Researchers have
spent a lot of efforts in exploring how many LSs can give a best result. Martin
Klein and Michael L. Nelson conclude 5 to 7 LSs are good enough in robust
hyperlinks [2] after extensive experiments. Martin and Michael did
not only conclude LS is a small set of terms derived from a document which can capture
the “aboutness” of that document [3], but also defined a LS from a
web page can discover the page at a different URL as well as to find relevant
pages on internet [3]. Through their experiments on huge amount of
web pages from 1996 – 2007 which were downloaded from Internet Archive, http://www.archive.org/index.php, they claimed
that 5-, 6- and 7-term LSs performed the best in returning the interested URLs
among the top 10 from Google, Yahoo, MSN live, Internet Archive, European
Archive, CiteSeer and NSDL [3]. By apply equation 2-1 to 2-2, the LS score versus number of terms in each query
were derived in Figure2.4.
Figure2.4 LS Performance by
Number of Terms [3]
Their experiments
also showed that 50% URLs are returned as the top1 result, and 30% URLs were
failed to re-locate/find by choosing LS in decreasing TF-IDF order [3]
when they were reviewing Phelps and Wilensky’s research. Meanwhile, they also carefully
studied the techniques for estimating IDF values which is a non-trivial issue
in generating LS for the web pages. In their recent paper, 2008, “A comparison
of techniques for estimating IDF values to generate lexical signatures for the
web” [19], they introduced 3 quite different ways to estimate terms’
IDF and carefully examined their performances.
1.
Local
universe which was a set of pages downloaded from 98 websites, starting from
1996 to September, 2007 in
each month [19].
2.
Screen
scraping Google web interface which was generated in January, 2008 [19].
3.
Google
N-Gram (NG) which was distributed in 2006 [19].
They compared these
3 IDF estimation techniques and claimed that local universe based data as well
as the screen scraping based data is similar compared to their baseline, Google
N-Gram based data.
Besides listing
the detail percentage of success and fail to retrieve a URL, they used the
following 2 equations in paper [3] to evaluate the score of LSs:
fair score and optimistic score.
 [3] 2-1
[3] 2-1
 [3] 2-2
[3] 2-2
R(i) shows the ith page’s rank returned by SE after
sending the query, when it gets bigger value, the fair score will be lower, N
is the total sample pages in their experiments which is 98 and  is the average value.
is the average value.
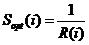 [3] 2-3
[3] 2-3
 [3] 2-4
[3] 2-4
In the optimistic
score equation, Sopt is different from Sfair which is
only determined by pages’ rank.  is the average fair
score value.
is the average fair
score value.
They set Rmax =
100 which makes Sfair can always be positive if the desired page
appears in first 100 results from SE. If R(o) > Rmax, when the
desired page does not appear in first 100 results, then simply set Sfair
= 0 and Sopt = 0. The final results of scores were from 2 terms to
15 terms per query and scores ranged from 0.2 to 0.8. They also concluded the
scores on one page since year 1996 to 2007 ranged from 0.1 to 0.6 [3].
More details and score curves in their paper are not included in this project
report.