在完成ASF集成REST以后,接到的任务就是要完成一个日志分析应用。需求没有很明确,只是要有这么一个东西能够满足分析收集后的日志,将分析后的原始数据入库,作为后期分析和统计使用。
在动手做之前,我还是给这个应用作了最基本的需求定义:灵活配置(输入源,输出目标,分析器的实现等),高效(并行任务分解)。就这两点能够做到,那么将来需求如何变化都可以适应。Tiger的Concurrent包是满足后面那项最好的实现,因此打算好好的实践一把,也就这部分Tiger的特性还没有充分使用过,里面的线程池,异步服务调用,并发控制都能够极好的完成并行任务分解的工作。也就是在这个过程中,看到了IBM开发者论坛上的一片文章,讲关于《应用fork-join框架》,谈到了在J2SE 7 的Concurrent包中将会增加fork-join风格的并行分解库,其实这个是更细粒度的任务分解,同时能够在当前多CPU的情况下提高执行效率,充分利用CPU的一种实现。无关的话不多说了,就写一下整个设计和实现的过程以及中间的一些细节知识。
背景:
由于服务路由应用访问量十分大,即时的将访问记录入库对于路由应用本身以及数据库来说无疑都会产生很大的压力和影响。因此考虑首先将访问信息通过log4j记录在本地(当然自己需要定制一下Log4j的Appender和Filter),然后通过服务器的定时任务脚本来将日志集中到日志分析应用所在的机器上(这里通过配置可以决定日志是根据什么时间间隔来产生新文件)。日志分析应用就比较单纯的读取日志,分析日志,输出分析结果(包括写入数据库或者是将即时统计信息存入到集中式缓存Memcached中)。网络结构图如下:
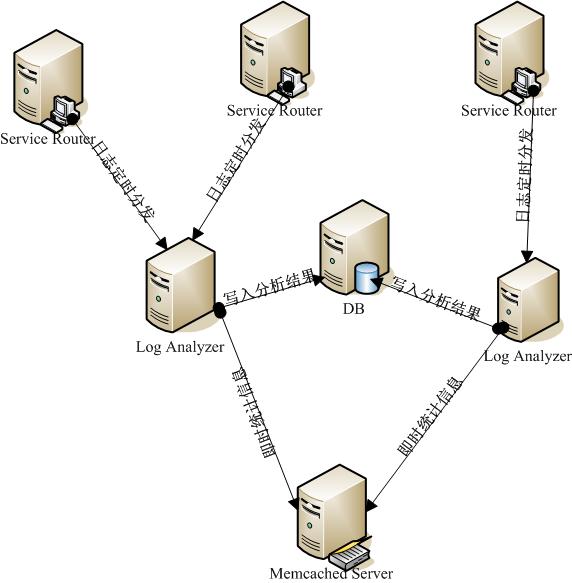
图1 网络结构图
Concurrent概述:
Tiger出来也有些年头了,但是每一个新的特性是否都在实际的工作中使用过,起码我自己是没有作到的,包括对于Concurrent包也只是看过,写了几个Test case玩一下,但具体使用到实际开发中还是比较少的。在这个工作之前,如果考虑要使用对象池或者线程池,那么一定会去采用apache的common pool,不过在现在jdk日益“强大”的基础下,能够通过jdk自己搞定的,就尽量不再引入第三方包了。看Java 的Doc很容易就理解了Concurrent,这里我只是大致的说一下几个自己在应用中使用的接口:
BlockingQueue<E>:看看名字就知道了,阻塞式队列,可以设置大小。适合于生产者和消费者模式,生产者在队列满时阻塞,消费者在队列空时阻塞。在日志分析应用开发中被用于分析任务(生产者)和输出任务(消费者)之间的分析结果存储通道。
Callable<V>:任何需要执行的任务都可以定义成Callable,类似于线程的Runnable接口,可以被Service Executor指派给内部的线程异步执行,并且返回对象或者抛出异常。在日志分析应用开发中,非定时性的任务都定义成为此类型。
ConcurrentMap<K,V>:这个以前常常使用,因为效率要远远高于Collections.synchronizedCollection和synchronized。后面还会提到实践中的几个实用的技巧来防止在高并发的情况下出现问题。在日志分析应用中,此类型的Map作为保存日志文件分析状态的缓存(日志文件分为两种状态:分析中,分析结束。如果不存在于Map中就认为尚未分析,那么将其纳入Map然后启动分析处理线程工作,如果存在于Map中标示为分析中,那么将不会再分析此文件,如果分析结束并且被输出,将会标示此文件分析结束,异步清理线程将会定时根据策略删除或移动文件)。
ExecutorService:内置线程池,异步执行指派任务,并可以根据返回的Future来跟踪执行情况。在日志分析应用开发中,被用于非定时性任务执行。
ScheduledExecutorService:内置线程池,定时异步执行指派任务,并可以根据返回的Future来跟踪执行情况。在日志分析应用开发中,被用于定时性任务执行。
以上就是被使用到的接口,具体实现策略配置就不在此赘述了。
整体结构设计:
整体设计还是基于开始设定的两个原则:灵活配置,高效性(任务分解,并行流水线执行)。说到任务分解又会想起读书时候的离散数学中关键路径等等。任务分解还是要根据具体情况来分析和设计,不然并行不但不会提高效率,反而还降低了处理效率。
就日志分析来看,主要的处理过程可以分成这么几个任务:
1. 检查日志来源目录,锁定需要分析的文件。(执行需要时间很短,可通过定时间隔执行)。
2. 分析已经被锁定的日志文件,产生分析结果。(执行需要时间根据日志文件大小来决定,因此需要线程异步执行,结果根据设定拆分成细粒度包,降低输出线程等待时间)。
3. 检查分析结果队列。(执行需要时间很短,当前是配置了SingleThreadExecutor来执行检查阻塞队列的工作,同时获取到分析结果包以后立刻创建线程来执行输出任务)
4. 输出分析结果,如果输出成功,将分析过的日志文件在日志文件状态缓存中的状态更新为已分析。(执行时间根据输出情况来定,当前实现的是批量输出到数据库中,根据配置来批量提交入库,后续还会考虑实时统计到集中式Cache作为监控使用)。
5. 清理分析日志文件。(执行时间较短,设定了定时线程池执行清理任务,根据策略配置来执行清理和移动文件任务,并且清除在日志文件状态缓存中的信息)
根据上面的分解可以看到,其实在单线程工作的过程中,容易造成阻塞而影响性能的主要是读取,分析和写出这三个过程的协调,一个一个读取分析和写出,性能一定低于读取和分析并行工作,而分析完毕才写出,性能一定低于分析部分,写出部分。
同时由于细分各个任务,因此任务与任务之间的耦合度降低,可以运行期获取具体的任务实现配置,达到灵活配置的目的。
下面就具体的看看整个流程,以及其中的一些细节的说明,这里根据下图中的序号来逐一描述:
1. 配置了Schedule Executor来检查日志所属目录中的日志文件,Executor的线程池大小以及检查时间间隔都根据配置来设定。
Tip:定时任务可以设置delay时间,那么可以根据你的任务数量以及时间间隔来设定每一个任务的delay时间,均匀的将这些任务分布,提高效率。
2. 当Read Schedule被执行时,将会去检查Analysis Log File State Concurrent Cache(也就是上面提到的ConcurrentMap)中是否存在此文件,如果不存在证明尚未分析,需要将其置入Cache,如果已经存在就去查询其他文件。Tip:这里用了一点小技巧,通常我们对于此类操作应该做两部分工作,get然后再put,但是这样可能就会在高并发的情况下出现问题,因为这两个操作不是一个原子操作。ConcurrentMap提供了putIfAbsent操作,这个操作意思就是说如果需要put的key没有存在于Map中,那么将会把key,value存入,并且返回null,如果已经存在了key那么就返回key在map已经对应的值。通过if (resources.putIfAbsent(filename, Constants.FILE_STATUS_ANALYSISING) == null)就可以把两个操作合并成为一个操作。
3. 日志读取的工作线程完成锁定文件以后,就将后续的工作交给Log Analysis Service Executor来创建分析任务异步执行分析操作,日志读取工作线程任务就此完成。
4. Log Analysis Schedule是运行期装载具体的接口实现类(采用的就是类似于JAXP等框架使用的META-INF/services来读取工厂类,载入接口实现)。Analysis Schedule执行的主要任务就是分析文件,并且根据配置将分析结果拆分并串行的置入到Block Queue中,提供给输出线程使用。
5. Receiver主要工作就是守候着Block Queue,当有数据结果产生就创建Write Schedule来异步执行输出。
6. Log Writer Service Executor根据配置来决定内置线程池大小,同时在Receiver获取到数据包时产生Write Schedule来异步执行输出工作。
7. Write Schedule和Analysis Schedule一样可以运行期装载接口实现类,这样提供了灵活的输出策略配置。
Tips:在数据库输出的时候需要配置批量提交记录最大数,分批提交提高性能,也防止过大结果集批量提交问题。
8. 写出完成以后需要更新锁定文件的状态,标示成为已经分析成功。这里还遗留一点问题,在一个日志文件分包的过程中每一个包都回记录隶属于哪一个分析文件,文件的最后一个数据包将会被标示。在输出成功以后会去检查哪些包是文件最后数据包,更新此文件为已分析成功,如果出现异常,那么将会把这些文件状态清除,接受下一次的重新分析。这里一个文件部分包提交暂时没有做到事务一致,如果出现部分成功可能会重复分析和记录。
9. 最后就是Clean Schedule被定时执行,根据策略来删除或者移动已经被分析过的文件。
Tips:
ScheduledExecutorService内部可以配置线程池,当执行定时任务比较耗时,线程池中的线程都被占用的情况下,定时任务将不会准确的按时执行,因此设计过程中需要注意的是,定时任务一般是简短的工作任务,如果比较耗时,那么应该结合ScheduledExecutorService和ExecutorService,定时任务完成必要工作以后将耗时工作转交给ExecutorService创建的即时执行异步线程去处理,保证Schedule Executor正常工作。
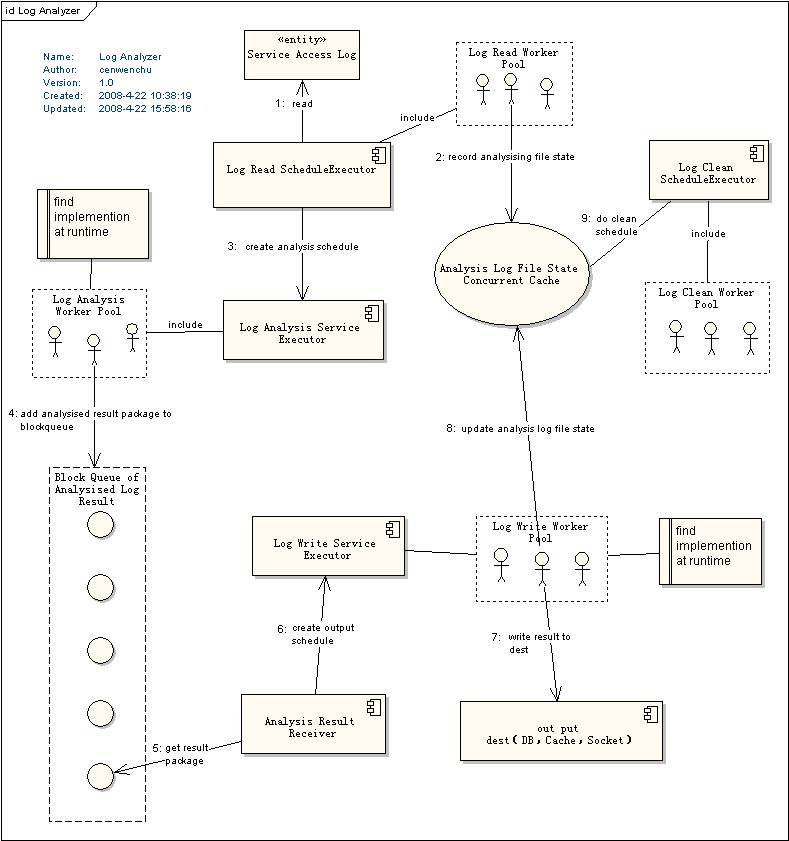
图2 流程结构设计
类图:
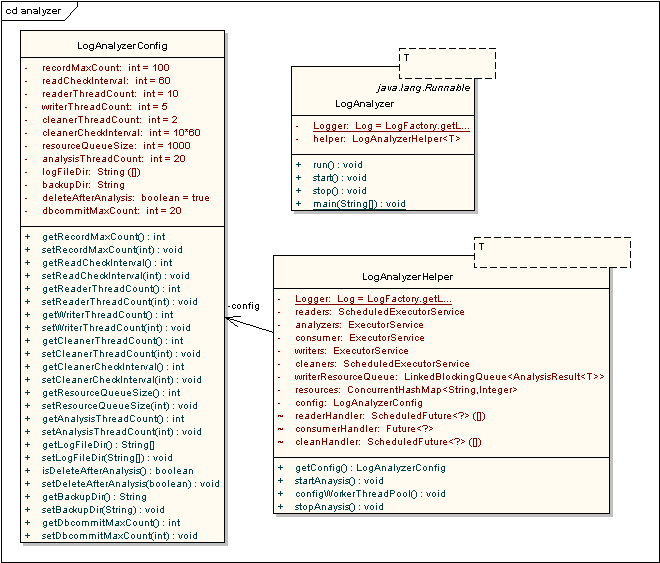
图3 类图1
上面的类图中主要描述的就是日志分析应用的三个主类:类似于控制台的LogAnalyzer,具体内部资源管理类,配置类。(T表示采用泛型)

图 4 类图2
类图2主要就是描述了在整个应用中所有的被分解可并行的任务定义。ClearSchedule是用来在控制台输入stop停止日志分析的时候,做后续资源回收工作的任务。CleanSchedule是用来清除被分析后的日志文件任务。ConsumerSchedule是阻塞队列消费者任务。
其他还有一些辅助工具类以及工厂类和定义类就不画了。
后话:
做这个设计和开发的过程中又好好的实践了一些编程细节方面的内容,作为架构设计来说,需要多一些全局观和业务观,作为一个良好的开发者来说需要多实践,多了解一些细节,在不断学习和掌握各种大方向技术框架的同时,适当的了解一些细节也是一种很好的补充,同时也可以衍生思考。
REST风格的服务结合云计算的思想,会被使用的更为广泛,而云计算其实就是一个问题分解和组合处理的过程,可以说是一种宏观的问题解决策略。高效解决问题,提供服务,通过组合体现业务最大价值,就是互联服务的最重要目的。
更多文章请访问:http://blog.csdn.net/cenwenchu79/