在这一章中,我们将涵盖:
- 多线程和队列
- 系统调整
- 改善带宽
- 使用不同分发工具
介绍
这里没有标准的RabbitMQ调优指南,因为不同应用程序会采用不同方式优化.
通常情况下,应用程序需要在客户端进行优化:
- 处理器密集型应用程序可以通过为每个处理器内核运行一个线程来进行优化
- I/O密集型应用程序可以通过在单核上运行多个线程来隐藏隐式延迟
在两种情况下,消息传递是完美的结合.为了优化网络传输速率,AMQP标准规定消息按束(bunches)进行传输,然后再由客户端一个一个地消费(参考第1章,使用AMQP).
RabbitMQ 允许多线程应用程序高效地消费消息;这部分内容将在多线程和队列食谱中涉及.
另一个常见的用例是当RabbitMQ在分布式应用程序服务大量客户的情况.在这种情况下,更为现实的瓶颈是broker而不是客户端应用程序。在这种情况下,重要的是,我们的经纪人有一个特点,即:可扩展性。
当客户数量超过当前的最大容量阀值时,可在集群在增加一个或多个节点来分散负载,并提高总吞吐量。
那为什么要到那时才来优化呢?其主要原因是减少硬件、电力、冷却或云计算资源的成本。
在章节中,我们将讨论RabbitMQ的性能,同时也会展示一些技巧来提高客户端的性能,并最终修改broker参数.
多线程和队列
使用多线程也改善应用程序的性能.在本食谱中,我们将展示如何使用连接、通道、多线程.在这个例子中,我们使用的是Java,但一般来说,在目前多数技术中,使用多线程来提高性能是一种很好的实践。
你可在这里找到源码:Chapter08/Recipe01.
准备
你需要Java 1.7+和Apache maven.
如何做
在这个例子中,我们继承了ReliableClient Java 类 (参考第7章,开发高可用应用程序) 创建了一个producer,一个consumer. 让我们看下面的详细步骤:
1. 创建一个maven project,并增加RabbitMQ client 依赖.
2. 创建一个继承ReliableClient的producer.
3. 创建一个继承ReliableClient的consumer.
4. 使用下面的方法,为consumer和producer类创建一个ExecutorService Java类:
ExecutorService exService =Executors.newFixedThreadPool(threadNumber);
5. 以线程数目创建Runnable任务.producer如下:
for (int i = 0; i<threadNumber; i++) {
exService.execute(new Runnable() {
@Override
public void run() {
try {
publishMessages();
6.以线程数目创建Runnable任务.consumer如下 :
for (int i = 0; i<threadNumber; i++) {
exService.execute(new Runnable() {
@Override
public void run() {
final Channel internalChannel;
try {
internalChannel = connection.createChannel();
@Override
public void handleDelivery(String consumerTag,Envelope envelope, BasicProperties properties,byte[] body) throws IOException {..}
如何工作
ReliableClient 类创建了一个名为perf_queue_08/01的队列, 它将绑定到一个producer和一个consumer. producer 和 consumer 都会打开一个连接,并会基于每个线程创建一个通道。
通道可以在多个线程之间共享,但为了避免同步次数和一些锁的问题,尽量对每个线程单独创建一个通道。
TIP
通道并不总是线程安全的.这依赖于实现,例如,在使用 .NET client API时,在使用其方法前,你应该该对IModel加锁.阅读https://www.rabbitmq.com/releases/rabbitmq-dotnet-client/v3.1.5/rabbitmqdotnet-client-3.1.5-user-guide.pdf中的IModel should not be shared between threads章节.
要开始多线程(步骤3),我们使用了Java ExecutorService 类的Executors.newFixedThreadPool(..).通过这种方式,你可以控制你的线程数目.
TIP
你可在 http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/ExecutorService.html找到更多关于ExecutorService类和Java线程池的信息.
在这个例子中,你可以选择消息大小,运行时间,以及消费的消息数目.你可以使用下面的命令来创建rmqThreadTest.jar 文件:
mvn clean compile assembly:single
现在,你可以使用下面的命令来测试producer:
java -cp rmqThreadTest.jar rmqexample.ProducerMain 4 10000 128
第1个参数是线程数目;第二个参数是以毫秒为单位的运行时间;最后一个是以byte为单位的缓冲区大小.
你可以使用下面的命令来测试consumer:
java -cp rmqThreadTest.jar rmqexample.ConsumerMain 4
参数是线程的数目.你可以结合producer和consumer参数来测试应用程序,并在你的环境中来找到更好的性能.打开web管理控制台来检查实际速率,如下面截图所示:
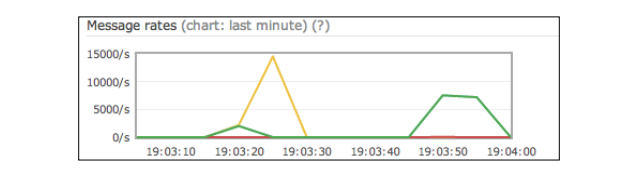

更多
当队列为空时,队列比较快,在设计应用程序时,应该尽可能地让队列保持空的状态. 在你的应用程序需要处理负载尖峰时,队列容量会很方便。
通过使用队列,消息最终会被缓存并在不丢失任何信息的情况下地被处理.
如果消费者的速度慢于生产者,那么你必须更加快速地消费消息,如:你可以尝试添加更多的线程或消费者来加速消息的消费.
TIP
从3.2.0版本开始, RabbitMQ支持队列联合(http://www.rabbitmq.com/blog/2013/10/23/federated-queuesin-3-2-0/), 它可以在没有集群的情况下, 均衡多个broker上的消息负载. 无论如何,如果你有一个以前版本的RabbitMQ,你必须将你的队列手动地分配更多的broker。
生产者和消费者线程的数量严格依赖于您的应用程序和部署环境。注意不要打开太多的线程,因为这可能会有相反的效果。
系统调优
在这个食谱中,我们会展示从RabbitMQ获得最大性能的一些有用步骤。我们将涵盖以下主题:
- vm_memory_high_watermark 配置 (http://www.rabbitmq.com/memory.html)
- Erlang High Performance Erlang (HiPE) (http://erlang.org/doc/apps/hipe/)
vm_memory_high_watermark配置用于设置消息被消耗或缓存到磁盘前,所占用的最大系统内存百分比.在达到极限前,默认情况下,在vm_memory_high_watermark设置的百分之五十时,(或适当设置vm_memory_high_watermark_paging_ratio参数,默认情况下设置为0.5),RabbitMQ会开始将消息从内存移动到磁盘分页空间上。
如果没有这个分页机制,或者消费者赶不上生产者的步伐,这将导致达到极限,然后RabbitMQ将阻塞生产者。
在某些情况下,加大这些参数是可能的,这样可以避免消息过早地转移到到磁盘上。在这个食谱中,我们将看到如何结合HIPE做。这里包含有两个不同的方面,但完成他们所需要的步骤是非常相似的。
你可以使用Chapter08/Recipe02目录下的代码.
准备
要尝试本食谱,你必须从RabbitMQ开始,并安装管理插件.接着,你还需要java 1.7+和Apache maven.
如何做
为了从RabbitMQ中获取最大性能,你可以执行下面的步骤:
1. 配置watermark:
rabbitmqctl set_vm_memory_high_watermark 0.6
或者直接在rabbitmq.config文件配置:
[{rabbit, [{vm_memory_high_watermark, 0.6}]}].
2. 修改Linux ulimit 参数,修改/etc/default/rabbitmqserver文件.然后,你可以使用HiPE来改善RabbitMQ自身.
3. 从http://www.erlang.org/download.html来安装最新版本的Erlang.
4. 在你的系统中安装HiPE.
5. 检查HiPE是否已正确激活;如果没有,你需要从源码来安装Erlang,并将其激活.
6. 在RabbitMQ 配置文件中激活Erlang HiPE. 创建rabbitmq.config文件并用下面的选项激活,或者现有的配置文件中添加下面的配置:
[
{rabbit, [{hipe_compile, true}]}
].
7. 重启RabbitMQ.
8. 检查RabbitMQ日志文件,确保没有HiPE没有激活的警告:
=WARNING REPORT==== 6-Oct-2013::00:38:23 ===
Not HiPE compiling: HiPE not found in this Erlang installation.
如何工作
watermark是RabbitMQ可使用的最大内存,默认情况下,其值为0.4,即它可使用安装物理内存的40%.当内存达到watermark时,broker会停止接受新的连接和消息.watermark 值可以是近似的.
在某些情况下,它可以不是默认的百分之40。无论如何,当服务器有大量的内存,你可以增加值,例如,只是为了容忍尖峰,可将增加到百分之60。
与rabbitmqctl变化是暂时的相比,当你修改rabbitmq.config文件,该选项将设置为永久生效。
默认情况下ulimit参数为1024。增加此值,可增加文件的数量和可用的RabbitMQ socket.
TIP
目前来说,Erlang HiPE是实验性质的.如果它能工作,我们可以使用它,但如果系统不稳定,你需要禁用它.
然而,对于RabbitMQ服务器来说,如果CPU是瓶颈的话,使用它,你可以获得百分之40的CPU使用上的改进。 例如,在下面的截图中,
你可以看到在一个生产者和消费者的标准配置在本地broker的行为:
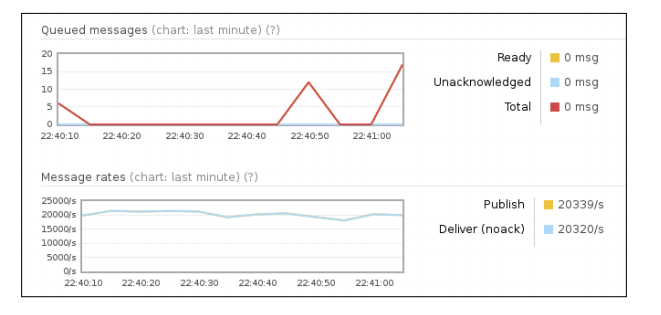

在这个例子中,我们在本地同时运行producer和consumer, 300秒发送了32字节消息, 并让消费者实时消费所有消息.
当 HiPE激活后,如下面的截图所示, 同样的测试将表现得更好:
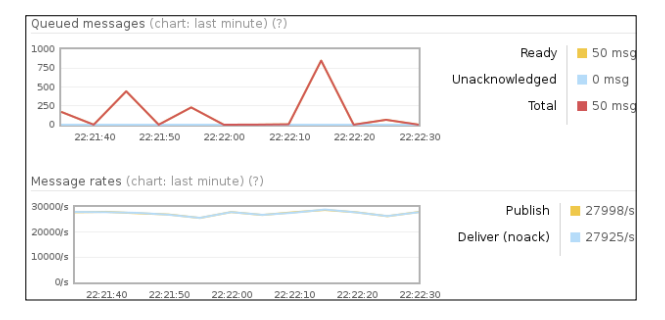

在RabbitMQ配置文件中激活HiPE前,你可以通过调用下面的erl命令进行检查:
# erl
Erlang R15B03 (erts-5.9.3.1) [source] [64-bit] [smp:2:2] [asyncthreads:0] [hipe] [kernel-poll:false]
EshellV5.9.3.1 (abort with ^G)
1>
这里HiPE是存在的,在启动时,你可以看到[hipe]选项.
TIP
在 Debian wheeze 系统中,当从Erlang网站下载了最新Erlang版本时,你可以通过下面的命令来安装HiPE模块:
apt-get install erlang-base-hipe
其它的发行包也有相似的可用包.
否则,你需要使用外部包或从 http://www.erlang.org/download.html下载Erlang源码包来安装,同时在配置时,需要记得指定 --enable-hipe 选项.
一旦RabbitMQ已经配置好了(步骤6),你将注意到服务器的重启会花费较长时间,一般需要数分钟.
TIP
在大部分Linux的发行版中,默认的RabbitMQ配置位于/etc/rabbitmq/rabbitmq.config.
此时,RabbitMQ broker是HiPE激活的. 最苛刻的部分不被解释了,但在启动时编译成本地机器代码.
你可以检查日志文件,确保你不会看到下面的消息:
=WARNING REPORT==== 6-Oct-2013::00:38:23 ===
Not HiPE compiling: HiPE not found in this Erlang installation.
TIP
默认情况下,在Linux RabbitMQ上, 日志文件存放在/var/log/rabbitmq. 在12章节,管理RabbitMQ 错误条件中可找到更多信息.
更多
因为HIPE是实验性的,我们不鼓励从一开始就使用, 考虑到通常需要的优化,来解决应用程序的优化和可扩展性.
然而,通过启用它,您可以减少服务器的使用率和功耗,因此这是一个可以在优化您的架构时考虑的选项。
改善带宽
使用noAck标志以及管理prefetch参数是另一种用来提高性能和带宽的客户端方式,它两者都由消费者来使用的.
在这个例子中,我们将使用这些参数来创建一个producer 和一个consumer. 你可在Chapter08/Recipe03找到源码.
准备
你需要Java 1.7+和Apache maven.
如何做
我们将跳过produce代码,因为它与多线程和队列食谱中是一样的. 我们仍然使用ReliableClient类来作基础类. 我们可通过执行下面的步骤来查看consumer:
1. 创建一个maven project,并添加RabbitMQ client依赖.
2. 创建一个 consumer 主类,它可读取args[]来管理consumer,其四个参数如下:
threadNumber = Integer.valueOf(args[0]);
prefetchcount = Integer.valueOf(args[1]);
autoAck = (Integer.valueOf(args[2]) != 0);
print_thread_consumer= (Integer.valueOf(args[3]) != 0);
3. 创建一个继承ReliableClient类的consumer,然后设置prefetch、noAck参数:
internalChannel.basicQos(prefetch_count);
internalChannel.basicConsume(Constants.queue, autoAck..
如何工作
如果设置了noAck选项时, 预提取大小(prefetch-size)将被忽略, 因此我们将本食谱分成两部分讲解:
- Prefetch
- noAck
其目标是理解如何管理客户端参数来改善性能和带宽.
Prefetch
要设置prefetch,使用basicQos(prefetch_count) (步骤3).
在第1章节使用AMQP,分发消息给多个消费者中,我们已经了解了channel QoS参数, 在那里,为了正解地负载均衡消息,消息是一个接一个地应答的.
预取数是未确认消息的最大数目:较大的值会让客户提前预取的许多消息,而不用等待正在被处理消息的应答. 正如本章开头所说的,优化时,没有一个通用的规则。
事实上,提高预取数可能会适得其反,当每个消息的处理时间很重要时,我们需要分配和平衡处理。
首先,Maven将使用下面的命令编译:
mvn clean compile assembly:single
然后, maven会创建rmqAckTest.jar包.
现在你可以尝试这个例子,通过修改参数来查看消息速率的改变.我们在MacBook pro Dual Core, 4 GB RAM机器上使用下面的参数来测试:
1.对于producer, 我们可以运行下面的命令:
java -cp rmqAckTest.jar rmqexample.ProducerMain 1 100000 64000
2.对于consumer,我们可以运行下面的两个测试:
java -cp rmqAckTest.jar rmqexample.ConsumerMain 2 50 0 0
java -cp rmqAckTest.jar rmqexample.ConsumerMain 2 1 0 0
producer使用 uses 1 thread for 100 seconds and 64000 bytes as the message size.
consumer 使用了 2个线程,在Test1中的预提取大小是50,Test2中是1, autoAck设为了false, 并且不在控制台中打印线程数目.
两种测试的结果如下:
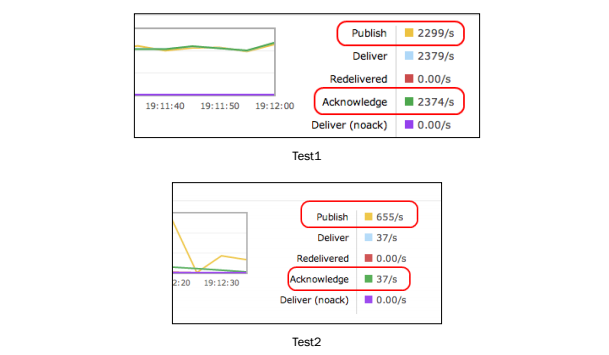

正如你所看到的,预提取大小不同,效果也不同,特别是有多个消费者绑定到同一个队列上的时候.
NoAck
要设置noAck,使用basicConsume(Constants.queue, true). 当消息是数据流或者根本不关心手动应答时,此参数是很有用处的.
TIP
在Java API中, 将Channel.basicConsume 的act参数名称作为Boolean类型的autoack,存在严重的误导,实际上autoack=true表示我们会设置noAck选项.
当设置了noAck时,你不能调用下面的方法:
internalChannel.basicAck(envelope.getDeliveryTag(), false);
尝试将第三个参数(忽略了第二个)设置为1来测试 :
java -cp rmqAckTest.jar rmqexample.ConsumerMain 1 1 1 0
更多
在优化消息传递操作时,可以通过应用方面的优化来获得性能提升。这是可行的,无论是“小”和“大”的消息:
- 如果消息太小, 在发送前,你可以手动对它们进行打包,然后在接收端再进行解包
- 如果消息太大,在发送前,你可以尝试压缩消息,并在消费端进行解压
也可参考 阅读http://www.rabbitmq.com/blog/2012/04/17/rabbitmqperformance-measurements-part-1/ 和 http://www.rabbitmq.com/blog/2012/04/25/rabbitmq-performance-measurements-part-2/来理解如何单个参数的重要性.
使用不同的分发工具
当应用程序需要提高性能的时候,你需要选择正确的分发工具. 在这个例子中,我们将展示发布消息时,镜像队列和非镜像队列之间的不同点.
准备
你需要Java 1.7+和Apache Maven.
如何做
你可以使用改善带宽食谱中的源码,并创建一个包含两个节点的RabbitMQ集群.
如何工作
使用HA镜像队列的集群相比单个broker较慢。镜像服务器的数目越高,应用程序就越慢,因为只有当消息全部存在镜像节点之后,生产者才能发送更多的消息。
TIP
这并不像它看起来的那样糟糕。一方面,对集群节点是并行执行的,所以开销不会随着节点的数量线性增长。另一方面,通常情况下,复制最多限制为两到三份,这部分内容已在第7章,开发高可用应用程序中看到过了.
我们使用下面的环境来执行测试:
以https://www.digitalocean.com/为云
两台Debian机器为RabbitMQ集群,如下所示:


一个Debian机具有相同特征的java客户端测试如下:Test 1: 使用下面的配置创建一个镜像(正如在第7章,开发高可用应用程序看到的),截图如下:
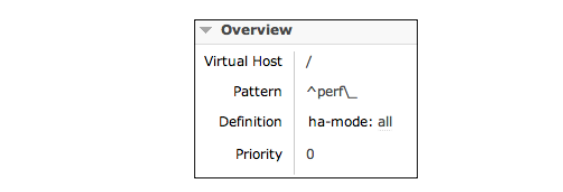

因此,集群会使用perf_ prefix来反射所有队列.
producer将使用下面的命令运行:
java -cp rmqAckTest.jar rmqexample.ProducerMain 1 100000 640
consumer使用下面的命令来运行:
java -cp rmqAckTest.jar rmqexample.ConsumerMain 1 0 0 0
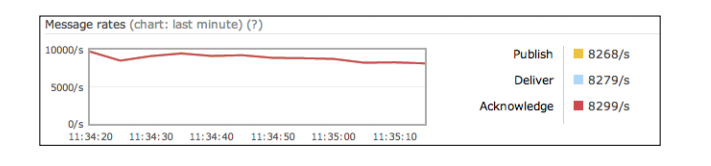
clients通过perf_queue_08/03队列来交换消息, 其性能如下所示:

Test 2: 删除HA策略并再次尝试. 在这种情况下,其结果类似于下面的截图:
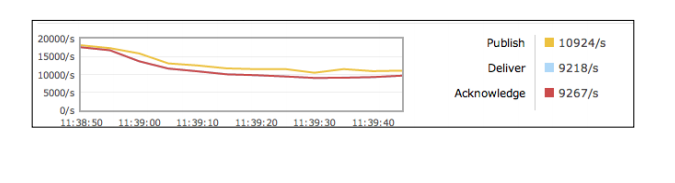

结论:通过使用小规模的消息,我们已经放大了差异。对于更大的信息,由差异不太明显. 在 Test 2中, 我们已经观察到比Test1每秒多了2000个消息,但同时也要看到,消息速率下降了,因为生产者快于消费者
TIP
作为通用规则,高可用性对性能有负面影响。所以,如果不具有强制性,最好把它关闭。
在这个例子中,我们已经尝试了最高性能,也看到镜像队列的影响.如果我们需要一定程度的复制,但对镜像要求不严格,那么可以使用shovel插件,或者简单地通过并行的方式将消息发布到两个独立的broker上.
在这个例子中,消息不是持久化的,且没有使用tx事务.
TIP
TX事务会扼杀性能,尤其是当你试图提交每一条消息的时候,因为它会等待每条消息的磁盘刷新。
更多由于在一个分布式应用程序中有大量的可变因素,因此在性能和可靠性之间找到正确的折衷是非常困难的。
一个典型的错误是试图优化每一个单个应用程序流丢失的可扩展性或最终高可用性的好处。
本章介绍了极端的情况下,但我们已经看到,有改善的利润率。
也可参考性能是RabbitMQ邮件列表中非常热门的话题。你可在http://rabbitmq.markmail.org/中找到很多有用的信息.
posted on 2016-07-15 14:53
胡小军 阅读(9417)
评论(0) 编辑 收藏 所属分类:
RabbitMQ