
2007年7月29日
摘要:
阅读全文
posted @
2010-02-04 15:30 xnabx 阅读(1650) |
评论 (1) |
编辑 收藏
摘要:
阅读全文
posted @
2010-01-25 11:10 xnabx 阅读(1075) |
评论 (1) |
编辑 收藏
摘要:
阅读全文
posted @
2010-01-21 09:52 xnabx 阅读(1753) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2010-01-15 10:10 xnabx 阅读(1446) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2010-01-15 09:57 xnabx 阅读(369) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-12-04 11:45 xnabx 阅读(643) |
评论 (3) |
编辑 收藏
摘要:
阅读全文
posted @
2009-12-03 15:26 xnabx 阅读(347) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-12-01 16:02 xnabx 阅读(218) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-12-01 11:05 xnabx 阅读(364) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-11-10 09:05 xnabx 阅读(797) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-03-18 14:06 xnabx 阅读(166) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-10-29 16:34 xnabx 阅读(131) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-07-30 15:18 xnabx 阅读(267) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-07-23 11:20 xnabx 阅读(403) |
评论 (0) |
编辑 收藏出处:http://www.blogjava.net/xmatthew/archive/2008/04/14/192450.html
(转)设计一个Tomcat访问日志分析工具
常使用web服务器的朋友大都了解,一般的web server有两部分日志:
一是运行中的日志,它主要记录运行的一些信息,尤其是一些异常错误日志信息
二是访问日志信息,它记录的访问的时间,IP,访问的资料等相关信息。
现在我来和大家介绍一下利用tomcat产生的访问日志数据,我们能做哪些有效的分析数据?
首先是配置tomcat访问日志数据,默认情况下访问日志没有打开,配置的方式如下:
编辑 ${catalina}/conf/server.xml文件.注:${catalina}是tomcat的安装目录
把以下的注释(<!-- -->)去掉即可。
<!--
<Valve className="org.apache.catalina.valves.AccessLogValve"
directory="logs" prefix="localhost_access_log." suffix=".txt"
pattern="common" resolveHosts="false"/>
-->
其中 directory是产生的目录 tomcat安装${catalina}作为当前目录
pattern表示日志生产的格式,common是tomcat提供的一个标准设置格式。其具体的表达式为 %h %l %u %t "%r" %s %b
但本人建议采用以下具体的配置,因为标准配置有一些重要的日志数据无法生。
%h %l %u %t "%r" %s %b %T
具体的日志产生样式说明如下(从官方文档中摘录):
* %a - Remote IP address
* %A - Local IP address
* %b - Bytes sent, excluding HTTP headers, or '-' if zero
* %B - Bytes sent, excluding HTTP headers
* %h - Remote host name (or IP address if resolveHosts is false)
* %H - Request protocol
* %l - Remote logical username from identd (always returns '-')
* %m - Request method (GET, POST, etc.)
* %p - Local port on which this request was received
* %q - Query string (prepended with a '?' if it exists)
* %r - First line of the request (method and request URI)
* %s - HTTP status code of the response
* %S - User session ID
* %t - Date and time, in Common Log Format
* %u - Remote user that was authenticated (if any), else '-'
* %U - Requested URL path
* %v - Local server name
* %D - Time taken to process the request, in millis
* %T - Time taken to process the request, in seconds
There is also support to write information from the cookie, incoming header, the Session or something else in the ServletRequest. It is modeled after the apache syntax:
* %{xxx}i for incoming headers
* %{xxx}c for a specific cookie
* %{xxx}r xxx is an attribute in the ServletRequest
* %{xxx}s xxx is an attribute in the HttpSession
现在我们回头再来看一下下面这个配置 %h %l %u %t "%r" %s %b %T 生产的访问日志数据,我们可以做哪些事?
先看一下,我们能得到的数据有:
* %h 访问的用户IP地址
* %l 访问逻辑用户名,通常返回'-'
* %u 访问验证用户名,通常返回'-'
* %t 访问日时
* %r 访问的方式(post或者是get),访问的资源和使用的http协议版本
* %s 访问返回的http状态
* %b 访问资源返回的流量
* %T 访问所使用的时间
有了这些数据,我们可以根据时间段做以下的分析处理(图片使用jfreechart工具动态生成):
* 独立IP数统计
* 访问请求数统计
* 访问资料文件数统计
* 访问流量统计
* 访问处理响应时间统计
* 统计所有404错误页面
* 统计所有500错误的页面
* 统计访问最频繁页面
* 统计访问处理时间最久页面
* 统计并发访问频率最高的页面

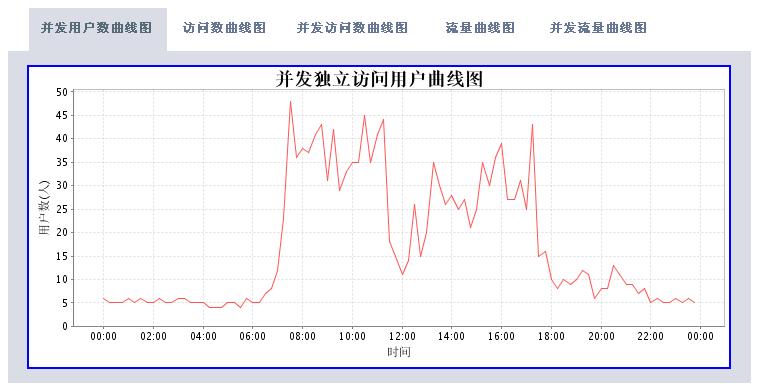
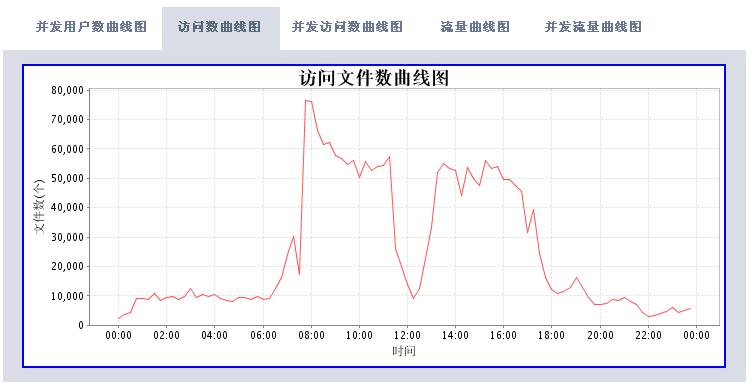
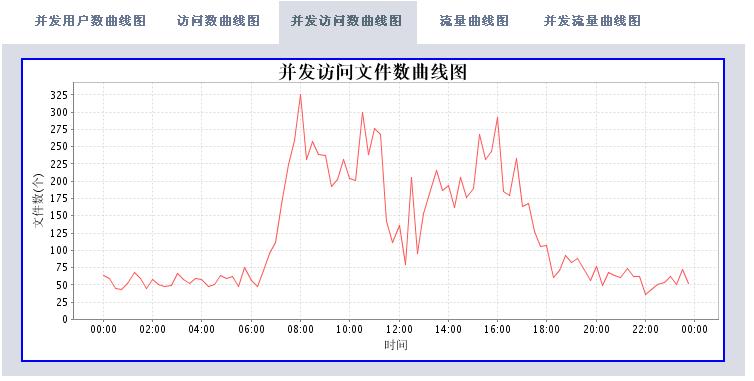
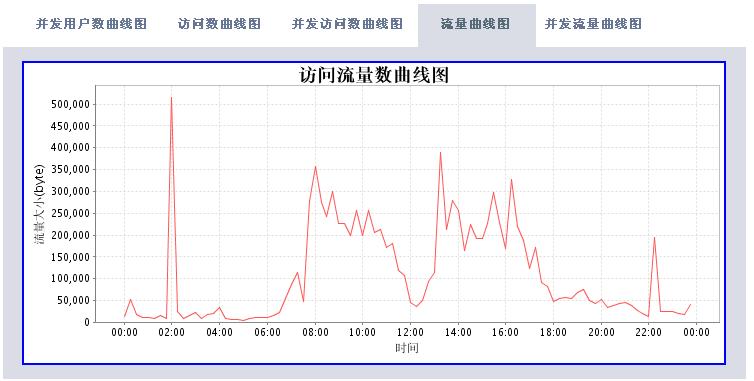
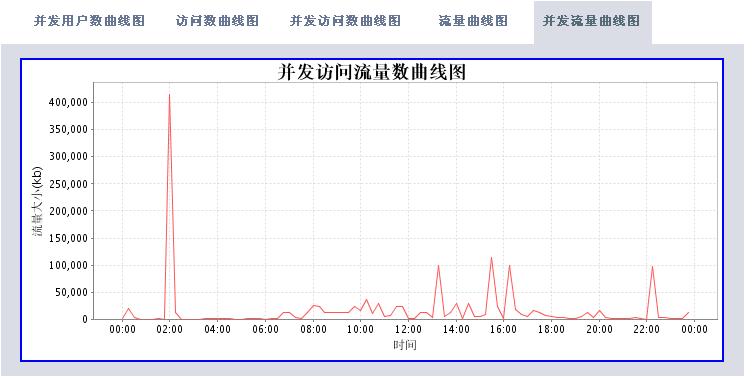

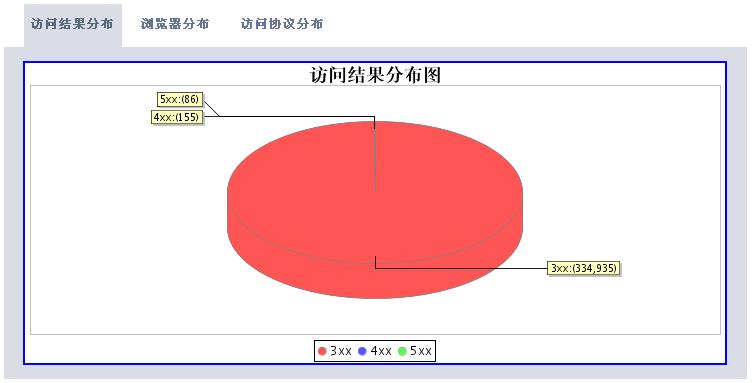
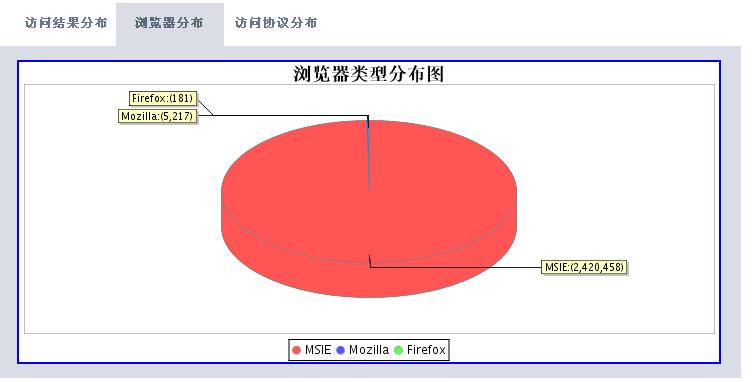
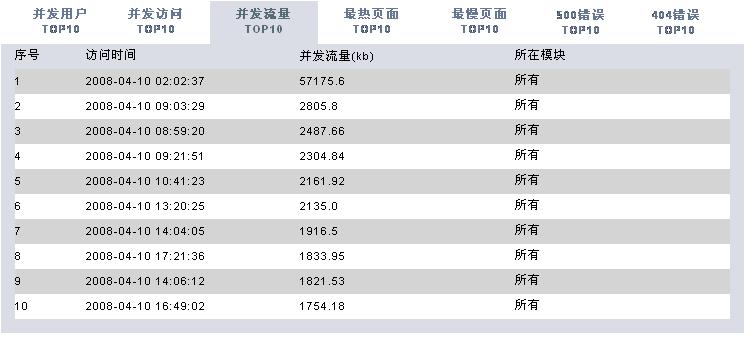
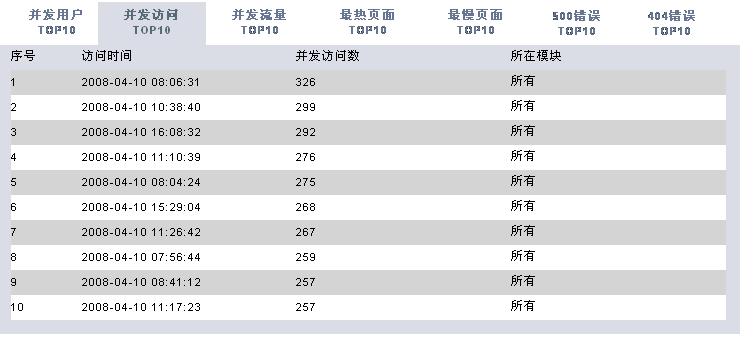
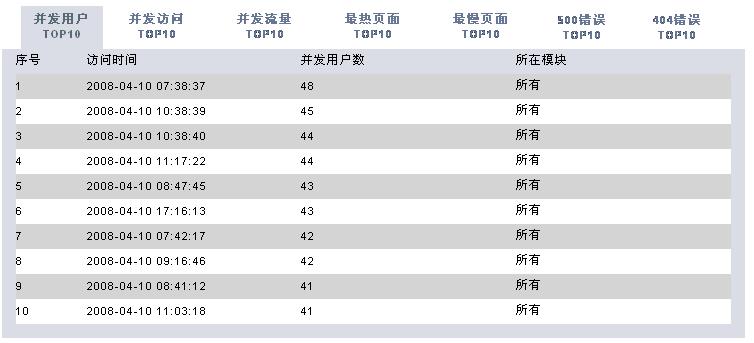

分析工具包括两大部分,一个是后台解释程序,每天执行一次对后台日志数据进行解析后保存到数据库中。
第二个是显示程序,从数据库中查询数据并生成相应的图表信息。
posted @
2008-04-15 12:06 xnabx 阅读(586) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-04-09 08:50 xnabx 阅读(36) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-03-19 13:00 xnabx 阅读(220) |
评论 (0) |
编辑 收藏如果你觉得你的Eclipse在启动的时候很慢(比如说超过20秒钟),也许你要调整一下你的Eclipse启动参数了,以下是一些``小贴士'':
1. 检查启动Eclipse的JVM设置。 在Help\About Eclipse SDK\Configuration Detail里面,你可以看到启动Eclipse的JVM。 这个JVM和你在Eclipse中设置的Installed JDK是两回事情。 如果启动Eclipse的JVM还是JDK 1.4的话,那最好改为JDK 5,因为JDK 5的性能比1.4更好。
C:\eclipse\eclipse.exe -vm "C:\Program Files\Java\jdk1.5.0_08\ bin\javaw.exe"
2. 检查Eclipse所使用的heap的大小。 在C:\eclipse目录下有一个配置文件eclipse.ini,其中配置了Eclipse启动的默认heap大小
-vmargs
-Xms40M
-Xmx256M
所以你可以把默认值改为:
-vmargs
-Xms256M
-Xmx512M
当然,也可以这样做,把堆的大小改为256 - 512。
C:\eclipse\eclipse.exe -vm "C:\Program Files\Java\jdk1.5.0_08\ bin\javaw.exe" -vmargs -Xms256M -Xmx512M
3. 其他的启动参数。 如果你有一个双核的CPU,也许可以尝试这个参数:
-XX:+UseParallelGC
让GC可以更快的执行。(只是JDK 5里对GC新增加的参数)
posted @
2007-12-25 10:55 xnabx 阅读(525) |
评论 (0) |
编辑 收藏Java对多线程的支持与同步机制深受大家的喜爱,似乎看起来使用了synchronized关键字就可以轻松地解决多线程共享数据同步问题。到底如何?――还得对synchronized关键字的作用进行深入了解才可定论。
总的说来,synchronized关键字可以作为函数的修饰符,也可作为函数内的语句,也就是平时说的同步方法和同步语句块。如果再细的分类,synchronized可作用于instance变量、object reference(对象引用)、static函数和class literals(类名称字面常量)身上。
在进一步阐述之前,我们需要明确几点:
A.无论synchronized关键字加在方法上还是对象上,它取得的锁都是对象,而不是把一段代码或函数当作锁――而且同步方法很可能还会被其他线程的对象访问。
B.每个对象只有一个锁(lock)与之相关联。
C.实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
接着来讨论synchronized用到不同地方对代码产生的影响:
假设P1、P2是同一个类的不同对象,这个类中定义了以下几种情况的同步块或同步方法,P1、P2就都可以调用它们。
1. 把synchronized当作函数修饰符时,示例代码如下:
Public synchronized void methodAAA()
{
//….
}
这也就是同步方法,那这时synchronized锁定的是哪个对象呢?它锁定的是调用这个同步方法对象。也就是说,当一个对象P1在不同的线程中执行这个同步方法时,它们之间会形成互斥,达到同步的效果。但是这个对象所属的Class所产生的另一对象P2却可以任意调用这个被加了synchronized关键字的方法。
上边的示例代码等同于如下代码:
public void methodAAA()
{
synchronized (this) // (1)
{
//…..
}
}
(1)处的this指的是什么呢?它指的就是调用这个方法的对象,如P1。可见同步方法实质是将synchronized作用于object reference。――那个拿到了P1对象锁的线程,才可以调用P1的同步方法,而对P2而言,P1这个锁与它毫不相干,程序也可能在这种情形下摆脱同步机制的控制,造成数据混乱:(
2.同步块,示例代码如下:
public void method3(SomeObject so)
{
synchronized(so)
{
//…..
}
}
这时,锁就是so这个对象,谁拿到这个锁谁就可以运行它所控制的那段代码。当有一个明确的对象作为锁时,就可以这样写程序,但当没有明确的对象作为锁,只是想让一段代码同步时,可以创建一个特殊的instance变量(它得是一个对象)来充当锁:
class Foo implements Runnable
{
private byte[] lock = new byte[0]; // 特殊的instance变量
Public void methodA()
{
synchronized(lock) { //… }
}
//…..
}
注:零长度的byte数组对象创建起来将比任何对象都经济――查看编译后的字节码:生成零长度的byte[]对象只需3条操作码,而Object lock = new Object()则需要7行操作码。
3.将synchronized作用于static 函数,示例代码如下:
Class Foo
{
public synchronized static void methodAAA() // 同步的static 函数
{
//….
}
public void methodBBB()
{
synchronized(Foo.class) // class literal(类名称字面常量)
}
}
代码中的methodBBB()方法是把class literal作为锁的情况,它和同步的static函数产生的效果是一样的,取得的锁很特别,是当前调用这个方法的对象所属的类(Class,而不再是由这个Class产生的某个具体对象了)。
记得在《Effective Java》一书中看到过将 Foo.class和 P1.getClass()用于作同步锁还不一样,不能用P1.getClass()来达到锁这个Class的目的。P1指的是由Foo类产生的对象。
可以推断:如果一个类中定义了一个synchronized的static函数A,也定义了一个synchronized 的instance函数B,那么这个类的同一对象Obj在多线程中分别访问A和B两个方法时,不会构成同步,因为它们的锁都不一样。A方法的锁是Obj这个对象,而B的锁是Obj所属的那个Class。
小结如下:
搞清楚synchronized锁定的是哪个对象,就能帮助我们设计更安全的多线程程序。
还有一些技巧可以让我们对共享资源的同步访问更加安全:
1. 定义private 的instance变量+它的 get方法,而不要定义public/protected的instance变量。如果将变量定义为public,对象在外界可以绕过同步方法的控制而直接取得它,并改动它。这也是JavaBean的标准实现方式之一。
2. 如果instance变量是一个对象,如数组或ArrayList什么的,那上述方法仍然不安全,因为当外界对象通过get方法拿到这个instance对象的引用后,又将其指向另一个对象,那么这个private变量也就变了,岂不是很危险。这个时候就需要将get方法也加上synchronized同步,并且,只返回这个private对象的clone()――这样,调用端得到的就是对象副本的引用了。
posted @
2007-10-11 14:19 xnabx 阅读(308) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2007-07-29 09:17 xnabx 阅读(416) |
评论 (0) |
编辑 收藏