2012年2月29日
版权信息: 可以任意转载, 转载时请务必以超链接形式标明文章原文出处, 即下面的声明.
原文出处:http://blog.chenlb.com/2009/06/java-classloader-architecture.html
jvm classLoader architecture:
- Bootstrap ClassLoader/启动类加载器
主要负责jdk_home/lib目录下的核心 api 或 -Xbootclasspath 选项指定的jar包装入工作。 - Extension ClassLoader/扩展类加载器
主要负责jdk_home/lib/ext目录下的jar包或 -Djava.ext.dirs 指定目录下的jar包装入工作。 - System ClassLoader/系统类加载器
主要负责java -classpath/-Djava.class.path所指的目录下的类与jar包装入工作。 - User Custom ClassLoader/用户自定义类加载器(java.lang.ClassLoader的子类)
在程序运行期间, 通过java.lang.ClassLoader的子类动态加载class文件, 体现java动态实时类装入特性。
类加载器的特性:
- 每个ClassLoader都维护了一份自己的名称空间, 同一个名称空间里不能出现两个同名的类。
- 为了实现java安全沙箱模型顶层的类加载器安全机制, java默认采用了 " 双亲委派的加载链 " 结构。

classloader-architecture

classloader-class-diagram
类图中, BootstrapClassLoader是一个单独的java类, 其实在这里, 不应该叫他是一个java类。因为,它已经完全不用java实现了。它是在jvm启动时, 就被构造起来的, 负责java平台核心库。
自定义类加载器加载一个类的步骤

classloader-load-class
ClassLoader 类加载逻辑分析, 以下逻辑是除 BootstrapClassLoader 外的类加载器加载流程:
- // 检查类是否已被装载过
- Class c = findLoadedClass(name);
- if (c == null ) {
- // 指定类未被装载过
- try {
- if (parent != null ) {
- // 如果父类加载器不为空, 则委派给父类加载
- c = parent.loadClass(name, false );
- } else {
- // 如果父类加载器为空, 则委派给启动类加载加载
- c = findBootstrapClass0(name);
- }
- } catch (ClassNotFoundException e) {
- // 启动类加载器或父类加载器抛出异常后, 当前类加载器将其
- // 捕获, 并通过findClass方法, 由自身加载
- c = findClass(name);
- }
- }
线程上下文类加载器
java默认的线程上下文类加载器是 系统类加载器(AppClassLoader)。
- // Now create the class loader to use to launch the application
- try {
- loader = AppClassLoader.getAppClassLoader(extcl);
- } catch (IOException e) {
- throw new InternalError(
- "Could not create application class loader" );
- }
-
- // Also set the context class loader for the primordial thread.
- Thread.currentThread().setContextClassLoader(loader);
以上代码摘自sun.misc.Launch的无参构造函数Launch()。
使用线程上下文类加载器, 可以在执行线程中, 抛弃双亲委派加载链模式, 使用线程上下文里的类加载器加载类.
典型的例子有, 通过线程上下文来加载第三方库jndi实现, 而不依赖于双亲委派.
大部分java app服务器(jboss, tomcat..)也是采用contextClassLoader来处理web服务。
还有一些采用 hotswap 特性的框架, 也使用了线程上下文类加载器, 比如 seasar (full stack framework in japenese).
线程上下文从根本解决了一般应用不能违背双亲委派模式的问题.
使java类加载体系显得更灵活.
随着多核时代的来临, 相信多线程开发将会越来越多地进入程序员的实际编码过程中. 因此,
在编写基础设施时, 通过使用线程上下文来加载类, 应该是一个很好的选择。
当然, 好东西都有利弊. 使用线程上下文加载类, 也要注意, 保证多根需要通信的线程间的类加载器应该是同一个,
防止因为不同的类加载器, 导致类型转换异常(ClassCastException)。
为什么要使用这种双亲委托模式呢?
- 因为这样可以避免重复加载,当父亲已经加载了该类的时候,就没有必要子ClassLoader再加载一次。
- 考虑到安全因素,我们试想一下,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义类型,这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况,因为String已经在启动时被加载,所以用户自定义类是无法加载一个自定义的ClassLoader。
java动态载入class的两种方式:
- implicit隐式,即利用实例化才载入的特性来动态载入class
- explicit显式方式,又分两种方式:
- java.lang.Class的forName()方法
- java.lang.ClassLoader的loadClass()方法
用Class.forName加载类
Class.forName使用的是被调用者的类加载器来加载类的。
这种特性, 证明了java类加载器中的名称空间是唯一的, 不会相互干扰。
即在一般情况下, 保证同一个类中所关联的其他类都是由当前类的类加载器所加载的。
- public static Class forName(String className)
- throws ClassNotFoundException {
- return forName0(className, true , ClassLoader.getCallerClassLoader());
- }
-
- /** Called after security checks have been made. */
- private static native Class forName0(String name, boolean initialize,
- ClassLoader loader)
- throws ClassNotFoundException;
上面中 ClassLoader.getCallerClassLoader 就是得到调用当前forName方法的类的类加载器
static块在什么时候执行?
- 当调用forName(String)载入class时执行,如果调用ClassLoader.loadClass并不会执行.forName(String,false,ClassLoader)时也不会执行.
- 如果载入Class时没有执行static块则在第一次实例化时执行.比如new ,Class.newInstance()操作
- static块仅执行一次
各个java类由哪些classLoader加载?
- java类可以通过实例.getClass.getClassLoader()得知
- 接口由AppClassLoader(System ClassLoader,可以由ClassLoader.getSystemClassLoader()获得实例)载入
- ClassLoader类由bootstrap loader载入
NoClassDefFoundError和ClassNotFoundException
- NoClassDefFoundError:当java源文件已编译成.class文件,但是ClassLoader在运行期间在其搜寻路径load某个类时,没有找到.class文件则报这个错
- ClassNotFoundException:试图通过一个String变量来创建一个Class类时不成功则抛出这个异常
一:使用场景
1)使用的地方:树形结构,分支结构等
2)使用的好处:降低客户端的使用,为了达到元件与组合件使用的一致性,增加了元件的编码
3)使用后的坏处:代码不容易理解,需要你认真去研究,发现元件与组合件是怎么组合的
二:一个实际的例子
画图形,这个模式,稍微要难理解一点,有了例子就说明了一切,我画的图是用接口做的,代码实现是抽象类为基类,你自己选择了,接口也可以。

1)先建立图形元件
package com.mike.pattern.structure.composite;
/**
* 图形元件
*
* @author taoyu
*
* @since 2010-6-23
*/
public abstract class Graph {
/**图形名称*/
protected String name;
public Graph(String name){
this.name=name;
}
/**画图*/
public abstract void draw()throws GraphException;
/**添加图形*/
public abstract void add(Graph graph)throws GraphException;
/**移掉图形*/
public abstract void remove(Graph graph)throws GraphException;
}
2)建立基础图形圆
package com.mike.pattern.structure.composite;
import static com.mike.util.Print.print;
/**
* 圆图形
*
* @author taoyu
*
* @since 2010-6-23
*/
public class Circle extends Graph {
public Circle(String name){
super(name);
}
/**
* 圆添加图形
* @throws GraphException
*/
@Override
public void add(Graph graph) throws GraphException {
throw new GraphException("圆是基础图形,不能添加");
}
/**
* 圆画图
*/
@Override
public void draw()throws GraphException {
print(name+"画好了");
}
/**
* 圆移掉图形
*/
@Override
public void remove(Graph graph)throws GraphException {
throw new GraphException("圆是基础图形,不能移掉");
}
}
3)建立基础图形长方形
package com.mike.pattern.structure.composite;
import static com.mike.util.Print.print;
/**
* 长方形
*
* @author taoyu
*
* @since 2010-6-23
*/
public class Rectangle extends Graph {
public Rectangle(String name){
super(name);
}
/**
* 长方形添加
*/
@Override
public void add(Graph graph) throws GraphException {
throw new GraphException("长方形是基础图形,不能添加");
}
/**
* 画长方形
*/
@Override
public void draw() throws GraphException {
print(name+"画好了");
}
@Override
public void remove(Graph graph) throws GraphException {
throw new GraphException("长方形是基础图形,不能移掉");
}
}
4)最后简历组合图形
package com.mike.pattern.structure.composite;
import java.util.ArrayList;
import java.util.List;
import static com.mike.util.Print.print;
/**
* 图形组合体
*
* @author taoyu
*
* @since 2010-6-23
*/
public class Picture extends Graph {
private List<Graph> graphs;
public Picture(String name){
super(name);
/**默认是10个长度*/
graphs=new ArrayList<Graph>();
}
/**
* 添加图形元件
*/
@Override
public void add(Graph graph) throws GraphException {
graphs.add(graph);
}
/**
* 图形元件画图
*/
@Override
public void draw() throws GraphException {
print("图形容器:"+name+" 开始创建");
for(Graph g : graphs){
g.draw();
}
}
/**
* 图形元件移掉图形元件
*/
@Override
public void remove(Graph graph) throws GraphException {
graphs.remove(graph);
}
}
5)最后测试
public static void main(String[] args)throws GraphException {
/**画一个圆,圆里包含一个圆和长方形*/
Picture picture=new Picture("立方体圆");
picture.add(new Circle("圆"));
picture.add(new Rectangle("长方形"));
Picture root=new Picture("怪物图形");
root.add(new Circle("圆"));
root.add(picture);
root.draw();
}
6)使用心得:的确降低了客户端的使用情况,让整个图形可控了,当是你要深入去理解,才真名明白采用该模式的含义,不太容易理解。
一:使用场景
1)使用的地方:我想使用两个不同类的方法,这个时候你需要把它们组合起来使用
2)目前使用的情况:我会把两个类用户组合的方式放到一起,编程思想think in java里已经提到个,能尽量用组合就用组合,继承一般考虑再后。
3)使用后的好处:你不需要改动以前的代码,只是新封装了一新类,由这个类来提供两个类的方法,这个时候:一定会想到facade外观模式,本来是多个类使用的情况,我新封装成一个类来使用,而这个类我采用组合的方式来包装新的方法。我的理解是,设计模式本身就是为了帮助解决特定的业务场景而故意把模式划分对应的模式类别,其实大多数情况,都解决了同样的问题,这个时候其实没有必要过多的纠缠到模式的名字上了,你有好的注意,你甚至取一个新的名字来概括这样的使用场景。
4)使用的坏处:适配器模式,有两种方式来实现。一个是组合一个是继承,我觉得,首先应该考虑组合,能用组合就不要用继承,这是第一个。第二个,你采用继承来实现,那肯定会加大继承树结构,如果你的继承关系本身就很复杂了,这肯定会加大继承关系的维护,不有利于代码的理解,或则更加繁琐。继承是为了解决重用的为题而出现的,所以我觉得不应该滥用继承,有机会可以考虑同样别的方案。
二:一个实际的例子
关联营销的例子,用户购买完商品后,我又推荐他相关别的商品
由于减少代码,方法我都不采用接口,直接由类来提供,代码只是一个范例而已,都精简了。
1)创建订单信息
public class Order {
private Long orderId;
private String nickName;
public Order(Long orderId,String nickName){
this.orderId=orderId;
this.nickName=nickName;
}
/**
* 用户下订单
*/
public void insertOrder(){
}
}
2)商品信息
public class Auction {
/**商品名称*/
private String name;
/**制造商*/
private String company;
/**制造日期*/
private Date date;
public Auction(String name,String company, Date date){
this.name=name;
this.company=company;
this.date=date;
}
/**
* 推广的商品列表
*/
public void commendAuction(){
}
}
3)购物
public class Trade {
/**用户订单*/
private Order order;
/**商品信息*/
private Auction auction;
public Trade(Order order ,Auction auction){
this.order=order;
this.auction=auction;
}
/**
* 用户产生订单以及后续的事情
*/
public void trade(){
/**下订单*/
order.insertOrder();
/**关联推荐相关的商品*/
auction.commendAuction();
}
}
4)使用心得:其实外面采用了很多继承的方式,order继承auction之后,利用super .inserOrder()再加一个auction.recommendAuction(),实际上大同小异,我到觉得采用组合更容易理解以及代码更加优美点。
一:使用场景
1)使用到的地方:如果你想创建类似汽车这样的对象,首先要创建轮子,玻璃,桌椅,发动机,外廓等,这些部件都创建好后,最后创建汽车成品,部件的创建和汽车的组装过程本身都很复杂的情况,希望把部件的创建和成品的组装分开来做,这样把要做的事情分割开来,降低对象实现的复杂度,也降低以后成本的维护,把汽车的部件创建和组装过程独立出两个对应的工厂来做,有点类似建立两个对应的部件创建工厂和汽车组装工厂两个工厂,而工厂只是创建一个成品,并没有把里面的步骤也独立出来,应该说Builder模式比工厂模式又进了一步。
2)采用Builder模式后的好处:把一个负责的对象的创建过程分解,把一个对象的创建分成两个对象来负责创建,代码更有利于维护,可扩性比较好。
3)采用Builder模式后的坏处:实现起来,对应的接口以及部件的对象的创建比较多,代码相对来讲,比较多了,估计刚开始你会有点晕,这个可以考虑代码精简的问题,增加代码的可读性。
二:一个实际的例子
汽车的组装
1)首先创建汽车这个成品对象,包含什么的成员
public class Car implements Serializable{
/**
* 汽车序列号
*/
private static final long serialVersionUID = 1L;
/**汽车轮子*/
private Wheel wheel;
/**汽车发动机*/
private Engine engine;
/**汽车玻璃*/
private Glass glass;
/**汽车座椅*/
private Chair chair;
public Wheel getWheel() {
return wheel;
}
public void setWheel(Wheel wheel) {
this.wheel = wheel;
}
public Engine getEngine() {
return engine;
}
public void setEngine(Engine engine) {
this.engine = engine;
}
public Glass getGlass() {
return glass;
}
public void setGlass(Glass glass) {
this.glass = glass;
}
public Chair getChair() {
return chair;
}
public void setChair(Chair chair) {
this.chair = chair;
}
}
2)创建对应汽车零部件
public class Wheel {
public Wheel(){
print("--汽车轮子构建完毕--");
}
}
public class Engine {
public Engine(){
print("--汽车发动机构建完毕--");
}
}
public class Glass {
public Glass(){
print("--汽车玻璃构建完毕--");
}
}
public class Chair {
public Chair(){
print("--汽车座椅构建完毕--");
}
}
3)开始重点了,汽车成品的组装过程
public interface Builder {
/**组装汽车轮子*/
public void buildWheel();
/**组装汽车发动机*/
public void buildEngine();
/**组装汽车玻璃*/
public void buildGlass();
/**组装汽车座椅*/
public void buildChair();
/**返回组装好的汽车*/
public Car getCar();
}
以及实现类
public class CarBuilder implements Builder {
/**汽车成品*/
private Car car;
public CarBuilder(){
car=new Car();
}
/**组装汽车轮子*/
@Override
public void buildChair() {
car.setChair(new Chair());
}
/**组装汽车发动机*/
@Override
public void buildEngine() {
car.setEngine(new Engine());
}
/**组装汽车玻璃*/
@Override
public void buildGlass() {
car.setGlass(new Glass());
}
/**组装汽车座椅*/
@Override
public void buildWheel() {
car.setWheel(new Wheel());
}
/**返回组装好的汽车*/
@Override
public Car getCar() {
buildChair();
buildEngine();
buildGlass();
buildWheel();
print("--整个汽车构建完毕--");
return car;
}
}
4)最后汽车创建测试
public static void main(String[] args) {
/**创建汽车组装*/
Builder carBuilder=new CarBuilder();
Car car=carBuilder.getCar();
}
最后输出:
--汽车座椅构建完毕--
--汽车发动机构建完毕--
--汽车玻璃构建完毕--
--汽车轮子构建完毕--
--整个汽车构建完毕--
5)体会心得:Builder模式实际的重点就把汽车的组装过程和零部件的生产分开来实现,零部件的生成主要靠自己的对象来实现,我上面只是在构造函数里创建了,比较简单,而重点汽车的组装则交给CarBuilder来实现,最终由builder来先负责零部件的创建,最后返回出成品的汽车。
一:使用场景
1)经常使用的地方:一个类只有一个实例,eg:页面访问统计pv,统计的个数就只能保证一个实例的统计。
2)我们目前使用的情况:比如我想创建一个对象,这个对象希望只有一份实例的维护,在内存的保存也只有一份,也就是在同一个jvm的java堆里只保存一份实例对象,所以你会想一办法,在创建这个对象的时候,就已经能保证只有一份。
3)怎么改进:定义该对象的时候,就保证是同一份实例,比如:定义为私有构造函数,防止通过new的方式可以创建对象,然后在对象里定义一个静态的私有成员(本身对象的一个实例),然后再创建一个外面访问该对象的方法就好了。
4)改进的好处:代码在编译代码这个级别就被控制了,不至于在jvm里运行的时候才来保证,把唯一实例的创建保证在编译阶段;jvm里内存只有一份,从而内存占有率更低,以及更方便java垃圾回收
5)改进后的坏处:只能是代码稍微需要更多点,其实大家最后发现改进后的坏处,都是代码定义比之间要多一点,但以后的维护代码就降下来了,也短暂的代码量偏大来换取以后代码的精简。
二:一个实际的例子
总体的例子
package com.mike.pattern.singleton;
/**
* 总统
*
* @author taoyu
*
* @since 2010-6-22
*/
public class President {
private President(){
System.out.println("总统已经选举出来了");
}
/**总统只有一个*/
private static President president=new President();
/**
* 返回总统
*/
public static President getPresident(){
return president;
}
/**
* 总统宣布选举成功
*/
public void announce(){
System.out.println("伟大的中国人民,我将成你们新的总统");
}
}
/**
* @param args
*/
public static void main(String[] args) {
President president=President.getPresident();
president.announce();
}
1.使用场景
1)子类过多,不容易管理;构造对象过程过长;精简代码创建;
2)目前我们代码情况: 编写代码的时候,我们经常都在new对象,创建一个个的对象,而且还有很多麻烦的创建方式,eg:HashMap<String,Float> grade=new HashMap<String,Float>(),这样的代码创建方式太冗长了,难道你没有想过把这个创建变的短一点么,比如:HashMap<String,Float>grade=HashMapFactory.new(),可以把你创建精简一点;你也可以还有别的需求,在创建对象的时候,你需要不同的情况,创建统一种类别的对象,eg:我想生成不同的汽车,创建小轿车,创建卡车,创建公交汽车等等,都属于同种类别:汽车,你难道没有想过,我把这些创建的对象在一个工厂里来负责创建,我把创建分开化,交给一人来负责,这样可以让代码更加容易管理,创建方式也可以简单点。
比如:Car BMW=CarFactory.create(bmw); 把创建new由一个统一负责,这样管理起来相当方便
3)怎么改进:这个时候,你会想到,创建这样同类别的东西,我把这个权利分出去,让一个人来单独管理,它只负责创建我的对象这个事情,所以你单独简历一个对象来创建同类的对象,这个时候,你想这个东西有点像工厂一样,生成同样的产品,所以取了个名字:工厂模式,顾名思义,只负责对象的创建
4)改进后的好处:代码更加容易管理了,代码的创建要简洁很多。
5)改进后的坏处:那就是你需要单独加一个工厂对象来负责创建,多需要写点代码。
2.一个实际的例子
创建宝马汽车与奔驰汽车的例子
1)先提取出一个汽车的公用接口Car
public interface Car{
/**行驶*/
public void drive();
}
2)宝马和奔驰汽车对象
public class BMWCar implements Car {
/**
* 汽车发动
*/
public void drive(){
System.out.println("BMW Car drive");
}
}
public class BengCar implements Car {
/**
* 汽车发动
*/
public void drive(){
System.out.println("BengChi Care drive");
}
}
3)单独一个汽车工厂来负责创建
public class FactoryCar {
/**
* 制造汽车
*
* @param company 汽车公司
* @return 汽车
* @throws CreateCarException 制造汽车失败异常
*/
public static Car createCar(Company company)throws CreateCarException{
if(company==Company.BMW){
return new BMWCar();
}else if(company==Company.Beng){
return new BengCar();
}
return null;
}
}
4)最后的代码实现:
Car BMWCar=FactoryCar.createCar(Company.BMW);
BMWCar.drive();
1. 我说下我对设计模式的理解:任何一样事物都是因为有需求的驱动才诞生的,所以设计模式也不例外,我们平时在编写代码的时候,随着时间的深入,发现很多代码很难维护,可扩展性级差,以及代码的效率也比较低,这个时候你肯定会想办法让代码变的优美又能解决你项目中的问题,所以在面向对象语言里,你肯定会去发现很多可以重用的公用的方法,比如:接口的存在,你自然就想到了,让你定义的方法与你的实现分开,也可以很方便把不同的类与接口匹配起来,形成了一个公用的接口,你会发现这样做,好处会是非常多的,解决了你平时想把代码的申明与逻辑实现的分开。
2. 这个时候,你发现了,本身面向对象的语言里,已经暗藏了很多好处,你肯定会仔细去分析面向对象这个语言,认真去挖掘里面更多的奥秘,最后,你发现了,原来你可以把面向对象的特性提取成一个公用的实现案例,这些案例里能帮助你解决你平时编写代码的困扰,而这样一群人,就是所谓gof的成员,他们从平时设计建筑方面找到了灵感,建筑的设计也可以公用化以及重用化,所以他们也提取了相关的软件设计方面的公用案例,也就有了下面的相关的所谓23种设计模式,而里面这么多模式,你也可以把他们归类起来,最后发现就几类模式:创建,结构,行为等模式类别,而这些现成的方案,也可以在实际应用中充分发挥作用,随着大家的使用以及理解,发现其实这些所谓的模式里,你的确可以让你的代码变的更加优美与简练。
3. 我比较喜欢把代码变的更加优美与简练,优美的代码就是一看就懂,结构很清晰,而简历就是一目了然,又可以解决你的问题,就是代码又少效率又高,所以平时要养成写java doc的习惯,这样的代码才为清晰,所以才会更加优美。
4. 这些就是我对设计模式的理解,所以这么好的宝贝,我们不去深入的了解,的确可惜了,这就叫站到巨人的肩膀上.....
一:网络配置
1.关掉防火墙
1) 重启后生效
开启: chkconfig iptables on
关闭: chkconfig iptables off
2) 即时生效,重启后失效
开启: service iptables start
关闭: service iptables stop
2.下载软件
wget curl
3.安装和解压
安装 rpm -ivh
升级 rpm -Uvh
卸载 rpm -e
tar -zxvf
二:网卡设置
1、 设置ip地址(即时生效,重启失效)
#ifconfig eth0 ip地址 netmask 子网掩码
2、 设置ip地址(重启生效,永久生效)
#setup
3、 通过配置文件设置ip地址(重启生效,永久生效)
#vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0 #设备名,与文件同名。
ONBOOT=yes #在系统启动时,启动本设备。
BOOTPROTO=static
IPADDR=202.118.75.91 #此网卡的IP地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=202.118.75.1 #网关IP
MACADDR=00:02:2D:2E:8C:A8 #mac地址
4、 重启网络服务
#service network restart //重启所有网卡
5、 禁用网卡,启动网卡
#ifdown eth0
#ifup eth0
6、 屏蔽网卡,显示网卡
#ifconfig eth0 down
#ifconfig eth0 up
7、 配置DNS客户端(最多三个)
#vi /etc/resolv.conf
nameserver 202.99.96.68
8、更改主机名(即时生效)
#hostname 主机名
9、更改主机名(重启计算机生效,永久生效)
#vi /etc/sysconfig/network
HOSTNAME=主机名
三:两台linux拷贝命令:scp
1.安装scp:yum install openssh-clients
2.scp -r 本地用户名@IP地址:文件名1 远程用户名@IP地址:文件名2
摘要: 作者:NetSeek http://www.linuxtone.org (IT运维专家网|集群架构|性能调优)欢迎转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明.首发时间: 2008-11-25 更新时间:2009-1-14目 录一、 Nginx 基础知识二、 Nginx 安装及调试三、 Nginx Rewrite四、 Nginx Redirect五、 Nginx 目录自动加斜线...
阅读全文
一:quartz简介 OpenSymphony 的Quartz提供了一个比较完美的任务调度解决方案。 Quartz 是个开源的作业调度框架,定时调度器,为在 Java 应用程序中进行作业调度提供了简单却强大的机制。
Quartz中有两个基本概念:作业和触发器。作业是能够调度的可执行任务,触发器提供了对作业的调度
二:quartz spring配置详解- 为什么不适用java.util.Timer结合java.util.TimerTask
1.主要的原因,适用不方便,特别是制定具体的年月日时分的时间,而quartz使用类似linux上的cron配置,很方便的配置每隔时间执行触发。
2.其次性能的原因,使用jdk自带的Timer不具备多线程,而quartz采用线程池,性能上比timer高出很多。
在spring里主要分为两种使用方式:第一种,也是目前使用最多的方式,spring提供的MethodInvokingJobDetailFactoryBean代理类,通过雷利类直接调用任务类的某个函数;第二种,程序里实现quartz接口,quartz通过该接口进行调度。
主要讲解通过spring提供的代理类MethodInvokingJobDetailFactoryBean 1.业务逻辑类:业务逻辑是独立的,本身就与quartz解耦的,并没有深入进去,这对业务来讲是很好的一个方式。
public class TestJobTask{ /**
*业务逻辑处理
*/ public void service(){
/**业务逻辑*/ 
..
}
}
2.增加一个线程池 <!-- 线程执行器配置,用于任务注册 --><bean id="executor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="corePoolSize" value="10" />
<property name="maxPoolSize" value="100" />
<property name="queueCapacity" value="500" />
</bean>
3.定义业务逻辑类
<!-- 业务对象 --><bean id="testJobTask" class="com.mike.scheduling.TestJobTask" />
4.增加quartz调用业务逻辑
<!-- 调度业务 --><bean id="jobDetail" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="testJobTask" />
<property name="targetMethod" value="service" />
</bean>
5.增加调用的触发器,触发的时间,有两种方式:
第一种触发时间,采用类似linux的cron,配置时间的表示发出丰富 <bean id="cronTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean"> <property name="jobDetail" ref="jobDetail" />
<property name="cronExpression" value="10 0/1 * * * ?" />
</bean>
Cron表达式“10 */1 * * * ?”意为:从10秒开始,每1分钟执行一次 第二种,采用比较简话的方式,申明延迟时间和间隔时间
<bean id="taskTrigger" class="org.springframework.scheduling.quartz.SimpleTriggerBean"> <property name="jobDetail" ref="jobDetail" />
<property name="startDelay" value="10000" />
<property name="repeatInterval" value="60000" />
</bean>
延迟10秒启动,然后每隔1分钟执行一次 6.开始调用
<!-- 设置调度 --><bean class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref bean="cronTrigger" />
</list>
</property>
<property name="taskExecutor" ref="executor" />
</bean>
7.结束:启动容器即可,已经将spring和quartz结合完毕。 Cron常用的表达式 "0 0 12 * * ?" 每天中午12点触发"0 15 10 ? * *" 每天上午10:15触发
"0 15 10 * * ?" 每天上午10:15触发
"0 15 10 * * ? *" 每天上午10:15触发
"0 15 10 * * ? 2005" 2005年的每天上午10:15触发
"0 * 14 * * ?" 在每天下午2点到下午2:59期间的每1分钟触发
"0 0/5 14 * * ?" 在每天下午2点到下午2:55期间的每5分钟触发
"0 0/5 14,18 * * ?" 在每天下午2点到2:55期间和下午6点到6:55期间的每5分钟触发
"0 0-5 14 * * ?" 在每天下午2点到下午2:05期间的每1分钟触发
"0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44触发
"0 15 10 ? * MON-FRI" 周一至周五的上午10:15触发
"0 15 10 15 * ?" 每月15日上午10:15触发
"0 15 10 L * ?" 每月最后一日的上午10:15触发
"0 15 10 ? * 6L" 每月的最后一个星期五上午10:15触发
"0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一个星期五上午10:15触发
"0 15 10 ? * 6#3" 每月的第三个星期五上午10:15触发
三:quartz原理
根据上面spring的配置,我们就比较清楚quartz的内部情况,下面我们主要详解配置涉及到的每个点 1.我们先从最后一个步骤看起,
SchedulerFactoryBean ,scheduler的工厂实现,里面可以生产出对应的多个jobDetail和trigger,每个jobDetail对应trigger代表一个任务
Quartz的SchedulerFactory是标准的工厂类,不太适合在Spring环境下使用。此外,为了保证Scheduler能够感知 Spring容器的生命周期,完成自动启动和关闭的操作,必须让Scheduler和Spring容器的生命周期相关联。以便在Spring容器启动后, Scheduler自动开始工作,而在Spring容器关闭前,自动关闭Scheduler。为此,Spring提供 SchedulerFactoryBean,这个FactoryBean大致拥有以下的功能: 1)以更具Bean风格的方式为Scheduler提供配置信息;
2)让Scheduler和Spring容器的生命周期建立关联,相生相息;
3)通过属性配置部分或全部代替Quartz自身的配置文件。
2.jobDetail,表示一个可执行的业务调用
3.trigger:调度的时间计划,什么时候,每隔多少时间可执行等时间计划
4.ThreadPoolTaskExecutor,线程池,用来并行执行每个对应的job,提高效率,这也是上面提到不推荐使用jdk自身timer的一个很重要的原因
一:事务的概念
事务必须服从ISO/IEC所制定的ACID原则。ACID是原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)的缩写 事务的原子性:表示事务执行过程中的任何失败都将导致事务所做的任何修改失效。
一致性表示当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态。
隔离性表示在事务执行过程中对数据的修改,在事务提交之前对其他事务不可见。
持久性表示已提交的数据在事务执行失败时,数据的状态都应该正确。 二:事务的场景
1.与银行相关的业务,重要的数据,与钱相关的内容不能出任何错。
2.系统内部认为重要的数据,都需要事务的支持,防止重要数据的不一致。
3.具体的业务场景:银行业务,支付业务,交易业务等。
三:事务的实现方式
首先说一下事务的类型,主要包含一下三种:JDBC事务,JTA事务,容器事务
1、JDBC事务 JDBC 事务是用 Connection 对象控制的。JDBC Connection 接口( java.sql.Connection )提供了两种事务模式:自动提交和手工提交。 java.sql.Connection 提供了以下控制事务的方法: public void setAutoCommit(boolean) public boolean getAutoCommit() public void commit() public void rollback() 使用 JDBC 事务界定时,您可以将多个 SQL 语句结合到一个事务中。JDBC 事务的一个缺点是事务的范围局限于一个数据库连接。一个 JDBC 事务不能跨越多个数据库。 2、JTA(Java Transaction API)事务 JTA是一种高层的,与实现无关的,与协议无关的API,应用程序和应用服务器可以使用JTA来访问事务。 JTA允许应用程序执行分布式事务处理--在两个或多个网络计算机资源上访问并且更新数据,这些数据可以分布在多个数据库上。JDBC驱动程序的JTA支持极大地增强了数据访问能力。 如果计划用 JTA 界定事务,那么就需要有一个实现 javax.sql.XADataSource 、 javax.sql.XAConnection 和 javax.sql.XAResource 接口的 JDBC 驱动程序。一个实现了这些接口的驱动程序将可以参与 JTA 事务。一个 XADataSource 对象就是一个 XAConnection 对象的工厂。 XAConnection s 是参与 JTA 事务的 JDBC 连接。 您将需要用应用服务器的管理工具设置 XADataSource 。从应用服务器和 JDBC 驱动程序的文档中可以了解到相关的指导。 J2EE 应用程序用 JNDI 查询数据源。一旦应用程序找到了数据源对象,它就调用 javax.sql.DataSource.getConnection() 以获得到数据库的连接。 XA 连接与非 XA 连接不同。一定要记住 XA 连接参与了 JTA 事务。这意味着 XA 连接不支持 JDBC 的自动提交功能。同时,应用程序一定不要对 XA 连接调用 java.sql.Connection.commit() 或者 java.sql.Connection.rollback() 。相反,应用程序应该使用 UserTransaction.begin()、 UserTransaction.commit() 和 serTransaction.rollback() 。 3、容器事务 容器事务主要是J2EE应用服务器提供的,容器事务大多是基于JTA完成,这是一个基于JNDI的,相当复杂的API实现。相对编码实现JTA事务管理,我们可以通过EJB容器提供的容器事务管理机制(CMT)完成同一个功能,这项功能由J2EE应用服务器提供。这使得我们可以简单的指定将哪个方法加入事务,一旦指定,容器将负责事务管理任务。这是我们土建的解决方式,因为通过这种方式我们可以将事务代码排除在逻辑编码之外,同时将所有困难交给J2EE容器去解决。使用EJB CMT的另外一个好处就是程序员无需关心JTA API的编码,不过,理论上我们必须使用EJB。 四、三种事务差异 1、JDBC事务控制的局限性在一个数据库连接内,但是其使用简单。 2、JTA事务的功能强大,事务可以跨越多个数据库或多个DAO,使用也比较复杂。 3、容器事务,主要指的是J2EE应用服务器提供的事务管理,局限于EJB应用使用。
五:详解事务
1.首先看一下目前使用最多的spring事务,目前spring配置分为声明式事务和编程式事务。
1)编程式事务
主要是实现接口PlatformTransactionManager

实现了事务管理的接口有非常多,这里主要讲DataSourceTransactionManager和数据库jdbc相关的事务处理方式
之前有接触过hadoop,但都比较浅显,对立面的东东不是很清楚!
打算后面在hadoop上花时间把里面的内容,好好学学,这篇博客将在后面陆续更新hadoop学习笔记。
一:Mina概要 Apache Mina是一个能够帮助用户开发高性能和高伸缩性网络应用程序的框架。它通过Java nio技术基于TCP/IP和UDP/IP协议提供了抽象的、事件驱动的、异步的API。
如下的特性:
1、 基于Java nio的TCP/IP和UDP/IP实现
基于RXTX的串口通信(RS232)
VM 通道通信
2、通过filter接口实现扩展,类似于Servlet filters
3、low-level(底层)和high-level(高级封装)的api:
low-level:使用ByteBuffers
High-level:使用自定义的消息对象和解码器
4、Highly customizable(易用的)线程模式(MINA2.0 已经禁用线程模型了):
单线程
线程池
多个线程池
5、基于java5 SSLEngine的SSL、TLS、StartTLS支持
6、负载平衡
7、使用mock进行单元测试
8、jmx整合
9、基于StreamIoHandler的流式I/O支持
10、IOC容器的整合:Spring、PicoContainer
11、平滑迁移到Netty平台
二:实践 首先讲一下客户端的通信过程:
1.通过SocketConnector同服务器端建立连接
2.链接建立之后I/O的读写交给了I/O Processor线程,I/O Processor是多线程的
3.通过I/O Processor读取的数据经过IoFilterChain里所有配置的IoFilter,IoFilter进行消息的过滤,格式的转换,在这个层面可以制定一些自定义的协议
4.最后IoFilter将数据交给Handler进行业务处理,完成了整个读取的过程
5.写入过程也是类似,只是刚好倒过来,通过IoSession.write写出数据,然后Handler进行写入的业务处理,处理完成后交给IoFilterChain,进行消息过滤和协议的转换,最后通过I/O Processor将数据写出到socket通道
IoFilterChain作为消息过滤链
1.读取的时候是从低级协议到高级协议的过程,一般来说从byte字节逐渐转换成业务对象的过程
2.写入的时候一般是从业务对象到字节byte的过程
IoSession贯穿整个通信过程的始终
客户端通信过程

1.创建服务器
package com.gewara.web.module.base;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.charset.Charset;
import org.apache.mina.core.service.IoAcceptor;
import org.apache.mina.filter.codec.ProtocolCodecFilter;
import org.apache.mina.filter.codec.textline.TextLineCodecFactory;
import org.apache.mina.filter.logging.LoggingFilter;
import org.apache.mina.transport.socket.nio.NioSocketAcceptor;
/**
* Mina服务器
*
* @author mike
*
* @since 2012-3-15
*/
public class HelloServer {
private static final int PORT = 8901;// 定义监听端口
public static void main(String[] args) throws IOException{
// 创建服务端监控线程
IoAcceptor acceptor = new NioSocketAcceptor();
// 设置日志记录器
acceptor.getFilterChain().addLast("logger", new LoggingFilter());
// 设置编码过滤器
acceptor.getFilterChain().addLast("codec",new ProtocolCodecFilter(new TextLineCodecFactory(Charset.forName("UTF-8"))));
// 指定业务逻辑处理器
acceptor.setHandler(new HelloServerHandler());
// 设置端口号
acceptor.setDefaultLocalAddress(new InetSocketAddress(PORT));
// 启动监听线程
acceptor.bind();
}
}
2.创建服务器端业务逻辑
package com.gewara.web.module.base;
import org.apache.mina.core.service.IoHandlerAdapter;
import org.apache.mina.core.session.IoSession;
/**
* 服务器端业务逻辑
*
* @author mike
*
* @since 2012-3-15
*/public class HelloServerHandler
extends IoHandlerAdapter {
@Override
/**
* 连接创建事件
*/ public void sessionCreated(IoSession session){
// 显示客户端的ip和端口
System.out.println(session.getRemoteAddress().toString());
}
@Override
/**
* 消息接收事件
*/ public void messageReceived(IoSession session, Object message)
throws Exception{
String str = message.toString();
if (str.trim().equalsIgnoreCase("quit")){
// 结束会话
session.close(
true);
return;
}
// 返回消息字符串
session.write("Hi Client!");
// 打印客户端传来的消息内容
System.out.println("Message written
" + str);
}
}
3.创建客户端
package com.gewara.web.module.base;
import java.net.InetSocketAddress;
import java.nio.charset.Charset;
import org.apache.mina.core.future.ConnectFuture;
import org.apache.mina.filter.codec.ProtocolCodecFilter;
import org.apache.mina.filter.codec.textline.TextLineCodecFactory;
import org.apache.mina.filter.logging.LoggingFilter;
import org.apache.mina.transport.socket.nio.NioSocketConnector;
/**
* Mina客户端
*
* @author mike
*
* @since 2012-3-15
*/
public class HelloClient {
public static void main(String[] args){
// 创建客户端连接器.
NioSocketConnector connector = new NioSocketConnector();
// 设置日志记录器
connector.getFilterChain().addLast("logger", new LoggingFilter());
// 设置编码过滤器
connector.getFilterChain().addLast("codec",
new ProtocolCodecFilter(new TextLineCodecFactory(Charset.forName("UTF-8"))));
// 设置连接超时检查时间
connector.setConnectTimeoutCheckInterval(30);
// 设置事件处理器
connector.setHandler(new HelloClientHandler());
// 建立连接
ConnectFuture cf = connector.connect(new InetSocketAddress("192.168.2.89", 8901));
// 等待连接创建完成
cf.awaitUninterruptibly();
// 发送消息
cf.getSession().write("Hi Server!");
// 发送消息
cf.getSession().write("quit");
// 等待连接断开
cf.getSession().getCloseFuture().awaitUninterruptibly();
// 释放连接
connector.dispose();
}
}
4.客户端业务逻辑
package com.gewara.web.module.base;
import org.apache.mina.core.service.IoHandlerAdapter;
import org.apache.mina.core.session.IoSession;
public class HelloClientHandler extends IoHandlerAdapter {
@Override
/**
* 消息接收事件
*/
public void messageReceived(IoSession session, Object message) throws Exception{
//显示接收到的消息
System.out.println("server message:"+message.toString());
}
}
5.先启动服务器端,然后启动客户端
2012-03-15 14:45:41,456 INFO logging.LoggingFilter - CREATED
/192.168.2.89:2691
2012-03-15 14:45:41,456 INFO logging.LoggingFilter - OPENED
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - RECEIVED: HeapBuffer[pos=0 lim=11 cap=2048: 48 69 20 53 65 72 76 65 72 21 0A]
2012-03-15 14:45:41,487 DEBUG codec.ProtocolCodecFilter - Processing a MESSAGE_RECEIVED
for session 1
Message written
Hi Server!
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - SENT: HeapBuffer[pos=0 lim=0 cap=0: empty]
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - RECEIVED: HeapBuffer[pos=0 lim=5 cap=2048: 71 75 69 74 0A]
2012-03-15 14:45:41,487 DEBUG codec.ProtocolCodecFilter - Processing a MESSAGE_RECEIVED
for session 1
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - CLOSED
1.首先看服务器
// 创建服务端监控线程
IoAcceptor acceptor = new NioSocketAcceptor();
// 设置日志记录器
acceptor.getFilterChain().addLast("logger", new LoggingFilter());
// 设置编码过滤器
acceptor.getFilterChain().addLast("codec",new ProtocolCodecFilter(new TextLineCodecFactory(Charset.forName("UTF-8"))));
// 指定业务逻辑处理器
acceptor.setHandler(new HelloServerHandler());
// 设置端口号
acceptor.setDefaultLocalAddress(new InetSocketAddress(PORT));
// 启动监听线程
acceptor.bind();
1)先创建NioSocketAcceptor nio的接收器,谈到Socket就要说到Reactor模式 当前分布式计算 Web Services盛行天下,这些网络服务的底层都离不开对socket的操作。他们都有一个共同的结构:1. Read request2. Decode request3. Process service 4. Encode reply5. Send reply 
但这种模式在用户负载增加时,性能将下降非常的快。我们需要重新寻找一个新的方案,保持数据处理的流畅,很显然,事件触发机制是最好的解决办法,当有事件发生时,会触动handler,然后开始数据的处理。
Reactor模式类似于AWT中的Event处理。
Reactor模式参与者
1.Reactor 负责响应IO事件,一旦发生,广播发送给相应的Handler去处理,这类似于AWT的thread
2.Handler 是负责非堵塞行为,类似于AWT ActionListeners;同时负责将handlers与event事件绑定,类似于AWT addActionListener
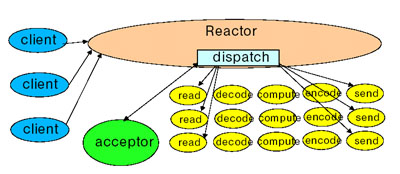
并发系统常采用reactor模式,简称观察者模式,代替常用的多线程处理方式,利用有限的系统的资源,提高系统的吞吐量。
可以看一下这篇文章,讲解的很生动具体,一看就明白reactor模式的好处
http://daimojingdeyu.iteye.com/blog/828696 Reactor模式是编写高性能网络服务器的必备技术之一,它具有如下的优点: 1)响应快,不必为单个同步时间所阻塞,虽然Reactor本身依然是同步的; 2)编程相对简单,可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销; 3)可扩展性,可以方便的通过增加Reactor实例个数来充分利用CPU资源; 4)可复用性,reactor框架本身与具体事件处理逻辑无关,具有很高的复用性; 2)其次,再说说NIO的基本原理和使用 NIO 有一个主要的类Selector,这个类似一个观察者,只要我们把需要探知的socketchannel告诉Selector,我们接着做别的事情,当有事件发生时,他会通知我们,传回一组 SelectionKey,我们读取这些Key,就会获得我们刚刚注册过的socketchannel,然后,我们从这个Channel中读取数据,放心,包准能够读到,接着我们可以处理这些数据。
Selector内部原理实际是在做一个对所注册的channel的轮询访问,不断的轮询(目前就这一个算法),一旦轮询到一个channel有所注册的事情发生,比如数据来了,他就会站起来报告,交出一把钥匙,让我们通过这把钥匙(SelectionKey表示 SelectableChannel 在 Selector 中的注册的标记。 )来读取这个channel的内容。
一:基本原理 主要是要实现网络之间的通讯,
网络通信需要做的就是将流从一台计算机传输到另外一台计算机,基于传输协议和网络IO来实现,其中传输协议比较出名的有http、 tcp、udp等等,http、tcp、udp都是在基于Socket概念上为某类应用场景而扩展出的传输协议,网络IO,主要有bio、nio、aio 三种方式,所有的分布式应用通讯都基于这个原理而实现。
二:实践
在分布式服务框架中,一个最基础的问题就是远程服务是怎么通讯的,在Java领域中有很多可实现远程通讯的技术:RMI、MINA、ESB、Burlap、Hessian、SOAP、EJB和JMS
既然引入出了这么多技术,那我们就顺道深入挖掘下去,了解每个技术框架背后的东西:
1.首先看RMI
RMI主要包含如下内容:
远程服务的接口定义
·远程服务接口的具体实现 ·桩(Stub)和框架(Skeleton)文件 ·一个运行远程服务的服务器 ·一个RMI命名服务,它允许客户端去发现这个远程服务 ·类文件的提供者(一个HTTP或者FTP服务器) ·一个需要这个远程服务的客户端程序 来看下基于RMI的一次完整的远程通信过程的原理:
1)客户端发起请求,请求转交至RMI客户端的stub类;
2)stub类将请求的接口、方法、参数等信息进行序列化;
3)基于tcp/ip将序列化后的流传输至服务器端;
4)服务器端接收到流后转发至相应的skelton类;
5)skelton类将请求的信息反序列化后调用实际的处理类;
6)处理类处理完毕后将结果返回给skelton类;
7)Skelton类将结果序列化,通过tcp/ip将流传送给客户端的stub;
8)stub在接收到流后反序列化,将反序列化后的Java Object返回给调用者。
RMI应用级协议内容:
基于Java串行化机制将请求的java object信息转化为流。
根据采用的协议启动相应的监听端口,当有流进入后基于Java串行化机制将流进行反序列化,并根据RMI协议获取到相应的处理对象信息,进行调用并处理,处理完毕后的结果同样基于java串行化机制进行返回。
tcp/ip。
原理讲了,开始实践:
创建RMI程序的6个步骤:
1、定义一个远程接口的接口,该接口中的每一个方法必须声明它将产生一个RemoteException异常。
2、定义一个实现该接口的类。
3、使用RMIC程序生成远程实现所需的残根和框架。
4、创建一个服务器,用于发布2中写好的类。
5. 创建一个客户程序进行RMI调用。
6、启动rmiRegistry并运行自己的远程服务器和客户程序
1)首先创建远程接口:
/**
* 远程接口
*
* @author mike
*
* @since 2012-3-14
*/
public interface Hello extends Remote {
/**
* 测试rmi
*
* @return hello
* @throws RemoteException
*/
public String hello()throws RemoteException;
}
2)创建接口实现
package com.gewara.rmi;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
/**
* 远程接口实现
*
* @author mike
*
* @since 2012-3-14
*/
public class HelloImpl extends UnicastRemoteObject implements Hello {
/**
* seria id
*/
private static final long serialVersionUID = -7931720891757437009L;
protected HelloImpl() throws RemoteException {
super();
}
/**
* hello实现
*
* @return hello world
* @throws RemoteException
*/
public String hello() throws RemoteException {
return "hello world";
}
}
3)创建服务器端
package com.gewara.rmi;
import java.rmi.Naming;
import java.rmi.registry.LocateRegistry;
public class Server {
private static final String RMI_URL="rmi://192.168.2.89:10009/server";
/**
* RMI Server
*/
public Server() {
try {
//创建远程对象
Hello hello=new HelloImpl();
//启动注册表
LocateRegistry.createRegistry(10009);
//将名称绑定到对象
Naming.bind(RMI_URL, hello);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* @param args
*/
public static void main(String[] args) {
new Server();
}
}
4)创建客服端
package com.gewara.rmi;
import java.rmi.Naming;
public class Client {
private static final String RMI_URL="rmi://192.168.2.89:10009/server";
/**
* @param args
*/
public static void main(String[] args) {
try {
String result=((Hello)Naming.lookup(RMI_URL)).hello();
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
5)先启动服务器端,然后再启动客户端
显示结果:hello world
由于涉及到的内容比较多,打算每一篇里讲一个远程通讯框架,继续详解RMI
三:详解RMI内部原理
1. RMI基本结构:包含两个独立的程序,服务器和客户端,服务器创建多个远程对象,让远程对象能够被引用,等待客户端调用这些远程对象的方法。客户端从服务器获取到一个或则多个远程对象的引用,然后调用远程对象方法,主要涉及到RMI接口、回调等技术。
2.RMI回调:服务器提供远程对象引用供客户端调用,客户端主动调用服务器,如果服务器主动打算调用客户端,这就叫回调。
3.命名远程对象:客户端通过一个命名或则一个查找服务找到远程服务,远程服务包含Java的命名和查找接口(Java Naming and Directory Interface)JNDI
RMI提供了一种服务:RMI注册rmiregistry,默认端口:1099,主机提供远程服务,接受服务,启动注册服务的命令:start rmiregistry
客户端使用一个静态类Naming到达RMI注册处,通过方法lookup()方法,客户来询问注册。
一:spring概要 简单来说,Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。
◆
控制反转——Spring通过一种称作控制反转(IoC)的技术促进了松耦合。当应用了IoC,一个对象依赖的其它对象会通过被动的方式传递进来,而不是这个对象自己创建或者查找依赖对象。你可以认为IoC与JNDI相反——不是对象从容器中查找依赖,而是容器在对象初始化时不等对象请求就主动将依赖传递给它。
◆
面向切面——Spring提供了
面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务(例如审计(auditing)和事务(transaction)管理)进行内聚性的开发。应用对象只实现它们应该做的——完成业务逻辑——仅此而已。它们并不负责(甚至是意识)其它的系统级关注点,例如日志或事务支持。
◆
容器——Spring包含并管理应用对象的配置和生命周期,在这个意义上它是一种容器,你可以配置你的每个bean如何被创建——基于一个可配置
原型(prototype),你的bean可以创建一个单独的实例或者每次需要时都生成一个新的实例——以及它们是如何相互关联的。然而,Spring不应该被混同于传统的重量级的EJB容器,它们经常是庞大与笨重的,难以使用。
◆
框架——Spring可以将简单的组件配置、组合成为复杂的应用。在Spring中,应用对象被声明式地组合,典型地是在一个XML文件里。Spring也提供了很多基础功能(事务管理、持久化框架集成等等),将应用逻辑的开发留给了你。
所有Spring的这些特征使你能够编写更干净、更可管理、并且更易于测试的代码。它们也为Spring中的各种模块提供了基础支持。
二:spring的整个生命周期 首先说一下spring的整个初始化过程,web应用中创建spring容器有两种方式: 第一种:在web.xml里直接配置spring容器,servletcontextlistener
第二种:通过load-on-startup servlet实现。
主要就说一下第一种方式:
spring提供了ServletContextListener的实现类ContextLoaderListener,该类作为listener使用,在创建时自动查找WEB-INF目录下的applicationContext.xml,该文件是默认查找的,如果只有一个就不需要配置初始化xml参数,如果需要配置,设置contextConfigLocation为application的xml文件即可。可以好好阅读一下ContextLoaderListener的源代码,就可以很清楚的知道spring的整个加载过程。
spring容器的初始化代码如下:
/** * Initialize the root web application context.
*/
public void contextInitialized(ServletContextEvent event) {
this.contextLoader = createContextLoader();
if (this.contextLoader == null) {
this.contextLoader = this;
}
this.contextLoader.initWebApplicationContext(event.getServletContext());//contextLoader初始化web应用容器
}
继续分析initWebApplicationContext做了什么事情:
/**
* Initialize Spring's web application context for the given servlet context,
* according to the "{@link #CONTEXT_CLASS_PARAM contextClass}" and
* "{@link #CONFIG_LOCATION_PARAM contextConfigLocation}" context-params.
* @param servletContext current servlet context
* @return the new WebApplicationContext
* @see #CONTEXT_CLASS_PARAM
* @see #CONFIG_LOCATION_PARAM
*/
public WebApplicationContext initWebApplicationContext(ServletContext servletContext) {
//首先创建一个spring的父容器,类似根节点root容器,而且只能是一个,如果已经创建,抛出对应的异常
if (servletContext.getAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE) != null) {
throw new IllegalStateException(
"Cannot initialize context because there is already a root application context present - " +
"check whether you have multiple ContextLoader* definitions in your web.xml!");
}
Log logger = LogFactory.getLog(ContextLoader.class);
servletContext.log("Initializing Spring root WebApplicationContext");
if (logger.isInfoEnabled()) {
logger.info("Root WebApplicationContext: initialization started");
}
long startTime = System.currentTimeMillis();
try {
// Determine parent for root web application context, if any.
ApplicationContext parent = loadParentContext(servletContext);//创建通过web.xml配置的父容器
具体里面的代码是怎么实现的,就不在这里进行详解了
// Store context in local instance variable, to guarantee that
// it is available on ServletContext shutdown.
this.context = createWebApplicationContext(servletContext, parent);//主要的创建过程都在改方法内,可以自己去看源代码
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, this.context);
//把spring初始好的容器加载到servletcontext内,相当于servletcontext包含webapplicationcontext
ClassLoader ccl = Thread.currentThread().getContextClassLoader();
if (ccl == ContextLoader.class.getClassLoader()) {
currentContext = this.context;
}
else if (ccl != null) {
currentContextPerThread.put(ccl, this.context);
}
if (logger.isDebugEnabled()) {
logger.debug("Published root WebApplicationContext as ServletContext attribute with name [" +
WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE + "]");
}
if (logger.isInfoEnabled()) {
long elapsedTime = System.currentTimeMillis() - startTime;
logger.info("Root WebApplicationContext: initialization completed in " + elapsedTime + " ms");
}
return this.context;
}
catch (RuntimeException ex) {
logger.error("Context initialization failed", ex);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, ex);
throw ex;
}
catch (Error err) {
logger.error("Context initialization failed", err);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, err);
throw err;
}
}
看到这里基本已经清楚了整个spring容器的加载过程,如果还想了解更加深入,请查看我红色标注的方法体。
其次再说一下spring的IOC和AOP使用的场景,由于原理大家都很清楚了,那就说一下它们使用到的地方:
IOC使用的场景:
管理bean的依赖关系,目前主流的电子商务网站基本都采用spring管理业务层代码的依赖关系,包括:淘宝,支付宝,阿里巴巴,百度等公司。