In the previous
sections, all the methods of extracting LSs disregard the natural language’s
consistency in the web pages by only considering the discrete terms. The
document’s terms are arranged in alphabetic order before applying TF or DF, which
totally destroys the linguistic information in web pages. Take an example from Thomas
A. Phelps and Robert Wilensk’s paper [3],
http://www.cs.berkeley.edu/˜wilensky/NLP.html cannot be located using this query “texttiling
wilensky disambiguation subtopic iago” in Google at current time, as shown in Figure2.8, Google only return 4 results with highly
related content but none of them have the same URL as required, however it was
claimed as successful in January, 2008. Meanwhile it can be returned by Yahoo
search with the same query but a different address like this in Figure2.9:
http://www.eecs.berkeley.edu/Faculty/Homepages/wilensky.html/NLP.html?lexical-signature=texttiling+wilensky+disambiguation+subtopic+iago
This shows the
fact that 2 different URLs can open the same page. About different URLs binding
on the same web page, it is not discussed in this project. It is supposed to be
a successful retrieval if document similarity is taken as a measurement,
however, the URL matching measurement will clearly put it into a false
retrieval.

Figure2.8

Figure2.9
From Figure2.8 and Figure2.9, we can see the un-stable performance from
traditional LS generation techniques even when they were as typical samples as in
papers years before. The studies on URL and its page content change have been
researched before, such as Martin Klein and Michael L. Nelson studied the pages
ranging from 1996 to 2007 [3], but they are not included in this
project. One single page bound by different URL actually happens quite often,
taking Binghamton
University’s home page as
an example, http://www.binghamton.edu/index.html
and http://www2.binghamton.edu actually
connect to the same page. In chapter 3, section 3.4 shows typical examples in
Yahoo news pages that Yahoo changes the same news page’s URL all the time.
One approach of solving
such kind of difficulty, which mainly focuses on finding relative or similar
web pages rather than locating web pages only by URLs matching, is referenced
by automatically generating key words and summarizations for academic papers. They
are introduced as having capabilities by reserving both the underlying language
information and relatively stable performance, because there are fewer chances to
have two documents with the same content but different URLs, and even this
happens, Martin and Michael studied the graph-based algorithms and concluded
that they actually had the ability to improve the relative/similar web page
re-finding/re-location when the original copy is lost [3].
Graph-based
ranking algorithm is a way of deciding the importance of a vertex within a graph,
by taking all text as global information and recursively computing from the
entire graph rather than relying only on local vertex-specific information [9][10].The
basic idea implemented by a graph-based ranking model is a vertex can receive
and cast “voting” or “recommendation” to the others [12][13]. When
one vertex links to another one, it is basically casting a vote to the other in
the graph. The higher the number of votes is received by a vertex, the higher
the importance of the vertex is taken [9]. Figure2.10 (a) is an example showing how it works
when a vertex casts all its weight to the other vertices. Figure2.10 (b) is an example a vertex casts 90% of
its weight to the others while it keeps 10%. Page-Rank is a typical
implementation of this graph-based ranking algorithm. The score of a vertex Vi
is defined as:
 [11] 2-5
[11] 2-5
Where d is a
damping factor that can be set between 0 and 1. In 2-5, j is the vertex points to i and Out(Vj)
is the score delivered from j to i.


(a) (b)
Figure2.10
Meanwhile, graph-based
ranking algorithm can also be split into 2 groups as Figure2.11 shows the combinations: weighted (on
edges) graph and un-weighted (on edges) graph, undirected-graph
and directed-graph. One group’s condition can be combined with the other group’s
condition.
Figure2.11
Because undirected
un-weighted (on both edges and vertices) graph does not have actual meaning in
this project, it is not discussed. Figure2.10 (a) and (b) are 2 examples of directed graph,
with weights on vertex, but without value on the edges. Figure2.12 is an example of undirected weighted (on
edges) graph. It is the case that assuming out-degree of a vertex is equal to
the in-degree of the vertex, take undirected edges like bi-directions edges [9][10]..
The weight from i to j and from j to i are same. The weight’s recursive
computation formula:
 [9] 2-6
[9] 2-6
 and
and  show Vi, Vj
and Vk are connected but cannot show any direction among Vi,
Vj and Vk. Figure2.13 is an example of directed weighted graph.
It is the case that a weight is added according to the direction from one
vertex to another. The weight from i to j is wij, but the weight
from j to i is 0.
show Vi, Vj
and Vk are connected but cannot show any direction among Vi,
Vj and Vk. Figure2.13 is an example of directed weighted graph.
It is the case that a weight is added according to the direction from one
vertex to another. The weight from i to j is wij, but the weight
from j to i is 0.
Figure2.12
Figure2.13
 [9] 2-7
[9] 2-7
Compared to the
un-directed weighted graph’s formula 2-6,  and
and  in formula 2-7 show the direction between Vj,
Vi and Vk, Vj.
in formula 2-7 show the direction between Vj,
Vi and Vk, Vj.
In 1997, Michal
Cutler proposed a method that makes use of structures and hyperlinks of HTML
documents to improve the effectiveness of retrieving HTML documents [6].
She classified the HTML into categories based on HTML’s tags, such as Title,
H1, H2, H3, H4, H5, H6 and so on, and claimed that the terms in different HTML
tags have different weight. Based on this idea, a new method for extracting lexical
signatures from a web page can use the terms that have the highest weights that
are computed with the HTML tag structures taken into consideration [6].
It is quite
necessary to outline Cutler’s two papers both: “Using the Structure of HTML
Documents to Improve Retrieval” [6] and “A New Study on Using HTML Structures
to Improve Retrieval” [7].
First of all, she
raised an excellent idea of differentiating the term weights for the different HTML
tags. The first paper classified an HTML page into following categories in Table2.1. The detailed specifications and functions
of each tag are not listed here in this section. She also mentioned that the tag
importance is Anchor > H1 – H2 > H3 – H6 > Strong > Title >
Plain Text [6].
|
Class Name
|
HTML
tags
|
|
Anchor
|
<a
href=>…<a>
|
|
H1-H2
|
<h1>…</h1>,
<h2>…</h2>
|
|
H3-H6
|
<h3>…</h3>,
<h4>…</h4>, <h5>…</h5>, <h6>…</h6>
|
|
Strong
|
<strong>...</strong>,
<b>…</b>, <em>…</em>, <i>…</i>,
<u>…</u>,
<dl>…</dl>, <ol>…</ol>, <ul>…</ul>
|
|
Title
|
<title>…</title>
|
|
Plain Text
|
None of the above
|
Table2.1 [6]
The second paper
classified an HTML page into following categories in Table2.2. The later paper combined all the header tags
together but split the strong tags into 2 categories: list and strong.
Meanwhile, the second paper considered the text in Title tag and Header tag to
be more important than the others rather than Anchor and Header tags are the 2
most important categories in Table2.1 [6]
The tags <dl>, <ol> and
<ul>’s functions are listed in Appendix A.
|
Class Name
|
HTML
tags
|
|
Title
|
<title>…</title>
|
|
Header
|
<h1>…</h1>,
<h2>…</h2>, <h3>…</h3>, <h4>…</h4>,
<h5>…</h5>,
<h6>…</h6>
|
|
List
|
<dl>…</dl>,
<ol>…</ol>, <ul>…</ul>
|
|
Strong
|
<strong>...</strong>,
<b>…</b>, <em>…</em>, <i>…</i>,
<u>…</u>
|
|
Anchor
|
<a href=>…<a>
|
|
Plain Text
|
None of the above
|
Table2.2 [6]
The basic ideas
behind the two papers’ categories are the same: split the text into different classes
based on their tags and then associate them with different weights. When a term
appears in more than one class, it only counts terms which appear in higher
level. For example, <H1><A href=”http//www.binghamton.edu”>university</A><H1>,
‘university’ is classified into Header category rather than Anchor directory
according to Table2.2 [6], but it is in Anchor category according to
Table2.1 [6].
Figure2.5 is a snapshot from http://research.binghamton.edu/.
The text in the squares is either in Strong tag or Anchor tag, they are
highlighted with either in bigger font size or different color rather than
regular black. Apparently, it is consistent with the author’s intention that he/she
wants people to notice these lines which should draw more attention to the highlighted
content and have more weight than the other un-highlighted text.

Figure2.5
However,
difficulties come along with applying different weight to different HTML tags.
Take the following piece of HTML as an example, in Figure2.6, which is from Yahoo news page:

Figure2.6
Take a careful
look at the red square and orange square, “Mario left a comment: Obama’s ….”,
is separated into 2 different parts, the terms in blue are in Anchor tag which
have HREF links to the other pages, while, ‘left a comment’ in orange square is
taken off from the Anchor tag, and clearly showed in a Strong text style as
compared to “to see what your Connections are…”. However, Yahoo put ‘left a
comment’ into a pre-defined <P> tag and set it into a Strong style. This
can lead the conventional ways in parsing HTML becoming inaccurate and destroy
the original order in the text. As Figure2.7 shows, the <P> tags and <A>
tags are mixed together, which can lead to confusion in differentiating the
text in those 2 kinds of tags if the program is not designed carefully.

Figure2.7
On the other hand,
because these 2 papers focused on their test search engine WEBOR [7]
which was developed by Weiyi Meng and Michal Cutler, Culter’s theory and research
were apparently going on with clearly understanding of the working mechanism in
WEBOR. Meanwhile, Cutler also had the access to control and modify WEBOR itself
according to the requirement of changing CIV [6][7].
The conclusion could be unclear
in applying this LS extraction method to Google, Yahoo or other commercial SEs
which keep their searching mechanism as top secrets from others.
‘Robust hyperlinks’
is a typical implementation from applying LSs in locating web pages. URL
combined with LSs can not only re-find the desired web page, but also discover
the most relevant pages if the desired page is missed or lost. Thomas A. Phelps
and Robert Wilensky in their “Robust Hyperlinks Cost Just Five Words Each” [2]
exhibited the problem when the desired page was deleted, renamed, moved, or
changed, and demonstrated a novel approach to this issue by argumenting LSs in
URLs so that they themselves became robust hyperlinks [2]. A novel
compatible with traditional URL called “robust hyper link aware” URL can be
like:
http://www.something.dom/a/b/c?lexical-signature="w1+w2+w3+w4+w5"
where w1, w2, w3,
w4 and w5 are 5 terms extracted from the original page by TF-IDF. They are
probably the first ones who raised the idea of lexical signature on a typical
web page and explore its the application value.
Researchers have
spent a lot of efforts in exploring how many LSs can give a best result. Martin
Klein and Michael L. Nelson conclude 5 to 7 LSs are good enough in robust
hyperlinks [2] after extensive experiments. Martin and Michael did
not only conclude LS is a small set of terms derived from a document which can capture
the “aboutness” of that document [3], but also defined a LS from a
web page can discover the page at a different URL as well as to find relevant
pages on internet [3]. Through their experiments on huge amount of
web pages from 1996 – 2007 which were downloaded from Internet Archive, http://www.archive.org/index.php, they claimed
that 5-, 6- and 7-term LSs performed the best in returning the interested URLs
among the top 10 from Google, Yahoo, MSN live, Internet Archive, European
Archive, CiteSeer and NSDL [3]. By apply equation 2-1 to 2-2, the LS score versus number of terms in each query
were derived in Figure2.4.
Figure2.4 LS Performance by
Number of Terms [3]
Their experiments
also showed that 50% URLs are returned as the top1 result, and 30% URLs were
failed to re-locate/find by choosing LS in decreasing TF-IDF order [3]
when they were reviewing Phelps and Wilensky’s research. Meanwhile, they also carefully
studied the techniques for estimating IDF values which is a non-trivial issue
in generating LS for the web pages. In their recent paper, 2008, “A comparison
of techniques for estimating IDF values to generate lexical signatures for the
web” [19], they introduced 3 quite different ways to estimate terms’
IDF and carefully examined their performances.
1.
Local
universe which was a set of pages downloaded from 98 websites, starting from
1996 to September, 2007 in
each month [19].
2.
Screen
scraping Google web interface which was generated in January, 2008 [19].
3.
Google
N-Gram (NG) which was distributed in 2006 [19].
They compared these
3 IDF estimation techniques and claimed that local universe based data as well
as the screen scraping based data is similar compared to their baseline, Google
N-Gram based data.
Besides listing
the detail percentage of success and fail to retrieve a URL, they used the
following 2 equations in paper [3] to evaluate the score of LSs:
fair score and optimistic score.
 [3] 2-1
[3] 2-1
 [3] 2-2
[3] 2-2
R(i) shows the ith page’s rank returned by SE after
sending the query, when it gets bigger value, the fair score will be lower, N
is the total sample pages in their experiments which is 98 and  is the average value.
is the average value.
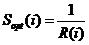 [3] 2-3
[3] 2-3
 [3] 2-4
[3] 2-4
In the optimistic
score equation, Sopt is different from Sfair which is
only determined by pages’ rank.  is the average fair
score value.
is the average fair
score value.
They set Rmax =
100 which makes Sfair can always be positive if the desired page
appears in first 100 results from SE. If R(o) > Rmax, when the
desired page does not appear in first 100 results, then simply set Sfair
= 0 and Sopt = 0. The final results of scores were from 2 terms to
15 terms per query and scores ranged from 0.2 to 0.8. They also concluded the
scores on one page since year 1996 to 2007 ranged from 0.1 to 0.6 [3].
More details and score curves in their paper are not included in this project
report.
1. Weiyi Meng, and Hai He. Data Search Engine. In Encyclopedia of
Computer Science and Engineering (Benjamin Wah, ed.), John Wiley & Sons,
pp.826-834, January 2009.
2. Thomas A. Phelps, Robert Wilensky, 2000.
Robust Hyperlinks Cost Just Five Words Each. Technical Report: CSD-00-1091.
Publisher: University of California at Berkeley.
3. Martin Klein, Michael L.
Nelson. 2008. Revisiting Lexical
Signatures to (Re-)Discover Web Pages. Proceedings of the 12th European
conference on Research and Advanced Technology for Digital Libraries Pages: 371
– 382
4. Seung-Taek, David M. Pennock, C. Lee Giles,
Robert Krovetz, 2002. Analysis of Lexical Signatures for Finding Lost or
Related Documents SIGIR' 02, August 11-15, 2002, Tampere, Finland.
5. Seung-Taek, David M. Pennock, C. Lee Giles,
Robert Krovetz, 2004. Analysis of Lexical Signatures for Improving Information
Persistence on the World Wide Web. ACM Transactions on Information Systems,
Vol. 22, No. 4, October 2004, Pages 540–572.
6. M. Cutler, Y. Shih, W. Meng. 1997. Using
the Structure of HTML Documents to Improve Retrieval. USENIX Symposium on
Internet Technologies and Systems.
7. M. Cutler, H. Deng, S. S.
Maniccam, W. Meng. Tools with
Artificial Intelligence, 1999. A new study on using HTML structures to improve
retrieval. Proceedings. 11th IEEE International Conference on Volume , Issue ,
1999 Page(s):406 – 409.
8. J. Lu, Y. Shih, W. Meng and M. Cutler.
1996. Web-based Search Tool for Organization Retrieval. http://nexus.data.binghamton.edu/~yungming/webor.html
9. Rada Mihalcea and Paul
Tarau. 2004. TextRank: Bring
Order into Texts. Proceedings of EMNLP 2004, pages 404–411, Barcelona, Spain.
10. Rada Mihalcea. 2004. Graph-based Ranking
Algorithms for Sentence Extraction, Applied to Text Summarization. In
Proceedings of the 20th International Conference on Computational Linguistics
(COLING 2004), Geneva, Switzerland.
11. Xiaojun Wang, Jianwu Yang. 2006.
WordRank-Based Lexical Signatures for Finding Lost or Related Web Pages. APWeb
2006, LNCS 3841, pp. 843-849.
12. Larry Page. 1998. The PageRank Citation
Ranking: Bringing Order to the Web. Computer Networks and ISND Systems.
13. Jon M. Kleinberg. 1999. Authoritative
Sources in a HyperLinked Environment. Journal of the ACM, 46(5): 604-632.
14.
WordNet, http://wordnet.princeton.edu/
15. C.Y.Lin and E.H.Hovy. 2003. Automatic
evaluation of summaries using n-gram co-occurrence statistics. In Proceedings
of Human Language Technology Conference (HLT-NAACL 2003), Edmonton, Canada,
May.
16. Weiyi Meng, Clement Yu, and King-Lup Liu.
2002. Building Efficient and Effective Metasearch Engines. ACM Computing Surveys,
Vol. 34, No. 1, March 2002, pp.48-89.
17. Weiyi Meng, Zonghuan Wu, Clement Yu, and
Zhuogang Li. 2001. A Highly-Scalable and Effective Method for Metasearch. ACM
Transactions on Information Systems 19(3), pp.310-335, July 2001.
18. Michael K. Bergman. 2001. White Paper: The
Deep Web: Surfacing Hidden Value. BrightPlanet. Ann Arbor, MI: Scholarly
Publishing Office, University of Michigan, University Library vol. 7, no. 1,
August, 2001
19. Martin Klein, Michael L.
Nelson. 2008. A comparison of
techniques for estimating IDF values to generate lexical signatures for the web.
Workshop on Web Information and Data Management. Proceeding of the 10th ACM
workshop on Web information and data management. Napa Valley, California,
USA. SESSION:
System issues. Pages 39-46.
20. Crunch, http://www.psl.cs.columbia.edu/crunch/
Before referencing
the related studies and works, the terminology “Lexical Signature” (LS) is quite
necessary to be mentioned first. LS is simply considered as an equivalent term to
“key words/terms/phrases” in chapter 1. There are many related works have given
LS various descriptions. Thomas A. Phelps and Robert Wilensky made this
definition: a relatively small set of such terms can effectively discriminate a
given document from all the others in a large collection [2]. They
also proposed a way to create LS that meets the desired criteria which is
selecting the first few terms of the document that have the highest "term
frequency-inverse document frequency" (TF-IDF) values [2]. Martin
Klein and Michael L. Nelson introduced the LS as a small set of terms derived
from a document that capture the “aboutness” of itself [3]. S. T. Park
studied and analyzed Phelps and Wilensky’s theory, and he claimed that, LS had
following characteristics by concluding from Phelps and Wilensky’s paper [4][5]:
(1) LSs should extract the desired document and
only that document [5].
(2) LSs should be robust enough to find
documents that have been slightly modified [5].
(3) New LSs should have minimal overlap with
existing LSs [5].
(4) LSs should have minimal search engine
dependency [5].
Seung-Park also
raised his own perspective about LS to help the user finding similar or
relevant documents:
(1) LSs should easily extract the desired
document. When a search engine returns more than one document, the desired
document should be the top-ranked documents [5].
(2) LSs should be useful enough to find
relevant information when the precise documents being searched for are lost [5].
After all, S. T. Park’s
studies on LS are very insightful and helpful in this project. If type “Lexical
Signature” as a search query into Google, then the first 10 results are most
likely going to have both of his 2 papers “Analysis of lexical signatures for
finding lost or related documents” [4] and “Analysis of lexical
signatures for improving information persistence on the www” [5].
S. T. Park
conducted a large amount of experiments with TF, DF, TFIDF, PW, TF3DF2, TF4DF1,
TFIDF3DF2, TFIDF4DF1 separately and combined them synthetically [4][5],
then, compared the results from Yahoo, MSN and AltaVista all in histograms.
Including unique result, 1st-rank result and top 10 results [5],
the success re-finding rate is more than 60% but less than 70% when take both 2
URLs match and 2 documents’ cosine value > 0.95 as a success re-finding into
consideration. Thus, if only taking 2 URLs comparison as a measurement and having
a success when they are matched, the success re-finding/re-locating rate would
be probably lower.



Figure2.1



Figure2.2



Figure2.3 [5]
In this project,
the LS’s definition follows S. T. Park’s theory: LSs are the key terms from the
web page and can help to both identify the web page from others uniquely and
retrieve the most relevant page effectively by search engines. Meanwhile, in
experiments, LS cannot be simply considered as the unchanged terms (words) from
the documents. Some necessary pre-procedures and transformations must be taken
before starting to process the web pages/documents in the information retrieval
ways, such as removing the stop words or transforming the words in different forms
but close meanings into one unique term, like “lexica” and “lexical” to “lex”. Other
than this, picking out only nouns and verbs or nouns and adjectives from the
text is also feasible based on word form data base. These steps are implemented
in Chapter 4 particularly by LUCENE and WORDNET, 2 open source Java projects
well accepted in practical industry world.
WWW shows
unprecedented expansion and innumerable styles which has led us to an
“information technology age” for over a decade. Thus, the ways of how to
efficiently and effectively retrieve the web documents according to the
specific needs raise the huge development in web search technology. Indeed,
searching is the second most popular activity on the web, behind e-mail, and
about 550 million web searches are performed every day [1]. Google
and Yahoo are now leading the most advanced technology in the web search
industry, by knowing some words, phrases, sentences, names, addresses, email
addresses, telephone numbers and date, the related web pages can be efficiently
searched up, which significantly changes the traditional ways of obtaining the information.
People are becoming professionals in web information retrieval even most of
them have no idea about information retrieval theory in their minds and they
are struggling in finding more related and closed to their desired pages. One
of the key challenges focuses on the input query. Generally speaking, it is
about how to effectively get better results by acquiring the certain key words/phrases
as search queries in the first step. The other one focuses on the order of
words in the query, same words but in different order can leads to quite
different result URLs, normally, the word appearing in the first shows more
importance than the others, therefore the results are not trying to match the
separated words in query at the same time equally. Other than this primitive
query, there are also several query grammars provided by many search engines,
such as double quotation marks, logical ‘and’, ‘or’ and ‘not’ operation, they
assure the same weight are put equally on the words when these logical
operators are applied. Meanwhile, given the same key words as a search query,
different search engines return different results, the measurements of how
‘good’ and how ‘comprehensive’ the results are drawing the attentions in the
related web research, meanwhile, the results quality is judged by the users and
it is not completed objective. Therefore, the measurements must be designed as much
objective and persuasive as possible. This leads to the initiative in this
project, an appropriate test system is built upon the web search engines by
analyzing their results. Then the analysis focuses on 2 aspects, the URL
quality and content quality. URL quality can only be tested by comparing the
user’s target URL and the result URLs returned by search engine, and a good URL
quality is only determined by 2 URL’s matching or not. Content quality is more
loose and unrestricted by comparing the target URL’s content and the result
URL’s content. A good content quality means high similarity between those 2. It
is critical that, before the above 2 methods being applied, the ways how to get
result URLs from search engine and maximize the quality measurements is leading
the main task in this project which is equal to getting a query best summarize
the page itself. In the following report, SE stands for Search Engine and LS
stands for Lexical Signature.
There are various
ways to extract key terms from the pure text file in information retrieval
theory, which can be applied on web pages. In this project, taking key terms
from a web page as search query to SE and then comparing the results from SE
with the previous page is considered as a way to measure SE. Develop such a
measurement which needs to be convincible and reliable is the key part of this
project and equals to the studies around re-find/re-locate a given HTML’s URL. Because
a valid web page online has a URL associate with it, there is an opportunity that
the URL can be located by SE after extracting key terms from its text content
into a query. It is not always the correct way because SE also takes links
information into ranking consideration such as page rank algorithm. But it can
show a high success rate in re-finding/re-locating the target URL by only
focusing on the page itself, disregarding the global links structure. This
re-finding/re-locating unique designated URL process excludes the subjective inferences
and offers a good practice in the SE measurements.
In this report, the related
researches and experiments such as removing the structural HTML tags,
extracting text from HTML, download document frequency for each term from
Google and count term frequency are practiced and tested, then, the query is
constructed and returned URL results from search engine among various methods
are compared. Chapter 2 lists related works and studies on the text processing
methods for a single web page/document. Chapter 3 introduces the data set,
search engine selection, HTML parsing and text extraction, the terms in term
frequency order, document frequency order and graph-based rank order, query
sending, result pages comparisons and success retrieval evaluations. Chapter 4 describes
the detailed experiments setup, different term order’s algorithms and URL comparisons
which are introduced in Chapter 3. All related results are recorded and shown
in the histograms, followed by the comparisons and analysis upon the differences.
Chapter 5 makes the conclusion, limitations and some potential improvements on
theories and experiments in this project.
Extensive pages
along with their URLs are taken as samples, a query which can best summarize
the page itself is constructed and sent to the search engine, the samples’ URLs
are compared with the returned URLs, if there is a match between them or their
content, consider the query as a lexical signature query or strong query. Assume
that the page and its URL in surface web are supposed to be found by general
search engine leads to the search engine’s quality measurement. By sending the
strong query to different search engines, the qualities are derived. It will be
a good source for the measurement only if the query extraction and processing
targeted on web pages are well designed and implemented. This process is called
find a lexical signature query for a given web page.
Keywords:
lexical signature, query, search engine, Google, Yahoo, HTML tags, term
frequency, document frequency, graph-based ranking algorithm, word rank,
sentence rank.
摘要: Normal
0
7.8 pt
0
2
false
false
false
EN-US
ZH-CN
X-NONE
MicrosoftInternetExplorer4
...
阅读全文
First, here is the following basic code:
1 package com.googlesites.qslbinghamton.corejava.database;
2
3 import java.sql.Connection;
4 import java.sql.DriverManager;
5 import java.sql.ResultSet;
6 import java.sql.SQLException;
7 import java.sql.Statement;
8
9 public class MySqlConn {
10 public static Connection getConnection() throws Exception {
11 String driver = "com.mysql.jdbc.Driver";
12 String url = "jdbc:mysql://localhost/t2";
13 String username = "root";
14 String password = "12345678";
15
16 Class.forName(driver);
17 Connection conn = DriverManager.getConnection(url, username, password);
18 return conn;
19 }
20
21 public static void main(String[] args) {
22 Connection conn = null;
23 Statement stmt = null;
24 ResultSet rs = null;
25 try {
26 conn = getConnection();
27 System.out.println("conn=" + conn);
28 // prepare query
29 String query = "select * from Employee";
30 // create a statement
31 stmt = conn.createStatement();
32 // execute query and return result as a ResultSet
33 rs = stmt.executeQuery(query);
34 // extract data from the ResultSet
35 while (rs.next()) {
36 String id = rs.getString(1);
37 String username = rs.getString(2);
38
39 System.out.println("id=" + id);
40 System.out.println("name=" + username);
41 System.out.println("---------------");
42 }
43 } catch (Exception e) {
44 e.printStackTrace();
45 System.exit(1);
46 } finally {
47 // release database resources
48 try {
49 rs.close();
50 stmt.close();
51 conn.close();
52 } catch (SQLException e) {
53 e.printStackTrace();
54 }
55 }
56 }
57 }
58
Here is a trivial question, why Class.forName in the first place.
Now, let's take a look at class com.mysql.jdbc.Driver source file:
1 package com.mysql.jdbc;
2
3 import java.sql.SQLException;
4
5 /**
6 * The Java SQL framework allows for multiple database drivers. Each driver
7 * should supply a class that implements the Driver interface
8 *
9 * <p>
10 * The DriverManager will try to load as many drivers as it can find and then
11 * for any given connection request, it will ask each driver in turn to try to
12 * connect to the target URL.
13 *
14 * <p>
15 * It is strongly recommended that each Driver class should be small and
16 * standalone so that the Driver class can be loaded and queried without
17 * bringing in vast quantities of supporting code.
18 *
19 * <p>
20 * When a Driver class is loaded, it should create an instance of itself and
21 * register it with the DriverManager. This means that a user can load and
22 * register a driver by doing Class.forName("foo.bah.Driver")
23 *
24 * @see org.gjt.mm.mysql.Connection
25 * @see java.sql.Driver
26 * @author Mark Matthews
27 * @version $Id$
28 */
29 public class Driver extends NonRegisteringDriver implements java.sql.Driver {
30 // ~ Static fields/initializers
31 // ---------------------------------------------
32
33 //
34 // Register ourselves with the DriverManager
35 //
36 static {
37 try {
38 java.sql.DriverManager.registerDriver(new Driver());
39 } catch (SQLException E) {
40 throw new RuntimeException("Can't register driver!");
41 }
42 }
43
44 // ~ Constructors
45 // -----------------------------------------------------------
46
47 /**
48 * Construct a new driver and register it with DriverManager
49 *
50 * @throws SQLException
51 * if a database error occurs.
52 */
53 public Driver() throws SQLException {
54 // Required for Class.forName().newInstance()
55 }
56 }
57
Take a close look in class Driver's static block:
java.sql.DriverManager.registerDriver(new Driver());
It ensures the new created Driver object is registered every time after Driver class is created or Driver instance is created.
Class.forName(driver); make sure the code in static block run at first which means a new Driver class object is created during the compile time.
For better understanding, here is a sample program which have a static block in the class
class A {
static {
System.out.println("Class A loaded");
}
public A() {
System.out.println("create a instance of A");
}
}
public class Main {
public static void main(String[] args) throws Exception {
Class.forName("com.javaye.A");
}
}
The output from class Main is
Class A loaded
Now, change the above code a little bit in public static void main function: only initiate class A a=null.
1 class A {
2 static {
3 System.out.println("Class A loaded");
4 }
5
6 public A() {
7 System.out.println("create a instance of A");
8 }
9 }
10
11 public class Main {
12
13 public static void main(String[] args) throws Exception {
14 A a = null;
15
16 }
17 }
There is no output at this time. This is because only with a variable name 'a' doesn't change the fact that no new object from class 'A' is created and the static block doesn't
run neither.
Change the code again:
1 class A {
2 static {
3 System.out.println("Class A loaded");
4 }
5
6 public A() {
7 System.out.println("create a instance of A");
8 }
9 }
10
11 public class Main {
12
13 public static void main(String[] args) throws Exception {
14 A a = new A();
15 A a2 = new A();
16 }
17 }
The outputs are:
Class A loaded
create a instance of A
create a instance of A
Clearly, with new A(), static block only runs once(The basic concept of static) and constructor of A runs twice as 2 objects are creates.