存储我们要讲两点内容:
实存管理:
存储我们只需要了解三种分配方法即 可:单一连续分配、固定分区分配、可变分区分配;其实我们经常讲对于一些不好区分的概念,我们画个表,把他们放在一起来进行对比,那么通过对比来理解,那 真的是太爽了;所以呢,我们也画个表,把这几个概念放在一起来进行区分和理解,看图:

这样一对比,我们就能看的出来,只有可变分区分配的空间是可变的;然后另外两个分配是静态的。其实顾名思义也就差不多能理解的差不多,没有难度的,我们再深入一点来了解:看几个图:
单一连续分配:

我们可以看得出来,把整个内存区画为一个区。它同一时间在内存当中只能装入一个程序,只能用于单用户、单任务的执行操作。
固定分区分配:

这个跟单一连续有相似之处,就是内存分配的还是比较固定了;但是这个分配还有自己的特点,就是把内存分为几个块,比如是:10K、22K、32K;那么 就会有可能能运行三个程序,当三个程序占用内存在这三个区域内的时候,我们就能运行。把这个分区给定死了,所以一旦有比这些区域要大的程序要运行,那么就 完蛋了,虽然总内存够用,但是也不能运行,因为分区分的太死了。
可变分区:
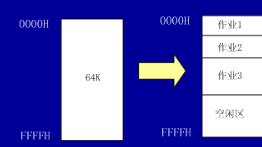
打个比方:有三个过程,一开始和单一连续分配是一样的,然后当有程序要运行的时候,就给该程序分配匹配的空间,当用完之后,释放出来之后,又能拼凑成一个空白的区域,回到最初的状态,特别灵活。
我们继续对可变分区分配方式进行探讨:
最佳适应法:选 择等于或最接近需求的内存自由区进行分配。这种方法可以减少碎片,但同时也可能带来更多小得无法再用的碎片。但是这个还算有弊端的,这个我们应该怎么理解 呢?比如我们有一个6K的空间,然后分配一个5K的空间给一个程序运行,那么剩余的1K一般来说就没法利用了,因为一般很少有1K的程序要运行,所以这个 1K就成了碎片了,那么循环下来的话,就有很多碎片产生了。但是相对来说,这个分配方法还算是挺好的。
首次适应法:首次就是寻找第一个可用的,可用就是寻找大于等于作业需求的内存的自由区分配给作业。这个的好处就是缩短查找时间。
最差适应法:选择整个主存中最大的内存自由区。比如我有一个5K的程序要运行,然后内存中最大的自由区是64K,那么一样把64K分配给5K的程序运行,然后剩下的59K自由区还能继续利用起来。
循环首次适应算法:不在每次都是从头开始分配,而是连续向下匹配。我们画个图来理解:
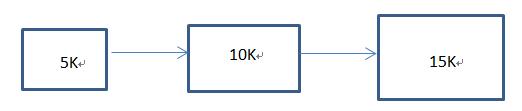
比如我们的内存是这么个分配,那么我们现在有个作业需要12K内存占用,我们就从5K、10K、15K连续查找合适 的,当找到15K的时候,我们就分配给12K,那么当我们剩余的3K的时候,刚好有一个程序是3K的需要分配内容来运行,要是我们按照首次适应法来进行分 配,因为首次适应法是每次都是从头开始的,所以我们就找到5K的区域,就把5K分配了;但是要是我们按照循环首次适应的话,我们是连续分配的,这样我们就 能刚好把剩余的3K分配给这个程序了;这就是首次和循环首次的区别;我这么讲应该没有问题了吧。
虚存管理:
页式存储存储管理:
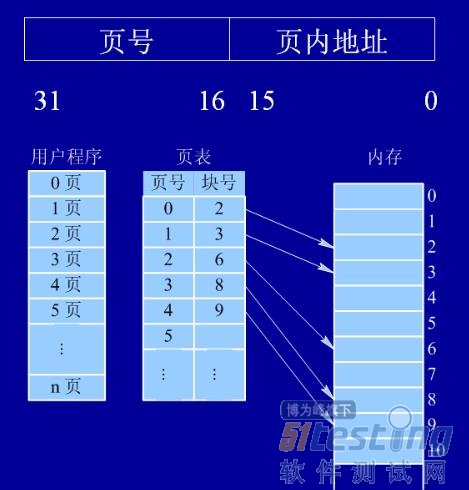
通过用户程序和内存的分块,用户程序分为n个页面,页表起记录的作用。接下来我们看地址转换图:
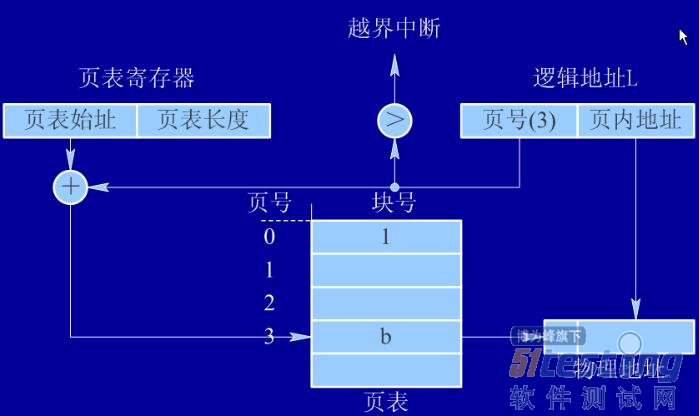
这个就是我们的地址转换器,我们想看这个是怎么个工作的,那么我们来看个例子,我们分析例子来进行理解:

我们设定页面大小为4K,图中的逻辑地址用十进制表示:我们来求a:
我们的过程应该是这样的,我们的逻辑地址是8644(十进制的),那么转换成二进制的为:10 0001 1100 0100;我们得知页面为4K=2的12次方,所以页内地址就为12位,所以a的后半部分为10 0001 1100 0100的后12位,为0001 1100 0100,那么剩下的最高两位为页号:10,转换成十进制为2,然后找出物理块号为8,8转换成二进制位1000,所以物理快号页内偏移拼合得1000 0001 1100 0100,化为十进制得33220。
其实只要我们懂得了这个过程,那么剩下的就是进制的转换了,不难。
段式存储组织
从用户出发,将一个程序分成几个块:

我们有页式存储的基础,这个就不在胯下,只是段的大小有点大。
我们再看看地址转换:

这个算法跟咱们的页式存储是一样的。大家动手试试。
存储讲起来挺有意思,我理解也许会有偏差,希望大家多多指正,不胜感激~
进程
1、进程的状态:
这里边我们主要是要讲的内容就是这两个图:我们通过这两个图来介绍一些相关的知识点:
三态图:
我们还是来看图进行分析:
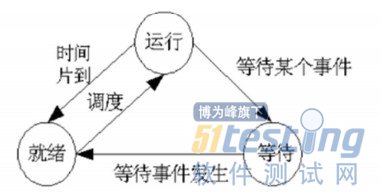
我们就这个图进行分析各个关键部分:这些关键在于理解,很Easy的,或者你把这个图画出来也就马上明白了。
就绪:就是“万事俱备只欠东风”,就差CPU的调度了,只要CPU一调度便可运行。
运行:就是在就绪状态的基础上得到了CPU的调度。
等待(阻塞):还没具备运行条件,等待时机的状态,我们从这个图也能看的出来,等待状态不能直接运行,必须要经过就绪这个状态的,所以等待状态除了等待CPU调度之外,还缺少某些运行所需的条件。
五态图:

我们把几个关键的概括一下:其实这个图跟咱们上面那个三态图是吻合的,只是把三态图分的更细了点我觉得;所以分析五态图咱们只需要把三态图掌握好就行, 就这么easy;我们再看看几个关键的:主要是三态图的一个动态的一个表示过程,所以这些概念的东西,结合前面的三态图理解就非常容易了:
就绪——>运行:就是三态图中的,条件被CPU选中了。
运行——>就绪:运行超时或者是条件被更高优先级进程剥夺。
运行——>等待:条件还没具备运行条件,等待某一事件的发生。
等待——>就绪:条件是等待的事件已发生,具备了运行条件。
在这里边,还非常要主要这些箭头的指向。
2、进程死锁:
死锁是进程管理设计不当造成的;进程死锁是一个进程在等待一个不可能发生的事;系统死锁是一个或多个进程产生死锁。
其实对于这方面的知识,跟咱们生活是很有联系的。比如我们使用过打印机都知道。所以把生活的场景投进去理解,就很简单了。
死锁产生的必要条件:
互斥条件:即一个资源每次只能被一个进程使用。
保持和等待条件:有一个进程已获得了一些资源,但因请求其他资源被阻塞时,对已获得的资源保持不放。
不剥夺条件:有些系统资源是不可剥夺的,当某个进程已获得这种资源后,系统不能强行收回,只能由进程使用完时自己释放。
环路等待条件:若干个进程形成环形链,每个都占用对方要申请的下一个资源。
解决死锁的策略
死锁预防:我们要求用户申请资源时一起申请所需的全部资源,这就破坏了保持和等待条件:将资源分层,得到上一层资源后,才能申请下一层资源,它破坏了环路等待条件。预防通常会降低系统的效率。
死锁避免:避免是指进程在每次申请资源时判断这些操作是否安全,典型算法是”银行家算法“。但这种算法会增加系统的开销。
死锁检测:前两者是事前措施,而死锁的检测则是判断系统是否处于死锁状态,如果是,则执行死锁解除策略。
死锁解除:这是与死锁检测结合使用的,它使用的方式就是剥夺。即将资源强行分配给别的进程。
接下来,我们来实战一下:
银行家算法:
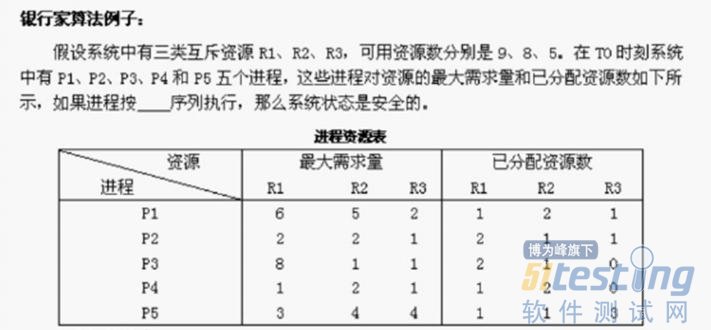
找了这么一个例子跟大家分析分析我的理解过程:
首先求剩下的资源数:
R1=9-(1+2+2++1)=2
R2=8-(2+1+1+2+1)=1
R3=5-(1+1+3)=0
我们从这个表中很容易的分析出:还需资源数=最大需求量-已分配资源数
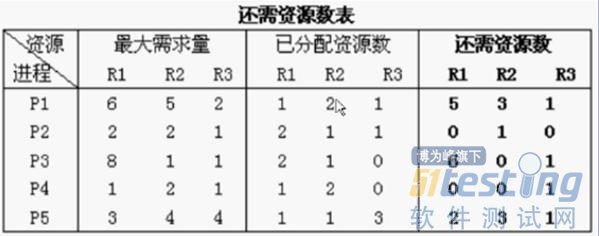
那么需要一个系统是安全的,那么这个进程就不能产生死锁。现在就一目了然了都:
从我们剩下的资源数和还需要的资源数,我们剩下的R1=2、R2=1、R3=0这个只能符合P2进程的0、1、0;
那么我们给P1运行完成之后,我们的资源要释放,所以我们资源=现有资源+已经分配的:

那么我们现在就有了R1、R2、R3的资源分别为:4、2、1;我们再观察一下看哪个进程需要资源符合我们的释放的资源的:
那只能是P4了,因为需要的资源为:0、0、1;而我们现在有的资源为:4、2、1,完全能满足这个进程P4的要求;我们看图:

那么这两个进程就完成了,接下来我们还继续对比着来看:
我们剩下的资源5、4、1。这时候我们发现了P5和P1都能满足他们所需的资源:所以P5和P1就可以随心所欲了,那我们不如就从需要资源小的开始分配试试;
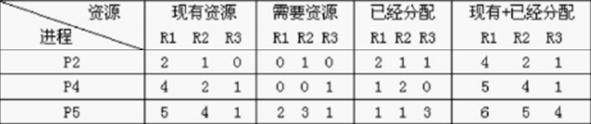
这时候我们发现我们剩余的资源又能满足到P3和P1进程了。所以我们的答案就不止一种了:

我们要是先分配P1,再分配P5,再到P3.结果就是:
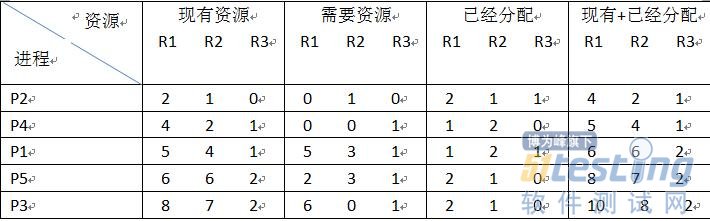
虽然进程的这个顺序有很多种,在都满足不造成死锁的情况下,是否有最优的排序呢?我觉得应该是有的,就是在不发生死锁的情况下,我们应该是优先给予需要资源少的进程。
我们需要建一个自己的bug管理系统,我就自己动手自己安装bugzilla了,在安装之前我在网上google了一下,看了一个网友的安装心得,不过基本上没有在ubuntu/debian上安装的。我就自己试着开始了。
不多说了:
sudo apt-get install mysql-server注意:需要设置mysql的root 用户的密码,注意要和以后的bugzilla的管理员密码一致
sudo apt-get install bugzilla按照需要输入管理员帐号,密码
ubuntu把需要的apache,sendmail,还有那些依赖的perl模块都一起安装了.
开始配置bugzilla
配置apache2
vi /etc/apache2/httpd.conf 添加
ServerName localhost:80
//网上人坑爹把单词拼错了
sudo /etc/init.d/apache2 restart
配置bugzilla
vi /etc/bugzilla/localconfig
修改相应的配置:
$webservergroup = "www-data";
#
# How to access the SQL database:
#
$db_host = "localhost"; # where is the database?
$db_port = 3306; # which port to use
$db_name = "bugs"; # name of the MySQL database
$db_user = "bugs"; # user to attach to the MySQL database
//不用改数据库 你安装bugzallia的时候会让你配置的 很简单
#
# Some people actually use passwords with their MySQL database ...
#
$db_pass = "1234";
#
# Should checksetup.pl try to check if your MySQL setup is correct?
# (with some combinations of MySQL/Msql-mysql/Perl/moonphase this doesn"t work)
#
$db_check = 1;
$index_html = 1;
配置数据库:
mysql -u root -p1234
Create database bugs;
GRANT SELECT, INSERT, UPDATE, DELETE, INDEX, ALTER, CREATE, LOCK TABLES,CREATE TEMPORARY TABLES, DROP, REFERENCES ON bugs.* TO bugs@localhost IDENTIFIED BY "1234";
Flush privileges;
quit;
退出数据库;
重新生成bugzilla数据库;
cd /usr/share/bugzilla/lib/
sudo perl checksetup.pl
根据提示输入
注意:在ubuntu上安装的bugzilla的主登录窗口有点bug,需要从页面地下的login按钮进入就可以了。
据调查显示,代码审查工作有助于提高软件开发质量,然而许多开发者却不愿意在他们的团队中实施代码审查工作,本文主要分析了开发者为什么会抵制代码审查工作的原因以及为什么他们会有此想法,目的是为了引导开发者加入代码审查工作。
代码审查究竟是什么样的工作呢?通常情况下它是指否决质量的一种过程。大量统计数据表明代码审查极大的提高了软件质量以及降低了技术风险,不仅如此,它还降低了开发成本。
一起来看下代码审查工作所带来的好处:
如图所示,代码审查工作带来这么多的益处,那为什么还有一些开发团队拒绝这一做法呢?我们一起来分析下原因:
first ,better code starts with review
fight bad code ,and find more bugs with code review!
good code reviews
tackle your code and design requirements/docunments

文化问题或许已成为一种巨大的障碍,大部分开发者会厌恶代码审查是因为他们无法忘记那些痛苦的审查会议,更槽糕的是,他们害怕因劣质代码而遭到管理 者的批评与指责(这个通常是管理者自身的原因,而不是坏代码)。代码审查工作有助于提升团队自身能力,我们应该持积极态度,而不是为了找机会来贬低同伴。
另一种可能性,当大家相互协作、积极互动时,管理者会误认为大家在“聊天”。敏捷性团队已经意识到快速创建软件工作需要积极的互动与协作。他们认为坚持代码审查工作,是通向成功的秘诀。
第三种可能性误解,开发者利用静态分析工具来查找bug,以致代码审查工作成为不必要性。然而事实并非如此,Capers Jones,一位软件质量度量领域的巨人,曾发表过一篇文章“结合视察、静态分析和测试能消除影响效率缺陷的95%”,这种三叉戟式的方法最能确保软件质 量。
静态分析只是其中的一个分叉。
静态分析工具有着很大的局限性,包括无法辨认出一些疑似代码,比如,静态分析工具不具备标记功能,因为它无法确定一个函数名为getRandomNumber是否应该总返回相同的值(with a hat tip toXKCD)。
Int getRandomNumber()
{<
return 4; //chosen by fair dice roll.
//guaranteed to be random
}
| |
也许代码审查最大障碍是恐惧。开发者担心错过最后期限,害怕分心,害怕投入过多时间。要知道,这些都是愚蠢的想法,代码审查的目的是在前端开发过程中最大限度的提高代码质量以及帮助你缩短开发周期。
最后,我认为,调用一个进程(代码审查工作)能够促进团队合作,提供指导且有助于技能的发展,鼓励开发者熟悉代码的基础部分,最终可达到提高整 个软 件质量。当然,如果您想快速输入代码,可以考虑一些代码审查工具,前提是,你要确保该工具是轻量级并且有趣。一旦你习惯了使用该工具便有了依赖性(许多使 用代码审工具用户都这么认为)“我们无法想象没有编码工具的日子”,我想你会发现它们的价值所在。
无论如何,请记住,拒绝代码审查是不可取的。
http://mirrors.163.com/centos/6.2/isos/i386/CentOS-6.2-i386-bin-DVD1.iso
6.3.6 POST Data
显示通过Post方式数据信息
以下是mail.163.com登录过程中POST Data,如下图所示:
https://reg.163.com/logins.jsp?type=1&url=http://fm163.163.com/coremail/fcg/ntesdoor2?lightweight%3D1%26verifycookie%3D1%26language%3D-1%26style%3D-1
上面的红框:application/x-www-form-urlencoded表示,post方式默认提交数据编码
备注:以下为Post方式提交数据编码几种方式:
| text/plain | 以纯文本的形式传送 |
| application/x-www-form-urlencoded | 默认的编码形式,即URL编码形式 |
| multipart/form-data | MIME编码,上传文件的表单必须选择该 |
Mime Type指的是如text/html,text/xml等类型
MIME>(Multipurpose Internet Email Extension),意为多用途Internet邮件扩展,它是一种多用途网际邮件扩充协议,在1992年最早应用于电子邮件系统,但后来也应用到浏览 器。服务器会将它们发送的多媒体数据的类型告诉浏览器,而通知手段就是说明该多媒体数据的MIME类型,从而让浏览器知道接收到的信息哪些是MP3文件, 哪些是JPEG文件等等。当服务器把把输出结果传送到浏览器上的时候,浏览器必须启动适当的应用程序来处理这个输出文档。在HTTP中,MIME类型被定 义在<head>、</head>部分的Content-Type中。
| 数据类型 | MIME类型 |
| 超文本标记语言文本 .htm,.html文件 | text/html(数据类别是text,种类是html,下同) |
| 纯文本,.txt文件 | text/plain |
| RTF文本,.rtf文件 | application/rtf |
| GIF图形,.gif文件 | image/gif |
| JPEG图形,.jpeg, .jpg文件 | image/jpeg |
| au声音,.au文件 | audio/basic |
| MIDI音乐,mid,.midi文件 | audio/midi,audio/x-midi |
| RealAudio音乐,.ra, .ram文件 | audio/x-pn-realaudio |
| MPEG,.mpg,.mpeg文件 | video/mpeg |
| AVI,.avi文件 | video/x-msvideo |
| GZIP,.gz文件 | application/x-gzip |
| TAR,.tar文件 | application/x-tar |
如上图红圈所表示,可以看到POST Data 中的password和username数据;

备注:get方法和Post方法区别
GET方法
GET方法是默认的HTTP请求方法,我们日常用GET方法来提交表单数据,然而用GET方法提交的表单数据只经过了简单的编码,同时它将作为URL的一部分向Web服务器发送,因此,如果使用GET方法来提交表单数据就存在着安全隐患上。例如
Http://127.0.0.1/login.jsp?Name=zhangshi&Age=30&Submit=%cc%E+%BD%BB
从上面的URL请求中,很容易就可以辩认出表单提交的内容。(?之后的内容)另外由于GET方法提交的数据是作为URL请求的一部分所以提交的数据量不能太大
POST方法
POST方法是GET方法的一个替代方法,它主要是向Web服务器提交表单数据,尤其是大批量的数据。POST方法克服了GET方法的一些缺点。通 过POST方法提交表单数据时,数据不是作为URL请求的一部分而是作为标准数据传送给Web服务器,这就克服了GET方法中的信息无法保密和数据量太小 的缺点。因此,出于安全的考虑以及对用户隐私的尊重,通常表单提交时采用POST方法。
7. >3.7 Content
统计显示收到的Http响应信息
如下图所示:可以查看

https://reg.163.com/logins.jsp?type=1&url=http://fm163.163.com/coremail/fcg/ntesdoor2?lightweight%3D1%26verifycookie%3D1%26language%3D-1%26style%3D-1
页响应具体内容:
8. >3.8 Stream
显示客户端发送的数据,然后服务器端返回的数据
客户端发送总数据:901 bytes sent to 218.107.55.86:80
客户端接受到服务器端返回总数据:247 bytes received by 192.168.52.188.10720
以下用请求一个mail.163.com中的Logo图标为例说明:


http://mimg.163.com/logo/163logo.gif
左边:客户端向服务器端发送数据流
1 GET /logo/163logo.gif HTTP/1.1
以上代码中“GET”代表请求方法,“closea_d.js”表示URI,“HTTP/1.1代表协议和协议的版本。
2 Accept: */*
指示能够接受的返回数据的范围, */*表示所有
3 Referer: http://g1a114.mail.163.com/a/f/js3/0712240954/index_v6.htm
包含一个URL,用户从该URL代表的页面出发访问当前请求的页面
4 Accept-Language: zh-cn
表示能够接受的返回数据的语言
5 Accept-Encoding: gzip, deflate
Accept-Encoding>表明了浏览器可接受的除了纯文本之外的内容编码的类型,比如gzip压缩还是deflate压缩内容。
6 User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)
客户端标识浏览器类型
7 Host: mimg.163.com
访问地址主机标识地址
8 Connection: Keep-Alive
保持Tcp连接(前台已有备注,这里不做说明)
9Cookie: vjuids=-1b9063da8.1173d33f879.0.9aab8b85a459d; vjlast=1199406314; _ntes_nnid=a1e69963f40453af8a9ad171cc4cd8da,0|tech|; NTES_UFC=3000000100000000000000000000000000000000000000000000000000000000; Province=021; City=021; ntes_mail_firstpage=normal; NTES_SESS=68LUOUH9ewcCBFyN5OXZ_0qf._IOMCkFscaGYrooXpjtVF7r8Vx7jAzg7HGdWo00GQEn1ZmrZcX7FMAXnb052r8XOFZZYk.hN; NETEASE_SSN=mayingbao2002; NETEASE_ADV=11&23&1199409658752; Coremail=VDeAMrrrDFaTa%XCVwJiXXsRLSLkbLhZXXZGqPJkEXFKNt; wmsvr_domain=g1a114.mail.163.com
Cookies>没什么说的,前面已列举了
右边:服务器端向客户端返回数据流
1 HTTP/1.0 304 Not Modified
服务器告诉客户,原来缓冲的文档还可以继续使用。
2 Date: Mon, 31 Dec 2007 21:42:27 GMT
发送HTTP消息的日期
3 Content-Type: image/gif
服务器返回请求类型是image/gif
4 Expires: Wed, 30 Jan 2008 21:42:27 GMT
指定实体的有效期
5 Last-Modified: Wed, 19 Apr 2006 03:46:16 GMT
指定被请求资源上次被修改的日期和时间
6 Age: 5607
表示Http接受到请求操作响应后的缓存时间
7 X-Cache: HIT from mimg68.nets.com
表示你的 http request 是由 proxy server 回的
8 Connection: keep-alive
保持Tcp请求连接状态
9. >3.9 HttpWatch>请求信息框
菜单区如上图红框所示:

Started: >表示开始记录请求一个URL时间
Time: >表示记录请求耗费的时间
Sent: >表示客户端向服务器端发送请求字节大小
Reveived:>表示客户端收到服务端发送请求字节大小
Method: >表示请求URL方式
Result: >表示服务器返回到客户端结果
以下是Httpwatch中http状态码列表
| 200 | OK/Success status code |
| 302 | Moved temporarily status code |
| 304 | Not modified status code |
| 401 | Access denied status code |
| 404 | Page or file not found |
| Aborted | Internet Explorer aborted the HTTP request before a response was received |
| (Cache) | Content read from cache without sending an HTTP request to the server |
| ERROR_* | An error occurred such as ERROR_INTERNET_NAME_NOT_RESOLVED |
| 2xx | Successful HTTP status code |
| 3xx | Redirection HTTP status code |
| 4xx | Client error HTTP status code |
| 5xx | Server error HTTP status code |
详细Http状态参数
| 态代码 | 状态信息 | 含义 |
| 100 | Continue | 初始的请求已经接受,客户应当继续发送请求的其余部分。(HTTP 1.1新) |
| 101 | Switching Protocols | 服务器将遵从客户的请求转换到另外一种协议(HTTP 1.1新) |
| 200 | OK | 一切正常,对GET和POST请求的应答文档跟在后面。 |
| 201 | Created | 服务器已经创建了文档,Location头给出了它的URL。 |
| 202 | Accepted | 已经接受请求,但处理尚未完成。 |
| 203 | Non-Authoritative Information | 文档已经正常地返回,但一些应答头可能不正确,因为使用的是文档的拷贝(HTTP 1.1新)。 |
| 204 | No Content | 没有新文档,浏览器应该继续显示原来的文档。如果用户定期地刷新页面,而Servlet可以确定用户文档足够新,这个状态代码是很有用的。 |
| 205 | Reset Content | 没有新的内容,但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容(HTTP 1.1新)。 |
| 206 | Partial Content | 客户发送了一个带有Range头的GET请求,服务器完成了它(HTTP 1.1新)。 |
| 300 | Multiple Choices | 客户请求的文档可以在多个位置找到,这些位置已经在返回的文档内列出。如果服务器要提出优先选择,则应该在Location应答头指明。 |
| 301 | Moved Permanently | 客户请求的文档在其他地方,新的URL在Location头中给出,浏览器应该自动地访问新的URL。 |
| 302 | Found | 类似于301,但新的URL应该被视为临时性的替代,而不是永久性的。注意,在HTTP1.0中对应的状态信息是 “Moved Temporatily”。 出现该状态代码时,浏览器能够自动访问新的URL,因此它是一个很有用的状态代码。 注意这个状态代码有时候可以和301替换使用。例如,如果浏览器错误地请求http://host/~user(缺少了后面的斜杠),有的服务器返回 301,有的则返回302。 严格地说,我们只能假定只有当原来的请求是GET时浏览器才会自动重定向。请参见307。 |
| 303 | See Other | 类似于301/302,不同之处在于,如果原来的请求是POST,Location头指定的重定向目标文档应该通过GET提取(HTTP 1.1新)。 |
| 304 | Not Modified | 客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。服务器告诉客户,原来缓冲的文档还可以继续使用。 |
| 305 | Use Proxy | 客户请求的文档应该通过Location头所指明的代理服务器提取(HTTP 1.1新)。 |
| 307 | Temporary Redirect | 和302(Found)相同。许多浏览器会错误地响应302应答进行重定向,即使原来的请求是POST,即使它实际上只 能在POST请求的应答是303时才能重定向。由于这个原因,HTTP 1.1新增了307,以便更加清除地区分几个状态代码:当出现303应答时,浏览器可以跟随重定向的GET和POST请求;如果是307应答,则浏览器只 能跟随对GET请求的重定向。(HTTP 1.1新) |
| 400 | Bad Request | 请求出现语法错误。 |
| 401 | Unauthorized | 客户试图未经授权访问受密码保护的页面。应答中会包含一个WWW-Authenticate头,浏览器据此显示用户名字/密码对话框,然后在填写合适的Authorization头后再次发出请求。 |
| 403 | Forbidden | 资源不可用。服务器理解客户的请求,但拒绝处理它。通常由于服务器上文件或目录的权限设置导致。 |
| 404 | Not Found | 无法找到指定位置的资源。这也是一个常用的应答。 |
| 405 | Method Not Allowed | 请求方法(GET、POST、HEAD、DELETE、PUT、TRACE等)对指定的资源不适用。(HTTP 1.1新) |
| 406 | Not Acceptable | 指定的资源已经找到,但它的MIME类型和客户在Accpet头中所指定的不兼容(HTTP 1.1新)。 |
| 407 | Proxy Authentication Required | 类似于401,表示客户必须先经过代理服务器的授权。(HTTP 1.1新) |
| 408 | Request Timeout | 在服务器许可的等待时间内,客户一直没有发出任何请求。客户可以在以后重复同一请求。(HTTP 1.1新) |
| 409 | Conflict | 通常和PUT请求有关。由于请求和资源的当前状态相冲突,因此请求不能成功。(HTTP 1.1新) |
| 410 | Gone | 所请求的文档已经不再可用,而且服务器不知道应该重定向到哪一个地址。它和404的不同在于,返回407表示文档永久地离开了指定的位置,而404表示由于未知的原因文档不可用。(HTTP 1.1新) |
| 411 | Length Required | 服务器不能处理请求,除非客户发送一个Content-Length头。(HTTP 1.1新) |
| 412 | Precondition Failed | 请求头中指定的一些前提条件失败(HTTP 1.1新)。 |
| 413 | Request Entity Too Large | 目标文档的大小超过服务器当前愿意处理的大小。如果服务器认为自己能够稍后再处理该请求,则应该提供一个Retry-After头(HTTP 1.1新)。 |
| 414 | Request URI Too Long | URI太长(HTTP 1.1新)。 |
| 416 | Requested Range Not Satisfiable | 服务器不能满足客户在请求中指定的Range头。(HTTP 1.1新) |
| 500 | Internal Server Error | 服务器遇到了意料不到的情况,不能完成客户的请求。 |
| 501 | Not Implemented | 服务器不支持实现请求所需要的功能。例如,客户发出了一个服务器不支持的PUT请求。 |
| 502 | Bad Gateway | 服务器作为网关或者代理时,为了完成请求访问下一个服务器,但该服务器返回了非法的应答。 |
| 503 | Service Unavailable | 服务器由于维护或者负载过重未能应答。例如,Servlet可能在数据库连接池已满的情况下返回503。服务器返回503时可以提供一个Retry-After头。 |
| 504 | Gateway Timeout | 由作为代理或网关的服务器使用,表示不能及时地从远程服务器获得应答。(HTTP 1.1新) |
| 505 | HTTP Version Not Supported | 服务器不支持请求中所指明的HTTP版本。(HTTP 1.1新) |
Type:请求URL的类型
Type: 请求URL的类型
以下是Httpwatch中的URL的类型列表
| text/html | Normal html based content |
| text/css | Cascading style sheets |
| text/xml | XML data, e.g. SOAP requests and responses |
| text/* | Any textual content type including all the above types |
| image/gif | GIF image |
| image/jpg | JPEG image |
| image/* | Any image including gifs, jpgs and png files |
| application/x-javascript | Javascript |
| application/* | Any application content, e.g. flash files (application/x-shockwave-flash) |
URL:列出请求的URL具体地址
以下主要是HttpWatch菜单区的功能介绍:
10.3.10 Record
点击”Record”按钮开始录制Http请求操作
11.3.11 Stop
点击”Stop”按钮停止录制Http请求操作
12.3.12 Clear
点击”Clear”按钮,清除所有录制Log记录如下图所示红框中内容:

13.3.13 Summary
点击”Summary”按钮,显示或隐藏所有请求信息概述
以下用httpwatch工具记录打开http://www.google.cn/过程,Summary信息如下:

Perfomance信息如上图所示:
Elapsed time Http URL请求时间总和
Network Round Trips 没搞明白
Downloaded Data 客户端接受到服务器端传来的数据总和
Uploaded Data 客户端发送到服务器端数据总和
Http compression savings http数据压缩
DNS Lookups DNS解析
Tcp Connets Tcp连接

Status codes信息如上图所示
Cache 表示缓存的数据有4处
200 ok 表示Http状态代码200 ok 1处
14.3.14 Find
点击”Find”按钮,可以打开一个查询对话框,在日志记录中去搜索字符串

15.3.15 Filter
点击”Filter”按钮, 可以打开一个过滤器对话框,如下图所示

16.3.16 Save
点击”Save”按钮,可以打开保存对话框,如下图所示:
可以保存的格式为.hwl (Httpwatch Log文件格式), .Xml, CVS格式
17.3.17 Help
点击”Help”按钮,没什么说的,就是英语Help
2 四定位问题技巧
1. 4.1 巧用Filter功能过滤信息
假设怀疑yun.js有问题,当然你要对js程序要有了解,可使用Filter过滤器,直接将需要的yun.js找出,查看其是否存在问题!
YSlow分析网页,并提出如何提高其性能的基础上一套规则,高性能的网页。我搜索一下”Yslow使用说明“,发现都是旧版本Yslow的使用介绍。于是翻译了一下yahoo官方关于新版Yslow的的使用帮助,希望给初次使用Yslow的朋友一些帮助。
注:英文不是很好,对着翻译软件翻译的,有不对的地方,大家指正。
安装 YSlow
先安装 Firebug https://addons.mozilla.org/en-US/firefox/addon/1843
Firebug 帮助文档 http://www.getfirebug.com/docs.html.
再下载安装 http://developer.yahoo.com/yslow
使用Yslow
Yslow是运行在Firebug窗口下,所有要运行Yslow,必须安装Firebug。
有两种方法启动Yslow
1、打开Firebug窗口,选择Yslow选项。
2、直接点击浏览器右下角的Yslow启动按钮。
你第一次打开Yslow时,以下图像作为Firebug的一部分被显示在的浏览器窗口。

点击 Run Test 运行Yslow,也可以点击 Grade, Components, 或Statistics选项开始对页面的分析。
你可以选择 Autorun YSlow each time a web page is loaded 它将自动对以后打开页面进行分析, 您也可以右击YSlow状态栏,然后选择或取消自动运行。
您也可以右击YSlow状态栏,然后选择或取消自动运行。
Yslow视图
YSlow显示测试结果的分析,分为等级、组件、统计信息。你可以浏览这些观点之间选择标签以观的名字在YSlow标签的Firebug控制台。
以下是说明的等级、组件、统计信息。
一、等级视图
查看一个分析,选择页面的性能等级标签或点击网页的字母等级在状态栏这页纸的底部。
视图显示了等级为网页的成绩单。整个字母等级为页面显示在顶部随着全面数值的表现。这个页面是基于22可分级的高性能网页的规则(见性能规则)。这些规则是列在按重要性的顺序,从最重要不重要。从 A 级到 F 级,A 级为最高。
下面是一个等级的例子:

如果页面与某一个规则无关,则显示 N/A ,表示不适用。
点击每一规则,都给出了改进建议。要查看更全面的改进方法进入前端性能优化指南
二、组件视图

分组显示页面组件,表格列出组件的信息,点击 Expand All展开显示给个分组内各的组件信息。
下面简要列在组件检视表:
TYPE:该组件的类型。该网页是由组成部分的下列类型: doc, js, css, flash, cssimage, image, redirect, favicon, xhr, and iframe.
SIZE(KB):该组件的大小以千字节。
GZIP(KB):该组件的gzip压缩的大小以千字节。
COOKIE RECEIVED(bytes):字节数在HTTP设置的Cookie响应头。
COOKIE SENT(bytes):节数的Cookie在HTTP请求报头
HEADERS:HTTP信息头,点击放大镜查看全面信息。
URL:链接地址
EXPIRES(Y/M/D):日期的Expires头,属于缓存设置一种。
RESPONSE TIME (ms):响应时间
ETAG:ETag响应头,也是缓存设置的一种
ACTION:额外的性能分析
三、统计信息视图

左侧图表显示是页面元素在空缓存的加载情况,右侧为页面元素使用缓存后的页面加载情况。我们可以看到,页面元素缓存后的使页面的http请求和页面总大小都减少,从而加快了页面打开时间。参看(页面的缓存设置)
YSlow菜单栏
一、规则集
1 、YSlow ( 2版) -这一规则集包含了所有22个测试的规则。
2 、精英( V1导联) -这个规则集包含原始13规则中使用了YSlow 1.0 。
3、小网站或博客-这个规则集包含14个规则,适用于小型网站或博客。参照下方的图片,看看哪一种规则,在这个规则集。

请注意,最后选定的规则集成为默认的规则集。默认规则集可以是一个预定义的三个之一或您自己创建的一个。
要创建您自己的规则集,单击Rulesets下拉菜单旁边的 Edit 按钮。新的规则集屏幕将显示:

1、点击左侧 New Set 按钮,出现全部22调规则,勾选你所需的
2、点击 Save ruleset as... 保存,会弹出个命名窗口,命名就可以了。
3、你还可以对自定义的规则再次编辑或者删除。

YSlow 工具
YSlow的工具菜单上提供了多种报告工具,您可以使用获得的信息,以帮助您的网页分析。以下是截图工具菜单:

1、JSLint
JSLint收集所有外部和内部的JavaScript从目前的网页,提交给JSLint ,一个JavaScript验证,并打开一个单独的窗口了一份报告,存在问题,该网页的JavaScript的。该报告包括大致位置的源代码的问题。很多 时候,这些问题是语法错误,但JSLint寻找风格公约的问题和结构性问题。

2、All JS
收集所有外部和内部的JavaScript的网页,并显示在一个单独的脚本窗口。您可能想要使用这个工具来查看某个脚本,以及是否实际使用是正确的。

3、All JS Beautified
将js以人们可读的方式展示。

4、All JS Minified
收集所有外部和内嵌JavaScript,删除评论和白色空间以缩小的脚本。以改善网页的性能。

5、All CSS
收集所有的行内和外部的样式表在网页上,并将其显示在一个单独的窗口。

6、All Smush.it
如果您按一下所有Smush.it , Smush.it将运行在网页上所有的图片组成。此工具将告诉你该图像可被优化,并创建一个压缩文件,来优化图像。当您选择此工具你会看到输出如下所示:

以上就是Yslow的使用指南,结束。
1、了解软件的原始需求(测试目的) 在编写一个软件或者模块的测试用例时候,一定要明白这个功能的原始需求,也就是软件的使用者(客户)的需求。理解原始需求后,编写的测试用例才更有目的性。
2、熟悉软件的功能需求(测试点)
这个功能需求是指软件的细化需求点,这个一般在需求文档里面都会体现。这里要做的是把 “粗略”的需求,细化成一个个小需求点。熟悉功能需求后,要知道软件是怎么使用的,这也才能覆盖到各种操作。
总之,测试用例一定要全部覆盖所有的需求点,这是最基本的一点。
3、熟悉软件的实现原理(测试点)
在理解原始需求和软件的功能需求后,根据需求编写的测试用例,基本上都能覆盖得比较全面了。
在此基础上,熟悉软件的实现原理,理解软件的内部处理。
(1)熟悉原理的过程是进一步深入熟悉软件的过程。如果单单是从需求点上面覆盖案例,测试用例只能覆盖“表面”的一层。一些内部的处理流程也许没有覆盖到,而这些没有覆盖到的代码很可能就是一个风险点。
(2)熟悉模块原理后,还有一点就是易于分析软件模块的关联性。一个大型的软件,都是一些小模块的组合而成。软件越是大型,耦合就越大,“互相影响”就会越多,若设计用例单单从模块本身考虑的话,很可能就会对其他模块造成风险。
4、用户场景和网上问题(测试点)
从用户的使用场景考虑,这在一些网络设备比较重要,比如软件后期在一些真实的使用环境中使用。
还要就是从一些网上问题总结出来的,那些地方容易出错,在设计案例的时候需要考虑进去 。
5、测试用例的框架
一个测试用例的框架体现了一个测试人员在设计测试用例的整体思路。框架也是从大到小划分下来,可以是:
UI界面,功能,容错,兼容,性能等几大类,每个大类在根据软件的逻辑等进行划分成小类,最后细分到测试点。
6、测试步骤(测试技巧方法)
前面4点都是从测试点的角度考虑,测试用例在完成测试点外,接下来就是测试步骤和测试结果啦。
测试用例可以写的很详细,也可以写的比较简单。这要看公司的要求,有些公司要求测试步骤很细很细,包括测试结果和测试步骤一一对应。
要求测试步骤写的很详细的公司,一般是怕执行人员的执行力不到位,导致没有理解案例的目的,导致漏测。一般出现在新员工对软件系统的不熟悉。
如果测试步骤写的很详细的话,会很耗时间,而且过于详细的会限制执行人员的思维。个人认为测试用例的重点在于测试点上。
7、测试用例的一些思路
在设计测试用例中,通常较多使用的是边界值,等价类,通过和不通过测试。下面从单个模块或者单个功能点考虑:(结合一些网上文章的观点)
(1)UI界面:易用性,提示信息,整体布局,按钮图标,色彩,中英文标点错别字。
(2)数据的多样性:有效数据,合法的无效数据(边界值),非法的异常数据,产生错误输出的合法数据组合等各种数据的组合。
(3)操作多样性:添加删除编辑查询 ,多用户的操作。
(4)容量测试
(5)用户权限:使用权限,各种操作的权限。
(6)升级安装卸载:平滑升级
(7)日志相关(包括调试日志)
(8)软件功能的逻辑划分:功能上划分未能覆盖的代码逻辑,可以添加白盒灰盒用例。
(9)可靠性,容错性
(10)兼容性:浏览器,系统,支撑软件。
(11)安全性
(12)性能(这里的性能是指,单个模块或者子系统的性能)
总之测试用例首先要能覆盖所有功能需求点,然后搞懂软件处理逻辑,可以找开发一起看测试用例,把没有覆盖到的代码流程相应的用例补充,至此,用例基本不会出现基本功能的问题。
在此基础上,可以进行一些可靠性,容错性,兼容性等用例的设计,测试下软件的稳定性。
概述:什么是测试管理的艺术?在物联网、云技术、移动互联网的兴起发展,三网合一成为大趋势的未来,测试管理艺术又将何去何从呢?本文旨在与对测试管理感兴趣的同仁进行探讨。
名家名言
艺术不是你所看到的东西,而是你让别人看到的东西。
——埃德加 德加(Edgar Hilaire Germain de Gas)
什么是测试管理的艺术?
一提到艺术我们马上就会想到绘画、雕塑、戏剧、建筑、舞蹈、诗歌等等,但在这里我们要讨论的,是关于测试管理的艺术。首先我们来看,什么是测试?ISTQB为测试做了如下定义:
测试是一个过程,它包括了软件生命周期的所有活动,有静态的也有动态的。它涉及到计划、准备和对软件及其相关工作产品的评估,目的是
● 判定软件或软件的工作产品是否满足特定需求;
● 证明它们是否符合目标;
● 发现缺陷。
但是什么时候做测试?是在产品将要完成的时候来做还是从产品需求定义的时候就开始做?实际经验又告诉我们,如果在产品将要完成的时候再做测试那么就太晚了,预防缺陷远比发现缺陷耗费的费用和时间少的多。所以,测试的目的应该是:
● 预防缺陷;
● 提供与产品质量相关的信息和信心;
● 发现缺陷。
什么是管理?
管:为了达成某一目的,行使一定的权力,组织分配人员执行任务。
理:在目标实现的过程中,控制过程,使其条理化、有序进行。
测试管理(manage)就是制定计划、执行计划、检查和改进过程从而达到测试目的的一切方法和活动。制定计划(或规定、规范、标准、法规等)是设计达 到目标的路径,将整体的大目标分成一个个阶段性的小目标,确定实现阶段性目标所需要采取的战略措施,部署相应的人力、物力、规定走向目标时应该遵循的规 范、标准、法规和过程等;执行就是按照计划去做,即实施;检查就是将执行的过程或结果与计划进行对比,总结出经验,找出差距;改进首先是推广通过检查总结 出的经验,将经验转变为长效机制或新的规定;再次是针对检查发现的问题进行纠正,制定纠正、预防措施,以持续改进。
测试管理的艺术就是创造管理方法和技巧,创造性的运用管理方法和技巧实现测试的目的。它应该是基于实践的,与时俱进的,同时也是感性的,反映人类内心的情感和诉求,反映对理想的追求。因为只有这样的艺术才会有生命力。
回顾国际上的管理学艺术之路,我们可以看到管理学经历了两大阶段:
第一阶段:从行为科学到战略管理
从个体行为到组织行为(1956—1965)
从组织中的人到人的组织(1966—1975)
从过程管理到战略管理(1976—1985)
第二阶段:从组织变革到知识管理 从职能组织到变革组织(1986—1995)
从组织管理到知识管理(1996—2005)
回顾软件测试的目的演变,我们可以看到如下的脉络:
以调试为主(从有软件开始-1956)
证明程序是正确的(1957–1978)
证明程序中有错误(1979–1982)
评估产品能力(1983–1987)
预防缺陷(1988–1992)
预防缺陷,发现缺陷,评估质量(1992– )
管理理念方法和技巧都是以目标为导向的。当我们的目标发生了变化的时候,管理的艺术也随之得到了发展。我们可以清楚的看到管理艺术随着测试目的的变化而变化,在有一个时间上一一对应(或者略带滞后)的关系。
比如在测试目的从“调试”转换到“证明程序是正确的”时,也是管理艺术从个体行为到组织行为转变的过程。再比如,当测试的目的从“证明程序中有错误”改变为“评估产品能力”时,管理艺术也经历了从过程管理到战略管理的转换。
随着物联网、云技术、移动互联网的兴起和发展,测试管理也受到了空前未有的挑战,因为测试对象的开发规模,组织形式,应用范围以及对人类生活的影响都产生了前所未有的革命。如何创造管理方法和技巧,创造性地运用管理方法和技巧来适应这场革命成为我们必须面对的课题。
笔者以为,未来的测试组织和测试过程应该体现:效率 Performance,安全 Security,随时可取 Availability,灵活收放 Scalability的特性。
未来的测试管理应该是
● 多种软件生命周期的组合 – V模型和敏捷开发敏捷测试的一体化;
● 多种测试组织形式的组合 – 内包、外包、研发测试人员角色互换,独立测试团队,第三方测试多种测试组织形式的一体化;
● 多种文化交融,超越地域分布,集目标管理、知识管理、人才管理、信息化管理为一体。
只有这样,我们才能与时俱进,适应新的形势发展,创造出新的测试管理艺术。
让我们听从内心的直觉,听从内心对美的呼唤和追求,一起去探索寻求21世纪新的测试管理艺术,并将这些艺术表现出来。因为正如法国古典印象主义画家埃德加.德加(Edgar Hilaire Germain de Gas)所说的:
“艺术不是你所看到的东西,而是你让别人看到的东西。”