
2009年10月25日
通过存储过程向数据库一下子插入了一千万(10000000)条记录,结果等了很长时间,PL/SQL都没有响应,我又瞎折腾了下,结果执行了好几次,导致数据库假死了,我只有删除当前的会话,从网上找到相关的脚本代码。
1> 通过此语句查询正在锁定的SESSION_ID:
1 SELECT SESSION_ID FROM V$LOCKED_OBJECT,USER_OBJECTS WHERE V$LOCKED_OBJECT.OBJECT_ID = USER_OBJECTS.OBJECT_ID
SELECT SESSION_ID FROM V$LOCKED_OBJECT,USER_OBJECTS WHERE V$LOCKED_OBJECT.OBJECT_ID = USER_OBJECTS.OBJECT_ID
2> 通过第一步查询到的SESSION_ID查询SERIAL#
1SELECT SERIAL# FROM V$SESSION WHERE SID='12'(此处'12'为上面查询到的'SESSION_ID')
3> 根据1,2步查询到的SESSION_ID和SERIAL#执行
1ALTER SYSTEM KILL SESSION '12,154'(12为SESSION_ID的值, 154为SERIAL#的值)
4> 如果利用上面的命令杀死一个进程后,进程状态被置为"killed",但是锁定的资源很长时间没有被释放,那么还可以在os一级再杀死相应的进程(线程),首先执行下面的语句获得当前进程(线程)的标示PID:
1select spid, osuser, s.program
2from v$session s,v$process p
3where s.paddr=p.addr and s.sid=12 (12是上面的SESSION_ID)
然后在OS通过任务管理器找到对应的进程,在杀死这个进程(线程)
posted @
2010-11-27 14:55 absolute 阅读(901) |
评论 (0) |
编辑 收藏
最近在学习存储过程,以前在项目中没有怎么接触过!
我通过存储过程像数据库中批量添加一千万(100000000)条记录,结果PL/SQL很长时间没有反映,结果不得已通过脚本杀掉当前进程,我重新通过存储过程插入10000条数据。
建表脚本:
1--删除用户表
2DROP TABLE T_PORTAL_USER;
3
4--创建用户表
5CREATE TABLE T_PORTAL_USER
6(
7 id NUMBER PRIMARY KEY, -- 用户表示
8 username VARCHAR2(24) NOT NULL,-- 用户名
9 password VARCHAR2(24) NOT NULL,-- 密码
10 realname VARCHAR2(24) NOT NULL,-- 真实姓名
11 sex VARCHAR2(2) DEFAULT '0',-- 性别 "0":Male "1":Female
12 registerDate TIMESTAMP NOT NULL,-- 注册日期
13 state VARCHAR2(2) NOT NULL -- 账号状态 "0":启用 "1":注销
14)
15
16--删除用户表序列
17DROP SEQUENCE SEQ_T_PORTAL_USER;
18
19--创建用户表序列
20CREATE SEQUENCE SEQ_T_PORTAL_USER
21START WITH 1
22INCREMENT BY 1
23NOMAXVALUE
24CACHE 20
-- 批量新增一万条用户
1-- 批量新增一万条用户
2CREATE OR REPLACE PROCEDURE PROC_USER_CREATE_BAT
3AS
4 startTime VARCHAR2(32);--开始时间
5 endTime VARCHAR2(32);--结束时间
6BEGIN
7 SELECT TO_CHAR(SYSDATE,'yyyy-mm-dd hh24:mi:ss:ff') INTO startTime FROM DUAL;
8 DBMS_OUTPUT.PUT_LINE('Start Time: '||startTime);
9 FOR i in 1..10000 LOOP
10 INSERT INTO T_PORTAL_USER VALUES(SEQ_T_PORTAL_USER.NEXTVAL,'owen'||i,'123456','gekunjin'||i,'0',sysdate,'0');
11 END LOOP;
12 SELECT TO_CHAR(SYSDATE,'yyyy-mm-dd hh24:mi:ss:ff') INTO endTime FROM DUAL;
13 DBMS_OUTPUT.PUT_LINE('End Time: '||endTime);
14END PROC_USER_CREATE_BAT;
posted @
2010-11-27 14:41 absolute 阅读(3739) |
评论 (1) |
编辑 收藏
摘要: 在项目中使用Apache开源的Services Framework CXF来发布WebService,CXF能够很简洁与Spring Framework 集成在一起,在发布WebService的过程中,发布的接口的入参有些类型支持不是很好,比如Timestamp和Map。这个时候我们就需要编写一些适配来实行类型转换。
Timestamp:
1/** *//**
&n...
阅读全文
posted @
2010-11-27 14:28 absolute 阅读(3466) |
评论 (1) |
编辑 收藏Web应用初始化Spring容器策略
以下软件测试环境为Spring,Struts1
1、通过struts1提供的插件机制,采用Spring提供的ContextLoaderPlugIn
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE struts-config PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 1.2//EN" "http://struts.apache.org/dtds/struts-config_1_2.dtd">
<struts-config>
<global-exceptions />
<global-forwards />
<message-resources parameter="com.portal.ApplicationResources" />
<!-- 通过S1提供的插件机制来初始化Spring容器,加载Spring配置文件
<plug-in
className="org.springframework.web.struts.ContextLoaderPlugIn">
<!--
1、ContextLoaderPlugIn默认加载配置文件命名规则是actionServlet-servlet.xml,其中actionServlet
是配置org.apache.struts.action.ActionServlet时指定的servlet名称
2、通过配置contextConfigLocation属性来指点Spring配置文件的位置,多个配置文件可以使用 逗号","、分号";"、空格" "
-->
<set-property property="contextConfigLocation"
value="/WEB-INF/conf/spring-application.xml,/WEB-INF/conf/**/spring*.xml" />
</plug-in>
-->
</struts-config>
2、采用Spring提供的ContextLoaderListener来初始化(应用服务器需要支持Listener,Servlet2.3版本及以上)
<context-param>
<description>通过配置contextConfigLocation属性来指点Spring配置文件的位置,多个配置文件可以使用 逗号","、分号";"、空格" "</description>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/conf/spring-application.xml /WEB-INF/conf/**/spring*.xml</param-value>
</context-param>
<listener>
<description>通过ContextLocaderListener来初始化Spring容器,加载Spring配置文件</description>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
3、采用load-on-startup Servlet 来初始化Spring容器
<servlet>
<description>
通过load-on-startup Servlet来初始化Spring容器
该如何Servlet 用于提供"后台"服务,作为容器管理应用中的其他bean,不需要响应客户请求,因此无须配置servlet-mapping
</description>
<servlet-name>applicationContext</servlet-name>
<servlet-class>org.springframework.web.context.ContextLoaderServlet</servlet-class>
<load-on-startup>0</load-on-startup>
</servlet>
posted @
2010-09-13 18:10 absolute 阅读(2339) |
评论 (0) |
编辑 收藏集群概念
1. 两大关键特性
集群是一组协同工作的服务实体,用以提供比单一服务实体更具扩展性与可用性的服务平台。在客户端看来,一个集群就象是一个服务实体,但事实上集群由一组服务实体组成。与单一服务实体相比较,集群提供了以下两个关键特性:
· 可扩展性--集群的性能不限于单一的服务实体,新的服务实体可以动态地加入到集群,从而增强集群的性能。
· 高可用性--集群通过服务实体冗余使客户端免于轻易遇到out of service的警告。在集群中,同样的服务可以由多个服务实体提供。如果一个服务实体失败了,另一个服务实体会接管失败的服务实体。集群提供的从一个出错的服务实体恢复到另一个服务实体的功能增强了应用的可用性。
2. 两大能力
为了具有可扩展性和高可用性特点,集群的必须具备以下两大能力:
· 负载均衡--负载均衡能把任务比较均衡地分布到集群环境下的计算和网络资源。
· 错误恢复--由于某种原因,执行某个任务的资源出现故障,另一服务实体中执行同一任务的资源接着完成任务。这种由于一个实体中的资源不能工作,另一个实体中的资源透明的继续完成任务的过程叫错误恢复。
负载均衡和错误恢复都要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图(信息上下文)必须是一样的。
3. 两大技术
实现集群务必要有以下两大技术:
· 集群地址--集群由多个服务实体组成,集群客户端通过访问集群的集群地址获取集群内部各服务实体的功能。具有单一集群地址(也叫单一影像)是集群的一个基本特征。维护集群地址的设置被称为负载均衡器。负载均衡器内部负责管理各个服务实体的加入和退出,外部负责集群地址向内部服务实体地址的转换。有的负载均衡器实现真正的负载均衡算法,有的只支持任务的转换。只实现任务转换的负载均衡器适用于支持ACTIVE-STANDBY的集群环境,在那里,集群中只有一个服务实体工作,当正在工作的服务实体发生故障时,负载均衡器把后来的任务转向另外一个服务实体。
· 内部通信--为了能协同工作、实现负载均衡和错误恢复,集群各实体间必须时常通信,比如负载均衡器对服务实体心跳测试信息、服务实体间任务执行上下文信息的通信。
具有同一个集群地址使得客户端能访问集群提供的计算服务,一个集群地址下隐藏了各个服务实体的内部地址,使得客户要求的计算服务能在各个服务实体之间分布。内部通信是集群能正常运转的基础,它使得集群具有均衡负载和错误恢复的能力。
集群分类
Linux集群主要分成三大类( 高可用集群, 负载均衡集群,科学计算集群)
高可用集群( High Availability Cluster)
负载均衡集群(Load Balance Cluster)
科学计算集群(High Performance Computing Cluster)
================================================
具体包括:
Linux High Availability 高可用集群
(普通两节点双机热备,多节点HA集群,RAC, shared, share-nothing集群等)
Linux Load Balance 负载均衡集群
(LVS等....)
Linux High Performance Computing 高性能科学计算集群
(Beowulf 类集群....)
分布式存储
其他类linux集群
(如Openmosix, rendering farm 等..)
详细介绍
1. 高可用集群(High Availability Cluster)
常见的就是2个节点做成的HA集群,有很多通俗的不科学的名称,比如"双机热备", "双机互备", "双机".
高可用集群解决的是保障用户的应用程序持续对外提供服务的能力。 (请注意高可用集群既不是用来保护业务数据的,保护的是用户的业务程序对外不间断提供服务,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度)。
2. 负载均衡集群(Load Balance Cluster)
负载均衡系统:集群中所有的节点都处于活动状态,它们分摊系统的工作负载。一般Web服务器集群、数据库集群和应用服务器集群都属于这种类型。
负载均衡集群一般用于相应网络请求的网页服务器,数据库服务器。这种集群可以在接到请求时,检查接受请求较少,不繁忙的服务器,并把请求转到这些服务器上。从检查其他服务器状态这一点上看,负载均衡和容错集群很接近,不同之处是数量上更多。
3. 科学计算集群(High Performance Computing Cluster)
高性能计算(High Perfermance Computing)集群,简称HPC集群。这类集群致力于提供单个计算机所不能提供的强大的计算能力。
高性能计算分类
高吞吐计算(High-throughput Computing)
有一类高性能计算,可以把它分成若干可以并行的子任务,而且各个子任务彼此间没有什么关联。象在家搜寻外星人( SETI@HOME -- Search for Extraterrestrial Intelligence at Home )就是这一类型应用。这一项目是利用Internet上的闲置的计算资源来搜寻外星人。SETI项目的服务器将一组数据和数据模式发给Internet上参加SETI的计算节点,计算节点在给定的数据上用给定的模式进行搜索,然后将搜索的结果发给服务器。服务器负责将从各个计算节点返回的数据汇集成完整的数据。因为这种类型应用的一个共同特征是在海量数据上搜索某些模式,所以把这类计算称为高吞吐计算。所谓的Internet计算都属于这一类。按照 Flynn的分类,高吞吐计算属于SIMD(Single Instruction/Multiple Data)的范畴。
分布计算(Distributed Computing)
另一类计算刚好和高吞吐计算相反,它们虽然可以给分成若干并行的子任务,但是子任务间联系很紧密,需要大量的数据交换。按照Flynn的分类,分布式的高性能计算属于MIMD(Multiple Instruction/Multiple Data)的范畴。
4. 分布式(集群)与集群的联系与区别
分布式是指将不同的业务分布在不同的地方。
而集群指的是将几台服务器集中在一起,实现同一业务。
分布式中的每一个节点,都可以做集群。
而集群并不一定就是分布式的。
举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成。
而分布式,从窄意上理解,也跟集群差不多, 但是它的组织比较松散,不像集群,有一个组织性,一台服务器垮了,其它的服务器可以顶上来。
分布式的每一个节点,都完成不同的业务,一个节点垮了,哪这个业务就不可访问了。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/tanghongru1983/archive/2009/04/28/4130356.aspx
posted @
2010-03-02 14:16 absolute 阅读(682) |
评论 (0) |
编辑 收藏
代码如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;

 public class MyEclipseGen
public class MyEclipseGen  {
{
 private static final String LL = "Decompiling this copyrighted software is a violation of both your license agreement and the Digital Millenium Copyright Act of 1998 (http://www.loc.gov/copyright/legislation/dmca.pdf). Under section 1204 of the DMCA, penalties range up to a $500,000 fine or up to five years imprisonment for a first offense. Think about it; pay for a license, avoid prosecution, and feel better about yourself.";
private static final String LL = "Decompiling this copyrighted software is a violation of both your license agreement and the Digital Millenium Copyright Act of 1998 (http://www.loc.gov/copyright/legislation/dmca.pdf). Under section 1204 of the DMCA, penalties range up to a $500,000 fine or up to five years imprisonment for a first offense. Think about it; pay for a license, avoid prosecution, and feel better about yourself.";

 public String getSerial(String userId, String licenseNum) {
public String getSerial(String userId, String licenseNum) {
java.util.Calendar cal = java.util.Calendar.getInstance();
cal.add(1, 3);
cal.add(6, -1);
java.text.NumberFormat nf = new java.text.DecimalFormat("000");
licenseNum = nf.format(Integer.valueOf(licenseNum));
String verTime = new StringBuilder("-").append(
new java.text.SimpleDateFormat("yyMMdd").format(cal.getTime()))
.append("0").toString();
String type = "YE3MP-";
String need = new StringBuilder(userId.substring(0, 1)).append(type)
.append("300").append(licenseNum).append(verTime).toString();
String dx = new StringBuilder(need).append(LL).append(userId)
.toString();
int suf = this.decode(dx);
String code = new StringBuilder(need).append(String.valueOf(suf))
.toString();
return this.change(code);
 }
}
private int decode(String s) {
int i;
char[] ac;
int j;
int k;
i = 0;
ac = s.toCharArray();
j = 0;
k = ac.length;
while (j < k) {
i = (31 * i) + ac[j];
j++;
}
return Math.abs(i);
}
private String change(String s) {
byte[] abyte0;
char[] ac;
int i;
int k;
int j;
abyte0 = s.getBytes();
ac = new char[s.length()];
i = 0;
k = abyte0.length;
while (i < k) {
j = abyte0[i];
if ((j >= 48) && (j <= 57)) {
j = (((j - 48) + 5) % 10) + 48;
} else if ((j >= 65) && (j <= 90)) {
j = (((j - 65) + 13) % 26) + 65;
} else if ((j >= 97) && (j <= 122)) {
j = (((j - 97) + 13) % 26) + 97;
}
ac[i] = (char) j;
i++;
}
return String.valueOf(ac);
}
public MyEclipseGen() {
super();
}
public static void main(String[] args) {
try {
System.out.println("please input register name:");
BufferedReader reader = new BufferedReader(new InputStreamReader(
System.in));
String userId = null;
userId = reader.readLine();
MyEclipseGen myeclipsegen = new MyEclipseGen();
String res = myeclipsegen.getSerial(userId, "5");
System.out.println("Serial:" + res);
reader.readLine();
} catch (IOException ex) {
}
}
 }
}
注册方法:
window -> preferences -> myeclipse -> subscription
posted @
2010-02-16 09:20 absolute|
编辑 收藏
Hibernate学习笔记
1、Hibernate核心类与接口
1-1.Configuration类
Configuration类是Hibernate的入口,它负责配置和启动Hibernate,Hibernate框架通过Configuration实例加载配置文件信息(hibernate.cfg.xml),然后读取指定对象关系映射文件(bean.hbm.xml)的内容并创建SessionFactory.
1-2.SessionFactory接口
SessionFactory接口负责初始化Hibernate,一个SessionFactory实例对应一个数据存储源(一般就是指一个数据库)。应用程序从SessionFactory中获得Session实例。SessionFactory具有以下特点:
1) 线程安全,即同一个 SessionFactory实例可以被应用 的多个线程共享。
2) 它是重量级的 ,因为它需要一个很大的缓存,用来存放预定义的SQL语句以及映射元数据等。
所以说 ,如果一个应用程序中只访问一个数据库 ,则只需要创建一个全局的 SessionFactory实例。
1-3.Session 接口
Session是Hibernate中应用最频繁的接口。Session也被称为持久化管理器 ,它负责管理所有与持久化相关的操作:如存储、更新、删除和加载对象等。Session接口具有以下特点:
1) 单线程,非共享的对象。线程不安全,在设计软件架构时候,应该避免多个线程共享同一个session实例。
2) Session 实例是轻量级的,它的创建和销毁不需要消耗太多的资源。可以为每个请分配一个Session实例,在每次请求过程汇总及时创建和销毁 Session实例。
3) Session有一个缓存,它存放当前工作单元加载的对象。Session的缓存被称为Hibernate的一级缓存。
1-4.Transaction接口
Transaction接口是 Hibernate框架的事务接口。它对底层的事务接口做了封装,包括:JDBC API和JTA.这样使得Hibernate应用可以通过一致的Transaction接口来申明事务边界,这有助于应用程序再不同的环境和容器中移植。
1-5.Query和Criteria接口
它们是 Hibernate的查询接口,用于从数据存储源查询对象及控制执行查询的过程。Query包装了一个 HQL(Hibernate Query Language);而Criteria接口完全封装了基本字符串形式的查询语句,比Query更加面向对象,Criteria接口擅长于执行动态查询。
2、Hibernate中常用的事务隔离级别
|
常量
|
值
|
说明
|
|
TRANSACTION_NONE
|
0
|
不支持事务
|
|
TRANSACTION_READ_UNCOMMITTED
|
1
|
指示可以发生脏读(dirty read)、不可重复读和虚读(phantom read)的常量。此级别允许被某一事务更改的行在已提交该行所有更改之前被另一个事务读取(“脏读”)。如果所有更改都被回滚,则第二个事务将获取无效的行。
|
|
TRANSACTION_READ_COMMITTED
|
2
|
指示不可以发生脏读的常量;不可重复读和虚读可以发生。此级别只禁止事务读取其中带有未提交更改的行。
|
|
TRANSACTION_REPEATABLE_READ
|
4
|
指示不可以发生脏读和不可重复读的常量;虚读可以发生。此级别禁止事务读取带有未提交更改的行,它还禁止这种情况:一个事务读取某一行,而另一个事务更改该行,第一个事务重新读取该行,并在第二次读取时获得不同的值(“不可重复读”)。
|
|
TRANSACTION_SERIALIZABLE
|
8
|
指示不可以发生脏读、不可重复读和虚读的常量。此级别包括TRANSACTION_REPEATABLE_READ 中禁止的事项,同时还禁止出现这种情况:某一事务读取所有满足 WHERE 条件的行,另一个事务插入一个满足 WHERE 条件的行,第一个事务重新读取满足相同条件的行,并在第二次读取时获得额外的“虚”行。
|
3、Hibernate中实例的状态

3-1:临时状态
该实例从未与任何持久化上下文关联过。它没有持久化标识(相当于主键值),临时状态下的对象有如下特征。
1) 不处于Session缓存中,也可以说不被任何一个Session关联
2) 在数据库中没有对应的记录
在以下情况下,Java对象进入临时状态
1) 当通过new语句刚创建一个Java对象,它处于临时状态,此时不和数据库中的任何记录对应。
2) Session的delete()方法能使一个持久化或临时脱管对象转换为临时对象。对于脱管对象,delete()方法从数据库中删除与它对应的记录,并且把它从Session缓存中删除。
3-2:持久化状态
该实例目前与某个持久化上下文有关联,它拥有持久化标识(相当于主键值),并且可能在数据库汇总有一个对应的行。对于某一个特定的持久化上下文,Hibernate保证标识与Java标识(其值代表对应在内存中的位置)等价。持久化对象有以下特征。
1) 位于一个Session实例的缓存中,也可以说,持久化对象总是被一个Session实例关联。
2) 持久化对象和数据库中的相关记录对应。
3) Session在清理缓存时,会根据持久化对象的属性变化,来同步更新数据库。
Session的许多方法都能够触发Java对象进入持久化状态。
4) Session的save()的方法能够把临时对象转变成持久化对象。
5) Session的load()或get()方法返回的对象总是处于持久化状态。
6) Query类的list()方法返回的list集合中存放的都是持久化对象。
7) Session的update()、saveOrUpdate()和lock()方法使脱管对象转变为持久化对象。
当一个持久化对象关联一个临时对象时,在允许级联保存的情况下,Session在清理缓存时会把这个临时对象也转变成持久化对象。Hibernate保证在同一个Session实例的缓存中,数据库表中的每条记录只对应唯一的持久化对象,也就是说在一个Session里load/get同一个OID得到 的是相同的对象。
3-3:脱管状态
实例曾经与某个持久化上下文发生过关联,不过那个上下文被关闭了,或者这个实例是被序列化(serialize)到另外的进程。它拥有持久化标识,并且在数据库中可能存在一个对应的行。对于脱管状态的实例,Hibernate不保证任何持久化标识和Java标识的关系。
脱管对象具有以下特征。
1) 不再位于Session的缓存中,也可以说,脱管对象不被Session关联。
2) 脱管对象是有持久化对象转变过来的,因此在数据库中可能还存在与它对应的记录(前提条件是没有其他程序删除了这条记录)。
3) 脱管对象与临时对象的相同指出在于两者都不被Session关联,因此Hibernate不会保证他们属性变化与数据库保持同步。脱管对象与临时对象的区别在于前者是由持久化对象转变过来的,因此可能在书库中还存在对应的记录,而后者在数据库中是没有对应的记录的。
Session的以下方法使持久化对象转变成脱管对象.
1) 当调用Session的close()方法时,Session 的缓存被清空,缓存中的所有持久化对象都变为脱管对象,如果在应用程序中没有引用变量引用这些脱管对象,他们就会结束生命周期。
2) Session的evict()方法能够从缓存中删除一个持久化对象,使它变为脱管状态,当Session的缓存中保存了大量的持久化对象时,会消耗许多内存空间,为了提高性能,可以考虑调用evict()方法,从缓存中删除一些持久化对象。但是多数情况下不推荐使用该方法,而应该通过查询语言,或者显示的导航来控制对象图的深度。
posted @
2010-01-09 19:08 absolute 阅读(724) |
评论 (0) |
编辑 收藏
最近在构思写一些设计模式方面的文章,用到UML图,以前用Visio和WithClass..但功能不多,所以就安装了Rose 2003..以下是安装过程:
1.安装Rose后,默认是需要许可证书的..去下载个破解的..我上传了破解文件..
点击这里下载Rose 2003破解
2.先用破解压缩包里的 rational.exe,lmgrd.exe 覆盖到你的 \安装目录的Rartional\commen\下
3.然后记事本打开 license.dat, 修改里面的 SERVER yourPC ANY DAEMON rational "C:\Program Files\Rational\Common\rational.exe"
改成 SERVER 你的机器名 ANY DAEMON rational "你的安装目录\rational.exe" ,拷贝到Common目录下..
4. 将Flexlm.cpl拷贝到C:\winnt\system32\下, 在控制面板里运行 FlexLm License Manager,
运行后, 在 Setup 面板配置文件路径,lmgrd.exe -> 你的安装目录 \Common\lmgrd.exe, 而 License File 为你改过的 license.dat ...
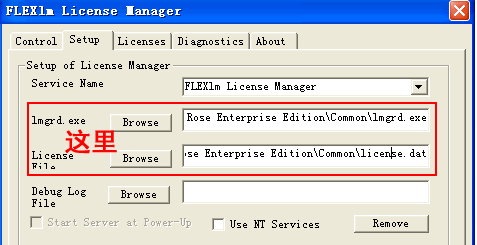
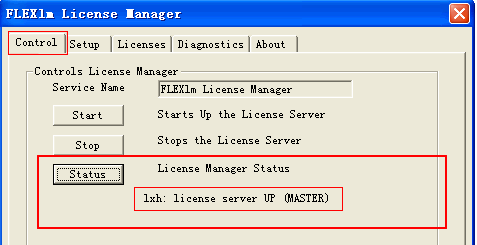
5.在Control面板点击Start,如果成功的话点击Status按钮将显示 你的机器名:license server UP (MASTER) 说明成功了
失败的话重启一下FlexLm License Manager就没问题了。
6.如果弹出对话框License Key Administrator Wizard后, 选定Point to a Rational License Server to get my licenses,单击下一步,
Server Name文本框中填写你的机器号(可能已经填好),单击完成。 (成功的话会出现两屏的licenses)
注意:本文转至:
http://www.cnblogs.com/lixianhuei/archive/2006/01/09/313644.html
posted @
2009-10-25 08:29 absolute 阅读(916) |
评论 (1) |
编辑 收藏