类设计
软件中起关键作用的类为CharCollector字符收集器类、SimpleDOMParser解析内核类和Manager中间层控制类。
字符收集器类
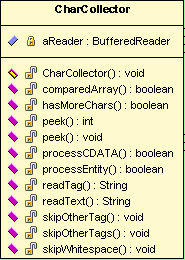
字符收集器类是软件的底层类,它与XML文件交互,读取文件中的字符信息,经过处理,形成标签,文本,属性等数据为上层提供服务。
成员变量介绍:
aReader:Reader对象,输入流为文件输入流,它将XML文件的字符数据以流的形式提供给类。
成员方法介绍:
comparedArray(): 输入:两个int型数组,输出:boolean型,返回两个数组是否相同。用于比较两个数组是否相同,在方法中,对两个数组的数逐一比较。
hasMoreChars(): 输入:无,输出:boolean型,表示文件中是否还有字符,该方法用于确定文件中是否还有字符。
peek(): 输入:int型数组。用于存储窥探到的字符,输出:无,该方法用于从文件中窥探数组长度的字符数据。窥探就是从文件中读取数据后,将输入流标记回以前的位置,以免丢失数据。
算法简述:
在aReader上标记数组的长度
aReader.mark(buffer.length);
2、将数据依次读入数组
for (int i = 0; i < buffer.length; i++) {
buffer[i] = aReader.read();
}
恢复aReader
aReader.reset();
peek(): 输入:无,输出:int型,是窥探到的字符,该方法从文件中窥探一个字符数据。
processCDATA(): 输入:StringBuffer型,用于存放CDATA数据,输出:无,用于处理XML文件中的CDATA节点。得到的CDATA节点存放到StringBuffer对象中。
算法简述:
预设两个数组
int[] cdataHead = {'<', '!', '[', 'C', 'D', 'A', 'T', 'A', '['};
int[] cdataTail = {']', ']', '>'};
窥探cdataHead长度的字符存在数组buf中
peek(buf);
比较buf与cdataHead数组的内容是否相同,如果不同返回falase,如果相同继续执行。
将aReader跳过cdataHead的长度,然后循环读取直到窥探的字符数组与cdataTail相同,将中间的字符存放到StringBuffer对象中。
while (true) {
peek(buf);
if (comparedArray(buf, cdataTail)) {
aReader.skip(cdataTail.length);
flag = true;
break;
} else {
bufChar = aReader.read();
if (bufChar == -1) {
throw new IOException("CDATA node without end tag");
}
sb.append((char) bufChar);
}
}
processEntity(): 输入:StringBuffer型,用于存放实体数据,输出:无,用语处理XML文件中的内建实体类型。得到的实体存放到StringBuffer对象中。
readTag(): 输入:无,输出:String型,是读到的标签,从XML文件中读取并整理成一个标签数据存放在String对象中。
算法简述:
窥探一个字符,如果不是’<’,抛出异常。否则继续执行。
int nextChar = peek();
if (nextChar != '<') {
throw new IOException("expect '<',but got '" + (char) nextChar +"'");
}
窥探一个字符aChar
int aChar = peek();
如果字符为’<’,进行CDATA节点处理
if (aChar == '<') {
if (processCDATA(sb)) {
aChar = peek();
continue;
}
}
如果字符为’&’,进行内建实体处理
if (aChar == '&') {
if (processEntity(sb)) {
aChar = peek();
continue;
}
}
如果字符为’>’或文件结束,返回StringBuffer对象。
如果是其它字符,加入到StringBuffer对象中。
readText(): 输入:无,输出:String型,是读到的文本内容,从XML文件中读取并整理成一个文本数据存放在Sting对象中。
skipOtherTag(): 输入:无,输出:无,跳过一个不处理的标签。
skipOtherTags(): 输入:无,输出:无,跳过多个不处理的标签。
skipWhitespace():输入:无,输出:无,跳过空格。
解析内核类
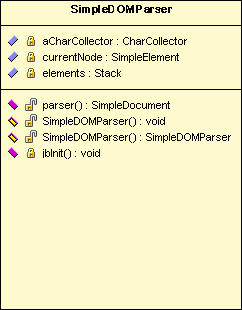
该类用于解析XML文件,包含parser()方法,是该类的核心方法。
成员变量介绍:
aCharCollector:CharCollector类对象,负责字符收集。
currentNode: SimpleElement类对象,表示当前处理的元素。
Elements: Stack类对象,用栈的存储结构,表示元素之间的层次关系。
成员方法介绍:
Parser(): 输入:无,输出:SimpleDocument类对象,是返回的整个文档树型结构。
算法简述:
1、读取一个标签
2、判断是开始标签还是结束标签,如果是结束标签,转入结束标签处理3
如果是开始标签,转入开始标签处理6
3、得到标签的名称,判断是否与currentNode的名称相同,如果相同,执行
4,否则抛出异常
4、判断是否还有标签,如果有继续执行5,否则退出。
5、从栈中弹出一个节点给currentNode,执行1
6、得到标签的名称,属性,文本内容,将标签加入到DOM树中,并且压栈。
执行1
算法的程序流程图

中间层管理类
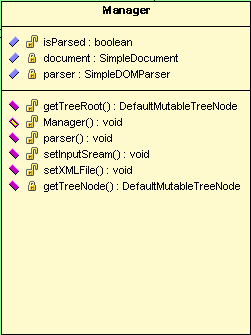
中间层管理类用于控制和协调解析器与用户界面。
成员变量介绍:
isParsered: boolean型,判断是否已经解析过了。
document: SimpleDocument型对象,表示整个XML文档树,也是解析器返回的。
parser: SimpleDOMParser型对象,表示解析器。
成员方法介绍:
getTreeRoot(): 输入:无,输出:DefaultMutableTreeNode型对象,是得到的树的根节点,用于得到树的根节点。
parser(): 输入:无,输出:无,用于执行解析操作。
setInputStream(): 输入:InputStream型对象,是要设置的输入流,输出:无,用于设置解析源。
setXMLFile(): 输入:File型对象,是要设置的XML文件,输出:无,用于设置XML文件源。
getTreeNode(): 输入:SimpleElement型对象,是要转换的对象,输出:DefaultMutableTreeNode型对象,是转换后的对象,用
于转换相应元素为树的节点对象。