|
#
代码
参考:http://www.python.org/dev/peps/pep-0318/
def singleton(cls):
instances = {}
def getinstance():
if cls not in instances:
print "new"
instances[cls] = cls()
return instances[cls]
return getinstance
@singleton
class MyClass:
pass
x1=MyClass()
#print new
x2=MyClass()
>>> def chomppy(k):
if k=="": return ""
if k=="\n" or k=="\r\n" or k=="\r": return ""
if len(k)==1: return k #depends on above case being not true
if len(k)==2 and (k[-1]=='\n' or k[-1]=='\r'): return k[0]
#done with weird cases, now deal with average case
lastend=k[-2:] #get last two pieces
if lastend=='\r\n':
outstr=k[:-2]
return outstr
elif (lastend[1]=="\n" or lastend[1]=="\r"):
outstr=k[:-1]
return outstr
return k
>>> chomppy(’cow\n’)
‘cow’
>>> chomppy(”)
”
>>> chomppy(’hat’)
‘hat’
>>> chomppy(’cat\r\n’)
‘cat’
>>> chomppy(’\n’)
”
>>> chomppy(’\r\n’)
”
>>> chomppy(’cat\r’)
‘cat’
>>> chomppy(’\r’)
”
代码可以直接运行,看结果
如果命令调试 python -m pdb pyaop.py
(Pdb)b pyaop:10
(Pdb)c
(Pdb)n .....自己来把
调试参考 : python pdb 基础调试
源文件 : pyaop.py
#!/usr/bin/python
# -*- coding: utf8 -*-
# 参考:http://www.cnblogs.com/Alexander-Lee/archive/2008/12/06/pythonaop.html
"""
py aop 代理类 ( metaclass 特性 )
由于使用 __metaclass__ = <type 'type'>
pyaop 继承 type
"""
class pyaop(type):
# before ; after 方法变量引用声明
beforeop=lambda e : None
afterop=lambda e : None
#class方法(静态方法)set
@classmethod
def setbefore(self,func):
pyaop.beforeop=func
@classmethod
def setafter(self,func):
pyaop.afterop=func
""" 使用调试
# python -m pdb pyaop.py
# 由下面 A类 < __metaclass__ = pyaop >
# 类初始 的 __new__ 指向 pyaop __new__
#
# (Pdb)b pyaop:36 (大概就是下面函数form types  的行号) 的行号)
# (Pdb)a (可以看看调试中,各参数的值,注意dict为A的初始对象传过来了)
# mcl = <class '__main__.pyaop'>
# name = A
# bases = (<type 'object'>,)
# dict = {'__module__': '__main__', 'foo': <function foo at 0x7fddced4>, '__metaclass__': <class '__main__.pyaop'>, 'foo2': <function foo2 at 0x7fddcf0c>}
# 本函数目的: 使用 新的另个对象挂载 被aop后的 A对象 方法
"""
def __new__(mcl,name,bases,dict):
from types import FunctionType
obj=object()
def aop(func):
def wrapper(*args, **kwds):
pyaop.beforeop(obj)
value = func(*args, **kwds)
pyaop.afterop(obj)
return value
return wrapper
#添加代理
for attr, value in dict.iteritems():
if isinstance(value, FunctionType):
dict[attr] = aop(value)
#挂载到 obj 上
obj=super(pyaop, mcl).__new__(mcl, name, bases, dict)
return obj
class A(object):
#被 aop 代理 声明!
__metaclass__ = pyaop
def foo(self):
total = 0
for i in range(100000):
total = total+1
print total
def foo2(self):
from time import sleep
total = 0
for i in range(100000):
total = total+1
#sleep(0.0001)
print total
"""#####################################################################################
# 测试
#####################################################################################"""
def beforep(self):
print('before')
def afterp(self):
print('after')
if __name__ == "__main__":
pyaop.setbefore(beforep)
pyaop.setafter(afterp)
a=A()
a.foo()
a.foo2()
其他aop:
使用 @
def addspam(fn):
def new(*args):
print "spam, spam, spam"
return fn(*args)
return new
@addspam
def useful(a, b):
print a**2 + b**2
useful(3,4)
#结果
#spam, spam, spam
#25
晚绑定!
def attrs(**kwds):
def decorate(f):
for k in kwds:
setattr(f, k, kwds[k])
return f
return decorate
@attrs(versionadded="2.2",author="Guido van Rossum")
def mymethod(f):
return mymethod
x=mymethod(1)
x.versionadded
#2.2 !这是什么好东西!!
mkdir -p cgi/cgi-bin ;
gvim time.py
#!/usr/bin/env python
# -*- coding utf8 -*-
import cgitb
cgitb.enable()
import time
print "Content-type: text/html"
print
print time.strftime('%Y-%m-%d %X', time.localtime() )
form = cgi.FieldStorage()
# Get data from field 'name'
name = form.getvalue('name')
cgi 服务器建立
cd cgi
python -m CGIHTTPServer
到 firefox 中
http://127.0.0.1:8000/cgi-bin/time.py
2009-04-07 23:26:03
数据:
希望 抓取
div > p id='da' > a text
和 div > p id='da' > html
<div>
<p id="tt">
<a href=/tag/php>no no</a>
</p>
<p id='da'>
<a href=/tag/php>php</a>
<a href=/tag/python>python</a>
<a href=/tag/vim>vim</a>
<a href=/tag/windows>windows</a>
<a href=/tag/wingide>wingide</a>
</p>
</div>
<p id='da'>
<a href=/tag/wingide>hehe</a>
</p>
希望结果为
$ python t.py
a_text: ["'php'", "'python'", "'vim'", "'windows'", "'wingide'"]
div_html[0]:
<p id="da">
<a href="/tag/php">php</a>
<a href="/tag/python">python</a>
<a href="/tag/vim">vim</a>
<a href="/tag/windows">windows</a>
<a href="/tag/wingide">刘凯毅</a>
</p>
#说明
其实 SGMLParser 我感觉最关键的是
#/usr/lib/python2.5/sgmllib.py
# Internal -- finish parsing of <tag/data/ (same as <tag>data</tag>)
def finish_shorttag(self, tag, data):
#而 finish_starttag finish_endtag 抓取会调用 end_* start_* 什么的
self.finish_starttag(tag, [])
self.handle_data(data)
self.finish_endtag(tag)
代码:
#!python
#coding=UTF-8
from sgmllib import SGMLParser
class TestSGMLParser(SGMLParser):
def reset(self, verbose=0):
SGMLParser.reset(self)
#提取 a text ; div html
self.a_text=[]
self.div_html=[]
#寄存变量
self.data_text = ""
self.data_html = ""
#业务逻辑表示变量
#抓取 div > p id="da" > a
#由于需要得到div p 的 html > test_div_p = 0 , 1 , 2
self.test_div=False
self.test_div_p=0
self.test_div_p_a=False
# 重写 handle_data
# 寄存变量 填充值
def handle_data(self, data):
self.data_text = self.data_text + data
if self.test_div_p :
self.data_html = self.data_html +data
# 重写 finish_starttag
# self.data_html 填充值
def finish_starttag(self, tag, attrs):
SGMLParser.finish_starttag(self, tag, attrs)
if self.test_div_p :
strattrs = "".join([' %s="%s"' % (key, value) for key, value in attrs])
self.data_html=self.data_html+"<%(tag)s%(strattrs)s>" % locals()
# 重写 finish_endtag
# self.data_html 填充值
def finish_endtag(self, tag):
SGMLParser.finish_endtag(self, tag)
if self.test_div_p == 2 :
self.data_html=self.data_html+"</%(tag)s>" % locals()
elif self.test_div_p == 1 :
self.data_html=self.data_html+"</%(tag)s>" % locals()
self.test_div_p = 0
# self.test_div 状态修改
def start_div(self, attrs):
self.test_div=True
# self.test_div 状态修改
# self.div_html 填充
def end_div(self):
if self.test_div :
self.div_html.append(self.data_html)
self.test_div=False
# self.test_div_p 状态修改 2 为可以填充
def start_p(self, attrs):
if self.test_div and attrs and 'id' in [ key for key, value in attrs ] and len([ value for key, value in attrs if key=='id' and value=='da'])>0 :
self.test_div_p=2
# self.test_div_p 状态修改 1 为只能填充最后一次
def end_p(self):
if self.test_div_p == 2 :
self.test_div_p=1
# self.test_div_p_a 状态修改
def start_a(self, attrs):
self.data_text = ""
if self.test_div_p :
self.test_div_p_a=True
# self.test_div_p_a 状态修改
# self.a_text 填充
def end_a(self):
if self.test_div_p and self.test_div and self.test_div_p_a :
self.a_text.append(repr(self.data_text))
self.test_div_p_a=False
def close(self):
SGMLParser.close(self)
if __name__ == '__main__':
try:
f = open('google.html', 'r')
data = f.read()
x=TestSGMLParser()
x.feed(data)
x.close()
# 我这 gvim utf8 ; cygwin gbk ,转码 unicode( str , 'utf8').encode('gbk')
print "a_text: %s \n div_html[0]: \n %s"%(x.a_text[:-1], unicode(x.div_html[0], 'utf8').encode('gbk') )
except IOError, msg:
print file, ":", msg
页面抓取
抓取 pycurl + 分析用 SGMLParser + 验证码用 pytesser
下面就差算法了,抓取的准备工作终于要完成了。
当手边没有IDE,面对着python调试犯愁时,你就可以参考下本文;(pdb 命令调试)
参考:http://docs.python.org/library/pdb.html
和 (pdb)help
首先你选择运行的 py
python -m pdb myscript.py
(Pdb) 会自动停在第一行,等待调试,这时你可以看看 帮助
(Pdb) h
说明下这几个关键 命令
>断点设置
(Pdb)b 10 #断点设置在本py的第10行
或(Pdb)b ots.py:20 #断点设置到 ots.py第20行
删除断点(Pdb)b #查看断点编号
(Pdb)cl 2 #删除第2个断点
>运行
(Pdb)n #单步运行
(Pdb)s #细点运行 也就是会下到,方法
(Pdb)c #跳到下个断点
>查看
(Pdb)p param #查看当前 变量值
(Pdb)l #查看运行到某处代码
(Pdb)a #查看全部栈内变量
>如果是在 命令行里的调试为:
import pdb
def tt():
pdb.set_trace()
for i in range(1, 5):
print i
>>> tt()
#这里支持 n p c 而已
> <stdin>(3)tt()
(Pdb) n
.
上面一般的调试工具大体上都能解决了,还有其他什么 调试时修改变量值,回到某断点等 ,可以在 pdb 中 help 下 (其实我也不太明白)
望那位知道的,能一起补全这篇文章。
尝试下使用 vim 以外 python 的工具
感觉 eric4 不错
去官方下载 eric4
windows 傻瓜安装
先安装 pyqt
再 到 eric3 的安装目录 下 python install.py
debian 系统
root 权限
apt-get install python-qt4
apt-get install python-QScintilla2
python install.py
对应脚本运用:
1. shell 统筹管理 脚本的运行。合理结合 crontab , ps -ef ,kill 等命令。
2. perl 处理短小快 。
3. python 有比较复杂结构和逻辑的。
本文主要介绍 perl 的行级命令使用 ,力求 短 小 快  :
 #最简单的 #最简单的
$ perl -e 'print "Hello World\n"'#处理文件 行
$ perl -n -e 'print $_' file1
#编码转换
#如果 有需要 在使用下 encode("UTF-8", decode("GBK",$_));在 linux 下默认 utf-8
perl -MEncode -ne 'print decode("GBK",$_);' file.txt
#正则使用
# if($_=~/.*\/(.*)$/){ print $1 ;} 这是perl 巨方便的地方 $1 xx
# next LINE 跳到下一个循环
$ perl -n -e 'next LINE unless /pattern/; print $_'
#去除换行 chomp
perl -e 'print split(/\n/,"asg\n");'
#像 awk 一样 Begin End
$ perl -ne 'END { print $t } @w = /(\w+)/g; $t += @w' file.txt
#像 awk -F"x" 一样 切割行
#-a 打开自动分离 (split) 模式
#@F 为 切割后的 数组
perl -F'\t' -ane '
if($F[1]=~/侃侃/ and $F[2]=~/爱情啊/){
print "$F[3]\t$F[4]\t$F[5]\n"
}
' all2_data.sort.st
实际处理:
perl -F'\|\|' -ane '
my $actor,$music ;
if ( $F[3] ){
$music=$F[2];
$actor=$F[3];
}else{
$music=$F[0];
$actor=$F[1];
}
$music =~ tr/[A-Z]/[a-z]/;
$music =~ s/\s*(.*)\s*\(.*\)/\1/g;
$actor =~ tr/[A-Z]/[a-z]/;
$actor =~ s/\s*(.*)\s*\(.*\)/\1/g;
print "$actor-$music\n";
' ring.utf8.txt |sort -u > ring.actor_music.sort.utf8.txt &
wc -l ring.actor_music.sort.utf8.txt
#像 sed 一样替换
# -i 和 sed 一样 perl 输出会替换调 源 file.txt
$ perl -i -pe 's/\bPHP\b/Perl/g' file.txt
#外部 传参
perl -ne'print "$ARGV[0]\t$ARGV[1]\n" ' file.txt 'par1' 'par2'
#结果 .. par1 par2 ..
# 查询出 重复列 次数,并 列举出来
cut -d" " -f 2 .collection_mobile.data |perl -ne '
END{
while (($key,$value)=each(%a)){print $key,"=",$value,"\n";};
}BEGIN{ %a =(); }
chomp;
$a{$_}+=1;
'
结果
Ring=532895
CRBT=68500
RingBoxes=880
Song=96765
#一些实际使用 :)
find . -name "*.mp3" | perl -pe 's/.\/\w+-(\w+)-.*/$1/' | sort | uniq
perl -F'\t' -ane 'if($F[1]=~/$ARGV[0]/ and $F[2]=~/$ARGV[1]/){print "$F[3]\t$F[4]\t$F[5]\n"}' all2_data.sort.st '侃侃' '爱情啊'
#与 find 合用 -e $ARGV[0] 批量 把 excel 倒成 文本 格式
find . -maxdepth 1 -name "*xls" -exec perl -e '
require("/home/xj_liukaiyi/src/perl/excel/excelUtil.pl");
my $file=$ARGV[0];
sub myRead{
my $str = "";
for $tmp(@_){
$str="$str$tmp\t";
}
$str="$str\n";
system "echo \"$str\" >> $file.data ";
}
&parse_excel("$file",0,\&myRead);
print "$file\n";
' {} \;
参考:
http://www.ibm.com/developerworks/cn/linux/sdk/perl/l-p101/index.html
http://bbs.chinaunix.net/viewthread.php?tid=499434
各位“蜘蛛侠”们大家可能在抓取页面中的验证码而耿耿于怀,关于这点我想我目前可能能帮助下大家,在python中找到最接近与“杀手级别”的工具(源于开源,报与开源,好东西不干独享)。
调下大家的积极性 ,上图
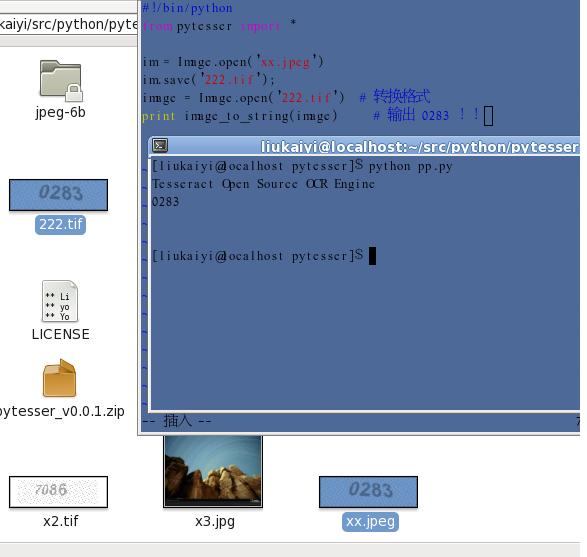
python 包>> pytesser| http://code.google.com/p/pytesser/(其实 py包 使用很简单的,关键在安装)
1. 首先安装 pil : easy_install --find-links http://www.pythonware.com/products/pil/ Imaging
2. pytesser 依赖包 tesseract-ocr| http://code.google.com/p/tesseract-ocr/
tesseract-ocr 依赖库| http://tesseract-ocr.googlecode.com/files/tesseract-2.00.eng.tar.gz 解压到 你安装的 tesseract-ocr 的 识别学习库下
re.search('(?ix)(?<=l)ike.*(?=s)','as Like as').group()
#结果 ike a
#说明
# 1. (?..) 匹配模式(就写有用的)
# >i 使匹配对大小写不敏感
# >x 正则中串中的空白符被忽略
# 比如 (?x)li k e 可以匹配 like
#2. (?<=l) 前驱匹配但不消费,
# 比如上面 (?<=l)(.*) 可以匹配 l(ike..)
#3. (?=s) 后驱匹配但不消费
# 比如上面 (?<=l)(.*)(?=s) 匹配 l(ike a)s
re.search('(?ix)(as)?(.*)(?(1)as)','As like as').group(2)
#结果 ' like '
#(as)? 条件
#(?(1)as) 如果条件1 为真 ,再匹配as
#
# 给 条件取名 (?P<name>....) (?(name)....)
#re.search('(?ix)(?P<rid>as)(.*)(?(rid)as)','As Like as').group(2)
# 结果 Like
详细参考 python >>> help(re)
或 http://www.python.org/doc/2.5/lib/re-syntax.html
|