阿里云主机推荐码,可以打九折8C0BAY 有效期 11-30号
posted @
2015-10-15 18:13 hellxoul 阅读(213) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2015-01-05 11:52 hellxoul 阅读(335) |
评论 (0) |
编辑 收藏
1 <!-- 配置路径扩展名映射的媒体类型 -->
2 <bean name="pathExtensionContentNegotiationStrategy"
3 class="org.springframework.web.accept.PathExtensionContentNegotiationStrategy">
4 <constructor-arg>
5 <props>
6 <!-- if romePresent -->
7 <prop key="atom">application/atom+xml</prop>
8 <prop key="rss">application/rss+xml</prop>
9 <!-- endif -->
10 <!-- if jackson2Present || jacksonPresent -->
11 <prop key="json">application/json</prop>
12 <!-- endif -->
13 <!-- if jaxb2Present -->
14 <prop key="xml">application/xml</prop>
15 <!-- endif -->
16 </props>
17 </constructor-arg>
18 </bean>
19
20 <!-- 配置映射媒体类型的策略 -->
21 <bean name="mvcContentNegotiationManager"
22 class="org.springframework.web.accept.ContentNegotiationManager">
23 <constructor-arg>
24 <list>
25 <ref bean="pathExtensionContentNegotiationStrategy" />
26 </list>
27 </constructor-arg>
28 </bean>
29
30 <bean class="org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping">
31 <property name="order" value="0"/>
32 <property name="removeSemicolonContent" value="false"/>
33 <property name="contentNegotiationManager" ref="mvcContentNegotiationManager"/>
34 </bean>
35
36 <!-- 配置数据转换服务,默认使用格式化数据转换服务,可以对日期和数字进行格式化 -->
37 <bean name="conversionService"
38 class="org.springframework.format.support.DefaultFormattingConversionService">
39 <constructor-arg index="0">
40 <null/>
41 </constructor-arg>
42 <constructor-arg index="1" value="true"/>
43 </bean>
44
45 <bean name="validator"
46 class="org.springframework.validation.beanvalidation.LocalValidatorFactoryBean"/>
47
48 <!-- 配置数据绑定,通过转换服务实现绑定,如果包含jsr303实现还将进行校验 -->
49 <bean name="webBindingInitializer"
50 class="org.springframework.web.bind.support.ConfigurableWebBindingInitializer">
51 <property name="conversionService" ref="conversionService" />
52 <!-- if jsr303Present -->
53 <property name="validator" ref="validator" />
54 <!-- endif -->
55 </bean>
56
57 <bean name="byteArrayHttpMessageConverter"
58 class="org.springframework.http.converter.ByteArrayHttpMessageConverter"/>
59
60 <bean name="stringHttpMessageConverter"
61 class="org.springframework.http.converter.StringHttpMessageConverter">
62 <property name="writeAcceptCharset" value="false" />
63 </bean>
64
65 <bean name="resourceHttpMessageConverter"
66 class="org.springframework.http.converter.ResourceHttpMessageConverter"/>
67 <bean name="sourceHttpMessageConverter"
68 class="org.springframework.http.converter.xml.SourceHttpMessageConverter"/>
69 <bean name="allEncompassingFormHttpMessageConverter"
70 class="org.springframework.http.converter.support.AllEncompassingFormHttpMessageConverter"/>
71 <bean name="atomFeedHttpMessageConverter"
72 class="org.springframework.http.converter.feed.AtomFeedHttpMessageConverter"/>
73 <bean name="rssChannelHttpMessageConverter"
74 class="org.springframework.http.converter.feed.RssChannelHttpMessageConverter"/>
75 <bean name="jaxb2RootElementHttpMessageConverter"
76 class="org.springframework.http.converter.xml.Jaxb2RootElementHttpMessageConverter"/>
77 <bean name="mappingJacksonHttpMessageConverter"
78 class="org.springframework.http.converter.json.MappingJacksonHttpMessageConverter"/>
79
80 <!-- 配置@RequestBody,@ResponseBody注解可用的转换器 -->
81 <util:list id="messageConverters"
82 list-class="org.springframework.beans.factory.support.ManagedList">
83 <ref bean="byteArrayHttpMessageConverter" />
84 <ref bean="stringHttpMessageConverter" />
85 <ref bean="resourceHttpMessageConverter" />
86 <ref bean="sourceHttpMessageConverter" />
87 <ref bean="allEncompassingFormHttpMessageConverter" />
88 <!-- if romePresent -->
89 <ref bean="atomFeedHttpMessageConverter" />
90 <ref bean="rssChannelHttpMessageConverter" />
91 <!-- endif -->
92 <!-- if jaxb2Present -->
93 <ref bean="jaxb2RootElementHttpMessageConverter" />
94 <!-- endif -->
95 <!-- if jacksonPresent -->
96 <ref bean="mappingJacksonHttpMessageConverter" />
97 <!-- endif -->
98 </util:list>
99
100 <!-- 将任意类型的Controller适配为Handler -->
101 <bean name="requestMappingHandlerAdapter"
102 class="org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter">
103 <property name="contentNegotiationManager" ref="mvcContentNegotiationManager" />
104 <property name="webBindingInitializer" ref="webBindingInitializer" />
105 <property name="messageConverters" ref="messageConverters" />
106 </bean>
107
108 <!-- 这个拦截器暴露转换器服务让spring:bind和spring:eval标签可用 -->
109 <bean name="csInterceptor"
110 class="org.springframework.web.servlet.handler.ConversionServiceExposingInterceptor">
111 <constructor-arg index="0" ref="conversionService"/>
112 </bean>
113
114 <!-- 现在所有拦截器都必须设定响应的路径映射 -->
115 <bean name="mappedCsInterceptor"
116 class="org.springframework.web.servlet.handler.MappedInterceptor">
117 <constructor-arg index="0">
118 <null/>
119 </constructor-arg>
120 <constructor-arg index="1" ref="csInterceptor"/>
121 </bean>
122
123 <!-- 使用@ExceptionHandler注解的方法来处理Exception,优先级为0(最高) -->
124 <bean name="exceptionHandlerExceptionResolver"
125 class="org.springframework.web.servlet.mvc.method.annotation.ExceptionHandlerExceptionResolver">
126 <property name="contentNegotiationManager" ref="mvcContentNegotiationManager" />
127 <property name="messageConverters" ref="messageConverters" />
128 <property name="order" value="0" />
129 </bean>
130
131 <!-- 如果抛出的Exception类带有@ResponseStatus注解,响应返回该注解的Http状态码,优先级为1 -->
132 <bean name="responseStatusExceptionResolver"
133 class="org.springframework.web.servlet.mvc.annotation.ResponseStatusExceptionResolver">
134 <property name="order" value="1" />
135 </bean>
136
137 <!-- SpringMvc内部异常处理 -->
138 <bean name="defaultExceptionResolver"
139 class="org.springframework.web.servlet.mvc.support.DefaultHandlerExceptionResolver">
140 <property name="order" value="2" />
141 </bean>
142
posted @
2014-08-03 22:35 hellxoul 阅读(2919) |
评论 (1) |
编辑 收藏
HeadFirst Servlet/JSP 学习笔记
1.容器加载类,调用servlet的无参构造方法,并调用servlet的init()方法,从而初始化servlet。
2.init()在servlet一生中只调用一次,往往在servlet为客户请求提供服务之前调用。
3.init()方法使servlet可以访问ServletConfig和ServletContext对象,servlet需要从这些对象得到有关servlet配置和web应用的信息。
4.容器通过调用servlet的destroy()方法来结束servlet的生命
5.servlet一生的大多时间都是在为某个客户端请求运行service()方法
6.对servlet的每个请求都在一个单独的线程中运行,任何特定servlet类都只有一个实例。
posted @
2014-07-05 15:21 hellxoul 阅读(288) |
评论 (0) |
编辑 收藏
转自:
http://www.cnblogs.com/peida/p/Guava_Ordering.html
Ordering是Guava类库提供的一个犀利强大的比较器工具,Guava的Ordering和JDK Comparator相比功能更强。它非常容易扩展,可以轻松构造复杂的comparator,然后用在容器的比较、排序等操作中。
本质上来说,Ordering 实例无非就是一个特殊的Comparator 实例。Ordering只是需要依赖于一个比较器(例如,Collections.max)的方法,并使其可作为实例方法。另外,Ordering提供了链式方法调用和加强现有的比较器。
下面我们看看Ordering中的一些具体方法和简单的使用实例。
常见的静态方法:
natural():使用Comparable类型的自然顺序, 例如:整数从小到大,字符串是按字典顺序;
usingToString() :使用toString()返回的字符串按字典顺序进行排序;
arbitrary() :返回一个所有对象的任意顺序, 即compare(a, b) == 0 就是 a == b (identity equality)。 本身的排序是没有任何含义, 但是在VM的生命周期是一个常量。
简单实例:
import java.util.List;
import org.junit.Test;
import com.google.common.collect.Lists;
import com.google.common.collect.Ordering;
public class OrderingTest {
@Test
public void testStaticOrdering(){
List<String> list = Lists.newArrayList();
list.add("peida");
list.add("jerry");
list.add("harry");
list.add("eva");
list.add("jhon");
list.add("neron");
System.out.println("list:"+ list);
Ordering<String> naturalOrdering = Ordering.natural();
Ordering<Object> usingToStringOrdering = Ordering.usingToString();
Ordering<Object> arbitraryOrdering = Ordering.arbitrary();
System.out.println("naturalOrdering:"+ naturalOrdering.sortedCopy(list));
System.out.println("usingToStringOrdering:"+ usingToStringOrdering.sortedCopy(list));
System.out.println("arbitraryOrdering:"+ arbitraryOrdering.sortedCopy(list));
}
} 输出:
list:[peida, jerry, harry, eva, jhon, neron]
naturalOrdering:[eva, harry, jerry, jhon, neron, peida]
usingToStringOrdering:[eva, harry, jerry, jhon, neron, peida]
arbitraryOrdering:[neron, harry, eva, jerry, peida, jhon]
操作方法:
reverse(): 返回与当前Ordering相反的排序:
nullsFirst(): 返回一个将null放在non-null元素之前的Ordering,其他的和原始的Ordering一样;
nullsLast():返回一个将null放在non-null元素之后的Ordering,其他的和原始的Ordering一样;
compound(Comparator):返回一个使用Comparator的Ordering,Comparator作为第二排序元素,例如对bug列表进行排序,先根据bug的级别,再根据优先级进行排序;
lexicographical():返回一个按照字典元素迭代的Ordering;
onResultOf(Function):将function应用在各个元素上之后, 在使用原始ordering进行排序;
greatestOf(Iterable iterable, int k):返回指定的第k个可迭代的最大的元素,按照这个从最大到最小的顺序。是不稳定的。
leastOf(Iterable<E> iterable,int k):返回指定的第k个可迭代的最小的元素,按照这个从最小到最大的顺序。是不稳定的。
isOrdered(Iterable):是否有序,Iterable不能少于2个元素。
isStrictlyOrdered(Iterable):是否严格有序。请注意,Iterable不能少于两个元素。
sortedCopy(Iterable):返回指定的元素作为一个列表的排序副本。

package com.peidasoft.guava.base;
import java.util.List;
import org.junit.Test;
import com.google.common.collect.ImmutableList;
import com.google.common.collect.Lists;
import com.google.common.collect.Ordering;
public class OrderingTest {
@Test
public void testOrdering(){
List<String> list = Lists.newArrayList();
list.add("peida");
list.add("jerry");
list.add("harry");
list.add("eva");
list.add("jhon");
list.add("neron");
System.out.println("list:"+ list);
Ordering<String> naturalOrdering = Ordering.natural();
System.out.println("naturalOrdering:"+ naturalOrdering.sortedCopy(list));
List<Integer> listReduce= Lists.newArrayList();
for(int i=9;i>0;i--){
listReduce.add(i);
}
List<Integer> listtest= Lists.newArrayList();
listtest.add(1);
listtest.add(1);
listtest.add(1);
listtest.add(2);
Ordering<Integer> naturalIntReduceOrdering = Ordering.natural();
System.out.println("listtest:"+ listtest);
System.out.println(naturalIntReduceOrdering.isOrdered(listtest));
System.out.println(naturalIntReduceOrdering.isStrictlyOrdered(listtest));
System.out.println("naturalIntReduceOrdering:"+ naturalIntReduceOrdering.sortedCopy(listReduce));
System.out.println("listReduce:"+ listReduce);
System.out.println(naturalIntReduceOrdering.isOrdered(naturalIntReduceOrdering.sortedCopy(listReduce)));
System.out.println(naturalIntReduceOrdering.isStrictlyOrdered(naturalIntReduceOrdering.sortedCopy(listReduce)));
Ordering<String> natural = Ordering.natural();
List<String> abc = ImmutableList.of("a", "b", "c");
System.out.println(natural.isOrdered(abc));
System.out.println(natural.isStrictlyOrdered(abc));
System.out.println("isOrdered reverse :"+ natural.reverse().isOrdered(abc));
List<String> cba = ImmutableList.of("c", "b", "a");
System.out.println(natural.isOrdered(cba));
System.out.println(natural.isStrictlyOrdered(cba));
System.out.println(cba = natural.sortedCopy(cba));
System.out.println("max:"+natural.max(cba));
System.out.println("min:"+natural.min(cba));
System.out.println("leastOf:"+natural.leastOf(cba, 2));
System.out.println("naturalOrdering:"+ naturalOrdering.sortedCopy(list));
System.out.println("leastOf list:"+naturalOrdering.leastOf(list, 3));
System.out.println("greatestOf:"+naturalOrdering.greatestOf(list, 3));
System.out.println("reverse list :"+ naturalOrdering.reverse().sortedCopy(list));
System.out.println("isOrdered list :"+ naturalOrdering.isOrdered(list));
System.out.println("isOrdered list :"+ naturalOrdering.reverse().isOrdered(list));
list.add(null);
System.out.println(" add null list:"+list);
System.out.println("nullsFirst list :"+ naturalOrdering.nullsFirst().sortedCopy(list));
System.out.println("nullsLast list :"+ naturalOrdering.nullsLast().sortedCopy(list));
}
}
//============输出==============
list:[peida, jerry, harry, eva, jhon, neron]
naturalOrdering:[eva, harry, jerry, jhon, neron, peida]
listtest:[1, 1, 1, 2]
true
false
naturalIntReduceOrdering:[1, 2, 3, 4, 5, 6, 7, 8, 9]
listReduce:[9, 8, 7, 6, 5, 4, 3, 2, 1]
true
true
true
true
isOrdered reverse :false
false
false
[a, b, c]
max:c
min:a
leastOf:[a, b]
naturalOrdering:[eva, harry, jerry, jhon, neron, peida]
leastOf list:[eva, harry, jerry]
greatestOf:[peida, neron, jhon]
reverse list :[peida, neron, jhon, jerry, harry, eva]
isOrdered list :false
isOrdered list :false
add null list:[peida, jerry, harry, eva, jhon, neron, null]
nullsFirst list :[null, eva, harry, jerry, jhon, neron, peida]
nullsLast list :[eva, harry, jerry, jhon, neron, peida, null]
posted @
2014-07-03 10:48 hellxoul 阅读(411) |
评论 (0) |
编辑 收藏
摘要: centos 6.5 安装rabbitmq
阅读全文
posted @
2014-06-25 22:23 hellxoul 阅读(2280) |
评论 (0) |
编辑 收藏转自:http://singo107.iteye.com/blog/1175084
数据库事务的隔离级别有4个,由低到高依次为Read uncommitted 、Read committed 、Repeatable read 、Serializable ,这四个级别可以逐个解决脏读 、不可重复读 、幻读 这几类问题。
√: 可能出现 ×: 不会出现
| 脏读 | 不可重复读 | 幻读 |
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable read | × | × | √ |
| Serializable | × | × | × |
注意:我们讨论隔离级别的场景,主要是在多个事务并发 的情况下,因此,接下来的讲解都围绕事务并发。
Read uncommitted 读未提交
公司发工资了,领导把5000元打到singo的账号上,但是该事务并未提交,而singo正好去查看账户,发现工资已经到账,是5000元整,非常高 兴。可是不幸的是,领导发现发给singo的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后singo实际的工资只有 2000元,singo空欢喜一场。

出现上述情况,即我们所说的脏读 ,两个并发的事务,“事务A:领导给singo发工资”、“事务B:singo查询工资账户”,事务B读取了事务A尚未提交的数据。
当隔离级别设置为Read uncommitted 时,就可能出现脏读,如何避免脏读,请看下一个隔离级别。
Read committed 读提交
singo拿着工资卡去消费,系统读取到卡里确实有2000元,而此时她的老婆也正好在网上转账,把singo工资卡的2000元转到另一账户,并在 singo之前提交了事务,当singo扣款时,系统检查到singo的工资卡已经没有钱,扣款失败,singo十分纳闷,明明卡里有钱,为 何......
出现上述情况,即我们所说的不可重复读 ,两个并发的事务,“事务A:singo消费”、“事务B:singo的老婆网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Read committed 时,避免了脏读,但是可能会造成不可重复读。
大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。如何解决不可重复读这一问题,请看下一个隔离级别。
Repeatable read 重复读
当隔离级别设置为Repeatable read 时,可以避免不可重复读。当singo拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),singo的老婆就不可能对该记录进行修改,也就是singo的老婆不能在此时转账。
虽然Repeatable read避免了不可重复读,但还有可能出现幻读 。
singo的老婆工作在银行部门,她时常通过银行内部系统查看singo的信用卡消费记录。有一天,她正在查询到singo当月信用卡的总消费金额 (select sum(amount) from transaction where month = 本月)为80元,而singo此时正好在外面胡吃海塞后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction ... ),并提交了事务,随后singo的老婆将singo当月信用卡消费的明细打印到A4纸上,却发现消费总额为1080元,singo的老婆很诧异,以为出 现了幻觉,幻读就这样产生了。
注:Mysql的默认隔离级别就是Repeatable read。
Serializable 序列化
Serializable 是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。
posted @
2014-06-15 15:15 hellxoul 阅读(255) |
评论 (0) |
编辑 收藏Google是一个非常优秀的公司。他们做出了很多令人称赞的东西—既是公司外部,人们可以看到的东西,也是公司内部。有一些在公司内部并不属于保密的事情,在外部并没有给予足够广泛的讨论。这就是我今天要说的。
让Google的程序如此优秀的一个最重要的事情看起来是非常的简单:代码审查。并不是只有Google做这个事情—代码审查已经被广泛的认可为一种非常好的做法,很多人都在这样做。但我还没有看到第二家这样大的公司能把这种事情运用的如此普遍。在Google,没有程序,任何产品、任何项目的程序代码,可以在没有经过有效的代码审查前提交到代码库里的。
所有人都要经过代码审查。并且很正规的:这种事情应该成为任何重要的软件开发工作中一个基本制度。并不单指产品程序——所有东西。它不需要很多的工作,但它的效果是巨大的。
从代码审查里能得到什么?
很显然:在代码提交前,用第二群眼睛检查一遍,防止bug混入。这是对其最常见的理解,是对代码审查的好处的最广泛的认识。但是,依我的经验来看,这反倒是它最不重要的一点。人们确实在代码审查中找到了bug。可是,这些在代码审查中能发现的绝大部分bug,很显然,都是微不足道的bug,程序的作者花几分钟的时间就能发现它们。真正需要花时间去发现的bug不是在代码审查里能找到的。
代码审查的最大的功用是纯社会性的。如果你在编程,而且知道将会有同事检查你的代码,你编程态度就完全不一样了。你写出的代码将更加整洁,有更好的注释,更好的程序结构——因为你知道,那个你很在意的人将会查看你的程序。没有代码审查,你知道人们最终还是会看你的程序。但这种事情不是立即发生的事,它不会给你带来同等的紧迫感,它不会给你相同的个人评判的那种感受。
还有一个非常重要的好处。代码审查能传播知识。在很多的开发团队里,经常每一个人负责一个核心模块,每个人都只关注他自己的那个模块。除非是同事的模块影响了自己的程序,他们从不相互交流。这种情况的后果是,每个模块只有一个人熟悉里面的代码。如果这个人休假或——但愿不是——辞职了,其他人则束手无策。通过代码审查,至少会有两个人熟悉这些程序——作者,以及审查者。审查者并不能像程序的作者一样对程序十分了解——但他会熟悉程序的设计和架构,这是极其重要的。
当然,没有什么事情能简单的做下来的。依我的经验,在你能正确的进行代码审查前,你需要花时间锻炼学习。我发现人们在代码审查时经常会犯一些错误,导致不少麻烦——尤其在一些缺乏经验的审查者中经常的出现,他们给了人们一个很遭的代码审查的体验,成为了人们接受代码审查制度的一个障碍。
最重要的一个原则:代码审查用意是在代码提交前找到其中的问题——你要发现是它的正确。在代码审查中最常犯的错误——几乎每个新手都会犯的错误——是,审查者根据自己的编程习惯来评判别人的代码。
对于一个问题,通常我们能找出十几种方法去解决。对于一种解决方案,我们能有百万种编码方案来实现它。作为一个审查者,你的任务不是来确保被审查的代码都采用的是你的编码风格——因为它不可能跟你写的一样。作为一段代码的审查者的任务是确保由作者自己写出的代码是正确的。一旦这个原则被打破,你最终将会倍感折磨,深受挫折——这可不是我们想要的结果。
问题在于,这种错误是如此的普遍而易犯。如果你是个程序员,当你遇到一个问题,你能想到一种解决方案——你就把你想到的方案作为标准答案。但事情不是这样的——作为一个好的审查者,你需要明白这个道理。
代码审查的第二个易犯的毛病是,人们觉得有压力,感觉非要说点什么才好。你知道作者用了大量的时间和精力来实现这些程序——不该说点什么吗?
不,你不需要。
只说一句“哇,不错呀”,任何时候都不会不合适。如果你总是力图找出一点什么东西来批评,你这样做的结果只会损害自己的威望。当你不厌其烦的找出一些东西来,只是为了说些什么,被审查人就会知道,你说这些话只是为了填补寂静。你的评论将不再被人重视。
第三是速度。你不能匆匆忙忙的进行一次代码审查——但你也要能迅速的完成。你的同伴在等你。如果你和你的同事并不想花太多时间进行代码复查,你们很快的完成,那被审查者会觉得很沮丧,这种代码审查带来的只有失望的感觉。就好象是打搅了大家,使大家放下手头的工作来进行审查。事情不该是这样。你并不需要推掉手头上的任何事情来做代码审查。但如果中途耽误了几个小时,你中间还要休息一会,喝杯茶,冲个澡,或谈会儿闲话。当你回到审查现场,你可以继续下去,把事情做完。如果你真是这样,我想没有人愿意在那干等着你。
posted @
2014-06-06 10:04 hellxoul 阅读(235) |
评论 (0) |
编辑 收藏
wps只有32位的,因此要安装wps必须安装32位的支持库,按照网上的教程先安装32位的一些依赖库
因为已经安装了libfreetype,网上也说64位的安装32位的libfreetype 会有问题,同时,自己系统也装不上32位的libfreetype 总是提示冲突。
没办法强制安装
sudo dpkg -i --force-all --ignore-depends=libfreetype6:i386 --ignore-depends=libfontconfig1:i386 wps-office_8.1.0.3724~b1p2_i386.deb
搞定
posted @
2014-04-20 21:40 hellxoul 阅读(1514) |
评论 (0) |
编辑 收藏
使用win8.1系统盘启动,进入系统修复-高级-命令行,使用bcdboot 命令复制启动盘的启动到现有系统中去
bcdboot h:\windows \s c:
h:为系统启动盘所在的盘符
posted @
2014-04-19 20:41 hellxoul 阅读(230) |
评论 (0) |
编辑 收藏基于云的应用与运行在私有数据中心的应用之间最大的差别就是可扩展性。云提供了按需扩展的能力,能够根据负载的波动对应用进行扩展和收缩。但是传统应用要充分发挥云的优势,并不是简单地将应用部署到云上就万事大吉,而是需要根据云的特点围绕可扩展性重新进行架构设计,近日AppDynamics的开发布道者Dustin.Whittle撰文阐述了适合云端部署的应用架构,对我们传统应用往云端部署有很大的启发和借鉴意义。
应用的架构
Dustin.Whittle给出了云应用的示例架构,它具有高度的可扩展性,如下图所示:

在这个图中,应用按照分层的理念进行了拆分,分别介绍如下:
客户端层:客户端层包含了针对目标平台的用户界面,可能会包括基于Web的、移动端的甚至是胖客户端的用户界面。一般来讲,这可能会是Web应用,包含诸如用户管理、会话管理、页面构建等功能,但是其他客户端所发起的交互都需要以RESTful服务的形式调用服务器。
服务:服务器包含了缓存服务以及聚合(aggregate)服务,其中缓存服务中持有记录系统(system of record)中最新的已知状态,而聚集服务会直接与记录系统交互,并且会执行一些破坏性的操作(会改变记录系统中的状态)。
记录系统:记录系统是领域特定的服务端,它会驱动业务功能,可能会包括客户管理系统、采购系统、预定系统等等,这些很可能是遗留系统,你的应用需要与其进行交互。聚集服务要负责将你的应用从这些特有的记录系统中抽象出来,并为你的应用提供一致的前端接口。
ESB:当记录系统发生数据变化的时候,它需要触发到指定主题(topic)的事件,这就是事件驱动架构(event-driven architecture,EDA)能够影响应用的地方了:当记录系统进行了一项其他系统可能感兴趣的变更时,它会触发一个事件,任何关注记录系统的其他系统会监听到这个事件,并作出对应的响应。这也是使用使用主题(topic)而不是队列(queue)的原因:队列支持点对点(point-to-point)的消息,而主题支持发布-订阅(publish-subscribe)的消息或事件。当与遗留系统进行集成时,我们很期望这些遗留的系统能够免遭负载的影响。因此,我们实现了一个缓存系统,这个缓存系统维持了记录系统中所有最新的已知状态。缓存系统会使用EDA的规则监听记录系统的变化,它会更新自己所保存数据的版本,从而保证与记录系统中的数据相匹配。这是一个很强大的策略,不过会将一致性模型变为最终一致性,也就是说如果你在社交媒体上发布一条状态的话,你的朋友可能在几秒钟甚至几分钟之后才能看到,数据最终是一致的,但有时你所看到的与你的朋友所看到的并不一致。如果能接受这种一致性的话,就能在很大程度上实现可扩展性的收益。
NoSQL:在数据存储方面,有很多的可选方案,但如果要存储大量数据的话,使用NoSQL存储能够更容易地扩展。有多种NoSQL存储可供选择,不过这要匹配所存储数据的特点,如MongoDB适合存储可搜索的数据,Neo4j适合存储高度互相关联的数据,而Cassandra适合存储键/值对,像Solr这样的搜索索引有利于加速对经常访问数据的查询。
将应用拆分为多个层的时候,最好的模式就是使用面向服务架构(service-oriented architecture,SOA)。要实现这一点,可以使用SOAP,也可以使用REST,但是REST更为合适,因为它可扩展性更强。作者接下来对REST的理念进行了深入的阐述,InfoQ上关于REST已有很多相关的文章,如这里和这里,甚至包括Roy Fielding经典博士论文的中译本,所以这里不再赘述。不过,作者在这里特别强调了RESTful Web服务能够保持无状态性(stateless)。无状态是实现可扩展性的关键需求,因为无状态,所以请求可以由任何一个服务器响应。如果你在服务层上需要更多的容量时,只需要为该层添加虚拟机即可,而不需关注客户端状态保持的问题,负载可以很容易地重新分配。
部署到云端
前面介绍了基于云的应用架构,接下来作者阐述了这样的应用该如何部署到云端。
RESTful Web服务要部署到Web容器中,并且要位于数据存储之前。这些Web服务是没有状态的,只会反映其暴露的底层数据的状态,因此可以根据需要部署任意数量的服务器。在基于云的部署中,开始时可以开启足够的实例以应对日常的需求,然后配置弹性策略,从而根据负载增加或减少服务器的数量。衡量饱和度的最好指标就是服务的响应时间。另外还需要考虑这些服务所使用的底层数据存储的性能。示例的部署图如下所示:

如果在云部署时有EDA的需求,那么就需要部署ESB,作者给出的建议是根据功能对ESB进行分区(partitioning),这样一个segment的过大负载不会影响到其他的segment。如下图所示:

这种分离使System 1的负载与System 2的负载实现了隔离。如果System 1产生的负载拖慢了ESB,它只会影响到自己的segment,并不会影响到System 2的segment,因为它部署在其他硬件上。如果ESB产品支持的话,我们还可以给指定的segment添加服务器来实现扩展。
基于云的应用与传统应用有着很大的差别,因为它有着不同的扩展性需求。基于云的应用必须有足够的弹性以应对服务器的添加与移除,必须松耦合,必须尽可能的无状态,必须预先规划失败的情况,并且必须能够从几台服务器扩展到成千上万台服务器。
针对云应用并没有唯一正确的架构,但是本文所阐述的RESTful服务以及事件驱动架构却是经过实践检验有效的架构。作者认为REST和EDA是实现云端可扩展应用的基本工具。
目前,国内许多传统的软件厂商正在逐渐往云端迁移,希望本文所阐述的架构理念能够为读者提供一些借鉴。
posted @
2014-03-25 09:18 hellxoul 阅读(386) |
评论 (0) |
编辑 收藏
收集帖: node.js 中文api (开放版) :http://nodeapi.ucdok.com/ node.js 中文api :http://jsfuns.com/ebook/#30d25070-118c-11e3-bc83-47c9e4e1d529 node.js入门中文版: http://nodebeginner.org/index-zh-cn.html express3.*中文API: http://expressjs.jser.us/ koa 中文文档:https://github.com/turingou/koa-guide //Express 原班人马打造的 比express更轻更富有表现力的web框架 深入理解Express: http://xvfeng.me/posts/understanding-expressjs/ meteor中文文档:http://d0cs.meteor.com/ NodeJS 和 Socket.io 中文入门教程:http://t.cn/zOMwxCg jade中文文档: http://expressjs.jser.us/jade.html Juicer 中文文档:http://juicer.name/docs/docs_zh_cn.html Mongoose 基本功能使用:http://t.cn/zOIKPeB 以下是一些blog教程系列: 让我们基于Node.js创建一个Web应用系列(5篇):http://t.cn/z8JnzkA 一周node.js系列(7篇) :http://t.cn/zOKuc9D 从零开始nodejs系列: http://blog.fens.me/series-nodejs/ 一起学node.js (荐): http://t.cn/zHxNXXt Node.js高级编程(荐): http://t.cn/zYmuqaH 深入浅出Node.js http://www.infoq.com/cn/master-nodejs Node.js零起点开发:http://blog.csdn.net/kaosini/article/details/8084268 node.js入门(共13篇)http://www.cnblogs.com/softlover/category/406516.html snoopyxdy的博客(大量node及express api的解读及进阶内容):http://t.cn/zQuKMKH 用node.js写web框架系列:http://my.oschina.net/Jeky/blog?catalog=262655 Luics的node.js系列: http://t.cn/zjATQlf 使用node.js建博客:http://witcheryne.iteye.com/blog/1172069 nodejs相关: 用socket.io 搭建聊天室: https://github.com/nswbmw/N-chat/wiki/_pages nodejs实体中文图书: 了不起的node.js: http://book.douban.com/subject/25767596/ 2014年1月 node.js高级编程: http://book.douban.com/subject/25799431/ 2013年12月 深入浅出nodejs: http://book.douban.com/subject/25768396/ 2013年12月 node.js入门经典: http://book.douban.com/subject/23780706/ 2013年4月 node.js开发指南: http://book.douban.com/subject/10789820/ 2012年7月 Node Web开发: http://book.douban.com/subject/10586326/ 2012年4月
posted @
2014-02-25 15:13 hellxoul 阅读(1113) |
评论 (0) |
编辑 收藏 mosquito 是一个MQTT 服务器。MQTT协议可用来做Android消息推送,服务器端采用mosquito+PhpMQTTClient(这个php用来做实验)
自己不会java,不会Android开发,推送的开发部分是同事做的。使用情况表明,单台服务器能满足几万的稳定的连接数,扩展起来也不难,加机器即可。
下载最新版的mosquitto
cd /usr/local/src
wget http://mosquitto.org/files/source/mosquitto-1.1.2.tar.gz
tar zxvf mosquitto-1.1.2.tar.gz
cd mosquitto-1.1.2
如果当前openssl版本低于1.0,修改config.mk中的WITH_TLS_PSK:=no
make
make install prefix=/usr/local/mosquitto
为方便管理,添加下面至/etc/profile
export PATH=”$PATH:/usr/local/mosquitto/bin”
export PATH=”$PATH:/usr/local/mosquitto/sbin”
source /etc/profile
[root@mysql230 mosquitto]# mosquitto #tab补全,四个命令
mosquitto mosquitto_passwd mosquitto_pub mosquitto_sub
mosquitto服务器主程序,实现了MQTT协议
mosquitto_pub mosquitto发布消息的命令行程序
mosquitto_sub mosquitto订阅消息的命令行程序
默认的配置文件在 /etc/mosquitto/里
将/usr/local/mosquitto/lib/添加至/etc/ld.so.conf
执行 ldconfig -f /etc/ld.so.conf 可能需要等待数秒
启动
mosquitto (-d后台启动)
可能提示没有用户 mosquitto,useradd mosquitto
终端测试
客户端 mosquitto_sub -h 192.168.1.230 -t test
另起命令行mosquitto_pub -t test -m ’123′
PhpMQTTClient安装
去https://github.com/tokudu/PhpMQTTClient 下载程序包,放置到服务器目录
可能需要结合实际情况,要修改的地方
index.php
$result = $conn->connect(SAM_MQTT, array(‘SAM_HOST’ => ’127.0.0.1′, ‘SAM_PORT’ => 1883));
SAM/MQTT/sam_mqtt.php
$this->port = 1883;
启动mosquitto在前台运行,以方便获取连接客户端的信息
mosquitto
在服务器另外一终端上启动订阅消息的进程,订阅所有tokudu开头topic
mosquitto_sub –t tokudu /+
注意,此处之所以要使用tokudu,可以看index.php的182行 var target = ‘tokudu/’ + $(‘#messageTarget’).val();
在mosquitto的终端获得mosquitto_sub客户端的id
1350006978: New client connected from 127.0.0.1 as mosqsub/8491-localhost..
访问http://host:port/ ,push notification target字段填写8491-localhost,push notification text填写需要推送的测试消息
在mosquitto的终端查看是否收到了推送的消息,如果收到,说明phpmqttclient已经安装配置成功
解决mosquitto占有cpu进程过高的问题 https://answers.launchpad.net/mosquitto/+question/189612
ulimit -u 4096
ulimit -n 4096
附:
配置文件
# =================================================================
# General configuration
# =================================================================
# 客户端心跳的间隔时间
#retry_interval 20
# 系统状态的刷新时间
#sys_interval 10
# 系统资源的回收时间,0表示尽快处理
#store_clean_interval 10
# 服务进程的PID
#pid_file /var/run/mosquitto.pid
# 服务进程的系统用户
#user mosquitto
# 客户端心跳消息的最大并发数
#max_inflight_messages 10
# 客户端心跳消息缓存队列
#max_queued_messages 100
# 用于设置客户端长连接的过期时间,默认永不过期
#persistent_client_expiration
# =================================================================
# Default listener
# =================================================================
# 服务绑定的IP地址
#bind_address
# 服务绑定的端口号
#port 1883
# 允许的最大连接数,-1表示没有限制
#max_connections -1
# cafile:CA证书文件
# capath:CA证书目录
# certfile:PEM证书文件
# keyfile:PEM密钥文件
#cafile
#capath
#certfile
#keyfile
# 必须提供证书以保证数据安全性
#require_certificate false
# 若require_certificate值为true,use_identity_as_username也必须为true
#use_identity_as_username false
# 启用PSK(Pre-shared-key)支持
#psk_hint
# SSL/TSL加密算法,可以使用“openssl ciphers”命令获取
# as the output of that command.
#ciphers
# =================================================================
# Persistence
# =================================================================
# 消息自动保存的间隔时间
#autosave_interval 1800
# 消息自动保存功能的开关
#autosave_on_changes false
# 持久化功能的开关
persistence true
# 持久化DB文件
#persistence_file mosquitto.db
# 持久化DB文件目录
#persistence_location /var/lib/mosquitto/
# =================================================================
# Logging
# =================================================================
# 4种日志模式:stdout、stderr、syslog、topic
# none 则表示不记日志,此配置可以提升些许性能
log_dest none
# 选择日志的级别(可设置多项)
#log_type error
#log_type warning
#log_type notice
#log_type information
# 是否记录客户端连接信息
#connection_messages true
# 是否记录日志时间
#log_timestamp true
# =================================================================
# Security
# =================================================================
# 客户端ID的前缀限制,可用于保证安全性
#clientid_prefixes
# 允许匿名用户
#allow_anonymous true
# 用户/密码文件,默认格式:username:password
#password_file
# PSK格式密码文件,默认格式:identity:key
#psk_file
# pattern write sensor/%u/data
# ACL权限配置,常用语法如下:
# 用户限制:user <username>
# 话题限制:topic [read|write] <topic>
# 正则限制:pattern write sensor/%u/data
#acl_file
# =================================================================
# Bridges
# =================================================================
# 允许服务之间使用“桥接”模式(可用于分布式部署)
#connection <name>
#address <host>[:<port>]
#topic <topic> [[[out | in | both] qos-level] local-prefix remote-prefix]
# 设置桥接的客户端ID
#clientid
# 桥接断开时,是否清除远程服务器中的消息
#cleansession false
# 是否发布桥接的状态信息
#notifications true
# 设置桥接模式下,消息将会发布到的话题地址
# $SYS/broker/connection/<clientid>/state
#notification_topic
# 设置桥接的keepalive数值
#keepalive_interval 60
# 桥接模式,目前有三种:automatic、lazy、once
#start_type automatic
# 桥接模式automatic的超时时间
#restart_timeout 30
# 桥接模式lazy的超时时间
#idle_timeout 60
# 桥接客户端的用户名
#username
# 桥接客户端的密码
#password
# bridge_cafile:桥接客户端的CA证书文件
# bridge_capath:桥接客户端的CA证书目录
# bridge_certfile:桥接客户端的PEM证书文件
# bridge_keyfile:桥接客户端的PEM密钥文件
#bridge_cafile
#bridge_capath
#bridge_certfile
#bridge_keyfile
# 自己的配置可以放到以下目录中
include_dir /etc/mosquitto/conf.d
本文出自 “Cooke Chen 我爱小贝” 博客,请务必保留此出处http://cswei.blog.51cto.com/3443978/1225617
posted @
2013-12-12 21:54 hellxoul 阅读(8987) |
评论 (0) |
编辑 收藏Sublime Text 2
---------------
非常好用的文本编辑器,虽是收费的,但是现在可以免费不限时间试用。
Shell代码

- sudo add-apt-repository ppa:webupd8team/sublime-text-2
- sudo apt-get update
- sudo apt-get install sublime-text-2
将 sublime 作为默认的文本编辑器
sudo subl /usr/share/applications/defaults.list
把所有的 gedit.desktop 替换为 sublime-text-2.desktop
Jupiter
----------------
据说可以让 Ubuntu 不那么耗电.... 我的本子跑的时候比较烫,权且相信了。这个工具还可以关闭触摸屏,这点比较实用。
Shell代码
- sudo add-apt-repository ppa:webupd8team/jupiter
- sudo apt-get update
- sudo apt-get install jupiter
Tweak
----------------
使用过后才发现确实比 MyUnity 要好用,功能也更多。
去官方网站下载吧:
网址代码
- http://ubuntu-tweak.com/
MyUnity
----------------
自 Ubuntu 转用 Unity 后就一直褒贬不一,我个人还是比较喜欢这种设计的,比较前卫,很漂亮;还把菜单栏和顶部栏合为一体,比较节省本子本来已经很小的垂直视野;但是也有些东西 很恼人,比如左侧栏总是会弹出,非常影响体验。有了这个工具就可以很方便的定制界面了。比如我就把左侧栏缩小到 40,然后固定,还是比较 Nice 的。
Shell代码
- sudo add-apt-repository ppa:myunity/ppa
- sudo apt-get update
- sudo apt-get install myunity
Guake
----------------------------------
非常好用的 Terminator,可以在 Ubuntu 软件中心安装。
Fish (Friendly Interactive Shell)
-----------------------------------
正如其名字,比默认的 shell terminate 更加友好,更加方便使用。添加的语法高亮,用下划线标出存在的地址,等等。
Shell代码
- sudo apt-get install fish
如果你和我一样喜欢把他作为默认的 shell 的话,可以按下面方法做:
1. 确定 fish 安装路径:
Shell代码
- whereis fish
2. 添加为默认:
Shell代码
- chsh -s /usr/local/bin/fish(注,这个地址由上面的命令得到)
dnsmasq
-------------------------
DNS 缓存,加速访问网站
1. 安装
Shell代码
- sudo apt-get install dnsmasq
2. 配置 dnsmasq.conf
Shell代码
- sudo vim /etc/dnsmasq.conf
- 查找 #listen-address=
- 修改为 listen-address=127.0.0.1
3. 配置 dhclient.conf
有些网站修改的是 /etc/dhcp3/dhclient.conf,我用的是 ubuntu 11.10,没有找到这个文件,修改的是 /etc/dhcp/dhclient.conf
Shell代码
- sudo vim /etc/dhcp/dhclient.conf
- 查找 #prepend domain-name-servers 127.0.0.1;
- 删除注释符号 #
- 变成 prepend domain-name-servers 127.0.0.1;
4. 配置 resolv.conf
Shell代码
- sudo vim /etc/resolv.conf
- 修改为:
- # Local Cached DNS
- nameserver 127.0.0.1
- # Google DNS
- nameserver 8.8.8.8
- nameserver 8.8.4.4
- # OpenDNS
- nameserver 208.67.220.220
- nameserver 208.67.222.222
5. 重启 dnsmasq
Shell代码
- sudo /etc/init.d/networking restart
posted @
2013-11-19 20:53 hellxoul 阅读(262) |
评论 (0) |
编辑 收藏
摘要: 【51CTO精选译文】Rsnapshot是一款开源本地/远程文件系统备份实用工具,它采用Perl语言编写而成,充分利用了Rsync和SSH程序的功能,可以针对Linux/Unix文件系统创建预定的增量备份,同时只占用了一套单个完全备份的空间(外加变化的数据),并将本地驱动器上的那些备份存放到不同的硬盘驱动器、外置USB驱动器、NFS挂载驱动器上,或者干脆经由SSH,通过网络存放到另一台机器上。安装...
阅读全文
posted @
2013-11-15 09:34 hellxoul 阅读(662) |
评论 (0) |
编辑 收藏TDDL动态数据源基本说明
总体描述
TDDL动态数据源主要分为2层,每一层都实现了jdbc规范,以方便地集成到各种orm框架或者直接使用.每一层都各司其职.

整体结构如上图,TGroupDataSource(tddl group ds)默认情况下依赖TAtomDataSource(tddl atom ds),但是可以扩展依赖普通数据源.这一层主要的职责是解决读写分离以及主备切换的问题,当然是在线执行这些动作,无需重启.一个TGroupDataSource底下会挂多个TAtomDataSource,每个TAtomDataSource都有相对应的读写权重.
TAtomDataSource(tddl atom ds)这一层并没有实现真正的数据源逻辑,而是依赖了一个近似第三方的包-我们从jboss剥离出来的datasource,这一层的职责主要是将单个数据源的配置放置到diamond服务器中,实现数据源配置的集中管理和动态变更.减少运维成本. TAtomDataSource实际对应了一个真正的数据源.
Tddl动态数据源暂时支持mysql和oracle ,但是因为每一层都是jdbc的实现,所以很容易扩展支持其他实现jdbc规范的数据源.
TGroupDataSource
- 基本功能
(1) 主备数据库动态容灾切换
支持进行主备的对调切换,状态对调后备库变为主库,主库变为备库
(2) 相同数据分片读写分离
针对mysql replication机制进行的数据主备复制,可以直接使用group datasource来支持读写分离。读写分离支持权重设置,允许对不同库使用不同的权重。
(3) 读重试
一台数据库挂掉后,如果是个fatal exception(有定义),那么会进入读重试,以确保尽可能多的数据访问可以在正常数据库中访问。
(4) 数据库挂掉排除,单线程重试
使用try – lock机制来进行线程保护,在第一次捕捉到fatal exception以后,只允许一个线程进入数据库进行数据访问,直到数据库可以正常的工作为止
(5) 流量控制,数据库保护
- 延展性功能
(1) 指定数据库访问(ThreadLocal)
一组对等数据库中,写库一般只配置一个,其余数据库都为备库,因为通过复制机制,所以主备主键有延迟,对于各种类型的读(实时读和延迟读),可以使用GroupDataSourceRouteHelper.executeByGroupDataSourceIndex(int dataSourceIndex)指定需要访问的数据库.
(2) 指定数据库访问(Hint)
这是指定数据库访问的另外一种方式. 这种方式是在sql之前加注释,告知tddl动态数据源该选择第几个数据库.类似: /*+TDDL_GROUP({groupIndex:0})*/select * from normaltbl_0001 where pk = ? 变幻groupIndex的数字即可指定具体的第几个库,从0开始.
TAtomDataSource
- 基本功能
(1) 数据源配置集中管控
(2) 定期密码变更
(3) Jboss数据源连接池的配置管理和推送
- 延展性功能
(1) 动态创建,添加,减少数据源
(2) 数据库R,W,NA状态通知,以及读写访问控制,如置为NA则数据库所有访问会直接抛出SQLException
(3) 数据库保护
Diamond中配置说明.
Tddl的动态数据源配置都放置在diamond配置中心,而一条diamond配置包括一个全局唯一的dataId和GROUP, tddl的配置数据也不例外,以下主要说明tddl动态数据源的dataId拼写以及每一个dataId下数据的内容.(详细示例请参考示例使用说明文档)
- 1. TGroupDataSource的配置
Group中的配置主要是配置一组对等的数据的读写权重
dataId组成规范:“com.taobao.tddl.jdbc.group_V2.4.1_”+dbGroupKey
配置内容(示例):tddl_sample_0:r10w10p0,tddl_sample_0_bac:r10w0p0
其中tddl_sample_0和tddl_sample_0_bak就是下一层需要的dbKey,后面r为读权重,w为写权重
- 2. TAtomDataSource的配置
atom ds中的配置分为了3部分(global,app,user),配置内容全部为java的properties格式
Global
dataId组成规范: “com.taobao.tddl.atom.global.”+dbKey
配置内容:
| 属性key | 说明 |
| ip | 数据实例的ip |
| port | 数据实例的端口 |
| dbname | 数据库名称 |
| dbType | MYSQL,ORACLE |
| dbStatus | RW,NA |
App
dataId组成规范: “com.taobao.tddl.atom.app.”+appName+”.”+dbKey
配置内容:
| 属性key | 说明 |
| username | 该应用使用的用户名 |
| oracleConType | oci,thin,如果db为mysql,则不用理会 |
| minPoolSize | 最小连接池 |
| maxPoolSize | 最大连接池 |
| idleTimeout | 连接的最大空闲时间 |
| blockingTimeout | 等待连接的最大时间 |
| preparedStatementCacheSize | Oracle专用 |
| writeRestrictTimes | 单位timeSliceInMillis写限制,默认空不限制 |
| readRestrictTimes | 单位timeSliceInMillis读限制,默认空不限制 |
| threadCountRestrict | 并发线程限制,默认空不限制 |
| timeSliceInMillis | 限制的时间单位 |
| connectionProperties | 连接参数 |
User
dataId组成规范: “com.taobao.tddl.atom.passwd.”+dbName+”.”+dbType+”.”+userName
配置内容:
| 属性key | 说明 |
| encPasswd | 密码 |
| encKey | 密钥 |
posted @
2013-11-10 11:13 hellxoul 阅读(1748) |
评论 (0) |
编辑 收藏Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析。该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Facebook 雇员中使用,运行超过 30000 个查询,每日数据在 1PB 级别。Facebook 称 Presto 的性能比诸如 Hive 和 Map*Reduce 要好上 10 倍有多。
Presto 当前支持 ANSI SQL 的大多数特效,包括联合查询、左右联接、子查询以及一些聚合和计算函数;支持近似截然不同的计数(DISTINCT COUNT)等。

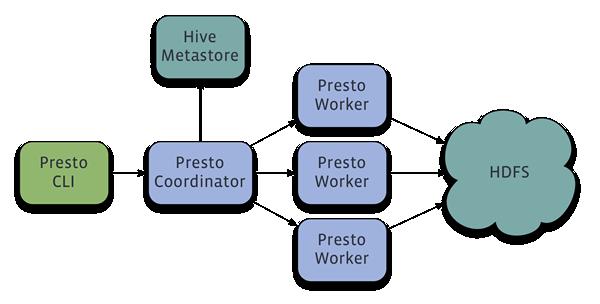
你可以通过下面地址了解该项目详情和获取代码:
Documentation | Code
原文链接:http://www.oschina.net/news/45706/facebook-open-sources-presto-homegrown-sql-query-engine
posted @
2013-11-07 23:15 hellxoul 阅读(398) |
评论 (1) |
编辑 收藏
摘要: 一款功能强大且实用的开发工具可以为开发者简化开发流程,提高工作效率,允许开发者在应用开发本身投入更多的时间和精力,从而提高作品质量。本文就为大家分享4款实用的Android应用架构工具。
阅读全文
posted @
2013-11-07 23:09 hellxoul 阅读(293) |
评论 (0) |
编辑 收藏
摘要: 首先先介绍一款知名的网站压力测试工具:webbench.Webbench能测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。webbench的标准测试可以向我们展示服务器的两项内容:每分钟相应请求数和每秒钟传输数据量。webbench不但能具有便准静态页面的测试能力,还能对动态页面(ASP,PHP,JAVA,CGI)进 行测试的能力。还有就是他支持对含有SSL的安全网站例如电子...
阅读全文
posted @
2013-11-07 23:06 hellxoul 阅读(3536) |
评论 (0) |
编辑 收藏转自:http://elf8848.iteye.com/blog/455676
如何修改Centos yum源
--------------------------------------
国内yum源: 163和搜狐的yum源。
本文章介绍的yum源支持的版本是CentOS 5系列,理论上支持RHEL5系列。
更新方法如下:
先进入yum源配置目录
cd /etc/yum.repos.d
备份系统自带的yum源
mv CentOS-Base.repo CentOS-Base.repo.save
下载其他更快的yum源
中科大的yum源:(现在打不开了 )
wget http://centos.ustc.edu.cn/CentOS-Base.repo
163的yum源:
wget http://mirrors.163.com/.help/CentOS-Base-163.repo
修改CentOS-Base.repo (不修改会报错),下载到本地把“$releasever”,替换成“5”
sohu的yum源
wget http://mirrors.sohu.com/help/CentOS-Base-sohu.repo
更新玩yum源后,建议更新一下,使操作立即生效
yum makecache
RedHat5.6使用CentOS yum源更新的方法
================================================================================
由于RedHat的yum在线更新是收费的,我们的RedHat没有注册,不能在线更新下载rpm包。
需将RedHat的yum卸载后,重启安装Centos的yum,再配置其他yum源。
一、确认RedHat的版本
cat /etc/redhat-release
uname -m
二、删除redhat原有的yum源
rpm -aq|grep yum|xargs rpm -e --nodeps
三、下载CentOS的yum安装包(163源) (可以在这里手工找rpm包:http://mirrors.163.com/centos/)
32位系统:
wget http://mirrors.163.com/centos/5/os/i386/CentOS/yum-metadata-parser-1.1.2-3.el5.centos.i386.rpm
wget http://mirrors.163.com/centos/5/os/i386/CentOS/yum-3.2.22-39.el5.centos.noarch.rpm
wget http://mirrors.163.com/centos/5/os/i386/CentOS/yum-fastestmirror-1.1.16-21.el5.centos.noarch.rpm
64位系统:
wget http://mirrors.163.com/centos/5/os/x86_64/CentOS/yum-metadata-parser-1.1.2-3.el5.centos.x86_64.rpm
wget http://mirrors.163.com/centos/5/os/x86_64/CentOS/yum-3.2.22-39.el5.centos.noarch.rpm
wget http://mirrors.163.com/centos/5/os/x86_64/CentOS/yum-fastestmirror-1.1.16-21.el5.centos.noarch.rpm
还依赖python-iniparse-0.2.3-4.el5.noarch.rpm,
但我的系统里已安装了,是系统默认Python2.4中自带的。
如果你的系统没有安装,请安装吧。
四、安装yum软件包
32位系统:
rpm -ivh yum-metadata-parser-1.1.2-3.el5.centos.i386.rpm
rpm -ivh yum-3.2.22-39.el5.centos.noarch.rpm yum-fastestmirror-1.1.16-21.el5.centos.noarch.rpm
注意:最后两个安装包要放在一起同时安装,否则会提示相互依赖,安装失败。
64位系统:
rpm -ivh yum-metadata-parser-1.1.2-3.el5.centos.x86_64.rpm
rpm -ivh yum-3.2.22-39.el5.centos.noarch.rpm yum-fastestmirror-1.1.16-21.el5.centos.noarch.rpm
注意:最后两个安装包要放在一起同时安装,否则会提示相互依赖,安装失败。
五、更改yum源 #我们使用网易的CentOS镜像源
cd /etc/yum.repos.d/
vi CentOS6-Base-163.repo
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#
[base]
name=CentOS-5 - Base - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=os
baseurl=http://mirrors.163.com/centos/5/os/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#released updates
[updates]
name=CentOS-5 - Updates - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=updates
baseurl=http://mirrors.163.com/centos/5/updates/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#packages used/produced in the build but not released
[addons]
name=CentOS-5 - Addons - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=addons
baseurl=http://mirrors.163.com/centos/5/addons/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#additional packages that may be useful
[extras]
name=CentOS-5 - Extras - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=extras
baseurl=http://mirrors.163.com/centos/5/extras/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-5 - Plus - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=centosplus
baseurl=http://mirrors.163.com/centos/5/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#contrib - packages by Centos Users
[contrib]
name=CentOS-5 - Contrib - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=contrib
baseurl=http://mirrors.163.com/centos/5/contrib/$basearch/
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
六、清理
yum clean all
yum makecache
如果报错:imary.sqlite.bz2 from base: [Errno 256] No more mirrors to try.
执行:yum makecache
七、更新
cd /etc/pki/rpm-gpg
wget http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-5
yum update
很长时间的下载后,报错:
warning: rpmts_HdrFromFdno: Header V3 DSA signature: NOKEY, key ID e8562897
GPG key retrieval failed: [Errno 5] OSError: [Errno 2] No such file or directory: '/etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5'
这是因为:指定的文件/etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5在本地不存在导致的。
解决:
去官网http://mirror.centos.org/centos/下载相应文件
cd /etc/pki/rpm-gpg
wget http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-5
================================================================================
RedHat6.0使用CentOS yum源更新的方法
--------------------------------------------------------------------
由于RedHat的yum在线更新是收费的,我们的RedHat没有注册,不能在线更新下载rpm包。
需将RedHat的yum卸载后,重启安装Centos的yum,再配置其他yum源。
一、确认RedHat的版本
cat /etc/redhat-release
uname -m
二、删除redhat原有的yum源
rpm -aq|grep yum|xargs rpm -e --nodeps
三、下载CentOS的yum安装包(163源)
32位系统 :
wget http://mirrors.163.com/centos/6/os/i386/Packages/yum-3.2.29-22.el6.centos.noarch.rpm
wget http://mirrors.163.com/centos/6/os/i386/Packages/yum-metadata-parser-1.1.2-16.el6.i686.rpm
wget http://mirrors.163.com/centos/6/os/i386/Packages/yum-plugin-fastestmirror-1.1.30-10.el6.noarch.rpm
wget http://mirrors.163.com/centos/6/os/i386/Packages/python-iniparse-0.3.1-2.1.el6.noarch.rpm
四、安装yum软件包
rpm -ivh python-iniparse-0.3.1-2.1.el6.noarch.rpm
rpm -ivh yum-metadata-parser-1.1.2-16.el6.i686.rpm
rpm -ivh yum-3.2.29-22.el6.centos.noarch.rpm yum-plugin-fastestmirror-1.1.30-10.el6.noarch.rpm
注意:最后两个安装包要放在一起同时安装,否则会提示相互依赖,安装失败。
五、更改yum源 #我们使用网易的CentOS镜像源
cd /etc/yum.repos.d/
vi CentOS6-Base-163.repo
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#
[base]
name=CentOS-6 - Base - 163.com
baseurl=http://mirrors.163.com/centos/6/os/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=6&arch=$basearch&repo=os
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6
#released updates
[updates]
name=CentOS-6 - Updates - 163.com
baseurl=http://mirrors.163.com/centos/6/updates/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=6&arch=$basearch&repo=updates
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6
#additional packages that may be useful
[extras]
name=CentOS-6 - Extras - 163.com
baseurl=http://mirrors.163.com/centos/6/extras/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=6&arch=$basearch&repo=extras
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6
#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-6 - Plus - 163.com
baseurl=http://mirrors.163.com/centos/6/centosplus/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=6&arch=$basearch&repo=centosplus
gpgcheck=1
enabled=0
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6
#contrib - packages by Centos Users
[contrib]
name=CentOS-6 - Contrib - 163.com
baseurl=http://mirrors.163.com/centos/6/contrib/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=6&arch=$basearch&repo=contrib
gpgcheck=1
enabled=0
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6
六、清理
yum clean all
yum makecache
如果报错:imary.sqlite.bz2 from base: [Errno 256] No more mirrors to try.
执行:yum makecache
至此,Redhat6可以使用CentOS的yum源在线安装软件了!
posted @
2013-10-23 13:39 hellxoul 阅读(1027) |
评论 (0) |
编辑 收藏one js validation framework
http://niceue.com/validator/demo/twitter-js.php?theme=yellow_right_effect
posted @
2013-10-10 10:37 hellxoul 阅读(373) |
评论 (0) |
编辑 收藏Linux操作系统:CentOS 6.3
1:下载:当前mysql版本到了5.6.10
下载地址:http://dev.mysql.com/downloads/mysql/5.6.html#downloads
选择“Source Code”
在此之前最好注册一个Oracle账号
2:必要软件包
yum -y install gcc gcc-c++ gcc-g77 autoconf automake zlib* fiex* libxml* ncurses-devel libmcrypt* libtool-ltdl-devel* make cmake
3:编译安装
[root@server182 ~]# groupadd mysql
[root@server182 ~]# useradd -r -g mysql mysql
[root@server182 ~]# tar -zxvf mysql-5.6.10.tar.gz
[root@server182 ~]# cd mysql-5.6.10
[root@server182 mysql-5.6.10]# cmake .
[root@server182 mysql-5.6.10]# make && make install
-------------------------默认情况下是安装在/usr/local/mysql
[root@server182 ~]# chown -R mysql.mysql /usr/local/mysql
[root@server182 ~]# cd /usr/local/mysql/scripts
[root@server182 ~]# ./mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
[root@server182 ~]# cd /usr/local/mysql/support-files
[root@server182 support-files]# cp mysql.server /etc/rc.d/init.d/mysql
[root@server182 support-files]# cp my-default.cnf /etc/my.cnf
[root@server182 ~]# chkconfig -add mysql
[root@server182 ~]# chkconfig mysql on
[root@server182 ~]# service mysql start
Starting MySQL SUCCESS!
[root@server182 support-files]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.6.10 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
mysql> status;
--------------
mysql Ver 14.14 Distrib 5.6.10, for Linux (i686) using EditLine wrapper
Connection id: 1
Current database:
Current user: root@localhost
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server version: 5.6.10 Source distribution
Protocol version: 10
Connection: Localhost via UNIX socket
Server characterset: utf8
Db characterset: utf8
Client characterset: utf8
Conn. characterset: utf8
UNIX socket: /tmp/mysql.sock
Uptime: 5 min 45 sec
Threads: 1 Questions: 5 Slow queries: 0 Opens: 70 Flush tables: 1 Open tables: 63 Queries per second avg: 0.014
-------------
mysql>
安装完毕。
原文链接:http://www.linuxidc.com/Linux/2013-02/79791.htm
posted @
2013-05-17 15:20 hellxoul 阅读(273) |
评论 (0) |
编辑 收藏MySQL 5.6正式版发布了,相对于5.5版本作出了不少改进,其源码安装配置方式也有所变化,本文根据实际操作,不断尝试,精确还原了安装的具体步骤。
环境:CentOS 6.3/6.4 最小化缺省安装,配置好网卡。
安装MySQL前,确认Internet连接正常,以便下载安装文件。
先使用 yum -y update 指令升级系统到最新版本。
本安装将MySQL的数据文件与执行文件分离,如果你打算设置到不同的路径,注意修改对应的执行命令和数据库初始化脚本。
# 修改防火墙设置,打开3306端口
vi /etc/sysconfig/iptables
-A INPUT -m state --state NEW -m tcp -p tcp --dport 3306 -j ACCEPT
# 重启防火墙使新设置生效
service iptables restart
# 新增用户组
groupadd mysql
# 新增用户
useradd mysql -g mysql
# 新建数据库执行文件目录
mkdir -p /usr/local/mysql
# 新建数据库数据文件目录
mkdir -p /db/mysql/data
# 编辑PATH搜索路径
vi /etc/profile
Append these 2 lines to the end of the file:
PATH=/usr/local/mysql/bin:/usr/local/mysql/lib:$PATH
export PATH
# 生效PATH搜索路径
source /etc/profile
# 编辑hosts文件,加入本机IP和主机名
vi /etc/hosts
192.168.211.100 centhost.centdomain
# 安装编译源码所需的工具和库
yum -y install wget gcc-c++ ncurses-devel cmake make perl
# 进入源码压缩包下载目录
cd /usr/local/src
# 下载源码压缩包,下载包34M大小,有点慢,等吧。
wget http://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.10.tar.gz/from/http://cdn.mysql.com/
# 解压缩源码包
tar -zxvf mysql-5.6.10.tar.gz
# 进入解压缩源码目录
cd mysql-5.6.10
# 从mysql5.5起,mysql源码安装开始使用cmake了,执行源码编译配置脚本。
cmake \
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql \
-DMYSQL_UNIX_ADDR=/usr/local/mysql/mysql.sock \
-DDEFAULT_CHARSET=utf8 \
-DDEFAULT_COLLATION=utf8_general_ci \
-DWITH_MYISAM_STORAGE_ENGINE=1 \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DWITH_ARCHIVE_STORAGE_ENGINE=1 \
-DWITH_BLACKHOLE_STORAGE_ENGINE=1 \
-DWITH_MEMORY_STORAGE_ENGINE=1 \
-DWITH_READLINE=1 \
-DENABLED_LOCAL_INFILE=1 \
-DMYSQL_DATADIR=/db/mysql/data \
-DMYSQL_USER=mysql \
-DMYSQL_TCP_PORT=3306
# 编译源码,这一步时间会较长,耐心等待。
make
# 安装
make install
# 清除安装临时文件
make clean
# 修改目录拥有者
chown -R mysql:mysql /usr/local/mysql
chown -R mysql:mysql /db/mysql/data
# 进入安装路径
cd /usr/local/mysql
# 执行初始化配置脚本,创建系统自带的数据库和表。
scripts/mysql_install_db --user=mysql --datadir=/db/mysql/data
初始化脚本在 /usr/local/mysql/my.cnf 生成了配置文件。需要更改该配置文件的所有者:
chown -R mysql:mysql /usr/local/mysql
多说两句:在启动MySQL服务时,会按照一定次序搜索my.cnf,先在/etc目录下找,找不到则会搜索"$basedir/my.cnf",在本例中就是 /usr/local/mysql/my.cnf,这是新版MySQL的配置文件的默认位置!注意:在CentOS 6.4版操作系统的最小安装完成后,在/etc目录下会存在一个my.cnf,需要将此文件更名为其他的名字,如:/etc/my.cnf.bak,否则,该文件会干扰源码安装的MySQL的正确配置,造成无法启动。
# 复制服务启动脚本
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
# 启动MySQL服务
service mysql start
# 设置开机自动启动服务
chkconfig mysql on
# 修改MySQL用户root的密码
mysql -u root
mysql>use mysql;
mysql>GRANT ALL PRIVILEGES ON *.* TO root@"%" IDENTIFIED BY "root";
mysql>update user set Password = password('123456') where User='root';
mysql>flush privileges;
mysql>exit;
# 可选:运行安全设置脚本,修改MySQL用户root(不是系统的root!)的密码,禁止root远程连接(防止破解密码),移除test数据库和匿名用户,强烈建议生产服务器使用:
/usr/local/mysql/bin/mysql_secure_installation
后记:
2013年3月18日更新:
如果要使Windows平台下的MySQL和Linux平台下的MySQL协同工作,你需要设置Linux平台下的全局变量lower_case_table_names=1,强制将数据表名称转换为小写(大小写不敏感)。参考我另一篇博文:http://www.cnblogs.com/jlzhou/archive/2013/03/18/2966106.html
>>>>> 版权没有 >>>>> 欢迎转载 >>>>> 原文地址 >>>>> http://www.cnblogs.com/jlzhou >>>>> 雄鹰在鸡窝里长大,就会失去飞翔的本领,野狼在羊群里成长,也会爱上羊而丧失狼性。人生的奥妙就在于与人相处。生活的美好则在于送人玫瑰。和聪明的人在一起,你才会更加睿智。和优秀的人在一起,你才会出类拔萃。所以,你是谁并不重要,重要的是,你和谁在一起。
posted @
2013-05-17 15:18 hellxoul 阅读(305) |
评论 (0) |
编辑 收藏
摘要: Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
--> 1 <project xmlns="http://maven.apache.org/POM/4.0.0 " &...
阅读全文
posted @
2013-05-16 11:26 hellxoul 阅读(14030) |
评论 (0) |
编辑 收藏
生成javadoc时,乱码问题要注意两个参数的设置
-encoding utf-8 -charset utf-8
前面的是文件编码,后面的是生成的javadoc的编码
例如用IntelliJ IDEA 6.0.1 生成javadoc时,在"Tools->Gerenate JavaDoc"面版的
"Other command line arguments:"栏里输入"-encoding utf-8 -charset utf-8",
就是以utf-8编码读取文件和生成javadoc
posted @
2013-05-01 12:24 hellxoul 阅读(518) |
评论 (0) |
编辑 收藏CREATE TABLE `config_info` (
`id` BIGINT(64) UNSIGNED NOT NULL AUTO_INCREMENT,
`data_id` VARCHAR(255) NOT NULL DEFAULT '',
`group_id` VARCHAR(128) NOT NULL DEFAULT '',
`content` LONGTEXT NOT NULL,
`md5` VARCHAR(32) NOT NULL DEFAULT '',
`gmt_create` DATETIME NOT NULL DEFAULT '2010-05-05 00:00:00',
`gmt_modified` DATETIME NOT NULL DEFAULT '2010-05-05 00:00:00',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_config_datagroup` (`data_id`,`group_id`)
);
posted @
2013-04-25 14:43 hellxoul 阅读(344) |
评论 (0) |
编辑 收藏
通过java client链接server@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
1. 通过设置参数
1 ConnectionFactory factory = new ConnectionFactory();
2 factory.setUsername(userName);
3 factory.setPassword(password);
4 factory.setVirtualHost(virtualHost);
5 factory.setHost(hostName);
6 factory.setPort(portNumber);
7 Connection conn = factory.newConnection();
1 ConnectionFactory factory = new ConnectionFactory();
2 factory.setUri("amqp://userName:password@hostName:portNumber/virtualHost");
3 Connection conn = factory.newConnection();
3.多地址
1 Address[] addrArr = new Address[]{ new Address(hostname1, portnumber1)
2 , new Address(hostname2, portnumber2)};
3 Connection conn = factory.newConnection(addrArr);
posted @
2013-04-11 10:27 hellxoul 阅读(384) |
评论 (0) |
编辑 收藏在CentOS下,源码安装Erlang:
下载Erlang源码
安装:官网地址,http://www.erlang.org
Java代码
# cd /opt/
# wget http://www.erlang.org/download/otp_src_R15B01.tar.gz
解压:
Java代码
# tar -zxvf otp_src_R15B01.tar.gz
# cd otp_src_R15B01
安装依赖:
Java代码
# yum install build-essential m4
# yum install openssl
# yum install openssl-devel
# yum install unixODBC
# yum install unixODBC-devel
# yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel
配置configure
Java代码
# ./configure --prefix=/usr/local/erlang --enable-hipe --enable-threads --enable-smp-support --enable-kernel-poll
make
make install
完成之后,设置环境变量
Java代码
vim /etc/profile
ERL_HOME=/usr/local/erlang
PATH=$ERL_HOME/bin:$PATH
export ERL_HOME PATH
完成后保存
Java代码
source /etc/profile
让环境变量立即生效
然后输入erl,出现erlang shell,如下:
Java代码
Erlang R15B01 (erts-5.9.1) [source] [64-bit] [smp:4:4] [async-threads:0] [hipe] [kernel-poll:false]
Eshell V5.9.1 (abort with ^G)
1>
hipe:支持Erlang编译成本地代码。好处:提高Erlang虚拟机执行代码性能。
参考文献:
[1] http://jinghong.iteye.com/blog/1075165
[2] http://my.oschina.net/hanyu363/blog/29727
[3] http://www.linuxidc.com/Linux/2011-07/39156.htm
rabbitmq启动:
sbin/rabbitmq-server
rabbitmq-server -detached
停止 rabbitmqctl stop
查看状态:rabbitmqctl status
插件安装rabbitmq-plugins enable rabbitmq_management 监控使用
http://www.rabbitmq.com/management.html
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
posted @
2013-04-09 15:20 hellxoul 阅读(269) |
评论 (0) |
编辑 收藏
只有注册用户登录后才能阅读该文。
阅读全文
posted @
2013-04-02 14:28 hellxoul|
编辑 收藏
1.下载MySQL
我下载的版本:mysql-5.5.22.tar.gz
2.安装之前先卸载CentOS自带的MySQL
[root@localhost ~]# yum remove mysql
3.编译安装Cmake
下载cmake源码包:http://www.cmake.org/files/v2.8/cmake-2.8.4.tar.gz
从共享目录移至usr目录
[root@localhost ~]# mv /mnt/hgfs/Share-CentOS/cmake-2.8.4.tar.gz /usr/cmake-2.8.4.tar.gz
[root@localhost ~]# cd /usr
解压并安装cmake
[root@localhost usr]# tar xzvf cmake-2.8.4.tar.gz
[root@localhost usr]# cd cmake-2.8.4
[root@localhost cmake-2.8.4]# ./bootstrap
---------------------------------------------
CMake 2.8.4, Copyright 2000-2009 Kitware, Inc.
---------------------------------------------
Error when bootstrapping CMake:
Cannot find appropriate C compiler on this system.
Please specify one using environment variable CC.
See cmake_bootstrap.log for compilers attempted.
---------------------------------------------
Log of errors: /usr/local/src/cmake-2.8.4/Bootstrap.cmk/cmake_bootstrap.log
---------------------------------------------
报错:缺少C的编译器
解决办法:安装gcc编译器
[root@localhost ~]# yum install gcc
继续安装Cmake
[root@localhost cmake-2.8.4]# ./bootstrap
---------------------------------------------
CMake 2.8.4, Copyright 2000-2009 Kitware, Inc.
C compiler on this system is: cc
---------------------------------------------
Error when bootstrapping CMake:
Cannot find appropriate C++ compiler on this system.
Please specify one using environment variable CXX.
See cmake_bootstrap.log for compilers attempted.
---------------------------------------------
Log of errors: /usr/local/src/cmake-2.8.4/Bootstrap.cmk/cmake_bootstrap.log
---------------------------------------------
报错:缺少C++编译器
解决办法:安装gcc-c++编译器
[root@localhost ~]# yum install gcc-c++
再次安装
[root@localhost cmake-2.8.4]# ./bootstrap
没有报错,编译安装
[root@localhost cmake-2.8.4]# gmake
[root@localhost cmake-2.8.4]# gmake install
4.正式开始安装MySQL
添加MySQL用户和用户组
[root@localhost ~]# groupadd mysql
[root@localhost ~]# useradd -g mysql mysql
MySQL源码包从共享文件夹移至/usr并解压
[root@localhost ~]mv /mnt/hgfs/Share-CentOS/mysql-5.5.22.tar.gz /usr/mysql-5.5.22.tar.gz
[root@localhost usr]# tar xzvf mysql-5.5.22.tar.gz
[root@localhost usr]# cd mysql-5.5.22
Cmake运行
[root@localhost mysql-5.5.22]# cmake .
开始编译安装
[root@localhost mysql-5.5.22]# make && make install
进入安装目录,将程序二进制的所有权改为root,数据目录的说有权改为mysql用户,更新授权表
[root@localhost mysql-5.5.22]# cd /usr/local/mysql/
[root@localhost mysql]# chown -R root .
[root@localhost mysql]# chown -R mysql .
[root@localhost mysql]# chgrp -R mysql .
[root@localhost mysql]# scripts/mysql_install_db --user=mysql
安全启动MySQL(默认密码为空)
[root@localhost mysql]#./bin/mysqld_safe --user=mysql&
报错:
120908 00:16:25 mysqld_safe Logging to '/usr/local/mysql/data/CentOS.err'.
120908 00:16:26 mysqld_safe Starting mysqld daemon with databases from /usr/local/mysql/data
解决方法:
[root@CentOS ~]# cd /usr/local/mysql/data
[root@CentOS data]# ls -l
总用量 29744
-rw-rw---- 1 mysql root 1585 9月 8 00:16 CentOS.err
-rw-rw---- 1 mysql mysql 6 9月 8 00:16 CentOS.pid
-rw-rw---- 1 mysql mysql 18874368 9月 8 00:16 ibdata1
-rw-rw---- 1 mysql mysql 5242880 9月 8 00:16 ib_logfile0
-rw-rw---- 1 mysql mysql 5242880 9月 8 00:16 ib_logfile1
drwxr-xr-x 2 mysql mysql 4096 9月 8 00:14 mysql
-rw-rw---- 1 mysql mysql 27293 9月 8 00:14 mysql-bin.000001
-rw-rw---- 1 mysql mysql 1031892 9月 8 00:14 mysql-bin.000002
-rw-rw---- 1 mysql mysql 107 9月 8 00:16 mysql-bin.000003
-rw-rw---- 1 mysql mysql 57 9月 8 00:16 mysql-bin.index
drwx------ 2 mysql mysql 4096 9月 8 00:14 performance_schema
drwxr-xr-x 2 mysql mysql 4096 9月 8 00:08 test
[root@CentOS data]# chgrp -R mysql CentOS.err
[root@CentOS data]# ls -l
总用量 29736
-rw-rw---- 1 mysql mysql 1585 9月 8 00:16 CentOS.err
-rw-rw---- 1 mysql mysql 6 9月 8 00:16 CentOS.pid
-rw-rw---- 1 mysql mysql 18874368 9月 8 00:16 ibdata1
-rw-rw---- 1 mysql mysql 5242880 9月 8 00:16 ib_logfile0
-rw-rw---- 1 mysql mysql 5242880 9月 8 00:16 ib_logfile1
drwxr-xr-x 2 mysql mysql 4096 9月 8 00:14 mysql
-rw-rw---- 1 mysql mysql 27293 9月 8 00:14 mysql-bin.000001
-rw-rw---- 1 mysql mysql 1031892 9月 8 00:14 mysql-bin.000002
-rw-rw---- 1 mysql mysql 107 9月 8 00:16 mysql-bin.000003
-rw-rw---- 1 mysql mysql 57 9月 8 00:16 mysql-bin.index
drwx------ 2 mysql mysql 4096 9月 8 00:14 performance_schema
drwxr-xr-x 2 mysql mysql 4096 9月 8 00:08 test
连接本机MySQL
[root@localhost mysql]#mysql –u root –p
提示输入password,默认为空,按Enter即可
断开连接
mysql>exit;
为root账户设置密码
[root@localhost ~]# cd /usr/local/mysql/bin
[root@localhost mysql]# ./bin/mysqladmin -u root password 123456
Enter Password:123456
设置选项文件,将配置文件拷贝到/etc下
[root@localhost mysql]# cp support-files/my-medium.cnf /etc/mysql.cnf
设置开机自启动
[root@localhost mysql]# cp support-files/mysql.server /etc/init.d/mysql
[root@localhost mysql]# chmod +x /etc/init.d/mysql
[root@localhost mysql]# chkconfig mysql on
通过服务来启动和关闭Mysql
[root@localhost ~]# service mysql start
[root@localhost ~]# service mysql stop
5.安装设置完毕,之后使用只需启动-连接-断开-关闭,命令如下:
[root@CentOS mysql]# service mysql start
Starting MySQL.. [确定]
[root@CentOS mysql]# mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.5.22 Source distribution
Copyright (c) 2000, 2011, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.07 sec)
mysql> exit;
Bye
[root@CentOS mysql]# service mysql stop
Shutting down MySQL. [确定]
6.其它:
查看进程命令 ps –ef|grep mysqld
kill进程命令 kill –9 进程号
posted @
2013-02-24 00:31 hellxoul 阅读(5522) |
评论 (1) |
编辑 收藏
摘要: Servlet 3.0作为Java EE6规范体系中一员,随着Java EE6规范一起发布。该版本在前一版本(Servlet 2.5)的基础上提供了若干新特性用于简化Web应用的开发和部署。
阅读全文
posted @
2013-01-16 11:08 hellxoul 阅读(52) |
评论 (0) |
编辑 收藏
摘要:
n 可以用来改变根据自己需要改变加载的优先级!
阅读全文
posted @
2013-01-16 10:50 hellxoul 阅读(69) |
评论 (0) |
编辑 收藏
只有注册用户登录后才能阅读该文。
阅读全文
posted @
2013-01-16 10:46 hellxoul 阅读(75) |
评论 (0) |
编辑 收藏
只有注册用户登录后才能阅读该文。
阅读全文
posted @
2013-01-16 10:44 hellxoul 阅读(67) |
评论 (0) |
编辑 收藏
只有注册用户登录后才能阅读该文。
阅读全文
posted @
2012-12-21 11:03 hellxoul 阅读(83) |
评论 (0) |
编辑 收藏接下来,我们将重点讨论一下Struts2中的拦截器的内部结构和执行顺序,并结合源码进行分析。
Interceptor结构 
让我们再来回顾一下之前我们曾经用过的一张Action LifeCycle的图:

图中,我们可以发现,Struts2的Interceptor一层一层,把Action包裹在最里面。这样的结构,大概有以下一些特点:
1. 整个结构就如同一个堆栈,除了Action以外,堆栈中的其他元素是Interceptor 2. Action位于堆栈的底部。由于堆栈"先进后出"的特性,如果我们试图把Action拿出来执行,我们必须首先把位于Action上端的Interceptor拿出来执行。这样,整个执行就形成了一个递归调用 3. 每个位于堆栈中的Interceptor,除了需要完成它自身的逻辑,还需要完成一个特殊的执行职责。这个执行职责有3种选择:
1) 中止整个执行,直接返回一个字符串作为resultCode
2) 通过递归调用负责调用堆栈中下一个Interceptor的执行
3) 如果在堆栈内已经不存在任何的Interceptor,调用Action
Struts2的拦截器结构的设计,实际上是一个典型的
责任链模式的应用。首先将整个执行划分成若干相同类型的元素,每个元素具备不同的逻辑责任,并将他们纳入到一个链式的数据结构中(我们可以把堆栈结构也看作是一个递归的链式结构),而每个元素又有责任负责链式结构中下一个元素的执行调用。
这样的设计,从代码重构的角度来看,实际上是将一个复杂的系统,分而治之,从而使得每个部分的逻辑能够高度重用并具备高度可扩展性。所以,Interceptor结构实在是Struts2/Xwork设计中的精华之笔。
Interceptor执行分析
Interceptor的定义 我们来看一下Interceptor的接口的定义:
Java代码

- public interface Interceptor extends Serializable {
-
- /**
- * Called to let an interceptor clean up any resources it has allocated.
- */
- void destroy();
-
- /**
- * Called after an interceptor is created, but before any requests are processed using
- * {@link #intercept(com.opensymphony.xwork2.ActionInvocation) intercept} , giving
- * the Interceptor a chance to initialize any needed resources.
- */
- void init();
-
- /**
- * Allows the Interceptor to do some processing on the request before and/or after the rest of the processing of the
- * request by the {@link ActionInvocation} or to short-circuit the processing and just return a String return code.
- *
- * @return the return code, either returned from {@link ActionInvocation#invoke()}, or from the interceptor itself.
- * @throws Exception any system-level error, as defined in {@link com.opensymphony.xwork2.Action#execute()}.
- */
- String intercept(ActionInvocation invocation) throws Exception;
- }
Interceptor的接口定义没有什么特别的地方,除了init和destory方法以外,intercept方法是实现整个拦截器机制的核心方法。而它所依赖的参数ActionInvocation则是我们之前章节中曾经提到过的著名的
Action调度者。
我们再来看看一个典型的Interceptor的抽象实现类:
Java代码
- public abstract class AroundInterceptor extends AbstractInterceptor {
-
- /* (non-Javadoc)
- * @see com.opensymphony.xwork2.interceptor.AbstractInterceptor#intercept(com.opensymphony.xwork2.ActionInvocation)
- */
- @Override
- public String intercept(ActionInvocation invocation) throws Exception {
- String result = null;
-
- before(invocation);
- // 调用下一个拦截器,如果拦截器不存在,则执行Action
- result = invocation.invoke();
- after(invocation, result);
-
- return result;
- }
-
- public abstract void before(ActionInvocation invocation) throws Exception;
-
- public abstract void after(ActionInvocation invocation, String resultCode) throws Exception;
-
- }
在这个实现类中,实际上已经实现了最简单的拦截器的雏形。或许大家对这样的代码还比较陌生,这没有关系。我在这里需要指出的是一个很重要的方法 invocation.invoke()。这是ActionInvocation中的方法,而ActionInvocation是Action调度者,所 以这个方法具备以下2层含义:
1. 如果拦截器堆栈中还有其他的Interceptor,那么invocation.invoke()将调用堆栈中下一个Interceptor的执行。 2. 如果拦截器堆栈中只有Action了,那么invocation.invoke()将调用Action执行。 所以,我们可以发现,invocation.invoke()这个方法其实是整个拦截器框架的实现核心。基于这样的实现机制,我们还可以得到下面2个非常重要的推论:
1. 如果在拦截器中,我们不使用invocation.invoke()来完成堆栈中下一个元素的调用,而是直接返回一个字符串作为执行结果,那么整个执行将被中止。 2. 我们可以以invocation.invoke()为界,将拦截器中的代码分成2个部分,在invocation.invoke()之前的代码,将会在 Action之前被依次执行,而在invocation.invoke()之后的代码,将会在Action之后被逆序执行。 由此,我们就可以通过invocation.invoke()作为Action代码真正的拦截点,从而实现AOP。
Interceptor拦截类型 从上面的分析,我们知道,整个拦截器的核心部分是invocation.invoke()这个函数的调用位置。事实上,我们也正式根据这句代码的调用位置,来进行拦截类型的区分的。在Struts2中,Interceptor的拦截类型,分成以下三类:
1. before before拦截,是指在拦截器中定义的代码,它们存在于invocation.invoke()代码执行之前。这些代码,将依照拦截器定义的顺序,
顺序执行。
2. after after拦截,是指在拦截器中定义的代码,它们存在于invocation.invoke()代码执行之后。这些代码,将一招拦截器定义的顺序,
逆序执行。
3. PreResultListener
有的时候,before拦截和after拦截对我们来说是不够的,因为我们需要在Action执行完之后,但是还没有回到视图层之前,做一些事 情。Struts2同样支持这样的拦截,这种拦截方式,是通过在拦截器中注册一个PreResultListener的接口来实现的。
Java代码
- public interface PreResultListener {
-
- /**
- * This callback method will be called after the Action execution and before the Result execution.
- *
- * @param invocation
- * @param resultCode
- */
- void beforeResult(ActionInvocation invocation, String resultCode);
- }
在这里,我们看到,Struts2能够支持如此多的拦截类型,与其本身的数据结构和整体设计有很大的关系。正如我在之前的文章中所提到的:
downpour 写道
因为Action是一个普通的Java类,而不是一个Servlet类,完全脱离于Web容器,所以我们就能够更加方便地对Control层进行合理的层次设计,从而抽象出许多公共的逻辑,并将这些逻辑脱离出Action对象本身。
我们可以看到,Struts2对于整个执行的划分,从Interceptor到Action一直到Result,每一层都职责明确。不仅如此,Struts2还为每一个层次之前都设立了恰如其分的插入点。使得整个Action层的扩展性得到了史无前例的提升。
Interceptor执行顺序 Interceptor的执行顺序或许是我们在整个过程中最最关心的部分。根据上面所提到的概念,我们实际上已经能够大致明白了Interceptor的执行机理。我们来看看Struts2的Reference对Interceptor执行顺序的一个形象的例子。
如果我们有一个interceptor-stack的定义如下:
Xml代码
- <interceptor-stack name="xaStack">
- <interceptor-ref name="thisWillRunFirstInterceptor"/>
- <interceptor-ref name="thisWillRunNextInterceptor"/>
- <interceptor-ref name="followedByThisInterceptor"/>
- <interceptor-ref name="thisWillRunLastInterceptor"/>
- </interceptor-stack>
那么,整个执行的顺序大概像这样:

在这里,我稍微改了一下Struts2的Reference中的执行顺序示例,使得整个执行顺序更加能够被理解。我们可以看到,递归调用保证了各种各样的拦截类型的执行能够井井有条。
请注意在这里,每个拦截器中的代码的执行顺序,在Action之前,拦截器的执行顺序与堆栈中定义的一致;而在Action和Result之后,拦截器的执行顺序与堆栈中定义的顺序相反。
源码解析
接下来我们就来看看源码,看看Struts2是如何保证拦截器、Action与Result三者之间的执行顺序的。
之前我曾经提到,ActionInvocation是Struts2中的调度器,所以事实上,这些代码的调度执行,是在 ActionInvocation的实现类中完成的,这里,我抽取了DefaultActionInvocation中的invoke()方法,它将向我 们展示一切。
Java代码
- /**
- * @throws ConfigurationException If no result can be found with the returned code
- */
- public String invoke() throws Exception {
- String profileKey = "invoke: ";
- try {
- UtilTimerStack.push(profileKey);
-
- if (executed) {
- throw new IllegalStateException("Action has already executed");
- }
- // 依次调用拦截器堆栈中的拦截器代码执行
- if (interceptors.hasNext()) {
- final InterceptorMapping interceptor = (InterceptorMapping) interceptors.next();
- UtilTimerStack.profile("interceptor: "+interceptor.getName(),
- new UtilTimerStack.ProfilingBlock<String>() {
- public String doProfiling() throws Exception {
- // 将ActionInvocation作为参数,调用interceptor中的intercept方法执行
- resultCode = interceptor.getInterceptor().intercept(DefaultActionInvocation.this);
- return null;
- }
- });
- } else {
- resultCode = invokeActionOnly();
- }
-
- // this is needed because the result will be executed, then control will return to the Interceptor, which will
- // return above and flow through again
- if (!executed) {
- // 执行PreResultListener
- if (preResultListeners != null) {
- for (Iterator iterator = preResultListeners.iterator();
- iterator.hasNext();) {
- PreResultListener listener = (PreResultListener) iterator.next();
-
- String _profileKey="preResultListener: ";
- try {
- UtilTimerStack.push(_profileKey);
- listener.beforeResult(this, resultCode);
- }
- finally {
- UtilTimerStack.pop(_profileKey);
- }
- }
- }
-
- // now execute the result, if we're supposed to
- // action与interceptor执行完毕,执行Result
- if (proxy.getExecuteResult()) {
- executeResult();
- }
-
- executed = true;
- }
-
- return resultCode;
- }
- finally {
- UtilTimerStack.pop(profileKey);
- }
- }
从源码中,我们可以看到,我们之前提到的Struts2的Action层的4个不同的层次,在这个方法中都有体现,他们分别是:拦截器 (Interceptor)、Action、PreResultListener和Result。在这个方法中,保证了这些层次的有序调用和执行。由此我 们也可以看出
Struts2在Action层次设计上的众多考虑,每个层次都具备了高度的扩展性和插入点,使得程序员可以在任何喜欢的层次加入自己的实现机制改变Action的行为。 在这里,需要特别强调的,是其中拦截器部分的执行调用:
Java代码
- resultCode = interceptor.getInterceptor().intercept(DefaultActionInvocation.this);
表面上,它只是执行了拦截器中的intercept方法,如果我们结合拦截器来看,就能看出点端倪来:
Java代码
- public String intercept(ActionInvocation invocation) throws Exception {
- String result = null;
-
- before(invocation);
- // 调用invocation的invoke()方法,在这里形成了递归调用
- result = invocation.invoke();
- after(invocation, result);
-
- return result;
- }
原来在intercept()方法又对ActionInvocation的invoke()方法进行递归调用,ActionInvocation 循环嵌套在intercept()中,一直到语句result = invocation.invoke()执行结束。这样,Interceptor又会按照刚开始执行的逆向顺序依次执行结束。
posted @
2012-12-14 10:41 hellxoul 阅读(285) |
评论 (0) |
编辑 收藏 自己制作ssl证书:自己签发免费ssl证书,为nginx生成自签名ssl证书
这里说下Linux 系统怎么通过openssl命令生成 证书。
首先执行如下命令生成一个key
openssl genrsa -des3 -out ssl.key 1024
然后他会要求你输入这个key文件的密码。不推荐输入。因为以后要给nginx使用。每次reload nginx配置时候都要你验证这个PAM密码的。
由于生成时候必须输入密码。你可以输入后 再删掉。
mv ssl.key xxx.key
openssl rsa -in xxx.key -out ssl.key
rm xxx.key
然后根据这个key文件生成证书请求文件
openssl req -new -key ssl.key -out ssl.csr
以上命令生成时候要填很多东西 一个个看着写吧(可以随便,毕竟这是自己生成的证书)
最后根据这2个文件生成crt证书文件
openssl x509 -req -days 365 -in ssl.csr -signkey ssl.key -out ssl.crt
这里365是证书有效期 推荐3650哈哈。这个大家随意。最后使用到的文件是key和crt文件。
如果需要用pfx 可以用以下命令生成
openssl pkcs12 -export -inkey ssl.key -in ssl.crt -out ssl.pfx
在需要使用证书的nginx配置文件的server节点里加入以下配置就可以了。
ssl on;
ssl_certificate /home/ssl.crt;
ssl_certificate_key /home/ssl.key;
ssl_session_timeout 5m;
ssl_protocols SSLv2 SSLv3 TLSv1;
ssl_ciphers ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+EXP;
ssl_prefer_server_ciphers on;
然后重启nginx就大功告成了
posted @
2012-11-29 16:50 hellxoul 阅读(2075) |
评论 (0) |
编辑 收藏 时间:2010-02-24 20:15:42 类别:技术 访问:11,529 views RSS 2.0 评论
请参考 Nginx Wiki http://wiki.nginx.org/NginxHttpSslModule
生成证书
$ cd /usr/local/nginx/conf
$ openssl genrsa -des3 -out server.key 1024
$ openssl req -new -key server.key -out server.csr
$ cp server.key server.key.org
$ openssl rsa -in server.key.org -out server.key
$ openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt
编辑 nginx.conf
server {
server_name YOUR_DOMAINNAME_HERE;
listen 443;
ssl on;
ssl_certificate /usr/local/nginx/conf/server.crt;
ssl_certificate_key /usr/local/nginx/conf/server.key;
}
OK, 完成了。但这样证书是不被信任的,自己玩玩还行,要被信任请看下面。
以下内容转载自
http://goo.gl/YOb5
http://goo.gl/Gftj
HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容 请看SSL。
它是一个URI scheme(抽象标识符体系),句法类同http:体系。用于安全的HTTP数据传输。https:URL表明它使用了HTTP,但HTTPS存在不同 于HTTP的默认端口及一个加密/身份验证层(在HTTP与TCP之间)。这个系统的最初研发由网景公司进行,提供了身份验证与加密通讯方法,现在它被广 泛用于万维网上安全敏感的通讯,例如交易支付方面。
1、自行颁发不受浏览器信任的SSL证书:
HTTPS的SSL证书可以自行颁发,Linux下的颁发步骤如下:
openssl genrsa -des3 -out api.bz.key 1024
openssl req -new -key api.bz.key -out api.bz.csr
openssl rsa -in api.bz.key -out api.bz_nopass.key

nginx.conf 的SSL证书配置,使用 api.bz_nopass.key,在启动Nginx是无需输入SSL证书密码,而使用 api.bz.key 则需要输入密码:
server {
server_name sms.api.bz;
listen 443;
index index.html index.htm index.php;
root /data0/htdocs/api.bz;
ssl on;
ssl_certificate api.bz.crt;
ssl_certificate_key api.bz_nopass.key;
......
}
自行颁发的SSL证书虽然能够实现加密传输功能,但得不到浏览器的信任,会出现以下提示:

posted @
2012-11-29 14:44 hellxoul 阅读(396) |
评论 (0) |
编辑 收藏
只有注册用户登录后才能阅读该文。
阅读全文
posted @
2012-11-08 12:52 hellxoul 阅读(39) |
评论 (0) |
编辑 收藏
只有注册用户登录后才能阅读该文。
阅读全文
posted @
2012-10-29 13:01 hellxoul 阅读(83) |
评论 (0) |
编辑 收藏1 $(document).ready(function () {
2 $('#test tr').each(function (){
3 alert($(this).children('td').eq(1).html());
4 });
5 });
posted @
2012-03-22 12:07 hellxoul 阅读(6867) |
评论 (4) |
编辑 收藏鉴于项目需要,开始边看Demo边使用JQuery。现将项目中暂时遇到的三种使用JQuery进行Ajax提交的方式做个总结。因为没有系统学习,有点山寨,只求在项目中实现功能。
1.URL+GET参数提交
这种方式是最普遍的,只要包含jquery.js就可以正常使用。
Java代码

- $.ajax({
- type: "get",
- url: "/openshop/control/getCustomerAddress",
- data:"customerId="+$.trim($("#customerId")[0].value),
- cache: false,
- success: function(msg){
- $("#addressInfo")[0].innerHTML = msg;
- showTipWindow(newid,oldid,0,e);
- }
- });
-
2.整个form的提交
如果不使用JQuery的form ajax提交,则必须手动组装所有的表单元素键值对。现在使用JQuery的一个插件:jquery.form.js。将jquery.js,jquery.form.js文件都包含到项目中。然后使用如下代码:
Java代码
- $('#'+newid+'_frmNewAddr').ajaxForm({ beforeSubmit: validate ,success: showResponse});
-
- ....
-
- function validate(formData, jqForm, options){
- var form = jqForm[0];
- if (!form.new_recipient.value ) {
- alert('收件人必须填写!');
- return false;
- }
- if (!form.new_address.value ) {
- alert('收件地址必须填写!');
- return false;
- }
-
- ....
-
- return true;
- }
-
- function showResponse(responseText, statusText, xhr, $form){
- var address = eval("("+removeDivTag(responseText)+")");
- $("#address_recipient")[0].innerHTML = address.recipient;
- $("#address_address")[0].innerHTML = address.address;
- $("#address_organization")[0].innerHTML = address.organization;
- ......
- }
-
其中$('#'+newid+'_frmNewAddr')获取表单对象,其中beforeSubmit对应的validate()是一个表单提交前调用 的方法,可以在此方法中做表单验证,只有该方法返回true,表单才会提交。而success对应的showResponse则是ajax对象成功返回后 的回调方法,可以将回调得到的内容无刷新呈现到当前页面的相应区域中。较方便的做法是在服务器端以JSON格式返回数据,然后在回调函数中使用 eval("("+removeDivTag(responseText)+")")方法获取具有指定结构的js对象。
3.使用JQuery做文件上传的ajax提交
本人寻找并比较了多种ajax或类ajax方式上传文件的做法,譬如使用iframe等。最终觉得使用JQuery是最方便的,不知各位使用后是否与我有 同感。我将我目前的做法总结如下,首先须在项目中包含jquery.js,ajaxfileupload.js,ajaxfileupload.css。
Java代码
- <script type="text/javascript">
- function ajaxFileUpload(imgName)
- {
- $("#loading")
- .ajaxStart(function(){
- $(this).show();
- })
- .ajaxComplete(function(){
- $(this).hide();
- });
-
- $.ajaxFileUpload
- (
- {
- url:'/productmgr/control/uploadProductImg',
- secureuri:false,
- fileElementId: imgName+'File',
- dataType: 'text',
- success: function (data, status)
- {
- data = removeDivTag(data);
- if(data=="ImgEmptyErr"){
- alert("请选择上传图片!");
- return;
- }
- if(data=="sysErr"){
- alert("上传失败,请重试!");
- return;
- }
- $("#"+imgName)[0].value = data;
- $("#"+imgName+"Div")[0].innerHTML = "上传成功!"
- //alert($("#"+imgName)[0].value);
- },
- error: function (data, status, e)
- {
- alert("添加产品图片时发生如下错误:"+e);
- }
- }
- )
- return false;
-
- }
- </script>
本人服务器端使用的是beanshell脚本,代码如下:
Java代码
- /*
- * 产品图片上传
- *
- * author : Emerson
- *
- * Yiihee , Inc. */
-
-
- import org.ofbiz.base.util.*;
- import org.ofbiz.base.util.string.*;
- import org.ofbiz.entity.*;
- import java.text.SimpleDateFormat;
- import java.util.*;
- import java.io.*;
- import org.apache.commons.fileupload.disk.*;
- import org.apache.commons.fileupload.servlet.*;
- import org.apache.commons.fileupload.*;
-
-
- configProperties = UtilProperties.getProperties("opencommon.properties");
- String imageUploadServerPath = configProperties.get("openb2c.image.upload.server.path");
-
- //SimpleDateFormat sf = new SimpleDateFormat("yyyyMMddHHmmss");
- //Date date = new Date();
- //String filename = sf.format(date);
- String fileName;
-
- File uploadPath = new File(imageUploadServerPath);//上传文件目录
- if (!uploadPath.exists()) {
- uploadPath.mkdirs();
- }
- // 临时文件目录
- File tempPathFile = new File(imageUploadServerPath+"\\temp\\");
- if (!tempPathFile.exists()) {
- tempPathFile.mkdirs();
- }
- try {
- // Create a factory for disk-based file items
- DiskFileItemFactory factory = new DiskFileItemFactory();
-
- // Set factory constraints
- factory.setSizeThreshold(4096); // 设置缓冲区大小,这里是4kb
- factory.setRepository(tempPathFile);//设置缓冲区目录
-
- // Create a new file upload handler
- ServletFileUpload upload = new ServletFileUpload(factory);
-
- // Set overall request size constraint
- upload.setSizeMax(4194304); // 设置最大文件尺寸,这里是4MB
-
- List items = null;
- items = upload.parseRequest(request);//得到所有的文件
-
- if(items==null||items.size()==0){
- String msg = "ImgEmptyErr";
- context.put("result", msg);
- return;
- }
-
- Iterator i = items.iterator();
-
- //此处实际只有一个文件
- while (i.hasNext()) {
- FileItem fi = (FileItem) i.next();
- fileName = fi.getName();
- if (!UtilValidate.isEmpty(fileName)) {
- File fullFile = new File(fi.getName());
- //File fullFile = new File(filename);
- File savedFile = new File(uploadPath, fullFile.getName());
- int j = 0;
- while(savedFile.exists()){
- j++;
- savedFile = new File(uploadPath, savedFile.getName().substring(0,savedFile.getName().lastIndexOf(".")-1)+"("+j+")"+savedFile.getName().substring(savedFile.getName().lastIndexOf("."),savedFile.getName().length()));
- }
- fi.write(savedFile);
- fileName = savedFile.getName();
- }else{
- String msg = "ImgEmptyErr";
- context.put("result", msg);
- return;
- }
- }
- context.put("result", fileName);
- } catch (Exception e) {
- Debug.log("上传产品图片发生错误:"+e);
- String msg = "sysErr";
- context.put("result", msg);
- return;
- }
然后将result结果渲染到freemarker模板,并经回调函数解析后展示给用户。
总结:JQuery强大异常,本文仅从自身使用角度列举了其部分用法,未曾深究最新最优最简用法,暂以此文作为经验总结,以待日后参考修正。代码片段山寨之处实属本人技拙,而非JQuery之过。
posted @
2012-03-22 12:04 hellxoul 阅读(7019) |
评论 (1) |
编辑 收藏 <html>
<head>
<script type="text/javascript" src="http://ajax.googleapis.com/ajax/libs/jquery/1.4.0/jquery.min.js"></script>
<title>表格</title>
<style type="text/css">
.editText
{
border-width:1px;
border-top-style:none;
border-left-style:none;
border-right-style:none;
border-bottom-style:solid;
border-color:#030;
width:100%;
}
</style>
<script src="jquery-1.3.2.js" type="text/javascript">
</script>
<script type="text/javascript">
function moveUp(obj)
{
var current=$(obj).parent().parent();
var prev=current.prev();
if(prev)
{
current.insertBefore(prev);
}
}
function moveDown(obj)
{
var current=$(obj).parent().parent();
var next=current.next();
if(next)
{
current.insertAfter(next);
}
}
</script>
</head>
<body>
<table class="grid" width="100%" border="1" cellspacing="0" cellpadding="0">
<tr>
<td>字段英文名</td>
<td>字段中文名</td>
<td>字段数据类型</td>
<td>列宽</td>
<td>是否显示</td>
<td>是否作为查询条件</td>
<td>调整顺序</td>
</tr>
<tr>
<td>1</td>
<td><input type="text" name="textfield" class="editText" id="textfield"></td>
<td> </td>
<td><input type="text" name="textfield5" id="textfield5"></td>
<td><input type="checkbox" name="checkbox" id="checkbox"></td>
<td><input type="checkbox" name="checkbox5" id="checkbox5"></td>
<td><a href="javascript:void(0)" onClick="moveUp(this)">上移</a><a href="javascript:void(0)" onClick="moveDown(this)">下移</a></td>
</tr>
<tr>
<td>2</td>
<td><input type="text" name="textfield2" id="textfield2"></td>
<td> </td>
<td><input type="text" name="textfield6" id="textfield6"></td>
<td><input type="checkbox" name="checkbox2" id="checkbox2"></td>
<td><input type="checkbox" name="checkbox6" id="checkbox6"></td>
<td><a href="javascript:void(0)" onClick="moveUp(this)">上移</a><a href="javascript:void(0)" onClick="moveDown(this)">下移</a></td>
</tr>
<tr>
<td>3</td>
<td><input type="text" name="textfield3" id="textfield3"></td>
<td> </td>
<td><input type="text" name="textfield7" id="textfield7"></td>
<td><input type="checkbox" name="checkbox3" id="checkbox3"></td>
<td><input type="checkbox" name="checkbox7" id="checkbox7"></td>
<td><a href="javascript:void(0)" onClick="moveUp(this)">上移</a><a href="javascript:void(0)" onClick="moveDown(this)">下移</a></td>
</tr>
<tr>
<td>4</td>
<td><input type="text" name="textfield4" id="textfield4"></td>
<td> </td>
<td><input type="text" name="textfield8" id="textfield8"></td>
<td><input type="checkbox" name="checkbox4" id="checkbox4"></td>
<td><input type="checkbox" name="checkbox8" id="checkbox8"></td>
<td><a href="javascript:void(0)" onClick="moveUp(this)">上移</a><a href="javascript:void(0)" onClick="moveDown(this)">下移</a></td>
</tr>
</table>
</body>
</html>
posted @
2012-03-22 12:02 hellxoul 阅读(2091) |
评论 (0) |
编辑 收藏if($ ("#id")){
}else{}
jquery不管对象存不存在都会返回object。
应该用
if($ ("#id").length>0){}else{}
or
if($ ("#id")[0]){ } else { }
or
if(document.getElementById("id")){} else {}
posted @
2012-03-22 12:01 hellxoul 阅读(405) |
评论 (1) |
编辑 收藏不可否认,OFBiz这个开源的系统功能是非常强大的,涉及到的东西太多了,其实对我们现在而言,最有用的只有这么几个:实体引擎、服务引擎、WebTools、用户权限管理。
最先要提醒各位的是,在配置一个OFBiz时,路径中千万不要包含空格,要不然老提示出错,无外乎是scoket write error之类的信息,会让你郁闷得不停^_^
用户登录鉴权这一块我们完全可以照搬OFBiz现有的东西,其实也就是调用包org.ofbiz.securityext.login.LoginEvents里面的一些方法来进行处理。
Component定义:component-load.xml,可根据需要调整需在启动时引入的Component,比如增加一个Study,定义:
<load-component component-location="${ofbiz.home}/components/study"/>
首先需要进行如下几个项目的总体配置:
1、 entityengine.xml:实体引擎配置,主要是配置该数据的方式,如通过oracle访问,就配置一下localoracle,特别需要注意的 是,在dataSource中配置中,一定要配置一个属性 - schema-name="OFBIZ",这个主要是为了在OFBiz启动时能够正常同数据库的对象进行匹配,如果没有进行配置,每次都会试图重新建立对 象,会报对象名已经被占用的情况。
2、 serviceengine.xml:服务引擎配置,这个基本上不用作太大的修改,如要必要,可在这里边进行一些参数的调优,比如访问线程数配置等。
之后需要在components目录下新建一个目录study,目录里面的一些文件可直接从模板中拷贝,之后再进行必要的修改,涉及修改内容:
1、 entitygroup.xml & entitymodel 实体定义(3.0版本开始,各实体定义可在各自的Component下定义,而不必统一集中在commonapp下);定义实体及实体的相关属性(其实也 就是相当于数据库的各种对象,需要注意的是,后续进行数据提取时,如果需要关联到多张表,也需要在这里面定义一个view-entity);
2、 services.xml:如果必要的话,可以这里边定义一些服务;
3、 data:一些初始配置数据,应该是相对固定,不经常变动的才放在这边,可通过Webtool工具导入到数据库中;
4、 src:如改动了一些Java源文件内容后,需要重新编译该目录的文件,可通过UltraEdit的工具配置来进行ant编译,非常方便,推荐使用,编译 后的文件将生成到build目录下,生成的文件有各个class文件,也有一些.jar包(放在lib目录下),这些jar包是我们在Web应用中需要引 用到的,当然,引用哪些包也是可配置的,下面会讲到;
5、 ofbiz-component.xml:主要的配置文件,需要注意的一些东西:
(1)<classpath type="jar" location="build/lib/*"/> 这是jar引用路径,我在考虑是否可改成直接引用class文件,也就是直接设置class文件所在的目录;
(2)title="Study" 这个就是我们通过appbar.ftl文件在主界面显示的那一排按钮上显示的内容,可根据需要调整,调整完要重启OFBiz,麻烦,可以考虑通过hot-deploy目录进行发布。
至于其他一些配置,很简单,看看就晓得。
下 面讲一下Web应用配置,Web应用配置中涉及到的最重要的两个文件是:controller.xml和regions.xml, controller.xml文件主要是配置request-map,也就是请求映射关系,所有的请求映射都需要在这里边进行配置,也就是我们在Web页 面上常看到的/login等,如果涉及到view-map类型是region,就需要从region.xml文件中去读取配置,其实也就是配置各个 region引用的处理页面(可以是各种开发语言,比如Jsp、ftl等等)。另外,在region.xml配置文件中最重要的一部分就是 MAIN_REGION的配置,就是整个网页布局的配置,包括header、appbar、error、content、footer等等,其中 appbar就是我们在前面刚刚提到的主界面上那一排按钮的配置了,header、footer和error太简单,不说了,我们主要要修改的东西都是在 content这一块上进行展现。
网页中用到的一些样式、公用的定义都是在main_template.jsp中写入的,也需要在MAIN_REGION的属性中配置引用的文件。样式定义文件是引用images这个component,所以这个也是关键,不能缺的。
最 后,讲一讲我对数据库访问的一些简单的了解:对数据库的访问主要是通过GenericDelegator进行控制,包括一些常用的方法,如 findAll、remove、store、create等等,具体的用法要去研究一下,其实也不算复杂,先建立一个GenericDelegator, 如果是create、store就可以通过makeValue方法将一些字段的值设置到GenericValue,之后再进行store或是 create,具体语法要去参考一些文档,还没去看这一块的东西。
最最需要访问的一些文档:OFBizChina 实体引擎配置指南、OFBizChina 区块(Region)指南、OFBizChina 服务引擎配置指南、OFBizChina JSP标签库指南,当然,研究OFBiz的前提是要首先要理解MVC模式的概念,也就是View-Model-Control,否则一切都是空谈。
补充几点:
1、 对于Ofbiz构造动态查询语句
(1) 构造查询条件
(2) 给每个条件之间加上逻辑关系,用mainCond = new EntityConditionList(andExprs, EntityOperator.AND);
(3) 设置要显示的字段列表
(4) 设置排序字段列表
(5) 设置Distinct列表
EntityFindOptions findOpts = new EntityFindOptions(true, EntityFindOptions.TYPE_SCROLL_INSENSITIVE, EntityFindOptions.CONCUR_READ_ONLY, true);
(6) 获取实体列表
EntityListIterator pli = delegator.findListIteratorByCondition(entityName, mainCond, null, fieldsToSelect, orderBy, findOpts);
(7) 一个动态查询语句的具体实例
<%
String entityName="study";
List andExprs = new ArrayList();
String number="";
String name="";
String sex="";
String tel="";
//GenericDelegator delegator = GenericDelegator.getGenericDelegator("default");
EntityConditionList mainCond=null;
if (request.getParameter("number")!=null)
number=request.getParameter("number").toString();
if (request.getParameter("name")!=null)
name=request.getParameter("name").toString();
if (request.getParameter("sex")!=null)
sex=request.getParameter("sex").toString();
if (request.getParameter("tel")!=null)
tel=request.getParameter("tel").toString();
//构造查询条件
if (number.compareTo("")!=0)
andExprs.add(new EntityExpr("number",EntityOperator.EQUALS,number));
if (name.compareTo("")!=0)
andExprs.add(new EntityExpr("name1",true,EntityOperator.LIKE,"%"+name+"%",true));
if (sex.compareTo("")!=0)
andExprs.add(new EntityExpr("sex1",true,EntityOperator.LIKE,"%"+sex+"%",true));
if (tel.compareTo("")!=0)
andExprs.add(new EntityExpr("tel",true,EntityOperator.LIKE,"%"+tel+"%",true));
//每个条件间的逻辑关系
if (andExprs.size() > 0)
mainCond = new EntityConditionList(andExprs, EntityOperator.AND);
//要显示的字段列表
List fieldsToSelect = new ArrayList();
fieldsToSelect.add("number");
fieldsToSelect.add("name1");
fieldsToSelect.add("sex1");
fieldsToSelect.add("tel");
//排序字段列表
List orderBy = UtilMisc.toList("number", "name1");
//Distinct列表
EntityFindOptions findOpts = new EntityFindOptions(true, EntityFindOptions.TYPE_SCROLL_INSENSITIVE, EntityFindOptions.CONCUR_READ_ONLY, true);
//获取实体列表
EntityListIterator pli = delegator.findListIteratorByCondition(entityName, mainCond, null, fieldsToSelect, orderBy, findOpts);
while(pli.hasNext())
{
GenericValue cust = (GenericValue)pli.next();%>
<tr>
<td><%=cust.getString("number")%></td>
<td><%=cust.getString("name1")%></td>
<td><%=cust.getString("sex1")%></td>
<td><%=cust.getString("tel")%></td>
</tr>
<%}%>
</table>
2、 对于所有的图片文件,都放在images目录下
3、 设置图片的标签<ofbiz:contenturl>图片路径</ofbiz:contenturl>
4、 链接Tag <ofbiz:url>control.xml里面设置的请求</ofbiz.url>
5、 <region:render section=‘header‘/>引入header定义的文件
header这个标识在regions.xml里面定义
<define id=‘MAIN_REG‘ template=‘/templates/main_template1.jsp‘>
<put section=‘title‘>Application Page</put> <!-- this is a default and is meant to overridden -->
<put section=‘header‘ content=‘/includes/bottom.jsp‘/>
<put section=‘leftbar‘ content=‘/includes/left.jsp‘/>
<put section=‘middle‘ content=‘/includes/middle.jsp‘/>
<put section=‘content‘ content=‘/includes/middle.jsp‘/> <!-- this is a default and is meant to overridden -->
<put section=‘top‘ content=‘/includes/top.jsp‘/>
<put section=‘error‘ type="jpublish" content=‘/includes/errormsg.ftl‘/>
<!--<put section=‘footer‘ type="jpublish" content=‘/includes/footer.ftl‘/>-->
</define>
然后其它页面只要如下定义即可
<define id=‘BasePubEmp‘ region=‘MAIN_REG‘>
<put section=‘title‘>View BasePubEmp</put>
<put section=‘content‘ content=‘/BasePubEmp.jsp‘/>
</define>
注意,这边的content所指定的区块就是我们上面定义的content
6、 这些标签都挺简单的,Ofbiz里面都有例子,参照一下就可以了
后续将对Ofbiz中的shark工作流进行描述。
http://www.cnpoint.com/mvnforum/mvnforum/viewthread?thread=67
posted @
2012-03-21 11:47 hellxoul 阅读(2433) |
评论 (0) |
编辑 收藏ofbiz 之entity实体
1. 实体定义文件
实体定义文件一般存放位置是在对应模块的entity文件夹下面,以party为例,party的实体定义文件路径为%ofbiz-home%\applications\party\entitydef\entitymodel.xml。
通过对应模块的ofbiz-component.xml进行加载。
<entity-resource type="model" reader-name="main" loader="main" location="entitydef/entitymodel.xml"/>
<entity-resource type="model" reader-name="main" loader="main" location="entitydef/entitymodel_old.xml"/>
实体定义文件可以为多个。
2. 实体类型
2.1. 普通实体
<entity entity-name="TenantDataSource" package-name="org.ofbiz.entity.tenant">
<description>
There should be one record for each tenant and each group-map for the active delegator.
The jdbc fields will override the datasource -> inline-jdbc values for the per-tenant delegator.
</description>
<field name="tenantId" type="id-ne"/>
<field name="entityGroupName" type="name"/>
<field name="jdbcUri" type="long-varchar"/>
<field name="jdbcUsername" type="long-varchar"/>
<field name="jdbcPassword" type="long-varchar"></field>
<prim-key field="tenantId"/>
<prim-key field="entityGroupName"/>
<relation type="one" fk-name="TNTDTSRC_TNT" rel-entity-name="Tenant">
<key-map field-name="tenantId"/>
</relation>
</entity>
普通实体和数据库中的表是一一对应的。程序会根据实体定义在数据库中创建表,索引,外键约束等。
2.2. 视图实体
<view-entity entity-name="WorkEffortAssocView"
package-name="org.ofbiz.workeffort.workeffort"
title="Work Effort Association Entity with Name">
<member-entity entity-alias="WA" entity-name="WorkEffortAssoc"/>
<member-entity entity-alias="WETO" entity-name="WorkEffort"/>
<alias-all entity-alias="WA"/>
<alias entity-alias="WETO" name="workEffortToName" field="workEffortName"/>
<alias entity-alias="WETO" name="workEffortToSetup" field="estimatedSetupMillis"/>
<alias entity-alias="WETO" name="workEffortToRun" field="estimatedMilliSeconds"/>
<alias entity-alias="WETO" name="workEffortToParentId" field="workEffortParentId"/>
<alias entity-alias="WETO" name="workEffortToCurrentStatusId" field="currentStatusId"/>
<alias entity-alias="WETO" name="workEffortToWorkEffortPurposeTypeId" field="workEffortPurposeTypeId"/>
<alias entity-alias="WETO" name="workEffortToEstimatedStartDate" field="estimatedStartDate"/>
<alias entity-alias="WETO" name="workEffortToEstimatedCompletionDate" field="estimatedCompletionDate"/>
<alias entity-alias="WETO" name="workEffortToActualStartDate" field="actualStartDate"/>
<alias entity-alias="WETO" name="workEffortToActualCompletionDate" field="actualCompletionDate"/>
<view-link entity-alias="WA" rel-entity-alias="WETO">
<key-map field-name="workEffortIdTo" rel-field-name="workEffortId"/>
</view-link>
<relation type="one-nofk" fk-name="WK_EFFRTASSV_FWE" title="From" rel-entity-name="WorkEffort">
<key-map field-name="workEffortIdFrom" rel-field-name="workEffortId"/>
</relation>
</view-entity>
View entity 一般用做多表连接复杂查询,view entity 不会在数据库中反映出来。
2.3. 扩展实体
<extend-entity entity-name="UserLogin">
<field name="partyId" type="id"></field>
<relation type="one" fk-name="USER_PARTY" rel-entity-name="Party">
<key-map field-name="partyId"/>
</relation>
<relation type="one-nofk" rel-entity-name="Person">
<key-map field-name="partyId"/>
</relation>
<relation type="one-nofk" rel-entity-name="PartyGroup">
<key-map field-name="partyId"/>
</relation>
</extend-entity>
继承已存在的实体并对其进行扩展。
2.4. 动态实体
DynamicViewEntity salesUsageViewEntity = new DynamicViewEntity();
salesUsageViewEntity.addMemberEntity("OI", "OrderItem");
salesUsageViewEntity.addMemberEntity("OH", "OrderHeader");
salesUsageViewEntity.addMemberEntity("ItIss", "ItemIssuance");
salesUsageViewEntity.addMemberEntity("InvIt", "InventoryItem");
salesUsageViewEntity.addViewLink("OI", "OH", Boolean.valueOf(false), ModelKeyMap.makeKeyMapList("orderId"));
salesUsageViewEntity.addViewLink("OI", "ItIss", Boolean.valueOf(false), ModelKeyMap.makeKeyMapList("orderId", "orderId", "orderItemSeqId", "orderItemSeqId"));
salesUsageViewEntity.addViewLink("ItIss", "InvIt", Boolean.valueOf(false), ModelKeyMap.makeKeyMapList("inventoryItemId"));
salesUsageViewEntity.addAlias("OI", "productId");
salesUsageViewEntity.addAlias("OH", "statusId");
salesUsageViewEntity.addAlias("OH", "orderTypeId");
salesUsageViewEntity.addAlias("OH", "orderDate");
salesUsageViewEntity.addAlias("ItIss", "inventoryItemId");
salesUsageViewEntity.addAlias("ItIss", "quantity");
salesUsageViewEntity.addAlias("InvIt", "facilityId");
EntityListIterator salesUsageIt = delegator.findListIteratorByCondition(salesUsageViewEntity,
EntityCondition.makeCondition(
UtilMisc.toList(
EntityCondition.makeCondition("facilityId", EntityOperator.EQUALS, facilityId),
EntityCondition.makeCondition("productId", EntityOperator.EQUALS, productId),
EntityCondition.makeCondition("statusId",
EntityOperator.IN,
UtilMisc.toList("ORDER_COMPLETED", "ORDER_APPROVED", "ORDER_HELD")),
EntityCondition.makeCondition("orderTypeId", EntityOperator.EQUALS, "SALES_ORDER"),
EntityCondition.makeCondition("orderDate", EntityOperator.GREATER_THAN_EQUAL_TO, checkTime)
),
EntityOperator.AND),null, null, null, null
);
在程序中手动创建实体,对其进行查询。
3实体定义
3.1. 命名规则
实体名称(entity-name)首字母大写,如果实体名称由多个关键字组成,那么关键字首字母大写,例如entity- name="TenantDataSource",ofbiz 会在创建数据库表的时候根据entity-name 实体名称除首字母之外的大写字母前加“_”,所以entity-name="TenantDataSource"生成的数据库表名为 “Tenant_Data_Source”.
所以要控制entity-name 实体名称不要超过25个字母。
Field 表字段,命名规则与实体名称差不多,唯一不同的是首字母小写。
3.2. 实体与数据库的关联
<entity-group group="org.ofbiz.olap" entity="SalesInvoiceItemFact"/>
<entity-group group="org.ofbiz.olap" entity="SalesInvoiceItemStarSchema"/>
Entity-group(一般定义在各个模块的\entitydef\entitygroupXXX.xml中) 对实体进行分组,使不同的实体分属不同的entity-group。
也许你会发现并不是每个entity都进行了entity-group 分组。事实上如果你没有对实体进行分组归类的话,系统启动的时候他会将实体默认归类到"org.ofbiz"中。
查看数据库定义文件%ofbiz_home%/framework/entity/config/entityengine.xml
可以发现:
<delegator name="default" entity-model-reader="main" entity-group-reader="main" entity-eca-reader="main" distributed-cache-clear-enabled="false">
<group-map group-name="org.ofbiz" datasource-name="localderby"/>
<group-map group-name="org.ofbiz.olap" datasource-name="localderbyolap"/>
<group-map group-name="org.ofbiz.tenant" datasource-name="localderbytenant"/>
</delegator>
可以发现delegator 将多个group-name组织到一起并将group-name与 datasource-name对应起来,datasource-name又是什么?通过查看 entityengine.xml 我们可以发现:
<datasource name="localderby"
helper-class="org.ofbiz.entity.datasource.GenericHelperDAO"
schema-name="OFBIZ"
field-type-name="derby"
check-on-start="true"
add-missing-on-start="true"
use-pk-constraint-names="false"
use-indices-unique="false"
alias-view-columns="false"
use-order-by-nulls="true">
<read-data reader-name="seed"/>
<read-data reader-name="seed-initial"/>
<read-data reader-name="demo"/>
<read-data reader-name="ext"/>
<inline-jdbc
jdbc-driver="org.apache.derby.jdbc.EmbeddedDriver"
jdbc-uri="jdbc:derby:ofbiz;create=true"
jdbc-username="ofbiz"
jdbc-password="ofbiz"
isolation-level="ReadCommitted"
pool-minsize="2"
pool-maxsize="250"
time-between-eviction-runs-millis="600000"/>
</datasource>
Datasource定义了数据库驱动,数据库用户名、密码等,所以datasource就是我们说的数据库。
总结一下:我们通过entity-group将各个实体和数据库之间关联起来,然后再将一个或多个数据库归属到一个delegator 中,那我们又是怎么使用数据库进行数据库操作的呢??查看每个模块应用底下的web.xml 我们可以发现:
<context-param>
<param-name>entityDelegatorName</param-name>
<param-value>default</param-value>
<description>The Name of the Entity Delegator to use, defined in entityengine.xml</description>
</context-param>
针对不同的应用,我们可以使用不同的delegator .如果不定义则使用default.
在启动各个应用模块的时候,系统会根据web.xml 中的 entityDelegatorName
生成delegator 对象,然后将delegator 对象存放到servletContext 中备用。
我们就是使用这个delegator对象执行数据库操作,以后会介绍如何使用。
delegator = DelegatorFactory.getDelegator(delegatorName);
servletContext.setAttribute("delegator", delegator);
3.3. no-auto-stamp
no-auto-stamp="false"
entity 属性之一: 将此值设置为true , 则 创建数据库表时将来不创建lastUpdatedStamp、lastUpdatedTxStamp、createdStamp、createdTxStamp
这四个字段。
3.4. Field.type
<field name="tenantId" type="id-ne"/>
Type , 将数据字段类型 与 java 类型关联起来的设置。 定义文件路径为:
%ofbiz_home%\framework\entity\fieldtype\fieldtypeXXXXX.xml
其中XXXX为你使用的数据库名称。
<field-type-def type="email" sql-type="VARCHAR(255)" java-type="String"/>
3.5. prim-key
<prim-key field="agreementId"/>
定义主键,其中field 需要是已经被定义过的字段,即field 定义过。
实体支持组合主键,即一个实体定义中可以有多个prim-key节点。
如果不定义主键的话,数据库是不会创建表的。
3.6. relation
relation 定义当前实体和其他实体之间的关系,一般用做创建外键和根据关系查询使用。
:rel-entity-name:被关联实体名称。
:fk-name:如果创建外键,那么定义外键的名称。
:title:给当前关系起个别名。
: field-name:当前实体的字段,指明当前实体的哪个字段与被关系实体有关系。
:rel-entity-name:被关系实体名称
:rel-field-name:被关系的实体的字段名称。指明field-name和被关系实体的哪个字段有关系。如果rel-field-name与field-name相同,那么rel-field-name可以不定义。
:type="one-nofk":关联类型,主要有三类 “one”、”one-nofk”、”many”
很多资料上将one 解释为 one-to-one ,将 many 解释为 one-to-many .
个人感觉不是很好理解,如果从数据库方面去理解的话,one、one-nofk 的使用条件是被关系实体的rel-field-name为主键,而many 的使用条件是被关系实体的rel-field-name为非主键。而one 与 one-nofk 的区别在于one会在数据库表结构中创建外键约束,而one-nofk 则不会。
Relation 除了用来创建外键约束之外还被用来做关系查询。
当访问关系的时候可以用 .getRelated("") 或者 .getRelatedOne("") 。用 title+entityName 作为参数。
当实体一个"many"关系的时候使用getRelated 返回一个列表,当实体一个"one"关系的时候使用getRelatedOne 返回一个实体对象。
3.7. Index
<index name="WEFF_KWD_KWD" unique="false">
<index-field name="keyword" function="lower"/>
</index>
创建索引。
: name:给索引起个别名。
: unique:是否唯一索引。
:index-field:name:对实体哪个字段创建索引,function待确定。
4. 定义视图实体
4.1. Member-entity
<member-entity entity-alias="EMPPOS" entity-name="EmplPosition"/>
<member-entity entity-alias="EMPPOSFUL" entity-name="EmplPositionFulfillment"/>
member-entity首先定义当前视图实体可能会用到的实体。entity-name实体名称
entity-alias实体别名。实体定义顺序很重要,除了第一个实体之外其他都是被关联实体。
4.2. alias
<alias entity-alias="EMPPOSFUL" name="partyId" field="partyId"/>
<alias entity-alias="EMPPOSFUL" name="emplPositionId" function="count"/>
<alias entity-alias="EMPPOSREPST" name="emplPositionIdReportingTo" group-by="true"/>
Alias 定义当前视图实体中会用到的字段。entity-alias为实体别名,指当前字段是哪个实体的,field实体字段名称,name字段别名。 group-by依据当前字段进行group-by 分组查询。function对当前字段执行function 函数处理 。
4.3. alias-all
<alias-all entity-alias="ODD" prefix="orderDate" group-by="true">
<exclude field="dimensionId"/>
</alias-all>
alias-all 将某个实体的全部字段定义进来。Prefix定义以规定字段字符开头的字段。
Exclude 将实体中某些字段剔除出去。
4.4. View-link
<view-link entity-alias="SOIF" rel-entity-alias="ODD" rel-optional="false">
<key-map field-name="orderDateDimId" rel-field-name="dimensionId"/>
</view-link>
视图实体中relation 只能用来做关系查询。
而view-link 用来做 join 关联查询。在entityengine.xml中<datasource ..>元素当中的join-style属性当中设置你的数据库join语法。
: rel-optional:关联类型,默认是内连接,如果将此属性值设为true ,则为外连接
4.5. Entity-condition
<entity-condition>
<order-by field-name="sequenceId"/>
</entity-condition>
待定
4.6. 复杂字段
<alias entity-alias="OI" name="quantityOrdered" function="sum">
<complex-alias operator="-">
<complex-alias-field entity-alias="OI" field="quantity" default-value="0"/>
<complex-alias-field entity-alias="OI" field="cancelQuantity" default-value="0"/>
</complex-alias>
</alias>
结果为:
Select SUM((COALESCE(OI.QUANTITY, 0) - COALESCE(OI.CANCEL_QUANTITY, 0))) 。。。。。。
一个缺省值是一个良好的习惯,否则当他们之中有一个为空就会导致结果为空
这个操作可以支持你使用数据库的所有函数例如 +, -, * 和 /,字符串连接符||。
你也可以添加一个 function="" 实现min, max, sum, avg, count, count-distinct, upper 和 lower 在 complex-alias-field中。比如:
<alias entity-alias="OI" >
<complex-alias operator="-">
<complex-alias-field entity-alias="OI" field="quantity" default-value="0" function="sum"/>
<complex-alias-field entity-alias="OI" field="cancelQuantity" default-value="0"
function="sum"/>
</complex-alias>
</alias>
结果为SELECT (SUM(COALESCE(OI.QUANTITY,'0')) - SUM(COALESCE(OI.CANCEL_QUANTITY,'0')))
posted @
2012-03-08 08:34 hellxoul 阅读(1116) |
评论 (0) |
编辑 收藏* 保持实体名称少于25个字符
这个限制主要是为了Oracle只支持30字符以内的数据库对象名称,再加上OFBiz会自动在单词之间加上"_",所以就得出了这么个限制.
* 关联的工作方式
它们定义于entitymodel.xml文件中的<entity>段,示例如下:
 <relation type="one" fk-name="PROD_CTGRY_PARENT" title="PrimaryParent" rel-entity-name="ProductCategory">
<relation type="one" fk-name="PROD_CTGRY_PARENT" title="PrimaryParent" rel-entity-name="ProductCategory">
<key-map field-name="primaryParentCategoryId" rel-field-name="productCategoryId"/>
</relation>
<relation type="many" title="PrimaryChild" rel-entity-name="ProductCategory">
<key-map field-name="productCategoryId" rel-field-name="primaryParentCategoryId"/>
</relation> type这个属性标签定义关联类型: "one"表示一对一,"many"表示从此实体引出的一对多关系
fk-name的属性值是数据库外键名.为自己的外键命名是一个好的习惯,虽然如果你不设置此属性,OFiz也会自己建外建.
rel-entity-name的属性值指向关联的实体名称
title用来区分两个实体之间的多重关系
<key-map>节点定义关联中使用到的字段.field-name指向本实体内的引用字段,rel-field-name定义关联的实体字段,你可以通过多个字段组合关联
当你访问一个关联,你可以使用title+entityName作为参数调用.getRelated("")或.getRelatedOne("")方 法.在关联为"many"时使用.getRelated("")是恰当的,因为它返回一个List,同样在关联为"one"时通 过.getRelatedOne("")方法获得一个值.
* view-entities相关内容
view-entities的功能非常强大,它允许你可以创建一个join-like查询,即使你的数据库不支持join.
关于你数据库的join语法存放在entityengine.xml的datasource节点下的join-style属性中.
当你通过<view-link...>节点将两上实体连接起来时,记住:
1. 实体名称顺序是重要的
2. 默认的连接方式是inner join(即同样的值存在于两个实体类中),外连接需要使用rel-optional="true"
如果多个实体中拥有相同的字段名称,比如statusId,结果集中的statusId使用第一个实体中的该列,其它实体中的同名列将被丢弃.如果你想要 同时获得这些列,你需要通过在其之前加入<alias-all>节点,一个方式是使用<alias ..>节点来为不同实体的同名字段起别名,示例:
<alias entity="EntityOne" name="entityOneStatusId" field="statusId"/>
<alias entity="EntityTwo" name="entityTwoStatusId" field="statusId"/> 另一种方法是在<alias-all>节点中使用<exclude field="">,如下:
<alias-all entity-alias="EN">
<exclude field="fieldNameToExclude1"/>
<exclude field="fieldNameToExclude2"/>
</alias-all> 这样也可以排除掉很多不打算使用到的信息,特别是在一个非常大的表中查询时.
如果你打算执行类似于以下的查询语句时:
SELECT count(visitId) FROM  GROUP BY trackingCodeId WHERE fromDate > '2005-01-01'
GROUP BY trackingCodeId WHERE fromDate > '2005-01-01' 需要包含字段visitId以及function="count" 标签,trackingCodeId需加上group-by="true"标签,fromDate需要加上group-by="false"标签
在你进行查询时,有一件非常重要的事情需要注意,比如说delegator.findByCondition方法,你必须指定检出的字段列表,并且你不能 指定fromDate字段,否则你将得到一个错误.这就是为webtools不能够使用view-entities来查看的原因.
你可以查看applications/marketing/entitydef/entitymodel.xml的底部内容学习,及通过 applications/marketing/webapp/marketing/WEB-INF/actions/reports学习 beanshell脚本的调用.
* 我可以在entitymodel.xml文件中定义自己的view-entities吗?
不能, 你可以动态定义它们.你可以查看org.ofbiz.party.party.PartyServices中的findParty方法学习它的使用
* 如果为有效期间创建条件?
我们提供了一组非常有用的方法EntityUtil.getFilterByDateExpr ,它能返回一个EntityConditionList根据有效期间来筛选一个结果集.
* 如何在大数据结果集下工作
如果你检出一个大的数据结果集,你应当使用EntityListIterator通过迭代方式读取数据,而非List.
示例,如果你使用:
List products = delegator.findAll("Product");
你可能获得一个"java.lang.OutOfMemoryError". 这是由于你通过findAll, findByAnd, findByCondition等方法来获得一个大的内存数据结果集导致内存溢出. 在这种情况下, 应该使用EntityListIterator迭代方式来读取你的数据. 这个示例应改写成:
productsELI = delegator.findListIteratorByCondition("Product", new EntityExpr("productId", EntityOperator.NOT_EQUAL, null), UtilMisc.toList("productId"), null);
注意获得EntityListIterator的方法只用通过条件, 所以你需要将你的条件重写为EntityExpr (在此次情况下,productId是主键字段不可能为空的, 所以将返回所有Proudct实例,)或 EntityConditionList.
此方法参数中包含检出的字段(这里为productId)以及排序字段(这里不需要,所以赋了null)
你可以传递一个null作为EntityCondition参数来获得所有结果.然后这不一定在所有数据库下都能正常工作! 在maxdb及其它不常用的数据库下时你要小心使用这些高级功能.
* 如何使用EntityListIterator
当我们通过EntityListIterator迭代访问数据时, 通常是这样:
 while ((nextProduct = productsELI.next()) != null) {
while ((nextProduct = productsELI.next()) != null) {
 .
.
// operations on nextProduct
 }
}
在EntityListIterator 中使用 .hasNext()方法是一种不经济的做法.
在你完成你的操作后,要记得关闭此迭代
productsELI.close();
* 如何查询无重结果集
当前只能通过list iterator方法并指定EntityFindOptions参数,示例如下:
listIt = delegator.findListIteratorByCondition(entityName, findConditions,
null, // EntityConditions参数
fieldsToSelectList,
fieldsToOrderByList,
//关键部分. 第一个true表示"specifyTypeAndConcur"
// 第二个true指完是一个滤重查询. 显然在实体引擎中只能通过这个方法来进行滤重查询
new EntityFindOptions(true, EntityFindOptions.TYPE_SCROLL_INSENSITIVE, EntityFindOptions.CONCUR_READ_ONLY, true));
在minilang, 它会更简单:
<entity-condition entity-name="${entityName}" list-name="${resultList}" distinct="true">
<select field="${fieldName}"/>
.
原文:
http://hi.baidu.com/longer84/blog/item/dbf027cf6e58933af9dc6117.html
posted @
2012-03-08 08:32 hellxoul 阅读(2289) |
评论 (1) |
编辑 收藏posted @
2012-02-13 00:10 hellxoul 阅读(188) |
评论 (0) |
编辑 收藏
摘要: 在2012新的一年里,对程序员们来说挑战自我是非常重要的,要么不断创新,要么技术停滞不前。新年伊始,我整理了12个月的目标,每个目标都是对技术或个人能力的挑战,而且可以年复一年循环使用。
阅读全文
posted @
2012-01-31 23:00 hellxoul 阅读(198) |
评论 (0) |
编辑 收藏
摘要: 我们已经踏进了2012年,很自然的也会为新的一年定下目标,那么我们在生活中真正能够实现的有哪一些目标呢?本文将详细地给您解说新年要做的10个决定。
阅读全文
posted @
2012-01-31 22:50 hellxoul 阅读(205) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2011-11-30 11:36 hellxoul 阅读(16875) |
评论 (5) |
编辑 收藏