Posted on 2012-12-12 12:41
FineReport——报表技术领跑者 阅读(419)
评论(0) 编辑 收藏 所属分类:
Java报表技术知识

FineReport缓存技术包括数据集缓存和模板结果共享缓存,合理的使用缓存可以有效的提高性能。
一、数据集缓存
数据集缓存分为取数缓存和共享数据集
A. 取数缓存
FineReport的报表取数模型用的是叫做数据集(TableData)的二维表模型。而数据集缓存指的就是针对“数据库查询”这种数据集的取数过程所作的缓存。
背景:
数据库查询,就是通过SQL或者存储过程,从数据库服务器查询取数据传送到服务器以供报表执行用。通常这个取数的过程就是报表执行过程的一部分,因此报表的性能很大程度上依赖于取数的性能,而取数缓存就是为了解决这种性能问题而产生的。特别是数据量较大时,合理的使用缓存,可以控制性能表现。
原理:
我们知道服务器各个硬件的I/O性能是不同的,内存I/O >> 硬盘I/O >> 网络 I/O, “>>”表示远快于。在实际应用环境中,数据库服务器和FineReport服务器通常是在不同的服务器上,它们之间的数据交互必须要通过网络I/O来实现。而通常情况下,报表执行过程中可能对一条记录需要使用多次,如果每次都需要到数据库服务器上面去查询取数,不但增加了数据库的压力,而且速度也会很慢。为什么我们不能在第一取数后,把该数据放到本地上的内存和磁盘上,从而提高性能。这就是一种“缓存”, 暂且称为取数本地缓存。
如果把缓存放到本地,那么是放到内存还是磁盘上呢?既然内存I/O的速度比磁盘快很多,可不可以把所有的数据都放在内存上?可以是可以,但不一定是最好的选择。因为相同容量的内存比磁盘的造价高很多,所以存储的成本也要高很多。所以通常情况下,服务器的内存容量也会比磁盘小很多,如果数据库的数据都放在内存上,就很容易造成OutOfMemory。另一个极端是把所有数据都放到磁盘上?这样也不合算,因为虽然空间够用了,但是速度却不够快。所以最好的解决方案是合理的分配内存和磁盘,把那些使用频率最高的数据尽量放在内存中,从而提高在内存中的命中率。这是另一种“缓存”, 我们称之为取数内存缓存。
综上,可以看出,利用缓存技术来优化提高性能,是各种硬件性能造价的差异造成的合理结果。FineReport致力于研究合理的缓存技术来提高报表的性能。
缺陷:
缓存能够很好的提高性能,但是也有一些缺陷,特别是实时数据敏感的应用。但对于通常的报表应用来说,影响并不大。
1. 拿取数本地缓存来说,数据缓存到本地后,在缓存存活有效期,再次取数时,就不会到数据库取数了。如果此时数据库的数据发生了更新,就不能及时的反应到本地。所以缓存会导致数据延迟,可能不是最新的数据。但是,这个数据延迟的时间可以通过参数来设定。
2. 对于服务器的集群来说,各个服务器之间的缓存需要同步化。比如:当客户端第一次访问报表服务器的时候,A机器计算了报表并在A机器作了缓存,当客户端第二次访问时,例如此时跳转到B机器,B机器上找不到报表的缓存,也找不到参数的缓存,于是只好报错或者重新计算。可以通过提供了集群服务器之间通讯的能力,解决负载均衡时服务器之间跳转访问带来的缓存同步的问题。其原理是,首先,客户端第一次访问报表服务器,A机器计算了报表并在A机器作了缓存,当客户端第二次访问时,例如此时跳转到B机器,B机器根据缓存id判断出是A机器做的缓存,于是B机器向A机器发送缓存请求,A机器读取缓存并把缓存结果发送给B机器,B机器再把结果返回给客户端。
使用说明:
1. 取数本地缓存:服务器|缓存参数设置
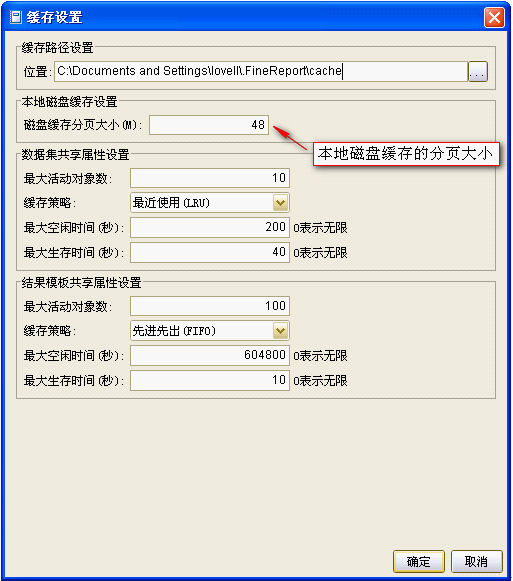
FineReport6.5对于数据库数据集内置了取数磁盘缓存技术,一般用户不需要手动设置,上图显示了本地磁盘缓存的分页大小。是否启用本地磁盘缓存,会根据下面取数内存缓存面板中的“启用磁盘缓存当记录数大于”编辑框,当编辑框中为0时,表示一直启用本地磁盘缓存
2.取数内存缓存:
打开报表设计器: 报表|数据集|数据集查询
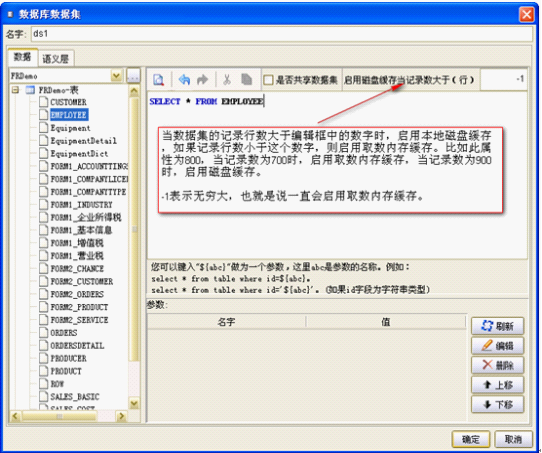
如上红色箭头所指编辑框,就是取数内存缓存设置的地方,编辑框中的数字表示查询结果记录集的记录数大于多少时启用本地磁盘缓存,否则使用取数内存缓存,-1表示全部缓存到内存。