
2012年1月6日
Microsoft SQL Server 2008 基本安装说明
安装SQL2008的过程与SQL2005的程序基本一样,只不过在安装的过程中部分选项有所改变,当然如果只熟悉SQL2000安装的同志来说则是一个革命性的变动,
一、安装前的准备
1. 需要.Net Framework 3.5,若在Vista或更高的OS上需要3.5 SP1的支持(在SQL2008安装的前会自动更新安装)
2. 需要Widnows PowerShell的支持,WPS是一个功能非常强大的Shell应用,命令与DOX/UNIX兼容并支持直接调用.NET模块做行命令编辑,是非常值得深入研究的工具(在SQL2008安装时会自动更新安装)
3. 需要确保Windows Installer的成功启动,需要4.5以上版本(需要检查服务启动状态service.msc)
4. 需要MDAC2.8 sp1的支持(XP以上系统中已集成)
5. 若机器上已经安装Visual studio 2008则需要VS 2008 sp1以上版本的支持(需要自己从MS的网站上下载安装http://www.microsoft.com/downloads/details.aspx?familyid=FBEE1648-7106-44A7-9649-6D9F6D58056E&displaylang=en)
二、安装配置过程
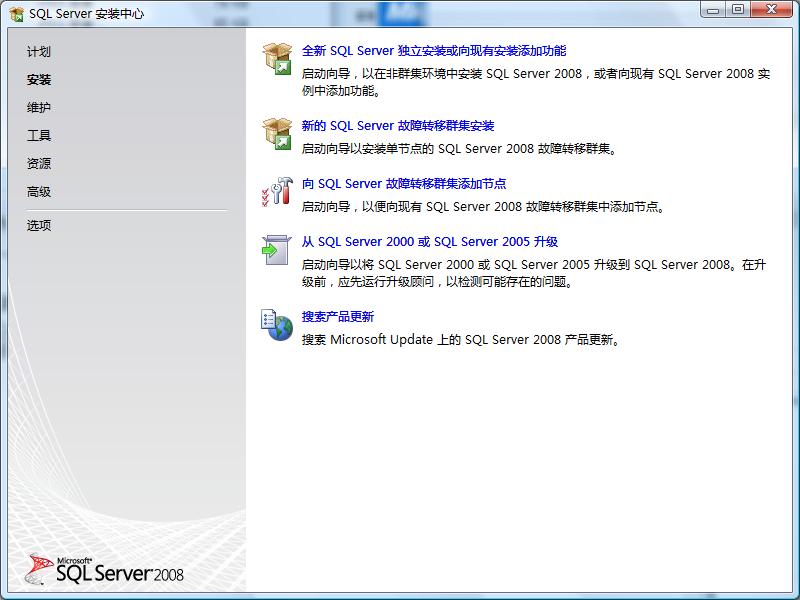
1.进行SQL Server安装中心,选择"安装"选项,在新的电脑上安装SQL2008可以直接选择“全新SQL Server独立安装或向现有安装功能",将会安装一个默认SQL实列,如下图
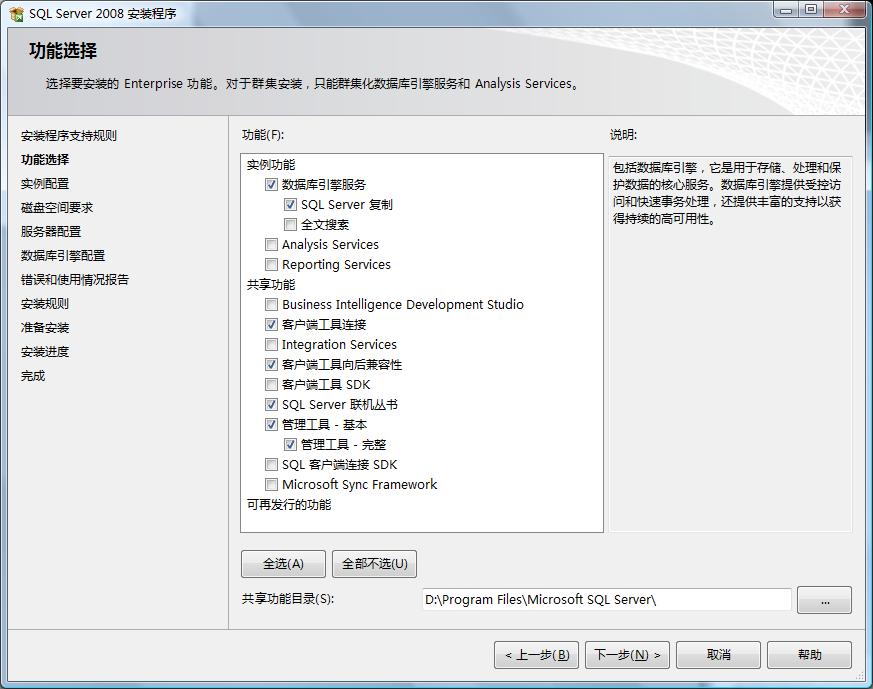
2.功能选择,对于只安装数据库服务器来说,功能的选择上可以按实际工作需要来制定,本人一般选择:数据库引擎服务、客户端工具连接、SQL Server 联机丛书、管理工具-基本、管理工具-完整
其中数据库引擎服务是SQL数据库的核心服务,Analysis及Reporting服务可按部署要求安装,这两个服务可能需要IIS的支持。如下图
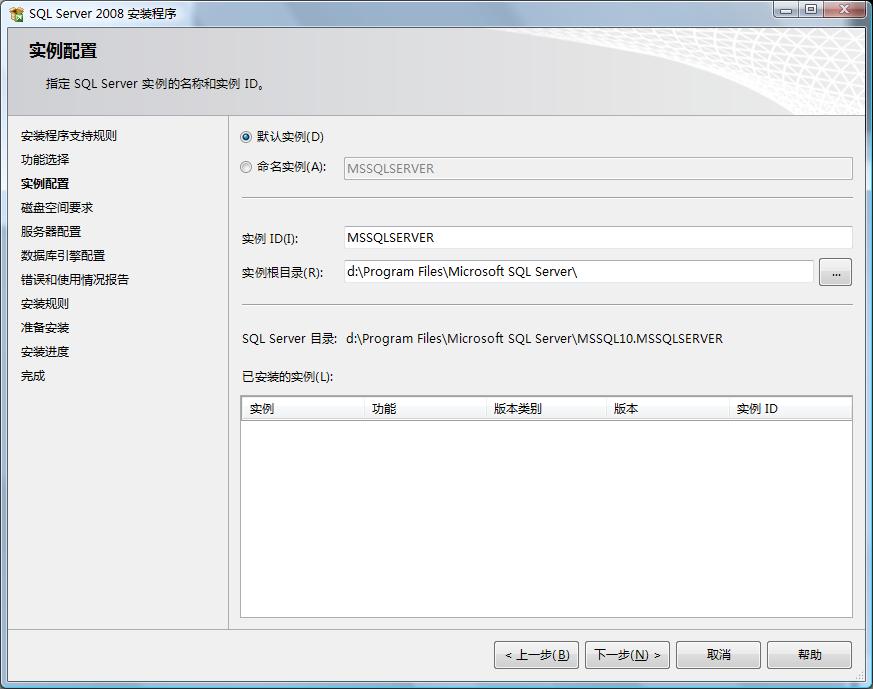
3.实列设置,可直接选择默认实例进行安装,或则若同一台服务器中有多个数据服务实列可按不同实列名进行安装。如图
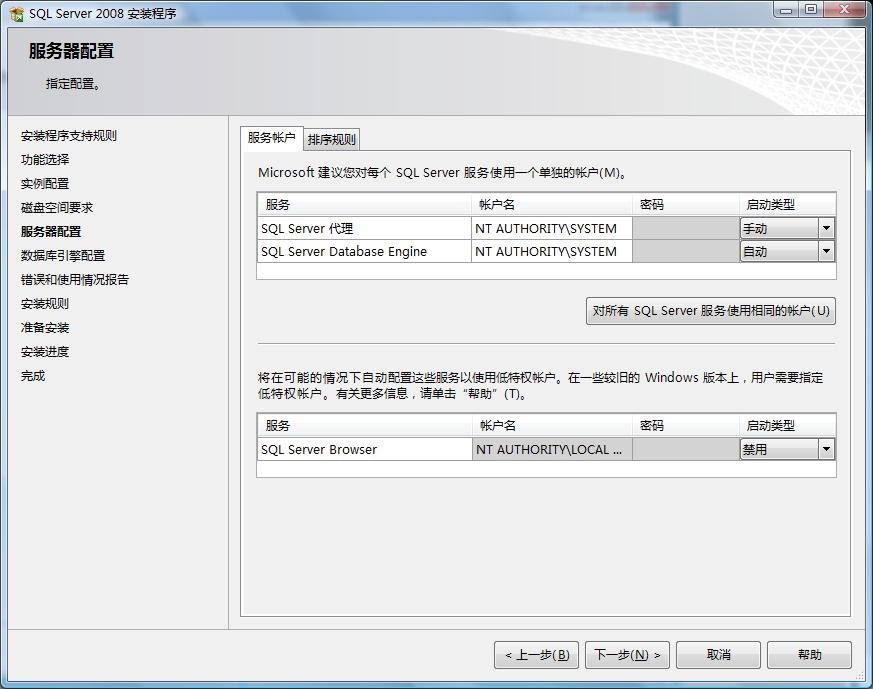
4.服务器配置,服务器配置主要是服务启动帐户的配置,服务的帐户名推荐使用NT AUTHORITY\SYSTEM的系统帐户,并指定当前选择服务的启动类型,如图
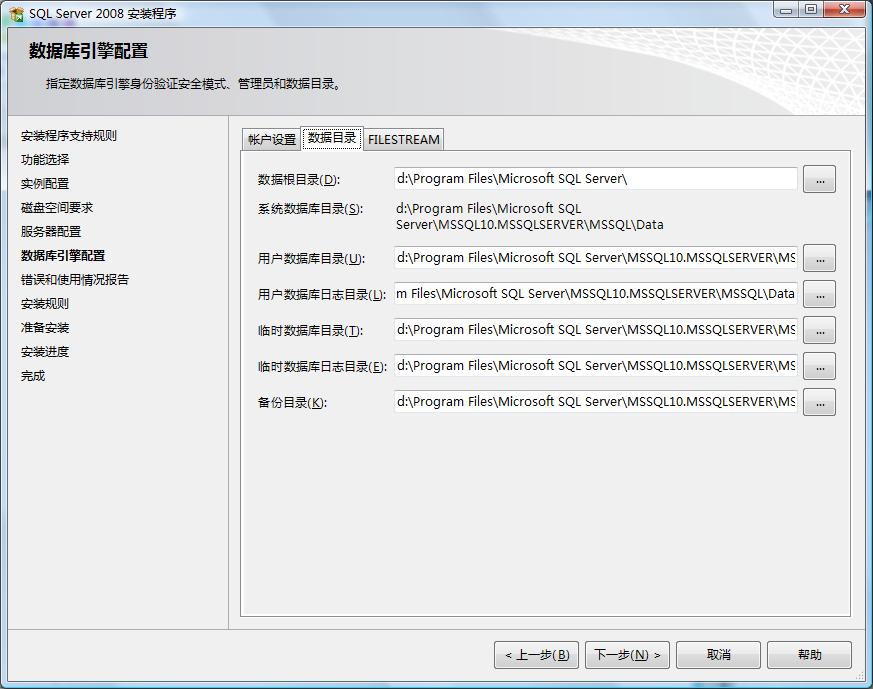
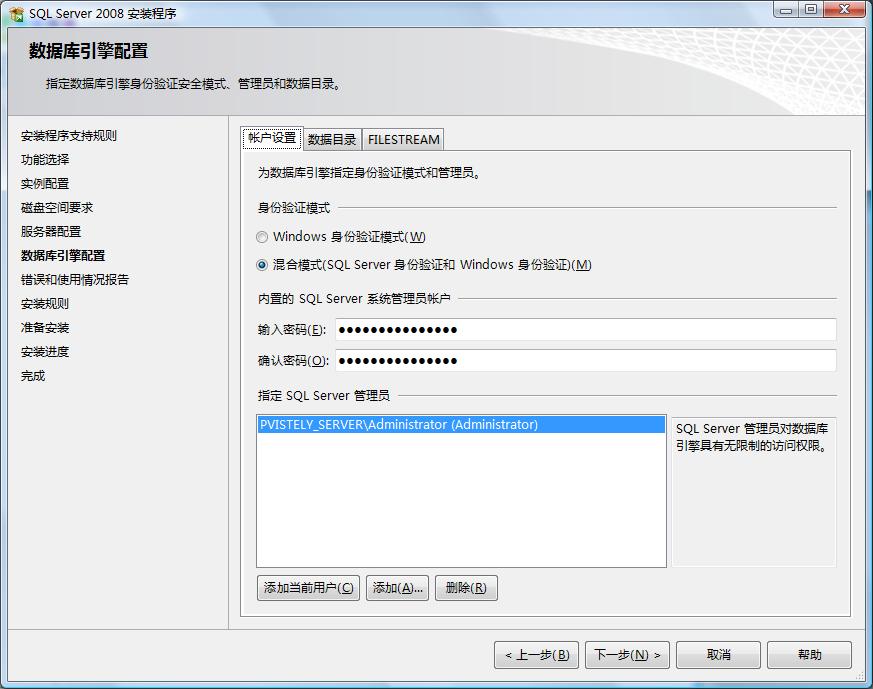
5.数据库引擎配置,在当前配置中主要设置SQL登录验证模式及账户密码,与SQL的数据存储目录,身份验证模式推荐使用混合模式进行验证,在安装过程中内置的SQL Server系统管理员帐户(sa)的密码比较特殊,SQL2008对SA的密码强度要求相对比较高,需要有大小写字母、数字及符号组成,否则将不允许你继续安装。在"指定Sql Server管理员"中最好指定本机的系统管理员administrator。如图
posted @
2013-09-27 13:27 RoyPayne 阅读(275) |
评论 (0) |
编辑 收藏
依次点击设置--高级选项--内容设置--cookies--选择“显示cookies和其他网站数据按钮就可以看到了
firefox:
依次点开FF浏览器工具选项: 工具》选项》隐私》在历史选项框中选择“使用自定义历史记录设置” 进入后,再选择“显示Cookies”.出来一个对话框,里面就是FF记录的所有Cookie。其值你也可以很方便查看到。
posted @
2013-01-28 06:54 RoyPayne 阅读(2953) |
评论 (1) |
编辑 收藏 死锁是一个经典的多线程问题,因为不同的线程都在等待那些根本不可能被释放的锁,
从而导致所有的工作都无法完成。假设有两个线程,分别代表两个饥饿的人,他们必须共享刀叉并轮流吃饭。
他们都需要获得两个锁:共享刀和共享叉的锁。假如线程 "A" 获得了刀,而线程 "B" 获得了叉。
线程 A 就会进入阻塞状态来等待获得叉,而线程 B 则阻塞来等待 A 所拥有的刀。
让所有的线程按照同样的顺序获得一组锁。这种方法消除了 X 和 Y 的拥有者分别等待对方的资源的问题。
将多个锁组成一组并放到同一个锁下。前面死锁的例子中,可以创建一个银器对象的锁。于是在获得刀或叉之前都必须获得这个银器的锁。
将那些不会阻塞的可获得资源用变量标志出来。当某个线程获得银器对象的锁时,就可以通过检查变量来判断是否整个银器集合中的对象锁都可获得。如果是,它就可以获得相关的锁,否则,就要释放掉银器这个锁并稍后再尝试。
最重要的是,在编写代码前认真仔细地设计整个系统。多线程是困难的,在开始编程之前详细设计系统能够帮助你避免难以发现死锁的问题。
posted @
2012-12-10 10:54 RoyPayne 阅读(392) |
评论 (0) |
编辑 收藏<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title> New Document </title>
<meta name="Generator" content="EditPlus">
<meta name="Author" content="">
<meta name="Keywords" content="">
<meta name="Description" content="">
</head>
<script type="text/javascript" src="jquery.js"></script>
<script type="text/javascript">
function go() {
var str="";
$("input[name='checkbox']:checkbox").each(function(){
if($(this).attr("checked")){
str += $(this).val()+","
}
})
//alert(str);
str.split(",");
alert(str[0]);
}
</script>
<body>
<div>
<input type="text" id="content" value="111"/>
<input type="checkbox" name="checkbox" value="1"/>
<input type="checkbox" name="checkbox" value="2"/>
<input type="checkbox" name="checkbox" value="3"/>
<input type="checkbox" name="checkbox" value="4"/>
<input type="checkbox" name="checkbox" value="5"/>
<input type="button" id="test" onclick="go();"/>
</div>
</body>
</html>
posted @
2012-03-02 09:40 RoyPayne 阅读(88907) |
评论 (21) |
编辑 收藏posted @
2012-02-01 14:50 RoyPayne 阅读(382) |
评论 (0) |
编辑 收藏
摘要: oracle脚本:drop table t_student cascade constraints;Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->/*==================================================...
阅读全文
posted @
2012-01-31 13:25 RoyPayne 阅读(2289) |
评论 (2) |
编辑 收藏在Session的缓存中存放的是相互关联的对象图。默认情况下,当Hibernate从数据库中加载Customer对象时,会同时加载所有关联的 Order对象。以Customer和Order类为例,假定ORDERS表的CUSTOMER_ID外键允许为null
以下Session的find()方法用于到数据库中检索所有的Customer对象:
List customerLists=session.find("from Customer as c");
运行以上find()方法时,Hibernate将先查询CUSTOMERS表中所有的记录,然后根据每条记录的ID,到ORDERS表中查询有参照关系的记录,Hibernate将依次执行以下select语句:
select * from CUSTOMERS;
select * from ORDERS where CUSTOMER_ID=1;
select * from ORDERS where CUSTOMER_ID=2;
select * from ORDERS where CUSTOMER_ID=3;
select * from ORDERS where CUSTOMER_ID=4;
通过以上5条select语句,Hibernate最后加载了4个Customer对象和5个Order对象,在内存中形成了一幅关联的对象图.
Hibernate在检索与Customer关联的Order对象时,使用了默认的立即检索策略。这种检索策略存在两大不足:
(1) select语句的数目太多,需要频繁的访问数据库,会影响检索性能。如果需要查询n个Customer对象,那么必须执行n+1次select查询语 句。这就是经典的n+1次select查询问题。这种检索策略没有利用SQL的连接查询功能,例如以上5条select语句完全可以通过以下1条 select语句来完成:
select * from CUSTOMERS left outer join ORDERS
on CUSTOMERS.ID=ORDERS.CUSTOMER_ID
以上select语句使用了SQL的左外连接查询功能,能够在一条select语句中查询出CUSTOMERS表的所有记录,以及匹配的ORDERS表的记录。
(2)在应用逻辑只需要访问Customer对象,而不需要访问Order对象的场合,加载Order对象完全是多余的操作,这些多余的Order对象白白浪费了许多内存空间。
为了解决以上问题,Hibernate提供了其他两种检索策略:延迟检索策略和迫切左外连接检索策略。延迟检索策略能避免多余加载应用程序不需要访问的关联对象,迫切左外连接检索策略则充分利用了SQL的外连接查询功能,能够减少select语句的数目。
对数据库访问还是必须考虑性能问题的, 在设定了1 对多这种关系之后, 查询就会出现传说中的n +1 问题。
1 )1 对多,在1 方,查找得到了n 个对象, 那么又需要将n 个对象关联的集合取出,于是本来的一条sql查询变成了n +1 条
2)多对1 ,在多方,查询得到了m个对象,那么也会将m个对象对应的1 方的对象取出, 也变成了m+1
怎么解决n +1 问题?
1 )lazy=true, hibernate3开始已经默认是lazy=true了;lazy=true时不会立刻查询关联对象,只有当需要关联对象(访问其属性,非id字段)时才会发生查询动作。
2)二级缓存, 在对象更新,删除,添加相对于查询要少得多时, 二级缓存的应用将不怕n +1 问题,因为即使第一次查询很慢,之后直接缓存命中也是很快的。
不同解决方法,不同的思路,第二条却刚好又利用了n +1 。
3) 当然你也可以设定fetch=join(annotation : @ManyToOne() @Fetch(FetchMode.JOIN))
posted @
2012-01-30 14:20 RoyPayne 阅读(10990) |
评论 (1) |
编辑 收藏<!-- Spring security Filter -->
<filter>
<filter-name>springSecurityFilterChain</filter-name>
<filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class>
</filter>
<filter-mapping>
<filter-name>springSecurityFilterChain</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
这个Filter会拦截所有的URL请求,并且对这些URL请求进行Spring Security的验证。
注意,springSecurityFilterChain这个名称是由命名空间默认创建的用于处理web安全的一个内部的bean的id。所以你在你的Spring配置文件中,不应该再使用这个id作为你的bean。
与Acegi的配置不同,Acegi需要自行声明一个Spring的bean来作为Filter的实现,而使用Spring Security后,无需再额外定义bean,而是使用<http>元素进行配置。
通过扩展Spring Security的默认实现来进行用户和权限的管理 事实上,Spring Security提供了2个认证的接口,分别用于模拟用户和权限,以及读取用户和权限的操作方法。这两个接口分别是:UserDetails和UserDetailsService。
public interface UserDetails extends Serializable {
GrantedAuthority[] getAuthorities();
String getPassword();
String getUsername();
boolean isAccountNonExpired();
boolean isAccountNonLocked();
boolean isCredentialsNonExpired();
boolean isEnabled();
}
public interface UserDetailsService {
UserDetails loadUserByUsername(String username)
throws UsernameNotFoundException, DataAccessException;
}
非常清楚,一个接口用于模拟用户,另外一个用于模拟读取用户的过程。所以我们可以通过实现这两个接口,来完成使用数据库对用户和权限进行管理的需求。在这里,我将给出一个使用Hibernate来定义用户和权限之间关系的示例。
posted @
2012-01-20 10:41 RoyPayne 阅读(1758) |
评论 (1) |
编辑 收藏
摘要: Quartz是一个强大的企业级任务调度框架,Spring中继承并简化了Quartz,下面就看看在Spring中怎样配置Quartz:
阅读全文
posted @
2012-01-19 14:53 RoyPayne 阅读(379) |
评论 (0) |
编辑 收藏
1.自定义拦截器继承AbstractInterceptor,重写public String intercept(ActionInvocation invocation)方法。
intercept方法有ActionInvocation对象,可以获取当前的Action请求。
public class AuthorityInterceptor extends AbstractInterceptor {
private static final long serialVersionUID = 1L;
private Logger LOG = Logger.getLogger(AuthorityInterceptor.class.getName());
private AuthorityUtil authorityUtil;
public String intercept(ActionInvocation invocation) throws Exception {
if (authorityUtil == null) {
authorityUtil = new AuthorityUtil();
}
//获取当前用户所有的权限
List<OperatorPurviewDO> operatorPurviews = getCurrentOperatorPurviews();
//获取当前操作的url
String currentUrl = getCurrentUrl();
//如果是超级管理员或有当前url的权限,那么直接返回。
if (OperatorUtil.getIsSuperAdmin() ||(OperatorUtil.getLoginName()!=null&&authorityUtil.checkUrl(operatorPurviews, currentUrl))){
return invocation.invoke();
}
if (!OperatorUtil.getIsSuperAdmin()&&operatorPurviews.size()==0) {
LOG.info("此用户:" + OperatorUtil.getLoginName() + " 没有任何角色,没有权限执行任何功能");
return "loginErr";
}
return "authorityErr";
}
2.struts2.xml 配置interceptor
2.1 定义自定义拦截器
<interceptor name="authorityInterceptor" class="com.wasu.eis.authority.AuthorityInterceptor" />
2.2 加上struts2默认拦截器,形成拦截器栈
<interceptor-stack name="eisManagerBasicStack">
<interceptor-ref name="exception"/>
<interceptor-ref name="alias"/>
<interceptor-ref name="servletConfig"/>
<interceptor-ref name="prepare"/>
<interceptor-ref name="i18n"/>
<interceptor-ref name="chain"/>
<interceptor-ref name="debugging"/>
<interceptor-ref name="profiling"/>
<interceptor-ref name="scopedModelDriven"/>
<interceptor-ref name="modelDriven"/>
<interceptor-ref name="checkbox"/>
<interceptor-ref name="staticParams"/>
<interceptor-ref name ="fileUploadStack" />
<interceptor-ref name="params">
<param name="excludeParams">dojo\..*</param>
</interceptor-ref>
<interceptor-ref name="conversionError"/>
<interceptor-ref name="validation">
<param name="excludeMethods">input,back,cancel,browse</param>
</interceptor-ref>
<interceptor-ref name="workflow">
<param name="excludeMethods">input,back,cancel,browse</param>
</interceptor-ref>
</interceptor-stack>
<interceptor-stack name="authorityInterceptorStack">
<interceptor-ref name="authorityInterceptor" />
<interceptor-ref name="eisManagerBasicStack" />
</interceptor-stack>
3.设置为缺省的拦截器
<default-interceptor-ref name="authorityInterceptorStack"/>
posted @
2012-01-17 16:35 RoyPayne 阅读(2791) |
评论 (0) |
编辑 收藏
摘要: 分页显示一直是web开发中一大烦琐的难题,传统的网页设计只在一个JSP或者ASP页面中书写所有关于数据库操作的代码,那样做分页可能简单一点,但当把网站分层开发后,分页就比较困难了,下面是我做Spring+Hibernate+Struts2项目时设计的分页代码,与大家分享交流。
阅读全文
posted @
2012-01-17 13:56 RoyPayne 阅读(702) |
评论 (1) |
编辑 收藏1.第一个例子:
<s:select list="{'aa','bb','cc'}" theme="simple" headerKey="00" headerValue="00"></s:select>
2.第二个例子:
<s:select list="#{1:'aa',2:'bb',3:'cc'}" label="abc" listKey="key" listValue="value" headerKey="0" headerValue="aabb">
3.第三个例子:
<%
java.util.HashMap map = new java.util.LinkedHashMap();
map.put(1,"aaa");
map.put(2,"bbb");
map.put(3,"ccc");
request.setAttribute("map",map);
request.setAttribute("aa","2");
%>
<s:select list="#request.map" label="abc" listKey="key" listValue="value"
value="#request.aa" headerKey="0" headerValue="aabb"></
s:select
>
headerKey headerValue 为设置缺省值
4.第四个例子
public class Program implements Serializable {
/** serialVersionUID */
private static final long serialVersionUID = 1L;
private int programid;
private String programName;
public int getProgramid() {
return programid;
}
public void setProgramid(int programid) {
this.programid = programid;
}
public String getProgramName() {
return programName;
}
public void setProgramName(String programName) {
this.programName = programName;
}
}
在 xxx extends extends ActionSupport {
private List<Program> programs ;
public List<Program> getPrograms() {
return programs;
}
public void setPrograms(List<Program> programs) {
this.programs = programs;
}
}
在jsp页面
<s:select list="programs " listValue="programName " listKey="programid " name="program" id="program"
headerKey="0l" headerValue=" " value="bean.programid "
></s:select>
红色部分为在action里面的list,黄色为<option value="xxx">value</option>对应bean里面的字段programName
绿色为<option value="xxx",对应bean里面的字段programid
紫色为设定select被选中的值,s:select 会自动在 bean选中 key对应的值
posted @
2012-01-12 15:10 RoyPayne 阅读(287) |
评论 (0) |
编辑 收藏工作中碰到个ConcurrentModificationException。代码如下:
List list = ...;
for(Iterator iter = list.iterator(); iter.hasNext();) {
Object obj = iter.next();
...
if(***) {
list.remove(obj);
}
}
在执行了remove方法之后,再去执行循环,iter.next()的时候,报java.util.ConcurrentModificationException(当然,如果remove的是最后一条,就不会再去执行next()操作了)
下面来看一下源码
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
public interface Collection<E> extends Iterable<E> {
...
Iterator<E> iterator();
boolean add(E o);
boolean remove(Object o);
...
}
这里有两个remove方法
接下来来看看AbstractList
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
//AbstractCollection和List都继承了Collection
protected transient int modCount = 0;
private class Itr implements Iterator<E> { //内部类Itr
int cursor = 0;
int lastRet = -1;
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification(); //特别注意这个方法
try {
E next = get(cursor);
lastRet = cursor++;
return next;
} catch(IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet == -1)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.remove(lastRet); //执行remove对象的操作
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount; //重新设置了expectedModCount的值,避免了ConcurrentModificationException的产生
} catch(IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount) //当expectedModCount和modCount不相等时,就抛出ConcurrentModificationException
throw new ConcurrentModificationException();
}
}
}
remove(Object o)在ArrayList中实现如下:
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++; //只增加了modCount
....
}
所以,产生ConcurrentModificationException的原因就是:
执行remove(Object o)方法之后,modCount和expectedModCount不相等了。然后当代码执行到next()方法时,判断了checkForComodification(),发现两个数值不等,就抛出了该Exception。
要避免这个Exception,就应该使用remove()方法。
这里我们就不看add(Object o)方法了,也是同样的原因,但没有对应的add()方法。一般嘛,就另建一个List了
下面是网上的其他解释,更能从本质上解释原因:
Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出 java.util.ConcurrentModificationException 异常。
所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 Iterator 本身的方法 remove() 来删除对象, Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。
posted @
2012-01-06 17:14 RoyPayne 阅读(238) |
评论 (0) |
编辑 收藏import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
本例介绍一个特殊的队列:BlockingQueue,如果BlockQueue是空的,从BlockingQueue取东西的操作将会被阻断进入等待状态,直到BlockingQueue进了东西才会被唤醒.同样,如果BlockingQueue是满的,任何试图往里存东西的操作也会被阻断进入等待状态,直到BlockingQueue里有空间才会被唤醒继续操作.
本例再次实现11.4线程----条件Condition中介绍的篮子程序,不过这个篮子中最多能放的苹果数不是1,可以随意指定.当篮子满时,生产者进入等待状态,当篮子空时,消费者等待.
*/
/**
使用BlockingQueue的关键技术点如下:
1.BlockingQueue定义的常用方法如下:
1)add(anObject):把anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则招聘异常
2)offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.
3)put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
4)poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null
5)take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到Blocking有新的对象被加入为止
2.BlockingQueue有四个具体的实现类,根据不同需求,选择不同的实现类
1)ArrayBlockingQueue:规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小.其所含的对象是以FIFO(先入先出)顺序排序的.
2)LinkedBlockingQueue:大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue有大小限制,若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定.其所含的对象是以FIFO(先入先出)顺序排序的
3)PriorityBlockingQueue:类似于LinkedBlockQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序.
4)SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成的.
3.LinkedBlockingQueue和ArrayBlockingQueue比较起来,它们背后所用的数据结构不一样,导致LinkedBlockingQueue的数据吞吐量要大于ArrayBlockingQueue,但在线程数量很大时其性能的可预见性低于ArrayBlockingQueue.
*/
public class BlockingQueueTest {
/**定义装苹果的篮子*/
public static class Basket{
//篮子,能够容纳3个苹果
BlockingQueue<String> basket = new ArrayBlockingQueue<String>(3);
//生产苹果,放入篮子
public void produce() throws InterruptedException{
//put方法放入一个苹果,若basket满了,等到basket有位置
basket.put("An apple");
}
//消费苹果,从篮子中取走
public String consume() throws InterruptedException{
//take方法取出一个苹果,若basket为空,等到basket有苹果为止
return basket.take();
}
}
//测试方法
public static void testBasket(){
final Basket basket = new Basket();//建立一个装苹果的篮子
//定义苹果生产者
class Producer implements Runnable{
public void run(){
try{
while(true){
//生产苹果
System.out.println("生产者准备生产苹果: " + System.currentTimeMillis());
basket.produce();
System.out.println("生产者生产苹果完毕: " + System.currentTimeMillis());
//休眠300ms
Thread.sleep(300);
}
}catch(InterruptedException ex){
}
}
}
//定义苹果消费者
class Consumer implements Runnable{
public void run(){
try{
while(true){
//消费苹果
System.out.println("消费者准备消费苹果: " + System.currentTimeMillis());
basket.consume();
System.out.println("消费者消费苹果完毕: " + System.currentTimeMillis());
//休眠1000ms
Thread.sleep(1000);
}
}catch(InterruptedException ex){
}
}
}
ExecutorService service = Executors.newCachedThreadPool();
Producer producer = new Producer();
Consumer consumer = new Consumer();
service.submit(producer);
service.submit(consumer);
//程序运行5s后,所有任务停止
try{
Thread.sleep(5000);
}catch(InterruptedException ex){
}
service.shutdownNow();
}
public static void main(String[] args){
BlockingQueueTest.testBasket();
}
}
posted @
2012-01-06 16:32 RoyPayne 阅读(269) |
评论 (0) |
编辑 收藏 Java? 语言包含两种内在的同步机制:同步块(或方法)和 volatile 变量。这两种机制的提出都是为了实现代码线程的安全性。其中 Volatile 变量的同步性较差(但有时它更简单并且开销更低),而且其使用也更容易出错。在这期的 Java 理论与实践中,Brian Goetz 将介绍几种正确使用 volatile 变量的模式,并针对其适用性限制提出一些建议。 Java 语言中的 volatile 变量可以被看作是一种 “程度较轻的 synchronized”;与 synchronized 块相比,volatile 变量所需的编码较少,并且运行时开销也较少,但是它所能实现的功能也仅是 synchronized 的一部分。本文介绍了几种有效使用 volatile 变量的模式,并强调了几种不适合使用 volatile 变量的情形。 锁提供了两种主要特性:互斥(mutual exclusion)和可见性(visibility)。互斥即一次只允许一个线程持有某个特定的锁,因此可使用该特性实现对共享数据的协调访问协议,这样,一次就只有一个线程能够使用该共享数据。可见性要更加复杂一些,它必须确保释放锁之前对共享数据做出的更改对于随后获得该锁的另一个线程是可见的 —— 如果没有同步机制提供的这种可见性保证,线程看到的共享变量可能是修改前的值或不一致的值,这将引发许多严重问题。Volatile 变量
Volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。这就是说线程能够自动发现 volatile 变量的最新值。Volatile 变量可用于提供线程安全,但是只能应用于非常有限的一组用例:多个变量之间或者某个变量的当前值与修改后值之间没有约束。因此,单独使用 volatile 还不足以实现计数器、互斥锁或任何具有与多个变量相关的不变式(Invariants)的类(例如 “start <=end”)。 出于简易性或可伸缩性的考虑,您可能倾向于使用 volatile 变量而不是锁。当使用 volatile 变量而非锁时,某些习惯用法(idiom)更加易于编码和阅读。此外,volatile 变量不会像锁那样造成线程阻塞,因此也很少造成可伸缩性问题。在某些情况下,如果读操作远远大于写操作,volatile 变量还可以提供优于锁的性能优势。正确使用 volatile 变量的条件
您只能在有限的一些情形下使用 volatile 变量替代锁。要使 volatile 变量提供理想的线程安全,必须同时满足下面两个条件: ● 对变量的写操作不依赖于当前值。 ● 该变量没有包含在具有其他变量的不变式中。 实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。 第一个条件的限制使 volatile 变量不能用作线程安全计数器。虽然增量操作(x++)看上去类似一个单独操作,实际上它是一个由读取-修改-写入操作序列组成的组合操作,必须以原子方式执行,而 volatile 不能提供必须的原子特性。实现正确的操作需要使 x 的值在操作期间保持不变,而 volatile 变量无法实现这点。(然而,如果将值调整为只从单个线程写入,那么可以忽略第一个条件。) 大多数编程情形都会与这两个条件的其中之一冲突,使得 volatile 变量不能像 synchronized 那样普遍适用于实现线程安全。清单 1 显示了一个非线程安全的数值范围类。它包含了一个不变式 —— 下界总是小于或等于上界。
清单 1. 非线程安全的数值范围类
@NotThreadSafe
public class NumberRange {
private int lower, upper;
public int getLower() {
return lower; }
public int getUpper() {
return upper; }
public void setLower(
int value) {
if (value > upper)
throw new IllegalArgumentException(

);
lower = value;
}
public void setUpper(
int value) {
if (value < lower)
throw new IllegalArgumentException(
);
upper = value;
}
}
这种方式限制了范围的状态变量,因此将 lower 和 upper 字段定义为 volatile 类型不能够充分实现类的线程安全;从而仍然需要使用同步。否则,如果凑巧两个线程在同一时间使用不一致的值执行 setLower 和 setUpper 的话,则会使范围处于不一致的状态。例如,如果初始状态是 (0, 5),同一时间内,线程 A 调用 setLower(4) 并且线程 B 调用 setUpper(3),显然这两个操作交叉存入的值是不符合条件的,那么两个线程都会通过用于保护不变式的检查,使得最后的范围值是 (4, 3) —— 一个无效值。至于针对范围的其他操作,我们需要使 setLower() 和 setUpper() 操作原子化 —— 而将字段定义为 volatile 类型是无法实现这一目的的。
性能考虑
使用 volatile 变量的主要原因是其简易性:在某些情形下,使用 volatile 变量要比使用相应的锁简单得多。使用 volatile 变量次要原因是其性能:某些情况下,volatile 变量同步机制的性能要优于锁。 很难做出准确、全面的评价,例如 “X 总是比 Y 快”,尤其是对 JVM 内在的操作而言。(例如,某些情况下 VM 也许能够完全删除锁机制,这使得我们难以抽象地比较 volatile和 synchronized 的开销。)就是说,在目前大多数的处理器架构上,volatile 读操作开销非常低 —— 几乎和非 volatile 读操作一样。而 volatile 写操作的开销要比非 volatile 写操作多很多,因为要保证可见性需要实现内存界定(Memory Fence),即便如此,volatile 的总开销仍然要比锁获取低。 volatile 操作不会像锁一样造成阻塞,因此,在能够安全使用 volatile 的情况下,volatile 可以提供一些优于锁的可伸缩特性。如果读操作的次数要远远超过写操作,与锁相比,volatile 变量通常能够减少同步的性能开销。正确使用 volatile 的模式
很多并发性专家事实上往往引导用户远离 volatile 变量,因为使用它们要比使用锁更加容易出错。然而,如果谨慎地遵循一些良好定义的模式,就能够在很多场合内安全地使用 volatile 变量。要始终牢记使用 volatile 的限制 —— 只有在状态真正独立于程序内其他内容时才能使用 volatile —— 这条规则能够避免将这些模式扩展到不安全的用例。 模式 #1:状态标志 也许实现 volatile 变量的规范使用仅仅是使用一个布尔状态标志,用于指示发生了一个重要的一次性事件,例如完成初始化或请求停机。 很多应用程序包含了一种控制结构,形式为 “在还没有准备好停止程序时再执行一些工作”,如清单 2 所示: 清单 2. 将 volatile 变量作为状态标志使用
volatile boolean shutdownRequested;
public void shutdown() { shutdownRequested =
true; }
public void doWork() {
while (!shutdownRequested) {
// do stuff
}
}
很可能会从循环外部调用 shutdown() 方法 —— 即在另一个线程中 —— 因此,需要执行某种同步来确保正确实现 shutdownRequested 变量的可见性。(可能会从 JMX 侦听程序、GUI 事件线程中的操作侦听程序、通过 RMI 、通过一个 Web 服务等调用)。然而,使用 synchronized 块编写循环要比使用清单 2 所示的 volatile 状态标志编写麻烦很多。由于 volatile 简化了编码,并且状态标志并不依赖于程序内任何其他状态,因此此处非常适合使用 volatile。 这种类型的状态标记的一个公共特性是:通常只有一种状态转换;shutdownRequested 标志从 false 转换为 true,然后程序停止。这种模式可以扩展到来回转换的状态标志,但是只有在转换周期不被察觉的情况下才能扩展(从 false 到 true,再转换到 false)。此外,还需要某些原子状态转换机制,例如原子变量。 模式 #2:一次性安全发布(one-time safe publication) 缺乏同步会导致无法实现可见性,这使得确定何时写入对象引用而不是原语值变得更加困难。在缺乏同步的情况下,可能会遇到某个对象引用的更新值(由另一个线程写入)和该对象状态的旧值同时存在。(这就是造成著名的双重检查锁定(double-checked-locking)问题的根源,其中对象引用在没有同步的情况下进行读操作,产生的问题是您可能会看到一个更新的引用,但是仍然会通过该引用看到不完全构造的对象)。 实现安全发布对象的一种技术就是将对象引用定义为 volatile 类型。清单 3 展示了一个示例,其中后台线程在启动阶段从数据库加载一些数据。其他代码在能够利用这些数据时,在使用之前将检查这些数据是否曾经发布过。 清单 3. 将 volatile 变量用于一次性安全发布
public class BackgroundFloobleLoader {
public volatile Flooble theFlooble;
public void initInBackground() {
// do lots of stuff
theFlooble =
new Flooble();
// this is the only write to theFlooble
}
}
public class SomeOtherClass {
public void doWork() {
while (
true) {
// do some stuff
// use the Flooble, but only if it is ready
if (floobleLoader.theFlooble !=
null)
doSomething(floobleLoader.theFlooble);
}
}
}
如果 theFlooble 引用不是 volatile 类型,doWork() 中的代码在解除对 theFlooble 的引用时,将会得到一个不完全构造的 Flooble。 该模式的一个必要条件是:被发布的对象必须是线程安全的,或者是有效的不可变对象(有效不可变意味着对象的状态在发布之后永远不会被修改)。volatile 类型的引用可以确保对象的发布形式的可见性,但是如果对象的状态在发布后将发生更改,那么就需要额外的同步。 模式 #3:独立观察(independent observation) 安全使用 volatile 的另一种简单模式是:定期 “发布” 观察结果供程序内部使用。例如,假设有一种环境传感器能够感觉环境温度。一个后台线程可能会每隔几秒读取一次该传感器,并更新包含当前文档的 volatile 变量。然后,其他线程可以读取这个变量,从而随时能够看到最新的温度值。 使用该模式的另一种应用程序就是收集程序的统计信息。清单 4 展示了身份验证机制如何记忆最近一次登录的用户的名字。将反复使用 lastUser 引用来发布值,以供程序的其他部分使用。 清单 4. 将 volatile 变量用于多个独立观察结果的发布 public class UserManager {
public volatile String lastUser;
public boolean authenticate(String user, String password) {
boolean valid = passwordIsValid(user, password);
if (valid) {
User u = new User();
activeUsers.add(u);
lastUser = user;
}
return valid;
}
}
该模式是前面模式的扩展;将某个值发布以在程序内的其他地方使用,但是与一次性事件的发布不同,这是一系列独立事件。这个模式要求被发布的值是有效不可变的 —— 即值的状态在发布后不会更改。使用该值的代码需要清楚该值可能随时发生变化。 模式 #4:“volatile bean” 模式 volatile bean 模式适用于将 JavaBeans 作为“荣誉结构”使用的框架。在 volatile bean 模式中,JavaBean 被用作一组具有 getter 和/或 setter 方法 的独立属性的容器。volatile bean 模式的基本原理是:很多框架为易变数据的持有者(例如 HttpSession)提供了容器,但是放入这些容器中的对象必须是线程安全的。 在 volatile bean 模式中,JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 方法必须非常普通 —— 除了获取或设置相应的属性外,不能包含任何逻辑。此外,对于对象引用的数据成员,引用的对象必须是有效不可变的。(这将禁止具有数组值的属性,因为当数组引用被声明为 volatile 时,只有引用而不是数组本身具有 volatile 语义)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性。清单 5 中的示例展示了遵守 volatile bean 模式的 JavaBean: 清单 5. 遵守 volatile bean 模式的 Person 对象
@ThreadSafe
public class Person {
private volatile String firstName;
private volatile String lastName;
private volatile int age;
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
public int getAge() { return age; }
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public void setAge(int age) {
this.age = age;
}
}
volatile 的高级模式 前面几节介绍的模式涵盖了大部分的基本用例,在这些模式中使用 volatile 非常有用并且简单。这一节将介绍一种更加高级的模式,在该模式中,volatile 将提供性能或可伸缩性优势。 volatile 应用的的高级模式非常脆弱。因此,必须对假设的条件仔细证明,并且这些模式被严格地封装了起来,因为即使非常小的更改也会损坏您的代码!同样,使用更高级的 volatile 用例的原因是它能够提升性能,确保在开始应用高级模式之前,真正确定需要实现这种性能获益。需要对这些模式进行权衡,放弃可读性或可维护性来换取可能的性能收益 —— 如果您不需要提升性能(或者不能够通过一个严格的测试程序证明您需要它),那么这很可能是一次糟糕的交易,因为您很可能会得不偿失,换来的东西要比放弃的东西价值更低。 模式 #5:开销较低的读-写锁策略 目前为止,您应该了解了 volatile 的功能还不足以实现计数器。因为 ++x 实际上是三种操作(读、添加、存储)的简单组合,如果多个线程凑巧试图同时对 volatile 计数器执行增量操作,那么它的更新值有可能会丢失。 然而,如果读操作远远超过写操作,您可以结合使用内部锁和 volatile 变量来减少公共代码路径的开销。清单 6 中显示的线程安全的计数器使用 synchronized 确保增量操作是原子的,并使用 volatile 保证当前结果的可见性。如果更新不频繁的话,该方法可实现更好的性能,因为读路径的开销仅仅涉及 volatile 读操作,这通常要优于一个无竞争的锁获取的开销。 清单 6. 结合使用 volatile 和 synchronized 实现 “开销较低的读-写锁” @ThreadSafe
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatileint value;
public int getValue() { return value; }
public synchronizedint increment() {
return value++;
}
}
之所以将这种技术称之为 “开销较低的读-写锁” 是因为您使用了不同的同步机制进行读写操作。因为本例中的写操作违反了使用 volatile 的第一个条件,因此不能使用 volatile 安全地实现计数器 —— 您必须使用锁。然而,您可以在读操作中使用 volatile 确保当前值的可见性,因此可以使用锁进行所有变化的操作,使用 volatile 进行只读操作。其中,锁一次只允许一个线程访问值,volatile 允许多个线程执行读操作,因此当使用 volatile 保证读代码路径时,要比使用锁执行全部代码路径获得更高的共享度 —— 就像读-写操作一样。然而,要随时牢记这种模式的弱点:如果超越了该模式的最基本应用,结合这两个竞争的同步机制将变得非常困难。 结束语 与锁相比,Volatile 变量是一种非常简单但同时又非常脆弱的同步机制,它在某些情况下将提供优于锁的性能和伸缩性。如果严格遵循 volatile 的使用条件 —— 即变量真正独立于其他变量和自己以前的值 —— 在某些情况下可以使用 volatile 代替 synchronized 来简化代码。然而,使用 volatile 的代码往往比使用锁的代码更加容易出错。本文介绍的模式涵盖了可以使用 volatile 代替 synchronized 的最常见的一些用例。遵循这些模式(注意使用时不要超过各自的限制)可以帮助您安全地实现大多数用例,使用 volatile 变量获得更佳性能。
posted @
2012-01-06 10:44 RoyPayne 阅读(340) |
评论 (1) |
编辑 收藏