很多人初学mainframe都觉得比较困难,就是因为mainframe不像unix或linux,在自己的PC机上很容易就可以搭建起来。但是mainframe操作系统z/OS又不像AIX,只有在IBM的power机上才可以安装运行。在普通的x86或者x64平台上搭建z/OS的虚拟系统,是完全可行的。当然,理论上讲,Mac OS上也是可以虚拟出z/OS的,只是,还没听说有人试过。
想要在自己的PC上搭建一个z/OS虚拟系统,你需要以下几样东西:
一台PC机,最好有2GHz CPU,1G以上内存,硬盘空间10G足矣
z/OS系统的卷文件。
卷文件有两种,一种是DEMOPKG,只对IBM内部员工发行。另外一种是ADCD,可惜,这一种卷文件也不是免费的,只针对IBM合作伙伴和mainframe用户发行,但是,通过某些非正常途径,也是可以获取到的,只要用于非商业目的,也无大碍,低调一点就好,你懂的。
电驴上一位无私的哥们,也提供了ADCD z/OS 1.9的下载源。地址是:http://www.verycd.com/topics/280391/
本文将以ADCD z/OS 1.6作为范例搭建虚拟z/OS,启动和配置过程与此处下载的1.9并无很大差别。如果哪位需要1.6的卷文件,可以在此留下email。
3270客户端。
- 最常用的当然是IBM Personal Communication,简称PCOM,该软件只能运行于windows平台,并且功能强大,也是最常用的3270客户端。PCOM并非是免费软件,但是你也可以很容易获得该软件,之前提到的verycd链接里就可以下载。同样,保持低调。
- TN3270也是一种不错的选择,虽然TN3270也并非免费,但是你可以通过在其官网注册,即可获得一个evaluation licence,有效期30天。详情请访问TN3270官网:http://www.sdisw.com
- 据我所知,目前唯一免费且开源的3270客户端就是x3270了,可以在http://x3270.bgp.nu下载到源码或者安装包(windows和Linux平台皆可安装)。另外,目前很流行的发行版Ubuntu linux,在其官方源也提供了x3270下载,可以通过命令sudo apt-get install x3270安装。
Hercules
正是有了Hercules,在PC机上虚拟z/OS操作系统才成为了现实。这是一个完全免费开源的软件,Hercules官网http://www.hercules-390.org/提供了hercules在windows,linux和Mac OS平台上的安装包以及源码。该网站上也有许多关于使用和配置hercules的文章,有兴趣可以常上去看看。
另外,如果你使用的是windows系统,为了操作方便,也可以下一个Hercules GUI,下载链接是http://www.softdevlabs.com/Hercules/hercgui-index.html,此处,需要注意一个叫Fish Lib的动态链接库,需要把这个DLL文件解压后跟HercGUI放在同一路径下,这样就不会运行的时候报错了。并且HercGUI要求安装VC Redistributable package,去微软的网站下载安装就好了。
TCP/IP支持软件,可选,不是必须安装的
说这个东东是TCPIP支持软件其实有点勉强。其实是网络封包抓取工具,使用这个可以在hercules上开启tcpip,让你的z/OS系统可以在你的物理局域网中使用FTP,DB2 DRDA等等,对于初学mainframe的人,这个不是必须的。没有这个也一样可以在自己的机器上运行z/OS的。所以,开启TCPIP将会在以后的文章中单独讨论。这里仅仅列出几个可选的封包抓取工具,他们是:CTCI-W32,WinPCap,FishPack和TunTap32。需要注意的是,根据PC机所使用的操作系统版本不同,这类工具所需要的版本也是不一样的,不是任何一种搭配都可以保证成功的在z/OS上开启TCP/IP的。我在Windows XP 32bit上使用WinPCAPC 4.0成功的开启了TCPIP,在win7下就失败了。
在linux下也可以选择一个类似于WinpCap的工具,名为libpcap,Ubuntu的官方源里也可以下载到。
说了这么多,发现有点乱,还是整理一个check list吧
在Windows平台下:
1. http://www.verycd.com/topics/280391/ 下载卷文件(后缀名为CCKD的),PCOM和配置文件zOS1.9.cnf
2. http://www.hercules-390.org/ 下载Hercules 3.07安装包,注意你的系统是32bit还是64bit的,选择相应的下载
3. 安装Microsoft Visual C++ 2008 Service Pack 1 Redistributable Package,google一下就可以了
4. http://www.softdevlabs.com/Hercules/hercgui-index.html 下载Hercules Windows GUI –Version 1.11.1以及FishLib
5. http://www.winpcap.org/ 下载winpcap 4.0
6. http://www.softdevlabs.com/Hercules/ctci-w32-index.html 下载CTCI-W32
在Linux平台下(以Ubuntu为例):
1. http://www.verycd.com/topics/280391/ 下载卷文件(后缀名为CCKD的)和配置文件zOS1.9.cnf
2. http://www.hercules-390.org/ 下载Hercules 3.07 source tarball。redhat也可以下载RPM包
3. 安装x3270,使用命令sudo apt-get update,然后sudo apt-get install x3270
4. 安装LibpCap,使用命令sudo apt-get install libpcap
注:在以上第一步所下载的CCKD文件在linux中直接使用可能会报错,说无法识别的格式。这是因为该CCKD文件是通过windows下的hercules压缩而来。所以,这里需要将CCKD文件在windows中还原为CKD,然后copy到linux下重新压缩为CCKD文件即可。一个3390-3卷对应的CKD文件大约是2.8GB,如果要进行转换,中途可能需要比较多的磁盘空间,压缩完成后,卷文件大小与原CCKD文件基本一样。具体方法在之后讲到在linux下启动z/os的时候再说。
首先,我们约定以下几个路径,以便存放z/OS模拟环境所需的各项文件和程序:
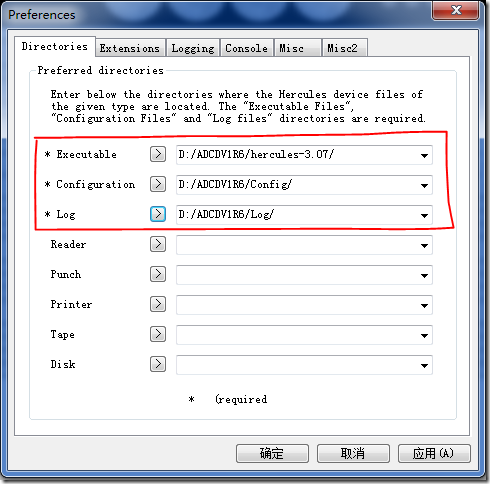
D:\ADCDV1R6 所有与模拟环境相关的东西都放在这个目录下
D:\ADCDV1R6\ZOSV1R6 存放卷文件,即CCKD文件
D:\ADCDV1R6\Config 存放启动配置文件
D:\ADCDV1R6\HercGUI-1.11.1 存放Hercules GUI和FishLib
D:\ADCDV1R6\hercules-3.07 存放Hercules的可执行文件和CTCI-W32
D:\ADCDV1R6\Log 存放系统运行日志
这样安排文件夹,可以把所有与z/OS模拟器运行相关的程序和文件都集中在一起,这样在系统重装,或者换另一台PC机运行的时候,只需要备份D盘下的ADCDV1R6文件夹,并且安装winpcap和PCOM就可以了。
然后,对照《准备工作》一文中的各项下载的文件,对应放入以上文件夹:
1. CCKD文件放入D:\ADCDV1R6\ZOSV1R6,cnf配置文件放入D:\ADCDV1R6\Config,PCOM稍后安装
2. Hercules-3.07,下载ZIP包,解压后放入D:\ADCDV1R6\hercules-3.07,注意不要多设置了一层文件夹,即D:\ADCDV1R6\hercules-3.07下面就是Hercules的运行文件了,而不是解压后的hercules-3.07文件夹,也就是说不要存在一个D:\ADCDV1R6\hercules-3.07\hercules-3.07文件夹。
3. VC++ Redistribute pack,这个自行默认安装就好了。如果已经安装过就跳过这一步。(装了office的机器一般都有这个了,直接跳过)
4. 将HercGUI和FishLib解压缩放入D:\ADCDV1R6\HercGUI-1.11.1
5. WinPCap也是在windows下默认安装就好
6. CTCI-W32压缩包里包括了FishPack, TunTap32和TT32Test,一并解压缩放入D:\ADCDV1R6\hercules-3.07即可。
最后,安装PCOM,一路点下一步,全部用默认设置就可以了。
在运行Hercules之前,还需要编辑一下Config文件夹下的配置文件。在配置文件中,以#开头的行表示注释。需要注意的是如下配置文件中,红色字体所标出的部分。
- LOADPARM是z/OS在IPL时需要用到的参数,参数选择不同,z/OS中启动后,运行的组件也不同,此参数见文章最后所附的LOADPARM Description。
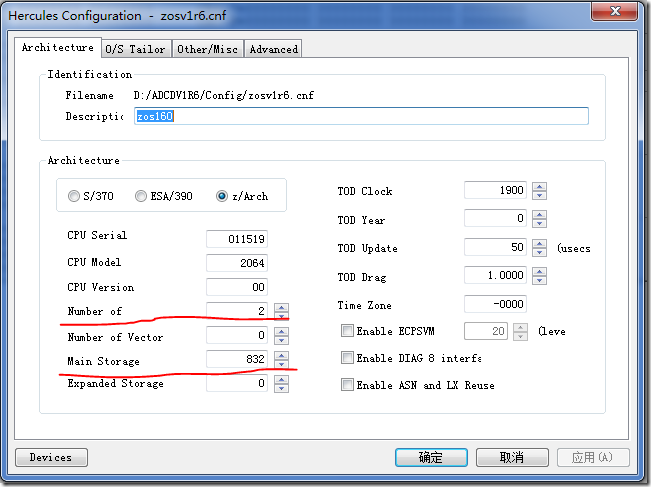
- MAINSIZE表示Hercules占用的物理内存大小,单位是MB,如果内存够大,最好设为1024,在这里暂且设为832,建议不要小于512,否则MIPS会很低,系统运行会非常的慢。
- NUMCPU表示虚拟的主机有多少个CPU,如果CPU不够强悍,就改为1吧,我的物理机上用的是Intel Core-Due E6400,设为2,运行起来速度还不错。
- Display Terminals 表示3270终端的数量,演示所用的3270终端号是从0700开始的,以十六进制记录,如0700-0710则表示16个端口,其中0700是控制台专用端口,0701至0710为用户连接端口。
- 然后是后面的DASD Device那一段,需要注意的是,要把所有下载的CCKD文件都列进去,这一段的每一行分为三个部分,第一个是设备编号,如0A80,第二个是设备类型,如3390,第三个是卷文件的路径和文件名,这里可以写绝对路径也可以是相对路径。个人觉得相对路径比较好,因为写相对路径,在还盘复制后,不需要重新配置这个文件。
- 最后一段CTC Adapters是跟启动TCPIP有关的,这里暂且放在那里,以后再说。
#
# Hercules Emulator Control file...
# Description: zos160
# MaxShutdownSecs: 15
#
#
# System parameters
#
ARCHMODE z/Arch
CNSLPORT 3270
CONKPALV (3,1,10)
CPUMODEL 2064
CPUSERIAL 011519
CPUVERID 00
ECPSVM NO
LOADPARM 0A8232M1
LPARNAME HERCULES
MAINSIZE 832
MOUNTED_TAPE_REINIT DISALLOW
NUMCPU 2
OSTAILOR Z/OS
PANRATE 30
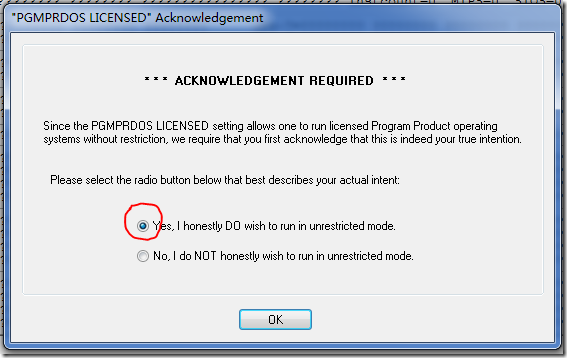
PGMPRDOS LICENSED
SHCMDOPT NODIAG8
SYSEPOCH 1900
TIMERINT 50
TZOFFSET -0000
YROFFSET 0
HERCPRIO 0
TODPRIO -20
DEVPRIO 8
CPUPRIO 15
# Display Terminals
0700-0708 3270
# DASD Devices
0A80 3390 ..\ZOSV1R6\Z6RES1.cckd
0A81 3390 ..\ZOSV1R6\Z6res2.cckd
0A82 3390 ..\ZOSV1R6\Z6SYS1.cckd
0A83 3390 ..\ZOSV1R6\Z6uss1.cckd
0A84 3390 ..\ZOSV1R6\Z6uss2.cckd
0A85 3390 ..\ZOSV1R6\Z6CIC1.cckd
0A86 3390 ..\ZOSV1R6\Z6db81.cckd
0A87 3390 ..\ZOSV1R6\Z6db82.cckd
0A88 3390 ..\ZOSV1R6\Z6ims1.cckd
0A89 3390 ..\ZOSV1R6\Z6was1.cckd
0A8A 3390 ..\ZOSV1R6\Z6was2.cckd
0AC1 3390 ..\ZOSV1R6\page01.cckd
0AC2 3390 ..\ZOSV1R6\page02.cckd
0AC3 3390 ..\ZOSV1R6\dump01.cckd
0AC4 3390 ..\ZOSV1R6\dump02.cckd
0AC5 3390 ..\ZOSV1R6\work01.cckd
0AC6 3390 ..\ZOSV1R6\work02.cckd
0AC7 3390 ..\ZOSV1R6\user01.cckd
0AC8 3390 ..\ZOSV1R6\user02.cckd
0AC9 3390 ..\ZOSV1R6\user03.cckd
0ACA 3390 ..\ZOSV1R6\user04.cckd
0AD1 3390 ..\ZOSV1R6\Z6TL01.CCKD
0AD2 3390 ..\ZOSV1R6\Z6TL02.CCKD
0AD3 3390 ..\ZOSV1R6\Z6TL03.CCKD
0AD4 3390 ..\ZOSV1R6\Z6TL04.CCKD
# CTC Adapters
0E20-0E21 CTCI 192.168.1.110 192.168.1.100
好了,现在就可以开机了。
--------------------------------------------------------------------------------
首先,找到D:\ADCDV1R6\HercGUI-1.11.1\HercGUI.exe (64bit系统中是运行HercGUI64.exe),双击运行后,出现下面的窗口,这就是Hercules GUI了

然后点击菜单栏中的File->Preference,对照本文开始所建的几个文件夹如下,然后确定
然后点击菜单栏中的Command->Power On,选择Config文件夹下的配置文件,打开

出现以下对话框,若不修改CPU数和内存大小,则无需设置,直接确定
然后,在下图对话框中,点选YES,然后OK
确定后,Hercules即开始运行,此时防火墙可能会弹出是否允许Hercules访问网络的报警,全部允许即可。
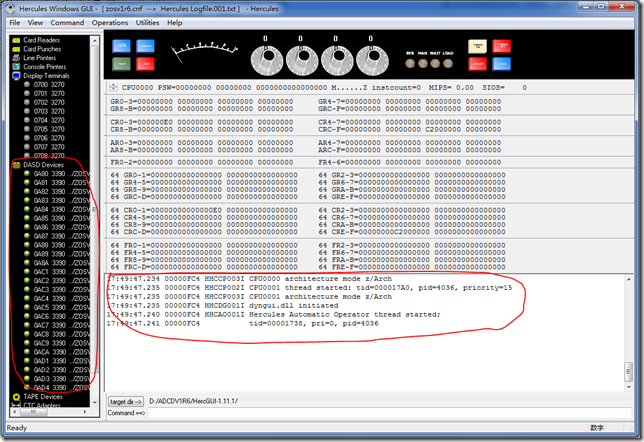
左侧框中会列出所有的卷,然后看右侧最下面的message box,如果没有异常,则Hercules mount所有卷成功。
此时,还没有3270 session连接到mainframe,所以左侧的Display Terminals处只显示了终端号,未显示终端IP。
现在,打开PCOM,开始->IBM Personal Communications->Start or Configure session

点New Session。

点Link Parameters

如上图,填入IP和Port,并且可以勾选Auto-Reconnect。点OK,回到Customize Communication对话框

点Session Parameter
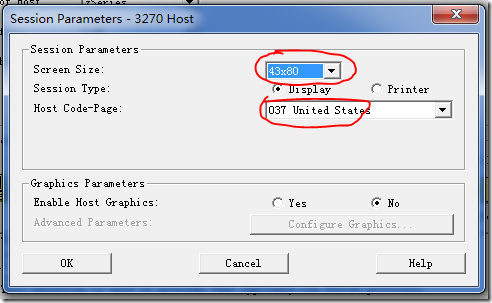
然后一路OK,回到PCOM的Session窗口
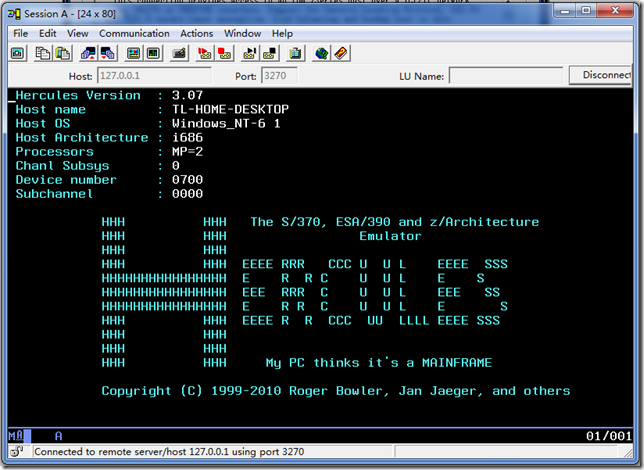
好了,第一个PCOM session已经连上了,看看Device Number,是0700,那么这个session就是控制台了,只要Hercules还在运行,那么这个session就不能关掉,一定要记住这一点。
在这里,可以用Ctrl+Home来定位光标,也可以通过File->Run the same来运行同样的一个session。
此时,最好通过File->Save,来保存一个WS文件,下次直接双击这个WS文件就可以开启session了。
到这里,z/OS还没有开始启动,我们回到Hercules GUI窗口,点菜单栏里的Command->IPL/Load
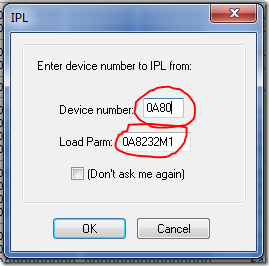
填入上面两项,然后点OK,这是z/OS就开始启动过程了

10.启动错误
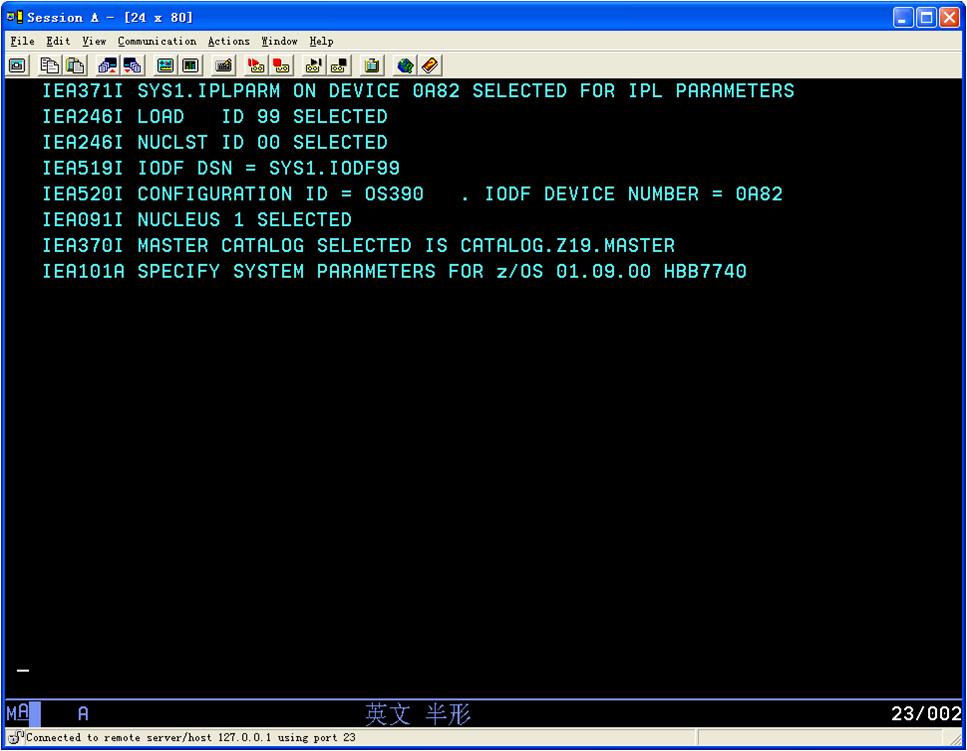
走到这里不动了就回车(MF里面的enter是ctrl)
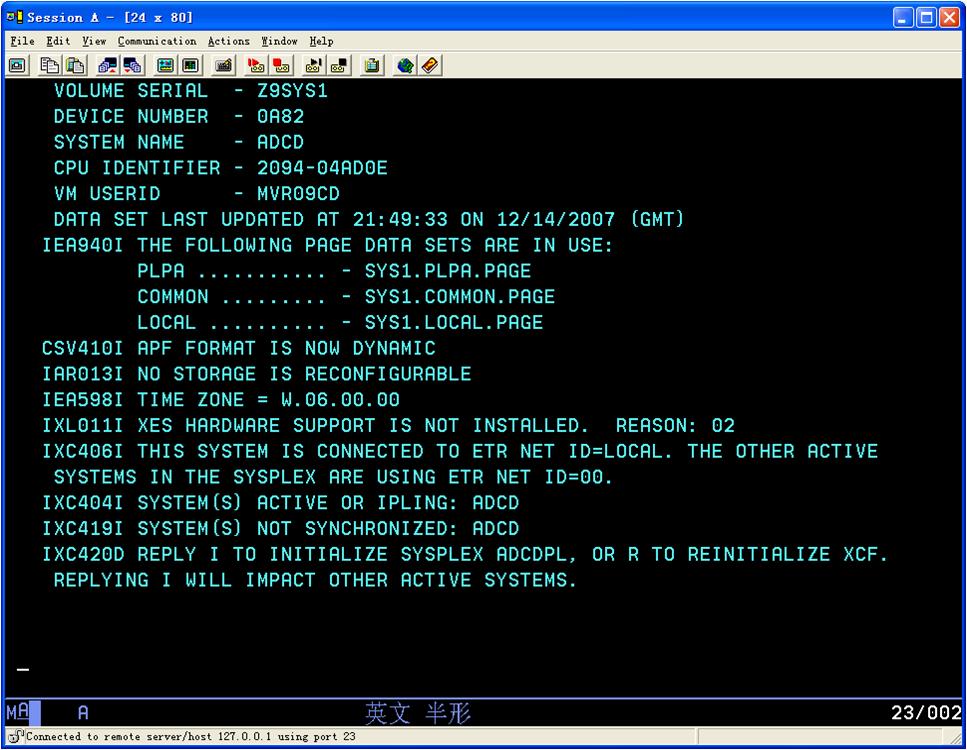
按回车时会提示如何输入
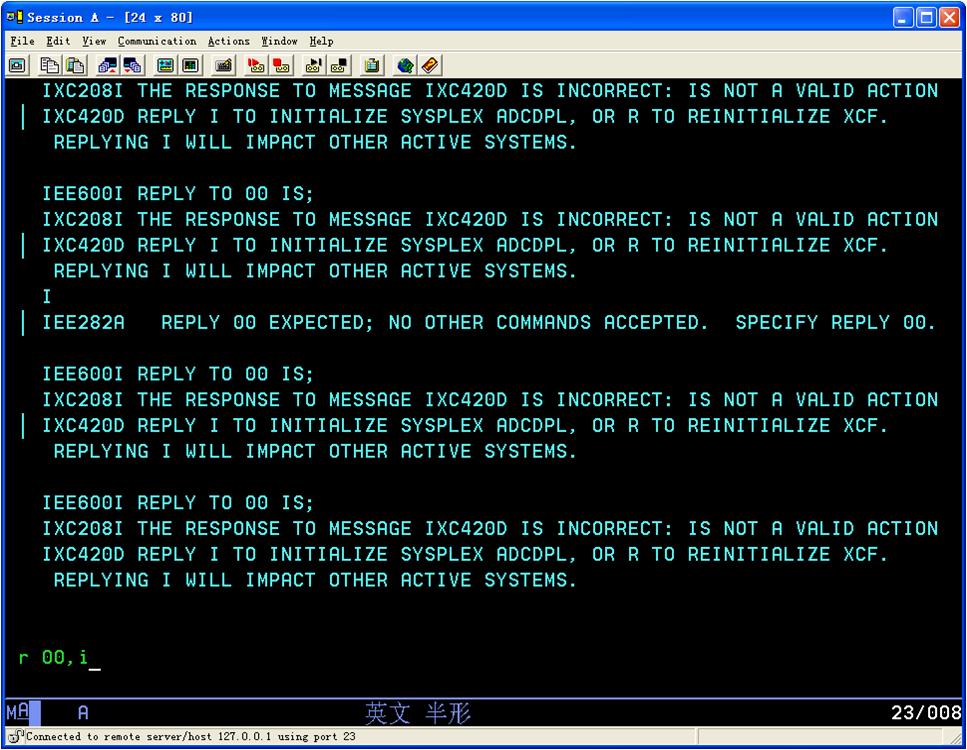
按照提示输入r 00,i

输入s jes2,,,parm='FORMAT,NOREQ'
注:第一次IPL需要JES2 COLD START
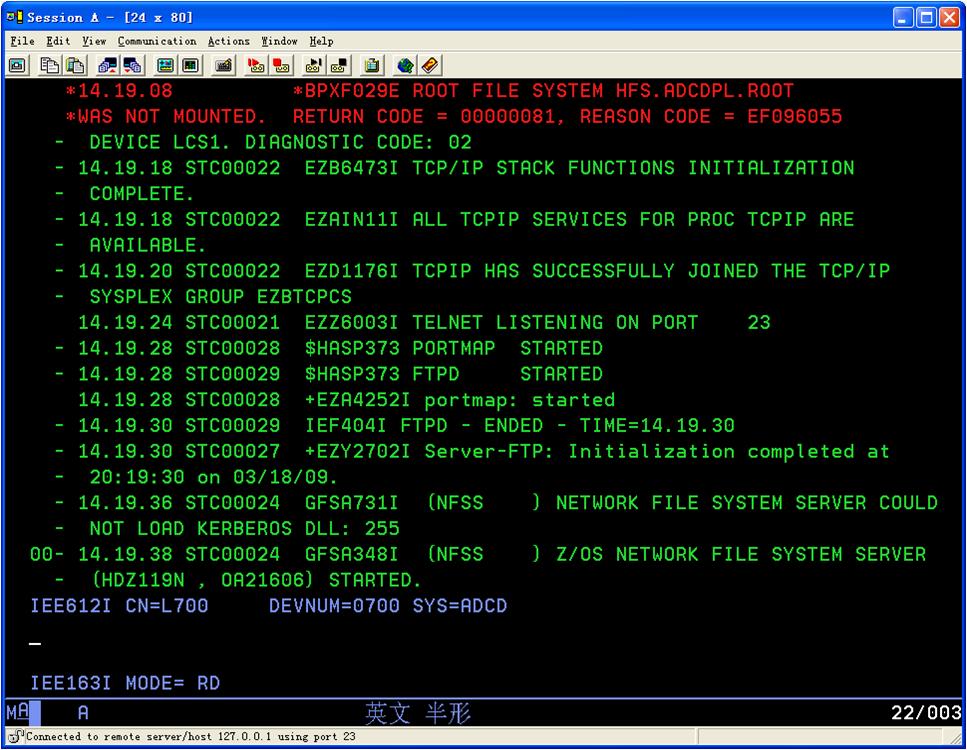
这个要登陆后解决。将HFS开头的data set全部catalog

用d a,l来查看启动起来的服务

11.登陆。
一般运行至少有2个terminal, 通常其中一个为3270 Console(控制大机用的),其它为TSO Terminal。

去掉登陆的打印提示:
[LT]
IgnoreWCCStartPrint=Y
UndefinedCode=Y
UndefinedDBCSChar=Y
PS:在PCOMM中,选择File -> Save As... 你就可以看到你的配置文件(.ws)保存的地方

默认用户 密码 权限
ADCDMST ADCDMST (RACF special authority)
IBMUSER IBMUSER (RACF special authority)
SYSADM SYSADM (DB2 and RACF special auth)
SYSOPR SYSOPR (DB2 and RACF special auth)
ADCDA - ADCDZ TEST
OPEN1 - OPEN3 SYS1
看看Hercules GUI窗口右上角的MIPS参数,这个参数越大,说明你的z/OS运行得越顺畅。如果MIPS很小,可以试试改变配置文件里MAINSIZE的值来调整一下,记住MAINSIZE千万不能大于物理内存,否则,MIPS将会只有零点几。
好了,回到PCOM的控制台session。
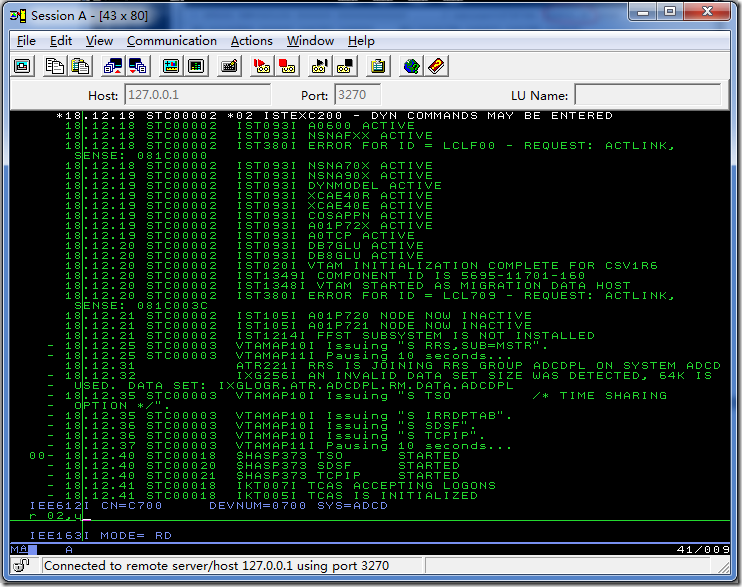
这里,绿色信息代表正常,红色的表示有错误或者警告,白色的信息如果有一个编号(如上图的*02),则需要操作员做应答,这里需要应答的信息是r 02,y
输入后按键盘右边的CTRL键(IBM PCOM默认的确认键是键盘右边的CTRL)
通过PCOM打开一个相同的session。

出现以上画面时,输入logon ibmuser,以IBMUSER用户的身份登录,出现打印信息对话框时,直接cancel就好了。
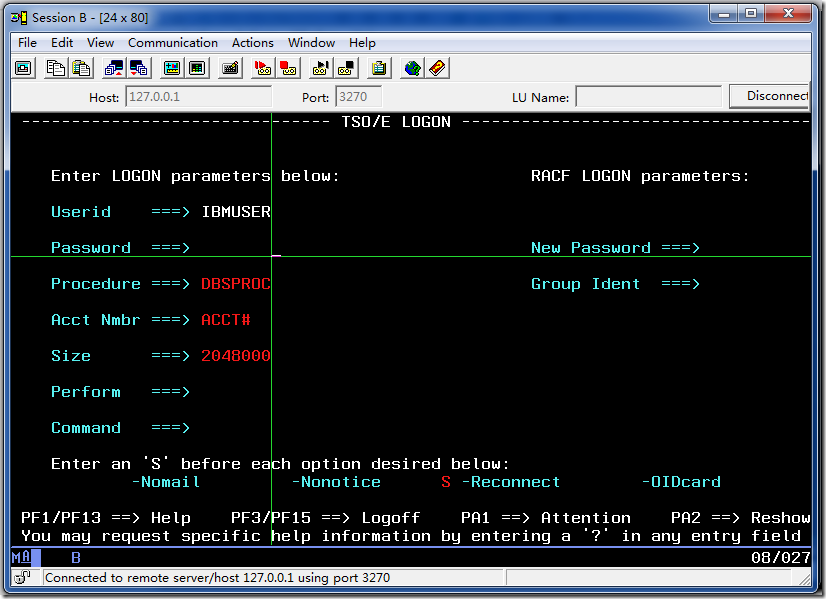
输入IBMUSER用户的密码,然后确认
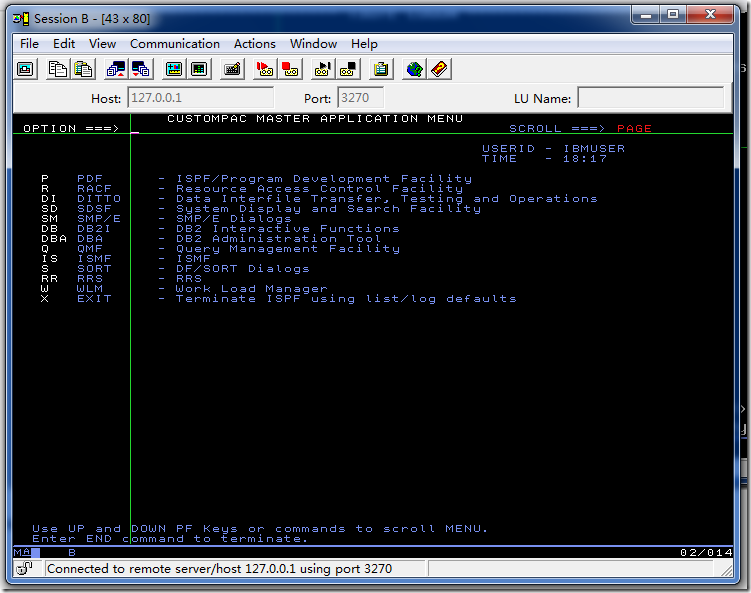
恭喜,成功登陆。到此,启动过程完毕。
--------------------------------------------------------------------------------
下一个问题就是如何关机了。
回到PCOM控制台session

在下面命令行处,输入S Shutdown,按右Ctrl,则z/OS关机过程开始
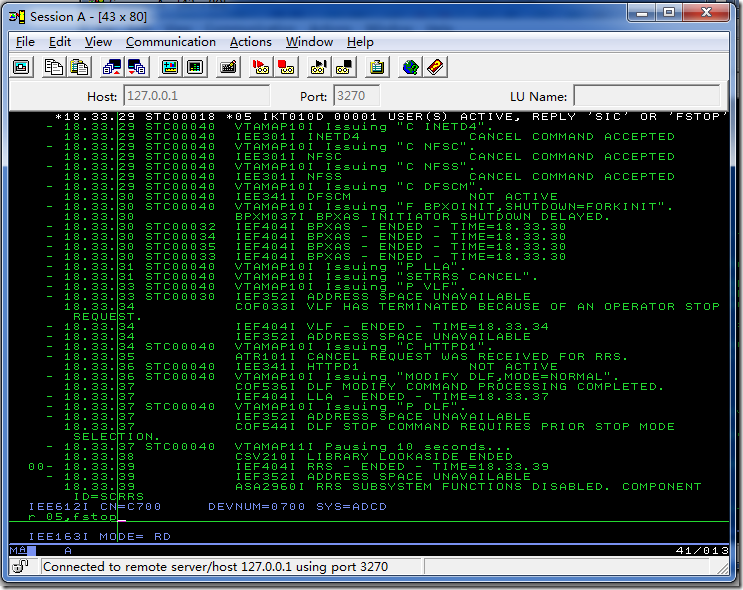
上图所示,出现的*05白色信息表示在关机开始时,还有用户登录到了z/OS,如果不打算等用户退出就关机,在下方输入命令r 05,fstop

几分钟后,出现如上图所示的SHUTDOWN - ENDED信息后,表示z/OS关机过程基本上结束,在下方命令行输入quiesce,确认后回到HercGUI窗口
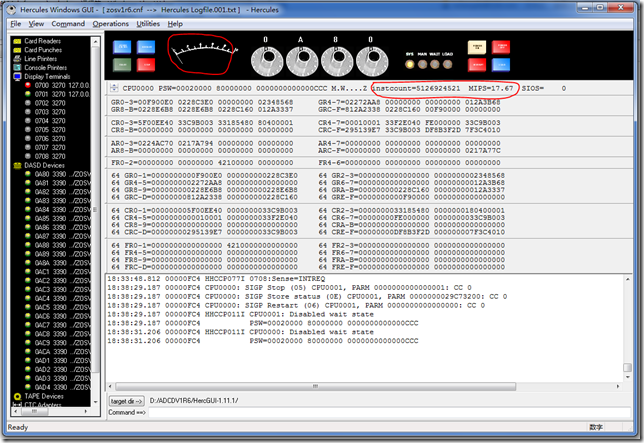
此时,上方的那个指针不在偏转,MIPS和INSTCOUNT数值也不便动了,说明所有CPU都已经停下来了。
点菜单Command->Power Off,关闭Hercules电源
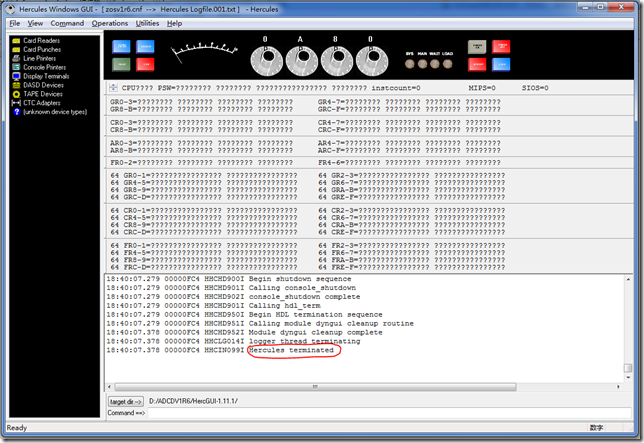
在信息框中出现Hercules terminated之后,可关掉该窗口。
注意:
1. 在启动hercules时,系统可能出现各种需要应答的信息,具体情况要具体分析,不同信息的处理方式是不同的,如果不知道怎么办,把控制台上的信息copy到google里搜一下看看。
2. 为了防止在PCOM登陆z/OS时出现打印对话框,可以用记事本打开保存的PCOM session的WS文件,在文件最后加入如下内容后,保存退出。
[LT]
IgnoreWCCStartPrint=Y
UndefinedCode=Y
UndefinedDBCSChar=Y
3. 关于IPL参数LOADPARM
在启动z/OS的时候,本文所用的启动参数是0A8032M1,这里的32代表冷启动,启动了TSO,CICS,DB2,WAS,JES2。也可以将这里的32换成以下参数来根据需要启动不同的组件
LOADPARM list(z/OS 1.6)
CS CLPA and cold start of JES2. Base z/OS system functions i.e. no CICS, DB2, IMS, WAS, etc.
00 Warm start of JES2. Base z/OS system functions i.e. no CICS, DB2, IMS, WAS, etc.
WS Warm start of JES2. Base z/OS system functions i.e. no CICS, DB2, IMS, WAS, etc.
DC CLPA, brings in CICS LPA modules, cold start of JES2, starts up DB2 and CICS.
DB Warmstart of JES2 and starts the DB2 and CICS.
DI CLPA and cold start of JES2 and loads the IMS Libraries. IMS must be manually started.
CC CLPA and cold start of JES2, loads the CICS Libraries, starts up CICS, no DB2.
CW Warm start of JES2, and starts up CICS.
7C CLPA, cold start of JES2, starts up DB2 V7, no CICS.
7W Warm start of JES2, starts up DB2 V7, no CICS.
8C CLPA, cold start of JES2, starts up DB2 v8, no CICS.
8W Warm start of JES2, starts up DB2 v8, no CICS.
IC CLPA and cold start of JES2 and load the IMS Libraries, start IMS, no DB2 or CICS.
IW Warm start of JES2 start IMS, no DB2 or CICS.
AC CLPA and cold start of JES2 load IMS and CICS libraries, start IMS, DB/2, and CICS.
AW Warmstart of JES2. start IMS, DB/2, and CICS.
BC CLPA and cold start of JES2, load WAS libraries, WAS is manually started
BW Warmstart of JES2. WAS is manually started.
99 Points to IODF99 for IPL on MP3000. Reply 00,SYSP=xx were xx is any of the above options i.e. for cics only
4.ADCD z/OS 1.6卷文件的内容
1, VOLUME的内容(z/OS 1.6)
VOLUME UCB Contents
Z6RES1 A80 - Res Volume 1 - Required for IPL
Z6RES2 A81 - Res Volume 2 - Required for IPL
Z6SYS1 A82 - IPLPARM, JES2 Spool, Public Work Volume, Mastercat required for IPL
Z6USS1 A83 - USS Root and accompanying HFS files - required for IPL
Z6USS2 A84 - Supplemental HFS files - required for IPL
Z6DIS1 A85 - Distribution Lib volume 1
Z6DIS2 A86 - Distribution Lib volume 2
Z6DIS3 A87 - Distribution Lib volume 3
Z6DIS4 A88 - Distribution Lib volume 4
Z6DIS5 A89 - Distribution Lib volume 5
Z6WAS1 A8A - Websphere Application Server Distribution Libs
Z6WAS2 A8B - Websphere Application Server Target Libs
Z6DB81 A8C - DB2 V8.1 Target Libs
Z6DB82 A8D - DB2 V8.1 Distribution Libs
Z6CIC1 A8E - CICS TS 2.3 Target and Dlibs
Z6IMS1 A8F - IMS 8.1 Target and Dlibs
SARES1 A90 - Stand Alone IPL volume
解决登陆时出现的错误。
系统在IPL的时候问IEA101A时,需要确认member LOAD99里面是否有SYSPARM和IEASYM这两个参数

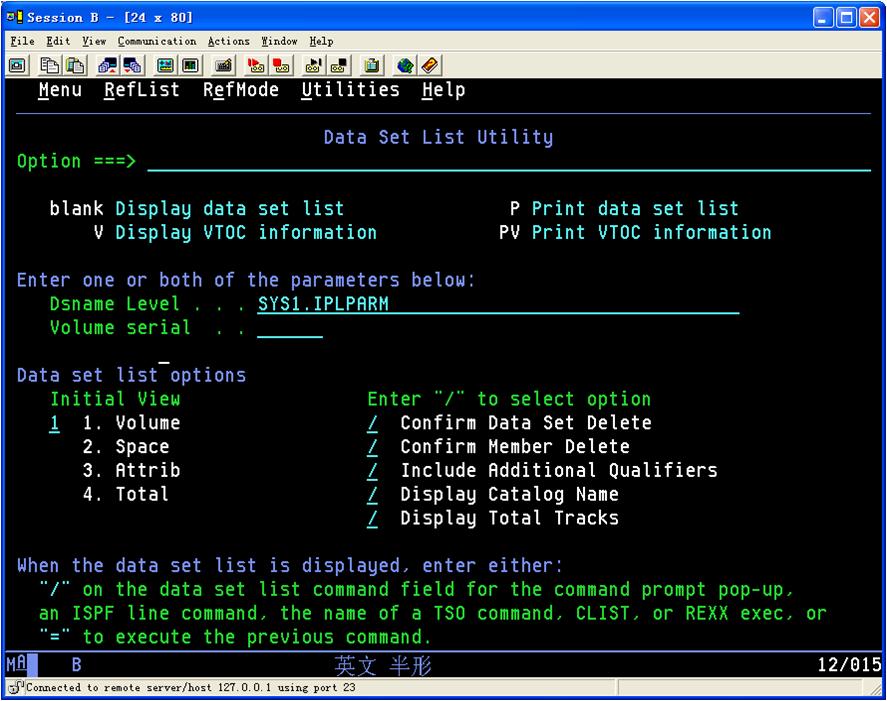

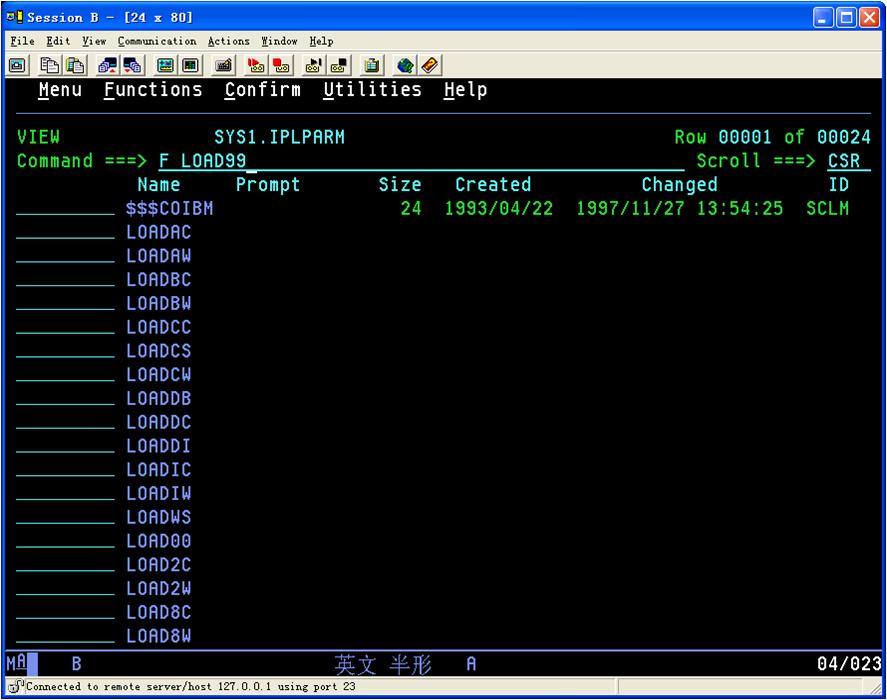


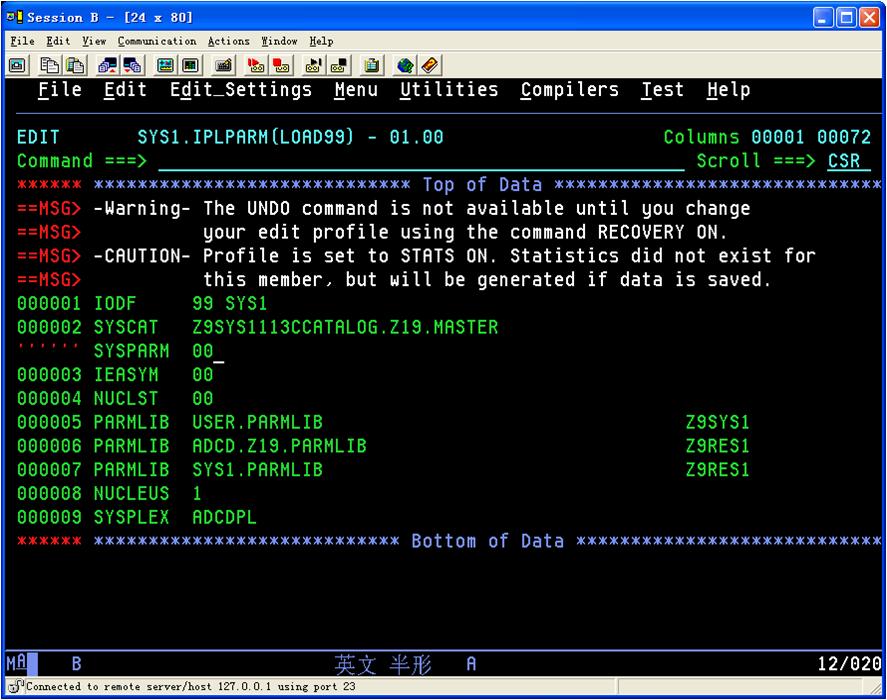
遇到HFS错误时,把HFS开头的data set全部catalog
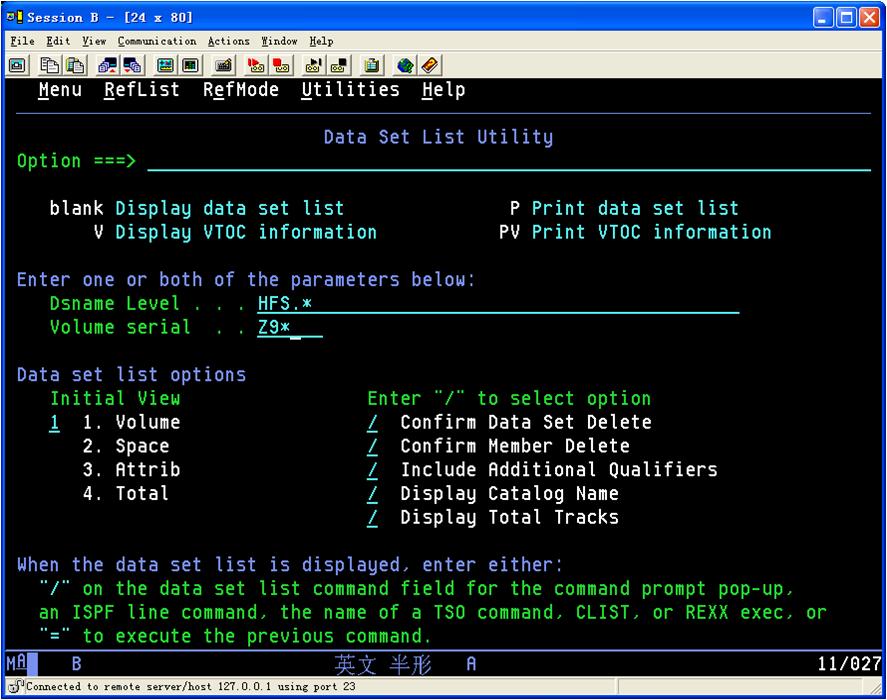
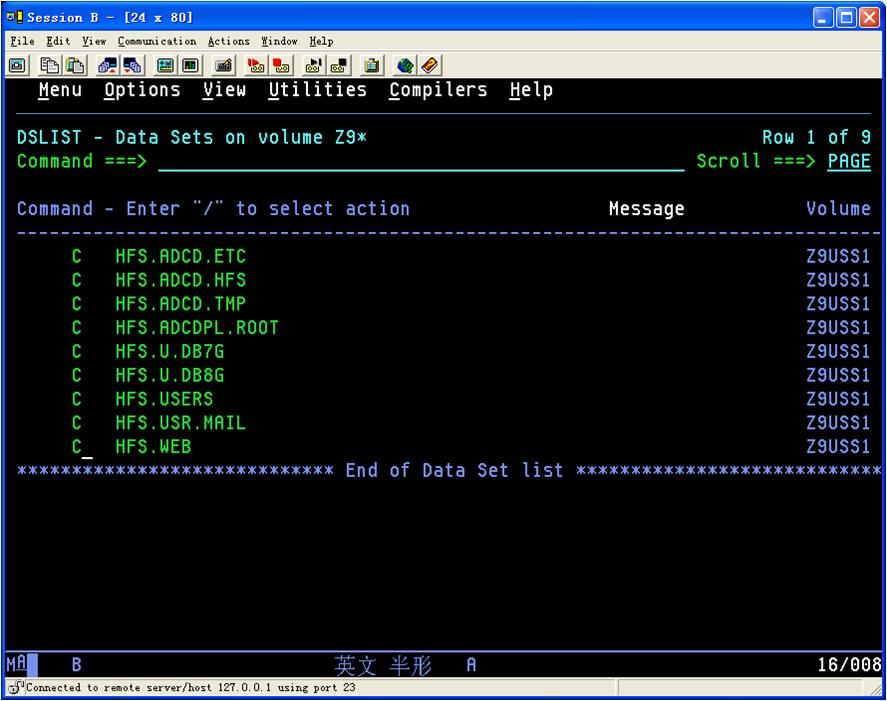
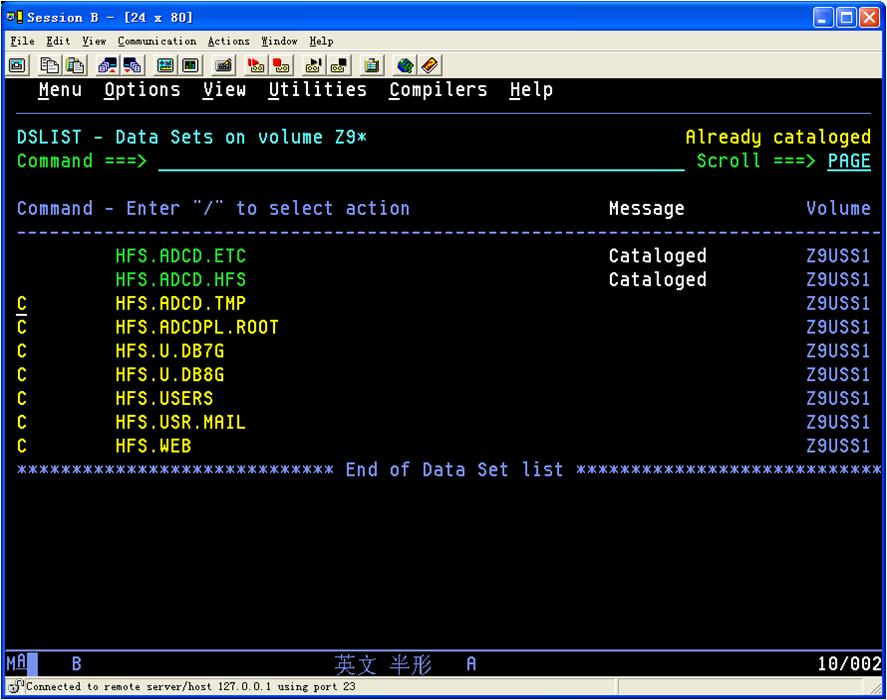
已经被catalog了