1 归并排序(MergeSort)
归并排序最差运行时间是O(nlogn),它是利用递归设计程序的典型例子。
归并排序的最基础的操作就是合并两个已经排好序的序列。
假设我们有一个没有排好序的序列,那么首先我们使用分割的办法将这个序列分割成一个一个已经排好序的子序列。然后再利用归并的方法将一个个的子序列合并成排序好的序列。分割和归并的过程可以看下面的图例。

从上图可以看出,我们首先把一个未排序的序列从中间分割成2部分,再把2部分分成4部分,依次分割下去,直到分割成一个一个的数据,再把这些数据两两归并到一起,使之有序,不停的归并,最后成为一个排好序的序列。
如何把两个已经排序好的子序列归并成一个排好序的序列呢?可以参看下面的方法。
假设我们有两个已经排序好的子序列。
序列A:1 23 34 65
序列B:2 13 14 87
那么可以按照下面的步骤将它们归并到一个序列中。
(1)首先设定一个新的数列C[8]。
(2)A[0]和B[0]比较,A[0] = 1,B[0] = 2,A[0] < B[0],那么C[0] = 1
(3)A[1]和B[0]比较,A[1] = 23,B[0] = 2,A[1] > B[0],那么C[1] = 2
(4)A[1]和B[1]比较,A[1] = 23,B[1] = 13,A[1] > B[1],那么C[2] = 13
(5)A[1]和B[2]比较,A[1] = 23,B[2] = 14,A[1] > B[2],那么C[3] = 14
(6)A[1]和B[3]比较,A[1] = 23,B[3] = 87,A[1] < B[3],那么C[4] = 23
(7)A[2]和B[3]比较,A[2] = 34,B[3] = 87,A[2] < B[3],那么C[5] = 34
(8)A[3]和B[3]比较,A[3] = 65,B[3] = 87,A[3] < B[3],那么C[6] = 65
(9)最后将B[3]复制到C中,那么C[7] = 87。归并完成。
如果我们清楚了上面的分割和归并过程,那么我们就可以用递归的方法得到归并算法的实现。
public class MergeSorter
{
private static int[] myArray;
private static int arraySize;
public static void Sort( int[] a )
{
myArray = a;
arraySize = myArray.Length;
MergeSort();
}
/// <summary>
/// 利用归并的方法排序数组,首先将序列分割
/// 然后将数列归并,这个算法需要双倍的存储空间
/// 时间是O(nlgn)
/// </summary>
private static void MergeSort()
{
int[] temp = new int[arraySize];
MSort( temp, 0, arraySize - 1);
}
private static void MSort(int[] temp, int left, int right)
{
int mid;
if (right > left)
{
mid = (right + left) / 2;
MSort( temp, left, mid); //分割左边的序列
MSort(temp, mid+1, right);//分割右边的序列
Merge(temp, left, mid+1, right);//归并序列
}
}
private static void Merge( int[] temp, int left, int mid, int right)
{
int i, left_end, num_elements, tmp_pos;
left_end = mid - 1;
tmp_pos = left;
num_elements = right - left + 1;
while ((left <= left_end) && (mid <= right))
{
if (myArray[left] <= myArray[mid]) //将左端序列归并到temp数组中
{
temp[tmp_pos] = myArray[left];
tmp_pos = tmp_pos + 1;
left = left +1;
}
else//将右端序列归并到temp数组中
{
temp[tmp_pos] = myArray[mid];
tmp_pos = tmp_pos + 1;
mid = mid + 1;
}
}
while (left <= left_end) //拷贝左边剩余的数据到temp数组中
{
temp[tmp_pos] = myArray[left];
left = left + 1;
tmp_pos = tmp_pos + 1;
}
while (mid <= right) //拷贝右边剩余的数据到temp数组中
{
temp[tmp_pos] = myArray[mid];
mid = mid + 1;
tmp_pos = tmp_pos + 1;
}
for (i=0; i < num_elements; i++) //将所有元素拷贝到原始数组中
{
myArray[right] = temp[right];
right = right - 1;
}
}
}
归并排序算法是一种O(nlogn)的算法。它的最差,平均,最好时间都是O(nlogn)。但是它需要额外的存储空间,这在某些内存紧张的机器上会受到限制。
归并算法是又分割和归并两部分组成的。对于分割部分,如果我们使用二分查找的话,时间是O(logn),在最后归并的时候,时间是O(n),所以总的时间是O(nlogn)。
2 堆排序(HeapSort)
堆排序属于百万俱乐部的成员。它特别适合超大数据量(百万条记录以上)的排序。因为它并不使用递归(因为超大数据量的递归可能会导致堆栈溢出),而且它的时间也是O(nlogn)。还有它并不需要大量的额外存储空间。
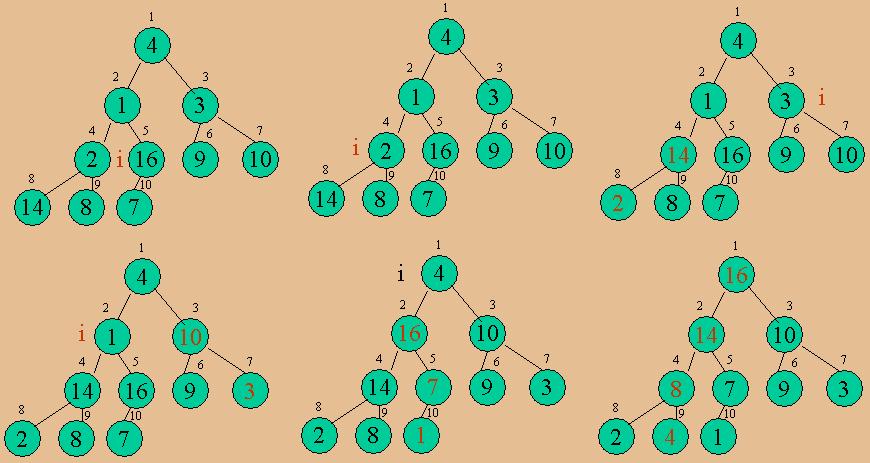
堆排序的思路是:
(1)将原始未排序的数据建成一个堆。
(2)建成堆以后,最大值在堆顶,也就是第0个元素,这时候将第零个元素和最后一个元素交换。
(3)这时候将从0到倒数第二个元素的所有数据当成一个新的序列,建一个新的堆,再次交换第一个和最后一个元素,依次类推,就可以将所有元素排序完毕。
建立堆的过程如下面的图所示:
堆排序的具体算法如下:
public class HeapSorter
{
private static int[] myArray;
private static int arraySize;
public static void Sort( int[] a )
{
myArray = a;
arraySize = myArray.Length;
HeapSort();
}
private static void HeapSort()
{
BuildHeap(); //将原始序列建成一个堆
while ( arraySize > 1 )
{
arraySize--;
Exchange ( 0, arraySize );//将最大值放在数组的最后
DownHeap ( 0 ); //将序列从0到n-1看成一个新的序列,重新建立堆
}
}
private static void BuildHeap()
{
for (int v=arraySize/2-1; v>=0; v--)
DownHeap ( v );
}
//利用向下遍历子节点建立堆
private static void DownHeap( int v )
{
int w = 2 * v + 1; // 节点w是节点v的第一个子节点
while (w < arraySize)
{
if ( w+1 < arraySize ) // 如果节点v下面有第二个字节点
if ( myArray[w+1] > myArray[w] )
w++; // 将子节点w设置成节点v下面值最大的子节点
// 节点v已经大于子节点w,有了堆的性质,那么返回
if ( myArray[v] >= myArray[w] )
return;
Exchange( v, w ); // 如果不是,就交换节点v和节点w的值
v = w;
w = 2 * v + 1; // 继续向下找子节点
}
}
//交换数据
private static void Exchange( int i, int j )
{
int t = myArray[i];
myArray[i] = myArray[j];
myArray[j] = t;
}
}
堆排序主要用于超大规模的数据的排序。因为它不需要额外的存储空间,也不需要大量的递归。3 几种O(nlogn)算法的初步比较我们可以从下表看到几种O(nlogn)算法的效率的区别。所有的数据都使用.Net的Random类产生,每种算法运行100次,时间的单位为毫秒。
| 500随机整数 | 5000随机整数 | 20000随机整数 |
| 合并排序 | 0.3125 | 1.5625 | 7.03125 |
| Shell排序 | 0.3125 | 1.25 | 6.875 |
| 堆排序 | 0.46875 | 2.1875 | 6.71875 |
| 快速排序 | 0.15625 | 0.625 | 2.8125 |
从上表可以明显地看出,快速排序是最快的算法。这也就给了我们一个结论,对于一般的应用来说,我们总是选择快速排序作为我们的排序算法,当数据量非常大(百万数量级)我们可以使用堆排序,如果内存空间非常紧张,我们可以使用Shell排序。但是这意味着我们不得不损失速度。 /****************************************************************************************** *【Author】:flyingbread *【Date】:2007年2月2日 *【Notice】: *1、本文为原创技术文章,首发博客园个人站点(http://flyingbread.cnblogs.com/),转载和引用请注明作者及出处。 *2、本文必须全文转载和引用,任何组织和个人未授权不能修改任何内容,并且未授权不可用于商业。 *3、本声明为文章一部分,转载和引用必须包括在原文中。 ******************************************************************************************/