
视图有以下几方面的功能:
1.简化应用程序。
视图做为数据库中的一种实体,实际上存在的只是它的脚本,而它的内容并不真正的单独存在一份。一般,可以对复杂的应用程序从功能角度进行分析,将可以与其它的应用程序共用的那一部分,分离出来。对这部分功能,视具体情况可做成不同的数据库实体(如过程),有些是可以做成视图的。这样,上层的应用程序就可以从视图中取数据了。
还有,可以把对远地数据库的访问封装在视图中,使之对上层应用程序透明。
2.可以对 UNION 后的记录集排序。
直接对以下语句的结果排序,是不可能的(至少我不知道怎么直接排序)。
select a.id id from a
union
select b.id id from b;
所以把以上语句作成视图后,就可以了。设视图名为A_B:
select id from A_B order by id;
3.可以实现一定的权限控制。
可以根据需要,对表中的一部分内容做一个视图,以供一定的角色使用。可以对表中的一部分记录做一个视图(纵向),也可以对一个表中的一部分字段做一个视图(横向),或二者兼而有之。
暂时想了这么多,希望大家多多指正与补充。
--------------------------------------------------------------------
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。分布式查询也可用于定义使用多个异类源数据的视图。如果有几台不同的服务器分别存储组织中不同地区的数据,而您需要将这些服务器上相似结构的数据组合起来,这种方式就很有用。
一、视图的作用
* 简单性。看到的就是需要的。视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
* 安全性。通过视图用户只能查询和修改他们所能见到的数据。数据库中的其它数据则既看不见也取不到。数据库授权命令可以使每个用户对数据库的检索限制到特定的数据库对象上,但不能授权到数据库特定行和特定的列上。通过视图,用户可以被限制在数据的不同子集上:
使用权限可被限制在基表的行的子集上。
使用权限可被限制在基表的列的子集上。
使用权限可被限制在基表的行和列的子集上。
使用权限可被限制在多个基表的连接所限定的行上。
使用权限可被限制在基表中的数据的统计汇总上。
使用权限可被限制在另一视图的一个子集上,或是一些视图和基表合并后的子集上。
* 逻辑数据独立性。视图可帮助用户屏蔽真实表结构变化带来的影响。
二、视图的优点
(1)视图能简化用户的操作
(2)视图机制可以使用户以不同的方式查询同一数据
(3)视图对数据库重构提供了一定程度的逻辑独立性
(4)视图可以对机密的数据提供安全保护
三、视图的安全性
视图的安全性可以防止未授权用户查看特定的行或列,是用户只能看到表中特定行的方法如下:
1 在表中增加一个标志用户名的列;
2 建立视图,是用户只能看到标有自己用户名的行;
3 把视图授权给其他用户。
四、逻辑数据独立性
视图可以使应用程序和数据库表在一定程度上独立。如果没有视图,应用一定是建立在表上的。有了视图之后,程序可以建立在视图之上,从而程序与数据库表被视图分割开来。视图可以在以下几个方面使程序与数据独立:
1 如果应用建立在数据库表上,当数据库表发生变化时,可以在表上建立视图,通过视图屏蔽表的变化,从而应用程序可以不动。
2 如果应用建立在数据库表上,当应用发生变化时,可以在表上建立视图,通过视图屏蔽应用的变化,从而使数据库表不动。
3 如果应用建立在视图上,当数据库表发生变化时,可以在表上修改视图,通过视图屏蔽表的变化,从而应用程序可以不动。
4 如果应用建立在视图上,当应用发生变化时,可以在表上修改视图,通过视图屏蔽应用的变化,从而数据库可以不动。
五、视图的书写格式
Create VIEW <视图名>[(列名组)]
AS <子查询>
Drop VIEW <索引名>
注意:视图可以和基本表一样被查询,但是利用视图进行数据增,删,改操作,会受到一定的限制。
(1)由两个以上的基本表导出的视图
(2)视图的字段来自字段表达式函数
(3)视图定义中有嵌套查询
(4)在一个不允许更新的视图上定义的视图
前段时间客户方一个系统上线后出现性能问题,就是查询报表的时候出现宕机现象,应项目组要求过去帮忙测试优化问题。
该项目的架构相对比较复杂,登录后要先进行认证服务器认证用户然后登录到应用系统A,在跳转到应用服务器B进行业务操作,如果有涉及到查询历史数据等需要使用到查询报表的,就要再次跳转到cognos服务器,然后从数据库中捞取数据,因为项目人员只是说登录很慢,而且应用系统也很慢,有时会内存溢出,经常重启,但是没说明是哪里出问题,所以对问题的定位分析确实很麻烦。
于是只能逐层剥离测试分析方式来对各层次服务器进行问题定位分析解决。
1、先测试挖掘分析web服务器问题,通过简单的测试系统登录退出,定位解决了apache配置问题。
2、认证服务慢的问题是存在,但是是另外一个系统问题,所以不做任何优化修改。
3、本项目的应用服务器问题诊断分析,通过测试一些交易类型的不跟报表打交道的业务功能点发现weblogic的JDBC、JVM等配置方面的问题,但是这时只能说发现问题,虽然JDBC调整大小可以解决连接数问题但是JVM设置问题,还需要考虑业务模型测试模型配比进行调整,因为报表展现的数据需要加载到应用JVM然后在展现出来,所以这方面的调整只能综合场景测试,才能进行分析优化调整。
服务配置测试诊断分析,通过测试查询报表数据,进行测试应用、报表展现分析问题,cognos的相关参数配置,如cognos Sort buffer size、CQEConfig.xml修改、最大进程数调整等进行调整然后针对JVM进行调整。
4、数据库问题,在测试过程没有发现SQL写法问题,引发数据性能问题都是数据库缓存配置问题引发的,报表服务器的数据库是可以适当把缓存参数设置大一些,提高性能,如数据缓存、高数区缓存等配置,提高数据命中率等问题。
5、JVM的配置差异性:虽然都是使用同种类型的linux操作系统和硬件配置,同样使用jrockit JDK,但是面对的处理的技术和业务逻辑的差异性,导致对JVM配置也相应有一定的差异,如应用服务器是面对不只是报表数据展现也有管理类交易的而cognos服务器是针对数据的展现,如果历史数据的查询展现等为主,所以应用服务器和报表服务器对于的JVM配置方式不能设置一样,如 应用服务器JVM配置如 -Xms1024m -Xmx1024m -Xns:256m -Xgc:gencon
而报表服务器配置-Xms1024m -Xmx1024m -Xgcprio:throughput –XnoOpt -Xverify:none,在测试过程中性能最佳。 –XnoOpt -Xverify:none这两个参数的使用虽然有测试过是否加入会影响性能,但是这两个参数的真正意义原理不是很了解。
6、应用展现设计问题,如查询类的不同机构的查询默认情况下,登录页面后都会把所有机构的数据展现出来,经讨论开发的改为该机构的用户只能展现本机构的机构以及下级机构的数据。 而不是设计而所有的一级行机构都展现然后在根据权限问题查看只能查看本机构的数据。而且也是要用的时候才去展现机构树,而不是每次登录都刷新展现加载一次。
经这些调整后响应时间从10个用户五十几秒,到50用户报表生成响应时间4.46S。
版权声明:本文出自 泊涯 的51Testing软件测试博客:http://www.51testing.com/?240349
以下备注所用test.html 的代码(我也是在网上找的,简单的修改显示文字而已),供大家使用:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd>
<html xmlns=http://www.w3.org/1999/xhtml>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Selenium Study</title>
<script language="JavaScript">
function check(){
var clientHeight = document.getElementById('text').clientHeight;
var scrollTop = document.getElementById('text').scrollTop;
var scrollHeight = document.getElementById('text').scrollHeight;
if(clientHeight + scrollTop < scrollHeight){
alert("Please view top news terms !"); return false;
}else{
alert("Thanks !");
}
}
function set()
{
document.getElementById('text').scrollTop=10000;
}
</script>
</head>
<body>
<form id="form1" method="post" onsubmit="return check();">
<textarea id="text" name="text" cols="70" rows="14">
Selenium IDE is the a Firefox plugin that does record-and-playback of interactions with the browser. Use this to either create simple scripts, assist in exploratory testing. It can also export Remote Control or WebDriver scripts, though they tend to be somewhat brittle and should be overhauled into some sort of Page Object-y structure for any kind of resiliency.
Selenium IDE is the a Firefox plugin that does record-and-playback of interactions with the browser. Use this to either create simple scripts, assist in exploratory testing. It can also export Remote Control or WebDriver scripts, though they tend to be somewhat brittle and should be overhauled into some sort of Page Object-y structure for any kind of resiliency.
Selenium IDE is the a Firefox plugin that does record-and-playback of interactions with the browser. Use this to either create simple scripts, assist in exploratory testing. It can also export Remote Control or WebDriver scripts, though they tend to be somewhat brittle and should be overhauled into some sort of Page Object-y structure for any kind of resiliency.
Selenium IDE is the a Firefox plugin that does record-and-playback of interactions with the browser. Use this to either create simple scripts, assist in exploratory testing. It can also export Remote Control or WebDriver scripts, though they tend to be somewhat brittle and should be overhauled into some sort of Page Object-y structure for any kind of resiliency.
</textarea><br /><br />
<input type="submit" id="submit" name="submit" value="Submit" />
</form>
</body>
</html> |
< xmlnamespace prefix ="o" ns ="urn:schemas-microsoft-com:office:office" />
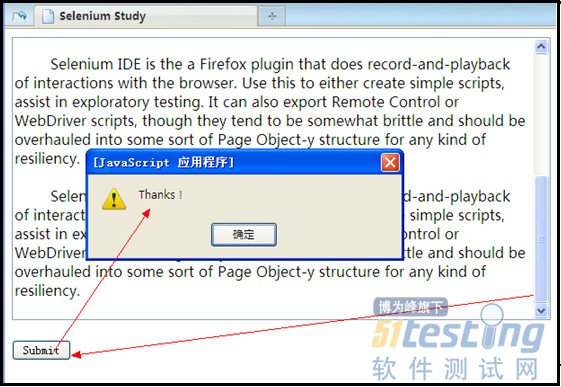
在工作中,遇到这样的问题,注册时的法律条文需要阅读,判断用户是否阅读的标准是:滚动条是否拉到最下方。以下是我模拟的2种情况:
1.滚动条在上方时,点击submit用户,提示:please view top new terms!

2.滚动条在最下方,点击submit用户,提示:Thanks!
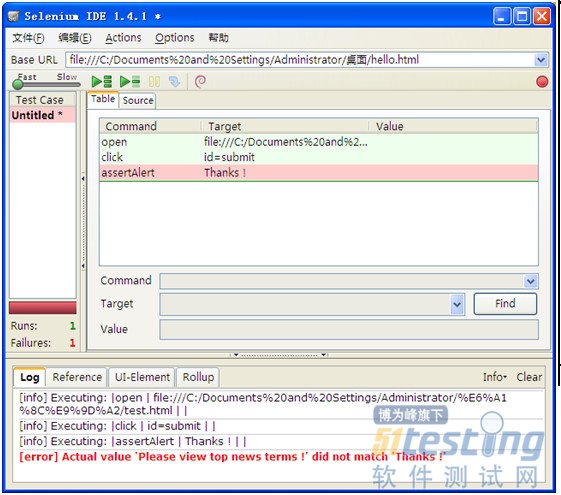
以上如果是手动测试显然很简单,那么如何用selenium测试呢。
经过IDE录制,发现拖动滚动条的动作并没有录制下来!那么能想到的方法只有利用javascript来设置了。
Baidu后得到的知识是:
<body onload= "document.body.scrollTop=0 ">
也就是说如果scrollTop=0 时,滚动条就会默认在最上方
<body onload= "document.body.scrollTop=100000 ">
也就是说如果scrollTop=100000 时,滚动条就会默认在最下方
通过以上,以及学习的selenium调用javascript的知识:
在javascript中调用页面上的元素的方法
this.browserbot.getUserWindow().document.getElementById('text')
这样设置元素的属性就很简单了
this.browserbot.getUserWindow().document.getElementById('text').scrollTop=10000"
经过修改的IDE脚本

以下备注所用test.html 的代码(我也是在网上找的,简单的修改显示文字而已),供大家使用:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd>
<html xmlns=http://www.w3.org/1999/xhtml>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Selenium Study</title>
<script language="JavaScript">
function check(){
var clientHeight = document.getElementById('text').clientHeight;
var scrollTop = document.getElementById('text').scrollTop;
var scrollHeight = document.getElementById('text').scrollHeight;
if(clientHeight + scrollTop < scrollHeight){
alert("Please view top news terms !"); return false;
}else{
alert("Thanks !");
}
}
function set()
{
document.getElementById('text').scrollTop=10000;
}
</script>
</head>
<body>
<form id="form1" method="post" onsubmit="return check();">
<textarea id="text" name="text" cols="70" rows="14">
Selenium IDE is the a Firefox plugin that does record-and-playback of interactions with the browser. Use this to either create simple scripts, assist in exploratory testing. It can also export Remote Control or WebDriver scripts, though they tend to be somewhat brittle and should be overhauled into some sort of Page Object-y structure for any kind of resiliency.
Selenium IDE is the a Firefox plugin that does record-and-playback of interactions with the browser. Use this to either create simple scripts, assist in exploratory testing. It can also export Remote Control or WebDriver scripts, though they tend to be somewhat brittle and should be overhauled into some sort of Page Object-y structure for any kind of resiliency.
Selenium IDE is the a Firefox plugin that does record-and-playback of interactions with the browser. Use this to either create simple scripts, assist in exploratory testing. It can also export Remote Control or WebDriver scripts, though they tend to be somewhat brittle and should be overhauled into some sort of Page Object-y structure for any kind of resiliency.
Selenium IDE is the a Firefox plugin that does record-and-playback of interactions with the browser. Use this to either create simple scripts, assist in exploratory testing. It can also export Remote Control or WebDriver scripts, though they tend to be somewhat brittle and should be overhauled into some sort of Page Object-y structure for any kind of resiliency.
</textarea><br /><br />
<input type="submit" id="submit" name="submit" value="Submit" />
</form>
</body>
</html> |
本节重点:
键盘按键用法
键盘组合键用法
send_keys() 输入中文运行报错问题
键盘按键键用法:
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys #需要引入keys包
import os,time driver = webdriver.Firefox()
driver.get("http://passport.kuaibo.com/login/?referrer=http%3A%2F%2Fwebcloud.kuaibo.com%2F") time.sleep(3)
driver.maximize_window() # 浏览器全屏显示 driver.find_element_by_id("user_name").clear()
driver.find_element_by_id("user_name").send_keys("fnngj") #tab的定位相相于清除了密码框的默认提示信息,等同上面的clear()
driver.find_element_by_id("user_name").send_keys(Keys.TAB)
time.sleep(3)
driver.find_element_by_id("user_pwd").send_keys("123456") #通过定位密码框,enter(回车)来代替登陆按钮
driver.find_element_by_id("user_pwd").send_keys(Keys.ENTER)
'''
#也可定位登陆按钮,通过enter(回车)代替click()
driver.find_element_by_id("login").send_keys(Keys.ENTER)
'''
time.sleep(3) time.sleep(3)
driver.quit() |
要想调用键盘按键操作需要引入keys包:
from selenium.webdriver.common.keys import Keys
通过send_keys()调用按键:
send_keys(Keys.TAB) # TAB
send_keys(Keys.ENTER) # 回车
注意:这个操作和页面元素的遍历顺序有关,假如当前定位在账号输入框,按键盘的tab键后遍历的不是密码框,那就不法输入密码。 假如输入密码后,还有需要填写验证码,那么回车也起不到登陆的效果。
这并不是一种好的方法,这里只是为了验证单个按键的用法
键盘组合键用法:
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import os,time driver = webdriver.Firefox() driver.get(http://www.baidu.com) #输入框输入内容
driver.find_element_by_id("kw").send_keys("selenium")
time.sleep(3) #ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')
time.sleep(3) #ctrl+x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'x')
time.sleep(3) #输入框重新输入内容,搜索
driver.find_element_by_id("kw").send_keys(u"虫师 cnblogs")
driver.find_element_by_id("su").click() time.sleep(3)
driver.quit() |
上面的操作没有实际意义,但向我们演示了键盘组合按键的用法。
输入中文问题
顺便解决了一个困扰我到现的一个输入中文件的问题。selenium2 python在send_keys()中输入中文一直报错,其实前面加个小u 就解决了:
send_keys(u"输入中文")
基本上键盘上所有的按键都可以模拟
module:selenium.webdriver.common.keys
• class Keys()
– NULL = u’ue000’
– CANCEL = u’ue001’ # ^break
– HELP = u’ue002’
– BACK_SPACE = u’ue003’
– TAB = u’ue004’
– CLEAR = u’ue005’
– RETURN = u’ue006’
– ENTER = u’ue007’
– SHIFT = u’ue008’
– LEFT_SHIFT = u’ue008’ # alias
– CONTROL = u’ue009’
– LEFT_CONTROL = u’ue009’ # alias
– ALT = u’ue00a’
– LEFT_ALT = u’ue00a’ # alias
– PAUSE = u’ue00b’
– ESCAPE = u’ue00c’
– SPACE = u’ue00d’
– PAGE_UP = u’ue00e’
– PAGE_DOWN = u’ue00f’
– END = u’ue010’
– HOME = u’ue011’
– LEFT = u’ue012’
– ARROW_LEFT = u’ue012’ # alias
– UP = u’ue013’
– ARROW_UP = u’ue013’ # alias
– RIGHT = u’ue014’
– ARROW_RIGHT = u’ue014’ # alias
– DOWN = u’ue015’
– ARROW_DOWN = u’ue015’ # alias
– INSERT = u’ue016’
– DELETE = u’ue017’
– SEMICOLON = u’ue018’
– EQUALS = u’ue019’
– NUMPAD0 = u’ue01a’ # numbe pad keys
– NUMPAD1 = u’ue01b’
– NUMPAD2 = u’ue01c’
– NUMPAD3 = u’ue01d’
– NUMPAD4 = u’ue01e’
– NUMPAD5 = u’ue01f’
– NUMPAD6 = u’ue020’
– NUMPAD7 = u’ue021’
– NUMPAD8 = u’ue022’
– NUMPAD9 = u’ue023’
– MULTIPLY = u’ue024’
– ADD = u’ue025’
– SEPARATOR = u’ue026’
– SUBTRACT = u’ue027’
– DECIMAL = u’ue028’
– DIVIDE = u’ue029’
– F1 = u’ue031’ # function keys
– F2 = u’ue032’
– F3 = u’ue033’
– F4 = u’ue034’
– F5 = u’ue035’
– F6 = u’ue036’
– F7 = u’ue037’
– F8 = u’ue038’
– F9 = u’ue039’
– F10 = u’ue03a’
– F11 = u’ue03b’
– F12 = u’ue03c’
– META = u’ue03d’
– COMMAND = u’ue03d’ |
相关文章:
轻松自动化---selenium-webdriver(python) (十一)
selenium-webdriver(python) (十三) -- cookie处理
今天帮公司测试部同事将bugfree从windows下迁移到centos下,大概步骤如下:
(1)、关闭Selinux
vi /etc/selinux/config
modify
SELINUX=enforcing
to
SELINUX=disabled
reboot |
(2)、安装 mysql
yum install mysql mysql-server
chkconfig --levels 235 mysqld on
service mysqld start |
(3)、让MySQL不区分大小写
vi /etc/my.cnf
add at [mysqld]
lower_case_table_names=1
service mysqld restart |
(4)、安装 php
yum install php php-mysql php-gd php-imap php-ldap php-odbc php-pear php-xml php-xmlrpc
(5)安装 php 插件 (有就不需要安装了)
rpm -ivh libmcrypt-2.5.8-9.el6.rpm
rpm -ivh php-mcrypt-5.3.3-1.el6.rpm
启动 httpd 服务
service httpd restart
(6)、安装 bugfree
unzip bugfree3.0.4.zip
mv bugfree /var/www/html
cd /var/www/html
chmod -R o+rwx bugfree |
在改目录下创建BugFile文件夹
mkdir BugFile
chmod -R o+rwx Bugfile
配置 bugfree
http://localhost/bugfree
(7)、数据导入
cd /usr/bin
mysqldump -u root -proot密码 bugfree > bugfree2.sql
把导出文件导入数据库
mysql -u root -p
mysql> use bugfree
mysql> source bugfree.sql
mysql> \q |
(8)、拷贝 BugFile 目录数据
1: 把原来 BugFile 目录压缩
2: 把 BugFile.zip 放到 /var/www/html/bugfree/ 目录下
unzip BugFile.zip
chmod -R o+rwx BugFile
(9)、设置 httpd 监听多个端口(不设置默认端口80)
vi /etc/httpd/conf/httpd.conf
在行 Listen 80 下增加
Listen 9011
在文件末尾增加
NameVirtualHost *:9011
<VirtualHost *:9011>
DocumentRoot /var/www/html/bugfree
ErrorLog logs/bugfree-error_log
CustomLog logs/bugfree-access_log common
</VirtualHost> |
(10)、添加防火墙端口
vi /etc/sysconfig/iptables
add
-A INPUT -m state --state NEW -m tcp -p tcp --dport 9011 -j ACCEPT
service iptables restart |
字符串操作无疑在各种编程语言及平台上都是必不可少的,功能相通,但用法却存在微妙的区别,比如java中取子串及相等的判断,切入正题。
1. substring
常用的用法包括:
(1)取索引为startidx之后(包括索引为startidx的字符)的字符串。
例:String strHello = "hello";
String strSub = strHello.substring(2); //得到"llo"
(2)取起始索引为startidx之后(包括索引为startidx的字符),及结束索引为(endidx-1)之前(包括索引为(endidx-1)的字符)。
例:String strHello = "hello";
String strSub = strHello.substring(2,4); //得到"ll"
2. 相等Equal与==
判断两个字符串相等,在尽可能的情况下用A.Equals(B)函数,可以得到预期的判断结果;而==考虑的不光是字符串的内容,还要考虑字符串实在池、还是堆上分配的内存机制,故尽量减少使用。
上回说到Memcahed的安装及java客户端的使用,现在我们使用memcached、Spring AOP技术来构建一个数据库的缓存框架。
数据库访问可能是很多网站的瓶颈。动不动就连接池耗尽、内存溢出等。前面已经讲到如果我们的网站是一个分布式的大型站点,那么使用memcached实现数据库的前端缓存是个很不错的选择;但如果网站本身足够小只有一个服务器,甚至是vps的那种,不推荐使用memcached,使用Hibernate或者Mybatis框架自带的缓存系统就行了。
一、开启memcached服务器端服务
如果已经安装了memcached服务器端程序,请确认服务器端服务已开启。
二、引入jar
1. alisoft-xplatform-asf-cache-2.5.1.jar
2. commons-logging-1.0.4.jar
3. hessian-3.0.1.jar
4. log4j-1.2.9.jar
5. stax-api-1.0.1.jar
6. wstx-asl-2.0.2.jar
三、创建memcached客户端配置文件
<memcached>
<!-- name 属性是程序中使用Cache的唯一标识;socketpool 属性将会关联到后面的socketpool配置; -->
<client name="mclient_0" compressEnable="true" defaultEncoding="UTF-8"
socketpool="pool_0">
<!-- 可选,用来处理出错情况 -->
<errorHandler>com.alisoft.xplatform.asf.cache.memcached.MemcachedErrorHandler
</errorHandler>
</client> <!--
name 属性和client 配置中的socketpool 属性相关联。
maintSleep属性是后台线程管理SocketIO池的检查间隔时间,如果设置为0,则表明不需要后台线程维护SocketIO线程池,默认需要管理。
socketTO 属性是Socket操作超时配置,单位ms。 aliveCheck
属性表示在使用Socket以前是否先检查Socket状态。
-->
<socketpool name="pool_0" maintSleep="5000" socketTO="3000"
failover="true" aliveCheck="true" initConn="5" minConn="5" maxConn="250"
nagle="false">
<!-- 设置memcache服务端实例地址.多个地址用","隔开 -->
<servers>127.0.0.1:11211</servers>
<!--
可选配置。表明了上面设置的服务器实例的Load权重. 例如 <weights>3,7</weights> 表示30% load 在
10.2.224.36:33001, 70% load 在 10.2.224.46:33001
<weights>3,7</weights>
-->
</socketpool>
</memcached> |
四、创建memcached客户端程序
客户端工具类:
package com.hl.usersmanager.memcached.client; import com.alisoft.xplatform.asf.cache.ICacheManager;
import com.alisoft.xplatform.asf.cache.IMemcachedCache;
import com.alisoft.xplatform.asf.cache.memcached.CacheUtil;
import com.alisoft.xplatform.asf.cache.memcached.MemcachedCacheManager; public class MemcachedCache {
private ICacheManager<IMemcachedCache> manager;
private IMemcachedCache cache;
public MemcachedCache(){
manager = CacheUtil.getCacheManager(IMemcachedCache.class,
MemcachedCacheManager.class.getName());
manager.setConfigFile("memcached.xml");
manager.setResponseStatInterval(5*1000);
manager.start();
cache = manager.getCache("mclient_0");
}
/**
* 获取缓存接口
* @return
*/
public IMemcachedCache getCache(){
return cache;
}
/**
* 数据放入缓存
* @param key
* @param object
*/
public void put(String key,Object object){
cache.put(key, object);
}
/**
* 从缓存中读取数据
* @param key
* @return
*/
public Object get(String key){
return cache.get(key);
}
} |
五、使用Spring AOP在数据查询的Service层实现数据缓存及读取
实现数据缓存的过程很简单,就是在Service层查询数据库操作前判断要查询的数据在缓存中是否存在,如果不存在就到数据库中查询,查询完成后将数据放入缓存系统;如果要查询的数据在缓存中已经存在,则直接从缓存中读取,不需要操作数据库。这就大大降低了数据库的连接次数。原理就是这么简单。
但是,如果直接对Service层代码进行修改,就违背了“开放-封闭”原则,也会导致缓存系统的操作代码散落到Service层的各处,不方便代码的管理和维护。所以,Spring AOP华丽登场了。它使用非入侵式的来创建、管理这些缓存操作代码。
关于Spring AOP本身的一些知识,我们这里不做讲述。参考资料:
由于首先要判断查询数据是否存在于缓存系统,如果存在直接从缓存中读取,也就是说Service层的查询代码根本不会执行;另一方面,如果数据在缓存系统中不存在,从数据库查询出的结果,我们需要将其放入缓存系统中。
我们来看Spring AOP的几个装备中哪个适用呢?那就是最强大的环绕通知装备@Around!
下面以UserService为例,其源代码如下:
package com.hl.usersmanager.service.impl; import java.util.List; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional; import com.hl.usersmanager.dao.IUserMapper;
import com.hl.usersmanager.model.Users;
import com.hl.usersmanager.service.IUserService; //使用Service注解 不需要再在配置文件中配置bean
@Service
public class UserServiceImpl implements IUserService{
@Autowired
private IUserMapper userMapper;
@Override
@Transactional
public Users findUserByName(String name) {
return userMapper.findUserByName(name);
} ……
} |
findUserByName主要实现按照用户名查询用户的功能,现在我们使用Spring AOP来实现缓存:
package com.hl.usersmanager.aop.service; import org.apache.log4j.Logger;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.beans.factory.annotation.Autowired; import com.hl.usersmanager.memcached.client.MemcachedCache;
import com.hl.usersmanager.model.Users; @Aspect
public class UserServiceInterceptor {
public static final Logger log = Logger
.getLogger(UserServiceInterceptor.class); //将缓存客户端工具类 MemcachedCache 织入进来
@Autowired
private MemcachedCache memcachedCache; /*
* 定义pointcunt
*/
@Pointcut("execution(* com.hl.usersmanager.service.impl.UserServiceImpl.*(..))")
public void aPointcut() { } /**
* 环绕装备 用于拦截查询 如果缓存中有数据,直接从缓存中读取;否则从数据库读取并将结果放入缓存
*
* @param call
* @param name
* @return
*/
@Around("aPointcut()&&args(name)")
public Users doFindUserByNameAround(ProceedingJoinPoint call, String name) {
Users users = null;
if (memcachedCache.getCache().containsKey("findUserByName_" + name)) {
users = (Users) memcachedCache.get("findUserByName_" + name);
log.debug("从缓存中读取!findUserByName_" + name);
} else {
try {
users = (Users) call.proceed();
if (users != null) {
memcachedCache.put("findUserByName_" + name, users);
log.debug("缓存装备被执行:findUserByName_" + name);
}
} catch (Throwable e) {
e.printStackTrace();
}
}
return users;
}
} |
环绕通知装备需要一个ProceedingJoinPoint 类型的参数,它的强大之处在于可以代理一个我们的切入点,指定切入点方法是否执行,或者获取执行后的返回结果!!
memcachedCache.getCache().containsKey("findUserByName_" + name)
可以判断缓存中是否有指定的数据。如果有则直接从缓存中读取:
users = (Users) memcachedCache.get("findUserByName_" + name);
否则调用切入点UserServiceImpl的findUserByName方法:
users = (Users) call.proceed();
call.proceed()表示执行切入点的方法。
使用Spring AOP以后,整个缓存系统代码看起来 就是这么优雅!UserServiceImpl根本不知道外界发了什么,更不知道外界调用它的findUserByName的时候已经被拦截了!
那天不用缓存系统,只需要将Aop这块的代码去掉即可。
当然,我们还需要在Spring配置文件中注册一个memcached客户端工具类的bean:
<!-- MemcachedCache缓存 -->
<bean id="MemcachedCache" class="com.hl.usersmanager.memcached.client.MemcachedCache"></bean>
|
最近我被裁员,去面试的时候有这个题目:
说一下对百度首页的测试用例设计。
以下内容除说明百度出来的以外全部原创。。。抛砖引玉,仅供参考。
××××××××××××××××××××××××××××××××××
先来一个一般上测试人员最喜欢最常用的测试方法,边界值法。
文本框边界值,一般可以测试一下输入字符的数量。
探索过程:
1.不输入文字,直接按搜索----->页面刷新,无变化---->结论1
2.复制粘贴一段很长的中文进入文本框----->被百度自动截取其中前100个字-->结论2
3.按下搜索按钮,百度跳转到搜索结果页面,并提示“"××" 及其后面的字词均被忽略,因为百度的查询限制在38个汉字以内”,将被自动截取的内容复制粘贴到word,统计字数为38--->结论3
5.复制粘贴一段很长的中文、英文、空格、符号混合文本进入文本框----->被百度自动截取其中一段内容。---->结果截取了100个字--->结论4
6.复制粘贴38个汉字进入搜索文本框,并中间加入62个连续空格后按下搜索----->搜索结果里最后一个汉字被忽略,因为前面有37个汉字加1个合并后的空格长度已达38.并且在文本框里原来62个空格的位置现在显示一个空格--->结论5
关于文本框字符数的结论:
1.最小输入值为0个字;
2.百度搜索文本框内可输入的最大字数是100个汉字;
3.百度搜索文本框的输入值在点击搜索按钮后,会被截取前38个汉字,其后面的字词均被忽略;
4.任意一个中文、英文、符号、空格在输入进文本框内第一次计数时均视同一个汉字;
5.连续的空格在点击搜索按钮后进行搜索时会自动合并,并转化一个单独的空格。
根据上述探索结果设计的文本框边界值测试用例(思路):
1.输入0个汉字:
什么也不输入直接点击搜索按钮,点击后应刷新首页
2.输入38个汉字:
输入38个汉字后点击搜索按钮,成功跳转到搜索结果页面
3.输入39个汉字:
输入39个汉字后点击搜索按钮,跳转到搜索结果页面,并在结果页面上显示“"×" 及其后面的字词均被忽略,因为百度的查询限制在38个汉字以内”
4.输入100个汉字:
输入100个汉字后点击搜索按钮,跳转到搜索结果页面,并在结果页面上显示“"×" 及其后面的字词均被忽略,因为百度的查询限制在38个汉字以内”
5.尝试输入100个以上的汉字:
尝试输入101个汉字,预期结果为尝试失败,只能输入100个汉字。
6.英文、符号的测试:
以英文、符号作为输入值,重复用例1到5,预期结果应与汉字相同。
7.空格的测试:
复制粘贴38个汉字进入搜索文本框,并中间加入62个连续空格后按下搜索,预期搜索结果里最后一个汉字被忽略,并在结果页面上显示“"×" 及其后面的字词均被忽略,因为百度的查询限制在38个汉字以内”同时,连续的空格应在搜索后的文本框内显示为一个空格。
可能的问题或者待改进的地方:
1.结论4导致百度搜索支持的英文关键字长度不足。与同类网站谷歌的对比,同样一段英文(约十几个单词)在谷歌里能正常搜索,在百度里会被截取前面38个字母。
2.结论1中不输入关键字点搜索没有任何提示,如果有提示会不会好一点。与同类网站谷歌对比,百度有明显的刷新页面动作,谷歌没有刷新页面(没有刷新页面进度条)。如果没有刷新页面动作会不会更好。
×××××××××××××××××××××××××××××××××××
然后是另一个测试人员最爱的测试,等价类法。
一般面试另一个经常出的题目就是问一个三角形,输入三个数字作为边长,然后要判断会变成正三角,等腰三角,还是普通三角,还是不能变成三角来划分等价类。这种case的设计就是基础的基础。
但如果测百度首页就比较复杂。因为用户输入值太多。
等价类可以这么划:
按区间划分。
按数值划分。
按数值集合划分。
按限制条件或规划划分。
按处理方式划分。
三角形问题显然按照数值和区间划分了。但百度首页的话就难划了。
按区间划 1.有意义的关键词做输入值,预期能搜出结果
2.无意义的关键词做输入值(比如用脸滚键盘来输入一些乱七八糟的关键字),预期搜不出任何结果
按数值划,不合适。
按数值集合划分,不合适。
按限制条件或规划划分,不合适。
按处理方式划分,需要知道百度是怎样处理关键字的。也就是说知道内部代码逻辑,有几种处理方式的话就可以划几个等价类,但是我不知道。。。
×××××××××××××××××××××××××××××××××××
第三种方法:写case就是按照需求和标准来写嘛
对于搜索引擎的测试需求和评价指标随便百度了一下就找到了:
1)搜索覆盖的网站或网页数目及范围;
2)结果的准确性,或者说相关度;
3)结果的全面性;
4)结果的时效性,比如说期望搜到最新的结果;
5)搜索的速度或者响应时间
6)易用性
7)链接有效性、稳定性等
对于这些我们可以一个个设计用例来测
比如
1.找一个很偏僻的小网站看看能不能被搜到。
2.挑一系列常用关键字,然后人工检查搜索结果的相关度。
3.挑一系列常用关键字,然后人工检查搜索结果的排序等等
其中的问题是,
1.这个偏僻的小网站应不应该被搜到呢。
2.我怎么知道这个搜索结果的相关度哪个应该算高,哪个应该算低。
3.我怎么知道这个搜索结果的哪个应该排第一哪个应该排第二。等等
这里应该超出黑盒测试的范围了。
假如能用白盒测试/自动化测试。常用方法有:
1.使用另一套完全不同的逻辑实现一套代码,来对比结果。(不常用,代价太高)
比如说为了测试百度,我们自己写了一个谷哥欠,然后对比两者的搜索结果
2.按照现有代码设计时的逻辑,人工计算验证该代码是否运行正确。(太难算。)
3.设计一些有一定通用性的规则,然后校验。(推荐)
比如说,给你一个数据库,告诉你里面所有记录都是数字,那么写脚本检查数据库的记录,当发现有字母时,脚本可以报异常。
同样,在百度里搜索一个关键字,然后根据预先定义好的某个规则,比如搜索结果页面在相关度一样的时候应当以时间为排序标准,检查出结果里有明显违背时,脚本可以报异常。
4.其他?(我上面都是自己根据自己经验总结的,真实情况毕竟不清楚)
5.还有特别提一下易用性。
百度里面有:
1.下拉框提示
2.搜索结果页提示”要找的是不是xxxx“
3.搜索结果页提示”关键字里去掉引号可以找到更多xxx“
4.搜索结果页提示”您输入的网址是不是xxx“
等等,都可以用探索性测试的方法试出来。然后针对他们设计对应的case。
×××××××××××××××××××××××××××××××××××
这样就完了?
没呢。。。百度首页还有用户登录、导航、天气预报、随心听、自定义主页、各种链接等等。
就光从功能测试角度来看也有很多东西需要测。
版权声明:本文出自 zhangting85 的51Testing软件测试博客:http://www.51testing.com/?207573
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
摘要: 1、WebDriver处理一些弹窗import java.util.Set;import org.openqa.selenium.Alert;import org.openqa.selenium.By;import org.openqa.selenium.NoAlertPresentException;import org.openqa.selenium.WebDriver;import...
阅读全文