看了网上的许多对于lucene 分词解析的文章一知半解且代码比较老旧,为透彻、系统、全面、深刻的了解分词是怎么一个过程,通过自定义一个分词器来分析理解。 其中分词部分利用ICTCLAS4j接口实现。结构如下所示:
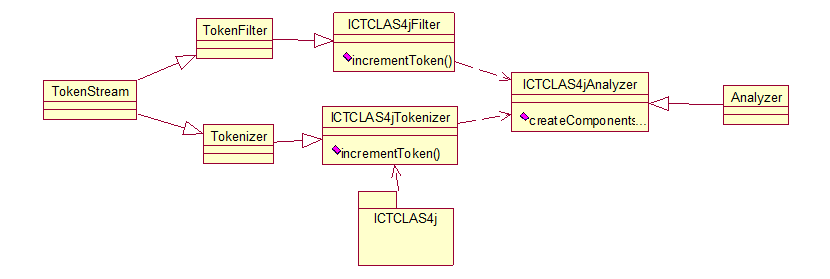
要实现自定义的ICTCLAS4jAnalyzer必须继承Analyzer类,并重写createComponents方法。直接上代码,看到了吧是从StandardAnalyzer 类中直接复制过来的。把实现ICTCLAS4j的ICTCLAS4jTokenizer替换就搞定了。
@Override
protected TokenStreamComponents createComponents(final String fieldName, final Reader reader) {
final ICTCLAS4jTokenizer src = new ICTCLAS4jTokenizer(reader);
//src.setMaxTokenLength(maxTokenLength);
TokenStream tok = new ICTCLAS4jFilter(matchVersion, src);
tok = new LowerCaseFilter(matchVersion, tok);
tok = new StopFilter(matchVersion, tok, STOP_WORDS_SET);
return new TokenStreamComponents(src, tok) {
@Override
protected void setReader(final Reader reader) throws IOException {
//src.setMaxTokenLength(ICTCLAS4jAnalyzer.this.maxTokenLength);
super.setReader(reader);
}
};
}
ICTCLAS4jTokenizer需重新incrementToken方法,并设定CharTermAttribute(存放词条),OffsetAttribute(存放词条的偏移地址),构造函数中写入需分词的字符串,通过ICTCLAS4j返回分词列表在通过incrementToken实现分词。代码如下:
package com.zhy.analysis.ictclas4j;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.Reader;
import java.util.ArrayList;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.ictclas4j.bean.SegResult;
import org.ictclas4j.segment.SegTag;
/**
* @author brockhong
*
*/
public class ICTCLAS4jTokenizer extends Tokenizer {
private static SegTag segment;
private StringBuilder sb = new StringBuilder();
private ArrayList<String> words = new ArrayList<String>();
private int startOffest = 0;
private int length = 0;
private int wordIdx = 0;
public ICTCLAS4jTokenizer(Reader input) {
super(input);
char[] buf = new char[8192];
int d = -1;
try {
while ((d = input.read(buf)) != -1) {
sb.append(buf, 0, d);
}
} catch (IOException e) {
e.printStackTrace();
}
SegResult sr = seg().split(sb.toString());
words = sr.getWords();
}
private static SegTag seg() {
try {
if (segment == null) {
final InputStream coreDictIn = new FileInputStream(
"data/coreDict.dct");
final InputStream bigramDictIn = new FileInputStream(
"data/BigramDict.dct");
final InputStream personTaggerDctIn = new FileInputStream(
"data/nr.dct");
final InputStream personTaggerCtxIn = new FileInputStream(
"data/nr.ctx");
final InputStream transPersonTaggerDctIn = new FileInputStream(
"data/tr.dct");
final InputStream transPersonTaggerCtxIn = new FileInputStream(
"data/tr.ctx");
final InputStream placeTaggerDctIn = new FileInputStream(
"data/ns.dct");
final InputStream placeTaggerCtxIn = new FileInputStream(
"data/ns.ctx");
final InputStream lexTaggerCtxIn = new FileInputStream(
"data/lexical.ctx");
segment = new SegTag(1, coreDictIn, bigramDictIn,
personTaggerDctIn, personTaggerCtxIn,
transPersonTaggerDctIn, transPersonTaggerCtxIn,
placeTaggerDctIn, placeTaggerCtxIn, lexTaggerCtxIn);
}
} catch (Exception e) {
e.printStackTrace();
}
return segment;
}
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
private final OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
@Override
public boolean incrementToken() throws IOException {
while (true) {
length = 0;
if (wordIdx < words.size()) {
String word = words.get(wordIdx);
termAtt.copyBuffer(word.toCharArray(), 0, word.length());
offsetAtt.setOffset(correctOffset(startOffest),
correctOffset(startOffest + length));
wordIdx++;
startOffest += length;
return true;
} else {
return false;
}
}
}
}
ICTCLAS4jFilter 分词过滤器直接使用StandardAnalyzer的过滤器,作为自定义过滤器。
ICTCLAS4j改造过程来自网上,修改SegTag的outputResult让其输出的分词输入到列表中。并修复了ICTCLAS4j 在分词中没有时报错代码。
附上analyzer 测试类如下:
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.util.Version;
import java.io.StringReader;
import com.zhy.analysis.ictclas4j.ICTCLAS4jAnalyzer;
/**
* @author brockhong
*/
public class Ictclas4janalyzer {
public static void main(String[] args) throws Exception {
Analyzer analyzer = new ICTCLAS4jAnalyzer(Version.LUCENE_45);
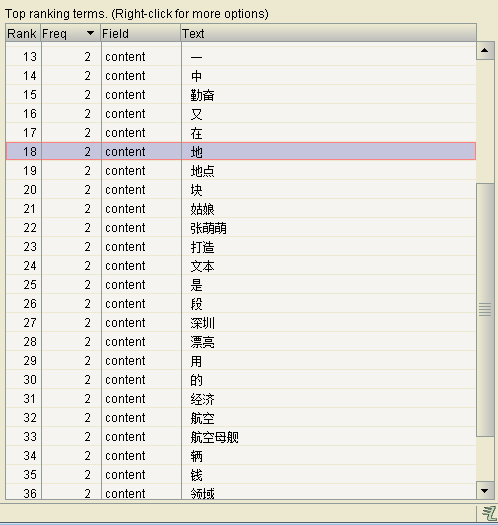
Reader r = new StringReader("张萌萌是勤奋地漂亮的姑娘,/用一块钱打造经济的航空领域中的航空母舰地点在深圳。ABCD.#$% Hello World!\n又一段文本123辆 !3.0");
TokenStream ts=analyzer.tokenStream("fff", r);
CharTermAttribute term=ts.addAttribute(CharTermAttribute.class);
ts.reset();
while(ts.incrementToken()){
System.out.println(term.toString());
}
ts.end();
ts.close();
}
}
Lucene写入测试类:
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import com.zhy.analysis.ictclas4j.ICTCLAS4jAnalyzer;
/** @author brockhong */
public class Testictclas4j {
public static void main(String[] args) throws Exception {
// 设置写入目录(好几种呵呵)
Directory d = FSDirectory.open(new File("D:/luceneTest2"));
// 设置分词 StandardAnalyzer(会把句子中的字单个分词)
Analyzer analyzer = new ICTCLAS4jAnalyzer(Version.LUCENE_45);
// 设置索引写入配置
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_45, analyzer);
IndexWriter indexwriter = new IndexWriter(d, config);
Document doc = new Document();
doc.add(new StringField("id", "1", Store.YES));
doc.add(new StringField("name", "brockhong", Store.YES));
doc.add(new TextField("content",
"张萌萌是勤奋地漂亮的姑娘,/用一块钱打造经济的航空领域中的航空母舰地点在深圳。ABCD.#$% Hello World!\n又一段文本123辆 !3.0",Store.YES));
// 写入数据
indexwriter.addDocument(doc);
// 提交
indexwriter.commit(); }}
下载jar/Files/brock/ictclas4j.7z