摘要: serverStatus.pdf原文:https://docs.mongodb.com/v3.0/reference/command/serverStatus/定义serverStatusserverStatus命令用于返回数据库进程状态的概述文档. 大部分监控程序都会定期运行此命令来收集实例相关的统计信息:{ serverStatus: 1 } 其值(即上面的1)不影响命令的操作。2.4版本中修...
阅读全文
posted @
2017-06-26 21:08 胡小军 阅读(2610) |
评论 (0) |
编辑 收藏SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
在MySQL中,实现了这四种隔离级别,分别有可能产生问题如下所示:

下面,将利用MySQL的客户端程序,分别测试几种隔离级别。测试数据库为test,表为tx;表结构:
两个命令行客户端分别为A,B;不断改变A的隔离级别,在B端修改数据。
(一)、将A的隔离级别设置为read uncommitted(未提交读)
在B未更新数据之前:
客户端A:
B更新数据:
客户端B:

客户端A:

经过上面的实验可以得出结论,事务B更新了一条记录,但是没有提交,此时事务A可以查询出未提交记录。造成脏读现象。未提交读是最低的隔离级别。
(二)、将客户端A的事务隔离级别设置为read committed(已提交读)
在B未更新数据之前:
客户端A:
B更新数据:
客户端B:

客户端A:

经过上面的实验可以得出结论,已提交读隔离级别解决了脏读的问题,但是出现了不可重复读的问题,即事务A在两次查询的数据不一致,因为在两次查询之间事务B更新了一条数据。已提交读只允许读取已提交的记录,但不要求可重复读。
(三)、将A的隔离级别设置为repeatable read(可重复读)
在B未更新数据之前:
客户端A:
B更新数据:
客户端B:

客户端A:

B插入数据:
客户端B:

客户端A:

由以上的实验可以得出结论,可重复读隔离级别只允许读取已提交记录,而且在一个事务两次读取一个记录期间,其他事务部的更新该记录。但该事务不要求与其他事务可串行化。例如,当一个事务可以找到由一个已提交事务更新的记录,但是可能产生幻读问题(注意是可能,因为数据库对隔离级别的实现有所差别)。像以上的实验,就没有出现数据幻读的问题。
(四)、将A的隔离级别设置为 可串行化 (Serializable)
A端打开事务,B端插入一条记录
事务A端:

事务B端:

因为此时事务A的隔离级别设置为serializable,开始事务后,并没有提交,所以事务B只能等待。
事务A提交事务:
事务A端

事务B端

serializable完全锁定字段,若一个事务来查询同一份数据就必须等待,直到前一个事务完成并解除锁定为止 。是完整的隔离级别,会锁定对应的数据表格,因而会有效率的问题。
转自:http://xm-king.iteye.com/blog/770721
posted @
2016-09-24 00:06 胡小军 阅读(286) |
评论 (0) |
编辑 收藏一、rsync的概述
rsync是类unix系统下的数据镜像备份工具,从软件的命名上就可以看出来了——remote sync。rsync是Linux系统下的文件同步和数据传输工具,它采用“rsync”算法,可以将一个客户机和远程文件服务器之间的文件同步,也可以 在本地系统中将数据从一个分区备份到另一个分区上。如果rsync在备份过程中出现了数据传输中断,恢复后可以继续传输不一致的部分。rsync可以执行 完整备份或增量备份。它的主要特点有:
1.可以镜像保存整个目录树和文件系统;
2.可以很容易做到保持原来文件的权限、时间、软硬链接;无须特殊权限即可安装;
3.可以增量同步数据,文件传输效率高,因而同步时间短;
4.可以使用rcp、ssh等方式来传输文件,当然也可以通过直接的socket连接;
5.支持匿名传输,以方便进行网站镜象等;
6.加密传输数据,保证了数据的安全性;
二、镜像目录与内容
rsync -av duying /tmp/test
查看/tmp/test目录,我们可以看到此命令是把duying这个文件夹目录连同内容全部考到当前目录下了
rsync -av duying/ /tmp/test 注意:比上一条命令多了符号“/”
再次查看/tmp/test目录,我们发现没有duying这个目录,只是看到了目录中的内容
三、增量备份本地文件
rsync -avzrtopgL --progress /src /dst
-v是“--verbose”,即详细模式输出; -z表示“--compress”,即传输时对数据进行压缩处理;
-r表示“--recursive”,即对子目录以递归的模式处理;-t是“--time”,即保持文件时间信息;
-o表示“owner”,用来保持文件属主信息;-p是“perms”,用来保持文件权限;
-g是“group”,用来保持文件的属组信息;
--progress用于显示数据镜像同步的过程;
四、镜像同步备份文件
rsync -avzrtopg --progress --delete /src /dst
--delete选项指定以rsync服务器端为基础进行数据镜像同步,也就是要保持rsync服务器端目录与客户端目录的完全一致;
--exclude选项用于排除不需要传输的文件类型;
五、设置定时备份策略
crontab -e
30 3 * * * rsync -avzrtopg --progress --delete --exclude "*access*"
--exclude "*debug*" /src /dst
如果文件比较大,可使用nohup将进程放到后台执行。
nohup rsync -avzrtopgL --progress /data/opt /data2/ >/var/log/$(date +%Y%m%d).mail.log &
六、rsync的优点与不足
与传统的cp、tar备份方式对比,rsync具有安全性高、备份迅速、支持增量备份等优点,通过rsync可以解决对实时性要求不高的数据备份需求,例如,定期地备份文件服务器数据到远端服务器,对本地磁盘定期进行数据镜像等。
但是随着系统规模的不断扩大,rsync的缺点逐渐被暴露了出来。首先,rsync做数据同步时,需要扫描所有文件后进行对比,然后进行差量传输。如果文 件很大,扫面文件是非常耗时的,而且发生变化的文件往往是很少一部分,因此rsync是非常低效的方式。其次,rsync不能实时监测、同步数据,虽然它 可以通过Linux守护进程的方式触发同步,但是两次触发动作一定会有时间差,可能导致服务器端和客户端数据出现不一致。
转自:http://blog.sina.com.cn/s/blog_6954b9a901011esn.html
posted @
2016-09-23 22:01 胡小军 阅读(306) |
评论 (0) |
编辑 收藏 Linux下如何查看版本信息, 包括位数、版本信息以及CPU内核信息、CPU具体型号等等,整个CPU信息一目了然。
1、# uname -a (Linux查看版本当前操作系统内核信息)
Linux localhost.localdomain 2.4.20-8 #1 Thu Mar 13 17:54:28 EST 2003 i686 athlon i386 GNU/Linux
2、# cat /proc/version (Linux查看当前操作系统版本信息)
Linux version 2.4.20-8 (bhcompile@porky.devel.redhat.com)
(gcc version 3.2.2 20030222 (Red Hat Linux 3.2.2-5)) #1 Thu Mar 13 17:54:28 EST 2003
3、# cat /etc/issue 或cat /etc/redhat-release(Linux查看版本当前操作系统发行版信息)
Red Hat Linux release 9 (Shrike)
4、# cat /proc/cpuinfo (Linux查看cpu相关信息,包括型号、主频、内核信息等)
processor : 0
vendor_id : AuthenticAMD
cpu family : 15
model : 1
model name : AMD A4-3300M APU with Radeon(tm) HD Graphics
stepping : 0
cpu MHz : 1896.236
cache size : 1024 KB
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 6
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr
sse sse2 syscall mmxext lm 3dnowext 3dnow
bogomips : 3774.87
5、# getconf LONG_BIT (Linux查看版本说明当前CPU运行在32bit模式下, 但不代表CPU不支持64bit)
32
6、# lsb_release -a
以上文章转载自:http://www.cnblogs.com/lanxuezaipiao/archive/2012/10/22/2732857.html
posted @
2016-09-23 21:58 胡小军 阅读(311) |
评论 (0) |
编辑 收藏
摘要: 原文:http://shiro.apache.org/reference.htmlApache Shiro介绍Apache Shiro是什么?Apache Shiro 是一个可干净处理认证,授权,企业会话管理以及加密的强大且灵活的开源安全框架.Apache Shiro的首要目标是易于使用和理解. 安全可以是非常复杂的,有时甚至是痛苦的,但它不是. 框架应该隐藏复杂的地方,暴露干净而方便的API,以...
阅读全文
posted @
2016-08-18 17:32 胡小军 阅读(2574) |
评论 (0) |
编辑 收藏- 在项目上右键进入Properties,选择Deployment Assembly,再点击Add...,如下图所示:
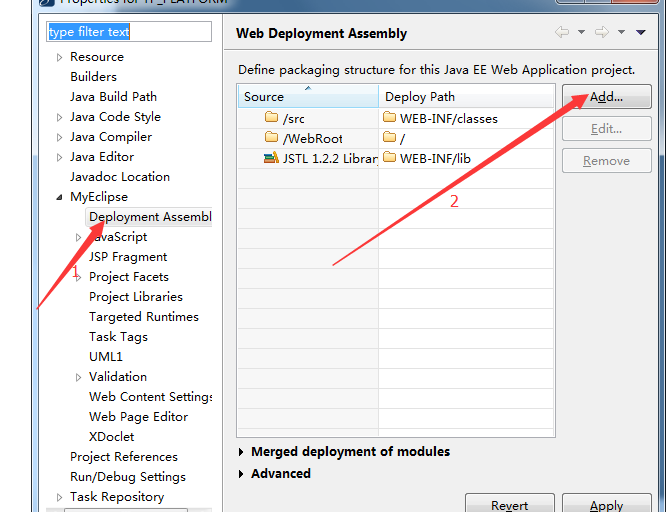
2.然后在弹出的窗口中,选择Java Build Path Entries,点击Next,如下图所示:
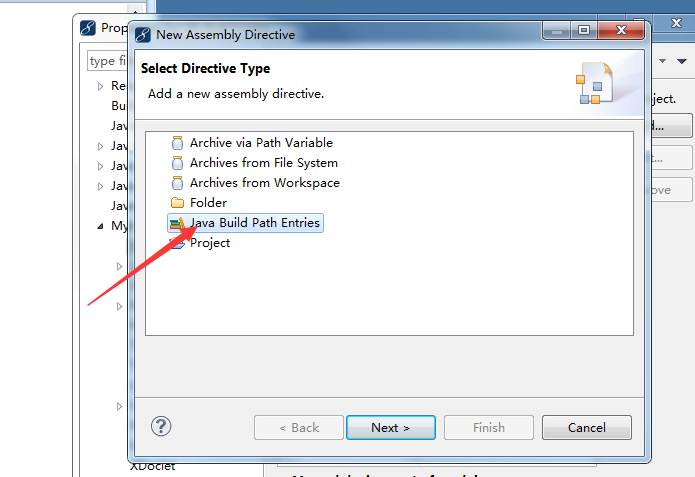
3.选择你要你引入的UserLibrary,点击Finish即可
注意:如果在Java Web Project引入了其它Java Project,默认引用的Java Project的编译后字节码是不会部署到WEB-INF/class下的,此时需要使用上面的Project进行导出.
posted @
2016-08-17 12:53 胡小军 阅读(2414) |
评论 (0) |
编辑 收藏介绍
除了帮助页面,所有URIs只会服务application/json类型的资源,并且需要HTTP基础认证(使用标准RabbitMQ用户数据库). 默认用户是guest/guest.
大多数URIs需要虚拟主机名称作为其路径的一部分, 因为名称是虚拟主机的唯一标识符对象. 默认虚拟主机称为"/", 它需要编码为"%2f".
PUT一个资源会对其进行创建. 你上传的JSON对象必须有某个键keys (下面文档有描述),其它的键会被忽略. 缺失键会引发错误.
在AMQP中,由于绑定没有名称或IDs,因此我们基于其所有属性人工合成了一个.
由于一般情况下很难预测这个名字, 你可以通过POST一个工厂URI来创建绑定.查看下面的例子.
注意事项
这些注意事项适用于当前管理AP的开发版本。在未来,他们将是固定的。
arguments 字段会被忽略.你不创建一个队列,交换器或使用参数进行绑定. 带有参数的队列,交换器或绑定也不会显示这些参数.- 权限偶尔才需要强制执行.如果一个用户能用HTTP API进行认证,那么它们可以做任何事情.
- 从GET请求中返回的对象中包含许多与监控相关的信息. 它们是无证实的,并且将来可能要发生变化.
示例
下面有几个快速例子,它们使用了Unix命令行工具curl:
- 获取虚拟主机列表:
$ curl -i -u guest:guest http://localhost:55672/api/vhosts
HTTP/1.1 200 OK
Server: MochiWeb/1.1 WebMachine/1.7 (participate in the frantic)
Date: Tue, 31 Aug 2010 15:46:59 GMT
Content-Type: application/json
Content-Length: 5
["/"]
- 创建一个新虚拟主机:
$ curl -i -u guest:guest -H "content-type:application/json" \ -XPUT http://localhost:55672/api/vhosts/foo
HTTP/1.1 204 No Content
Server: MochiWeb/1.1 WebMachine/1.7 (participate in the frantic)
Date: Fri, 27 Aug 2010 16:56:00 GMT
Content-Type: application/json
Content-Length: 0
注意: 你必须将mime类型指定为application/json.
Note: 在上传的JSON对象中,对象名称是不需要的,因为它已经包含在了URI中. 由于一个虚拟主机除了名称外没有其它属性,这意味着你完全不需要指定一个body.
- 在默认虚拟主机中创建一个新的交换器:
$ curl -i -u guest:guest -H "content-type:application/json" \ -XPUT -d'{"type":"direct","auto_delete":false,"durable":true,"arguments":[]}' \ http://localhost:55672/api/exchanges/%2f/my-new-exchange
HTTP/1.1 204 No Content
Server: MochiWeb/1.1 WebMachine/1.7 (participate in the frantic)
Date: Fri, 27 Aug 2010 17:04:29 GMT
Content-Type: application/json
Content-Length: 0注意: 在PUT或DELETE的响应中, 除非失败了,否则我们绝不会返回一个body.
- 再删除它:
$ curl -i -u guest:guest -H "content-type:application/json" \ -XDELETE http://localhost:55672/api/exchanges/%2f/my-new-exchange
HTTP/1.1 204 No Content
Server: MochiWeb/1.1 WebMachine/1.7 (participate in the frantic)
Date: Fri, 27 Aug 2010 17:05:30 GMT
Content-Type: application/json
Content-Length: 0
参考
| GET | PUT | DELETE | POST | Path | Description |
|---|
| X |
|
|
| /api/overview | 描述整个系统的各种随机信息。 |
| X |
|
|
| /api/connections | 所有打开连接的列表. |
| X |
| X |
| /api/connections/name | 一个单独的连接. DELETE它会导致连接关闭. |
| X |
|
|
| /api/channels | 所有打开通道的列表. |
| X |
|
|
| /api/channels/channel | 单个通道的详情. |
| X |
|
|
| /api/exchanges | 所有交换器的列表. |
| X |
|
|
| /api/exchanges/vhost | 指定虚拟主机中所有交换器列表. |
| X | X | X |
| /api/exchanges/vhost/name | 一个单独的交换器.要PUT一个交换器,你需要一些像下面这样的body:{"type":"direct","auto_delete":false,"durable":true,"arguments":[]} |
| X |
|
|
| /api/exchanges/vhost/name/bindings | 指定交换器中的绑定列表. |
| X |
|
|
| /api/queues | 所有队列的列表. |
| X |
|
|
| /api/queues/vhost | 指定虚拟主机中所有队列列表. |
| X | X | X |
| /api/queues/vhost/name | 一个单独队列.要PUT一个队列, 你需要一些像下面这样的body:{"auto_delete":false,"durable":true,"arguments":[]} |
| X |
|
|
| /api/queues/vhost/queue/bindings | 指定队列中的所有绑定列表. |
| X |
|
|
| /api/bindings | 所有绑定列表. |
| X |
|
|
| /api/bindings/vhost | 指定虚拟主机上的所有绑定列表. |
| X |
|
| X | /api/bindings/vhost/queue/exchange | 队列和交换器之间的所有绑定列表. 记住,队列和交换器可以绑定多次!要创建一个新绑定, POST 这个URI.你需要一些像下面这样的body:{"routing_key":"my_routing_key","arguments":[]}响应会包含一个Location header,它会告诉你新绑定的URI. |
| X | X | X |
| /api/bindings/vhost/queue/exchange/props | 队列和交换器之间的单个绑定. URI的props部分是一个名称,用于由路由键和属性组成的绑定.你可以通过PUT这个URI来创建一个绑定,它比上面POST URI更方便. |
| X |
|
|
| /api/vhosts | 所有虚拟主机列表. |
| X | X | X |
| /api/vhosts/name | 单个虚拟主机.由于虚拟主机只有一个名称,因此在PUT时不需要body. |
| X |
|
|
| /api/users | 所有用户列表. |
| X | X | X |
| /api/users/name | 单个用户. 要PUT一个用户, 你需要一些像下面这样的body:{"password":"secret"} |
| X |
|
|
| /api/users/user/permissions | 指定用户的所有权限列表. |
| X |
|
|
| /api/permissions | 所有用户的所有权限列表. |
| X | X | X |
| /api/permissions/vhost/user | 一个虚拟主机中某个用户的个人权限. 要PUT一个权限,你需要一些像下面这样的body:{"scope":"client","configure":".*","write":".*","read":".*"} |
posted @
2016-08-13 21:50 胡小军 阅读(7425) |
评论 (0) |
编辑 收藏
摘要: 3.1.15 消息监听器容器配置有相当多的配置SimpleMessageListenerContainer 相关事务和服务质量的选项,它们之间可以互相交互.当使用命名空间来配置<rabbit:listener-container/>时,下表显示了容器属性名称和它们等价的属性名称(在括号中).未被命名空间暴露的属性,以`N/A`表示.Table 3.3. 消...
阅读全文
posted @
2016-08-13 16:24 胡小军 阅读(6665) |
评论 (0) |
编辑 收藏
摘要: 3.1.10 配置broker介绍AMQP 规范描述了协议是如何用于broker中队列,交换器以及绑定上的.这些操作是从0.8规范中移植的,更高的存在于org.springframework.amqp.core包中的AmqpAdmin 接口中. 那个接口的RabbitMQ 实现是RabbitAdmin,它位于org.springframework.amqp.rabbit.core 包.A...
阅读全文
posted @
2016-08-13 16:07 胡小军 阅读(5042) |
评论 (0) |
编辑 收藏
摘要: 3.1.9 Request/Reply 消息介绍AmqpTemplate 也提供了各种各样的sendAndReceive 方法,它们接受同样的参数选项(exchange, routingKey, and Message)来执行单向发送操作. 这些方法对于request/reply 场景也是有用的,因为它们在发送前处理了必要的"reply-to"属性配置,并能通过它在专...
阅读全文
posted @
2016-08-13 15:59 胡小军 阅读(6737) |
评论 (0) |
编辑 收藏
摘要: Consumer Tags从1.4.5版本开始,你可以提供一种策略来生成consumer tags.默认情况下,consumer tag是由broker来生成的.public interface ConsumerTagStrategy { String createConsumerTag(String queue); }该队列是可用的,所以它可以(可选)在tag中使用。参考Sectio...
阅读全文
posted @
2016-08-13 12:48 胡小军 阅读(13121) |
评论 (0) |
编辑 收藏
摘要: Queue Affinity 和 LocalizedQueueConnectionFactory当在集群中使用HA队列时,为了获取最佳性能,可以希望连接到主队列所在的物理broker. 虽然CachingConnectionFactory 可以配置为使用多个broker 地址; 这会失败的,client会尝试按顺序来连接. LocalizedQueueConnectionFac...
阅读全文
posted @
2016-08-13 12:38 胡小军 阅读(6391) |
评论 (0) |
编辑 收藏
摘要: 3. 参考这部分参考文档详细描述了组成Sring AMQP的各种组件. main chapter 涵盖了开发AMQP应用程序的核心类. 这部分也包含了有关示例程序的章节.3.1 使用 Spring AMQP在本章中,我们将探索接口和类,它们是使用Spring AMQP来开发应用程序的必要组件 .3.1.1 AMQP 抽象介绍Spring ...
阅读全文
posted @
2016-08-13 12:21 胡小军 阅读(6643) |
评论 (0) |
编辑 收藏
摘要: 原文:http://docs.spring.io/spring-amqp/docs/1.6.0.RELEASE/reference/html/1. 前言Spring AMQP项目将其核心Spring概念应用于基于AMQP消息解决方案的开发中.我们提供了一个发送和接收消息的高级抽象模板.同时,我们也提供了消息驱动POJO的支持.这些包有助于AMQP资源的管理,从而提升依赖注入和声明式配置的使用. 在...
阅读全文
posted @
2016-08-13 12:03 胡小军 阅读(5986) |
评论 (0) |
编辑 收藏
摘要: 1 概述1.1 本文档的目标此文档定义了一个网络协议-高级消息队列协议(AMQP), 它使一致的客户端程序可以与一致的消息中间件服务器进行通信.我们面对的是这个领域有经验的技术读者,同时还提供了足够的规范和指南.技术工程师可以根据这些文档,在任何硬件平台上使用各种编程语言来构建遵从该协议的解决方案。1.2 摘要1.2.1 为什么使用AMQP?AMQP在一致性客户端和消息中间件(也称为"broker...
阅读全文
posted @
2016-08-12 18:30 胡小军 阅读(10981) |
评论 (0) |
编辑 收藏
摘要: 原文:http://docs.spring.io/spring/docs/current/spring-framework-reference/htmlsingle/#beans-java7.12.1 基本概念: @Bean 和 @Configuration在Spring新的Java配置支持中,其核心构件是@Configuration注解类和@Bean注解方法.@Bean 注解用来表示方...
阅读全文
posted @
2016-08-05 17:04 胡小军 阅读(2352) |
评论 (0) |
编辑 收藏
摘要: RabbitMQ内置支持TLS。自RabbitMQ 3.4.0起, 为防止 POODLE attack 攻击,已经自动禁用了SSLv3.使用TLS时,推荐安装的Erlang/OTP版本为17.5或以上版本. R16版本在某些证书中可以工作,但存在major limitations.必须安装Erlang加密程序,并且保证它能工作.对于那些从源码进行Erlang编译的Windows...
阅读全文
posted @
2016-08-02 22:25 胡小军 阅读(12054) |
评论 (0) |
编辑 收藏
摘要: 原文:http://www.rabbitmq.com/configure.htmlRabbitMQ 提供了三种方式来定制服务器:环境变量定义端口,文件位置和名称(接受shell输入,或者在环境配置文件(rabbitmq-env.conf)中设置)配置文件为服务器组件设置权限,限制和集群,也可以定义插件设置.运行时参数和策略可在运行时进行修改集群设置大部分设置都使用前面的两种方法,但本指南会全部讲解...
阅读全文
posted @
2016-08-02 09:38 胡小军 阅读(49460) |
评论 (0) |
编辑 收藏名称
rabbitmqctl — 用于管理中间件的命令行工具
语法
rabbitmqctl [-n node] [-t timeout] [-q] {command} [command options...]
描述
RabbitMQ是AMQP的实现, 后者是高性能企业消息通信的新兴标准. RabbitMQ server是AMQP 中间件健壮的,可扩展的实现.
rabbitmqctl 用来管理RabbitMQ中间件的命令行工具.它通过连接中间件节点来执行所有操作。
如果中间件没有运行,将会显示诊断信息, 不能到达,或因不匹配Erlang cookie而拒绝连接.
选项
[-n node]
默认节点是"rabbit@server",此处的server是本地主机. 在一个名为"server.example.com"的主机上, RabbitMQ Erlang node 的节点名称通常是rabbit@server (除非RABBITMQ_NODENAME在启动时设置了非默认值). hostname -s 的输出通常是"@" 标志后的东西.查看rabbitmq-server(1)来了解配置RabbitMQ broker的细节.
[-q]
使用-q标志来启用宁静(quiet)模式,这会一致消息输出.
[-t timeout]
操作超时时间(秒为单位). 只适用于"list" 命令. 默认是无穷大.
命令
应用程序和集群管理
stop [pid_file]
用于停止运行RabbitMQ的Erlang node.如果指定了pid_file,还将等待指定的过程结束。例如:
rabbitmqctl stop
此命令会终止RabbitMQ node的运行.
stop_app
停止RabbitMQ application,但Erlang node会继续运行.此命令主要用于优先执行其它管理操作(这些管理操作需要先停止RabbitMQ application),如. reset.例如:
rabbitmqctl stop_app
start_app
启动RabbitMQ application.
此命令典型用于在执行了其它管理操作之后,重新启动停止的RabbitMQ application。如reset.例如:
rabbitmqctl start_app
此命令来指导RabbitMQ node来启动RabbitMQ application.
wait {pid_file}
等待RabbitMQ application启动.此命令用来等待RabbitMQ application来启动node。它会等待创建pid文件,然后等待pid文件中的特定pid过程启动,最后等待RabbitMQ application 来启动node.
pid file是通过rabbitmq-server 脚本来创建的.默认情况下,它存放于Mnesia目录中. 修改RABBITMQ_PID_FILE 环境变量可以改变此位置。如:
rabbitmqctl wait /var/run/rabbitmq/pid
此命令会在RabbitMQ node启动后返回.
reset
将RabbitMQ node还原到最初状态.包括从所在群集中删除此node,从管理数据库中删除所有配置数据,如已配置的用户和虚拟主机,以及删除所有持久化消息.
执行reset和force_reset之前,必须停止RabbitMQ application ,如使用stop_app.
示例:
rabbitmqctl reset
此命令会重设RabbitMQ node.
force_reset
强制RabbitMQ node还原到最初状态.
不同于reset , force_reset 命令会无条件地重设node,不论当前管理数据库的状态和集群配置是什么. 它只能在数据库或集群配置已损坏的情况下才可使用。
执行reset和force_reset之前,必须停止RabbitMQ application ,如使用stop_app.
示例:
rabbitmqctl force_reset
此命令会重设RabbitMQnode.
rotate_logs {suffix}
指示RabbitMQ node循环日志文件.
RabbitMQ 中间件会将原来日志文件中的内容追加到原始名称和后辍的日志文件中,然后再将原始日志文件内容复制到新创建的日志上。实际上,当前日志内容会移到以此后辍结尾的文件上。当目标文件不存在时,将会进行创建。如果不指定后辍,则不会发生循环,日志文件只是重新打开。示例:
rabbitmqctl rotate_logs .1
此命令指示RabbitMQ node将日志文件的内容追加到新日志文件(文件名由原日志文件名和.1后辍构成)中。如. rabbit@mymachine.log.1 和 rabbit@mymachine-sasl.log.1. 最后, 日志会在原始位置恢复到新文件中.
集群管理
join_cluster {clusternode} [--ram]
- clusternode
加入集群的节点.
[--ram]
如果进行了设置,节点将以RAM节点身份加入集群.
指导节点成为集群中的一员. 在加入集群之前,节点会重置,因此在使用此命令时,必须小心. 这个命令要成功,RabbitMQ应用程序必须先停止,如stop_app.
集群节点可以是两种类型: 磁盘节点(Disc Node) 或 内存节点(RAM Node).磁盘节点会在RAM和磁盘中复制数据, 通过冗余可以防止节点失效事件,并可从断电这种全局事件中进行恢复. RAM节点只在RAM中复制数据(除了队列的内容外,还依赖于队列是否是持久化的或者内容对于内存来说是否过大) ,并主要用于可伸缩性. RAM节点只有当管理资源(如,增加/删除队列,交换机,或绑定)的时候才具有更高的性能.一个集群必须至少有一个磁盘节点,通常来说还不止一个.
默认情况下,节点是磁盘节点.如果你想要创建内存节点,需要提供--ram 标志.
在执行cluster命令之后, 无论何时,当前节点上启动的RabbitMQ 应用程序在节点宕机的情况下,会尝试连接集群中的其它节点。
要脱离集群, 必须重设(reset)节点. 你也可以通过forget_cluster_node 命令来远程删除节点.
更多详情,参考集群指南.
例如:
rabbitmqctl join_cluster hare@elena --ram
此命令用于指示RabbitMQ node以ram节点的形式将 hare@elena 加入集群.
cluster_status
按节点类型来分组展示集群中的所有节点,包括当前运行的节点.
例如:
rabbitmqctl cluster_status
此命令会显示集群中的所有节点.
change_cluster_node_type {disc | ram}
修改集群节点的类型. 要成功执行此操作,必须首先停止节点,要将节点转换为RAM节点,则此节点不能是集群中的唯一disc节点。
例如:
rabbitmqctl change_cluster_node_type disc
此命令会将一个RAM节点转换为disc节点.
forget_cluster_node [--offline]
[--offline]
允许节点从脱机节点中删除. 这只在所有节点都脱机且最后一个掉线节点不能再上线的情况下有用,从而防止整个集群从启动。它不能使用在其它情况下,因为这会导致不一致.
远程删除一个集群节点.要删除的节点必须是脱机的, 而在删除节点期间节点必须是在线的,除非使用了--offline 标志.
当使用--offline 标志时,rabbitmqctl不会尝试正常连接节点;相反,它会临时改变节点以作修改.如果节点不能正常启动的话,这是非常有用的.在这种情况下,节点将变成集群元数据的规范源(例如,队列的存在),即使它不是以前的。因此,如果有可能,你应该在最新的节点上使用这个命令来关闭。
例如:
rabbitmqctl -n hare@mcnulty forget_cluster_node rabbit@stringer
此命令会从节点hare@mcnulty中删除rabbit@stringer节点.
rename_cluster_node {oldnode1} {newnode1} [oldnode2] [newnode2 ...]
支持在本地数据库中重命名集群节点.
此子命令会促使rabbitmqctl临时改变节点以作出修改. 因此本地集群必须是停止的,其它节点可以是在线或离线的.
这个子命令接偶数个参数,成对表示节点的旧名称和新名称.你必须指定节点的旧名称和新名称,因为其它停止的节点也可能在同一时间重命名.
同时停止所有节点来重命名也是可以的(在这种情况下,每个节点都必须给出旧名称和新名称)或一次停止一个节点来重命名(在这种情况下,每个节点只需要被告知其名句是如何变化的).
例如:
rabbitmqctl rename_cluster_node rabbit@misshelpful rabbit@cordelia
此命令来将节点名称rabbit@misshelpful 重命名为rabbit@cordelia.
update_cluster_nodes {clusternode}
- clusternode
用于咨询具有最新消息的节点.
指示已集群的节点醒来时联系clusternode.这不同于join_cluster ,因为它不会加入任何集群 - 它会检查节点已经以clusternode的形式存在于集群中了.
需要这个命令的动机是当节点离线时,集群可以变化.考虑这样的情况,节点A和节点B都在集群里边,这里节点A掉线了,C又和B集群了,然后B又离开了集群.当A醒来的时候,它会尝试联系B,但这会失败,因为B已经不在集群中了.update_cluster_nodes -n A C 可解决这种场景.
force_boot
确保节点将在下一次启动,即使它不是最后一个关闭的。通常情况下,当你关闭整个RabbitMQ 集群时,你重启的第一个节点应该是最后一个下线的节点,因为它可以看到其它节点所看不到的事情. 但有时这是不可能的:例如,如果整个集群是失去了电力而所有节点都在想它不是最后一个关闭的.
在这种节点掉线情况下,你可以调用rabbitmqctl force_boot .这就告诉节点下一次无条件的启动节点.在此节点关闭后,集群的任何变化,它都会丢失.
如果最后一个掉线的节点永久丢失了,那么你需要优先使用rabbitmqctl forget_cluster_node --offline, 因为它可以确保在丢失的节点上掌握的镜像队列得到提升。
例如:
rabbitmqctl force_boot
这可以强制节点下次启动时不用等待其它节点.
sync_queue [-p vhost] {queue}
- queue
同步队列的名称
指示未同步slaves上的镜像队列自行同步.同步发生时,队列会阻塞(所有出入队列的发布者和消费者都会阻塞).此命令成功执行后,队列必须是镜像的.
注意,未同步队列中的消息被耗尽后,最终也会变成同步. 此命令主要用于未耗尽的队列。
cancel_sync_queue [-p vhost] {queue}
- queue
取消同步的队列名称.
指示同步镜像队列停止同步.
purge_queue [-p vhost] {queue}
- queue
要清除队列的名称.
清除队列(删除其中的所有消息).
set_cluster_name {name}
设置集群名称. 集群名称在client连接时,会通报给client,也可用于federation和shovel插件记录消息的来源地. 群集名称默认是来自在群集中的第一个节点的主机名,但可以改变。
例如:
rabbitmqctl set_cluster_name london
设置集群名称为"london".
用户管理
注意rabbitmqctl 管理RabbitMQ 内部用户数据库. 任何来自其它认证后端的用户对于rabbitmqctl来说是不可见的.
add_user {username} {password}
- username
要创建的用户名称.
- password
设置创建用户登录broker的密码.
rabbitmqctl add_user tonyg changeit
此命令用于指示RabbitMQ broker 创建一个拥有非管理权限的用户,其名称为tonyg, 初始密码为changeit.
delete_user {username}
- username
要删除的用户名称.
例如:
rabbitmqctl delete_user tonyg
此命令用于指示RabbitMQ broker删除名为tonyg的用户
change_password {username} {newpassword}
- username
要修改密码的用户名称.
- newpassword
用户的新密码.
例如:
rabbitmqctl change_password tonyg newpass
此命令用于指定RabbitMQ broker将tonyg 用户的密码修改为newpass.
clear_password {username}
- username
要清除密码的用户名称.
例如:
rabbitmqctl clear_password tonyg
此命令会指示RabbitMQ broker清除名为tonyg的用户密码.现在,此用户不能使用密码登录(但可以通过SASL EXTERNAL登录,如果配置了的话).
authenticate_user {username} {password}
- username
用户的名称.
- password
用户的密码.
例如:
rabbitmqctl authenticate_user tonyg verifyit
此命令会指示RabbitMQ broker以名称为tonyg, 密码为verifyit来进行验证.
set_user_tags {username} {tag ...}
- username
要设置tag的用户名称.
- tag
用于设置0个,1个或多个tags.任何现有的tags都将被删除.
例如:
rabbitmqctl set_user_tags tonyg administrator
此命令指示RabbitMQ broker用于确保tonyg 是administrator.当通过AMQP来登录时,这没有什么效果,但用户通过其它的途经来登录时,它可用来管理用户,虚拟主机和权限(如使用管理插件).
rabbitmqctl set_user_tags tonyg
此命令会指示RabbitMQ broker删除tonyg上的任何现有的tag.
list_users
列出用户. 每个结果行都包含用户名,其后紧跟用户的tags.
例如:
rabbitmqctl list_users
此命令指示RabbitMQ broker列出所有用户.
访问控制
注意rabbitmqctl 会管理RabbitMQ的内部用户数据库. 无权限的用户将不能使用rabbitmqctl.
add_vhost {vhost}
- vhost
要创建虚拟主机名称.
创建一个虚拟主机.
例如:
rabbitmqctl add_vhost test
此命令指示RabbitMQ broker来创建一个新的名为test的虚拟主机.
delete_vhost {vhost}
- vhost
要删除的虚拟主机的名称.
删除一个虚拟主机.
删除一个虚拟主机,同时也会删除所有交换机,队列,绑定,用户权限,参数和策略.
例如:
rabbitmqctl delete_vhost test
此命令指示RabbitMQ broker删除名为test的虚拟主机.
list_vhosts [vhostinfoitem ...]
列出所有虚拟主机.
vhostinfoitem 参数用于标识哪些虚拟主机应该包含在结果集中.结果集中的列顺序会匹配参数的顺序.vhostinfoitem 可接受下面的值:
- name
虚拟主机的名称.
- tracing
是否对虚拟主机启用追踪.
如果没有指定vhostinfoitem 参数,那么会显示虚拟主机名称.
例如:
rabbitmqctl list_vhosts name tracing
此命令用于指示RabbitMQ broker显示所有虚拟主机.
set_permissions [-p vhost] {user} {conf} {write} {read}
- vhost
授予用户可访问的虚拟机名称,默认是/.
- user
可访问指定虚拟主机的用户名称.
- conf
一个用于匹配用户在哪些资源名称上拥有配置权限的正则表达式
- write
一个用于匹配用户在哪些资源名称上拥有写权限的正则表达式.
- read
一个用于匹配用户在哪些资源名称上拥有读权限的正则表达式.
设置用户权限.
例如:
rabbitmqctl set_permissions -p /myvhost tonyg "^tonyg-.*" ".*" ".*"
此命令表示RabbitMQ broker授予tonyg 用户可访问 /myvhost虚拟主机,并在资源名称以"tonyg-"开头的所有资源上都具有配置权限,并在所有资源上都拥有读写权限。
clear_permissions [-p vhost] {username}
- vhost
用于设置禁止用户访问的虚拟主机名称,默认为/.
- username
禁止访问特定虚拟主机的用户名称.
设置用户权限.
例如:
rabbitmqctl clear_permissions -p /myvhost tonyg
此命令用于指示RabbitMQ broker禁止tonyg 用户访问/myvhost虚拟主机.
list_permissions [-p vhost]
- vhost
用于指定虚拟主机名称,将会列出所有可访问此虚拟主机的所有用户名称和权限.默认为/.
显示虚拟机上权限.
例如:
rabbitmqctl list_permissions -p /myvhost
此命令指示RabbitMQ broker列出所有已授权访问/myvhost 虚拟主机的用户,同时也会列出这些用户能在虚拟主机资源可操作的权限.注意,空字符串表示没有任何授予的权限。
list_user_permissions {username}
- username
要显示权限的用户名称.
列出用户权限.
例如:
rabbitmqctl list_user_permissions tonyg
此命令指示RabbitMQ broker列出tonyg可授权访问的所有虚拟主机名称,以及在这些虚拟主机上的操作.
参数管理
RabbitMQ的某些特性(如联合插件)是动态控制的. 每个参数都是与特定虚拟主机相关的组件名称, name和value构成的. 组件名称和name都是字符串,值是Erlang term. 参数可被设置,清除和显示.通常你可以参考文档来了解如何设置参数.
set_parameter [-p vhost] {component_name} {name} {value}
设置一个参数.
- component_name
要设置的组件名称.
- name
要设置的参数名称.
- value
要设置的参数值,作不JSON项。在多数shells中,你更喜欢将其引起来.
例如:
rabbitmqctl set_parameter federation local_username '"guest"'
此命令用于在默认虚拟主机上设置federation 组件的local_username 参数值"guest".
clear_parameter [-p vhost] {component_name} {key}
清除参数.
- component_name
要清除参数的组件名称.
- name
要清除的参数名称.
例如:
rabbitmqctl clear_parameter federation local_username
此命令用于清除默认虚拟主机上的federation 组件的local_username 参数值.
list_parameters [-p vhost]
列出虚拟主机上的所有参数.
示例:
rabbitmqctl list_parameters
此命令用于列出默认虚拟主机上的所有参数.
策略管理
策略用于在集群范围的基础上用于控制和修改队列和交换机的行为. 策略应用于虚拟主机,由name, pattern, definition或可选的priority组成. 策略可被设置,清除和列举.
set_policy [-p vhost] [--priority priority] [--apply-to apply-to] {name} {pattern} {definition}
设置策略.
- name
策略名称.
- pattern
正则表达式, 匹配要应用的资源
- definition
策略的定义,JSON形式.在大多数shells中,你很可能需要引用这个
- priority
策略的整数优先级. 数字越高则优先级越高.默认是0.
- apply-to
策略适用的对象类型,其值可为 "queues", "exchanges" 或 "all".默认是"all".
例如:
rabbitmqctl set_policy federate-me "^amq." '{"federation-upstream-set":"all"}'此命令在默认虚拟主机上设置策略为federate-me,这样内建的交换器将进行联合.
clear_policy [-p vhost] {name}
清除策略.
- name
要清除的策略名称.
例如:
rabbitmqctl clear_policy federate-me
此命令来清除默认虚拟主机上的federate-me 策略.
list_policies [-p vhost]
显示虚拟主机上的所有策略.
例如:
rabbitmqctl list_policies
此命令会显示默认虚拟主机上的所有策略.
服务器状态
服务器状态查询查询服务器返回一个结果以制表符分隔的列表. 某些查询(list_queues, list_exchanges, list_bindings, 和 list_consumers) 接受一个可选的vhost 参数. 如果这个参数出现了,那么它必须指定在查询的后面.
list_queues, list_exchanges and list_bindings 命令接受一个可选的虚拟主机参数以显示其结果.默认值为"/".
list_queues [-p vhost] [queueinfoitem ...]
返回队列的详细信息. 如果无-p标志,将显示/虚拟主机上的队列详情."-p" 标志可用来覆盖此默认值.
queueinfoitem 参数用于指示哪些队列信息项会包含在结果集中.结果集的列顺序将匹配参数的顺序.queueinfoitem 可以是下面列表中的任何值:
- name
非ASCII字符的队列名称.
- durable
服务器重启后,队列是否能幸存.
- auto_delete
不再使用时,是否需要自动删除队列.
- arguments
队列参数.
- policy
应用到队列上的策略名称.
- pid
关联队列的Erlang进程ID.
- owner_pid
表示队列专用所有者的代表连接的Erlang进程ID.如果队列是非专用的,此值将为空.
- exclusive
True:如果队列是专用的(即有owner_pid), 反之false
- exclusive_consumer_pid
表示此channel的专用消费者订阅到此队列的Erlang进程Id. 如果没有专用消费者,则为空.
- exclusive_consumer_tag
专用消费者订阅到此队列的Consumer tag.如果没有专用消费者,则为空.
- messages_ready
准备分发给客户端的消息数目.
- messages_unacknowledged
分发到客户端但尚未应答的消息数目.
- messages
准备分发和未应答消息的总和(队列深度).
- messages_ready_ram
驻留在ram中messages_ready的消息数目.
- messages_unacknowledged_ram
驻留在ram中messages_unacknowledged的消息数目.
- messages_ram
驻留在ram中的消息总数.
- messages_persistent
队列中持久化消息的数目(对于瞬时队列总是0).
- message_bytes
队列中所有消息体的大小总和.这不包括消息属性(包括headers) 或任何开销(overhead)。
- message_bytes_ready
类似于message_bytes ,但只统计准备投递给clients的那些消息.
- message_bytes_unacknowledged
类似于message_bytes ,但只统计那些已经投递给clients但还未应答的消息
- message_bytes_ram
类似于message_bytes ,但只统计那些在RAM中的消息
- message_bytes_persistent
类似于message_bytes ,但只统计那些持久化的消息
- head_message_timestamp
如果存在,只显示队列中第1个消息的timestamp属性. 消息的时间戳只出现在分页情况下.
- disk_reads
从队列启动开如,已从磁盘上读取该队列的消息总次数.
- disk_writes
从队列启动开始,已向磁盘队列写消息总次数.
- consumers
消费者数目.
- consumer_utilisation
时间分数(0.0与1.0之间),队列可立即向消费者投递消息. 它可以小于1.0,如果消费者受限于网络堵塞或预提取数量.
- memory
与队列相关的Erlang进程消耗的内存字节数,包括栈,堆以及内部结构.
- slave_pids
如果队列是镜像的,这里给出的是当前slaves的IDs.
- synchronised_slave_pids
如果队列是镜像的,当前slaves的IDs是master同步的- 即它们可在无消息丢失的情况下,接管master.
- state
队列状态.正常情况下是'running', 但如果队列正在同步也可能是"{syncing, MsgCount}". 处于集群下的节点如果掉线了,队列状态交显示'down' (大多数queueinfoitems 将不可用).
如果没有指定queueinfoitems,那么将显示队列名称和队列深度.
例如:
rabbitmqctl list_queues -p /myvhost messages consumers
此命令显示了/myvhost虚拟主机中每个队列的深度和消费者数目.
list_exchanges [-p vhost] [exchangeinfoitem ...]
返回交换器细节.如果没有指定"-p"选项,将返回 / 虚拟主机的细节. "-p" 选项可用来覆盖默认虚拟主机.
exchangeinfoitem 参数用来表示哪些交换器信息要包含在结果中. 结果集中列的顺序将与参数顺序保持一致. exchangeinfoitem 可接受下面的列表中任何值:
- name
交换器名称.
- type
交换器类型(如[direct, topic, headers, fanout]).
- durable
当服务器重启时,交换器是否能复活.
- auto_delete
当不再使用时,交换器是否需要自动删除.
- internal
交换器是否是内部的,即不能由client直接发布.
- arguments
交换器参数
- policy
- 应用到交换器上的策略名称.
如果没有指定exchangeinfoitems,那么将会显示交换器类型和类型
例如:
rabbitmqctl list_exchanges -p /myvhost name type
此命令会显示/myvhost中每个交换器的名称和类型.
list_bindings [-p vhost] [bindinginfoitem ...]
返回绑定细节.默认情况下返回的是 / 虚拟主机上的绑定详情.可使用"-p" 标记来覆盖默认虚拟主机.
bindinginfoitem 参数用来表示结果中包含哪些绑定信息. 结果集中列的顺序将匹配参数的顺序.bindinginfoitem可接受下面列表的任意值:
- source_name
绑定中消息来源的名称. C中非ASCII转义字符.
- source_kind
绑定中消息来源的类别.当前总是exchange. C中非ASCII转义字符.
- destination_name
绑定中消息目的地名称.C中非ASCII转义字符.
- destination_kind
绑定中消息目的地的种类. C中非ASCII转义字符.
- routing_key
绑定的路由键,C中非ASCII转义字符.
- arguments
绑定参数.
如果没有指定bindinginfoitems,将会显示所有上述条目.
例如:
rabbitmqctl list_bindings -p /myvhost exchange_name queue_name
此命令来显示/myvhost虚拟主机上绑定的交换器名称和队列名称.
list_connections [connectioninfoitem ...]
返回TCP/IP连接统计.
connectioninfoitem 参数用来表示在结果中包含哪些连接信息. 结果集中列的顺序将匹配参数的顺序. connectioninfoitem可接受下面列表的任意值:
- pid
与连接相关的Erlang进程ID.
- name
连接的可读名称.
- port
服务器端口.
- host
返回反向DNS获取的服务器主机名称,或 IP地址(反向DNS解析失败) 或者未启用.
- peer_port
Peer 端口.
- peer_host
- 返回反向DNS获取的Peer主机名称,或 IP地址(反向DNS解析失败) 或者未启用.
- ssl
用Boolean来表示连接是否是SSL的.
- ssl_protocol
SSL 协议(如. tlsv1)
- ssl_key_exchange
SSL key exchange 算法 (如 rsa)
- ssl_cipher
SSL cipher 算法 (如aes_256_cbc)
- ssl_hash
SSL hash 函数 (如 sha)
- peer_cert_subject
peer的 SSL 安全证书的主体, RFC4514形式.
- peer_cert_issuer
peer的 SSL安全证书的发行者, RFC4514 形式.
- peer_cert_validity
peer的SSL安全证书的有效期.
- state
连接状态(可为[starting, tuning, opening, running, flow, blocking, blocked, closing, closed]其中一个).
- channels
使用连接的channel数。
- protocol
使用的AMQP协议版本(当前是{0,9,1} 或{0,8,0}). 注意,如果client请求的是AMQP 0-9 连接, 我们会视为AMQP 0-9-1.
- auth_mechanism
使用的SASL认证机制,如PLAIN.
- user
与连接相关的用户名
- vhost
虚拟主机名称,C中非ASCII转义字符.
- timeout
连接超时/协商的心跳间隔,秒为单位.
- frame_max
最大 frame 大小(字节).
- channel_max
- 此连接上channel的最大数目.
- client_properties
连接建立期间由client发送的信息属性.
- recv_oct
Octets已收到.
- recv_cnt
Packets 已收到.
- send_oct
Octets 发送.
- send_cnt
Packets 发送.
- send_pend
发送队列大小.
- connected_at
连接建立的日期和时间,当作timestamp.
如果没有connectioninfoitems, 那么会显示user, peer host, peer port,流量控制和内存块状态的时间
例如:
rabbitmqctl list_connections send_pend port
此命令会显示发送队列的大小以及第个连接的服务器端口.
list_channels [channelinfoitem ...]
返回所有当前channel上的信息,逻辑容器执行大部分 AMQP命令.这将包含最初AMQP连接的部分,以及不同插件和其它扩展创建的channels.
channelinfoitem 参数用来表示在结果集中包含哪些channel信息.结果集中列的顺序将匹配参数的顺序. channelinfoitem 可接受下面列表中的任何一个参数:
- pid
与连接相关的Erlang进程ID.
- connection
channel所属的连接Erlang进程ID.
- name
channel的可读名称.
- number
channel的数目,在一个连接中,它有唯一的标识符.
- user
与channel相关的用户名称.
- vhost
channel操作的虚拟主机.
- transactional
True:如果channel处于事务模式,其它情况为false.
- confirm
True:如果channel是确认模式,其它情况为false.
- consumer_count
在channel中接收消息的逻辑AMQP消费者数目.
- messages_unacknowledged
在channel中消息已投递但还未应答的消息数目.
- messages_uncommitted
在channel中已收到消息但还没有提交事务的消息个数.
- acks_uncommitted
确认收到一个还未提交的事务数。
- messages_unconfirmed
尚未确认已发布消息的数目。在通道不在确认模式下时,这将是0。
- prefetch_count
新消费者QoS预提取限制, 0表示无上限.
- global_prefetch_count
整个channel QoS预提取限制, 0表示无上限.
如果没有指定channelinfoitems,那么将显示pid, user, consumer_count,messages_unacknowledged.
例如:
rabbitmqctl list_channels connection messages_unacknowledged
此命令会显示每个channel中连接进程和未应答消息的数目.
list_consumers [-p vhost]
列举消费者, 即订阅队列的消息流. 每行将打印出由制表符分隔的已订阅队列的名称,创建并管理订阅的channel进程的标识,channel中订阅的consumer tag唯一标识符, boolean值表示投递到此消费者的消息是否需要应答,整数值表示表示预提取限制(为0表示无限制), 以及关于此消费者的任何其它参数.
status
显示 broker 状态信息,如当前Erlang节点上运行的应用程序, RabbitMQ 和 Erlang 的版本信息, OS 名称, 内存和文件描述符统计信息. (查看cluster_status 命令来找出那些节点是集群化的以及正在运行的.)
例如:
rabbitmqctl status
此命令显示了RabbitMQ broker的相关信息.
environment
显示每个运行程序环境中每个变量的名称和值.
report
为所有服务器状态生成一个服务器状态报告,输出应该重定向到一个文件.
例如:
rabbitmqctl report > server_report.txt
此命令创建了一个服务器报告,可将它附着在支持请求的电子邮件中.
eval {expr}
执行任意Erlang表达式.
例如:
rabbitmqctl eval 'node().'
此命令用于返回rabbitmqctl连接的节点名称
杂项
close_connection {connectionpid} {explanation}
- connectionpid
要关闭的与连接相关的Erlang进程ID.
- explanation
解释字符串.
指示broker关闭与Erlang进程id相关的连接(可通过list_connections 命令查看), 通过为连接客户端传递解释字符串(作为AMQP连接关闭协议的一部分).
例如:
rabbitmqctl close_connection "<rabbit@tanto.4262.0>" "go away"
此命令指示RabbitMQ broker关闭与Erlang 进程id<rabbit@tanto.4262.0>相关联的连接, 同时向客户端传递go away字符串.
trace_on [-p vhost]
- vhost
要开启追踪的虚拟主机的名称.
开启追踪.注意,追踪状态不是持久化的; 如果服务器重启,追踪状态将会丢失.
trace_off [-p vhost]
- vhost
要停止追踪的虚拟主机名称.
停止追踪.
set_vm_memory_high_watermark {fraction}
- fraction
当一个浮点数大于或等于0时,会触发流量控制新内存阈值部分。
set_vm_memory_high_watermark absolute {memory_limit}
- memory_limit
流程控制触发的新内存限制, 以字节来表示大于或等于0的整数或以字符串和内存单位来表示(如 512M或1G). 可用的单位是: k, kiB: kibibytes (2^10 bytes) M, MiB: mebibytes (2^20) G, GiB: gibibytes (2^30) kB: kilobytes (10^3) MB: megabytes (10^6) GB: gigabytes (10^9)
set_disk_free_limit {disk_limit}
- disk_limit
以整数或字符串单位的可用磁盘下限限制(查看vm_memory_high_watermark), 如 512M or 1G. 一旦可用磁盘空间达到这个限制,就会设置磁盘报警.
set_disk_free_limit mem_relative {fraction}
- fraction
相对于整个可用内存的限制,其值为非负浮点数. 当值小于1.0时是很危险的,应该谨慎使用.
posted @
2016-07-30 16:52 胡小军 阅读(12905) |
评论 (0) |
编辑 收藏介绍
像RabbitMQ这样的数据服务经常有许多的可调参数.某些配置对于开发环境来说是意义的,但却不适合产品环境. 单个配置不能满足每种使用情况. 因此,在进入产品环境时,评估配置是很重要的. 这就是本指南提供帮助的目的.
虚拟主机,用户,权限
Virtual Hosts
在单租户环境中,例如,当RabbitMQ在产品环境中只致力于为某单个系统服务时,使用默认虚拟主机 (/)是非常好的.
在多租户环境中,为每个租户/环境使用单独的虚拟主机,如:project1_development, project1_production, project2_development, project2_production, 等等.
用户
在产品环境中,删除默认用户(guest). 默认情况下,默认用户只能通过本地来连接, 因为它有众所周的凭证.为了不启用远程连接,可考虑使用带有administrative权限和生成密码的独立用户来代替
强烈建议在每个程序中使用单独的用户,例如,如果你有一个mobile app, 一个Web app, 和一个数据聚合系统, 你最好有3个独立的用户. 这会使许多事情变得更简单:
- 使 client 连接与程序相关联
- 使用细粒度的权限
- 凭据翻滚(如. 周期性地或遭到破坏的情况下)
如果有许多相同应用程序的实例,有一个更好安全性权衡(每一个实例的凭据)和方便的配置(共享一些或所有实例之间的一组凭据)。物联网的应用涉及很多客户执行相同或相似的功能,有固定的IP地址,它可以使用X509证书或源IP地址范围验证。
资源限制
内存
默认情况下, RabbitMQ会使用可用RAM的40%. 这专门针对于那些运行RabbitMQ的节点,通常情况下,提高此限制是合理的. 然而,应注意的是,操作系统和文件系统的缓存也需要内存来运行。如果不这样做,会由于操作系统交换导致严重的吞吐量下降,甚至导致操作系统会终止RabbitMQ过程的运行。
- 至少有128 MB
- 当RAM达到4GB时,可配置为75%的RAM限制
- 当RAM达到4GB-8GB时,可配置为80%的RAM限制
- 当RAM达到8GB-16GB时,可配置为85%的RAM限制
- 当RAM大于16GB时,可配置为90%的RAM限制
高于0.9的值是很危险的,不推荐配置
可用磁盘空间
必要的可用磁盘空间可防止disk space alarms.(磁盘空间报警) .默认情况下,RabbitMQ始终需要 50 MiB的可用磁盘空间.在大多数Linux发行者,根据开发者的经验,可将放置到小分区的/var 目录下. 然而,对于产品环境来说,这不是一个推荐值, 因为它们可能明显的更高的RAM 限制. 下面是一些基本的指导方针,如何确定有多少空闲磁盘空间是推荐的: - 至少有2 GB
- 当限制为1到8GB的RAM时,可配置为RAM限制的50%
- 当限制为8到32GB的RAM时,可配置为RAM限制的40%
- 当限制超过32GB的RAM时,可配置为RAM限制的30%
rabbit.disk_free_limit 配置可通过 {mem_relative, N}来完成,使其相对于RAM限制的百分比来计算. 例如, 使用{mem_relative, 0.5} 设为50%, {mem_relative, 0.25}设为25%等等.
打开文件句柄限制
操作系统限制了并发打开的文件句柄的最大数量,其中包括网络套接字。确保您的限制设置得足够高,以允许预期数量的并发连接和队列。
对于有效RabbitMQ用户,确保你的环境允许至少50K的打开文件描述符,包括开发环境。
作为经验法则,并发连接数的95%乘以2再加上队列的总数可以计算出打开文件句柄限制( multiple the 95th percentile number of concurrent connections by 2 and add total number of queues to calculate recommended open file handle limit). 值高于500K也是恰当地,它不会消耗太多的硬件资源,因此建议在生产环境中设置. 查看Networking guide 来了解更多信息. 安全注意事项
用户和权限
查看vhosts, users, 和 证书章节.
Erlang Cookie
在Linux 和BSD 系统中, 有必要限制只有运行RabbitMQ和rabbitmqctl工具的用户才能访问Erlang cookie. TLS
虽然RabbitMQ试图提供一个默认的安全TLS 配置 (如.SSLv3是禁用的), 我们推荐评估TLS 版本和密码套件. 请参考TLS guide 了解更多信息. 网络配置
自动连接恢复
某些client libraries, 例如 Java, .NET, 和 Ruby, 在网络失败后,支持自动连接恢复.如果client提供了这种功能,建议使用它来代替你自己的恢复机制. 集群化考虑
集群大小
当确定集群大小时,需要重点考虑下面的几个因素:
- 希望的吞吐量
- 希望的复制( mirrors的数目)
- 数据局部性
因为客户端可以连接到任何节点,RabbitMQ可能需要进行集群间消息路由和内部操作。尝试使消费者和生产者连接到同一个节点,如果可能的话:这将减少节点间的流量。 使消费者连接到持有队列的master上(可使用HTTP API进行推断),也是有帮助的.当考虑到数据局部性时,总的集群吞吐量可以达到不平凡的量。 对于大多数环境中,镜像超过一半的群集节点是足够的。建议使用一个奇数的节点(3,5,等等)的集群。
分区处理策略
posted @
2016-07-30 16:47 胡小军 阅读(1707) |
评论 (0) |
编辑 收藏
原文:
http://www.rabbitmq.com/memory.html
RabbitMQ服务器在启动时以及abbitmqctl set_vm_memory_high_watermark fraction 执行时,会检查计算机的RAM总大小. 默认情况下下, 当 RabbitMQ server 的使用量超过RAM的40% ,它就会发出内存警报,并阻塞所有连接. 一旦内存警报清除 (如,服务器将消息转存于磁盘,或者将消息投递给clients),服务又地恢复.
默认内存阀值设置为已安装RAM的40%. 注意这并不会阻止RabbitMQ server使用内存量超过40%, 它只是为了压制发布者. Erlang的垃圾回收器最坏情况下,可使用配置内存的2倍(默认情况下t, RAMr的80%). 因此强制建议开启OS swap或page files .
32位架构倾向于每一个进程有2GB的内存限制. 64位架构的一般实现(i.e. AMD64 和 Intel EM64T) 只允许每个进程为256TB. 64-位 Windows 限制为8TB. 但是,请注意,即使是64位操作系统下,一个32位的过程往往只有一个2GB的最大地址空间。
配置内存阀值
[{rabbit, [{vm_memory_high_watermark, 0.4}]}].
默认值0.4 代表的是已安装RAM的 40% , 有时候还更小.如:在 32位平台中,如果你安装有4GB RAM , 4GB 的40% 是 1.6GB, 但是 32-位 Windows 正常情况下限制进程为2GB,因此实际阀值是2GB的40% (即820MB).
另外, 内存阀值也可以设置为绝对值. 下面的例子将阀值设为了1073741824 字节 (1024 MB):
[{rabbit, [{vm_memory_high_watermark, {absolute, 1073741824}}]}].
同例, 也可使用内存单位:
[{rabbit, [{vm_memory_high_watermark, {absolute, "1024MiB"}}]}].
如果绝对上限大于了安装的RAM可用的虚拟地址空间, 阀值上限会略小.
当RabbitMQ服务器启动时,内存限制将追加到RABBITMQ_NODENAME.log 文件中:
=INFO REPORT==== 29-Oct-2009::15:43:27 === Memory limit set to 2048MB.
内存限制也可以使用rabbitmqctl status命令查询.
其阀值也可以在broker运行时,通过rabbitmqctl set_vm_memory_high_watermark fraction 命令或 rabbitmqctl set_vm_memory_high_watermark absolute memory_limit 命令修改. 内存单位也可以在命令中使用. 此命令会在broker重启后生效. 当执行此命令时,内存限制可能会改变热插拔RAM,而不会发生报警,这是因为需要全部数量的系统RAM.
禁止所有发布
其值为0时,会立即触发报警并禁用所有发布 (当需要禁用全局发布时,这可能是有用的); use rabbitmqctl set_vm_memory_high_watermark 0.
限制的地址空间
当在64位操作系统中运行32位 Erlang VM时,(or a 32 bit OS with PAE), 可用地址内存是受限制的. 服务器探测到后会记录像下边的日志消息:
=WARNING REPORT==== 19-Dec-2013::11:27:13 === Only 2048MB of 12037MB memory usable due to limited address space. Crashes due to memory exhaustion are possible - see http://www.rabbitmq.com/memory.html#address-space
内存报警系统是不完美的.虽然停止发布通常会防止任何进一步的内存使用,但可能有其他东西继续增加内存使用。通常情况下,当这种情况发生时,物理内存耗尽,操作系统将开始交换。但是当运行一个有限的地址空间,超过限制的运行会导致虚拟机崩溃。
因此强制建议在在64位操作系统上运行64位的Erlang VM.
配置分页阈值
在broker达到最高水位阻塞发布者之前,它会尝试将队列内容分页输出到磁盘上来释放内存. 持久化和瞬时消息都会分页输出 (已经在磁盘上的持久化消息会被赶出内存).
默认情况下,在达最高水位的50%时,就会发生这种情况. (即,默认最高水位为0.4, 这会在内存使用达到20%时就会发生). 要修改此值,可修改vm_memory_high_watermark_paging_ratio 配置的0.5默认值. 例如:
[{rabbit, [{vm_memory_high_watermark_paging_ratio, 0.75}, {vm_memory_high_watermark, 0.4}]}].
上面的配置表示在内存使用达到30%时,就会启动,40%的时候会阻塞发布者.
也可以将vm_memory_high_watermark_paging_ratio 值设为大于1.0的值.在这种情况下,队列不会把它的内容分页到磁盘上.如果这引起了内存报警关闭,那么生产者会如上面预期的一样被阻塞.
未确认的平台
如果RabbitMQ服务器不能识别你的系统,它将在RABBITMQ_NODENAME.log 文件中追加警告.
然后它会假设安装了超过了1GB的RAM:
=WARNING REPORT==== 29-Oct-2009::17:23:44 === Unknown total memory size for your OS {unix,magic_homebrew_os}. Assuming memory size is 1024MB.
在这种情况下,vm_memory_high_watermark 配置值假设为1GB RAM. 在 vm_memory_high_watermark 默认设为 0.4的情况下, RabbitMQ的内存阀值设为了410MB, 因此当RabbitMQ使用了多于410M内存时,它会阻塞生产者.因此当RabbitMQ不能识别你的平台时,如果你实际有8GB RAM,并且你想让RabbitMQ内存使用量超过3GB阻塞生产者,你可以设置vm_memory_high_watermark为3.
posted @
2016-07-30 15:05 胡小军 阅读(8020) |
评论 (0) |
编辑 收藏鸟欲高飞先振翅,人求上进先读书。本文是原书的第9章 线程的监控及其日常工作中如何分析里的9.3.3节常见的内存溢出的三种情况。
3. 常见的内存溢出的三种情况:
1)JVM Heap(堆)溢出:java.lang.OutOfMemoryError: Java heap space
JVM在启动的时候会自动设置JVM Heap的值, 可以利用JVM提供的-Xmn -Xms -Xmx等选项可进行设置。Heap的大小是Young Generation 和Tenured Generaion 之和。在JVM中如果98%的时间是用于GC,且可用的Heap size 不足2%的时候将抛出此异常信息。
解决方法:手动设置JVM Heap(堆)的大小。
2)PermGen space溢出: java.lang.OutOfMemoryError: PermGen space
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域。为什么会内存溢出,这是由于这块内存主要是被JVM存放Class和Meta信息的,Class在被Load的时候被放入PermGen space区域,它和存放Instance的Heap区域不同,sun的 GC不会在主程序运行期对PermGen space进行清理,所以如果你的APP会载入很多CLASS的话,就很可能出现PermGen space溢出。一般发生在程序的启动阶段。
解决方法: 通过-XX:PermSize和-XX:MaxPermSize设置永久代大小即可。
3)栈溢出: java.lang.StackOverflowError : Thread Stack space
栈溢出了,JVM依然是采用栈式的虚拟机,这个和C和Pascal都是一样的。函数的调用过程都体现在堆栈和退栈上了。调用构造函数的 “层”太多了,以致于把栈区溢出了。 通常来讲,一般栈区远远小于堆区的,因为函数调用过程往往不会多于上千层,而即便每个函数调用需要 1K的空间(这个大约相当于在一个C函数内声明了256个int类型的变量),那么栈区也不过是需要1MB的空间。通常栈的大小是1-2MB的。通俗一点讲就是单线程的程序需要的内存太大了。 通常递归也不要递归的层次过多,很容易溢出。
解决方法:1:修改程序。2:通过 -Xss: 来设置每个线程的Stack大小即可。
4. 所以Server容器启动的时候我们经常关心和设置JVM的几个参数如下(详细的JVM参数请参看附录三):
-Xms:java Heap初始大小, 默认是物理内存的1/64。
-Xmx:ava Heap最大值,不可超过物理内存。
-Xmn:young generation的heap大小,一般设置为Xmx的3、4分之一 。增大年轻代后,将会减小年老代大小,可以根据监控合理设置。
-Xss:每个线程的Stack大小,而最佳值应该是128K,默认值好像是512k。
-XX:PermSize:设定内存的永久保存区初始大小,缺省值为64M。
-XX:MaxPermSize:设定内存的永久保存区最大大小,缺省值为64M。
-XX:SurvivorRatio:Eden区与Survivor区的大小比值,设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10
-XX:+UseParallelGC:F年轻代使用并发收集,而年老代仍旧使用串行收集.
-XX:+UseParNewGC:设置年轻代为并行收集,JDK5.0以上,JVM会根据系统配置自行设置,所无需再设置此值。
-XX:ParallelGCThreads:并行收集器的线程数,值最好配置与处理器数目相等 同样适用于CMS。
-XX:+UseParallelOldGC:年老代垃圾收集方式为并行收集(Parallel Compacting)。
-XX:MaxGCPauseMillis:每次年轻代垃圾回收的最长时间(最大暂停时间),如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
-XX:+ScavengeBeforeFullGC:Full GC前调用YGC,默认是true。
实例如:JAVA_OPTS=”-Xms4g -Xmx4g -Xmn1024m -XX:PermSize=320M -XX:MaxPermSize=320m -XX:SurvivorRatio=6″
posted @
2016-07-26 23:05 胡小军 阅读(379) |
评论 (0) |
编辑 收藏学习如何在你的应用程序中集成WebSockets.
Published April 2013
对于许多基于客户端-服务器程序来说,老的HTTP 请求-响应模型已经有它的局限性. 信息必须通过多次请求才能将其从服务端传送到客户端.
过去许多的黑客使用某些技术来绕过这个问题,例如:长轮询(long polling)、基于 HTTP 长连接的服务器推技术(Comet).
然而,基于标准的、双向的、客户端和服务器之间全双工的信道需求再不断增加。
在2011年, IETF发布了标准WebSocket协议-RFC 6455. 从那时起,大多数Web浏览器都实现了支持WebSocket协议的客户端APIs.同时,许多Java 包也开始实现了WebSocket协议.
WebSocket协议利用HTTP升级技术来将HTTP连接升级到WebSocket. 一旦升级后,连接就有了在两个方向上相互独立(全双式)发送消息(数据桢)的能力.
不需要headers 或cookies,这大大降低了所需的带宽. 通常,WebSockets来周期性地发送小消息 (例如,几个字节).
额外的headers常常会使开销大于有效负载(payload)。
JSR 356
JSR 356, WebSocket的Java API, 明确规定了API,当Java开发者需要在应用程序中集成WebSocket时,就可以使用此API—服务端和客户端均可. 每个声明兼容JSR 356的WebSocket协议,都必须实现这个API.
因此,开发人员可以自己编写独立于底层WebSocket实现的WebSocket应用。这是一个巨大的好处,因为它可以防止供应商锁定,并允许更多的选择、自由的库、应用程序服务器。
JSR 356是即将到来的java EE 7标准的一部分,因此,所有与Java EE 7兼容的应用服务器都有JSR 365标准WebSocket的实现.一旦建立,WebSocket客户端和服务器节点已经是对称的了。客户端API与服务器端API的区别是很小的,JSR 356定义的Java client API只是Java EE7完整API的子集.
客户段-服务器端程序使用WebSockets,通常会包含一个服务器组件和多个客户端组件, 如图1所示:

图1
在这个例子中,server application 是通过Java编写的,WebSocket 协议细节是由包含在Java EE 7容器中JSR 356 实现来处理的.
JavaFX 客户端可依赖任何与JSR 356兼容的客户端实现来处理WebSocket协议问题.
其它客户端(如,iOS 客户端和HTML5客户端)可使用其它 (非Java)与RFC6455兼容的实现来与server application通信.
编程模型
JSR 356定义的专家小组,希望支持Java EE开发人员常用的模式和技术。因此,JSR 356使用了注释和注入。
一般来说,支持两种编程模型:
- 注解驱动(annotation-driven). 通过使用注解POJOs, 开发者可与WebSocket生命周期事件交互.
- 接口驱动(interface-driven). 开发者可实现
Endpoint接口和与生命周期交互的方法.
生命周期事件
典型的WebSocket 交互生命周期如下:
- 一端 (客户端) 通过发送HTTP握手请求来初始化连接.
- 其它端(服务端) 回复握手响应.
- 建立连接.从现在开始,连接是完全对称的.
- 两端都可发送和接收消息.
- 其中一端关闭连接.
大部分WebSocket生命周期事件都与Java方法对应,不管是 annotation-driven 还是interface-driven.
Annotation-Driven 方式
接受WebSocket请求的端点可以是以 @ServerEndpoint 注解的POJO.
此注解告知容器,此类应该被认为是WebSocket端点.
必须的value 元素指定了WebSocket端点的路径.
考虑下面的代码片断:
@ServerEndpoint("/hello") public class MyEndpoint { } 此代码将会以相对路径hello来发布一个端点.在后续方法调用中,此路径可携带路径参数,如: /hello/{userid}是一个有效路径,在这里{userid} 的值,可在生命周期方法使用@PathParam 注解获取.
在GlassFish中,如果你的应用程序是用上下文mycontextroot 部署的,且在localhost的8080端口上监听, WebSocket可通过使用ws://localhost:8080/mycontextroot/hello来访问.
初始化WebSocket连接的端点可以是以 @ClientEndpoint 注解的POJO.@ClientEndpoint 和 @ServerEndpoint的主要区别是ClientEndpoint 不接受路径路值元素,因为它监听进来的请求。
@ClientEndpoint public class MyClientEndpoint {} Java中使用注解驱动POJO方式来初始化WebSocket连接,可通过如下代码来完成:
javax.websocket.WebSocketContainer container = javax.websocket.ContainerProvider.getWebSocketContainer(); container.conntectToServer(MyClientEndpoint.class, new URI("ws://localhost:8080/tictactoeserver/endpoint")); 此后,以 @ServerEndpoint 或@ClientEndpoint 注解的类都称为注解端点.
一旦建立了WebSocket连接 ,就会创建 Session,并且会调用注解端点中以@OnOpen注解的方法.
此方法包含了几个参数:
javax.websocket.Session 参数, 代表创建的SessionEndpointConfig 实例包含了关于端点配置的信息- 0个或多个以
@PathParam注解的字符串参数,指的是端点路径的path参数
下面的方法实现了当打开WebSocket时,将会打印session的标识符:
@OnOpen public void myOnOpen (Session session) { System.out.println ("WebSocket opened: "+session.getId()); } Session实例只要WebSocket未关闭就会一直有效. Session类中包含了许多有意思的方法,以允许开发者获取更多关于的信息。
同时,Session 也包含了应用程序特有的数据钩子,即通过getUserProperties() 方法来返回 Map<String, Object>.
这允许开发者可以使用session-和需要在多个方法调用间共享的应用程序特定信息来填充Session实例.
i当WebSocket端收到消息时,将会调用以@OnMessage注解的方法.以@OnMessage 注解的方法可包含下面的参数:
javax.websocket.Session 参数.- 0个或多个以
@PathParam注解的字符串参数,指的是端点路径的path参数 - 消息本身. 下面有可能消息类型描述.
当其它端发送了文本消息时,下面的代码片断会打印消息内容:
@OnMessage public void myOnMessage (String txt) { System.out.println ("WebSocket received message: "+txt); } 如果以@OnMessage i注解的方法返回值不是void, WebSocket实现会将返回值发送给其它端点.下面的代码片断会将收到的文本消息以首字母大写的形式发回给发送者:
@OnMessage public String myOnMessage (String txt) { return txt.toUpperCase(); } 另一种通过WebSocket连接来发送消息的代码如下:
RemoteEndpoint.Basic other = session.getBasicRemote(); other.sendText ("Hello, world"); 在这种方式中,我们从Session 对象开始,它可以从生命周期回调方法中获取(例如,以 @OnOpen注解的方法).session实例上getBasicRemote() 方法返回的是WebSocket其它部分的代表RemoteEndpoint. RemoteEndpoint 实例可用于发送文本或其它类型的消息,后面有描述.
当关闭WebSocket连接时,将会调用@OnClose 注解的方法。此方法接受下面的参数:
javax.websocket.Session 参数. 注意,一旦WebSocket真正关闭了,此参数就不能被使用了,这通常发生在@OnClose 注解方法返回之后.- A
javax.websocket.CloseReason 参数,用于描述关闭WebSocket的原因,如:正常关闭,协议错误,服务过载等等. - 0个或多个以
@PathParam注解的字符串参数,指的是端点路径的path参数
下面的代码片段打印了WebSocket关闭的原因:
@OnClose public void myOnClose (CloseReason reason) { System.out.prinlnt ("Closing a WebSocket due to "+reason.getReasonPhrase()); } 完整情况下,这里还有一个生命周期注解:如果收到了错误,将会调用 @OnError 注解的方法。
Interface-Driven 方式
annotation-driven 方式允许我们注解一个Java类,以及使用生命周期注解来注解方法.
使用interface-driven方式,开发者可继承javax.websocket.Endpoint 并覆盖其中的onOpen, onClose, 以及onError 方法:
public class myOwnEndpoint extends javax.websocket.Endpoint { public void onOpen(Session session, EndpointConfig config) {...} public void onClose(Session session, CloseReason closeReason) {...} public void onError (Session session, Throwable throwable) {...} } 为了拦截消息,需要在onOpen实现中注册一个javax.websocket.MessageHandler:
public void onOpen (Session session, EndpointConfig config) { session.addMessageHandler (new MessageHandler() {...}); } MessageHandler 接口有两个子接口: MessageHandler.Partial和 MessageHandler.Whole.
MessageHandler.Partial 接口应该用于当开发者想要收到部分消息通知的时候,MessageHandler.Whole的实现应该用于整个消息到达通知。
下面的代码片断会监听进来的文件消息,并将文本信息转换为大小版本后发回给其它端点:
public void onOpen (Session session, EndpointConfig config) { final RemoteEndpoint.Basic remote = session.getBasicRemote(); session.addMessageHandler (new MessageHandler.Whole<String>() { public void onMessage(String text) { try { remote.sendString(text.toUpperCase()); } catch (IOException ioe) { // handle send failure here } } }); } 消息类型,编码器,解码器
WebSocket的JavaAPI非常强大,因为它允许发送任或接收任何对象作为WebSocket消息.
基本上,有三种不同类型的消息:
- 基于文本的消息
- 二进制消息
- Pong 消息,它是WebSocket连接自身
当使用interface-driven模式,每个session最多只能为这三个不同类型的消息注册一个MessageHandler.
当使用annotation-driven模式,针对不同类型的消息,只允许出现一个@onMessage 注解方法. 在注解方法中,消息内容中允许的参数依赖于消息类型。
Javadoc for the @OnMessage annotation 明确指定了消息类型上允许出现的消息参数:
- "如果方法用于处理文本消息:
- 如果方法用于处理二进制消息:
- 如果方法是用于处理pong消息:
任何Java对象使用编码器都可以编码为基于文本或二进制的消息.这种基于文本或二进制的消息将转输到其它端点,在其它端点,它可以解码成Java对象-或者被另外的WebSocket 包解释.
通常情况下,XML或JSON用于来传送WebSocket消息, 编码/解码然后会将Java对象编组成XML或JSON并在另一端解码为Java对象.
encoder是以javax.websocket.Encoder 接口的实现来定义,decoder是以javax.websocket.Decoder 接口的实现来定义的.
有时,端点实例必须知道encoders和decoders是什么.使用annotation-driven方式, 可向@ClientEndpoint 和 @ServerEndpoint l注解中的encode和decoder元素传递 encoders和decoders的列表。
Listing 1 中的代码展示了如何注册一个 MessageEncoder 类(它定义了MyJavaObject实例到文本消息的转换). MessageDecoder 是以相反的转换来注册的.
@ServerEndpoint(value="/endpoint", encoders = MessageEncoder.class, decoders= MessageDecoder.class) public class MyEndpoint { ... } class MessageEncoder implements Encoder.Text<MyJavaObject> { @override public String encode(MyJavaObject obj) throws EncodingException { ... } } class MessageDecoder implements Decoder.Text<MyJavaObject> { @override public MyJavaObject decode (String src) throws DecodeException { ... } @override public boolean willDecode (String src) { // return true if we want to decode this String into a MyJavaObject instance } } Listing 1
Encoder 接口有多个子接口:
Encoder.Text 用于将Java对象转成文本消息Encoder.TextStream 用于将Java对象添加到字符流中Encoder.Binary 用于将Java对象转换成二进制消息Encoder.BinaryStream 用于将Java对象添加到二进制流中
类似地,Decoder 接口有四个子接口:
Decoder.Text 用于将文本消息转换成Java对象Decoder.TextStream 用于从字符流中读取Java对象Decoder.Binary 用于将二进制消息转换成Java对象Decoder.BinaryStream 用于从二进制流中读取Java对象
结论
WebSocket Java API为Java开发者提供了标准API来集成IETF WebSocket标准.通过这样做,Web 客户端或本地客户端可使用任何WebSocket实现来轻易地与Java后端通信。
Java Api是高度可配置的,灵活的,它允许java开发者使用他们喜欢的模式。
也可参考
posted @
2016-07-24 01:35 胡小军 阅读(2842) |
评论 (0) |
编辑 收藏
摘要: Servlets定义为JSR 340,可以下载完整规范.servlet是托管于servlet容器中的web组件,并可生成动态内容.web clients可使用请求/响应模式同servlet交互. servlet容器负责处理servlet的生命周期事件,接收请求和发送响应,以及执行其它必要的编码/解码部分.WebServlet它是在POJO上使用@WebServlet注...
阅读全文
posted @
2016-07-24 01:32 胡小军 阅读(901) |
评论 (0) |
编辑 收藏