()的方法
2定义一个逻辑类,GetUserList
select * from User;
Collection listuser;
while(rs.next()){
user.setname(rs.getString(username));
....
listuser.add(user);
}
3比如list.jsp做为要显示下拉菜单的页面,那么在/list 对应的action ListUser中应该
request.setAttribute("userlist",user);
4,在list.jsp中用
//actionForm中定义的变量
即可
不过这样显示的只是简单的菜单,要实现能动态得跳转得不知道用什么办法
posted @
2005-10-27 16:51 rkind 阅读(1169) |
评论 (2) |
编辑 收藏
丰富多样的颜色可以分成两个大类无彩色系和有彩色系:
1.无彩色系 无彩色系是指白色、黑色和由白色黑色调合形成的各种深浅不同的灰色。无彩色按照一定的变化规律,可以排成一个系列,由白色渐变到浅灰、中灰、深灰到黑色,色度学上称此为黑白系列。黑白系列中由白到黑的变化,可以用一条垂直轴表示,一端为白,一端为黑,中间有各种过渡的灰色。纯白是理想的完全反射的物体,纯黑是理想的完全吸收的物体。可是在现实生活中并不存在纯白与纯黑的物体,颜料中采用的锌白和铅白只能接近纯白,煤黑只能接近纯黑。无彩色系的颜色只有一种基本性质——明度。它们不具备色相和纯度的性质,也就是说它们的色相与纯度在理论上都等于零。色彩的明度可用黑白度来表示,愈接近白色,明度愈高;愈接近黑色,明度愈低。黑与白做为颜料,可以调节物体色的反射率,使物体色提高明度或降低明度。
2.有彩色系(简称彩色系) 彩色是指红、橙、黄、绿、青、蓝、紫等颜色。不同明度和纯度的红橙黄绿青蓝紫色调都属于有彩色系。有彩色是由光的波长和振幅决定的,波长决定色相,振幅决定色调。
色彩的基本特性 有彩色系的颜色具有三个基本特性:色相、纯度(也称彩度、饱和度)、明度。在色彩学上也称为色彩的三大要素或色彩的三属性。
1.色相 色相是有彩色的最大特征。所谓色相是指能够比较确切地表示某种颜色色别的名称。如玫瑰红、桔黄、柠檬黄、钴蓝、群青、翠绿……从光学物理上讲,各种色相是由射人人眼的光线的光谱成分决定的。对于单色光来说,色相的面貌完全取决于该光线的波长;对于混合色光来说,则取决于各种波长光线的相对量。物体的颜色是由光源的光谱成分和物体表面反射(或透射)的特性决定的。
2.纯度(彩度、饱和度)
色彩的纯度是指色彩的纯净程度,它表示颜色中所含有色成分的比例。含有色彩成分的比例愈大,则色彩的纯度愈高,含有色成分的比例愈小,则色彩的纯度也愈低。可见光谱的各种单色光是最纯的颜色,为极限纯度。当一种颜色掺人黑、白或其他彩色时,纯度就产生变化。当掺人的色达到很大的比例时,在眼睛看来,原来的颜色将失去本来的光彩,而变成掺和的颜色了。当然这并不等于说在这种被掺和的颜色里已经不存在原来的色素,而是由于大量的掺人其他彩色而使得原来的色素被同化,人的眼睛已经无法感觉出来了。
有色物体色彩的纯度与物体的表面结构有关。如果物体表面粗糙,其漫反射作用将使色彩的纯度降低;如果物体表面光滑,那么,全反射作用将使色彩比较鲜艳。
3.明度 明度是指色彩的明亮程度。各种有色物体由于它们的反射光量的区别而产生颜色的明暗强弱。色彩的明度有两种情况:一是同一色相不同明度。如同一颜色在强光照射下显得明亮,弱光照射下显得较灰暗模糊;同一颜色加黑或加白掺和以后也能产生各种不同的明暗层次。二是各种颜色的不同明度。每一种纯色都有与其相应的明度。黄色明度最高,蓝紫色明度最低,红、绿色为中间明度。色彩的明度变化往往会影响到纯度,如红色加入黑色以后明度降低了,同时纯度也降低了;如果红色加白则明度提高了,纯度却降低了。
有彩色的色相、纯度和明度三特征是不可分割的,应用时必须同时考虑这三个因素。
色彩生理理论:色彩的错视与幻觉 当外界物体的视觉刺激作用停止以后,在眼睛视网膜上的影像感觉并不会立刻消失,这种视觉现象叫做视觉后像。视觉后像的发生,是由于神经兴奋所留下的痕迹作用,也称为视觉残像。如果眼睛连续视觉两个景物,即先看一个后再看另一个时,视觉产生相继对比,因此又称为连续对比。视觉后像有两种:当视觉神经兴奋尚未达到高峰,由于视觉惯性作用残留的后像叫正后像;由于视觉神经兴奋过度而产生疲劳并诱导出相反的结果叫负后像。无论是正后像还是负后像均是发生在眼睛视觉过程中的感觉,都不是客观存在的真实景像。
正后像 节日之夜的烟花,常常看到条条连续不断的各种造型的亮线。其实,任意一瞬间,烟火无论在任何位置上只能是一个亮点,然而由于视觉残留的特性,前后的亮点却在视网膜上引成线状。再如你在电灯前闭眼三分钟,突然睁开注视电灯两三秒钟,然后再闭上眼睛,那么在暗的背景上将出现电灯光的影像。以上现象叫正后像。电视机、日光灯的灯光实际上都是闪动的,因为它闪动的频率很高,大约100次/秒上,由于正后像作用,我们的眼睛并没有观察到。电影技术也是利用这个原理发明的,在电影胶卷上,当一连串个别动作以16图形/秒以上的速度移动的时候,人们在银幕上感觉到的是连续的动作。现代动画片制作根据以上原理,把动作分解绘制成个别动作,再把个别动作续起来放映,即复原成连续的动作。
负后像 正后像是神经正在兴奋而尚未完成时引起的,负后像则是经兴奋疲劳过度所引起的,因此它的反映与正后像相反。例如:当你长时间(两分钟以上)的凝视一个红色方块后,再把目光迅速转移到一张灰白纸上时,将会出现一个青色方块。这种现象在生理学上可解释为:含红色素的视锥细胞,长时间的兴奋引起疲劳,相应的感觉灵敏度也因此而降低,当视线转移到白纸上时,就相当于白光中减去红光,出现青光,所以引起青色觉。由此推理,当你长时间凝视一个红色方块后,再将视线移向黄色背景,那么,黄色就必然带有绿味(红视觉后像为青,青+黄=绿,参见下表)。
又例如:在一白色和灰色背景上,长时间地(两分钟以上)注视一红色方块,然后迅速抽去色块,继续注视背景的同一地方,背景上就会呈现青色方块。这一诱导出的补色时隐时现多次复现,直至视觉的疲劳恢复以后才完全消失。这种现象也是负后像。明度对比也会产生负后像。
--------------------------------------------------------------------------------
先看的色彩 后看的色彩 对比后的色彩感觉
红 橙 黄味橙
红 黄 绿味黄
红 绿 蓝味绿
红 蓝 绿味蓝
红 紫 蓝味紫
橙 红 紫味红
橙 黄 绿味黄
橙 绿 蓝味绿
橙 紫 蓝味紫
橙 蓝 紫味蓝
黄 红 紫味红
黄 橙 红味橙
黄 绿 蓝味绿
黄 蓝 紫味蓝
黄 紫 蓝味紫
绿 红 紫味红
绿 橙 红味橙
绿 黄 橙味黄
绿 蓝 紫味蓝
绿 紫 红味紫
蓝 红 橙味红
蓝 橙 黄味橙
蓝 黄 橙味黄
蓝 绿 黄味绿
蓝 紫 红味紫
紫 红 橙味红
紫 橙 黄味橙
紫 黄 绿味黄
紫 绿 黄味绿
紫 蓝 绿味蓝
-------------------------------------------------------------------------------
灰色的背景上,如果注视白色(或黑色)方块,迅速抽去白色(或黑色)方块,灰底上上将呈现较暗(或较亮)的方块。
视觉负后像的干扰常常使我们在判断颜色时发生困难。例如,初学色彩者在练习看色时,长时间的色彩刺激会引起视觉疲劳而产生后像,感受色彩的灵敏度不断降低,色彩分辨能力迅速下降。解决问题的方法是注意观察与看色的节奏,避免视觉疲劳。
同时对比
结果使相邻之色改变原来的性质,都带有相邻色的补色光。
例如:
同一灰色在黑底上发亮,在白底上变深。
同一黑色在红底上呈绿灰味,在绿底上呈红灰味,在绿底上呈红灰味,在紫底上呈黄灰味,在黄底上呈紫灰味
同一灰色在红、橙、黄、绿、青、紫底上都稍带有背景色的补色味红与紫并置,红倾向于橙,紫倾向于蓝。相邻之色都倾向于将对方推向自己的补色方向。
红与绿并置,红更觉其红,绿更觉其绿。
色彩同时对比,在交界处更为明显,这种现象又称为边缘对比。现将色彩同时对比的规律归纳如下:
1、亮色与暗色相邻,亮者更亮,暗者更暗;灰色与艳色并置,艳者更艳,灰者更灰;冷色与暖色并置,冷者更冷、暖者更暖。
2、不同色相相邻时,都倾向于将对方推向自己的补色。
3、补色相邻时,由于对比作用强烈,各自都增加了补色光,色彩的鲜明度也同时增加。
4、同时对比效果,随着纯度增加而增加,同时以相邻交界之处即边缘部分最为明显。
5、同时对比作用只有在色彩相邻时才能产生,其中以一色包围另一色时效果最为醒目。
强化同时对比效果的方法:
(1)提高对比色彩的纯度,强化纯度对比作用;
(2)使对比之色建立补色关系,强化色相对比作用;
(3)扩大面积对比关系,强化面积对比作用。
抑制的方法: (1)改变纯度,提高明度,缓和纯度对比作用;
(2)破坏互补关系,避免补色强烈对比;
(3)采用间隔、渐变的方法,缓冲色彩对比作用;
(4)缩小面积对比关系,建立面积平衡关系。
例如:橙色底上配青灰能强化同时对比作用;而橙色底上配黄灰就能抑制同时对比作用。
伊顿在《色彩艺术》中指出:“连续对比与同时对比说明了人类的眼睛只有在互补关系建立时,才会满足或处于平衡。”“视觉残像的现象和同时性的效果,两者都表明了一个值得注意的生理上的事实,即视力需要有相应的补色来对任何特定的色彩进行平衡,如果这种补色没有出现,视力还会自动地产生这种补色。”“互补色的规则是色彩和谐布局的基础,因为遵守这种规则便会在视觉中建立精确的平衡。”伊顿提出的“补色平衡理论”揭示了一条色彩构成的基本规律,对色彩艺术实践具有十分重要的指导意义。如果色彩构成过分暖昧而缺少生气时,那么互补色的选择是十分有效的配色方法,无论是舞台环境色彩对人物的烘托和气氛的渲染,还是商品广告及陈列等等,巧妙地运用互补色构成,是提高艺术感染力的重要手段。
“补色平衡理论”在医疗实践中已被广泛采用。根据视觉色彩互补平衡的原理,医院手术室、手术台、外科医生护士的衣服一般都采用绿色,这不仅因为绿色是中性的温和之色,更重要的是绿色能减轻外科医生因手术中长时间受到鲜红血液的刺激引起的视觉疲劳,避免发生视觉残像而影响手术正常进行。
posted @
2005-10-27 13:19 rkind 阅读(398) |
评论 (0) |
编辑 收藏
摄影构图的基本要领
中国民俗摄影协会教学培训委员会编辑
摄影者确定了要表现的主题后,摆在面前的首先是如何安排和处理摄影画面的构图问题。所谓摄影构图,就是把要表现的客观对象有机地安排在一幅摄影画面中,使其产生一定的艺术形式,通过它把摄影者的意图和观念表达出来。这里包括:被摄主体在画幅中所处的位置,照片画幅的长宽比例、透视与空间深度的处理、影像清晰与模糊程度的控制、色彩的配置、影调与线条的应用、气氛的渲染……总之,就是处理构成摄影画面总印象的一切造型因素。摄影的这种构图过程,并非在产生作品的最后阶段才完成的,而是从考虑画面时就开始了。
研究摄影构图的目的是为了更好地表达照片的主题内容,使作品更有艺术感染力,更能给观众留下深刻的印象,增强照片的效果。它的基本要求是鲜明、易懂、有表现力。这意味着在考虑摄影画面的构成时,要尽可能注意简化。简化决不是简单化,而是精化,即对各种事物进行最准确、最迅速的分析、判断和取舍,把画幅中不需要的那些因素排除在构图之外;尽量使被摄主体从周围环境中突出出来;被摄体相互之间的关系要协调、统一,不可互相争夺视线;被摄体的形状要处理好……总之,尽量使你所塑造的艺术形象鲜明突出,能深深地感染观众。
摄影画面的构图有一些为大多数人公认的一般性的法则,但这些法则有时又不是绝对的,不可以生搬硬套。大家所能接受的一些构图法则,也常常会有例外,而且也会随着时代的变化而改变——新生的将最终取代陈腐的。由此可见,艺术创作在表现方法上是极其灵活的,它没有既定的公式,也不应有僵死的、一成不变的教条,要依靠摄影者根据被摄现场的具体情况,根据创作主题的要求和摄影者自己的意图进行灵活处理。摄影者在现场有充分的选择和决断的自由。这样说,并不意味着摄影画面的构图就可以随心所欲,草率从事。相反,构图的好坏,常会影响到一幅摄影作品的主题是否表达得鲜明,它的艺术形式是否有感染力。
一幅优秀的摄影艺术作品,总是作者按照自己的创作意图对生活素材进行选择和布局,以使画面完整、严谨,具有一定的章法。正如一篇好文章,必须主题明确,语言清晰,段落分明,有一定的章法一样。被摄影者框到画面上来的图象,已不再是生活中各自独立的存在,而是赋予它们在画面上各自不同的地位,相互之间产生了一种新的关系,为表达一定思想内容起着不同的作用。仔细分析一些优秀摄影作品之后,便会发现这样的规律:被摄影者组织到画面上来的对象,有的是用来表达内容和结构画面的主要对象,是摄影者最感兴趣的,吸引他举起相机拍摄的对象,我们称它为主体;有的对象是与画面上的主体构成情节,来说明主体内涵的,我们称它为陪体;有的对象是作为环境的组成部分用以陪衬、烘托主体的,我们将它分为前景和背景;另外,除了这些实体对象外,还有空白部分,它是联系画面上各个对象之间关系的纽带;还有把各个部分有机组织起来时应注意的法则如均衡、多样统一等。以上这些就是画面结构的基本章法。下面我们具体谈谈它们在画面上的地位和作用:
一、主体提纲挈领
主体是画面上用以表达内容的主要对象,是画面内容和结构的中心。结构画面,首先要立主体。主体可以是一个对象,也可以是一组对象。主体既是表达内容的中心,也是结构中心,画面上其他景物的配置都以主体为转移。
一般来说,主体作为内容中心和结构中心在画面上是统一在一起的。但是,在一些表现环境气氛为主的画面中,主体作为结构中心的任务更为突出,如盛大的群众场面,景物层次众多的风光画面等,它们以气势和气氛为主,内容上难以分清明显的主次,但要使这样的画面结构不松散,有章法,也要选择一个对象作为结构上的支点,用以呼应全局,提纲挈领,把画面上的景物结成一个整体。我们常常看到,有的风光照片以某一小桥、亭台为结构中心,有的以船帆或挺拔的树木为结构中心来裁割画面,使它们对前后景物起联系和照应作用。这样的画面,主体在内容上倒不一定比其它景物更为重要,而在结构中心的作用却是非常明显的。
如何安排主体在画面上的位置,一些外国摄影书刊介绍说,如果把画面分成九宫格的样式,那么中间的四个交叉点上,是安排主体最好的位置;有的说画面对角线的交点到各个角的二分之一处是处理主体最好的位置;有的说线条会聚点上是处理主体最好的位置……等等,这些说法从形式和视觉习惯上总结了一些规律,有一定道理。比如九宫格的各交点上安排主体,有倚角之势,易于对画面的各部分进行顾盼和照应。而且各交点的位置接近于画幅边缘的黄金分割点,容易获得较好的视觉效果。很少有人将主体安排在正中,因为人是用两眼来观看对象的,正中的位置反而是视觉上最薄弱的地区,而且主体在正中,对全局的呼应容易顾此失彼。所以不是特殊要求,一般应避开正中的位置。但是上述的一些说法只是从形式出发,而不是考虑具体内容的要求,是离内容来谈形式。事实上,主体的位置并没有什么死板的公式,而是以事物本身的特点及作者的创作意图为转移的。
总之,一幅有内容的画面,不能没有主体,画面失去了主体也就失去了内容,主体表现不明确,内容也会含混。
二、陪体构成情节
陪体是指画面上与主体构成一定的情节,帮助表达主体的特征和内涵的对象。组织到画面上来的对象有的是处于陪体地位,它们与主体组成情节,对深化主体内涵,帮助说明主体的特征起着重要作用。画面上由于有陪体,视觉语言会准确生动得多。
一般在有动作情节的画面上常常是有陪体的。它能使观众更好地理解人物的神情动作,不致于产生歧意。
画面处理好陪体,实质上就是要处理好情节。陪体的选择要能用来刻画人物的性格,说明事件的特征,也就是要有典型性。
画面陪体的安排必须以不削弱主体为原则,不能喧宾夺主。陪体在画面所占面积的多少,色调的安排、线条的走向、人物的神情动作,都要与主体配合紧密,息息相关,不能游离于主体之外。由于画面经营有轻重主次之分,所以陪体在画面上常常是不完整的,只需留下能够说明问题的那一部分就够了。陪体过全,主体就会削弱。拍摄作机器的工人一般只需留下机器的主要部位即可,机器全了人物在画面上的面积必然缩小,影响对人物的表现。陪体留舍的这种分寸感,对摄影者的结构能力是一个检验。应做到“增之一分则太长,减之一分则太短”,恰到好处。
陪体的处理也有直接处理和间接处理之分,陪体不论多或少,全或不全,它是出现在画面上的。另外,还有陪体不直接见诸于画面的情况。虽说陪体是与主体构成情节的对象,但有一些画面与主体构成情节的对象不在画面之中,而是在画面之外。画面上主体的动作神情是与画面以外的某一对象有联系,这一对象虽然没有出现在画面之上,却一定会出现在观众的想象之中。这种情况我们就叫陪体的间接表现。民俗摄影在选取素材,经营画面时,要考虑观众越来越追求抒情性、哲理性及含蓄的审美要求,适当地利用间接表现陪体的手法,会加强摄影画面的表现力和感染力。
三、环境渲染洪托
画面上有些对象是作为环境的组成部分,对主体、情节起烘托作用,以加强主题思想的表现力。作为环境组成部分的对象是处于主体前面的,我们称它为前景;处于主体后面的,我们称它为背景。
1.前景:
前景处在主体前面,靠近相机位置,它们的特点是呈像大,色调深,大都处于画面的四周边缘。前景可以是树木、花草,也可以是人和物。陪体也可以同时是前景,但许多情况下,前景却不起陪体的作用。在一些场面较大、景物层次丰富的画面中,常常是有前景的。下面我们具体分析一下前景的安排在表现内容上所起的作用:
①一些富有季节和地方特征的花草树木做前景渲染季节气氛和地方色彩;使画面具有浓郁的生活气息。春天的桃花、迎春花作前景,画面充满春意,用菊花、红叶做前景,秋色洋溢画面;用冰挂、雪枝作前景,北国冬日的景象如在目前。拍摄海南风光用椰树、芭蕉作前景,富有南国情调;用潇湘竹、英雄树、雪莲作前景,具有湖、广、天山的乡土气息。这些前景常常对主题是有力的烘托。
②前景用来加强画面的空间感。结构画面时,镜头有意靠近某些人或物,利用其成像大、色调深的特点,与远处的景物形成明显的形体大小对比和色调深浅的对比,以调动人们的视觉去感受画面的空间距离。一些有经验的摄影者在拍摄展示空间场面的内容时,总力求找到适当的前景,来强调出近大远小的透视感。而且常常利用前景与远景中有同类景物,如同是人或树,由于远近不同,在画面上所占面积相差越大,则调动人们的视觉规律,来想象空间的能力就越强,纵深轴线的感受就越鲜明。
③在表现一些内容丰富、复杂的事物时,有意将所要表现的事物中最富有特征的部分放置在前景位置上,以加强画面内容的概括力。比如一幅表现解放军帮助农民割麦的画面,许多人在割麦,很难分辨哪是军人,哪是老百姓。如果在画面的前景上,有意安排放得整整齐齐的衣帽、水壶,便将军队有组织地来帮助割麦这一事物的特征突出了,加强了视觉的形象语言。又如历史照片《淮海战场的一角》,用一尊大炮作前景,把具有战场气氛的形象放在显著位置上,在视觉上就给人以先声夺人的深刻印象。中层景物是解放军押着一队俘虏走下战场,再远处是弥漫的硝烟,画面上战场气氛很浓。而且这前景的大炮告诉我们,当时国民的武器是精锐的,但仍然被打败了,这就反衬出了我军攻无不克的坚强意志。拍篮球比赛用球架作前景,拍足球赛用球门作前景,都明显地将这一运动的性质强调出来。利用一些富有特点的广告、标语作前景,突出某种时代特征,这在电影摄影中是常用的。
④设置前景以与后景景物作内容上的对比,来完成摄影艺术常用的对比手法。比如,前景是丰盛的食物摊,摆着面包,挂着香肠,后景是饥饿的儿童望着这些精美的食品,对比之下就把儿童的饥饿形象化了。香港摄影家的一些作品,用破烂不堪的棚子作前景与远处的高楼大厦对比;用衣服破烂的小姐弟作前景,看着远处阳光下穿着华丽衣裳去上学的富家子弟的对比,来表现香港社会贫富不均的阶级矛盾。有一幅反映青年题材的摄影作品,前景是两个穿着入时,提着录音机瞎逛的青年,后景是在公园长凳上专心看书的青年,两者对比,形成了令人深思的主题。
⑤前景的运用还给予观众一种主观的地位感,加强画面的感染力。如用门、窗、床或桌子的一角等具有地位特征的景物作前景,让其在画面上占有较大的位置,给观众以心理上的影响,无形中就会缩短观众与画面之间的距离,产生一种身临其境的亲切感,这对增加画面的艺术感染力是有利的。
⑥前景的运用还能增加画面的装饰美,一些有规则排列的物体,以及一些具有图案形状的物体,用来作前景,使画面象装饰了一个精美的画框或花边,增加了美感,显得生动活泼。如有的通过大型的圆钢管的内壁来拍工人的劳动场面,画面具有圆型的图案;的通过花枝的空隙来拍人物活动,周围就像装饰了一个美丽的花环。一些有规则排列的竹篱,曲折变化的回廊,具有图案美的窗框等都可以装饰画面。
⑦前景还有均衡画面的作用,比如天空无云显得单调时,用下垂的枝叶置于上方。有时画面下方压不住,就用山石、栏杆做前景,因色调深,使画面压住了阵角,达到稳定均衡。
⑧近年来,在前景的运用上,人们常常用虚焦点、杂乱的景物来作前景,虚而且乱,观众不但能够接受,而且还觉得有意思。这是由于人们对摄影艺术的审美趣味也在变化发展,越来越趋向自然,要求有现场的气氛。前景的虚和乱可以强调出这种现场气氛,而且前景的虚也有助于突出主题的实,以虚衬实。前景的乱也是要打引号的,事实上是乱中有治,形似乱,却是以不妨害主体突出为原则,如果乱得连主体也淹没了,恐怕观众就难以接受了。
以上谈的是前景的几种作用,当然,这是为叙述方便起见分开来谈的,事实上,前景的运用往往是同时起其中的几种作用,一箭数雕。适当运用前景可以丰富画面的“词汇”,增加画面的“文采”。但是,前景不可滥用,可有可无时,宁可不用,以求画面的简洁。另外前景的形状、线条结构要尽可能优美,与主体紧密联系和呼应,结成一个整体,帮助表达主题思想。
2.背景:
背景,是指在主体的后面用来衬托主体的景物,以强调主体是处在什么环境之中,背景对突出主体形象及丰富主体的内涵都起着重要的作用。一切造型艺术家都很重视背景的作用,雕塑、绘画、建筑等艺术都非常重视背景对主体的烘托。黑格尔在《美学》中说:“艺术家不应该先把雕刻作品完全雕好,然后再考虑把它摆在什么地方,而是在构思时就要联想到一定的外在世界和它的空间形式及地方部位。”罗丹曾点明将他的一尊小爱神的雕像放在花园里,让花园作背景来装饰它。法国一位有名大画家的朋友,想送自己的儿子到他那儿学画,朋友谦虚地说:“我的儿子没有什么才能,但可以帮你画画背景。”大画家听了幽默地说:“要是这样,就不是他向我学画,而是我要向他学画,因为我画画到现在,常常最苦恼的就是画不好背景。”从以上的事例可以看出,雕塑、绘画艺术家对背景重视的程度。摄影艺术家同样懂得,背景对一幅摄影作品的成败有举足轻重之势。往往有这种情形:拍摄一幅作品,主体、陪体、神情、姿态都很理想,但由于背景处理的不好而功亏一篑。
摄影画面的背景选择,应注意以下三个方面。一是抓特征;二是力求简洁;三是要有色调对比。
①首先要抓取一些富有地方特征、时代特征的景物作背景,明显地交代出事件发生的时间、地点和时代气氛,以加深观众对主题的理解。比如有意地将一些能标志出地方特征的对象保留在画面中,如拉萨的布达拉宫,西安的鼓楼,上海外滩的钟楼等。这样,用不着看标题,就知道事件发生的地方。另外,还要注意抓取具有时代特征的景物,使观众了解画面内容的时代背景。如用立交桥为背景来拍摄北京的事件,让人一看,便联想到这事件可能发生在进入八十年代的北京。用冒烟的火车头或工厂的烟囱作背景,在五十年代还是使人感到生产蒸蒸日上,祖国欣欣向荣的景象,能启发人们的审美感情。但如果在八十年代拍摄的工厂,仍然以冒烟的烟囱或火车头来作背景,就不会唤起人们的美感,反而使人产生有空气污染的忧虑。
有人拍摄人像很重视选取富有特征的环境背景来衬托人物的职业和性格特征,创造典型环境中的典型性格。画面上给背景留下足够的面积,选取一些足以产生丰富联想的景物来丰富人物形象的视觉语言,具有说明的象征的意义,有人称之为“环境肖像”。这种背景处理,无疑是象征性的。油画家汤晓铭画白求恩大夫肖像,背景是延安窑洞的土黄色,隐约地看到壁洞里的一盏小油灯。这盏小油灯便很能说明白求恩大夫所处的艰苦环境,没有电,自然也没有一切现代化的设施,但白求恩大夫精神饱满,乐观坚定,更显示出他伟大的国际主义精神。背景对衬托人物的性格,起了有力的烘托作用。摄影艺术同样应重视环境对人物的烘托。
背景的衬托有正衬、反衬之分,比如,幸福的儿童用鲜花盛开的花园作环境背景,是正衬;饥饿贫穷的儿童处在花花世界的繁华街道上,是反衬。
②背景的处理力求简洁。有人说过这样的话:绘画和摄影艺术表现手段的不同,在于绘画用的是加法,摄影用的是减法。在一般情况下,这话是有一定道理的。绘画反映生活总是给画面添上些东西,而摄影反映生活则总是千方百计地减去那些不必要的东西,而其中重要的是将背景中可有可无的、妨碍主体突出的东西减去,以达到画面的简洁精练。贪得无厌是失败之源,精简凝炼是成功之母。
仔细分析过许多摄影作品之后,就会发现许多有经验的摄影者都充分调动各种摄影手段以达到背景的简洁。有的是用仰角度避开地平线上杂乱的景物,将主要对象干干净净地衬托在空上;有的用俯角度以马路、水面、草地为背景,使主体轮廓清晰分明;还有的用逆光,将背景杂乱的线条隐藏在阴影中;有的用晨雾将背景掩藏在白色的雾霭之中;有的用长焦距镜头缩小背景范围,将不需要的背景景物排除在画面之外;有的用虚焦点柔化背景线条……。这些方法都可以收到简洁背景的效果。
③背景要力求与主体形成影调上的对比(在彩色摄影中要有色调对比),使主体具有立体感、空间感和清晰的轮廓线条,加强视觉上的力度。达·芬奇在《绘画论》中表达了这样一个塑造轮廓形状的法则:“你应当把那暗色的体态配置在淡色的背景上,如果体态是淡色的,那就应该把它配置在暗色的背景上。如果体态是有淡有暗的,那就应当把暗色的部分配置在淡色的背景上,而把淡色的部分配置在暗色的背景上。”这里揭示了绘画艺术的一条重要规律,即背景对主体形象的影调对比,是将所要表现的形象奉送于观众眼前的重要手段。所以,在摄影同行中也流传着这样一些处理背景的口诀:“暗的主体衬在亮的背景上,亮的主体衬在暗的背景上;亮的或暗的主体衬在中性灰的背景上;主体亮,背景亮,中间要有暗的轮廓线;主体暗,背景暗,中间要有亮的轮廓线。”大家在分析一些照片之后,就会相信这是必须遵守的。因为绘画和摄影都是平面造型艺术,如果没有影调或色调上的对比和间隔,主体形象就会和背景溶成一片,丧失被视觉识别的可能性。所以有人把画面影调色调的对比,比作运载手段,有了它,画面形象才会凸出来,送到观众面前。
背景的处理是摄影画面结构中的一个重要环节,只有在拍摄中细心选择,才能使画面内容精练准确,视觉形象得到完美的表现。
四、空白疏通气脉
摄影画面上除了看得见的实体形象之外,还有一些空白部分,它们是由单一色调的背景所组成,形成实体形象之间的空隙。单一色调的背景可以是天空、水面、草原、土地或者其它景物,由于运用各种摄影手段的结果它们已失去了原来的实体形象,而在画面上形成单一的色调,来衬托其他的实体形象。
空白虽然不是实体形象,但在画面上同样是不可缺少的组成部分。它是沟通画面上各对象之间的联系,组成它们之间相互关系的纽带。空白在画面上的作用,如同标点符号在文章中的作用一样,能使画面章法清楚、段落分明、气脉通畅,还能帮助作者表达感情色彩。下面具体分析一下画面空白部分的处理及其所起的作用。
画面上留有一定的空白是突出主体的需要。有经验的摄影者都有这样的体会,要使主体醒目,具有视觉的冲击力,就要在它的周围留有一定的空白。比如拍摄北海白塔,人们很自然地就将塔安排在明净的天空上,周围不与其它物体重叠,使塔轮廓清晰并具有吸引人们视线的力量。拍摄人物也总是避免头部、身体与树木、房屋、路灯及其它物体重叠,而将人物安排在单一色调的背景所形成的空白处。在主体物的周围留有一定空白,可以说是造型艺术的一种规律。因为,人们对物体的欣赏是需要空间的,一件精美的艺术品,如果将它置于一堆杂乱的物体之中,很难欣赏它的美,只有在它周围留有一定的空间,精美的艺术品才会放出它的艺术光芒。欣赏芭蕾舞剧会发现,凡是男女主角的精彩表演段落,群众演员都不在场,整个舞台空间都让位给主角表演。这样,舞姿的每一个细节,手臂的颤动,脚步的轻盈,就会和盘托出,拨动观众的心弦。如果满台都是演员,观众的感受就不会细致了。北京故宫的建筑也体现了这一特点。其空白布局,使建筑条理分明,严谨有序。其主体建筑太和殿周围留有三万平方米的空间,使它的雄伟气势更具有震撼人心的威力。摄影艺术的画面布局也应遵循这一法则,给主体周围留下单一色调的空白来突出主体。
画面上的空白有助于创造画面的意境。一幅画面如果被实体对象塞得满满的,没有一点空白,就会给人臃肿、压抑的感觉。画面上空白留得恰当,才会使人的视觉有回旋的余地,思路也有生发的可能。人们常说“画留三分空,生气随之发”,空白留取得当,会使画面生动活泼,空灵俊秀。空白处,常常洋溢着作者的感情,观众的思绪,作品境界也能得到升华。画面的空白不是孤立存在的,它总是实处的延伸,所谓空处不空,正是空白处与实处的互相映衬,才形成不同的联想和情调。比如齐白石画虾,几只透明活泼的小虾周围大片空白,没有画水,但人们觉得周围空白处都是水。建筑艺术也很讲究运用空白的布局,来创造某种意境。如北京的天坛,本是封建帝王祭天的场地,向天祈祷丰年,祈祷平安。所以这一建筑回绕这一意图创造了一种神圣的意境。天坛的占地面积比故宫大三倍,但建筑物只占全部面积的二十分之一,长长的通道,直达高高的台墀,一边是苍穹似的蓝色圆顶的祈年殿,一边是祭天的圜丘。那时,城郊再也没有比圜丘更高的建筑物了,周围一片空旷,白玉栏杆的圜丘,一层一层高出于凡尘之上,一层九级,拾级而上时,使人不觉有升腾之感,立在圜丘中央,似与天接,与苍天说话似乎也近了。可以想像,当年皇帝祭天之时,即使再昏庸,此刻也不能不慑于上天的鉴察,要为老百姓祈祷丰年了。古代的庙宇、佛塔,其造型都像升向天国的阶梯一般,映衬在空阔的蓝天之上,其建筑都是讲究意境的。各类艺术总是相通的,摄影艺术在经营画面的空白时,应从中吸收营养。
空白还是画面上组织各个对象之间的呼应关系的条件。不同的空间安排,能体现出不同的呼应关系。所谓呼应,总是由两个对象之间有一定距离构成的。如两个对象紧挨在一起,也就无所谓呼应,反而处于相对安静状态,互相之间的吸引也消失了。一切物体因形状不同,使用情况不同、线条伸展方向不同、光线照射不同等等情况,都会显出一定的方向性,有向背关系。要仔细体察物体的方向性,合理地安排空白距离,以组织其相互的呼应关系。古代画论说,画面应当做到“人有向背,物有朝揖”。就是指的画面上对象与对象之间要有联系和呼应,而这是靠一定的空白留取、安排来达到的。
空白的留取还与对象的运动有关。一般的规律是:正运动着的物体,如行进的人,奔驰的汽车等对象,前面要留有一些空白处,这样,才能使运动中的物体有伸展的余地,观众心理上也觉通畅,加深对物体运动的感受。如果运动着的物体前面顶住了其他的对象或紧挨在画面的边缘,运动就像受到了阻碍,观众看着也不舒服。人的视线也是一种具有运动感的力量,在人物视线的前方多留一些空白处,也是合乎人们欣赏的心理要求的。当然,这是一般的规律,在创作中常有例外。比如,行走的人如果强调其后面飘拂的头巾、衣裙,强调奔驰的汽车、马匹后面腾起的泥土烟尘,这时,后面留下的空间可以比前面多,那是因为条件有所转化。顶住画面边缘的人如果正回头往后看,后面的空白处就有了意义,画面也就不别扭了。总之,要善于灵活地、具有独创性地运用空白。
画面上的空白与实物所占的面积大小,还要合乎一定的比例关系,防止面积相等、对称。一般来说,画面上空白处的总面积大于实体对象所占的面积,这样画面显得空灵、清秀。如果实体对象所占的总面积大于空白处,画面重在写实。但如果两者在画面上的总面积相等,给人的感觉就显得呆拙,平庸,这是一个形式感觉的问题。对此,艺术家们常常有所突破,有所强调。我国古代画论说“疏可走马,密不通风。”也就是说在疏和密的布局上走点极端,以强化观众的某种感受,创造自己的风格。摄影画面上空白的布局也应创造性的运用,在只尺画幅之中变化出万千世界,或近或远、或疏或密、或虚或实,用心经营,使画面常出新意。我国老摄影家薛子江的《千里江陵一日还》,密密叠叠的山群,一线江流,画面雄浑。空白的留舍及空白处与实处的比例变化,的确是一项创造性的画面布局的内容。
五、整体力求均衡
在把画面的各个部分组成一个完整的整体的过程中,还要审度一下画面是否均衡。因为均衡是人们在长期生活中形成的一种心理要求和形式感觉。画面均衡与否,不仅对整体结构有影响,还与观众的欣赏心理紧密地联系着。现实生活中,一切稳定的物体都有均衡的形式,桌子四条腿是稳定的,如果三条腿则一定将它们形成均衡的鼎足之势才会稳定。盖房子如果下面小上面大,就给人一种不稳定的感觉,挑担子一头重一头轻时,支撑点只有偏向重的一头才会稳定。劳动中人们的姿态虽然变化着、运动着,但在变化中又达到新的均衡,形成劳动的节奏,如锄地必须前腿弓、后腿蹬,这是求得身体均衡以合乎这一劳动特点的姿势……许许多多的生活现象培养了人们要求均衡的心理,并且在人们的审美过程中起作用。
一幅画面在一般情况下应该是均衡、安定的,使人感到稳定、和谐、完整。但艺术作品的均衡不等于对称和平均。因为对称和平均虽然容易取得均衡的效果,但常常平板、呆滞,不能引起人们的兴趣。而艺术上的均衡应是变化中的均衡,和心理感觉上的均衡。比如有这样一幅照片:下方是一片空白,远处无任何景物,天空连一点云彩也没有。这样,上方就没有吸引人们视线的东西,显得下重上轻不均衡。相反,上方若隐约地显示出一座塔影,虽然面积小,影调浅,但它具有吸引人们视线的力量。因为人们在欣赏画面时,视线能由上至下移动流转。上下有了呼应,画面就能达到均衡。如果没有塔影,而是两只小鸟在飞翔,同样也可起到均衡画面的作用。远方塔影或小鸟的地位,就叫补白的地位。
利用人们要求均衡的心理因素,可以从几个方面来加强画面的表现力。如强调一种庄重、肃穆的气氛时,则要求画面均衡平稳,甚至有意地采取对称式的均衡,从四平八稳的对称均衡中显出一种古朴的庄重的美。如拍摄中国的古建筑、庙宇、庄严的会议全景等等,常有意地运用对称的均衡形式。在一些强调幽雅、恬静、柔媚的抒情性风光画面及生动活泼的人物、情节画面中,要求的是变化中的均衡。画面上可以有疏有密,有虚有实,但整体的感觉应该是均衡的。如果画面有不均衡处,则会成为明显的缺点,甚至招致失败。
均衡还可以从另一方面来加以运用。即有意地违反均衡的法则,使画面从不均衡中造成某种动荡感,像受到外界冲击一样。如有些表现滑雪、冲浪等运动的画面,常常采取对角的斜线,整个的线条都向一方倾倒,使观众感受到强烈的动感。看上去很不均衡,但是它突破了一般的构图原则。仔细分析一下,作者正是在对一般构图法则的深刻理解的基础上,大胆地利用不均衡的变格形式来深刻地表达主题的。
六、正确选择拍摄点
所谓拍摄点,是指照相机与被摄对象之间的空间位置。它包括拍摄距离、拍摄方位和拍摄角度。
拍摄点的选择,是摄影构图学中的一个重要问题。我们都知道,摄影创作离不开构图,就象文学写作不能没有章法一样。摄影创作的对象不外乎人、景、物,摄影构图就是要处理好人、景、物在照片画面中的布局和相互关系,借以表现作品思想形象的本质,披露作品的内在含意。在摄影构图的诸因素中,拍摄点的选择是首当其冲的,拍摄点选择得是否妥当,是直接影响摄影构图优劣的重要因素。摄影画面的布局与构成,主要是由选择拍摄点来完成的。
当我们选定了拍摄对象之后,照相机与被摄对象之间的距离、方位和角度,是决定着所摄照片画面性质的三要素。其中,距离是一个基本要素。一般来说,照片画面形式的一般特征是由景的大小决定的,距离之远近与景之大小有直接关系;方位和角度的功能,则在于更好地描绘和表现被摄对象的基本特征,使之更富有生气和魅力。
1.拍摄距离
拍摄距离,是指拍摄点与被摄对象之间距离远近变化的关系。拍摄距离的选择,体现在照片画面上就是景别的变化。通过距离的远近变化,来确定景物形象的大小以及所包含的空间范围。通常所说的景别包括远景、全景、中景、近景、特写。在摄影创作中具体选择哪一种景别,是由摄影者根据被摄对象的性质所产生的艺术构思和立意来决定的,其目的在于更鲜明地表达主题内容,更生动地表现对象特征,更完美地创造新颖的构图形式。
使用同一焦距镜头的照相机,由于拍摄距离的变化,产生了远景、全景、中景、近景、特写等不同的景别。现分述如下:
①远景
距离被摄对象远处拍摄,它包括的景物范围大。远景主要以大自然为表现对象。古代画论说“远取其势”。远景总是以自然的气势取胜,表现地形特征,地理位置,山川形势及气候变化所产生的环境氛围等等。因此,结构远景画面,要从大处着眼,注意整体气势,处理好大自然本身的线条,如山岳的起伏、河流的走向、田野的图案、沙漠、海洋所特有的色调和线条等,并且要善于运用各种流动的因素,比如大气的状况,云彩的变幻,风雨阴晴,它们都是远景画面中动人的因素。
②全景
以表现某一个被摄对象的全貌和它所处的环境为目的。全景用来交待事件发生的环境及主体物与周围环境的关系。与远景比较,全景有较明确的内容中心。全景范围的大小总是与主体对象有关,是与主体对象的大小相对而确定的。比如人和其所处的室内的全景,自然要比人民大会堂的全景范围小得多,但它对主体事物来说都是以全景来称呼。结构全景画面,主要考虑环境与主体物的某种关联,注意主体整体的固有特征的轮廓线条,主体与周围环境的呼应关系。以达到内容上的丰富和结构上的完整。
③中景
目的在于表现某一事件或对象的富有表现力的情节性和动作性强的局部,表现事物矛盾的焦点,人与人之间的感情交流和联系等。中景常常以动作情节取胜,环境降到次要地位,如果是静的物体,也总以该对象中最有趣味,最引人注意的部分,如人民大会堂的中景,可能是突出正门的一排有气势的廊柱。中景人物中,手势动作常常是画面中的主要部分。
④近景
近景主要用以突出人物的神情或者物体的细腻的质感。“近取其神”、“近取其质”都说明了近景表现的特点。人物近景,面部表情是画面的主要内容,眼睛成了画面的中心部分,所以近景要处理好眼神光,以眼传神。近景拍摄物体时要运用好光线,表现好物体的纹理、质地。
⑤特写
较近景更进一步,把对象的某一局部充满画面,从细微处来揭示对象的内部特征。较之近景,特写更重视揭示内在的动感,通过细微之处看本质。拍摄特写,成功的关键在于独具慧眼的观察力,能抓取一些值得特写的局部,以打开观众窥见事物内在的窗户。比如人物的眼睛常常是特写的内容,因为人们常说眼睛是心灵的窗户,的确,通过人的眼睛,可以窥见人物的内心感情。其次特写人的手,手是一个人行为和动作的焦点,能看出人的职业、年龄等特征。手还有丰富的“表情”,戏曲行话中说:“指能语”,日常生活中人们就常常运用各种手势来帮助表达感情。特写雪枝下的一朵小迎春花,春天的一株小草芽,夏日的一朵荷花,秋天的一片红叶,都能给人以生命的欢悦,比其他的景别更容易触动观众的心弦。所以,特写常常富有寓意性和抒情性,较为含蓄,能启发人们的想象力。
景别的确定是摄影者创作构思的重要组成部分,景别运用是否恰当,决定于作者的主题思想是否明确,思路是否清晰,以及对景物各部分的表现力的理解是否深刻。比如,拍摄芭蕾舞演员的舞姿,若不远不近恰恰去掉舞蹈者的足尖;拍精心检验产品,而手却不在画面之内;需要强调神情又远得看不清面目;需要强调气氛的没有给予舒展的空间等等,都是思路不清的毛病。至于有些人事先不构思好景别的运用,往往先拍下来再说,需要中景、特写靠放大后再剪裁,这就是不了解拍摄距离对画面形象的质量和表现力的影响。要保证完美的画面质量,景别的确定要尽可能在拍摄时一次完成。
2、拍摄方位
拍摄方位,是指拍摄点与被摄对象之间在同一平面上的对应关系。
以被摄对象为中心,在同一水平线上的三百六十度范围内,任何一个方位都可以作为拍摄点。不同的方位有各自不同的方向,不同的方向能获得不同的画面结构。
拍摄方位的变化,体现在照片画面上就是构图形式的变化。通过方位的选择来确定被摄对象在画面中的结构方式,使主体、陪体与背景三者有机地结合起来,使构图形式更富有表现力和感染力。
由于拍摄方位的变化,产生了正面构图、侧面构图、斜侧面构图、后侧面构图和背面构图等不同的构图形式。
①正面构图
照相机的方位正对着被摄对象的正面拍摄,即产生正面构图效果。这种构图形式在国画中称为正局。
正面构图,能够清楚地展现出被摄对象正面的形象特征,让观众可以看到正面的全貌。在这种构图中,被摄人物占据画面的中心部位,面对着观众,似乎可以通过眼神、表情和姿态与观众产生交流和联系,具有吸引力和亲切感。被摄景物则可表现其对称的风格特征。假如用正面构图拍摄天安门,许多平行匀称的线条,构成一种平稳、凝重的感觉,以国徽为中心,左右两侧完全对称的建筑风格,在构图中更加强了均衡的效果,让人产生一种肃穆、庄严、稳定的视觉印象。在新闻摄影中,每当报道代会或人大会议时,常采用正面构图来拍摄大会的正面场景,往往以俯摄角度表现主席台上的横幅会标和众多的与会者,突出体现会议的庄严隆重气氛。
在人像摄影中,对于那些五官端正、面部结构正常的人物形象,可以采用正面的方位拍摄。正面构图的形式能够塑造端正脸型的正面特征,通过眼睛的神情和面部的表情来揭示人物的内在性格特征。拍摄正面人物肖像,除了选择面部形象正常的被摄对象以外,还要注意处理好被摄对象的姿势和手势,使双手处于合理的位置。在拍摄时要准确地抓取人物面部的细微表情,这种神情往往是通过眼神来传递和流露的。
任何构图形式都有其长处,也有其不足。正面构图的缺陷和不足之处有三点:其一,容易给人一种呆板、缺乏生气的印象;其二,画面中的各种平行线条难以产生透视效果,不易表现空间深度;其三,画面是平均地展现正面的各部位,不易使主体突出。这种构图形式不适于表现活泼气氛和富有运动性的主题。
②侧面构图
照相机的方位与被摄对象成90度角拍摄,即产生侧面构图效果。这种构图形式在国画中称为偏局。
侧面构图,能够明确地表达出被摄对象的侧面形象特征,适于表现人物或景物的侧面轮廓效果,使整个画面结构具有明显的方向性。在拍摄某些运动中的被摄对象时,能够加强活跃、动荡的效果。例如在体育摄影中表现运动员跑步、跳跃和赛车赛马等运动项目,侧面构图可以产生强烈的动感,具有你追我赶的动势。
在人像摄影中,运用侧面构图可以塑造被摄对象的侧面轮廓形状。凡是侧面形象比较端正的人物,均可采用侧方位拍摄,表达其侧面的某些特征,表现侧面轮廓形象的健美或秀美。拍摄侧面人物肖像,除了那些五官端正、侧面轮廓线条富于变化的人物之外,尚有少部分面部形象不够端正,或脸面左右存在某些缺陷的人物,可以运用侧面构图来掩饰有缺陷的部分,美化人物形象。
侧面构图的缺陷和不足之处是:运用侧面方位拍摄某些建筑物或其他物体,由于只能表现侧面的特征,同样产生了正面构图的某些缺陷,侧面的一些平行线条也难以产生汇聚,使主体物的透视效果大为减弱,这是其一;其二,由于只能看到侧面特征,正面的主要特征难以表达,构图容易流于散漫和不集中。这种构图不适于表现平静、严肃的主题。
③斜侧面构图
照相机的方位处在被摄对象的正面至侧面之间的某点上拍摄,即产生斜侧面构图效果。
斜侧面构图,既能表达出人、景、物各种被摄对象正面的主要特征,又能展示侧面的基本特征,实际上是表现了被摄对象的“两个面”,使构图形式生动活泼,富有立体感。在这种构图中,各类线条均按一定的方向由近而远汇聚,具有明显的方向性,有利于加强空间纵深感和表现物体的立体感。运用斜侧方位拍摄,将画面中的主体、陪体、前景、背景等配置适当,可以产生强烈的透视感,增加景物的层次,使构图清新活泼,富有生气。在某些情况下,把主要的被摄对象置于线条透视的会合处,虽然主体占据了较小的面积,并处于画面的深处成为一个“点”,但是观众的视线却能够随着透视的变化而落到这个“点”上,这种最引人注目的点,通常称为视点。
在摄影创作实践中,由于广大摄影者充分认识到斜侧面构图能够加强立体感,富有层次和透视感,易于突出主体的特点,所以采用斜侧方位进行拍摄者居多。运用这种构图形式所创作的优秀摄影作品举不胜举。
在人像摄影中,采用斜侧面构图和侧逆光照明,可以使被摄对象的正面和侧面的“两个面”形成鲜明的明暗对比。使人物五官中的眉、眼、鼻、嘴各部位的线条产生透视变化,更加强了人物的立体形象,能较好地表现人物面部的皮质感。同时,斜侧面构图还能够使人物所处的环境特征得到适当的表达,用环境的空间深度、明暗对比、虚实变化来烘托主体对象,使人物形象更加鲜明突出。在拍摄人物肖像时,可能会遇到个别人物的两只眼睛或两只耳朵大小不一样,在这种情况下,可以采用斜侧方位来拍摄,把眼睛较小的一侧靠近照相机镜头,依赖镜头的近大远小的透视变化,使两眼大小不一的缺陷得到适当纠正;至于两耳大小不一,则可将一只有“缺陷”的耳朵“隐藏”在观众所看不到的背侧面,在画面上只出现一只耳朵,观众就会感到一切都是正常的。拍摄人像时,要尽量调动各种艺术手段来塑造和美化人物形象。
④后侧面构图
照相机的方位处于被摄对象的侧面至背面之间的某点上拍摄,即产生后侧面构图效果。
后侧面构图,是表现被摄对象背面和侧面某些特征的一种构图形式。它与斜侧面构图的拍摄方位正好相反,所类似的是同样表现了被摄对象的“两个面”,立体感较强,各类线条也与斜侧面构图一样具有明显的方向性和透视感。这种构图形式大多用于表现人物的背部特征,或以人物后侧面作为前景来展示环境和背景特征。
在人物肖像摄影中,有时为表现人物的背面和侧面的某些特征,常采用后侧方位来拍摄。例如表现某些少数民族的服装头饰,运用后侧面构图形式,既可清楚地表达人物头部和背部的一些精美图案的色彩效果,又可看到人物侧面的基本形象。
⑤背面构图
照相机的方位处于被摄对象的正后方,对着被摄对象的背部拍摄,即产生背面构图效果。
背面构图,能够表现被摄对象的背部特征,通过背面形象来表达作者艺术构思中的含蓄意念。
利用背面构图形式所创作 的优秀摄影作品并不少见。在这类作品中,通常是以人物的背影姿态作为前景,透过背影看到远景环境或背景特征。例如前苏联摄影艺术作品《未来的船长》(加利娜·桑科摄影),表现两个孩子站在岸边,凭栏眺望远处起航的巨轮,向往着将来能成为扬帆远航的船长。这幅作品的构图方式是以两个孩子的背影为前景,由深黑色的前景影调透视到远处朦胧中的船只,形成了较强烈的影调对比,远景与近景之间的虚实对比,产生了以虚托实的效果,有利于主题的表达。
选择不同的拍摄方位,产生不同的构图形式,都是作为摄影造型的表现方法而存在的。从理论上讲,不同方位所构成的构图形式均有其自己的特点和缺陷,但不能因此而主观武断地给各种构图形式打上优劣的印记。任何一种构图形式,只要它与某些被摄对象特点相结合,充分发扬其特点而避免其不足,能够深刻地揭示主题思想,并给人一种美感,即可称之为优良的构图形式,且有可能成为优秀的摄影作品。
3、拍摄角度
拍摄角度,是指拍摄点与被摄对象之间的水平线高度的变化关系。
拍摄角度的选择,体现在照片画面上就是地平线之高低和被摄对象平面结构的变化。通过角度的选择来确定拍摄方位在垂直线上的高度,以适应塑造主体形象和表达主题思想的需要。
在日常生活中,当我们观察处于不同高度的各种物体时,常采用的方法不外乎三种:等高的则平视,较高的则仰视,较低的则俯视。如果对同一物体采用平视、仰视、俯视来观察,则可看到垂直面、底面与顶面三种不同结构的立体效果。如果在同一环境中拍摄同一个人物的肖像照片平视角度可以表现人物的正常脸型,地平线处于人物头部以下的适当位置,背景是天地各半;仰视角度以天空为背景,表现人物形象的高大,地平线则被压低到画面以外;俯视角度自头部向下产生透视,显得头大身体小,地平线升高到画面上端,以水面和地面作为背景。
将生活中以不同的高度观察物体的三种视觉现象,应用到摄影创作实践中,就形成了平摄角度,仰摄角度和俯摄角度三种造型效果。
①平摄角度
拍摄点与被摄对象于同一水平线上,以平视的角度来拍摄,这种角度称为平摄角度。
平摄角度所构成的画面效果,接近于人们观察事物的视觉习惯,它所形成的透视感比较正常,不会使被摄对象因透视变形而遭到歪曲和损害。因此,这种平摄角度的表现方法在摄影实践中应用最广泛,运用起来比较快捷方便。
在人像摄影中,凡属身份证、工作证所用的半身免冠照片,均应以平摄角度和正面构图来拍摄;其他肖像照片,运用平摄角度也居多数。凡是人物面部结构比较正常者,通常应采用平摄角度,它可以使五官端正的脸型得到较好的表现。这种角度所拍摄的人物肖像,容易引起与观众之间的情感交流,有一种平易亲近的感觉。
平摄角度的拍摄方法,适于表现具有明显线条结构或有规则图案的物体,不致因透视变形而损害线条和图案的正常结构。凡是翻拍一些平面的文件资料之类的东西,均需采用平摄角度来拍摄。
平摄角度的缺陷和不足之处是往往把处于同一水平线上的前后各种景物,相对地压缩在一起,缺乏空间透视效果,不利于层次感的表现。
②仰摄角度
拍摄点低于被摄对象,以仰视的角度来拍摄处于较高位置的物体,这种角度称为仰摄角度。
仰摄角度的视平线较低,如果以仰摄角度拍摄室外的各种景物,可以在照片画面中造成很低的地平线或水平线,使杂乱的背景掩盖在较低的地平线以下,天空作为背景占据了画面中相当大的面积,前景高大,主体突出,能够改变前后景物的自然比例,产生一种异常的透视效果。
在体育、舞台摄影中为了强调表现某些运动员和舞蹈演员的跳跃动作的高度,采用拍摄点较低的仰摄角度极为有效。这种低角度可以把被摄对象有限的跳跃高度极大地夸张,形成一种展翅凌空的视觉效果。
用仰摄角度拍摄某些竖立的物体和高大的建筑物,可以收到挺拔直立、刺破青天的效果;拍摄有人物活动的某些场面,能够获得朝气蓬勃,升腾向上的效果。
在人像摄影中,仰摄角度不仅可以突出表现人物形象之高大,还可以纠正和弥补某些脸型上宽下窄或下巴以及口型比例过小的缺陷。
运用仰摄角度拍摄,仰角之大小,与距离的远近有关,距离愈近,仰角愈大;距离愈远,仰角愈小。根据不同被摄对象的具体情况,选择适当的仰摄角度,才能增强摄影构图的表现力。如果仰摄角度运用不当,容易产生严重变形或使直立的物体向后倾倒。这样的构图效果,将损害被摄对象的正常形象。
③俯摄角度
拍摄点高于被摄对象,以俯视的角度来拍摄处于较低位置的物体,这种角度称为俯摄角度。
俯视角度的视平线较高,如果以俯摄影角度拍摄带有地平线的景物,地平线往往被置于照片画面的上方,地面景物占据画面中的绝大部分,天空常常只占一线的位置。在有些情况下,俯摄角度较高时,整个画面全部被地面所占据,天空和地平线在画面上完全消失。在俯摄角度所拍摄的画面中,主体人物或景物与广阔的空间相比,显得渺小。犹如登上泰山极顶,环顾四周,有“一览众山小”之感。
“欲穷千里目,更上一层楼”。要想在照片画面上表现更广阔的场景,就需要尽可能升高拍摄点。当拍摄点升高到空中时,即通常所说的航空摄影,简称航拍。航拍所构成的画面,可以使远近景物在照片中由上至下有层次地平展铺开,最大限度地表现自然的空间感,能够清晰地交待总体环境和地理位置的完整概念。航空摄影所形成的俯摄角度,一般称为鸟瞰。
俯摄角度适于表现规模和气势,能富有表现力地展示巨大的空间效果。它适于表现辽阔的原野、大规模经济建设场面以及群众集会壮观的宏大场面等等。在体育运动和文艺表演中,常常用俯摄角度来展现优美的图案效果,或以净化的背景衬托被摄对象形体姿态。
在人物摄影中,俯摄角度应用不当,会对人物的形象起到丑化作用。一般来说,不宜用过大的俯摄角度拍摄面部结构正常的人物肖像。在特殊情况下可以例外,个别脸型上窄下宽的人物,用俯摄角度拍摄,利用近大远小的透视变化,可以适当纠正和弥补脸型上的缺陷,获得面部结构正常的效果。
拍摄角度是依据拍摄点的高低变化而产生的,不同的拍摄角度具有不同的表现力。在摄影实践中,要依据被摄对象的形象特征,根据摄影者的创作要求,来选择运用各种拍摄角度,创造出富有表现力的艺术造型手法和理想的构图形式。
“横看成岭侧成峰,远近高低各不同”。选择拍摄点不能离开距离、方位、角度三要素,这三个方面相互之间既是互相制约,又是相辅相成的。正象大文学家苏东坡的妙句中所概括的那样,对任何景物采用“横看”或“侧看”,以不同的“远近”或“高低”来观察,均可以得到“成岭”或“成峰”的“各不同”的印象。在摄影创作中,选择不同的拍摄点,所形成的照片画面的构图形式是千变万化的。在这“万变”之中,有一点是不变的,即拍摄点的选择必须符合客观实际的需要,必须符合摄影者的创作意图。只有这样,作者对客观世界的体验、认识、评价和感情色彩,才能够通过恰当的拍摄点所形成的新颖的构图形式表达出来。
最后,我们可以得出这样的结论:优秀的摄影作品取决于鲜明的主题和完美的构图形式;完美的构图形式取决于拍摄点的选择;理想的拍摄点取决于三要素:距离、方位、角度。
posted @
2005-10-27 13:18 rkind 阅读(153) |
评论 (0) |
编辑 收藏
因此,本文谨真诚的献给那些不了解BBE和SRS WOW音效有什么不同却又企图将它们分出个高下的玩家。
大家所说的,现在市面上销售的MP3播放器所用的SRS音效,并非SRS音效的全部,而是其中一种:SRS WOW,它由SRS, TruBass和FOCUS组成。
官方对WOW的描述如下(受英语和音乐两方面水平所限,翻译难免有错漏之处,请指正):
WOW可以突破小型扬声器和耳机的固有局限,通过提供3D音频图象在水平及垂直方位上扩展声音使其超越器材本身的能力。这样,小型音频设备,电视,无线和个人/便携产品的制造商不用增大扬声器尺寸便可显著改善其产品的声响效果。特别在诸如MP3,WMA和音频CD这些经数码压缩使空间感被极大削弱的单声道或立体声音频格式上,WOW的修饰效果尤其显著。
SRS: SRS能恢复被传统录制和播放设备掩盖住的空间信息。通过将立体声信号分解为多个部分,它可以分离并恢复空间信号或原始录音所呈现的环境信息。 并且把它们放在直接声音的正常空间。这些空间信号被专利幅频响应校正曲线所处理。这样,再现的声音会非常接近艺术家最初设想的那种现场效果。SRS没有所谓的最佳听音位置(sweet spot),因此,音乐和声音好像充满了房间,使听者完全处在全三维声音包围中。
TruBass: TruBass是一种SRS专利技术,运用人类声音心理学专利技术来增强低音性能。这些技术能利用原始音源中表现的和声再现低频信息。恢复基本低频音调的感觉 - 即使该信息低于扬声器和耳机的低频极限。因此TruBass可以呈现出比小型、中型和大型扬声器和耳机的低频极限还低八度,并且深邃丰富的听感。
FOCUS: FOCUS通过提升声场来生成声音图象的高度感。当于SRS 3D结合时,FOCUS会放大声音图象,产生一个非常高广,最佳听音位置(sweet spot)宽广的声场。另外,FOCUS能改善高频通透度让听者沉浸其中。在扬声器低于音场的产品中,比如内投影电视或固定在门板上的汽车扬声器,FOCUS将可用电子学方法调节重新将声场定位于听者前方的最佳位置上。
注:
最新iriver T10上SRS WOW效果中有一项BOOST,在SRS lab官方网站没有找到相关信息,不知道这是不是网站没有及时更新的原因。根据字面意思理解,其作用应该是多种效果的整体提升。
________________________________________________________________________________________
同样,iAudio所用的BBE音效也并非BBE的全部,而是其中的BBE、BBE Mach3Bass、BBE MP三种。
网上有相当详细BBE和BBE MP的技术说明,也是来自官方网站,可以到这里查看:
http://mp3.zol.com.cn/2005/0224/152039.shtml
不过原文没有,网上也找不到BBE Mach3Bass技术的说明,我翻译了这段说明按顺序放在中间。另外两个仅稍作介绍。
BBE系统具有两个基本功能,其中之一是调节低、中和高频相位之间的关系。第二个功能是增强了高频和低频信号。此外,BBE还具有静噪功能。BBE电路内部设有噪声门和高截止滤波器,能对输入的杂散信号进行衰减。
BBE Mach3Bass用电子学方法扩展特定扩音器的低音响应并能精确调整需要的低频极限。在世界知名的BBE处理相位误差校正技术的帮助下,BBE Mach3Bass可提供比标准低音提升电量更深,更密,更精确的低音频率。BBE Mach3Bass不影响中低段声音,否则会在中低频段产生混浊并改变角色的嗓音。
BBE MP (最小化多项非线性饱和)技术通过数字压缩复原和增强谐波损失,进而提高经数字压缩处理的音频(如MP3)音效。BBE MP从原始资料中复原声音,因而有效地恢复声音的温暖感、细腻感和细微差别。BBE MP可将声级平均提高3个分贝,同时保持峰间摇摆不变。由于声音输出高出3个分贝,信噪比也相应地得到了改善。
________________________________________________________________________________________
通过上面技术描述的对比可以发现,虽然都可以提升低音,但两者对音乐的实质影响是完全不同的,SRS WOW带给音乐的改变是在空间感方面,就是听上去感觉声音范围更大了,而BBE提高声音的清晰度,整个声场强度都上了个台阶)
这篇《音效之后-BBE》中有同一段音乐经两种不同音效处理后的效果演示。
http://www.easydigi.com/news/2004/12/13/news_514.htm
其实我费了好几天劲只是把SRS WOW的全部和BBE的部分技术描述翻译出来而已,看不懂的朋友知道这两种音效没有可比性就可以了
posted @
2005-10-27 13:18 rkind 阅读(276) |
评论 (0) |
编辑 收藏
耳机(耳塞)可以说是发挥CD音质的一最后一道门槛,耳机搭配的好与坏,直接影响了CD最后传达到耳朵中音乐的质量,但是大家在搭配耳机(耳塞)的时候往往注意的更多的是音质与材料,忽略了产品的外形,是否和所拥有的机器搭配,俗话说夫妻和睦,看是否连像,所以我今天以个人使用随身听的经验来给CD乱点一次点鸳鸯(剥大家一笑,也希望个位能够愉快)。
START
既然这里是IMP3.net论坛 cd播放器主论坛,我们就以CD Walkman现在主流的CD随身听来说明,老机器我就不多费口舌了,也为即将配机,选耳机(耳塞)的兄弟姐妹们参考之用,但是内容是否能入个位法眼,我心里没有底。首先谢谢观赏。
对于现在主流的CD随身听,大家都心里有数,iRiver的iMP-550 IMP-900 松下panasonic的CT-700 CT-710 CT-720 CT-800 CT-810 CT-820 CT-905 CT-910 SONY的 d NE-D10 d d NE-900 d NE-20 d NE-920 等这次,我要讨论的就是这几款机器他(它)们的另一半,不光是音质,在外形上也要追根问底。
OK先以(非)日货的机器来说,IMP-900的外号“宙斯盾”但是我感觉IMP-900外形可以说是与sony公司的d-NE系列机器有一拼,很另类的感觉一个倒立门形的机器,左上叫本咬了一口,(呵呵,我的形容也够另类的了,低头挨众FAN拍砖)但是在机器上的表现,有着诸多的不近如人意的地方,外形太另类,边角容易摩擦,出现边角、漆面、过早脱落,但是瑕不掩玉,采用菲利普的芯片,对音质的提高,有很明显。收音功能更加稳定等,优点不多说了,不然就不是CD配耳机了,改成随身听评测算了,

!IMP-900搭配的是深海塞尔的mx400耳塞,在声音效果上算是很到位了,但是这个耳机还是无法在多元化的音乐方面有所突破,所以我们来找找有什么更突出的耳机(耳塞可以搭配)所以我感觉搭配音KOSS KSC35原因是,音质细腻、逼真,低频强劲动感强劲。同时可以很好的避免了900在播放暖音色是出现的明显底噪音,同时在外形上KOSS KSC35的样子也是如此的另类感觉想挂在耳朵上一个车轮子一样(低头哎KOSS KSC35FAN的砖头),另外KOSS KSC50 也是非常好的选择,外观时尚,坚固耐用。一个耳机银色,一个机器黑色亚光也是非常不错的。



iMP-550 对于使用过这部机器的人,他的特性,应该比我知道的很详细,这部机器的音色、优点在于“音色效果适合听POP类、金属类这样高频比较突出刺激,动态比较大的现代音乐作品。”机器本身搭配的耳机是深海的MX-300“这个耳机的优缺点就是音场偏紧,中频,有些瘦,低频,量感少,容易出现音色混浊。(相比其他的耳机来说的,例如H100,MX500来说)这个效果肯定是无法来满足imp-550的需要了,在外形上也无法来满足IMP-550的要求,本身这部机器就是一款强调浑源一体的,在机器上没有一个按键,全部的功能按键都是在线控上我们应该来搭配什么样子的耳机才可以体现出这个呢,本身机器的颜色提供了两款(银边黑面款和全银色款两种)所以我们来找什么样子的耳机(耳塞)是银色,黑色结合的,可以体现出这个特点,我认为既然在机器搭配的时候使用的深海塞尔的品牌我们就着手相同的品牌耳机(耳塞)来下功夫,初步的选择是同厂家的PX100,PX200这两款耳机是深海家族中很有历史的耳机,同时这两款耳机,也是个有胜长,例如PX100是很在古典上面有优势,特点是低音超强,中音不错,高音略有不足,PX200是在流行,轻音乐等方面相当的流畅,比PX100 表现力更强。但是因为耳机的使用材料上有所不同,价格方面也有所区别。所以选择那个就是看你的欣赏方向来定了(这个不是因价格来选择的)。





不得不进入的领域日系机器,现在在小家电方面,是无论如何也不回避日系产品的,虽然在中国,也在开始萌发了小家电的研发生产,但是毕竟还是比较晚的起步。在日本cd领军人物非sony,开创walkman领域的创始者,和日本家电之王的松下panasonic电子公司,松下在现在的随身听领域可以说是少数几个可以和sony公司抗衡的。(另外如日本夏普,日立,东芝,荷兰非利普,韩国艾利和iRiver但是因为这些公司在产品规模上,响度比较少,所以还是以cd领域,松下,艾利和公司的为主)。
松下公司的cd产品无论在质量和类型方面都是不压与SONY公司的,即使在今天此公司也先后推出了panasonic的CT-700 CT-710 CT-720 CT-800 CT-810 CT-820 CT-905 CT-910 等型号的主流机种,不得不让人对此公司的研发能力刮目相看,好了不说废话了,进入松下配机话题。
首先是CT-700,作为低端机型来说本机器是对音质要求不高,对价格比较苛刻的用户所拥有的机型,所以我推荐的是定位于时尚,来配的,其他的就不说了,作为低端机器,不能避免的就是使用材料的主要原因,此机器全机使用工程塑料,但是因为在颜色方面的丰富,很受女性消费者,和流行性消费者的喜爱,所以一般搭配的耳机在价格方面要严格的把关,同时在外形上面一顶要突出时尚主题来。主要面向的就是SONY的众多耳挂式,SONY的MDR-NQ1时尚耳机,特点,中高音表现更好,低音沉重,很好的中和了松下机器在低音方面的优势。





CT-710是松下公司对ct700的一种改进在原有基础上进行了大方向的改革,加入了D.SOUND放大技术的同时在原有S-XBS、火车模式加入了S-XBS+模式使得在音效均衡方面给了用户更多的选择。但是因为是以低端机器来改革的,所以在音质方面来说还是很捉襟见腹的,所以在音质提高来说还是很局限的,例如在声音方面还是有些浑浊,不清,高音方面还有和费劲的提高,中频来说还是很松下的(比较饱满)。所以以机
器的样子,音质定位,推荐的耳机,在上面的基础上.


CT-800相对于ct710来说虽然没有710型号来的新,但是在音质上的提高,才是松下本色的一种体现,多了对WMA的支持,可以说让得到用户更多的选择权,声音的改进,使用材料的变为机盖更加的坚固,等等的优势,可以说才体现了高端松下CD的品质,在声音上虽然,没有+S-SBX,但是在声音上即使是使用了D.SOUND放大技术的后续产品CT-810也是不遑多让的。所以推荐的耳机(耳塞也是非常的要考究的)因为使用这款机器的用户是很对音质考究的,不是简单的时尚就可以敷衍的,现在定位的耳机方向是以SONY的 E868,E888,耳挂铁三角的EHT-EM7,耳机以深海塞尔的PX100,(主要是体现松下机器的古典音乐对应)PX200(主要是补偿松下机器的对流行音乐,爵士,等音乐的缺陷)。来体现的,推荐这几个耳机的原因是在E0868可以说是SONY当时来说尽次于E888的地位,在各方面都体现的很完美,当然了现在的E868感觉是有所退步,同时不想E888的古典等方向的单一,来说说推荐使用EHT-EM7的原因,主要是体现在特三角耳机的声音细腻,低音很有烘托感,可以很好的表现出ct800的相对其他松下机器的冷色调来说。耳机推荐的原因就不用多说了,推荐于iMP-550的时候就说的很原因。




CT-800 CT-810 CT-820 CT-905 CT-910,对于这个机器其实应该不用在多说了,在论坛这部机器可以说是一个神话了,在各个方面都体现出松下对机器的全方位的追求所以在很多的时候,个位买的耳机搭配,在很多的时候,都是很体现机器的多样化的步调。低调的MX500RC,中掉的E888,CM5,CM7,高要求的A8,等等,都是这个机器的搭配主流,但是我认为,还是以银色的机器搭配E800的方式更为经典,同时在耳机方面px100,px200都是存在或多或少的缺陷与优点同在的配制,对于CT-820来说,因为在机器的设计方面来说基本是以ct810电路来进行改良来进行的,所以在细节方面有些不同的地方来说,基本是相同的产品唯一改良的地方是D.SOUND放大技术增加了3D+与3D-音效有增加了用户对音乐方向的调整,与选择所以在耳机方面,可以延续810的设计思路。对于说一在音色方面对于CT-905 CT-910来说,因为在机器设计上的另类,所以关注的也是不差于ct810,ct820的关注程度。整体来说CT-800 CT-810 CT-820 CT-905 CT-910是在一个成次面上的机器,在搭配耳机的时候,注意个人音乐方向,机器颜色,样子在搭配就可以说是很容易的选择。

sony的机器,在随身听领域特别是作为cd格式创作者之一的身份,以大贺为首的艺术,技术,等等因素结合来生产的产品的CD Walkman已经成为了,一个神话,成为了牛津词典的标准用词。在一系列经典机器的诞生中,一次又一次的出现的名门,不光是机器,连搭配的耳机也是经典的一个。所以成为在提到CD Walkman 的时候无论如何也无法忽略的存在。
NE-10 NE-900 NE-20 NE-920 作为2003-2005这段时间里的旗舰,次期间机器来说无论是外形,功能,都是一个张扬个性,体现音质的典范,在选择耳机的时候一般是以SONY原厂耳机为首其他厂家耳机为补进行说明。
NE10作为SONY首个瓷盆样式设计的产品,在多个方面产生了,第一的机器,有的时候根本是无法用语言来说什么的,当然这样的设计有的时候得到的是有人喜欢有人不喜欢的下场,在音色上,将sony的声音体现得很完美,但是对于SONY的低频来说,还是薄弱,解决的不够彻底,所以在估计颜面,和声音的时候,尽量选择一些可以补偿的耳机(耳塞来代替),一般使用的,我们可以选择EM7,在ne10黑色款上,体现的尤为完美,一样的拉丝工艺,配合上ne10上面的一小快拉丝面板,更显高贵,ne900的屏幕虽然是个不小的麻烦,但是以e888的网状耳机,我想也是可以很好的弥补这个缺陷的,同时在900的屏幕更加的显得有活力,不象ne10那样的不容易接近,有跳跃感。(
!有动感)同时也推荐使用在ne920上面。对于ne20感觉还是使用px200(怎么又是px200)遗憾此px200非彼px200乃苹果版的白色px200款,在颜色上会给于搭配的很好,声音上也可以很好的与ne20 搭配。


水平有限就打这些吧,里面的错别字一定非常的多,全拼打的,我想这个也可以作为一次活动来参加(就来找错字吧),说来说去也许很多的人感觉翻来覆去就是A8,CM7,PX100,PX200,E888,E868,等耳机,我是以可以消费的底线来考虑的,有很多的耳机没有参加进来,主要原因就是价格,我感觉可以消费得起A8就已经是发烧级别了,再高的耳机用在随身听上,可以说是暴敛天物的说,随身听也无法消受得起,所以就是以这几个耳机来定义随身听可以承受的底线。好了就这样,再打就是骗人的说了。希望大家配机器的时候多想想,整体的配制,不光是音质不错,外观也是要兼顾的,不然不算成功,本身随身听就是来绚的。
posted @
2005-10-27 13:16 rkind 阅读(390) |
评论 (0) |
编辑 收藏1.认识记忆效应
2.电池需要激活吗
3.前三次要充12小时吗
4.充电电池有最佳状态吗
5.真的是充电电流越大,充电越快吗
6.直充标的输出电流就等于充电电流吗
7.循环充放电一次就是少一次寿命吗
8.电池容量越高越好吗
9.充饱的电池进行存储好吗
10.座充的绿灯亮了以后在多充一个小时有用吗
11.座充充电比直充饱吗
1.认识记忆效应
电池记忆效应是指电池的可逆失效,即电池失效后可重新回复的性能。记忆效应是指电池长时间经受特定的工作循环后,自动保持这一特定的倾向。这个最早定义在镍镉电池,镍镉的袋式电池不存在记忆效应,烧结式电池有记忆效应。而现在的镍金属氢(俗称镍氢)电池不受这个记忆效应定义的约束。
因为现代镍镉电池工艺的改进,上述的记忆效应已经大幅度的降低,而另外一种现象替换了这个定义,就是镍基电池的“晶格化”,通常情况,镍镉电池受这两种效应的综合影响,而镍氢电池则只受“晶格化”记忆效应的影响,而且影响较镍镉电池的为小。
在实际应用中,消除记忆效应的方法有严格的规范和一个操作流程。操作不当会适得其反。
对于镍镉电池,正常的维护是定期深放电:平均每使用一个月(或30次循环)进行一次深放电(放电到1.0V/每节,老外称之为exercise),平常使用是尽量用光电池或用到关机等手段可以缓解记忆效应的形成,但这个不是exercise,因为仪器(如手机)是不会用到1。0V/每节才关机的,必须要专门的设备或线路来完成这项工作,幸好许多镍氢电池的充电器都带有这个功能。
对于长期没有进行exercise的镍镉电池,会因为记忆效应的累计,无法用exercise进行容量回复,这时则需要更深的放电(老外称recondition),这是一种用很小的电流长时间对电池放电到0.4V每节的一个过程,需要专业的设备进行。
对于镍氢电池,exercise进行的频率大概每三个月一次即可有效的缓解记忆效应。因为镍氢电池的循环寿命远远低于镍镉电池,几乎用不到recondition这个方法。
▲建议1:每次充电以前对电池放电是没有必要,而且是有害的,因为电池的使用寿命无谓的减短了。
▲建议2:用一个电阻接电池的正负极进行放电是不可取的,电流没法控制,容易过放到0V,甚至导致串联电池组的电池极性反转。
2.电池需要激活吗?
回答是电池需要激活,但这不是用户的要做的事。我参观过锂离子电池的生产厂,锂离子电池在出厂以前要经过如下过程:
锂离子电池壳灌输电解液-封口-化成,就是恒压充电,然后放电,如此进行几个循环,使电极充分浸润电解液,充分活化,以容量达到要求为止,这个就是激活过程--分容,就是测试电池的容量选取不同性能(容量)的电池进行归类,划分电池的等级,进行容量匹配等。这样出来的锂离子电池到用户手上已经是激活过的了。我们大家常用的镍镉电池和镍氢电池也是如此化成激活以后才出厂的。其中有些电池的激活过程需要电池处于开口状态,激活以后再封口,这个工序也只可能有电芯生产厂家来完成了。
这里存在一个问题,就是电池厂出厂的电池到用户手上,这个时间有时会很长,短则1个月,长则半年,这个时候,因为电池电极材料会钝化,所以厂家建议初次使用的电池最好进行3~5次完全充放过程,以便消除电极材料的钝化,达到最大容量。
在2001年颁布的三个关于镍氢。镍镉和锂离子电池的国标中,其初始容量的检测均有明确规定,对电池可以进行5次深充深放,当有一次符合规定时,试验即可停止。这很好的解释了我说的这个现象。
★那么称之为“第二次激活”也是可以的,用户初次使用的“新”电池尽量进行几次深充放循环。
●然而据我的测试(针对锂离子电池),存储期在1~3个月之内的锂离子电池,对它进行深充深放的循环处理,其容量提高现象几乎不存在。(我在专题讨论区有关于电池激活的测试报告)
3.前三次要充12小时吗?
这个问题是紧扣上面的电池激活问题的,姑且设出厂的电池到用户手上有电极钝化现象,为了激活电池进行深充深放电循环3次。其实这个问题转化为深充是不是就是要充12个小时的问题。那么我的另一片文章《论手机电池的充电时间》已经回答了这个问题。
★★★答案是不需要充12小时。
早期的手机镍氢电池因为需要补充和涓流充电过程,要达到最完美的充饱状态,可能需要5个小时左右,但是也是不需要12个小时的。而锂离子电池的恒流恒压充电特性更是决定了它的深充电时间无需12个小时。
对于锂离子电池有人会问,既然恒压阶段锂离子电池的电流逐渐减小,是不是当电流小到无穷小的时候才是真正的深充。我曾经画出恒压阶段电流减小对时间的曲线,对它进行多次曲线拟合,发现这个曲线可以用1/x的函数方式接近与零电流,实际测试时因为锂离子电池本身存在的自放电现象,这个零电流是永远不可能到达的。
以600mAh的电池为例,设置截至电流为0.01C(即6mA),它的1C充电时间不超过150分钟,那么设置截至电流为0.001C(即0.6mA),它的充电时间可能为10小时--这个因为仪器精度的问题,已经无法精确获得,但是从0.01C到0.001C获的容量经计算仅为1.7mAh,以多用的7个多小时来换取这仅仅的千分之三不到的容量是没有任何实际意义的。
何况,还有其它的充电方式,比如脉冲充电方式使锂离子电池来达到4.2V的限制电压,它根本没有截止最小电流判断阶段,一般150分钟后它就是100%充饱了。许多手机都是用脉冲充电方式的。
有人曾经用手机显示充饱后,再用座充进行充电来确认手机的充饱程度,这个测试方法欠严谨。
首先座充显示绿灯不是检测真正充饱与否的一个依据。
★★检测锂离子电池充饱与否的唯一最终的方法就是测试在不充电(也不放电)状态时的锂离子电池的电压。
所谓恒压阶段电流减小其真正的目的就是逐渐减小在电池内阻上因充电电流而产生的附加电压,当电流小到0.01C,比如6mA,这个电流乘与电池内阻(一般在200毫欧之内)仅为1mV,可以认为这时的电压就是无电流状态的电池电压。
其次,手机的基准电压不一定等于座充的基准电压,手机认为充饱的电池到了座充上,座充却不认为已经充饱,却继续进行充电。
4.充电电池有最佳状态吗?
有一种说法就是,充电电池使用得当,会在某一段循环范围出现最佳的状态,就是容量最大.这个要分情况,密封的镍氢电池和镍镉电池,如果使用得当(比如定期的维护,防止记忆效应的产生和累计),一般会在100~200个循环处达到其容量的最大值,比如出厂容量为1000mAh的镍氢电池用了120次循环后,其容量有可能达到1100mAh。几乎所有的日本镍氢电池生产商的技术规格书中描述镍基电池的循环特性的图上我都能看到这样的描述。
★镍基电池有最佳状态,一般在100~200循环次数之间达到其最大容量
对于液态锂离子电池,却根本不存在这样一个循环容量的驼峰现象,从锂离子电池出厂到最终电池报废为止,其容量的表现就是用一次少一次。我在对锂离子电池做循环性能的时候也从来没有看到过有容量回升的迹象。
★锂离子电池没有最佳状态。
值得一提的是,锂离子电池更容易受环境温度的变化而表现不同的性能,在25~40度的环境温度会表现其最好性能,而低温或高温状态,他的性能就大打折扣了。要使你的锂离子电池充分展现它的容量,一定要细心的注意使用环境,防止高低温现象,比如手机放在汽车的前台上,中午的太阳直射很容易就可以使其超过60度,北方的用户的电池待机时间,同等网络情况下,就没有南方的用户长了。
5.真的是充电电流越大,充电越快吗?
《论手机电池的充电时间》一文中已经讲了这个问题,对于恒流充电的镍基电池,可以这么说,而对应锂离子电池,这个是不完全正确的。
★★对于锂离子电池的充电,在一定电流范围内(1.5C~0.5C),提高恒流恒压充电方式的恒流电流值,并不能缩短充饱锂离子电池的时间。
6.直充标的输出电流就等于充电电流吗?
这就要讨论手机的充电方式了,对于充电管理在手机里面的,设定同样一个直充(实际应称为电源适配器)的输出如:5.3V 600mA
A. 充电管理是开关方式(高频脉宽调整PWM方式),这个充电方式,手机并没有完全利用直充的输出能力,直充工作在恒压段,输出5.3V,此时真正的充电电流由手机的充电管理进行调整,而且肯定要小于600mA,一般在300~400mA。这个时候,大家看到的直充的输出电流就不是手机的充电电流。比如Motorola的许多直充其输出为5.0V 1A,真正对电池充电的也就用到了500mA足矣,因为手机的电池容量也不过580mAh。
★这时直充上标的输出电流就不等于实际充电电流
B. 充电管理为脉冲方式的,这个充电方式,手机完全利用了直充的限流电流,就是用了600mA在电池上,这个时候,直充的输出电流就是充电电流了。
当然以上的都是指在锂离子电池的恒流阶段或镍氢电池的充电而言。
如果手机没有充电管理,把充电的管理移到了直充上,比如许多的CDMA手机都是如此,这个就没什么好说的,它的输出写的很明白,比如输出:4.2V 500mA,这个就是锂离子电池恒流恒压两个数据了。
7.循环充放电一次就是少一次寿命吗?
循环就是使用,我们是在使用电池,关心的是使用的时间,为了衡量充电电池的到底可以使用多长时间这样一个性能,就规定了循环次数的定义。实际的用户使用千变万化,因为条件不同的试验是没有可比性的,要有比较就必须规范循环寿命的定义。
国标如是规定锂离子电池的循环寿命测试条件及要求:在25度室温条件下以恒流恒压方式1C的充电制度充电150分钟,以恒流1C的放电制度放电到2.75V截止为一次循环。当有一次放电时间小于36分钟时试验结束,循环次数必须大于300次。
解释:
A. 这个定义规定了循环寿命的测试是以深充深放方式进行的
B. 规定了循环寿命按照这个模式执行后必须超过300次以后容量仍然有60%以上。
实际上,不同的循环制度得到的循环次数是截然不同的,比如以上其它的条件不变,仅仅把4.2V的恒压电压改为4.1V的恒压电压对同一个型号的电池进行循环寿命测试,这样这个电池就已经不是深充方式了,最后测试得到循环寿命次数可以提高近60%。那么如果把截止电压提高到3.9V进行测试,其循环次数应该可以增加数倍。
这个关于循环一次就少一次寿命的说法已经有许多友人进行了讨论,我只是补充说明一下而已,大家在谈论循环次数的时候不能忽视循环的条件。
●抛开规则谈论循环次数是没有任何意义的,因为循环次数是检测电池寿命的手段,而不是目的!
▲误区:许多人喜欢把手机锂离子电池用到自动关机再充电。这个完全没有必要。
实际上,用户不可能按照国标测试模式对电池进行使用,没有一个手机会在2.75V才关机,而其放电模式也不是大电流恒流放电,而是GSM的脉冲放电和平时的小电流放电混合的方式。
有另外一种关于循环寿命的衡量方法,就是时间。有专家提出一般民用的锂离子电池的寿命是2~3年,结合实际的情况,比如以60%的容量为寿命的终止,加上锂离子电池的时效作用(参考第9点),用时间来表述循环寿命我认为更为合理。
铅蓄电池的充电机理就类似与锂离子电池,是限流限压方式,使用的方式就是浅充浅放,他的寿命表述就是时间,没有次数,比如10年。
★★★所以,对于锂离子电池,没有必要用到关机再充电,锂离子电池本来就适合用随时充电的方式进行使用,这也是他针对镍氢电池的最大优势之一,请大家善加利用这个特性。
8.电池容量越高越好吗?
不同型号(特别是不同体积)的电池,他的容量越高,提供使用的时间越长。抛开体积和重量的因素,当然容量越高越好。
但是同样的电池型号,标称容量(比如600mAh)也相同,实际测的初始容量不同:比如一个为660mAh,另一个是605mAh,那么660mAh的就比605mAh的好吗?
实际情况可能是容量高的是因为电极材料中多了增加初始容量的东西,而减少了电极稳定用的东西,其结果就是循环使用几十次以后,容量高的电池迅速容量衰竭,而容量低的电池却依然坚挺。许多国内的电芯厂家往往以这个方式来获得高容量的电池。而用户使用半年以后待机时间却是差得一塌糊涂。
民用的那些AA镍氢电池(就是五号电池),一般是1400mAh,却也有标超高容量的(1600mAh),道理也是一样。
★提高容量的代价就是牺牲循环寿命,厂家不在电池材料的改性上下文章,是不可能真正“提高”电池容量的。
9.充饱的电池进行存储好吗?
锂离子电池有一个特性非常不好,就是锂离子电池的时效(或称老化,老外称为aging),就是锂离子电池在存储一段时间后,即使不进行循环使用,其部分容量也会永久的丧失,这是因为锂离子电池的正负极材料从一出厂就已经开始了它的衰竭历程。不同的温度和电池充饱状态,其时效后果不同,以下数据摘自参考文献[1],以容量的百分比形式列出:
存储温度--40%充电状态-------100%充电状态
0度-------98%(一年以后)-----94%(一年以后)
25度------96%(一年以后)-----80%(一年以后)
40度------85%(一年以后)-----65%(一年以后)
60度------75%(一年以后)-----60%(3个月以后)
由此可见,存储温度越高和电池充的越饱,其容量损失就越厉害。所以不推荐长期的保存锂离子电池,反之,厂家应该象对待腐烂的食物一样将其回收。用户要密切留意电池的生产日期。
★如果用户手中有闲置的电池,那么专家推荐的存储条件为充电水平是40%,存储温度低于15度或更低。
而镍氢电池和镍镉电池则几乎不受这个时效作用,长期存储的镍基电池在进行几个深充深放以后就可以恢复其原始容量了。
10.座充的绿灯亮了以后在多充一个小时有用吗?
绿灯只是一个指示,真正充饱与否在于座充对电池充电过程的控制和判断。以4.2V的锂离子电池为例讨论这个问题。
首先是控制,控制对电池的输出是先恒流,后恒压(电流逐渐减小)。
然后是判断,判断电流小于某个电流值时,显示绿灯,因为模数转换的精度和本身的电压精度是受限制的,座充通常设定这个电流值为50mA,此时显示绿灯,那么电池确实离它真正的充饱还有10%不到(据我所测,现在的锂离子电池以50mA截止充电的话,其容量已经可以达到95%,充电接受能力大大提高)。现在的问题是座充接下去在干什么:
A. 如果接下去,座充彻底关断充电回路,没有继续进行恒压充电,那么在座充上再放置10个小时也是于事无补。许多的座充设计方案就是这样的,比如TI(德州仪器)的BQ2057系列充电芯片,linear(凌特)的LT1800系列都是如此。
B. 座充继续进行恒压充电,并严格控制电压不超出4.2V,无疑再多充一个小时,确实可以增加电池的容量。
C. 座充继续充电,但是它的电流控制很糟糕,不小心就使电池超出了4.2V,而且继续往上跑。因为锂离子电池不能吸收任何过充。持续对电池施加电流,就会造成这个后果,那么过充就发生了。这个当然是设计不好的座充,比如常见的即可充锂离子电池又可充镍氢电池的十几块钱的“蛋充”。
D. 还有一种充电管理芯片,比如maxim(美信)的1679芯片,与许多手机充电管理相同,它采用脉冲方式充电,它在显示绿灯的时候,就是锂离子电池已经100%充饱了,当然再放置一个小时,它也不会过充,显然又是在做无用功。
用户实际上不知道绿灯亮了以后座充到底在干什么,A或B或D,都有可能,座充说明书不写这些东西的。排除不合格的座充,我们其实应该相信合格和原装的座充,绿灯亮着的话,为什么不取下来用呢?这对用户实际没有什么太大的影响,充的不饱又不影响循环寿命(如上第7点所述),95%的容量也是可以接受的。除非有爱好者能深入分析自己的座充到底是以那种方式的在充电,否则我们不妨--
★亮绿灯后就取下来用。
11.座充充电比直充饱吗?
看完了前面的婆婆妈妈的话,这个问题就是最好回答的了,问题的实质就是充电方式的区别。
★不存在座充一定比直充充的饱的说法,也不存在直充一定比座充充的饱的说法。重要的是它们的充电方式是不是能最快最大的充饱电池。
posted @
2005-10-27 13:16 rkind 阅读(260) |
评论 (0) |
编辑 收藏
购小I将近一月,通过这段时间的使用,同时也看了很多EQ设置相关的帖子,也有一些体会和心得想和大家分享。
正如大家所言,EQ设置是个很个人化的事情,因人(个体感觉和喜好)、因地(听音的环境)、因时(听音的时间、当时的心情)、因乐(音乐的类型风格)而异,没有绝对的标准,不可强求一律。因为音乐欣赏说到底不是一个理性分析的过程,而是一个感性的过程。但是话又说回来,音乐欣赏也不纯粹就是一个感性的过程,完全排斥理性的分析同样有失偏颇。所以我觉得分析一下EQ设置的原理还是相当有必要的。尽管没有绝对的标准,但应该有一个相对的标准;就是说,一般性的通用的标准还是客观存在的,乱设一气也不是理性的做法。我们在这里既可以探讨好的设置,也可以分析一下不好的设置(当然,好与不好都是相对而言的)。这样有助于我们更好地用好手中的小I,从而欣赏到更为动听的音乐。
这个通用的标准我以为没有上限,就是说没有最好;但是应该有一个下限,这个下限我的理解是不能破坏音乐的整体的平衡感。好的回放,应该是高中低三频均衡,这样才能最低程度地减少音乐的失真。
AlbertDing网友在帖子里说,“声音在传播过程中低频率的声波传的慢,也就是说衰减的快,因此要多补偿些。而多补偿了低音,整个音乐会显的沉闷些,因此补偿一些高音区,就可以降低这个感觉。”我觉得这段分析说到点上了。但这只是就低频和高频而言,我在这里想补充的是,5段均衡器的第2档和第4档调节的注意点。
5段均衡器的首档(1)、中档(3)和末档(5)分别代表的是低、中、高频,关于这几档的调节大家已经分析得很深入了。但是对于第2档和第4档就我所知尚属语焉不详(也可能以前的帖子里有),以小弟个人管见,第2档和第4档应该分别代表中低频(60 Hz~200 Hz)和中高频(1000 Hz~3000 Hz),具体如下图:

所谓中低频,转台湾发烧宗师刘汉盛的《音响二十要》(帖参:http://www.iriverchina.com/forum/discussion_show.asp?idx=172916)的说法是:“从80Hz-160Hz之间,我称为中低频。这个频段是台湾音响迷最头痛的一段,因为它是造成耳朵轰轰然的元凶。为什么这个频段特别容易有峰值呢?这与小房间的长、宽、高尺寸有关。大部份的人为了去除这段恼人的峰值,费尽心力吸收这个频段,使耳朵不致于轰轰然。可惜,当您耳朵听起来不致轰轰然时,下边的低频与上边的中频恐怕都已随着中低频的吸收而呈凹陷状态,而使得声音变瘦,缺乏丰润感。更不幸的是大部份的人只因峰值消失而认为这种情形是对的。这就是许多人家里声音不够丰润的原因之一。”刘氏关于音频的划分和IRIVER的5档EQ有些小的出入,但大致不差。关于频段的划分,其实也无统一的精确标准,刘氏的划分算是其中一个比较权威的说法。
从上述分析中我们可以看出,此段其实极为难调:调高了,容易“造成耳朵轰轰然”;调低了,则会“使得声音变瘦,缺乏丰润感”。所以就我自己的感受来讲,此段设在0~+6范围内为宜。这当然也是因人而异,喜欢声音丰厚一点的,比如听ROCK(包括某些动感强烈的POP)类型的音乐,可以调得高一点,但是最高也不要超过6,否则声音会显得沉、闷;反之,喜欢声音清澈一点的,比如听NewAge、Classic(包括一些人声为主的POP)类型的音乐,可以适当低点,但是最低也不要低于0,否则声音干、瘦。
至于这中高频,依据刘氏的说法,“从1280Hz-2560Hz称为中高频。这个频段有什么乐器呢?小提琴约有四分之一的较高音域在此,中提琴的上限、长笛、单簧管、双簧管的高音域、短笛的一半较低音域、钹、三角铁等。请注意,小喇叭并不在此频段域中。其实中高频很容易辨认,只要弦乐群的高音域及木管的高音域都是中高频。这个频段很多人都会误以为是高频,因此请您特别留意。”但是我认为考虑到MP3的有损编码的特殊性,它的实际频段一般并没有取得这么高,而要比上图中标示的3KHz(3000Hz)为低,尤其是在有些MP3取样位率较低的情况下;实际应该在中频的上端,也就是女声里的高音域。这么说比较抽象,你若问我依据在哪我也说不上来。就我的感觉,具体说来,此段调得过高,比如+6以上,女声的唇齿音马上变得十分明显,也就是那些以j、q、x(拼音,非英语字母)等舌尖音和z、c、s(拼音)等唇齿音为声母的字词听来刺耳,如若不信,大家可以听一听孙燕姿的《遇见》,明显感觉得出来。这档调为+3,上述这些音节就自然、圆润多了。当然物极必反,这段如设置过低,也会使得高音不够通透,所以我以为这段在+3~+6范围之间是比较好的设置。
上述关于EQ的设置只是我实际使用小I中的一点心得,具体的设置还需自己来体会和摸索。最后一并附上我自己目前最喜欢的EQ设置,主要用来听POP:+9,0,+3,+3,+9/+6(3D EQ,平时主要使用的音效)。我自己觉得这个EQ听POP还是比较合适的,高、中、低音都比较均衡,低频厚实而不激烈,中频润泽富有感染力,高频延伸广失真少。整个声音较为通透,层次分明,细节丰富,没有一频盖过另一频的现象。(个人感觉:)
不当之处,还请拍砖。
posted @
2005-10-27 13:15 rkind 阅读(205) |
评论 (0) |
编辑 收藏Q:为什么要“煲”耳塞
A: 随身听爱好者们常常会拥有一副好的耳塞,但在开始使用时发现并没有像其他人谈论的这么好,难道是自己买到了假货?非也!其实那是因为没有进行购买后的第一道工序——“煲”。
为什么要“煲”耳塞
其实在音响界,很多东西都需要“煲”。包括音源、功放、音箱等等。所谓的“煲”就是让这些东西运作一段时间,以达到最佳的效果。
我们刚买回来的耳塞,不出意外的话都应该是刚出厂的产品。这些耳塞从生产线上下来的时候,震膜一次都没有用过,因而会很硬。这种情况下的震膜突然震动起来,会感觉很不自在,声音也会略微走样。如果一开始就好好的“煲”一下耳塞,那么就会把它的震膜逐渐弄松,这样再听音乐时,震膜震动起来就会非常的自如,音质也较先前提高不少。
“煲”耳塞前的准备
其实“煲”耳塞(机)并不困难,但是需要时间和一定的技巧。首先,你需要一个可用来长时间放音的音源。因为“煲”耳塞可不是一会儿半会儿的事情,有时候甚至需要100个小时以上。其次音源中要有频响范围很宽、动态效果舒缓、层次清晰、高中低音各成分适中的音乐有这样效果的音乐要比一般音乐“煲”起来效果更明显。还有一点就是音源输出功率一定要够大,而且要和用户的耳塞档次匹配。比如要“煲”HD580就不能用普通随身听,随身听可能连推都推不动,还怎么让震膜松动呢?一般来说,随身听只适合耳塞和一些低阻抗耳机使用。一般而言,如用电脑声卡和收音机“煲”耳塞的话,需要比较长一点的时间。而用输出功率很大的CD随身听来“煲”,时间要短一些。
“煲”耳塞的操作
首先,我们需要数张CD碟,这是因为CD音质是目前民用级别(撇开并不实用的SACD和DVD-AUDIO)可以达到最好效果的音乐质量,而且爹片相对来说比较便宜,以下所有操作也均以CD随身听为例。“煲”机碟最好是张频响范围非常宽广的碟片,单独使用一般的纯人声碟肯定不行。推荐一些正版的发烧碟,比如《TITANIC》、《阿姐鼓》和《1812序曲》等等。还有一些优秀的流行音乐和中国民乐也是很不错的选择。下面笔者就来“煲”好你的耳塞。
《TITANIC》电影原声CD中的第3段《SOUNTHAMPTON》、第9段《THE SINKING》和第10段《DEATH OF TITANIC》。《SOUTHAMPTON》虽有抄袭贝多芬的《欢乐颂》之嫌,但声音层次非常分明,乐曲包含的信息量也很丰富。高中音柔顺致密,隐隐而来的阵阵低频能量予人一种深邃感。这首曲目在全频段都有突出表现,对于耳塞的全面震动是非常有好处的。而《THE SINKING》和《DEATH OF TITANIC》除了与上面一首有同样出色的全频表现以外,在动态上更胜一筹,整体声音能量十足,如果没有“煲”就听这样的曲子,耳塞的震膜要“受苦”了!
国产动画电影《宝莲灯》电影原声CD中的第4段《序曲:宝莲灯》和第13段《望月节的舞蹈》。《序曲:宝莲灯》一开始声音较为轻柔,但越到后来,声音动态越大,能量也越多。中间还夹杂着一些人声的合唱,应该说是非常不错的曲子,唯独其低音略微少了一些。《望月节的舞曲》中一开声的低频以及中间一段女声对于耳塞中低频的提高都很有帮助。
《滚石24K24BIT金碟--万芳》CD中的第一段《猜心》是笔者用作试音的保留曲目,用来“煲”耳塞也是非常不错的选择。这首曲目的第一段主要是人声独唱,不过到了后面,乐器就越来越丰富,但整体仍可算是轻柔。“煲”耳塞不能一直用大动态来“煲”,也需要在中间做一些调整。而且,这首曲目中的人声非常出色,可以用作“煲”耳塞结束以后的试听之用。
其实优秀的曲目太多了,笔者在这里推荐的只不过是冰山一角而已!把随身听和耳塞准备好,放入碟片,音量上要开的大一些。现在的随身听为了延长播放的时间,输出功率普遍较低,用户大可以把音量开到90%以上,不过最好不要开效果!“煲”耳塞的过程中要一步一步的来,首先用一些舒缓的音乐,比如上问中提到的《猜心》,先放5~10个小时。然后再换略微"厉害"一点的音乐,如《SOUTHAMPTON》,继续播放10小时以上,最后才是诸如《THE SINKING》和《DEATHOF TITANIC》之类的音乐,一直要播放到耳塞基本上“煲”好。为了确定耳塞“煲”的情况,用户可以每隔10小时听一次,一般来说,效果都会有一些差距,等到差距不明显的时候,就可算是“煲”好了。当然,这种鉴别方法也不是很容易实现,那么就准备“煲”50~100个小时好了。不过要达到大功告成就需要日常不断的使用才行,要使耳塞真正达到最佳效果,时间上一般需要2个月左右。
前后声音的对比
笔者“煲”耳塞“煲”过很多,最有感触的就是索尼(SONY)MDR-E888了。这是一款目前相当高级的耳机,市售价在人民币400元左右。但是这款耳塞刚买回来试听的时候,常常都会有高音发干,中频毛刺多多等问题,让人觉得完全不值400大元。不过一旦MDR-E888“煲”好了,那么她就会放射出耀眼的光芒:柔顺的高频、温暖但绝无毛刺的中频、深沉有力的低频,简直不敢相信是同一个耳塞。个人认为,MDR-E888是笔者见过的耳塞中最需要“煲”的一款,这可能和它独特的生物震膜有关系。其它的耳塞也都需要“煲”,“煲”过以后都主要体现在低频弹性感得到加强,高频柔顺感有了提高,只是结果好象没有MDR-E888那么夸张!
“煲”耳塞是一个漫长的过程,需要将“煲”和日常合理使用相结合,如果能正确的“煲”好你的耳塞,那么,相信她一定会给你带来不一样的惊喜!
Q:如何选购耳机?
A:立体声耳机选购有如下技巧:
选购耳机就没有音箱选购那么复杂了,这要简单一些。现如今,耳机已成了不少人的享受音乐的必备了,它不仅小巧玲珑,活动性大,不会干扰到他人,而且听音效果的较普通音箱要更真实,它更具有更强的临场感,立体声的渲染效果是非常强的。如何选购一款好电脑用立体声耳机变得十分重要,但大多数人对耳机的了解不是很多,所以,我们要来先了解一下耳机,那就请听本人给你来说一说。
1.首先,我们说一说立体声耳机的分类。
根据形状来分可分为封闭式、开放式和半开放式:
封闭式耳机就是通过其自带的软音垫来包裹你的耳朵,使其被完全覆盖起来。此类耳机因为有大的音垫,所以个头也较大,但有了音垫就可以在噪音较大的环境下使用而不受影响。
开放式耳机是目前比较流行的耳机样式。此类机种的特点是通过采用海绵状的微孔发泡塑料制作透声耳垫。它体积小巧,佩带很舒适,不再使用厚重的染音垫,于是没有了与外界的隔绝感,但它的低频损失较大。在听音方面,这款耳机还是不错的。
半开放式耳机是综合了封闭式和开放式两种耳机优点的新型耳机(它是一个混血儿,融合了前两种耳机的优点,改进了不足之处),此类耳机采用了多振膜结构,除了一个主动有源振膜之外,还有多个无源从动振膜。它具有低频描述丰满浑厚,高频描述明亮自然、层次清晰等很多特点,如今许多较高档次的耳机上广泛的应用的就是这种耳机。
根据功能可以分为头戴式和耳塞式:
头戴式大多是封闭结构,所以携带不太方便,但其表现力十分强,能使与世隔绝享受音乐的美妙。并且此类耳机做得十分坚固,抗摔打能力强,因此在家里或办公的地方都可使用此类耳机,为了配合语音接口大多还带有话筒(也就是我们平时常见到的耳麦)。
耳塞式主要易于外出旅游听音乐,因为它的体积很小。此类耳机主要用于CD随声听、MP3播放机、MD上。它的声音品质较好,声音互动性强,但它的抗干扰能力很弱,功能也不强。
根据制造原理来分可分为电动式和电容式:
电动式(也称动圈式)具有结构简单、音质音色稳定、承受功率大、灵敏度高等特点。
电容式(也称静电式)具有音质好、频带宽的优点,但是结构很复杂,造成了制造难度大,使得很少有厂家来做此类耳机,现在市面上也很少见到采用这种机型的立体声耳机。
双分频式耳机:
双分频耳机是在半开放式耳机的基础上整合了电动式和电容式两者各自的优点的双段分频耳机。它把电动式、电容式、封闭式、开放式四种耳机的优点集于一身,(这可是个实实在在的“杂交”)此类耳机无论从动态范围、瞬态响应、放音质量、音色厚度等等方面都是十分出众的,而且它的声音解析准确是音乐发烧友的最佳选择。
2.既然知道了耳机的结构就该来看看如何选购耳机了。
发烧级音乐迷最爱什么?HiFi当然是HiFi,要想耳机也能HiFi,选购时必须注意以下几点:
由使用情况来看,一般说来,电动式的耳机具有结构简单、音质稳定、价格便宜、音质并不出众等特点,适合于一般人士选用,它能满足一般的需求;电容式耳机,音质好且频带宽,但由于工艺复杂,价格就比较高,适合于发烧友们选用,它的听音品质相当好。
从耳机的使用性质看,耳机需要长时间佩戴在头上,这就要求耳机的耳垫十分柔软和舒适,头环的压力比较小,耳机不能压迫头部的血管引起不适。
根据我的使用经验,你最好既买耳塞式又买头戴式。夏天天热,用耳塞式耳朵不会受罪;冬天天冷,头戴式可以防止耳朵冻伤,一举两得。
选购耳机时,耳机说明书上的性能指标要留意一下,因为质量差的耳机往往是一些小厂生产的,它的性能指标有的是胡乱添写,有的是夸大其词。耳机一般最低要达到20~20kHz的频率范围,大于100mW的功率,小于或略等于0.5%的谐波失真等。如果达不到以上要求的话,你最好还是不要选购。如果说明书上的性能写得太高的产品最好也不要买。
如果从外观和手感来判断,大的厂家生产的较正宗耳机使用工程塑料所以外观十分平滑,又有一定的应力和韧性,没有生硬感,做工比较精细,手感极好,没有采用劣质塑料的粗糙感。还有,耳机的引线线径比较较粗,可以保证传输稳定,线的触感柔软而发硬。插头做得干净利落,不会留有毛刺,镀层平滑均匀。如果不符条件最好不要买。
其实说了这么多,同音箱一样最重要的还是要你亲自去试听一下。有人说试听不就是听一听耳机放音吗?其实,这里面的学问可大着呢!试听最好要选用干净的节目源,所谓“干净”就是音源本身不能有无故爆音和颤音以及声音失真。
Q:如何改善MP3的音质?
A:影响MP3播放器回放表现的最重要因素有两点:MP3播放器本身所采用的解码芯片和随机配置的耳机。不同价位的MP3播放器所采用的解码芯片往往不同,而随机配置的耳机却大同小异,这就导致了这样一种结果:即使有了好的音源,也不能充分表现出来。而对于打算购买或者已经购买了MP3播放器的朋友来说,在不更换主机的前提下,重新配置一副合适的耳机就成为改善MP3播放器音质最简单有效的方法。
1200元以上的MP3播放器可以看作是高端产品,在这个价位上的产品基本上都是一线厂商技术含量较高的东西。这一个档次的MP3播放器主机解码芯片具有较高的回放水准,加上可以选择丰富的音效模式,所以可以考虑一些中高音表现力不错、低音弹性较好的耳机,如索尼的E888和爱华的V743、V741。这类耳机的价格大多在250-400元之间,虽然算不上是极品耳机,但是对于MP3播放器的回放来说,应付起来还是绰绰有余的。这类耳机具有高音通透、清澈,人声表现力清晰,低音弹性较好的特点,刚好可以弥补MP3播放器高音表现力不足以及低音质感较差的缺陷。
中端产品在500-1200元之间。这个价位上的MP3播放器其主机所采用的解码芯片品质往往参差不齐,所以回放的效果也不尽相同,不过使用原配耳机的听感都不能让人满意。往往表现在高音苍白无力,中音表现一般,而低音则是比较混浊。为这个价格段的MP3播放器选择耳机的话,要考虑均衡性的问题。所以,总体均衡性表现不错的耳机就成为首选,这其中值得购买的有森海塞尔的MX500、索尼的E848以及爱华的V553。这些耳机的价格一般在160-230元之间,它们在高、中、低频的表现力虽然都不能达到顶尖的标准,但是都有相当出色的表现。中端主机各频段表现不佳的缺点可以靠这种类型的耳机来弥补。
500元以下的MP3播放器 “鱼龙混杂”,低端MP3播放器大多采用廉价的解码芯片,回放效果较差。再加上原配耳机表现平平,完全没有修饰效果,所以主机的回放中的缺陷暴露无余。即使使用很好的耳机,也不能修补主机回放的“硬伤”。为低端MP3播放器选择匹配耳机,要更多地从经济性方面来考虑,80-150元之间的耳机是不错的选择,如森海塞尔的MX400、MX300和索尼的E838、E837。这个价位的耳机一般外形设计比较普通,能够较好弥补的只是主机一个频段的表现力,不过总体音质表现相对于它们的价格来说,还是比较超值的。偏好低音的用户可以选择森海塞尔的MX系列,而希望中、高音有所改善的用户则可以考虑索尼的耳机。这样的匹配虽然不能对音质表现有绝对的改变,但是听感上的改善还是可以很容易感觉到的。
Q:Mp3随身听,何种数据速率好?
A:现在MP3随身听越来越流行,大家都希望能够在路途上听到更好的声音,究竟多大的数据速率才合适MP3随身听呢?这个取决下面4个因素.
1、数据速率的支持极限
不是所有的MP3播放器都支持320kbps的MP3,不少机型无法播放224kbps以上速率的MP3,这主要受限于解码芯片的性能,在制定VCD规范的时候,224kbps的音频流成为了VCD的标准,而不少MP3解码芯片都是从VCD解码芯片简化而来,因此要特别注意一下,自己测试很容易,播放一首320kbps的MP3就可以了,如果不兼容,可能听到的是噪声,或者是放慢了速度的曲子,好像磁带机电力不足那样。这种问题一般出现在老式的光盘载体的机型上。
2、VBR是否合适?
VBR就是可变码率,MP3支持这种技术,但是只有很少的机器能完美的支持VBR,支持不好不是表现在播放的音质方面,而是时间计算方面,由于VBR是可变化的,那些根据MP3文件大小判断时间长度的算法就无法获得正确的曲子时长,而这种算法是最常见的。时长计算不对会带来快进快退找不到正确的位置。另外,有些机器可以较好支持VBR,但却无法支持224kbps以上的数据码率,遇到瞬间超过224kbps的码率时,会出现杂音。
3、多大的数据速率合适?
MP3播放器可以有很多中媒介载体,一般有光盘和闪存两种,光盘容量大,且方便更换,因此无所谓文件大小,只要没有数据速率问题,我们建议采用256kbps以上的数据速率。对于闪存载体的MP3播放器就必须考虑容量问题了,一般而言,都是采用64M或者128M的容量,要计算能存储多长的音乐很容易,以64M存储256kbps的MP3为例:64×1024÷(256÷8)=2048,也就是说64M只能存储2048秒的音乐,还不够一张CD的,如果换成192kbps的数据速率,就可以存储2730秒的音乐,还是不够一张CD的,如果换成128kbps就可以存储4096秒,差不多可以装一张CD了。从听感上而言,128kbps的问题太多,192kbps才能够满足音乐需求,因此,我们建议最低数据速率也要有192kbps。
4、编码器也很重要
数据速率对音质的影响很重要,编码器的编码质量一样也很重要,我们在这里推荐一个顶级的MP3编码器——LAME,LAME版本众多,实际比较下来,3.90和3.92的编码质量是最好的,这是一个来自民间程序员的大手笔,比起各种各样收费的MP3编码器,这个LAME要好上很多,而且是免费的,使用LAME,192kbps的音质甚至好过其他编码器320kbps的水平,不要小看编码器,他一样可以帮你提高音质还可以帮你节约不多的存储空间。
封闭式耳机就是通过其自带的软音垫来包裹你的耳朵,使其被完全覆盖起来。此类耳机因为有大的音垫,所以个头也较大,但有了音垫就可以在噪音较大的环境下使用而不受影响。
开放式耳机是目前比较流行的耳机样式。此类机种的特点是通过采用海绵状的微孔发泡塑料制作透声耳垫。它体积小巧,佩带很舒适,不再使用厚重的染音垫,于是没有了与外界的隔绝感,但它的低频损失较大。在听音方面,这款耳机还是不错的。
半开放式耳机是综合了封闭式和开放式两种耳机优点的新型耳机(它是一个混血儿,融合了前两种耳机的优点,改进了不足之处),此类耳机采用了多振膜结构,除了一个主动有源振膜之外,还有多个无源从动振膜。它具有低频描述丰满浑厚,高频描述明亮自然、层次清晰等很多特点,如今许多较高档次的耳机上广泛的应用的就是这种耳机。
根据功能可以分为头戴式和耳塞式:
头戴式大多是封闭结构,所以携带不太方便,但其表现力十分强,能使与世隔绝享受音乐的美妙。并且此类耳机做得十分坚固,抗摔打能力强,因此在家里或办公的地方都可使用此类耳机,为了配合语音接口大多还带有话筒(也就是我们平时常见到的耳麦)。
耳塞式主要易于外出旅游听音乐,因为它的体积很小。此类耳机主要用于CD随声听、MP3播放机、MD上。它的声音品质较好,声音互动性强,但它的抗干扰能力很弱,功能也不强。
根据制造原理来分可分为电动式和电容式:
电动式(也称动圈式)具有结构简单、音质音色稳定、承受功率大、灵敏度高等特点。
电容式(也称静电式)具有音质好、频带宽的优点,但是结构很复杂,造成了制造难度大,使得很少有厂家来做此类耳机,现在市面上也很少见到采用这种机型的立体声耳机。
双分频式耳机:
双分频耳机是在半开放式耳机的基础上整合了电动式和电容式两者各自的优点的双段分频耳机。它把电动式、电容式、封闭式、开放式四种耳机的优点集于一身,(这可是个实实在在的“杂交”)此类耳机无论从动态范围、瞬态响应、放音质量、音色厚度等等方面都是十分出众的,而且它的声音解析准确是音乐发烧友的最佳选择。
2.既然知道了耳机的结构就该来看看如何选购耳机了。
发烧级音乐迷最爱什么?HiFi当然是HiFi,要想耳机也能HiFi,选购时必须注意以下几点:
由使用情况来看,一般说来,电动式的耳机具有结构简单、音质稳定、价格便宜、音质并不出众等特点,适合于一般人士选用,它能满足一般的需求;电容式耳机,音质好且频带宽,但由于工艺复杂,价格就比较高,适合于发烧友们选用,它的听音品质相当好。
从耳机的使用性质看,耳机需要长时间佩戴在头上,这就要求耳机的耳垫十分柔软和舒适,头环的压力比较小,耳机不能压迫头部的血管引起不适。
根据我的使用经验,你最好既买耳塞式又买头戴式。夏天天热,用耳塞式耳朵不会受罪;冬天天冷,头戴式可以防止耳朵冻伤,一举两得。
选购耳机时,耳机说明书上的性能指标要留意一下,因为质量差的耳机往往是一些小厂生产的,它的性能指标有的是胡乱添写,有的是夸大其词。耳机一般最低要达到20~20kHz的频率范围,大于100mW的功率,小于或略等于0.5%的谐波失真等。如果达不到以上要求的话,你最好还是不要选购。如果说明书上的性能写得太高的产品最好也不要买。
如果从外观和手感来判断,大的厂家生产的较正宗耳机使用工程塑料所以外观十分平滑,又有一定的应力和韧性,没有生硬感,做工比较精细,手感极好,没有采用劣质塑料的粗糙感。还有,耳机的引线线径比较较粗,可以保证传输稳定,线的触感柔软而发硬。插头做得干净利落,不会留有毛刺,镀层平滑均匀。如果不符条件最好不要买。
其实说了这么多,同音箱一样最重要的还是要你亲自去试听一下。有人说试听不就是听一听耳机放音吗?其实,这里面的学问可大着呢!试听最好要选用干净的节目源,所谓“干净”就是音源本身不能有无故爆音和颤音以及声音失真。
Q:如何改善MP3的音质?
A:影响MP3播放器回放表现的最重要因素有两点:MP3播放器本身所采用的解码芯片和随机配置的耳机。不同价位的MP3播放器所采用的解码芯片往往不同,而随机配置的耳机却大同小异,这就导致了这样一种结果:即使有了好的音源,也不能充分表现出来。而对于打算购买或者已经购买了MP3播放器的朋友来说,在不更换主机的前提下,重新配置一副合适的耳机就成为改善MP3播放器音质最简单有效的方法。
1200元以上的MP3播放器可以看作是高端产品,在这个价位上的产品基本上都是一线厂商技术含量较高的东西。这一个档次的MP3播放器主机解码芯片具有较高的回放水准,加上可以选择丰富的音效模式,所以可以考虑一些中高音表现力不错、低音弹性较好的耳机,如索尼的E888和爱华的V743、V741。这类耳机的价格大多在250-400元之间,虽然算不上是极品耳机,但是对于MP3播放器的回放来说,应付起来还是绰绰有余的。这类耳机具有高音通透、清澈,人声表现力清晰,低音弹性较好的特点,刚好可以弥补MP3播放器高音表现力不足以及低音质感较差的缺陷。
中端产品在500-1200元之间。这个价位上的MP3播放器其主机所采用的解码芯片品质往往参差不齐,所以回放的效果也不尽相同,不过使用原配耳机的听感都不能让人满意。往往表现在高音苍白无力,中音表现一般,而低音则是比较混浊。为这个价格段的MP3播放器选择耳机的话,要考虑均衡性的问题。所以,总体均衡性表现不错的耳机就成为首选,这其中值得购买的有森海塞尔的MX500、索尼的E848以及爱华的V553。这些耳机的价格一般在160-230元之间,它们在高、中、低频的表现力虽然都不能达到顶尖的标准,但是都有相当出色的表现。中端主机各频段表现不佳的缺点可以靠这种类型的耳机来弥补。
500元以下的MP3播放器 “鱼龙混杂”,低端MP3播放器大多采用廉价的解码芯片,回放效果较差。再加上原配耳机表现平平,完全没有修饰效果,所以主机的回放中的缺陷暴露无余。即使使用很好的耳机,也不能修补主机回放的“硬伤”。为低端MP3播放器选择匹配耳机,要更多地从经济性方面来考虑,80-150元之间的耳机是不错的选择,如森海塞尔的MX400、MX300和索尼的E838、E837。这个价位的耳机一般外形设计比较普通,能够较好弥补的只是主机一个频段的表现力,不过总体音质表现相对于它们的价格来说,还是比较超值的。偏好低音的用户可以选择森海塞尔的MX系列,而希望中、高音有所改善的用户则可以考虑索尼的耳机。这样的匹配虽然不能对音质表现有绝对的改变,但是听感上的改善还是可以很容易感觉到的。
Q:Mp3随身听,何种数据速率好?
A:现在MP3随身听越来越流行,大家都希望能够在路途上听到更好的声音,究竟多大的数据速率才合适MP3随身听呢?这个取决下面4个因素.
1、数据速率的支持极限
不是所有的MP3播放器都支持320kbps的MP3,不少机型无法播放224kbps以上速率的MP3,这主要受限于解码芯片的性能,在制定VCD规范的时候,224kbps的音频流成为了VCD的标准,而不少MP3解码芯片都是从VCD解码芯片简化而来,因此要特别注意一下,自己测试很容易,播放一首320kbps的MP3就可以了,如果不兼容,可能听到的是噪声,或者是放慢了速度的曲子,好像磁带机电力不足那样。这种问题一般出现在老式的光盘载体的机型上。
2、VBR是否合适?
VBR就是可变码率,MP3支持这种技术,但是只有很少的机器能完美的支持VBR,支持不好不是表现在播放的音质方面,而是时间计算方面,由于VBR是可变化的,那些根据MP3文件大小判断时间长度的算法就无法获得正确的曲子时长,而这种算法是最常见的。时长计算不对会带来快进快退找不到正确的位置。另外,有些机器可以较好支持VBR,但却无法支持224kbps以上的数据码率,遇到瞬间超过224kbps的码率时,会出现杂音。
3、多大的数据速率合适?
MP3播放器可以有很多中媒介载体,一般有光盘和闪存两种,光盘容量大,且方便更换,因此无所谓文件大小,只要没有数据速率问题,我们建议采用256kbps以上的数据速率。对于闪存载体的MP3播放器就必须考虑容量问题了,一般而言,都是采用64M或者128M的容量,要计算能存储多长的音乐很容易,以64M存储256kbps的MP3为例:64×1024÷(256÷8)=2048,也就是说64M只能存储2048秒的音乐,还不够一张CD的,如果换成192kbps的数据速率,就可以存储2730秒的音乐,还是不够一张CD的,如果换成128kbps就可以存储4096秒,差不多可以装一张CD了。从听感上而言,128kbps的问题太多,192kbps才能够满足音乐需求,因此,我们建议最低数据速率也要有192kbps。
4、编码器也很重要
数据速率对音质的影响很重要,编码器的编码质量一样也很重要,我们在这里推荐一个顶级的MP3编码器——LAME,LAME版本众多,实际比较下来,3.90和3.92的编码质量是最好的,这是一个来自民间程序员的大手笔,比起各种各样收费的MP3编码器,这个LAME要好上很多,而且是免费的,使用LAME,192kbps的音质甚至好过其他编码器320kbps的水平,不要小看编码器,他一样可以帮你提高音质还可以帮你节约不多的存储空间。
posted @
2005-10-27 13:14 rkind 阅读(483) |
评论 (0) |
编辑 收藏
今天晚上有的朋友发帖子问均衡器使用的问题。以前我也多次做过解答了,今天干脆整理一下,让大家了解一些相关的东西。
首先来看看什么是均衡器。在音响器材中,均衡器是一种可以分别调节各种频率成分电信号放大量的电子设备,通过对各种不同频率的电信号的调节来补偿扬声器和声场的缺陷,补偿和修饰各种声源及其它特殊作用,一般调音台上的均衡器仅能对高频、中频、低频三段频率电信号分别进行调节。
严格地说应先要根据音响的频响曲线用均衡器来校正成平直的,就是说音响的频率响应曲线本来不是水平的直线,但是为了真实还原声音,我们可以通过均衡器的调节把原来的曲线变成直线。但大多数朋友都没这个条件,不知道耳机或者耳塞的频响曲线,所以我们只能根据自己的听觉来进行调节。
这里是均衡器分段后的每个部分的作用:
1、20Hz--60Hz部分
这一段提升能给音乐强有力的感觉,给人很响的感觉,如雷声。是音乐中强劲有力的感觉。如果提升过高,则又会混浊不清,造成清晰度不佳,特别是低频响应差和低频过重的音响设备。
2、60Hz--250Hz部分
这段是音乐的低频结构,它们包含了节奏部分的基础音,包括基音、节奏音的主音。它和高中音的比例构成了音色结构的平衡特性。提升这一段可使声音丰满,过度提升会发出隆隆声。衰减这两段会使声音单薄。
3、250Hz--2KHz部分
这段包含了大多数乐器的低频谐波,如果提升过多会使声音像电话里的声音。如把600Hz和1kHz过度提升会使声音像喇叭的声音。如把3kHz提升过多会掩蔽说话的识别音,即口齿不清,并使唇音“mbv”难以分辨。如把1kHz和3kHz过分提升会使声音具有金属感。由于人耳对这一频段比较敏感,通常不调节这一段,过分提升这一段会使听觉疲劳。
4、2KHz--4kHz部分
这段频率属中频,如果提升得过高会掩盖说话的识别音,尤其是3kHz提升过高,会引起听觉疲劳。
5、4kHz--5KHz部分
这是具有临场感的频段,它影响语言和乐器等声音的清晰度。提升这一频段,使人感觉声源与听者的距离显得稍近了一些;衰减5kHz,就会使声音的距离感变远;如果在5kHz左右提出升6dB,则会使整个混合声音的声功率提升
3dB。
6、6kHz--16kHz部分
这一频段控制着音色的明亮度,宏亮度和清晰度。一般来说提升这几段使声音宏亮,但不清晰,不可能会引起齿音过重,衰减时声音变得清晰,但声音不宏亮。
posted @
2005-10-27 13:13 rkind 阅读(196) |
评论 (0) |
编辑 收藏
在mp3随身听的硬件中,影响音质主要有几个因素:解码芯片,EQ算法及耳机。Iriver使用的是菲利普的解码芯片,音质自然有保证,但是要发挥它的功力,必须有出色的EQ设置辅助。如果你是使用2.01版本(1xx系列)或1.01版本(3xx系列)的固件,我建议你用Extrme EQ进行个人设置而不用机器预设的EQ。在我的使用过程中发现预设EQ的低音比较混浊,高音有点破,而用Extrme EQ进行调节可以有效的改善这些情况,从而调出很优秀适合个人听觉习惯的音效。
比起以前版本的UserEQ设置只有高低音的设置,Extrme EQ有着很大的改进,引入了中频的调节,这更有利于我们调节出更出色的音效,更适合玩家的个性设置。Extrme EQ分为五档,每档从-12db到+12db分成八段调节。在经过一段时间的使用及反复尝试后我得出的经验是:第二档容易导致压迫感的出现,要注意不要调得太高,否则会出现背景音“混乱”的感觉;第三档是中频调节,这在人声及背景音效方面有很大的提高,但也必须注意到调得太高容易出现声音的失真;最后一挡是高音的调节,过高的调节容易出现破音现象(有点失望,以前的版本很少有破音现象的出现),也要谨慎调节。我这里介绍一个比较简捷的方法:根据波形的形状进行调节。我的经验是波形的形状越平滑,高中低频断过渡越自然,音效就会越连贯。怎样看波形呢?有个小窍门:在播放状态下,按住EQ键选择EQ时屏幕右下角的小波形就是实际的波形形状。另外各位玩家也可以参考winamp的EQ波形进行调节,可能会有令你惊喜的发现!
在新版本的固件中增加了一个Metal的EQ,感觉有点怪,但是听许多网友说很适合听金属的音乐,因为我很少听此类型的音乐所以并不清楚实际效果如何,喜欢这类型音乐的朋友可以试试。
我的推荐设置: +12,-3,-3,+3,+3 这是我最喜欢的配置,低音表现很好,感觉超越了以前的版本,有力而不发散,而且下潜很好,高中低频也很连贯,高音清晰而不刺耳基本没有破音现象,人声的表现力也不错。基本可以适合所有音乐,如果是用来听摇滚会更好。强烈推荐!!
+12,+3,+3,+3,0在这个EQ设置中可以调节出一种很现场的气氛,,音场的范围缩小了,感觉像是在音乐馆一样,很适合听一些现场的音乐。我用这个配置听Eagles的现场版Hotel Carifonia就很过瘾,背景音乐,观众的欢呼,乐器的表现都相对出色,以前的UserEQ是提供不了这种效果的。
+12,-3,0,+3,+6比较接近以前版本高音14,低音4的效果,我用它来听流行音乐感觉还不错,
以上的EQ设置只是我根据个人的喜好进行的配置,可能并不适合任何人,仅供音乐爱好者进行参考。希望Iriver以后能提供官方的EQ设置,能给爱好者一个设置的参考。由于我本人比较喜欢低音的效果,所以第一档调到了+12db,如果各位嫌高,可以适当降低调出你所满意的效果。
posted @
2005-10-27 13:13 rkind 阅读(182) |
评论 (0) |
编辑 收藏
贝的日子,也结束从父母兄长那里拿钱的幸福时光。
我们从家里搬了出来,提着自己半新不旧的行囊找了间不能再廉价的破房子租了下
来,开始了闯荡的生活。
我们的眼光充满了好奇,我们的血液里流淌着激情,我们的钱夹却空前的瘦小。
在面对第一个老板第一批同事第一份工作的时候,我们是那样的慷慨激昂,我们认
为自己无所不能,我们幻想很快就可以打造一片属于自己的天地,我们对未来充满了信
心。并且希望从别人艳羡的目光中找到一点点骄傲的资本。
可是渐渐的我们才知道,其实现实和自己的理想有着天壤之别。我们发现了老板是
多么的阴险狠毒同事是多么的势利小气工作是多么的枯燥无趣,我们也发现了房租水电
气费把人愁死了。发薪的日子总好像遥不可及,商店里的东西仿佛只是为别人摆设,我
们还发现了只有周末跑到母校瞎逛才感觉释然,只有和老同学一起聊天玩耍才真正开心
只有在步行街上看美女才不无聊。
渐渐的我们也学会了泡吧,酒吧迪吧水吧网吧玩具吧都是我们打发无聊时间的场
所。可是我们还是泡不到妞,以前自以为是的那些爱情理论泡马子技巧在金钱时代都是
狗屁,都出奇的苍白无力。于是我们感叹世界变得太快,快得让我们这些穷小子根本就
无所适从。
渐渐的我们也变得深沉起来,不再为一个很幼稚的笑话就哈哈大笑,不再动不动就
乱发牢骚,也不再把内心深处的秘密轻易地跟别人诉说。我们也说不清楚这到底是成
还是消沉,对着镜子看,却发现里面那张脸陌生得可怕。
渐渐的我们似乎大彻大悟了,什么都看透了,一切都虚无缥缈了,然后我们什么都
很漠然,坐公交车也不让座了,看到小偷偷东西也懒得理了,吃点小亏想想也就算了,
但是我们却在每天下班之前发愁晚餐该吃什么了,在大家一起喝茶的时候盘算着自己
不要买单,在临睡之前把这个月的开支算了又算。
渐渐的我们感觉自己其实什么都不是,没有钱没有名没有地位,身高也太矮了皮肤
也太黑了长相也太难看了,什么都要看人家的脸色,走在哪里都似乎低人一等,有时真
恨不得割脉上吊服毒跳楼自行了断。
渐渐的我们也不想看书了,也不想谈理想了,也不想谈前途了,也不想花太多精力
胡思乱想。我们也不想听音乐了,也不想看电影了,不过倒时常看些成人的碟子,交流
些黄色的笑话。我们开始沉迷于酒液里,沉迷于方城中,沉迷于低级场所内。家的概念
越来越模糊了,亲情的感觉越来越遥远了,除了在梦中偶尔回到家乡之外,我们挺多可
以借助一条冰冷的电话线和家人说说一些开始偏离生活的话,却看不到老爹老妈又长出
了多少根白头发又多了几道皱纹。
看到有人在球场上酣战,我们似乎也想上去来两脚,其实很久没有运动的身体已经
无法支撑我们再跑多远了,而且几乎荒废的球技让我们怀疑自己那些踢球的年岁是不是
上辈子的事。
望着满街穿着前卫的少男少女,我们开始表现出厌恶的表情,却忘了自己前些年其
实有过之而无不及。遇到在大庭广众之下举止亲热的学生情侣,我们的目光也变成了不
屑,并恶狠狠地骂他们伤风败俗。
经过彩票销售点的时候,我们忍不住也掏出一点本该买书的钱来买几注,然后天
天
做梦中了五百万之后多少万买房子多少万买车多少万胡乱挥霍,可是每一次开奖虽然屡
屡有人中头奖却始终与自己无缘,于是在短暂的失望之后,我们依然锲而不舍地做着美
梦。
渐渐的我们的人生观、价值观、爱情观也有所改变。我们已经不认为为了往上爬而
不择手段有什么不妥,我们对努力就有回报的说法嗤之以鼻,我们嘲笑所谓的贞节
观,
所谓的责任感,希望甚至去找寻一夜情。
我们开始关注街上跑的车是宝马还是奥拓,关注哪个酒廊的吧台小姐酒量如何,关
注哪款手机用起来更加叉人眼,关注哪个牌子的西服穿起来更有派头。但也就只是关注
而已,因为我们清楚无论是宝马还是奥拓,我们都买不起,吧台小姐酒量再不行,我
们
也不能把人家怎么样,至于手机和西服,还是用自己买了很久的老款式。
不知从什么时候开始,我们为自己的遭遇感到愤愤不平了,我们越来越看不惯老板
狰狞的面目,越来越无法忍受同事的卑鄙龌龊,越来越不堪就这样生活下去。于是我
在感叹运气不好的同时迫切地想改变自己的命运,我们左顾右盼,寻找机会,却始终看
不到出路。
终于有一天,我们像火山爆发一样,一冲动之下把老板炒了。收拾东西昂然地走
出
办公室的那一刻我们有英雄离去那种豪迈与无悔,只从同事愕然与嘲讽夹杂的眼神中
隐看到一丝无奈,却不知道等待自己的,将是无尽的痛苦与折磨。
我们很快发现了虽然自己拥有并不低的学历和一定的工作经验,并像跑场子一样
从
这家公司跑到那家公司,一次接一次地应聘,可是根本就无法找到适合的工作。
时间一天一天过去,工作依然遥远得不知子丑寅卯,钱包越来越瘪了,交房租的日
子也越来越近了,我们心如火焚,有着世界末日即将来临的惶恐。我们也开始有点后悔
自己太轻率就辞职了,也开始萌生铤而走险的念头,但又不敢真的去抢银行绑架什么
的,心情低沉到了极点,我们的脾气也大了,唉叹声也响了。
所幸这样的日子终于结束了。我们又到了新的工作单位。这时候我们虽然或多或少
有点激动,但更多的是谨慎与惨淡。我们不会再对老板抱什么幻想,不会认为他会给我
们多好的待遇,我们也不会和同事谈什么知心话,因为我们已经知道,不可能与有利益
冲突的人成为朋友,当然我们也不再愚蠢地把这个工作当事业一样拼命,只把这里当
成
自己的一个跳板,一旦有机会就立马走人。
接下来的生活无趣又无味,但我们渐渐的也就无所谓了。我们也不想泡吧了,不想
什么活着的意义了,老同学在一起也开始有点话不投机了,以前很少联系的朋友,现在
更不想去联系了,就算有时候接到他们打来的电话,也只是随便吭吭唷唷的应付几
句。
虽然酒还是经常喝,但很多时候都一个人独饮独醉了。这时候我们的寂寞更是深入骨
髓,我们的苦痛更加真切而细腻。我们空前地怀念在学校的那些岁月,我们会捧着毕业
合照发半天呆,我们却不想再到母校去闲逛了,如果是偶然经过,看到曾经熟悉无比的
景物,心里还真的翻涌起一股酸
楚,但是我们不会流眼泪。毕业时曾经很贱的男儿泪如今又变得珍贵起来。
当然我们也还是经常上网,不过很多时候都是为了打发时间。我们很可能迷上了传
奇之类的游戏,却很少再光顾同学录网页,更不想在上面留言了。
我们无师自通的学会了自欺欺人,虽然我们在夜深梦回时也会憎恨自己的虚伪与
无
为,更讨厌这种猪狗不如的生活方式,但是我们就象被囚禁的鸟,根本就无能为力。有
时候我们会自嘲似的给找很多借口来解释自己的某种行为,尽管我们也知道这样做其
实
毫无意思,也毫无必要。
我们开始不断地听到老同学们结婚的消息、升职的消息。然后我们不经意地就想到
某某在学校时的样子,然后我们不由得感叹时间流逝之无情,然后我们就想在尘封已
久
的日记本上写点什么,然后我们不知不觉地眼角竟然也有点湿润了。
我们夜里躺在床上睁大眼睛,却无法在漆黑中排遣郁闷
我们夜里躺在床上睁大眼睛,却无法在漆黑中排遣郁闷时,就会格外的想有个人陪在身
边。很多往事会像潮水一样向我们扑来。我们曾经暗恋过的人、曾经追求过但失败了的
人、
曾经相爱过的人,都一一地闪过脑海,于是,心里会有种伤感,很纯粹的伤感。因为我
们知
道,爱情其实真的已经与我们离得很远。
我们试着通过各种途径来结交朋友,但是每每交往了几次,我们就不想再与他们来往。
说不清楚是因为他们太过于现实还是我们太封闭。我们于是感慨万千,在这个很多人都
戴面
具生活的社会,原来交一个真正的朋友竟然那么难。我们也试着去约会,可是爱情并非
喝水
吃饭那么简单,到最后都还是以失败告终。高不成低不就的我们继续高举单身的旗帜游
走于
大街小巷。
我们非常怀念学生时代那种单纯的恋情,非常羡慕那些还能坐在教室中的年轻人,非常
希望自己可以再读一次大学,但是我们也知道,泼出去的水怎么能够收回,远逝的时光
如何
可能重来?
我们的酒量越来越大,一打啤酒喝下去一只手指在眼前竖着也无法看成两只手指。我们
的腰越来越粗背越来越宽肚皮越来越大,日渐增多的脂肪很是晃眼。我们爬上楼梯的动
作越
来越笨拙,也越来越吃力,才到三楼就已经气喘吁吁。
我们向往着能到外面去走一走,看一看,却又害怕沦落天涯,苦不堪言。我们越来越觉
得钱钟书老人的围城理论精辟有理。我们越来越体会到人在江湖身不由己的无奈。我们
越来
越感到心力交瘁,压抑茫然。
……
……
可是,以后的路还很长,无论如何,我们得活下去。不管是痛苦还是快乐,我们都要面
对。毕竟想逃避也逃避不了的。所以,我们还是希望,明天是一个阳光灿烂的大好日
子。而
且,我们骨子里仍然相信自己会走出阴霾,出人头地。
再回首,灯火阑珊处没有伊人,只有自己的梦想在风中轻轻地摇曳……
posted @
2005-10-27 13:12 rkind 阅读(219) |
评论 (0) |
编辑 收藏
有位心理学家曾写道,一个成熟称得上真爱的恋情
必须经过四个阶段,那就是:
共存(codependent)
反依赖(counterdependent)
独立(independent)
共生(interdependent)
阶段之间转换所需的时间不一定,因人而易。
第一个阶段:共存。
这是热恋时期,情人不论何时何地总希望能腻在一起。
第二个阶段:反依赖。
等到情感稳定后,
至少会有一方想要有多一点自己的时间作自己想做的事,这时另一方就会感到被
冷落。
第三个阶段:独立。
这是第二个阶段的延续,要求更多独立自主的时间。
第四个阶段:共生。
这时新的相处之道已经成形,
你(妳)的他(她)已经成为你(妳)最亲的人。
你们在一起相互扶持、一起开创属于你们自己的人生。
你们在一起不会互相牵绊,而会互相成长。
但是,大部分的人都通不过第二或第三阶段,
而选择分手一途,这是非常可惜的。
很多事只要好好沟通都会没事的,不要耍个性,
不要想太多要互相信任,这样第二、三阶段的时间就会缩短。
和所爱的人相遇相恋是非常不容易的,不要轻言放弃。
两人相聚是因为有缘,相知是因为有心,真的得好好珍惜这福份莫说分手不是
无由,
希望看到上述的四个阶段,
真能给大家一些启示与领悟并惜缘
我们会逐渐变成我们所爱的人。
妳和他本来没有相同之处,外表不相像,性格也是南辕北辙,一旦爱上了,年深
日久,
妳会惊讶妳的眼睛有点像他的眼睛,他的微笑也有点像妳的微笑。
你们走路的步伐也有点相似,说话的语气也愈来愈相像。他的脖子上有一颗痣,
一天,妳发现自己脖子上也多了一颗痣,原来我们会变成我们所爱的人。
妳本来喜欢脚踏实地的人,而他一向比较轻佻,但你们爱上了,
他竟会不知不觉变成一个老实人,这个改变,连他自己也不曾察觉。
他本来喜欢活泼的女孩子,却爱上了拘谨的妳,这些日子,妳竟愈来愈活泼,
妳差点认不出自己。我们会逐渐变成对方理想中的人,这种改变,
绝对不是刻意的。两个人愈爱得长久,气质也愈来愈相近,
妳曾经以为他不是妳梦寐以求的那种类型,然而,有一天,妳惊讶地发现,
他已经变成妳喜欢的那种类型,妳不必再到处寻觅,他就是妳要找的人。
深深爱着一个人的时候,妳原来真的会一点一点的失去自己,
为甚么妳还会觉得快乐呢?
大概是因为妳在失去的当儿,也是赚了,妳把他的气质和他的微笑都赚回来..
幸福很单纯...
所以要很单纯的人才容易获得.....
与我亲爱的朋友们分享之
posted @
2005-10-27 13:11 rkind 阅读(237) |
评论 (0) |
编辑 收藏
Struts和JSF/Tapestry都属于表现层框架,这两种分属不同性质的框架,后者是一种事件驱动型的组件模型,而Struts只是单纯的MVC模式框架,老外总是急吼吼说事件驱动型就比MVC模式框架好,何以见得,我们下面进行详细分析比较一下到底是怎么回事?
首先事件是指从客户端页面(浏览器)由用户操作触发的事件,Struts使用Action来接受浏览器表单提交的事件,这里使用了Command模式,每个继承Action的子类都必须实现一个方法execute。
在Struts中,实际是一个表单Form对应一个Action类(或DispatchAction),换一句话说:在Struts中实际是一个表单只能对应一个事件,Struts这种事件方式称为application event,application event和Component event相比是一种粗粒度的事件。
Struts重要的表单对象ActionForm是一种对象,它代表了一种应用,这个对象中至少包含几个字段,这些字段是Jsp页面表单中的input字段,因为一个表单对应一个事件,所以,当我们需要将事件粒度细化到表单中这些字段时,也就是说,一个字段对应一个事件时,单纯使用Struts就不太可能,当然通过结合JavaScript也是可以转弯实现的。
而这种情况使用JSF就可以方便实现
<h:inputText id="userId" value="#{login.userId}">
<f:valueChangeListener type="logindemo.UserLoginChanged" />
</h:inputText> |
#{login.userId}表示从名为login的JavaBean的getUserId获得的结果,这个功能使用struts也可以实现,name="login" property="userId"
关键是第二行,这里表示如果userId的值改变并且确定提交后,将触发调用类UserLoginChanged的processValueChanged(...)方法。
JSF可以为组件提供两种事件:Value Changed和 Action. 前者我们已经在上节见识过用处,后者就相当于struts中表单提交Action机制,它的JSF写法如下:
<h:commandButton id="login" commandName="login">
<f:actionListener type=”logindemo.LoginActionListener” />
</h:commandButton> |
从代码可以看出,这两种事件是通过Listerner这样观察者模式贴在具体组件字段上的,而Struts此类事件是原始的一种表单提交Submit触发机制。如果说前者比较语言化(编程语言习惯做法类似Swing编程);后者是属于WEB化,因为它是来自Html表单,如果你起步是从Perl/PHP开始,反而容易接受Struts这种风格。
基本配置
Struts和JSF都是一种框架,JSF必须需要两种包JSF核心包、JSTL包(标签库),此外,JSF还将使用到Apache项目的一些commons包,这些Apache包只要部署在你的服务器中既可。
JSF包下载地址:http://java.sun.com/j2ee/javaserverfaces/download.html选择其中Reference Implementation。
JSTL包下载在http://jakarta.apache.org/site/downloads /downloads_taglibs-standard.cgi
所以,从JSF的驱动包组成看,其开源基因也占据很大的比重,JSF是一个SUN伙伴们工业标准和开源之间的一个混血儿。
上述两个地址下载的jar合并在一起就是JSF所需要的全部驱动包了。与Struts的驱动包一样,这些驱动包必须位于Web项目的WEB-INF/lib,和Struts一样的是也必须在web.xml中有如下配置:
<web-app>
<servlet>
<servlet-name>Faces Servlet</servlet-name>
<servlet-class>javax.faces.webapp.FacesServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Faces Servlet</servlet-name>
<url-pattern>*.faces</url-pattern>
</servlet-mapping>
</web-app> |
这里和Struts的web.xml配置何其相似,简直一模一样。
正如Struts的struts-config.xml一样,JSF也有类似的faces-config.xml配置文件:
<faces-config>
<navigation-rule>
<from-view-id>/index.jsp</from-view-id>
<navigation-case>
<from-outcome>login</from-outcome>
<to-view-id>/welcome.jsp</to-view-id>
</navigation-case>
</navigation-rule>
<managed-bean>
<managed-bean-name>user</managed-bean-name>
<managed-bean-class>com.corejsf.UserBean</managed-bean-class>
<managed-bean-scope>session</managed-bean-scope>
</managed-bean>
</faces-config> |
在Struts-config.xml中有ActionForm Action以及Jsp之间的流程关系,在faces-config.xml中,也有这样的流程,我们具体解释一下Navigation:
在index.jsp中有一个事件:
<h:commandButton label="Login" action="login" /> |
Action的值必须匹配form-outcome值,上述Navigation配置表示:如果在index.jsp中有一个login事件,那么事件触发后下一个页面将是welcome.jsp
JSF有一个独立的事件发生和页面导航的流程安排,这个思路比struts要非常清晰。
managed-bean类似Struts的ActionForm,正如可以在struts-config.xml中定义ActionForm的scope一样,这里也定义了managed-bean的scope为session。
但是如果你只以为JSF的managed-bean就这点功能就错了,JSF融入了新的Ioc模式/依赖性注射等技术。
Ioc模式
对于Userbean这样一个managed-bean,其代码如下:
public class UserBean {
private String name;
private String password;
// PROPERTY: name
public String getName() { return name; }
public void setName(String newValue) { name = newValue; }
// PROPERTY: password
public String getPassword() { return password; }
public void setPassword(String newValue) { password = newValue; }
}
<managed-bean>
<managed-bean-name>user</managed-bean-name>
<managed-bean-class>com.corejsf.UserBean</managed-bean-class>
<managed-bean-scope>session</managed-bean-scope>
<managed-property>
<property-name>name</property-name>
<value>me</value>
</managed-property>
<managed-property>
<property-name>password</property-name>
<value>secret</value>
</managed-property>
</managed-bean> |
faces-config.xml这段配置其实是将"me"赋值给name,将secret赋值给password,这是采取Ioc模式中的Setter注射方式。
Backing Beans
对于一个web form,我们可以使用一个bean包含其涉及的所有组件,这个bean就称为Backing Bean, Backing Bean的优点是:一个单个类可以封装相关一系列功能的数据和逻辑。
说白了,就是一个Javabean里包含其他Javabean,互相调用,属于Facade模式或Adapter模式。
对于一个Backing Beans来说,其中包含了几个managed-bean,managed-bean一定是有scope的,那么这其中的几个managed-beans如何配置它们的scope呢?
<managed-bean>
...
<managed-property>
<property-name>visit</property-name>
<value>#{sessionScope.visit}</value>
</managed-property> |
这里配置了一个Backing Beans中有一个setVisit方法,将这个visit赋值为session中的visit,这样以后在程序中我们只管访问visit对象,从中获取我们希望的数据(如用户登陆注册信息),而visit是保存在session还是application或request只需要配置既可。
UI界面
JSF和Struts一样,除了JavaBeans类之外,还有页面表现元素,都是是使用标签完成的,Struts也提供了struts-faces.tld标签库向JSF过渡。
使用Struts标签库编程复杂页面时,一个最大问题是会大量使用logic标签,这个logic如同if语句,一旦写起来,搞的JSP页面象俄罗斯方块一样,但是使用JSF标签就简洁优美:
<jia:navigatorItem name="inbox" label="InBox"
icon="/images/inbox.gif"
action="inbox"
disabled="#{!authenticationBean.inboxAuthorized}"/> |
如果authenticationBean中inboxAuthorized返回是假,那么这一行标签就不用显示,多干净利索!
先写到这里,我会继续对JSF深入比较下去,如果研究过Jdon框架的人,可能会发现,Jdon框架的jdonframework.xml中service配置和managed-bean一样都使用了依赖注射,看来对Javabean的依赖注射已经迅速地成为一种新技术象征,如果你还不了解Ioc模式,赶紧补课。
posted @
2005-10-27 13:07 rkind 阅读(165) |
评论 (0) |
编辑 收藏
| Struts常见错误汇总 |
以下所说的struts-config.xml和ApplicationResources.properties等文件名是缺省时使用的,如果你使用了多模块,或指定了不同的资源文件名称,这些名字要做相应的修改。
1、“No bean found under attribute key XXX”
在struts-config.xml里定义了一个ActionForm,但type属性指定的类不存在,type属性的值应该是Form类的全名。或者是,在Action的定义中,name或attribute属性指定的ActionForm不存在。
2、“Cannot find bean XXX in any scope”
在Action里一般会request.setAttribute()一些对象,然后在转向的jsp文件里(用tag或request.getAttribute()方法)得到这些对象并显示出来。这个异常是说jsp要得到一个对象,但前面的Action里并没有将对象设置到request(也可以是session、servletContext)里。
可能是名字错了,请检查jsp里的tag的一般是name属性,或getAttribute()方法的参数值;或者是Action逻辑有问题没有执行setAttribute()方法就先转向了。
还有另外一个可能,纯粹是jsp文件的问题,例如<logic:iterate>会指定一个id值,然后在循环里<bean:write>使用这个值作为name的值,如果这两个值不同,也会出现此异常。(都是一个道理,request里没有对应的对象。)
3、“Missing message for key "XXX"”
缺少所需的资源,检查ApplicationResources.properties文件里是否有jsp文件里需要的资源,例如:
<bean:message key="msg.name.prompt"/>
这行代码会找msg.name.prompt资源,如果AppliationResources.properties里没有这个资源就会出现本异常。在使用多模块时,要注意在模块的struts-config-xxx.xml里指定要使用的资源文件名称,否则当然什么资源也找不到,这也是一个很容易犯的错误。
4、“No getter method for property XXX of bean teacher”
这条异常信息说得很明白,jsp里要取一个bean的属性出来,但这个bean并没有这个属性。你应该检查jsp中某个标签的property属性的值。例如下面代码中的cade应该改为code才对:
<bean:write name="teacher" property="cade" filter="true"/>
5、“Cannot find ActionMappings or ActionFormBeans collection”
待解决。
6、“Cannot retrieve mapping for action XXX”
在.jsp的<form>标签里指定action='/XXX',但这个Action并未在struts-config.xml里设置过。
7、HTTP Status 404 - /xxx/xxx.jsp
Forward的path属性指向的jsp页面不存在,请检查路径和模块,对于同一模块中的Action转向,path中不应包含模块名;模块间转向,记住使用contextRelative="true"。
8、没有任何异常信息,显示空白页面
可能是Action里使用的forward与struts-config.xml里定义的forward名称不匹配。
9、“The element type "XXX" must be terminated by the matching end-tag "XXX".”
这个是struts-config.xml文件的格式错误,仔细检查它是否是良构的xml文件,关于xml文件的格式这里就不赘述了。
10、“Servlet.init() for servlet action threw exception”
一般出现这种异常在后面会显示一个关于ActionServlet的异常堆栈信息,其中指出了异常具体出现在代码的哪一行。我曾经遇到的一次提示如下:
java.lang.NullPointerException
at org.apache.struts.action.ActionServlet.parseModuleConfigFile(ActionServlet.java:1003)
at org.apache.struts.action.ActionServlet.initModuleConfig(ActionServlet.java:955)
为解决问题,先下载struts的源码包,然后在ActionServlet.java的第1003行插入断点,并对各变量进行监视。很丢人,我竟然把struts-config.xml文件弄丢了,因此出现了上面的异常,应该是和CVS同步时不小心删除的。
11、“Resources not defined for Validator”
这个是利用Validator插件做验证时可能出现的异常,这时你要检查validation.xml文件,看里面使用的资源是否确实有定义,form的名称是否正确,等等。 |
posted @
2005-10-27 13:06 rkind 阅读(225) |
评论 (0) |
编辑 收藏
Jbuilder2006自带了1.5的JDK,但如果你还想继续用JDK1.42,如果只是在Jbuilder2006的tool->configure->JDKs中添加一个JDK1.42或更低版本,那么即使你只写一个最简单的HelloWorld程序,Jbuilder2006都会给你报出长长一串错误,编写的代码在Jbuilder2005中也无法运行。我在刚使用Jbuilder2006时,被这个问题困惑了好久,在网上查了好久也没有找到解决的方法。
今天花了两个小时,终于在Jbuilder2006的帮助中查到了问题的原因。Jbuilder2006在运行编译工程时,会针对特定版本的VM进行编译,默认的是Java 2 SDK, v 5.0 And Late,因此,如果工程用的是1.5以下的JDK,碰到都是java.lang.UnsupportedClassVersionError这个错误。
解决的办法其实很简单,只要更改这个选项就行了。具体步骤如下:
----------------------------------------------------------
1、右键点击工程文件,选择属性(properties),
2、在属性窗口中选择 Build-->Java,在右边的选项中有四个下拉框,就可以看到编译选项了,
3、其中Compiler和Debug Option可以不用管,只在Languege features和Target VM中选择相应的JDK版本就可以了,然后确定,一切OK。
附件中是配置的图片。
-----------------------------------------------------------
如果在Target VM中选择了All Java SDKs,那么你的class文件在使用JDK1.1的VM上都可以运行(Jbuilder2006帮助中是这么说的,估计没几个人的机子上还在用JDK1.1吧 :-)
posted @
2005-10-27 13:06 rkind 阅读(297) |
评论 (0) |
编辑 收藏打算要做一个工作总结平台,考虑到要实现周工作总结的功能就得先把一年先按某周某周区分开来,查了查Api
采用了calendar类,并把最后分的结果传到数据库,
year week content
2005 1 1月3日~1月9日
... ... ....................
源码如下(其中DB类是我用来实现数据库连接用的)
import java.util.*;
import java.util.Date;
import java.sql.*;
import rkind.db;
public class shijian {
public static void main(String args[]){
int day,mon,year,week,dayofweek;
db base=new db();
String content="";
Calendar nova = Calendar.getInstance();
Date d1=new Date();
nova.setTime(d1);
nova.set(2005,Calendar.JANUARY,1);
//nova.add(Calendar.DATE,6);
//day=nova.get(Calendar.WEEK_OF_YEAR );
dayofweek=nova.get(Calendar.DAY_OF_WEEK );
while(dayofweek!=2){
nova.add(Calendar.DATE,1);
dayofweek=nova.get(Calendar.DAY_OF_WEEK );
}
year=nova.get(Calendar.YEAR);
//String sql=new String("insert into shijian(year,week,content) values('"+year+"','"+week+"','"+content+"')");
//System.out.println("day+++:"+day);
while(year==2005){
week=nova.get(Calendar.WEEK_OF_YEAR );
mon=nova.get(Calendar.MONTH)+1;
day=nova.get(Calendar.DATE);
content=mon+"月"+day+"日"+"~~ ";
System.out.print("第"+week+"周"+": "+mon+"月"+day+"日");
nova.add(Calendar.DATE,6);
week=nova.get(Calendar.WEEK_OF_YEAR );
mon=nova.get(Calendar.MONTH)+1;
day=nova.get(Calendar.DATE);
content+=mon+"月"+day+"日";
try{
String sql=new String("insert into shijian(year,week,content) values('"+year+"','"+week+"','"+content+"')");
base.executeUpdate(sql);
}catch(Exception e){System.out.println(e);}
System.out.println("~~~~"+mon+"月"+day+"日");
nova.add(Calendar.DATE,1);
week=nova.get(Calendar.WEEK_OF_YEAR );
mon=nova.get(Calendar.MONTH)+1;
day=nova.get(Calendar.DATE);
year=nova.get(Calendar.YEAR);
}
}
}
虽然功能上实现了,但是还有大量的重复代码,和费语句,这就是没有好好重视J2se的结果,没办法,
边学J2EE边看Se吧,:)
posted @
2005-10-27 13:05 rkind 阅读(211) |
评论 (0) |
编辑 收藏今天在Mysql中建立了一个名叫Option的表,结果无论如何都不能访问,后来换了个名字就OK了,应而想到了是Mysql的保留字,搜了一下,发现以下字段都是它的保留字
action add aggregate all
alter after and as
asc avg avg_row_length auto_increment
between bigint bit binary
blob bool both by
cascade case char character
change check checksum column
columns comment constraint create
cross current_date current_time current_timestamp
data database databases date
datetime day day_hour day_minute
day_second dayofmonth dayofweek dayofyear
dec decimal default delayed
delay_key_write delete desc describe
distinct distinctrow double drop
end else escape escaped
enclosed enum explain exists
fields file first float
float4 float8 flush foreign
from for full function
global grant grants group
having heap high_priority hour
hour_minute hour_second hosts identified
ignore in index infile
inner insert insert_id int
integer interval int1 int2
int3 int4 int8 into
if is isam join
key keys kill last_insert_id
leading left length like
lines limit load local
lock logs long longblob
longtext low_priority max max_rows
match mediumblob mediumtext mediumint
middleint min_rows minute minute_second
modify month monthname myisam
natural numeric no not
null on optimize option
optionally or order outer
outfile pack_keys partial password
precision primary procedure process
processlist privileges read real
references reload regexp rename
replace restrict returns revoke
rlike row rows second
select set show shutdown
smallint soname sql_big_tables sql_big_selects
sql_low_priority_updates sql_log_off sql_log_update sql_select_limit
sql_small_result sql_big_result sql_warnings straight_join
starting status string table
tables temporary terminated text
then time timestamp tinyblob
tinytext tinyint trailing to
type use using unique
unlock unsigned update usage
values varchar variables varying
varbinary with write when
where year year_month zerofill
posted @
2005-10-27 13:05 rkind 阅读(284) |
评论 (0) |
编辑 收藏最近用JSP做新闻发布时发现,用rs.getString()获得的字符串里面空格和换行都表现不出来,
先分析原因,我用的是Mysql数据库,新闻内容采用的是Text类型,查看数据库中上传的新闻发现里面换行和空格都能表现出来,这就说明,肯定是用Rs.getstring时显示的问题,先查看了Java.sql.*的Api想用别的Get方法,试了几个结果都不行,
网上也有这样类似的问题,但大多是在Servlet里面或者Bean里面专门的做一个函数解决的,我觉得这样做很复杂
最后终于找到了的解决方法,在调用Rs.getstring的页面里面的表格中加入style="word-break:break-all"
并用<pre>rs.getString()<>标签来显示就解决了换行的问题。其中<pre></pre>这句话一定不能少
然而加入这些以后,当一行内容过长时,表格依然会被撑开,需要在表格胡Style属性修改成style="table-layout: fixed; word-wrap: break-word" 这样才能真正解决中文撑开表格的问题。
posted @
2005-10-27 13:04 rkind 阅读(317) |
评论 (0) |
编辑 收藏安全域是Tomcat服务器中用来保护Web应用资源的一种机制,在安全域中可以配置安全验证信息,即用户以及用户和角色的映射关系,每个用户可以拥有一或多个角色,每个角色限定了可以用来访问的WEb资源
它包括以下四种类型
1 内存域 MemoryRealm 从XML中读取安全验证信息,并把它们以一组对象的形式存放在内存中
2 Jdbc域 JDBCREALM 通过JDBC驱动访问存放在数据库中的安全验证信息,
3 数据源域 DataSouceRealm 通过JNDI数据源访问存在数据库中安全信息
4Jndi 域 JNDIRealm 通过JNDI provider访问基于LDAP的目录服务器中安全验证信息
配置过程有以下2部
1为WEB资源设置安全约束
(1)在web.xml中加入<sercurity-constraint>元素,对要过滤的文件类型限制
(2)在WEB中加入<logiin-config> Tomcat中支持三种验证方法,1基本验证,2摘要验证3基于表单验证
摘要验证其实就是对第一种方法进行过密码加密的方法,而表单验证是通过自己的做的longin的页面实现
(3)在web.xml中加入<security-role>元素指明手所有角色的名字
2在CONF/SERVER.XML中配置REALM,这个元素中指定安全域的类名以及相关属性。
需要注意的是内存域是把用户和角色数据存放在Tomcat-users.xml中
后2种都是存放在数据库中,尤其是配置数据源域的时候,一定要把DATASOURCE存放在《GlobalNamingResouces》标签下,否则虽然能正常使用但做验证时会访问不到数据库,不能验证成功
posted @
2005-10-27 13:04 rkind 阅读(223) |
评论 (0) |
编辑 收藏前两天得到了一个成绩的数据库,可是是DBF的,因为想在Mysql环境中做一个成绩分析,可是没办法导入
,于是先导入SQlsever2000中,想生成SQL脚本,然后再在Mysql Front中改入。SQL文件,可是发现导出来的脚本只有创建表的SQL脚本,没有数据的脚本,无奈,
后来又想找个软件试一下,下了一个什么DBF To Mysql 在未破解的情况下,只可以导入6行数据(!汗)
用了破解补丁以后导入的时候出错,软件上说库限制的是8M,可是我的库只有6M多一点,试了几次也不行
然后只好继续用Sql2000试,选导出的时候发现可以选择导出文本和CSV文件,而在我的MYsqlfront里面支持导
入CSV文件,于是先用SQl2000导出文本文件,把后缀名改为CSv,再从Mysql中一导入OK,
后来在使用中才发现,用这种方法导入以后,有的是Char类型的字段在Mysql front中被认为是Int类型的,
可是在Phpmyadmin中字段显示正常。
posted @
2005-10-27 13:03 rkind 阅读(862) |
评论 (0) |
编辑 收藏Datasource对象是由Tomcat提供的,因而需要使用JNDI来获得Datasouce
在Javax.naming 中提供了Context接口,
数据源的配置涉及到Server.xml和web.xml,需要在server.xml中加入如下内容:说明一下:我的数据库是MYsql
<Context path="/text" docBase="d:/upload" debug="0">
<Resource name="jdbc/testDb" auth="Container"
type="javax.sql.DataSource"/>
<ResourceParams name="jdbc/testDB">\\数据源的名称
<parameter><name>username</name><value>root</value></parameter>数据库的名称
<parameter><name>password</name><value>password</value></parameter>数据库密码
<parameter><name>driverClassName</name>
<value>org.gjt.mm.mysql.Driver</value></parameter>\\要加载的驱动
<parameter><name>url</name>
<value>jdbc:mysql://172.20.0.73/rk?</value></parameter>\\要连接的URL
</ResourceParams>
</Context>
具体还有一些详细的选项例如:MaxActive等,参加Server.xml中说明
另外在Web.xml中加入如下内容:
<description>test connection</description>\\描述
<res-ref-name>jdbc/testDB</res-ref-name>\\名称与上对应
<res-type>javax.sql.DataSource</res-type>\\与上对应
<res-auth>Container</res-auth>\\与上一置
</resource-ref>
配置以上内容后,只要在你的Jsp或Javabean 中按以下方式创建连接,就可以
Context ctx=new InitialContext();
DataSource ds=(DataSource)ctx.lookup("java:comp/env/jdbc/testDB");
conn = ds.getConnection();
以上代码均测试成功,但是在Server.xml中配置数据库的URL中我不能加入useUnicode=true&characterEncoding=GBK,所以从数据库中取出来的汉字都是????
刚刚解决了上面的问题,可以这样加入
jdbc:mysql://172.20.0.73/rk?useUnicode=true&characterEncoding=GBK
因为&是特殊字符
我用如下代码来解决这个问题:
public static String toChinese(String strvalue) {
try{
if(strvalue==null)
{
return null;
}
else {
strvalue = new String(strvalue.getBytes("ISO8859_1"), "GBK");
return strvalue;
}
}catch(Exception e){
return null;
}
}
写Blog 的时候停了几次电,真是郁闷,数据库的连接池的概念我现在还是不太清晰,加强学习,看书去了1
posted @
2005-10-27 13:03 rkind 阅读(256) |
评论 (0) |
编辑 收藏今天做了一个新闻上传的页面,遇到一些问题
首先是数据库的设计,考虑新闻有一个优先级的问题,因些我在表中需要设置一个recommand的字段,我想设成一个布尔类型,可是发现在mysql里面没有这种类型,查查了都推荐使用ENUM这种类型,可以设置两个值
一个设成true一个设成false,然后我在JSP中就可以通过Insert一个布尔值往这个字段传值,
今天在表单中使用了单选框,原来以为需要使用request.getparameterValus,后来发现不用
最后在上传新闻的过程中,tomcat提示一个叫invalid column 什么 key的错误,调试了很多次才发现是表中的
有一个ID 的主建,本来是自动增长的,可是死了几次机,居然变成不是自动增长的,狂晕
这几天电压总是不够,一天死很多次机,搞的现在一个劲按ctrl+s
posted @
2005-10-27 13:02 rkind 阅读(186) |
评论 (0) |
编辑 收藏今天在原来上传文件页面的基础上,想添加一段文件的简介
因为同时要上传文件,所以ENCTYPE="multipart/form-data" 必须要加在form里面
可是这样的话,我再servlet里面用request.getParameter()方法无论如何都只是获得null值,
不是一般的郁闷,百度了一下,有人出现了同样的问题可是它用的是jspsmartupload组件实现文件上传的,
而我用的commons fileupload组件,仔细看了一下这个组件的api,可是英语太差了,没有发现相关的信息
我又尝试用session传递参数,可是发现有点麻烦,因为在表单提交之时你就得赋给session表单上它的数值,
这似乎要javascript,可是偶也不会,
后来只有google了,搜索了一些中文网页,也没有找到资料,试试不限制语言,呵呵呵,一大片,后来被俺发
现了这个
I cannot read the submitter using request.getParameter("submitter") (it returns null). ]
Situation:
javax.servlet.HttpServletRequest.getParameter(String) returns null when the ContentType is multipart/form-data
Solutions:
Solution A:
1. download http://www.servlets.com/cos/index.html
2. invoke getParameters() on com.oreilly.servlet.MultipartRequest
Solution B:
1. download http://jakarta.apache.org/commons/sandbox/fileupload/
2. invoke readHeaders() in
org.apache.commons.fileupload.MultipartStream
Solution C:
1. download http://users.boone.net/wbrameld/multipartformdata/
2. invoke getParameter on
com.bigfoot.bugar.servlet.http.MultipartFormData
Solution D:
Use Struts. Struts 1.1 handles this automatically.
说是不详细,接着往下看,另一种解决方法
> Solution B:
> 1. download
> http://jakarta.apache.org/commons/sandbox/fileupload/
> 2. invoke readHeaders() in
> org.apache.commons.fileupload.MultipartStream
The Solution B as given by my dear friend is a bit hectic and a bit complex :(
We can try the following solution which I found much simpler (at least in usage).
1. Download one of the versions of UploadFile from http://jakarta.apache.org/commons/fileupload/
2. Invoke parseRequest(request) on org.apache.commons.fileupload.FileUploadBase which returns list of org.apache.commons.fileupload.FileItem objects.
3. Invoke isFormField() on each of the FileItem objects. This determines whether the file item is a form paramater or stream of uploaded file.
4. Invoke getFieldName() to get parameter name and getString() to get parameter value on FileItem if it's a form parameter. Invoke write(java.io.File) on FileItem to save the uploaded file stream to a file if the FileItem is not a form parameter.
按照上面的步骤来,果然一切都ok,GOOGLE真不错,主要是getFieldName和getString,
虽然说这种做法有一点麻烦,但稍微判断加工一下,总比获取不到强
posted @
2005-10-27 13:01 rkind 阅读(894) |
评论 (0) |
编辑 收藏
大家在JSP的开发过程中,经常出现中文乱码的问题,可能一至困扰着您,我现在把我在JSP开发中遇到的中文乱码的问题及解决办法写出来供大家参考。
一、JSP页面显示乱码
下面的显示页面(display.jsp)就出现乱码:
<html>
<head>
<title>JSP的中文处理</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
</head>
<body>
<%
out.print("JSP的中文处理");
%>
</body>
</html>
对不同的WEB服务器和不同的JDK版本,处理结果就不一样。原因:服务器使用的编码方式不同和浏览器对不同的字符显示结果不同而导致的。解决办法:在JSP页面中指定编码方式(gb2312),即在页面的第一行加上:<%@ page contentType="text/html; charset=gb2312"%>,就可以消除乱码了。完整页面如下:
<%@ page contentType="text/html; charset=gb2312"%>
<html>
<head>
<title>JSP的中文处理</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
</head>
<body>
<%
out.print("JSP的中文处理");
%>
</body>
</html>
二、表单提交中文时出现乱码
下面是一个提交页面(submit.jsp),代码如下:
<html>
<head>
<title>JSP的中文处理</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
</head>
<body>
<form name="form1" method="post" action="process.jsp">
<div align="center">
<input type="text" name="name">
<input type="submit" name="Submit" value="Submit">
</div>
</form>
</body>
</html>
下面是处理页面(process.jsp)代码:
<%@ page contentType="text/html; charset=gb2312"%>
<html>
<head>
<title>JSP的中文处理</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
</head>
<body>
<%=request.getParameter("name")%>
</body>
</html>
如果submit.jsp提交英文字符能正确显示,如果提交中文时就会出现乱码。原因:浏览器默认使用UTF-8编码方式来发送请求,而UTF-8和GB2312编码方式表示字符时不一样,这样就出现了不能识别字符。解决办法:通过request.seCharacterEncoding("gb2312")对请求进行统一编码,就实现了中文的正常显示。修改后的process.jsp代码如下:
<%@ page contentType="text/html; charset=gb2312"%>
<%
request.seCharacterEncoding("gb2312");
%>
<html>
<head>
<title>JSP的中文处理</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
</head>
<body>
<%=request.getParameter("name")%>
</body>
</html>
三、数据库连接出现乱码
只要涉及中文的地方全部是乱码,解决办法:在数据库的数据库URL中加上useUnicode=true&characterEncoding=GBK就OK了。
四、数据库的显示乱码
在mysql4.1.0中,varchar类型,text类型就会出现中文乱码,对于varchar类型把它设为binary属性就可以解决中文问题,对于text类型就要用一个编码转换类来处理,实现如下:
public class Convert {
/** 把ISO-8859-1码转换成GB2312
*/
public static String ISOtoGB(String iso){
String gb;
try{
if(iso.equals("") || iso == null){
return "";
}
else{
iso = iso.trim();
gb = new String(iso.getBytes("ISO-8859-1"),"GB2312");
return gb;
}
}
catch(Exception e){
System.err.print("编码转换错误:"+e.getMessage());
return "";
}
}
}
把它编译成class,就可以调用Convert类的静态方法ISOtoGB()来转换编码。
如果你还有什么不懂之处:我给大家推荐一个好的JSP-JAVA网站:
http://www.phy.hbnu.edu.cn/dsp/
Linux和Java是互联网的宠儿,更是互联网时代的两头雄师, Linux的网络安全性和开放源代码,Java的平台独立性和安全易用性,正好符合Internet平台的要求,Linux和Java真是天生一对鸳鸯。双狮资源网给你提供了最好的Linux和Java学习资源, 欢迎大家多多访问并宣传:
http://www.phy.hbnu.edu.cn/dsp/
posted @
2005-10-27 13:00 rkind 阅读(169) |
评论 (0) |
编辑 收藏
前言:
本来我都是使用JBuilderX当主力IDE、但使用了Eclipse后
发现...Eclipse原来也这么好用...渐渐的就爱上了它......
Eclipse优点:免费、程序代码排版功能、有中文化包、可增
设许多功能强大的外挂、支持多种操作系统(Windows、
Linux、Solaris、Mac OSX)..等等。
开此篇讨论串的目的,是希望能将Eclipse的一些使用技巧集
合起来...欢迎大家继续补充下去...由于Eclipse的版本众多
,希望补充的先进们能顺便说明一下您所使用的版本~
Eclipse网站:
http://www.eclipse.org/
Eclipse中文化教学:JavaWorld站内文章参考
(使用版本:Eclipse 2.1.2 Release + 中文化)
热键篇:
Template:Alt + /
修改处:窗口->喜好设定->工作台->按键->编辑->内容辅助。
个人习惯:Shift+SPACE(空白)。
简易说明:编辑程序代码时,打sysout +Template启动键,就
会自动出现:System.out.println(); 。
设定Template的格式:窗口->喜好设定->Java->编辑器->模板。
程序代码自动排版:Ctrl+Shift+F
修改处:窗口->喜好设定->工作台->按键->程序代码->格式。
个人习惯:Alt+Z。
自动排版设定:窗口->喜好设定->Java->程序代码格式制作程序。
样式页面->将插入tab(而非空格键)以内缩,该选项取消勾选
,下面空格数目填4,这样在自动编排时会以空格4作缩排。
快速执行程序:Ctrl + F11
个人习惯:ALT+X
修改处:窗口->喜好设定->工作台->按键->执行->启动前一次的启动作业。
简易说明:第一次执行时,它会询问您执行模式,
设置好后,以后只要按这个热键,它就会快速执行。
<ALT+Z(排版完)、ATL+X(执行)>..我觉得很顺手^___^
自动汇入所需要的类别:Ctrl+Shift+O
简易说明:
假设我们没有Import任何类别时,当我们在程序里打入:
BufferedReader buf =
new BufferedReader(new InputStreamReader(System.in));
此时Eclipse会警示说没有汇入类别,这时我们只要按下Ctrl+Shift+O
,它就会自动帮我们Import类别。
查看使用类别的原始码:Ctrl+鼠标左键点击
简易说明:可以看到您所使用类别的原始码。
将选取的文字批注起来:Ctrl+/
简易说明:Debug时很方便。
修改处:窗口->喜好设定->工作台->按键->程序代码->批注
视景切换:Ctrl+F8
个人习惯:Alt+S。
修改处:窗口->喜好设定->工作台->按键->窗口->下一个视景。
简易说明:可以方便我们快速切换编辑、除错等视景。
密技篇:
一套Eclipse可同时切换,英文、繁体、简体显示:
1.首先要先安装完中文化包。
2.在桌面的快捷方式后面加上参数即可,
英文-> -nl "zh_US"
繁体-> -nl "zh_TW"
简体-> -nl "zh_CN"。
(其它语系以此类推)
像我2.1.2中文化后,我在我桌面的Eclipse快捷方式加入参数-n1 "zh_US"。
"C:\Program Files\eclipse\eclipse.exe" -n "zh_US"
接口就会变回英文语系噜。
利用Eclipse,在Word编辑文书时可不必将程序代码重新编排:
将Eclipse程序编辑区的程序代码整个复制下来(Ctrl+C),直接贴(Ctrl+V)到
Word或WordPad上,您将会发现在Word里的程序代码格式,跟Eclipse
所设定的完全一样,包括字型、缩排、关键词颜色。我曾试过JBuilder
、GEL、NetBeans...使用复制贴上时,只有缩排格式一样,字型、颜
色等都不会改变。
外挂篇:
外挂安装:将外挂包下载回来后,将其解压缩后,您会发现features、
plugins这2个数据夹,将里面的东西都复制或移动到Eclipse的features
、plugins数据夹内后,重新启动Eclipse即可。
让Eclipse可以像JBuilderX一样使用拖拉方式建构GUI的外挂:
1.Jigloo SWT/Swing GUI Builder :
http://cloudgarden.com/jigloo/index.html
下载此版本:Jigloo plugin for Eclipse (using Java 1.4 or 1.5)
安装后即可由档案->新建->其它->GUI Form选取要建构的GUI类型。
2.Eclipse Visual Editor Project:
http://www.eclipse.org/vep/
点选下方Download Page,再点选Latest Release 0.5.0进入下载。
除了VE-runtime-0.5.0.zip要下载外,以下这2个也要:
EMF build 1.1.1: (build page) (download zip)
GEF Build 2.1.2: (build page) (download zip)
3.0 M8版本,请下载:
EMF build I200403250631
GEF Build I20040330
VE-runtime-1.0M1
安装成功后,便可由File->New->Visual Class开始UI设计。
安装成功后,即可由新建->Java->AWT与Swing里选择
所要建构的GUI类型开始进行设计。VE必须配合着对应
版本,才能正常使用,否则即使安装成功,使用上仍会
有问题。
使用Eclipse来开发JSP程序:
外挂名称:lomboz(下载页面)
http://forge.objectweb.org/project/showfiles.php?group_id=97
请选择适合自己版本的lomboz下载,lomboz.212.p1.zip表示2.1.2版,
lomboz.3m7.zip表示M7版本....以此类推。
lomboz安装以及设置教学:
Eclipse开发JSP-教学文件
Java转exe篇:
实现方式:Eclipse搭配JSmooth(免费)。
1.先由Eclipse制作包含Manifest的JAR。
制作教学
2.使用JSmooth将做好的JAR包装成EXE。
JSmooth下载页面:
http://jsmooth.sourceforge.net/index.php
3.制作完成的exe文件,可在有装置JRE的Windows上执行。
Eclipse-Java编辑器最佳设定:
编辑器字型设定:工作台->字型->Java编辑器文字字型。
(建议设定Courier New -regular 10)
编辑器相关设定:窗口->喜好设定->Java->编辑器
外观:显示行号、强调对称显示的方括号、强调显示现行行、
显示打印边距,将其勾选,Tab宽度设4,打印编距字段设80。
程序代码协助:采预设即可。
语法:可设定关键词、字符串等等的显示颜色。
附注:采预设即可。
输入:全部字段都勾选。
浮动说明:采预设即可。
导览:采预设即可。
使自动排版排出来的效果,最符合Java设计惯例的设定:
自动排版设定:窗口->喜好设定->Java->程序代码制作格式。
换行:全部不勾选。
分行:行长度上限设:80。
样式:只将强制转型后插入空白勾选。
内缩空格数目:设为4。
Eclipse的教学文件:
Eclipse 3.0系列热键表 - 中英对照解说版 (by sungo) ~New~
Window+GCC+CDT用Eclipse开发C、C++ (by sungo) ~New~
其它:
扩充Eclipse的Java 开发工具(中文)
使用Eclipse开发J2EE 应用程序(中文)
使用Eclipse平台进行除错(中文)
用Eclipse进行XML 开发(中文)
开发Eclipse外挂程序(中文)
国际化您的Eclipse外挂程序(英文)
将Swing编辑器加入Eclipse(英文)
如何测试你的Eclipse plug-in符合国际市场需求(英文)
Eclipse的相关网站:
http://eclipse-plugins.2y.net/eclipse/index.jsp
http://www.eclipseplugincentral.com/
Eclipse相关教学[简体]
写程序写到很累了,想休息一下??玩玩小Game是
不错的选择,下面介绍使用Eclipse玩Game的Plug-in。
补充外挂篇:
Eclipse-Games:
http://eclipse-games.sourceforge.net/
版本选:Latest Release 3.0.1 (Release Notes) Sat, 3 Jan 2004
外挂安装完后,重新开启Eclipse。
窗口->自订视景->其它->勾选Game Actions。
再将Eclipse关闭,重新再启动,就可以开始玩噜。
(共有4种:采地雷I、采地雷II、贪食蛇、仓库番。)
(Eclipse 2.1.2 +中文化 玩Game -仓库番)
补充:(于Eclipse使用assertion机制)
Eclipse版本:2.1.3 release。
JDK1.4版新加入的assertion机制(关键词:assert),由于JDK1.4编译器
预设是兼容1.3,所以要使用assert必须在编译时加上-source 1.4的参数。
C:\>javac -source 1.4 XXX.java
执行时则必须加-ea 或-enableassertions参数启动。
C:\>java -ea XXX
如要在Eclipse中使用assertion机制,请作以下设定:
设定一:(编译设定)
Windows->Preferance->Java->Compiler->Compliance and Classfiles
页面。将..JDK Compliance level->Compiler compliance level调成1.4。
设定二:(执行设定)
Run->Run->(x)=Arguments页面,在VM arguments加入-da参数,按下
Run button便可看到启动assertion后的执行结果。
(Eclipse 2.1.3 release + assertion测试)
<assert判别为false,所以show出AssertionError>
新版(m8+)的eclipse可以设vm arguments
另外提供一种设法,是在eclipse启动时加入vm arguments(跟加大eclipse预设内存大小的方式一样)
这样就不用每次run都得需去设vm arguments
posted @
2005-10-27 13:00 rkind 阅读(200) |
评论 (0) |
编辑 收藏
1、 企业级应用框架的需求
在许多企业级应用中,例如数据库连接、邮件服务、事务处理等都是一些通用企业需求模块,这些模块如果每次再开发中都由开发人员来完成的话,将会造成开发周期长和代码可靠性差等问题。于是许多大公司开发了自己的通用模块服务。这些服务性的软件系列同陈为中间件。
2、 为了通用必须要提出规范,不然无法达到通用
在上面的需求基础之上,许多公司都开发了自己的中间件,但其与用户的沟通都各有不同,从而导致用户无法将各个公司不同的中间件组装在一块为自己服务。从而产生瓶颈。于是提出标准的概念。其实J2EE就是基于JAVA技术的一系列标准。
注:中间件的解释 中间件处在操作系统和更高一级应用程序之间。他充当的功能是:将应用程序运行环境与操作系统隔离,从而实现应用程序开发者不必为更多系统问题忧虑,而直接关注该应用程序在解决问题上的能力 。我们后面说到的容器的概念就是中间件的一种。
二、相关名词解释
容器:充当中间件的角色
WEB容器:给处于其中的应用程序组件(JSP,SERVLET)提供一个环境,使JSP,SERVLET直接更容器中的环境变量接口交互,不必关注其它系统问题。主要有WEB服务器来实现。例如:TOMCAT,WEBLOGIC,WEBSPHERE等。该容器提供的接口严格遵守J2EE规范中的WEB APPLICATION 标准。我们把遵守以上标准的WEB服务器就叫做J2EE中的WEB容器。
EJB容器:Enterprise java bean 容器。更具有行业领域特色。他提供给运行在其中的组件EJB各种管理功能。只要满足J2EE规范的EJB放入该容器,马上就会被容器进行高效率的管理。并且可以通过现成的接口来获得系统级别的服务。例如邮件服务、事务管理。
WEB容器和EJB容器在原理上是大体相同的,更多的区别是被隔离的外界环境。WEB容器更多的是跟基于HTTP的请求打交道。而EJB容器不是。它是更多的跟数据库、其它服务打交道。但他们都是把与外界的交互实现从而减轻应用程序的负担。例如SERVLET不用关心HTTP的细节,直接引用环境变量session,request,response就行、EJB不用关心数据库连接速度、各种事务控制,直接由容器来完成。
RMI/IIOP:远程方法调用/internet对象请求中介协议,他们主要用于通过远程调用服务。例如,远程有一台计算机上运行一个程序,它提供股票分析服务,我们可以在本地计算机上实现对其直接调用。当然这是要通过一定的规范才能在异构的系统之间进行通信。RMI是JAVA特有的。
JNDI:JAVA命名目录服务。主要提供的功能是:提供一个目录系统,让其它各地的应用程序在其上面留下自己的索引,从而满足快速查找和定位分布式应用程序的功能。
JMS:JAVA消息服务。主要实现各个应用程序之间的通讯。包括点对点和广播。
JAVAMAIL:JAVA邮件服务。提供邮件的存储、传输功能。他是JAVA编程中实现邮件功能的核心。相当MS中的EXCHANGE开发包。
JTA:JAVA事务服务。提供各种分布式事务服务。应用程序只需调用其提供的接口即可。
JAF:JAVA安全认证框架。提供一些安全控制方面的框架。让开发者通过各种部署和自定义实现自己的个性安全控制策略。
EAI:企业应用集成。是一种概念,从而牵涉到好多技术。J2EE技术是一种很好的集成实现。
三、J2EE的优越性
1、 基于JAVA 技术,平台无关性表现突出
2、 开放的标准,许多大型公司已经实现了对该规范支持的应用服务器。如BEA ,IBM,ORACLE等。
3、 提供相当专业的通用软件服务。
4、 提供了一个优秀的企业级应用程序框架,对快速高质量开发打下基础
四、现状
J2EE是由SUN 公司开发的一套企业级应用规范。现在最高版本是1.4。支持J2EE的应用服务器有IBM WEBSPHERE APPLICATION SERVER,BEA WEBLOGIC SERVER,JBOSS,ORACLE APPLICATION SERVER,SUN ONE APPLICATION SERVER 等。.
posted @
2005-10-27 12:59 rkind 阅读(181) |
评论 (0) |
编辑 收藏1
java中当前日期的获取方法
旧方法(已不常用):
int year = 0;
int month = 0;
int day = 0;
java.util.Date now = new java.util.Date();
year = now.getYear() + 1900;
month = now.getMonth() + 1;
day = now.getDate();
新方法:
SimpleDateFormat formatter = new SimpleDateFormat(“yyyy-mm-dd”);
Calendar cal_today = Calendar.getInstance();
int m_day = cal_today.get(cal_today.DAY_OF_MONTH);
int m_month = cal_today.get(cal_today.MONTH) + 1;
int m_hour = cal_today.get(cal_today.HOUR_OF_DAY);
int m_minute = cal_today.get(cal_today.MINUTE);
String d = formatter.format(cal_today.getTime());
我采用前一种方法实现了按日期生成文件夹.
2
jsp传给mysql当前系统时间的方法
insert into youDB(date) values(NOW())
不过这样只能获得当前日期
3
判断要建立的文件夹是否存在,如果不则新建立一个文件夹
int year,mm,dd;
String month,day;
Date d1=new Date();
year=d1.getYear()+1900;
mm=d1.getMonth()+1;
if (mm<10) month="0"+mm;
else month=""+mm;
dd=d1.getDate();
if (dd<10) day="0"+dd;
else day=""+dd;
String filepath="d:\\upload"+"\\"+year+month+day+"\\";
if(!new File(filepath).isDirectory())
new File(filepath).mkdirs();
posted @
2005-10-27 12:59 rkind 阅读(340) |
评论 (0) |
编辑 收藏今天在linux下完成了配置了jsp+tomcat+mysql,
因为linux没怎么用过,也是边学边查
装tomcat和jdk比较顺利,可是当我把自己做的那个使用mysql注册的jsp+javaben上传时,却出现了http 500的错误,因为tomcat 在linux下看不到调试情况,只能猜了,mysql的问题,驱动没加载?
先下载好驱动org.gjt.mm.mysql.Driver放到/usr/local/tomcat 下面的common /lib目录下
然后在vi /etc/profile
添加上面那个jar文件.
上面操作完成以后,运行 jsp提示访问被拒绝,我用的phpmyadmin做mysql的前台,修改localhost的权限后,一切ok了
对了,还有个发现,用tomcat的admin管理界面添加任何东西以后,都要再点一次上面的commit change,
要不再一启动又回到以前
学了vi的两个命令,按i是插入的意思,退出时遇到了麻烦,先按esc,再按Q怎么也退出不了,
后来用shift+zz才退出了
刚看到vi的资料,原来刚才少看了一个: 郁闷啊{说了半天,可能你的文件已经编辑完成了,但如何存盘呢?现在我们还是保持在命令状态,按:w按后回车即完成了存盘工作,而退出vi返回到Linux的命令是:q,这两个命令也可以组合使用,如:wq代表存盘退出。
好了,说了半天,可能你的头已经大了,上面讲到的那些只是vi中最常用的功能,至于其它的功能你可以在使用中慢慢体会。顺便说一句,不要强记那些命令,它们看起来多而毫无规律,多用几次自然就熟练了,现在我觉得比Windows中的记事本方便多了。}
posted @
2005-10-27 12:58 rkind 阅读(257) |
评论 (0) |
编辑 收藏本文主要参考了,JSP+javabean循序渐进
开发平台:winxp+tomcat4+mysql+javabean
在实现在了用servlet注册还有登录以后,打算做一个注册页面
首先创建一个表:username VARCHAR2(20) 用户名
password VARCHAR2(20) 密码
email VARCHAR2(30) Email地址
homepage VARCHAR2(50) 主页
signs VARCHAR2(200) 签名
regtime DATE 注册时 //这个date我没有实现
主要有三个jsp页面:
addnewuser.jsp,主要用来实现注册用户的界面,
doadduser.jsp 实现填加到数据库中的具体功能
listuser.jsp 来实现显示所有用户信息
两个bean:
db.java实现数据库的操作,主要有两个方法public ResultSet executeQuery(sql)返回rs用来进行记录的查询
public boolean executeUpdate(String sql)用来进行记录的更新
adduser.java继承了db类用来提供所需更新和查询的sql语句;
我直接调用原文的代码时后发现调用了span什么,不太懂,而且有很多字符不对,所以调试时的问题基本上都是html代码的问题.这是一个仅有基本功能,很多方面还需进一步完善,比如实现注册时间(虽然这不难,可是我还没看util.date和sql.date 区别),email地址的识别,连登录都没有做 :) ,我发现基于这种bean结构的功能很吸引人,比servlet要好,肤浅之见
源码如下:db.java
package rkind;
import java.net.*;
import java.sql.*;
import java.lang.*;
import java.io.*;
import java.util.*;
public class db {
//成员变量初始化
Connection conn = null; //数据库连接
ResultSet rs = null; //记录集
String Username=""; //用户名
String Password=""; //密码
String Email=""; //email
String Homepage=""; //主页
String Signs=""; //签名
String url="jdbc:mysql://172.20.0.73/rk";
//db的构建器
public db() {
try {
//注册数据库驱动程序为Oracle驱动
String name="org.gjt.mm.mysql.Driver";
Class.forName(name);
conn = DriverManager.getConnection(url,"root","你的密码");
System.out.println("success");
}
catch(Exception e) {
//这样写是为了方便调试程序,出错打印mydb()就知道在什么地方出错了
System.err.println("mydb(): " + e.getMessage());
}
}
//executeQuery方法用于进行记录的查询操作
//入口参数为sql语句,返回ResultSet对象
public ResultSet executeQuery(String sql) {
rs = null;
try {
//建立数据库连接,使用Oracle的一种thin连接方式,demo为主机名字,demodb为数据库,后面的两个
//demo为用户名和密码
Statement stmt = conn.createStatement();
//执行数据库查询操作
rs = stmt.executeQuery(sql);
}
catch(SQLException ex) {
System.err.println("db.executeQuery: " + ex.getMessage());
}
return rs;
}
//executeUpdate方法用于进行add或者update记录的操作
//入口参数为sql语句,成功返回true,否则为false
public boolean executeUpdate(String sql) {
boolean bupdate=false;
rs = null;
try {
//建立数据库连接,其它参数说明同上面的一样
Statement stmt = conn.createStatement();
int rowCount = stmt.executeUpdate(sql);
//如果不成功,bupdate就会返回0
if(rowCount!=0)bupdate=true;
}
catch(SQLException ex) {
//打印出错信息
System.err.println("db.executeUpdate: " + ex.getMessage());
}
return bupdate;
}
//toChinese方法用于将一个字符串进行中文处理
//否则将会是???这样的字符串
public static String toChinese(String strvalue) {
try{
if(strvalue==null)
{
return null;
}
else {
strvalue = new String(strvalue.getBytes("ISO8859_1"), "GBK");
return strvalue;
}
}catch(Exception e){
return null;
}
}
}
adduser.java
package rkind;
import java.sql.*;
import java.lang.*;
import java.util.Date;
//adduser由db派生出来,拥有db的成员变量和方法
public class adduser extends db {
//构建器
public boolean addNewUser(){
boolean boadduser=false;
try {
//进行用户注册的记录添加操作,生成sql语句
String sSql=new String("insert into demo(username,password,email,homepage, signs)");
sSql=sSql+ " values('"+Username+"','"+Password+"','"+Email+"','"+Homepage +"','"+Signs+"')";
//一种调试的方法,可以打印出sql语句,以便于查看错误
System.out.println(sSql);
//调用父类的executeUpdate方法,并根据成功以否来设置返回值
if(super.executeUpdate(sSql))boadduser=true;
}
catch(Exception ex) {
//出错处理
System.err.println("adduser.addNewUser: " + ex.getMessage());
}finally{
//无论是否出错,都要返回值
return boadduser;
}
}
//checkUser()方法用来检查用户名是否重复
//如果重复返回一个false
public boolean checkUser(){
boolean boadduser=false;
try {
//构建sql查询语句
String sSql="select * from demo where username='"+Username+"'";
//调用父类的executeQuery方法
if((super.executeQuery(sSql)).next()){
//查询出来的记录集为空
boadduser=false;
}else{
boadduser=true;
}
}
catch(Exception ex) {
//出错处理
System.err.println("adduser.addNewUser: " + ex.getMessage());
}finally{
//返回值
return boadduser;
}
}
public String getUsername(){ return Username;}
public void setUsername(String newUsername){
//用户名有可能是中文,需要进行转换
Username =db.toChinese(newUsername);}
//属性密码Password的get/set方法
public String getPassword(){
return Password;}
public void setPassword(String newPassword){ Password = newPassword;}
//属性Email的get/set方法
public String getEmail(){ return Email;}
public void setEmail(String newEmail){ Email = newEmail;}
//属性主页Homepage的get/set方法
public String getHomepage(){ return Homepage;}
public void setHomepage(String newHomepage){ Homepage = newHomepage;}
//属性主页Signs的get/set方法
public String getSigns(){ return Signs;}
public void setSigns(String newSigns){
//签名有可能是中文,需要进行转换
Signs = db.toChinese(newSigns);}
}
newuser.jsp
<%@ page contentType="text/html;charset=gb2312"%>
<% response.setHeader("Expires","0"); %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<meta name="GENERATOR" content="Microsoft FrontPage 4.0">
<meta name="ProgId" content="FrontPage.Editor.Document">
<title>新用户注册 </title>
</head>
<body bgcolor="#FFFAD9">
<script language="JavaScript">
function valid(form)
{
if(form.username.value.length==0)
{
alert("Please enter username!");
form.username.focus();
return false;
}
if(form.Password.value==form.password1.value){
alert("你输入的验证密码不正确");
form.password1.focus();
}
}
</script>
<p align="center"><font color="#8484FF"><strong><big>新个人
用户注册 </font>
<form onsubmit="return valid(this)" method="POST" name="formreg" action="donewuser.jsp">
<div align="center"><center>
<table width="49%" height="281"
border="1"
cellspacing="0">
<tr>
<td width="27%" bgcolor="#DDDDFF" align="center">用户名:
<td width="73%" bgcolor="#DDDDFF"><input type="text"
name="username" size="20" >
<font color="#00CCFF"><b>* </b></font>
</tr>
<tr>
<td width="27%" bgcolor="#DDDDFF" align="center">输入密码:
<td width="73%" bgcolor="#DDDDFF"><input type="password" name="password" size="20"
>
<font color="#FF0000"><b>* </b></font>
</tr>
<tr>
<td width="27%" bgcolor="#DDDDFF" align="center">校验密码:
<td width="73%" bgcolor="#DDDDFF"><input type="password" name="password1" size="20"
>
<font color="#FF0000"><b>* </b></font>
</tr>
<tr>
<td width="27%" bgcolor="#DDDDFF" align="center">E-mail
<td width="73%" bgcolor="#DDDDFF"><input type="text" name="email" size="20" >
<font color="#FF0000">* </font>
</tr>
<tr>
<td width="27%" bgcolor="#DDDDFF" align="center">主页地址:
<td width="73%" bgcolor="#DDDDFF"><input type="text" name="homepage" size="20"
value="http://">
</tr>
<tr>
<td width="100%" height="20" colspan="2" bgcolor="#DDDDFF"><br>
<center>
<font color="red"><b>介绍自己: (介绍自己,不能超过120字)</span></b></font>
</center> </tr>
<td width="70%">
<tr>
<td><textarea rows="6"
name="signs" cols="30" ></textarea>
</tr>
<tr>
<td width="30%" bgcolor="#DDDDFF" colspan="2"><center>
<p>
<input
type="submit" value="递交" onClick="return checkmsg();" name="B1" >
<input type="reset" value="清除" name="B2" >
</center>
</tr>
</table>
</div>
</form>
<hr size="1" color="#FF0000">
<p align="center">Better View:800*600 Best View:1024x768
为了本系统能够更好的为您服务,请使用IE4.0或以上版本浏览器
<font color="#000000"></font><a href="javascript:%20newGuide("copyright.htm")"
target="_self">版权所有 </a>
</body>
</html>
listuser.jsp
<%@ page contentType="text/html;charset=gb2312"%>
<% response.setHeader("Expires","0"); %>
<%@ page import="java.sql.ResultSet" %>
<%@ page import="org.gjt.mm.mysql.Driver.*" %>
<!--生成一个JavaBean:lyf.db的实例-->
<jsp:useBean id="db" class="rkind.db" scope="request"/>
<jsp:setProperty name="db" property="*"/>
<%
java.lang.String strSQL; //SQL语句
int intPageSize; //一页显示的记录数
int intRowCount; //记录总数
int intPageCount; //总页数
int intPage; //待显示页码
java.lang.String strPage;
int i,j,k;
//设置一页显示的记录数
intPageSize = 15;
//取得待显示页码
strPage = request.getParameter("page");
if(strPage==null){//表明在QueryString中没有page这一个参数,此时显示第一页数据
intPage = 1;
}
else{//将字符串转换成整型
intPage = java.lang.Integer.parseInt(strPage);
if(intPage<1) intPage = 1;
}
//获取记录总数
strSQL = "select count(*) from demo";
ResultSet result = db.executeQuery(strSQL); //执行SQL语句并取得结果集
result.next(); //记录集刚打开的时候,指针位于第一条记录之前
intRowCount = result.getInt(1);
result.close(); //关闭结果集
//记算总页数
intPageCount = (intRowCount+intPageSize-1) / intPageSize;
//调整待显示的页码
if(intPage>intPageCount) intPage = intPageCount;
strSQL="select * from demo ";
//执行SQL语句并取得结果集
result = db.executeQuery(strSQL);
//将记录指针定位到待显示页的第一条记录上
i = (intPage-1) * intPageSize;
for(j=0;j<i;j++) result.next();
%>
<html>
<head>
<meta http-equiv="Content-Language" content="zh-cn">
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<meta name="GENERATOR" content="Microsoft FrontPage 3.0">
<meta name="ProgId" content="FrontPage.Editor.Document">
<title>用户列表</title>
</head>
<body bgcolor="#FFEBBD">
<div align="center"><center>
<table border="1"
borderColorDark="#FFFFFF" borderColorLight="#000000" cellspacing="0" height="22"
width="100%">
<tr bgcolor="#FFEBAD">
<td height="1" width="691" class="main">
第<%=intPage%>页 共<%=intPageCount%>页
<a href="listuser.jsp?page=0">首页</a>
<%if(intPage>1){%><a href="listuser.jsp?page=<%=intPage-1%>">上一页</a><%}%>
<%if(intPage<=1){%>上一页<%}%>
<%if(intPage<intPageCount){%><a href="listuser.jsp?page=<%=intPage+1%>">下一页</a><%}%>
<%if(intPage>=intPageCount){%>下一页<%}%>
<a href="listuser.jsp?page=<%=intPageCount%>">尾页</a>
第<input type="text" class="main" name="page" size="3" value="<%=intPage%>" tabindex="1">页<input type="submit" class="main" value="go" name="B1" tabindex="2"><class="main">
</td></tr></table></form>
<table border="1" width="100%" cellspacing="0" bordercolorlight="#000000"
bordercolordark="#FFFFFF" class="main">
<tr bgcolor="#FFEBAD">
<td >
<div align="left">用户名</div>
</td>
<td >
<p align="center">Email
</td>
<td >
<p align="center">主页
</td>
<td>
<p align="center">登记时间
</td>
<td>
<p align="center">说明
</td>
</tr>
<%
//显示数据
i = 0;
while(i<intPageSize && result.next()){
%>
<tr bgcolor="#FFEBAD">
<td>
<div align="left"><%=result.getString("username") %></div></td>
<td><div align="center"><%=result.getString("email") %></a></div></td>
<td><div align="center"><font color="#0000CC"><%=result.getString("homepage") %></font></div></td>
<td><div align="center"><font color="#FF6666"><%=result.getDate("regtime") %></font></div></td>
<td><div align="center"><font color="#0000FF"><%=result.getString("signs") %></font></div></td></tr>
<%
i++;
}
%>
</table>
<% result.close(); //关闭结果集%>
</body>
</html>
donewuser.jsp
<%@ page contentType="text/html;charset=gb2312"%>
<% response.setHeader("Expires","0"); %>
<!--生成一个JavaBean:lyf.adduser的实例,id为adduser,生存范围为page-->
<jsp:useBean id="adduser" class="rkind.adduser" scope="page"/>
<!--设置JavaBean中各个属性的值,这会调用JavaBean中各个属性的set方法,以便JavaBean得到正确的属性值,”*”代表进行所有属性的匹配-->
<jsp:setProperty name="adduser" property="*"/>
<html>
<head>
<meta http-equiv="Content-Language" content="zh-cn">
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<meta name="GENERATOR" content="Microsoft FrontPage 3.0">
<meta name="ProgId" content="FrontPage.Editor.Document">
<title>用户添加</title>
</head>
<body bgcolor="#FFEBBD">
<div align="center"><center>
<%
//调用lyf.adduser的checkUser()方法检查是否有重复的用户名
//如果有重复就显示对应的信息
if(!adduser.checkUser())
{
//页面文字输出信息,使用jsp内置对象out的println方法,相当于asp中的response.write方法
out.println("对不起,这个用户名"+adduser.getUsername()+"已经被申请了,请重新选择!");
//return代表返回,运行时候碰到return就不会进行下面的处理了,功能相当于asp中的response.end
return;
}
%>
<%
//如果没有用户名重复的问题,调用lyf.adduser的addNewUser()方法来将用户数据添加到数据库中,并根据数据添加成功否来显示对应的信息
if(adduser.addNewUser()){
%>
<H2>添加用户成功!</P>
<%}else{%>
<H2>添加用户失败,请和管理员联系!</P>
<%}%>
</BODY>
</HTML>
posted @
2005-10-27 12:56 rkind 阅读(1287) |
评论 (0) |
编辑 收藏今天在用java实现远程连接mysql数据库后,我打算做一个用servlet实现登录注册功能,
平台是xp+mysql+tomcat4
从网上搜了一下:从一篇叫::::<<<Servlet学习笔记(四)-----使用Servlet处理用户注册和登陆>>
中搜到了一些源代码,它有两个html页面:分别是login.html和register.html
然后分别调用了两个servlet:LoginForm.java用来实现用户和密码的验证,
和RegisterForm.java用来实现注册,住数据库中添加字段
由于加载的jdbc驱动不同,我加载的是mm.mysql-2.0.4-bin.jar稍微做了修改
遇到的问题
1,给的源码中login页面中的按纽用的是图片,我都把其换成按纽,可是跳转到reigster页面的按钮点击时没有任何反应,换了N次链接地址后,还是不管用,于是把type换成文字结果就OK了,用dreamweaver打开以后发现在表单里button只有提交和重置的功能,而不能用来实现链接页面,
这说明我的html知识太过匮乏,因为主要做的是servlet,就凑合着用吧,以后还得加强html的学习
2在配置好web.xml后,发现点击submit跳转到正确的url,但是servlet并没有起任何作用,
这时有点困惑,不知道从什么地方入手,还是先修改servlet加点print看看执行到哪一步才出的问题,
可是加入以后在ie中还是没有反应,后来才想起来print应该是在tomcat的窗口中输出,一看exception
是连接数据库失败,可是连接没有问题,这点我比较肯定,那肯定是tomcat的jdbc驱动没有加载
于是把mm.mysql-2.0.4-bin.jar拷到tomcat目录下comman/lib目录下,
一测试数据库没问题了,但是抛出一个nullpointer的异常,检查了一下解决了
在这次做的过程中发现自己的基础知识相当缺乏,尤其是html和sql语句,以后要加强学习,同时感觉自己效率太低了.
posted @
2005-10-27 12:56 rkind 阅读(588) |
评论 (0) |
编辑 收藏一.介绍
1.eclipse官方网站:
2.赛迪网
3.Eclipse平台入门
二.教程
3Plus4 Software
Omondo
Tutorial for building J2EE Applications using JBOSS and ECLIPSE
Getting Started with Eclipse and the SWT
我认为最好的教程还是eclipse软件自带的帮助文件(现在有了中文帮助)。
三.插件
三.插件
Eclipse Plugin Resource Center and Marketplace
eclipse-plugins
eclipse-workbench
以上3个网站都是综合性插件网站,你可以查询自己所需的插件,而且还有各种排名。
Jigloo SWT/Swing GUI Builder
Lomboz
Matrix网站介绍eclipse plugins
posted @
2005-10-27 12:55 rkind 阅读(185) |
评论 (0) |
编辑 收藏
一、通过ResultSet对象对结果集进行处理
从前面的学习中,我们掌握了通过Statement类及其子类传递SQL语句,对数据库管理系统进行访问。一般来说,对数据库的操作大部分都是执行查询语句。这种语句执行的结果是返回一个ResultSet类的对象。要想把查询的结果返回给用户,必须对ResultSet对象进行相关处理。今天,我们就来学习对结果集的处理方法。
按照惯例,让我们先来看一个例子:
package com.rongji.demo;
import java.sql.*;
public class dataDemo {
public dataDemo() {
}
public static void main(String[] args) {
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
//建立连接
//第二步是用适当的驱动程序连接到DBMS,看下面的代码[自行修改您所连接的数据库相关信息]:
String url = "jdbc:oracle:thin:@192.168.4.45:1521:oemrep";
String username = "ums";
String password = "rongji";
//用url创建连接
Connection con = DriverManager.getConnection(url, username, password);
Statement sta = con.createStatement();
String sql = "select * from rbac_application ";
ResultSet resultSet = sta.executeQuery(sql);
while (resultSet.next()) {
int int_value = resultSet.getInt(1);
String string_value = resultSet.getString(2);
String a = resultSet.getString(3);
String b = resultSet.getString(4);
//从数据库中以两种不同的方式取得数据。
System.out.println(int_value + " " + string_value + " " + a + " " +
b);
//将检索结果在用户浏览器上输出。
}
//获取结果集信息
ResultSetMetaData resultSetMD = resultSet.getMetaData();
System.out.println("ColumnCount:" + resultSetMD.getColumnCount());
for (int i = 1; i < resultSetMD.getColumnCount(); i++) {
System.out.println("ColumnName:" + resultSetMD.getColumnName(i) + " " +
"ColumnTypeName:" +
resultSetMD.getColumnTypeName(i));
System.out.println("isReadOnly:" + resultSetMD.isReadOnly(i)
+ " isWriteable:" + resultSetMD.isWritable(i)
+ " isNullable:" + resultSetMD.isNullable(i));
System.out.println("tableName:" + resultSetMD.getTableName(i));
}
//关闭
con.close();
}
catch (Exception ex) {
ex.printStackTrace();
}
}
}
1、ResultSet类的基本处理方法
一个ResultSet对象对应着一个由查询语句返回的一个表,这个表中包含所有的查询结果,实际上,我们就可以将一个ResultSet对象看成一个表。对ResultSet对象的处理必须逐行进行,而对每一行中的各个列,可以按任何顺序进行处理。
ResultSet对象维持一个指向当前行的指针。最初,这个指针指向第一行之前。Result类的next()方法使这个指针向下移动一行。因此,第一次使用next()方法将指针指向结果集的第一行,这时可以对第一行的数据进行处理。处理完毕后,使用next()方法,将指针移向下一行,继续处理第二行数据。next()方法的返回值是一个boolean型的值,该值若为true, 说明结果集中还存在下一条记录,并且指针已经成功指向该记录,可以对其进行处理;若返回值是false,则说明没有下一行记录,结果集已经处理完毕。
在对每一行进行处理时,可以对各个列按任意顺序进行处理。不过,按从左到右的顺序对各列进行处理可以获得较高的执行效率.ResultSet类的getXXX()方法可以从某一列中获得检索结果。其中XXX是JDBC中的Java数据类型,如int, String ,Date等,这与PreparedStatement类和CallableStatement类设置SQL语句参数值相类似。 Sun公司提供的getXXX() API提供两种方法来指定列名进行检索:一种是以一个int值作为列的索引,另一种是以一个String对象作为列名来索引。大家可以参照一下上面的例子。
2、获取结果集的信息
在对数据库的表结构已经了解的前提下,可以知道返回的结果集中各个列的一些情况,如:列名数据类型等等。有时并不知道结果集中各个列的情况,这时可以使用Resultset类的getMetaData方法来获取结果集的信息。如上面的例子:
ResultSetMetaData resultSetMD = resultSet.getMetaData();
GetMetaData()方法返回一个ResultSetMetaData类的对象,使用该类的方法,得到许多关于结果集的信息,下面给出几个常用的方法:
(1) getColumnCount()返回一个int值,指出结果集中的列数。
(2) getTableName(int column)返回一个字符串,指出参数中所代表列的表的名称。
(3) getColumnLabel(int column)返回一个String对象,该对象是column所指的列的显示标题。
(4) getColumnName(int column)返回的是该列在数据库中的名称。可以把此方法返回的String对象作为Resultset类的getXXX()方法的参数。不过,并没有太大的实际意义。
(5) getColumnType(int comlumn)返回指定列的SQL数据类型。他的返回值是一个int值。在java.sql.Types类中有关于各种SQL数据类型的定义。
(6) getColumnTypeName(int comlumn)返回指定列的数据类型在数据源中的名称。他的返回值是一个String对象。
(7) isReadOnly(int column) 返回一个boolean值,指出该列是否是只读的。
(8) isWriteable(int column) 返回一个boolean值,指出该列是否可写。
(9) isNullable(int column)返回一个boolean值,指出该列是否允许存入一个NULL 值。
posted @
2005-10-27 12:53 rkind 阅读(197) |
评论 (0) |
编辑 收藏
Java和SQL各自有一套自己定义的数据类型(jsp的数据类型实际上就是Java的数据类型),我们要在Jsp程序和数据库管理系统之间正确的交换数据,必然要将二者的数据类型进行转换。先让我们来看两个表:
表SQL到Java数据类型影射表
SQL 数据类型
JAVA数据类型
CHAR
String
VARCHAR
String
LONGVARCHAR
String
NUMERIC
java.math.BigDecimal
DECIMAL
java.math.BigDecimal
BIT
Boolean
TINYINT
Byte
SMALLINT
Short
INTEGER
Int
BIGINT
Long
REAL
Float
FLOAT
Double
DOUBLE
Double
BINARY
byte[]
VARBINARY
byte[]
LONGVARBINARY
byte[]
DATE
java.sql.Date
TIME
java.sql.Time
TIMESTAMP
java.sql.Timestamp
Java到SQL数据类型影射表
JAVA数据类型
SQL 数据类型
String
VARCHAR or LONGVARCHAR
java.math.BigDecimal
NUMERIC
Boolean
BIT
Byte
TINYINT
Short
SMALLINT
Int
INTEGER
Long
BIGINT
Float
REAL
Double
DOUBLE
byte[]
VARBINARY or LONGVARBINARY
java.sql.Date
DATE
java.sql.Time
TIME
java.sql.Timestamp
TIMESTAMP
这里,大伙要注意了,并不是所有的数据类型在各种数据库管理系统中都被支持。下面,就几种常用的数据类型之间的转化进行说明:
(1) CHAR, VARCHAR, 和 LONGVARCHAR
在SQL语言中,有三种分别表示不同长度的字符类型CHAR, VARCHAR, 和 LONGVARCHAR,在Java/Jsp中并没有相应的三种不同的数据类型与之一一对应,JDBC的处理方法是将其与String或者char[]对应起来。在实际编程中不必对着三种SQL数据类型进行区分,全部将他们转化为Sting或者char[]就可以了。而且通常使用应用的非常普遍的String类型。我们还可以利用String类提供的方法将一个String对象转化为char[],或者用char[]为参数构造一个Stirng对象。
对于定长度的SQL数据类型CHAR(n),当从数据库管理系统中获得的结果集提取该类型的数据时,JDBC会为其构造一个长度为n的String对象来代表他,如果实际的字符个数不足’n’,系统会自动为String对象补上空格。当向数据库管理系统写入的数据类型应该是CHAR(n)时,JDBC也会将该String对象的末尾补上相应数量的空格。
一般情况下,CHAR, VARCHAR, LONGVARCHAR和String之间可以无差错的进行转换。但非常值得注意的是LONGVARCHAR,这种SQL的数据类型有时在数据库中代表的数据可能有几兆字节的大小,超过了String对象的承受范围。JDBC解决的办法是用Java的Input Stream来接受这种类型的数据[以后我们回涉及到]。Input Stream不仅支持ASCII,而且支持Unicode,我们可以根据需要进行选择。
(2) DECIMAL 和 NUMERIC
SQL的DECIMAL 和 NUMERIC通常用来表示需要一定精度的定点数。在Java的简单数据类型中,没有一种类型与之相对应。但从JDK1.1开始,Sun公司在java.math.*包中加入了一个新的类BigDecimal,该类的对象可以与DECIMAL 、NUMERIC进行转换。
另外,当从数据库管理系统中读取数据时,还可以用getString()方法来获取DECIMAL 和 NUMERIC。
(3) BINARY, VARBINARY, 和 LONGVARBINARY
在编程时无须精确区分这三种SQL数据类型,JDBC将他们统一影射为byte[]。其中LONGVARBINARY和LONGVARCHAR相似,可以代表几兆字节的数据,超出数组的承受范围。解决的办法依然是用Input Stream来接受数据。
(4) BIT
代表一个二进制位的BIT类型被JDBC影射为boolean型。
(5) TINYINT, SMALLINT, INTEGER, 和 BIGINT
SQL语言的TINYINT, SMALLINT, INTEGER, 和 BIGINT分别代表8位、16位、32位、64位的数据。他们分别被影射为Java的byte, short, int, 和 long
(6) REAL, FLOAT, 和 DOUBLE
SQL定义了REAL, FLOAT, DOUBLE来支持浮点数。JDBC将REAL影射到Java的float,将FLOAT,DOUBLE影射到java的double。
(7) DATE, TIME, 和 TIMESTAMP
SQL定义了三种和日期相关的数据类型。 DATE代表年、月、日,TIME代表时、分、秒,TIMESTAMP结合了DATE和TIME的全部信息,而且增加了更加精确的时间计量单位。
在java的标准类库中,java.util.*包中的Date类用来表示日期和时间。但是该类和SQL中的DATE, TIME, 和 TIMESTAMP直接影射关系并不清晰。并且,该类也不支持TIMESTAMP的精确时间计量单位。因此,Sun公司在java.sql.*中为java.util.Date增加了三个子类:java.sql.Date,java.sql.Time ,java.sql.Timestamp,分别与SQL中的三个日期数据类型相对应。
总之,关于SQL与JAVA之见数据类型的转化,还有很多细节方面的东西,这里就不一一介绍了,有需要的朋友自己可以去查一下相关文档。这里给大家介绍一个我常去的网站:
http://java.sun.com/docs/books/tutorial/jdbc。
posted @
2005-10-27 12:52 rkind 阅读(337) |
评论 (0) |
编辑 收藏
二、通过PreparedStatement对象访问数据库
前面,我们讨论了用连接对象Connection产生Statement对象,然后用Statement与数据库管理系统进行交互。Statement对象在每次执行SQL语句时都将该语句传递给数据库。在多次执行同一语句时,这样做效率较低。解决这个问题的办法是使用PreparedStatement对象。如果数据库支持预编译,可以在创建PreparedStatement对象时将SQL语句传递给数据库做预编译,以后每次执行这个SQL语句时,速度就可以提高很多。如果数据库不支持预编译,则在语句执行时,才将其传给数据库。这对于用户来说是完全透明的。
PreparedStatement对象的SQL语句还可以接受参数。在语句中指出需要接受那些参数,然后进行预编译。在每一次执行时,可以将不同的参数传递给SQL语句,大大提高了程序的效率与灵活性。一般情况下,使用PreparedStatement对象都是带输入参数的。
为了更好的理解,请看下面这个例子:
package com.rongji.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
import java.sql.DatabaseMetaData;
import java.sql.PreparedStatement;
public class DataConn {
public DataConn() {
}
public static void main(String[] args) {
try
{
//加载驱动程序
//下面的代码为加载JDBD-ODBC驱动程序
Class.forName("oracle.jdbc.driver.OracleDriver");
//建立连接
//第二步是用适当的驱动程序连接到DBMS,看下面的代码[自行修改您所连接的数据库相关信息]:
String url="jdbc:oracle:thin:@192.168.4.45:1521:oemrep";
String user = "ums1";
String password = "rongji";
//用url创建连接
Connection con=DriverManager.getConnection(url,user,password);
//当前的表中有如下几个字段:ID,NAME,PASSWORD,TEXT,NOTE
PreparedStatement insertStatement = con.prepareStatement(
"INSERT INTO rbac_application values(?,?,?,?,?)");
insertStatement.setInt(1,10);
insertStatement.setString(2,"thinkersky");
insertStatement.setString(3,"88888");
insertStatement.setString(4,"这是个测试的应用程序");
insertStatement.setString(5,"备注");
int result = insertStatement.executeUpdate();
System.out.println("the result is" + result);
con.close();
}
catch (Exception e)
{
//输出异常信息
System.err.println("SQLException :"+e.getMessage());
e.printStackTrace();
}
}
}
相信通过这个例子,对PreparedStatement这个类的应用应该有了初步的了解。恩,让我详细介绍一下这个例子吧:)
1、 创建一个PreparedStatement对象
PreparedStatement类是Statement类的子类。同Statemetn类一样,PreparedStatement类的对象也是建立在Connection对象之上的。如下所示:
PreparedStatement insertStatement = con.prepareStatement(
"INSERT INTO rbac_application values(?,?,?,?,?)");
创建该PreparedStatement对象时,相应的插入记录的SQL语句已经被传递到数据库管理系统中进行预编译。
2、 为PreparedStatement对象提供参数
如果以带输入参数的SQL语句形式创建了一个PreparedStatement对象(绝大多数情况下都是如此)。在SQL语句被数据库管理系统正确执行之前,必须为参数(也就是SQL语句中是’?’的地方)进行初始化。初始化的方法是调用PreparedStatement类的一系列setXXX()方法。如果输入参数的数据类型是int型,则调用setInt()方法;如果输入参数是String型,则调用setString()方法。一般说来,Java中提供的简单和复合数据类型,都可以找到相应的setXXX()方法。
现在,让我们再回头看看我们例子中对几个参数的初始化情况:
insertStatement.setInt(1,10);
insertStatement.setString(2,"thinkersky");
insertStatement.setString(3,"88888");
insertStatement.setString(4,"这是个测试的应用程序");
insertStatement.setString(5,"备注");
这里,setXXX()方法一般有两个参数,第一个参数都是int型,该参数指示JDBC PreparedStatement对象的第几个参数将要被初始化。第二个参数的值就是PreparedStatemetn将要被初始化的参数取值,数据类型自然也就相同。这里要说明的是当PreparedStatement的一个对象的参数被初始化以后,该参数的值一直保持不变,直到他被再一次赋值为止。
3、 调用PreparedStatement对象的executeUpdate()方法
这里,要清楚PreparedStatement对象的executeUpdate()方法不同于Statement对象的executeUpdate()方法,前者是不带参数的,其所需要的SQL语句型的参数已经在实例化该对象时提供了。另外,executeUpdate()方法将返回一个整数,这个整数代表executeUpdate()方法执行后所更新的数据库中记录的行数。执行完上面的例子,其结果返回为1。那么什么情况下返回0呢?其实啊,当PreparedStatement对象的executeUpdate()方法的返回值是0时。有两种可能:
(1) 所执行的SQL语句是对数据库管理系统的记录进行操作;并且没有记录被 更新
(2) 所执行的SQL语句是对数据库管理系统的表、视图等对象进行操作的DDL语言,没有数据记录被直接修改。
posted @
2005-10-27 12:52 rkind 阅读(1859) |
评论 (1) |
编辑 收藏
一、通过DatabaseMetaData对象了解数据库的信息
JSP通过JDBC对数据库管理系统进行连接以后,得到一个Connection 对象,可以从这个对象获得有关数据库管理系统的各种信息,包括数据库中的各个表,表中的各个列,数据类型,触发器,存储过程等各方面的信息。根据这些信息,JDBC可以访问一个实现事先并不了解的数据库。获取这些信息的方法都是在DatabaseMetaData类的对象上实现的,而DataBaseMetaData对象是在Connection对象上获得的。
按照惯例,让我们先来看看下面这个例子:
package com.rongji.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
import java.sql.DatabaseMetaData;
public class DataConn {
public DataConn() {
}
public static void main(String[] args) {
try
{
//加载驱动程序
//下面的代码为加载JDBD-ODBC驱动程序
Class.forName("oracle.jdbc.driver.OracleDriver");
//建立连接
//用适当的驱动程序连接到DBMS,看下面的代码[自行修改您所连接的数据库相关信息]:
String url="jdbc:oracle:thin:@192.168.4.45:1521:oemrep";
String user = "ums";
String password = "rongji";
//用url创建连接
Connection con=DriverManager.getConnection(url,user,password);
//获取数据库的信息
DatabaseMetaData dbMetaData = con.getMetaData();
//返回一个String类对象,代表数据库的URL
System.out.println("URL:"+dbMetaData.getURL()+";");
//返回连接当前数据库管理系统的用户名。
System.out.println("UserName:"+dbMetaData.getUserName()+";");
//返回一个boolean值,指示数据库是否只允许读操作。
System.out.println("isReadOnly:"+dbMetaData.isReadOnly()+";");
//返回数据库的产品名称。
System.out.println("DatabaseProductName:"+dbMetaData.getDatabaseProductName()+";");
//返回数据库的版本号。
System.out.println("DatabaseProductVersion:"+dbMetaData.getDatabaseProductVersion()+";");
//返回驱动驱动程序的名称。
System.out.println("DriverName:"+dbMetaData.getDriverName()+";");
//返回驱动程序的版本号。
System.out.println("DriverVersion:"+dbMetaData.getDriverVersion());
//关闭连接
con.close();
}
catch (Exception e)
{
//输出异常信息
System.err.println("SQLException :"+e.getMessage());
e.printStackTrace();
}
}
}
通过上面的例子,我们可以看出,DatabaseMetaData类的对象的实现,如下语句
<%
DatabaseMetaData datameta=con.getMetaData();
%>
DatabaseMetaData类中提供了许多方法用于获得数据源的各种信息,通过这些方法可以非常详细的了解数据库的信息。就如我们上面例子中所显示的几个信息[其他的方法请读者参考JDK API中的DatabaseMetaData类]:
getURL()
返回一个String类对象,代表数据库的URL。
getUserName()
返回连接当前数据库管理系统的用户名。
isReadOnly()
返回一个boolean值,指示数据库是否只允许读操作。
getDatabaseProductName()
返回数据库的产品名称。
getDatabaseProductVersion()
返回数据库的版本号。
getDriverName()
返回驱动驱动程序的名称。
getDriverVersion()
返回驱动程序的版本号。
posted @
2005-10-27 12:51 rkind 阅读(100) |
评论 (0) |
编辑 收藏
JSP调用JDBC API访问数据库管理系统是通过以下五个步骤来实现的:
(1)加载特定的JDBC驱动程序
为了与特定的数据源连接,JDBC必须加载相应的驱动程序。这些驱动程序都是通过语句:Class.forName("Driver Name"); 来加载的。这里面有一个小技巧,我们可以在”Driver Name”出填入一系列的驱动程序名称,例如:“Class.forName("sun.jdbc.odbc.JdbcOdbcDriver:oracle.jdbc.driver.OracleDriver”); 中间用冒号隔开。JSP将按照列表顺序搜索驱动程序,并且加载第一个能与给定的URL相连的驱动程序。在搜索驱动程序列表时,JSP将跳过包含不可信任代码的驱动程序,除非他与要打开的数据库管理系统是来源于同一处.
(2)用已注册的驱动程序建立到数据库管理系统的连接
我们要做的第二步是用已经注册的驱动程序建立到数据库管理系统的连接,这要通过DriverManager类的getConncetion方法来实现。这里特别需要注意的是String类型 url 参数的取值,url代表一个将要连接的特定的数据库管理系统的数据源。使用不同的数据库驱动程序,url的取值方式是不同的。例程中加载了“com.mysql.jdbc.Driver”驱动,url的取值方式“jdbc:mysql://localhost:3306/ums_db?useUnicode=true&characterEncoding=GB2312”,如果加载“oracle.jdbc.driver.OracleDriver”驱动,url的取值方式应该是“jdbc:oracle:thin:@host name:port number:service name”。其他驱动程序的url的取值方式,各位自行参阅相应的文挡。
例程中的GetConnection()方法只有一个参数String url,代表ODBC数据源,如果连接大型数据库,则需要三个参数:String url、Strng user、String password。User和password代表数据库管理系统的用户名和口令。一般的大型数据库如Oracle、MS SQL Server、DB2等用户名和口令是必须的。而小型的数据库如ACCESS、Foxpro等并不需要。
如果连接成功,则会返回一个Connection类的对象con。以后对数据库的操作都是建立在con对象的基础上的。GetConnection()方法是DriverManager类的静态方法,使用时不用生成DriverManager类的对象,直接使用类名DriverManager就可以调用。
(3)创建Statement声明,执行SQL语句
在实例化一个Connection类的对象con,成功建立一个到数据库管理系统的连接之后。我们要做的第三步是利用该con对象生成一个Statement类的对象stmt。该对象负责将SQL语句传递给数据库管理系统执行,如果SQL语句产生结果集,stmt对象还会将结果集返回给一个ResultSet类的对象。
Statement类的主要的方法有三个:
executeUpdate(String sql)
executeQuery(String sql)
execute(String sql)
executeUpdate(String sql)方法用于执行DDL类型的SQL语句,这种类型的SQL语句会对数据库管理系统的对象进行创建、修改、删除操作,一般不会返回结果集。
executeQuery(String sql)方法用于执行一条查询数据库的SELECT语句。如果有符合查询条件的数据存在,该方法将返回一个包含相应数据的ResultSet类对象,否则,该对象的next()方法将返回false。
execute(String sql)方法用于执行一个可能返回多个结果集的存储过程(Stored Procedure)或者一条动态生成的不知道结果集个数的SQL语句。如果存储过程或者SQL语句产生一个结果集,该方法返回false.如果产生多个结果集,该方法返回true。我们可以综合运用Statement类的getResultSet(), getUpdateCount(), getMoreResults()方法来检索不同的结果集。
服务器对JSP程序进行编译时,并不对将要执行的SQL语句作语法检查,只是将其作为一个String对象。只有当客户端发出HTTP请求,Java虚拟机对Servlet进行解释执行,将SQL语句传递给数据库管理系统时,才能知道他是否正确。对于错误的SQL语句,在执行时会产生SQLExcepion。其实,所有与JDBC操作的JSP语句都与数据库管理系统及相应的驱动程序有关,是超出JSP的控制范围的。这些语句只有在实际的解释执行中才能检验出是否能顺利执行,因此一定要声明并捕获例外:
try{
….
}catch(SQLException e)
{
Sytem.err.println(“SQLException:”+e.getMessage());
}
否则,JSP程序无法被编译成Servlet。
(4)关闭Statement对象
一个Statement对象在打开后可以多次调用executeQuery(String sql)、executeUpdate(String sql)、execute(String sql)方法来执行SQL语句,与数据库管理系统进行交互。但一个Statement对象在同一时间只能打开一个结果集,对第二个结果集的打开隐含着对第一个结果集的关闭。如果想对多个结果集同时进行操作,必须创建多个Statement对象,在每个Statement对象上执行SQL语句获得相应的结果集。
(5)关闭Connection对象
在处理完对数据库的操作后,一定要将Connection对象关闭,以释放JDBC占用的系统资源。在不关闭Connection对象的前提下再次用DriverManager静态类初始化新的Connection对象会产生系统错误。而一个已经建立连接的Connection对象可以同时初始化多个Statement对象。对应不同的数据库管理系统的Connection对象可以初始化Statement对象的个数是不同的。在Oracle中是50个。
posted @
2005-10-27 12:51 rkind 阅读(221) |
评论 (0) |
编辑 收藏首先加载mm.mysql2.0.4-bin.jar驱动,并把其加入classpath,注意一定要打开远程mysql的你的主机的访问权限
然后编写如下代码
String name="org.gjt.mm.mysql.Driver";///加载jdbc driver
String url="jdbc:mysql://172.20.0.73/jilei"; //连接到172.20.0.73上的jilei的mysql数据库
Class.forName(name),//创建类
con=DriverManager.getConnection(url,"你的username","你的密码")//创建连接
输入以下代码供测试使用
Statement stmt=con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_UPDATABLE);
String sql="select * from student";
ResultSet rs=stmt.executeQuery(sql);
while(rs.next()) {
System.out.println("您的第一个字段内容为:"+rs.getString(1));
System.out.println("您的第二个字段内容为:"+rs.getString(2) );
System.out.println("您的第三个字段内容为:"+rs.getString(3) );
}
rs.close();
stmt.close();
con.close();
posted @
2005-10-27 12:49 rkind 阅读(1081) |
评论 (0) |
编辑 收藏孔子说:“学而不思则罔,思而不学则殆。”从我做项目的经历,我深深感叹古人的智慧。
去年我毕业设计时候做的一个项目是毕业设计管理系统。当时老师给我们的要求是用Jsp 和 Javabean来实现。我主要负责项目建模和Javabean部分,后来负责数据库的同学被SARS困在家不能返校,所以数据库部分也由我来完成了。当时对java的知识是非常贫乏的,只有简单的语法基础,连jsp、 javabean都是第一次听到过。不知道从哪里开始,于是就研究老师给的一个非常简单的演示项目,首先觉得javabean是个比较简单的东西,于是就先开始分析用户需求。
需求怎么来描述呢?由于学校教育的局限,加上自己研究了很长时间高数,政治,英语(干什么用大家都明白吧),造成了知识的严重匮乏。我就以参加毕业设计人员为中心,建立他们的需求列表。但是这样的需求描述是非常片面的,几乎都是静态的需求,而且很难设计几个用户的交互过程,和某些状态的改变。而且这种需求是否有真正符合需要是个问题,所以我立刻和同学一起设计web界面,目的很简单,因为用户的需求都是通过界面来实现的,对界面的设计能涵盖最终提交用户的功能,而且还能发掘很多非用户的需求。这样我在实现这些功能的时候会有数。在一年后当我仔细看过用例分析,uml后感觉是如获至宝。心头的结全部打开。
建模该怎么建?当时真是什么概念都没有,虽然知道uml,但是仅仅知道皮毛。于是我就很简单的从对象的角度考虑问题,首先找毕业设计管理系统中涉及的人员,这个是很明显找出来的,涉及到学生,教师,管理员,进一步提取出项目对象,各个人员之间通讯的消息对象,毕业设计文档对象,等等。接下来设计数据库表,由于学校教数据库的时候只有讲述了ER图到关系模式的转化,而根本没有讲ODL到关系模式的转化(现在看来,ODL应该更好,对理解O/R Mapping有更多的帮助。)于是就画ER图,建立各种表,设定主键,外键,等等。
我遇到的首要问题就是学生,教师,管理员该怎么办,每一个对象建一个表,似乎也没有什么问题。但是在建立消息对象的时候就有问题了,因为消息是要在学生,教师,管理员任意两者都能传送的,我建消息表的时候是这样设计的:一个消息的内容,消息的发送人,消息的接收人(消息内容和发送人一个表,为解决冗余接收人单独一个表),这样这个消息就有很大的灵活程度了,消息发送人可以是三种角色间的随便一种,更进一步,这样的消息可以是系统生成的消息,而且接收者可以是随便哪种角色。但随之带来的问题是:消息发送人、接收者该去参照谁呢?显然填一个发送者、接收者的id是不够的,必须连发送者的角色也填上。第二种方法,每个角色有一个收到消息的列表,让它去参照单一的消息表id,这样也能解决问题。第三种方法,把学生,教师,管理员合并成一个用户表,那么消息发送人,接收人只要简单的参照一个通用的用户id了。这种合并子类的方法会造成教师,管理员的行有些null值,但是考虑到教师和管理员的数目远远小于学生的数目,所以这样的冗余是忽略不计的。最后我还是选择了最后一种方法。不过我还是觉的是对象模型向关系模型的一种妥协。
接着我着手设计javabean,访问数据库用的是单纯的JDBC。因为我对前台界面要访问一个对象的哪些属性是不了解的,事实上也不该了解。所以我只能从数据库取出一个完整的对象,让他来决定究竟要访问哪些属性。而且对对象的修改也是这样,前台修改好新的对象的属性,我来进行更数据库的同步。于是我的javabean就出现了这样的方法:load()、 store()、 update()、delete()这样的对象和数据库表同步的方法。这在一年后的今天看来,实际上我已经自己做了一个O/R Mapping的工作了。当时自己做这样的O/R Mapping是相当痛苦的事情,而且用的方法也是最粗浅的,就是整个对象更数据库同步,即使没有修改的属性也同步,所以要同步的话,必须要先把对象从数据库取出来,修改后再写回。而且要求所有属性必须是nullable的non-primitive类型。第二个问题,对表中的外键怎么反应到bean中?比如每个学生有一个辅导教师,在数据库中很明显学生表需要一个外键参照教师id,但是在StudentBean中教师属性是写Teacher对象呢,还是Teacher id值呢,按照面向对象,很明显应该Teacher对象,但是我就觉得这是个多么heavy的事情呀!再想想教师情况,一个教师有一个Collection的Student对象是多么“重”!意味着load一个教师要load所有的students。于是我采用的方法是:还是用对象,比如teacher 的学生属性,还是一个collection Student对象,同时提供了一个loadStudents()的方法,load teacher对象的时候并不load 学生属性,只有bean的用户显式调用loadStudents()的时候才会加载一组student对象,这在现在看来似乎我自觉不自觉的实现了lazy loading?
现在审视当时编写的javabean,犯的最大最大的错误就是把data access object和business workflow混在一起了。比如把教师所有要调用的功能都放在教师对象里面,而有些功能有时是要涉及几个bean的。现在看了简直是惨不忍睹的设计,虽然当时也困惑过,但是却没有动动脑筋来解决,我现在看了session bean 的思路时,觉得是那么的舒畅、自然。
当时困惑的还有关于jsp的处理,jsp只是负责显示的,但是为什么一个jsp提交的数据要给另外一个jsp去处理呢?这是很不舒畅的做法,于是有了最初的servlet做控制器的想法,但是当时顾不了研究那么多,也没有最终实现,毕竟前台不是我负责的。当我现在知道了Structs,MVC Model2的时候,我以前的困惑都随之解决。又一次感觉非常舒畅。
以上是我一个新手的第一个项目的一些情况,是在非常闭塞的环境里面做的,上网都是电话卡拨号,根本没有接触到主流技术,但是正是这种环境下积累的无数困惑,使我遇到EJB、Hibernate、Structs的时候如饮甘露,迅速的吸收了他们的营养。否则我想学习这些技术无疑是很耗时间的,因为根本没有更这种技术产生共鸣,不知道他们搞那么多框框究竟想干什么,而我产生了一种共鸣,他们这些框框,正是开我心头疑惑的锁。
又回到开头孔子的话,事实上我在做项目中,一直都是按自己的思考方式在“思”而没有去“学”,所以常常感到疲倦而无所得,即“殆”。但是如果不实际自己去动手做,而光光学j2ee,必然会很迷惑,即“罔”。我感觉先有困惑再有解决,是掌握技术的十分有效的而且巩固的方法,而且很有创造性,是属于归纳的思考方式。所以碰到问题,首先需要想想按常理该怎么去解决,再去寻找别人怎么解决的,这样自己提高会十分迅速。
现在我正在用EJB、Structs来重写那个项目。虽然我对整个需求已经相当清楚,毕竟有了第一个项目作为原型,但是我还是试图使用比较规范的方法来设计。首先分析了很多use case,并且使用Rational的RequisitePro来跟踪需求的变化。接着又使用Rose对use case画了use case diagram。对关键对象交互过程画了 sequence diagram,对某些对象的状态画了state diagram。最后很自然的导出了最重要的class diagram。
我现在最大的困惑在Entity Bean上面,建模的时候很自然会有一个User对象,Student, Teacher, Manager 对象继承自这个User对象。那数据库表怎么设计呢?第一种,三个对象三个表,对应StudentBean TeacherBean ManagerBean三个EntityBean。第二种,三个对象一个表,只有一个UserBean。第三种,把User单独一个对象,那么就是四个对象四个表,这样一个子对象,要映射两张表EntityBean不行吧。
暂时不管究竟用什么设计,来考察一下文档对像DocBean,我们主要看看它的cmr部分,一个cmr是author 属性,它应该是三种角色对象中的一种,问题来了,如果三个对象三个表,那么我这里的cmr怎么写?
public abstract StudentLocal getAuthor(); ?
public abstract TeacherLocal getAuthor(); ?
public abstract ManagerLocal getAuthor(); ?
考察第二种,三个对象一个表,只有一个UserBean。那这个是相当简单的只需要
public abstract UserLocal getAuthor();
那最后只有第二种方式才能解决问题,就是只有一个User对象,于是我为了使用EntityBean不得不对我的模型进行修改,把原来清晰的三个对象揉合到一起,虽然说以后某个student变成了teacher 或者manager可以很方便的升级,但是这种情况在我这个例子里面是很少有的,而且数据库这种合并子类的方法给teacher,manager形成了很多的null值,虽然这是忽略不计的,但是总不是优雅的做法,最关键的是我的对象模型又一次向关系模型妥协了。
CMR的另外一个问题是,要CMR必须把所有相关的Bean放一个包里面,在一个xml文件里面配置,我的项目里面的entity bean都是要更user有关系的,那我都需要把这些bean打成一个包,用一个xml描述!我的还是小项目,如果一个项目有100个entity bean,这些entity bean都是相互关联的,那我要把这100个entity bean放在打成一个包,用一个xml配置!那这个xml文件该有多长!一个小小的错误全部完蛋。
看来Entity Bean确实如很多人说的那样不是十分灵活,我也开始倾向于用hibernate来做持久化了,但是我需要有足够的灵活性,我想继承和多态的支持还是很重要的,这样才能真正是“object-oriented domain models”方式,而不是以数据库表为中心的方式,引用Hibernate的一句话“Hibernate may not be the best solution for data-centric applications that only use stored-procedures to implement the business logic in the database, it is most useful with object-oriented domain models and business logic in the Java-based middle-tier”
我对AOP也是十分关注,因为它实在是太激动人心的概念了,有了AOP那么我们还要容器干什么,容器的功能完全可以通过AOP来实现,就像Spring框架,除了没有分布式外几乎都能支持吧。而jboss4.0也已经通过AOP实现了。考察我的项目,我发现有一个这样的需求需要满足,就是:在执行某些business logic之前必须要检测对这个方法的调用是否超过期限了,比如学生去选择研究课题,如果选择过了就不能再次选择,虽然这个方法可以由前台很简单的解决,但是我觉得在业务逻辑层防止这种行为的发生是业务完整性的一个部分。而通过AOP,把这样一个很多方法都要调用的公共功能作为一个aspect是很好的。我的问题是在容器中运行的EJB能够用AOP吗?在Jboss4.0里面各种EJB都是通过AOP方式来提供服务的,似乎我自己多加一层业务层面的服务应该是可行的(使用jboss aop),但是这样的EJB放在别的容器里面运行会怎么样?会影响到容器对EJB的干预吗?请各位前辈指点。
posted @
2005-10-27 12:48 rkind 阅读(184) |
评论 (0) |
编辑 收藏
在这里我谈谈我在学习J2EE流程,并谈到在此过程中领会的经验和教训。以便后来者少走弯路。
Java发展到现在,按应用来分主要分为三大块:J2SE,J2ME和J2EE。这三块相互补充,应用范围不同。
J2SE就是Java2的标准版,主要用于桌面应用软件的编程;
J2ME主要应用于嵌入是系统开发,如手机和PDA的编程;
J2EE是Java2的企业版,主要用于分布式的网络程序的开发,如电子商务网站和ERP系统。
先学习J2SE
要学习J2EE就要先学习J2SE,刚开始学习J2SE先建议不要使用IDE,然后渐渐的过渡到使用IDE开发,毕竟用它方便嘛。学习J2SE推荐两本书,《java2核心技术一二卷》,《java编程思想》,《java与模式》。其中《java编程思想》要研读,精读。这一段时间是基本功学习,时间会很长,也可能很短,这要看学习者自身水平而定。
不要被IDE纠缠
学习java和J2EE过程中,你会遇到五花八门的IDE,不要被他们迷惑,学JAVA的时候,要学语言本身的东西,不要太在意IDE的附加功能,JAVA编程在不同IDE之间的转换是很容易的,过于的在意IDE的功能反而容易耽误对语言本身的理解。目前流行的IDE有jbuilder,eclipse和eclipse的加强版WSAD。用好其中一个就可以了,推荐从eclipse入手J2EE。因为Jbuilder更适合于写J2SE程序。
选择和学习服务器使用配置
当你有了J2SE和IDE的经验时,可以开始J2EE的学习了,web服务器:tomcat,勿庸置疑,tomcat为学习web服务首选。而应用服务器目前主要有三个:jboss、weblogic、websphere。有很多项目开始采用jboss,并且有大量的公司开始做websphere或weblogic向jboss应用服务器的移植(节省成本),这里要说的是,学习tomcat和jboss我认为是首选,也是最容易上手的。
学习服务器使用配置最好去询问有经验的人(有条件的话),因为他们或许一句话就能解决问题,你自己上网摸索可能要一两天(我就干过这种傻事),我们应该把主要时间放在学习原理和理论上,一项特定技术的使用永远代替不了一个人的知识和学问。
学习web知识
如果你是在做电子商务网站等时,你可能要充当几个角色,这是你还要学习:
1、html,可能要用到dreamwave等IDE。
2、Javascript,学会简单的数据校验,数据联动显示等等
J2EEAPI学习
学习J2EEAPI和学习服务器应该是一个迭代的过程。先学习jsp和servlet编程,这方面的书很多,我建立看oreilly公司的两本《jsp设计》和《java servlet编程》,oreilly出的书总是那么优秀,不得不佩服
。学习jdbc数据库编程,J2EE项目大多都是MIS系统,访问数据库是核心。这本应属于J2SE学习中,这里拿出来强调一下。学习jndi api,它和学习ejb可以结合起来。学习ejb api,推荐书《精通ejb》。经过上面的这些的学习,大概可以对付一般的应用了。有人说跟着sun公司的《J2EE tutorial》一路学下来,当然也可以。
学习ejb设计模式和看代码(最重要)
设计模式是练内功,其重要性可以这么说吧,如果你不会用设计模式的话,你将写出一堆使用了ejb的垃圾,有慢又是一堆bug,其结果不如不用ejb实现(ejb不等于J2EE)。无论学习什么语言,都应该看大量代码,你看的代码量不到一定数量,是学不好J2EE的。
目前有很多开源的工程可以作为教材:
jive论坛
petstore sun公司
dune sun公司等等,研读一个,并把它用到自己的工程中来。
J2EE其他学习
当你渐渐对J2EE了解到一定深度时,你要开始关注当前领域中的一些技术变化,J2EE是一块百家争鸣的领域,大家都在这里提出自己的解决方案,例如structs,hiberate,ofbiz等等,学习这些东西要你的项目和目标而定,预先补充一下未尝不可,但不用涉及太深,毕竟学习原理和理论是最最重要的事。
目前常见J2EEAPI
JavaServer Pages(JSP)技术1.2
Java Servlet技术2.3
JDBC API 2.0
Java XML处理API(JAXP)1.1
Enterprise JavaBeans技术2.0
Java消息服务(JMS)1.0
Java命名目录接口(JNDI)1.2
Java事务API(JTA) 1.0
JavaMail API 1.2
JavaBeans激活架构(JAF)1.0
J2EE连接器体系结构(JCA)1.0
Java认证和授权服务(JAAS)1.0
posted @
2005-10-27 12:47 rkind 阅读(195) |
评论 (0) |
编辑 收藏
现在JDK1.4里终于有了自己的正则表达式API包,JAVA程序员可以免去找第三方提供的正则表达式库的周折了,我们现在就马上来了解一下这个SUN提供的迟来恩物- -对我来说确实如此。
1.简介:
java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包。
它包括两个类:Pattern和Matcher Pattern 一个Pattern是一个正则表达式经编译后的表现模式。
Matcher 一个Matcher对象是一个状态机器,它依据Pattern对象做为匹配模式对字符串展开匹配检查。 首先一个Pattern实例订制了一个所用语法与PERL的类似的正则表达式经编译后的模式,然后一个Matcher实例在这个给定的Pattern实例的模式控制下进行字符串的匹配工作。
以下我们就分别来看看这两个类:
2.Pattern类:
Pattern的方法如下: static Pattern compile(String regex)
将给定的正则表达式编译并赋予给Pattern类
static Pattern compile(String regex, int flags)
同上,但增加flag参数的指定,可选的flag参数包括:CASE INSENSITIVE,MULTILINE,DOTALL,UNICODE CASE, CANON EQ
int flags()
返回当前Pattern的匹配flag参数.
Matcher matcher(CharSequence input)
生成一个给定命名的Matcher对象
static boolean matches(String regex, CharSequence input)
编译给定的正则表达式并且对输入的字串以该正则表达式为模开展匹配,该方法适合于该正则表达式只会使用一次的情况,也就是只进行一次匹配工作,因为这种情况下并不需要生成一个Matcher实例。
String pattern()
返回该Patter对象所编译的正则表达式。
String[] split(CharSequence input)
将目标字符串按照Pattern里所包含的正则表达式为模进行分割。
String[] split(CharSequence input, int limit)
作用同上,增加参数limit目的在于要指定分割的段数,如将limi设为2,那么目标字符串将根据正则表达式分为割为两段。
一个正则表达式,也就是一串有特定意义的字符,必须首先要编译成为一个Pattern类的实例,这个Pattern对象将会使用matcher()方法来生成一个Matcher实例,接着便可以使用该 Matcher实例以编译的正则表达式为基础对目标字符串进行匹配工作,多个Matcher是可以共用一个Pattern对象的。
现在我们先来看一个简单的例子,再通过分析它来了解怎样生成一个Pattern对象并且编译一个正则表达式,最后根据这个正则表达式将目标字符串进行分割:
import java.util.regex.*;
public class Replacement{
public static void main(String[] args) throws Exception {
// 生成一个Pattern,同时编译一个正则表达式
Pattern p = Pattern.compile("[/]+");
//用Pattern的split()方法把字符串按"/"分割
String[] result = p.split(
"Kevin has seen《LEON》seveal times,because it is a good film."
+"/ 凯文已经看过《这个杀手不太冷》几次了,因为它是一部"
+"好电影。/名词:凯文。");
for (int i=0; i<result.length; i++)
System.out.println(result[i]);
}
}
输出结果为:
Kevin has seen《LEON》seveal times,because it is a good film.
凯文已经看过《这个杀手不太冷》几次了,因为它是一部好电影。
名词:凯文。
很明显,该程序将字符串按"/"进行了分段,我们以下再使用 split(CharSequence input, int limit)方法来指定分段的段数,程序改动为:
tring[] result = p.split("Kevin has seen《LEON》seveal times,because it is a good film./ 凯文已经看过《这个杀手不太冷》几次了,因为它是一部好电影。/名词:凯文。",2);
这里面的参数"2"表明将目标语句分为两段。
输出结果则为:
Kevin has seen《LEON》seveal times,because it is a good film.
凯文已经看过《这个杀手不太冷》几次了,因为它是一部好电影。/名词:凯文。
由上面的例子,我们可以比较出java.util.regex包在构造Pattern对象以及编译指定的正则表达式的实现手法与我们在上一篇中所介绍的Jakarta-ORO 包在完成同样工作时的差别,Jakarta-ORO 包要先构造一个PatternCompiler类对象接着生成一个Pattern对象,再将正则表达式用该PatternCompiler类的compile()方法来将所需的正则表达式编译赋予Pattern类:
PatternCompiler orocom=new Perl5Compiler();
Pattern pattern=orocom.compile("REGULAR EXPRESSIONS");
PatternMatcher matcher=new Perl5Matcher();
但是在java.util.regex包里,我们仅需生成一个Pattern类,直接使用它的compile()方法就可以达到同样的效果:
Pattern p = Pattern.compile("[/]+");
因此似乎java.util.regex的构造法比Jakarta-ORO更为简洁并容易理解。
3.Matcher类:
Matcher方法如下: Matcher appendReplacement(StringBuffer sb, String replacement)
将当前匹配子串替换为指定字符串,并且将替换后的子串以及其之前到上次匹配子串之后的字符串段添加到一个StringBuffer对象里。
StringBuffer appendTail(StringBuffer sb)
将最后一次匹配工作后剩余的字符串添加到一个StringBuffer对象里。
int end()
返回当前匹配的子串的最后一个字符在原目标字符串中的索引位置 。
int end(int group)
返回与匹配模式里指定的组相匹配的子串最后一个字符的位置。
boolean find()
尝试在目标字符串里查找下一个匹配子串。
boolean find(int start)
重设Matcher对象,并且尝试在目标字符串里从指定的位置开始查找下一个匹配的子串。
String group()
返回当前查找而获得的与组匹配的所有子串内容
String group(int group)
返回当前查找而获得的与指定的组匹配的子串内容
int groupCount()
返回当前查找所获得的匹配组的数量。
boolean lookingAt()
检测目标字符串是否以匹配的子串起始。
boolean matches()
尝试对整个目标字符展开匹配检测,也就是只有整个目标字符串完全匹配时才返回真值。
Pattern pattern()
返回该Matcher对象的现有匹配模式,也就是对应的Pattern 对象。
String replaceAll(String replacement)
将目标字符串里与既有模式相匹配的子串全部替换为指定的字符串。
String replaceFirst(String replacement)
将目标字符串里第一个与既有模式相匹配的子串替换为指定的字符串。
Matcher reset()
重设该Matcher对象。
Matcher reset(CharSequence input)
重设该Matcher对象并且指定一个新的目标字符串。
int start()
返回当前查找所获子串的开始字符在原目标字符串中的位置。
int start(int group)
返回当前查找所获得的和指定组匹配的子串的第一个字符在原目标字符串中的位置。
(光看方法的解释是不是很不好理解?不要急,待会结合例子就比较容易明白了)
一个Matcher实例是被用来对目标字符串进行基于既有模式(也就是一个给定的Pattern所编译的正则表达式)进行匹配查找的,所有往Matcher的输入都是通过CharSequence接口提供的,这样做的目的在于可以支持对从多元化的数据源所提供的数据进行匹配工作。
我们分别来看看各方法的使用:
★matches()/lookingAt ()/find():
一个Matcher对象是由一个Pattern对象调用其matcher()方法而生成的,一旦该Matcher对象生成,它就可以进行三种不同的匹配查找操作:
matches()方法尝试对整个目标字符展开匹配检测,也就是只有整个目标字符串完全匹配时才返回真值。
lookingAt ()方法将检测目标字符串是否以匹配的子串起始。
find()方法尝试在目标字符串里查找下一个匹配子串。
以上三个方法都将返回一个布尔值来表明成功与否。
★replaceAll ()/appendReplacement()/appendTail():
Matcher类同时提供了四个将匹配子串替换成指定字符串的方法:
replaceAll()
replaceFirst()
appendReplacement()
appendTail()
replaceAll()与replaceFirst()的用法都比较简单,请看上面方法的解释。我们主要重点了解一下appendReplacement()和appendTail()方法。
appendReplacement(StringBuffer sb, String replacement) 将当前匹配子串替换为指定字符串,并且将替换后的子串以及其之前到上次匹配子串之后的字符串段添加到一个StringBuffer对象里,而appendTail(StringBuffer sb) 方法则将最后一次匹配工作后剩余的字符串添加到一个StringBuffer对象里。
例如,有字符串fatcatfatcatfat,假设既有正则表达式模式为"cat",第一次匹配后调用appendReplacement(sb,"dog"),那么这时StringBuffer sb的内容为fatdog,也就是fatcat中的cat被替换为dog并且与匹配子串前的内容加到sb里,而第二次匹配后调用appendReplacement(sb,"dog"),那么sb的内容就变为fatdogfatdog,如果最后再调用一次appendTail(sb),那么sb最终的内容将是fatdogfatdogfat。
还是有点模糊?那么我们来看个简单的程序:
//该例将把句子里的"Kelvin"改为"Kevin"
import java.util.regex.*;
public class MatcherTest{
public static void main(String[] args)
throws Exception {
//生成Pattern对象并且编译一个简单的正则表达式"Kelvin"
Pattern p = Pattern.compile("Kevin");
//用Pattern类的matcher()方法生成一个Matcher对象
Matcher m = p.matcher("Kelvin Li and Kelvin Chan are both working in Kelvin Chen's KelvinSoftShop company");
StringBuffer sb = new StringBuffer();
int i=0;
//使用find()方法查找第一个匹配的对象
boolean result = m.find();
//使用循环将句子里所有的kelvin找出并替换再将内容加到sb里
while(result) {
i++;
m.appendReplacement(sb, "Kevin");
System.out.println("第"+i+"次匹配后sb的内容是:"+sb);
//继续查找下一个匹配对象
result = m.find();
}
//最后调用appendTail()方法将最后一次匹配后的剩余字符串加到sb里;
m.appendTail(sb);
System.out.println("调用m.appendTail(sb)后sb的最终内容是:"+ sb.toString());
}
}
最终输出结果为:
第1次匹配后sb的内容是:Kevin
第2次匹配后sb的内容是:Kevin Li and Kevin
第3次匹配后sb的内容是:Kevin Li and Kevin Chan are both working in Kevin
第4次匹配后sb的内容是:Kevin Li and Kevin Chan are both working in Kevin Chen's Kevin
调用m.appendTail(sb)后sb的最终内容是:Kevin Li and Kevin Chan are both working in Kevin Chen's KevinSoftShop company.
看了上面这个例程是否对appendReplacement(),appendTail()两个方法的使用更清楚呢,如果还是不太肯定最好自己动手写几行代码测试一下。
★group()/group(int group)/groupCount():
该系列方法与我们在上篇介绍的Jakarta-ORO中的MatchResult .group()方法类似(有关Jakarta-ORO请参考上篇的内容),都是要返回与组匹配的子串内容,下面代码将很好解释其用法:
import java.util.regex.*;
public class GroupTest{
public static void main(String[] args)
throws Exception {
Pattern p = Pattern.compile("(ca)(t)");
Matcher m = p.matcher("one cat,two cats in the yard");
StringBuffer sb = new StringBuffer();
boolean result = m.find();
System.out.println("该次查找获得匹配组的数量为:"+m.groupCount());
for(int i=1;i<=m.groupCount();i++){
System.out.println("第"+i+"组的子串内容为: "+m.group(i));
}
}
}
输出为:
该次查找获得匹配组的数量为:2
第1组的子串内容为:ca
第2组的子串内容为:t
Matcher对象的其他方法因比较好理解且由于篇幅有限,请读者自己编程验证。
4.一个检验Email地址的小程序:
最后我们来看一个检验Email地址的例程,该程序是用来检验一个输入的EMAIL地址里所包含的字符是否合法,虽然这不是一个完整的EMAIL地址检验程序,它不能检验所有可能出现的情况,但在必要时您可以在其基础上增加所需功能。
import java.util.regex.*;
public class Email {
public static void main(String[] args) throws Exception {
String input = args[0];
//检测输入的EMAIL地址是否以 非法符号"."或"@"作为起始字符
Pattern p = Pattern.compile("^\\.|^\\@");
Matcher m = p.matcher(input);
if (m.find()){
System.err.println("EMAIL地址不能以'.'或'@'作为起始字符");
}
//检测是否以"www."为起始
p = Pattern.compile("^www\\.");
m = p.matcher(input);
if (m.find()) {
System.out.println("EMAIL地址不能以'www.'起始");
}
//检测是否包含非法字符
p = Pattern.compile("[^A-Za-z0-9\\.\\@_\\-~#]+");
m = p.matcher(input);
StringBuffer sb = new StringBuffer();
boolean result = m.find();
boolean deletedIllegalChars = false;
while(result) {
//如果找到了非法字符那么就设下标记
deletedIllegalChars = true;
//如果里面包含非法字符如冒号双引号等,那么就把他们消去,加到SB里面
m.appendReplacement(sb, "");
result = m.find();
}
m.appendTail(sb);
input = sb.toString();
if (deletedIllegalChars) {
System.out.println("输入的EMAIL地址里包含有冒号、逗号等非法字符,请修改");
System.out.println("您现在的输入为: "+args[0]);
System.out.println("修改后合法的地址应类似: "+input);
}
}
}
例如,我们在命令行输入:java Email www.kevin@163.net
那么输出结果将会是:EMAIL地址不能以'www.'起始
如果输入的EMAIL为@kevin@163.net
则输出为:EMAIL地址不能以'.'或'@'作为起始字符
当输入为:cgjmail#$%@163.net
那么输出就是:
输入的EMAIL地址里包含有冒号、逗号等非法字符,请修改
您现在的输入为: cgjmail#$%@163.net
修改后合法的地址应类似: cgjmail@163.net
5.总结:
本文介绍了jdk1.4.0-beta3里正则表达式库--java.util.regex中的类以及其方法,如果结合与上一篇中所介绍的Jakarta-ORO API作比较,读者会更容易掌握该API的使用,当然该库的性能将在未来的日子里不断扩展,希望获得最新信息的读者最好到及时到SUN的网站去了解。
6.结束语:
本来计划再多写一篇介绍一下需付费的正则表达式库中较具代表性的作品,但觉得既然有了免费且优秀的正则表达式库可以使用,何必还要去找需付费的呢,相信很多读者也是这么想的:,所以有兴趣了解更多其他的第三方正则表达式库的朋友可以自己到网上查找或者到我在参考资料里提供的网址去看看。
posted @
2005-10-27 12:44 rkind 阅读(208) |
评论 (0) |
编辑 收藏采用了tomcat发布,调用了jarkarta的一个common-fileup组件,
着先配置好classpath,加上servlet.jar和commons-fileupload-1.0.jar,
然后把commons-fileupload-1.0.jar放到root下的web-inf/lib/下
编写up.java并编绎,放到web-inf/classes目录下
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
import java.util.regex.*;
import org.apache.commons.fileupload.*;
public class up extends HttpServlet {
private static final String CONTENT_TYPE = "text/html; charset=GB2312";
//Process the HTTP Post request
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType(CONTENT_TYPE);
PrintWriter out=response.getWriter();
try {
DiskFileUpload fu = new DiskFileUpload();
// 设置允许用户上传文件大小,单位:字节,这里设为2m
fu.setSizeMax(2*1024*1024);
// 设置最多只允许在内存中存储的数据,单位:字节
fu.setSizeThreshold(4096);
// 设置一旦文件大小超过getSizeThreshold()的值时数据存放在硬盘的目录
fu.setRepositoryPath("c:\\windows\\temp");
//开始读取上传信息
List fileItems = fu.parseRequest(request);
// 依次处理每个上传的文件
Iterator iter = fileItems.iterator();
//正则匹配,过滤路径取文件名
String regExp=".+\\\\(.+)$";
//过滤掉的文件类型
String[] errorType={".exe",".com",".cgi",".asp"};
Pattern p = Pattern.compile(regExp);
while (iter.hasNext()) {
FileItem item = (FileItem)iter.next();
//忽略其他不是文件域的所有表单信息
if (!item.isFormField()) {
String name = item.getName();
long size = item.getSize();
if((name==null||name.equals("")) && size==0)
continue;
Matcher m = p.matcher(name);
boolean result = m.find();
if (result){
for (int temp=0;temp<errorType.length;temp++){
if (m.group(1).endsWith(errorType[temp])){
throw new IOException(name+": wrong type");
}
}
try{
//保存上传的文件到指定的目录
//在下文中上传文件至数据库时,将对这里改写
item.write(new File("d:\\" + m.group(1)));
out.print(name+" "+size+"<br>");
}
catch(Exception e){
out.println(e);
}
}
else
{
throw new IOException("fail to upload");
}
}
}
}
catch (IOException e){
out.println(e);
}
catch (FileUploadException e){
out.println(e);
}
}
}
然后布署好web.xml,在其中加入
<servlet>
<servlet-name>up</servlet-name>
<servlet-class>up</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>up</servlet-name>
<url-pattern>/fileup</url-pattern>
</servlet-mapping>
好了现在再编写一个htm测试一下就ok了,注意url-pattern里面的路径必须跟表格中action的属性一样.
<html>
<h1>文件上传演示</h1>
<form name="uploadform" method="POST" action="/fileup" ENCTYPE="multipart/form-data">
<table border="1" width="450" cellpadding="4" cellspacing="2" bordercolor="#9BD7FF">
<tr><td width="100%" colspan="2">
文件1:<input name="x" size="40" type="file">
</td></tr>
<tr><td width="100%" colspan="2">
文件2:<input name="y" size="40" type="file">
</td></tr>
<tr><td width="100%" colspan="2">
文件3:<input name="z" size="40" type="file">
</td></tr>
</table>
<br/><br/>
<table>
<tr><td align="center"><input name="upload" type="submit" value="开始上传"/></td></tr>
</table>
</form>
</html>
posted @
2005-10-27 12:43 rkind 阅读(290) |
评论 (0) |
编辑 收藏
解决Win2000Sever登录时“不支持网络请求,系统无法让您登陆”问题

文章来源:
http://blog.csdn.net/rkind/archive/2005/09/16/482030.aspx
posted @
2005-10-27 09:12 rkind 阅读(288) |
评论 (0) |
编辑 收藏