
美国时间2014年11月13日,PHP开发团队,在「PHP 5.6.3 is available|PHP: Hypertext Preprocessor」上公布了PHP5.6系的最新版本「PHP 5.6.3」。
在最新的版本5.6.3不仅修改了多个Bug,并且修改了fileinfo模块里存在的安全漏洞。
PHP团队推荐使用PHP5.6系列的用户,升级到最新版本5.6.3。
简单介绍一下,如何在CentOS上安装PHP5.6。
配置yum源
追加CentOS 6.5的epel及remi源。
# rpm -Uvh http://ftp.iij.ad.jp/pub/linux/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm
# rpm -Uvh http://rpms.famillecollet.com/enterprise/remi-release-6.rpm
以下是CentOS 7.0的源。
# yum install epel-release # rpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-7.rpm
使用yum list命令查看可安装的包(Packege)。
# yum list --enablerepo=remi --enablerepo=remi-php56 | grep php
安装PHP5.6
yum源配置好了,下一步就安装PHP5.6。
# yum install --enablerepo=remi --enablerepo=remi-php56 php php-opcache php-devel php-mbstring php-mcrypt php-mysqlnd php-phpunit-PHPUnit php-pecl-xdebug php-pecl-xhprof
用PHP命令查看版本。
# php --version PHP 5.6.0 (cli) (built: Sep 3 2014 19:51:31) Copyright (c) 1997-2014 The PHP Group Zend Engine v2.6.0, Copyright (c) 1998-2014 Zend Technologies with Zend OPcache v7.0.4-dev, Copyright (c) 1999-2014, by Zend Technologies with Xdebug v2.2.5, Copyright (c) 2002-2014, by Derick Rethans
在这里安装的版本是PHP5.6.0,细心的用户可能已经发现ZendGuardLoader变成Zend OPcahe了。
对从PHP5.5开始PHP代码缓存从APC变成了Zend OPcache了。
posted @
2016-03-23 12:16 华梦行 阅读(191) |
评论 (0) |
编辑 收藏posted @
2016-03-23 11:43 华梦行 阅读(226) |
评论 (0) |
编辑 收藏
1、d:\mysql\bin\>mysql -h localhost -u root //这样应该可以进入MySQL服务器
2、mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION //赋予任何主机访问数据的权限
3、mysql>FLUSH PRIVILEGES //修改生效
4、mysql>EXIT //退出MySQL服务器
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.6/en/server-configuration-defaults.html
修改默认端口
[mysqld]
port=3309
posted @
2016-02-24 14:34 华梦行 阅读(197) |
评论 (0) |
编辑 收藏1. Change root user
2. Install Remi repository
## CentOS 6 and Red Hat (RHEL) 6 ## rpm -Uvh http://rpms.famillecollet.com/enterprise/remi-release-6.rpm
3. Check Available MySQL versions
yum --enablerepo=remi,remi-test list mysql mysql-server
Output:
Loaded plugins: changelog, fastestmirror, presto, refresh-packagekit ... remi | 3.0 kB 00:00 remi/primary_db | 106 kB 00:00 Available Packages mysql.i686 5.5.37-1.fc18.remi @remi mysql-server.i686 5.5.37-1.fc18.remi @remi |
4. Update or Install MySQL 5.5.37
yum --enablerepo=remi install mysql mysql-server
5. Start MySQL server and autostart MySQL on boot
/etc/init.d/mysqld start ## use restart after update ## OR ## service mysqld start ## use restart after update chkconfig --levels 235 mysqld on
6. MySQL Secure Installation
/usr/bin/mysql_secure_installation
7. Connect to MySQL database (localhost) with password
mysql -u root -p ## OR ## mysql -h localhost -u root -p
8. Create Database, Create MySQL User and Enable Remote Connections to MySQL Database
## CREATE DATABASE ## mysql> CREATE DATABASE webdb; ## CREATE USER ## mysql> CREATE USER 'webdb_user'@'10.0.15.25' IDENTIFIED BY 'password123'; ## GRANT PERMISSIONS ## mysql> GRANT ALL ON webdb.* TO 'webdb_user'@'10.0.15.25'; ## FLUSH PRIVILEGES, Tell the server TO reload the GRANT TABLES ## mysql> FLUSH PRIVILEGES;
posted @
2015-12-07 19:36 华梦行 阅读(214) |
评论 (0) |
编辑 收藏mysql> use mysql;
查询host值:
mysql> select user,host from user;
如果没有"%"这个host值,就执行下面这两句:
mysql> update user set host='%' where user='root';
mysql> flush privileges;
或者也可以执行:
mysql>grand all privileges on *.* to root@'%' identifies by ' xxxx';
其中 第一个*表示数据库名;第二个*表示该数据库的表名;如果像上面那样 *.*的话表示所有到数据库下到所有表都允许访问;
‘%':表示允许访问到mysql的ip地址;当然你也可以配置为具体到ip名称;%表示所有ip均可以访问;
后面到‘xxxx'为root 用户的password;
举例:
任意主机以用户root和密码mypwd连接到mysql服务器
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'mypwd' WITH GRANT OPTION;
mysql> flush privileges;
IP为192.168.1.102的主机以用户myuser和密码mypwd连接到mysql服务器
mysql> GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'192.168.1.102' IDENTIFIED BY 'mypwd' WITH GRANT OPTION;
mysql> flush privileges;
posted @
2015-12-06 22:29 华梦行 阅读(284) |
评论 (0) |
编辑 收藏Linux(centos) 更改MySQL数据库目录位置MySQL默认的数据文件存储目录为/var/lib/mysql。假如要把目录移到/home/data下需要进行下面几步:
1、home目录下建立data目录
cd /homemkdir data
2、把MySQL服务进程停掉:
mysqladmin -u root -p shutdown
3、把/var/lib/mysql整个目录移到/home/data
mv /var/lib/mysql /home/data/
这样就把MySQL的数据文件移动到了/home/data/mysql下
4、找到my.cnf配置文件
如果/etc/目录下没有my.cnf配置文件,请到/usr/share/mysql/下找到*.cnf文件,拷贝其中一个到/etc/并改名为my.cnf)中。命令如下:
[root@test1 mysql]# cp /usr/share/mysql/my-medium.cnf /etc/my.cnf
5、编辑MySQL的配置文件/etc/my.cnf
为保证MySQL能够正常工作,需要指明mysql.sock文件的产生位置。修改socket=/var/lib/mysql/mysql.sock一行中等号右边的值为:/home/mysql/mysql.sock 。操作如下:
vi my.cnf (用vi工具编辑my.cnf文件,找到下列数据修改之)# The MySQL server[mysqld] port = 3306#socket = /var/lib/mysql/mysql.sock(原内容,为了更稳妥用“#”注释此行)socket = /home/data/mysql/mysql.sock (加上此行)
6、修改MySQL启动脚本/etc/init.d/mysql
最后,需要修改MySQL启动脚本/etc/init.d/mysql,把其中datadir=/var/lib/mysql一行中,等号右边的路径改成你现在的实际存放路径:home/data/mysql。
[root@test1 etc]# vi /etc/init.d/mysql#datadir=/var/lib/mysql(注释此行)datadir=/home/data/mysql (加上此行)
如果是CentOS还要改 /usr/bin/mysqld_safe 相关文件位置;
最后 做一个mysql.sock 链接:
ln -s /data/ljl/mysql/mysql.sock /var/lib/mysql/mysql.sock
7、重新启动MySQL服务
/etc/init.d/mysqld start
或用reboot命令重启Linux
如果工作正常移动就成功了,否则对照前面的7步再检查一下。还要注意目录的属主和权限。
复制内容到剪贴板
代码:
[root@sample ~]# chown -R mysql:mysql /home/data/mysql/ ← 改变数据库的归属为mysql
[root@sample ~]# chmod 700 /home/data/mysql/test/ ← 改变数据库目录属性为700
[root@sample ~]# chmod 660 /home/data/mysql/test/* ← 改变数据库中数据的属性为660
posted @
2015-12-06 22:28 华梦行 阅读(262) |
评论 (0) |
编辑 收藏
1. title 是关键字 ,尽量不要用
posted @
2015-11-24 23:18 华梦行 阅读(115) |
评论 (0) |
编辑 收藏
CSS Sprites 原理:其实就是把网页中一些背景图片整合到一张图片文件中,再利用CSS的“background-image”,“background- repeat”,“background-position”的组合进行背景定位,background-position可以用数字精确的定位出背景图片的位置。
CSS Sprites 优点:
1、利用CSS Sprites能很好地减少网页的http请求,从而大大的提高页面的性能,这也是CSS Sprites最大的优点,也是其被广泛传播和应用的主要原因;
2、CSS Sprites能减少图片的字节,曾经比较过多次3张图片合并成1张图片的字节总是小于这3张图片的字节总和。
3、解决了网页设计师在图片命名上的困扰,只需对一张集合的图片上命名就可以了,不需要对每一个小元素进行命名,从而提高了网页的制作效率。
4、更换风格方便,只需要在一张或少张图片上修改图片的颜色或样式,整个网页的风格就可以改变。维护起来更加方便。
通过打开目前您的CSS文件夹下面的CSS图片碎片后,您可以自行拖拽CSS图片碎片技进行适当的位置调整,可以通过双击图片来移除该图片,进行CSS Sprite 操作时,拖拽与CSS Sprite 两个选项可随时切换使用。
posted @
2015-10-25 21:52 华梦行 阅读(120) |
评论 (0) |
编辑 收藏
最近朋友在搞网易的企业免费邮箱,拥有自己的独立域名,这个其实很简单,只要网易的邮箱mx设置就行了,但是尝试了很久,按照设置设置完之后还是不行,我用的是万网的域名解析,如下图 :

最主要的就是网易的帮助缺少了一个cname的解析,主机记录设置mail 然后记录值和mx的一致,然后重要的是 mx和txt的设置主机记录都要是@。这里网易都没有说,所以完整的来说就是这样的:
设置mx主机记录为@记录值为mx.ym.163.cin mx优先级是10
设置txt主机记录为@ 记录值为v=spf1 include:spf.163..com ~all
设置cname 主机记录为mail 记录值是ym.163.com
posted @
2015-10-20 11:24 华梦行 阅读(210) |
评论 (0) |
编辑 收藏
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u60-b27/jdk-8u60-linux-x64.rpm
posted @
2015-10-13 23:19 华梦行 阅读(158) |
评论 (0) |
编辑 收藏posted @
2015-10-03 18:38 华梦行 阅读(462) |
评论 (0) |
编辑 收藏 iptables -I INPUT -p tcp -s 115.28.190.242 --dport 83 -j ACCEPT
[root@www.jstong.com bin]# service iptables save
iptables:将防火墙规则保存到 /etc/sysconfig/iptables: [确定]
[root@ZWCLC bin]# service iptables restart
posted @
2015-09-17 23:57 华梦行 阅读(204) |
评论 (0) |
编辑 收藏1、方法一,编辑rc.loacl脚本
Ubuntu开机之后会执行/etc/rc.local文件中的脚本,
所以我们可以直接在/etc/rc.local中添加启动脚本。
当然要添加到语句:exit 0 前面才行。
如:
sudo vi /etc/rc.local
/usr/local/ssdb/ssdb-server -d /usr/local/ssdb/ssdb.conf
然后在 exit 0 前面添加好脚本代码。
posted @
2015-09-12 20:25 华梦行 阅读(213) |
评论 (0) |
编辑 收藏 Ubuntu 默认是DHCP自动获取IP。设定好静态IP,重启了也会变。
1、设定IP
sudo vi /etc/network/interfaces
auto lo
iface lo inet loopback #lo 是本地回环地址:127.0.0.1
auto eth0
iface eth0 inet static #将dhcp修改为static
address 192.168.1.152 #添加下面的IP、网关等
gateway 192.168.1.1
netmask 255.255.255.0
network 192.168.1.0
broadcast 192.168.1.255
2. 修改dns解析
因为以前是dhcp解析,所以会自动分配dns服务器地址
而一旦设置为静态ip后就没有自动获取到的dns服务器了
要自己设置一个
sudo vim /etc/resolv.conf
写上一个公网的DNS
nameserver 114.114.114.114
(注意:8.8.8.8是谷歌的DNS服务器,但是解析速度慢,还是找到一个国内的dns来用)
3. 重启网卡:
sudo /etc/init.d/networking restart
注意:重启Ubuntu后发现又不能上网了,问题出在/etc/resolv.conf。重启后,此文件配置的dns又被自动修改为默认值。所以需要永久性修改DNS。方法如下:
# vim /etc/resolvconf/resolv.conf.d/base
nameserver 192.168.1.1
nameserver 114.114.114.114
posted @
2015-09-12 16:46 华梦行 阅读(815) |
评论 (0) |
编辑 收藏
在Solr中该如何使用IK分词器呢,这是小伙伴们问的频率比较高的一个问题,今晚特此更新此篇博客。其实之前我在其他博客里已经使用了IK分词器,只是我没做详细说明。
在schema.xml配置中其实有很多关于分词器的配置示例,我从中摘录一段配置示例,比如:
fileType是用来定义域类型的,name即表示域名称,class即表示域类型对应的class类,如果是solr内置的域类型则可以直接使用solr.前缀+域类型的类名即可,如果是你自定义的域类型,则class表示自定义域类型的完整类名(包含完整的包路径),在fileType元素下有analyzer元素,用来配置当前域类型使用什么分词器,你肯定很奇怪,为什么要配置两个analyzer,其实主要是为了区分两个阶段:索引建立阶段和Query查询阶段,索引建立阶段需要分词毋庸置疑,查询阶段是否需要分词,则取决于你的业务需求,用过Google的知道,用户在查询输入框里输入查询关键字,这时候我们需要对用户输入的查询关键字进行分词器,这时候我们就需要配置查询阶段使用什么分词器,为什么把分开配置?两者可以使用统一配置不行吗,配置两遍不是显得很冗余且繁琐吗?analyzer的type元素就表示这两个阶段,之所以要分阶段配置分词器,是为了满足用户潜在的需求,因为查询阶段的分词需求和索引阶段的分词需求不一定是相同的。我们都知道分词器Analyzer是由一个Tokenizer + N个tokenFilter组成,这就是为什么analyzer元素下会有tokenizer元素和filter元素,但tokenizer元素只允许有一个,filter元素可以有N个。之所以这样设计是为了为用户提供更细粒度的方式来配置分词器的行为,即你可以任意组合tokenizer和filter来实现你的特定需求,当然你也可以把这种组合写在Analyzer类里,然后直接在analyzer元素的class属性里配置自定义分词器的完整类名,这样就不需要这么繁琐的配置tokenizer和filter,即把实现细节屏蔽在analyzer类内部,但这样做的话,如果你需要更改实现细节,则需要修改Analyzer源码,然后重新打包成jar,相对来说,比较麻烦点,而使用analyzer,tokenizer,filter这样来配置,虽然繁琐点,但更灵活。而且采用
然后我们在代码里String useSmart = DOMUtil.getAttr(attrs,"useSmart");就可以获取到属性值了,然后就是通过反射把属性值设置到IKAnalyzer类的useSmart属性中了,这是基本的Java反射操作,下面我提供几个反射工具方法:
/**
* 循环向上转型, 获取对象的DeclaredField. 若向上转型到Object仍无法找到, 返回null.
*/
protected static Field getDeclaredField(final Object object, final String fieldName) {
if (null == object || null == fieldName || fieldName.equals("")) {
return null;
}
for (Class superClass = object.getClass(); superClass != Object.class; superClass = superClass.getSuperclass()) {
try {
return superClass.getDeclaredField(fieldName);
} catch (NoSuchFieldException e) {
// Field不在当前类定义,继续向上转型
continue;
}
}
return null;
}
/**
* 直接设置对象属性值, 无视private/protected修饰符, 不经过setter函数.
*/
public static void setFieldValue(final Object object, final String fieldName, final Object value) {
Field field = getDeclaredField(object, fieldName);
if (field == null) {
throw new IllegalArgumentException("Could not find field [" + fieldName + "] on target [" + object + "]");
}
makeAccessible(field);
try {
field.set(object, value);
} catch (IllegalAccessException e) {
throw new RuntimeException("直接设置对象属性值出现异常", e);
}
}
/**
* 强行设置Field可访问
*/
protected static void makeAccessible(final Field field) {
if (!Modifier.isPublic(field.getModifiers()) || !Modifier.isPublic(field.getDeclaringClass().getModifiers())) {
field.setAccessible(true);
}
}
直接调用setFieldValue方法即可,比如在 Analyzer analyzer = clazz.newInstance();这句下面添加一句
setFieldValue(analyzer,"useSmart",Boolean.valueOf( useSmart ));
这样我们在xml中配置的useSmart参数就设置到Analyzer类中了,这样才能起作用。solr源码如何导入Eclipse上篇博客里我已经介绍过了,至于如果把修改过后的代码打包成jar,直接使用eclipse自带的export功能即可,如图:
然后一路Next即可。我只是说说思路,剩下留给你们自己去实践。
但是采用改源码方式不是很优雅,因为你本地虽然是修改好了,哪天你由Solr5.1.0升级到5.2.0,还要再改一遍,没升级一次就要改一次,你的代码copy给别人用,别人运行代码后看不到效果,增加沟通成本,你还得把你改过源码的jar包共享给别人,这也就是为什么有那么多人找我要什么IK jar包。
在Solr中可以使用TokenizerFactory方式来解决我刚才提出的问题:IKAnalyzer分词器的useSmart参数无法通过schema.xml配置文件进行设置。我花了点时间扩展了IKTokenizerFactory类,代码如下:
package org.apache.lucene.analysis.ik;
import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeFactory;
import org.wltea.analyzer.lucene.IKTokenizer;
public class IKTokenizerFactory extends TokenizerFactory {
public IKTokenizerFactory(Map
args) {
super(args);
useSmart = getBoolean(args, "useSmart", false);
}
private boolean useSmart;
@Override
public Tokenizer create(AttributeFactory attributeFactory) {
Tokenizer tokenizer = new IKTokenizer(attributeFactory,useSmart);
return tokenizer;
}
}
同时我对 IKTokenizer类也稍作了修改,修改后源码如下:
/**
* IK分词器 Lucene Tokenizer适配器类
* 兼容Lucene 4.0版本
*/
public final class IKTokenizer extends Tokenizer {
//IK分词器实现
private IKSegmenter _IKImplement;
//词元文本属性
private final CharTermAttribute termAtt;
//词元位移属性
private final OffsetAttribute offsetAtt;
//词元分类属性(该属性分类参考org.wltea.analyzer.core.Lexeme中的分类常量)
private final TypeAttribute typeAtt;
//记录最后一个词元的结束位置
private int endPosition;
private Version version = Version.LATEST;
/**
* Lucene 4.0 Tokenizer适配器类构造函数
* @param in
* @param useSmart
*/
public IKTokenizer(Reader in , boolean useSmart){
//super(in);
offsetAtt = addAttribute(OffsetAttribute.class);
termAtt = addAttribute(CharTermAttribute.class);
typeAtt = addAttribute(TypeAttribute.class);
_IKImplement = new IKSegmenter(input , useSmart);
}
public IKTokenizer(AttributeFactory factory, boolean useSmart) {
super(factory);
offsetAtt = addAttribute(OffsetAttribute.class);
termAtt = addAttribute(CharTermAttribute.class);
typeAtt = addAttribute(TypeAttribute.class);
_IKImplement = new IKSegmenter(input , useSmart);
}
/* (non-Javadoc)
* @see org.apache.lucene.analysis.TokenStream#incrementToken()
*/
@Override
public boolean incrementToken() throws IOException {
//清除所有的词元属性
clearAttributes();
Lexeme nextLexeme = _IKImplement.next();
if(nextLexeme != null){
//将Lexeme转成Attributes
//设置词元文本
termAtt.append(nextLexeme.getLexemeText());
//设置词元长度
termAtt.setLength(nextLexeme.getLength());
//设置词元位移
offsetAtt.setOffset(nextLexeme.getBeginPosition(), nextLexeme.getEndPosition());
//记录分词的最后位置
endPosition = nextLexeme.getEndPosition();
//记录词元分类
typeAtt.setType(nextLexeme.getLexemeTypeString());
//返会true告知还有下个词元
return true;
}
//返会false告知词元输出完毕
return false;
}
/*
* (non-Javadoc)
* @see org.apache.lucene.analysis.Tokenizer#reset(java.io.Reader)
*/
@Override
public void reset() throws IOException {
super.reset();
_IKImplement.reset(input);
}
@Override
public final void end() {
// set final offset
int finalOffset = correctOffset(this.endPosition);
offsetAtt.setOffset(finalOffset, finalOffset);
}
修改后重新打包的IKAnalyzer jar请见底下的附件。
然后我把它打包成了 solr-analyzer-ik-5.1.0.jar,只需要把这个jar包复制到你的core\lib目录下即可,然后你就可以像配置StandardTokenizerFactory一样的使用我们自定义的IKTokenizerFactory类了,并且能配置useSmart参数,这正是我想要的,能灵活的控制分词器参数,so cool。配置示例如下:
然后field域里应用我们配置的这个text_ik域类型,如图:
然后你还需要把IKAnalyzer jar包以及我们自定义的IKTokenizerFactory的jar包copy到你当前core\lib目录下,如图:
IKAnalyzer jar建议使用底下附件里我新上传的,因为源码我稍作了修改,上面已经提到过了。然后你需要把IKAnalyzer.cfg.xml配置文件copy到E:\apache-tomcat-7.0.55\webapps\solr\WEB-INF\classes目录下,其中E
:\apache-tomcat-7.0.55为我的Tomcat安装根目录,请类比成你自己的tomcat安装根目录,你懂的。如图:
IKAnalyzer.cfg.xml配置如图:
ext.dic为IK分词器的自定义扩展词典,内容如图:
我就在里面加了两个自定义词语。
然后你就可以启动你的tomcat,然后如图进行分词测试了,
上图是用来测试useSmart参数设置是否有生效,如果你看到如图的效果,说明配置成功了。
上图是用来测试自定义词典是否有生效,因为我在ext.dic自定义词典里添加了 劲爆 和 屌丝 这两个词,所以IK能分出来,逆袭和白富美没有在自定义扩展词典里添加,所以IK分不出来。如果你能看到如图效果,说明IK的自定义扩展词典也配置成功了。到此,关于在Solr中使用IK分词器就介绍到这儿了,如果你还有任何疑问,请通过以下方式联系到我,谢谢!!!博客里提到的相关jar包配置文件等等资源文件,我待会儿都会上传到底下的附件里,特此提醒!!!!!
posted @
2015-09-11 17:26 华梦行 阅读(796) |
评论 (0) |
编辑 收藏“以直代曲”的思想是利用直线段来近似曲线,也即通过某点的切线来代替曲线,这样使得有关曲线的问题转化到直线段上来,从而得到简化。
posted @
2015-09-02 16:13 华梦行 阅读(337) |
评论 (0) |
编辑 收藏


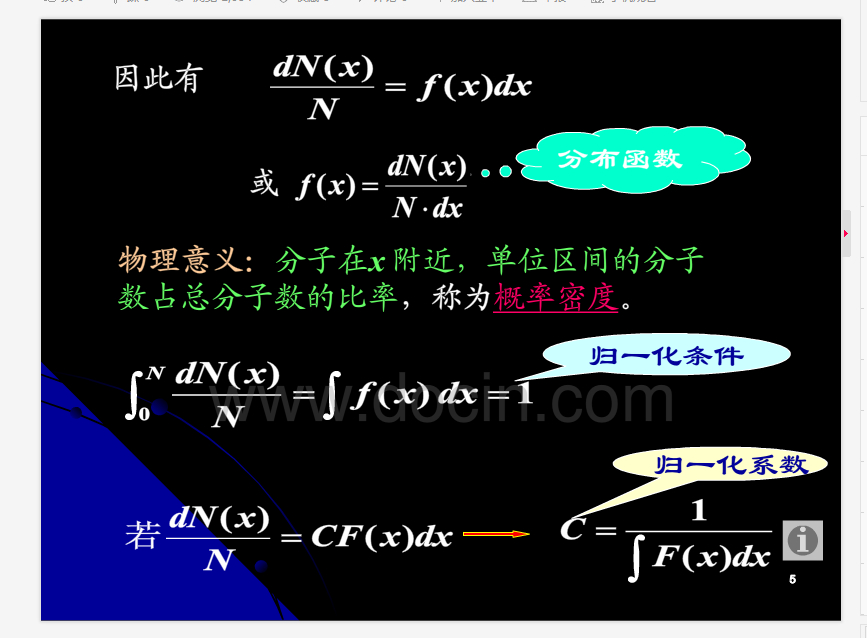


posted @
2015-09-01 23:24 华梦行 阅读(171) |
评论 (0) |
编辑 收藏随机变量x的分布函数

A=0B=0.5 c=2
clc;
clf;
x=-3:0.01:3;
length(x)
for i=1:length(x)
if x(i)<0
y(i)=0;
else if x(i)<1
y(i)=0.5*(x(i)^2);
else if x(i)<2
y(i)=2*x(i)-0.5*(x(i)^2)-1;
else
y(i)=1;
end
end
end
end
plot(x,y);
grid on;
hold on;
posted @
2015-09-01 00:19 华梦行 阅读(178) |
评论 (0) |
编辑 收藏
% 格式 binopdf (k, n, p) , p — 每次试验事件A发生的概率;K—事件A发生K次;n—试验总次数
clear;
px=binopdf(45,100,0.5) % 计算x=45的概率
%作图
x=1:100;
p=binopdf(x,100,0.5);
plot(x,p);title('概率分布图')
posted @
2015-08-26 22:35 华梦行 阅读(166) |
评论 (0) |
编辑 收藏for i=1:size(a,2)
for j=1:size(a,2)
c(i,j)=sum((a(:,i)-mean(a(:,i))).*(a(:,j)-mean(a(:,j))))/(size(a,1)-1);
end
end
c =
10.3333 -4.1667 3.0000
-4.1667 2.3333 -1.5000
3.0000 -1.5000 1.0000
c为求得的协方差矩阵,在matlab以矩阵a的每一列为变量,对应的每一行为样本。这样在矩阵a中就有3个列变量分别为a(:,1), a(:,2), a(:,3)。
在协方差矩阵c中,每一个元素c(i,j)为对第i列与第j列的协方差,例如c(1,2) = -4.1667为第一列与第二列的协方差。
拿c(1,2)的求解过程来说
c(1,2)=sum((a(:,1)-mean(a(:,1))).*(a(:,2)-mean(a(:,2))))/(size(a,1)-1);
1. a(:,1)-mean(a(:,1)),第一列的元素减去该列的均值得到
-1.3333
-2.3333
3.6667
2, a(:,2)-mean(a(:,2)),第二列的元素减去该列的均值得到
-0.3333
1.6667
-1.3333
3, 再将第一步与第二部的结果相乘
-1.3333 -0.3333 0.4444
-2.3333 .* 1.6667 = -3.8889
3.6667 -1.3333 -4.8889
4, 再将结果求和/size(a,1)-1 得 -4.1667,该值即为c(1,2)的值。
再细看一下是不是与协方差公式:Cov(X,Y) = E{ [ (X-E(X) ] [ (Y-E(Y) ] } 过程基本一致呢,只是在第4步的时候matlab做了稍微的调整,自由度为n-1,减少了一行的样本值个数。
>> a=[-1,1,2;-2,3,1;4,0,9]
a =
-1 1 2
-2 3 1
4 0 9
>> cov(a)
ans =
10.3333 -4.1667 14.0000
-4.1667 2.3333 -5.5000
14.0000 -5.5000 19.0000
>> dim1=a(:,1)
dim1 =
-1
-2
4
>> dim2=a(:,2)
dim2 =
1
3
0
>> dim3=a(:,3)
dim3 =
2
1
9
>> dim1-mean(dim1)
ans =
-1.3333
-2.3333
3.6667
>> dim2-mean(dim2)
ans =
-0.3333
1.6667
-1.3333
>> m=dim1-mean(dim1)
m =
-1.3333
-2.3333
3.6667
>> m=dim2-mean(dim2)
m =
-0.3333
1.6667
-1.3333
>> m=dim1-mean(dim1)
m =
-1.3333
-2.3333
3.6667
>> n=dim2-mean(dim2)
n =
-0.3333
1.6667
-1.3333
>> m.*n
ans =
0.4444
-3.8889
-4.8889
>> size(a,1)
ans =
3
>> sum(m.*n)
ans =
-8.3333
>> ans/2
ans =
-4.1667
posted @
2015-08-26 19:06 华梦行 阅读(285) |
评论 (0) |
编辑 收藏