首先要说明的是,这部分内容和第一篇不同,必须对照代码看才会理解其中的含义,光看设计实现会比较难懂其中所说的细节点。代码:https://github.com/cenwenchu/beatles
IComponent:
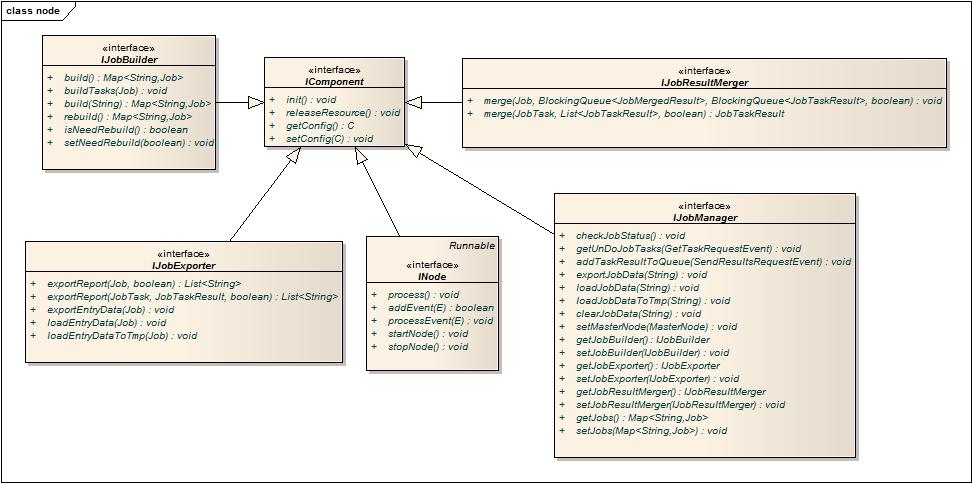
做系统就像搭积木一样,这些组件最后都会拼装起来,而积木往往由于内部机制可定制化需要config,同时组合在一起的积木往往会有一个传递的Config(可以认为是静态的Context)。
INode:
Node的设计比较简单,自身是Runnable的单线程循环体,内置一个单线程事件监听分
发器。Node的主线程主要负责该Node自身产生的事件处理(常规已知事件处理):Master就是维护任务列表状态,并根据任务执行情况做一些Action,Slave就是重复的获取,执行任务,返回结果。而Node中的事件监听器主要用于外部消息驱动事件处理(偶发性事件处理),例如Master收到Slave的请求,外部要求导出载入中间结果等。这里会发现采用的是单线程阻塞检查获取事件:
1.多线程并发检查事件,对于事件承载者(队列)就要求做好并发控制,也就是最终在获取事件的过程中依然是串行化,所以大部分事件处理框架对于事件检查都采用单线程,简单高效。
2.单线程可以用于检查事件,但执行事件会采用多线程或者主线程直接处理,取决于事件执行速度和可靠性(外部依赖),如果事件可以快速执行(无外部依赖,逻辑简单),则采用检查线程直接处理(NIO中对于连接建立和销毁直接在主线程中处理掉,这里Master对于获取任务事件的前半段采用直接处理),如果事件消耗时间较久,或者依赖与外部系统稳定性和处理情况,则需要采用多线程异步处理(这里很多都是让内部组件来保证方法执行的快速返回,例如JobExporter的所有方法等处理都是内部线程异步完成,对外接口快速返回),如果必须要有结果回执,那么可以采用回调模式或者直接提交新事件(带有上下文可以接着上次处理)到事件处理引擎。
3.另一种方式会选择将事件分开放置来提高处理效率,例如TimeOut事件和普通外部激发事件,注意尽量避免通过轮询对象状态来判断事件发生,除了Timeout必须这么做,其他尽量通过对对象状态变更操作内置事件产生器来创建真实事件,这样事件处理者只需要阻塞等待事件即可,系统内状态规模增大对于事件处理时间复杂度还是O(1)。对于Timeout这类事件后续介绍SlaveConnector中有更详细介绍,至此略过。那是否需要将不同业务处理放置在不同的队列交由不同的单线程处理,取决于系统事件产生速度,就好比NIO中可以起多个Selector来处理,由于起多个单线程守护到队列如果利用率不高,其实对于系统来说也是一种负担,所以可以做成可配置的方式提供给外部(beatles中是没有提供配置,就一个线程,因为本身并不是大并发的web前端系统,接上千个slave的话消息量分布也不会非常密集,毕竟任务分析本身需要消耗时间)。
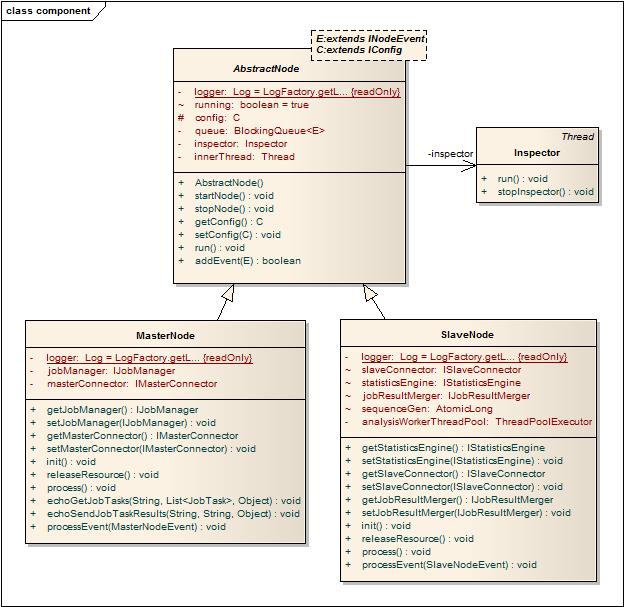
MasterNode中有两个组件:JobManager和MasterConnector,一个负责上层业务处理,一个负责消息通信,在MasterNode运作的时候,两者其实需要协调工作,例如MasterConnector可能会收到消息,需要提交给JobManager处理并获得结果返回。为了实现内部组件不会相互依赖(MasterNode内部成为网状结构),采用MasterNode作为中间消息传递者,通过事件或回调方式相互驱动,同时利用上下文(将Channel作为Event的一部结构,用于后续消息返回)来传递一些环境信息。需要注意的是,这种解耦的做法势必带来性能的下降,因此可以和前面提到的事件处理为多线程还是单线程一样,对于消息机制的依赖也不要盲从,按需使用,例如Connector通过事件提交给MasterNode,MasterNode接收事件后调用JobManager处理,处理后的结果也可以利用事件机制反向驱动Master去调用Connector,但也可以直接将MasterNode植入JobManager,反向利用代理模式来直接处理,这里关键看你是否需要释放掉你当前的线程,让任务异步去做,而当前线程可以回收去做更多的处理,带来的是线程切换和事件驱动的消耗。不过总体上来说让组件的宿主来完成交互,能够减少模块间依赖带来的耦合性和复杂度。
FileJobExporter
这个类主要用于文件输出,但在输出部分的代码中有lazymerge的部分,所谓的lazy merge指的是部分entry<key,value>的结果是依赖于处理后的部分结果而得到,例如成功率这个指标就是用成功数/总数。作为分析系统来说,如果成功数的<key,value>需要长期保存,总数的<key,value>需要长期保存,那是否需要在最终产出报表以前就将成功率的<key,value>计算并保存在内存中呢?其实大可不必,不仅浪费了cpu资源,也浪费了大量的内存资源,同时slave传递给master还会使得网络io消耗增大。在beatles中认为export就是最后的一步,因此在这个时候做计算和导出。在我们很多系统中,考虑一下很多中间结果是否需要输出,还是保留在最后一步输出(并不是保留在最后一步一定好,取决于代价,如果最后一步有大量的计算要做,那么可以用内存换机算,提早计算来减缓最后导出时的压力,如果导出时计算不大,而系统整体处理内存资源紧张,那么就滞后处理)。衍生开来很多时候,需要考虑重复计算带来的成本和节省内存带来的收获谁更有利,如果计算节点分散且规模巨大,则可以靠虑利用外部计算能力来减少集中式处理的代价(好比很多前端处理的结果可以滞后到客户端处理而不是服务端集中处理,开放平台的数据序列化推后到业务方集群处理而不是开放平台统一处理)
JobManager
由于MasterNode中是单线程调用,因此对于任务状态变更变得非常简单(无需并发控制和原子操作),但由于MasterNode将来还是可扩展为多个线程处理,因此暂时保留原子操作的处理模式。
1. 对于对象状态管理,如果对象层次比较多,尽量扁平化处理,就好比把TaskStatus直接保存,有利于检查和原子操作,带来的问题就是另一部分对象的状态同步变更(Task中的状态),其实简单来说就是两个数据结构修改要做到事务性,做法比较简单,细粒度的原子操作模拟锁争夺,例如要修改Task的Status首先要并发的修改TaskStatus的数据(if (statusPool.replace(taskId, JobTaskStatus.DOING, JobTaskStatus.DONE)),如果修改成功,才可以修改原始对象内的数据。其实如果是单线程都不需要并发控制(因为并发的模式还是有些消耗的)。
2. 事件驱动模型中很重要一点就是事件状态必须在所有必要操作后再改变(即创建事件),例如:早一个版本中,Master收到Slave返回结果时,将会把结果设置到Master的某一个Task的result属性中,同时改变Task的状态为done,这两个动作就必须保持一定的顺序,也就是先要把内容设置进去,然后再改变状态,因为如果先改变状态,外部事件处理线程如果发现状态已经改变,又没有锁保证结果放进去以前不能处理这个事件,就会发现事件开始被处理了,但是内容还是错过了处理,出现线程并发问题。这点在这个版本的源码注释上面有点问题,后续修改掉它。
3. 在主流程上有一个方法mergeAndExportJobs,用于检查Job内部的Tasks完成状态,决定是否合并或者导出结果,首先受限制于JobManager主流程是单线程处理,同时内部Tasks状态随时会变,因此要求主流程的所有操作和检查都必须非阻塞,保证处理的即时性,但如果这个方法里面的所有操作都变成另起线程异步处理的话,就同样会发生上面我谈过的事件检查多线程模式最终还是会并发控制下变成串行化,效率不升反降,因此采用同一业务性数据处理守护进程唯一性的方式(其实简单来说就是在这里Master中管理多个Job,多个Job其实就好比多个事件队列,因此必须并行处理,否则会有互相影响的风险,但是单个Job的处理可以只有一个守护线程处理,因此对Job加事件锁,保证不同Job之间同一个事件并行,同一个job不同事件并行(这里由于都是顺序化的,虽然并行了,但还是要等待上一个事件完成后才会修改内部状态继续往下走))
4. 在第一篇里面说到,这个框架对于任务执行异常的处理十分简单,事先规定好单个任务执行的最长可接受时间,如果到了时间尚未获得反馈,就认为出现问题,任务重置可以接受下一个计算节点的处理请求。(结果谁先返回就用谁的)这里其实要注意两点:任务时间可评估是基于任务切分粒度够细,其实很多时候可以考虑通过任务细化来降低任务出现问题解决的复杂度,同时也可以降低计算节点重新做任务的代价。另一方面需要设置重置次数透明化,保证如果任务本身有问题(例如数据来源出现问题),不会使得所有的计算节点陷入单个任务处理死循环。
5. 合并数据的代码优化:
A. Master合并时每一个Job只有一个主干,也就是最后job的所有Task Result都必须合并到这个主干,假设这是个svn主干,可以想象多个人(多线程)是无法并行合并的。那么当主线程在A时刻发现有4个结果需要合并的时候,它开始把4个结果合并到主干,合并的过程中可能又来了3个结果,那么这三个结果就必须等待下一轮的合并开始,此时这三个结果耗费的内存就会增加系统的负担,同时系统如果Slave越多,这样的情况越严重。因此引入下面一种模式,多线程合并,但主干和虚拟分支同时进行,当需要合并时首先竞争主干锁,得到主干锁的线程将这次需要合并的结果和以前合并的虚拟分支一起合并到主干,而如果没有得到主干锁的线程并行的合并结果到虚拟分支上。此时充分利用多核的计算能力来压缩对于内存的需求(结果合并后会大大减少存储的需求)。
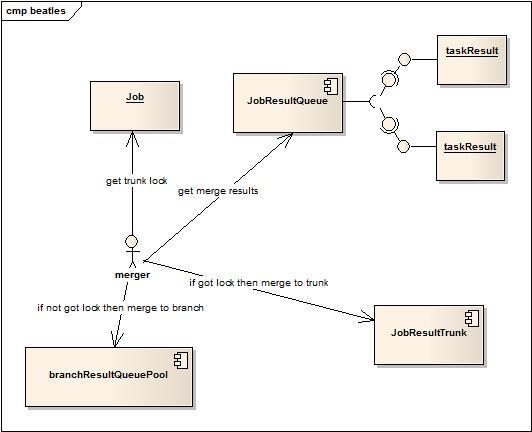
B. 由于A中的描述可以看到,主干在整个Job的任务执行合并过程中都被保存在内存中,因此当结果集越大,主干对系统内存消耗就越大,而Job的多轮合并是否可以最后载入上一轮的主干和本轮增量结果合并,这样可以大大减少内存消耗,但是内容的导出和载入带来的序列化代价和IO的消耗势必会增加每一轮的处理时间,和减少GC带来的节省时间的优势可能会冲抵甚至有负面效果。因此通过异步载入和导出,即节省了内存占用,减少FullGC带来的停顿,又不影响处理,另一方面其实也是利用两个阶段的CPU闲置率较高来交换内存的代价。(这部分代码参看jobexporter和jobmanager)
SlaveNode:
充分利用Slave单机CPU的方式可以是:一台机器可以跑多个Slave。也可以跑一个Slave,单个Slave一次要求获取多个Task,这样可以并行利用多个cpu处理多个任务。
为了减少Master的合并压力,可以让Slave直接输出,也可以通过Slave要求多个Task,执行完多个Task在本地合并(Task必须是同一个Job才可以合并),再将合并后的结果会送给Master。
对于同一个数据源可以通过创建同样的多个Task来增加对其的处理速度,例如A机器的日志增长比B机器的快,那么可以配置,两个数据来源是A机器的Task,配置一个B机器的Task,来差别对待处理速度。
对于处理后的数据如果还需要二次处理,可以构建Job的数据来源是一次处理后的数据输出地,当一次数据输出以后,自然二次处理才会开始。
简单来说,很多复杂的sharding设计,reduce的考虑,任务迭代处理,其实都可以通过扁平化的方式来解决,有时候花很很大力气去做的看似很fancy的设计,不如归一化处理。(再大的数字都是从一衍生出来的)
Connector:
这部分设计主要是屏蔽掉分布式概念的误区,很多分布式设计开始的时候不是注重对于主节点和次节点的业务交互上,而是纠结于底层设计上,最后就会落得调试难,扩展难的情形。和上面的归一化设计思想一样,所谓的分布式其实可以是一个进程内(虚拟机内)的交互协作,一台机器多进程的交互协作,多台机器多进程的交互协作,因此如何能够适合这三个场景,就会让设计变得简单,容易扩展,实现与接口分离。
Event:
Event中需要考虑一些上下文设计,例如序列号保证松散交互的会话可维护性,Channel等后续操作的基础传递。Event尽量做到无业务侵入,例如虽然需要Channel,但不同的实现Channel是不同的,MemChannel和SocketChannel就不同,将来扩展更是不同,做好一些就抽象一些接口(但可能需要对一些实现做外壳封装适应接口),或者就直接Object弱化类型。
InputAdaptor&OutputAdaptor:
任务的自描述性除了业务规则的自描述性,更需要输入输出的自描述性,所有计算归结到底无非是输入,处理,输出,如果三者定义清楚,并且可以通过支持协议扩展适配,那么对于计算节点来说就非常通用了,不必因为业务的差别,数据来源和输出的差别来分别建立多个集群,最终还是发现多个集群无法很好的充分利用资源的高低峰(对于明确要保护的计算集群可以直接构建,对于一些非关键性的计算任务可以丢到一个集群中搞定),降低成本。
Job:
本身是一组任务的集合,自身有多个状态位,当前通过多个状态来表示(可以合并为一个原子状态位),内置一些锁来控制主干的并发访问,守护进程的分配。(这点在另一个PipeComet项目中对于长连接管道下行守护进程按需分配也有充分利用到)。
Operation:
这个包里面是将耗时的操作封装为可以被外部线程独立执行的Runnable,可以看见在整体代码里面有用外部线程异步执行的,也有直接在线程里面阻塞执行的,取决于对于结果返回的同步性需求,如果同步性需求明确,那么可以用异步+锁的方式来模拟同步,也可以直接同步,但前者代价较大,所以将这类操作抽象,上下文通过参数传递来构建出可以异步也可以同步执行的逻辑块,提高了功能执行的灵活性。
CreateReportOperation中的输出模式还是比较节省空间的,可以看一下如何基于<key,value>列矩阵输出报表这样的行式记录保持对内存较小的占用。
ReportUtil:
是个工具大杂烩。
1. mergeEntryResult。将多个矩阵结果合并的函数,里面有不少的节省内存的做法,首先选取第一个矩阵作为base,节省申请和合并的过程,合并过程中不断删除合并后的数据,节省后续合并成本,释放资源。
2. compressString。尝试采用不可逆压缩来减少处理中中间key占用的内存,例如每一个entry的key是几个列的组合,而key仅仅表示唯一性,如果能够做到压缩且不失唯一性,那么最终不会影响需要输出的结果。这里采用短链接的处理方式。(md5+16以上的进制模式)
TimeOutQueue:
最前面提到过,基本所有的外部对象状态变更都可以被捕获,然后产生一个事件,而超时事件必须是主动检查才可以判断,因此当对象数据量增加的时候,超时检查的消耗就会变成O(N),一般会推荐使用分区模式(时间轮盘,时间槽)来缩减N增加带来的影响,另一种方式比较适合于超时时间不会变动的情况,就好比将一个对象放入后,它的超时时间从创建初期到销毁都不会再改变,如果是这种情况,那么可以采用这个类的实现方式。
内置一个有顺序的单向链或者队列,按照超时时间的前后建立先后顺序,最早超时的对象放在最前面,内部线程每次从队列或者链的第一位开始检查,如果发现超时,则处理,继续往后走,当发现没有超时的时候,获得该对象距离超时时间的间隔,然后挂起这间隔的时间。期间有任何数据加入,如果超时时间小于队列第一个对象超时时间,则加入队列,然后唤醒检查线程(切记顺序不要反,先加入队列,再唤醒)。最后在增加一个防止队列为空的消费者生产者的标识,保证不要空循环。