Regexp是一个学习这种表达式的好工具。
Regexp是一个由100%纯java正则式处理包,是Jonathan Locke捐给Apache软件基金会的。 他最初开发这个软件是在1996年, 它包括完整的Javadoc文档,以及一个简单的Applet来做可视化调试和兼容性测试.
2)RE类regexp包中非常重要的一个类,它是一个高效的、轻量级的正则式计算器/匹配器的类,RE是regular expression的缩写。正则式是能够进行复杂的字符串匹配的模板,而且当一个字符串能匹配某个模板时,你可 以抽取出那些匹配的部分,这在进行文本解析时非常有用。下面讨论一下正则式的语法。
为了编译一个正则式,你需要简单地以模板为参数构造一个RE匹配器对象来完成,然后就可调用任一个 RE.match方法来对一个字符串进行匹配检查,如果匹配成功/失败,则返回真/假值。例如:
RE r = new RE("a*b");
boolean matched = r.match("aaaab");
RE.getParen可以取回匹配的字符序列,或者匹配的字符序列的某一部分(如果模板中有相应的括号的 话),以及它们的位置、长度等属性。如:
RE r = new RE("(a*)b"); // Compile expression
boolean matched = r.match("xaaaab"); // Match against "xaaaab"
String wholeExpr = r.getParen(0); // wholeExpr will be 'aaaab'
String insideParens = r.getParen(1); // insideParens will be 'aaaa'
int startWholeExpr = r.getParenStart(0); // startWholeExpr will be index 1
int endWholeExpr = r.getParenEnd(0); // endWholeExpr will be index 6
int lenWholeExpr = r.getParenLength(0); // lenWholeExpr will be 5
int startInside = r.getParenStart(1); // startInside will be index 1
int endInside = r.getParenEnd(1); // endInside will be index 5
int lenInside = r.getParenLength(1); // lenInside will be 4
RE支持正则式的后向引用,如:
([0-9]+)=\1
匹配 n=n (象 0=0 or 2=2)这样的字符串
3)RE支持的正则式的语法如下:
字符
unicodeChar Matches any identical unicode character
\ Used to quote a meta-character (like '*')
\\ Matches a single '\' character
\0nnn Matches a given octal character
\xhh Matches a given 8-bit hexadecimal character
\\uhhhh Matches a given 16-bit hexadecimal character
\t Matches an ASCII tab character
\n Matches an ASCII newline character
\r Matches an ASCII return character
\f Matches an ASCII form feed character
字符集
[abc] 简单字符集
[a-zA-Z] 带区间的 字符集
[^abc] 字符集的否定
标准POSIX 字符集
[:alnum:] Alphanumeric characters.
[:alpha:] Alphabetic characters.
[:blank:] Space and tab characters.
[:cntrl:] Control characters.
[:digit:] Numeric characters.
[:graph:] Characters that are printable and are also visible.(A space is printable, but not visible, while an `a' is both.)
[:lower:] Lower-case alphabetic characters.
[:print:] Printable characters (characters that are not control characters.)
[:punct:] Punctuation characters (characters that are not letter,digits, control characters, or space characters).
[:space:] Space characters (such as space, tab, and formfeed, to name a few).
[:upper:] Upper-case alphabetic characters.
[:xdigit:] Characters that are hexadecimal digits.
非标准的 POSIX样式的字符集
[:javastart:] Start of a Java identifier
[:javapart:] Part of a Java identifier
预定义的字符集
. Matches any character other than newline
\w Matches a "word" character (alphanumeric plus "_")
\W Matches a non-word character
\s Matches a whitespace character
\S Matches a non-whitespace character
\d Matches a digit character
\D Matches a non-digit character
边界匹配符
^ Matches only at the beginning of a line
$ Matches only at the end of a line
\b Matches only at a word boundary
\B Matches only at a non-word boundary
贪婪匹配限定符
A* Matches A 0 or more times (greedy)
A+ Matches A 1 or more times (greedy)
A? Matches A 1 or 0 times (greedy)
A{n} Matches A exactly n times (greedy)
A{n,} Matches A at least n times (greedy)
非贪婪匹配限定符
A*? Matches A 0 or more times (reluctant)
A+? Matches A 1 or more times (reluctant)
A?? Matches A 0 or 1 times (reluctant)
逻辑运算符
AB Matches A followed by B
A|B Matches either A or B
(A) Used for subexpression grouping
(?:A) Used for subexpression clustering (just like grouping but no backrefs)
后向引用符
\1 Backreference to 1st parenthesized subexpression
\2 Backreference to 2nd parenthesized subexpression
\3 Backreference to 3rd parenthesized subexpression
\4 Backreference to 4th parenthesized subexpression
\5 Backreference to 5th parenthesized subexpression
\6 Backreference to 6th parenthesized subexpression
\7 Backreference to 7th parenthesized subexpression
\8 Backreference to 8th parenthesized subexpression
\9 Backreference to 9th parenthesized subexpression
RE运行的程序先经过RECompiler类的编译. 由于效率的原因,RE匹配器没有包括正则式的编译类. 实际上, 如果要预编译1个或多个正则式,可以通过命令行运行'recompile'类,如
java org.apache.regexp.recompile a*b
则产生类似下面的编译输出(最后一行不是):
// Pre-compiled regular expression "a*b"
char[] re1Instructions =
{
0x007c, 0x0000, 0x001a, 0x007c, 0x0000, 0x000d, 0x0041,
0x0001, 0x0004, 0x0061, 0x007c, 0x0000, 0x0003, 0x0047,
0x0000, 0xfff6, 0x007c, 0x0000, 0x0003, 0x004e, 0x0000,
0x0003, 0x0041, 0x0001, 0x0004, 0x0062, 0x0045, 0x0000,
0x0000,
};
REProgram re1 = new REProgram(re1Instructions);
RE r = new RE(re1);
通过利用预编译的req来构建RE匹配器对象,可以避免运行时进行编译的成本。 如果需要动态的构造正 则式,则可以创建单独一个RECompiler对象,并利用它来编译每个正则式。注意,RE 和 RECompiler 都不是 threadsafe的(出于效率的原因), 因此当多线程运行时,你需要为每个线程分别创建编译器和匹配器。
3、例程
1)regexp包中带有一个applet写的小程序,运行如下:
java org.apache.regexp.REDemo
运行后:
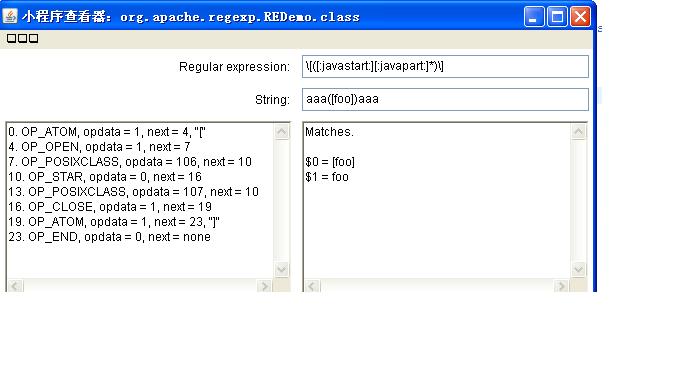
2)Jeffer Hunter写了一个例程,可以下载。
3)regexp自带的测试例程,也很有参考价值。它把所有正则式及相关的字符串以及结果都放在一个单独的文件 里,在$REGEXPHOME/docs/RETest.txt中。当然,这个例程的运行也要在$REGEXPHOME目录下。
cd $REGEXPHOME
java org.apache.regexp.RETest