摘要:XML作为过去十年中出现的最流行的技术之一,得到了广泛的应用,而其中XML解析技术是XML应用的关键。本文介绍了XML解析技术的研究动向,分析和比较了4种XML解析技术的优劣,并归纳总结了应用系统设计中选取合适的XML解析技术的原则。
1 引言
XML(eXtensible Markup Language,可扩展标记语言)是由World Wide Web联盟(W3C)定义的元语言,即一种关于语言的语言。XML的设计源于SGML (Standard Generalized Markup Language,标淮通用标记语言) ,是SGML的子集,其目的是为了促进Internet上结构化文档的交换。简单的说,XML是一组规则和准则的集合,用于以无格式文本来描述结构化数据[1]。1996年W3C联盟就开始从事XML的标准化工作,并于1998年2月10日发布了XML1.0。
XML的出现给分布式计算领域带来了重大影响,其力量源于它的数据独立性[1]。XML是纯数据描述,与编程语言、操作系统或传输协议无关,从而将数据从以代码为中心的基础结构所产生的约束中解放出来,让数据能够在Web上更自由的流通。
然而XML本身只是以纯文本对数据进行编码的一种格式,要想利用XML,或者说利用XML文件中所编码的数据,必须先将数据从纯文本中解析出来,因此,必须有一个能够识别XML文档中信息的解析器,用来解释XML文档并提取其中的数据。然而,根据数据提取的不同需求,又存在着多种解析方式,不同的解析方式有着各自的优缺点和适用环境。选择合适的XML解析技术能够有效提升应用系统的整体性能,因此,了解和区分各种不同的XML解析技术就显得尤为重要。
2 XML解析技术分析
所有的XML处理都从解析开始,无论是使用XSLT或Java语言,第一步都是要读入XML文件,解码结构和检索信息等等,这就是解析,即把代表XML文档的一个无结构的字符序列转换为满足XML语法的结构化组件的过程。
2.1 XML解析技术的分类
根据从XML中获取数据的简易性,性能和最终所得到的数据模型的不同,XML解析技术大致可分为以下四类:
1) 面向文档的流式解析;
2) 面向文档的对象式解析;
3) 面向文档的指针式解析;
4) 面向应用的对象式解析;
这四类解析技术分别处于不同的抽象层次,适用于不同的应用场景,有着各自的优缺点。针对具体的应用需求,选择合适的解析技术,往往能够减少内存消耗,缩短处理时间,更方便地获取数据,提高应用系统的整体性能。
2.2 面向文档的流式解析技术
流式解析是一种基于事件的解析过程,解析器顺序读取XML文档,产生一个对应的事件流,并向事件处理程序发送所捕获的各种事件,如元素开始和元素结束等,而事件处理程序则通过不同的方法处理这些事件。
流式解析是将XML文档作为一个数据流来处理,因此,它具有类似于流媒体的优点,能够立即开始读取数据,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,不需要将整个文档一次加载到内存中,使得在处理大型文档时具有较好的时间和空间上的效率。然而效率的代价是易用性的降低,流式解析编程较为复杂,程序员需要负责更多的操作。并且由于应用程序没有以任何方式存储数据,所以使得更改数据或在数据流中往后移是不可能的。再加上它的单遍解析特性,意味着它也不支持随机访问。
流式解析又分为两种解析方式:推式解析(SAX)和拉式解析(StAX)。这两种方式的主要区别在于是由解析器还是应用程序控制读循环(读入文件的循环)。
2.2.1 推式解析(SAX解析技术)
SAX(Simple API for XML)解析技术就是一种推式解析,在这种解析方式中,解析器控制着读循环,在文档结束之前控制权不会返回给应用程序[3]。解析器通过回调的方式进行数据处理。
SAX提供了一个用于处理XML的,基于事件驱动的简单API。它的设计开始于XML-DEV邮件列表成员间的讨论,他们开发出的第一个接口草案SAX1.0于1998年1月发布,其后在2000年5月发布了SAX2.0,目前最新版本是2004年4月发布的SAX2.0.2。SAX没有经过官方的标准机构认可,它不由W3C联盟或其它任何官方机构维护(现在,SAX由David Megginson维护) [4],但它被广泛使用并视为XML社区事实上的标准。SAX最初是为Java而定义的,但也可以用于Python、Perl、C++等其它语言。
SAX是基于事件驱动的,即SAX解析器在读取XML文档的过程中生成一个事件流,并且对于每个事件通过回调事件处理程序中相应的方法来进行处理。比如元素开始和结束标记,元素内容,实体,语法分析错误等事件。针对下面的简单XML文档,所产生的事件如图1所示,注意针对元素内的空格或回车也会生成一个文本事件。

图1 SAX解析器生成的事件
SAX中的核心事件处理程序是一个实现了ContentHandler接口的类。此接口中定义了处理与XML文档本身关联的事件的方法,如 startDocument、endDocument、startElement、endElement、Characters等
SAX解析技术具有所有流式解析技术的优点和缺点,但是由于在整个解析过程中,解析器掌握着控制权直到文档结束,应用程序很难在获得所需的部分数据后停止解析过程(可以通过抛出异常的方式终止解析过程,但较为复杂,而且终止后也无法继续解析过程),因此产生了由应用程序掌握控制权的拉式解析方式。
2.2.2 拉式解析(StAX解析技术)
StAX(Streaming API for XML)解析技术是一种拉式解析,在这种解析方式中,应用程序控制着读循环。循环中,应用程序负责反复调用解析器获得下一个事件,直到文档结束。通过保留解析过程的控制权,可以简化调用代码来准确地处理它预期的内容,并且可随时停止解析。此外,由于该方式没有基于处理程序回调,应用程序也不需要像SAX中那样模拟解析器的状态。
StAX针对同样的XML文档所获得事件类型和SAX基本相同,但是StAX包含了两套处理XML的API:基于指针的API和基于迭代器的API,分别提供了不同程度的抽象[5]。
基于指针的API简单的返回事件,此时事件用数值形式来表示。这是一种低层API,没有提供底层XML结构的抽象,所有的状态信息直接从流读取器获得,不需要创建额外的对象。从而节约内存,拥有较高的效率。
而较为高级的基于迭代器的API则以对象方式返回事件,每个事件对象都封装了它所表示的特定XML结构固有的信息,因此可直接利用其方法获得属于该结构的信息,但也需要额外的对象创建开销。相对于基于指针的API,基于迭代器的API具有更多的面向对象特征,因此更便于应用于模块化的体系结构。
StAX也是用Java定义的,其StAX1.0于2004年3月发布,并且成为了JSR-173 规范,最新版本为2006年6月发布的StAX1.2。StAX作为用Java语言处理XML的最新标准,比早期出现的XPP (Xml Pull Parser)拉式解析器功能更为强大,也得到了更为广泛的应用。
2.3 面向文档的对象式解析技术
由于流式解析方式固有的无法更改数据和不支持随机访问特性,尤其是没有对XML文档的结构建模,使得应用程序很难对XML文档进行搜索、修改、添加和删除等操作。为了解决这些问题,产生了面向文档的对象式解析技术--DOM。
DOM(Document Object Model)是用与平台和语言无关的方式对XML文档进行建模的官方W3C标准[6],其目标是提供一个可以通用于各种程序语言、操作系统和应用程序的接口。DOM最初被当作Web浏览器识别和处理页面元素的方式,即在W3C介入之前的功能,称为“DOM Level 0”。W3C于1998年10月提出了“DOM Level 1”建议,支持XML1.0和HTML处理。随后于2000年11月提出了“DOM Level 2”建议,对Level 1进行了扩展,支持XML1.0、命名空间和CSS,也支持用户接口和树形操作事件,并且添加了DOM树形操作功能。最新的“DOM Level 3”建议于2003年6月提出,在level 2的基础上添加了对DTD、XML模式和XPath的支持[1]。
DOM作为一种对象式解析技术,定义了层次化对象模型来表示XML文档。即为XML语法中的每个概念(如元素,属性,实体,文档等)定义对应的类,而解析器在读入XML文档的时候,会建立XML语法和类之间的一一映射。实际上,DOM的层次化对象模型是一个树形结构,它将一个XML文档看作一棵节点树,每个节点代表一个XML文档中的元素。DOM的基本节点对象有5个[1]:(1)Document对象:是树的最高节点,也是对整个文档操作的入口;(2)Element和Attr对象:对文档中元素和元素属性的映射;(3)Text对象:作为Element和Attr对象的子节点,代表了元素或属性的文本内容;(4)NodeList对象:对节点按指定的方式进行遍历。
例如对于2.2.1中的XML文档,其对应的DOM节点树如下图所示(注意元素内的空格或回车也会被当作文本对象):

图2 DOM节点树 (矩形框表示元素节点,椭圆表示文本节点)
利用DOM在内存中建立的完整的XML文档的树形结构,开发人员就可以方便的对XML文档进行一系列操作,如遍历、增加、删除、修改文档内容等,且具有良好的导航能力。同时DOM所具有的对象特性也非常便于面向对象编程。然而,由于DOM在使用数据前需要完整的遍历XML文档,在内存中构建树形结构表示,因此需要消耗大量的内存,尤其是对于大型文档,性能下降的很快。而且必须一次解析整个XML文档,不可能只做部分解析,当只关注XML文档的小部分数据时,效率很低。(Axis2项目中的Axiom对象模型实现了对XML文档的部分解析,可构建不完整的节点树,但实现较为复杂)
由于DOM是与语言无关的,当DOM接口进入指定语言的数据结构时,会产生不必要的复杂性,无法利用语言本身的优势。因此出现了许多与DOM类似的针对特定语言的对象模型。如JDOM就是针对Java的特定文档对象模型,JDOM使用具体类而不使用接口,简化了API,并在API中大量使用了Java集合类。DOM4J则是JDOM的一种智能分支,它提供了对XPath和XML Schema的支持,并且通过DOM4J API和标准DOM接口使其具有并行访问功能[5]。它们都属于面向文档的对象式解析技术。
2.4 面向文档的指针式解析技术
前面提到的面向文档的流式解析效率较高,但易用性差,而对象式解析易用性强,却效率较低,这两种方式似乎处于两个极端。其效率问题主要在于两种方式都是提取解析模式,即解析时,提取一部分源文件,一般来说是一个字符串,然后在内存中进行解析构建。这种解析模式注定了需要大量的创建和销毁对象,而且还存在更新效率问题,在DOM中(SAX并不支持更新),每一次改动都需要将DOM模型重新完整的解析成XML字符串,原文件并没有被利用,即DOM并不支持增量更新。为了解决这些问题,提出了一种较新颖的指针式解析技术,即VTD-XML。
VTD-XML是一种无提取的XML解析方法,它较好的解决了DOM占用内存过大的缺点,并且还提供了快速的解析与遍历、对XPath的支持和增量更新等特性。VTD-XML是一个开源项目,目前有Java、C两种平台支持,第一个版本是2004年6月发布的VTD-XML0.5,其VTD- XML1.0版本于2005年10月发布,最新的版本为2007年10月发布的VTD-XML2.2。
VTD(Virtual Token Descriptor,虚拟令牌描述符)是一个64bits长度的数值类型,记录了每个元素的起始位置,长度,深度以及令牌的类型等信息,如图3所示。64bits固定长度使得可以用数组这种高效的结构来组织VTD,大幅提高性能。VTD是实现无提取解析的关键,它类似于XML文档中元素的指针,通过它可以快速定位到某个元素。
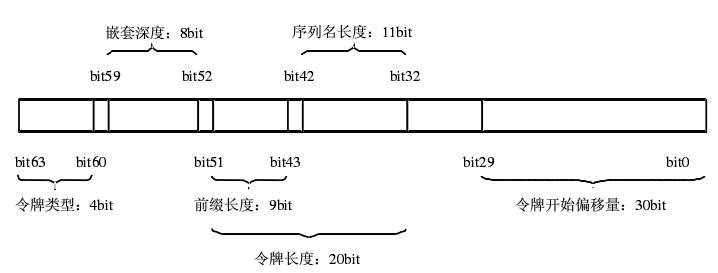
图3 VTD记录的比特层格式
令牌开始偏移量(即相对于XML文档头部的距离)是30 bits,也就是说它能解析的最大文件是1G。令牌长度为20 bits,即一个令牌的最大长度是1M。令牌类型4bits,说明支持16种词汇类型。
为了实现无提取这个目的,VTD-XML将原XML文件原封不动的以二进制的方式读进内存,不做解码,然后在这个比特数组上解析每个元素的位置并把一些信息,如XML令牌的开始偏移量、长度、深度和令牌类型,记录下来,保存为VTD数组,之后的遍历操作便可在VTD数组上进行。如果需要提取XML内容,就查找VTD数组,利用VTD记录中的位置等信息在原始比特数组上进行解码并返回字符串。
而且VTD-XML还可以高效的实现增量更新,例如,如果想在一个大型XML文档中找出一个节点元素并删除它,那么只需要找到这个元素的VTD,将这个VTD从VTD数组中删除,然后再利用所有的VTD写出到另一个二进制数组中就可以了,因为删除的VTD标明了要删除的元素的位置,所以在新写入的二进制数组中就不会出现这段元素了。用VTD写入新的二进制数组的过程实际上就是一个二进制数组的拷贝过程,其效率是非常高的[2]。
由此可见,VTD很好的解决了前两种解析方式的缺点,通过其巧妙的设计使得在解析XML文档时内存占用少,效率高,并且还能够实现XML文档的快速解析与遍历、提供对XPath的支持。VTD的出现是XML解析技术的一大进步,会对XML解析技术的发展产生巨大影响。
2.5 面向应用的对象式解析技术
前面所谈到的三种解析技术都是从XML的角度来处理文档和建立模型,这对于主要关心文档的XML结构的应用程序来说是适用的,但是有很多应用程序仅仅将XML作为数据交换的媒介,它们更关心的是文档数据本身。此时,面向应用的对象式解析(或称为XML数据绑定)可以使应用程序在很大程度上忽略XML文档的实际结构,而直接使用文档的数据内容。
数据绑定是指将数据从一些存储媒介(如XML文档、文本文件和数据库)中取出,并通过应用程序表示这些数据的过程,即把数据绑定到虚拟机能够理解并且可以操作的某种内存中的结构[9]。数据绑定并不是一个新鲜的概念,其在关系数据库上早已得到了广泛的应用,如Hibernate就是针对数据库的轻量级数据绑定框架。而针对XML数据绑定的Castor框架在2000年就已经出现,目前已经涌现出了许多类似的框架,如JBind、JAXB、JiBX、Quick和Zeus等。
其中JAXB(Java Architecture for XML Binding)是一个处于不断发展中的应用于Java平台的数据绑定框架,提供了一套在XML文档和Java对象之间自动映射的API,符合JSR31--XML数据绑定规范(XML Data Binding Specification)。该项目始于1999年8月,由Java Community Process开发,其1.0版本于2002年10月发布,目前最新版本为2007年9月17日发布的JAXB2.1.5。
如图4,显示了数据绑定在数据库和XML文档中的应用。
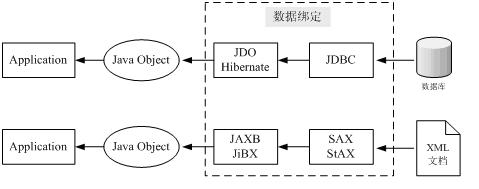
图4 数据绑定
在数据绑定中有三个重要概念[9]:
l 编组(Marshalling):把内存中的数据转换到存储介质中的过程。在Java和XML环境中,编组就是把一些Java对象转化为一个(或多个)XML文档。其核心就在于把Java中的面向对象结构转化成适用于XML的扁平结构。
l 解组(Unmarshalling):把数据从存储媒介转换到内存中的过程。在Java和XML环境中,即将XML文档解组到Java虚拟机中,其复杂性在于从数据到Java代码变量的映射。
l 映射(Mapping):用于编组和解组的一套规则。
初看起来XML数据绑定和面向文档的对象式解析较为相似,都在内存中构建文档表示,同时内部表示和标准的XML文档之间可以互相转换。但两者之间的不同在于文档模型尽可能接近的保存XML的文档结构,而数据绑定只关心应用程序使用的文档数据[7]。如图5所示,同一个XML文档的文档模型和数据绑定模型是完全不同的。

图5 文档模型和数据绑定模型比较
如果应用程序使用文档模型方法,那么获得所需要的数据就必须在节点树中根据父子节点关系进行遍历。而使用数据绑定方法,只需进行正常的Java编程,访问数据更加容易,速度也比文档模型快得多。而且,XML数据绑定并不只是简化编程,由于它把许多文档细节抽象出来,所以数据绑定所需的内存通常少于文档模型所需的内存,如上图中,文档模型方法使用了10个单独的对象,而数据绑定才使用2个。此外,由于要构建的对象少得多,所以为XML文档构建数据绑定表示还可能更快[7]。
在XML数据绑定中最为核心的是怎样由XML文档生成Java对象。目前有两种方式:映射绑定方式和代码生成方式[8]。在映射绑定方式中,构建自己的Java类,并向绑定框架指定这些类如何与XML文档相关联。如框架Castor和Quick就支持这种方式。而代码生成方式则根据XML文档结构(即DTD或Schema形式的文法)自动构建相应的Java类,如JAXB、Castor和JBind提供了根据XML文档的Schema描述生成Java代码,Quick和Zeus可根据DTD描述生成Java代码。
代码生成方式所构造的类可以包括完整的数据类型信息,还能够对所构造的类进行验证。但该方式使得程序代码和文档结构之间紧密耦合,如果文档结构发生变化,就需要重新生成代码。而映射绑定方式则具有更大的灵活性,其使用自己构建的对象类将数据和行为组合在一起,通过修改映射定义(而不是改变应用程序代码)来处理XML文档结构中的微小变化,可以在一定程度上解除对象类与实际XML文档之间的耦合[8]。其缺点在于需要编写较为复杂的映射文件。
Author: orangelizq
email: orangelizq@163.com
posted on 2009-07-19 15:25
桔子汁 阅读(17183)
评论(9) 编辑 收藏 所属分类:
Web Service