Pros: simple REST
API which can be directly accessed via Javascript or virtually any server-side
language; offers up to 1,000 results in chunks of up to 50 at a time; offers
results in at least three different formats: xml, JSON, and serialized php.
Cons: no access to
Google search services, only Yahoo; only offers up to 1,000 results in chunks
of up to 50 at a time; per-IP address rate limit of 5,000 queries/24-hour
period; absolutely no UI elements. It brings difficulty in programming, such as
if people want to build a client-side approach, they have to build it from
scratch almost. People are expected to route any links through Yahoo’s servers
so they can track traffic.

Figure3.9 Yahoo Web Search API
Java snippet
Figure3.9 is an
implementation of Yahoo web search API, with typical address in red box. While
applying Yahoo news search API, the address in red square can be changed into
String
se =
"http://search.yahooapis.com/NewsSearchService/V1/newsSearch?appid="+uid+"&query="+query+"&results="+total+"&language=en";
Both Google Ajax
and Google Base Data API have restriction on the number of results and the
client application does not have a free control like manually browsing the web
page. It appears that Google is checking the User-Agent header
to make sure that people are doing this from a browser that it knows about, otherwise
it will deny people’s access (i.e. they don't want people doing this from an
application unless they use their API service such as section 3.2.1
and section 3.2.2. It blocks the client’s java program access).
Now, one method is found by simply changing some parts of java code. By
following the piece of code in the red box can solve this problem.
Figure3.8
Google Base Data
API is another way for programmers who want to write client applications that
interact with Google Base. With the query like this:
http://base.google.com/base/feeds/snippets?bq=query&key=xxxxxxx
The value of “bq”
is the input query and the value of “key” is a unique ID provided by Google after
registered in Google. The result is returned in clean XML format. However,
there are still some limits, with the same query, Google Base Data API returns
different results compared to its original web interface.

Google’s SOAP Search
API would have the ability to access Google’s results, but it has been
deprecated since late 2006 and no new license keys have been distributed. Instead
of SOAP API, Google released its new Ajax
for researchers and the search query should like this:
http://ajax.googleapis.com/ajax/services/search/web?start=1&rsz=large&v=1.0&q=“query”

Figure3.6 Google Ajax code snippet
The
result is returned in JSON format which can be parsed by JSON library from http://www.json.org/java/. By changing the “start=”
value, the offset is decided easily. However, using new API Google Ajex, the
maximum number of result URL returned from Google is limited. In 2008, the
maximum number is 32. Currently, the maximum number is 64.
As 2 of the most powerful
search engines, Google and Yahoo have the strongest abilities in searching the
surface web and they also provide all kinds of different special search
functions such as web search, news search, image search which are familiar by
the people all over the world. A general experiment in exploring the search
abilities without testing these 2 search engines is certainly not conclusive.
Meanwhile, the
detailed search ability test implementation on Google, Yahoo or other search engine
needs programming according to their result pages, specifically speaking, they
are shown in different HTML templates. For example, Figure3.3 and Figure3.5 are the returned pages from Google and
Yahoo, with the same query “job search”, currently, the differences or quality
are not compared in this section. Although the 2 result pages Figure3.3 and Figure3.5 show a very similar format such as the
search engine input interface at the top, the main content is in left and takes
more than 2/3 spaces and leaving the right 1/3 to commercial websites as advertisements,
the HTML behind the pages show quite different grammar and make extracting the
result title, result summary, result URL not a single general template, but
specifically one extracting algorithm for one search engine.
Here is a segment
from Google result page, the texts shown in Figure3.3 are also in the red boxes in Figure3.2.
Figure3.2

Figure3.3
Here is one
segment from Yahoo web search result page.

Figure3.4
Figure3.4 is a segment from Yahoo result page and
the text shown in Figure3.5 is also in the red square in Figure3.4.
Before parsing the
HTML in Figure3.2 and Figure3.4, both Google and Yahoo provide easier ways
for the developers to parse and extract results information. It is quite
necessary to carefully examine their API first. Meanwhile different kinds of
API provided by Google and Yahoo show quite different capabilities in returning
the result links.

Figure3.5
The project is
designed to find a best query (LS query) which can represent the web page and be
searched by search engine easily. The web pages are picked up from the surface
web which is easily accessed without any authority restrictions. The
experiments are arranged in following general steps:
(1) Find a large amount of web pages which will
be used for LS extraction and re-finding/relocation, download them as test
pages into local disk and save their URLs at the same time. The source of web
pages used for experiments requires careful considerations as all kinds of web
sites showing up today, some of them are ill-formatted or have poor information.
Obviously, they are not the ideal sources in experiments. The detail of web
pages selection and crawling is non-trivial and will be introduced in section 3.3.1
specifically.
(2) HTML parsing and text extraction are needed
before extracting LSs. The preprocessing reasons and steps will be in section 3.3.2.
(3) Apply the algorithms in chapter 2 which are
designed to extract lexical signatures from these downloaded pages. In chapter 4,
TF, DF, TFIDF, TF3DF2, TF4DF1, TFIDF3DF2, TFIDF4DF1 as well as word rank and sentence
rank will be applied to the pages after step2. But different from S. T. Park’s
experiments, in this project, varying term numbers in a query is accepted,
which make such as TF3DF2 and TFIDF3DF2 to 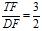 and
and , the ratio in selecting between DF order terms and TF or TFIDF
order terms is not changed. For convenience, the selections on TF, DF and their
mixed forms are listed from (a) to (h) which have been precisely described in
S. T. Park’s paper. Although the topic of how many terms are going to help
getting better searching results is studied and unveiled by Martin and Michael,
they claim that 5 terms a query is the most efficient number in getting the
desired result appeared in top 10 from SE [3]. More terms in a query
means obviously more feasible in sentence-rank. Meanwhile, Google raised their
web search limit to 32 words 4 years ago back to 2005. In this project, up to 15
words are allowed per query, with succeeding words being ignored. The
performance with different number of terms in a query is an interesting topic
and they will be explored in chapter 4.
, the ratio in selecting between DF order terms and TF or TFIDF
order terms is not changed. For convenience, the selections on TF, DF and their
mixed forms are listed from (a) to (h) which have been precisely described in
S. T. Park’s paper. Although the topic of how many terms are going to help
getting better searching results is studied and unveiled by Martin and Michael,
they claim that 5 terms a query is the most efficient number in getting the
desired result appeared in top 10 from SE [3]. More terms in a query
means obviously more feasible in sentence-rank. Meanwhile, Google raised their
web search limit to 32 words 4 years ago back to 2005. In this project, up to 15
words are allowed per query, with succeeding words being ignored. The
performance with different number of terms in a query is an interesting topic
and they will be explored in chapter 4.
a)
TF: Select
terms in decreasing term frequency (TF) order. If there is a tie, then pick terms
based on increasing document frequency (DF). If there is another tie, randomly
select the terms [5].
b)
DF: Select
terms in increasing DF order. If there is a tie, then pick terms based on
decreasing TF order. If there is another tie, randomly select the terms [5].
c)
TFIDF:
Select terms in decreasing term-frequency inverse-document frequency (TFIDF)
order. If there is a tie, then pick terms based on increasing DF order. If
there is another tie, randomly select the terms [5].
d)
PW: Select
terms based on Phelps and Wilensky’s [3] method: First, list terms
in TF order and then pick LS in decreasing TFIDF order (i.e., decreasing TFIDF
order where the TF term is capped at five). If there is a tie, then pick terms
based on increasing DF order. If there is another tie, randomly select the terms
[5].
e)
TF3DF2:
Select two terms in increasing DF order. If there is a tie, then pick terms
based on decreasing TF order. If there is another tie, randomly select the terms.
Then filter out all terms which have DF value 1. Select three terms maximizing
TF. If there is a tie, it is resolved the same way as with TF method [5].
f)
TF4DF1:
Select one term based on increasing DF order first. Then filter out all terms
which have DF value 1. Select four terms maximizing TF [5].
g)
TFIDF3DF2:
Select two terms based on increasing DF order first. Then filter out all terms
which have DF value 1. Select three terms maximizing TFIDF [5].
h)
TFIDF4DF1:
Select one term based on increasing DF order first. Then filter out all terms
which have DF value 1. Select four terms maximizing TFIDF [5].
(4) Select several search engines which support
developer mode. Google web search and news search, Yahoo web search and news
search are picked as general search engines in the test. More details are in
section 3.2.
(5) Download the result links in first page returned
by SE as well as their corresponding HTML pages. If there is a URL match
between test URL and result URL, a successful retrieval is recorded. However if
there is no match between test URL and first 10 result URLs, then, comparison
between the test page and result pages from search engine is done to see if they
have the same topic or content. It is similar to step 2 because both of them
need HTML page parsing, extraction and converting them to understandable pure
text without noises from HTML tags. Also, the criterion of considering whether
2 pages are in the same topic or have similar content is another important issue
in this project. It has been introduced in the beginning of section 2.5. The
details will be discussed in section 3.4.
(6) Repeat step 2 to step 5 on all test pages
downloaded by step 1, count all the success retrievals and compute a success
retrieval rate which is in 3.1. This is the most straightforward measurement
which is also adopted in both S. T. Park and Xiaojun Wang’s researches. Martin
and Michael’s LS score is also a good way to evaluate the query generation,
however, their score is not as straightforward as 3.1
 3.1
3.1
(7) A stable and reliable LS extraction
algorithm should help the success retrieval rate be higher than 90% as the ultimate
requirement. The traditional ways which do not maintain the linguistic meaning
such as TF shows quite different results comparing to graph-based rank
algorithms which maintain the linguistic meaning. For example, after step 3,
all terms are listed in alphabetic order and query’s terms are picked from a to
z. In chapter 4, the results from Google and Yahoo show both of those search
engines have a strong ability in returning desired pages by meaningful query
rather than discrete terms simply ordered from TF, IDF and so on, even some
stop words are included. The results and analysis will be in chapter 4.
Figure3.1
Figure3.1 is the flow chart showing the overall
procedure in experiments including from step 1 to step 7. The URL in the left
top rectangle of Figure3.1 is a directory built with a large amount
of effective URL which can be accessed online. The corresponding pages are then
downloaded and saved on local disk.
The algorithms in
extracting lexical signatures from a page are in 3 rectangles in the right top
of Figure3.1. They are the core in this project.
Another key programming issue is 2 rectangles in button of Figure3.1 page content comparison and results
record. The middle rectangles in Figure3.1’s left and right are a pipeline showing
all the operations.
Similar to Xiaojun
Wang’s applying word rank on web pages, this project applies sentence rank on
web page. The passages in the web pages can be extracted as shown in Figure2.19’s red square.
Figure2.19
However, there are
conditions sentence rank can not work. Some web pages may not have sentences or
passages, which make sentence rank on those pages not effective when there are only
titles or phrases. Take Figure2.20 as an example, there is not any passage in
Yahoo’s home page, and although there are several sentences in the center 3 red
squares which are shown in anchor tags separately, it brings difficulties to
construct connections among those independent sentences, because they actually
come from completely different topics. Meanwhile, there are a bunch of simple
words and phrases in the left blue squares, such as “answer”, “auto” and “finance”.
It brings challenges in combining the terms and sentences as well as applying
sentence rank. Therefore, the page like Figure2.20 is not a typical type can be applied by
sentence rank.
Figure2.20 A typical example of
link-based page
There is a simple
way to exclude the pages which are not suitable for sentence rank. A threshold
p is defined to separate the pages into 2 categories linked-based page and
content-based page after using formula 2-11.
 2-11
2-11
The pages like Figure2.20 can be concluded as a linked-based page
which has a high portion with text in link. The linked-based pages are easily
found from the websites’ home page and index page. Compared to Figure2.19, a content-based page has high portion in
plain text without link such as Figure2.20.
In previous
section, a graph-based ranking algorithm on words is introduced. In this
section, the vertex in the graph is applied on the sentences. Compared to
word-rank, sentence rank preserves much more linguistic information and the
results from sentence rank are more understandable because now the LS is
composed by whole sentence rather than terms and phrases.
Similar to the
word rank graph, without considering the un-weighted graph, there are 2 kinds
of graph construction for sentences in a document: undirected weighted graph and directed
weighted graph. Moreover, Rada and Paul proposed another form of directed
weighted graph and they classify directed weighted graph into directed forward weighted graph and directed backward weighted graph [9]. In
undirected weighted graph, the
assumption is that every sentence in the document has connection with all other
sentences. In directed forward weighted graph, every sentence
points to all the following sentences in text, while every sentence receives all
the previous sentences in text. In directed
backward weighted graph, every sentence points to all the previous
sentences in text, while every sentence receives all the following sentences in
text.
Figure2.17
Figure2.18 shows a 5-sentences passage. Figure2.18 shows the 3 graphs in detail. In Figure2.18 (a), as an undirected graph, every
sentence has connection with other 4 sentences with a pair of in coming pointer
and out coming pointer. In Figure2.18 (b), as a directed forward graph, sentence
1 points to sentences 2, 3, 4, 5; sentence 2 points to sentences 3, 4, 5;
sentence 3 points to sentences 4, 5; sentence 4 points to sentence 5 and
sentence 5 does not have out coming pointer. As a directed backward graph, Figure2.18 (c) shows the (b)’s reversed order,
sentence 5 points to sentences 1, 2, 3, 4; sentence 4 points to sentences 1, 2,
3; sentence 3 points to sentences 1, 2; sentence 2 points to sentence 1 and
sentence 1 does not have out coming pointer.



a. undirected b.
directed forward c. directed backward
Figure2.18
Therefore, after the
direction being decided, the weight between the connections is about computing
the 2 sentences’ similarity, as in equation 2-10, the common terms shared by both sentences
are divided by the length of both sentences in log form. Length can be simply considered as the terms number in
sentence.
 [10] 2-10
[10] 2-10
Generally, Wk
is a word appearing in both Si and Sj. Wk can
also be the words with same meaning but different forms such as “interested”
and “interesting” which could finally prove the ability in finding the similar
or related documents. If there is no common word Wk, then the edge
between Si and Sj can be removed.
After iterations
on 2-8 and 2-9, the sentences from text with the highest
rank are selected and taken as an abstraction. In [9], 4 highest ranked sentences
are extracted after the iteration, resulting in a summary of about 100 words. Rada
and Paul also evaluated the abstraction from this graph ranking algorithm with
other methods such as HITS and Positional Power Function (POS) by ROUGE
evaluation [15]. It turned out the sentence rank from page rank
provided good performance. The details are not included in this report.
After all, Rada and
Paul concluded that, based on this sentence rank algorithm, the abstraction
from the extracted sentences are more informative for the given text and it
does not require deep linguistic language nor domain or language specific
annotated corpora [10].
Xiaojun Wang
applied the word-rank algorithm to the LS extraction on web pages for finding
lost or related web pages [11]. He also compared the results from
this graph-based ranking algorithm with the traditional ways in extracting the
terms from documents, such as TF, DF, TFIDF, PW, TF3DF2, TF4DF1, TFIDF3DF2 and
TFIDF4DF1. He pointed out, with word rank algorithm, which takes the semantic
relation between words into account and chooses the most representative and
salient words as Lexical Signatures, the highly relevant web pages can be found
when the desired web pages can not be retrieved [11].
In their
experiments, Wang not only used the basic word-rank algorithm, but also
combined it with DF to select the terms. In [11], Wang only constructed
undirected weighted graph model G=(V, E), V is the vertex set containing all
words except stop words. E is a set of undirected and weighted edges. Each
vertex’s initial score is the normalized  value and set the damping
factor d=0.85. Wang did not use window size but WordNet [14] to
recognize the semantically related words and Wang did not mention the value of
weight on edges. These 2 detailed implementations are definitely related to a
large amount of work but they were not listed in their paper “WordRank-Based
Lexical Signatures for Finding Lost or Related Web Pages” [11].
value and set the damping
factor d=0.85. Wang did not use window size but WordNet [14] to
recognize the semantically related words and Wang did not mention the value of
weight on edges. These 2 detailed implementations are definitely related to a
large amount of work but they were not listed in their paper “WordRank-Based
Lexical Signatures for Finding Lost or Related Web Pages” [11].
 [11] 2-8
[11] 2-8
 [11] 2-9
[11] 2-9
Similar to 2-7 and set the convergence threshold to
0.0001, 2-8 is run on the graph until it converges based
on 2-9.
In Wang’s
experiments, he selected Google and MSN Search, randomly crawled 2000 URLs from
domain DMOZ.org and kept 1337 pages after filtering out the unqualified pages,
such as too short in content, non-HTML format like .pdf, .ps and .doc. Wang
constructed each query with 5 terms by implementing TF, DF, TFIDF, PW, TF3DF2,
TF4DF1, TFIDF3DF2, TFIDF4DF1, WordRank, WordRank3DF2 and WordRank4DF1.
Including the unique returned by SE, top 1 and top 10, the average success rate
among 1337 pages are generally from 40% - 60%, for Google, except WordRank3Df2
which is a little higher than 60%. Meanwhile, the results from MSN show poor
performance in TF, which is lower than 30%, TFIDF is lower than 40%, the others
are between 40% and 60%.

Figure2.15 Retrieval performance of LS from Google search [11]
Figure2.16 Retrieval performance of LS from MSN live search [11]
In the
summarization, Wang concluded that DF was the best method for uniquely
identifying the desired documents; TF was easy to compute and did not need to
be updated unless documents were modified; TFIDF and the hybrid method
combining TFIDF and DF were good candidates for extracting the desired
documents [11]. By computing the average cosine similarity values of
top 10 returned pages with the desired page, WordRank based methods such as
WordRank3DF2 are best for retrieving highly relevant documents [11].
Word-rank is one
implementation of weighted graph ranking algorithm including undirected
weighted (on edges) graph and directed weighted (on edges) graph when a single
word/term is considered as a vertex and all content is a graph. A window size
parameter ‘w’ is introduced for
implementing connection among vertices. In undirected weighted graph, each word
has connection with other words only in the window size distance, including previous
w words and following w words. In directed weighted graph,
each word has connection with the following words only in the window size
distance. Take Figure2.14 as an example and set window size to 2, ‘packing’
has connections with ‘ferocious’, ‘storm’, ‘freezing’ and ‘rain’ in undirected
weighted graph, while it only has connections with ‘freezing’ and ‘rain’ in
directed weighted graph. The score associated with each vertex is set to an
initial value of 1 and ranking algorithm, 2-6 for undirected weighted graph and 2-7 for directed weighted graph, is run on graph repeatedly
until it converges – usually for 20-30 iterations, at a threshold of 0.0001 [9].

Figure2.14
The expected end
result for this application is a set of words or phrases that are
representative for a natural language text. The terms to be ranked are
therefore sequences of one or more lexical units extracted from text, and these
represent the vertices that are added to the text graph. If more than 1 term
happened to be neighbors, they can be connected as a key phrase. Thus, the
language consistency in the content is preserved. Rada and Paul in their paper “TextRank:
Bring Order into Texts” gave a clear view of this passage “Compatibility of
systems of linear constraints over the set of natural numbers. Criteria of
compatibility of a system of linear Diophantine equations, strict inequations,
and nonstrict inequations are considered. Upper bounds for components of a
minimal set of solutions and algorithms of construction of minimal generating
sets of solutions for all types of systems are given. These criteria and the
corresponding algorithms for constructing a minimal supporting set of solutions
can be used in solving all the considered types systems and systems of mixed
types.” and extracted the following terms as results: “linear constraints”, “linear
Diophantine equations”, “natural
numbers”, “nonstrict inequations”,
“strict inequations” and “uper bounds” [9].