
2006年3月17日
在一个项目里面有这么一个技术需求:
1.集合中元素个数,10M
2.根据上限和下限从一个Set中过滤出满足要求的元素集合.
实际这个是个很典型的技术要求, 之前的项目也遇见过,但是因为当时的类库不多, 都是直接手写实现的. 方式基本等同于第一个方式.
在这个过程中, 我写了四个方式, 基本记录到下面.
第一个方式:对Set进行迭代器遍历, 判断每个元素是否都在上限和下限范围中.如果满足则添加到结果集合中, 最后返回结果集合.
测试效果:集合大小100K, 运算时间 3000ms+
过滤部分的逻辑如下:
1 void filerSet(Set<BigDecimal> targetSet, String lower, String higher) {
2 BigDecimal bdLower = new BigDecimal(Double.parseDouble(lower));
3 BigDecimal bdHigher = new BigDecimal(Double.parseDouble(higher));
4
5 Set<BigDecimal> returnSet = new HashSet<BigDecimal>();
6 for (BigDecimal object : targetSet) {
7 if (isInRange(object, bdLower, bdHigher)) {
8 returnSet.add(object);
9 }
10 }
11 }
12
13 private boolean isInRange(BigDecimal object, BigDecimal bdLower,
14 BigDecimal bdHigher) {
15 return object.compareTo(bdLower) >= 0
16 && object.compareTo(bdHigher) <= 0;
17 }
第二个方式: 借助TreeSet, 原始集合进行排序, 然后直接subset.
测试效果: 集合大小10M, 运算时间: 12000ms+(获得TreeSet) , 200ms(获得结果)
过滤部分的逻辑如下(非常繁琐):
1 Set<BigDecimal> getSubSet(TreeSet<BigDecimal> targetSet, String lower,
2 String higher) {
3
4 BigDecimal bdLower = new BigDecimal(Double.parseDouble(lower));
5 BigDecimal bdHigher = new BigDecimal(Double.parseDouble(higher));
6
7 if ((bdHigher.compareTo(targetSet.first()) == -1)
8 || (bdLower.compareTo(targetSet.last()) == 1)) {
9 return null;
10 }
11
12 boolean hasLower = targetSet.contains(bdLower);
13 boolean hasHigher = targetSet.contains(bdHigher);
14 if (hasLower) {
15 if (hasHigher) {
16 System.out.println("get start:" + bdLower);
17 System.out.println("get end:" + bdHigher);
18 return targetSet.subSet(bdLower, true, bdHigher, true);
19 } else {
20 BigDecimal newEnd = null;
21 System.out.println("get start:" + bdLower);
22 SortedSet<BigDecimal> returnSet = null;
23 if (bdHigher.compareTo(targetSet.last()) != -1) {
24 newEnd = targetSet.last();
25 } else {
26 SortedSet<BigDecimal> newTargetSet = targetSet
27 .tailSet(bdLower);
28 for (BigDecimal object : newTargetSet) {
29 if (object.compareTo(bdHigher) == 1) {
30 newEnd = object;
31 break;
32 } else if (object.compareTo(bdHigher) == 0) {
33 newEnd = object;
34 break;
35 }
36 }
37 }
38 returnSet = targetSet.subSet(bdLower, true, newEnd, true);
39 if (newEnd.compareTo(bdHigher) == 1) {
40 returnSet.remove(newEnd);
41 }
42 return returnSet;
43 }
44
45 } else {
46 if (hasHigher) {
47 System.out.println("get end:" + bdHigher);
48 TreeSet<BigDecimal> newTargetSet = (TreeSet<BigDecimal>) targetSet
49 .headSet(bdHigher, true);
50 BigDecimal newStart = null;
51 SortedSet<BigDecimal> returnSet = null;
52
53 if (bdLower.compareTo(targetSet.first()) == -1) {
54 newStart = targetSet.first();
55 } else {
56 for (BigDecimal object : newTargetSet) {
57 if (object.compareTo(bdLower) != -1) {
58 newStart = object;
59 break;
60 }
61 }
62 }
63 returnSet = targetSet.subSet(newStart, true, bdHigher, true);
64
65 return returnSet;
66 } else {
67 System.out.println("Not get start:" + bdLower);
68 System.out.println("Not get end:" + bdHigher);
69 BigDecimal newStart = null;
70 BigDecimal newEnd = null;
71 if (bdHigher.compareTo(targetSet.last()) != -1) {
72 newEnd = targetSet.last();
73 }
74 if (bdLower.compareTo(targetSet.first()) == -1) {
75 newStart = targetSet.first();
76 }
77 for (BigDecimal object : targetSet) {
78 if (newStart == null) {
79 if (object.compareTo(bdLower) != -1) {
80 newStart = object;
81 if (newEnd != null) {
82 break;
83 }
84 }
85 }
86
87 if (newEnd == null) {
88 if (object.compareTo(bdHigher) != -1) {
89 newEnd = object;
90 if (newStart != null) {
91 break;
92 }
93 }
94 }
95 }
96
97 if (newStart == null) {
98 if (newEnd == null) {
99 if ((bdHigher.compareTo(targetSet.first()) == -1)
100 || (bdLower.compareTo(targetSet.last()) == 1)) {
101 return null;
102 }
103 return targetSet;
104 } else {
105 SortedSet<BigDecimal> newTargetSet = targetSet.headSet(
106 newEnd, true);
107 if (newEnd.compareTo(bdHigher) == 1) {
108 newTargetSet.remove(newEnd);
109 }
110 return newTargetSet;
111 }
112 } else {
113 if (newEnd == null) {
114 SortedSet<BigDecimal> newTargetSet = targetSet.tailSet(
115 newStart, true);
116 return newTargetSet;
117 } else {
118 SortedSet<BigDecimal> newTargetSet = targetSet.subSet(
119 newStart, true, newEnd, true);
120 if (newEnd.compareTo(bdHigher) == 1) {
121 newTargetSet.remove(newEnd);
122 }
123 return newTargetSet;
124 }
125 }
126 }
127 }
128 }
第三种方式: 使用Apache Commons Collections, 直接对于原始Set进行filter.
测试效果:集合大小10M,过滤结果1M, 运算时间: 1000ms+
过滤部分的代码如下:
1 //过滤的主体逻辑
2 void filterSet(Set<BigDecimal> targetSet, String lower, String higher) {
3 final BigDecimal bdLower = new BigDecimal(Double.parseDouble(lower));
4 final BigDecimal bdHigher = new BigDecimal(Double.parseDouble(higher));
5
6 Predicate predicate = new Predicate() {
7 public boolean evaluate(Object object) {
8 BigDecimal bDObject = (BigDecimal) object;
9 return bDObject.compareTo(bdLower) >= 0
10 && bDObject.compareTo(bdHigher) <= 0;
11 }
12 };
13
14 CollectionUtils.filter(targetSet, predicate);
15 }
第四种方式:使用Guava(google Collections), 直接对于原始Set进行Filter
测试效果:集合大小10M,过滤结果1M, 运算时间: 100ms-
过滤部分的代码如下:
1 //guava filter
2
3 Set<BigDecimal> filterSet(Set<BigDecimal> targetSet, String lower,
4 String higher) {
5 final BigDecimal bdLower = new BigDecimal(Double.parseDouble(lower));
6 final BigDecimal bdHigher = new BigDecimal(Double.parseDouble(higher));
7
8 Set<BigDecimal> filterCollection = Sets.filter(targetSet,
9 new Predicate<BigDecimal>() {
10 @Override
11 public boolean apply(BigDecimal input) {
12 BigDecimal bDObject = (BigDecimal) input;
13 return bDObject.compareTo(bdLower) >= 0
14 && bDObject.compareTo(bdHigher) <= 0;
15 }
16 });
17
18 return filterCollection;
19 }
四种方式对比如下:
第一种方式: 仅依赖于JAVA原生类库 遍历时间最慢, 代码量很小
第二种方式: 仅依赖于JAVA原生类库 遍历时间比较慢(主要慢在生成有序Set), 代码量最多
第三种方式: 依赖于Apache Commons Collections, 遍历时间比较快, 代码量很少
第四种方式: 依赖于Guava, 遍历时间最快, 代码量很少
基于目前个人的技术水平和视野, 第四种方式可能是最佳选择.
记录一下, 以后可能还会有更好的方案.
posted @
2014-06-21 23:33 混沌中立 阅读(7477) |
评论 (10) |
编辑 收藏
在几年之前,在大学里面的时候,认为系统的架构设计,就像建筑设计一样,会把骨架搭成,然后有具体人员进行详细的开发.
在后来,工作中,慢慢有了一些变化,因为原先的想法不太切合实际,系统就是在变化之中的,如果固定了骨架,那就很难的敏捷面对变化.
所以,系统的架构设计,应该是面向接口的设计,确定各个部分之间的数据接口和方法接口.这样,即使有了变化,只要遵循接口的定义,就还是可以面对变化.
最近,又有了想法的变化.架构的设计,应该就是规则和规约的设计.设计出一系列,统一的,和谐的规则,在这些规则之前圈住的部分,实际就是系统的全貌.
接口的设计,实际只是规则和规约设计的一个部分.
架构的设计,不应该只是程序方面的事情,同时也包含了心理学方面和社会学方面的一些规则.例如:团队在面对变化时候,需要采用的规则和流程.
只有包含了这些非程序上的规则之后,才能保证架构风格的统一协调.
以上,是我对系统设计的想法的转变过程.记录于此,以供回溯.
posted @
2009-09-02 10:53 混沌中立 阅读(284) |
评论 (0) |
编辑 收藏
面对着满屏幕的程序
是三年前,项目刚刚启动的时候,同事写的代码.
三年过去了,项目由第一期变成了第七期.
这段代码还是在这里,有个属性是list,其中每个cell都是一个长度18的String数组.
数组里面放置了所需要导出到页面table的内容.
现在要开始修改了,需要向页面的table中增加4列.
繁琐的让人要命的工作,需要跟踪这个循环,判断每个pattern下面,这个长度18的数组里面放了哪些内容.
好吧,对象化维护从数组开始,把数组对折,因为这个数组时一个比较数组,前面9个元素是之前的情况,后面9个事之后的情况.
用一个bean,放入两次就可以了.但是bean中,需要一个标志,标识是之前的情况还是之后的情况.
同时需要一个transform方法,把之前从几个来源过来的情况,变成bean的属性.
接下来需要一个values方法,把bean里面的属性直接按顺序转化成数组.
本期新增的4个属性,直接放入bean中就可以了.
这样原来很复杂的数组,就可以简单的用对象来解决.外部的接口完全没有变化.
维护程序,从把数组(特别是异型数组)对象化开始.
posted @
2009-08-20 13:43 混沌中立 阅读(1391) |
评论 (1) |
编辑 收藏
这个小的project是前一个阶段,待业在家的时候,迷恋sudoku的时候,自己写来玩的。
正好当时在看Uncle Bob的《Agile Software Development: Principles, Patterns, and Practices》 (敏捷软件开发:原则、模式与实践),所以就按照自己对书中的一些概念和方法的理解,结合自己之前的开发经验写出来一段小的代码。
代码行数: < 900
类的个数: 18
抽象类的个数:2
工厂类的个数:1
包的个数:5
一些关于类和包作用的说明:
1.Cell:表示一个Cell,是一个游戏中的一个单元格。
Cell主要由3个部分组成,Point,Value,Status.
2.Point:表示一个坐标,主要格式为:(2,3).
!!!注意:由于个人比较懒,所以开始的错误被贯彻了下来。
这个错误就是(2,3)表示的是由最左上的位置为坐标原点,第二行和第三列所确定的那个单元格。也就是纵坐标在前,横坐标在后了。
3.Value:表示一个值
4.Status:表示Cell的状态,只有两个状态,一个是NotSure,另一个是Sure.
5.AbstractCells:表示一些cell的集合,主要有三个子类
BlockCells:表示一个由多个Cell组成的块,例如一个2*2由4个Cell组成的块,或者一个2*3由6个Cell组成的块
HorizonCells:表示一个横行,即:从(0,0)到(0,n)坐标确定的所有Cell的集合。
VerticalCells:表示一个纵行,即:从(0,0)到(n,0)坐标确定的所有Cell的集合。
6.AbstractPolicy:就是游戏的策略。
这个主要表示的是:4*4的游戏,还是9*9的游戏。
可以在以后对此类进行继承和扩展,例如16*16的游戏我就没有实现。
主要扩展3个方法:
1)getValueRange,返回当前policy的value的个数。4*4的游戏的getValueRange返回的就应该是4。
2)getStep:表示当前policy中相邻的两个BlockCells的坐标差。
3)getIncrease:说不明白了:)(只可意会不可言传。)
7.Game:进行Policy的场所(我一直想抛弃这个类)
8.TestGame:游戏运行的地方,包括从PolicyFactory取得指定的Policy,设置输入输出文件的路径。
9.PolicyFactory:取得Policy的工厂。
getPolicy(int x) :这个方法获得的是正方形的sudoku的策略。例如:4*4的,9*9,16*16。
getPolicy(int x, int y):这个方法获得的是长方形的Sudoku的策略。例如:9*12的。
虽然是尽量避免bad code smell,但是由于能力有限,还是出现了一些不好的地方。
例如:之间的关联关系还是很多,而且很强;抽象的方法和抽象类的个数偏少等等。
里面实现了三个解决sudoku的方法:
1.在一个Cell中出现的Value,不会在和这个Cell处在同一个AbstractCells中的所有Cell中出现;
2.如果一个Cell中,所有可能出现的Value的个数为1,那么Cell的Value必然是这个最后的Value;
2.如果一个Value,如果在当前AbstractCells的所有其他的Cell中都不可能出现,那么它必然是最后一个Cell的Value。
附件1:src code
http://www.blogjava.net/Files/GandofYan/sudoku.rar
附件2:输入输出文件的example
http://www.blogjava.net/Files/GandofYan/temp.rar
posted @
2006-07-13 16:19 混沌中立 阅读(2223) |
评论 (4) |
编辑 收藏
如同Tom DeMacro说的:无法控制的东西就不能管理,无法测量的东西就无法控制。
软件的度量对于设计者和开发者非常重要,之前只是对这些有一个简单的了解。今天看来,了解的还远远不够。
- Cyclomatic Complexity (圈复杂性)
- Response for Class (类的响应)
- Weighted methods per class (每个类重量方法)
一个系统中的所有类的这三个度量能够说明这个系统的设计上的一些问题(不是全部),这三个度量越大越不好。
如果一个类这三个度量很高,证明了这个类需要重构了。
以第一个度量来说,有下面的一个表格:
CC Value | Risk |
1-10 | Low
risk program |
11-20 | Moderate
risk |
21-50 | High
risk |
>50 | Most
complex and highly unstable method |
CC数值高,可以通过减少if else(switch case也算)判断来达到目的;
可以通过减少类与其他类的调用来减少RFC;
通过分割大方法和大类来达到减少WMPC.
而Uncle Bob和Jdepend的度量标准应该算是另一个度量系统。
用包中的每个类平均的内部关系数目作为包内聚性的一种表示方式。用于表示包和它的所有类之间的关系。
H=(R+1)/N
R:包内类的关系数目(与包外部的类没有关系)
N:包内类的数量
被分析package的具体和抽象类(和接口)的数量,用于衡量package的可扩展性。
依赖于被分析package的其他package的数量,用于衡量pacakge的职责。
被分析package的类所依赖的其他package的数量,用于衡量package的独立性。
被分析package中的抽象类和接口与所在package所有类数量的比例,取值范围为0-1。
A=Cc/N
用于衡量package的不稳定性,取值范围为0-1。I=0表示最稳定,I=1表示最不稳定。
I=Ce/(Ce+Ca)
被分析package和理想曲线A+I=1的垂直距离,用于衡量package在稳定性和抽象性之间的平衡。理想 的package要么完全是抽象类和稳定(x=0,y=1),要么完全是具体类和不稳定(x=1,y=0)。
取值范围为0-1,D=0表示完全符合理想标准,D=1表示package最大程度地偏离了理想标准。
D = |A+I-1|/0.70710678
注:0.70710678*0.70710678 =2,既为“根号2“
我认为D是一个综合的度量,架构和设计的改善可以通过D数值的减少来体现,反之就可以认为是设计和架构的退化。
读过http://javaboutique.internet.com/tutorials/metrics/index.html之后的一些想法
另一篇中文的内容相近的文章可以参考http://www.jdon.com/artichect/coupling.htm
不过第二篇的中文文章中间关于Cyclomatic Complexity,有一个情况遗漏了
public void findApplications(String id, String name){
if(id!=null && name!=null) {
//do something
}else{
//do something
}
}
这种情况的CC不是2+1,而是2+1+1,依据是公式(1)。公式(2)应该是公式(1)的简化版。
Cyclomatic Complexity (CC) = no of decision points + no of logical operations +1 (1)
Cyclomatic Complexity (CC) = number of decision points +1 (2)
参考了JDepend的参数和Uncle Bob的《Agile Software Development: Principles, Patterns, and Practices》 (敏捷软件开发:原则、模式与实践)
posted @
2006-06-07 10:52 混沌中立 阅读(1552) |
评论 (3) |
编辑 收藏转自:http://www.keyusoft.cn/Contentview.aspx?year=2005&month=$10&day=$6&postid=123
通过一周左右的研究,对规则引擎有了一定的了解。现在写点东西跟大家一起交流,本文主要针对RETE算法进行描述。我的文笔不太好,如果有什么没讲明白的或是说错的地方,请给我留言。
首先申明,我的帖子借鉴了网上很流行的一篇帖子,好像是来自CSDN;还有一点,我不想做太多的名词解释,因为我也不是个研究很深的人,定义的不好怕被笑话。
好现在我们开始。
首先介绍一些网上对于规则引擎比较好的帖子。
1、 来自JAVA视频网
2、 RETE算法的最原始的描述,我不知道在哪里找到的,想要的人可以留下E-mail
接着统一一下术语,很多资料里的术语都非常混乱。
1、 facts 事实,我们实现的时候,会有一个事实库。用F表示。
2、 patterns 模板,事实的一个模型,所有事实库中的事实都必须满足模板中的一个。用P表示。
3、
conditions
条件,规则的组成部分。也必须满足模板库中的一条模板。用C表示。我们可以这样理解facts、patterns、conditions之间的关系。
Patterns是一个接口,conditions则是实现这个接口的类,而facts是这个类的实例。
4、 rules 规则,由一到多个条件构成。一般用and或or连接conditions。用R表示。
5、 actions 动作,激活一条rule执行的动作。我们这里不作讨论。
6、 还有一些术语,如:working-memory、production-memory,跟这里的概念大同小异。
7、 还有一些,如:alpha-network、beta-network、join-node,我们下面会用到,先放一下,一会讨论。
引用一下网上很流行的例子,我觉得没讲明白,我在用我的想法解释一下。
假设在规则记忆中有下列三条规则
if A(x) and B(x) and C(y) then add D(x)
if A(x) and B(y) and D(x) then add E(x)
if A(x) and B(x) and E(x) then delete A(x)
RETE算法会先将规则编译成下列的树状架构排序网络

而工作记忆内容及顺序为{A(1),A(2),B(2),B(3),B(4),C(5)},当工作记忆依序进入网络后,会依序储存在符合条件的节点中,直到完全符合条件的推论规则推出推论。以上述例子而言, 最后推得D(2)。
让我们来分析这个例子。
模板库:(这个例子中只有一个模板,算法原描述中有不同的例子, 一般我们会用tuple,元组的形式来定义facts,patterns,condition)
P: (?A , ?x) 其中的A可能代表一定的操作,如例子中的A,B,C,D,E ; x代表操作的参数。看看这个模板是不是已经可以描述所有的事实。
条件库:(这里元组的第一项代表实际的操作,第二项代表形参)
C1: (A , <x>)
C2: (B , <x>)
C3: (C , <y>)
C4: (D , <x>)
C5: (E , <x>)
C6: (B , <y>)
事实库:(第二项代表实参)
F1: (A,1)
F2: (A,2)
F3: (B,2)
F4: (B,3)
F5: (B,4)
F6: (C,5)
规则库:
R1: c1^c2^c3
R2: c1^c2^c4
R3: c1^c2^c5
有人可能会质疑R1: c1^c2^c3,没有描述出,原式中:
if A(x) and B(x) and C(y) then add D(x),A=B的关系。但请仔细看一下,这一点已经在条件库中定义出来了。
下面我来描述一下,规则引擎中RETE算法的实现。
首先,我们要定一些规则,根据这些规则,我们的引擎可以编译出一个树状结构,上面的那张图中是一种简易的表现,其实在实现的时候不是这个样子的。
这就是beta-network出场的时候了,根据rules我们就可以确定beta-network,下面,我就画出本例中的beta-network,为了描述方便,我把alpha-network也画出来了。
上图中,左边的部分就是beta-network,右边是alpha-network,圆圈是join-node.
从上图中,我们可以验证,在beta-network中,表现出了rules的内容,其中r1,r2,r3共享了许多BM和join-node,这是由于这些规则中有共同的部分,这样能加快match的速度。
右
边的alpha-network是根据事实库构建的,其中除alpha-network节点的节点都是根据每一条condition,从事实库中
match过来的,这一过程是静态的,即在编译构建网络的过程中已经建立的。只要事实库是稳定的,即没有大幅度的变化,RETE算法的执行效率应该是非常
高的,其原因就是已经通过静态的编译,构建了alpha-network。我们可以验证一下,满足c1的事实确实是w1,w2。
下
面我们就看一下,这个算法是怎么来运行的,即怎么来确定被激活的rules的。从top-node往下遍历,到一个join-node,与AM for
c1的节点汇合,运行到match c1节点。此时,match c1节点的内容就是:w1,w2。继续往下,与AM for
c2汇合(所有可能的组合应该是w1^w3,w1^w4,w1^w5,w2^w3,w2^w4,w2^w5),因为c1^c2要求参数相同,因此,
match
c1^c2的内容是:w2^w3。再继续,这里有一个扇出(fan-out),其中只有一个join-node可以被激活,因为旁边的AM只有一个非空。
因此,也只有R1被激活了。
解决扇出带来的效率降低的问题,我们可以使用hashtable来解决这个问题。
RETE算法还有一些问题,如:facts库变化,我们怎么才能高效的重建alpha-network,同理包括rules的变化对beta-network的影响。这一部分我还没细看,到时候再贴出来吧。
posted @
2006-05-30 15:30 混沌中立 阅读(1121) |
评论 (2) |
编辑 收藏最近插件又加多了,eclipse老是死掉
一怒之下,删除重装
以前因为懒,没有把插件的目录和主体的目录分开,这次也给它分开了
插件少了之后,eclipse确实快了不少
附eclipse启动参数: -nl en_US vmargs -Xverify:none -Xms256M -Xmx1024M
-XX:PermSize=50M -XX:+UseParallelGC
posted @
2006-05-30 13:48 混沌中立 阅读(620) |
评论 (0) |
编辑 收藏
freemind一个比较不错free的
mind map 软件,很多人建议使用这个来管理自己的思路.
visio,就不介绍了.office里面有的东西.做流程图来说,确实是比较好的软件.但是在思路不清楚的时候,很难画出什么有用的东西来.这点就比不上前面两个东西了.不过对我来说visio可能更顺手,因为我经常画的是软件流程图........
posted @
2006-05-30 13:36 混沌中立 阅读(1810) |
评论 (2) |
编辑 收藏
在最近的围绕domain
object的讨论中浮现出来了三种模型,(还有一些其他的旁枝,不一一分析了),经过一番讨论,各种问题逐渐清晰起来,在这里我试图做一个总结,便于大家了解和掌握。
第一种模型:只有getter/setter方法的纯数据类,所有的业务逻辑完全由business
object来完成(又称TransactionScript),这种模型下的domain object被Martin Fowler称之为“贫血的domain
object”。下面用举一个具体的代码来说明,代码来自Hibernate的caveatemptor,但经过我的改写:
一个实体类叫做Item,指的是一个拍卖项目
一个DAO接口类叫做ItemDao
一个DAO接口实现类叫做ItemDaoHibernateImpl
一个业务逻辑类叫做ItemManager(或者叫做ItemService)
|
java代码:
|
|
public
class Item implementsSerializable{
privateLong id = null;
privateint version;
privateString name;
private User seller;
privateString description;
private MonetaryAmount
initialPrice;
private MonetaryAmount
reservePrice;
privateDate startDate;
privateDate endDate;
privateSet categorizedItems = newHashSet();
privateCollection bids = newArrayList();
private
Bid successfulBid;
private ItemState state;
private
User approvedBy;
privateDate approvalDatetime;
privateDate created = newDate();
//
getter/setter方法省略不写,避免篇幅太长
}
|
|
java代码:
|
|
public
interface ItemDao {
public Item
getItemById(Long id);
publicCollection findAll();
publicvoid
updateItem(Item item);
}
|
ItemDao定义持久化操作的接口,用于隔离持久化代码。
|
java代码:
|
|
public
class
ItemDaoHibernateImpl implements ItemDao extends
HibernateDaoSupport {
public Item
getItemById(Long id){
return(Item) getHibernateTemplate().load(Item.class, id);
}
publicCollection findAll(){
return(List) getHibernateTemplate().find("from
Item");
}
publicvoid updateItem(Item item){
getHibernateTemplate().update(item);
}
}
|
ItemDaoHibernateImpl完成具体的持久化工作,请注意,数据库资源的获取和释放是在ItemDaoHibernateImpl
里面处理的,每个DAO方法调用之前打开Session,DAO方法调用之后,关闭Session。(Session放在ThreadLocal中,保证一次调用只打开关闭一次)
|
java代码:
|
|
public
class ItemManager {
private ItemDao itemDao;
publicvoid
setItemDao(ItemDao itemDao){
this.itemDao = itemDao;}
public Bid
loadItemById(Long id){
itemDao.loadItemById(id);
}
publicCollection listAllItems(){
return itemDao.findAll();
}
public Bid placeBid(Item item, User bidder, MonetaryAmount
bidAmount,
Bid currentMaxBid, Bid
currentMinBid)throws BusinessException
{
if(currentMaxBid != null &&
currentMaxBid.getAmount().compareTo(bidAmount) > 0){
throw new
BusinessException("Bid too low.");
}
// Auction is active
if( !state.equals(ItemState.ACTIVE))
throw new
BusinessException("Auction is not active yet.");
// Auction still valid
if( item.getEndDate().before(newDate()))
throw new
BusinessException("Can't place new bid, auction already
ended.");
// Create new Bid
Bid newBid =
new Bid(bidAmount, item, bidder);
// Place bid for this Item
item.getBids().add(newBid);
itemDao.update(item);
// 调用DAO完成持久化操作
return newBid;
}
}
|
事务的管理是在ItemManger这一层完成的,ItemManager实现具体的业务逻辑。除了常见的和CRUD有关的简单逻辑之外,这里还有一个placeBid的逻辑,即项目的竞标。
以上是一个完整的第一种模型的示例代码。在这个示例中,placeBid,loadItemById,findAll等等业务逻辑统统放在ItemManager中实现,而Item只有getter/setter方法。
第二种模型,也就是Martin Fowler指的rich domain object是下面这样子的:
一个带有业务逻辑的实体类,即domain object是Item
一个DAO接口ItemDao
一个DAO实现ItemDaoHibernateImpl
一个业务逻辑对象ItemManager
|
java代码:
|
|
public
class Item implementsSerializable{
// 所有的属性和getter/setter方法同上,省略
public Bid
placeBid(User bidder, MonetaryAmount
bidAmount,
Bid currentMaxBid, Bid currentMinBid)
throws BusinessException
{
// Check highest bid (can also be a different
Strategy (pattern))
if(currentMaxBid != null &&
currentMaxBid.getAmount().compareTo(bidAmount) > 0){
throw new
BusinessException("Bid too low.");
}
// Auction is active
if( !state.equals(ItemState.ACTIVE))
throw new
BusinessException("Auction is not active yet.");
// Auction still valid
if( this.getEndDate().before(newDate()))
throw new
BusinessException("Can't place new bid, auction already
ended.");
// Create new Bid
Bid newBid = new
Bid(bidAmount, this, bidder);
// Place bid for this Item
this.getBids.add(newBid); //
请注意这一句,透明的进行了持久化,但是不能在这里调用ItemDao,Item不能对ItemDao产生依赖!
return newBid;
}
}
|
竞标这个业务逻辑被放入到Item中来。请注意this.getBids.add(newBid);
如果没有Hibernate或者JDO这种O/R
Mapping的支持,我们是无法实现这种透明的持久化行为的。但是请注意,Item里面不能去调用ItemDAO,对ItemDAO产生依赖!
ItemDao和ItemDaoHibernateImpl的代码同上,省略。
|
java代码:
|
|
public
class ItemManager {
private ItemDao itemDao;
publicvoid
setItemDao(ItemDao itemDao){
this.itemDao = itemDao;}
public Bid
loadItemById(Long id){
itemDao.loadItemById(id);
}
publicCollection listAllItems(){
return itemDao.findAll();
}
public Bid placeBid(Item item, User bidder, MonetaryAmount
bidAmount,
Bid currentMaxBid, Bid
currentMinBid)throws BusinessException
{
item.placeBid(bidder, bidAmount, currentMaxBid,
currentMinBid);
itemDao.update(item);
// 必须显式的调用DAO,保持持久化
}
}
|
在第二种模型中,placeBid业务逻辑是放在Item中实现的,而loadItemById和findAll业务逻辑是放在
ItemManager中实现的。不过值得注意的是,即使placeBid业务逻辑放在Item中,你仍然需要在ItemManager中简单的封装一层,以保证对placeBid业务逻辑进行事务的管理和持久化的触发。
这种模型是Martin Fowler所指的真正的domain
model。在这种模型中,有三个业务逻辑方法:placeBid,loadItemById和findAll,现在的问题是哪个逻辑应该放在Item
中,哪个逻辑应该放在ItemManager中。在我们这个例子中,placeBid放在Item中(但是ItemManager也需要对它进行简单的封装),loadItemById和findAll是放在ItemManager中的。
切分的原则是什么呢? Rod Johnson提出原则是“case by case”,可重用度高的,和domain
object状态密切关联的放在Item中,可重用度低的,和domain object状态没有密切关联的放在ItemManager中。
我提出的原则是:看业务方法是否显式的依赖持久化。
Item的placeBid这个业务逻辑方法没有显式的对持久化ItemDao接口产生依赖,所以要放在Item中。请注意,如果脱离了Hibernate这个持久化框架,Item这个domain
object是可以进行单元测试的,他不依赖于Hibernate的持久化机制。它是一个独立的,可移植的,完整的,自包含的域对象。
而loadItemById和findAll这两个业务逻辑方法是必须显式的对持久化ItemDao接口产生依赖,否则这个业务逻辑就无法完成。如果你要把这两个方法放在Item中,那么Item就无法脱离Hibernate框架,无法在Hibernate框架之外独立存在。
第三种模型印象中好像是firebody或者是Archie提出的(也有可能不是,记不清楚了),简单的来说,这种模型就是把第二种模型的domain
object和business object合二为一了。所以ItemManager就不需要了,在这种模型下面,只有三个类,他们分别是:
Item:包含了实体类信息,也包含了所有的业务逻辑
ItemDao:持久化DAO接口类
ItemDaoHibernateImpl:DAO接口的实现类
由于ItemDao和ItemDaoHibernateImpl和上面完全相同,就省略了。
|
java代码:
|
|
public
class Item implementsSerializable{
// 所有的属性和getter/setter方法都省略
privatestatic ItemDao itemDao;
publicvoid
setItemDao(ItemDao itemDao){this.itemDao = itemDao;}
publicstatic Item
loadItemById(Long id){
return(Item) itemDao.loadItemById(id);
}
publicstaticCollection findAll(){
return(List) itemDao.findAll();
}
public Bid placeBid(User bidder, MonetaryAmount bidAmount,
Bid currentMaxBid, Bid currentMinBid)
throws BusinessException
{
// Check highest bid (can also be a different
Strategy (pattern))
if(currentMaxBid != null &&
currentMaxBid.getAmount().compareTo(bidAmount) > 0){
throw new
BusinessException("Bid too low.");
}
// Auction is active
if( !state.equals(ItemState.ACTIVE))
throw new
BusinessException("Auction is not active yet.");
// Auction still valid
if( this.getEndDate().before(newDate()))
throw new
BusinessException("Can't place new bid, auction already
ended.");
// Create new Bid
Bid
newBid = new
Bid(bidAmount, this, bidder);
// Place bid for this Item
this.addBid(newBid);
itemDao.update(this);
// 调用DAO进行显式持久化
return newBid;
}
}
|
在这种模型中,所有的业务逻辑全部都在Item中,事务管理也在Item中实现。
在上面三种模型之外,还有很多这三种模型的变种,例如partech的模型就是把第二种模型中的DAO和
Manager三个类合并为一个类后形成的模型;例如frain....(id很长记不住)的模型就是把第三种模型的三个类完全合并为一个单类后形成的模型;例如Archie是把第三种模型的Item又分出来一些纯数据类(可能是,不确定)形成的一个模型。
但是不管怎么变,基本模型归纳起来就是上面的三种模型,下面分别简单评价一下:
第一种模型绝大多数人都反对,因此反对理由我也不多讲了。但遗憾的是,我观察到的实际情形是,很多使用Hibernate的公司最后都是这种模型,这里面有很大的原因是很多公司的技术水平没有达到这种层次,所以导致了这种贫血模型的出现。从这一点来说,Martin
Fowler的批评声音不是太响了,而是太弱了,还需要再继续呐喊。
第二种模型就是Martin
Fowler一直主张的模型,实际上也是我一直在实际项目中采用这种模型。我没有看过Martin的POEAA,之所以能够自己摸索到这种模型,也是因为从02年我已经开始思考这个问题并且寻求解决方案了,但是当时没有看到Hibernate,那时候做的一个小型项目我已经按照这种模型来做了,但是由于没有O/R
Mapping的支持,写到后来又不得不全部改成贫血的domain
object,项目做完以后再继续找,随后就发现了Hibernate。当然,现在很多人一开始就是用Hibernate做项目,没有经历过我经历的那个阶段。
不过我觉得这种模型仍然不够完美,因为你还是需要一个业务逻辑层来封装所有的domain
logic,这显得非常罗嗦,并且业务逻辑对象的接口也不够稳定。如果不考虑业务逻辑对象的重用性的话(业务逻辑对象的可重用性也不可能好),很多人干脆就去掉了xxxManager这一层,在Web层的Action代码直接调用xxxDao,同时容器事务管理配置到Action这一层上来。
Hibernate的caveatemptor就是这样架构的一个典型应用。
第三种模型是我很反对的一种模型,这种模型下面,Domain
Object和DAO形成了双向依赖关系,无法脱离框架测试,并且业务逻辑层的服务也和持久层对象的状态耦合到了一起,会造成程序的高度的复杂性,很差的灵活性和糟糕的可维护性。也许将来技术进步导致的O/R
Mapping管理下的domain object发展到足够的动态持久透明化的话,这种模型才会成为一个理想的选择。就像O/R
Mapping的流行使得第二种模型成为了可能(O/R Mapping流行以前,我们只能用第一种模型,第二种模型那时候是不现实的)。
既然大家都统一了观点,那么就有了一个很好的讨论问题的基础了。Martin Fowler的Domain
Model,或者说我们的第二种模型难道是完美无缺的吗?当然不是,接下来我就要分析一下它的不足,以及可能的解决办法,而这些都来源于我个人的实践探索。
在第二种模型中,我们可以清楚的把这4个类分为三层:
1、实体类层,即Item,带有domain logic的domain
object
2、DAO层,即ItemDao和ItemDaoHibernateImpl,抽象持久化操作的接口和实现类
3、业务逻辑层,即ItemManager,接受容器事务控制,向Web层提供统一的服务调用
在这三层中我们大家可以看到,domain
object和DAO都是非常稳定的层,其实原因也很简单,因为domain object是映射数据库字段的,数据库字段不会频繁变动,所以domain
object也相对稳定,而面向数据库持久化编程的DAO层也不过就是CRUD而已,不会有更多的花样,所以也很稳定。
问题就在于这个充当business workflow facade的业务逻辑对象,它的变动是相当频繁的。业务逻辑对象通常都是无状态的、受事务控制的、Singleton类,我们可以考察一下业务逻辑对象都有哪几类业务逻辑方法:
第一类:DAO接口方法的代理,就是上面例子中的loadItemById方法和findAll方法。
ItemManager之所以要代理这种类,目的有两个:向Web层提供统一的服务调用入口点和给持久化方法增加事务控制功能。这两点都很容易理解,你不能既给Web层程序员提供xxxManager,也给他提供xxxDao,所以你需要用xxxManager封装xxxDao,在这里,充当了一个简单代理功能;而事务控制也是持久化方法必须的,事务可能需要跨越多个DAO方法调用,所以必须放在业务逻辑层,而不能放在DAO层。
但是必须看到,对于一个典型的web应用来说,绝大多数的业务逻辑都是简单的CRUD逻辑,所以这种情况下,针对每个DAO方法,xxxManager都需要提供一个对应的封装方法,这不但是非常枯燥的,也是令人感觉非常不好的。
第二类:domain
logic的方法代理。就是上面例子中placeBid方法。虽然Item已经有了placeBid方法,但是ItemManager仍然需要封装一下Item的placeBid,然后再提供一个简单封装之后的代理方法。
这和第一种情况类似,其原因也一样,也是为了给Web层提供一个统一的服务调用入口点和给隐式的持久化动作提供事务控制。
同样,和第一种情况一样,针对每个domain logic方法,xxxManager都需要提供一个对应的封装方法,同样是枯燥的,令人不爽的。
第三类:需要多个domain object和DAO参与协作的business
workflow。这种情况是业务逻辑对象真正应该完成的职责。
在这个简单的例子中,没有涉及到这种情况,不过大家都可以想像的出来这种应用场景,因此不必举例说明了。
通过上面的分析可以看出,只有第三类业务逻辑方法才是业务逻辑对象真正应该承担的职责,而前两类业务逻辑方法都是“无奈之举”,不得不为之的事情,不但枯燥,而且令人沮丧。
分析完了业务逻辑对象,我们再回头看一下domain object,我们要仔细考察一下domain
logic的话,会发现domain logic也分为两类:
第一类:需要持久层框架隐式的实现透明持久化的domain
logic,例如Item的placeBid方法中的这一句:
|
java代码:
|
|
this.getBids().add(newBid);
|
上面已经着重提到,虽然这仅仅只是一个Java集合的添加新元素的操作,但是实际上通过事务的控制,会潜在的触发两条SQL:一条是insert一条记录到bid表,一条是更新item表相应的记录。如果我们让Item脱离Hibernate进行单元测试,它就是一个单纯的Java集合操作,如果我们把他加入到Hibernate框架中,他就会潜在的触发两条SQL,这就是隐式的依赖于持久化的domain logic。
特别请注意的一点是:在没有Hibernate/JDO这类可以实现“透明的持久化”工具出现之前,这类domain logic是无法实现的。
对于这一类domain logic,业务逻辑对象必须提供相应的封装方法,以实现事务控制。
第二类:完全不依赖持久化的domain logic,例如readonly例子中的Topic,如下:
|
java代码:
|
|
class Topic {
boolean
isAllowReply(){
Calendar dueDate =
Calendar.getInstance();
dueDate.setTime(lastUpdatedTime);
dueDate.add(Calendar.DATE, forum.timeToLive);
Date now = newDate();
return
now.after(dueDate.getTime());
}
}
|
注意这个isAllowReply方法,他和持久化完全不发生一丁点关系。在实际的开发中,我们同样会遇到很多这种不需要持久化的业务逻辑(主要发生在日期运算、数值运算和枚举运算方面),这种domain
logic不管脱离不脱离所在的框架,它的行为都是一致的。对于这种domain
logic,业务逻辑层并不需要提供封装方法,它可以适用于任何场合。
posted @
2006-05-30 13:31 混沌中立 阅读(3112) |
评论 (1) |
编辑 收藏
原文地址:
http://www.cnblogs.com/idior/archive/2005/07/04/186086.html近日 有关o/r m的讨论突然多了起来. 在这里觉得有必要澄清一些概念, 免的大家讨论来讨论去, 才发现最根本的理解有问题.
1. 何谓实体?
实体(类似于j2ee中的Entity Bean)通常指一个承载数据的对象, 但是注意它也是可以有行为的! 只不过它的行为一般只操作自身的数据. 比如下面这个例子:
class Person
{
string firstName;
string lastName;
public void GetName()
{
return lastName+firstName;
}
}
GetName就是它的一个行为.
2 何谓对象?
对象最重要的特性在于它拥有行为. 仅仅拥有数据,你可以称它为对象, 但是它却失去它最重要的灵魂.
class Person
{
string firstName;
string lastName;
Role role;
int baseWage;
public void GetSalary()
{
return baseWage*role.GetFactory();
}
}
这样需要和别的对象(不是Value Object)打交道的对象,我就不再称其为实体. 领域模型就是指由这些具有业务逻辑的对象构成的模型.
3. E/R M or O/R M?!!
仔细想想我们为什么需要o/r m,无非是想利用oo的多态来处理复杂的业务逻辑, 而不是靠一堆的if else.
而现在在很多人的手上o/r m全变成了e/r m.他们不考虑对象的行为, 而全关注于如何保存数据.这样也难怪他们会产生将CRUD这些操作放入对象中的念头. 如果你不能深刻理解oo, 那么我不推荐你使用o/r m, Table Gateway, Row Gateway才是你想要的东西.
作为一个O/R M框架,很重要的一点就是实现映射的透明性(Transparent),比较显著的特点就是在代码中我们是看不到SQL语句的(框架自动生成了)。这里所指的O/R M就是类似于此的框架,
4. POEAA中的相关概念
很多次发现有人错用其中的概念, 这里顺便总结一下:
1. Table Gateway
以表为单位的实体,基本没有行为,只有CRUD操作.
2. Row Gateway
以行为单位的实体,基本没有行为,只有CRUD操作.
3. Active Record
以行为单位的实体,拥有一些基本的操作自身数据的行为(如上例中的GetName),同时包含有CRUD操作.
其实Active Record最符合某些简单的需求, 接近于E/R m.
通常也有很多人把它当作O/R m.不过需要注意的是Active Record中是充满了SQL语句的(不像orm的SQL透明), 所以有人想起来利用O/R m来实现"Active Record", 虽然在他们眼里看起来很方便, 其实根本就是返祖.
用CodeGenerator来实现Active Record也许是一个比较好的方法.
4. Data Mapper
这才是真正的O/R m,Hibernate等等工具的目标.
5.O/R M需要关注的地方 (希望大家帮忙完善一下)
1. 关联, O/R M是如何管理类之间的关联.当然这不仅于o/r m有关与设计者的设计水平也有很大关系.
2. O/R M对继承关系的处理.
3. O/R M对事务的支持.
4. O/R M对查询的支持.
以上观点仅属个人意见, 不过在大家讨论有关O/R m之前, 希望先就一些基本概念达成共识, 不然讨论下去会越离越远.
(建议: 如果对oo以及dp没有一定程度的了解, 最好别使用o/r m, dataset 加上codesmith或许是更好的选择)
posted @
2006-05-30 13:20 混沌中立 阅读(418) |
评论 (0) |
编辑 收藏
from http://www.code365.com/web/122/Article/17927.Asp
Thomas Bayes,一位伟大的数学大师,他的理论照亮了今天的计算领域,和他的同事们不同:他认为上帝的存在可以通过方程式证明,他最重要的作品被别人发行,而他已经去世241年了。
18世纪牧师们关于概率的理论成为应用发展的数学基础的一部分。
搜索巨人Google和Autonomy,一家出售信息恢复工具的公司,都使用了贝叶斯定理(Bayesian
principles)为数据搜索提供近似的(但是技术上不确切)结果。研究人员还使用贝叶斯模型来判断症状和疾病之间的相互关系,创建个人机器人,开发
能够根据数据和经验来决定行动的人工智能设备。
 虽然听起来很深奥,而这个原理的意思--大致说起来--却很简单:某件事情发生的概率大致可以由它过去发生的频率近似地估计出来。研究人员把这个原理应用在每件事上,从基因研究到过滤电子邮件。
虽然听起来很深奥,而这个原理的意思--大致说起来--却很简单:某件事情发生的概率大致可以由它过去发生的频率近似地估计出来。研究人员把这个原理应用在每件事上,从基因研究到过滤电子邮件。
在明尼苏达州大学的网站上能够找到一份详细的数学概要。而在Gametheory.net上的一个Bayes Rule Applet程序让你能够回答诸如“如果你测试某种疾病,有多大风险”之类的问题。
贝叶斯理论的一个出名的倡导者就是微软。该公司把概率用于它的Notification Platform。该技术将会被内置到微软未来的软件中,而且让计算机和蜂窝电话能够自动地过滤信息,不需要用户帮助,自动计划会议并且和其他人联系。
如果成功的话,该技术将会导致“context server”--一种电子管家的出现,它能够解释人的日常生活习惯并在不断变换的环境中组织他们的生活。
“Bayes的研究被用于决定我应该怎样最好地分配计算和带宽,” Eric Horvitz表示,他是微软研究部门Adaptive
Systems & Interaction
Group的高级研究员和分组管理者。“我个人相信在这个不确定的世界里,你不能够知道每件事,而概率论是任何智能的基础。”
到今年年底,Intel也将发布它自己的基于贝叶斯理论的工具包。一个关于照相机的实验警告医生说病人可能很快遭受痛苦。在本周晚些时候在该公司的Developer Forum(开发者论坛)上将讨论这种发展。
虽然它在今天很流行,Bayes的理论并不是一直被广泛接受的:就在10年前,Bayes研究人员还在他们的专业上踌躇不前。但是其后,改进的数学模型,更快的计算机和实验的有效结果增加了这种学派新的可信程度。
“问题之一是它被过度宣传了,” Intel微处理器实验室的应用软件和技术管理经理Omid Moghadam表示。“事实上,能够处理任何事情的能力并不存在。真正的执行在过去的10年里就发生了。”
Bayes哑元
Bayes的理论可以粗略地被简述成一条原则:为了预见未来,必须要看看过去。Bayes的理论表示未来某件事情发生的概率可以通过计算它过去发生的频率来估计。一个弹起的硬币正面朝上的概率是多少?实验数据表明这个值是50%。
 “Bayes表示从本质上说,每件事都有不确定性,你有不同的概率类型,”斯坦佛的管理科学和工程系(Department of Management Science and Engineering at Stanford)的教授Ron Howard表示。
“Bayes表示从本质上说,每件事都有不确定性,你有不同的概率类型,”斯坦佛的管理科学和工程系(Department of Management Science and Engineering at Stanford)的教授Ron Howard表示。
例如,假设不是硬币,一名研究人员把塑料图钉往上抛,想要看看它钉头朝上落地的概率有多大,或者有多少可能性是侧面着地,而钉子是指向什么方向的。形状,成型过程中的误差,重量分布和其他的因素都会影响该结果。
Bayes技术的吸引力在于它的简单性。预测完全取决于收集到的数据--获得的数据越多,结果就越好。另一个优点在于Bayes模型能够自我纠正,也就是说数据变化了,结果也就跟着变化。
概率论的思想改变了人们和计算机互动的方式。“这种想法是计算机能够更象一个帮助者而不仅仅是一个终端设备,” Peter Norvig表示。他是Google的安全质量总监。他说“你在寻找的是一些指导,而不是一个标准答案。”
从这种转变中,研究获益非浅。几年前,所谓的Boolean搜索引擎的一般使用需要把搜索按照“if, and, or but”的语法进行提交,然后去寻找匹配的词。现在的搜索引擎采用了复杂的运算法则来搜索数据库,并找出可能的匹配。
如同图钉的那个例子显示的那样,复杂性和对于更多数据的需要可能很快增长。由于功能强大的计算机的出现,对于把好的猜测转变成近似的输出所必须的结果进行控制成为可能。
更重要的是,UCLA的Judea Pearl这样的研究人员研究出如何让Bayes模型能够更好地追踪不同的现象之间条件关系的方法,这样能够极大地减少计算量。
例如,对于人口进行大规模的关于肺癌成因的调查可能会发现它是一种不太广泛的疾病,但是如果局限在吸烟者范围内进行调查就可能会发现一些关联性。对于肺癌患者进行检查能够帮助调查清楚习惯和这种疾病之间的关系。
 “每一个单独的属性或者征兆都可能取决于很多不同的事情,但是直接决定它的却是为数不多的事情,”斯坦佛计算机科学系(computer
science department at Stanford)的助理教授Daphne
Koller表示。“在过去的15年左右的时间里,人们在工具方面进行了改革,这让你能够描绘出大量人群的情况。”
“每一个单独的属性或者征兆都可能取决于很多不同的事情,但是直接决定它的却是为数不多的事情,”斯坦佛计算机科学系(computer
science department at Stanford)的助理教授Daphne
Koller表示。“在过去的15年左右的时间里,人们在工具方面进行了改革,这让你能够描绘出大量人群的情况。”
和其他一些项目一样,Koller是使用概率论技术来更好地把病症和疾病联系起来,并把遗传基因和特定的细胞现象联系起来。
记录演讲
一项相关的技术,名为Hidden Markov模型,让概率能够预测次序。例如,一个演讲识别应用知道经常在“q”之后的字母是“u”。除了这些,该软件还能够计算“Qagga”(一种灭绝了的斑马的名称)一词出现的概率。
概率技术已经内置在微软的产品中了。Outlook Mobile
Manage是一个能够决定什么时候往移动设备上发出一封内勤的电子邮的软件。它是从Priorities发展而来的,Priorities是微软在
1998年公布的一个实验系统。Windows XP的故障检修引擎也依赖于概率计算。
随着该公司的Notification Platform开始内置在产品中,在未来的一年中会有更多的应用软件发布,微软的Horvitz这样表示。
Notification
Platform的一个重要组成部分名为Coordinate,它从个人日历,键盘,传感器照相机以及其他来源收集数据,来了解某个人生活和习惯。收集的
数据可能包括到达的时间,工作时间和午餐的时间长度,哪种类型的电话或电子邮件被保存,而哪些信息被删除,在某天的特定时间里键盘被使用的频率,等等。
这些数据可以被用来管理信息流和使用者收到的其他信息。例如,如果一位经理在下午2:40发送了一封电子邮件给一名员工,
Coordinate可以检查该员工的日历程序,然后发现他在下午2:00有一个会议。该程序还可以扫描关于该员工习惯的数据,然后发现该员工通常会在有
会议之后大约一个小时才重新使用键盘。该程序可能还能够发现该名员工通常会在5分钟之内回复该经理的电子邮件。根据上面这些数据,该软件能够估计出该员工
可能至少在20分钟之内不可能回复该电子邮件,该软件可能会把这条信息发送到该员工的手提电话上。同时,该软件可能会决定不把别人的电子邮件也转发出去。
“我们正在平衡以打搅你为代价所获得信息的价值,” Horvitz表示。使用这个软件,他坚持道,“能够让更多的人跟上事情的发展,而不被大量的信息所淹没。”
Horvitz补充道,隐私和对于这些功能的用户控制是确定的。呼叫者并不知道为什么一条信息可能会被优先或推迟处理。
微软还把Bayes模型使用在其他的一些产品上,包括DeepListener 以及Quartet (语音激活),SmartOOF 以及TimeWave (联系控制)。消费者多媒体软件也获益非浅,Horvitz表示。
Bayes技术不仅仅被应用在PC领域。在University of
Rochester,研究人员发现一个人的步伐可以在一步前发生改变。虽然这种改变对于人类来说太过于细微,一台和电脑连接在一起的照相机可以捕捉并跟踪
这种动作。如果行走异常出现,计算机就能够发出警报。
一个实验用的安全照相机采用了同样的原理:大部分到达机场的人都会在停车以后直接走向目的地,所以如果有人停了车,然后走向另一辆车就不太正常,因此就可能引发警报。今年秋天一个创建Bayes模型和技术信息的基本引擎将会公布在Intel的开发者网站上。
理论冲突
虽然该技术听起来简单易懂,关于它的计算可能却比较慢。Horvitz回忆说他是斯坦佛20世纪80年代仅有的两个概率和人工智能的毕业生之一。其他所有的人学习的是逻辑系统,采用的是“if and then”的模式和世界互动。
 “概率论那时候不流行,” Horvitz表示。但是当逻辑系统不能够预测所有的意外情况时,潮流发生了转变。
“概率论那时候不流行,” Horvitz表示。但是当逻辑系统不能够预测所有的意外情况时,潮流发生了转变。
很多研究人员开始承认人类的决策过程比原来想象的要神秘的多。“在人工智能领域存在着文化偏见,” Koller表示。“人们现在承认他们并不知道他们的脑子是如何工作的。”
即便在他的时代,Bayes发现他自己置身于主流之外。他于1702年出生于伦敦,后来他成为了一名Presbyterian
minister。虽然他看到了自己的两篇论文被发表了,他的理论很有效,但是《Essay Toward Solving a Problem in
the Doctrine of Chances》却一直到他死后的第三年,也就是1764年才被发表。
他的王室成员身份一直是个谜,直到最近几年,新发现的一些信件表明他私下和英格兰其他一些思想家看法一致。
“就我所知,他从来没有写下贝叶斯定理,” Howard表示。
神学家Richard Price和法国的数学家Pierre Simon
LaPlace成为了早期的支持者。该理论和后来George Boole,布尔数学之父,的理论背道而驰。George
Boole的理论是基于代数逻辑的,并最终导致了二进制系统的诞生。也是皇室成员之一的Boole死于1864年。
虽然概率的重要性不容置疑,可是关于它的应用的争论却没有停止过。批评者周期性地声称Bayes模型依赖于主观的数据,而让人类去判断答案是否正确。而概率论模型没有完全解决在人类思维过程中存在的细微差别的问题。
“儿童如何学习现在还不是很清楚,”IBM研究部门的科学和软件副总裁 Alfred
Spector这样表示。他计划把统计学方法和逻辑系统在他的Combination
Hypothesis之中结合起来。“我最初相信是统计学的范畴,但是从某方面说,你将会发现不仅仅是统计学的问题。”
但是,很有可能概率论是基础。
“这是个基础,” Horvitz表示。“它被忽略了一段时间,但是它是推理的基础。”
posted @
2006-05-30 12:51 混沌中立 阅读(469) |
评论 (0) |
编辑 收藏
此篇内容来自一下两处
http://blog.joycode.com/microhelper/archive/2004/11/30/40013.aspx
http://www.blogjava.net/ghawk/
另:关于面向对象设计的原则比较权威的是Uncle Bob--
Robert C. Martin的
http://c2.com/cgi/wiki?PrinciplesOfObjectOrientedDesign
单一职责原则——SRP
就一个类而言,应该仅有一个引起它的变化的原因
原则
最简单,最单纯的事情最容易控制,最有效
类的职责简单而且集中,避免相同的职责分散到不同的类之中,避免一个类承担过多的职责
减少类之间的耦合
当需求变化时,只修改一个地方
组件
每个组件集中做好一件事情
组件的颗粒度
发布的成本
可重用的成本
方法
避免写臃肿的方法
Extract Method
重构
Move Field/Move Class
Extract Method/Extract Class
最简单的,也是最难以掌握的原则
实例分析
单一职责很容易理解,也很容易实现。所谓单一职责,就是一个设计元素只做一件事。什么是“只做一件事”?简单说就是少管闲事。现实中就是如此,如果要你专心做一件事情,任何人都有信心可以做得很出色。但如果,你整天被乱七八糟的事所累,还有心思和精力把每件事都作好么?

“单一职责”就是要在设计中为每种职责设计一个类,彼此保持正交,互不干涉。这个雕塑(二重奏)就是正交的一个例子,钢琴家和小提琴家各自演奏自己的乐
谱,而结果就是一个和谐的交响乐。当然,真实世界中,演奏小提琴和弹钢琴的必须是两个人,但是在软件中,我们往往会把两者甚至更多搅和到一起,很多时候只
是为了方便或是最初设计的时候没有想到。
这样的例子在设计中很常见,书中就给了一个很好的例子:调制解调器。这是一个调制
解调器最基本的功能。但是这个类事实上完成了两个职责:连接的建立和中断、数据的发送和接收。显然,这违反了SRP。这样做会有潜在的问题:当仅需要改变
数据连接方式时,必须修改Modem类,而修改Modem类的结果就是使得任何依赖Modem类的元素都需要重新编译,不管它是不是用到了数据连接功能。
解决的办法,书中也已经给出:重构Modem类,从中抽出两个接口,一个专门负责连接、另一个专门负责数据发送。依赖Modem类的元素也要做相应的细
化,根据职责的不同分别依赖不同的接口。最后由ModemImplementation类实现这两个接口。
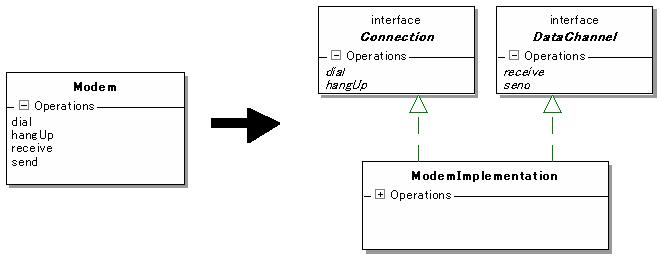
从这个例子中,我们不难发现,违反SRP通常是由于过于“真实”地设计了一个类所造成的。因此,解决办法是往更高一层进行抽象
化提取,将对某个具体类的依赖改变为对一组接口或抽象类的依赖。当然,这个抽象化的提取应该根据需要设计,而不是盲目提取。比如刚才这个Modem的例子
中,如果有必要,还可以把DataChannel抽象为DataSender和DataReceiver两个接口。
开放封闭原则——OCP
软件实体(类,模块,函数)应该是可以扩展的,但是不可修改的
原则
对扩展是开放的,当需求改变时我们可以对模块进行扩展,使其具有新的功能
对更改是封闭的,对模块扩展时,不需要改动原来的代码
面对抽象而不是面对细节,抽象比细节活的更长
僵化的设计——如果程序中一处改动产生连锁反应。
方法
条件case if/else 语句
重构
Replace Type Code With Class
Replace Type Code With State/Strategy
Replace Conditional with polymorphism
实例
开闭原则很简单,一句话:“Closed for Modification; Open for Extension”——“对变更关闭;对扩展开放”。开闭原则其实没什么好讲的,我将其归结为一个高层次的设计总则。就这一点来讲,OCP的地位应该比SRP优先。
OCP的动机很简单:软件是变化的。不论是优质的设计还是低劣的设计都无法回避这一问题。OCP说明了软件设计应该尽可能地使架构稳定而又容易满足不同的需求。
为什么要OCP?答案也很简单——重用。
“重用”,并不是什么软件工程的专业词汇,它是工程界所共用的词汇。早在软件出现前,工程师们就在实践“重用”了。比如机械产品,通过零部
件的组装得到最终的能够使用的工具。由于机械部件的设计和制造过程是极其复杂的,所以互换性是一个重要的特性。一辆车可以用不同的发动机、不同的变速箱、
不同的轮胎……很多东西我们直接买来装上就可以了。这也是一个OCP的例子。(可能是由于我是搞机械出身的吧,所以就举些机械方面的例子^_^)。
如何在OO中引入OCP原则?把对实体的依赖改为对抽象的依赖就行了。下面的例子说明了这个过程:
05赛季的时候,一辆F1赛车有一台V10引擎。但是到了06赛季,国际汽联修改了规则,一辆F1赛车只能安装一台V8引擎。车队很快投入了新赛车
的研发,不幸的是,从工程师那里得到消息,旧车身的设计不能够装进新研发的引擎。我们不得不为新的引擎重新打造车身,于是一辆新的赛车诞生了。但是,麻烦
的事接踵而来,国际汽联频频修改规则,搞得设计师在“赛车”上改了又改,最终变得不成样子,只能把它废弃。
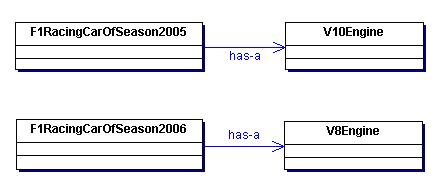
为了能够重用这辆昂贵的赛车,工程师们提出了解决方案:首先,在车身的设计上预留出安装引擎的位置和管线。然后,根据这些设计好的规范设计引擎(或是引擎的适配器)。于是,新的赛车设计方案就这样诞生了。
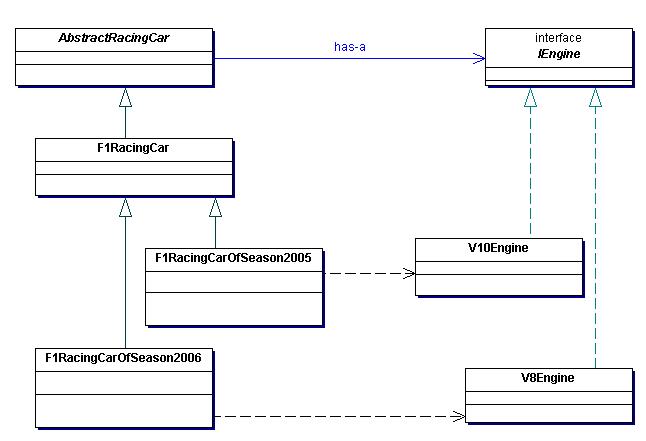
显然,通过重构,这里应用的是一个典型的Bridge模式。这个实现的关键之处在于我们预先给引擎留出了位置!我们不必因为对引擎的规则的频频变更而制造相当多的车身,而是尽可能地沿用和改良现有的车身。
说到这里,想说一说OO设计的一个误区。
学
习OO语言的时候,为了能够说明“继承”(或者说“is-a”)这个概念,教科书上经常用实际生活中的例子来解释。比如汽车是车,电车是车,F1赛车是汽
车,所以车是汽车、电车、F1赛车的上层抽象。这个例子并没有错。问题是,这样的例子过于“形象”了!如果OO设计直接就可以将现实生活中的概念引用过
来,那也就不需要什么软件工程师了!OO设计的关键概念是抽象。如果没有抽象,那所有的软件工程师的努力都是徒劳的。因为如果没有抽象,我们只能去构造世
界中每一个对象。上面这个例子中,我们应该看到“引擎”这个抽象的存在,因为车队的工程师们为它预留了位置,为它制定了设计规范。
上面这个设计也
实现了后面要说的DIP(依赖倒置原则)。但是请记住,OCP是OO设计原则中高层次的原则,其余的原则对OCP提供了不同程度的支持。为了实现OCP,
我们会自觉或者不自觉地用到其它原则或是诸如Bridge、Decorator等设计模式。然而,对于一个应用系统而言,实现OCP并不是设计目的,我们
所希望的只是一个稳定的架构。所以对OCP的追求也应该适可而止,不要陷入过渡设计。正如Martin本人所说:“No significant
program can be 100% closed.”“Closure not complete but strategic”
Liskov替换原则—— LSP
子类型必须能够替换它的基类型
原则
主要针对继承的设计原则
所有派生类的行为功能必须和客户程序对其基类所期望的保持一致。
派生类必须满足基类和客户程序的约定
IS-A是关于行为方式的,依赖客户程序的调用方式
重构
Extract Supper Class
实例
依赖倒置原则—— DIP
a:高层模块不应依赖于底层模块,两者都应该依赖于抽象
b:抽象不应该依赖于细节,细节应该依赖于抽象
原则
如何解释倒置
高层依赖底层,重用变得困难,而最经常重用的就是framework和各个独立的功能组件
高层依赖底层,底层的改动直接反馈到高层,形成依赖的传递
面向接口的编程
实例
Ioc模式
DomainObject / DomianObjectDataService
接口隔离原则—— ISP
使用多个专门的接口比使用单一的总接口总要好。换而言之,从一个客户类的角度来讲:一个类对另外一个类的依赖性应当是建立在最小接口上的。
原则过于臃肿的接口是对接口的污染。不应该强迫客户依赖于它们不用的方法。
My object-oriented umbrella(摘自Design Patterns Explained)
Let me tell you about my great umbrella. It is large enough to get
into! In fact, three or four other people can get in it with me. While
we are in it, staying out of the rain, I can move it from one place to
another. It has a stereo system to keep me entertained while I stay
dry. Amazingly enough, it can also condition the air to make it warmer
or colder. It is one cool umbrella.
My umbrella is convenient. It sits there waiting for me. It has
wheels on it so that I do not have to carry it around. I don't even
have to push it because it can propel itself. Sometimes, I will open
the top of my umbrella to let in the sun. (Why I am using my umbrella
when it is sunny outside is beyond me!)
In Seattle, there are hundreds of thousands of these umbrellas in all kinds of colors. Most people call them cars.
实现方法:
1、 使用委托分离接口
2、 使用多重继承分离接口
想到一个朋友说的话:所有的接口都只有一个方法,具体的类根据自己需要什么方法去实现接口
posted @
2006-04-09 14:06 混沌中立 阅读(641) |
评论 (0) |
编辑 收藏
工作了几年,在不同的公司进入了几个不同的团队.感觉团队之间的差异很大.
1.一个好的团队,是需要时间来培养的.团队中的成员需要时间来互相熟悉,这个熟悉不单是平常说的认识,还要包括熟悉其他的编程方式设计倾向,工作习惯.只有这样以后,在讨论问题讨论方案的时候,可以形成默契,基本简单几句就会明白在说什么问题.团队也需要时间来形成团队的风格,一个有团队所有成员的风格组合在一起形成的风格.包括文档,编码,设计,沟通等方面上的一致风格.中间需要不断进行review,按照review的结果,对所有成果物进行修改.
2.一个好的团队的人员流动应该是良性的.这个良性流动指的是有人员的变化,但是变化的数量和范围不会使得团队的风格发生大的变化,如果一个10人的团队,突然发生的5人的变化,就是说调整到其他团队5个人,又调整进来5个人,那对于这个团队基本可以算是重新形成一个新的团队了.
3.一个好的团队,不单需要团队内部成员的努力,同时也需要SPEG和QA在团队之外对团队的开发流程的监督和规范.如果没有了解开发流程和开发规范的SPEG对流程进行监督,即使团队形成了风格,那这个风格很有可能不是健康的风格,可能会导致团队在以后的开发的过程中产生问题.
4.一个好的团队,需要比较有控制力的PM,能力强的PSM,设计能力优秀的SA.正因为有这样的人,才能快速的将加入团队的新成员,融入团队.
好像具备了上面这些条件想不形成一个好的团队也是很不容易的事情了:)
posted @
2006-04-08 20:01 混沌中立 阅读(1085) |
评论 (2) |
编辑 收藏
最近一直在想这个事情,从近几年的web application的发展情况和工作项目的用户需求来看,rich client应该又要成为一个潮流了。
主要原因有两点:
一是网速的提高,过去使用browser是因为过去的网络速度比较慢,所以只能给客户端传送很少的信息量,让客户通过网络传输的信息尽可能少的完成操作。而现在网络速度的提高,让这样的要求变少了,网速慢的这个瓶颈也不再存在了。
二是用户的要求,用户实际上不在意什么client还是brower,用户在意的是使用是否方便,响应是否迅速,能否满足业务需要。如果网速慢,机器配置差的瓶颈在今天的技术条件下不存在了,用户对于易用性和快速响应的要求就要提高了。这个快速响应不是指那种客户端<----->服务器的响应,而已一个操作之后快速的出现结果,这个就要求有一部分在C/S模式下在客户端实现的功能但是在B/S情况下被转移到服务器上的一些功能需要在客户端实现。
但是这个rich client不是几年前的那种臃肿的不行的方式了,应该是比现在的应用的client包含的内容多,但是比以前的client的内容要少。主要解决的问题是,快速响应用户的操作,让用户的操作更简单。
(思路不是很清晰,暂时是这样,之后再修改)
posted @
2006-03-17 10:12 混沌中立 阅读(305) |
评论 (0) |
编辑 收藏