1、ssh 登录linux时,报: ssh_exchange_identification: Connection closed by remote host
google了好一阵,才找到线索。主要由于我前晚写shell脚本调试的时候,误将一些系统文件的宿主为新用户了。后来新的会话怎么都登录不上去了,好在还有一个root登录的会话,找到/var/empty/sshd,修改宿主及权限。
chown -R root:root /var/empty/sshd
chmod 700 /var/empty/sshd
2、su 切换用户,输入密码总是提示:密码不正确。
也是权限问题,root切到其他账号时没有问题;其他账号之间切换就是不行,密码输入也正确。后来其到/bin/su 文件的权限不正确,调整如下解决问题:
-rwsr-xr-x 1 root root 61144 Jul 30 2007 /bin/su
posted @
2009-08-13 18:34 josson 阅读(255) |
评论 (0) |
编辑 收藏
一般业务系统中总会存在一些基础数据,在其他的业务单据中会被套引用。因此,系统必须保证这些被业务单据引用的基础数据不能任意的删除。最常见的做法就是,在删除基础数据时,预先校验该类数据是否在相关业务表中存在,若不存在才允许用户删除,否则给用户以提示。
但这样的处理方法,有些缺点,就是需要编码对每个业务类提供查询方法,或在删除逻辑中增加判断逻辑。因此,每次引用关系变化,增加或减少时免不了要修改原来的逻辑,时间越长,系统的维护成本就越来越高了。因此,有必要对系统进行重构,将这类的处理逻辑进行抽象,单独封装成一个服务,当引用关系有变更时,不用再修改原有逻辑,通过配置就可以完成变更。
通用引用关系查询服务,主要就是通过db表或xml配置文件,对系统中每个基础数据有引用的所有关系进行定义,定义属性主要是引用的表及字段名称。查询时,从配置文件中读取指定类别的引用关系,并逐一查询这些表中的记录,以确定数据是否被引用。这种处理方法的优点为,易扩展、可维护性强,引用关系变更时,仅通过维护配置文件,不必进行编码,就能实现,这样能大大的提高系统的稳定性。
xml配置文件如下:
<rule bizName='product' desc="产品关联项定义">
<item>
<refTable>sale_item</refTable>
<refField>product_id</refField>
<!-- 用于查询条件的扩展,允许为空 -->
<extCondition>CORP_ID = #corpId#</extCondition>
</item>
<item>
<refTable>sale_order_item</refTable>
<refField>product_id</refField>
<extCondition>CORP_ID = #corpId#</extCondition>
</item>
</rule>
<rule bizName='customer' desc="客户关联项定义">
<item>
<refTable>sale_order</refTable>
<refField>cust_id</refField>
<extCondition>CORP_ID = #corpId#</extCondition>
</item>
<item>
<refTable>sale_bill</refTable>
<refField>cust_id</refField>
<extCondition></extCondition>
</item>
... ...
</rule>
通用业务引用查询类代码片段如下:
public class BizReferenceService implements IBizReferenceService {
private static Map<String,List<BizReferenceRule>> ruleMaps;
private static final String PATTERN = "#[\\w]+#";
private static final String CFG_FILE = "bizReferenceRule.xml";
... ...
/**
* 查询指定业务数据是否被其他业务表关联依赖.
* @param bizName 关联业务名称
* @param bizId 关联业务ID.
* @param extParam 扩展条件
* @return true 被关联/false 未被关联.
*/
public boolean isBizReference(String bizName,String bizId,Map<String,Object>extParam) throws ServiceException {
Assert.notNull(bizName, "业务名称不能为空,bizName is NULL。");
Assert.notNull(bizId, "记录ID不能为空,bizId is NULL。");
try {
//逐个检查依赖项是否有数据关联.
List<BizReferenceRule> rules = getBizRelationRule(bizName);
for(BizReferenceRule rule : rules){
StringBuilder sqlBuilder = new StringBuilder();
sqlBuilder.append("select count(*) from ").append(rule.getRelTable()).append(" where ")
.append(rule.getRelField()).append("='").append(bizId).append("' ");
String extConditon = rule.getExtCondition();
if(StringUtil.isNotBlank(extConditon)){
initTenantParam(extParam);
sqlBuilder.append(" and ").append(getExtParamSql(extConditon,extParam));
}
logger.debug(sqlBuilder);
int nCount = bizReferenceDao.getBizRelationCount(sqlBuilder.toString());
if (nCount != 0) return true;
}
return false;
}
catch(Exception ex){
logger.error("调用业务关联服务错误。"+bizName+",bizId:"+bizId+",extParam"+LogUtil.parserBean(extParam),ex);
throw new ServiceException("调用业务关联服务错误。");
}
}
/**
* 组装扩展查询条件的sql
* @param condition
* @param extParam
* @return
* @throws Exception
*/
private String getExtParamSql(String condition,Map<String,Object>extParam) throws Exception {
List<String> paramList = parseDyncParam(condition);
for(String param : paramList){
String simpleParam = simpleName(param);
if(!extParam.containsKey(simpleParam)){
throw new ServiceException("动态参数值未设置! param:"+param+",extParam:"+LogUtil.parserBean(extParam));
}
condition = condition.replaceAll(param, "'"+String.valueOf(extParam.get(simpleParam))+"'");
}
return condition;
}
/**
* 解析扩展查询条件中的动态参数名.
* @param condition
* @return
* @throws Exception
*/
private List<String> parseDyncParam(String condition) throws Exception {
PatternCompiler compiler = new Perl5Compiler();
PatternMatcher matcher = new Perl5Matcher();
MatchResult result = null;
PatternMatcherInput input = null;
List<String> paramList = new ArrayList<String>();
input = new PatternMatcherInput(condition);
Pattern pattern = compiler.compile(PATTERN,Perl5Compiler.CASE_INSENSITIVE_MASK);
while (matcher.contains(input, pattern)){
result = matcher.getMatch();
input.setBeginOffset(result.length());
paramList.add(result.group(0));
}
return paramList;
}
/**
* 获取业务关联查询规则.
*/
private List<BizReferenceRule> getBizRelationRule(String bizName){
Assert.notNull(bizName, "业务名称不能为空,bizName is NULL。");
//配置定义未加载到内存时,读取配置文件
if(ruleMaps == null){
parseRuleConfig();
if(ruleMaps == null) return null;
}
return ruleMaps.get(bizName);
}
/**
* 读取业务关联规则配置文件
*/
@SuppressWarnings("unchecked")
private synchronized void parseRuleConfig(){
if(ruleMaps != null){
return;
}
//解析业务引用定义文件.

}
/**
* 读取Xml文档
* @return
*/
private Document getXmlDocument(){
InputStream is = null;
try {
ClassLoader loader = Thread.currentThread().getContextClassLoader();
is = loader.getResourceAsStream(CFG_FILE);
SAXBuilder sb = new SAXBuilder();
return sb.build(new BufferedInputStream(is));
}
catch(Exception ex) {
logger.error("读取配置文件错误. file:"+CFG_FILE, ex);
return null;
}
finally {
try {
if(is != null){
is.close();
is = null;
}
}
catch(Exception ex) {
logger.error(ex);
}
}
}
}
其他的一些可选处理方法:
b. 在客户表增加引用计数字段;
需额外维护引用计数字段,在引用的业务逻辑增加或删除记录时,需对该字段的数值进行更新。适用于需要直接查询记录被引用次数的场景,但在集群环境下,需注意并发问题。
posted @
2009-07-14 14:42 josson 阅读(419) |
评论 (0) |
编辑 收藏
在IE、FireFox、Netscape等不同的浏览器里,对于document.body 的 clientHeight、offsetHeight 和 scrollHeight 有着不同的含义,比较容易搞混,现整理一下相关的内容:
clientHeight:在上述浏览器中, clientHeight 的含义是一致的,定义为网页内容可视区域的高度,即在浏览器中可以看到网页内容的高度,通常是工具条以下到状态栏以上的整个区域高度,与具体的网页页面内容无关。可以理解为,
在屏幕上通过浏览器窗口所能看到网页内容的高度。
offsetHeight:关于offsetHeight,ie和firefox等不同浏览中意义有所不同,需要加以区别。在ie中,offsetHeight 的取值为 clientHeight加上滚动条及边框的高度;而firefox、netscape中,其取值为是实际网页内容的高度,可能会小于clientHeight。
scrollHeight:scrollHeight都表示浏览器中网页内容的高度,但稍有区别。在ie里为实际网页内容的高度,可以小于 clientHeight;在firefox 中为网页内容高度,最小值等于 clientHeight,即网页实际内容比clientHeight时,取clientHeight。
clientWidth、offsetWidth 和 scrollWidth 的含义与上述内容雷同,不过是高度变成宽度而已。
若希望clientHeight、offsetHeight和scrollHeight三个属性能取值一致的话,可以通过设置DOCTYPE,启用不同的解析器,如:<!DOCTYPE HTML PUBLIC "DTD XHTML 1.0 Transitional">,设置DOCTYPE后,这三个属性都表示实际网页内容的高度。
通过以下HTML代码,可以了解一下这三个属性的含义:
<!DOCTYPE HTML PUBLIC "DTD XHTML 1.0 Transitional"> //设置DOCTYPE
<HTML>
<HEAD>
<TITLE> 测试。 </TITLE>
</HEAD>
<script type='text/javascript'>
window.onload = function(){
var ch = document.body.clientHeight;
var sh = document.body.offsetHeight;
var ssh = document.body.scrollHeight;
alert('clientHeight:'+ch+'; offsetHeight:'+sh+"; scrollHeight:"+ssh);
}
</script>
<BODY style='margin:0px'>
<div style='background-color:#ccc; height:400px; padding:0px'>
text
</div>
</BODY>
</HTML>
根据页面内容调整窗口高度的方法:
Ext.util.ResizeWin = function() {
try {
var sh = document.documentElement.scrollHeight
|| document.body.scrollHeight;
var ch = document.documentElement.clientHeight
|| document.body.clientHeight;
window.resizeBy(0,(sh-ch));
}catch (e){}
};
posted @
2009-06-14 16:48 josson 阅读(1542) |
评论 (0) |
编辑 收藏
我们通常依赖单元测试工具Luntbuild,来发现代码中有许多隐藏的错误或不良的编码,然后再去修正。这样从发现问题,到解决问题花费很多功夫。其实我们可以利用一些java代码分析工具,来及时发现相关的问题。如findbugs,luntbuild就是集成了findbugs插件来发现一些代码上的问题。
findbugs 当前版本为:1.3.9,其下载地址如下(包括eclipse插件):
findbugs :http://findbugs.sourceforge.net/index.html
findbugs for eclipse : http://findbugs.sourceforge.net/downloads.html
documents: http://findbugs.sourceforge.net/manual/
插件安装比较简单,将findbugs for eclipse 插件文件(zip)下载后,直接解压至$eclipse.home$/plugins/目录下,重启eclipse即可使用。你可以通过查看:(eclipse 3.4) about ecliplse platform -> plug-ins details 中找到findbugs 插件安装信息。
Findbugs 的使用:
在Package Explorer或Navigator视图中,选中你的Java项目,右键,可以看到“Find Bugs”菜单项,子菜单项里有“Find Bugs”和“Clear Bug Markers”等项。点击Find Bugs 后,开始分析项目中隐藏的代码问题,发现的问题会在相应的代码行上进行标记,或者在Bug Explorer中显示所有的问题(findbug视图,window -> show view -> others 可以找到Bug Explorer.) 我们就可以根据findbugs发现的问题,进行逐一解决,提高代码质量。
Findbugs 的一些配置说明:
FindBugs是一个基于“Bug Patterns”进行分析并找出Java程序中隐藏的Bugs。打开 Window -> preferences ,对findbugs 的分析规则进行定义,如图:
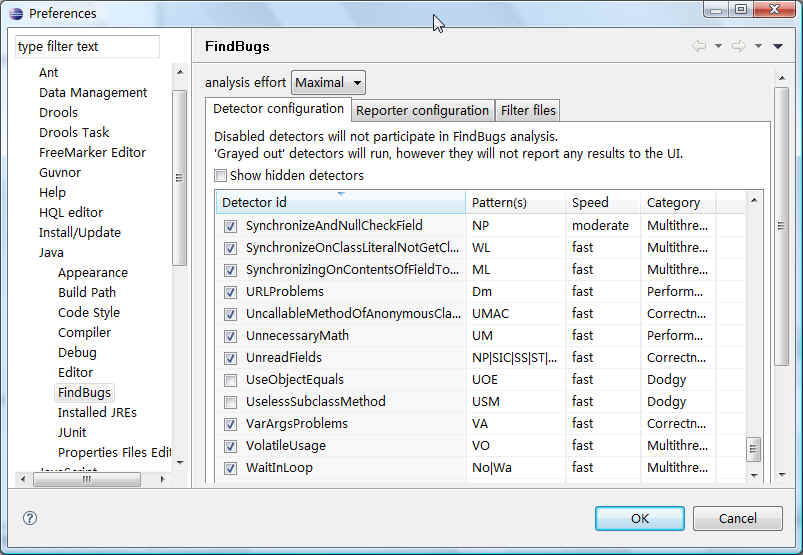
posted @
2009-06-13 23:55 josson 阅读(1275) |
评论 (0) |
编辑 收藏
http://java.decompiler.free.fr/
一个不错的java反编译工具,有gui及eclipse插件。
posted @
2009-05-21 08:34 josson 阅读(268) |
评论 (0) |
编辑 收藏
实现javascript文件压缩的批处理脚本,脚本完成的内容:
1、利用一个windows script 删除js文件中的空白字符及注释;
2、通过gzip.exe 将js文件压缩打包成gzjs文件。gzip.exe 下载地址:
http://www.gzip.org
相关文件请下载附件:
js 压缩批处理 。
使用方法:
a. 双击运行 gzjs.bat ,提示输入javascript文件名(带路径).
b. 输入待压缩的js文件,或者拖动js文件到command窗口(可直接在eclipse视图中拖动js文件到cmd窗口)。
c. 回车后,在js文件所在目录会生成一个相同文件名的gzjs文件。
批处理文件内容如下:
 @echo off
@echo off
if not "%1" == "" (
set JSFILE=%1
goto ZIPING
)
:INPUT_FILENAME
set /P JSFILE=请输入待压缩的JS文件名:
if "%JSFILE%"=="" (
echo ERROR: JS文件名称必须指定!
goto INPUT_FILENAME
)
:ZIPING
set MINJS_FILENAME=c-ziped.js
if not exist %JSFILE% (
echo ERROR: 文件:%JSFILE%不存在!
goto INPUT_FILENAME
)
rem 压缩Javascript文件.
if exist %MINJS_FILENAME% del %MINJS_FILENAME%
CScript /nologo pack.wsf %JSFILE% >> %MINJS_FILENAME%
if not "%ERRORLEVEL%"=="0" (
echo ERROR: JS文件压缩失败:%JSFILE%
goto END
)
rem 打包js文件为.gzjs
gzip -9 %MINJS_FILENAME%
for %%i in ("%JSFILE%") do (
set FILENAME=%%~ni
set JS_FILEPATH=%%~di%%~pi
rem echo %JS_FILEPATH%
)
rem 压缩文件名及重命名的文件名.
set GZIPED_FILE=%FILENAME%.gzjs
set TMP_GZIPED_FILE="%MINJS_FILENAME%.gz"
rem 重命名.
if exist %GZIPED_FILE% del %GZIPED_FILE%
call ren %TMP_GZIPED_FILE% %GZIPED_FILE%
if not "%ERRORLEVEL%"=="0" (
echo ERROR: JS压缩文件打包失败:%TMP_GZIPED_FILE%
goto END
)
rem 移动压缩文件到源目录.
set TARGET_GZJS=%JS_FILEPATH%%GZIPED_FILE%
call move /Y %GZIPED_FILE% %TARGET_GZJS%
echo done. %TARGET_GZJS%
:END
pause
Apache配置,以支持gzjs文件格式(http header的Content-Encoding=gzip):
<FilesMatch "\.gzjs$">
Header add Content-Encoding gzip
</FilesMatch>
posted @
2009-03-19 22:22 josson 阅读(1128) |
评论 (0) |
编辑 收藏
一、Use Case 概述 Use Case,它描述的是一个操作,而不是一个功能。传统的软件模型设计喜欢在需求分析把业务分解成功能模块,这样的弊端就是混淆了需求和设计的界限,因为功能模块的划分牵涉到系统的概要设计。在RUP里面提倡用use case来代替功能模块的划分。与功能模块不同的是,用例是站在用户的角度来分解系统,用户并不想了解系统的内部结构和设计,他们关心的是系统所能提供的服务,即系统是如何去操作的,这就是用例的基本思想。用例模型主要由以下元素组成:
1、参与者(Actor):参与者是与系统发生交互的外部用户、系统或其他硬件设备,参与者可以是人、另一个计算机系统或一些可运行的进程等。
2、用例(Use Case):用例用于表示系统所提供的服务,它定义了系统是如何被参与者所使用的,它描述的是参与者为了使用系统所提供的某一完整功能而与系统之间发生的一段对话。
3、通讯关联(Communication Association) :通讯关联用于表示参与者和用例之间的对应关系,它表示参与者使用了系统中的哪些服务(用例),或者说系统所提供的服务(用例)是被哪些参与者所使用的。
二、用例之间的关系
1、包含(include),将若干用例中一些相同的行为,单独抽象成一个的用例,然后其他用例来包含这个用例。这样避免在多个用例里面重复设计同一个操作,也避免同一个操作在不同的用例里面的描述出现不一致。需要修改的时候,也只需要一个用例,避免修改多个用例出现的不一致和重复工作。例如:银行ATM系统,用户取款、存款时,都会打印凭证,我们将打印凭证抽象出来,取款、存款等操作时包含打印任证这个行为。

2、扩展(extend),扩展是将事件流中一些相对独立并且可选的行为扩展为新的用例,并且在基用例上的扩展点进行扩展。与包含关系不同的是,包含的事件是必须存在的动作,并且该用例的事件流一定要插入到基础用例中;而扩展是提供一些备选动作,可根据条件来决定是否将扩展用例的事件流插入基础用例的事件流中。扩展也可以抽象为基用例的备选流,扩展出来的用例可以让基用例变得更加简练。例如:在通话业务的基础上可扩展一些增值业务,如语音信箱、呼叫转移等。

3、泛化(generalization) ,也叫继承(泛化是分析领域术语,继承是设计和实现领域术语,通常用继承来解决泛化问题)。当多个用例拥有相同的结构、行为时,我们可以把它们的共性部份抽象出来成为父用例,而其他用例作为泛化关系中的子用例。在泛化关系中,子用例是父用例的特殊形式,子用例继承了父用例所有的结构、行为以及关系。例如:订票是网上订票用例和电话订票用例的抽象。

三、建立用例模型
1、确定参与者,可以从以下问题入手:
系统开发完成之后,有哪些人会使用这个系统?
系统需要从哪些人或其他系统中获得数据?
系统会为哪些人或其他系统提供数据?
系统会与哪些其他系统相关联?
系统是由谁来维护和管理的?
2、确定用例,寻找用例可以从以下问题入手(针对每一个参与者):
参与者为什么要使用该系统?
参与者是否会在系统中创建、修改、删除、访问、存储数据?如果是的话,参与者又是如何来完成这些操作的?
参与者是否会将外部的某些事件通知给该系统?
系统是否会将内部的某些事件通知该参与者?
posted @
2009-03-19 22:21 josson 阅读(541) |
评论 (1) |
编辑 收藏UML(统一建模语言 Unified Modeling Language)是一种标准的图形化建模语言,是面向对象分析与设计的一种标准表示。
UML体系统比较复杂,内容较多,我们可以根据实际情况选择性的学习,部份内容可日后再做深入学习。首先了解一下UMl中相关的一些概念:
UML视图
视图只是表达系统某一方面特征的U M L建模组件的子集。按结构划分,描述系统中的结构成员及其相互关系,包括静态视图、用例视图和实现视图。按动态行为划分,描述系统随时间变化的行为,包括状态机视图、活动视图和交互视图。模型管理,说明了模型的分层组织结构,包括模型管理视图。
|
主要的域
|
视图
|
图
|
主要概念
|
|
结构
|
静态视图
|
类图
|
类、关联、泛化、依赖关系、实现、接口
|
|
用例视图
|
用例图
|
用例、角色、关联、扩展、包括、用例泛化
|
|
实现视图
|
构件图
|
构件、接口、依赖关系、实现
|
|
部署视图
|
部署图
|
节点、构件、依赖关系、位置
|
|
状态
|
状态机视图
|
状态图
|
状态、事件、转换、动作
|
|
活动视图
|
活动图
|
状态、活动、完成转换、分叉、结合
|
|
交互视图
|
顺序图
|
交互、对象、消息、激活
|
|
|
协作图
|
协作、交互、协作角色、消息
|
|
模型管理
|
模型管理视图
|
类图
|
包、子系统、模型
|
|
可扩展性
|
所有
|
所有
|
约束、构造型、标记值
|
UML 图
图是一个具体视图的组成部分,由模型元素的符号化的图片组成。UML中包含以下9种:
1、用例图(use-case diagram),用于显示若干角色(actor)以及这些角色与系统提供的用例之间的连接关系。角色代表外部实体,如用户、硬件设备或与系统发生交互的另一个外部系统。
2、类图(class diagram),用来表示系统中的类和类与类之间的关系,是对系统静态结构的描述。
3、对象图,类似于类图,区别在于对象图表示类的对象实例,而不是类。
4、状态图,描述类的所有对象可能具有的状态,以及引起状态变化的事件。
5、序列图,反映若干个对象之间的动态协作关系,也就是随着时间的流逝,对象之间是如何交互的。
6、协作图,其作用同序列图,除了显示消息变化外,协作图还显示对象及其之间的关系。
7、活动图(activity diagram),描述某个操作执行时的活动状况。
8、组件图(component diagram),反应代码的物理结构,可为源代码、二进制文件或可执行文件组件。
9、展开图(deployment diagram),用来显示系统中软件和硬件的物理架构,通常在图中以结点的形式显示实际的计算机和设备,以及各个结点之间的关系。
UML建模工具
1、StarUML http://staruml.sourceforge.net/en/
小巧的建模工具,才20来M,目前版本是 5.0 。是一个韩国人用delphi写的,免费很关键。
2、JUDE http://jude.change-vision.com/jude-web/download/index.html
posted @
2009-03-19 22:21 josson 阅读(344) |
评论 (0) |
编辑 收藏
近日,有同事遇到一个奇怪问题:在开发环境,apache能正常支持中文文件下载,但切换到测试环境就404错误,找不文件,两个环境都是linux系统。我起先怀疑的是linux下需要对apache进行配置,以支持中文名。但研究了一下两个环境的配置,开发环境除apache版本高了点外,并没有其他特殊配置。所以怀疑版本问题,又把开发环境的apache及配置同步到了测试环境,重启依然无效。
折腾半天,基本上可以判定这个问题应该与apache配置和版本无关了。
网上google了一把,有很多关于mod_encoding.so模块实现中文支持和IE浏览器中取消"发送UTF-8 URL"的设置,考虑到开发环境并没有加入额外的module,也没设置IE选项,所以也没在意这些方案,况且这两个方案也不便于生产环境布署或实际应用。
后来,又请教了SA和其他同学,还是没有结果。只能继续摸索,查找原因。通过两个环境的反复比较,终于发现了问题所在:
通过 locale 查看了系统的字符集,开发机上是en_US.UTF-8,而测试机上是zh_CN.GBK;开发机上显示的中文文件名是乱码,测试机上显示正常,但反而显示为乱码的开发机上能被下载,而测试机上显示正常的文件不能被下载。后来,将测试环境的字符集也设为:en_US.UTF-8,并从svn重新迁出了中文名的文件,发现确实可以被读取到。
分析一下原因,ie客户是发送"UTF-8 URL"到apache,apache以utf-8编码的文件名查找相关目录下的文件,如果此时中文文件是以GBK或其他字符集保存时,就无法找到匹配的文件。所以网上说的IE浏览器中取消"发送UTF-8 URL"的设置就有效的说法就可以解释了。
结论:linux环境下apache中文文件下载支持与该文件的字符集有关,只要创建或从svn迁出中文文件文件时,linux系统为UTF-8的字符集,或中文文件名以UTF-8编码的文件,即能被apache正确读取。网上有资料说,apache 2.x 以上版本即支持中文文件名,虽然未经验证,但至少可以肯定apache 2.0.55、2.0.63是没有问题的。
posted @
2009-03-13 21:37 josson 阅读(1191) |
评论 (0) |
编辑 收藏1、常用命令
mvn compile
编译主程序源代码,不会编译test目录的源代码。第一次运行时,会下载相关的依赖包,可能会比较费时。
mvn test-compile
编译测试代码,compile之后会生成target文件夹,主程序编译在classes下面,测试程序放在test-classes下。
mvn test
运行应用程序中的单元测试
mvn site
生成项目相关信息的网站
mvn clean
清除目标目录中的生成结果
mvn package
依据项目生成 jar 文件,打包之前会进行编译,测试。
mvn install
在本地 Repository 中安装 jar。
mvn eclipse:eclipse
生成 Eclipse 项目文件及包引用定义,注意,需确保定义Classpath Variables: M2_REPO,指向本地maven类库目录。
2、pom.xml 说明
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorial.struts2</groupId>
<artifactId>tutorial</artifactId>
<packaging>war</packaging>
<version>1.0-SNAPSHOT</version>
<name>Struts 2 Starter</name>
<url>http://www.myComp.com</url>
<description>Struts 2 Starter</description>
<dependencies>
<!-- Junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
<version>2.5.5</version>
</dependency>
</dependencies>
</project>
说明:
modelversion pom.xml 使用的对象模型版本
groupId 创建项目的组织或团体的唯一 Id
artifactId> 项目唯一Id, 项目名
packaging 打包扩展名(JAR、WAR、EAR)
version 项目版本号
name 显示名,用于生成文档
url 组织站点,用于生成文档
description 项目描述,用于生成文档
dependency之scope 管理依赖部署,取值如下:
compile 缺省值,用于所有阶段,随项目一起发布;
provided 期望JDK、容器或使用者提供此依赖。如servlet.jar;
runtime 只在运行时使用;
test 只在测试时使用,不随项目发布;
system 需显式提供本地jar,不在代码仓库中查找;
3、创建Maven Web项目
mvn archetype:generate -DgroupId=com.demo -DartifactId=web-app -DarchetypeArtifactId=maven-archetype-webapp
groupId 组织名,对应项目的package;artifactId 项目名;archetypeArtifactId 项目类型
posted @
2009-02-27 17:42 josson 阅读(1137) |
评论 (0) |
编辑 收藏