1.在10g中,如果启用了归档模式,则自动归档,即使log_archive_start为false
2.在9i中要启用自动归档的话,需要alter system archive log start to '/path'
3.如果数据库设置了db_recovery_file_dest,就不能设置log_archive_dest
4.默认的归档日志存放于db_recovery_file_dest中,如果设置了log_archive_dest_n,那么归档日志不再存放于db_recovery_file_dest中,而是存放于设置的log_archive_dest_n目录中,如果想要归档日志继续存放在db_recovery_file_dest中,可以通过如下命令
alter system set log_archive_dest_2='location=USE_DB_RECOVERY_FILE_DEST';
5.log_archive_dest只能与 log_archive_duplex_dest共存,作用一样
6.如果设置的log_archive_dest_n不正确,那么ORACLE会在设置的上一级目录归档
7.指定多个archive进程工作 log_archive_max_process,最多10个
8.alter system archive log current通知server process去将写满的联机重做日志归档,用于手工归档
9.归档日志格式(log_archive_format):s/S:log sequence number,t/T:thread number,如果为单实例的话,thread===1
posted @
2011-05-02 10:31 xrzp 阅读(258) |
评论 (0) |
编辑 收藏NOARCHIVELOG 模式
缺省情况下,数据库是以NOARCHIVELOG 模式创建的。
1.在NOARCHIVELOG 模式下操作数据库时有以下特性:
(1)重做日志文件以循环的方式使用。
(2)重做日志文件可以在检查点发生之后立即重新使用。
(3)重做日志被覆盖后,介质恢复将只能恢复到上一次完全备份。
2.NOARCHIVELOG 模式的含义
(1)如果某个表空间由于故障而不可用,将无法继续对数据库进行操作,除非删除了该表空间或从备份还原了整个数据库。
(2)只能在数据库关闭时对数据库执行操作系统备份。而且,必须使用NORMAL、IMMEDIATE 或TRANSACTIONAL 选项关闭数据库。
(3)必须在每次备份时完整备份所有的数据文件和控制文件。尽管也可以备份联机重做日志文件,但这是不必要的。由于此类备份中日志文件是一致的,无需恢复,因此,不需要备份联机日志。
(4)如果联机重做日志文件已被覆盖,则将丢失上次完全备份后的所有数据。
3.NOARCHIVELOG 模式下的介质恢复选项
必须从数据库的完全备份中还原数据文件和控制文件。如果使用导出实用程序来备份数
据库,则可使用导入实用程序还原丢失的数据。但是,通过这种方法恢复的数据并不完
整,在导出后执行的事务处理工作将丢失。
ARCHIVELOG 模式
在发生检查点并且已经通过ARCn 后台进程备份重做日志文件之前,不能重新使用填满的重做日志文件。控制文件中将有一个条目记录归档日志文件的日志序列号。
对数据库的最新更改在任何时候均可用于例程恢复,而归档重做日志文件可以用于介质恢复。
1.归档要求
(1)数据库必须处于ARCHIVELOG 模式。通过发出命令将数据库置于ARCHIVELOG 模式可以更新控制文件。可以启用ARCn 后台进程来实现自动归档。
(2)应该有足够的资源来存放生成的归档重做日志文件。
2.将数据库设置为ARCHIVELOG 模式的含义
(1)出现介质故障时,可以防止数据库丢失数据。
(2)可以在数据库联机时对其进行备份。
(3)由于介质故障导致表空间(非SYSTEM)脱机时,数据库的其余部分仍可用,因为表空间(非SYSTEM)可以在数据库打开时恢复。
3.介质恢复选项
(1)无论数据库处于联机或脱机状态,都可以还原损坏文件的备份副本,并使用归档日志文件将数据文件更新为当前的版本。
(2)可以将数据库恢复至特定的时间点。
(3)可以将数据库恢复至指定归档日志文件的末尾。
(4)可以将数据库恢复至特定的系统更改号(SCN)。
4.在设置归档日志模式时,应该考虑以下因素:
下述情况中,NOARCHIVELOG 模式可能比较合适:
(1)容许备份之间的数据损失(在开发、培训期间等)
(2)重新应用事务处理(从批处理文件)的速度更快
(3)数据极少更改(非OLTP)
下述情况中,ARCHIVELOG 模式则更合适:
(1)无法关闭数据库以执行关闭的数据库的备份
(2)不允许数据损失
(3) 使用归档重做日志文件比重新应用事务处理(OLTP) 更易于恢复
posted @
2011-05-02 01:20 xrzp 阅读(611) |
评论 (0) |
编辑 收藏RAID 0+ 1
优点:
正常使用中,考虑性能上讲,RAID0+1 好,就是先做RAID 0 条带,再做 RAID 1 MIRROR,这样写入速度快,读的速度和RAID1+0一样.
缺点,一旦一个硬盘坏了,一半的硬盘无法工作,如果1个条带上各坏1个硬盘(RAID0+1只有2个条带),GAME OVER....即使是只有一个硬盘坏了,做数据恢复也很慢,因为一半的硬盘要rebuild(大家该知道为什么吧).
RAID 1+0
优点 数据安全性好,只要不是1个条带上的2个硬盘同时坏,没有问题,还可以继续跑数据.数据恢复快.
缺点 写性能稍微比RAID 0+1 差(读性能一样)
这里举个例子,20个硬盘
做RAID 0+1,共2个条带做MIRROR,每个条带10个硬盘,如果坏了1个硬盘,只能是另外一个完好的条带(10个硬盘)同时工作,这边条带9个好的硬盘也要休息.
做RAID 1+0,共10个条带,每个条带2个硬盘做MIRROR,如果坏了1个硬盘,没关系,其它19个硬盘还要同时工作,只要不是坏在一个MIRROR里面的,没事.
建议,硬盘很多时,同时坏的几率就比较大,建议使用安全系数高的RAID 1+0,宁愿损失点性能(其实差不多).
如果仅仅是4块硬盘或者不考虑安全,不是关键业务,只是为了追求速度快感,你可以选择RAID 0+1
posted @
2011-04-28 11:14 xrzp 阅读(212) |
评论 (0) |
编辑 收藏RAID是通过磁盘阵列与数据条块化方法相结合,以提高数据可用率的一种结构.IBM早于1970年就开始研究此项技术.RAID 可分为RAID级别1到RAID级别6, 通常称为:RAID 0, RAID 1, RAID 2, RAID 3,RAID 4, RAID 5,RAID6.每一个RAID级别都有自己的强项和弱项. "奇偶校验"定义为用户数据的冗余信息, 当硬盘失效时,可以重新产生数据.
RAID 0: RAID 0 并不是真正的RAID结构, 没有数据冗余. RAID 0 连续地分割数据并并行地读/写于多个磁盘上. 因此具有很高的数据传输率. 但RAID 0在提高性能的同时,并没有提供数据可靠性,如果一个磁盘失效,将影响整个数据.因此RAID 0 不可应用于需要数据高可用性的关键应用.
RAID 1: RAID 1通过数据镜像实现数据冗余,在两对分离的磁盘上产生互为备份的数据. RAID 1可以提高读的性能, 当原始数据繁忙时,可直接从镜像拷贝中读取数据.RAID 1是磁盘阵列中费用最高的, 但提供了最高的数据可用率. 当一个磁盘失效,系统可以自动地交换到镜像磁盘上, 而不需要重组失效的数据.
RAID 2: 从概念上讲, RAID 2 同RAID 3类似, 两者都是将数据条块化分布于不同的硬盘上, 条块单位为位或字节.然而RAID 2 使用称为"加重平均纠错码"的编码技术来提供错误检查及恢复.这种编码技术需要多个磁盘存放检查及恢复信息, 使得RAID 2技术实施更复杂.因此,在商业环境中很少使用.
RAID 3: 不同于RAID 2, RAID 3使用单块磁盘存放奇偶校验信息. 如果一块磁盘失效, 奇偶盘及其他数据盘可以重新产生数据. 如果奇偶盘失效,则不影响数据使用.RAID 3对于大量的连续数据可提供很好的传输率, 但对于随机数据, 奇偶盘会成为写操作的瓶颈.
RAID 4: 同RAID 2, RAID 3一样, RAID 4, RAID 5也同样将数据条块化并分布于不同的磁盘上, 但条块单位为块或记录. RAID 4使用一块磁盘作为奇偶校验盘, 每次写操作都需要访问奇偶盘, 成为写操作的瓶颈. 在商业应用中很少使用.
RAID 5: RAID 5没有单独指定的奇偶盘, 而是交叉地存取数据及奇偶校验信息于所有磁盘上.在RAID5 上, 读/写指针可同时对阵列设备进行操作, 提供了更高的数据流量.RAID 5更适合于小数据块, 随机读写的数据.RAID 3 与RAID 5相比, 重要的区别在于RAID 3每进行一次数据传输,需涉及到所有的阵列盘.而对于RAID 5来说, 大部分数据传输只对一块磁盘操作, 可进行并行操作.在RAID 5中有"写损失", 即每一次写操作,将产生四个实际的读/写操作, 其中两次读旧的数据及奇偶信息, 两次写新的数据及奇偶信息.
RAID 6: RAID 6 与RAID 5相比,增加了第二个独立的奇偶校验信息块. 两个独立的奇偶系统使用不同的算法, 数据的可靠性非常高.即使两块磁盘同时失效,也不会影响数据的使用.但需要分配给奇偶校验信息更大的磁盘空间, 相对于RAID 5有更大的"写损失".RAID 6 的写性能非常差, 较差的性能和复杂的实施使得RAID 6很少使用.
posted @
2011-04-28 11:12 xrzp 阅读(198) |
评论 (0) |
编辑 收藏
web服务器数据库服务器分离-->垂直分割(按功能)-->分布式(按用户数)-->增加数据缓存层
页面静态化(apache?)
存储分离,页面图片分开
数据库的水平分割和垂直分割
各层的缓存技术:Oracle(cache group),hibernate(session缓存,sessionFactory缓存,好像名字叫Ehcache ),memcache,oscache
负载均衡:集群? 7层模型每一层都有解决方案
posted @
2011-04-28 11:05 xrzp 阅读(207) |
评论 (0) |
编辑 收藏这个类型支持前后滚动取得纪录next()、previous(),回到第一行first(),同时还支持要去的ResultSet中的第几行absolute(int n),以及移动到相对当前行的第几行relative(int n),要实现这样的ResultSet在创建Statement时用如下的方法。
Statement st = conn.createStatement(int resultSetType, int resultSetConcurrency)
ResultSet rs = st.executeQuery(sqlStr)
其中两个参数的意义是:
resultSetType是设置ResultSet对象的类型可滚动,或者是不可滚动。取值如下:
ResultSet.TYPE_FORWARD_ONLY只能向前滚动
ResultSet.TYPE_SCROLL_INSENSITIVE和Result.TYPE_SCROLL_SENSITIVE这两个方法都能够实现任意的前后滚动,使用各种移动的ResultSet指针的方法。二者的区别在于前者对于修改不敏感,而后者对于修改敏感。
resultSetConcurency是设置ResultSet对象能够修改的,取值如下:
ResultSet.CONCUR_READ_ONLY 设置为只读类型的参数。
ResultSet.CONCUR_UPDATABLE 设置为可修改类型的参数。
所以如果只是想要可以滚动的类型的Result只要把Statement如下赋值就行了。
Statement st = conn.createStatement(Result.TYPE_SCROLL_INSENITIVE,
ResultSet.CONCUR_READ_ONLY);
ResultSet rs = st.excuteQuery(sqlStr);
posted @
2011-01-10 17:19 xrzp 阅读(432) |
评论 (1) |
编辑 收藏
我们根据统计信息的详细程度可以设置不同的级别,每种级别见STATS$level_DESCRIPTION;
0: 一性性能统计:包含回退段状态、字典缓存、SGA、系统事件、后台事件、会话事件、系统统计、等待统计、锁统计、闩锁统计
5: 增加了收集SQL的信息、并包括0级收集的信息。
6: 增强了在SQL收集信息方面的功能(列出占用资源较高的SQL),并包所有低级别的信息。
7 增加了收集段级别的统计信息(如段的逻辑读与物理读、行锁、ITL及buffer busy waits), 并包括所有低级别的信息。
10 : 增加了收集子LATCH锁的信息,并包括所有低级别的信息。
如果你收用statspack确定热表及热索引,那就需要使用7/10的级别来收集快照。
9I默认是5级
我们可以手工修改这个级别:
永久修改收集级别
SQL>EXECUTE STATSPACK.SNAP(I_SNAP_LEVEL=>0,I_MODIFY_PARAMETER=>’TRUE’);
临时修改
SQL>EXECUTE STATSPACK.SNAP(I_SNAP_LEVEL=>0);
posted @
2010-12-26 22:31 xrzp 阅读(382) |
评论 (0) |
编辑 收藏一些常用的动态性能试图
1.先来张总的
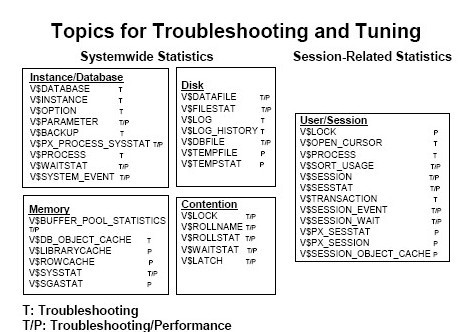
2.
实例级别统计
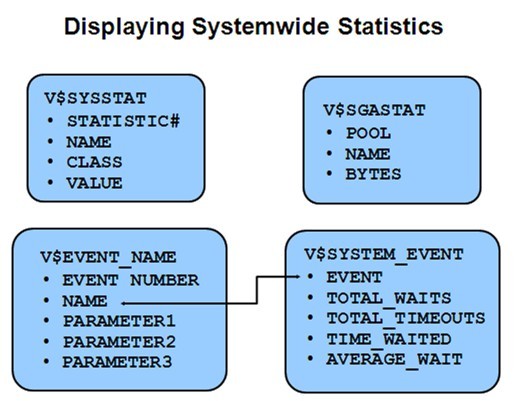
上面两个框是系统统计信息,包括了一些性能指标,有STAT关键字
下面两个框是事件统计信息,有EVENT关键字,包括了各种不同类型的等待事件信息
3.会话级别统计

上面三个框是会话的系统统计信息,包括了一些性能指标,有STAT关键字。
下面三个框是会话的事件统计信息,包括了该会话各种不同类型的等待事件信息,有EVENT或WAIT关键字。
4.这些事件都列在V$EVENT_NAME视图中,拥有以下字段:
EVENT#
事件号
NAME
事件名
PARAMETER1
第一个参数名
PARAMETER2
第二个参数名
PARAMETER3
第三个参数名

5.事件统计信息
V$SYSTEM_EVENT: 所有会话对一个事件的总等待,它是累计信息。
V$SESSION_EVENT: 每个会话对一个事件的总等待,它是累计信息。
V$SESSION_WAIT:正在等待的当前活动对一个事件的等待,它是实时状态。
6.V$SYSTEM_EVENT:整个实例某个特定等待事件的统计值

7.V$SESSION_EVENT:
某个会话特定等待事件的统计值

8. V$SESSION_WAIT :当前会话正在等待的事件及统计信息,我们通过它能准确的发现当前性能问题的现象是什么
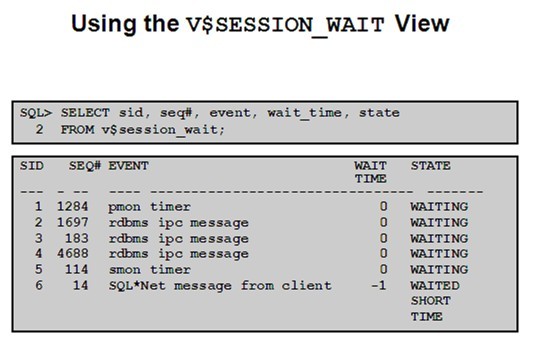
WAIT_TIME
非0:最近一次等待的时间, (当STATE为waited known time,单位为厘秒)
0:当前正在等待
STATE
waiting:
正在等待中,该状态,通常seconds_in_wait会有值
waited known time:
现在已经不等待了,但提供了详细的等待信息
waited short time:
现在已经不等待了,但提供了简短的等待信息
posted @
2010-12-26 22:30 xrzp 阅读(251) |
评论 (0) |
编辑 收藏
一.调优的目标:
1.减少响应时间
2.减少数据库块访问
3.尽量把常用的块CACHE到内存中,提高访问的速度
4.提高OLTP的吞吐量
5.设置系统的负载
二.数据库的系统响应时间:
response time = service time + wait time
service's meaning:cpu used by this session
 select * from v$sysstat t where t.name ='CPU used by this session';
select * from v$sysstat t where t.name ='CPU used by this session';
时间单位:9i以后单位是百万分之一秒
其中
Service Time = SQL解析时间 + 递归调用时间 + 其他时间
1.视图的使用
--实例级系统性能视图:v$sysstat
使用:(以CPU used by this session为例)
select * from v$sysstat t where t.name ='CPU used by this session';
--会话级系统性能试图:
select a.STATISTIC# from v$statname a where a.NAME like '%CPU used by this session%';
找到STATISTIC#,代入到下面
--当前所有session的
select * from v$sesstat b where b.STATISTIC# = &STATISTIC#;
--自己的session的
select * from v$mystat c where c.STATISTIC# = &STATISTIC#;
--或者直接
select b.sid, a.STATISTIC#, a.name, b.value
from v$statname a, v$mystat b
where a.STATISTIC# = b.STATISTIC#;
and a.name like '%xxxxxxx%'
2.sql解析时间(sql解析过程..比较重要,后面专门写一篇)
select name, sid, value "Total parse Cpu time"
from v$statname a, v$mystat b
where a.name like '%parse%'
and a.statistic# = b.statistic#
3.递归调用时间是用在语义分析阶段查找数据字典或者PLSQL内部包造成的解析所花的CPU时间
select * from v$statname a where a.NAME like '%recursive cpu%';
实例级和会话级查询方法同上
4.其它CPU时间:通常占绝大多数,它是执行内存BUFFER搜索,索引和全表扫描涉及的IO操作所占有的CPU
select a.VALUE as "Total CPU",
b.VALUE as "Parse CPU",
c.VALUE as "Recursive CPU",
a.VALUE - b.VALUE - c.VALUE as "Others"
from v$sysstat a, v$sysstat b, v$sysstat c
where a.NAME = 'CPU used by this session'
and b.NAME = 'parse time cpu'
and c.NAME = 'recursive cpu usage';
5.等待常是由于并发,需要等待别的会话处理完独占的资源后所花的时间,这通常也是最常见的性能问题.
如果等待时间(wait time)占响应时间(Pesponse time)的大多数时,我们需要减小等待时间来提高系统性能。我们需要剥离等待时间来分析和优化等待时间
select d.EVENT, d.TIME_WAITED, d.AVERAGE_WAIT
from v$system_event d
where d.EVENT not in
('pmon timer', 'rdbms ipc message', 'smon timer',
'virtual circuit status', 'SQL*Net message from client')
not in 里面的event通常被认为是不会产生等待的事件
三.相关视图
1.v$sysstat
这个使徒列出系统统计数据.为找到与每个统计数据号(STATISTIC#)关联的统计数据
名称,请参阅V$STATNAME.
列 数据类型 说明
STATISTIC# NUMBER 统计数据号
NAME VARCHAR2 统计数据名
CLASS NUMBER 统计数据类别:1(用户);2(重做);
4(排队);8(高速缓存);16(操
作系统);32(并行服务器);64
(SQL);128(调试)
VALUE NUMBER 统计数据值
CLASS NUMBER 统计数据类别:
2.v$sesstat
这个视图给出用户会话的统计数据.为了找到与每个统计数据号(STATISTIC#)有关的
统计数据名称,请参阅V$STATNAME.
列 数据类型 说明
SID NUMBER 会话标识符
STATISTIC# NUMBER 统计数据名(标识符)
VALUE NUMBER 统计数据值
3.v$mystat
这个视图包含当前会话的统计数据。
列 数据类型 说明
SID NUMBER 当前会话的ID
STATISTIC NUMBER 统计数据号
VALUE NUMBER 统计数据值
4.v$statname
这个视图显示列在V$SESSTAT 和V$SYSSTAT 表中的统计数据的解码统计数据名。详细信
息,请参阅V$SESSTAT 和SYSSTAT。
列 数据类型 说明
STATISTIC# NUMBER 统计数据号
NAME VARCHAR2 统计数据名。参见表B-13
CLASS NUMBER 1(用户);2(重做);4(排
队);8(高速缓存);16(操
作系统);32(并行服务器);
128(调试)
posted @
2010-12-22 22:55 xrzp 阅读(320) |
评论 (2) |
编辑 收藏
摘要:
DB Name
DB Id
Instance
...
阅读全文
posted @
2010-12-20 23:06 xrzp 阅读(694) |
评论 (0) |
编辑 收藏