倒排文件(Inverted file)描述了一个词项集合(TERMS)元素和一个文档集合(DOCS)元素对应关系的数据结构。在倒排文件中,可以直接给出一个Term出现在哪些Document中,和在某个Document中出现的位置和频率。在Lucene 2.1中InvertDoucment会对文档进行倒排处理。
下面是信息检索研究中常用的几个相关量:
N:文档集合的大小
M:词项集合的大小
Sj=|PL(tj)|:词项tj所涉及文档的个数
DF(tj)=sj/N:词项tj的文档频率
IDF(tj)=-logDF(tj):倒置文档频率;其值越小表示出现的频率越高
fi,j:第j个词项tj在第i个文档di中出现的次数
TN=
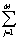 fi,j:系统所有文档分解后包含词项的总量(包括重复,即一个多重集(multi-set))
fi,j:系统所有文档分解后包含词项的总量(包括重复,即一个多重集(multi-set))
TF(tj)=(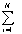 fi,j)/TN:词项tj在文档中出现的频度(词频)
fi,j)/TN:词项tj在文档中出现的频度(词频)
ITF(tj)=logTF(tj):倒置词频;越小表示出现的频率越高
倒排文件分为两部分:第一部分是由不同词项组成的索引,称为词表(Vocabulary),第二部分由每个词项出现过的文档集合构成,称为记录文件(Posting File),每个词项的对应部分称为倒排表(Posting Lists),可以通过词表访问。
posted on 2007-06-11 08:14
Terry Liang 阅读(2758)
评论(0) 编辑 收藏 所属分类:
Lucene 2.1研究