NetBeans IDE 6.5 Release Candidate Now Available,同时官网表示,netbeans6.5最终版本将于今年11月发布(The final NetBeans IDE 6.5 release is planned for November 2008),虽说是11月,不过这个版本发布后,相信最终版发布时间估计也不久了。
详情参看官网
http://www.netbeans.org/servlets/NewsItemView?newsItemID=1298
posted @
2008-10-23 09:24 GoKu 阅读(1394) |
评论 (2) |
编辑 收藏JavaScript Eclipse 插件助您一臂之力,提高 JavaScript 生产力指日可待
JavaScript Development Toolkit(JSDT)是一种开放源码插件,它将健壮的 JavaScript 编程工具引入到 Eclipse 平台中。JSDT 使开发更加流畅、简化了编码并提高了纯 JavaScript 源文件和 HTML 内置的 JavaScript 的生产力。
JavaScript 开发并不容易。浏览器兼容性参差不齐、文档非常糟糕、工具贫乏,这些因素使问题进一步恶化。幸运的是,随着最近针对 Eclipse 的插件集 JavaScript Development Toolkit(JSDT)的发布,工具匮乏的局面有望得到改善。
Eclipse 是一个开源的 IDE 框架,具有提高扩展性和灵活性的架构。JSDT 作为插件在 Eclipse 中运行。在 Eclipse 中,JavaScript 并不是什么新鲜的概念,因为已经可以从其他插件获得 HTML 和一些 JavaScript 支持,但是 JSDT 的独特之处在于其所提供的工具的健壮性和复杂性,这可显著提高 Web 开发的生产力。
JSDT 提供的许多特性和核心设计都可以在 Java Development Toolkit(JDT)中找到。JSDT 将要代替 Web Tools Platform V3.0 发行版中当前的 JavaScript 编辑器。
IDE 和 JavaScript
您可能想知道为什么 JavaScript IDE 会如此流行。随着 Web 2.0 的流行以及大量开发人员都热衷于在博客和社区页面中使用 JavaScript,大量新的 JavaScript 工具不断出现。尽管如此,Notepad 和浏览器的 Refresh 按钮仍然是大多数程序员首选的 JavaScript 开发环境。
问题在于 JavaScript 语言的解释性。与 Java™ 或 C 语言不同,JavaScript 是一种松类型的语言,并且很难实现精确建模。对于较为正式的语言,需要优先考虑已编译代码的效率,并且对语言的灵活性有所限制。JavaScript 的目标则不一样。各种因素试图分化趋向同一个平台的开发人员,这导致了语言的不一致性。从工具和开发的角度来看,这些不一致性使问题更加复杂。
浏览器并不是惟一的问题。面向对象的 JavaScript 是一种补充而不是关注的焦点。Ajax 工具箱努力使 JavaScript 朝面向对象方面转变 — 但是各自采取不同的方式。这可能会使标识对象和类结构变得很困难。这种语言有几个严重的漏洞,程序员利用它们实现一些使用其他方式难以实现的技巧,这使问题更加严重(或者更好,取决于您询问的对象)。其中一个例子是将主要的代码块封装到一个 evalf(..) 函数中,使它只在运行时有效。我们目前仍然在克服这个问题,以便在 JSDT 中精确建模。
现有的 JavaScript IDE
目前可以使用一些并不完整的 JavaScript 工具。但是很多流行的工具还不能提供真正的上下文感知内容帮助,因为它们缺少真正的 JavaScript 语言建模机制。在模型较少的 IDE 中,通过使用静态平面文件列出可用的类型,可以实现内容完成和工具功能。这些类型根据输入的部分字符动态调整,并且通常不会选择代码中定义的对象成员。内容完成对上下文不敏感,因为如果没有模型的话,可实现的功能将受到很大限制。
如果没有语言模型,则很难或者不可能将代码放入到上下文中。由于很多编程元素都依赖于代码的上下文,因此使用工具建立上下文十分重要。缺少模型和代码上下文的 IDE 同样也会缺少充分的类型解析和验证、作用域、可视性,或者其他任何对简化开发非常重要的良好验证功能。
JSDT 设计
图 1. JSDT 语言抽象栈

JSDT 对 JavaScript 语言建模并实时隐含类结构,这通过一种全新的方式来实现。首先,构建基本的语言元素。其次,推理引擎或引擎帮助填补所有类结构和语言差异。
基本语言模型
可以将推理和建模流程看作一个操作栈。模型的开始部分是 JavaScript 源代码。通过使用类似 Eclipse JDT 的引擎,将源代码转换为私有的语言模型。语言的纯模型遵守 ECMA-3 标准。
类型和类推理
对 JavaScript 语言建模后,下一步是管理类型和类推理。许多基于 JavaScript 的工具箱(例如 Dojo、Rico、Prototype)通过自己的技术使 JavaScript 面向对象编程更加方便。JSDT 使用定制的、工具箱感知的推理引擎在工具箱内部识别类和类型结构。这些类和类型随后可以添加到语言模型中。
公开模型
最后,将私有模型及其推理部分转换为公共语言模型。公共语言模型可用于源代码、重构和 as-you-type 工具。如果其中一种工具需要修改一些 JavaScript 源代码,就得先在公共模型中进行修改,并最终转换到 JavaScript 源代码。
管理变量和成员作用域
即使语言模型为描述 JavaScript 源代码和上下文提供了基础,还需要另外一个重要因素:环境上下文。JSDT 必须在运行 JavaScript 的全局作用域时建立可用的变量和类型。这些变量和类型根据 JavaScript 的运行时环境而有所不同。当 JavaScript 在 Web 浏览器上下文中运行时,对象、类型、表示屏幕数据的字段以及浏览器对象在全局作用域中都是可用的。如果代码是针对其他内容而不是浏览器,那么整个对象集可能会不同。
图 2. JSDT 库配置

JSDT 使用库机制管理项目中的通用对象、变量和类型。可以将库添加到项目中,以提供特定于用户目标运行时环境的对象和变量集。如果存在两个定义冲突成员的库,则在相应的用户接口中聚合并注释这些成员。这有助于创建在浏览器或环境之间通用的方法。
为流行的浏览器预打包库非常简单。库被捆绑在一个插件中,该插件包含有定义对象和类型的 JavaScript 源文件。当 JSDT 对源代码编辑器中打开的文件进行建模时,它首先对文件的源代码建模,然后将项目的库集合中的所有源文件添加到模型。库源文件永远不会进行验证,只用于定义对象结构、附加在悬浮式帮助和内容完成中可见的 JsDoc。
虽然库的主要功能是管理 JavaScript 的运行时上下文,但是它还提供了另一个重要特性 — 处理源文件交叉引用。纯 JavaScript 不具备显式的 include 函数。开发人员的一个不良习惯就是将函数散布到多个源文件中。库配置页面可以帮助管理源文件之间的交叉项目可见性。如果某个项目文件夹被标记为一个源文件,那么该文件夹中的所有 JavaScript 将包括在全局作用域中。使用 exclude 模式可以限制文件夹。
工具
撇开较高层的设计不谈,我们仔细看看这些特性。JSDT 的一些可视性较弱但非常重要的特性包括:相同文字突出显示、自动闭合大括号(以及圆括号、引号)以及自动缩进等。因此可以说,“只要是良好 IDE 应该具备的,JSDT 都提供支持”。
图内容帮助
图 3. 内容帮助

内容完成可以通过 Ctrl+Space 键任意调用。图 3 展示了内容帮助调用文档对象。内容完成对上下文敏感,并且基于全局作用域和 JavaScript 模型。完成条目显示字段名、字段类型和字段的声明类型。
检测和纠正错误
如果 IDE 可以主动确定代码错误,它将非常有用。JSDT 可以检测三种主要错误类型:语法/语言错误、类型/字段/方法可视性、流或逻辑错误。所有的错误警告级别都可以通过首选项页面进行单独配置。
图 4. 未解析的方法

JSDT 试图解析对象的所有字段和方法。未解析的方法则标记为错误。
图 5. 语法错误

JSDT 还可以查找并标记语法错误。下面的 for() 语句丢失了一个分号。
图 6. 流分析

图 6 演示了流分析。由于 return 语句后面的所有代码都不能执行,因此将其标记为错误。
图 7. 快速修复

一些错误具有快速修复选项。在图 7 中,当用户单击未解析变量 formyValue 旁边的错误标记时,JSDT 将显示一些纠正错误的选项。
代码格式化
源代码有时会混乱。您可能期望易于阅读、结构良好、格式化良好的代码。这就需要在进行开发和调试时对代码进行格式化。JSDT 支持许多 as-you-type 格式化特性,比如可配置自动缩进和字符成对匹配。这些特性都有助于加快开发和提高可读性。
如果您收到的代码非常混乱,该怎么办?只需要单击一下鼠标,JSDT 代码格式化程序就可以整理并重新格式化混乱的 JavaScript 代码。格式化引擎是高度可配置的,因此可以导出配置供团队共享。
其他 JSDT 特性
上面列出的仅是 JSDT 支持的特性的一部分。下面列出非常简单但必须具备的 JSDT 特性:
- 语法突出显示
- 折叠/行号
- 完整描述、显示类、函数和字段
- 突出显示并检查大括号/圆括号匹配
- 自动完成大括号、圆括号和缩进
- 标记出现位置
- 注释切换(行或块)
- 生成元素 JsDoc
- 用 do,for,try/catch,while 包围
- 用户可配置的完成模板
- 提取函数/修改函数签名
- 缩排纠正
- 打开声明
- 开放类型结构
- 开放调用结构
- 可定制的代码格式化
- 全搜索
- 重构/重命名/移动
- 断点支持
- 使用 JsDoc 为 Firefox、Internet Explorer 和 ECMA-3 定义浏览器库
- 通过 JsDoc + JavaScript 原型定义支持用户定义的库
- 库映像支持
- ATF Project 提供的调试支持
结束语
如果需要一种免费的 Web 开发环境,请选择 Eclipse。由于新增了 JSDT,Eclipse 的 JavaScript 能力超越了市场上其他同类产品。开放源码项目促成了 JSDT 的快速发展,JSDT 将像 JavaScript 一样快速地演进。
参考资料
学习
获得产品和技术
讨论
关于作者
 |
|

|
|
Bradley Childs 2004 年毕业于 Texas A&M University。他在 IBM 从事中间件开发,后来又转到新兴技术方面。他和 Phil Berkland 密切合作开发 JSDT。他在 Ajax Tooling Framework 项目社区中非常活跃。
|
http://www.spitv.net
http://goku.spitv.net
http://sxin99.com
posted @
2008-07-18 22:58 GoKu 阅读(2010) |
评论 (5) |
编辑 收藏
PHP 支持更加完善,HTML CSS编辑也做得更好了
http://www.spitv.net http://goku.spitv.net


posted @
2008-07-09 12:24 GoKu 阅读(1595) |
评论 (2) |
编辑 收藏下面是最新一期的Web服务器排名,其中Nginx已经上升到了第四位,太牛X了
| Vendor | Product | Web Sites |
| Apache |
Apache |
84,309,103 |
| Microsoft |
IIS |
60,987,087 |
| Google |
GFE |
10,465,178 |
| Unknown |
Unknown |
4,903,174 |
| nginx |
nginx |
2,125,160 |
| Oversee |
Oversee |
1,953,848 |
| lighttpd |
lighttpd |
1,532,952 |
| Other |
Other |
1,150,202 |
| GNR |
GNR |
425,029 |
| Zeus |
Zeus |
405,724 |
| IdeaWebServer |
IdeaWebServer |
382,524 |
| Sun |
Sun-ONE-Web-Server |
349,704 |
| Apache |
Coyote |
338,376 |
| Resin |
Resin |
321,746 |
| Jetty |
Jetty |
259,558
|
http://www.spitv.net
http://goku.spitv.net
http://www.sxin99.com
posted @
2008-07-06 15:15 GoKu 阅读(2747) |
评论 (4) |
编辑 收藏
Updates for MyEclipse include:
- Maven support (Maven4MyEclipse)
- MyEclipse Spring Tools update (to Spring 2.5)
- Portlet/Portal support
- improvements to the visual JSF/Facelets tool set
- JAX-WS Web Services
- update to MyEclipse Hibernate Tools
- UML tooling upgrades
- more。。。
下载地址:http://www.myeclipseide.com/module-htmlpages-display-pid-4.html
另外还有
Blue Edition: ALM & Open Source for WebSphere
MyEclipse is proud to announce availability of MyEclipse 6.5 Blue Edition as well. This release introduces a new standard of ALM management and open source capabilities for WebSphere.
依然没有Struts2,下个版本可能会支持Eclipse3.4了
http://www.sxin99.com
http://www.spitv.net
http://goku.spitv.net
posted @
2008-06-27 15:19 GoKu 阅读(2322) |
评论 (3) |
编辑 收藏
最近学了一些PHP和Ruby的东西,忽然想把这些东西应用做个比较.
首先,我们把Java .Net PHP应用方面占有率做个比较,简单的把目前主流应用分成两个大类,一个是企业应用,一个是Web网站应用,下面这个表格是我归纳的,不一定准确,但是能说明一个大概.
| 应用 / 语言 |
Java |
.Net |
PHP |
| 大型企业应用 |
多 |
少 |
少 |
| 中型企业应用 |
多 |
中 |
少 |
| 小型企业应用 |
中 |
中 |
少 |
| 大型Web应用 |
多 |
少 |
中 |
| 中型Web应用 |
中 |
中 |
多 |
| 小型Web应用 |
少 |
中 |
多 |
从表中可以看到,Java和PHP都有各自擅长的领域,但是.Net却没有突出的地方,从占有率来看情况十分尴尬.
我们再来看看技术方面,首先声明,我对其中每种语言技术都不是很熟悉,只能大概分析一下...
先说说Java,在企业级方面,可以说是绝对的老大,许多企业级技术,开发思想都是由Java发展出来的.缺点是Java开发部署比较麻烦 ,不太适合超小型的项目.
再说.Net,在1.x时代,.Net可以说基本上没有多少企业级开发的特性,到了3.0,微软各种框架技术虽然弥补了这些不足,但是相对于Java世界,还是有一定距离. 在Web网站方面,.Net服务器控件的优势,变成了弱势,由于服务器空间产生垃圾代码,并且不方便美工调整,导致在前台界面要求较高的门户站点难以使用(虽然有第三方MVC框架,但是没有IDE支持,体现不出.Net的优势)
再说说PHP,他的定位非常明显,就是Web开发,所以有很多适合Web开发的特性,比如部署十分简单,几个文件随便找个虚拟主机扔上去就能运行.在国内因为Discuz , DedeCMS等著名产品的鼎立推广,PHP在中小型网站开发中有很大的优势.,最近大量的开源框架出现,给PHP企业开发注入了一些生命力,可以说潜力十足.
综合以上我们可以看到,.Net定位不太明确,微软这个想吃那个也想吃,最后没一个能吃饱吃好..
最后还想说一下Ruby,其实应该说ROR,大家喜欢的应该是ROR的特性,二Ruby是个怪怪的东西,如果没有ROR框架,我想他也很难出名.因为ROR本身构架不是很复杂,众多PHP框架可以说都是模仿他的思想来的,而且也学得7 8成功力了,个人认为ROR很难再做大起来,可能是个昙花一现的东西,只是思想新潮大家都来赶时髦学两下,学到了,大家又都觉得其实也就那样,其他语言也能做到.
http://goku.spitv.net/
http://www.spitv.net/
http://www.sxin99.com/
posted @
2008-06-01 20:12 GoKu 阅读(2870) |
评论 (9) |
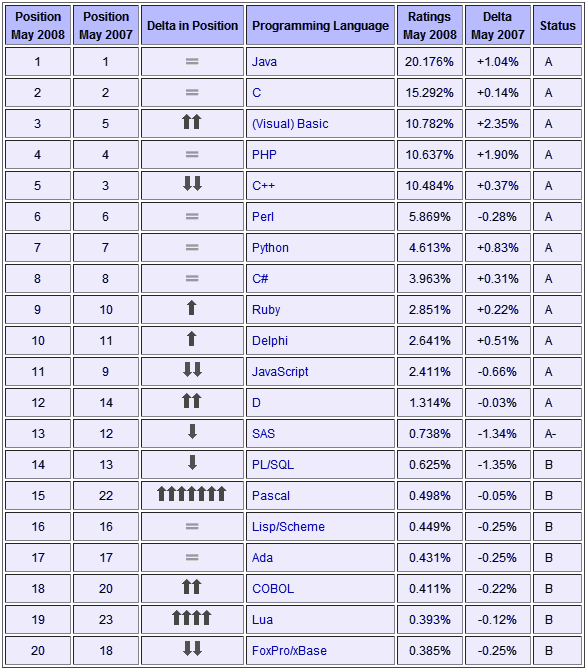
编辑 收藏开发语言排行榜参考资深开发者、开发供货商等人建议的计算方式,从2002年开始,每个月从常见搜索引擎中,计算出不同开发语言的流行指数,并公布排行。
Java依然是第一位,不过从形式上看PHP很有前途,毕竟未来C/S应用越来越少,PHP相对C和VB的优势明显,有望成为第二位
下面是前20强:
 http://www.spitv.net
http://www.spitv.net
http://goku.spitv.net
http://www.sxin99.com
posted @
2008-05-30 19:03 GoKu 阅读(2288) |
评论 (5) |
编辑 收藏
刚听说jQuery 1.2.4发布,才2天1.2.5又来了,估计是个bug修复版本
看了1.2.5的代码,
真的改变了很多,看上去理性多了.
jQuery目前仍然是同类框架中的首选.
下载地址: http://code.google.com/p/jqueryjs/downloads/detail?name=jquery-1.2.5.js
介绍一下我的网站:
精灵影视 http://goku.spitv.net http://www.sxin99.com
posted @
2008-05-24 15:59 GoKu 阅读(1881) |
评论 (2) |
编辑 收藏
Download M1 here!
Updates for the two products include the addition of Spring 2.5 capabilities, portel support, extensive improvements to the visual JSF/Facelets tool set, the addition of JAX-WS Web Services and more.
Additionally for Blue Edition users, MyEclipse now supports project migration from RAD.
刚才收到myeclipseide的邮件,说发行了6.5,不过依然没有struts2的支持
另外邮件提到Pulse 2,不知道是什么东西,谁介绍一下
推荐网站:http://www.spitv.net
http://goku.spitv.net
http://www.sxin99.com
posted @
2008-05-19 15:44 GoKu 阅读(2882) |
评论 (4) |
编辑 收藏 两个月之前,Netbeans官方网针对Netbeans6.1举办了博客大赛。而现在,这个比赛的结果已经公布了。
这次比赛最终大约有300个参赛博客,前10名的参赛者将会获得价值500美元的礼劵。前100名参赛者将获得Netbeans T-shirt一件。
另,获得前10名的参赛者中有一个是来自中国的丁亮,他的博客地址:简约设计の艺术。在这里恭喜他:-)

下面是前十名的名单以及博客地址:
引用
来自:http://www.netbeans.org
http://goku.spitv.net http://www.sxin99.com
posted @
2008-05-17 16:17 GoKu 阅读(1462) |
评论 (3) |
编辑 收藏从获得一千万美元风投开始算起刚满一年,如今SpringSource(Spring框架背后的公司)摇身一变,成为应用服务器提供商,并且举着SpringSource应用平台(SpringSource Application Platform)的黄钺白旄对现有的Java EE服务器阵营发起挑战。SpringSource应用平台是构建在Spring、OSGi和Apache Tomcat之上的应用服务器,这个新的应用服务器摒弃了原有的Java EE服务器标准,自然而然地将Spring编程模型展现其中,随之而来的还有一套基于OSGi内核构建的全新部署和打包系统。今天是该项目在SpringSource评估许可下Beta发布版发布的重要里程碑。在随后一个月内会有基于开源许可(GPLv3)版本和订阅版本的通用发布版(General Availability,GA)放出。
SpringSource应用平台不是Java EE应用服务器。尽管对于WAR部署它提供了支持,但EAR部署和其它EE的规范,如EJB等,都不在支持范围之列。SpringSource应用平台被重新设计,并把关注点直接放在对被开源项目所广泛使用的Spring组合的支持上。特别地,这个应用服务器是基于Spring组合编程模型构建的,利用Spring Dynamic Module实现基于OSGi的部署。SpringSource在Eclipse基金会的Equinox OSGi运行时环境的基础上创建了一个具备日志、跟踪、启动、类加载、管理和其它特性的“内核”,Tomcat被作为一个包(bundle)纳入到平台当中,从而实现对Web功能的支持。
InfoQ借此机会对Spring框架的共同创始人兼SpringSource的CEO Rod Johnson进行一次采访,对这个新的应用服务器展开探讨。在阐释这个新平台的必要性时,Rod一针见血地指向目前开发和生产环境的许多痛处,比如跨配置文件出现的元数据重复现象,还有本质上在项目中常常在服务器上再部署服务器(即在部署应用时,在同一个部署单元附带部署许多工具和框架),而与此同时这些部件却主要只使用它们应用服务器中的Web容器部分的事实。因此,SpringSource希望在当今的开发需要的基础上提供一个更为简单的平台。
在谈到这个新应用服务器的优点时,Johnson强调了模块化:对于服务器本身以及提供给开发人员的打包和部署模式来说,这是个两全之策。通过利用OSGi,以及OSGi包之间依赖关系相互作用的性质,运行的应用服务器只会激活在它上面运行的应用所需要的特性,从而削减服务器的内存占用和启动时间。这个依赖关系支持的功能还允许依赖类库的多个版本共存,以支持不同应用;因而应用服务器的某些部分就可以很容易地更新和重启,而无需重启整个服务器。从开发的角度看,服务器的模块化也使得在代码变化时,可以很快地进行极其细粒度的重部署。
Johnson在言及OSGi和SpringSource对Eclipse Equinox OSGi的使用时,高度评价了OSGi规范的运行时实现所带来的基础平台,但也表示OSGi在日常的应用开发上属于比较底层的地位。Johnson阐述到,SpringSource希望帮助开发人员在企业环境中轻松获得价值。在新的编程模式的构造背后,这个新的应用服务器将OSGi的许多复杂性抽象了出来。Johnson接着说,应用服务器将会支持PAR,一套新的可部署单元,简化企业应用在使用OSGi上的复杂性(下文会详细说明)。
当被问到对于没有对OSGi提供原生支持的遗留类库的支持时,Johnson回应到,他们已经在上面花费了很大心血,使得应用服务器环境和类加载功能能够以兼容的方式和遗留类库协作。
当被问到对不提供OSGi原生支持的类库的遗留支持时,Johnson回答说他们已经在这方面投入了大量精力,保证应用服务器环境和类加载功能可以和遗留类库兼容工作。SpringSource还会为他们在如Tomcat之类的项目上所做的任何变更给这些项目提交补丁,使这些类库可以和OSGi包兼容。
Johnson解释到,应用服务器的主题代码将在GPL v3的许可证下发布。开发人员在服务器、编程模式和部署单元上要接触到的所有部分都会以开源的形式提供。SpringSource还将提供应用服务器的商业版本,包括支持、保障、管理和监控的功能。
谈到Spring应用平台发布之后对Spring组合继续支持JavaEE有什么影响,Johnson回答说:
……我们从根本上说并不打算把Spring用户社区驱赶到任何方向。我们仅仅是给用户另一种选择。Spring的哲学是用户总是正确的。用户是聪明的,他们完全明白自己的需要。不管用户是否选择SpringSource应用平台,我们觉得用户总会欢迎多一点选择的……
Johnson保证SpringSource一定会继续确保Spring组合以及其他SpringSource产品兼容于其它应用平台。接着Johnson还评论了即将到来的Java EE 6规范:
Java EE 6重点在模块性,这个方向是正确的。很可能SpringSource应用服务器会在一定程度上符合Java EE 6。Java EE 6分成A、B、C三种规格(profile)。我们几乎肯定会实现A和B规格,C规格里面我非常确定将实现Entity Beans 1.1模型以及一些遗留技术。我还不能说是100%确定,因为Java EE 6规范还没有定案。
最后,InfoQ和Johnson讨论到了SpringSource应用平台的大局方面。对于转换到OSGi,他的回答是:
传统的应用服务器模型正逐渐过时。BEA和IBM正在用OSGi逐步重新实现他们的应用服务器。 SpringSource现在就提供OSGi支持。从统计数字上看,大多数人都不会部署到完整的平台上,他们部署到Tomcat。他们选择了Spring 编程模型而非Java EE。市场已经作出了选择,问题只是开发者还要和服务器斗争多长时间。
Johnson解释说他对SpringSource应用平台成功的自信来自三个原因:
- 它是第一个建立在现代技术基础上的产品。符合Java EE规范已经不是至高无上的目标。干净的代码基础是我们的一项竞争优势。我们在设计和实现中满足的是现今的需求,而不是10年前的需求。
- POJO编程是现在行业的方向所在。过去POJO编程是被强行嫁接到其它产品上的。在我们的产品中,POJO编程是设计的前提。
- SpringSource应用平台采用的OSGi技术是下一代技术的基础。
除了Rod Johnson,InfoQ还与SpringSource的Rob Harrop探讨了新应用服务器的一些技术细节。对于与传统Java EE应用服务器相比有何增减,他说:
……JPA和JMS都支持,但我们没有包含任何特定实现。对于JPA,我们支持Hibernate、 OpenJPA和Toplink。我们在OSGi环境中增加了对加载时织入的支持,而且会尊重应用的边界,因此不会意外污染应用间共享的库。不包括 JNDI,我们用OSGi Service Registry来取代它。Servlets是通过内嵌的Tomcat来支持的。JEE中有而SpringSource应用平台没有的东西包括 Entity Beans等等。
接下来InfoQ问到Spring Dynamic Modules。Spring DM成为公开项目已经有一段时间了。对于模块化部署,我们向Harrop询问Spring DM是否增加了什么新东西:
这个平台引入了应用的概念,应用由一个或多个Bundle组成。应用中的包有明确的作用域,可以防止发生应用间的冲突。在应用把服务发布到OSGi service registry的情况下,防止冲突尤其重要,谁也不想见到服务之间发生冲突。
我们引入了Import-Library语句,因此在应用中使用第三方库变得更加简单。你不需要再写一大串不直观的 Import-Package声明,Import-Library可以自动为指定的库引入所有必需的package。像Hibernate JPA这样的库还可以跨多个Bundle,可见Import-Library确实物有所值。
至于为了让Spring DM在平台中运行而进行的扩展,为数不多。
Harrop接下来说明了新的PAR格式:
Spring DM掌控下的Bundle(Spring DM powered bundles)是包含META-INF/spring/*.xml文件的普通OSG Bundle。Bundle启动的时候META-INF/spring/*.xml文件会自动成为该Bundle的 ApplicationContext。Spring DM提供了一种机制让各Bundle通过Spring NamespaceHandler导入和导出服务。
一个PAR(Platform ARchive)本质上是一组OSGi Bundle,通常其中有一部分是在Spring DM掌控下的。这些Bundle共同组成了一个逻辑上的应用。编程的时候完全是纯粹的OSGi、Spring和Spring DM——PAR没有改变什么。
以前一般用Buddy Classloaders之类的技术来解决遗留/非OSGi库的问题,SpringSource这次是怎么做的呢?Rob回答说:
简单来说我们避免做这样的事。Buddy类装载、动态import、require-bundle,这些我们都明确回避,因为维持一致的类空间太困难了。我们也不会提供任何专有的替代机制。
相反,我们给Equinox增加了一些低级的钩子,以实现典型的场景下的资源装载。我们扩展了类装载来支持加载时织入,并且把装载语义丢到一边。我们操纵context classloader,让第三方一如既往地看到类。PAR是其中的核心角色,因为它定义了上下文类装载以及加载时织入的可见范围。
对于一些最糟糕的情况,我们会提供修补版的库,让它们能在OSGi中工作。修补版的库可以通过SpringSource Enterprise Bundle Repository获得,我们的修改也会提交回相应的项目。
最后Harrrop着重强调了这个应用服务器在模块化上的优势,应用服务器因此可以维持最低的内存占用。平台在运行中才设置依赖项,因此只有确实用到的依赖项才会被装载。
最近几年中有过许多关于Java EE标准是否已经死亡的讨论,而今天我们看到一个可能很重要的应用服务器不带Java EE支持。这种变化对于未来有何影响?你怎么看?
转载自:InfoQ中文站 http://www.infoq.com/cn/
posted @
2008-05-01 20:37 GoKu 阅读(1804) |
评论 (2) |
编辑 收藏虽然现在出现了很多ORM框架,可是还是有很多朋友也许还在使用JDBC,就像我现在一样,除了学习的时候在使用Hibernate、Spring类似这些优秀的框架,工作时一直都在使用JDBC。本文就简单介绍一下利用Jakarta Commons旗下beanutils、dbutils简化JDBC数据库操作,以抛砖引玉,希望对像我一样在使用JDBC的朋友有所帮助。
下面就分两部分简单介绍beanutils、dbutils在基于JDBC API数据库存取操作中的运用。第一部分显介绍beanutils在JDBC数据库存取操作中的运用,第二部分介绍dbutils在JDBC数据库存取操作中的运用,最后看看他们的优缺点,谈谈本人在项目运用过程中对他们的一点心得体会,仅供参考,其中有错误的地方希望大虾不吝赐教,大家多多交流共同进步。
一、Jakarta Commons beanutils
Beanutils是操作Bean的锐利武器,其提过的BeanUtils工具类可以简单方便的读取或设置Bean的属性,利用Dyna系列,还可以在运行期创建Bean,符合懒人的习惯,正如LazyDynaBean,LazyDynaClass一样,呵呵。这些用法已经有很多文章提及,也可以参考apache的官方文档。
对于直接利用JDBC API访问数据库时(这里针对的是返回结果集ResultSet的查询select),大多数都是采用两种方式,一种是取出返回的结果集的数据存于Map中,另一种方式是Bean里。针对第二种方式,Beanutils里提供了ResultSetDynaClass结合DynaBean以及RowSetDynaClass结合DynaBean来简化操作。下面用以个简单的例子展示一下beanutils的这两个类在JDBC数据库操作中的运用。
请在本机建立数据库publish,我用的是MySQL,在publish数据库中建立表book,脚本如下:
CREATE TABLE book(
id int(11) NOT NULL auto_increment,
title varchar(50) character set latin1 NOT NULL,
authors varchar(50) character set latin1 default NULL,
PRIMARY KEY (id)
)
然后用你喜欢的编辑器建立一个类BeanutilsJDBCTest,我们先用ResultSetDynaClass来处理,然后再用RowSetDynaClass来实现同样的类,之后看看他们之间有什么不同,用ResultSetDynaClass处理的源代码如下所示:
package cn.qtone.test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Iterator;
import org.apache.commons.beanutils.DynaBean;
import org.apache.commons.beanutils.PropertyUtils;
import org.apache.commons.beanutils.ResultSetDynaClass;
public class BeanutilsJDBCTest{
public static void main(String[] args) {
Connection con = null;
Statement st = null;
ResultSet rs = null;
try {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1:3306/publish?useUnicode=true&characterEncoding=GBK";
con = DriverManager.getConnection(url, "root", "hyys");
st = con.createStatement();
rs = st.executeQuery("select * from book");
ResultSetDynaClass rsDynaClass = new ResultSetDynaClass(rs);
Iterator itr = rsDynaClass.iterator();
System.out.println("title-------------authors");
while (itr.hasNext()) {
DynaBean dBean = (DynaBean) itr.next();
System.out.println(PropertyUtils.getSimpleProperty(dBean,"title")
+ "-------------"+ PropertyUtils.getSimpleProperty(dBean, "authors"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (rs != null) {
rs.close();
}
if (st != null) {
st.close();
}
if (con != null) {
con.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
用RowSetDynaClass处理的源代码如下所示:
package cn.qtone.test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Iterator;
import java.util.List;
import org.apache.commons.beanutils.DynaBean;
import org.apache.commons.beanutils.PropertyUtils;
import org.apache.commons.beanutils.RowSetDynaClass;
public class BeanutilsJDBCTest{
public static void main(String[] args) {
List rsDynaClass = rsTest();
System.out.println("title ------------- authors ");
Iterator itr = rsDynaClass.iterator();
while (itr.hasNext()) {
DynaBean dBean = (DynaBean) itr.next();
try {
System.out.println(PropertyUtils.getSimpleProperty(dBean,"name")
+ "-------------"+ PropertyUtils.getSimpleProperty(dBean, "mobile"));
} catch (Exception e) {
// TODO 自动生成 catch 块
e.printStackTrace();
}
}
}
private static List rsTest() {
Connection con = null;
Statement st = null;
ResultSet rs = null;
try {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1:3306/publish?useUnicode=true&characterEncoding=GBK";
con = DriverManager.getConnection(url, "root", "hyys");
st = con.createStatement();
rs = st.executeQuery("select * from book");
RowSetDynaClass rsdc = new RowSetDynaClass(rs);
return rsdc.getRows();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (rs != null) {
rs.close();
}
if (st != null) {
st.close();
}
if (con != null) {
con.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
}
这两个方法输出的结果应该是一样的。但是很显然第二种方式比第一种方式要好,它把数据访问部分抽取出来放到一个方法中,显得简单清晰。
其实在利用ResultSetDynaClass时,必须在ResultSet等数据库资源关闭之前,处理好那些数据,你不能在资源关闭之后使用DynaBean,否则就会抛出异常,异常就是说不能在ResultSet之后存取数据(具体的异常名我也忘了),当然你也可以采用以前的方式一个一个的把数据放到Map里,如果你一定要那样做,建议还是别用Beanutils,因为这没带给你什么好处。总之利用ResultSetDynaClass你的程序的扩展性非常部好。
从第二中方式可以看出,利用RowSetDynaClass可以很好的解决上述ResultSetDynaClass遇到的问题,RowSetDynaClass的getRows()方法,把每一行封装在一个DynaBean对象里,然后,把说有的行放到一个List里,之后你就可以对返回的List里的每一个DynaBean进行处理,此外对于DynaBean你还可以采用标准的get/set方式处理,当然你也可以用PropertyUtils. getSimpleProperty(Object bean, String name)进行处理。
从上面的分析中,你应该可以决定你应该使用ResultSetDynaClass还是RowSetDynaClass了。
未完待续……
=============================
二、Jakarta Commons dbutils:
用JDBC API时最令人讨厌的就是异常处理,也很烦琐,而且很容易出错,本人曾考虑过利用模板进行处理,后来看到了dbutils,之后就采用那个dbutils,采用模板的方式各位朋友可以参考Spring,Spring的JdbcTemplate不灵活而强大,呵呵,说句闲话,实在太佩服Rod Johnson了,Rod Johnson真的很令人尊敬。
Dbutils的QueryRunner把大多数与关闭资源相关的封装起来,另外,你也可以使用DbUtils进行关闭,当然DbUtils提供的功能当然不止这些,它提过了几个常用的静态方法,除了上述的关闭资源外,DbUtils. commitAndClose(Connection conn)还提供事务提及等操作。
还是以一个例子来说说吧,毕竟我不是搞业务的,小嘴巴吧嗒吧哒不起来啊,呵呵。
为了和采用Beanutils更好的进行对比,这个例子还是实现同样的功能,数据库同样采用前一篇文章中提到的publish。
同样的,用你喜欢的编辑器建立一个类DbutilsJDBCTest,示例代码如下所示:
package cn.qtone.test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.List;
import java.util.Map;
import org.apache.commons.dbutils.DbUtils;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.MapListHandler;
public class DbutilsJDBCTest{
public static void main(String[] args) {
Connection conn = null;
String jdbcURL = "jdbc:mysql://127.0.0.1:3306/publish?useUnicode=true&characterEncoding=GBK";
String jdbcDriver = "com.mysql.jdbc.Driver";
try {
DbUtils.loadDriver(jdbcDriver);
// Username "root". Password "root"
conn = DriverManager.getConnection(jdbcURL, "root", "root");
QueryRunner qRunner = new QueryRunner();
System.out.println("***Using MapListHandler***");
//以下部分代码采用Map存储方式,可以采用Bean的方式代替进行处理
List lMap = (List) qRunner.query(conn,
"select title,authors from books", new MapListHandler());
//以下是处理代码,可以抽取出来
System.out.println("title ------------- authors ");
for (int i = 0; i < lMap.size(); i++) {
Map vals = (Map) lMap.get(i);
System.out.println(vals.get("title")+"-------------"+ vals.get("authors"));
}
} catch (SQLException ex) {
ex.printStackTrace();
} finally {
DbUtils.closeQuietly(conn);
}
}
}
怎么样?是不是比采用Beanutils的ResultSetDynaTrial和RowSetDynaClass好多了?采用Beanutils令人难缠的是关闭那些资源以及处理那些异常,而这里采用Dbutils显然代码量减少了很多。
上例在处理结果集时,它把数据库中的每一行映射成一个Map,其中列名作为Key,该列对应的值作为Value存放,查询的所有的数据一起放在一个List里,然后进行处理,当然,一个更明智的处理是直接返回List然后再单独进行处理。
事实上上例返回的结果集中的每一行不必放在一个Map里,你可以放在一个Bean里,当然如果你真的很懒,你也可以使用Beanutils的LazyDynaClass和LazyDynaBean,不过也许没有必要那么做,至于原因请看下文。
如果使用Bean而不是用Map,那么,你也许需要建立一个Bean,如下:
package cn.qtone.test;
public class Book {
public int id;
public String title;
public String authors ;
public StudentBean() {
}
public String getAuthors() {
return authors;
}
public void setAuthors(String authors) {
this.authors = authors;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}
然后简单修改一下DbutilsJDBCTest 中的部分代码即可,代替之后的源代码如下:
package cn.qtone.test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.List;
import java.util.Map;
import org.apache.commons.dbutils.DbUtils;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
public class DbutilsJDBCTest{
public static void main(String[] args) {
Connection conn = null;
String jdbcURL = "jdbc:mysql://127.0.0.1:3306/publish?useUnicode=true&characterEncoding=GBK";
String jdbcDriver = "com.mysql.jdbc.Driver";
try {
DbUtils.loadDriver(jdbcDriver);
// Username "root". Password "root"
conn = DriverManager.getConnection(jdbcURL, "root", "root");
QueryRunner qRunner = new QueryRunner();
System.out.println("***Using BeanListHandler ***");
//以下部分代码采用Map存储方式,可以采用Bean的方式代替进行处理
List lBeans = (List) qRunner.query(conn," select title,authors from books ", new BeanListHandler(Book.class));
//以下是处理代码,可以抽取出来
System.out.println("title ------------- authors ");
for (int i = 0; i < lBeans.size(); i++) {
Book vals = (Book) lBeans.get(i);
System.out.println(vals.getTitle ()+"-------------"+ vals. getAuthors ());
}
} catch (SQLException ex) {
ex.printStackTrace();
} finally {
DbUtils.closeQuietly(conn);
}
}
}
这两种法输出的结果应该是一样的。两种处理方式都差不多,但我更愿意采用第一种,因为第一种少写一个bean,而且我测试过采用Map的方式即第一种方式性能要好的多,采用Bean性能比较低可能是因为采用反射的缘故,采用反射的东东性能和不采用反射的还是有点差距。也是这个原因,不推荐采用LazyDynaClass和LazyDynaBean,因为采用这二者是在运行期动态创建Bean类和Bean属性,然后再创建Bean对象的,其性能可想而知了(不过我没有测试过啊,所以我说这个话可说是没有根据的,感兴趣的朋友自己测试一下,记得告诉我结果哦,呵呵),除了MapListHandler以及BeanListHandler之外,DButils还提供了其他的Handler,如果这些不能满足你的需求,你也可以自己实现一个Handler。
最后,也是最大的体会,也许是最大的收获吧,那就是:对于每一个项目,在根据每一个需求获取相应解决方案时,先寻找开源组件,看是否已经有满足某些功能需求的开源组件,如果没有,再考虑自主开发或者向第三方购买,否则尽量采用开源组件.
请尽量享用开源的魅力,尽情的拥抱开源吧。
posted @
2008-04-24 16:39 GoKu 阅读(808) |
评论 (0) |
编辑 收藏