基于MapReduce的配置型日志分析组件
Author:放翁(文初)
Email:fangweng@taobao.com
Blog: http://blog.csdn.net/cenwenchu79/
目录
需求场景
组件功能设计关键点
设计点分析
分析模型抽象
分析实体抽象:
分析流程抽象:
关键路径任务分割
分析过程生命周期定义:
基于命令行方式执行阶段性任务
单任务并行处理化
低耦合多机协作
需求场景
从海量的访问日志中分析得到系统健康情况,业务增长趋势。
组件功能设计关键点
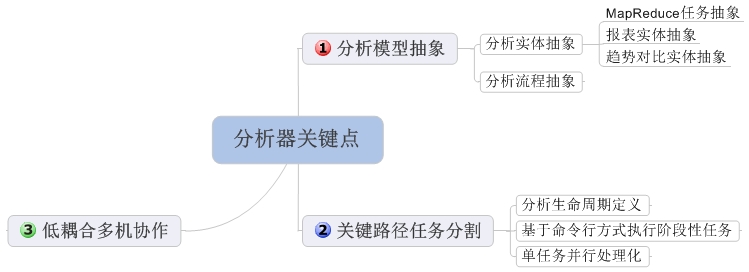
图1 组件功能设计点描述图
这个组件与传统的MapReduce框架(例如Hadoop)的不同之处在于:
1. 解决问题域侧重于日志分析统计及趋势对比。通过抽象分析对象,分析流程,分析结果定制了配置模型和规则解析处理引擎,实现配置替代编码实现自定义分析。
2. 对于多机协作采用松散方式,简化多机协作控制流程。
设计点分析
分析模型抽象
分析模型抽象主要分为两部分:分析模型抽象和分析流程抽象。分析模型抽象就是将MapReduce的Key-Value统计,转化成为传统意义上的报表结构。
分析的输入:
c1,c2,c3,c4,c5,c6…(通常情况下就是用一定的分割符与内容组合起来的字符串)
MapReduce可以处理的:

如下图,传统报表的一行可以看作是多个相同key但不同统计字段组合的结果。
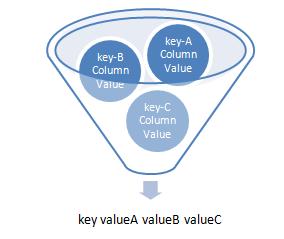
例如:输入的数据结构如下:
服务名称,服务类型,服务上行数据流量,服务处理结果(错误码),服务耗时
那么定制如下MapReduce组合:
Key:服务名称,Value:服务上行数据流量总和。
Key:服务名称,Value:服务耗时总和。
Key:服务名称,Value:服务平均耗时。
Key:服务名称,Value:服务最大耗时。
Key:服务名称,Value:服务最小耗时。
那么将这些MapReduce处理后的Key-value在组合一次就可以得到:
Key:服务名称,Value:服务上行数据流量总和,服务耗时总和,服务平均耗时,服务最大耗时,服务最小耗时。
可以看出,现在就已经成为了我们传统意义上的报表结构。
分析实体抽象:

图2 实体抽象类图
Alias对象
对Key和Value生成时需要指定是对那一列或者几列作分析,因此需要直接指定列号,但是当日志数据结构改变以后,那么就会影响所有的配置,为了便于使用和维护,设定了Alias来规避直接使用列号,具体的使用可以参看最后的配置说明。
ReportEntry对象
MapReduce的Key-Value处理列和规则的定义。
keys表示生成key的列(可以直接使用行号或者使用Alias),Map就是通过对keys的定义将key的列用特定的分割符串联起来形成新的key串,然后根据后面valueExpression的表达式获得value(表达式支持通过对列的简单(+-*/)的计算,也支持对于其他Reportentry的计算获得value)。
valueExpression是Recude的简单定义。当前抽象ReportEntryValueType定义的那些类型:min(取最小),max(取最大),sum(总和),average(平均),count(总次数),plain(无需处理,这主要用于显示key那些列)。具体使用参看后面的配置说明。
conditions可以过滤不符合规则的输入。(支持简单的条件表达式组合)
valueFilter可以过滤计算后不符合定义的结果。(支持简单的条件表达式组合)
MapClass,MapParams,ReduceClass,ReduceParams是用于如果满足不了现有规则的情况下自定义Map,Reduce,需要实现对应的接口IReportMap或者IReportReduce。
Format可以对最后的结果在输出的时候格式化一下,当前只支持小数点round。
Report对象
包含了一个和多个ReportEntry对象,同时也支持在Report中定义ReportEntry对象(区别在于是否需要将这个ReportEntry共享给其他Report)。file指定了将会输出的文件名称。
Report Alert对象
报表的结果是一天的数据,只能做一些纵向比较,如果需要对多天的数据作横向比较以及趋势分析,就需要将多天的报表结合起来分析。具体配置也参见后面的数据定义。
分析流程抽象:
分析流程如下:

图3 分析流程抽象
流程中可以扩展的在第三步和第四步,第三步影响了Key的生成(当简单的列组合成字符串无法满足生成key的情况下可扩展),第四步影响value的生成。(当map的value生成以及Reduce无法满足需求的情况下可扩展),要使用min,max…以外的reduce,可以直接在ReduceClass中作处理,然后使用plain输出实现。
这种流程比传统的MapReduce的写法好处在于可以对输入只读取一次(海量的日志文件为了多种条件分析,反复读取本身就是最大的损耗)。可以看到在文件IO操作上,不会随着分析模型配置的增多而增长,中间数据也不会随着报表组合的不同而过快膨胀(只要报表复用Entry足够多)。
关键路径任务分割
分析过程生命周期定义:
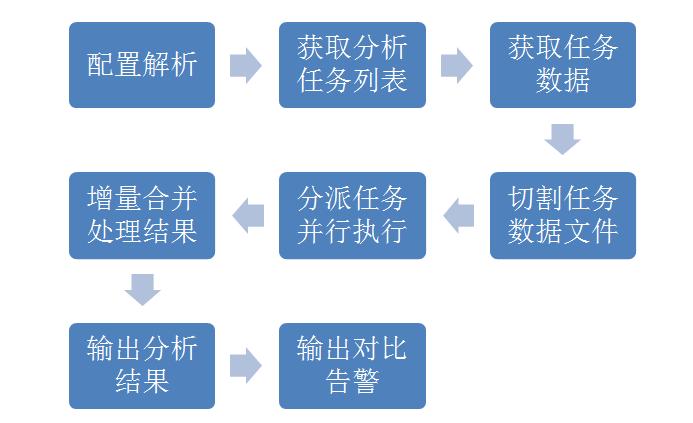
图4 分析过程生命周期定义
各阶段设计描述:(这些阶段都是接口的方法定义)
配置解析:运行期载入,支持在线配置更新,提高系统灵活性。(本地或者URL资源)
获取分析列表:获取要分析的文件列表,并根据本地已有数据现状,选择性的生成需要获取的文件数据。
获取任务数据:从外部文件系统或者数据库获得数据。
切割任务数据文件:根据配置的文件块大小,将任务文件切割到合适的块。当前实现了实际切割和虚拟切割。TIPS:切割工作可以是并行多线程实现,实际切割是消耗CPU和内存的,特别是使用管道的方式,因此需要评估资源情况来开线程。虚拟切割,只是建立虚拟文件,定义好对应到实体文件的块起始。前者切割时候消耗较大,执行分析时分析线程干扰较小效率高,后者切割时无太大消耗,执行分析时会有干扰效率不是很高。(这个原因还没有细查,测试效果是这样)
分派任务并执行:单机多线程或者多机并行执行分析流程。由于单机会受到CPU和IO的限制,当到达一定数量线程以后,分析效率反而降低,因此才会有分布式的需求。
增量合并处理结果:分派好任务以后,多线程或者多机并性分析时,可以根据执行的情况部分增量式合并处理结果,当所有任务完成以后,结果合并结束。
输出分析结果:可以根据需求来创建报表格式。当前采用了csv的文件格式来创建报表,易于阅读和使用。同时也作了入库处理,也可以直接用Google Chart API创建图形化的Html。
输出对比告警:支持当日阀值预警,当日与昨日,当日与上周同期,当日与上月同期数据横向对比,到达阀值生成预警页面。
基于命令行方式执行阶段性任务
由于整个分析流程已经是任务化了,因此应用只需要具备命令接收功能就可以从任何一步开始执行分析流程,也可以选择执行到任何步骤直接返回或者输出中间结果。
当前应用启动通过监听端口数据包,接收命令并执行。
单任务并行处理化
希望通过并行化处理来提高效率,就必须要分析场景。
以下情况不适于用并行化执行来提高效率:
1. 串行化任务。(上一个任务的输出成为下一个任务的输入,或者是有任务顺序的限制)
2. 执行任务时有共享资源竞争。例如CPU,IO,网络等等,不是并行数越大越好,关键还是要看资源分配状况以及竞争状况。
3. 并行化开销大于带来的收益。应用复杂度(并发控制),并行本身需要的资源消耗(计算能力,空间存储,带宽消耗等)较大。(在MapReduce中涉及到一点就是计算代价总是小于数据传输,因此让数据靠近计算,也就能极大提高效率,反过来看,如果为了分布式而将数据远离于计算,就得不偿失了)
4. 流程瓶颈不在于当前并行处理的任务。也就是关键路径的问题。
在分析流程上,对于文件获取,文件切割,任务分析都是可以做并行化处理,但是还是要根据以上不适合的情况来考虑并行的规模和单机多线程或者多机多线程的方式来做,提升效率。
低耦合多机协作

图5 两种Master-Slave模式
上图画了两种Master-Slave模式,看起来没什么区别,但是箭头的方向不同带来的协作模式也有很大的区别。Hadoop Master负责维护任务的分派,任务执行监控,任务合并指派和监控的工作,而松散的M-S模式,Master处于被动状态,Master的设计更加简单化同时也增加了处理的灵活度。
用一种形象的描述来说明松散方式下的Master-Slave的协作模式。(就拿年底买火车票来说事)
1. Master要买去成都,武汉,长沙,北京,西安,广州的火车票各10张。(get Jobs)
2. SlaveA联系上Master要求领取任务,Master将买成都的火车票任务交给SlaveA,将任务标示为正在执行。(require job)
3. SlaveA自己托关系去开始买票。(do job)
4. SlaveB联系上Master要求领取任务,Master将买武汉的火车票任务交给SlaveB,将任务标示为正在执行。
5. SlaveB自己托关系开始买票。
6. ……
7. Master发现SlaveA在预期时间内还没有返回,将任务重置为未分配,允许其他Slave来获取任务。
8. SlaveB将买到的票给Master,Master将任务标示为完成,并且与其它已经完成的任务统计合并。
9. SlaveA返回,但是发现任务已经被别人完成,则无功而回。(计算资源被浪费)
10. Master发现所有任务已经完成,则向上级汇报,本次任务已经全部完成,输出结果。
其实从上面的描述可以看到Master设计十分简单,Slave功能也十分单一,带来的优势就是处理简单,易与管理,同时任何时候都允许新的Slave加入,充分利用资源。缺点就是可能在某些Slave不正常的时候不知情(浪费了部分时间),不过由于Master会有预期结果返回时间,因此这个时间设置小一些会减少浪费时间的场景,但也可能带来重复劳动的代价,这里可以通过算法来最大程度降低异常节点时间消耗,增加Slave有效工作。
Master职责:获取任务列表,分派任务,维护任务列表,合并分析结果,出最终结果报表。
Slave职责:请求任务,执行任务,返回分析结果。
下面两个图描述了具体的多机协作流程和任务状态转换情况。

图6 多机协作基本流程图

图7 任务状态转换图
附录
项目结构说明:

图8 项目包图
com.taobao.top.analysis:单机版和多机版的运行实例类在此包内。
com.taobao.top.analysis.data:抽象配置对象定义。
com.taobao.top.analysis.jobmanager:流程抽象接口和实现。
com.taobao.top.analysis.transport:NIO的底层通信实现。
com.taobao.top.analysis.map:Map接口定义和范例实现。
com.taobao.top.analysis.reduce:Reduce接口定义和范例实现。
com.taobao.top.analysis.util:工具类包。
com.taobao.top.analysis.worker:并行处理的工作者线程实现。
具体配置及说明:
top-report.xml
<?xml version="1.0" encoding="UTF-8"?>
<top_reports>
<!-- 全局条件自动会应用到所有的entity中,
具体condition的定义和使用方式参看后面entity中condition的定义 -->
<global-condition value="$logflag$!=session"/>
<global-condition value="$RECORD_LENGTH$>16&$RECORD_LENGTH$<26"/>
<!-- 全局条件自动会应用到所有的entity中,
具体valuefilter的定义和使用方式参看后面entity中valuefilter的定义
<global-valuefilter value=""/>
-->
<!-- 别名,用于定义分析文件中的列,
防止因为列的移位导致整个报表都需要修改,多个别名可以对应一个列,key代表列数值 -->
<aliases>
<alias name="logflag" key="1"/>
<alias name="remoteIp" key="1"/>
<alias name="partnerId" key="2"/>
<alias name="format" key="3"/>
<alias name="appKey" key="4"/>
<alias name="apiName" key="5"/>
<alias name="readBytes" key="6"/>
<alias name="errorCode" key="7"/>
<alias name="subErrorCode" key="8"/>
<alias name="localIp" key="9"/>
<alias name="nick" key="10"/>
<alias name="version" key="11"/>
<alias name="signMethod" key="12"/>
<alias name="timestamp1" key="13"/>
<alias name="timestamp2" key="14"/>
<alias name="timestamp3" key="15"/>
<alias name="timestamp4" key="16"/>
<alias name="timestamp5" key="17"/>
<alias name="timestamp6" key="18"/>
<alias name="timestamp7" key="19"/>
<alias name="timestamp8" key="20"/>
<alias name="timestamp9" key="21"/>
<alias name="timestamp10" key="22"/>
<alias name="timestamp11" key="23"/>
<alias name="timestamp12" key="24"/>
<alias name="timestamp13" key="25"/>
</aliases>
<!-- 统计列的定义:
id是唯一索引,
name表示在报表中显示的名称,
key可以是alias也可以直接定义列号(不推荐)主要表示对那一列或者几列作为主键进行统计例如key=apiname表示对apiName作分类统计,
相同的apiname的纪录作为一组作后面value的运算,key有保留字GLOBAL_KEY代表对所有记录作总计统计
value表示计算方式当前支持:min,max,average,count,sum,plain。分别代表统计最小值,最大值,平均值,计数,总和。plain表示直接显示,一般用于主键列的显示
同时min,max,average,sum,plain支持表达式,用$$围起来的代表列,entry()表示对统计后的entry作再次计算得到新的entry的结果。
condition表示key的过滤条件,支持对列的过滤条件,支持大于,小于,不等于,大于等于,小于等于的表达式(大于小于需要转义),
同时可以多个条件串联用&串联。注意,表达式中不支持有空格。
valuefilter表示value的过滤条件,支持计算出来的结果过滤,有大于,小于,不等于,大于等于,小于等于,是否是数字(isnumber),大于小于需要转义,
同时可以多个条件串联用&串联。注意,表达式中不支持有空格。
支持自定义map和reduce函数:范例如下:
mapClass="com.taobao.top.analysis.map.TimeMap" mapParams="xxx=xxx"
reduceClass="com.taobao.top.analysis.reduce.TimeReduce" reduceParams="xxx=xxx"
-->
<entrys>
<ReportEntry id="1" name="服务请求总次数" key="apiName" value="count()"/>
<ReportEntry id="2" name="访问成功次数" key="apiName" value="count()" condition="$errorCode$=0" />
<ReportEntry id="3" name="访问失败次数" key="apiName" value="count()" condition="$errorCode$!=0" />
<ReportEntry id="4" name="业务平均处理时间" key="apiName" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="5" name="TOP平均处理时间" key="apiName" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="6" name="业务处理最小时间" key="apiName" value="min($timestamp4$ - $timestamp3$)" valuefilter=">=0&isnumber"/>
<ReportEntry id="7" name="业务处理最大时间" key="apiName" value="max($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber"/>
<ReportEntry id="8" name="TIP服务调用前处理时间" key="apiName" value="average($timestamp3$ - $timestamp1$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="9" name="TIP服务调用后处理时间" key="apiName" value="average($timestamp5$ - $timestamp4$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="10" name="日志及输出消耗时间" key="apiName" value="average($timestamp6$ - $timestamp5$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="api_AverageSuccessTIPTimeConsume" name="成功请求TOP处理平均时间" key="apiName" condition="$errorCode$=0"
value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&isnumber&round:3"/>
<ReportEntry id="api_AverageFailTIPTimeConsume" name="失败请求TOP处理平均时间" key="apiName" condition="$errorCode$!=0"
value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&isnumber&round:3"/>
<ReportEntry id="11" name="访问总数" key="GLOBAL_KEY" value="count()" />
<ReportEntry id="12" name="成功总数" key="GLOBAL_KEY" value="count()" condition="$errorCode$=0" />
<ReportEntry id="13" name="失败总数" key="GLOBAL_KEY" value="count()" condition="$errorCode$!=0" />
<ReportEntry id="14" name="业务平均消耗时间(ms)" key="GLOBAL_KEY" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="15" name="TOP平均消耗时间(ms)" key="GLOBAL_KEY" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="16" name="错误次数" key="errorCode" value="count()" condition="$errorCode$!=0" />
<ReportEntry id="17" name="单机访问总量" key="localIp" value="count()" />
<ReportEntry id="18" name="单机访问成功量" key="localIp" value="count()" condition="$errorCode$=0" />
<ReportEntry id="19" name="单机访问失败量" key="localIp" value="count()" condition="$errorCode$!=0" />
<ReportEntry id="20" name="单机业务平均消耗时间(ms)" key="localIp" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="21" name="单机TOP平均消耗时间(ms)" key="localIp" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="22" name="应用访问总量" key="appKey" value="count()" />
<ReportEntry id="23" name="应用成功访问总量" key="appKey" value="count()" condition="$errorCode$=0" />
<ReportEntry id="24" name="应用失败访问总量" key="appKey" value="count()" condition="$errorCode$!=0"/>
<ReportEntry id="25" name="应用访问业务平均耗时(ms)" key="appKey" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="26" name="应用访问TOP平均耗时(ms)" key="appKey" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
<ReportEntry id="27" name="时间段内访问总量" key="timestamp1" value="count()"
mapClass="com.taobao.top.analysis.map.TimeMap"/>
<ReportEntry id="28" name="时间段内访问成功总量" key="timestamp1" value="count()" condition="$errorCode$=0"
mapClass="com.taobao.top.analysis.map.TimeMap"/>
<ReportEntry id="29" name="时间段内访问失败总量" key="timestamp1" value="count()" condition="$errorCode$!=0"
mapClass="com.taobao.top.analysis.map.TimeMap" valuefilter=">=0&isnumber&round:3"/>
<ReportEntry id="30" name="时间段内访问业务平均耗时(ms)" key="timestamp1" value="average($timestamp4$ - $timestamp3$)"
mapClass="com.taobao.top.analysis.map.TimeMap" valuefilter=">=0&isnumber&round:3"/>
<ReportEntry id="31" name="时间段内访问TOP平均耗时(ms)" key="timestamp1" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)"
mapClass="com.taobao.top.analysis.map.TimeMap" valuefilter=">=0&isnumber&round:3"/>
<ReportEntry id="api_sysFailCount" name="TOP平台级错误量" key="apiName" value="count()"
condition="$errorCode$<100&$errorCode$>0" />
<ReportEntry id="api_serviceSysFailCount" name="服务系统级错误量(900到901)" key="apiName" value="count()"
condition="$errorCode$<902&$errorCode$>899" />
<ReportEntry id="api_serviceSysFailCount1" name="服务系统级错误量(大于901)" key="apiName" value="count()"
condition="$errorCode$>901"/>
<ReportEntry id="api_serviceAPIFailCount" name="服务业务级错误量" key="apiName" value="count()"
condition="$errorCode$>100&$errorCode$<900"/>
<ReportEntry id="api_serviceSysFailTotalCount" name="服务系统级总错误量" key="apiName" value="count()"
condition="$errorCode$>899" />
</entrys>
<!--
报表定义:
id为报表主键,除了数字也可以用英文字符串
file为报表保存的名称,不建议使用中文
entryList描述了报表包含的所有的entry,可以引用上面定义的全局性的entry,也可以内部定义私有的entry。
-->
<reports>
<report id="0" file="totalTIPConsumeReport">
<entryList>
<entry name="TOP获取参数耗时" key="GLOBAL_KEY" value="average($timestamp7$)" condition="$errorCode$=0"/>
<entry name="TOP获取参数最小耗时" key="GLOBAL_KEY" value="min($timestamp7$)" condition="$errorCode$=0"/>
<entry name="TOP获取参数最大耗时" key="GLOBAL_KEY" value="max($timestamp7$)" condition="$errorCode$=0"/>
<entry name="获取API信息耗时" key="GLOBAL_KEY" value="average($timestamp8$)" condition="$errorCode$=0"/>
<entry name="获取API信息最小耗时" key="GLOBAL_KEY" value="min($timestamp8$)" condition="$errorCode$=0"/>
<entry name="获取API信息最大耗时" key="GLOBAL_KEY" value="max($timestamp8$)" condition="$errorCode$=0"/>
<entry name="处理协议必选参数耗时" key="GLOBAL_KEY" value="average($timestamp9$)" condition="$errorCode$=0"/>
<entry name="处理协议必选参数最小耗时" key="GLOBAL_KEY" value="min($timestamp9$)" condition="$errorCode$=0"/>
<entry name="处理协议必选参数最大耗时" key="GLOBAL_KEY" value="max($timestamp9$)" condition="$errorCode$=0"/>
<entry name="频率黑名单校验耗时" key="GLOBAL_KEY" value="average($timestamp10$)" condition="$errorCode$=0"/>
<entry name="频率黑名单校验最小耗时" key="GLOBAL_KEY" value="min($timestamp10$)" condition="$errorCode$=0"/>
<entry name="频率黑名单校验最大耗时" key="GLOBAL_KEY" value="max($timestamp10$)" condition="$errorCode$=0"/>
<entry name="协议可选参数校验耗时" key="GLOBAL_KEY" value="average($timestamp11$)" condition="$errorCode$=0"/>
<entry name="协议可选参数校验最小耗时" key="GLOBAL_KEY" value="min($timestamp11$)" condition="$errorCode$=0"/>
<entry name="协议可选参数校验最大耗时" key="GLOBAL_KEY" value="max($timestamp11$)" condition="$errorCode$=0"/>
<entry name="业务必选参数校验耗时" key="GLOBAL_KEY" value="average($timestamp12$)" condition="$errorCode$=0"/>
<entry name="业务必选参数校验最小耗时" key="GLOBAL_KEY" value="min($timestamp12$)" condition="$errorCode$=0"/>
<entry name="业务必选参数校验最大耗时" key="GLOBAL_KEY" value="max($timestamp12$)" condition="$errorCode$=0"/>
<entry name="业务可选参数校验耗时" key="GLOBAL_KEY" value="average($timestamp13$)" condition="$errorCode$=0"/>
<entry name="业务可选参数校验最小耗时" key="GLOBAL_KEY" value="min($timestamp13$)" condition="$errorCode$=0"/>
<entry name="业务可选参数校验最大耗时" key="GLOBAL_KEY" value="max($timestamp13$)" condition="$errorCode$=0"/>
</entryList>
</report>
<report id="1" file="totalReport">
<entryList>
<entry id="11"/>
<entry name="访问总流量(M)" key="GLOBAL_KEY" value="sum($readBytes$/#1000000#)" valuefilter=">=0&isnumber&round:4"/>
<entry id="12"/>
<entry name="访问成功率" key="GLOBAL_KEY" value="plain(entry(12)/entry(11))" valuefilter=">=0&isnumber&round:4"/>
<entry id="13"/>
<entry name="平台系统错误率(占总错误百分比)" key="GLOBAL_KEY" value="plain(entry(sysFailCount)/entry(13))" valuefilter=">=0&isnumber&round:4"/>
<entry name="服务系统错误率(占总错误百分比)" key="GLOBAL_KEY" value="plain(entry(serviceSysFailCount)/entry(13))" valuefilter=">=0&isnumber&round:4"/>
<entry name="服务业务错误率(占总错误百分比)" key="GLOBAL_KEY" value="plain(entry(serviceAPIFailCount)/entry(13))" valuefilter=">=0&isnumber&round:4"/>
<entry id="14"/>
<entry id="15"/>
<entry name="TOP成功处理平均耗时" key="GLOBAL_KEY"
value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" condition="$errorCode$=0" valuefilter=">=0&isnumber&round:3"/>
<entry id="sysFailCount" name="平台系统错误数" key="GLOBAL_KEY" value="count()" condition="$errorCode$<100&$errorCode$>0"/>
<entry id="serviceSysFailCount" name="服务系统错误数" key="GLOBAL_KEY" value="count()" condition="$errorCode$>899"/>
<entry id="serviceAPIFailCount" name="服务业务错误数" key="GLOBAL_KEY" value="count()" condition="$errorCode$>100&$errorCode$<900"/>
</entryList>
</report>
<report id="2" file="apiReport">
<entryList>
<entry name="服务名称" key="apiName" value="plain($apiName$)" />
<entry id="1"/>
<entry name="占总量比例" key="apiName" value="plain(entry(1)/entry(sum:1))" valuefilter=">=0&isnumber&round:3"/>
<entry id="2"/>
<entry name="服务请求成功率" key="apiName" value="plain(entry(2)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
<entry id="3"/>
<entry id="4"/>
<entry id="5"/>
<entry name="TOP占总处理时间百分比" key="apiName" value="plain(entry(5)/entry(5+4))" valuefilter=">=0&isnumber&round:3"/>
<entry id="api_AverageSuccessTIPTimeConsume"/>
<entry id="api_AverageFailTIPTimeConsume"/>
<entry id="6"/>
<entry id="7"/>
<entry id="8"/>
<entry id="9"/>
<entry id="10"/>
<entry id="api_sysFailCount"/>
<entry id="api_serviceSysFailTotalCount"/>
<entry id="api_serviceAPIFailCount"/>
</entryList>
</report>
<report id="3" file="errorCodeReport">
<entryList>
<entry id="33" name="错误码" key="errorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
<entry id="16"/>
<entry name="错误比例" key="errorCode" value="plain(entry(16)/entry(sum:16))" condition="$errorCode$!=0" valuefilter=">=0&isnumber&round:3"/>
</entryList>
</report>
<report id="4" file="machineReport">
<entryList>
<entry name="服务器IP" key="localIp" value="plain($localIp$)" />
<entry id="17"/>
<entry name="占总量比例" key="localIp" value="plain(entry(17)/entry(sum:17))" valuefilter=">=0&isnumber&round:3"/>
<entry id="18"/>
<entry name="成功率" key="localIp" value="plain(entry(18)/entry(17))" valuefilter=">=0&isnumber&round:3"/>
<entry id="19"/>
<entry id="20"/>
<entry id="21"/>
<entry name="TOP占总处理时间比值" key="localIp" value="plain(entry(21)/entry(20+21))" valuefilter=">=0&isnumber&round:3"/>
</entryList>
</report>
<report id="5" file="appReport">
<entryList>
<entry name="应用ID" key="appKey" value="plain($appKey$)" />
<entry id="22"/>
<entry name="占总访问比例" key="appKey" value="plain(entry(22)/entry(sum:22))" valuefilter=">=0&isnumber&round:3"/>
<entry id="23"/>
<entry name="应用访问成功率" key="appKey" value="plain(entry(23)/entry(22))" valuefilter=">=0&isnumber&round:3"/>
<entry id="24"/>
<entry id="25"/>
<entry id="26"/>
</entryList>
</report>
<report id="6" file="periodReport">
<entryList>
<entry name="时间段" key="timestamp1" value="plain($timestamp1$)"
mapClass="com.taobao.top.analysis.map.TimeMap"
reduceClass="com.taobao.top.analysis.reduce.TimeReduce"/>
<entry id="27"/>
<entry name="占请求总量比例" key="timestamp1" value="plain(entry(27)/entry(sum:27))" valuefilter=">=0&isnumber&round:3"/>
<entry id="28"/>
<entry name="请求成功率" key="timestamp1" value="plain(entry(28)/entry(27))" valuefilter=">=0&isnumber&round:3"/>
<entry id="29"/>
<entry id="30"/>
<entry id="31"/>
</entryList>
</report>
<report id="7" file="appAPIReport">
<entryList>
<entry name="应用ID" key="appKey,apiName" value="plain($appKey$)" condition="$errorCode$=0"/>
<entry name="服务名称" key="appKey,apiName" value="plain($apiName$)" condition="$errorCode$=0"/>
<entry id="app_api_successCount" name="访问成功总量" key="appKey,apiName" value="count()" condition="$errorCode$=0"/>
</entryList>
</report>
<report id="8" file="errorCodeAndSubErrorCodeReport">
<entryList>
<entry name="错误码" key="errorCode,subErrorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
<entry name="子错误码" key="errorCode,subErrorCode" value="plain($subErrorCode$)" condition="$errorCode$!=0"/>
<entry name="错误总数" key="errorCode,subErrorCode" value="count()" condition="$errorCode$!=0"/>
</entryList>
</report>
<report id="9" file="apiFailDetailReport">
<entryList>
<entry name="服务名称" key="apiName" value="plain($apiName$)" />
<entry id="1"/>
<entry id="3"/>
<entry name="失败数占服务请求量比例" key="apiName" value="plain(entry(3)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
<entry name="失败数占失败总量比例" key="apiName" value="plain(entry(3)/entry(sum:3))" valuefilter=">=0&isnumber&round:3"/>
<entry id="api_sysFailCount"/>
<entry name="平台级错误占总服务请求比例" key="apiName" value="plain(entry(api_sysFailCount)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
<entry id="api_serviceSysFailCount"/>
<entry name="服务系统级错误量(900到901)占总服务请求比例" key="apiName" value="plain(entry(api_serviceSysFailCount)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
<entry id="api_serviceSysFailCount1"/>
<entry name="服务系统级错误量(大于901)占总服务请求比例" key="apiName" value="plain(entry(api_serviceSysFailCount1)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
<entry id="api_serviceAPIFailCount"/>
<entry name="服务业务级错误占总服务请求比例" key="apiName" value="plain(entry(api_serviceAPIFailCount)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
</entryList>
</report>
<report id="10" file="appApiErrorReport">
<entryList>
<entry name="应用ID" key="appKey,apiName,errorCode" value="plain($appKey$)" condition="$errorCode$!=0"/>
<entry name="服务名称" key="appKey,apiName,errorCode" value="plain($apiName$)" condition="$errorCode$!=0"/>
<entry name="错误码" key="appKey,apiName,errorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
<entry name="错误次数" key="appKey,apiName,errorCode" value="count()" condition="$errorCode$!=0"/>
</entryList>
</report>
<report id="11" file="verionAndSignTypeReport">
<entryList>
<entry name="版本号" key="version,signMethod" value="plain($version$)" condition="$errorCode$=0"/>
<entry name="签名类型" key="version,signMethod" value="plain($signMethod$)" condition="$errorCode$=0"/>
<entry name="访问成功总数" key="version,signMethod" value="count()" condition="$errorCode$=0"/>
</entryList>
</report>
<report id="12" file="appErrorCodeReport">
<entryList>
<entry name="应用ID" key="appKey,errorCode" value="plain($appKey$)" condition="$errorCode$!=0"/>
<entry name="错误码" key="appKey,errorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
<entry name="错误总数" key="appKey,errorCode" value="count()" condition="$errorCode$!=0"/>
</entryList>
</report>
</reports>
<alerts>
<!-- 对比告警 alerttype:now,day,week,month。
valve代表阀值:<(now类型代表小于告警,如果是同期比较代表下降超过),
>(now类型代表大于告警,如果是同期比较代表上升),没有符号代表绝对值超过告警-->
<alert reportId="1" entryname="访问成功率" alerttype="now" valve="<0.9" />
<alert reportId="1" entryname="访问总数" alerttype="day" valve="5000000" />
<alert reportId="1" entryname="访问成功率" alerttype="day" valve="<0.01" />
<alert reportId="1" entryname="平台系统错误率" alerttype="day" valve=">0.05" />
<alert reportId="1" entryname="服务系统错误率" alerttype="day" valve=">0.05" />
<alert reportId="1" entryname="服务业务错误率" alerttype="day" valve=">0.05" />
<alert reportId="1" entryname="TOP平均消耗时间(ms)" alerttype="day" valve=">10" />
<alert reportId="1" entryname="业务平均消耗时间(ms)" alerttype="day" valve=">10" />
<alert reportId="2" keyentry="服务名称" entryname="占总量比例" alerttype="day" valve=">0.01" />
<alert reportId="2" keyentry="服务名称" entryname="服务请求成功率" alerttype="day" valve="<0.01" />
<alert reportId="2" keyentry="服务名称" entryname="业务平均处理时间" alerttype="day" valve=">20" />
<alert reportId="2" keyentry="服务名称" entryname="TOP平均处理时间" alerttype="day" valve=">20" />
<alert reportId="3" keyentry="错误码" entryname="错误比例" alerttype="day" valve=">0.01" />
<alert reportId="4" keyentry="服务器IP" entryname="成功率" alerttype="day" valve="<0.01" />
<alert reportId="5" keyentry="应用ID" entryname="占总访问比例" alerttype="day" valve="0.01" />
<alert reportId="5" keyentry="应用ID" entryname="应用访问成功率" alerttype="day" valve="<0.05" />
<alert reportId="7" keyentry="应用ID,服务名称" entryname="访问成功总量" alerttype="day" valve=">10000000" />
<alert reportId="9" keyentry="服务名称" entryname="失败数占总量比例" alerttype="day" valve=">0.01" />
<alert reportId="10" keyentry="应用ID,服务名称,错误码" entryname="错误次数" alerttype="day" valve=">10000" />
<alert reportId="11" keyentry="版本号,签名类型" entryname="访问成功总数" alerttype="day" valve="<1000000" />
<alert reportId="12" keyentry="应用ID,错误码" entryname="错误总数" alerttype="day" valve=">100000" />
</alerts>
</top_reports>