启示一:String和StringBuffer的不同之处
相信大家都知道String和StringBuffer之间是有区别的,但究竟它们之间到底区别在哪里?我们就再本小节中一探究竟,看看能给我们些什么启示。还是刚才那个程序,我们把它改一改,将本程序中的String进行无限次的累加,看看什么时候抛出内存超限的异常,程序如下所示:
public class MemoryTest{
public static void main(String args[]){
String s="abcdefghijklmnop";
System.out.print("当前虚拟机最大可用内存为:");
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.print("循环前,虚拟机已占用内存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
int count = 0;
while(true){
try{
s+=s;
count++;
}
catch(Error o){
System.out.println("循环次数:"+count);
System.out.println("String实际字节数:"+s.length()/1024/1024+"M");
System.out.print("循环后,已占用内存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
System.out.println("Catch到的错误:"+o);
break;
}
}
}
}
|
程序运行后,果然不一会儿的功夫就报出了异常,如图
3 3所示。
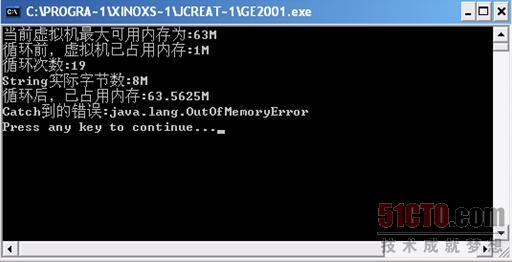
我们注意到,在String的实际字节数只有8M的情况下,循环后已占内存数竟然已经达到了63.56M。这说明,String这个对象的实际占用内存数量与其自身的字节数不相符。于是,在循环19次的时候就已经报"OutOfMemoryError"的错误了。
因此,应该少用String这东西,特别是
String的"+="操作,不仅原来的String对象不能继续使用,而且又要产生多个新对象,因此会较高的占用内存。
所以必须要改用StringBuffer来实现相应目的,下面是改用StringBuffer来做一下测试:
public class MemoryTest{
public static void main(String args[]){
StringBuffer s=new StringBuffer("abcdefghijklmnop");
System.out.print("当前虚拟机最大可用内存为:");
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.print("循环前,虚拟机已占用内存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
int count = 0;
while(true){
try{
s.append(s);
count++;
}
catch(Error o){
System.out.println("循环次数:"+count);
System.out.println("String实际字节数:"+s.length()/1024/1024+"M");
System.out.println("循环后,已占用内存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
System.out.println("Catch到的错误:"+o);
break;
}
}
}
}
|
我们将String改为StringBuffer以后,在运行时得到了如下结果,如图
3 4所示。
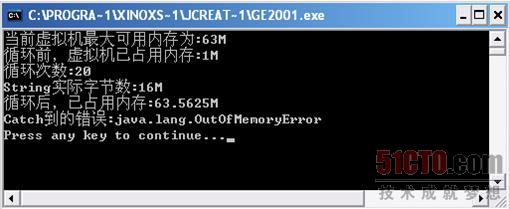
这次我们发现,当StringBuffer所占用的实际字节数为"16M"的时候才产生溢出,整整比上一个程序的String实际字节数"8M"多了一倍。
启示2:用"-Xmx"参数来提高内存可控制量
前面我们介绍过"-Xmx"这个参数的用法,如果我们还是处理刚才的那个用StringBuffer的Java程序,我们用"-Xmx1024m"来启动它,看看它的循环次数有什么变化。
输入如下指令:
得到结果如图 3 5所示。
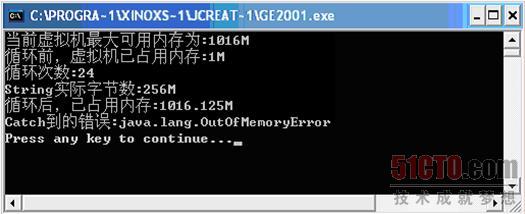
那么通过使用"-Xmx"参数将其可控内存量扩大至1024M后,那么这个程序到了1G的时候才内存超限,从而使内存的可控性提高了。
但扩大内存使用量永远不是最终的解决方案,如果你的程序没有去更加的优化,早晚还是会超限的。
启示3:二维数组比一维数组占用更多内存空间
对于内存占用的问题还有一个地方值得我们注意,就是二维数组的内存占用问题。
有时候我们一厢情愿的认为:
二维数组的占用内存空间多无非就是二维数组的实际数组元素数比一维数组多而已,那么二维数组的所占空间,一定是实际申请的元素数而已。
但是,事实上并不是这样的,对于一个二维数组而言,它所占用的内存空间要远远大于它开辟的数组元素数。下面我们来看一个一维数组程序的例子:
public class MemFor{
public static void main (String[] args) {
try{
int len=1024*1024*2; //设定循环次数
byte [] abc=new byte[len];
for (int i=0;i<len;i++){
abc[i]=(byte)i;
}
System.out.print("已占用内存:");
System.out.println(
Runtime.getRuntime().totalMemory()/1024/1024+"M");
}
catch(Error e){
}
}
}
|
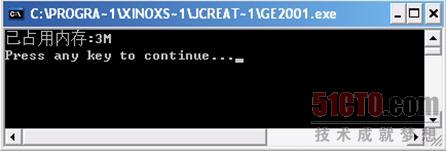
这个程序是开辟了"1024*1024*2"即2M的数组元素的一维数组,运行这个程序得到的结果如图
3 6所示,程序运行结果提示"已占用内存:3M"。
我们再将这个程序进行修改,改为一个二维数组,这个二维数组的元素数量我们也尽量的和上一个一维数组的元素数量保持一致。
public class MemFor{
public static void main (String[] args) {
try{
int len=1024*1024; //设定循环次数
byte [][] abc=new byte[len][2];
for (int i=0;i<len;i++){
abc[i][0]=(byte)i;
abc[i][1]=(byte)i;
}
System.out.print("已占用内存:");
System.out.println(
Runtime.getRuntime().totalMemory()/1024/1024+"M");
}
catch(Error e){
}
}
}
|
当我们把申请的元素数量未变,只是将二维数组的行数定为"1024*1024"列数定为"2",和刚才的那个一维数组"1024*1024*2"的数量完全一致,但我们得到的运算结果如图
3 7所示,竟然占用达到了29M的空间。
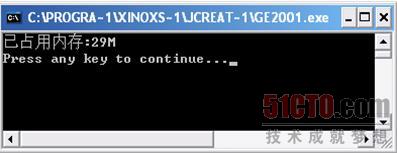
我们姑且不管造成这种情况的原因,我们只要知道一点就够了,那就是"二维数组占内存"。所以,在编写程序的时候要注意,能不用二维数组的地方尽量用一维数组,要求内存占用小的地方尽量用一维数组。
4.4.4 启示4:用HashMap提高内存查询速度
田富鹏主编的《大学计算机应用基础》中是这样描述内存的:
……
DRAM:即内存条。常说的内存并不是内部存储器,而是DRAM。
……CPU的运行速度很快,而外部存储器的读取速度相对来说就很慢,如果CPU需要用到的数据总是从外部存储器中读取,由于外部设备很慢,……,CPU可能用到的数据预先读到DRAM中,CPU产生的临时数据也暂时存放在DRAM中,这样的结果是大大的提高了CPU的利用率和计算机运行速度。
……
这是一个典型计算机基础教材针对内存的描述,也许作为计算机专业的程序员对这段描述并不陌生。但也因为这段描述,而对内存的处理速度有神话的理解,认为内存中的处理速度是非常快的。
以使持有这种观点的程序员遇到一个巨型的内存查询循环的较长时间时,而束手无策了。
请看一下如下程序:
public class MemFor{
public static void main (String[] args) {
long start=System.currentTimeMillis(); //取得当前时间
int len=1024*1024*3; //设定循环次数
int [][] abc=new int[len][2];
for (int i=0;i<len;i++){
abc[i][0]=i;
abc[i][1]=(i+1);
}
long get=System.currentTimeMillis(); //取得当前时间
//循环将想要的数值取出来,本程序取数组的最后一个值
for (int i=0;i<len;i++){
if ((int)abc[i][0]==(1024*1024*3-1)){
System.out.println("取值结果:"+abc[i][1]);
}
}
long end=System.currentTimeMillis(); //取得当前时间
//输出测试结果
System.out.println("赋值循环时间:"+(get-start)+"ms");
System.out.println("获取循环时间:"+(end-get)+"ms");
System.out.print("Java可控内存:");
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.print("已占用内存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
}
}
|
运行这个程序:
程序的运行结果如下:
取值结果:3145728
赋值循环时间:2464ms
获取循环时间:70ms
Java可控内存:1016M
已占用内存:128M
我们发现,这个程序循环了3145728次获得想要的结果,循环获取数值的时间用了70毫秒。
你觉得快吗?
是啊,70毫秒虽然小于1秒钟,但是如果你不得不在这个循环外面再套一个循环,即使外层嵌套的循环只有100次,那么,想想看是多少毫秒呢?
回答:70毫秒*100=7000毫秒=7秒
如果,循环1000次呢?
70秒!
70秒的运行时间对于这个程序来说就是灾难了。
面对这个程序的运行时间很多程序员已经束手无策了,其实,Java给程序员们提供了一个较快的查询方法--哈希表查询。
我们将这个程序用"HashMap"来改造一下,再看看运行结果:
import java.util.*;
public class HashMapTest{
public static void main (String[] args) {
HashMap has=new HashMap();
int len=1024*1024*3;
long start=System.currentTimeMillis();
for (int i=0;i<len;i++){
has.put(""+i,""+i);
}
long end=System.currentTimeMillis();
System.out.println("取值结果:"+has.get(""+(1024*1024*3-1)));
long end2=System.currentTimeMillis();
System.out.println("赋值循环时间:"+(end-start)+"ms");
System.out.println("获取循环时间:"+(end2-end)+"ms");
System.out.print("Java可控内存:");
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.print("已占用内存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
}
}
|
运行这个程序:
java -Xmx1024m HashMapTest
|
程序的运行结果如下:
取之结果:3145727
赋值循环时间:16454ms
获取循环时间:0ms
Java可控内存:1016M
已占用内存:566M
那么现在用HashMap来取值的时间竟然不到1ms,这时我们的程序的效率明显提高了,看来用哈希表进行内存中的数据搜索速度确实很快。
在提高数据搜索速度的同时也要注意到,赋值时间的差异和内存占用的差异。
赋值循环时间:
HashMap:16454ms
普通数组:2464ms
占用内存:
HashMap:566M
普通数组:128M
因此,可以看出HashMap在初始化以及内存占用方面都要高于普通数组,如果仅仅是为了数据存储,用普通数组是比较适合的,但是,如果为了频繁查询的目的,HashMap是必然的选择。
启示5:用"arrayCopy()"提高数组截取速度
当我们需要处理一个大的数组应用时往往需要对数组进行大面积截取与复制操作,比如针对图形显示的应用时单纯的通过对数组元素的处理操作有时捉襟见肘。
提高数组处理速度的一个很好的方法是"System.arrayCopy()",这个方法可以提高数组的截取速度,我们可以做一个对比试验。
例如我们用普通的数组赋值方法来处理程序如下:
public class arraycopyTest1{
public static void main( String[] args ){
String temp="abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz";
char[] oldArray=temp.toCharArray();
char[] newArray=null;
long start=0L;
newArray=new char[length];
//开始时间记录
start=System.currentTimeMillis();
for(int i=0;i<10000000;i++){
for(int j=0;j<length;j++){
newArray[j]=oldArray[begin+j];
}
}
//打印总用时间
System.out.println(System.currentTimeMillis()-start+"ms");
}
}
|
程序运行结果如图 3 8所示。
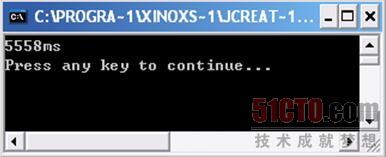
那么下面我们再用arrayCopy()的方法试验一下:
public final class arraycopyTest2{
public static void main( String[] args ){
String temp="abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz";
char[] oldArray=temp.toCharArray();
char[] newArray=null;
long start=0L;
newArray=new char[length];
//记录开始时间
start=System.currentTimeMillis();
for(int i=0;i<10000000;i++ ){
System.arraycopy(oldArray,100,newArray,0,120);
}
//打印总用时间
System.out.println((System.currentTimeMillis()-start)+"ms");
}
}
|
程序运行结果如图 3 9所示。
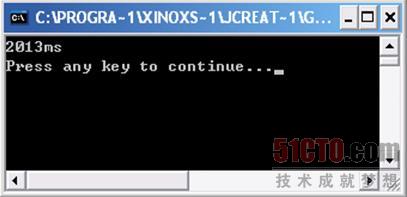
两个程序的差距再3秒多,如果处理更大批量的数组他们的差距还会更大,因此,可以在适当的情况下用这个方法来处理数组的问题。
有时候我们为了使用方便,可以在自己的tools包中重载一个arrayCopy方法,如下:
public static Object[] arrayCopy(int pos,Object[] srcObj){
return arrayCopy(pos,srcObj.length,srcObj);
}
public static Object[] arrayCopy(int pos,int dest,Object[] srcObject){
Object[] rv=null;
rv=new Object[dest-pos];
System.arraycopy(srcObject,pos,rv,0,rv.length);
return rv;
}
|